
c2738510
104
Informix Product Family Informix Warehouse Accelerator Version 11.70 IBM Informix Warehouse Accelerator Administration Guide SC27-3851-00
-
Upload
sergio-peres -
Category
Documents
-
view
74 -
download
8
Transcript of c2738510

Informix Product FamilyInformix Warehouse AcceleratorVersion 11.70
IBM Informix Warehouse AcceleratorAdministration Guide
SC27-3851-00
���


Informix Product FamilyInformix Warehouse AcceleratorVersion 11.70
IBM Informix Warehouse AcceleratorAdministration Guide
SC27-3851-00
���

NoteBefore using this information and the product it supports, read the information in “Notices” on page E-1.
Edition
This document contains proprietary information of IBM. It is provided under a license agreement and is protectedby copyright law. The information contained in this publication does not include any product warranties, and anystatements provided in this manual should not be interpreted as such.
When you send information to IBM, you grant IBM a nonexclusive right to use or distribute the information in anyway it believes appropriate without incurring any obligation to you.
© Copyright IBM Corporation 2010, 2011.US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contractwith IBM Corp.

Contents
Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vAbout this publication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . v
Types of users . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vSoftware dependencies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vAssumptions about your locale . . . . . . . . . . . . . . . . . . . . . . . . . . . . v
What's New in the Informix Warehouse Accelerator . . . . . . . . . . . . . . . . . . . . . . viExample code conventions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . viiAdditional documentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . viiCompliance with industry standards . . . . . . . . . . . . . . . . . . . . . . . . . . viiiSyntax diagrams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . viii
How to read a command-line syntax diagram . . . . . . . . . . . . . . . . . . . . . . . ixKeywords and punctuation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xIdentifiers and names . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . x
How to provide documentation feedback . . . . . . . . . . . . . . . . . . . . . . . . . xi
Chapter 1. Overview of Informix Warehouse Accelerator . . . . . . . . . . . . . . 1-1Accelerator architecture options . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-3Accelerated query considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-6
Queries that benefit from acceleration . . . . . . . . . . . . . . . . . . . . . . . . . 1-6Types of queries that are not accelerated . . . . . . . . . . . . . . . . . . . . . . . . 1-8
Supported data types . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-9Supported functions and expressions . . . . . . . . . . . . . . . . . . . . . . . . . . 1-9Supported and unsupported joins . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-10Software prerequisites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-11Hardware prerequisites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-12
Chapter 2. Accelerator installation . . . . . . . . . . . . . . . . . . . . . . . 2-1Accelerator directory structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-1Preparing the Informix database server . . . . . . . . . . . . . . . . . . . . . . . . . . 2-2Installing the accelerator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-3Installing the administration interface . . . . . . . . . . . . . . . . . . . . . . . . . . 2-4Uninstalling the accelerator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-5
Chapter 3. Accelerator configuration . . . . . . . . . . . . . . . . . . . . . . 3-1Configuring the accelerator (non-cluster installation) . . . . . . . . . . . . . . . . . . . . . 3-1Configuring the accelerator (cluster installation) . . . . . . . . . . . . . . . . . . . . . . . 3-2dwainst.conf configuration file . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-3Connecting the database server to the accelerator . . . . . . . . . . . . . . . . . . . . . . 3-6Enabling and disabling query acceleration . . . . . . . . . . . . . . . . . . . . . . . . . 3-7The ondwa utility . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-9
Users who can run the ondwa commands . . . . . . . . . . . . . . . . . . . . . . . . 3-9ondwa setup command . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-10ondwa start command . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-11ondwa status command . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-12ondwa getpin command . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-13ondwa tasks command . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-13ondwa stop command . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-14ondwa reset command . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-14ondwa clean command . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-15
Chapter 4. Accelerator data marts and AQTs . . . . . . . . . . . . . . . . . . . 4-1Creating data marts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-1
Designing effective data marts . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-2Creating data mart definitions by using the administration interface . . . . . . . . . . . . . . . 4-8
© Copyright IBM Corp. 2010, 2011 iii

