

Chapter 13: Parsing with Context-Free Grammars Heshaam Faili [email protected] University of...
60
-
Upload
ashley-shields -
Category
Documents
-
view
221 -
download
1
Transcript of Chapter 13: Parsing with Context-Free Grammars Heshaam Faili [email protected] University of...

2
Context-Free Grammars Context-Free Grammars are of the form:
A , where is a string of terminals and/or non-terminals
Note that the regular grammars are a proper subset of the context-free grammars.
This means that every regular grammar is context-free, but there are context-free grammars that aren’t regular
CFGs only specify what trees look like, not how they should be computationally derived We need to parse the sentences

3
Parsing Intro Input: a string Output: a (single) parse tree
A useful step in the process of obtaining meaning We can view the problem as searching through all
possible parses (tree structures) to find the right one Strategies
Top-Down (goal-directed) vs. Bottom-Up (data-directed)
Breadth-First vs. Depth-First Adding Bottom-Up to Top-Down: Left-Corner Parsing
Example Book that flight!

4
Grammar and Desired Tree

5
Top-Down Parsing Expand rules, starting with S and
working down to leaves Replace the left-most non-terminal with
each of its possible expansions. While we guarantee that any parse in
progress will be S-rooted, it will expand non-terminals that can’t lead to the existing input e.g., 5 of 6 trees in third ply = level of the
search space None of the trees take the properties of the
lexical items into account until the last stage

6
Expansion techniques Breadth-First Expansion All the nodes at
each level are expanded once before going to the next (lower) level. This is memory intensive when many grammar
rules are involved Depth-First
Expand a particular node at a level, only considering an alternate node at that level if the parser fails as a result of the earlier expansion
i.e., expand the tree all the way down until you can’t expand any more

7
Top-Down Depth-First Parsing There are still some choices that have to be made:
1. Which leaf node should be expanded first? Left-to-right strategy moves through the leaf nodes in a
left-to-right fashion 2. Which rule should be applied first?
There are multiple NP rules; which should be used first? Can just use the textual order of rules from the grammar
There may be reasons to take rules in a particular order (e.g., probabilities)

