
Classification and clustering methods development and implementation for unstructured documents...
51
Classification and clustering methods development and implementation for unstructured documents collections by Osipova Nataly St.Petesburg State University Faculty of Applied Mathematics and Control Processes Department of Programming Technology
-
date post
21-Dec-2015 -
Category
Documents
-
view
219 -
download
0
Transcript of Classification and clustering methods development and implementation for unstructured documents...

Classification and clustering methods development and implementation for unstructured documents collections
byOsipova Nataly
St.Petesburg State University Faculty of Applied Mathematics and Control Processes Department of Programming Technology

Contents
IntroductionMethods descriptionInformation Retrieval SystemExperiments

Contextual Document Clustering
was developed in joined project of
Applied Mathematics and Control Processes Faculty, St. Petersburg State University and
Northern Ireland Knowledge Engineering Laboratory (NIKEL), University of Ulster.

Definitions
DocumentTerms dictionaryDictionaryClusterWord contextContext or document conditional
probability distributionEntropy

Document conditional probability distribution
Document x
y
word1
word2
word3
…
wordn
tf(y)
5
10
6
16
p(y|x)
5/m
10/m
6/m
16/m
y – words
tf(y) – y frequency
p(y|x) – y conditional probability in document x
m – document x size
(5/m, 10/m,6/m,…,16/m ) – document conditional probability distribution

Word context
Word w
Document x1 Document x2 Document xk
y
word1
word2
…
wordn1
tf(y)
5
10
16
p(y|x1)
5/m1
10/m1
16/m1
y
word1
word3
…
wordn2
tf(y)
7
12
4
p(y|x1)
7/m1
12/m1
4/m1
y
word1
word4
…
wordnk
tf(y)
20
9
3
p(y|x1)
20/mk
9/mk
3/mk
…
y
word1
word2
word3
…
wordnk
tf(y)
5+7+20=32
10
12
3
p(y|w)
32/m
10/m
12/m
3/m
…
Context conditional probability distribution

Contents
IntroductionMethods descriptionInformation Retrieval SystemExperiments

Methods
document clustering methoddictionary build methodsdocument classification method using
training set
Information retrieval methods:keyword search methodcluster based search methodsimilar documents search method

Contextual Documents Clustering
DocumentsDictionary Narrow context
words
Clusters
Distances calculation

Entropy
(HH
n
i
pipi1
)log(*)
p1 pnp2
y context conditional probability distribution
p1+p2+…+pn=1
p1 pnp2
Uncertainly measure, here it is used to characterize commonness (narrowness) of the word context.

Contextual Document Clustering
maxH(y)=H (
)

Entropy
α0 10.5
)2(log2 1, 21 pp
)loglog(]),([ 221121 ppppppH
H( ) H( ) H( )
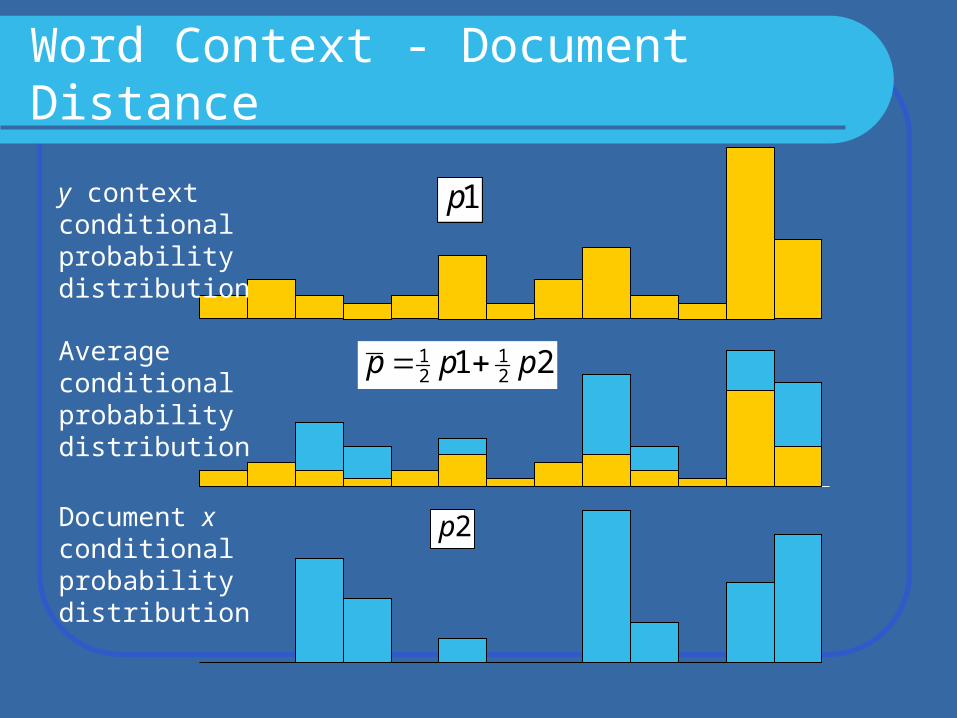
Word Context - Document Distance
1p
2p
21 21
21 ppp
y context conditional probability distribution
Document x conditional probability distribution
Average conditional probability distribution