Creating data mart definitions by using workload analysis . . . . . . . . . . . . . . . . . . 4-10Deploying a data mart . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-20Loading data into data marts . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-21
Refreshing the data in a data mart . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-22Updating the data in a data mart . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-23Drop a data mart . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-23Handling schema changes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-23Removing probing data from the database . . . . . . . . . . . . . . . . . . . . . . . . 4-24Monitoring AQTs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-24
Chapter 5. Reversion requirements for an Informix warehouse edition server andInformix Warehouse Accelerator . . . . . . . . . . . . . . . . . . . . . . . . 5-1
Chapter 6. Troubleshooting . . . . . . . . . . . . . . . . . . . . . . . . . . 6-1Missing sbspace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-1Memory issues for the coordinator node and the worker nodes . . . . . . . . . . . . . . . . . . 6-1Ensuring a result set includes the most current data . . . . . . . . . . . . . . . . . . . . . 6-1
Appendix A. Sample warehouse schema. . . . . . . . . . . . . . . . . . . . . A-1
Appendix B. Sysmaster interface (SMI) pseudo tables for query probing data. . . . . B-1
Appendix C. Supported locales . . . . . . . . . . . . . . . . . . . . . . . . . C-1
Appendix D. Accessibility . . . . . . . . . . . . . . . . . . . . . . . . . . . D-1Accessibility features for IBM Informix products . . . . . . . . . . . . . . . . . . . . . . D-1
Accessibility features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . D-1Keyboard navigation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . D-1Related accessibility information . . . . . . . . . . . . . . . . . . . . . . . . . . . D-1IBM and accessibility. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . D-1
Dotted decimal syntax diagrams . . . . . . . . . . . . . . . . . . . . . . . . . . . . D-1
Notices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . E-1Trademarks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . E-3
Index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . X-1
iv IBM Informix Warehouse Accelerator Administration Guide

Introduction
About this publicationThis publication contains comprehensive information about using the Informix®
Warehouse Accelerator to process data warehouse queries more quickly thanprocessing the queries using the Informix database server.
Types of users
This publication is written for the following users:v Database administratorsv System administratorsv Performance engineersv Application developers
This publication is written with the assumption that you have the followingbackground:v A working knowledge of your computer, your operating system, and the utilities
that your operating system providesv Some experience working with relational and dimensional databases or exposure
to database conceptsv Some experience with database server administration, operating-system
administration, network administration, or application development
You can access the Informix information centers, as well as other technicalinformation such as technotes, white papers, and IBM® Redbooks® publicationsonline at http://www.ibm.com/software/data/sw-library/.
Software dependencies
This publication is written with the assumption that you are using IBM InformixVersion 11.70.xC2 or later as your database server.
Assumptions about your locale
IBM Informix products can support many languages, cultures, and code sets. Allthe information related to character set, collation and representation of numericdata, currency, date, and time that is used by a language within a given territoryand encoding is brought together in a single environment, called a GlobalLanguage Support (GLS) locale.
The IBM Informix OLE DB Provider follows the ISO string formats for date, time,and money, as defined by the Microsoft OLE DB standards. You can override thatdefault by setting an Informix environment variable or registry entry, such asDBDATE.
The examples in this publication are written with the assumption that you areusing one of these locales: en_us.8859-1 (ISO 8859-1) on UNIX platforms oren_us.1252 (Microsoft 1252) in Windows environments. These locales support U.S.
© Copyright IBM Corp. 2010, 2011 v

