
Chapter 3homes.ieu.edu.tr/ucelikkan/SE309_2015/Week2/SE309... · Lexical Analysis (continued)...
47
ISBN 0-321-49362-1 Chapter 3 Describing Syntax and Semantics
Transcript of Chapter 3homes.ieu.edu.tr/ucelikkan/SE309_2015/Week2/SE309... · Lexical Analysis (continued)...

ISBN 0-321-49362-1
Chapter 3
Describing Syntax and Semantics

Copyright © 2009 Addison-Wesley. All rights reserved. 1-2
Chapter 3 Topics
• Introduction
• The General Problem of Describing Syntax
• Formal Methods of Describing Syntax

Copyright © 2009 Addison-Wesley. All rights reserved. 1-3
Introduction
• Syntax: the form or structure of the expressions, statements, and program units
• Semantics: the meaning of the expressions, statements, and program units
• Syntax and semantics provide a language’s definition – Users of a language definition
• Other language designers
• Implementers
• Programmers (the users of the language)

Copyright © 2009 Addison-Wesley. All rights reserved. 1-4
The General Problem of Describing Syntax: Terminology
• A sentence is a string of characters over some alphabet
• A language is a set of sentences
• A lexeme is the lowest level syntactic unit of a language (e.g., *, sum, begin)
• A token is a category of lexemes (e.g., identifier)

Copyright © 2009 Addison-Wesley. All rights reserved. 1-5
Formal Definition of Languages
• Recognizers – A recognition device reads input strings over the alphabet
of the language and decides whether the input strings belong to the language
– Example: syntax analysis part of a compiler
- Detailed discussion of syntax analysis appears in
Chapter 4
• Generators – A device that generates sentences of a language
– One can determine if the syntax of a particular sentence is syntactically correct by comparing it to the structure of the generator

Copyright © 2009 Addison-Wesley. All rights reserved. 1-6
BNF and Context-Free Grammars
• Context-Free Grammars
– Developed by Noam Chomsky in the mid-1950s
– Language generators, meant to describe the syntax of natural languages
– Define a class of languages called context-free languages
• Backus-Naur Form (1959)
– Invented by John Backus to describe Algol 58
– BNF is equivalent to context-free grammars

Copyright © 2009 Addison-Wesley. All rights reserved. 1-7
BNF Fundamentals
• In BNF, abstractions are used to represent classes of syntactic structures--they act like syntactic variables (also called nonterminal symbols, or just nonterminals) – <assign> → <var>=<expression>
• Terminals are lexemes or tokens • A rule has a left-hand side (LHS), which is a nonterminal, and a right-hand side (RHS),
which is a string of terminals and/or nonterminals
• Nonterminals are often enclosed in angle brackets
– Examples of BNF rules: <ident_list> → identifier | identifier, <ident_list>
<if_stmt> → if <logic_expr> then <stmt>
• Grammar: a finite non-empty set of rules
• A start symbol is a special element of the nonterminals of a grammar

BNF Grammar
NS
A N
(NT)*
A
G = (N,T,P,S) P : Set of productions T : terminal symbols: N : nonterminal symbols :start symbol A production has the form where and
N = {S,A}
T= {a,b,c}
P={SaAc,AaA,
Ab}

Copyright © 2009 Addison-Wesley. All rights reserved. 1-9
BNF Rules
• An abstraction (or nonterminal symbol) can have more than one RHS
<stmt> <single_stmt>
| begin <stmt_list> end

Copyright © 2009 Addison-Wesley. All rights reserved. 1-10
Describing Lists
• Syntactic lists are described using recursion
<ident_list> ident
| ident, <ident_list>
• A derivation is a repeated application of rules, starting with the start symbol and ending with a sentence (all terminal symbols)

Copyright © 2009 Addison-Wesley. All rights reserved. 1-11
An Example Grammar
<program> <stmts>
<stmts> <stmt> | <stmt> ; <stmts>
<stmt> <var> = <expr>
<var> a | b | c | d
<expr> <term> + <term> | <term> - <term>
<term> <var> | const

