
CLASS 1. - synergy.ac.in lecture... · Web viewan extension of IDL (Interface Description...
88
CLASS 1. Introduction to DBMS What is a database (DB)? `a collection of data that exists over a long period of time, often many years' [FCDB] p. 2 managed through a database management system What is a database management system (DBMS)? or simply `database system' `a powerful tool for creating and managing [and manipulating] large amounts of data [(several gigabytes; 10 9 bytes)] efficiently and allowing it to persist over long periods of time, safely [(ACID)]' [FCDB] p. 1 (sound like something familiar?) focus on secondary, rather than main, memory powerful, but simple, programming interface Why do we need database systems? data management problem think of analogies from your personal information space
-
Upload
truongthien -
Category
Documents
-
view
214 -
download
0
Transcript of CLASS 1. - synergy.ac.in lecture... · Web viewan extension of IDL (Interface Description...

CLASS 1. Introduction to DBMS
What is a database (DB)?
`a collection of data that exists over a long period of time, often many years' [FCDB] p. 2 managed through a database management system
What is a database management system (DBMS)?
or simply `database system' `a powerful tool for creating and managing [and manipulating] large amounts of data
[(several gigabytes; 109 bytes)] efficiently and allowing it to persist over long periods of time, safely [(ACID)]' [FCDB] p. 1 (sound like something familiar?)
focus on secondary, rather than main, memory powerful, but simple, programming interface
Why do we need database systems?
data management problem think of analogies from your personal information space
DBMS vs. `just a file system'
DBMS's evolved from file systems

file systems also store large amounts of data over a long period of time in secondary memory
however, file systems o can lack efficient accesso have no direct support for querieso limit organization to directory creation and hierarchical organizationo have no sophisticated support for concurrencyo do not ensure durability
ACID properties
(all good DBMS's should guarantee these)
Atomicity o should not be able to execute half of an operationo either all or none of the effects of a transaction are made permanent
Consistency o there should be no surprises in the world, e.g., gpa > 4.0, balance < 0, cats should
never have more than 1 tail!o the effect of concurrent transactions is equivalent to some serial executiono use constraints, triggers, active DB elements (context-free)
Isolation o concurrency controlo transactions should not be able to observe the partial effects of other transactionso use locks (whole relations or individual tuples?)
Durability o if power goes out, nothing bad should happeno once accepted, the effects of a transaction are permanent (until, of course,
changed by another transaction)o use logs
Who uses DBMS's?
parametric users, e.g., the travel agent, the application programmer o create, update, or query content

o use DML (Data Manipulation Language) or query language: language which changes the instance (contents)
database administrators (DBA) o create or modify schemao uses DDL (Data Definition Language): language which programs the schema
(structure)
Applications of database systems
(shifts in application domains help illustrate evolution of DBMS's)
reservation systems, banking systems record/book keeping (corporate, university, medical), statistics bioinformatics, e.g., gene databases criminal justice
o fingerprint matchingo how do you encode `looks like'?
multimedia systems o require terabytes (1012 bytes) of storageo tertiary storage devices, e.g., CD, DVDso image/audio/video retrievalo streaming, interactivity
satellite imaging; can require petabytes (1015 bytes) of storage the web
o client-server and multi-tier architectureso almost all data-intensive websites are database-driven; IMDB.com is an exception
information integration o over the webo legacy systems; must deal with issues of
synonymy: different words having the same meaning, e.g., coffee shop vs. café
polysemy: same word (homonym) having different meanings, e.g., shoto data warehouseso data mining (KDD, Knowledge Discovery in Databases), e.g., association rules:
`diapers → beer'; we pass these on to the marketing folks in sum, databases are everywhere!

Three classical data models
1. hierarchical model2. network model
o each tuple is a separate record, e.g., (AN 145) --- [Perugini] --- (CPS 430)o no separation between logical and physical viewso used record-at-a-time languageso too low-level
3. relational model o proposed by E.F. Codd in 1969o most popular and successful modelo de facto standard for databaseso (relational) databases are one of the most popular success stories of simple
theoretical ideaso the focus of CPS 430/542
... semistructured data and XML
o semistructured data is self-describing o web data tends to be semistructuredo in between structured and unstructured data (free text)o the study of the storage and retrieval of unstructured data is called IR
(Information Retrieval)
Main themes of relational database management systems (RDBMS's)
data stored in a relation (for now, a table), e.g., a simple relation ------------------- | ID GPA major |} ← attributes ------------------- | 001 3.7 CPS |} ← tuple or record 005 3.9 ART | 007 4.0 CIS | 987 2.0 CPE | ------------------- |o attributes (columns), tuples (rows, records)

o 2-tuple = pair, 3-tuple = triple, m-tuple
clean separation between logical and physical views, ANSI Sparc architecture, 3-tier organization of databases (layers of abstraction)
views↑
relations↑
physical storage
gives rise to powerful, yet declarative, relation-at-a-time query languages, e.g., SQL (Structured Query Language; pronounced `sequel')
a simple SQL query illustrating the SELECT-FROM-WHERE construct SELECT id FROM Students WHERE major = 'CPS' AND GPA > 3.7;
relational query languages (QLs) are declarative o you specify what you want, not how to get it (à la PROLOG)o e.g., SQL
closure property
Object-relational Databases
relational model not always the best fit user might need to supply complex data operations, e.g., for multimedia data;
o object-orientation has been used to help support such extensionso led to object-relational systems
How can we study database systems?

1. design of databases, i.e., how do you structure your data in a database? o entity-relationship (E/R) modelo relational model
2. database programming o how do you use a DBMS?o study of DDLs and DMLs (query languages) such SQL and OQL (Object Query
Language); SQL is both, i.e., SQL = DDL + DML
3. database system implementation, i.e., how do you build the next Oracle?
CPS 430/542 focuses on (1) and (2). CPS 432/562 focuses on (3).
Course objectives
Establish an understanding of database principles and the technologies and theory underlying database management systems.
Establish an understanding of data models (with an emphasis on the relational model), physical data organization, data design, normalization, and querying.
Establish an understanding of how databases interface with the web.
CLASS 2. historical database context
Historical context

1960s: Charles Bachman has `information-centric' ideas and with others developed a network DBMS called IDS (Integrated Data Store) for Honeywell
1970: Edgar F. Codd writes paper in CACM o espoused relational model of datao used an algebra to manipulate/query data
1971: two camps, with differing viewpoints, formed o Bachman's COBOL/CODASYL (Committee on Data Systems and Languages)
camp championing network model DBTG (DataBase Task Group) espoused record-oriented queries said relational camp is too theoretical no efficiency in relational approach
o Codd's relational camp championing relational, theoretical ideas espoused set-oriented queries said COBOL/CODASYL camp is not theoretical
1973: Charles Bachman receives Turing Award 1975: ACM SIGMOD panel discussion (`The Great Debate'): Codd vs. Bachman late 1970s:
o two camps understand each other bettero more usable relational languages
QUEL (1975) SQL (1976)
o relational prototypes, with reasonable efficiency, built System R INGRES
1974-78: System R(elational) o at IBM Almaden, San Joseo developed their own filesystemo two levels
RSS (Relational Storage System) RDS (Relational Data System)
o used SEQUELo RSS largely influenced by Jim Gray and K.P. Eswarano went commercial
evolved into ESVAL (formed by Eswaran) and then into HP's ALLBASE Cullinet's IDMS/SQL; Britton-Lee (which was part of NCR)
helped to build the IDM software later independently became IBM's DB2 and SQL/DS eventually become Oracle
1973-77: INGRES o at UC Berkeley, only 50 miles awayo used the UNIX System V filesystem (no support for crash recovery)o developed on 16-bit PDP-11o used QUELo largely influenced by Mike Stonebraker

o also went commercial INGRES Corporation is now part of Computer Associates Sybase focused on transaction processing
1981: Codd receives Turing Award for relational model 1998: Gray receives Turing Award for transaction processing (employed at Microsoft
Research) 2003: Codd dies in April 2007: Jim Gray lost at sea off the coast of San Francisco in January (still missing)
The DB Industry
RDBMS's are the perennial success story of simple theoretical ideas `Big 3' database companies are among the largest in the software industry
o Oracle, Informix, Sybaseo others trying to get a piece of the pie: Microsoft
Terdata, Inc. (a former division of NCR) locally in Dayton, OH
CLASS 3. Physical Data Storage
Anatomy of a DBMS (organizational diagram)
storage manager = file manager + buffer manager o its purpose it to access data and put it in main memoryo memory hierarchy
primary volatile fast expensive e.g., caches, main memory
secondary (HDD) non-volatile random access 100x cheaper, 2000x slower

tertiary e.g., tapes
sequential non-volatile
e.g., CD's, DVD's are non-volatileo DBMS storage is secondary and tertiaryo file manager (secondary)o buffer manager (primary); replacement policies, e.g., LRU
query processor o query compiler → query plan
existence of an index index: a data structure which takes a property of records are input and
returns records with that property, quicklyo query optimization; database tuning helps by selecting efficient data structureso execution engine
transaction manager o mediator b/t query processor and storage managero job is to ensure ACID properties
actual data store, contains o datao meta-data - data about data (e.g., column names)
Structure of a Disk
cylinder: a set of all tracks with same diameter data stored in units called `disk blocks'
o a contiguous sequence of bytes (212 = 4,096 bytes)o a unit of read/write accesso consists of multiple sectors
disk arms, disk head access time = seek time + rotational delay + transfer time
o 10-20 mso seek time: time to position head on correct track, on which desired block in
located biggest bottleneck of any computer system is I/O; disk access is expensive
Strategies for improving disk access

use indices o data structures
b-trees (secondary memory) B(alanced)-tree a generalization of a binary search tree all leaves at same level each node can have >2 children each node of b-tree = 1 disk block
binary search trees (main memory) use parallel computing efficient disk access not sufficient to guarantee efficient query processing; also need
query decomposition algorithms which render distributed or parallel computation worthwhile
CLASS 4. Essential E/R Elements
Database modeling
why? to determine structure of database prior to implementation start with ideas and English specifications use entity-relationship (E/R) model
o developed at MITo analogies to OOP
entity = object entity set = class attribute = property
o not standardized; textbooks vary end goal: a set of relations
Building blocks of the E/R model
has syntax (form) and semantics (meaning)

entity set (square), usually plural nouns relationship (diamond), usually verbs attribute (oval), usually adjectives undirected edge (many-many relationship) uni-directional arrow (many-one relationship) bi-directional arrow (one-one relationship)
Example entity set with attributes
Types of relationships
binary, teriary, and so on can we have a unary relationship?
Multiplicity of binary relationships
many-many relationship, e.g.,

relationship set: a set of tuples connecting entities
{(linus, cps430), (linus, cps444), (lucy, cps430), (lucy, cps444)}
many-one relationship, e.g.,
relationship set:
{(linus, perugini), (lucy, courte), (linus, perugini), (linus, smith)}
one of the last two tuples violates the semantics of the diagram
o means `at most' one, not `exactly' one or `at least' oneo special case of many-many relationshipo any property which holds for a many-many relationship also will hold for a many-
one relationship
one-one relationship, e.g.,
relationship set:
{(linus, lucy), (tom, sally), (tom, cindy)}
one of the last two tuples violates the semantics of the diagram

o special case of many-one relationshipo any property which holds for a many-one relationship
also will hold for a one-one relationship, but may not hold for a many-many relationship
Relationship roles
an entity set may participate in more than one relationship an entity set may participate more than once in a single relationship label the edges to differentiate roles father relationship
manager relationship

