
Chap.7 Memory system
73
Chap.7 Memory system Jen-Chang Liu, Spring 2006
-
Upload
cain-flores -
Category
Documents
-
view
42 -
download
1
description
Chap.7 Memory system. Jen-Chang Liu, Spring 2006. Big Ideas so far. 15 weeks to learn big ideas in CS&E Principle of abstraction, used to build systems as layers Pliable Data: a program determines what it is Stored program concept: instructions just data - PowerPoint PPT Presentation
Transcript of Chap.7 Memory system

Chap.7 Memory system
Jen-Chang Liu, Spring 2006

Big Ideas so far
15 weeks to learn big ideas in CS&E Principle of abstraction, used to build systems as layers
Pliable Data: a program determines what it is Stored program concept: instructions just data
Greater performance by exploiting parallelism (pipeline)
Principle of Locality, exploited via a memory hierarchy (cache)
Principles/Pitfalls of Performance Measurement

Five components of computer
Input, output, memory, datapath, control

Outline Introduction Basics of caches Measuring cache performance
Set associative cache Multilevel cache
Virtual memory
Make memory system fast
Make memory system big

Introduction Programmer’s view about memory
Unlimited amount of fast memory How to create the above illusion?
無限大的快速記憶體
Scene: library Book shelf
desk
onebook
books

Principle of locality Program access a relatively small portion
of their address space at any instant of time
Temporal locality If an item is referenced, it will tend to be
referenced again soon Spatial locality
If an item is referenced, items whose address are close by will tend to be referenced soon

Cost and performance of memory
How to build a memory system from the above memory technologies?
Access time $ per GB in 2004
SRAM 0.5-5ns $4000-$10000
DRAM 50-70ns $100-$200
Magnetic disk 5-20 million ns $0.5-$2
•SRAM: static random access memory•DRAM: dynamic random access memory

Memory hierarchy 記憶體階層
Memory
CPU
Memory
Size Cost ($/bit)Speed
Smallest
Biggest
Highest
Lowest
Fastest
Slowest Memory
Ex.
disk
DRAM
SRAM
data
Alldata
Subsetof data
Subsetof data

Operation in memory hierarchy
Processor
Data are transferred
If data is found /* hit */ transfer to processor;
else /* miss */ transfer data to upper level;
accesstime
Hit time
Misspenalty

Outline Introduction Basics of caches Measuring cache performance
Set associative cache Multilevel cache
Virtual memory
How to design memory hierarchy?

