
Chapter 11staff.camas.wednet.edu/blogs/cmarshall08/files/2012/06/DNA-and-Genes.pdf · Last chapter...
68
Chapter 11
Transcript of Chapter 11staff.camas.wednet.edu/blogs/cmarshall08/files/2012/06/DNA-and-Genes.pdf · Last chapter...

Chapter 11





Quiz #8: February 13th
You will distinguish between the famous
scientists and their contributions towards DNA
You will demonstrate replication, transcription,
and translation from a sample strand of DNA
You will identify mutations by type and result

When trying to figure out what our genes were
made of, most scientists always assumed they
were proteins.
Proteins were discovered in 1838; Nucleic acids
were discovered in 1871.
The function of proteins was discovered in 1926.
Nucleic acids not until 1952.
There are 20 different amino acids that make
proteins. There are only 4 different nucleotides
that make up nucleic acids.
There’s more of a variety of proteins and
we’ve known about them longer.

Alfred Hershey and Martha Chase devised an
experiment to answer this question in 1952.
Proteins contain sulfur, but nucleic acids don’t.
Nucleic acids contain phosphorus, but proteins
don’t.
First the two scientists put radioactive isotopes
of both phosphorus and sulfur into a virus.
The radiation would show up under a special light,
and will shine a different color for phosphorus and
sulfur.
After this, they let the virus infect an E. coli
cell, which reproduced over and over again.


After the E. coli reproduced and grew, Hershey and Chase shined radioactive detectors over the cells.
They found that the color for phosphorus appeared, but not for sulfur.
This proved that when the virus reproduced, they passed on phosphorus, not sulfur.
Since only nucleic acids have phosphorus, nucleic acids must have been what was passed on.
Conclusion: Genes were made of nucleic acids, not proteins.
All of a sudden, people were desperate to learn more about our genetic material: nucleic acids.

There are only 5 different types of nucleic
acids.
Adenine, Thymine, Guanine, Cytosine, and Uracil
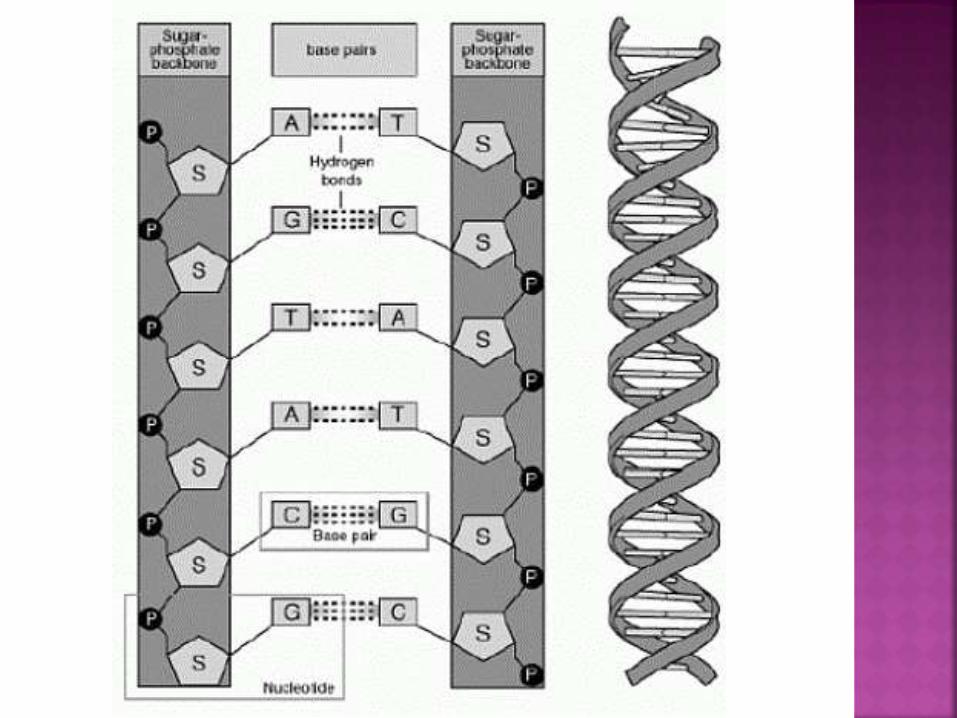
Each nucleotide contains three parts
A 5-carbon ribose sugar, which is the structural
backbone of nucleic acids
A phosphate molecule, which links nucleotides
together
A nitrogenous base, which is the genetic code.
The different nitrogenous bases give each
nucleotide it’s specific name.