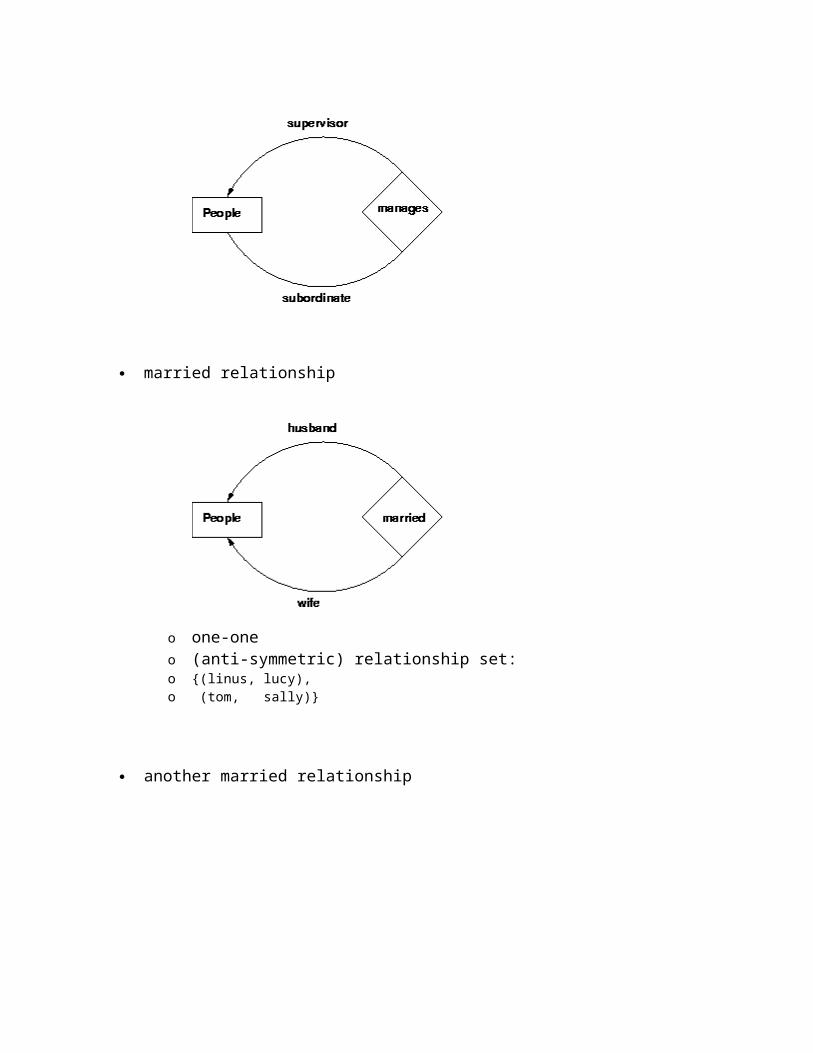
married relationship
o one-oneo (anti-symmetric) relationship set: o {(linus, lucy),o (tom, sally)}
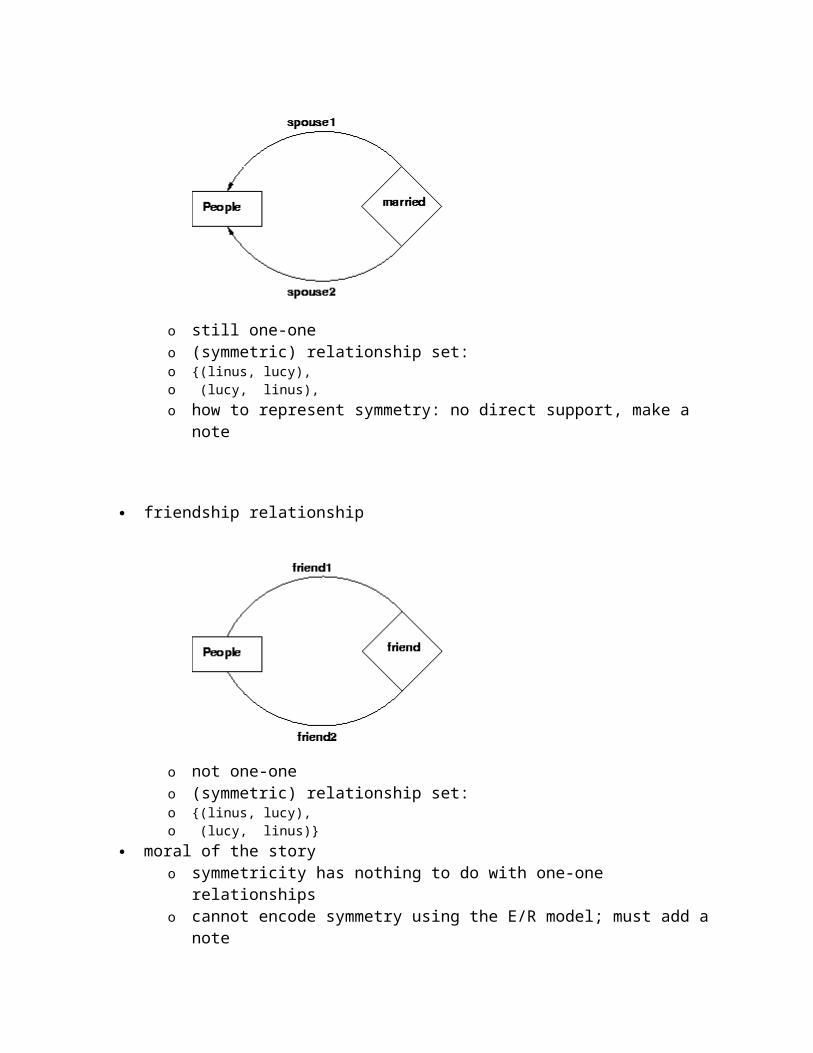
another married relationship
o still one-oneo (symmetric) relationship set: o {(linus, lucy),o (lucy, linus),o how to represent symmetry: no direct support, make a note
friendship relationship

o not one-oneo (symmetric) relationship set: o {(linus, lucy),o (lucy, linus)}
moral of the story o symmetricity has nothing to do with one-one relationshipso cannot encode symmetry using the E/R model; must add a note
can a many-one relationship be symmetric?
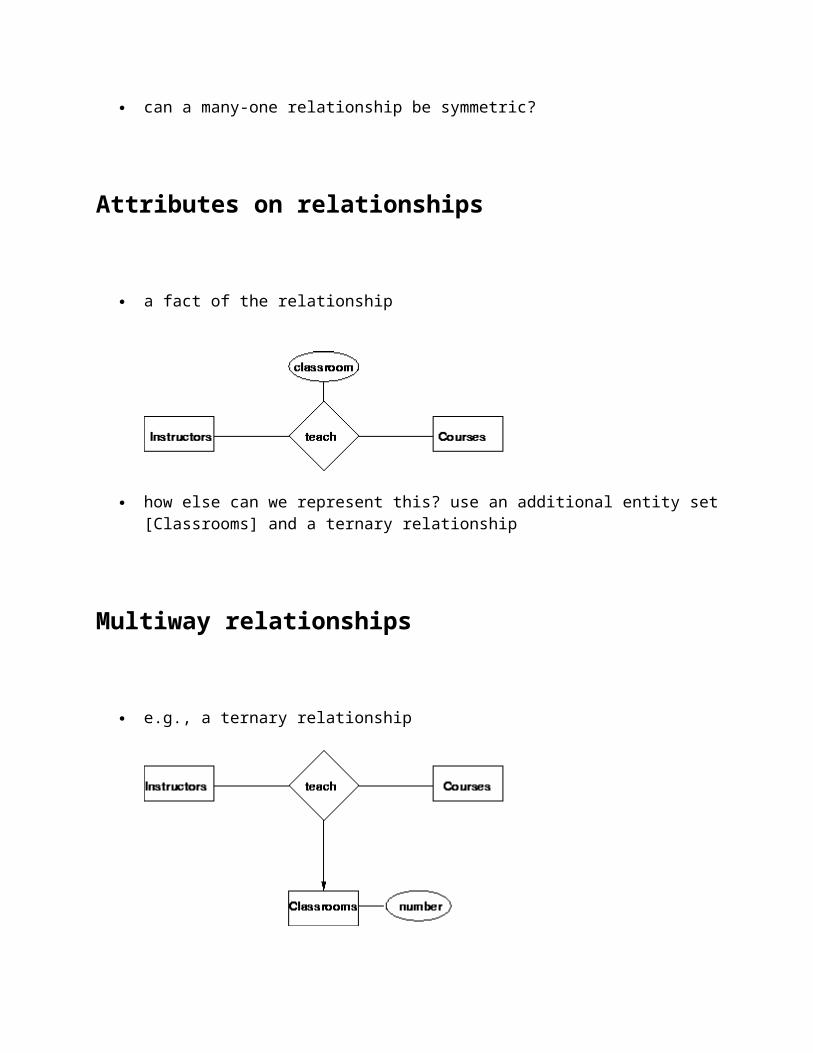
Attributes on relationships
a fact of the relationship
how else can we represent this? use an additional entity set [Classrooms] and a ternary relationship
Multiway relationships

