
Chapter 9, Virtual Memory Overheads, Part 1 Sections 9.1-9.5 1.
180
Chapter 9, Virtual Memory Overheads, Part 1 Sections 9.1-9.5 1
-
Upload
brooke-benson -
Category
Documents
-
view
212 -
download
0
Transcript of Chapter 9, Virtual Memory Overheads, Part 1 Sections 9.1-9.5 1.

1
Chapter 9, Virtual MemoryOverheads, Part 1Sections 9.1-9.5

2
9.1 Background
• Remember the sequence of developments of memory management from the last chapter:
• 1. The simplest approach: • Define a memory block of fixed size large
enough for any process and allocate such a block to each process (see MISC)
• This is tremendously rigid and wasteful

3
• 2. Allocate memory in contiguous blocks of varying size
• This leads to external fragmentation and a waste of 1/3 of memory
• There is overhead in maintaining allocation tables down to the byte level

4
• 3. Do paging. • Memory is allocated in fixed size blocks• This solves the external fragmentation problem• This also breaks the need for allocation of
contiguous memory• The costs as discussed so far consist of the
overhead incurred from maintaining and using a page table

5
Limitations of Paging—Loading Complete Programs
• Virtual memory is motivate by several limitations in the paging scheme as presented so far
• One limitation is that it’s necessary to load a complete program for it to run

6
• These are examples of why it might not be necessary to load a complete program:
• 1. Error handling routines may not be called during most program runs
• 2. Arrays of predeclared sizes may never be completely filled

7
• 3. Other routines besides error handling may also be rarely used
• 4. For a large program, even if all parts are used at some time during a run, by definition, they can’t all be used at the same time
• This means that at any given time the complete program doesn’t have to be loaded

8
• Reasons for wanting to be able to run a program that’s only partially loaded
• 1. The size of a program is limited to the physical memory on the machine
• Given current memory sizes, this by itself is not a serious limitation, although in some environments it might still be

9
• 2. For a large program, significant parts of it may not be used for significant amounts of time.
• If so, it’s an absolute waste to have the unused parts loaded into memory
• Even with large memory spaces, conserving memory is desirable in order to support multi-tasking

10
• 3. Another area of saving is in loading or swapping cost from secondary storage
• If parts of a program are never needed, reading and writing from secondary storage can be saved
• In general this means leaving more I/O cycles available for useful work

11
• Not having to load a complete program also means:
• A program will start faster when initially scheduled because there is less I/O for the long term scheduler to do
• The program will be faster and less wasteful during the course of its run in a system that does medium term scheduling or swapping

12
Limitations of Paging—Fixed Mapping to Physical Memory
• There is also another, in a sense more general, limitation to paging as presented so far:
• The idea was that once a logical page was allocated a physical frame, it didn’t move
• It’s true that medium term scheduling, swapping, and compaction may move a process, but this has to be specially supported
• Once scheduled and running, a process’s location in memory doesn’t change

13
• If page locations are fixed in memory, that implies a fixed mapping between the logical and physical address space throughout a program run
• More flexibility can be attained if the logical and physical address spaces are delinked
• That would mean address resolution at run time would handle finding a logical page in one physical frame at one time and in another physical frame at another time

14
Definition of Virtual Memory
• Definition of virtual memory:• The complete separation of logical memory
space from physical memory space from the programmer’s point of view

15
• At any given time during a program run, any page, p, in the logical address space could be at any frame, f, in the physical memory space
• Only that part of a program that is running has to have been loaded into main memory from secondary storage
• That means that in fact, any page, p, in the logical address space could be in a frame, f, in memory, or still located in secondary storage

16
• Side note:• Both segmentation and paging were mentioned in
the last chapter• In theory, virtual memory can be implemented
with segmentation• However, that’s a mess• The most common implementation is with paging• That is the only approach that will be covered here

17
9.2 Demand Paging
• If it’s necessary to load a complete process in order for it to run, then there is an up-front cost of swapping all of its pages in from secondary storage to main memory
• It it’s not necessary to load a complete process in order for it to run, then a page only needs to be swapped into main memory if the process generates an address on that page
• This is known as demand paging

18
• In general, when a process is scheduled it may be given an initial allocation of frames in memory
• From that point on, additional frames may be allocated through demand paging
• If a process is not even given an initial footprint and it acquires all of its memory through paging, this is known as pure demand paging

19
• Demand paging from secondary storage to main memory is roughly analogous to what happens on a miss between the page table and the TLB
• Initially, the TLB can be thought of as empty• The first time the process generates an
address on a given page, that causes a TLB miss, and the page entry is put into the TLB

20
• An earlier statement characterized virtual memory as completely separating the logical and physical address spaces
• Another way to think about this is that from the point of view of the logical address space, there is no difference between main memory and secondary storage

21
• In other words, the logical address space may refer to parts of programs which have been loaded into memory and parts of programs which haven’t
• Accessing memory that hasn’t been loaded is slower, but the loading is handled by the system

22
• From the point of view of the address, the running process doesn’t know or care whether it’s in main memory or secondary storage
• The MMU and the disk management system work together to provide transparent access to the logical address space of a program
• The IBM AS/400 is an example of a system where addresses literally extended into the secondary storage space

23
• This is a side issue, but note the following:• The maximum address space is limited by the
architecture—how many bits are available for holding an address
• However, even if the amount of attached memory is not the maximum, the maximum address space extends into secondary storage
• Virtual memory effectively means that secondary storage functions as a transparent extension of physical main memory

