
Classificação e principais espécies de importância sanitária
Upload
alexandre-duarteCategory
view
457download
1
Ordenação e Recuperação de Dados
Prof. Alexandre Duarte - http://alexandre.ci.ufpb.br
Centro de Informática – Universidade Federal da Paraíba
Aula 6: Classificação e Ponderação
11

Agenda
❶ Revisão
❷ Por que recuperação com classificação?
❸ Frequência de Termos
❹ Classificação tf-idf
2

Agenda
❶ Revisão
❷ Por que recuperação com classificação?
❸ Frequência de Termos
❹ Classificação tf-idf
3
4
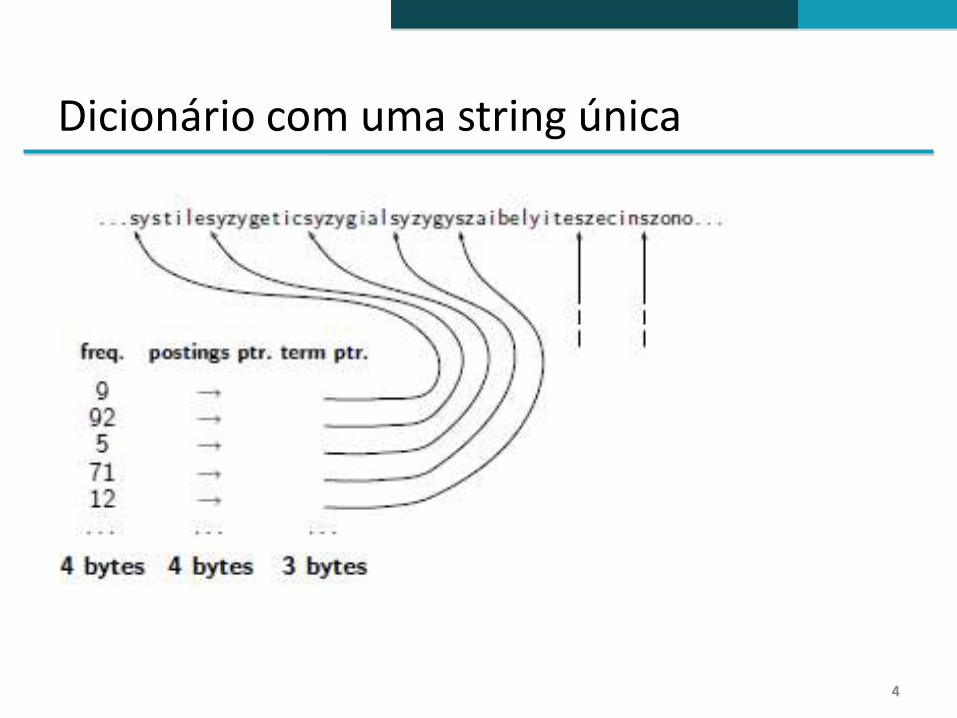
Dicionário com uma string única
4

5
Codificando as diferenças
5

6
Codificação de tamanho variável
Dedicar 1 bit (mais significativo) para ser o bit de continuação c.
Se o valor couber em 7 bits, codifique-o e set o bit c = 1.
Senão: set c = 0, codifique os 7 bits mais significativos e use bytes adicionais para codificar o restante dos bits segundo o mesmo algoritmo.
6

7
Compressão da Reuters
7
Estrutura de dados Tamanho em MB
dicionário, estrutura fixadictionário, ponteiroes para string∼, com blocos, k = 4∼, com blocos & codificação de prefixocoleção (texto, xml etc)coleção (texto)matriz de incidência T/D postings, sem compressão (32-bits)postings, sem compressão (20 bits)postings, codificação de tamanho variável
11.27.67.15.9
3600.0960.0
40,000.0400.0250.0116.0
8
Aula de hoje
Classificando resultados de buscas: porque isto é importante (em constrate a simplesmente apresentar os resultados de forma não-ordenada como ocorre com a busca booleana)
Frequência de Termos: Este é o ingrediente chave na classificação.
Classificação Tf-idf: esquema de classificação mais conhecido
8

Agenda
❶ Revisão
❷ Por que recuperação com classificação?
❸ Frequência de Termos
❹ Classificação tf-idf
9

10
Recuperação classificada
Até agora todas as nossas consultas foram Booleanas.
O documento atende a consulta ou não
Isso é bom para usuários especialistas com entendimento preciso de suas necessidades e do conteúdo da coleção de documentos.
Também é bom para aplicações: Aplicações podem consumir facilmente 1000s de resultados.
Mas não é interessante para a maioria dos usuários
A maioria dos usuários não é capaz de escrever consultas booleanas . . .
. . . podem até ser, mas eles consideram ser algo muito trabalhoso.
A maioria dos usuários não quer ter que processar 1000s de resultados manualmente.
Isto é particularmente verdadeiro para pesquisas na web.
10