8
Top-Down breath-First Parsing
Search states are kept in an agenda Search states consist of partial trees and a pointer to the
next input word in the sentence Based on what we’ve seen before, apply the next
item on the agenda to the current tree Add new items to (the front of) the agenda, based
on the rules in the grammar which can expand at the (leftmost) node
We maintain the depth-first strategy by adding new hypotheses (rules) to the front of the agenda
If we added them to the back, we would have a breadth-first strategy
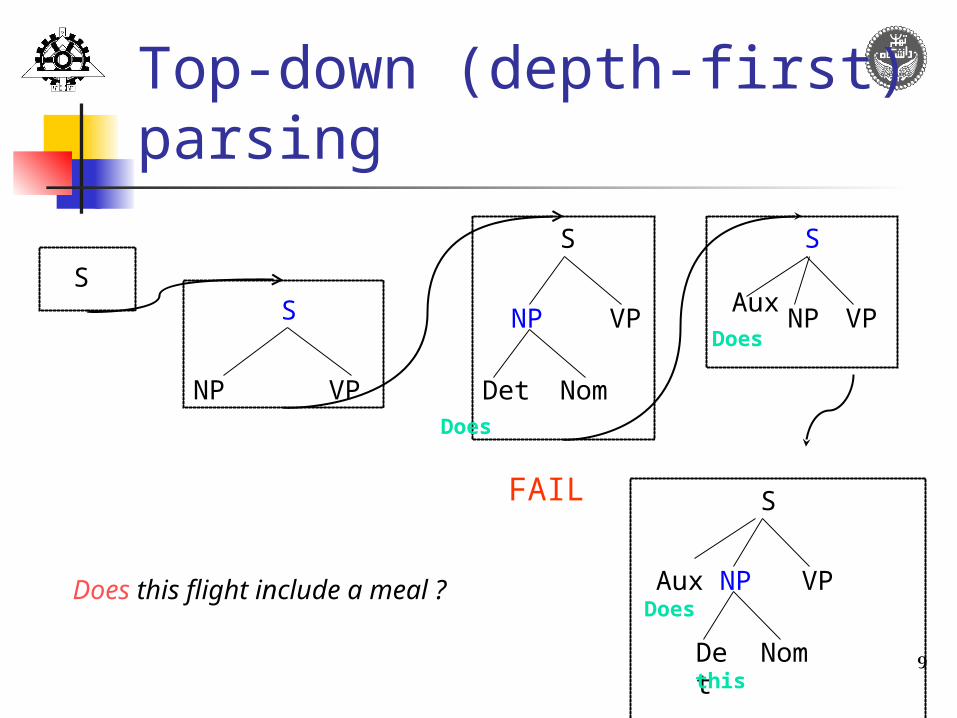
9
Top-down (depth-first) parsing
S
NP VP
S
S
NP VPAuxDoes
S
NP VP
Det Nom
DoesAux
this
S
NP VP
Det NomDoes
FAIL
Does this flight include a meal ?
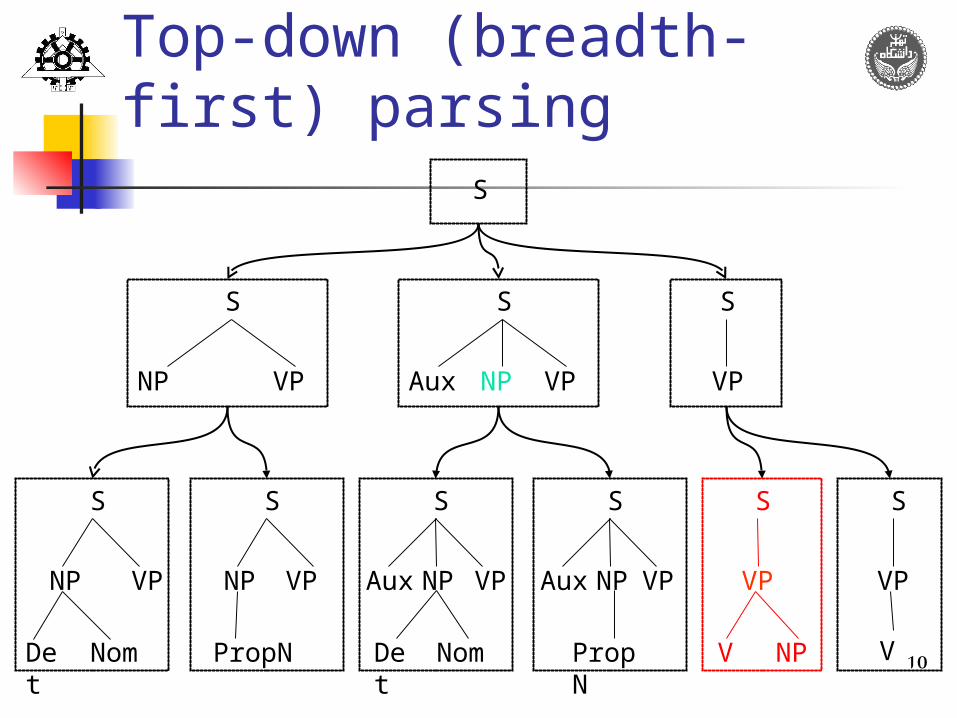
10
Top-down (breadth-first) parsing
S
S
NP VP
S
VP
S
Aux VPNP
S
NP VP
Det Nom
S
NP VP
PropN
S
NP VP
Det Nom
Aux
S
NP VPAux
PropN
S
VP
V NP
S
VP
V

11
Bottom-Up Parsing Bottom-Up Parsing is input-driven start from the
words and move up to form a tree Here we match one or more nodes on the upper
fringe of the parse tree against the right-hand side of a CFG rule, building the left-hand side as a parent node of those nodes.
We can also have breadth-first and depth-first approaches The example on the next slide (p. 362, Fig. 10.4) moves in
a breadth-first fashion While any parse in progress will be tied to the
input, many may not lead to an S! e.g., left-most trees in plies 1-4 of next Figure

12
Bottom-up parsing

13
Comparing Top-Down and Bottom-Up Parsing Top-Down:
While we guarantee that any parse in progress will be S-rooted, it will expand non-terminals that can’t lead to the existing input, e.g., first 4 trees in third ply.
Bottom-Up: While any parse in progress will be tied to the
input, many may not lead to an S, e.g., left-most trees in plies 1-4 of Figure.
So, both pure top-down and pure bottom up approaches are highly inefficient.

