
Chapter 13 Reduced Instruction Set Computersrahimi/cs401/slides/sh-chap13.pdf · —Emphasis on...
58
Chapter 13 Reduced Instruction Set Computers
Transcript of Chapter 13 Reduced Instruction Set Computersrahimi/cs401/slides/sh-chap13.pdf · —Emphasis on...

Chapter 13Reduced Instruction Set Computers

Contents• Instruction execution characteristics• Use of a large register file• Compiler-based register optimization• Reduced instruction set architecture• RISC pipelining• MIPS R4000• SPARC• RISC vs CISC controversy

Major Advances in Computers• The family concept
—IBM System/360 in 1964—DEC PDP-8—Separates architecture from implementation
• Microprogrammed control unit—Idea by Wilkes in 1951—Produced by IBM S/360 in 1964—Each machine instruction is interpreted as a sequence
of microinstructions
• Cache memory—IBM S/360 model 85 in 1968

Major Advances in Computers• Microprocessors
—Intel 4004 in 1971
• Pipelining—Introduces parallelism into instruction execution
• Multiple processors• RISC architecture
—Large number of GPRs– Use of compiler technique to optimize register usage
—Limited and simple instruction set—Emphasis on optimizing the instruction pipeline
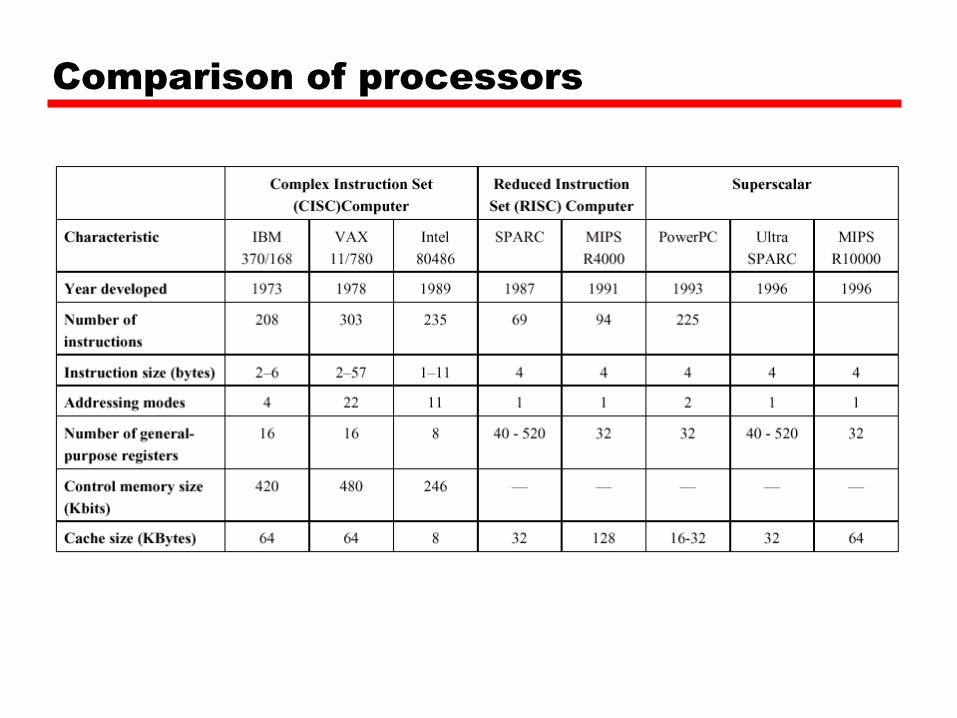
Comparison of processors

13.1 Execution Characteristics• Evolution of program execution
—Problems with software development– High cost and unreliability
—More powerful and complex languages are developed– Can express algorithms more concisely– Take care of the detail
—Semantic gap problem– Difference between HLL operations and machine instructions– Execution inefficiency, excessive program size, and compiler
complexity
—Architecture to close this gap– Large instruction set, many addressing modes, and HLL
statements implemented in hardware
—Simple architecture : RISC

Execution Characteristics• Aspects of instruction execution
—Operations performed– Functions performed by CPU
—Operands used– Operand characteristics determine memory organization and
addressing modes
—Execution sequencing– Determines control and pipeline organization

Relative Dynamic Frequency of HLL Operations

Analysis• Assignment statements predominate
—Simple movement of data is highly important
• Quite of conditional statements—Sequence control mechanism is important
• Results do not reveal which statements use the most time in execution of a typical program—Which statement causes the execution of the most
machine-language instructions?