Word Context - Document Distance
JS[p1,p2]=H( )
- 0.5H( )
- 0.5H( )

Jensen-Shannon divergence
210]2,1[
0]2,1[
},{
},{
21
21
21
21
ppppJS
ppJS

Dictionary construction
Why:
- big volumes:
60,000 documents, 50,000 words => 15,000 words in a context
- narrow context words importance

Dictionary construction
Delete words with
1. High or low frequency
2. High or low document frequency
3. 1. and 2.

Retrieval algorithms
keyword search methodcluster based search methodsearch by example method

Keyword search method
Document 1
word 1
word 2
word 3
…
word n1
Document 2
word 10
word 25
word 30
…
word n2
Document 3
word 15
word 2
word 32
…
word n3
Document 4
word 11
word 21
word 3
…
word n4
Request: word 2 Result set:
document 1
document3

Cluster based search method
Documents
Cluster 3
word 1
word 23
…
word n3
Documents Documents
Cluster 2
word 12
word 26
…
word n2
Cluster 1
word 1
word 2
…
word n1
Cluster context words
Request: word 1 Result set:
Cluster 1
Cluster 3

Similar documents search
document 1Cluster name
Cluster
Minimal Spanning Tree
document 2
document 3
document 4
document 5
document 6
document 7
Request: document 3
Result set:
document 6
document 7

Document classification: method 1
Clusters List of topics Training set
Topics contexts
Distances between topics and clusters contexts
Classification result:cluster1 – topic 10cluster 2 – topic 3
…cluster n – topic 30
Test documents

Clusters
Topics listTraining set
Classification result:cluster1 – topic 10cluster 2 – topic 3
…cluster n – topic 30
Document classification: method 2
Test documents
All documents set

Contents
IntroductionMethods descriptionInformation Retrieval SystemExperiments

Information Retrieval System
ArchitectureFeaturesUse

Information Retrieval System architecture.
data base serverclient

IRS architecture
Data Base
Data Base ServerMS SQL Server 2000
Local AreaNetwork
Local AreaNetwork
“thick” clientC#

IRS architecture
DBMS MS SQL Server 2000:High-performanceScalableSecureHuge volumes of data treatT/SQLStored procedures

IRS features
In the IRS the following problems are solved:document clusteringkeyword search methodcluster based search methodsimilar documents search methoddocument classification with the use of
training set

DB structure
The Data Base of the IRS consists of the following tables: documents all words dictionary dictionary table of relations between documents and words: document-word words contexts words with narrow contexts clusters intermediate tables for main tables build and for retrieve realization