Cache Cache: a safe place for hiding or storing
things.
Cache Memory hierarchy between CPU and main
memory Any storage managed to take advantage of
locality of access
Webster’s dictionary
快取記憶體
Memory
CPU
Memory
Size Cost ($/bit)Speed
Smallest
Biggest
Highest
Lowest
Fastest
Slowest Memory
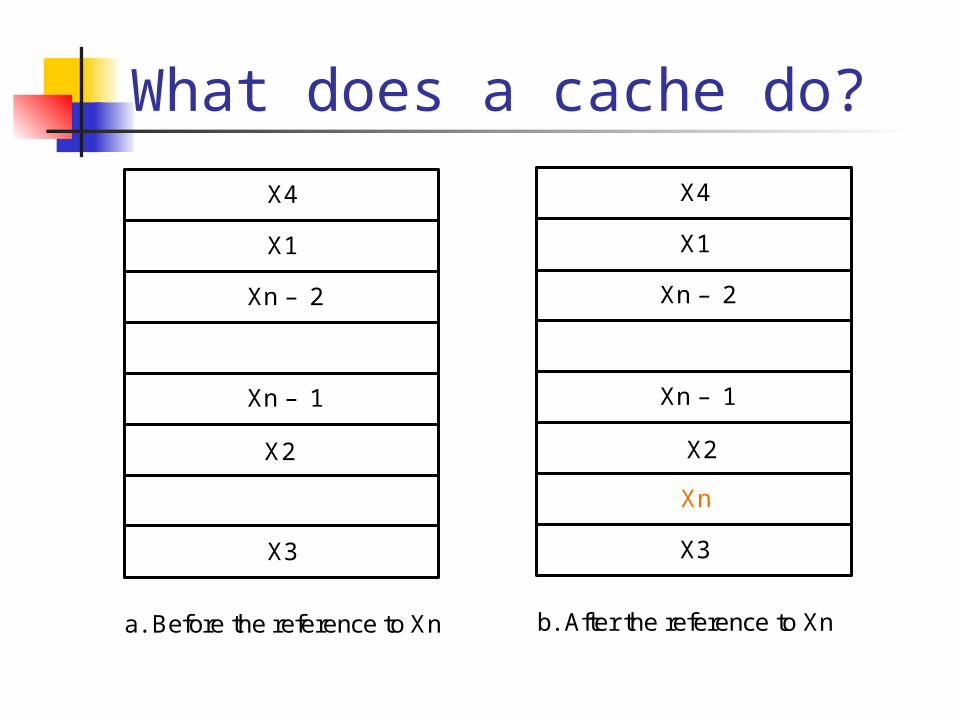
What does a cache do?
a. Before the reference to Xn
X3
Xn – 1
Xn – 2
X1
X4
b. After the reference to Xn
X3
Xn – 1
Xn – 2
X1
X4
Xn
X2X2
a. Before the reference to Xn
X3
Xn – 1
Xn – 2
X1
X4
b. After the reference to Xn
X3
Xn – 1
Xn – 2
X1
X4
Xn
X2X2
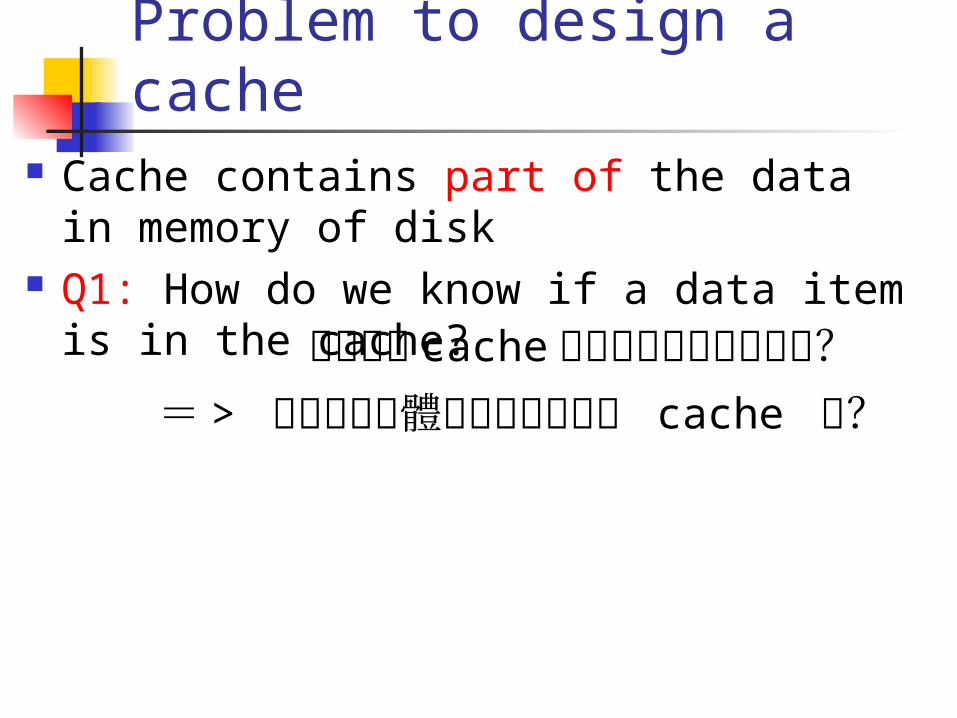
Problem to design a cache Cache contains part of the data in
memory of disk Q1: How do we know if a data item is in
the cache?如何知道 cache 有沒有現在要用的資料?= > 如何把記憶體抓到的資料放到 cache 裡?

Direct mapped cache (Fig 7.5)
Ex. (block address) modulo (no. of cache blocks in the cache)
Address of word Location in cache
00001 00101 01001 01101 10001 10101 11001 11101
000
Cache
Memory
001
010
011
100
101
110
111

Direct mapped cache (cont.)
Many memory words one location in cache
Q: Which memory word in the cache? Use tag to identify
Q: Whether the memory block is valid? Ex. Initially, the cache is empty Use valid bit to identify
data word
…
Cacheaddr. valid ta
g

Fig7.6

Fig7.6
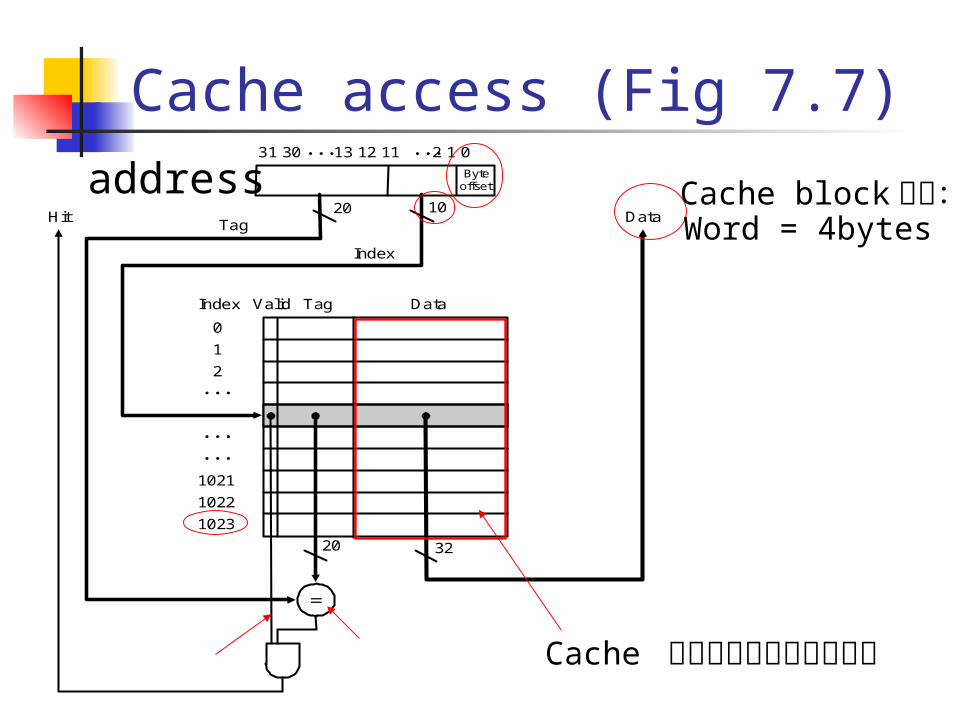
Cache access (Fig 7.7)Address (showing bit positions)
20 10
Byteoffset
Valid Tag DataIndex
0
1
2
1021
1022
1023
Tag
Index
Hit Data
20 32
31 30 13 12 11 2 1 0
Word = 4bytesaddress
Cache 裡真正用來存資料的部分
Cache block 大小:

Ex. Calculate bits in a cache
How many bits are required for a direct-mapped cache with 64KB of data and one-word blocks, assuming a 32-bit address?
32-bitaddress
31 0
1 Word data
2
64KB = 16K words = 214 words2
14
3 Tag = 32-14-2 = 16
16
4 Cache bit: 214 x (32 + 16 + 1) = 98KB
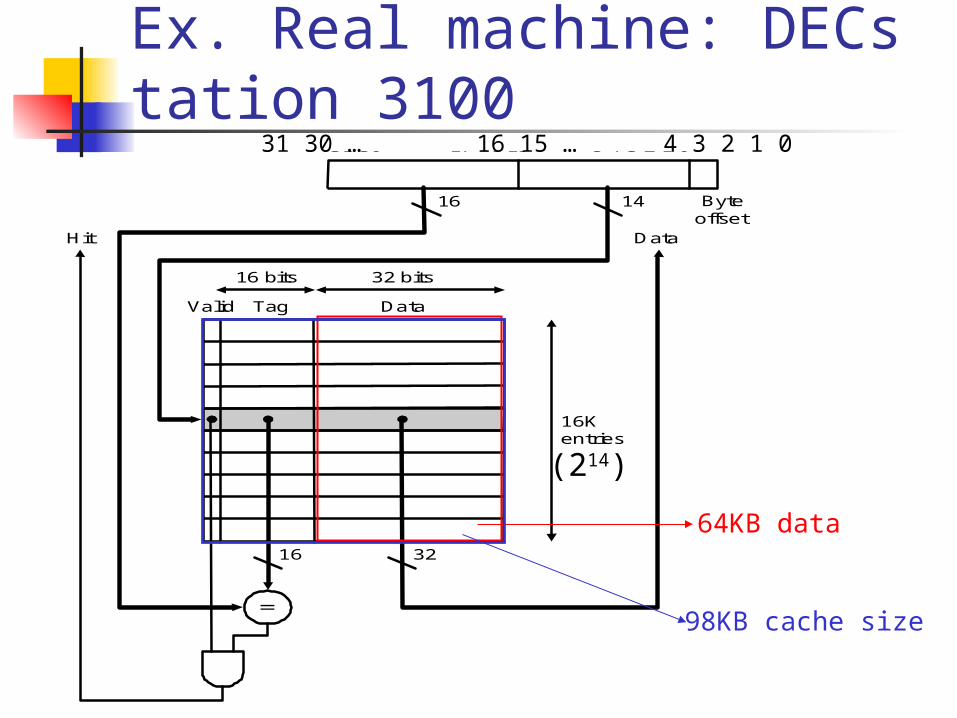
Ex. Real machine: DECstation 3100
Address (showing bit positions)
16 14 Byteoffset
Valid Tag Data
Hit Data
16 32
16Kentries
16 bits 32 bits
31 30 17 16 15 5 4 3 2 1 031 30 … 16 15 … 4 3 2 1 0
64KB data
98KB cache size
(214)

Ex. DECStation 3100 Use MIPS R2000 CPU Use pipeline as in Chap. 6
Instructionfetch
Reg ALUData
accessReg
8 nsInstruction
fetchReg ALU
Dataaccess
Reg
8 nsInstruction
fetch
8 ns
Time
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
2 4 6 8 10 12 14 16 18
2 4 6 8 10 12 14
...
Programexecutionorder(in instructions)
Instructionfetch
Reg ALUData
accessReg
Time
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
2 nsInstruction
fetchReg ALU
Dataaccess
Reg
2 nsInstruction
fetchReg ALU
Dataaccess
Reg
2 ns 2 ns 2 ns 2 ns 2 ns
Programexecutionorder(in instructions)
Instructionfetch
Reg ALUData
accessReg
8 nsInstruction
fetchReg ALU
Dataaccess
Reg
8 nsInstruction
fetch
8 ns
Time
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
2 4 6 8 10 12 14 16 18
2 4 6 8 10 12 14
...
Programexecutionorder(in instructions)
Instructionfetch
Reg ALUData
accessReg
Time
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
2 nsInstruction
fetchReg ALU
Dataaccess
Reg
2 nsInstruction
fetchReg ALU
Dataaccess
Reg
2 ns 2 ns 2 ns 2 ns 2 ns
Programexecutionorder(in instructions)
Data memory
Instruction memory
Two memoryUnits?