Weighted Relative Dynamic Frequency
For the data in columns four and five, each value in the secondand third columns is multiplied by the number of machineinstructions produced by the compiler and then normalized.
The sixth and seventh columns are obtained by multiplying thefrequency of occurrence of each statement type by the relativenumber of memory references caused by each statement.

Operands• Dynamic frequency of occurrence of classes of
variables—Mainly local scalar variables
– Optimization should concentrate on accessing local variables
—One study shows that each instruction references 0.5 operand in memory and 1.4 registers
– Fast operand accessing is important

Procedure Calls
Procedure Arguments and Local Scalar Variables

Procedure Calls• Most time-consuming operations• Two important aspects
—Number of parameters passed—Depth of nesting
• Studies show—Number of words required per procedure is not large—Nesting is not that deep
• Operand references are highly localized

Implications• Conclusions of experiments
—Instruction set architecture close to HLL is not the most effective design
—We need to optimize performance of the most time consuming parts of programs
• Characteristics of RISC architecture—Large number of registers
– To optimize operand referencing
—Careful design of pipelines– There are many conditional branch and call instructions
—Simplified (reduced) instruction set

13.2 Use of Large Register File• Register size is limited, so
—We need to keep most frequently accessed operands—We need to minimize register-memory operations
• Software solution—Require compiler to allocate registers
– Allocate based on most used variables in a given time– Requires sophisticated program analysis
• Hardware solution—Have more registers—Thus more variables will be in registers

Register Windows• Organization of large set of registers
—Most registers for local scalars– A few for global variables
—Definition of local changes with each procedure call– Only a few parameters and local variables– Depth of nested call is relatively narrow– So multiple small set of registers can be used
—Register window– Consists of 3 fixed-size areas
+ Parameter, local, and temporary registers
—Circular buffer of register windows– Used in SPARC, and IA-64– N-window register file can hold N-1 procedure activations– Berkeley RISC use 8 windows of 16 registers each

Overlapping Register Windows

Circular Buffer diagram

Operation of Circular Buffer• When a call is made, a current window pointer
is moved to show the currently active register window
• If all windows are in use, an interrupt is generated and the oldest window (the one furthest back in the call nesting) is saved to memory
• A saved window pointer indicates where the next saved windows should restore to

Global Variables• Two options
—Assign memory locations– There may be frequently accessed global variables
—Assign a set of global registers– Fixed and available to all procedure

Large Register File vs Cache

Referencing a Scalar -Window Based Register File

Referencing a Scalar - Cache

13.3 Compiler Based Register Optimizing• Case when only a small number of registers is
available—Compiler is responsible for the optimized usage
• Approach—Variable is assigned to a symbolic(virtual) register—Symbolic registers whose usage does not overlap can
share the same real register—Which symbolic registers to which real registers?
– Graph coloring can be used here– If two symbolic registers are live during the same program
fragment, they are joined by an edge to depict interference– Try to color the graph with n colors, where n is the number
of registers

Graph Coloring Problem• Given a graph consists of nodes and edges,
assign colors to nodes such that adjacent nodes have different colors and do this in such a way as to minimize the number of different colors
• Konigsburg bridges problem—Introduced by Euler

Graph Coloring Approach

13.4 RISC Architecture• Why CISC?
—Richer instruction sets– Larger number and more complex instructions
—Reasons– To simplify compilers– To improve performance
—Can CISC simplify compilers?– If there are machine instructions that resemble HLL
statements, task can be simplified– But complex instructions are hard to exploit– Optimizing the code is much more difficult with a complex
instruction set

RISC Architecture• Why CISC?
—Is CISC program smaller?– Not quite– CISC program may have fewer instructions– But each instruction is longer
+ Longer opcodes and address fields
—Is CISC program faster?– A complex HLL operation will execute more quickly as a
single machine instruction rather than as a series of more primitive instructions
+ Use of complex instructions are quite limited
– Control unit must be made more complex

Code Size Relative to RISC I

RISC Architecture• Characteristics of RISC
—Common properties– One instruction per cycle– Register-to-register operations– Simple addressing modes– Simple instruction formats
—One machine instruction per machine cycle– Machine instruction is directly executed by H/W
—Register-to-register operations– Only LOAD/STORE instructions access memory– Instruction set and control unit can be simplified
+ RISC may have only one or two ADD instructions+ VAX(CISC) has 25 different ADD instructions

