
Clasificador Bayesiano de Documentos MedLine a partir de Datos … · Clasificador Bayesiano de...
19
Clasificador Bayesiano de Documentos MedLine a partir de Datos No Balanceados Raquel Laza y Reyes Pavón Sistemas de Software Inteligentes y Adaptables, Universidad de Vigo, Ourense, España. [email protected] , [email protected] Resumen. La presencia de clases no balanceadas es un problema frecuente en muchas aplicaciones de aprendizaje automático y cuyos efectos sobre el desempeño de clasificadores estándar son notables. Se han desarrollado numerosas técnicas para hacer frente al problema de las clases no balanceadas en el aprendizaje automático. En este artículo se ha investigado acerca de la aplicación de técnicas de balanceado de datos en la clasificación de documentos MedLine, donde cada documento se ha representado por un conjunto de términos de la ontología MeSH y donde el clasificador se ha basado en una red bayesiana. Abstract. Imbalanced datasets is a common problem in many applications of machine learning and its effects on the performance of standard classifiers are remarkable. Numerous methods have been developed to face the problem of unbalanced class in machine learning. In this paper we investigate the application of techniques for balancing data to classify MedLine documents, where each document is identified by a set of MeSH ontology terms and where the classifier is based on a bayesian network. Palabras clave: Aprendizaje automático,clasificadores, datos no balanceados, redes bayesianas, documentos MedLine, términos MeSH. 1 Introducción La clasificación automática de textos en categorías predefinidas se basa principalmente en el uso de técnicas de aprendizaje automático: procesos inductivos que construyen clasificadores de forma automática a partir de conjuntos preclasificados de documentos. Uno de los principales problemas con los que se enfrenta esta tarea es la presencia de categorías o clases no balanceadas. El problema de clases desbalanceadas ocurre cuando el número de instancias pertenecientes a cada clase es muy diferente. Ello provoca que los clasificadores tengan gran exactitud para calcular modelos sobre la clase mayoritaria pero una pobre exactitud predictiva sobre los datos de la clase minoritaria [1]. Esto ocurre puesto que el clasificador intenta reducir el error global, de forma que el error de clasificación no tiene en cuenta la distribución de los datos. El contar con pocos datos
-
Upload
trinhkhanh -
Category
Documents
-
view
214 -
download
0
Transcript of Clasificador Bayesiano de Documentos MedLine a partir de Datos … · Clasificador Bayesiano de...

Clasificador Bayesiano de Documentos MedLine a partir de Datos No Balanceados
Raquel Laza y Reyes Pavón
Sistemas de Software Inteligentes y Adaptables, Universidad de Vigo, Ourense, España.
[email protected], [email protected]
Resumen. La presencia de clases no balanceadas es un problema frecuente en muchas aplicaciones de aprendizaje automático y cuyos efectos sobre el desempeño de clasificadores estándar son notables. Se han desarrollado numerosas técnicas para hacer frente al problema de las clases no balanceadas en el aprendizaje automático. En este artículo se ha investigado acerca de la aplicación de técnicas de balanceado de datos en la clasificación de documentos MedLine, donde cada documento se ha representado por un conjunto de términos de la ontología MeSH y donde el clasificador se ha basado en una red bayesiana. Abstract. Imbalanced datasets is a common problem in many applications of machine learning and its effects on the performance of standard classifiers are remarkable. Numerous methods have been developed to face the problem of unbalanced class in machine learning. In this paper we investigate the application of techniques for balancing data to classify MedLine documents, where each document is identified by a set of MeSH ontology terms and where the classifier is based on a bayesian network. Palabras clave: Aprendizaje automático, clasificadores, datos no balanceados, redes bayesianas, documentos MedLine, términos MeSH.
1 Introducción
La clasificación automática de textos en categorías predefinidas se basa principalmente en el uso de técnicas de aprendizaje automático: procesos inductivos que construyen clasificadores de forma automática a partir de conjuntos preclasificados de documentos. Uno de los principales problemas con los que se enfrenta esta tarea es la presencia de categorías o clases no balanceadas. El problema de clases desbalanceadas ocurre cuando el número de instancias
pertenecientes a cada clase es muy diferente. Ello provoca que los clasificadores tengan gran exactitud para calcular modelos sobre la clase mayoritaria pero una pobre exactitud predictiva sobre los datos de la clase minoritaria [1]. Esto ocurre puesto que el clasificador intenta reducir el error global, de forma que el error de clasificación no tiene en cuenta la distribución de los datos. El contar con pocos datos

para una clase dificulta el desempeño de los clasificadores porque existen pocos datos para soportar los posibles patrones que se van construyendo. El problema de los datos no balanceados en minería de datos es un tema que ha
cobrado gran interés para muchos investigadores, quienes han desarrollado sus propias técnicas para solventar este problema, el cual está presente no solo en la clasificación de textos, sino en muchos otros dominios de aplicación entre los que podemos citar la detección de fraude, detección de derrames de petróleo a partir de imágenes de radar, detección de fallas en procesos industriales, diagnósticos médicos, etc [2]. En muchas de estas aplicaciones la clase minoritaria es justamente la clase de mayor interés y la que más nos interesa clasificar correctamente, puesto que está formada por los casos que ocurren con menor frecuencia o que son más difíciles de identificar [4]. Por ejemplo, en el caso de detección de cáncer, tenemos pocos pacientes enfermos (clase minoritaria) y gran cantidad de pacientes sanos (clase mayoritaria). En este caso, nos interesa detectar correctamente a los pacientes enfermos, y permitir un pequeño error en la clase mayoritaria, ya que un falso negativo (caso en el que un paciente enfermo se clasifica como sano) es grave, puesto que rara vez un paciente al que no le detectan cáncer pide una segunda opinión. En este artículo trataremos el problema de los conjuntos de datos desequilibrados
en clasificación de textos biomédicos. Se parte de un trabajo previo en el que se realizó una propuesta de modelo binario de clasificación automática de documentos MedLine1 a partir de su vocabulario MeSH2 [13]. El modelo binario de clasificación utiliza Redes Bayesianas, para representar las relaciones de dependencia e independencia entre términos MeSH de un conjunto de documentos previamente clasificados en dos categorías: relevantes y no relevantes. Dado un nuevo documento para ser clasificado, sus términos MeSH se utilizan como evidencias en la red y la probabilidad de relevancia es calculada utilizando el proceso de inferencia de la red bayesiana. Finalmente el documento es clasificado en relevante o no relevante en función de la probabilidad obtenida. El conjunto de datos utilizado para la creación y prueba del modelo se tomó de los documentos presentados en “TREC 2005 Genomics track” [14]. Los resultados obtenidos fueron prometedores, pero se detectó un problema de sobreentrenamiento de la red con documentos no relevantes, debido a que el conjunto de datos del que se dispone está desequilibrado, donde la mayoría de los documentos pertenecen a la clase de no relevantes. El objetivo de este documento es tratar este problema, estudiando las técnicas ya
existentes y adaptándolas a nuestro caso de estudio, intentando mejorar la clasificación de documentos relevantes. Como solución se han planteado diversos métodos: redimensionar el conjunto de entrenamiento o utilizar pesos para las categorías dando mayor peso a las minoritarias. Además de esta introducción el artículo incluye otras secciones. En la Sección 2 se
describen las técnicas existentes para tratar el problema de datos no balanceados. La Sección 3 está dedicada al estado del arte, incluyendo trabajos existentes en el dominio que nos ocupa. En la Sección 4 se describen los datos utilizados para la
1 base de datos de documentos médicos de los que dispone la National Library of Medicine
(NLM) 2 Medicine Subject Headings. Taxonomía jerárquica de términos médicos y biológicos creada por la NLM para indexar artículos de revistas biomédicas