e.g., a ternary relationship
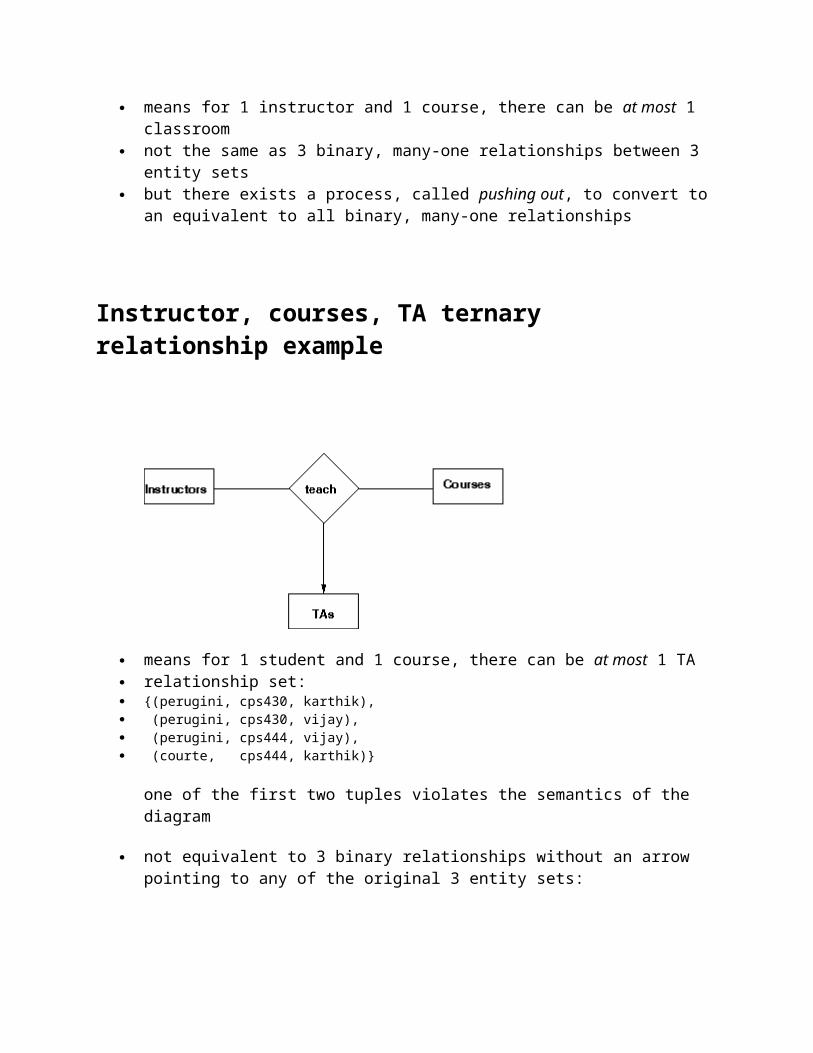
means for 1 instructor and 1 course, there can be at most 1 classroom not the same as 3 binary, many-one relationships between 3 entity sets but there exists a process, called pushing out, to convert to an equivalent to all binary,
many-one relationships
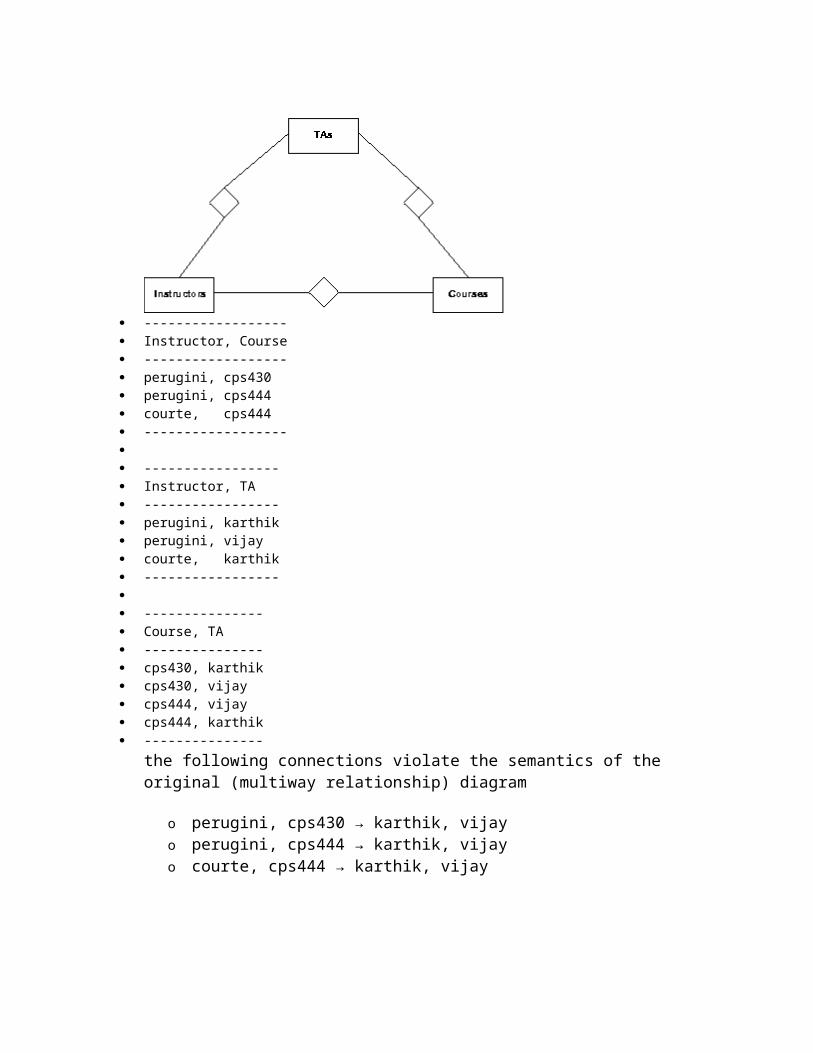
Instructor, courses, TA ternary relationship example
means for 1 student and 1 course, there can be at most 1 TA relationship set: {(perugini, cps430, karthik), (perugini, cps430, vijay), (perugini, cps444, vijay), (courte, cps444, karthik)}
one of the first two tuples violates the semantics of the diagram
not equivalent to 3 binary relationships without an arrow pointing to any of the original 3 entity sets:
------------------ Instructor, Course ------------------ perugini, cps430 perugini, cps444 courte, cps444 ------------------ ----------------- Instructor, TA ----------------- perugini, karthik perugini, vijay courte, karthik ----------------- --------------- Course, TA --------------- cps430, karthik cps430, vijay cps444, vijay cps444, karthik ---------------
the following connections violate the semantics of the original (multiway relationship) diagram
o perugini, cps430 → karthik, vijayo perugini, cps444 → karthik, vijayo courte, cps444 → karthik, vijay
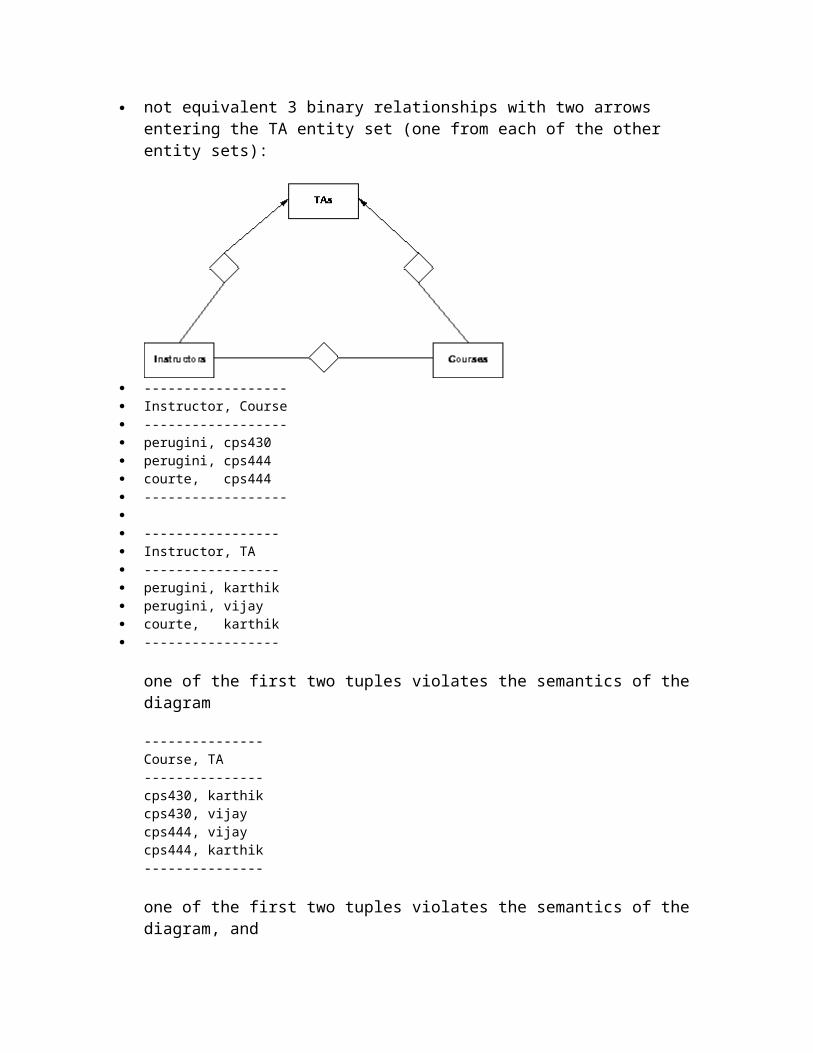
not equivalent 3 binary relationships with two arrows entering the TA entity set (one from each of the other entity sets):
------------------ Instructor, Course ------------------ perugini, cps430 perugini, cps444 courte, cps444 ------------------ ----------------- Instructor, TA ----------------- perugini, karthik perugini, vijay courte, karthik -----------------
one of the first two tuples violates the semantics of the diagram
---------------Course, TA---------------cps430, karthikcps430, vijaycps444, vijaycps444, karthik---------------
one of the first two tuples violates the semantics of the diagram, and one of the last two tuples violates the semantics of the diagram
now, 1 instructor can have at most 1 TA for any course, and 1 course, taught by any instructor, can have at most 1 TA
Pushing out
are the diagrams equivalent? 1 instructor, 1 course → 1 TA constraint not met new entity set [teach] is called a connecting entity set may think of entities of new entity set [teach] as the tuples of the relationship set for the
multiway relationship
teach-----{(perugini, cps430, karthik), (perugini, cps430, vijay), ← violates original constraints! (perugini, cps444, vijay), (courte, cps444, karthik)}
teach1 → (perugini, cps430, karthik)teach1 → (perugini, cps430, vijay) ← violates original constraints!teach2 → (perugini, cps444, karthik)teach3 → (courte, cps444, karthik)
to do the reverse, we would need the contents of the entity set [teach] in order to determine to which of the original 3 entity sets arrows should point
why push out? o to learn the E/R modelo converting pushed out designs to relations might be easier than converting designs
with ternary relationshipso some data models, e.g., Object Definition Language (ODL), limit relationships to
binary relationships
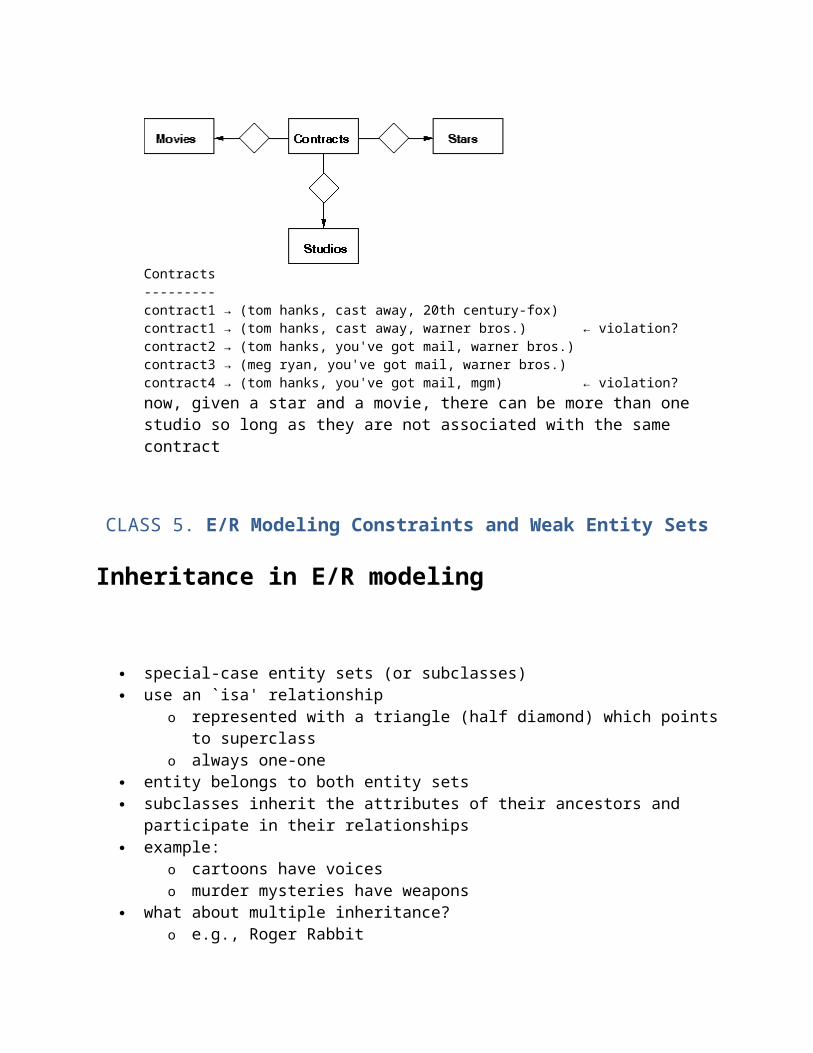
Another `pushing out' example
more natural if the relationship corresponds to something tangible in the real world
convert
to
Contracts---------contract1 → (tom hanks, cast away, 20th century-fox)contract1 → (tom hanks, cast away, warner bros.) ← violation?contract2 → (tom hanks, you've got mail, warner bros.)contract3 → (meg ryan, you've got mail, warner bros.)contract4 → (tom hanks, you've got mail, mgm) ← violation?now, given a star and a movie, there can be more than one studio so long as they are not associated with the same contract
CLASS 5. E/R Modeling Constraints and Weak Entity Sets
Inheritance in E/R modeling
special-case entity sets (or subclasses) use an `isa' relationship
o represented with a triangle (half diamond) which points to superclasso always one-one
entity belongs to both entity sets subclasses inherit the attributes of their ancestors and participate in their relationships example:
o cartoons have voiceso murder mysteries have weapons
what about multiple inheritance? o e.g., Roger Rabbito not every situation can be modeled with an E/R diagram
Types of Graphs (DAGs and trees)
a directed graph with no cycles, e.g., a C++ class inheritance hierarchy involving multiple inheritance
in a tree, there is only one path from the root to each leaf every tree is also a DAG, but some DAGs are not trees how can we model these types of graphs using the E/R model?
Constraints
additional requirements some of which the modeling language can enforce and others for which it cannot
reflection of schema, not contents examples single-valued constraints
o attributes may only have a single valueo no way to indicate the absence of an attribute valueo many-one relationships
keys referential integrity domain constraints
Keys
attribute or set of attributes from an entity class which uniquely identifies an entity two members of an entity set may not have the same value for a key, e.g., ssn underline key attributes in E/R can consist of more than one attribute there may be more than one key
o but no way to represent this in E/Ro choose one
sometimes key attributes do not belong to entity set: weak entity sets (coming soon ...) storage implications, e.g., C int vs. linked list of ints analogy
Referential Integrity
strengthens at most one to exactly one use curved arrow head in E/R ---) ---) = ---> + `referenced entity must exist', i.e., you can only add a curved arrow head
if you already have a regular arrow head movie-studios example
enforcement o prevent deletion of referenced entity (in [Studios]) until no referents (in [Movies])
refer to ito if referenced entity deleted, all referent entities are deleted as wello force the entry or association of a referenced entity when inserting a member of
the referent entity set 3 ways to enforce
o 2 involve deletionso 1 involves insertion
extended example

