
CIS 601 Graduate Seminar Presentation -...
24
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu
Transcript of CIS 601 Graduate Seminar Presentation -...

CIS 601 Graduate Seminar PresentationIntroduction to MapReduce--Mechanism and Applicatoin
Presented by:Suhua WeiYong Yu

Papers:
• MapReduce: Simplified Data Processing on Large Clusters1
--Jeffrey Dean and Sanjay Ghemawat
• Introduction
• Model
• Implementation
• Performance
• Hive – A Warehousing Solution over a Map-Reduce Framework2
--Ashish Thusoo, Joydeep Sen Sarma, Namit Jain, Zheng Shao,Prasad Chakka, Suresh Anthony, Hao Liu, Pete Wyckoff
and Raghotham Murthy
• Introduction
• Hive Database
• Hive Architecture
• Demonstration Description
1, https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf
2, http://202.118.11.61/papers/db%20in%20the%20cloud/hive.pdf

Introduction
• Background: google, past 5 years @2004
• Hundreds of special-purpose computations:
-- To process large amount of raw data:crawled documents, web request logs, etc.
• The computations have to be distributed across
hundreds of machines
-- Most computations are conceptually straightforward, but input data is
large: (3,288TB /29,423 jobs ~ 100GB/job)
• Issues:
-- How to parallelize the computation, distribute the data, and handle
failures

Solution: MapReduce
• Designed a new abstraction
--to express the simple computations: hides the messy details of parallelization, fault-tolerance, data distribution and load balancing in a library.
• Use of a functional model
-- inspired by the map and reduce primitives present in Lisp
--specified map and reduce operations to parallelize large computation easily and use re-execution as the primary mechanism for fault tolerance
• Contributions:
--Simple and powerful interface on large clusters of commodity of PCs: automatic parallelization and distribution of larger-scale computations

Programming Model
• Computation: MapReduce library
--Take a set of input key/value pairs
--Produce a set of output key/value pairs
• Map: takes an input pair and produces a set of
intermediate key/value pairs
-- groups together all intermediate values associated with the same
intermediate key I and passes them to reduce function
• Reduce: accepts an intermediate key I and a set of
value for that key
-- merges together these values to form a possibly smaller set of values

Example
• Counting the # of occurrences of each words

Examples of MapReduce Computations
• Distributed GrepMap: Emits the certain line that matches a supplied pattern
Reduce: Identity function, copies the intermediate data to output
• Count of URL Access FrequencyMap: Process logs of web page requests and output(URL, 1)
Reduce: Adds all values and emits (URL, total count) pair
• Reverse Web-Link Graph
• Term-Vector Per Host
• Inverted Index
• Distributed Sort