14
Left-Corner Parsing Motivation:
Both pure top-down and bottom-up approaches are inefficient
The correct top-down parse has to be consistent with the left-most word of the input
Left-corner parsing: a way of using bottom-up constraints as part of a top-down strategy.
Left-corner rule: expand a node with a grammar rule only if the current input can serve as the left corner from this rule.
Left-corner from a rule: first word along the left edge of a derivation from the rule
Put the left-corners into a table, which can then guide parsing

15
Left-Corner Example
S NP VPS VPS Aux NP VPNP Det Nominal | ProperNounNominal Noun Nominal |
NounVP Verb | Verb NPNoun book | flight | meal |
moneyVerb book | include | preferAux doesProperNoun Houston | TWA
Left Corners S => NP …=> Det,
ProperNoun VP => Verb Aux … => Aux NP => Det,
ProperNounVP => VerbNominal => Noun

16
Other problems: Left-Recursion Left-corner parsers still guided by top-down parsing Consider rules like:
S S and SNP NP PP A top-down left-to-right depth-first parser could apply a rule to
expand a node (e.g., S), and then apply that same rule again, and again, ad infinitum.
Left Recursion: A grammar is left-recursive if a non-terminal leads to a derivation that includes itself as its leftmost immediate or non-immediate child (i.e., along its leftmost branch).
PROBLEM: Top-Down parsers may not terminate on a left-recursive grammar

17
Other problems: Repeated Parsing of Subtrees When parser backtracks to an alternative expansion
of a non-terminal, it loses all parses of sub-constituents that it built.
There is a good chance that it will rebuild the parses of some of those constituents again.
This can occur repeatedly. a flight from Indianopolis to Houston on TWA
NP Det Nom Will build an NP for a flight, before failing when the parser
realizes the input PPs aren’t covered NP NP PP
Will again build an NP for a flight, before failing when the parser realizes the two remaining PPs in the input aren’t covered
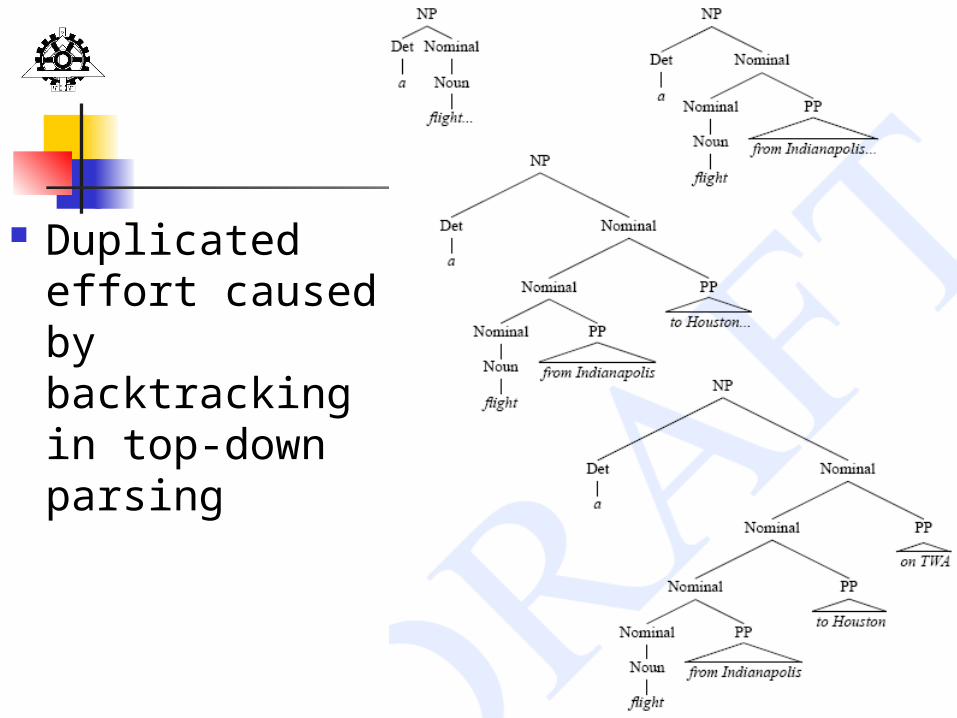
18
Duplicated effort caused by backtracking in top-down parsing