o studios can exist without a president,o but you cannot call yourself a president if you are not the president of a studio
Other kinds of modeling constraints
attributes o types (int, floats)o ranges
≤ 4.0 (gpa) ≤ 25 (baseball roster)
cardinality on relationships write `Note(s): ...' on the margin of the page for aspects which cannot be represented
using the E/R model
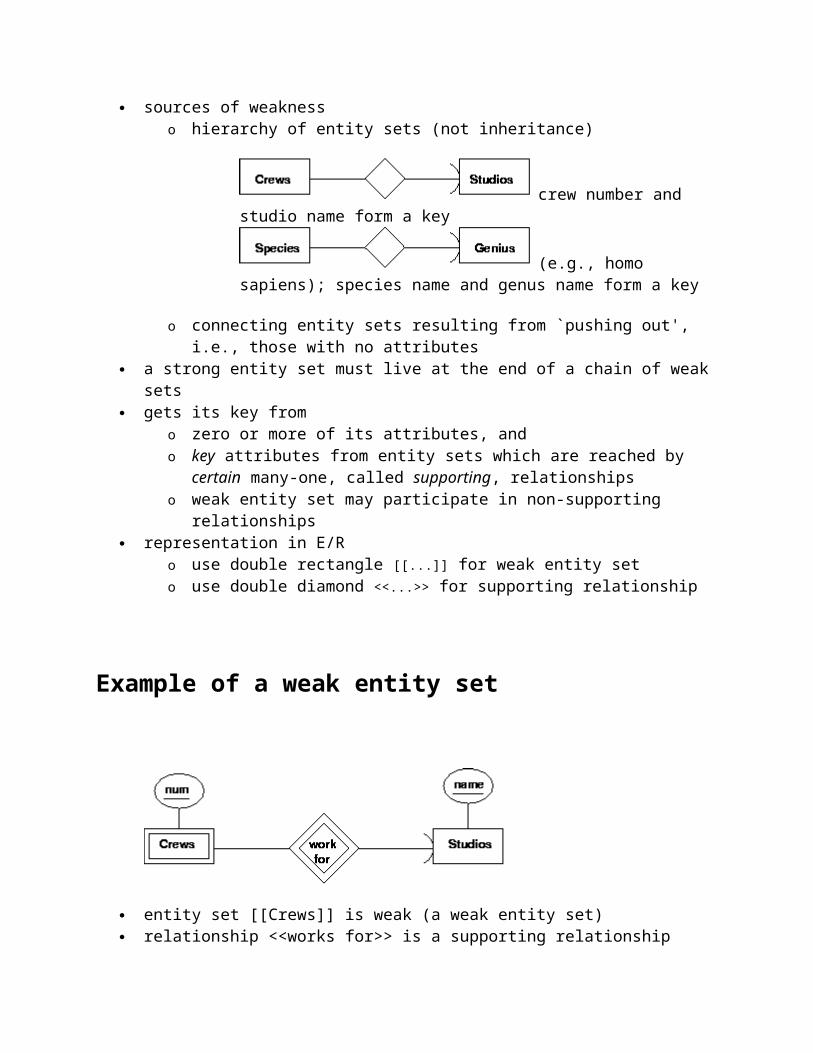
Weak-entity sets
an entity set which derives a subset of its key attributes from other entity sets sources of weakness
o hierarchy of entity sets (not inheritance)
crew number and studio
name form a key (e.g., homo sapiens); species name and genus name form a key
o connecting entity sets resulting from `pushing out', i.e., those with no attributes a strong entity set must live at the end of a chain of weak sets gets its key from
o zero or more of its attributes, ando key attributes from entity sets which are reached by certain many-one, called
supporting, relationshipso weak entity set may participate in non-supporting relationships
representation in E/R

o use double rectangle [[...]] for weak entity set o use double diamond <<...>> for supporting relationship
Example of a weak entity set
entity set [[Crews]] is weak (a weak entity set) relationship <<works for>> is a supporting relationship key of entity set [[Crews]] consists of its attribute (number) and the key attribute (name)
from entity set [Studios] entity set [[Crews]] gets part of its key from the key of entity set [[Studios]]
Requirements for supporting relationship
binary many-one (includes one-one) referential integrity attributes supplied from referenced entity set F to help form key for weak entity set E
must be key attributes of F if referenced entity set F is weak, following the chain to a non-weak entity set rationale behind requirements, especially binary, many-one, and referential integrity
requirements
CLASS 6 .E/R Design Principles
Rules and guidelines
remain faithful to the requirements avoid redundancy: less is more; say things at most once
o e.g., do not add an attribute which is already captured in a relationship, or vice versa
o not only inefficient use of storage, buto we desire a single point of modification
KISS sometimes unnecessary to encode every possible relationship entity set/relationship combo vs. attribute multiway relationship vs. all binary relationships there are many tradeoffs
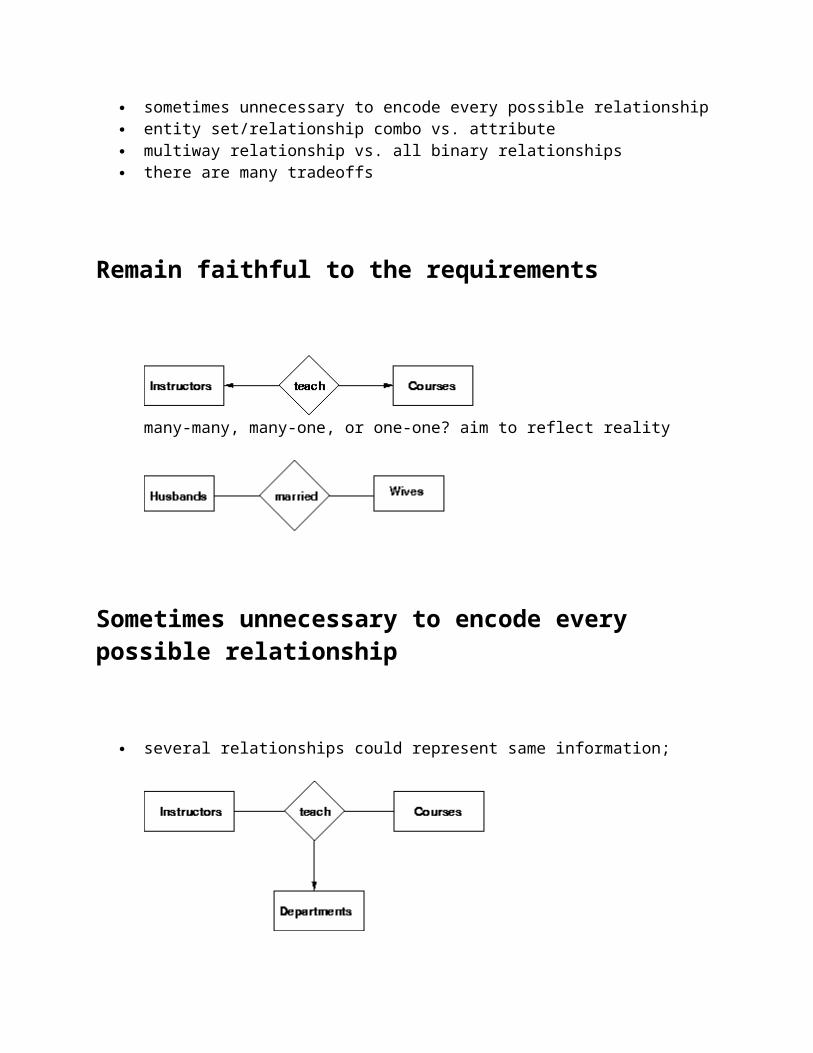
Remain faithful to the requirements
many-many, many-one, or one-one? aim to reflect reality
Sometimes unnecessary to encode every possible relationship
several relationships could represent same information;