Implementation
• Different implementations depends on the environments
--small shared-memory machine; large NUMA multi-processor; large collection of networked machines
• In google’s environment:
--x86 processors; Linux; 2-4 GB of memory
--Commodity networking hardware
--Cluster consists of hundreds or thousands of machines
--Storage: inexpensive IDE disks
--Users submit jobs to a scheduling system
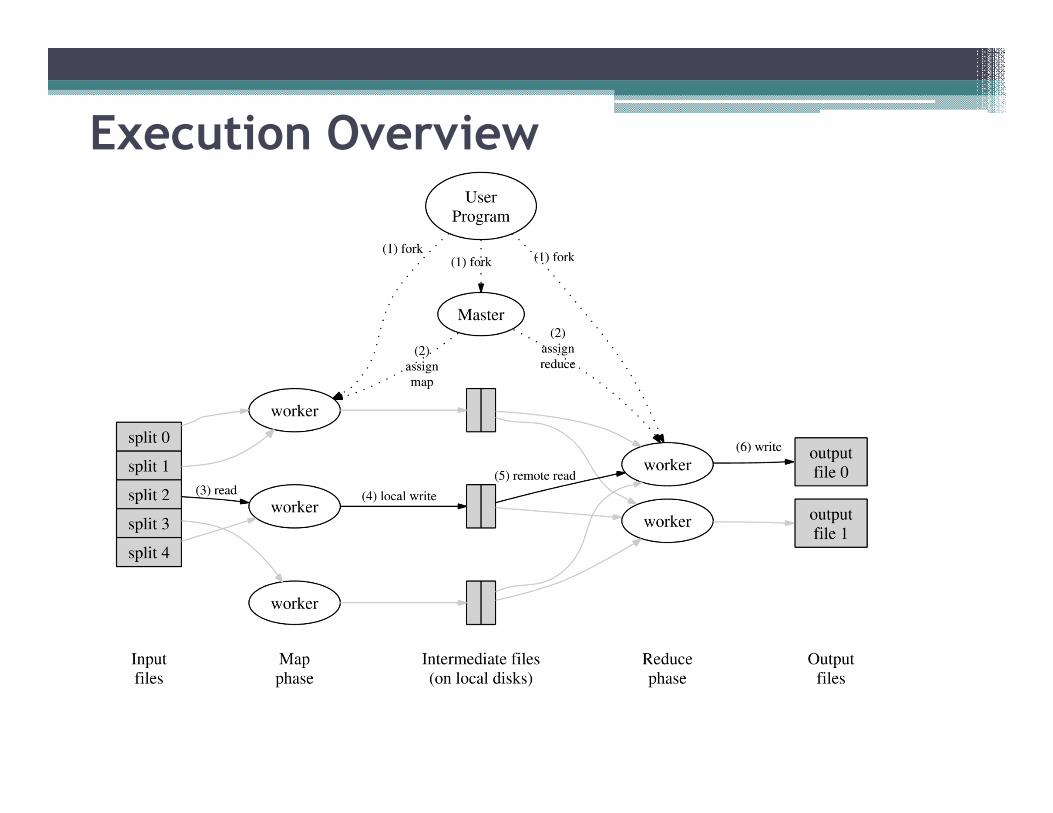
Execution Overview

Sequence of Actions
• 1, The input files are splited into M pieces, 16 ~ 64M per piece
• 2, Master assigns works to workers
• 3, worker reads the contents of the input split
• 4, The buffered pairs are written to local disk
• 5, Master read the buffered data, reduce works sort all intermediate
data, group key and value
• 6, The reduce worker passes the key and values to reduce function
• 7, Master wakes up the user program