RISC Architecture—Simple addressing modes
– Almost all instructions use simple register addressing
—Simple instruction formats– Only a few formats are used– Instruction length is fixed and aligned on word boundaries

Two Comparisons

RISC Architecture• Benefits of RISC approach
—Performance– More effective optimizing compilers can be developed– Most instructions are directly executed by H/W– Instruction pipelining can be applied more effectively– More responsive to interrupts
—VLSI implementation– Single-chip processor– Devote chip area to those activities that occur frequently
+ Simple instructions and local scalars+ RISC I devotes 6% of its area to control unit+ Typical CISC devotes about 50%
– Design-and-implementation time

Design and Layout Effort
rahimi
rahimi
rahimi
rahimi
MMU: Short for memory management unit, the hardware component that manages virtual memory systems. Typically, the MMU is part of the CPU, though in some designs it is a separate chip. The MMU includes a small amount of memory that holds a table matching virtual addresses to physical addresses. This table is called the Translation Look-aside Buffer (TLB). All requests for data are sent to the MMU, which determines whether the data is in RAM or needs to be fetched from the mass storage device. If the data is not in memory, the MMU issues a page fault interrupt.

RISC v CISC• No clear cut
—Many designs borrow from both philosophies– PowerPC and Pentium II
• Typical characteristics of RISC– Single instruction size of 4 bytes– Small number of addressing modes, <5– No indirect addressing– No operations that combine load/store with arithmetic– No more than one memory-addressed operand per
instruction– No support for arbitrary alignment for data– Number of memory access for a data address is 1– At least 32 integer registers– At least 16 floating-point registers
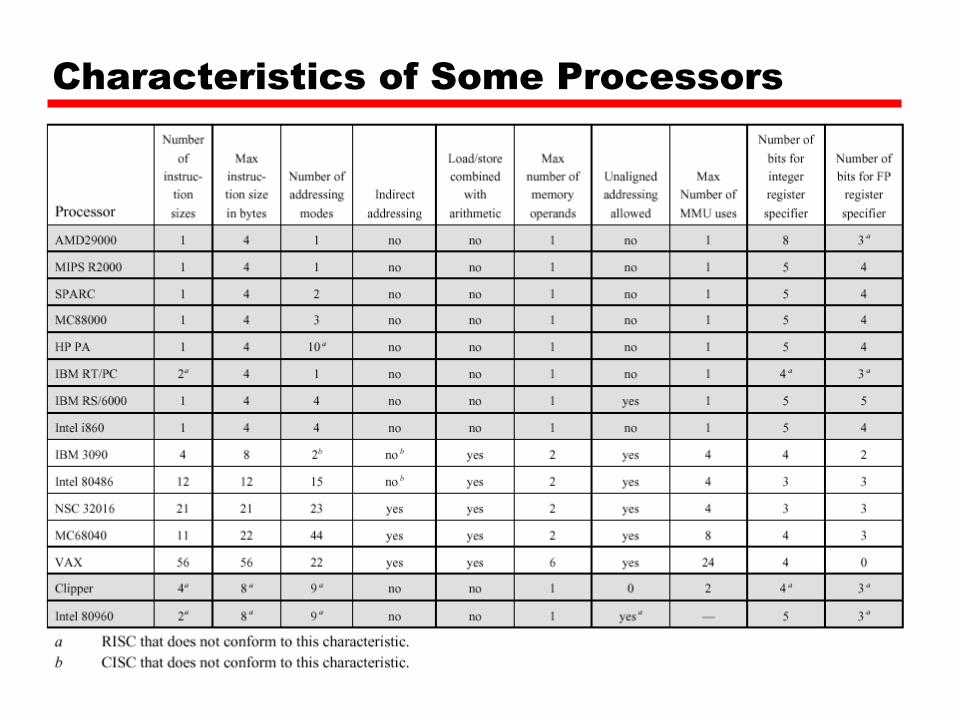
Characteristics of Some Processors

13.5 RISC Pipelining• Pipelining with regular instructions
—Most instructions are register to register—Two phases of execution
– I: Instruction fetch– E: Execute
+ ALU operation with register input and output
—For load and store– I: Instruction fetch– E: Execute
+ Calculate memory address
– D: Memory+ Register to memory or memory to register operation