Ex. DECStation 3100 caches Instruction cache and data cache
Memory
CPU
Memory
Size Cost ($/bit)Speed
Smallest
Biggest
Highest
Lowest
Fastest
Slowest Memory
64KBInstruction
cache
64KBdata
cache

Ex. DECStation 3100 Cache access: Read
Memory
CPU
Memory
Size Cost ($/bit)Speed
Smallest
Biggest
Highest
Lowest
Fastest
Slowest Memory
64KBInstruction
cache
64KBdata
cache
PC Address calculated from ALUCachehit
Cachemiss
Updatecache

Peer Instruction
A. Mem hierarchies were invented before 1950. (UNIVAC I wasn’t delivered ‘til 1951)
B. If you know your computer’s cache size, you can often make your code run faster.
C. Memory hierarchies take advantage of spatial locality by keeping the most recent data items closer to the processor.
ABC1: FFF2: FFT3: FTF4: FTT5: TFF6: TFT7: TTF8: TTT

CS61C L31 Caches I (26) Garcia 2005 © UCB
Peer Instructions
1. All caches take advantage of spatial locality.
2. All caches take advantage of temporal locality.
3. On a read, the return value will depend on what is in the cache.
ABC1: FFF2: FFT3: FTF4: FTT5: TFF6: TFT7: TTF8: TTT

Handling cache misses Cache miss processing
Stall the processor Fetch the data from memory Write the cache entry
Put the data Update the tag field Update the valid bit
Continue execution

Ex. DECStation 3100Cache access: Write
Processor
Data are transferred
Store data
new value
Data in cacheand memory isinconsistent!!!資料不相符
1. Write-through
更改快取記憶體同時也寫回記憶體
2. Write-back
不寫回記憶體

Problems with write-through
Writing to main memory slows down the performance Ex. CPI without cache miss = 1.2 clock cycles write to memory causes extra 10 cycles 13% store instructions in gcc 1.2+10x13% = 2.5 clock cycles
記憶體存取造成效率變差
Solution: write buffer Store the data into write buffer while the data is
waiting to be written to memory The process can continue execution after writing
data into cache and write buffer
寫入資料暫存在 write buffer,等待寫入記憶體,程式繼續執行
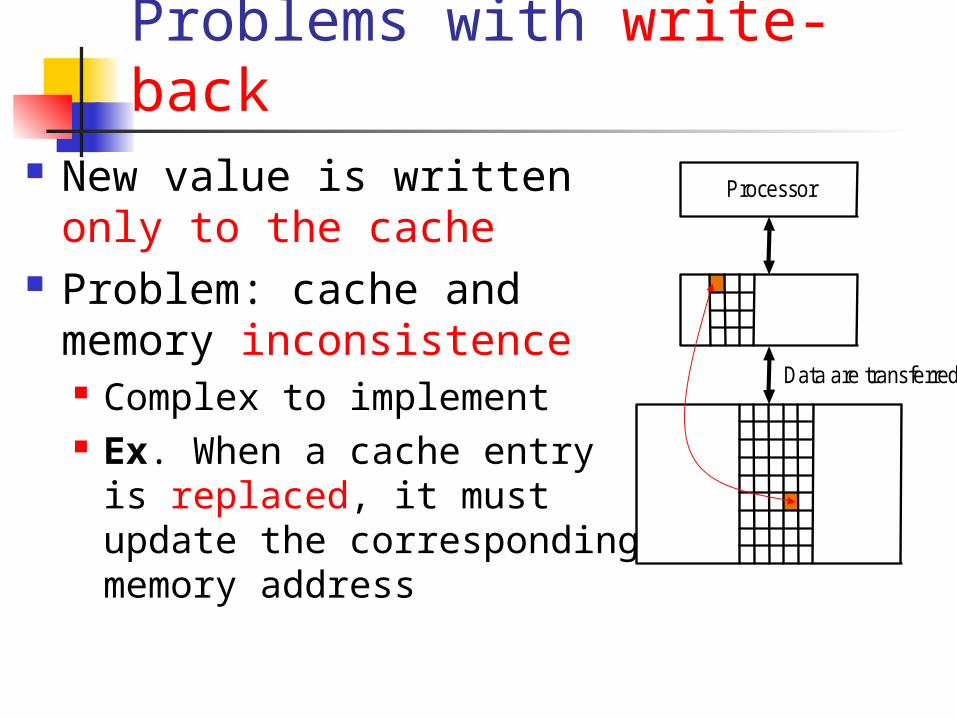
Problems with write-back New value is written only
to the cache Problem: cache and
memory inconsistence Complex to implement Ex. When a cache entry is
replaced, it must update the corresponding memory address
Processor
Data are transferred

Use of spatial locality Previous cache design takes advantage
of temporal locality Use spatial locality in cache design
A cache block that is larger than 1 word in length
With a cache miss, we will fetch multiple words that are adjacent
時間上的局部性
空間上的局部性
一次抓多個相鄰的 words

One-word cache (Fig 7.7)Address (showing bit positions)
20 10
Byteoffset
Valid Tag DataIndex
0
1
2
1021
1022
1023
Tag
Index
Hit Data
20 32
31 30 13 12 11 2 1 0
address

Multiple-word cacheAddress (showing bit positions)
16 12 Byteoffset
V Tag Data
Hit Data
16 32
4Kentries
16 bits 128 bits
Mux
32 32 32
2
32
Block offsetIndex
Tag
31 16 15 4 32 1 0
4-word blockaddr.