19
Other problems: Ambiguity Repeated parsing of sub-trees is even more of a
problem for ambiguous sentences 2 kinds of ambiguities: attachment, coordination
PP attachment: NP or VP: I shot an elephant in my pajamas. NP bracketing: the meal [on flight 286] [from SF] [to Denver]
Coordination: [old men] and women vs. old [men and women]
Parsers have to disambiguate between lots of valid parses or return all parses
Using statistical, semantical and pragmatic knowledge as the source of disambiguation
Local ambiguity: even if the sentence isn’t ambiguous it can be inefficient because of local ambiguity: e.g: parsing “Book” in sentence “Book that flight”

20
Ambiguity (PP-attachment)
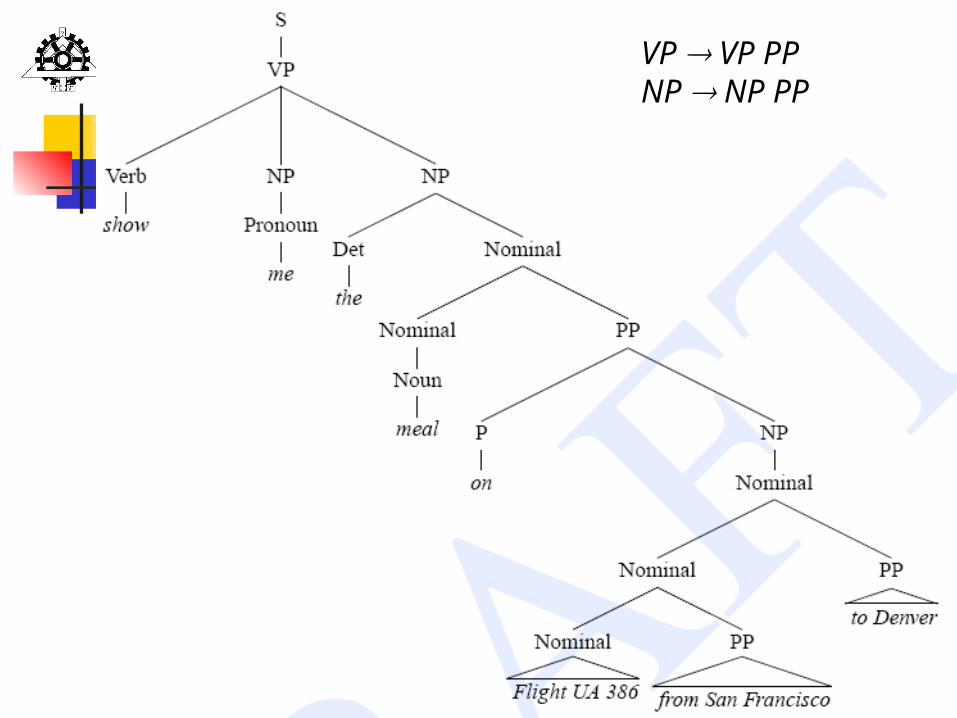
21
VP VP PPNP NP PP

22
Addressing the problems: Chart Parsing More or less a standard method for
carrying out parsing; keeps tables of constituents that have been parsed earlier, so it doesn’t reduplicate the work.
Each possible sub-tree is represented exactly once. This makes it a form of dynamic
programming (which we saw with minimum edit distance and the Viterbi algorithm)
Combines bottom-up and top-down parsing

23
CYK Parsing The DP method by using CNF grammar
ABC Am
Any CFG can be converted to CNF: should be care of 3 types of rules
Rule that mix terminal and non-terminal on the right-hand side
Adding dummy non-terminal to handle terminals Rules that have a single non-terminal on the right-
hand side (unit productions ) AB : unit productions (can be rewrited by A for any
B) Rule where the right-hand side length more that two