Effects of Pipelining

Optimization of Pipelining• Simple and regular instructions make pipelining
work efficiently• Problems to deal with
—Data dependency—Branch instruction
• Delayed branch—Normal branch—Delayed branch
– No need to clear the pipeline
—Optimized delayed branch– Clock cycle can be saved

Normal and Delayed Branch

Use of Delayed Branch

Optimization of Pipelining• For conditional branches, procedure cannot be
blindly applied—Still, compiler can seek to insert a useful instruction
in delay slot
• Delayed load—Target register for load is locked—Continue execution until it reaches an instruction
requiring that register—Try to rearrange instructions so that useful work can
be done while loading

13.6 MIPS R4000• System
—Developed at Stanford—R2000, R3000, and R4000—64-bit machine
– Bigger address space– Easy to handle double-precision FP numbers
—Partitioned into two sections– CPU– Coprocessor for memory management
—32 64-bit registers– R0 always contains 0
—128 KB cache– Instruction + Data

MIPS R4000• Instruction set
—94 instructions with a single 32-bit format– Simplifies instruction fetch and decode
—All data operations are register-register– Load/store instructions for memory references– lw r2, 128(r3)
+ Load word at address 128 offset from r3 into r2

MIPS Instruction Formats

MIPS R4000• Evolution of MIPS pipeline
—One instruction per clock cycle initially—Two improvements on this
– Superscalar+ Multiple pipelines so that two or more instructions at the same
stage can be processed simultaneously+ Dependencies between instructions in different pipelines+ Extra logic is required to handle this
– Superpipeline+ Makes use of more fine-grained pipeline stages
o More instructions can be in the pipeline+ Overhead associated with transferring instructions from one
stage to the next+ MIPS R4000

MIPS R4000• Evolution of MIPS pipeline(Cont’d)
—5-stage R3000 pipeline– Stages
+ Instruction fetch+ Source operand fetch from register+ ALU operation or data operand address generation+ Data memory reference+ Write back into register
– 60-ns clock cycle is divided into 2 30-ns stages+ Some operations require 60 ns, while some other 30 ns
– There is also parallelism within the execution of a single instruction
+ Instruction decode and register fetch
– Functions performed in each stage

Enhancing the R3000 Pipeline

R3000PipelineStages

MIPS R4000• Evolution of MIPS pipeline(Cont’d)
—R4000 technical advances over R3000– 30-ns clock cycle– Halved access time to register– On-chip cache
—8-stage R4000 pipeline– Pipeline advances two stages per clock cycle– Stages
+ Instruction fetch first half+ Instruction fetch second half+ Register file+ Instruction execute+ Data cache first+ Data cache second+ Tag check+ Write back

13.7 SPARC• Scalable Processor Architecture
—Designed by Sun and made public
• SPARC register set—Uses register windows
– Each window with 24 registers– Consists of 3 parts : Ins, Locals, Outs
—Example 8 windows implementation– 136 registers for 8 windows– 8 global registers(0 ~ 7)
+ R0 is hardwired with 0

SPARC RegisterWindow Layout

Eight Register Windows FormingCircular Stack in SPARC

SPARC• Instruction set
—Types of instructions– Load/store– Shift– Boolean– Arithmetic– Jump/branch– Others
—Most instructions are register-register– Rd <-- Rs1 op S2– S2 can either be a register or 13-bit immediate operand
—Synthesizing other addressing modes

Synthesizing Other Addressing Modes with SPARC Addressing

SPARC• Instruction format
—69 instructions with a single 32-bit format—Types of formats
– Call format+ 30 bits + 00 --> 32 bit displacement in twos complement form
– Branch format+ 22 bits + 00 --> 24 bit displacement in twos complement form+ Annul bit
o Specifies what to do for the delay slot instruction
– SETHI format+ Used to load/store a 32-bit value+ 22 high-order bits + 10 lower-order zeros
– Floating-point format– General format
+ Used for load, store, arithmetic, and logical operations

SPARCInstructionFormats

13.8 RISC vs CISC Controversy• Comparison categories
—Quantitative– Compare program sizes and execution speeds
—Qualitative– Examine issues of high level language support and use of
VLSI real estate
• Problems—No pair of RISC and CISC that are directly
comparable—No definitive set of test programs—Difficult to separate hardware effects from complier
effects—Most comparisons done on “toy” rather than
production machines—Most commercial devices are mixtures


