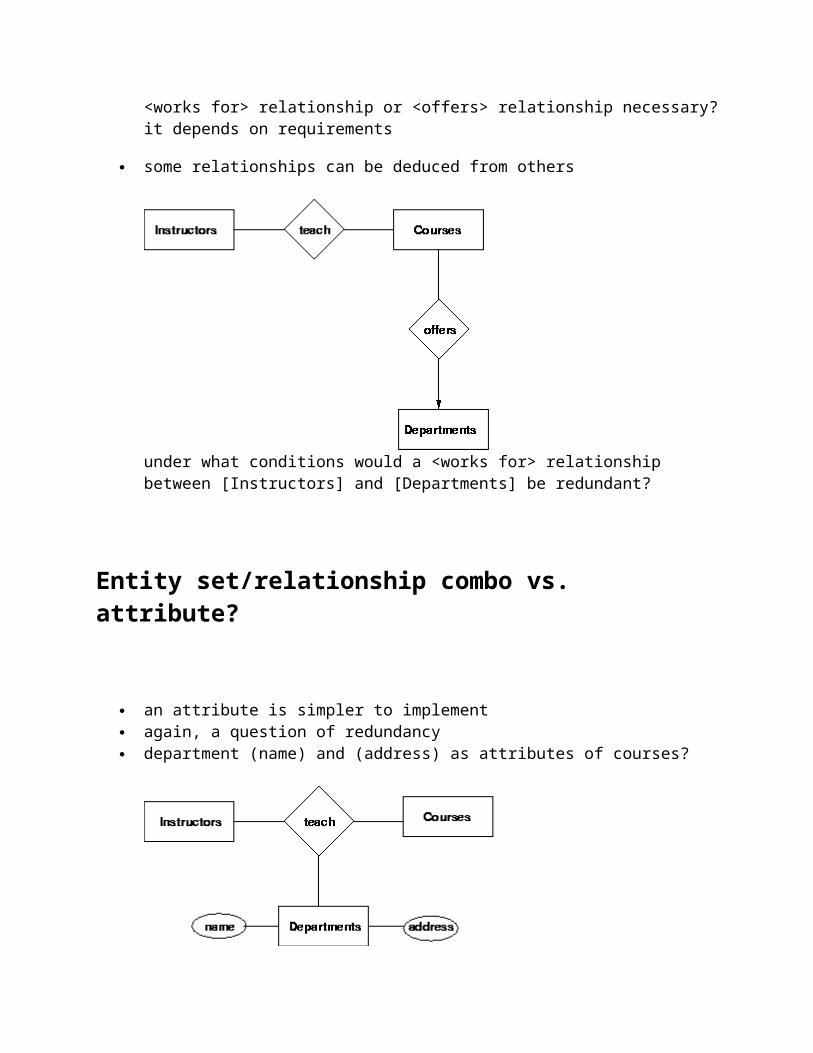
<works for> relationship or <offers> relationship necessary? it depends on requirements
some relationships can be deduced from others
under what conditions would a <works for> relationship between [Instructors] and [Departments] be redundant?
Entity set/relationship combo vs. attribute?
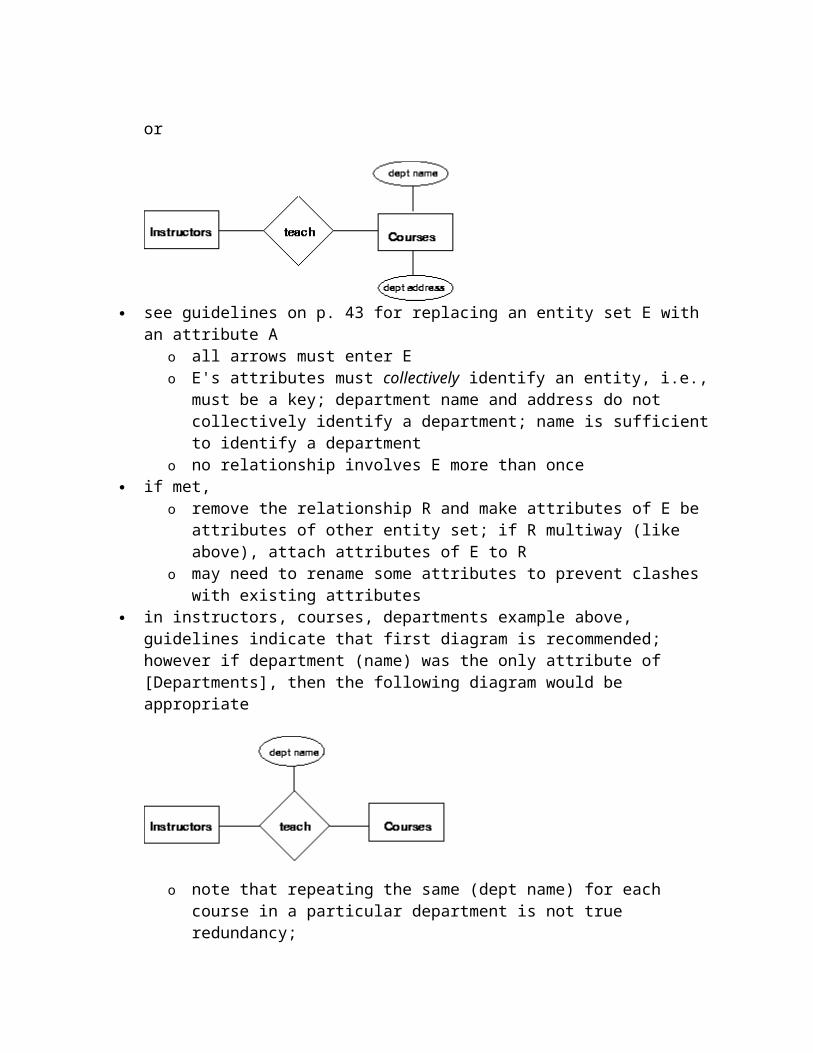
an attribute is simpler to implement again, a question of redundancy department (name) and (address) as attributes of courses?

or
see guidelines on p. 43 for replacing an entity set E with an attribute A o all arrows must enter Eo E's attributes must collectively identify an entity, i.e., must be a key; department
name and address do not collectively identify a department; name is sufficient to identify a department
o no relationship involves E more than once if met,
o remove the relationship R and make attributes of E be attributes of other entity set; if R multiway (like above), attach attributes of E to R
o may need to rename some attributes to prevent clashes with existing attributes in instructors, courses, departments example above, guidelines indicate that first diagram
is recommended; however if department (name) was the only attribute of [Departments], then the following diagram would be appropriate
o note that repeating the same (dept name) for each course in a particular department is not true redundancy;
o however repeating the address for each would be redundant

Multiway relationships vs. all binary
depends on requirements know the differences
Keep in mind
no syntax to specify referential integrity on a many-many relationship; write a note [FCDB] presents the classical notation for E/R modeling there are several extensions to the classical syntax which involve, e.g., the representation
of multivalued attributes the syntax can only constrain the semantics in the multiplicity of relationships; all else is
common sense, e.g., a married person should not be placed in the single entity set even though there is no constraint implicit in the syntax of the diagram forbidding one from doing so
data modeling is more of an art than a science
CLASS 7. Object Definition Language
Review of object-oriented concepts
class extent (of a class): the set of objects belonging to that class object: an instance of a class method ADTs, encapsulation object identity inheritance types
o atomic or primitiveo records or structso collection: arrays, lists, sets
o reference: pointers [FCDB] example 4.1 (p. 134)
Introduction to the Object Definition Language (ODL)
an object-oriented data description language an extension of IDL (Interface Description Language) which is a component of CORBA
(Common Object Request Broker Architecture) -- a standard for distributed OO computing
standardized by ODMG (Object Data Management Group) OID (object identity): a point of departure with E/R model properties
o attributeso relationshipso methods
associated with OQL (Object Query Language) what does a programming language (e.g., C) describe? what does a modeling language (e.g., ODL) describe?
Attributes
unlike the E/R model, attributes are not restricted to simple types, such as integers and strings
why use typedef? o attribute enum {color,blackAndWhite} filmType; vs. attribute enum
Film {color,blackAndWhite} filmType;o latter can be referenced using scoped name, e.g., attribute Movie::Film
uses;
Relationships

use inverse to specify inverse relationships `at most one' semantics remain multiplicity
o if many-many between C and D, then use Set<D> and Set<C>, respectivelyo if many-one from C to D, then use D in C and Set<C> in Do if many-one from D to C, then use C in D and Set<D> in Co if one-one between C and D, then use D and C, respectively
Methods
signatures (or prototypes); why use these? defined using host language (not ODL) hidden argument of method; permits overloading parameter modes:
o in (passed by value),o out (passed by reference), ando in-out (passed by reference)
can raise exceptions [FCDB] example 4.7 (pp. 142-143)
Datatypes
basis o atomic: integer, float, character, character string, boolean, and enumerationo classes
type constructors (can be composed to create complex types) o set: Set<T>o bag: Bag<T>o list: List<T> (sequential access)o array: Array<T,i> (random access)o dictionary: Dictionary<T,S>o structures
difference between sets, bags, and lists rules for types and relationships
o `type of a relationship is either a class type or a (single use of a) collection type constructor applied to a class type' [FCDB]
o `type of an attribute is built starting with atomic type(s)' [FCDB] relationship types cannot involve
o atomic types (e.g., Set<integer>),o structures (e.g., Struct N {Movie field1, Star field2}, oro two applications of collection types (e.g., Set<Array<Star, 10>>)
Additional concepts
multiway relationships not supported; must `push out'; see [FCDB] example 4.9 (pp. 148-149)
multiple inheritance permitted, use :; see [FCDB] example 4.11 (pp. 150-151); conflict resolution
keys are optional; why? o use key or keyso possible to represent all keyso classes without keys are not considered weako relationships and methods can be included in a key; semantics?
method in key: guaranteed to return distinct values on when invoked on distinct objects of the class
many-one relationship in key = weak entity seto [FCDB] examples 4.13-4.15 (pp. 153-154)
extents are contents (analog of entity sets); class is schema o use extent keyword while following singular/plural conventiono interfaces
Similarities between E/R and ODL
both support all multiplicities of relationships both support inheritance
Differences between E/R and ODL
attributes are single-valued in E/R; can be multivalued in ODL keys required in E/R, optional in ODL can only model one key in E/R; can model all (or any subset) in ODL multiway relationships supported in E/R; only binary relationships supported in ODL no multiple inheritance in E/R; ODL supports multiple inheritance
CLASS 8. Mistakes in the Design of Databases
Common Mistakes in the Design of Databases
Unfaithfulness to the domain being modeled. You are expected to use some real-world assumptions when modeling an application. Some common mistakes include stating that one person can be in two places at the same time or one team can play both basketball and football, or not recognizing the multiplicity of relationships (whether it is many-many, many-one, or one-one).
Repeating (reusing) names for entity sets and relationships, i.e., using the same name to denote two different things.
Missing (curved or sharp) arrows in a many-one and/or a one-one relationship.
Forgetting to underline key attributes in E/R.
Using inheritance when there is no ISA connection between two entity sets, i.e., `cooking up' examples of inheritance.
Forgetting that when entity set B inherits from entity set A, B gets everything that A has, and perhaps adds attributes of its own. Thus, there is no need to repeat all the attributes which entity set A has for entity set B.
Reasoning in the following way: ``Entity set B inherits from entity set A. Entity set A participates in a many-many relationship with entity set C, but entity set B does not have a many-many relationship to entity set C; it has no relationship to C.''
This kind of reasoning is flawed. If entity set B inherits from entity set A, it inherits everything from A. Thus, you do not have the right to make exceptions to this rule.
Desire to do so probably means that this is not a real example of inheritance, but rather a cooked up example.
When converting a multiway relationship to many binary relationships using a connecting entity set, forgetting to use only many-one relationships.
Missing arrows from a weak entity set to the set(s) which provide its key attribute(s).
`Cooking up' examples of weak entity sets.
(the remainder are specific to ODL)
Incompatibility between E/R and ODL designs. They say different things.
There is no such thing as an `ODL diagram.' Only E/R has diagram(s). For ODL, you need to produce a listing of the class definitions.
Using declarations such as attribute time today; and not defining time in ODL.
Modeling a single number with Set<integer> instead of just an integer in ODL.
Forgetting to specify the inverses of relationships in ODL.
In an ODL model, note that every relationship has an inverse. Thus, you must specify inverses in all directions.
Forgetting that ODL does not have support for multiway relationships. You must convert such relationships to multiple binary relationships.
Carelessness in defining weak classes in ODL. You should either opt for the `no weak classes, we will use the OID' principle or make the key to contain the identifying relationship for the weak class. Thus, you do not need to `take over' the attributes from the `strong class' and place them with the weak class and/or specify these attributes in the key for the weak class.
CLASS 9. Introduction to Relational Database Model
Introduction to the relational data model

proposed by Edgar Codd in 1969 centered around its primary element: the relation everything is a relation in this model
Why the relational model?
clean separation between physical and logic layers; ANSI Sparc architecture lead to powerful and declarative query languages such as SQL runaway success of simple theoretical concepts put into practice why not design using the relational model from the start?
o E/R good basis for designo E/R not good basis for DMLo since the relational model has only one main element (the relation) in contrast to
the E/R model (which has entity sets, relationships, and so on), it is less flexible for design
o these inflexibilities are best handled after a design has been constructedo relational model has its own design theory (normalization)
there are many normal forms depend on design goals
Overview

Overview of what we will study
E/R (or ODL) → R R → better R (process called normalization) functional dependencies (generalize concept of key) design theory, normal forms
Essential elements of the relational model
a relation is a set of tuples theoretically, a relation is a subset of the Cartesian product: R ⊆ S1 × S2 × ⋅⋅⋅ × Sn
A = {a, b, c}, B = {d, e} (each set specifies a domain)
A × B = {(a,d), (a,e), (b,d), (b,e), (c,d), (c,e)} (each element is called a tuple)
R ⊆ A × B (binary relation)
Students relation ------------------- | ID GPA major |} ← attributes ------------------- | tuple or record → { 001 3.7 CPS |}

005 3.9 ART |} instance: a set of (legal) tuples for a given relation
007 4.0 CIS |} 987 2.0 CPE |} ------------------- | tuple: (001, 3.7, cps) components of a tuple
o 001o 3.7o cps
domain (of gpa is a floating point number between 0.0 and 4.0) instance: a set of (legal) tuples for a given relation relational schema: Students(id, gpa, major) relational database schema (or simply database schema): set of all relational schema in a
database design column order and tuple order is irrelevant a struct in C is a relation, e.g., struct example_relation {int x; float y;};
(Cartesian product of set of all possible values for int and set of all possible values for float)
worked out exercises for several of equivalent relations o exercise 3.1.2 (all parts) on p. 65 from [FCDB]o general form: n! * m!
what changes more frequently: instance or schema? what do we use to change each?
CLASS 10. Converting E/R to Relational Model
From E/R diagrams to relations
(a relation can represent more than just entity sets)
1. convert each entity set into a relation; make all attributes of the entity set attributes of the relation
2. convert each relationship into a relation o make the key attributes of the participating entity sets as well as the attributes of
the relationship attributes of the relation (renaming attributes as appropriate)o what to do with multiple roles?