experimentación, las pruebas realizadas y se presentan los resultados obtenidos. Y en la última sección se plantean las conclusiones y el trabajo futuro.
2 El Problema de las Clases No Balanceadas
Existen distintas propuestas para resolver la problemática de construcción de modelos de clasificación a partir de datos no balanceados. Algunas propuestas afectan a los algoritmos de clasificación y otras a los datos. En el primer caso, se asigna un coste diferencial a las instancias de entrenamiento
según las frecuencias de las clases [4]. En el segundo caso, se muestrea el conjunto de datos original, ya sea agregando casos sintéticos o repetidos de la clase minoritaria, o eliminando casos de la clase mayoritaria [3].
2.1 Estrategias a Nivel de los Algoritmos
En este tipo de estrategias no se modifica la distribución de los datos y, por consiguiente, no se sobrecargan los conjuntos de datos. Los clasificadores sensibles al coste (costsensitive) han sido desarrollados para
tratar los problemas con diferentes costes de error de clasificación. Estos clasificadores pueden ser usados en conjuntos de datos no balanceados configurando un coste mayor a los ejemplos mal clasificados de la clase minoritaria que los de la clase mayoritaria. Estos métodos se utilizan en muchas aplicaciones reales, como puede ser en
dominios médicos, donde un error de tipo “falso negativo” puede provocar que no se hagan más pruebas a un paciente enfermo diagnosticado sano y que, con el paso del tiempo, desarrolle la enfermedad. La incorporación de coste lleva a los algoritmos de clasificación a cometer menos
errores en la clase minoritaria, lo que en este caso de problemas es deseable. El problema principal con el aprendizaje sensible al coste es que los costes son
generalmente desconocidos y difíciles de encontrar porque dependen del problema en cuestión. Sin embargo, existe una relación directa entre aumentar el coste de clasificación y aumentar el número de ejemplos de la clase minoritaria. Otros métodos que se sitúan en este tipo de estrategias son el ajuste de probabilidad
en las hojas del árbol de decisión y el aprendizaje de una única clase (recognitionbased) en lugar de a partir de dos clases (discriminationbased).
2.2 Estrategias a Nivel de los Datos
Una de las técnicas más utilizadas para solucionar el problema de datos no balanceados es el muestreo. A continuación se definen dos formas de muestro de datos:
1. Sobre muestreo (oversampling): Consiste en balancear la distribución de las clases añadiendo ejemplos a la clase minoritaria. Podemos diferenciar dos métodos. Randomoversampling que consiste en generar ejemplos de la clase minoritaria de forma aleatoria hasta que la clase minoritaria tenga tantos ejemplos como la

mayoritaria. Focusedoversampling que consiste en generar ejemplos de la clase minoritaria de forma aleatoria pero limitando el número de nuevas instancias. Alguno de los algoritmos más representativos es SMOTE (Synthetic Minority Oversampling TEchnique) [5] que crea nuevos ejemplos de la clase minoritaria interpolando los valores de vecinos más cercanos a ejemplos de la clase minoritaria.
2. Submuestreo (undersampling): Se eliminan ejemplos de la clase mayoritaria. Existen dos métodos como en el caso de oversampling. Randomundersampling que consiste en reducir de forma aleatoria la clase mayoritaria hasta obtener el mismo tamaño que la clase minoritaria. Focusedundersampling que se diferencia de la anterior en que se limita el número de ejemplos a eliminar.
El muestreo de datos presenta tanto ventajas como inconvenientes. El submuestreo aleatorio puede provocar pérdida de información al eliminar ejemplos de la clase mayoritaria que resultan útiles, pero tiene como ventaja que reduce el tiempo de procesado del conjunto de datos. El sobremuestreo aleatorio tiene la ventaja de no perder información pero puede añadir ejemplos de la clase minoritaria con ruido además de aumentar el tiempo de procesado del conjunto de datos. Existen métodos que intentan mitigar estos problemas mejorando las estrategias de
muestreo. Así, el uso de Tomek links[8][10] es una estrategia de submuestreo que elimina sólo ejemplos de la clase mayoritaria que sean redundantes o que se encuentren muy próximos a los de la clase minoritaria. Existen también estrategias para combinar oversampling y undersampling [6].
3 Estado del Arte
Hay investigadores que han desarrollado diferentes métodos para resolver el problema de las clases desbalanceadas. Métodos que incluyen cambiar el tamaño del conjunto de datos de entrenamiento, ajuste de costes de error de clasificación y aprendizaje de la clase minoritaria. Ling & Li [9] sobremuestrearon la clase minoritaria añadiendo copias de los
ejemplos de la clase minoritaria al conjunto de datos de entrenamiento. En submuestreo, los ejemplos podían ser seleccionados de forma aleatoria, ejemplos que están lejos de los ejemplos de la clase minoritaria. En otro experimento, sobremuestrearon los ejemplos de la clase minoritaria con reemplazamiento para que coincidiese el número de ejemplos de la clase mayoritaria y minoritaria. La combinación de undersampling y oversampling no proporcionó una mejora significante en la clasificación. Kubat y Matwin [10] estudiaron varios métodos de reducción de la clase
mayoritaria. Ellos usaron la media geométrica como medida de mejora del clasificador, que se relaciona con un simple punto en la curva ROC. La clase minoritaria fue dividida en 4 categorías: ruido solapando la región de decisión de la clase minoritaria, ejemplos frontera, ejemplos redundantes y ejemplos seguros. Los ejemplos frontera fueron detectados usando el concepto Tomek links [10].