Advantage of multiple-word block (spatial locality)
Ex. access word with byte address 16,24,20
…
…
162024284-word block cache
1-word block cache
16 - cache miss24 - cache miss20 - cache miss
16 – cache miss load 4-word block
24 – cache hit20 – cache hit
memory

Multiple-word cache: write miss
Address (showing bit positions)
16 12 Byteoffset
V Tag Data
Hit Data
16 32
4Kentries
16 bits 128 bits
Mux
32 32 32
2
32
Block offsetIndex
Tag
31 16 15 4 32 1 0
addr. 1-word data01
Reload4-wordblock
1-word data
miss

CS61C L32 Caches II (37) Garcia, 2005 © UCB
1. Read 0x00000014
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
• 000000000000000000 0000000001 0100
Index
Tag field Index field Offset
00000000
00

CS61C L32 Caches II (38) Garcia, 2005 © UCB
So we read block 1 (0000000001)
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
• 000000000000000000 0000000001 0100
Index
Tag field Index field Offset
00000000
00

CS61C L32 Caches II (39) Garcia, 2005 © UCB
No valid data
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
• 000000000000000000 0000000001 0100
Index
Tag field Index field Offset
00000000
00

CS61C L32 Caches II (40) Garcia, 2005 © UCB
So load that data into cache, setting tag, valid
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 0100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (41) Garcia, 2005 © UCB
Read from cache at offset, return word b• 000000000000000000 0000000001 0100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (42) Garcia, 2005 © UCB
2. Read 0x0000001C = 0…00 0..001 1100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 1100
Index
Tag field Index field Offset
0
000000
00
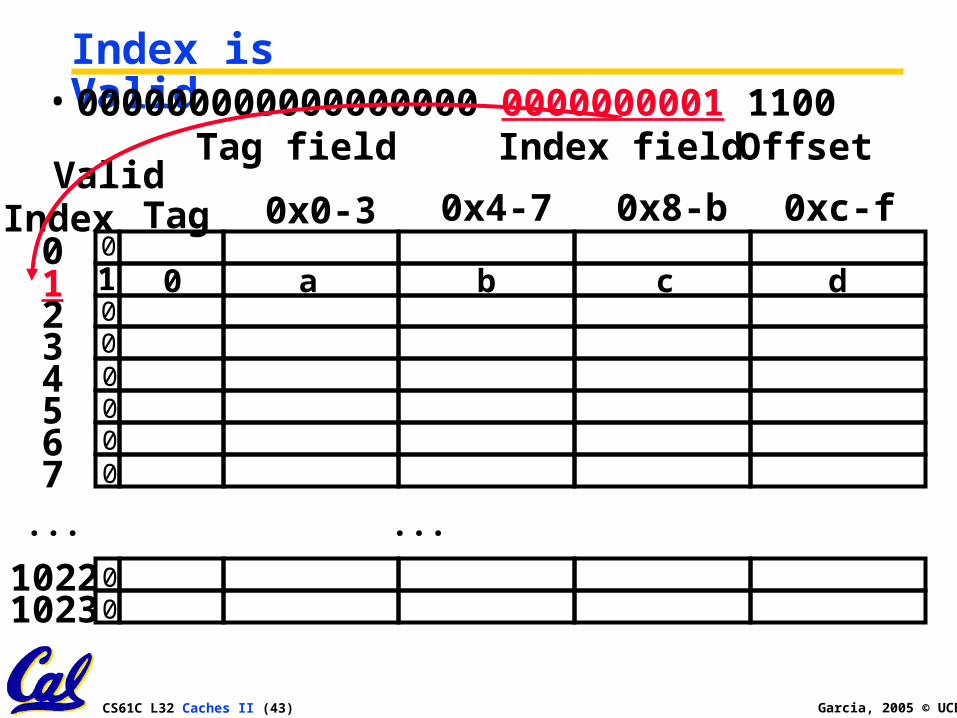
CS61C L32 Caches II (43) Garcia, 2005 © UCB
Index is Valid
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 1100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (44) Garcia, 2005 © UCB
Index valid, Tag Matches
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 1100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (45) Garcia, 2005 © UCB
Index Valid, Tag Matches, return d
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 1100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (46) Garcia, 2005 © UCB
3. Read 0x00000034 = 0…00 0..011 0100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (47) Garcia, 2005 © UCB
So read block 3
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (48) Garcia, 2005 © UCB
No valid data
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (49) Garcia, 2005 © UCB
Load that cache block, return word f
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

