
Ceph File System in Science DMZ - Events | Internet2 · Ceph File System in Science DMZ Shawfeng...
48
Ceph File System in Science DMZ Shawfeng Dong [email protected] University of California, Santa Cruz 2017 Technology Exchange, San Francisco, CA
Transcript of Ceph File System in Science DMZ - Events | Internet2 · Ceph File System in Science DMZ Shawfeng...

Ceph File Systemin Science DMZ
Shawfeng Dong
University of California, Santa Cruz
2017 Technology Exchange, San Francisco, CA

Outline
Science DMZ @UCSC
Brief Introduction to Ceph
Pulpos – a pilot Ceph Storage for SciDMZ @UCSC
Mounting Ceph File System
Applications
2

Science DMZ @UCSC
Northbound Dark Fiber (2009) Fiber path north to Sunnyvale, CA
Southbound Dark Fiber (2017) Connected Central Coast project, funded by a $13.3M grant from
California Public Utilities Commission (CPUC)
A new fiber backbone path from Santa Cruz to Soledad, CA
UCSC is allocated 6 strands of fiber
100g Science DMZ (2014) $500K award from NSF CC-NIE program
Cyberinfrastructure Engineer (2016 – 2018) $400K award from NSF CC-DNI program
3

Source:John Hess, CENIC
4

A brief history of Ceph
Ceph was initially created by Sage Weil, while he was a PhD student at UCSC!
Sage Weil, Scott Brandt, Ethan Miller & Carlos Maltzahn published the seminal paper, "CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data", in 2006
After his graduation in fall 2007, Weil continued to work on Ceph full-time
In 2012, Weil created Inktank Storage for professional services and support for Ceph
In 2014, Red Hat bought Inktank for $175M in cash
Ceph is the most popular choice of distributed storage for OpenStack[1]
[1]. http://www.openstack.org/assets/survey/Public-User-Survey-Report.pdf (October 2015)
5

Key Features of Ceph
Distributed Object Storage Files are stripped onto predictably named objects
CRUSH algorithm maps objects to storage devices
OSDs handle migration, replication, failure detection and recovery
Redundancy
Efficient scale-out
Built on commodity hardware
6
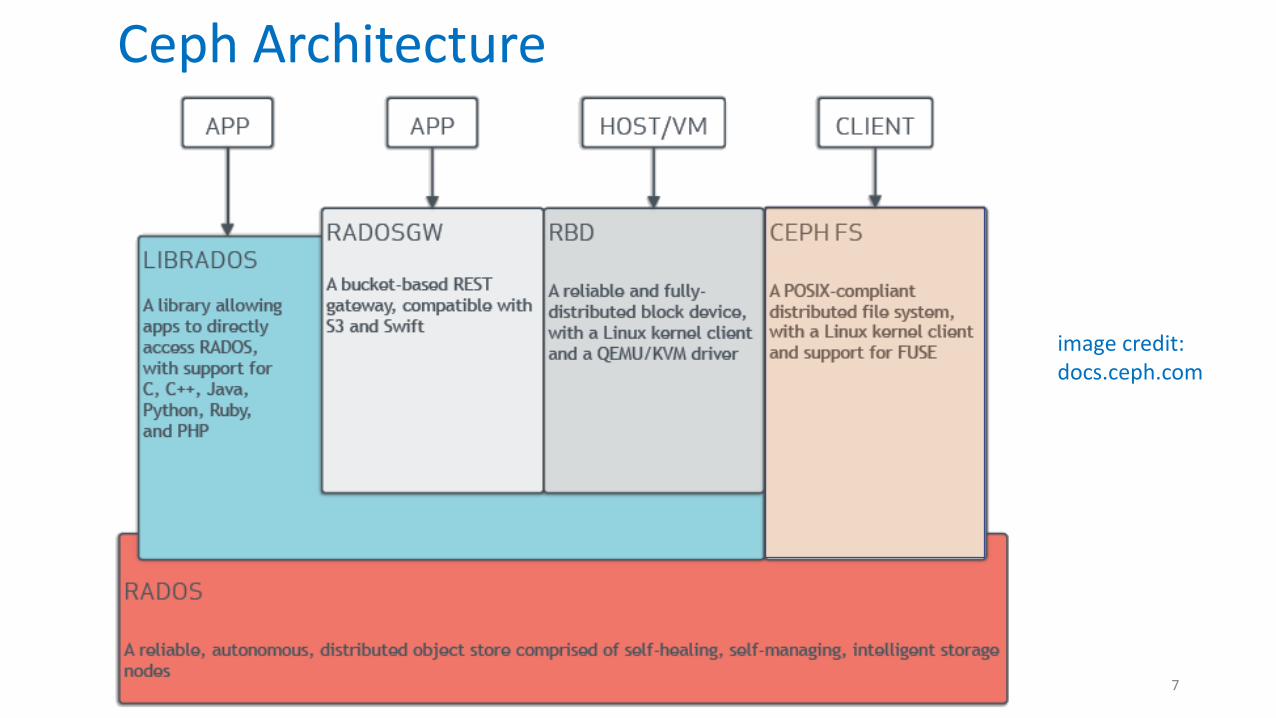
Ceph Architecture
image credit:docs.ceph.com
7