Around the same time as Hershey and Chase,
Erwin Chargoff noticed an interesting trend
with nucleotides.
Chargoff separated all the DNA in a
chromosome into individual nucleotides.
He then weighed each nucleotide to see how
much of each was in a chromosome.
Though the numbers were always different,
the amount of adenine was always similar to
the amount of thymine, and the amount of
guanine was similar to the amount of
cytosine

Species A T G C
Bacillus Subtillus (Bacillus bacteria) 28.4 29.0 21.0 21.6
Escherichia coli (E. coli) 24.6 24.3 25.5 25.6
Neurospora crassa (Bread mold) 23.0 23.3 27.1 26.6
Zea mays (Corn) 25.6 25.3 24.5 24.6
Drosophila melanogaster (Fruit fly) 27.3 27.6 22.5 22.5
Homo Sapiens (Human) 31.0 31.5 19.1 18.4


One year after Hershey and Chase, James
Watson and Francis Crick made what is
considered one of the greatest discoveries in
science: they decoded the structure of DNA.
Using photographs from their colleague,
Rosalind Franklin, the amount of each
nucleotide from Chargoff, and tinker toys,
they built large models showing how to build
a DNA strand.




Watson and Crick proved that even though
there are only four nucleotides, they could
be rearranged and linked billions of times to
create long sequences.
Thus, genes could be created by linking
hundreds, thousands, or tens of thousands of
nucleotides together.


There are three processes we will discuss in
this chapter. The first is DNA replication.
DNA replication is how cells copy their DNA
These copies will be used by each cell during
mitosis and meiosis.
To learn replication, you must first learn the
structure of DNA chains

DNA is described as a double helix, because
it is two sequences of DNA that wrap around
each other.
These sequences attach to each other at the
nucleotides using hydrogen bonds.
Adenines always attach to Thymines
Guanines always attach to Cytosines.
(This explains Chargoff’s rule)
Because these pairs always attach to each
other, each strand of DNA can be used as a
template, or guide, for building a new strand

The first step in DNA replication is that an
enzyme has to break the hydrogen bonds
between each strand.
After breaking the first hydrogen bond, the
enzyme continues down the strand like a
zipper.
Meanwhile, the endoplasmic reticulum has
been building new nucleotides.
These nucleotides are carried by enzymes to
the nucleus to be attached to the unzipped
strand.


While the strands unzip, enzymes attach new
nucleotides to each strand.
The enzymes know which nucleotides to use
because each nucleotide can only pair with
it’s partner—no one else.
The result: each new DNA strand has one old
copy of DNA and one new copy of DNA.
This process of using an old strand to build a
new is called semi-conservative replication.




Structurally, not much is
different between DNA and
RNA.
DNA stands for
DeoxyriboNucleic Acid
RNA stands for RiboNucleic
Acid
The only difference in
structure is that DNA is
missing an oxygen atom

There are other differences with how DNA
and RNA is used
DNA is double stranded, RNA is single stranded
(the nucleotides do not have to pair up)
RNA does not contain Thymine. Instead, it
contains a unique nucleotide called Uracil.
DNA’s only form is double helix. RNA comes in
many forms. You will learn about two of these
forms: messenger RNA, and transfer RNA
The DNA is the main blueprint. RNA not only
are copies of the blueprint, but do most of
the constructing as well.

Last chapter we talked about how genes are
passed on. This chapter, we will talk about
how our body reads genes and turns them
into our traits.
To do this, we will introduce the second
process of this chapter: DNA Transcription.
Transcription is the process of creating an
RNA sequence using a DNA template.
This RNA sequence will then be carried out of
the nucleus and to a ribosome to build a
protein.

Transcription begins similar to Replication. An
enzyme breaks the hydrogen bonds between
the DNA strands and begins to unzip a section
of DNA
This section contains only the necessary genetic
information for making a specific protein.
As it unzips, enzymes attach new nucleotides
to the DNA segment
Guanine pairs with Cytosine (same as replication)
Adenine pairs with URACIL (not Thymine this time)

When the section of nucleotides is completed,
the RNA strand breaks off of the DNA strand.
This section of RNA is called Messenger RNA (or
mRNA) because it will be the messenger carrying
the genetic information to the ribosome.
Another enzyme reattaches the DNA strand, and
the process of transcription is complete.


Before moving on, the mRNA strand first gets
modified by the cell
Sections of the mRNA are removed by an enzyme
and returned to the nucleus.
The sections that are removed are called introns.
The remaining sections, called exons, are what
get expressed (read) by ribosomes


Why introns and exons?
The short answer is…who knows?
Introns create redundancy, which helps reduce the
likelihood that a mutation will cause a problem
If 100% of the nucleotides are turned into a protein, then a
mutation will cause a problem 100% of the time.
If only 100 nucleotides out of 10,000 code for a gene, the
likelihood of a mutation hitting those specific 100
nucleotides is very small.
Introns allow for more variety of gene sequences
Take the word “hearth”.
From this word, you get the words “he,” “ear,” “art,”
“heart,” and “earth,” depending on which letters you cut
out.