Zhang y Mani [3] investigaron el efecto de undersampling sobre el algoritmo KNN con diferentes métodos de selección de ejemplos. Seleccionaron un porcentaje dado de ejemplos de la clase mayoritaria (negativa) de diferentes formas: selección aleatoria, selección de ejemplos negativos más próximos a ejemplos positivos y selección de ejemplos negativos con mayor distancia a los positivos. Como medidas de mejora se utilizaron la medida de exhaustividad (recall), precisión y Fmeasure. En su estudio, la exhaustividad decrementaba al incrementar el porcentaje de selección de ejemplos negativos, mientras que la precisión incrementaba. Entre los métodos de selección de ejemplos que utilizaron, el método aleatorio y la selección de ejemplos más próximos a todos los ejemplos positivos dieron mejores resultados. Otra propuesta fue la que propuso Domingos[11]. El comparó MetaCost, método
para hacer clasificadores sensibles al coste, con undersampling de la clase mayoritaria y con oversampling de la clase minoritaria. Obtuvo que metacost mejora sobre cualquiera y que undersampling es preferible a oversampling. La probabilidad de cada clase es estimada y los ejemplos son etiquetados con respecto al coste de clasificación incorrecta (misclassification costs). El dominio de recuperación de información (Information Retrieval) [12] también
se enfrenta al problema de las clases desbalanceadas. Un documento o página web es convertido en una representación de bagofwords: un vector de características reflejando las ocurrencias de palabras en la página. Normalmente, hay muy pocas instancias de la categoría interesante en categorización de textos. Al estar más representada la clase negativa ésta puede causar problemas en la evaluación de los clasificadores. Como medida de evaluación de los clasificadores en recuperación de información se utiliza normalmente la exhaustividad y precisión. Mladenié y Grobelnik [15] propusieron una selección de características con datos
no balanceados en el dominio de recuperación de información. Ellos experimentaron con varios métodos de selección de características, y encontraron que el odds ratio combinado con el clasificador Naïve Bayes mejora en su dominio. Odds ratio es una medida de probabilidad usada para clasificar documentos en función de su relevancia para la clase minoritaria.
4 Caso de Estudio
En este trabajo se aborda el problema de la clasificación de documentos MedLine a partir de su vocabulario MeSH utilizando un conjunto de datos no balanceado y empleando diferentes estrategias de balanceado de datos.
4.1 Datos Disponibles
Como ya se ha mencionado, para la realización de este estudio se ha partido de un trabajo previo de clasificación de documentos MedLine usando términos MeSH [13]. Dicho trabajo utilizaba los documentos del “TREC 2005 Genomic track”, los cuales estaban organizados en 4 categorías (A,E,G,T). Para cada categoría, la distribución de documentos relevantes y no relevantes es la que se observa en la Tabla 1. Se puede ver que el número de documentos no relevantes es mucho mayor que el de relevantes

en todos los conjuntos de entrenamiento y test. Nos encontramos ante una clara situación de desbalanceado de datos.
Tabla 1. Número de documentos relevantes y no relevantes en los conjuntos de datos TREC 2005 para cada una de las cuatro categorías.
Categoría Conjuntos Relevantes No Relevantes
A Entrenamiento 338 5499 Test 253 4705
E Entrenamiento 81 5756 Test 80 4878
G Entrenamiento 462 5376 Test 400 4558
T Entrenamiento 36 5801 Test 13 4945
Para realizar los experimentos se utilizó la herramienta Weka3 [7], lo cual obligó al
preprocesamiento de los documentos disponibles. Cada documento se convirtió en el conjunto de términos Mesh que contenía. Como consecuencia se generaron ocho matrices binarias que representan los conjuntos de datos de entrenamiento y test de las cuatro categorías definidas en TREC 2005. En estas matrices cada fila se corresponde con un documento MedLine y cada
columna con un término MeSH. Cada posición ij de cada matriz tomará valor 1 si el término MeSH correspondiente a la columna j está presente en el documento Medline i. En otro caso ij contendrá el valor 0. La Figura 1 muestra un ejemplo de matriz con doce documentos y doce términos
MeSH. La columna Class tomará valor 1 si un documento es relevante y 0 cuando pertenece a la categoría no relevante. Para la generación de las matrices se ha considerado que si un término MeSH está
presente en un documento, también lo están todos sus ancestros en la jerarquía MeSH. Por ejemplo, aquel documento que contenga el término A01.047.025.600.451 tendrá en esta columna un 1, pero también tendrá un 1 en las columnas correspondientes a sus términos padres (A01, A01.047, A01.047.025, A01.047.025.600) presentes en el documento. El volumen de datos soportado por cada matriz aconsejó tomar 2 medidas: 1. Representar los documentos por únicamente los términos que pertenezcan al
mismo nivel de la jerarquía de términos MeSH, alcanzando como máximo el nivel 10. De esta forma, en lugar de disponer de dos matrices binarias para cada categoría
(A,E,G,T), se dispone de 20 (2 x 10 niveles). Con esta división se perseguía: ─ Establecer las relaciones entre términos de diferentes categorías desde niveles tempranos, pudiendo ver si estas relaciones cambian al añadir más información.
─ Disminuir el tiempo de procesado que Weka necesita para generar la red a partir de los datos cuando los documentos tienen muchos atributos.
3 Waikato Environment for Knowledge Analysis. Colección de algoritmos de aprendizaje automático para realizar tareas de minería de datos. Formado por herramientas de preprocesado de datos, clasificación, regresión, clustering, reglas de asociación y visualización.