24
Support for Virtual Memory and Demand Paging
• From a practical point of view, it becomes necessary to have support to tell which pages have been loaded into physical memory and which have not
• This is part of the hardware support for the MMU
• In the earlier discussions of page tables, the idea of a valid/invalid bit was introduced

25
• Under that scheme, the page table was long enough to accommodate the maximum number of allocated frames
• If a process wasn’t allocated the maximum, then page addresses outside of its allocation were marked invalid

26
• The scheme can be extended for demand paging:
• Valid means valid and in memory.• Invalid means either invalid or not loaded

27
• Under the previous scheme, if an invalid page was accessed, a trap was generated, and the running process was halted due to an attempt to access memory outside of its range
• Under the new scheme, an attempt to access an invalid page also generates a trap, but this is not necessarily an error
• The trap is known as a page fault trap

28
• This is an interrupt which halts the user process and triggers system software which does the following:
• 1. It checks a table to see whether the address was really invalid or just not loaded
• 2. If invalid, it terminates the process

29
• 3. If valid, it gets a frame from the list of free frames (the frame table), allocates it to the process, and updates the data structures to show that the frame is allocated to page x of the process
• 4. It schedules (i.e., requests) a disk operation to read the page from secondary storage into the allocated frame

30
• 5. When the read is complete, it updates the data structures to show that the page is now valid
• 6. It allows the user process to restart on exactly the same instruction that triggered the page fault trap in the first place

31
• Note two things about the sequence of events outlined above.
• First:– Restarting is just an example of context switching– By definition, the user process’s state will have been
saved– It will resume at the IP value it was on when it
stopped– The difference is that the page will now be in
memory and no fault will result

32
• Second:– The statement was made, “get a frame from the list
of free frames”.– You may be wondering, what if there are no free
frames?– At that point, memory is “over-allocated”.– That means that it’s necessary to take a frame from
one process and give it to another– What this involves will be covered in more detail
later

33
Demand Paging and TLB’s as a Form of Caching
• Demand paging from secondary storage to main memory is analogous to bringing an entry from the page table to the TLB
• Remember that the TLB is a specialized form of cache
• Its effectiveness relies on locality of reference• If references were all over the map, it would
provide no benefit

34
• In practice, memory references tend to cluster in certain areas over certain periods of time, and then move on
• This means that entries remain in the TLB and remain useful over a period of time

35
• The logic of bringing pages from secondary storage to memory is also like caching
• Pages that have been allocated to frames should remain useful over time, and can profitably remain in those frames
• Pages should tend not to be used only once and then have to be swapped out immediately because another page is needed and over-allocation of memory has occurred

36
Hardware Support for Demand Paging
• Hardware support for demand paging is the same as for regular paging
• 1. A page table that records valid/invalid pages
• 2. Secondary storage—a disk.– Recall that program images are typically not
swapped in from the file system. – The O/S maintains a ready queue of program
images in the swap space, a.k.a., the backing store

37
Problems with Page Faults
• A serious problem can occur when restarting a user process after a page fault
• This is not a problem with context switching per se
• It is a problem that is reminiscent of the problems of concurrency control

38
• An individual machine instruction actually consists of multiple sub-parts
• Each of the sub-parts may require memory access• Thus, a page fault may occur on different sub-
parts• Memory is like a resource, and when a process is
halted mid-instruction, any prior action it’s taken on memory may have to be “rolled back” before it can be restarted

39
• Instruction execution can be broken down into these steps:
• 1. Fetch the instruction• 2. Decode the instruction• 3. Fetch operands, if any• 4. Do the operation (execute)• 5. Write the results, if any

40
• A page fault can occur on the instruction fetch• In other words, during execution, the IP
reaches a value that hasn’t been loaded yet• This presents no problem• The page fault causes the page containing the
next instruction to be loaded• Then execution continues on that instruction

41
• A page fault can also occur on the operand fetches• In other words, the pages containing the addresses
referred to by the instruction haven’t been loaded yet
• A little work is wasted on a restart, but there are no problems
• The page fault causes the operand pages to be loaded (making sure not to replace the instruction page)
• Then execution continues on that instruction

42
Specific Problem Scenario
• In some hardware architectures there are instructions which can modify more than one thing (write >1 result).
• If the page fault occurs in the sequence of modifications, there is a potential problem
• Whether the problem actually occurs is simply due to the vagaries of scheduling and paging
• In other words, this is a problem like interrupting a critical section

43
• The memory management page fault trap handling mechanism has to be set up to deal with this potential problem
• The book gives two concrete examples of machine instructions which are prone to this
• One example was from a DEC (rest in peace) machine.
• It will not be pursued

44
• The other example comes from an IBM instruction set
• There was a memory move instruction which would cause a block of 256 bytes to be relocated to a new address
• Memory paging is transparent• Application programs simply deal in logical
addresses

45
• There is not, and there should not be any kind of instruction where an application program does memory operations with reference to the pages that it is using
• Put simply, the move could be from a location on one page to a location on another page
• This should be legal and it should be of no concern to the application program

46
• Also, the move instruction in question allowed the new location to overlap with the old location
• In other words, the move instruction could function as a shift
• From an application point of view, this is perfectly reasonable
• Why not have a machine instruction that supports shifting?