Ceph is Object-based Storage
image credit:Scott Brandt
8

Ceph File System
Ceph provides a traditional file system interface
POSIX-compliant Provides stronger consistency semantics than NFS!
Can be mounted either with the kernel driver or as FUSE
Benefits[1] : Provides strong data safety Provides virtually unlimited storage Automatically balances the file system to deliver maximum performance
[1]. http://ceph.com/ceph-storage/file-system/
9

Pulpos
A pilot Ceph storage system for SciDMZ at UCSCMostly using the Ceph file system interface
EtymologyUCSC's mascot is a banana slug called "Sammy". Banana slugs are
gastropods, which are a class of molluscs
The name "Ceph" is a common nickname given to pet octopusesand derives from cephalopods, also a class of molluscs
Pulpos is the Spanish word for octopuses
UCSC is a Hispanic Serving Institution
10

Hardware Overview
Four node in a Supermicro 6028TP-HTR 2U-Quad-Nodes chassis: pulpo-admin, pulpo-dtn, pulpo-mon01 & pulpo-mds01
Three 2U OSD servers: pulpo-osd01, pulpo-osd02 & pulpo-osd03
A white box, QuantaMesh BMS T3048-LY2R, switch 48x 10GbE SFP+ ports
4x 40GbE QSFP+ ports
Runs Pica8 PicOS
11
image credit:www.qct.io
image credit:supermicro.com

Supermicro 6028TP-HTR 2U-Quad-Nodes
pulpo-admin Two 8-core Intel
Xeon E5-2620 v4 processors @ 2.1 GHz
32GB DDR4 memory @ 2400 MHz
One 480GB Intel DC S3500 Series SSD
Intel X520-DA2 10GbE adapter, with 2 SFP+ ports
12
pulpo-dtn Two 8-core Intel
Xeon E5-2620 v4 processors @ 2.1 GHz
32GB DDR4 memory @ 2400 MHz
One 480GB Intel DC S3500 Series SSD
Intel X520-DA2 10GbE adapter, with 2 SFP+ ports
pulpo-mon01 Two 10-core Intel
Xeon E5-2630 v4 processors @ 2.2 GHz
64GB DDR4 memory @ 2400 MHz
Two 480GB Intel DC S3500 Series SSDs
Intel X520-DA2 10GbE adapter, with 2 SFP+ ports
pulpo-mds01 Two 10-core Intel
Xeon E5-2630 v4 processors @ 2.2 GHz
64GB DDR4 memory @ 2400 MHz
Two 480GB Intel DC S3500 Series SSDs
Intel X520-DA2 10GbE adapter, with 2 SFP+ ports