11
Problemas da pesquisa Booleana: 8 ou 80
Consultas booleanas geralmente resultam em um número muito pequeno de resultados (=0) ou em um número muito grande de resultados (1000s).
Consulta 1 (conjunção booleana): [standard user dlink 650]
→ 200,000 hits
Consulta 2 (conjunção booleana): [standard user dlink 650 no card found]
→ 0 hits
Utilizar pesquisas booleanas requer habilidade para produzir consultas que recuperem um número gerenciavel de resultados.
11

12
8 ou 80: Isso não é problema para a consulta com classificação
Com classificação, um grande número de resultados não é um problema para o usuário.
Basta mostrar apenas os 10 melhores resultados, por exemplo
Não sobrecarregar o usuário
Premissa: o algorítmo de classificação funciona: Resultados mais relevantes têm melhor classificação que resultados menos relevantes.
12

13
Scoring como base da recuperação com classificação
Queremos atribuir uma melhor classificação aos documentos que são mais em relação aos documentos que são menos relevantes.
Como podemos fazer essa classificação dos documentos de uma coleção em relação a uma determinada consulta?
Atribuir um score a cada par consulta-documento.
Este score mede o quão bem um determinado documento atende uma determinada consulta.
13

14
Score de pares Consulta-documento
Como calculamos o valor de um par consulta-documento?
Comecemos com consultas de um único termo.
Se o termo não aparece no documento: o score deve ser 0.
Quanto mais frequente o termo no documento maior o score
Veremos algumas alternativas para fazer essa contabilização.
14

15
Tentativa 1: Coeficiente de Jaccard
Uma medida comum para a sobreposição de dois conjuntos
Sejam A e B dois conjuntos
O coeficiente de Jaccard para A e B vale:
JACCARD (A, A) = 1
JACCARD (A, B) = 0 if A ∩ B = 0
A e B não precisam ter o mesmo tamanho.
Sempre atribui um valor entre 0 e 1.
15

16
Coeficiente de Jaccard: Exemplo
Qual é o score consulta-documento que o Coeficiente de Jaccard retorna para:
Consulta: “ides of March”
Documento “Caesar died in March”
JACCARD(c, d) = 1/6
16

17
Problemas com o coeficiente de Jaccard
Ele não considera a frequência do termo (quantas ocorrências o termo tem).
Termos raros são mais informativos que termos frequentes. Jaccard não considera essa informação.
Precisamos de mecanismos mais sofisticados!
17

Agenda
❶ Revisão
❷ Por que recuperação com classificação?
❸ Frequência de Termos
❹ Classificação tf-idf
18

19
Matriz de incidências Termo-Documento
Cada documento é representado por um vetor binário ∈ {0, 1}|V|.
19
Anthony andCleopatra
Julius Caesar
The Tempest
Hamlet Othello Macbeth . . .
ANTHONYBRUTUSCAESARCALPURNIACLEOPATRAMERCYWORSER. . .
1110111
1111000
0000011
0110011
0010011
1010010

20
Matriz de incidências Termo-Documento
Agora cada documento é representado por um vetor de contagem ∈ N|V|.
20
Anthony andCleopatra
Julius Caesar
The Tempest
Hamlet Othello Macbeth . . .
ANTHONYBRUTUSCAESARCALPURNIACLEOPATRAMERCYWORSER. . .
1574
2320
5722
73157227
10000
0000031
0220081
0010051
1000085

21
Modelo da sacola de palavras
Nós não consideramos a ordem das palavras em um documento.
John is quicker than Mary e Mary is quicker than John são representadas da mesma forma.
Isto é chamado de modelo da sacola de palavras.
De certa forma estamos dando um passo para trás: índices posicionais são capazes de distinguir entre estes dois documentos.
Veremos como recuperar a informação posicional ainda neste curso.
Por enquanto: modelo da sacola de palavras21

22
Frequência de termos tf
A frequencia de um termo t em um documento d, tft,d é definida como o número de vezes que t ocorre em d.
Queremos utilizar o tf no cálculo dos scores de pares consulta-documento.
Como fazer isso?
Não podemos utilizar indiscriminadamente o tf pois:
Um documento com tf = 10 ocorrências de um determinado termo é mais relevante que um outro documento com tf = 1 ocorrências do mesmo termo.
Mas não 10 vezes mais relevante.
A relevância não cresce de forma proporcional a frequência de termos.
22