47
• The problem scenario goes like this:• You have a 256 byte block of interest, and it is
located at the end of a page• This page is in memory, but the following page
is not in memory• For the sake of argument, let the move
instruction in fact cause a shift to the right of 128 bytes

48
• Instruction execution starts by “picking up” the full 256 bytes
• It shifts to the right and lays down the first 128 of the 256 bytes
• It then page faults because the second page isn’t in memory yet

49
• Restarting the user process on the same instruction after the page fault without protection will result in an error condition
• Memory on the first page has already been modified
• When the instruction starts over, it will then shift the modified memory on the first page 128 bytes to the right

50
• You do not get the original 256 bytes shifted 128 bytes to the right
• At a position 128 bytes to the right you get 128 blank bytes followed by the first 128 bytes of the original 256
• The problem is that the effects of memory access should be all or nothing.
• In this case you get half and half

51
Solving the Problem
• There are two basic approaches to solving the problem
• They are reminiscent of solutions to the problem of coordinating locking on resources
• The instruction needs a lock on both the source and the destination in order to make sure that it executes correctly

52
• Solution approach 1:• Have the instruction try to access both the
source and the destination addresses before trying to shift
• This will force a page fault, if one is needed, before any work is done
• This is the equivalent of having the process acquire all needed resources in advance

53
• Solution approach 2:• Use temporary registers to hold operand values• In other words, let the system store the
contents of the source memory location before any changes are made
• If a page fault occurs when trying to complete the instruction, restore the prior state to memory before restarting the instruction

54
• Solution 2 is the equivalent of rolling back a half finished process
• Note that it is also the equivalent of extending the state saving aspect of context switching from registers, etc., to memory.

55
• The problem of inconsistent state in memory due to an instruction interrupted by a page fault is not the only difficulty in implementing demand paging
• Other problems will be discussed• It is worth reiterating that demand paging should be
transparent• In other words, the solutions to any problems
should not require user applications to do anything but merrily roll along generating logical addresses

56
Demand paging performance
• Demand paging performance• Let the abbreviation ma stand for memory
access time—the time to access a known address in main memory
• In the previous chapter, a figure of 100 ns. was used to calculate costs
• The author gives 10-200 ns. as the range of memory access times for current computers

57
• All previous cost estimates were based on the assumption that all pages were in memory
• The only consideration was whether you had a TLB hit or miss and incurred the cost of one or more additional hits to memory for the page table

58
• In the following discussion, the memory access time, ma, will not be broken down into separate parts based on TLB hits and misses
• In other words, ma will be the average cost of accessing a page in memory, given whatever parameters the TLB and page table in the system might have

59
• Under demand paging an additional, very large cost can be incurred:
• The cost of a page fault, requiring a page to be read from secondary storage
• This turns out to be the most significant part of the calculation of the cost of supporting virtual memory

60
• Given a probability p, 0 <= p <= 1, of a page fault, the average effective access time of a system can be calculated
• Average effective memory access time• That is, the average cost of one memory
access• = (1 – p) * ma + p * (page fault time)

61
• Page fault time includes twelve components:• 1. The time to send the trap to the O/S• 2. Context switch time (saving process state,
registers, etc.)• 3. Determining that the interrupt was a page
fault (i.e., interrupt handling mechanism time)• 4. Checking that the page reference was legal
and determining the location on disk (this is the interrupt handling code in action)

62
• 5. Issuing a read from the disk to a free frame.
• This means a call through the disk management system code and includes– A. Waiting in a queue for this device until the read
request is serviced– B. Waiting for the device seek and latency time– C. Beginning the transfer of the page to a free
frame

63
• 6. While waiting for the disk read to complete, optionally scheduling another process.
• Note what this entails:– A. It has the desirable effect of increasing multi-
programming and CPU utilization– B. There is a small absolute cost simply to schedule
another process– C. From the point of view of the process that
triggered the page fault, there is a long and variable wait before being able to resume

64
• 7. Receiving the interrupt (from the disk when the disk I/O is completed)
• 8. Context switching the other process out if step 6 was taken
• 9. Handling the disk interrupt• 10. Correcting (updating) the frame and page
tables to show that the desired page is now in a frame in memory

65
• 11. As noted in 6.C, waiting for the CPU to be allocated again to the process that generated the page fault
• 12. Context switch—restoring the user registers, process state, and updated page table;
• Then the process that generated the page fault can be restarted at the instruction that generated the fault

66
• The twelve steps listed above fall into three major components of page fault service time:
• 1. Servicing the page fault interrupt• 2. Reading in the page• 3. Restarting the process

67
• The time taken for the whole process is easily summarized in terms of the three components
• 1. Service the page fault interrupt: • Several hundred machine instructions; • 1-100 microseconds

68
• 2. Read the page from the drive– Latency: 3 milliseconds– Seek: 5 milliseconds– Transfer: .05 milliseconds– Total: 8.05 milliseconds

69
• 3. Restart the process. • This is similar to #1: 1-100 microseconds• Points 1 and 3 are negligible compared to the
cost of accessing secondary storage• The overall cost of 1 + 2 + 3 can be
approximated at 8 milliseconds

70
Demand Paging Performance—with Representative Numbers
• The performance of demand paging can now be gauged using actual numbers
• Average effective access time• = (1 – p) * ma + p * (page fault time)• Let ma = 200 ns. and page fault time = 8
milliseconds as estimated above

71
• For some probability p of a page fault, average effective access time
• = (1 – p) * 200 ns. + p * (8 milliseconds)• Converting the whole expression to
nanoseconds, average effective access time• = (1 – p) * 200 + p * 8,000,000• = 200 + 7,999,800 * p