OSD Servers
3 OSD servers: pulpo-osd01, pulpo-osd02 & pulpo-osd03, each with:
Supermicro 2U chassis, with 12x 3.5” drive bays
Two 10-core Intel Xeon E5-2630 v4 processors @ 2.2 GHz
64GB DDR4 memory @ 2400 MHz
Two 1TB Micron 1100 3D NAND Client SATA SSDs
Two 1.2TB Intel DC P3520 Series PCIe SSDs
LSI SAS 9300-8i 12GB/s Host Bus Adapter
Twelve 8TB Seagate Enterprise SATA Hard Drives
An Intel X520-DA2 10GbE adapter, with 2 SFP+ ports
A single-port Mellanox ConnectX-3 Pro 10/40/56GbE Adapter
13
image credit:supermicro.com

Ceph Network
Choose the fastest you can afford
Separate public and cluster networks
Cluster network should be 2x public bandwidth
Ethernet (1, 10, 40 GigE) or IPoIB
14

Pulpos Network Topology
15

Luminous (Ceph v12.2.x)
Luminous is the new stable release of Ceph Luminous 12.2.0 was released on August 29, 2017
Luminous 12.2.1 was released on September 28, 2017
Major changes from Kraken (v11.2.x) and Jewel (v10.2.x)[1] : The new BlueStore backend for ceph-osd is now stable and the
default for newly created OSDs
Erasure coded pools now have full support for overwrites, allowing them to be used with RBD and CephFS
Etc.
16
[1]. http://ceph.com/releases/v12-2-0-luminous-released/

FireStore
17
image credit:Sage Weil
FireStoreobject = file
PG= collection = directory
Leveldb large xattr
spillover
object omap(key/value) data POSIX FAILS: OSDs are built around transactional updates,
which are awkward and inefficient to implement properly on top of a standard file system!

FireStore vs. BlueStore
18
image credit:http://ceph.com/community/new-luminous-bluestore/

BlueStore
BlueStore = Block + NewStore data written directly to block device
key/value database (RocksDB) for metadata
BlueFS is a super-simple "file system"
For more, see BlueStore, A New Storage Backend for Ceph, One Year In
BlueStore offers better performance (roughly 2x for writes), full data checksumming, and built-in compression
19

Ceph Redundancy
Replication n exact full-size copies
Increase read performance (striping)
More copies lower throughput
Increased cluster network utilization for writes
Rebuilds leverage multiple sources
Significant capacity impact
20
Erasure Coding Data split into k parts plus m
redundancy codes
Better space efficiency
Higher CPU overhead
Significant CPU & cluster network impact, especially during rebuild
In Kraken and earlier releases, a cache tier is required for EC pools to be used with RBD and CephFS
In Luminous, a cache tier is no longer required!
vs.

Ceph Deployment Options
FireStore
NVMes Journals for OSDs based on HDDs
Metadata pool
Cache tier
HDDs Replicated pools
Erasure coded pools
21
BlueStore
NVMes DB devices for OSDs based on HDDs
WAL (Write-ahead Log) devices for OSDs based on HDDs
Metadata pool
Cache tier
HDDs Replicated pools
Erasure coded pools
vs.

Kraken Deployment Example
OSDs: Create an OSD on each of the 8TB SATA HDDs, using the default FileStore backend
Use a partition on the first NVMe SSD of each OSD server as the journal for each of the OSDs backed by HDDs
Create an OSD on the second NVMe SSD of each OSD server, using the default FileStore backend
CephFS: Create an Erasure Coded data pool on the OSDs backed by HDDs
Create a replicated metadata pool on the OSDs backed by HDDs
Create a replicated pool on the OSDs backed by NVMes, as the cache tier of the Erasure Code data pool
22

Creating OSDs
23
#!/bin/bash### HDDsfor i in {1..3}do
j=1for x in {a..l}do
ceph-deploy osd prepare pulpo-osd0${i}:sd${x}:/dev/nvme0n1ceph-deploy osd activate pulpo-osd0${i}:sd${x}1:/dev/nvme0n1p${j}j=$[j+1]sleep 10
donedone### NVMefor i in {1..3}do
ceph-deploy osd prepare pulpo-osd0${i}:nvme1n1ceph-deploy osd activate pulpo-osd0${i}:nvme1n1p1sleep 10
done