DictionaryDocuments
Table “document-word”
Words contexts
Clusters Centroid
Cluster based search
Keyword search
Words with narrow contexts
All words dictionary
Similar documents search
Algorithms implementation

document1document2
document5 document3
document4
Cluster
0,16285
0,98154
0,57231
0,23851
0,26967
0,211
0,87310,7231
0,1011
Similar documents search

Minimal Spanning Tree
document 1
Cluster name
Cluster
document 2
document 3
document 4
document 5

Similar documents search
Clusterstable
Tree tableDistances
table
Similar documents
search

IRS use

IRS use

IRS use

IRS use

IRS use

IRS use

Contents
IntroductionMethods descriptionInformation Retrieval SystemExperiments

Experiments
Test goals were:algorithm accuracy testdifferent classification methods
comparisonalgorithm efficiency evaluation

Experiments
60,000 documents100 topicsTraining set volume = 5% of the
collection size

Experiments
1000)(,2)( ydfydf
1000)(,5)( ytfytf

Result analysis
- Russian Information Retrieval Evaluation Seminar
- Such measures as macro-average recallprecision F-measure
were calculated.
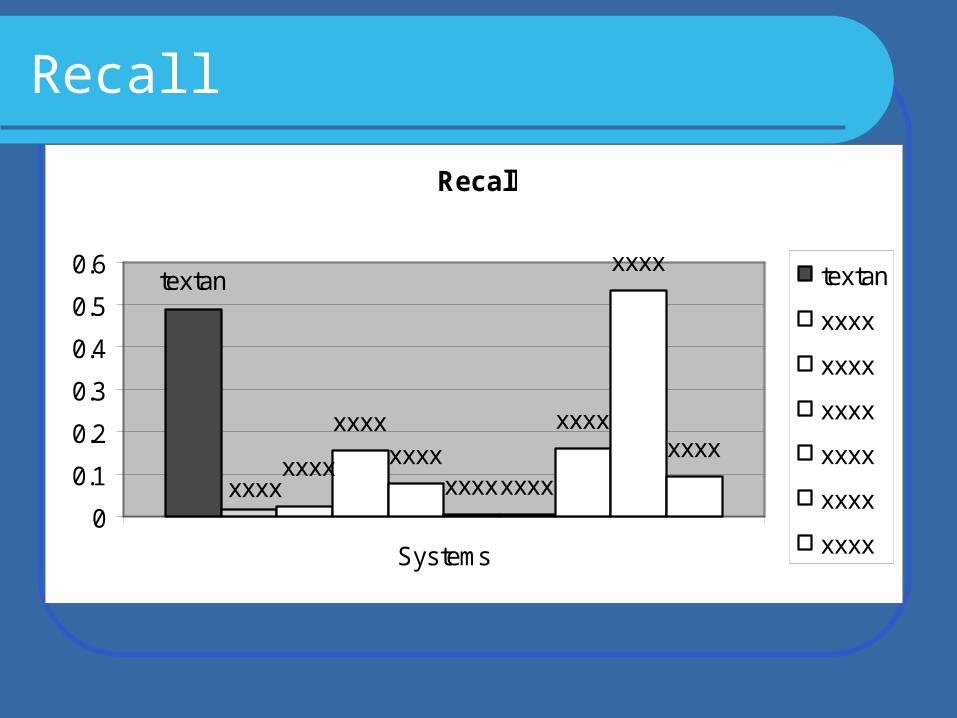
Recall
textan
xxxxxxxxxxxx
xxxx
xxxx
xxxx
xxxxxxxx
xxxx
0
0.1
0.2
0.3
0.4
0.5
0.6
Systems
textan
xxxx
xxxx
xxxx
xxxx
xxxx
xxxx
Recall