Fault Tolerance
• Tolerate machine failure gracefully
--very large amount of data & hundreds or thousands of machines
• Worker Failure:
-- The master pings every worker periodically:
worker is failed with no response
Any map/reduce task on a failed worker is reset to idle
• Master Failure:
--Master write periodic checkpoints of the master data structure
Master task dies: a new copy can be started from last checkpoint
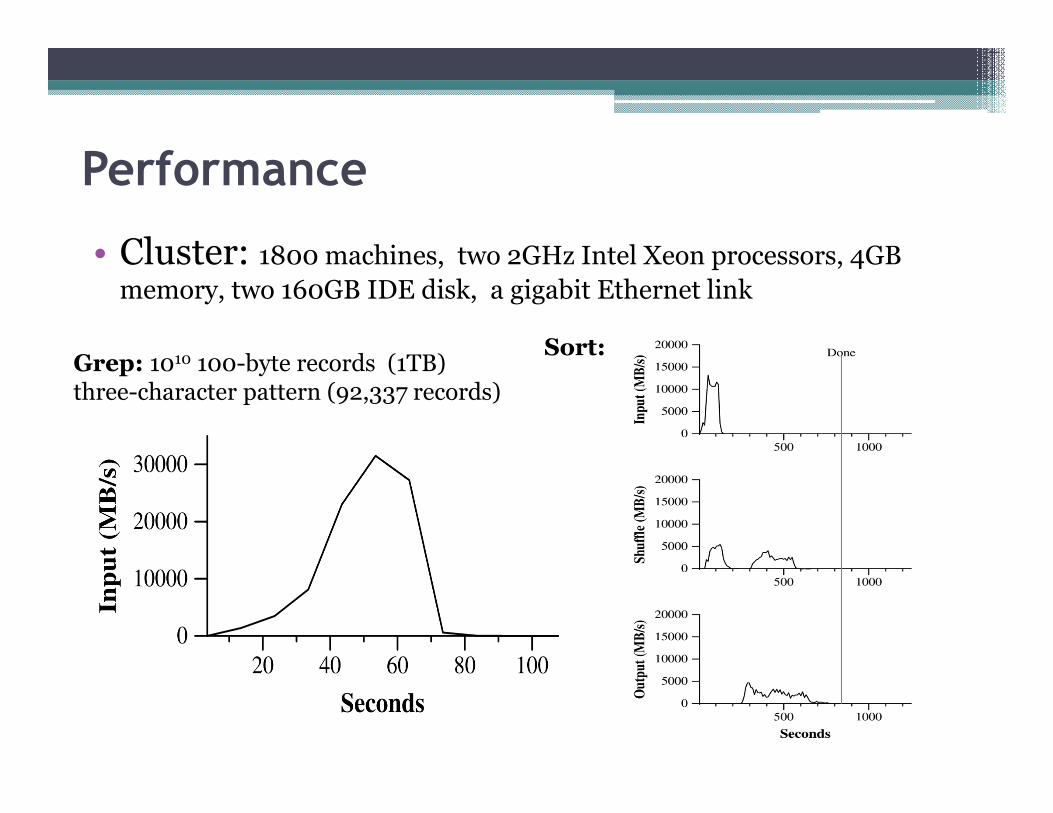
Performance
• Cluster: 1800 machines, two 2GHz Intel Xeon processors, 4GB
memory, two 160GB IDE disk, a gigabit Ethernet link
Grep: 1010 100-byte records (1TB)three-character pattern (92,337 records)
Sort:
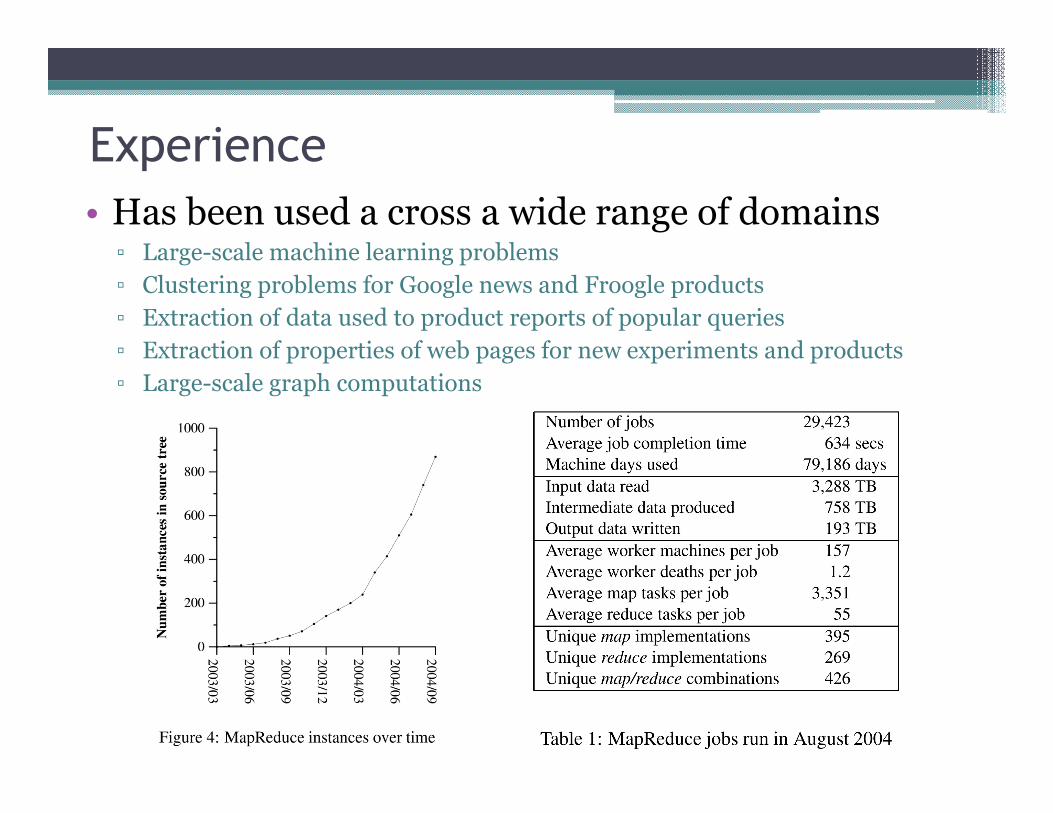
Experience
• Has been used a cross a wide range of domains▫ Large-scale machine learning problems
▫ Clustering problems for Google news and Froogle products
▫ Extraction of data used to product reports of popular queries
▫ Extraction of properties of web pages for new experiments and products
▫ Large-scale graph computations