24
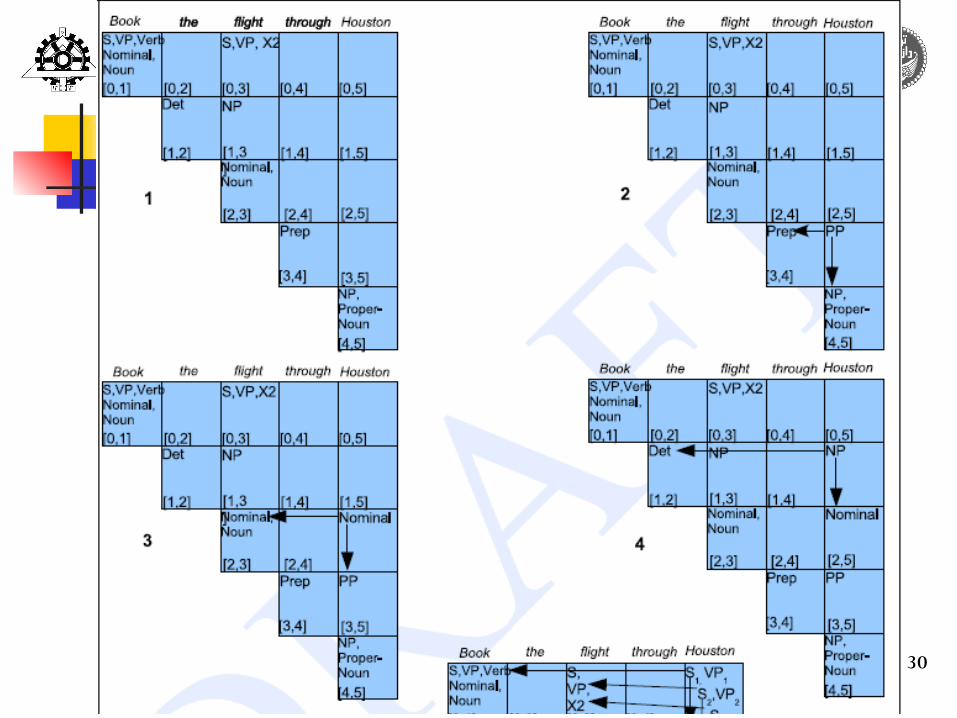
CYK Parsing, cont,d Like other DP methods, a simple
(n+1)*(n+1) matrix used to encode the structure of the sentence (n: sentence length) Indexed is the gap between words [0 Book 1 that 2 flight 3 ]
[i,j] : is a set of non-terminals that represent all the constituents that span positions i through j of the input

25
CYK Parsing, cont,d Since our grammar is in CNF, the non-
terminal entries in the table have exactly two daughters in the parse.
for each constituent represented by an entry [i, j] in the table there must be a position in the input, k, where it can be split into two parts such that i < k < j. Given such a k, the first constituent [i,k]
must lie to the left of entry [i, j] somewhere along row i, and the second entry [k, j] must lie beneath it, along column j

26

27
CYK Algorithm

28
CYK example(CNF Grammar)

29
CYK example(Book the flight through Houston)
30

31

32
CYK in practice Does not have major problem
theoretically The resulted parse tree are not
consistent to syntacticians…(because of CNF formal)
Syntax to Semantic approach complicated …
Post-processing needed to return-back the result to more acceptable form

33
Earley Parsing Uses DP to implement top-down search Single left-to-right pass and filling a
table named Chart(N+1 entry) 3 kind of information in each entry:
A Subtree corresponding to a single grammar rule
Information about progress made in completing this subtree
Position of the subtree respect to the input

34
Earley Parsing Representation
The parser uses a representation for parse state based on dotted rules. S NP VP
Dotted rules distinguish what has been seen so far from what has not been seen (i.e., the remainder).
The constituents seen so far are to the left of the dot in the rule, the remainder is to the right.
Parse information is stored in a chart, represented as a graph.
The nodes represent word positions. The labels represent the portion (using the dot notation)
of the grammar rule that spans that word position. In other words, at each position, there is a set of labels
(each of which is a dotted rule, also called a state), indicating the partial parse tree produced until then.

35
Example: Chart for A Dog Given a trivial grammar
NP D ND aN dog
Here’s the chart for the complete parse of “a dog”D a [0,1] (scan)N dog [1,2] (scan)NP D N [0,0] (predict)NP D N [0,1] (complete)NP D N [0,2] (complete)

36
More Early Parsing Terminology A state is complete if it has a dot at the right-
hand side of its rule. Otherwise, it is incomplete. At each position, there is a list (actually, a
queue) of states. The parser moves through the N+1 sets of states in the
chart left-to-right, processing the states in each set in order.
States will be stored in a FIFO (first-in first-out) queue at each start position
The processing applies one of three operators, each of which takes a state and produces new states added to the chart.
Scanner, Predictor, Completer There is no backtracking.