CRUSH map
24
# ceph osd treeID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY-1 265.17267 root default-2 88.39088 host pulpo-osd010 7.27539 osd.0 up 1.00000 1.000001 7.27539 osd.1 up 1.00000 1.000002 7.27539 osd.2 up 1.00000 1.000003 7.27539 osd.3 up 1.00000 1.000004 7.27539 osd.4 up 1.00000 1.000005 7.27539 osd.5 up 1.00000 1.000006 7.27539 osd.6 up 1.00000 1.000007 7.27539 osd.7 up 1.00000 1.000008 7.27539 osd.8 up 1.00000 1.000009 7.27539 osd.9 up 1.00000 1.0000010 7.27539 osd.10 up 1.00000 1.0000011 7.27539 osd.11 up 1.00000 1.0000036 1.08620 osd.36 up 1.00000 1.00000-3 88.39088 host pulpo-osd02...-4 88.39088 host pulpo-osd03...

Modifying CRUSH map
Kraken doesn't differentiate between OSDs backed by HDDs and those backed by NVMes!
In order to place different pools on different OSDs, one must manually edit the CRUSH map.
25

Modified CRUSH map
26
# ceph osd mapID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY-8 3.25800 root nvme-5 1.08600 host pulpo-osd01-nvme36 1.08600 osd.36 up 1.00000 1.00000-6 1.08600 host pulpo-osd02-nvme37 1.08600 osd.37 up 1.00000 1.00000-7 1.08600 host pulpo-osd03-nvme38 1.08600 osd.38 up 1.00000 1.00000-1 261.90002 root hdd-2 87.30000 host pulpo-osd01-hdd0 7.27499 osd.0 up 1.00000 1.000001 7.27499 osd.1 up 1.00000 1.000002 7.27499 osd.2 up 1.00000 1.000003 7.27499 osd.3 up 1.00000 1.000004 7.27499 osd.4 up 1.00000 1.00000...-3 87.30000 host pulpo-osd02-hdd...-4 87.30000 host pulpo-osd02-hdd...

Creating a new Erasure Code profile
The default Erasure Code (EC) profile uses all OSDs
Create a new EC profile that only uses OSDs backed by HDDs:
27
# ceph osd erasure-code-profile set pulpo_ec k=2 m=1 ruleset-root=hdd \plugin=jerasure technique=reed_sol_van
# ceph osd erasure-code-profile get pulpo_ecjerasure-per-chunk-alignment=falsek=2m=1plugin=jerasureruleset-failure-domain=hostruleset-root=hddtechnique=reed_sol_vanw=8

Creating pools for CephFS
Create an replicated metadata pool on OSDs backed by HDDs, using the default CRUSH ruleset replicated_ruleset:
28
# ceph osd pool create cephfs_data 1024 1024 erasure pulpo_ec
Create an Erasure Coded data pool on OSDs backed by HDDs, using the pulpo_ec profile:
# ceph osd pool create cephfs_metadata 1024 1024 replicated

Kraken requires a Cache Tier for EC data pool
A cache tier is required for EC data pool in Kraken!
With Luminous, if you enable partial write for the EC data pool, a cache tier is unnecessary!
29
# ceph fs new pulpos cephfs_metadata cephfs_dataError EINVAL: pool 'cephfs_data' (id '1') is an erasure-code pool
With Kraken, if you try to create a Ceph file system at this point, you'll get an error:
# ceph osd pool set cephfs_data allow_ec_overwrites trueset pool 1 allow_ec_overwrites to true

Creating the Cache Tier
Create a replicated cache pool:
30
# ceph osd crush rule create-simple replicated_nvme nvme host
Create a new CRUSH ruleset for the cache pool that uses only OSDs backed by NVMes:
# ceph osd pool create cephfs_cache 128 128 replicated replicated_nvme
Create the cache tier:
# ceph osd tier add cephfs_data cephfs_cache
Configure the cache tier

Creating the Ceph File System
31
# ceph fs new pulpos cephfs_metadata cephfs_datanew fs with metadata pool 2 and data pool 1
Finally, you can create the Ceph file system:

Luminous Deployment Example
OSDs: Create an OSD on each of the 8TB SATA HDDs, using the default BlueStore backend
Use a partition on the first NVMe SSD of each OSD server as the DB device for each of the OSDs backed by HDDs
Use a partition on the first NVMe SSD of each OSD server as the WAL device for each of the OSDs backed by HDDs
Create an OSD on the second NVMe SSD of each OSD server, using the default BlueStore backend
CephFS: Create an replicated data pool on the OSDs backed by HDDs
Create a replicated metadata pool on the OSDs backed by NVMes
32

Creating OSDs
33
#!/bin/bash### HDDsfor i in {1..3}do
for x in {a..l}do
ceph-deploy osd prepare --bluestore --block-db /dev/nvme0n1 \--block-wal /dev/nvme0n1 pulpo-osd0${i}:sd${x}
ceph-deploy osd activate pulpo-osd0${i}:sd${x}1sleep 10
donedone### NVMefor i in {1..3}do
ceph-deploy osd prepare --bluestore pulpo-osd0${i}:nvme1n1ceph-deploy osd activate pulpo-osd0${i}:nvme1n1p1sleep 10
done

CRUSH map
34
# ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF-1 265.29291 root default-3 88.43097 host pulpo-osd010 hdd 7.27829 osd.0 up 1.00000 1.000001 hdd 7.27829 osd.1 up 1.00000 1.000002 hdd 7.27829 osd.2 up 1.00000 1.000003 hdd 7.27829 osd.3 up 1.00000 1.000004 hdd 7.27829 osd.4 up 1.00000 1.000005 hdd 7.27829 osd.5 up 1.00000 1.000006 hdd 7.27829 osd.6 up 1.00000 1.000007 hdd 7.27829 osd.7 up 1.00000 1.000008 hdd 7.27829 osd.8 up 1.00000 1.000009 hdd 7.27829 osd.9 up 1.00000 1.0000010 hdd 7.27829 osd.10 up 1.00000 1.0000011 hdd 7.27829 osd.11 up 1.00000 1.0000036 nvme 1.09149 osd.36 up 1.00000 1.00000-5 88.43097 host pulpo-osd02...-7 88.43097 host pulpo-osd03...

CRUSH device class
Luminous adds a new property to each OSD: device class
We no longer need to manually edit the CRUSH map in order to place different pools on different classes of OSDs!
35
# ceph osd crush class ls[
"hdd","nvme"
]

Creating new Replication rules
The default CRUSH rule for replicated pool, replicated_rule, will use all classes of OSDs
Create a replication rule, pulpo_hdd, that targets the hdd device class; and another replication rule, pulpo_nvme, that targets the nvme device class :
36
# ceph osd crush rule create-replicated pulpo_hdd default host hdd
# ceph osd crush rule create-replicated pulpo_nvme default host nvme

Creating pools for CephFS
Create a replicated metadata pool on OSDs backed by NVMes, using the pulpo_nvme CRUSH rule:
37
# ceph osd pool create cephfs_data 1024 1024 replicated pulpo_hdd
Create a replicated data pool on OSDs backed by HDDs, using the pulpo_hdd CRUSH rule:
# ceph osd pool create cephfs_metadata 256 256 replicated pulpo_nvme
You can change the replication size of the pools from the default 3 to 2.

Creating the Ceph File System
38
# ceph fs new pulpos cephfs_metadata cephfs_datanew fs with metadata pool 2 and data pool 1
Finally, you can create the Ceph file system:

ceph-fuse
More up to date in terms of bug fixes
Enhanced functionalities
More portable Linux
FreeBSD
Windows (Ceph-Dokan)
macOS[1] (?)
Kernel CephFS driver
Better performance
Limited to Linux clients
2 ways to mount CephFS on a client
39
vs.
[1]. Not working yet; but porting appears to be feasible.