Fig. 1. Matriz con doce documentos y doce términos MeSH.
2. Aplicar a cada documento un método de selección de características que permita reducir el número de términos MeSH que le identifican, quedándonos con los más representativos. De esta forma, para nuestras pruebas tenemos un conjunto de entrenamiento para cada nivel con los atributos más característicos de ese nivel. Los conjuntos de test contienen los mismos atributos que los conjuntos de entrenamiento [13]. En el trabajo previo [13] se han realizado las pruebas con los documentos
pertenecientes a la categoría A del TREC 2005 y se concluyó que a medida que aumentamos la cantidad de términos MeSH que representan los documentos, los diferentes datos estadísticos que miden la calidad de la clasificación obtenida mejoran. Y a partir del nivel seis se obtuvo un porcentaje de documentos bien clasificados de más del 95%. La Tabla 2 muestra los datos estadísticos obtenidos.
4.2 Pruebas Realizadas
Partiendo de los datos disponibles, el objetivo de este trabajo es aplicar las técnicas existentes para solucionar el problema de datos no balanceados en el proceso de clasificación de documentos mencionado y analizar los resultados obtenidos, comparándolos con los resultados del trabajo previo. Precisamente las conclusiones de dicho trabajo previo han motivado que el estudio
experimental realizado en este trabajo se reduzca a los documentos de la categoría A de TREC y a partir del nivel seis de la jerarquía de términos MeSH. Para la realización de nuestras pruebas hemos utilizado igualmente la herramienta
Weka. Para la inducción del modelo Bayesiano se ha utilizado el mismo algoritmo que se había utilizado en el estudio previo [13], el algoritmo BayesNet que se encuentra en la ruta weka.classifiers.bayes.BayesNet y se han configurado los parámetros del algoritmo K2 como se proponía en [13]. Para el balanceado de datos se ha utilizado, por un lado la herramienta de pre
procesado de datos, donde las estrategias a nivel de datos utilizadas se encuentran en la ruta weka.filters.supervised.instance. Se trata de estrategias de muestreo, en las que se puede diferenciar estrategia de undersampling (SpreadSubsample) y combinación

de ambas oversampling/undersampling (Resample). Y por otro lado, una estrategia a nivel de algoritmo, con la herramienta de clasificación, que se encuentra en la ruta weka.classifiers.meta.CostSensitiveClassifier. En esta sección se ilustran las pruebas realizadas con las diferentes estrategias
proporcionadas por Weka y se han analizado los resultados obtenidos.
Tabla 2. Resultados de la categorización para los 10 niveles MeSH
Nivel Clase FPr Precisión Recall Fmeasure
1 0 0,885 0,954 0,987 0,970 1 0.013 0.330 0.115 0.170
2 0 0.739 0.961 0.982 0.971 1 0.018 0.437 0.261 0.327
3 0 0.530 0.972 0.977 0.974 1 0.023 0.524 0.470 0.496
4 0 0.628 0.967 0.982 0.974 1 0.018 0.519 0.372 0.433
5 0 0.462 0.975 0.972 0.973 1 0.028 0.506 0.538 0.521
6 0 0.514 0.973 0.979 0.976 1 0.021 0.554 0.486 0.518
7 0 0.514 0.973 0.979 0.976 1 0.021 0.554 0.486 0.518
8 0 0.431 0.977 0.974 0.975 1 0.026 0.537 0.569 0.553
9 0 0.439 0.976 0.974 0.975 1 0.026 0.534 0.561 0.547
10 0 0.514 0.973 0.98 0.976 1 0.02 0.567 0.486 0.523
El desempeño de los algoritmos de aprendizaje automático es típicamente
evaluado por una matriz de confusión como se ilustra en la Figura 2 (para problemas de 2 clases). Las columnas son la clase predicha y las filas la clase real. En la construcción de la matriz, TN es el número de ejemplos negativos correctamente clasificados (True Negatives), FP es el número de ejemplos negativos incorrectamente clasificados como positivos (False Positives), FN es el número de ejemplos incorrectamente clasificados como negativos (False Negatives) y TP es el número de ejemplos positivos correctamente clasificados (True Positives). Weka nos proporciona numerosos datos estadísticos. Uno de ellos es la matriz de
confusión. Permite ver el porcentaje de ejemplos negativos mal clasificados (False positive rate) (1), la exhaustividad (2), la precisión (3) o el valor Fmeasure (4) entre otras. Estas medidas se tendrán en cuenta a lo largo de todas las pruebas realizadas en este artículo. En nuestro caso de estudio, los ejemplos de la clase negativa se corresponden con los documentos no relevantes y los de la clase positiva con los relevantes.

Clasificado
Real Negativa Positiva
Negativa TN FP
Positiva FN TP
Fig. 2. Matriz de Confusión
FP rate= !"
!"#$% (1)
recall= $"
$"#!%
(2)
precision = $"
$"#!"
(3)
F‐measure = & . )*+,-.-/0 . *+,122()*+,-.-/0 # *+,122)
(4)
4.2.1 Resultados Experimentales con Undersampling
En esta sección hablaremos de las pruebas realizadas con la estrategia de muestreo undersampling que se encuentra en la ruta weka.filters.supervised.instance.SpreadSubsample de Weka. Esta técnica produce una submuestra aleatoria de un conjunto de datos. Permite
especificar el máximo “spread” (relación) entre la clase más común y la clase menos frecuente. Por ejemplo, se puede especificar que hay a lo sumo un 2:1 de diferencia en la frecuencia de clases. Es decir, la clase mayoritaria tiene dos veces más ejemplos que la clase minoritaria. Esta técnica nos permite además configurar la opción de ajuste de pesos (adjustWeights) que pondremos a falso para que los pesos de las instancias no se ajusten para minimizar el error global. En nuestro caso queremos