The final process to learn this chapter is
translation.
Translation is the process of converting a
strand of mRNA into an amino acid sequence
for a protein
Translation occurs at ribosomes
Remember chapter 7? What is the role of
ribosomes?
The first step involves the second form of
RNA: Transfer RNA (tRNA)

The tRNA have two parts.
On one end, they have what is called an
anticodon.
A codon is a sequence of three nucleotides in
mRNA
An anticodon is a sequence that pairs with a
codon
On the other end, they are holding on to an
amino acid.


The beginning of the sequence of mRNA is
read by multiple tRNA’s until one is found
whose anticodon matches the mRNA’s codon
Once the right tRNA has latched onto the
mRNA, another tRNA will latch onto the next
3-nucleotide codon sequence.
This process will continue until the entire
strand has been covered
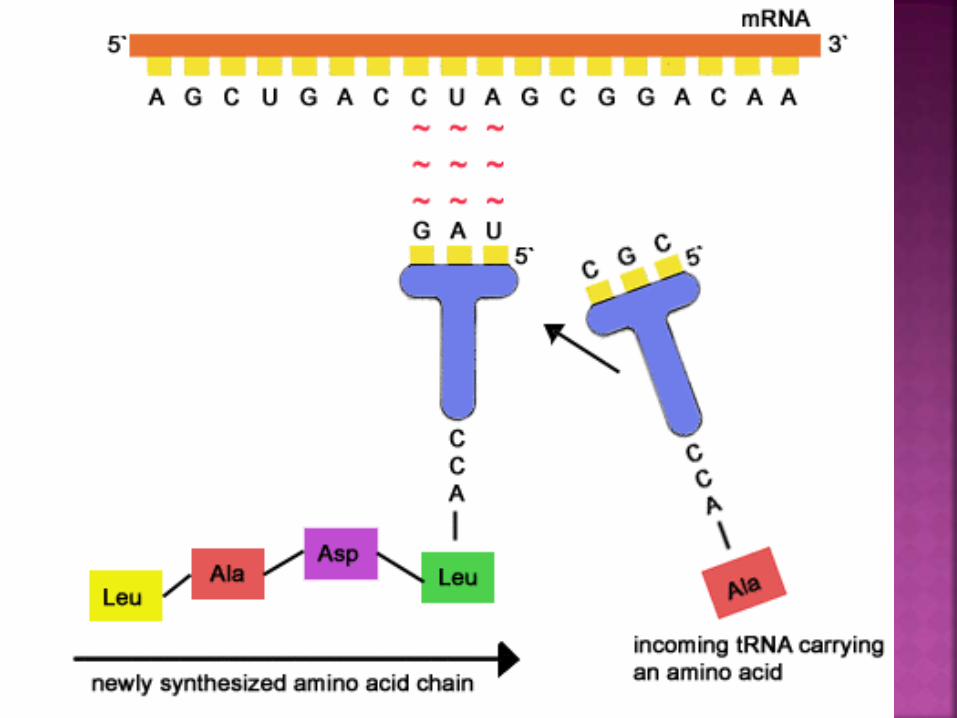

While tRNA’s match their anticodon’s to the
mRNA’s codons, the amino acids on the other
ends of the tRNA’s are lining up too.
Another enzyme will remove the amino acids
from the tRNA and attach them to each
other.
The type of bond that holds the amino acids
together is called a peptide bond
Once the amino acid sequence is completed,
the amino acids will fold together and form a
protein


How does the mRNA know that the amino acid sequence it is coding for is the right one?
Each tRNA has a specific anticodon. That anticodon will ALWAYS go with a specific amino acid
Each three-nucleotide sequence on the mRNA can therefore only code for a specific amino acid. One sequence always indicates the *Start*
position, and three sequences indicate the *Stop* positions


The four possible nucleotides for RNA are
Uracil (U)
Cytosine (C)
Adenine (A)
Guanine (G)
Name some possible 3-nucleotide codons that
we will test to see what amino acid they
code for.