Precision
xxxx
xxxxxxxx
xxxxxxxx
xxxx
textanxxxxxxxx
xxxx
00.1
0.20.30.40.5
0.60.7
Systems
textan
xxxx
xxxx
xxxx
xxxx
xxxx
xxxx
Precision
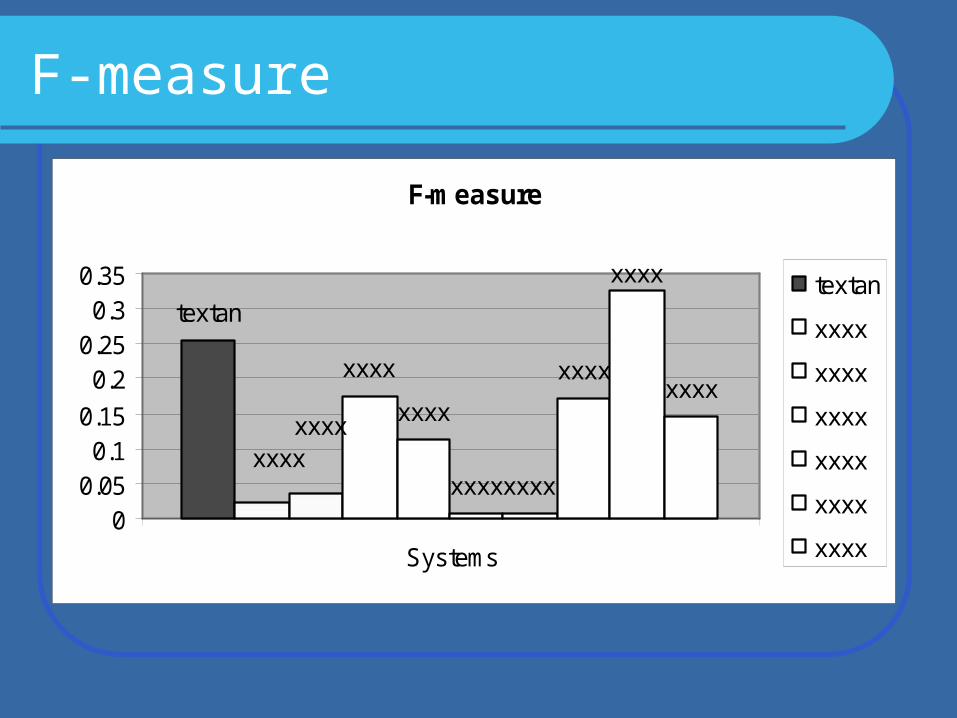
F-measure
textan
xxxx
xxxxxxxx
xxxxxxxx
xxxxxxxx
xxxx
xxxx
00.050.1
0.15
0.20.250.3
0.35
Systems
textan
xxxx
xxxx
xxxx
xxxx
xxxx
xxxx
F-measure

Result analysis
List of some topics
test documents
were classified in
№ Category
1 Family law
2 Inheritance law
3 Water industry
4 Catering
5 Inhabitants’ consumer services
6 Rent truck
7 International law of the space
8 Territory in international law
9 Off-economic relations fellows
10 Off-economic dealerships
11 Economy free trade zones. Customs unions.

Result analysis
Recall results for every category.
Results which were the best for the category are selected with bold type.
All results are set in percents. СV 1 2 3 4 5 6 7 8 9 10 11
textan 33 34 35 60 46 26 27 98 75 25 100
xxxx 1 0 0.2 3 4 0 0.9 0 3 0 2
xxxx 0 0 4.3 2.3 0 5 0.9 8 3 0 0.8
xxxx 55 86 75 19 59 51 80 0 41 82 0
xxxx 21 39 2 22 15 6 0 1.4 0 5 0
xxxx 40 43 16 11 25 23 10 1.4 1.2 5 0
xxxx 23 4 2.5 1.1 18 7 0.9 0 1.2 10 0
xxxx 2.7 0 0 0 1.5 0 0 0 0 0 0
xxxx 2.2 0 0 0 1.5 0 0 0 0 0 0
xxxx 37 21 12 22 18 27 51 0 0 0 0

Thank you for your attention!


