Copyright © 2009 Addison-Wesley. All rights reserved. 1-12
An Example Derivation
<program> => <stmts> => <stmt>
=> <var> = <expr>
=> a = <expr>
=> a = <term> + <term>
=> a = <var> + <term>
=> a = b + <term>
=> a = b + const
<program> <stmts>
<stmts> <stmt> | <stmt> ; <stmts>
<stmt> <var> = <expr>
<var> a | b | c | d
<expr> <term> + <term> | <term> - <term>
<term> <var> | const

Copyright © 2009 Addison-Wesley. All rights reserved. 1-13
Derivations
• Every string of symbols in a derivation is a sentential form
• A sentence is a sentential form that has only terminal symbols
• A leftmost derivation is one in which the leftmost nonterminal in each sentential form is the one that is expanded
• A derivation may be neither leftmost nor rightmost

Copyright © 2009 Addison-Wesley. All rights reserved.
1-14
Parse Tree
• A hierarchical representation of a derivation
<program>
<stmts>
<stmt>
const
a
<var> = <expr>
<var>
b
<term> + <term>
<program> => <stmts> => <stmt>
=> <var> = <expr>
=> a = <expr>
=> a = <term> + <term>
=> a = <var> + <term>
=> a = b + <term>
=> a = b + const

Copyright © 2009 Addison-Wesley. All rights reserved. 1-15
Ambiguity in Grammars
• A grammar is ambiguous if and only if it generates a sentential form that has two or more distinct parse trees

Copyright © 2009 Addison-Wesley. All rights reserved. 1-16
An Ambiguous Expression Grammar
<expr> <expr> <op> <expr> | const
<op> / | -
<expr>
<expr> <expr>
<expr> <expr>
<expr>
<expr> <expr>
<expr> <expr>
<op>
<op>
<op>
<op>
const const const const const const - - / /
<op>

Copyright © 2009 Addison-Wesley. All rights reserved. 1-17
An Unambiguous Expression Grammar
• If we use the parse tree to indicate precedence levels of the operators, we cannot have ambiguity
<expr> <expr> - <term> | <term>
<term> <term> / const| const
<expr>
<expr> <term>
<term> <term>
const const
const /
-

Copyright © 2009 Addison-Wesley. All rights reserved. 1-18
Associativity of Operators
• Operator associativity can also be indicated by a grammar
<expr> -> <expr> + <expr> | const (ambiguous)
<expr> -> <expr> + const | const (unambiguous)
<expr> <expr>
<expr>
<expr> const
const
const
+
+

Copyright © 2009 Addison-Wesley. All rights reserved. 1-19
Extended BNF
• Optional parts are placed in brackets [ ]
<proc_call> -> ident [(<expr_list>)]
• Alternative parts of RHSs are placed inside parentheses and separated via vertical bars
<term> → <term> (+|-) const
• Repetitions (0 or more) are placed inside braces { }
<ident> → letter {letter|digit}

Copyright © 2009 Addison-Wesley. All rights reserved. 1-20
BNF and EBNF
• BNF
<expr> <expr> + <term>
| <expr> - <term>
| <term>
<term> <term> * <factor>
| <term> / <factor>
| <factor>
• EBNF
<expr> <term> {(+ | -) <term>}
<term> <factor> {(* | /) <factor>}

Copyright © 2009 Addison-Wesley. All rights reserved. 1-21
Recent Variations in EBNF
• Alternative RHSs are put on separate lines
• Use of a colon instead of =>
• Use of opt for optional parts
• Use of oneof for choices
<ForStatement>::= for ( <ForInitopt >; <Expressionopt >; <ForUpdateopt >) Statement

ISBN 0-321-49362-1
Chapter 4
Lexical and Syntax Analysis

Copyright © 2009 Addison-Wesley. All rights reserved. 1-23
Chapter 4 Topics
• Introduction
• Lexical Analysis
• The Parsing Problem
• Top-Down Parsing (Recursive-Descent Parsing)
• Bottom-Up Parsing
A language that is simple to parse for the compiler is
also simple to parse for the human programmer.
N. Wirth