Restricting CephFS client capabilities
Completely restrict a client (e.g., hydra) to a directory (e.g., /hydra) [1] :
40
# ceph auth add client.hydra mon 'allow r' mgr 'allow r' \mds 'allow rw path=/hydra' osd 'allow rw pool=cephfs_data'
One use case is to allow a user to mount his/her directory of CephFS on his/her own machine
Add a Ceph client user (e.g., hydra) with limited caps[1] :
# ceph fs authorize pulpos client.hydra /hydra rw
[1]. The two constrains must match! The official documentation is not yet up to date as of 10/15/2017.

Mounting a subdirectory of CephFS
There are 2 methods to mount CephFS automatically on startup : /etc/fstab
systemd
41
# ceph-fuse -n client.hydra \-m 1.2.3.4:6789,1.2.3.5:6789,1.2.3.6:6789 -r /hydra /mnt/pulpos
Mount a directory of CephFS (e.g., /hydra) on a client:

Applications
1-step fast data transfer using Globus, GridFTP, FDT, bbcp, etc.
A candidate scratch file system for HPC and a possible replacement for parallel file systems like Lustre & GPFS
A data warehousing platform for data science and machine learning
etc.
42

Globus
43

CephFS as scratch file system for HPC?
Local File Systems Examples: ext2/3/4, XFS, Btrfs, ZFS, etc.
Distributed File Systems Designed to let processes on multiple computers access a common set
of files But not designed to give multiple processes efficient, concurrent access
to the same file Examples: NFS (Network File System), AFS, DFS, etc.
Parallel File Systems Lustre GPFS BeeGS CephFS (?)
44

MPI-IO write example: writeFile1.c/* write to a common file using explicit offsets */#include "mpi.h"#define FILESIZE (1024 * 1024)int main(int argc, char **argv) {
int *buf, i, rank, size, bufsize, nints, offset;MPI_File fh;MPI_Status status;MPI_Init(&argc, &argv);MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size);bufsize = FILESIZE/size;buf = (int *) malloc(bufsize);nints = bufsize/sizeof(int);for (i=0; i<nints; i++) buf[i] = rank*nints + i;offset = rank*bufsize;MPI_File_open(MPI_COMM_WORLD, "datafile", MPI_MODE_CREATE|MPI_MODE_WRONLY,
MPI_INFO_NULL, &fh);MPI_File_write_at(fh, offset, buf, nints, MPI_INT, &status);MPI_File_close(&fh); free(buf);MPI_Finalize();return 0;
}
0 1 2 3

MPI-IO read example: readFile1.c/* read from a common file using individual file pointers */#include "mpi.h"#define FILESIZE (1024 * 1024)int main(int argc, char **argv){
int *buf, rank, size, bufsize, nints;MPI_File fh;MPI_Status status;MPI_Init(&argc, &argv);MPI_Comm_rank(MPI_COMM_WORLD, &rank);MPI_Comm_size(MPI_COMM_WORLD, &size);bufsize = FILESIZE/size;buf = (int *) malloc(bufsize);nints = bufsize/sizeof(int);MPI_File_open(MPI_COMM_WORLD, "datafile", MPI_MODE_RDONLY, MPI_INFO_NULL, &fh);MPI_File_seek(fh, rank * bufsize, MPI_SEEK_SET);MPI_File_read(fh, buf, nints, MPI_INT, &status);MPI_File_close(&fh);free(buf);MPI_Finalize();return 0;
}
0 1 2 3

Testing MPI-IO CephFS
MPI-IO works out-of-the-box with CephFS (Luminous v12.2.x)!
47
### Install Open MPI (on a CentOS 7 machine)# yum install openmpi openmpi-devel
### Go to the mountpoint of CephFS$ cd /mnt/pulpos
### Compile MPI-IO programs$ export PATH=/usr/lib64/openmpi/bin:$PATH$ mpicc readFile1.c -o readFile1.x$ mpicc writeFile1.c -o writeFile1.x
### run MPI-IO programs$ mpirun --mca btl self,sm,tcp -n 4 ./writeFile1.x$ mpirun --mca btl self,sm,tcp -n 4 ./readFile1.x

Thank you!
Questions?
48


