The human genome contains between
20,000-40,000 genes. The sequence of DNA to
make these genes is around 6.6 billion
nucleotides.
Amazingly, most of us have survived this long
without a single, lethal mistake.
But…errors will occur.
An error that causes a change in a DNA/RNA
sequence is called a mutation.
In this chapter, we will talk about 4 types of
mutations

Mutations can take place in gametes, and
affect the offspring, or take place in another
cell in the body and only affect that organism
Mutations can have both positive or negative
results. They can also have no affect
Mutations can be problems with DNA
replication/transcription/translation, or come
from environmental factors

A point mutation is when only one nucleotide
is incorrect.
Even though it is only 1 nucleotide out of 3.3
billion, this one mistake has the potential to
completely change an organism’s health.
Example: “I have a pet cat.” This could be “I
gave a pet cat;” “I wave a pet cat;” “I have a
wet cat.” “I have a pet rat.”
Sickle cell anemia is a disease caused by a
single point mutation that tells the cell to
replace a glutamine with a valine



Frameshift mutations are when at least one
nucleotide is added or deleted from the DNA
or RNA sequence
The correct sequence of amino acids is
dependent on maintaining the 3-nucleotide
codon pattern.
If one nucleotide is added or deleted, the
codon pattern does not start at the right spot
This results in an entire sequence of amino
acids being incorrect.


Chromosome mutations are when the
chromosome itself is damaged before the
DNA is able to be replicated or transcribed
Chromosome mutations tend to occur during
mitosis or meiosis, and usually result in the
death of the cell
It is possible, though rare, for healthy
zygotes to grow with chromosome mutations.
If this happens, the organism will most likely
be sterile

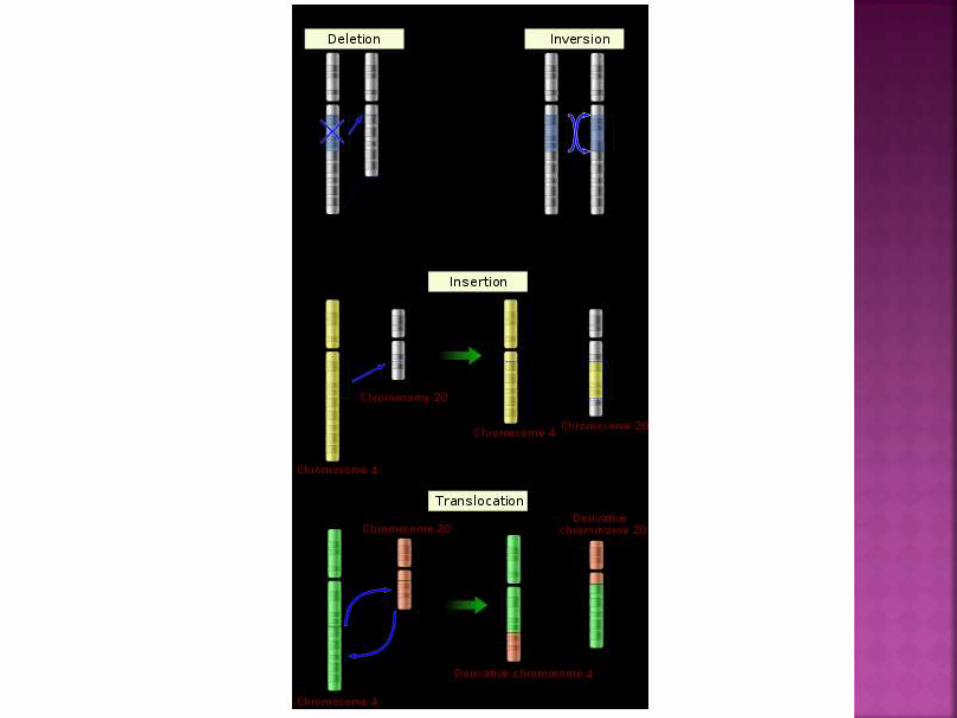
There are four types of chromosome
mutations
1) Deletion. When a section of a chromosome is
deleted
2) Insertion. When part of a chromatid breaks off
and attaches to it’s sister chromatid, resulting in
a duplicate of a chromosome
3) Inversion. When part of a chromosome breaks
but is reattached backwards.
4) Translocation. When part of one chromosome
breaks and attaches to a different chromosome

Mutagens are environmental factors that
cause changes in DNA.
1) Radiation. X-rays, ultraviolet light, cosmic
rays, nuclear radiation all cause radiation by
breaking apart and/or changing DNA
2) Chemicals. Asbestos, benzenes,
formaldehyde react with chemicals in the
DNA
3) High temperatures. High temperatures can
break hydrogen bonds and cause the DNA
strands to fall apart

With all these possibilities, and with 3.3
billion nucleotides, how come mutations
don’t happen more often?
The enzymes that build DNA and RNA strands
have the ability to check for mistakes.
Mistakes happen constantly (probably 1-10
every second). But whenever they do,
enzymes repair the mistake.
Mutations only occur when a mistake occurs
but the enzymes don’t notice OR when an
organism is subjected to multiple mutagens.

This question is worth an extra 5 pts on the biweekly
quiz.
You may check your answers with me ahead of time
for a yes or no response as many times as you like.
Under ideal conditions E. coli can finish
mitosis in only 36 minutes. But it takes 40
minutes to finish replication. How is that
possible?


