Copyright © 2009 Addison-Wesley. All rights reserved. 1-24
Introduction
• Language implementation systems must analyze source code, regardless of the specific implementation approach
• Nearly all syntax analysis is based on a formal description of the syntax of the source language (BNF)

Copyright © 2009 Addison-Wesley. All rights reserved. 1-25
Syntax Analysis
• The syntax analysis portion of a language processor nearly always consists of two parts:
– A low-level part called a lexical analyzer (mathematically, a finite automaton based on a regular grammar)
– A high-level part called a syntax analyzer, or parser (mathematically, a push-down automaton based on a context-free grammar, or BNF)

Copyright © 2009 Addison-Wesley. All rights reserved. 1-26
Advantages of Using BNF to Describe Syntax
• Provides a clear and concise syntax description
• The parser can be based directly on the BNF
• Parsers based on BNF are easy to maintain

Copyright © 2009 Addison-Wesley. All rights reserved. 1-27
Reasons to Separate Lexical and Syntax Analysis
• Simplicity - less complex approaches can be used for lexical analysis; separating them simplifies the parser
• Efficiency - separation allows optimization of the lexical analyzer
• Portability - parts of the lexical analyzer may not be portable, but the parser always is portable

Copyright © 2009 Addison-Wesley. All rights reserved. 1-28
Lexical Analysis
• A lexical analyzer is a pattern matcher for character strings
• A lexical analyzer is a “front-end” for the parser
• Identifies substrings of the source program that belong together - lexemes – Lexemes match a character pattern, which is
associated with a lexical category called a token
– sum is a lexeme; its token may be IDENT

Copyright © 2009 Addison-Wesley. All rights reserved. 1-29
Lexical Analysis (continued)
• The lexical analyzer is usually a function that is called by the parser when it needs the next token
• Three approaches to building a lexical analyzer:
– Write a formal description of the tokens and use a software tool that constructs table-driven lexical analyzers given such a description(i.e. lex on UNIX)
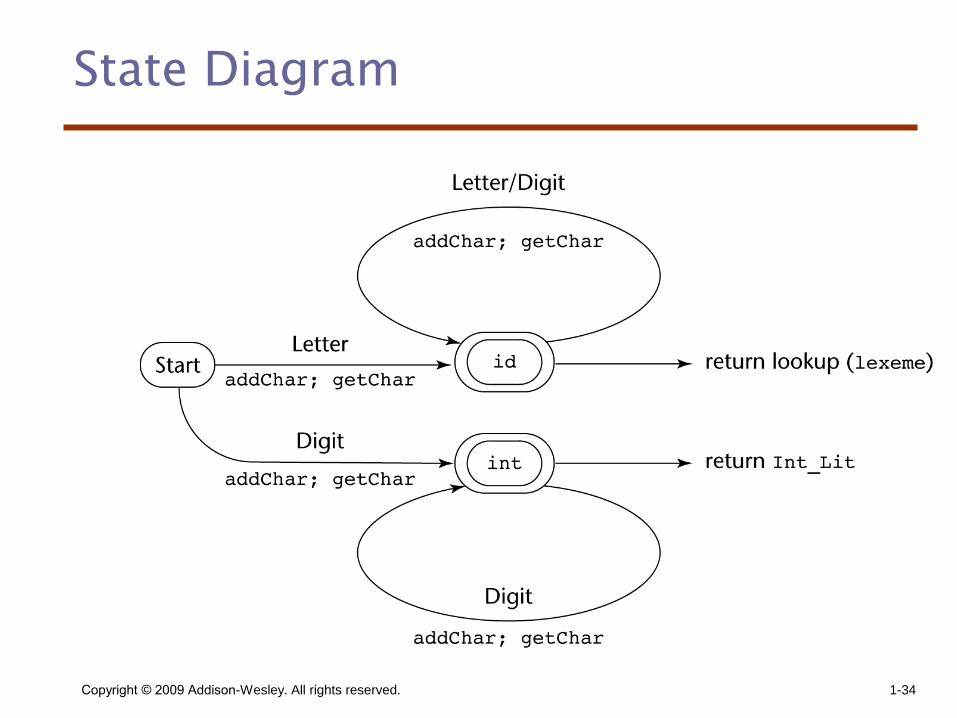
– Design a state diagram that describes the tokens and write a program that implements the state diagram
– Design a state diagram that describes the tokens and hand-construct a table-driven implementation of the state diagram