72
• The effective access time is directly proportional to the page fault rate
• Not surprisingly, the cost of a fault (to secondary storage) dominates the expression for the cost overall

73
• Say, for example, that p = 1/1000. • In other words, the fault rate was .1%, or the
“hit” rate was 99.9%• Then the expression for average memory
access time becomes:• 200 + 7,999,800 * p ~= 200 + 8,000

74
• 8,000 is 40 times as large as 200, the cost for a simple memory access
• In other words, under this scenario virtual memory with demand paging incurs an overhead cost that is 40 times the base cost
• Put in more frightening terms, the overhead cost is 4,000% of the base cost

75
• You can use the equation in another way, do a little algebra, and figure out what the page fault rate would have to be in order to attain a reasonable overhead cost
• If 10% overhead is reasonable, 10% of 200 nanoseconds is 20 nanoseconds, and average effective access time would have to be 220 nanoseconds

76
• Putting this into the equation gives• 220 = (1 – p) * 200 + p * (8,000,000)• 220 = 200 – p * 200 + p * 8,000,000• 20 = 8,000,000p – 200p• 20 = 7,999,800p

77
• p = 20/7,999,800• ~= 20/8,000,000• = 2/800,000 = 1/400,000 = .0000025• = .00025%• In other words, if you have a page fault rate of
1 page or less in 400,000 memory accesses, the overhead of demand paging is 10% or less

78
• Some conclusions that can be drawn from this:
• 1. The page fault rate has to be quite low to get good performance
• 2. This can only happen if there is locality of reference

79
• 3. This means that memory has to be relatively large.
• It has to be large enough to hold most of the pages a program will use during a period of time
• Keep in mind that this is in the context of multi-programming
• Complex memory management would not be needed if only one program at a time could run

80
• Programs themselves have to be relatively large/long/repetitive.
• If they did not reuse pages, the initial page reads to load the program would dominate the overall cost

81
Virtual Memory and Swap Space
• Swap space in secondary storage is managed differently from file space
• There does not have to be a complex directory structure
• The size of the blocks in which data are managed in swap space may be bigger than the size in the file system
• When doing virtual memory paging, there are implementation choices to be made in how to use swap space

82
• There are basically two approaches to swapping
• 1. When a program is started, copy it completely into swap space and page from there
• 2. If swap space is limited, do initial program page demand reads from the file system, but as pages enter the active address space, copy them to the swap space

83
9.3 Copy on Write
• Using demand paging to bring in an initial set of pages for a process can cause a lag at start-up time
• Pure demand paging, where only one page is initially brought in causes quicker start-up, but complete paging costs are simply incurred over time
• A technique based on shared memory can reduce paging costs, or extend the costs over the course of a program run

84
• In a Unix like system, a fork() call spawns a new process, a child of some parent process
• As shown in a previous chapter, the child may be a copy of the parent, or the code of the parent may be replaced by doing an exec() call
• Copy-on-write means that the child is not a copy of the parent—the child shares the parent’s address space

85
• The shared pages are marked copy-on-write, information which may be stored like valid/invalid bits or protections
• The basic idea is this: If the child process tries to write to a shared page, then a page fault is triggered
• A new page is allocated to the child• The new page has the image of the parent’s page copied
into it and the child modifies its copy, not the original• This technique is used in Linux, Solaris, and Windows XP

86
• Another system call in Unix and Linux is vfork()• If this is called, the child is given the parent’s
address space and the parent is suspended• For all practical purposes, this is the end of the
parent• The child doesn’t incur any paging costs though• The memory remains “constant” and the
identity of the owner is changed

87
• It is desirable for copy-on-write page requests to be satisfied quickly
• It is also important for requests by a program for dynamic allocation to be met quickly
• Such requests do not imply reading something from secondary storage
• For example, at run time a program may need more space for the heap or stack

88
• In order to support quick memory allocation not dependent on reading from secondary storage, a free frame pool is maintained
• In other words, memory is never completely allocated to user processes
• The system always maintains a reserve of free frames• These frames are allocated using zero-fill-on-demand• This means that any previous contents are zeroed out
before a frame is allocated to a process

89
9.4 Page Replacement
• The underlying scenario of virtual memory with demand paging is this:
• Most programs, most of the time, don’t have to be fully loaded in order to run
• However, if a program isn’t fully loaded, as time passes it may trigger a page fault

90
• A simple illustration might go like this:• Suppose the system has 40 frames• Suppose you have 8 processes, which if loaded
completely would take 10 pages each• Suppose that the 8 processes can actually run
effectively with only 5 pages allocated apiece• Memory is fully allocated and multi-
programming is maximized

91
• It is true that no one process can literally use all of its pages simultaneously
• However, a program can enter a stage where it accesses all or most of its pages repeatedly in rapid succession
• In order to be efficient (without incurring a paging cost for each page access) all or most of the pages would have to be loaded

92
• In the example given, you might ask, what happens when one of the 8 processes needs 10 pages instead of 5?
• Keep in mind that it’s not just user processes that make demands on memory
• The O/S maintains a free frame pool• It also requires memory for the
creation/allocation of I/O buffers to processes, and so on

93
• In some systems, a certain amount of memory may be strictly reserved for system use
• In other systems, the system itself has to complete for the free memory pool with user processes
• In short, what can happen is known as over-allocation of memory
• What this means is that the free frame pool is empty• In other words, the demand for memory exceeds
what is available

94
• More formally, you know that memory is over-allocated when this happens:
• 1. A running process triggers a page fault• 2. The system determines that the address is
valid, the page is not in memory, and there is no free frame to load the page into