Some impurities
many-one relationships (are source of consolidation) weak entity sets isa relationships
Combining relations
many-one relationships o relations for the many entity set [E] and the many-one relationship <R> each
should have a key for [E] in their relationo non-key attributes of [E], key attributes of [F], and attributes of <R>, are uniquely
determined by the key of [E]o combine
1. all attributes of [E]2. the key attributes of [F]3. the attributes of <R>
(2) and (3) might be NULL if the one in [F] does not exist!
more efficient to answer queries involving attributes from one relation than attributes distributed across more than one relation
example:
Players(ssn, name, no) --- PlaysFor(ssn, tname)

Teams(name, city) ----
Playsfor(ssn, name, no, tname) ---Teams(name, city) ----
why not add city to combined relation as well?
o riskyo source of redundancy
Converting weak entity sets
incorporate all key attributes of weak entity set [[E]] in relation for E no relation necessary for any supporting relationship unless it has its own attributes
Eliminating relations
what is a proper subset? proper superset? subset is necessary, but not sufficient IRS example: People(name, ssn) and TaxPayers(name, ssn, amount) movies example: Stars(name, address) and Studios(name, address) moral of the story: cannot consolidate blindly

ISA relationships
why no relation necessary for isa relationship? 3 approaches
o E/R style: one relation per entity seto OO style: one relation per sub-tree (including the root)
closed form: 2n, where n is number of nodes, excluding the root there are 4 sub-trees in the movies example
can combine the first two, though we loose some info, i.e., which movies are cartoons
can combine the last two, though, again, though we loose some info, i.e., which movies are cartoons
o NULLs approach: use only one big relation advantages and disadvantages of each approach?
o consider queries NULLs approach minimizes number of relations required to produce an
answer tradeoffs between E/R and OO
o number of relations (small number preferred) nulls at top E/R OO
o storage (prefer to minimize) 1 tuple per entity
OO nulls, though the tuples might be long
more than 1 tuple per entity: E/R, but only key duplicated
Formula possible?
Can we develop a formula for the number of relations necessary for an E/R diagram having e entity sets and r relations?
may need to partition e into weak and non-weak entity sets may need to partition r into supporting, isa, and non-supporting-or-non-isa relationships

CLASS 11. Functional Dependences and Rules of FD's
Keys of relations
a set of one or more attributes of a relation forms a key for that relation if they functionally determine every other attribute of the relation
key must be minimal, i.e., no proper subset is a key remember there may be more than one key underline all of the attributes of one key, called the primary key difference between
o minimal, where no attribute can be removed, and o minimum, which is the smallest possible
E/R model does not require minimal keys superkeys (superset of a key)
o every key is a superkeyo not every superkey is a key
Functional dependencies (FD's)
concept related to keys; a generalization of the idea of keys a constraint: on schema or instance? critical to reducing redundancy key ingredient in the relational database design theory functional dependency: if two tuples agree on a set of attributes, then they must agree on
the other attribute, e.g., A → B o says if two tuples agree on attribute A, they must agree on attribute Bo A and B can also be sets
A1 A2 ... An → B1 A1 A2 ... An → B2 ... A1 A2 ... An → Bm

A1 A2 ... An → B1, B2 ... Bm
Combinations
How to determine keys
keyness many-one English
Determining keys for relations
after a conversion from E/R key for relation derived from entity sets (easy) key for relation derived from relationship
o depends on the relationship typeo remember problem from exam
under what conditions will the key for a relation derived from a many-many relationship always contain all attributes from both participating entity sets?
multiway relationships, what is guaranteed?

Rules of FD's (Armstrong's axioms)
splitting/combining
A1 A2 ... An → B1 B2 ... Bm = A1 A2 ... An → B1 A1 A2 ... An → B2 A1 A2 ... An → B3 ... A1, A2 ... An → Bm
can only split/combine rhs, e.g., title year → length ≠ title → length and year → length
reflexivity: if B is a subset of A, then A → B o these are called trivial FD'so an FD is nontrivial if at least one of the attributes on the rhs does not appear on
the lhs (assume A, B, C are disjoint set of attributes), e.g., A C → B Co an FD is completely nontrivial if none of the attributes on the rhs appear on the
lhs, e.g., A → B augmentation: if A → B, then A C → B C transitivity: if A → B and B → C, then A → C these rules are called Armstrong's axioms; see box on [FCDB] p. 99
CLASS 12. Attribute and FD Closure Algorithms and Canonical Cover
Basic review of logic
`if it is raining outside, I carry an umbrella'; what can you conclude about the state of the world if you see me roaming around Miriam hall with an umbrella in my hand?
if and only if review (iff), bidirectional, ↔ concept of a model concept of entailment in logic, |=
o X |= Y: (read left to right) X entails Yo X |= Y: (read right to left) Y follows from X, or Y is a semantic consequence of X
p ∧ q |= p ∨ q p ∨ q does not entail p ∧ q and, therefore, p ∧ q is not equivalent to p ∨ q

p q p ∨ q p ∧ q
T T T TT F T FF T T FF F F F
if X |= Y and Y |= X, then X <=> Y DeMorgan's Laws
o ¬(A ∨ B) ⇔ ¬A ∧ ¬Bo ¬(A ∧ B) ⇔ ¬A ∨ ¬B
Fixpoints
fixpoint of a function is a point that is mapped to itself by the function f(x) = x 2 is fixpoint for f(x) = x2 - 3x + 4 because f(2) = 2 sometimes there is more than one fixpoint, least fixpoint and greatest fixpoint
o e.g., in f(x) = x2,o x = 0 is the least fixpoint, ando x = 1 is the greatest fixpoint
not all functions have fixpoints, e.g., f(x) = x+1 calculator example: square root function, Newton's method
Newton's method
Newton's method of approximate of successive approximations which says that whenever we have a guess y for the value of the square root of x, we can perform a simple manipulation to get a better guess (one closer to the actual square root) by averaging y with x/y
e.g., we can compute the square root of 2 as follows (suppose the initial guess is 1): guess quotient average -------------------------------------------------------

1 2/1 = 2 (2+1)/2 = 1.5 1.5 2/1.5 = 1.3333 (1.3333+1.5)/2 = 1.4167 1.4167 2/1.4167 = 1.4118 (1.4167+1.4118)/2 = 1.4142 1.4142 ... ... ... ... ... ------------------------------------------------------- continuing this process, we progressively obtain more accurate approximations to the
square root
Closure of a set of FD's
(courtesy [DBSC] Fig. 7.8 [p. 280]) F+ = F repeat
for each FD f ∈ F+ apply reflexivity and augmentation rules on f add the resulting FD's to F+
for each pair of FD's f1 and f2 ∈ F+ if f1 and f2 can be combined using transitivity
add the resulting FD to F+ until F+ does not change any further
When does one set of FD's S follow from another T (i.e., T |= S)?
if every relation instance which satisfies all FD's in T also satisfies all the FD's in S
When are two sets of FD's S and T equivalent (i.e., T ⇔ S)?
if S+ = T+

iff S follows from T and T follows from S; T |= S and S |= T; S ⇔ T if the set of relation instances satisfying S is exactly the same as the set of relation
instances satisfying T
Closure of a set of attributes
closure of a set of attributes A under the set of FD's S is the set of attributes B such that every relation which satisfies all of the FD's in S also satisfies A → B [FCDB]
in other words, A → B `follows from' S (we can also say S |= A → B) closure of a set of attributes {A1, A2, ..., An} is denoted {A1, A2, ..., An}+
X+F = {A | X → A ∈ F+}
X+F = {A | F+ |= X → A}
algorithm (courtesy [DBSC] Fig. 7.9 [p. 281])
F given
result = A
while (changes to result)
for each FD X → Y ∈ F do
if X ⊆ result
result = result ∪ Y
another approach
1. start with initial set of attributes X2. identify FD's A → B where A ∈ X, but B ∉ X3. add B to X4. repeat until no more attributes can be added to the closure, or, in other words,
when you reach a fixpoint what is the running time of the attribute closure algorithm?

Simple exercise
R(A, B, C, D, E, F), S = {A B → C, B C → A D, D → E, C F → B} compute {AB}+
{AB}+ = {ABCDE} means S |= AB → CDE
Basic properties
when is {A1, A2, ..., A2}+ the set of all attributes in a relation? a set of attributes A is a superkey for R iff {A}+ = R a set of attributes A is a key for R iff {A}+ = R and no subset X of A exists where X+ = R
Uses of the attribute closure algorithm?
(see [DBSC] p. 282)
determine if a set of attributes X is a superkey; X+ = {all attributes in R} can check if an FD A → B holds in a relation (i.e., S |= A → B)?
1. compute {A}+
2. check if B ∈ {A}+ 3. if so, A → B
o examples [DBAA] example 6.4.3 (pp. 205-206) does A B → D follow from S? approach, compute {AB}+
does D → E follow from S? approach, compute {D}+
can infer all FD's which follow from a given set of FD's; an alternative to F+
for each Δ ⊆ R

compute Δ+ for each S ⊆ of Δ+
output FD Δ → S
o this is an exponential algorithm (in the number of attributes)o is it NP-complete?o optimizations
the empty set and the set containing all attributes will never lead to any nontrivial FD's
once we determine that a set of attributes S is a superkey, we need not compute the closure of any supersets of S because they will never lead to any new nontrivial FD's
Example
consider the relation R(A, B, C, D) derive all FD's which follow from S = {A B → C, C → D, D → A} look at all subsets of {A,B,C,D} and see which lead to new FD's all singletons
{A}+ = {A} {B}+ = {B} {C}+ = {A,C,D} {D}+ = {A,D}
new FD: C → A
all pairs {A,B}+ = {A,B,C,D} {A,C}+ = {A,C,D} {A,D}+ = {A,D} {B,C}+ = {A,B,C,D} {B,D}+ = {A,B,C,D} {C,D}+ = {A,C,D}
new FD's: A B → D, B C → A B D → C
all triples {A,B,C}+ = {A,B,C,D} {A,B,D}+ = {A,B,C,D} {A,C,D}+ = {A,C,D}