23
Ponderação de frequências por Log
O peso da frequência de um termo t em um documento d édefinido como
tft,d → wt,d : 0 → 0, 1 → 1, 2 → 1.3, 10 → 2, 1000 → 4, etc.
O score de um par consulta-documento pode então sercalculado pela soma dos pesos dos termos t que estão tanto na consulta quanto no documento
tf-matching-score(q, d) = t∈q∩d (1 + log tft,d )
O score será 0 se nenhum dos termos da consulta estiver presente no documento.
23

24
Exercícios
Calcular o Coeficiente de Jaccard e o Score tf para os seguintes pares de consultas-documentos.
c: [information on cars] d: “all you’ve ever wanted to know about cars”
c: [information on cars] d: “information on trucks, information on planes, information on trains”
c: [red cars and red trucks] d: “cops stop red cars more often”
24

Agenda
❶ Revisão
❷ Por que recuperação com classificação?
❸ Frequência de Termos
❹ Classificação tf-idf
25

26
Frequêcia no documento vs. frequência na coleção
Além da frequência do termo em um documento. . .
. . .queremos utilizar também a frequência do termo na coleção para ponderação e classificação.
26

27
Peso desejado para termos raros
Termos raros são mais informativos que termos frequentes.
Considere um termo na consulta que é raro na coleção (e.g., ARACHNOCENTRIC).
Um documento que contém este termo tem uma probabilidade muito grande de ser relevante para a consulta.
→ Queremos atribuir pesos maiores para termos raros.
27

28
Peso desejado para termos raros
Termos frequêntes são menos informativos que termos raros.
Considere um termo na consulta que é frequente na coleção (e.g., GOOD, INCREASE, LINE).
Um documento contendo estes termos tem mais chances de ser relevante que um documento que não os contém . . .
. . . porém, palavras como GOOD, INCREASE e LINE não são bons indicadores de relevância.
→Queremos pesos positivos para termos frequentes como GOOD, INCREASE e LINE, . . .
. . . mas menores que os pesos de termos raros.
28

29
Frequência em documentos
Queremos pesos maiores para termos raros como ARACHNOCENTRIC.
Queremos pesos menores (positivos) para termos
frequêntes como GOOD, INCREASE e LINE.
Usaremos a frequência em documentos para considerar este aspecto no cálculo dos scores.
A frequência em documentos é o número de documentos na coleção nos quais o termo ocorre.
29

30
Ponderação idf
dft é a frequência em documentos, o número de documentos nos quais t ocorre.
dft é uma medida inversa de quão informativo é o termo t.
Definimos o peso idf de um termo t como segue:
(N é o número de documentos na coleção.)
idft é uma medida de quão informativo um determinado termo é.
Utilizamos [log N/dft ] ao invés [N/dft ] para “suavizar” o efeito do idf
Note que utilizamos uma transformação logarítmica tanto para a frequêcia do termo quanto para a frequência em documento.
30

31
Exemplos para o idf
Calcule o idft usando a formula
31
termo dft idft
calpurniaanimalsundayflyunderthe
1100
100010,000
100,0001,000,000
643210

32
Efeitos do idf na classificação
O idf afeta a classificação de documentos para consultas com pelo menos dois termo.
Por exemplo, para consultas com “arachnocentric line”, a ponderação do idf aumenta o peso relativo de ARACHNOCENTRIC e diminui o peso relativo de LINE.
O idf tem pouco efeito na classificação de consultas com um único termo.
32

33
Frequência na coleção vs. Frequência em documento
Frequência na coleção de t: número de termos t na coleção
Frequência em documento de t: número de documentos onde t ocorre
Qual palavra representa um melhor termo de busca (e, portanto, deve ter um maior peso)?
Este exemplo sugere que df (e idf) é melhor para ponderação do cf (e “icf”).
33
palavra Frequência na coleção
Frequência em documento
INSURANCETRY
1044010422
39978760

34
Ponderação tf-idf
O tf-idf de um termo é o produto do seus pesos tf e idf.
Este é o esquema de ponderação mais conhecido na área de recuperação da informação
Note: o “-” em tf-idf é um hífen e não um sinal de menos!
Nomes alternativos: tf.idf, tf x idf
34

35
Sumário: tf-idf
Atribua um peso tf-idf para cada termo t em cada documento d:
O peso tf-idf . . .
. . . aumenta com o número de ocorrências do termo em um documento. (frequência de termo)
. . . aumenta com a raridade do termo na coleção. (inverso da frequência em documento)
35


