Copyright © 2009 Addison-Wesley. All rights reserved. 1-30
State Diagram Design
– A naïve state diagram would have a transition from every state on every character in the source language - such a diagram would be very large!

Copyright © 2009 Addison-Wesley. All rights reserved. 1-31
Lexical Analysis (cont.)
• In many cases, transitions can be combined to simplify the state diagram
– When recognizing an identifier, all uppercase and lowercase letters are equivalent
• Use a character class that includes all letters
– When recognizing an integer literal, all digits are equivalent - use a digit class

Copyright © 2009 Addison-Wesley. All rights reserved. 1-32
Lexical Analysis (cont.)
• Reserved words and identifiers can be recognized together (rather than having a part of the diagram for each reserved word)
– Use a table lookup to determine whether a possible identifier is in fact a reserved word

Copyright © 2009 Addison-Wesley. All rights reserved. 1-33
Lexical Analysis (cont.)
• Convenient utility subprograms:
– getChar - gets the next character of input, puts it in nextChar, determines its class and puts the class in charClass
– addChar - puts the character from nextChar into the place the lexeme is being accumulated, lexeme
– lookup - determines whether the string in lexeme is a reserved word (returns a code)
Copyright © 2009 Addison-Wesley. All rights reserved. 1-34
State Diagram

Copyright © 2009 Addison-Wesley. All rights reserved. 1-35
Lexical Analyzer
Implementation:
SHOW front.c (pp. 194-199)
- Following is the output of the lexical analyzer of
front.c when used on (sum + 47) / total
Next token is: 25 Next lexeme is (
Next token is: 11 Next lexeme is sum
Next token is: 21 Next lexeme is +
Next token is: 10 Next lexeme is 47
Next token is: 26 Next lexeme is )
Next token is: 24 Next lexeme is /
Next token is: 11 Next lexeme is total
Next token is: -1 Next lexeme is EOF

Copyright © 2009 Addison-Wesley. All rights reserved. 1-36
The Parsing Problem
• Goals of the parser, given an input program:
– Find all syntax errors; for each, produce an appropriate diagnostic message and recover quickly
– Produce the parse tree, or at least a trace of the parse tree, for the program

Copyright © 2009 Addison-Wesley. All rights reserved. 1-37
The Parsing Problem (cont.)
• Two categories of parsers
– Top down - produce the parse tree, beginning at the root
• Order is that of a leftmost derivation
• Traces or builds the parse tree in preorder
– Bottom up - produce the parse tree, beginning at the leaves
• Order is that of the reverse of a rightmost derivation
• Useful parsers look only one token ahead in the input

Copyright © 2009 Addison-Wesley. All rights reserved. 1-42
Recursive-Descent Parsing
• There is a subprogram for each nonterminal in the grammar, which can parse sentences that can be generated by that nonterminal
• EBNF is ideally suited for being the basis for a recursive-descent parser, because EBNF minimizes the number of nonterminals

Copyright © 2009 Addison-Wesley. All rights reserved. 1-43
Recursive-Descent Parsing (cont.)
• A grammar for simple expressions:
<expr> <term> {(+ | -) <term>}
<term> <factor> {(* | /) <factor>}
<factor> id | int_constant | ( <expr> )

Copyright © 2009 Addison-Wesley. All rights reserved. 1-44
Recursive-Descent Parsing (cont.)
• Assume we have a lexical analyzer named lex, which puts the next token code in nextToken
• The coding process when there is only one RHS:
– For each terminal symbol in the RHS, compare it with the next input token; if they match, continue, else there is an error
– For each nonterminal symbol in the RHS, call its associated parsing subprogram