{B,C,D}+ = {A,B,C,D}
no new FD's?
all subsets of size 4: no need to look at them so the complete set of completely nontrivial FD's is {A B → C, C → D, D → A, C → A,
A B → D, B C → A, B D → C} we need not have computed the closure of sets {ABC}, {ABD}, and {BCD}
Basis set of FD's
a set of FD's F is a basis set of FD's iff F+ = {all FD's of the relation} a basis set of FD's f is a minimal basis iff no proper subset of it is also a basis a relation may have several minimal bases
What is a minimal basis (canonical cover) Fc?
Fc is a minimal basis iff F |= Fc and Fc |= F, and Fc has no extraneous attributes, and all lhs are unique
Concept of extraneousness
two ways to be extraneous

o extraneous FD, e.g., A → C is an extraneous FD in the set {A → B, B → C, A → C}
o extraneous attribute (on either side of an FD)
AB → C, A → C (B is extraneous in the first FD) AB → CD, A → C (is any attribute extraneous?)
given X → Y ∈ F
A is extraneous if A ∈ X and F |= (F-(X → Y)) ∪ {(X-A) → Y}
I=X-A
check if F |= I → Y
if Y ⊆ IF+, then A is extraneous
or
A is extraneous if A ∈ Y and (F-(X → Y)) ∪ {(X → (Y-A))} |= F
F' = (F-(X → Y)) ∪ {X → (Y-A)}
F' |= X → A
if A ⊆ XF'+, then A is extraneous
example: F = {AB → CD, A → E, E → C}, is C extraneous in the first FD?
ABF'+ = {AB → D, A → E, E → C} = {ABCDE}
The answer is yes.
Canonical cover algorithm
Fc = F repeat
use join rule to combine X → Y, X → Z to X → YZ

find an FD in Fc with an extraneous attribute in either X or Y and delete it from X → Y
until you reach a fixpoint for Fc
Canonical cover example
A → BC B → C A → B AB → C
(C is extraneous in the first FD and A is extraneous in the last FD)
minimal basis: {A → B, B → C}
a minimal basis does not always have the smallest number of FD's, e.g., which of the following two sets of FD's is a minimal basis? {A → B, B → C} or {A → C}
remember a minimal basis must be a basis first
Soundness and completeness of algorithms
sound: finds no false positives (returns no wrong answers) complete: finds all true positives (returns all right answers) ideally we want both means Armstrong's axioms are sound and complete
FD's in projected relations
what is projection?

what FD's hold in the projected relation? example 5 (courtesy [FCDB] example 3.23, pp. 99-100): R(A, B, C, D) with S = {A → B,
B → C, C → D}, project to S(A, C, D), take closure of all subsets, add FD X → E for each attribute E that is in X+ and S, but not R
CLASS 13. Overview of first-order predicate logic
What types of logics are there?
propositional logic, a proposition logical statement which is either true or false (e.g., Socrates is a man).
predicate logic (also called quantified logic) (e.g., Man(Socrates))
Logic programming
re-curring theme: mismatch between formal systems and computer systems logic programming is based on formal logic `formal logic was developed to provide a method for describing propositions, with the
goal of allowing those formally stated propositions to be checked for validity' [COPL] `symbolic logic can be used for the three basic needs of formal logic: to
o express propositions,o express relationships between propositions, ando to describe how new propositions can be inferred from other propositions which
are assumed to be true' [COPL] the form of symbolic logic relevant to logic programming is called first-order predicate
calculus

essence of logic programming: `a collection of propositions are assumed to be axioms (i.e., universal truths) and from these axioms, a desired fact is proved by applying the rules of inference in some automated way' [PLPP].
Propositions
Propositional Logic (courtesy Randal Nelson and Tom LeBlanc, Predicate Logic (courtesy Randal Nelson and Tom LeBlanc, University of Rochester)
atomic propositions: o examples:
man(socrates). friend(larry, sallie).
o man is called the functoro larry, sallie is the ordered list of parameterso when the functor and the ordered list of parameters are written together in the
form of a function as one element of a relation, the result is called a compound term
o no intrinsic semantics (they can mean whatever you want them to mean)o man(socrates). can be a fact or query
compound propositions: two or more atomic propositions connected by the following logical connectors, or operators:
Concept Symbol Example Meaningnegation ¬ ¬a not aconjunction ∧ a ∧ b a and bdisjunction ∨ a ∧ b a or bequivalence ⇔ a ⇔ b a is equivalent to bimplication ⊃ a ⊃ b a implies bimplication ⊂ a ⊂ b b implies a
(precedence proceeds top-down)
examples:

a ∨ b ⊃ c
a ∨ ¬b ⊃ d ⇔ (a ∨ (¬b)) ⊃ d
a ⊃ b ⇔ ¬ a ∨ b
entailment (semantic consequence): o P |= Q
read left to right says: `P entails Q' read right to left says: `Q follows from P' or `Q is a semantic consequence
of P' o means that all of the models (i.e., true rows in the truth table) on the left hand side
must also be models on the right hand sideo for instance, a ∧ b |= a ∨ bo entailment (|=) is not implication (⊃)o implication is a statment, entailment is a meta-statement
quantifiers (introduce variables):
Quantifier Example Meaninguniversal ∀ X.P ∀ X, P is trueexistential ∃ X.P ∃ a value of X such that P is true
o examples:
∀ X.(USpresident(X) ⊃ UScitizen(X)). ∃ X.(USpresident(X) ∧ servedmorethan2terms(X)). ∃ X.(hascar(larry, X) ∧ sportscar(X)).
o scope is attached to atomic propositiono use parentheses to indicate scopeo quantifiers have highest precedence
great deal of redundancy in predicate calculus o one proposition can be stated several different ways

o fine for logicians, but poses a problem if we are to implement symbolic logic in a computer system
Clausal form
a standard (simplified) form for propositions: B1 ∨ B2 ∨ ... ∨ Bn ⊂ A1 ∧ A2 ∧ ... ∧ Am. o A's and B's are termso left hand side is consequento right hand side is antecedento interpretation: if all of the A's are true, then at least one of the B's must be true
examples (courtesy [COPL]):
likes(bob, trout) ⊂ likes(bob, fish) ∧ fish(trout). father(louis, al) ∨ father(louis, violet) ⊂ father(al, bob) ∧ mother(violet, bob) ∧ grandfather(louis, bob).
advantages o existential quantifiers are unnecessaryo universal quantifiers are implicit in the use of variables in the atomic propositionso no operators other than conjunction and disjunction are requiredo all predicate calculus propositions can be converted to clausal form
Horn clauses
`when propositions are used for resolution, only a restricted kind of clausal form called a Horn clause can be used, which further simplifies the resolutions process' [COPL]
Horn clause: a proposition with 0 or 1 terms in the consequent o headless Horn clause: a proposition with 0 terms in the consequent (e.g., {} ⊂
man(jake). (or false ⊂ man(jake).) (called a goal or query in PROLOG))

o headed Horn clause: a proposition with 1 atomic term in the consequent (e.g., likes(bob, trout) ⊂ {}. (or likes(bob, trout) ⊂ true.) (called a fact in
PROLOG) likes(bob, trout) ⊂ like(bob, fish) ∧ fish(trout). (called a rule in
PROLOG)
)
`most, but not all, propositions can be stated as Horn clauses' [COPL] (e.g., p(a) and (∃x,
not(p(x))) [PLPP], pp. 565-566)
logic PROLOGheadless Horn clause goal/queryheaded Horn clause fact/rule
Conversion examples
(courtesy [PLPP])
basic idea: `remove or (∨) connectives by writing separate clauses and treat the lack of quantifiers by assuming that variables appearing in the head are universally quantified, while variables appearing in the body (not also in the head) are existentially quantified' [PLPP]
greatest common divisor: o specification of GCD (proposition):
the gcd of u and 0 is u the gcd of u and v, if v is not 0, is the same as the gcd of v and the remainder of dividing v into u
o FOPL:
∀ u, gcd(u, 0, u). ∀ u, ∀ v, ∀ w, gcd(u, v, w) ⊂ ∼ zero(v) ∧ gcd(v, u mod v, w).
o Horn clauses:

gcd(u, 0, u). gcd(u, v, w) ⊂ ¬ zero(v) ∧ gcd(v, u mod v, w).
grandparent:
o specification of grandparent (proposition):
x is a grandparent of y if x is the parent of someone who is the parent of y
o FOPL:
∀ x, ∀ y, (∃ z, grandparent(x,y) ⊂ parent(x,z) ∧ parent(z,y)).
o Horn clause:
grandparent(x,y) ⊂ parent(x,z) ∧ parent(z,y).
remember, universal quantifier is implicit and existential quantifier is not required: all variables on lhs of ⊂ are universally quantified and those on rhs (which do not appear on the lhs) are existentially quantified
mammal: o specification of mammal (proposition):
∀ x, if x is a mammal, then x has two or four legs
o FOPL:
∀ x, legs(x,2) ∨ legs(x,4) ⊂ mammal(x).
o Horn clauses:
legs(x,2) ⊂ mammal(x) ∧ ¬ legs(x,4). legs(x,4) ⊂ mammal(x) ∧ ¬ legs(x,2).
`in general the more connectives which appear on the lhs of the ⊂, the harder to translate
into a set of Horn clauses' [PLPP] skolemization: a technique to eliminate existential quantifiers (courtesy Thoralf Skolem)
involving Skolem constants and functions

Use of all of this: proving theorems (P |= ?)
what can we infer from known axioms and theorems? need a deductive apparatus known as rules of inference
Resolution
there are many rules of inference in formal systems resolution (courtesy Alan Robinson) is the primary rule of inference used in logic
programming resolution is a rule of inference which allows new propositions to be inferred from given
propositions resolution was devised to be used with propositions in clausal form
(a ⊃ b) ∧ (b ⊃ c)
a ⊃ c
how do we apply resolution? (example)
b ⊂ a. c ⊂ b.
b ∧ c ⊂ a ∧ b. c ⊂ a.
or more generally (assume bi matches a):
a ⊂ a1 ∧ ... ∧ an b ⊂ b1 ∧ ... ∧ bm
b ⊂ b1 ∧ ... ∧ bi-1 a1 ∧ ... ∧ an ∧ bi+1 ∧ ... ∧ bm

example (courtesy [COPL]):
older(joanne, jake) ⊂ mother(joanne, jake). wiser(joanne, jake) ⊂ older(joanne, jake).
older(joanne, jake) ∧ wiser(joanne, jake) ⊂ mother(joanne, jake) ∧ older(joanne, jake). wiser(joanne, jake) ⊂ mother(joanne, jake).
example (courtesy [COPL]):
father(bob, jake) ∨ mother(bob, jake) ⊂ parent(bob, jake). grandfather(bob, fred) ⊂ father(bob, jake) ∧ father(jake, fred).
(father(bob, jake) ∨ mother(bob, jake)) ∧ grandfather(bob, fred) ⊂ parent(bob, jake) ∧ father(bob, jake) ∧ father(jake, fred).
mother(bob, jake) ∨ grandfather(bob, fred) ⊂ parent(bob, jake) ∧ father(jake, fred).
backward chaining systems (PROLOG) vs. forward chaining systems (CLIPS)
hypothesis vs. goal
fact vs. goal
mammal(human) ⊂ {}. (a fact) {} ⊂ mammal(human). (a goal) {} ⊂ mammal(human) ∧ legs(x,2). (a goal; each term on rhs is called a sub-goal)
proof by contradiction: goodday(thu). ?- goodday(thu).
goodday(thu) ⊂ true. false ⊂ goodday(thu).

false ⊂ true (a contradiction)
resolution algorithm ([PLPP]):
goal: {} ⊂ a rule: a ⊂ a1 ∧ ... ∧ an
match goal with head of one of the known clauses, and replace the matched goal with the body of the clause, creating a new list of sub-goals
therefore, the original goal is replaced with subgoals: {} ⊂ a1 ∧ ... ∧ an
if, after multiple iterations of this process, we end up with the empty Horn clause {} ⊂ {}, then the proposition has been proved (i.e., it is a theorem)
resolution can be slow on a large database
the presence of variables in propositions makes the process of resolution more complex than this
o requires temporary assignment of values to variables called instantiationo the process of determining useful values for variables is called unificationo unification often involves backtracking
logic programming = resolution + unification
Resolution examples
example (courtesy [PLPP]):
mammal(human) ⊂ {}.
{} ⊂ mammal(human).
mammal(human) ⊂ mammal(human).