CS61C L32 Caches II (50) Garcia, 2005 © UCB
4. Read 0x00008014 = 0…10 0..001 0100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00
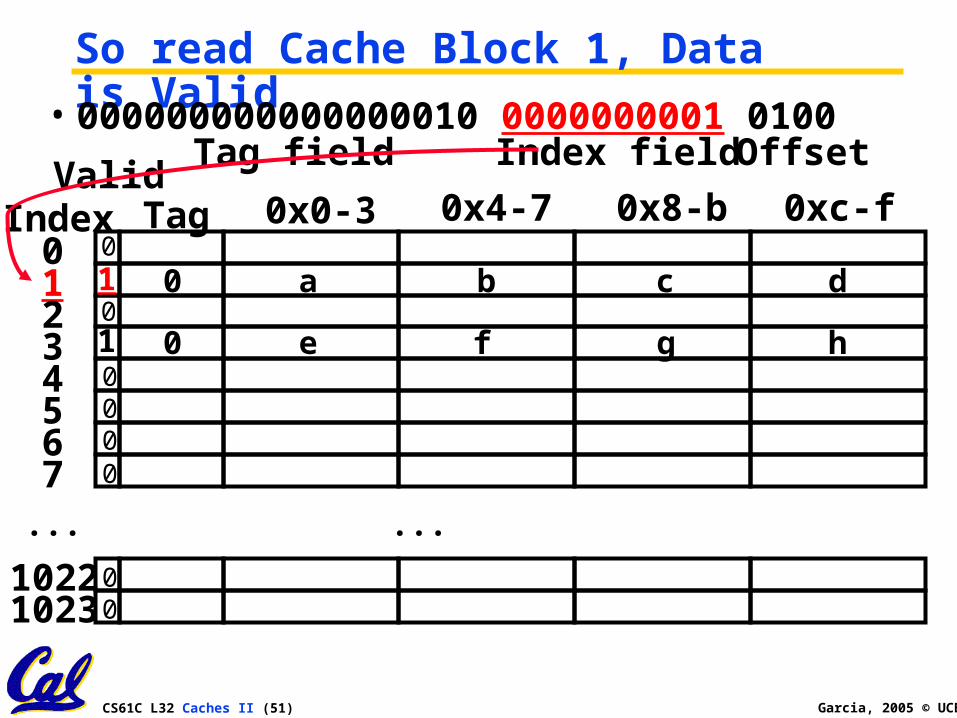
CS61C L32 Caches II (51) Garcia, 2005 © UCB
So read Cache Block 1, Data is Valid
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00
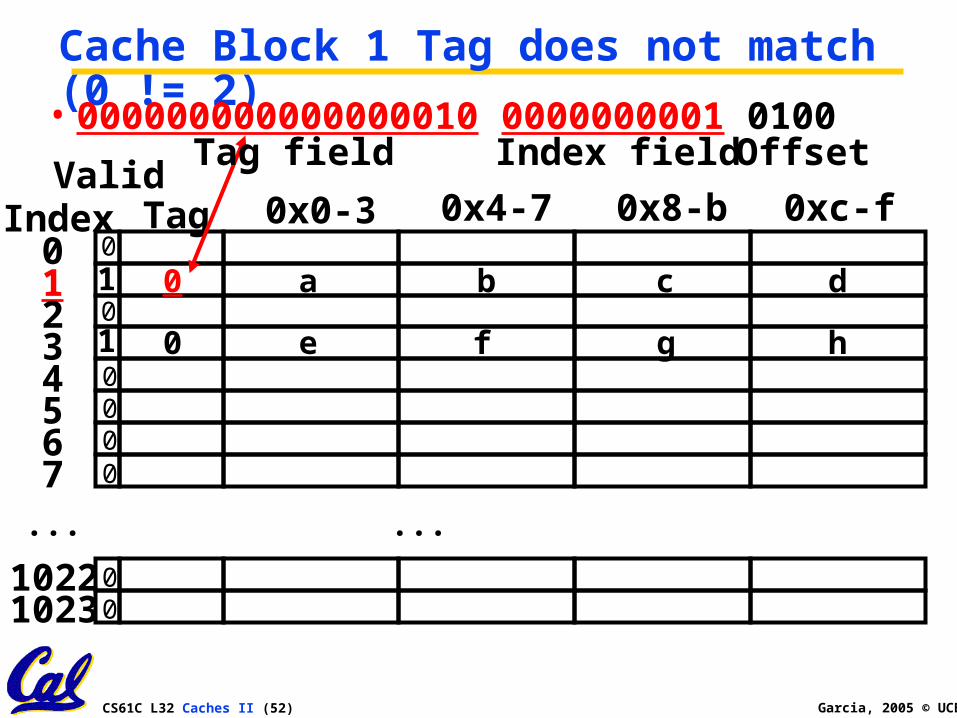
CS61C L32 Caches II (52) Garcia, 2005 © UCB
Cache Block 1 Tag does not match (0 != 2)
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

CS61C L32 Caches II (53) Garcia, 2005 © UCB
Miss, so replace block 1 with new data & tag
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 2 i j k l
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

CS61C L32 Caches II (54) Garcia, 2005 © UCB
And return word j
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 2 i j k l
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

Advantage of multiple-word block (spatial locality)
Comparison of miss rateBlock sizein words
program Instructionmiss rate
Datamiss rate
gcc 1 6.1% 2.1%4 2.0% 1.7%
spice 1 1.2% 1.3%4 0.3% 0.6%
Why improvement oninstruction miss is significant?
Instruction references have betterspatial locality

Miss rate v.s. block size
1 KB
8 KB
16 KB
64 KB
256 KB
256
40%
35%
30%
25%
20%
15%
10%
5%
0%
Mis
s ra
te
64164
Block size (bytes)Why?Block 數變少 !