minimizar el error de la clase minoritaria, aunque con ello aumente el error en la clase mayoritaria. Hemos aplicado a la clase mayoritaria diferentes “spread” de submuestreo. En la
Tabla 3 se ilustra la matriz de confusión para el nivel 9 del conjunto de datos no balanceado. En la Tabla 4 podemos ver la matriz de confusión tras aplicar submuestreo con spread 1:1 al nivel 9 del conjunto de entrenamiento. El valor 0 se corresponde con documentos no relevantes, mientras que el 1 serán los relevantes. Como se puede observar en la Tabla 4 el número de documentos relevantes bien clasificados aumenta con respecto a los de la Tabla 3. Por otra parte, el número de documentos clasificados incorrectamente como relevantes también aumenta. En la Tabla 5 podemos ver los datos estadísticos obtenidos para cada uno de los niveles analizados y por spread de submuestreo. Una relación de 16:1 en la columna Spread de la Tabla 5, significa que se trata del
conjunto de datos no balanceado.
Tabla 3. Matriz de confusión del nivel 9 con datos no balanceados
Clasificado
Real 0 1
0 4581 124
1 111 142
Tabla 4. Matriz de confusión del nivel 9 con spread 1:1
Clasificado
Real 0 1
0 4185 520
1 34 219
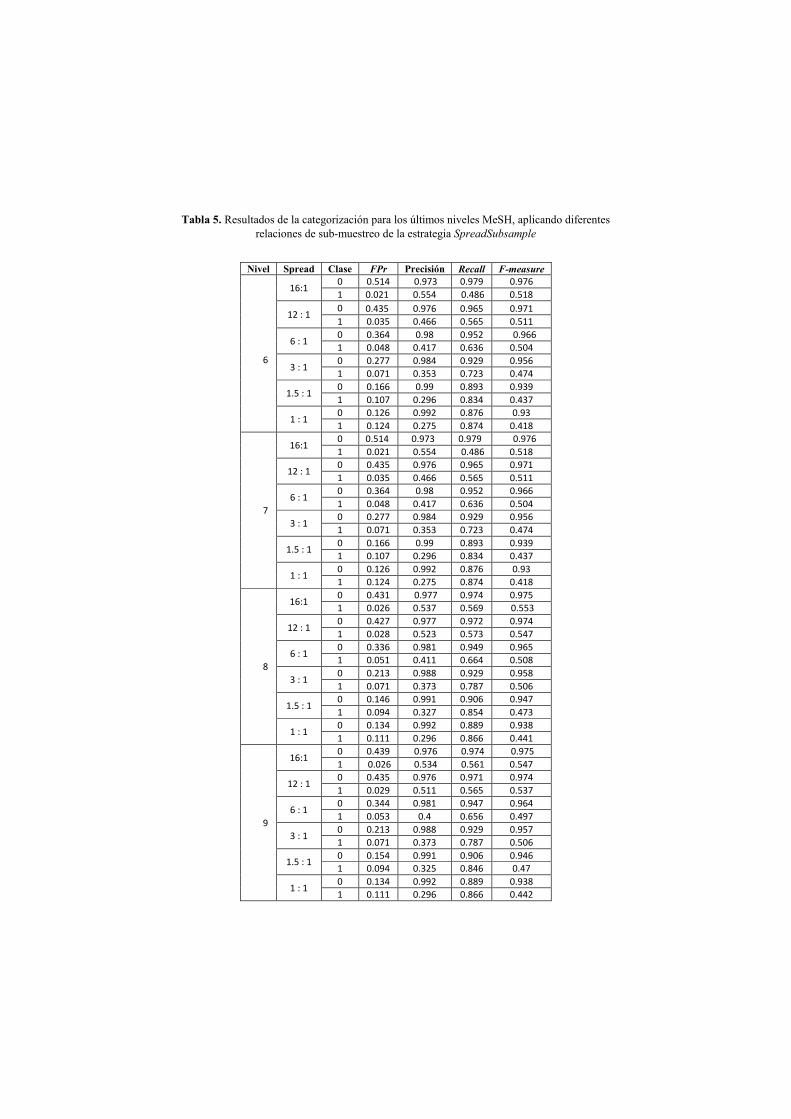
Tabla 5. Resultados de la categorización para los últimos niveles MeSH, aplicando diferentes relaciones de submuestreo de la estrategia SpreadSubsample
Nivel Spread Clase FPr Precisión Recall Fmeasure
6
16:1 0 0.514 0.973 0.979 0.976 1 0.021 0.554 0.486 0.518
12 : 1 0 0.435 0.976 0.965 0.971 1 0.035 0.466 0.565 0.511
6 : 1 0 0.364 0.98 0.952 0.966 1 0.048 0.417 0.636 0.504
3 : 1 0 0.277 0.984 0.929 0.956 1 0.071 0.353 0.723 0.474
1.5 : 1 0 0.166 0.99 0.893 0.939 1 0.107 0.296 0.834 0.437
1 : 1 0 0.126 0.992 0.876 0.93 1 0.124 0.275 0.874 0.418
7
16:1 0 0.514 0.973 0.979 0.976 1 0.021 0.554 0.486 0.518
12 : 1 0 0.435 0.976 0.965 0.971 1 0.035 0.466 0.565 0.511
6 : 1 0 0.364 0.98 0.952 0.966 1 0.048 0.417 0.636 0.504
3 : 1 0 0.277 0.984 0.929 0.956 1 0.071 0.353 0.723 0.474
1.5 : 1 0 0.166 0.99 0.893 0.939 1 0.107 0.296 0.834 0.437
1 : 1 0 0.126 0.992 0.876 0.93 1 0.124 0.275 0.874 0.418
8
16:1 0 0.431 0.977 0.974 0.975 1 0.026 0.537 0.569 0.553
12 : 1 0 0.427 0.977 0.972 0.974 1 0.028 0.523 0.573 0.547
6 : 1 0 0.336 0.981 0.949 0.965 1 0.051 0.411 0.664 0.508
3 : 1 0 0.213 0.988 0.929 0.958 1 0.071 0.373 0.787 0.506
1.5 : 1 0 0.146 0.991 0.906 0.947 1 0.094 0.327 0.854 0.473
1 : 1 0 0.134 0.992 0.889 0.938 1 0.111 0.296 0.866 0.441
9
16:1 0 0.439 0.976 0.974 0.975 1 0.026 0.534 0.561 0.547
12 : 1 0 0.435 0.976 0.971 0.974 1 0.029 0.511 0.565 0.537
6 : 1 0 0.344 0.981 0.947 0.964 1 0.053 0.4 0.656 0.497
3 : 1 0 0.213 0.988 0.929 0.957 1 0.071 0.373 0.787 0.506
1.5 : 1 0 0.154 0.991 0.906 0.946 1 0.094 0.325 0.846 0.47
1 : 1 0 0.134 0.992 0.889 0.938 1 0.111 0.296 0.866 0.442