{} ⊂ {} (proved!)
another example (courtesy [PLPP]):
legs(x,2) ⊂ mammal(x) ∧ arms(x, 2). legs(x,4) ⊂ mammal(x) ∧ arms(x, 0). mammal(horse) ⊂ {}. arms(horse,0) ⊂ {}.
{} ⊂ legs(horse, 4).
legs(x,4) ⊂ mammal(x) ∧ arms(x,0) ∧ legs(horse, 4). (using the second rule above)
now to cancel out, we need unification (bind x to horse)
legs(horse,4) ⊂ mammal(x) ∧ arms(x,0) ∧ legs(horse, 4). {} ⊂ mammal(x) ∧ arms(x,0).
mammal(horse) ⊂ mammal(horse) ∧ arms(horse,0). (using the third rule above) {} ⊂ arms(horse,0).
arms(horse,0) ⊂ arms(horse,0). (using the fourth rule above) {} ⊂ {}. (proved!)
CLASS 14. Normalization
The BIG picture
ideas → E/R → relations → better (normalized) relations why study FD's? inferring FD's is very important to identifying flaws in the design of a
database final goal: Boyce-Codd Normal Form (BCNF)
Students relation

key: {id, advisor_id} FD's: {id → name level favorite_advisor, advisor_id → advisor_office}
name | id | level | advisor_id | advisor_office | favorite_advisor------------------------------------------------------------------Mark 1 Senior 349 AN151 350??? 1 ??? 350 MH134 ???Kathy 2 Senior 146 AN240 146??? 1 ??? 351 AN130 ?????? 1 ??? 352 AN131 ?????? 2 ??? 351 ??? ???David 3 Junior 349 ??? 349------------------------------------------------------------------`???' denotes redundant, i.e., can be inferred from other tuples
Sources of redundancy
update anomaly (more serious of the two): what happens if we update the favorite_advisor of Mark?
deletion anomaly: if 350 is not the advisor for anybody, we lose their room info!
Root cause of the problem
main idea: if each FD is not in the form `key → {all other attributes}' then the relation has too much stuff in it
specifically, each FD has a lhs which is a proper subset of the key! (a BCNF violation)
Normalization

process of making relations better by decomposing them into smaller relations to o reduce redundancyo eliminate update anomalieso eliminate deletion anomalies
final goal: all relations in Boyce-Codd Normal Form (BCNF)
Boyce-Codd Normal Form
the lhs of every nontrivial FD is a super-key above anomalies are guaranteed not to exist in relations which satisfy this condition formally, R is in BCNF if for every nontrivial FD X → A in R, X is a superkey advantages
o removes redundancyo removes update anomalieso removes deletion anomalies
Proof that every two-column relation is in BCNF
1. there are no nontrivial FD's; key: {A, B}; R in BCNF2. A → B is the only nontrivial FD; key: {A}; R in BCNF3. B → A is the only nontrivial FD; key: {B}; R in BCNF4. A → B, B → A are the only nontrivial FD's keys: {A}, {B}; R in BCNF
Decomposition into BCNF
need to ensure that we can reconstruct the decomposed relation therefore, we cannot just break a relation schema into a collection of two-attribute
relations process:

1. find a nontrivial FD where the lhs is not a superkey; make sure the rhs is maximally expanded
2. split the original relation into two new relations one containing only the attributes from both sides of the violating FD the other containing all attributes from the original relation except the rhs
of the violating FD
Decomposing Movies
Movies(title, year, length, filmType, studioName, starName)
has update and deletion anomalies is it in BCNF? no; violating FD: title year → length, filmType, studioName decompose into
o Movies1(title, year, length, filmType, studioName)o Movies2(title, year, starName)
are these relations in BCNF? must determine its complete set of FD's by computing the closure of each subset of its
attributes, using the full set of FD's satisfied by the decomposed relation does Movies2 have an update anomaly?
Another Movie example
MovieStudio(title, year, length, filmType, studioName, studioAddr) FD's: title year → length filmType studioName studioAddr, studioName →
studioAddr key: {title, year} decomposition:
o MovieStudio1(title, year, length, filmType, studioName)o MovieStudio2(studioName, studioAddr)
Is one application sufficient? No

StudioPres(title, year, studioName, president, presAddr) FD's: title year → studioName studioName → president + president → presAddr -------------------------- title year → studioName president presAddr studioName → president presAddr president → presAddr key: {title, year} decomposition:
o StudioPres1(title, year, studioName)o StudioPres2(studioName, president, presAddr)
StudioPres1 is in BCNF; key: {title, year} StudioPres2 is not in BCNF;
o key: {studioName}o violating FD: president → presAddr
solution: decompose again final relational schema
o R1(title, year, studioName)o R2(studioName, president)o R3(president, presAddr)
Reconstructing a relation from a decomposition
join the relations on the common attributes guaranteed to produce the original relation if we decomposed based on the BCNF
decomposition (a violating FD) decomposing in a way not based on an FD: ----- A B C ----- 1 2 3 4 2 5 ----- --- A B --- 1 2 4 2 ---

--- B C --- 2 3 2 5 ---
after joining, we get
-----A B C-----1 2 31 2 54 2 34 2 5-----
CLASS 15 . Third Normal Form(3NF)
Third Normal Form (3NF)
consider: o Bookings(title, theatre, city) witho FD's: {theatre → city, title city → theatre}
FD theatre → city violates the condition for BCNF decompose:
o R1(theatre, city)o R2(theatre, title) -------------------- theatre | city -------------------- Guild | Menlo Park Park | Menlo Park -------------------- ----------------- theatre | title ----------------- Guild | The Net Park | The Net -----------------

------------------------------ theatre | city | title ------------------------------ Guild | Menlo Park | The Net Park | Menlo Park | The Net ------------------------------
now FD title city → theatre is not preserved solution: slightly relaxing BCNF requirement leads to the third normal form (3NF) a relation is in 3NF if for each nontrivial FD X → Y, either X is a superkey or Y is prime
(a member of some key) decomposition into relations in 3NF
o does not lose any information, ando allows FD's to be verified,o but if the relations are not also in BCNF, then there will be some redundancy in
the schema
Recap
the decomposition into BCNF provides a lossless join decomposition, i.e., we can reconstruct the tuples of the original relation by joining
the BCNF decomposition however does not preserve dependencies 3NF is weaker than BCNF decomposition into 3NF (not covered)
o preserves dependencies, and o provides a lossless join,o but does not guarantee the elimination of redundancy (unless, of course, the
relations are also in BCNF)
Good properties of breakups (if such things exist :-)
1. removes redundancy2. lossless join decomposition3. dependency preservation
BCNF guarantees 1 & 2

3NF guarantees 2 & 3 no normal form guarantees all 3
Interesting example
----------------------name address car----------------------Carla 1 HondaCarla 1 ToyotaCarla 2 HondaCarla 2 ToyotaChuck 1 FordChuck 1 ChevyChuck 3 FordChuck 3 Chevy ----------------------There are no nontrivial FD's in this relation.
Is this relation in BCNF?
Is there any redundancy?
for one person, each address repeated for each car means attribute address is independent of attribute car specified by MVD: name →→ address
Multivalued dependencies (MVD's)
assertion that two attributes or sets of attributes are independent of each other schematic view written A →→ B MVD's are a generalization of FD's: all FD's are MVD's, why?
Every FD is an MVD

Every FD X → Y is also an MVD X →→ Y:
Consider the following relation which satisfies the FD id → name: -----------------------id name likes_color-----------------------1 X red1 X blue2 Y red2 Y blue-----------------------We want to see if this relation also satisfies the MVD id →→ name.
To do that we need to find a tuple v which
o agrees with two tuples t and u on the lhs of the MVD (id),o agrees with t on the rhs of the MVD (name), ando agrees on all else (likes_color) with u.
---------------------------------- id name likes_color----------------------------------(t) 1 X red(u & v) 1 X blue----------------------------------
The tuple u can be such a tuple v. Tuple v agrees with both t and u on id, it agrees with t on name, and it agrees with u on likes_color. Must find such a tuple v for every id.
Therefore this relation satisfies the MVD id →→ likes_color.
In general, every FD is also a MVD. You can find never an FD satisfied by a relation R that is not also a MVD satisfied by R.
Note that every MVD is not necessarily an FD.
Rules for MVD's
MVD's do not obey all of the rules of FD's MVD's do not obey the splitting/combining rule
o i.e., X →→ Y and X →→ Z does not imply X →→ Y Z

o e.g., name →→ street does not hold in StarsIn complementation rule
o means name →→ caro has no analog in the world of FD's
transitive rule every FD is a MVD; why? trivial dependencies rule (resembles reflexivity)
Fourth Normal Form (4NF)
eliminates the redundancy caused by MVD's nontrivial MVD A →→ B
o none of the Bs are among the Aso A ∪ B ≠ R
condition: essentially BCNF condition applied to MVD's o for all nontrivial MVD's A →→ B, A is a superkeyo means every BCNF violation is a 4NF violationo every relation in 4NF is in BCNF
Decomposition into 4NF
analogous to decomposition in BCNF; just string replace acronym FD with MVD Cars example
o now MVD name →→ address is trivialo ditto for name →→ car
how to determine the new MVD's? there is no easy way (such as computing the closure in BCNF)
Relationship of normal forms

concentric circles: 4NF ⊂ BCNF ⊂ 3NF 1NF: requires every column to have an atomic value 2NF: primarily historical at this point 5NF
o further generalization of MVD's to JDso beyond the scope of CPS 430/542
Good properties of breakups (final)
1. removes redundancy caused by FD's2. removes redundancy caused by MVD's3. lossless join decomposition4. preserves FD's5. preserves MVD's
4NF guarantees 1, 2, & 3 BCNF guarantees 1 & 3 3NF guarantees 3 & 4 no normal form guarantees all 5
Goal
BCNF (no redundancy due to FD's & lossless join) if not possible, aim for
o 3NFo lossless joino dependency preservation
Frequenty asked question (and summary)

If a relation R is in BCNF, then it is automatically in 3NF because 3NF is a weaker normal form than BCNF. Then does not BCNF preserve dependencies like 3NF if all relations in BCNF are also in 3NF?
First, we must realize we are talking about two different things (`normal forms' and `decomposition algorithms') and we should not confuse the two.
When we talk of normal forms, the following holds:
the set of relations in 4NF is a proper subset of the set of relations in BCNF the set of relations in BCNF is a proper subset of the set of relations in 3NF
This means any relation in BCNF is automatically in 3NF.
Now, when we talk of properties of `decompositions' (not normal forms), there is no such subset relationship.
We say the `decomposition into BCNF' removes redundancy (but for all we know, the smaller relations resulting may not be in BCNF at all (and we saw such an example in class). In such cases, we must apply the decomposition algorithm again.
We say the `decomposition into 3NF' preserves dependencies. Saying that relations in 3NF preserve dependencies is nonsense (what would that mean?).
When we talk of good properties of breakups, we are talking about `decompositions' NOT normal forms. We say that the `decomposition procedure into 3NF' preserves FD's, but that has nothing to do with saying that all relations in BCNF are also in 3NF. You will notice that we never showed the `decomposition procedure into 3NF.' We only covered the breakup procedure into BCNF and 4NF.
One can never find a relation in BCNF that is not in 3NF.
In summary, a relation is in
3NF, if for every nontrivial FD X → Y, X is either a superkey or Y is part of a key BCNF, if for every nontrivial FD X → Y, X is a superkey 4NF if for every nontrivial MVD X →→ Y, X is a superkey
To decompose into
3NF (not covered in this course) BCNF: find a violating FD X → Y
o create a new relation R1(X, Y)o create a new relation R2(X, R-Y)
4NF: find a violating MVD X →→ Y o create a new relation R1(X, Y)

o create a new relation R2(X, R-Y)


