Copyright © 2009 Addison-Wesley. All rights reserved. 1-45
Recursive-Descent Parsing (cont.)
/* Function expr
Parses strings in the language
generated by the rule:
<expr> → <term> {(+ | -) <term>}
*/
void expr() {
/* Parse the first term */
term();
/* As long as the next token is + or -, call
lex to get the next token and parse the
next term */
while (nextToken == ADD_OP ||
nextToken == SUB_OP){
lex();
term();
}
}
<expr> <term> {(+ | -) <term>}
<term> <factor> {(* | /) <factor>}
<factor> id | int_constant | ( <expr> )

Copyright © 2009 Addison-Wesley. All rights reserved. 1-46
Recursive-Descent Parsing (cont.)
• This particular routine does not detect errors
• Convention: Every parsing routine leaves the next token in nextToken

Copyright © 2009 Addison-Wesley. All rights reserved. 1-47
Recursive-Descent Parsing (cont.)
• A nonterminal that has more than one RHS requires an initial process to determine which RHS it is to parse
– The correct RHS is chosen on the basis of the next token of input (the lookahead)
– The next token is compared with the first token that can be generated by each RHS until a match is found
– If no match is found, it is a syntax error

Recursive-Descent Parsing (cont.)
/* term
Parses strings in the language generated by the rule:
<term> -> <factor> {(* | /) <factor>)
*/
void term() {
/* Parse the first factor */
factor();
/* As long as the next token is * or /,
next token and parse the next factor
*/
while (nextToken == MULT_OP || nextToken == DIV_OP) {
lex();
factor();
}
} /* End of function term */
Copyright © 2009 Addison-Wesley. All rights reserved. 1-48
<expr> <term> {(+ | -) <term>}
<term> <factor> {(* | /) <factor>}
<factor> id | int_constant | ( <expr> )

Copyright © 2009 Addison-Wesley. All rights reserved. 1-49
Recursive-Descent Parsing (cont.)
/* Function factor
Parses strings in the language generated by the rule:
<factor> -> id | (<expr>) */
void factor() {
/* Determine which RHS */
if (nextToken) == ID_CODE || nextToken == INT_CODE)
/* For the RHS id, just call lex */
lex();
/* If the RHS is (<expr>) – call lex to pass over the left parenthesis, call expr, and check for the right parenthesis */
else if (nextToken == LP_CODE) { lex();
expr();
if (nextToken == RP_CODE)
lex();
else
error();
} /* End of else if (nextToken == ... */
else
error(); /* Neither RHS matches */
}
<expr> <term> {(+ | -) <term>}
<term> <factor> {(* | /) <factor>}
<factor> id | int_constant | ( <expr> )

Copyright © 2009 Addison-Wesley. All rights reserved. 1-50
Recursive-Descent Parsing (cont.)
- Trace of the lexical and syntax analyzers on (sum + 47) / total
Next token is: 25 Next lexeme is ( Next token is: 11 Next lexeme is total
Enter <expr> Enter <factor>
Enter <term> Next token is: -1 Next lexeme is EOF
Enter <factor> Exit <factor>
Next token is: 11 Next lexeme is sum Exit <term>
Enter <expr> Exit <expr>
Enter <term>
Enter <factor>
Next token is: 21 Next lexeme is +
Exit <factor>
Exit <term>
Next token is: 10 Next lexeme is 47
Enter <term>
Enter <factor>
Next token is: 26 Next lexeme is )
Exit <factor>
Exit <term>
Exit <expr>
Next token is: 24 Next lexeme is /
Exit <factor>

Copyright © 2009 Addison-Wesley. All rights reserved. 1-70
Summary
• Syntax analysis is a common part of language implementation
• A lexical analyzer is a pattern matcher that isolates small-scale parts of a program – Detects syntax errors
– Produces a parse tree
• A recursive-descent parser is a top down parser – EBNF


