95
• There are two preliminary, simple-minded, and undesirable solutions to this problem:
• 1. Terminate the process which triggered the fault (very primitive and not good)
• 2. Swap out another process, freeing all of its frames (somewhat less primitive, but also not good)
• The point is that there has to be a better way

96
• The basic scheme:• If no frame is free, find one that’s allocated
but not currently being used• Notice that this is a simplification. Under
concurrency no other page is literally currently being used
• Ultimately it will be necessary to define “not currently being used”

97
• At any rate, “free” the unused page by writing its contents to swap space
• Notice that swap space now has a very important role
• You don’t write currently unused pages to file space
• The assumption is that if the process they belong to is still going, those pages will have to be swapped in again at some point

98
• Notice also that this deals with the general case, where memory pages can be written to
• In general, you have to copy a page back to swap space because it might have been changed
• If it hadn’t been changed, it would be possible to rely on the original image that was in swap space when the page was loaded

99
• In any case, the conclusion of this sequence of events goes as follows:
• Update the frame table to show that the frame no longer belongs to the one process
• Update the page table to show that the page is no longer in memory
• Read in the page belonging to the new process• Update the tables to reflect that fact

100
• Summary of page fault service with page replacement
• 0. A process requests a page address. A fault occurs because the address is valid but the page hasn’t been loaded into memory
• 1. Find the location of the requested page on the disk

101
• 2. Find a free frame• A. If there’s a free frame in the frame pool,
use it• B. If there is no free frame, use a page
replacement algorithm to choose a victim frame
• C. Write the victim page to disk and update the page and frame tables accordingly

102
• 3. Read the desired page into the newly freed frame; update the page and frame tables
• 4. Restart the user process

103
• Page fault cost and dirty bits• Note that if no frame is free, the page
replacement algorithm costs two page transfers from secondary storage—one to write out the victim, another to read in the requested page
• If the victim hasn’t been changed, writing it out is an avoidable expense

104
• In the page table, entries may include valid/invalid bits or protection bits
• It is also possible to maintain a dirty, or modify bit
• If a page is written to, the dirty bit is set• If it hasn’t been written to, the dirty bit remains
unset• If a page is chosen as a victim, it only needs to
be written out if its dirty bit has been set

105
• Nothing is simple• Depending on how the system is coded, it may
still be necessary to write out clean pages• Swap space may be managed in such a way that
“unneeded” pages in swap space are overwritten
• If so, the only copy of a given page may be in main memory, and if that page is purged, it will have to be written out to swap space

106
• Everything so far has been discussed in general terms
• Specifically, in order to implement demand paging you need two algorithms:
• 1. A page replacement algorithm: Briefly stated, how do you choose a victim?
• 2. A frame allocation algorithm: Briefly stated, how many frames does a given process get?

107
• The overall goal is to pick or devise algorithms that will lead to the lowest possible page fault rate
• It is possible to do simple, thumbnail analyses of page replacement algorithms that are similar in scope to the thumbnail analyses of scheduling algorithms
• With scheduling algorithms, Gantt charts were used• With paging, memory reference strings and
representations of memory are used

108
• The phrase “memory reference string” simply refers to a sequence of memory addresses that a program refers to
• In practice, examples can be obtained by tracing the behavior of a program in a system
• Examples can also be devised by running a random number generator
• Paging algorithms can be compared by checking how many page faults each one generates on one or more memory reference strings

109
• Suppose that an address space is of size 10,000
• In other words, valid addresses, base 10, range from 0000 to 9999
• Here is an example of a reference string:• 0100, 0432, 0101, 0612, 0102, 0103, …

110
• The string can be simplified for two reasons:• 1. You’re only interested in the pages, not the offets• 2. Consecutive accesses to the same page can’t
cause a fault• Suppose the page size is 100• Then the first two digits of the reference string
values represent page id’s• For the purposes of analyzing paging behavior, the
example string can be simplified to 1, 4, 1, 6, 1, 1, …

111
• Here is a simple, initial example• Suppose you had 3 frames available• The sequence given above would cause exactly
3 page faults• There would be one page fault each for reading
in pages 1, 4, and 6 the first time• The reference string as given requests no other
pages, and 1, 4, and 6 would stay memory resident

112
• An equally simple extension of the example to an extreme case
• Suppose you had only 1 frame available• The sequence given above would cause 5 page
faults• There would be one page fault each for reading in 1,
4, 1, 6, and 1• The last page access, to page 1, would not cause a
fault since 1 would be memory resident at that point

113
• Not surprisingly, the more frames are available, the fewer the number of page faults generated
• The behavior is generally negative exponential

114

115
• FIFO page replacement• The idea is that the victim is always the oldest
page• Note, this is not least recently used page
replacement; it’s least recently read in page replacement
• There’s no need to timestamp pages as long as you maintain a data structure like a queue that is ordered by age

116
• The book makes thumbnail examples with a reference string of length 20 and 3 available frames
• The frames are drawn for each case where there’s a fault. There’s no need to redraw them when there’s no fault
• The book’s representation of the frames does not show which one is oldest. While following the example you have to keep track of which one is the oldest

117
• Here is the simple FIFO example. • The reference string goes across the top• The frame contents are shown in the rectangles
below the string• It’s not hard to keep track of the one least
recently read• replacement just cycles through the three frames• The one least recently read is the one after the
last one you just updated (replaced)