10
16:1 0 0.514 0.973 0.98 0.976 1 0.02 0.567 0.486 0.523
12 : 1 0 0.435 0.976 0.967 0.972 1 0.033 0.48 0.565 0.519
6 : 1 0 0.344 0.981 0.949 0.964 1 0.051 0.407 0.656 0.502
3 : 1 0 0.237 0.986 0.926 0.955 1 0.074 0.357 0.763 0.487
1.5 : 1 0 0.17 0.99 0.912 0.95 1 0.088 0.337 0.83 0.479
1 : 1 0 0.146 0.991 0.895 0.941 1 0.105 0.304 0.854 0.448
Fig. 3. Variación de precisión del nivel Fig. 4. Variación de recall del nivel 9 por spread 9 por spread
En la Tabla 5 se puede observar que el comportamiento de cada uno de los datos
estadísticos para los distintos niveles es similar. Para comprender mejor este comportamiento nos hemos centrado en el nivel nueve. Aplicando undersampling, el porcentaje de documentos relevantes mal clasificados disminuye, y aunque el porcentaje de documentos no relevantes mal clasificados aumenta, aumenta en menor proporción, llegando a un equilibrio entre las dos clases (ver columna FPr). La precisión de la clasificación de documentos relevantes disminuye a medida que reducimos el número de ejemplos negativos, esto es debido al ligero aumento de documentos no relevantes mal clasificados. Por otra parte recall aumenta para los documentos relevantes, el porcentaje de documentos relevantes bien clasificados es mayor. En las Figuras 3 y 4 se puede observar esta evolución de la precisión y exhaustividad a medida que se reduce el número de documentos no relevantes en el nivel nueve para las distintas clases.
4.2.2 Resultados Experimentales con combinación de Oversampling y Undersampling
En esta sección se han realizado pruebas combinando oversampling y undersampling. Para ello, hemos utilizado el método proporcionado por Weka y que se encuentra en la ruta weka.filters.supervised.instance.Resample. Esta técnica produce un

subconjunto de datos aleatorio, se combina la técnica de oversampling con la técnica de undersampling. Weka nos permite la configuración de opciones de Resample, en especial a través
del parámetro biasToUniformClass. Un valor 0 deja la distribución de clases como está, un valor 1 asegura que la distribución de las clases es uniforme (similar cantidad de ejemplos en cada clase). Valores intermedios de bias balancearan las clases para mantener la distribución (oversampling y undersampling). Se mantendrá el porcentaje de instancias que se crean nuevas a 100, para indicar que el número de instancias que se genera es el mismo al conjunto original. En la Tabla 6 se muestra la matriz de confusión para el nivel 9 con un balanceado
de datos al 75%. Si la comparamos con la Tabla 3, se puede ver que el número de documentos relevantes bien clasificados aumenta. La Tabla 7 muestra los datos estadísticos para los niveles 6 a 10 con la distribución de las clases que se especifica en la columna Bias. La distribución cero indica que se trata del conjunto de datos no balanceado. Centrándonos en el nivel nueve de la Tabla 7, se puede observar que a medida que aumentamos el porcentaje de undersampling y oversampling el número de documentos relevantes clasificados incorrectamente va disminuyendo hasta un
Tabla 6. Matriz de confusión del nivel 9 con Resample bias=0.75
Clasificado
Real 0 1
0 4264 441
1 49 204
porcentaje de undersampling y oversampling del 75%. Con una distribución uniforme de las clases el número de documentos relevantes mal clasificados aumenta un poco. La precisión de los documentos relevantes disminuye a medida que las clases se balancean, debido al aumento de los documentos no relevantes clasificados como relevantes (FP). El porcentaje de documentos relevantes clasificados correctamente (recall) aumenta hasta conseguir una distribución al 75%, a partir de ese momento disminuye ligeramente. Esto no ocurre con el resto de niveles, en los que recall va aumentando hasta que se consigue una distribución uniforme de las clases. Este empeoramiento en el nivel nueve podría ser debido a la eliminación de ejemplos de la clase mayoritaria potencialmente útiles o a la inclusión de ejemplos con ruido. Las Figuras 5 y 6 muestran la evolución de la precisión y exhaustividad a medida que la distribución de las clases tiende a ser uniforme.