Hive – A Warehouse Solution
Over a Map-Reduce Framework
By Ashish Thusoo, Joydeep Sen Sarma, Namit Jain, Zheng Shao, Prasad Chakka, Suresh Anthony, Hao Liu, Pete Wyskoff and Raghotham MurthyFace Book Data Infrastructure Team
Presented by Suhua Wei, Yong Yu

Introduction
• The map-reduce programing model is very low level and requires developers to write custom programs which are hard to maintain and reuse
• Build on the top of Hadoop
• Supports queries expressed in a SQL-like declarative language-HiveQL
• HiveQL

Hive Database• Data Model
▫ Tables� Analogous to tables in relational database� Each table has a corresponding HDFS directory� Hive provides built-in serialization formats which exploit compression and
lazy-serialization
▫ Partitions� Each table can have one or more partitions� Example: table T in the directory : /wh/T. If Tis partitioned on columns ds =
‘20090101’, and ctry = ‘US’, will be stored /wh/T/ds=20090101/ctry=US.
▫ Buckets� Data in each partition may in turn be divided into buckets based on the hash
of a column in the table� Each bucket is stored as a file in the partition directory

Hive Database• Query Language
▫ HiveQL
� Supports select, project, join, aggregate, union all and sub-queries in the from clause
� Supports data definition (DDL) statements and data manipulation (DML) statements like load and insert (except for updating and deleting)
� Supports user defined column transformation (USF) and aggregation(UDAF) functions implemented in java
� Users can embed custom map-reduce scripts written in any language using a simple row-based streaming interface