118

119
• FIFO page replacement is easy to understand and program
• Its performance isn’t particularly good• It goes against locality of reference• A page that is frequently used will often end
up being the one least recently read in• Under FIFO it will become a victim and have to
read in again right away

120
• Some page replacement algorithms, like FIFO, have a particularly unpleasant characteristic, known as Belady’s anomaly
• Under FIFO, increasing the number of available frames may increase the number of page faults
• In other words, the general, negative exponential curve shown earlier, is not smoothly descending under FIFO page replacement

121
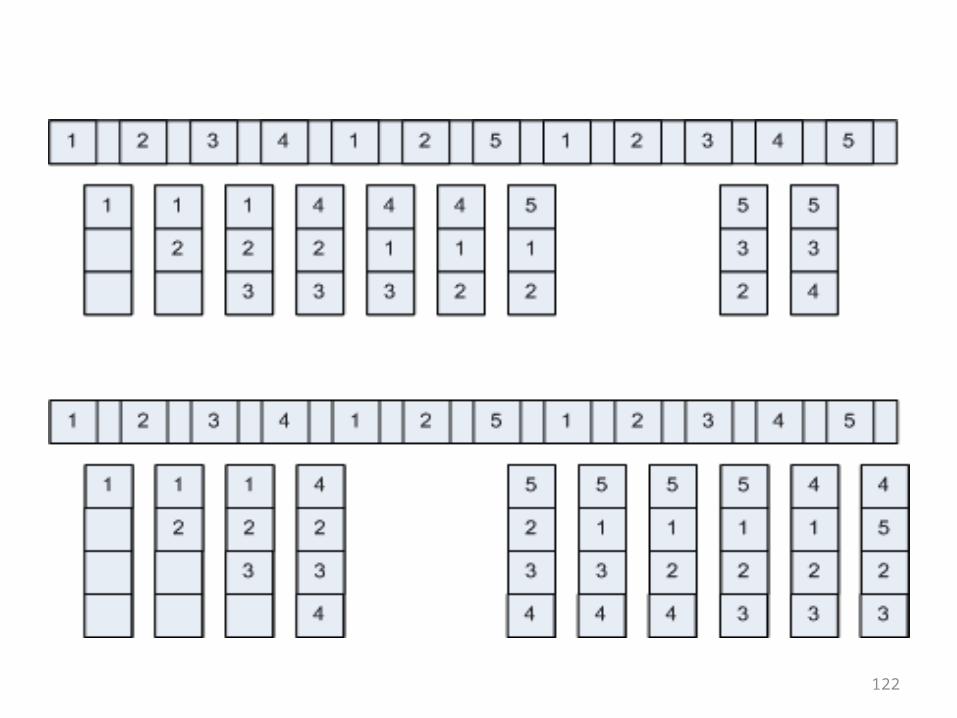
• On the next overhead the same reference string is processed using FIFO with 3 and 5 available memory frames
• This reference string exhibits Belady’s anomaly.
• With 3 frames there are 9 page faults• With 5 frames there are 10 faults
122

123
• Optimal page replacement• An optimal page replacement algorithm would
be one with the lowest page fault rate• This means an algorithm that chooses for
replacement the page that will not be used for the longest period of time
• Assuming the number of frames is fixed over time, such an algorithm would not suffer from Belady’s anomaly

124
• It is possible to do a thumbnail example of optimal replacement
• When the time comes to do a replacement, choose the victim by looking ahead (to the right) in the memory reference string
• Choose as a victim that page, among those in the memory, which will be used again farthest in the future
• The first example memory reference string is repeated on the next overhead with 3 frames and optimal replacement

125

126
• The same reference string and number of frames with FIFO replacement had 15 page faults
• Optimal page replacement has 9 faults• In both cases the first 3 reads are unavoidable• Then marginally, FIFO had 12 faults and optimal
had 6• In this sense, for this example, optimal is twice
as good as FIFO

127
• Notice the similarity of optimal page replacement with SJF scheduling
• To implement the optimum, you would need knowledge of future events
• Since this isn’t possible, it is necessary to approximate optimal page replacement with some other algorithm

128
• LRU page replacement• This is a rule of thumb for predicting future
behavior• The idea is that something that hasn’t been
used lately isn’t likely to be used again soon• Conversely, something that has been used lately
is likely to be used again soon• This is the same reasoning that is used with
caching

129
• The author makes the following observation:• LRU page replacement is the optimal page
replacement strategy looking backward in time rather than forward
• For those interested in logical puzzles, consider a memory reference string S the same string reversed, SR

130
• SR is like “looking at S backwards” and the following relationships hold:
• The page fault rate for optimal page replacement on S and SR are the same
• The page fault rate for LRU page replacement on S and SR are the same
• LRU applied to the memory reference string is illustrated on the next overhead

131

132
• LRU gives 12 faults total, which is midway between the 9 of optimal and the 15 of FIFO page replacement
• It is possible to identify places where LRU is an imperfect predictor of future behavior
• At the spot marked with a star, 2 has to be read in again when it was the value most recently replaced
• When read in, it would be better if it replace 4 instead of 3, because 4 is never accessed again
• However, the algorithm can’t foresee this, and 4 was the most recently used page, so it isn’t chosen as the victim

133
• Implementing LRU• For the time being, the assumption is that each
process has a certain allocation of frames, and when a victim is selected, it is selected from the set of frames belonging to that process
• In other words, victim selection is not global—although in reality the second challenge of virtual memory remains to be solved—how to determine the allocation to give to each process

