
Chinese Word Segmentation Method for Domain-Special Machine Translation Su Chen; Zhang Yujie; Guo...
23
Chinese Word Segmentation Method for Domain-Special Machine Translation Su Chen; Zhang Yujie; Guo Zhen; Xu Jin’an Beijing Jiaotong University
-
Upload
charles-baldwin -
Category
Documents
-
view
222 -
download
0
Transcript of Chinese Word Segmentation Method for Domain-Special Machine Translation Su Chen; Zhang Yujie; Guo...

Chinese Word Segmentation Method for Domain-Special Machine Translation
Su Chen; Zhang Yujie; Guo Zhen; Xu Jin’an
Beijing Jiaotong University

Outline
Motivation
Method of combining multiple segmentation results
Experiment & Evaluation
Conclusion

Motivation 1/2
Training data
Test data F-measure
News domain
News domain
97.62%
Science 83.89%
●CTB test data●OOV : 3.47%
●Science annotated data●OOV : 22.4%
CTB training data

Motivation 2/2
Background: Development of a domain-specific Chinese-English machine translation system,
Problem: Accuracy of Chinese Word Segmentation (CWS) on large amounts of training text often decreases.
• Many errors in translation knowledge extraction
• Therefore seriously affects translation quality

Our resolution
Related work• Domain-Adapted Chinese Word Segmentation Based on
statistical Features
• In previous work, only 1-best result is adopted generally, and ignored the lower ranking result.
• Bilingually motivated domain-adapted word segmentation
• Many characters are aligned to NULL which decrease accuracy of Chinese segmentation.
Our goal : Extend these method to augment domain adaptation of CWS

Our approach
We propose a linear model to combine multiple Chinese word segmentation results of the two segmenters to augment domain adaptation.
• Segmenter based on n-gram features of Chinese raw corpus.
• Segmenter based on bilingually motivated features.
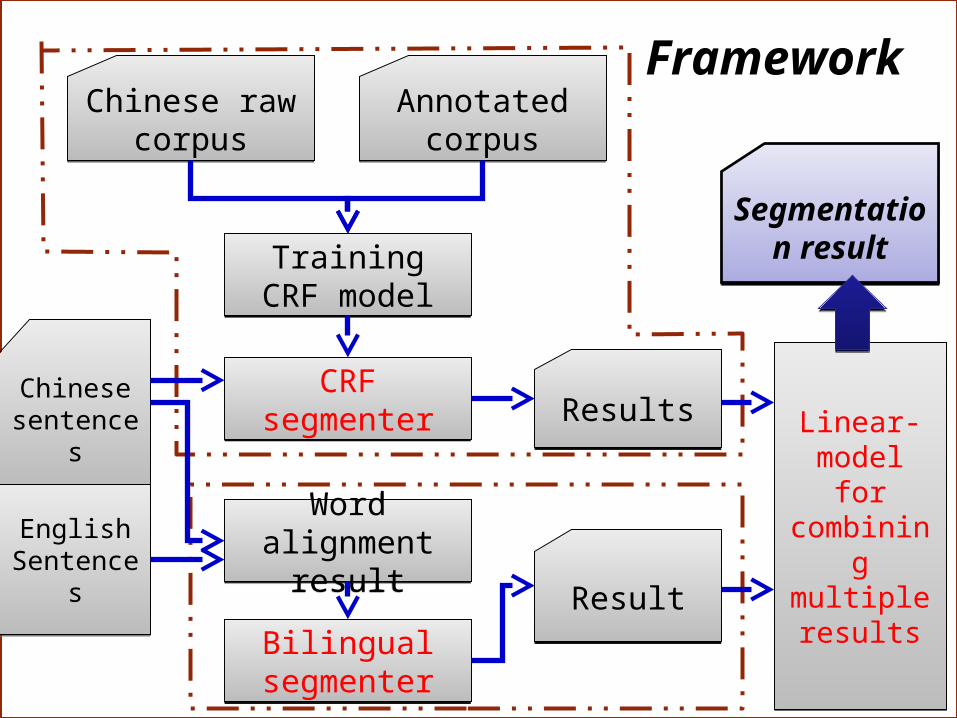
Chinese raw corpus
Chinese raw corpus
Annotated corpus
Annotated corpus
ChinesesentencesChinese
sentences
EnglishSentences
EnglishSentences
Training CRF model
Training CRF model
CRF segmenterCRF segmenter
Word alignment result
Word alignment result
Bilingual segmenterBilingual
segmenter
ResultsResults
ResultResult
Linear-model forcombining
multipleresults
Linear-model forcombining
multipleresults
Segmentation result
Segmentation result
Framework

Annotated corpus
Annotated corpus
Extractingstatistical features
Extractingstatistical features
TrainingCRF model
TrainingCRF model
N-gram statisticalfeatures
N-gram statisticalfeatures
Raw corpusRaw corpus Test dataTest data
Extractingstatistical features
Extractingstatistical features
CRF Decoding
CRF Decoding
CRF segmenter Segmentation
resultSegmentation
result

CRF segmenter
Exploring statistical features of large-scale domain-specific Chinese raw corpus
• N-gram frequency feature
• N-gram AV (Accessor Variety) feature
Output of CRF models• N-best list of segmentation results
• Corresponding probability scores

Observation
Some erroneous segmentations in 1-best result are segmented correctly in the low-ranking results.
We intend to utilize correct parts within the 10-best results and the corresponding probability scores.