Short conclusion Direct mapped cache
Map a memory word to a cache block Valid bit, tag field
Cache read Hit, read miss, miss penalty
Cache write Write-through Write-back Write miss penalty
Multi-word cache (use spatial locality)

Outline Introduction Basics of caches Measuring cache performance
Set associative cache Multilevel cache
Virtual memory
Make memory system fast

Cache performance How cache affects system
performance?CPU time= ( CPU execution clock cycles ) x clock cycle time
+ Memory-stall clock cycles
cache hit
cache miss
Memory-stall cycles = Read-stall cycles + Write-stall cycles
Read-stall cycles = Program
ReadsX Read miss rate x read miss penalty
Assume read and write miss penalty are the same
Memory-stall cycles = Program
Mem. accessX miss rate x miss penalty

Ex. Calculate cache performance
CPI = 2 without any memory stalls For gcc, instruction cache miss rate=2% data cache miss rate=4% miss penalty = 40 cycles Sol: Set instruction count = I
Instruction miss cycles = I x 2% x 40 = 0.8 x I
Data miss cycles = I x 36% x 4% x 40 = 0.58 x Ipercentage of lw/sw
Memory-stall cycles = 0.8I + 0.58I = 1.38ICPU timestalls
CPU timeperfect cache=
2I + 1.38I2I
=1.69

Why memory is bottleneck for system performance?
In previous example, if we make the processor faster, change CPI from 2 to 1
Memory-stall cycles remains the same=1.38ICPU timestalls
CPU timeperfect cache=
I + 1.38II
=2.38
Percentage of memory stall:
1.383.38
=41%1.382.38
=58%
CPU 變快 (CPI 降低,或 clock rate 提高 )Memory 對系統效能的影響百分比越重

Outline Introduction Basics of caches Measuring cache performance
Set associative cache (reduce miss rate) Multilevel cache
Virtual memory
Make memory system fast

How to improve cache performance ?
Larger cache Set associative cache
Reduce cache miss rate New placement rule other than direct
mapping Multi-level cache
Reduce cache miss penalty
Memory-stall cycles = Program
Mem. accessX miss rate x miss penalty

Flexible placement of blocks
Recall: direct mapped cache One address -> one block in cache
00001 00101 01001 01101 10001 10101 11001 11101
000
Cache
Memory
001
010
011
100
101
110
111
? One address -> more than one block in cache 一個 memory address 可以對應到 cache 中一個以上的 block

Full-associative cache A memory data can be placed in any
block in the cache Disadvantage:
Search all entries in the cache for a match
Using parallel comparators
1
2Tag
Data
Block # 0 1 2 3 4 5 6 7
Search
Direct mapped
1
2Tag
Data
Set # 0 1 2 3
Search
Set associative
1
2Tag
Data
Search
Fully associative可放在 cache 任意位置

Set-associative cache Between direct mapped and full-
associative A memory data can be placed in a set
of blocks in the cache
Disadvantage: Search all entries in the set for a match Parallel comparators
可放在 cache 中某一個集合中
1
2Tag
Data
Block # 0 1 2 3 4 5 6 7
Search
Direct mapped
1
2Tag
Data
Set # 0 1 2 3
Search
Set associative
1
2Tag
Data
Search
Fully associative
(address) modulo (number of sets in cache)
Ex. 12 modulo 4 = 0

Example: 4-way set-associative cache
Address
22 8
V TagIndex
0
1
2
253
254255
Data V Tag Data V Tag Data V Tag Data
3222
4-to-1 multiplexor
Hit Data
123891011123031 0
Parallelcomparators
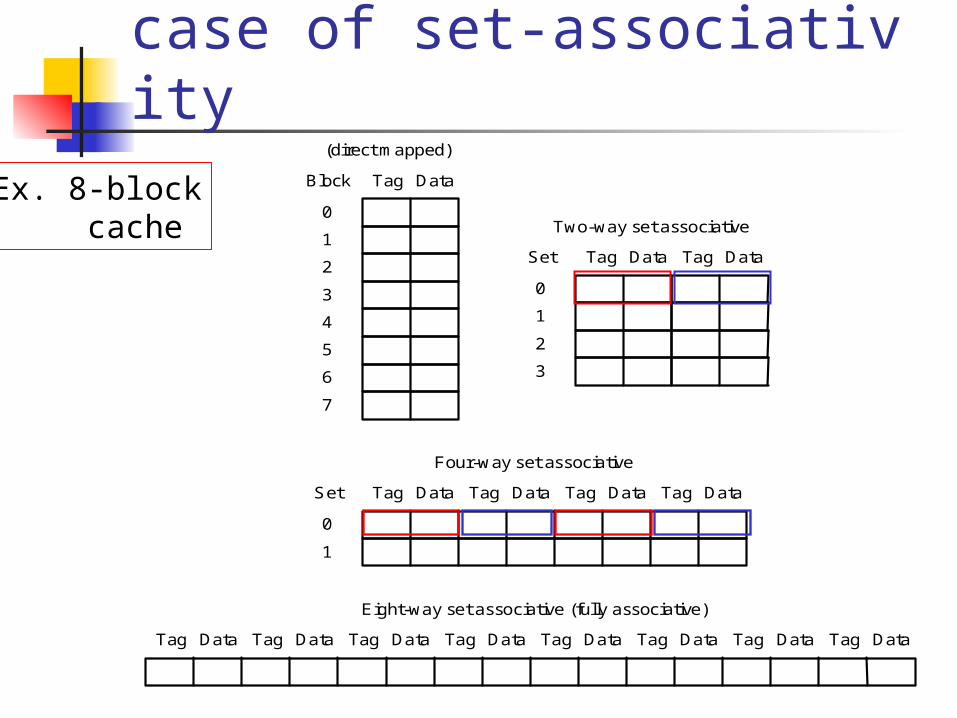
Take all schemes as a case of set-associativity
Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data
Eight-way set associative (fully associative)
Tag Data Tag Data Tag Data Tag Data
Four-way set associative
Set
0
1
Tag Data
One-way set associative(direct mapped)
Block
0
7
1
2
3
4
5
6
Tag Data
Two-way set associative
Set
0
1
2
3
Tag Data
Ex. 8-block cache