134
• LRU provides a pretty good page replacement strategy, but implementation is more difficult than looking at a diagram with 3 frames
• The book gives two general approaches to solving the problem
• 1. Use counters (clocks) to record which page was least recently used
• 2. Use a stack like data structure to organize pages in least recently used order

135
• Using counters to implement LRU page replacement
• A. The CPU has a clock• B. Every page table entry will now have a time
stamp• C. Finding a victim means searching the page
table by time stamp

136
• D. The time stamp is updated for every access to the page. This will require a write to the page table in memory
• E. Note that the time stamp entries will have to be persistent because different processes have their own page tables which populate the TLB when they are scheduled
• F. The implementation also has to take into account the possibility of clock overflow (since the time stamp is likely to be a minutes/seconds subset of the overall system time)

137
• Using a stack to implement LRU page replacement• The basic idea is to use a data structure ordered
by page access• In a classic stack, elements can only be removed
from or added to the top• For LRU, it is desirable to be able to access any
page, anywhere in the stack, and then place it at the top, indicating it was the most recently used

138
• In other words, this isn’t a pure stack. A pure stack would only allow access to the most recently used page
• Under this scheme, the least recently used page migrates to the bottom of the stack
• In other words, the victim is always selected from the bottom of the stack

139
• This pseudo-stack can be implemented as a form of doubly-linked list
• An update would involve at most 6 pointer operations
• This would be a reasonable approach if implementing in software or microcode
• It will shortly be pointed out, however, that a software solution without hardware support would be too slow

140
• Concluding remarks on optimal and LRU page replacement
• Neither optimal nor LRU suffer from Belady’s anomaly
• They are both examples of what are called stack algorithms, which are free of this

141
• The defining characteristic of such algorithms is that the pages that would be in memory for an allocation of n pages is always a subset of what would be in memory for an allocation of n + 1 pages

142
• The reality is that either counter or stack based implementations of LRU page replacement would require hardware support
• Each memory reference would affect either the time stamp in the page table or order of the entries in the stack
• Not only does this cost a memory access, if completely software driven, it would cost interrupt handling
• The author asserts that overall this would slow memory access by a factor of 10 (not 10%, 1000%)

143
• LRU approximation page replacement• Most systems don’t provide hardware support
for full LRU page replacement• It is possible to get most of the benefits of LRU
page replacement by providing hardware support for LRU approximation

144
• Consider this simple approach:• 1. Let every page table entry have one additional bit, a
reference bit• 2. The reference bit is set by hardware (without a
separate interrupt) every time the page is referenced (either read or write)
• 3. This alone would allow a choice between used an unused
• 4. Under demand paging, all pages would be used, but under pre-loading, you could in theory choose an unused page as a victim

145
• Additional reference bits algorithm• Adding more bits to the page table entry makes it
possible to enhance the algorithm to the point of usefulness
• 1. Let the page table keep 8 reference bits for each entry in addition to the reference bit
• 2. At regular clock intervals (say every 100 ms.) an interrupt triggers writing the reference bit into the high order place of the 8 bit entry, shifting everything to the right by 1 bit

146
• 3. The result is that instead of used/not used, you have used/not used for each of the last 8 time intervals
• 4. If you treat the 8 bits as a number, the higher the number, the more recently used the page
• 5. You choose as a victim the page with the smallest number

147
• 6. The scheme actually gives up to 28 groups of pages by frequency of usage
• You choose the victim from the group with the least frequent usage
• In case there are >1 page in the least frequent group, you can swap out all of the pages in that group or pick one victim using FIFO, for example

148
• The second chance algorithm• This is also known as the clock algorithm—but
it shouldn’t be confused with counter algorithms which depend on the system clock
• This is called the clock algorithm because it is supported by a circularly linked list which can be visualized as a clock
• The clock algorithm is based on a single reference bit

149
• 1. As a process acquires pages, let them be recorded in a circularly linked list
• 2. When the list is full (i.e., the process has as many frames as it will be allowed) and a fault occurs, you need to find a victim
• 3. Begin with the oldest page (i.e., the one after the one most recently replaced) and traverse the circular list

150
• 4. If you encounter a page with a 1 bit, don’t select it. Give it a second chance, but set its reference bit to 0 so that it won’t get a third chance
• 5. Select as a victim the first page you encounter with a reference bit of 0
• 6. The next time a fault occurs, pick up searching where you left off before

151
• If all of the pages have been referenced since the last fault, all of the reference bits will be set to 1
• This means the algorithm will go all the way around the list before selecting a victim
• The victim will end up being the first page that was touched
• This is not a complete waste though—because all of the 1 bits will have been cleared

152
• If all of the pages are consistently referenced before the next fault, the clock algorithm degenerates into FIFO page replacement
• The next diagram illustrates how the clock algorithm works

153

154
• Enhanced second chance algorithm• This algorithm makes use of the reference bit
and the modify bit• It prefers as victims those pages that don’t
have to be written back because this saves time
• The two bits together make four classes of pages

155
• These are the four classes, given in descending order of preference for replacement:
• 1. (0, 0), not recently used, not modified• 2. (0, 1), not recently used, modified• 3. (1, 0), recently used, not modified• 4. (1, 1,), recently used, modified• Cycling through the list is similar to the original
algorithm• This algorithm is implemented in the MacIntosh

156
• Counting based page replacement• Two algorithms will be given as examples• It turns out that they are not easy to implement• They don’t approximate the performance of
optimal page replacement very well• They are infrequently used• I guess they’re given here in the same spirit as the
“worst fit” memory allocation scheme—food for thought