Bilingual segmenter
The boundaries of Chinese word are inferable on parallel corpus.
• Marked word boundaries in English sentences.
• Alignment from English word to Chinese word.

Inference step
1. Conduct word alignments using GIZA++, regarding each character of Chinese sentence as one word.
2. For each alignment ai=< ei, C>, if the characters in C
are consecutive in the sentence. Take C as a word
Calculate its confidence score (refer to paper)

Linear model
Calculate score of Cij being a word by combine
multiple segmentation results
K
kkkk jisegjiConfjiF
1
),(),(),(
F(i, j) denotes the score of characters from i to j being a
word.
λ (1≤k≤K) are weights of K segmentation results.
Confk(i,j) (1≤k≤K) is the confidence score of the kth segmentation
result.
segk(i, j) (1≤k≤K) is a two-valued function.

Decoding
Cij and F(i, j) being represented in a lattice
The best sequence is found by dynamic programming algorithm.
• Search a sequence of words with a maximum product of their scores.

Training parameter λ
Initial point λl (1≤l≤K): A point in K-dimensional
parameter space is randomly selected.
The parameters λl are optimized through iterative
process. • In each step, only one parameter is optimized, while
keeping all other parameters fixed.

Experiment setting
Experimental data: NTCIR-10 Chinese-English parallel patent description sentences
Annotation set: randomly selected 300 sentence pairs.
• 150 sentences used for training the lattice parameters.
• 150 sentences used for evaluation.

Evaluation
We conduct evaluations from two aspects:• Evaluation (1): accuracy of Chinese word segmentation
(F-measure)
• Evaluation (2): translation quality of MT system (BLEU)

Evaluation(1)
MethodPrecision
[%]Recall[%]
F-measure[%]
Bilingually motivated segmenter
73.1312 61.4480 66.7825
1-best of CRF segmenter(baseline)
90.2439 90.7710 90.5067
Linear-model(our approach)
91.6650 91.8614 91.7631
Accuracy of Chinese word segmentation

Evaluation(2)
We develop a phrase-based SMT with Moses, using different Chinese segmenters
• 1-best of CRF segmenter (baseline)
• Linear model (our approach)
• Stanford Chinese segmenter
• NLPIR Chinese segmenter

Evaluation (2): result
SMT using different Chinese segmenter BLEU[%]
1-best of CRF segmenter (baseline) 30.53
Linear model (our approach) 31.15
Stanford Chinese segmenter 30.98
NLPIR Chinese segmenter 30.56
Our approach increased by 0.62% compared to baseline. Performance of our approach is better than the two
popular segmenters.
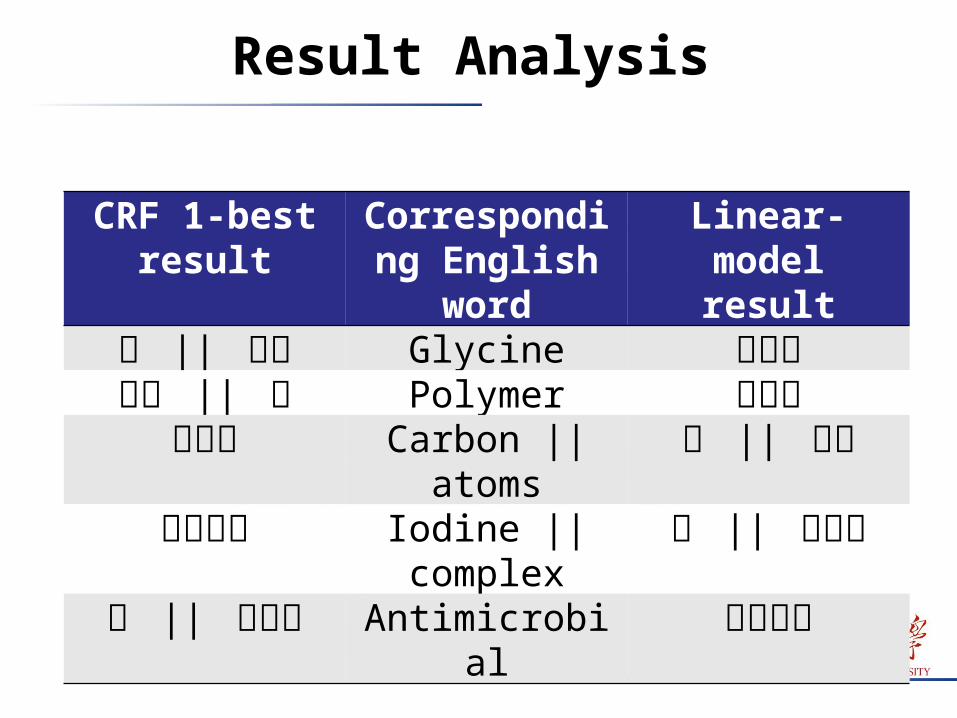
Result Analysis
CRF 1-best result
Corresponding English word
Linear-model result
甘 || 氨酸 Glycine 甘氨酸聚合 || 物 Polymer 聚合物碳原子 Carbon || atoms 碳 || 原子碘复合物 Iodine || complex 碘 || 复合物
抗 || 微生物 Antimicrobial 抗微生物

Conclusion
We propose a linear model to combine multiple segmentation results from two segmenters to augment domain-adaptation.
• one based on n-gram statistical feature of large Chinese raw corpus.
• the other one based on bilingually motivated features of parallel corpus.
The experimental results show that both F-measure of CWS result and the BLEU score of SMT are improved.

Thanks!
Q&A


