Example: set-associative caches (p. 500)
A cache with 4 blocks Load data with block addresses
0,8,0,6,8one-way set-associative cache (direct mapped)
5 misses

Example: set-associative caches
2-way set-associative cache
4-way set-associative cache
4 misses
3 misses

Short conclusion Higher degree of associativity
Lower miss rate More hardware cost to search

Outline Introduction Basics of caches Measuring cache performance
Set associative cache Multilevel cache (reduce miss penalty)
Virtual memory
Make memory system fast
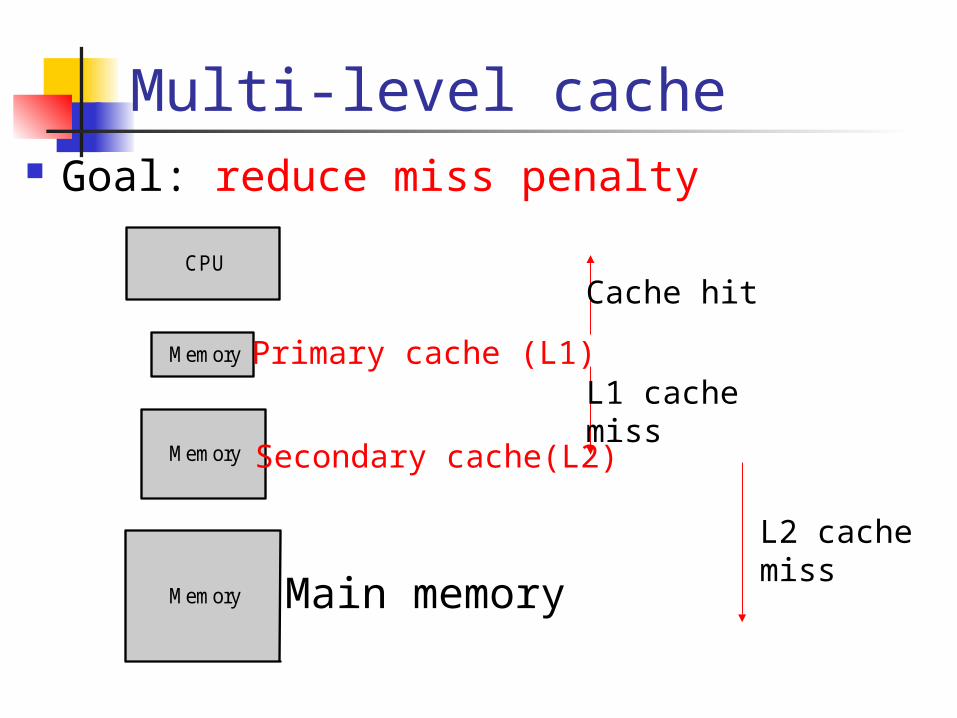
Multi-level cache Goal: reduce miss penalty
Memory
CPU
Memory
Size Cost ($/bit)Speed
Smallest
Biggest
Highest
Lowest
Fastest
Slowest Memory
Primary cache (L1)
Secondary cache(L2)
L1 cachemiss
L2 cachemiss
Cache hit
Main memory

Example: Performance of multilevel cache
CPI = 1 without cache miss, clock rate = 500MHz
Primary cache, miss rate=5% Secondary cache, miss rate=2%, access
time=20ns Main memory, access time=200 ns
Total CPI = Base CPI + memory-stall CPI
1 ?

Example: Performance of multilevel cache (cont.)
Total CPI = Base CPI + memory-stall CPI
1 ?
access to main memory=200ns x 500M clock/sec=100clock
access to L2 cache = 20ns x 500M clock/sec =10 clock
Total CPI = 1 + L1 miss penalty + L2 miss penalty = 1 + 5% x 10 + 2% x 100 = 3.5
One-level cache
Two-level cache
Total CPI = 1 + 5% x 100 = 6


