Hive Database
• Running time example: Status Meme
When Facebook users update their status, the updates are logged into flat files in an NFS directory /logs/status_updates
Compute daily statistics on the frequency of status updates based on gender and school
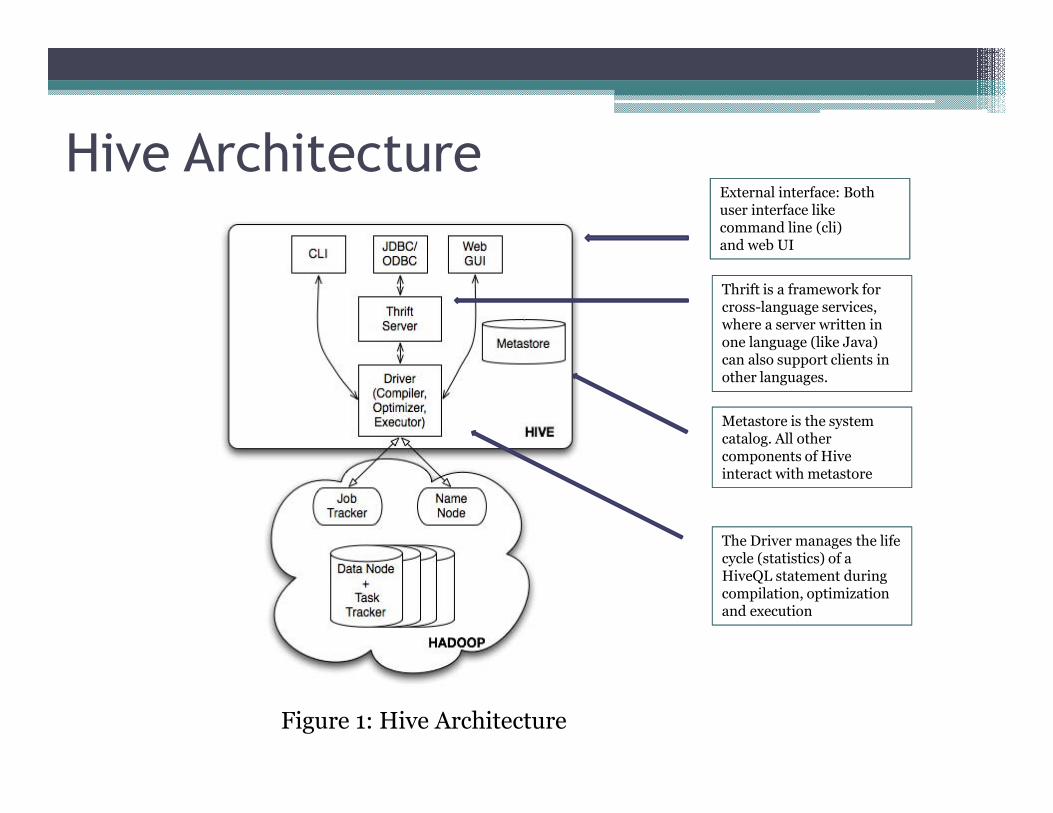
Hive Architecture
Figure 1: Hive Architecture
External interface: Both user interface like command line (cli)and web UI
Thrift is a framework for cross-language services, where a server written in one language (like Java) can also support clients in other languages.
Metastore is the system catalog. All other components of Hive interact with metastore
The Driver manages the life cycle (statistics) of a HiveQL statement during compilation, optimization and execution

Top
Bottom
Figure 2: Query plan with 3 map-reduce jobs for multi-table insert query
Hive Architecture

Hive Architecture• MetaStore
▫ The system catalog which contains metadata about the tables stored in Hive
▫ This data is specified during table creation and reused very time the table is referenced in HiveQL
▫ Contains the following objects
� database : the namespace for tables
� table : metadata for table contains list of columns and their types, owners, storage and SerDeinformation
� Partition: each partition can have its own columns and SerDe and storage information

Hive Architecture• Compile
▫ The compiler converts the string(DDL/DML/query statement) to a plan.
� The parser transforms a query string to a parse tree representation
� The semantic analyzer transforms the parse tree to a block-based internal query representation
� The logical plan generator converts the internal query represnetationto a logical plan
� The optimizer performs multiple passes over the logical plan and rewrites it in several ways
� Combined multiple joins which share the join key into a single multi-way join, and hence a single map-reduce job
� adds repartition operators
� Prunes columns early and pushes predicates closer to the table scan operators
…

Hive Architecture• Compile (continue..)
� The optimizer performs multiple passes over the logical plan and rewrites it in several ways
� Combined multiple joins which share the join key into a single multi-way join, and hence a single map-reduce job
� adds repartition operators
� Prunes columns early and pushes predicates closer to the table scan operators
� In case of partitioned tables, prunes partitions that are not needed by the query
� In case of sampling queries, prunes buckets that are not needed
Users can also provide hints to the optimizer to
� Add partial aggregation operators to handle large cardinality grouped aggregation
� Add repartition operators to handle skew in grouped aggregations
� Perform joins in the map phrase instead of the reduce phase
� The Physical Plan generator converts the logical plan into physical plan, consisting a directed-acyclic graph(DAG)of map-reproduce jobs

Summary
• Hive is a first step in building an open-source warehouse over a web-scale map-reduce data processing system(Hadoop), and work towards(2009)▫ working towards subsume SQL syntax▫ Hive has a naïve rule-based optimizer with a small
number of simple rules. Plan to build a cost-based optimizer and adaptive optimization techniques
▫ Exploring columnar storage and more intelligent data placement to improve scan performance
▫ Enhancing the drivers for integration with commercial BI tools
▫ Exploring methods for multi-query optimization techniques.


