157
• 1. LFU = least frequently used. The theory is that active pages should have a large number of accesses per unit time
• 2. MFU = most frequently used. The theory is that a high count of uses should be a sign that the process is ready to move on to another address
• LFU seems more plausible to me than MFU

158
• Page buffering algorithm• This is something that may be done in addition
to any page replacement algorithm that might be chosen
• There are three basic approaches

159
• 1. Always keep a free frame pool• This saves time for the currently running
process when a victim is chosen for it• The currently running process gets a free
frame from the pool immediately• The victim can be written out when cycles are
available and then added to the free frame pool

160
• 2. Maintain a data structure providing access to modified pages
• When cycles are available, write out copies of modified pages
• That means that if chosen as a victim, the currently running process won’t have to wait for a write
• Note that this does in advance what the previous approach accomplishes after the fact

161
• Keep a free frame pool, but don’t erase the records for them
• The idea is that a frame that has been moved to the free frame pool still has a second chance
• Whenever a page fault occurs, always check first to see whether the desired page is in the free frame pool
• This was implemented in the VAX/VMS system

162
• Applications and page replacement• Most application programs are completely reliant on the
O/S for paging• The application programs may have no special paging
needs that can’t be met by the O/S• The O/S may not support applications that attempt to
manage their own paging• Even if applications have special needs and the O/S would
support separate management, the application programmers don’t want to load down the application with that functionality

163
• On the other hand, some applications, like database management systems, have their own internal logic for data access
• The application is better suited to determining an advantageous paging algorithm than the underlying operating system

164
• Some systems will allow an application to use a disk partition without O/S support
• This is just an array of addresses in secondary storage known as a raw disk
• In some systems, applications like database management systems, are integrated with the O/S
• The AS/400 is an example

165
9.5 Allocation of Frames
• Recall the two problems identified at the beginning: Page replacement and frame allocation
• We have dealt with page replacement. Now it’s time for frame allocation
• The simplest possible case would be a system that allowed one user process at a time

166
• Under this scenario you could implement demand paging
• The process could acquire memory until it was entirely consumed. All of the frames would be allocated to that process
• If a fault then occurred, some sort of page replacement could be used

167
• Minimum number of frames• As soon as you contemplate multiprogramming,
you can have >1 process• In that situation, it becomes undesirable for a
single process to acquire all of memory• If the memory allocated to a process is limited,
what is the minimum allowable?• There is both a practical minimum and an
absolute minimum

168
• If a process has too little memory, its performance will suffer. This is the practical minimum
• There is also an absolute theoretical minimum needed in order for paging to work
• This depends on the nature of the machine instruction set and the fetch, decode, execute cycle

169
• Recall the execution cycle• Fetch• Decode• Fetch operands• Do the operation• Write the results

170
• Consider this scenario:• 1. A process is only allocated one frame• 2. Fetch instruction from one page• 3. Decode• 4. Try to fetch operands and discover they’re on
another page• 5. Page fault to get operands• 6. Restart halted instruction• 7. Cycle endlessly

171
• The previous scenario would require a minimum of two pages
• For an instruction set with an instruction that had multiple operands or had operands that could span an address space of >1 page, more than two pages could be required
• Let n be the maximum number of page references possible in a single fetch, decode, execute cyle
• n is the minimum number of frames that can be allocated to a process

172
• System support for indirection can affect the minimum number of frames
• Indirection refers to the idea that an operand can be a special value which has this meaning:
• Do not use the value found—let the value serve as an address, and use the value found at that address

173
• If the value found at the address is another of the indirection type, multiple levels of indirection result
• The instruction takes the form of, act on the value found at(the value found at(…))
• Every system architecture has to set a fixed limit on the number of levels of indirection that are allowed
• If n levels of indirection are allowed, then a process needs to be allocated n + 1 frames so that fetching the operands for one instruction doesn’t cause n page faults

174
• Allocation algorithms• Between the minimum necessary and the
maximum allowed (possibly all), there is a wide range of number of frames that could be allocated to a process
• There is also a choice of how to decide how many to allow
• Some suggestions follow

175
• 1. Equal allocation• This is the simplest approach• Divide the number of available frames by the
number of processes• Limit the number of processes so that none
fall below the minimum necessary allocation

176
• 2. Proportional allocation• Divide the frame pool in proportion to the
sizes of the processes (where size is measured in the number of frames in the swap image)
• Again, limit the number of processes so that they all have more than the minimum allocation

177
• 3. Proportional allocation based on priority• Devise a formula that gives higher priority jobs
more frames• The formula may include job size as an
additional factor• ***Note that in reality, frame allocation will
go beyond these three simplistic suggestions

178
• Global Versus Local Allocation• The question is, when a page fault occurs, do
you choose the victim among the pages belonging to the faulting process, or do you choose a victim among all pages?
• In other words, is a process allowed to “steal” pages from other processes—meaning that the frame allocations to processes can vary over time

179
• Global replacement opens up the possibility of better use of memory and better throughput
• On the other hand, local replacement makes individual processes more autonomous
• With a fixed frame allocation, their paging behavior alone determines their performance
• They would not have their pages stolen, which would change performance due to outside factors
• This is just a preview of this topic. More will come later

180
The End


![9-Statistical Physics 9.1 ~ 9.5.ppt [호환 모드]](https://static.fdocuments.in/doc/165x107/616889c5d394e9041f705d56/9-statistical-physics-91-95ppt-.jpg)