Tabla 7. Resultados de la categorización para los últimos niveles MeSH, aplicando diferentes distribuciones de oversampling y undersampling de la estrategia Resample
Nivel Bias Clase FPr Precisión Recall Fmeasure
6
0 0 0.514 0.973 0.979 0.976 1 0.021 0.554 0.486 0.518
0.25 0 0.391 0.978 0.952 0.965 1 0.048 0.406 0.609 0.487
0.5 0 0.289 0.984 0.933 0.958 1 0.067 0.365 0.711 0.483
0.75 0 0.249 0.986 0.912 0.947 1 0.088 0.314 0.751 0.443
1 0 0.202 0.988 0.885 0.934 1 0.115 0.273 0.798 0.406
7
0 0 0.514 0.973 0.979 0.976 1 0.021 0.554 0.486 0.518
0.25 0 0.391 0.978 0.952 0.965 1 0.048 0.406 0.609 0.487
0.5 0 0.289 0.984 0.933 0.958 1 0.067 0.365 0.711 0.483
0.75 0 0.249 0.986 0.912 0.947 1 0.088 0.314 0.751 0.443
1 0 0.202 0.988 0.885 0.934 1 0.115 0.273 0.798 0.406
8
0 0 0.431 0.977 0.974 0.975 1 0.026 0.537 0.569 0.553
0.25 0 0.344 0.981 0.955 0.968 1 0.045 0.44 0.656 0.527
0.5 0 0.249 0.986 0.928 0.956 1 0.072 0.36 0.751 0.487
0.75 0 0.19 0.989 0.906 0.946 1 0.094 0.316 0.81 0.455
1 0 0.174 0.99 0.896 0.941 1 0.104 0.3 0.826 0.44
9
0 0 0.439 0.976 0.974 0.975 1 0.026 0.534 0.561 0.547
0.25 0 0.372 0.979 0.95 0.964 1 0.05 0.402 0.628 0.49
0.5 0 0.269 0.985 0.93 0.956 1 0.07 0.359 0.731 0.482
0.75 0 0.194 0.989 0.906 0.946 1 0.094 0.316 0.806 0.454
1 0 0.209 0.988 0.896 0.94 1 0.104 0.291 0.791 0.426
10
0 0 0.514 0.973 0.98 0.976 1 0.02 0.567 0.486 0.523
0.25 0 0.316 0.982 0.947 0.965 1 0.053 0.411 0.684 0.513
0.5 0 0.281 0.984 0.924 0.953 1 0.076 0.337 0.719 0.459
0.75 0 0.229 0.987 0.913 0.948 1 0.087 0.323 0.771 0.455

1 0 0.206 0.988 0.904 0.944 1 0.096 0.308 0.794 0.444
Fig. 5. Variación de precisión por porcentaje Fig. 6. Variación de recall por porcentaje
de muestreo del nivel 9. de muestreo del nivel 9.
4.2.3 Resultados Experimentales Aplicando Aprendizaje Sensible al Coste
Otra de las estrategias utilizadas en nuestro caso de estudio ha sido emplear un metaclasificador sensible al coste para darle alto coste a los ejemplos mal clasificados de la clase minoritaria. Weka nos proporciona un metaclasificador que se encuentra en la ruta weka.classifiers.meta.CostSensitiveClassifier. Se usa como clasificador base BayesNet, el mismo con el que se han desarrollado todas las pruebas. Se configura la matriz de coste para dos clases y cambiando el coste de los
ejemplos mal clasificados de la clase minoritaria (falsos negativos). Los costes de la matriz de coste como ya habíamos comentado, no son fáciles de encontrar. Pero existe una relación entre aumentar el coste de la clasificación y aumentar el número de ejemplos negativos. En las pruebas se han empleado costes 2, 3, 5, 8 y 15 sobre los falsos positivos. En la Tabla 8 se ilustra la matriz de confusión para el nivel 9 con un coste 15. Se puede observar que el número de documentos relevantes correctamente clasificados es mayor que el número de documentos relevantes bien clasificados de la Tabla 3. En la Tabla 9 se muestran los datos estadísticos para los niveles estudiados aplicando diferentes costes a la clase minoritaria. Podemos ver en la Tabla 9 que con esta técnica a medida que aumentamos el coste
de clasificación de la clase minoritaria los ejemplos de la clase minoritaria son mejor clasificados. El porcentaje de documentos relevantes mal clasificados disminuye y el porcentaje de documentos relevantes correctamente clasificados aumenta. Las Figuras 7 y 8 muestran la evolución de la precisión y exhaustividad del nivel nueve por coste de clasificación de la clase minoritaria. Se puede observar que la exhaustividad aumenta para la clase positiva y disminuye ligeramente para la clase negativa debido al error de clasificación que se introduce a la clase negativa con el balanceado de datos. La precisión disminuye para los documentos relevantes por el mismo motivo.

Tabla 8. Matriz de confusión del nivel 9 con CostSensitiveClassifier. Coste =15
Clasificado
Real 0 1
0 4239 466
1 40 213
Tabla 9. Resultados de la categorización para los últimos niveles MeSH, aplicando diferentes costes a los ejemplos mal clasificados de la clase minoritaria.
Nivel Coste Clase FPr Precisión Recall Fmeasure
6
0 0 0.514 0.973 0.979 0.976 1 0.021 0.554 0.486 0.518
2 0 0.387 0.979 0.965 0.972 1 0.035 0.486 0.613 0.542
3 0 0.312 0.983 0.95 0.966 1 0.05 0.425 0.688 0.526
5 0 0.292 0.984 0.943 0.963 1 0.057 0.402 0.708 0.513
8 0 0.229 0.987 0.927 0.956 1 0.073 0.362 0.771 0.492
15 0 0.138 0.992 0.887 0.936 1 0.113 0.291 0.862 0.435
7
0 0 0.514 0.973 0.979 0.976 1 0.021 0.554 0.486 0.518
2 0 0.387 0.979 0.965 0.972 1 0.035 0.486 0.613 0.542
3 0 0.312 0.983 0.95 0.966 1 0.05 0.425 0.688 0.526
5 0 0.292 0.984 0.943 0.963 1 0.057 0.402 0.708 0.513
8 0 0.229 0.987 0.927 0.956 1 0.073 0.362 0.771 0.492
15 0 0.138 0.992 0.887 0.936 1 0.113 0.291 0.862 0.435
8
0 0 0.431 0.977 0.974 0.975 1 0.026 0.537 0.569 0.553
2 0 0.364 0.98 0.965 0.972 1 0.035 0.492 0.636 0.555
3 0 0.304 0.983 0.951 0.967 1 0.049 0.433 0.696 0.534