37
Earley Parsing Algorithm In the top level loop, for each position,
for each state, it calls the predictor, or else the scanner, or else the completer. The algorithm never backtracks and never
removes states, so we don’t redo any work The goal is to have S α• as the last chart
entry, i.e. the dot has moved over the entire input to derive an S

38
The Earley Algorithm

39

40
PredictionProcedure PREDICTOR((AB, [i, j]))For each (B) in grammar do Enqueue((B , [j, j]), chart[j])End Predicting is the task of saying what kinds
of input we expect to see Add a rule to the chart saying that we have not
seen , but when we do, it will form a B The rule covers no input, so it goes from j to j
Such rules provide the top-down aspect of the algorithm

41
Scanning
Procedure SCANNER ((AB, [i, j]))If B is a part-of-speech for word[j] then Enqueue((B word[j], [j, j+1]), chart[j+1])Scanning reads in lexical items
We add a dotted rule indicating that a word has been seen between j and j+1
This is then added to the following (j+1) chart Such a completed dotted rule can be used to
complete other dotted rules These rules also show how the Earley parser
has a bottom-up component

42
CompletionProcedure COMPLETER((B, [j, k]))For each (AB, [i, j]) in chart[j] do Enqueue((A B, [i, k]), chart[k])End Completion combines two rules in order to move
the dot, i.e., indicate that something has been seen A rule covering B has been seen, so any rule A which refers
to B in its RHS moves the dot Instead of spanning from i to j, A now spans from i to k,
which is where B ended Once the dot is moved, the rule will not be created
again

43
Example (Book that flight)

44
Example(Book that flight)

45
Example(Book that flight), cont

46
Example(Book that flight), cont

47
Example(Book that flight), cont

48
Earley parsing The Earley algorithm is efficient,
running in polynomial time. Technically, however, it is a recognizer,
not a parser To make it a parser, each state needs to be
augmented with a pointer to the states that its rule covers
For example, a VP would point to the state where its V was completed and the state where its NP was completed

49
Chart Parser In both the CKY and Earley algorithms, the
order in which events occur (adding entries to the table, reading words, making predictions, etc.) is statically determined by the procedures that make up these algorithms.
Unfortunately, dynamically determining the order in which events occur based on the current information is often necessary
Chart Parsing facilitates just such dynamic determination of the order in which chart entries are processed.
Using Agenda

50
Chart Parser fundamental rule: generalized the ideas
in CYK and Earley: if the chart contains two edges A → α • B β ,
[i, j] and B → γ •, [ j,k] then we should add the new edge A →α B • β [i,k] to the chart
Prediction can be top-down of botton-up

51

52
Prediction in Chart Parser

53
Partial Parsing
Many applications do not require complete parse Partial parse, Shallow parse Chunking [NP The morning flight] [PP
from] [NP Denver] [VP has arrived.]

54
Finite-State Rule-Based Chunking
chunking proceeds from left-to-right, finding the longest matching chunk from the beginning of the sentence, it then continues with the first word after the end of the previously recognized chunk.

55
Finite State Partial Parsing

56
Machine Learning-Based Approaches to Chunking Chunking as a sequential classifier
same a POS tagging IOB tagging: introducing tags as
Beginning or Internal part of category or Outside of any category
Tagset size : 2n+1 where n is #categories The morning flight from Denver has arrived
B_NP I_NP I_NP B_PP B_NP B_VP I_VP The morning flight from Denver has arrivied B_NP I_NP I_NP B_PP B_NP O O

57
Building the Chunker
training a classifier to label each word of an input sentence with one of the IOB tags from the tagset
Determine the context window Previous two words with pos and
chunk and next two words with only pos is the feature for detecting the chunk of the current word

58
Context Window

59
Evaluating Chunking Systems
evaluation of chunkers proceeds by comparing the output of a chunker against gold-standard answers

60
Practice
13.3, 13.6, Project #4


