5 0 0.277 0.984 0.944 0.964 1 0.056 0.408 0.723 0.522
8 0 0.19 0.989 0.919 0.953 1 0.081 0.351 0.81 0.49
15 0 0.138 0.992 0.896 0.942 1 0.104 0.309 0.862 0.455
9
0 0 0.439 0.976 0.974 0.975 1 0.026 0.534 0.561 0.547
2 0 0.403 0.032 0.968 0.973 1 0.032 0.5 0.597 0.544
3 0 0.32 0.982 0.95 0.966 1 0.05 0.424 0.68 0.522
5 0 0.281 0.984 0.942 0.963 1 0.058 0.4 0.719 0.514
8 0 0.19 0.989 0.919 0.953 1 0.081 0.35 0.81 0.489
15 0 0.158 0.991 0.901 0.842 1 0.099 0.314 0.842 0.457
10
0 0 0.514 0.973 0.98 0.976 1 0.02 0.567 0.486 0.523
2 0 0.391 0.979 0.964 0.971 1 0.036 0.475 0.609 0.534
3 0 0.34 0.981 0.956 0.968 1 0.044 0.447 0.66 0.533
5 0 0.261 0.985 0.94 0.962 1 0.06 0.399 0.739 0.518
8 0 0.198 0.989 0.915 0.95 1 0.085 0.337 0.802 0.475
15 0 0.158 0.991 0.901 0.944 1 0.099 0.313 0.842 0.457
Fig. 7. Variación de precisión por coste del Fig. 8. Variación de recall por coste del
nivel 9 nivel 9

5 Conclusiones y Trabajos Futuros
En este documento hemos descrito la aplicación de diferentes técnicas de balanceado de datos a un problema de clasificación en recuperación de información con clases no balanceadas. Especialmente, estudiamos los efectos de random undersampling , la combinación de oversampling y undersampling y la aplicación de costes de clasificación para los ejemplos positivos. Con los resultados obtenidos por nuestro clasificador podemos concluír que el
número de documentos relevantes bien clasificados aumenta con las tres técnicas. En el 99% de los casos con una distribución totalmente uniforme de las clases se obtienen los mejores resultados. El otro 1 % puede ser debido a la eliminación de ejemplos representativos de la clase mayoritaria o la inclusión de ejemplos con ruido en la clase minoritaria. Con la mejora en clasificación de documentos relevantes empeoramos un poco la clasificación de documentos no relevantes. Pero no resulta tan grave tener un documento no relevante clasificado como relevante que viceversa. Leerse documentos no relevantes no tiene tantos efectos negativos como no leerse alguno relevante. Entre las tres técnicas utilizadas, SpreadSubsample y CostSensitiveClassifier
mejoran los resultados para los documentos relevantes. Los resultados obtenidos con una selección aleatoria de ejemplos (SpreadSubsample) son buenos pero sería interesante aplicar técnicas más sofisticadas y observar si existe una clara ventaja usándo estas nuevas técnicas. En futuros trabajos deberíamos estudiar algunas de esas técnicas de selección de
ejemplos de la clase mayoritaria, para descartar ejemplos negativos de la región frontera, que son ruido o redundantes [10][16] y aplicarlas a nuestro caso de estudio. Así como técnicas de selección de características, utilizando como medidas de clasificación odds ratio e information gain entre otras [15]. Como trabajo a realizar inmediatamente se plantea terminar las pruebas con los
datos disponibles del TREC 2005, ya que en algunos trabajos previos donde se han utilizado estos conjuntos de entrenamiento, los clasificadores no tenían igual comportamiento en las cuatro categorías.
6 Referencias
1. Chawla, N.V, Lazarevic, A., Hall, L.O. and Bowyer, K.W. SMOTEBoost: Improving
Prediction of the Minority Class in Boosting. Journal Title: Principles of Data Mining and Knowledge Discovery. pp. 112. 2003.
2. Chawla, N.V, Japkowicz, N. and Kolcz, A. Editorial: Special Issue on Learning from Imbalanced Data Sets. SIGKDD Explorations. Volume 6, Issue 1, pp. 16, 2004.
3. Zhang, J. and Mani, I. KNN Approach to Unbalanced Data Distributions: A Case Study involving Information Extraction, ICML, Washington DC, 2003.
4. Morales, E.F. and González , J.A. El Problema de las clases desbalanceadas. Instituto Nacional de Astrofísica, Óptica y Electrónica, 2007.

5. Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer W.P. SMOTE: Syntetic Minority Oversampling Technique. Journal of Artificial Intelligence Research. Volume 16, pp. 321357. 2002.
6. Batista, G., Prati, R. and Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explorations. Volume 6:1, pp. 20 29, June 2004.
7. Weka Data Mining with Open Source Machine Learning Software in Java. http://www.cs.waikato.ac.nz The University of Waikato, New Zealand, 2009.
8. Herrera, F. Clasificación con Datos no Balanceados. http://sci2s.ugr.es/docencia/index.php 9. Ling, C., and Li, C. Data Mining for Direct Marketing Problems and Solutions. In
Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining (KDD98) New York, NY. AAAI Press. 1998.
10. Kubat, M., and Matwin, S. Addressing the Curse of Imbalanced Training Sets: One Sided Selection. In Proceedings of the Fourteenth International Conference on Machine Learning, pp. 179–186. 1997.
11. Domingos P. MetaCost: A General Method for Making Classifiers CostSensitive. Proceedings of the fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego,CA. pp. 155164. 1999.
12. Dumais, S., Platt, J., Heckerman, D., and Sahami, M. Inductive Learning Algorithms and Representations for Text Categorization. In Proceedings of the Seventh International Conference on Information and Knowledge Management, pp. 148–155. 1998.
13. GlezPeña, D., López, S., Pavón R., Laza, R., Iglesias, E. and Borrajo, L. Classification of MedLine Documents Using MeSH Terms. Lecture Notes in Computer Science. Springer Berlin/Heidelberg. Distributed Computing, Artificial Intelligence, Bioinformatics, Soft Computing, and Ambient Assisted Living. Volume 5518, pp. 926929. 2009.
14. Dayanik, A., Genkin, A., Kantor, P., Lewis, D.D. and Madigan, D. DIMACS at the TREC 2005 genomics track. DIMACS, Rutgers University, 2006
15. Mladenié, D., and Grobelnik, M. Feature Selection for Unbalanced Class Distribution and Naive Bayes. In Proceedings of the 16th International Conference on Machine Learning, Morgan Kaufmann, pp. 258–267. 1999.
16. Suman, S., Laddhad, K. and Deshmukh, U. Methods for Handling Highly Skewed Datasets. 2005.


