English format conventions for displaying and entering date, time, number, andcurrency values. They also support the ISO 8859-1 code set (on UNIX and Linux)or the Microsoft 1252 code set (on Windows), which includes the ASCII code setplus many 8-bit characters such as é, è, and ñ.
You can specify another locale if you plan to use characters from other locales inyour data or your SQL identifiers, or if you want to conform to other collationrules for character data.
What's New in the Informix Warehouse AcceleratorThis publication includes information about new features and changes in existingfunctionality.
The following changes and enhancements are relevant to this publication.
Table 1. What's New in IBM Informix Warehouse Accelerator Administration Guide for IBM Informix Version 11.70.xC4.
Overview Reference
Install Informix Warehouse Accelerator on a cluster system
You can now install Informix Warehouse Accelerator on a clustersystem. Using a cluster for Informix Warehouse Accelerator takesadvantage of the parallel processing power of multiple clusternodes. The accelerator coordinator node and each worker nodecan run on a different cluster node. The Informix WarehouseAccelerator software and data are shared in the cluster filesystem. You can administer Informix Warehouse Accelerator fromany node in the cluster.
See “Configuring the accelerator (clusterinstallation)” on page 3-2.
Refresh data mart data during query acceleration
You can now refresh data in the Informix Warehouse Acceleratorwhile queries are accelerated. You no longer need to suspendquery acceleration in order to drop and re-create the original datamart. Using the existing administrator tools, you create a newdata mart that has the same data mart definition as the originaldata mart, but has a different name. You can then load the newdata mart while query acceleration still uses the original datamart. Once the new data mart is loaded, the acceleratorautomatically uses the new data mart with the latest data toaccelerate queries.
See “Refreshing the data in a data mart” on page4-22.
User informix can run the ondwa commands
The ondwa commands can now be run by user informix providedthat the shell limits are set correctly.
See “Users who can run the ondwa commands”on page 3-9.
Support for new functions is implemented
v DECODE
v NVL
v TRUNC
See the list of scalar functions at “Supportedfunctions and expressions” on page 1-9.
New options for monitoring AQTs
New columns have been added to the output of the onstat -g aqtcommand that include counters for candidate AQTs.
See onstat -g aqt command.
vi IBM Informix Warehouse Accelerator Administration Guide

Table 2. What's New in IBM Informix Warehouse Accelerator Administration Guide for IBM Informix Version 11.70.xC3
Overview Reference
Create data mart definitions automatically
Creating data mart definitions is one of the more time consumingtasks in setting up the accelerator. You can use a new capability inInformix Warehouse Accelerator to automatically create the datamart definitions for you. This capability is especially useful ifthere are a very large number of tables in your database andusing the administration interface to create the data martdefinitions is cumbersome. It is also useful when you are notintimately familiar with the table schemas in your database.
See “Creating data mart definitions by using theadministration interface” on page 4-8.
Additional locales supported
Previously Informix Warehouse Accelerator supported only thedefault locale en_us.8859-1. Additional locales are now supported.
See Appendix C, “Supported locales,” on pageC-1.
Example code conventionsExamples of SQL code occur throughout this publication. Except as noted, the codeis not specific to any single IBM Informix application development tool.
If only SQL statements are listed in the example, they are not delimited bysemicolons. For instance, you might see the code in the following example:CONNECT TO stores_demo...
DELETE FROM customerWHERE customer_num = 121
...
COMMIT WORKDISCONNECT CURRENT
To use this SQL code for a specific product, you must apply the syntax rules forthat product. For example, if you are using an SQL API, you must use EXEC SQLat the start of each statement and a semicolon (or other appropriate delimiter) atthe end of the statement. If you are using DB–Access, you must delimit multiplestatements with semicolons.
Tip: Ellipsis points in a code example indicate that more code would be added ina full application, but it is not necessary to show it to describe the concept beingdiscussed.
For detailed directions on using SQL statements for a particular applicationdevelopment tool or SQL API, see the documentation for your product.
Additional documentationDocumentation about this release of IBM Informix products is available in variousformats.
You can access or install the product documentation from the Quick Start CD thatis shipped with Informix products. To get the most current information, see theInformix information centers at ibm.com®. You can access the information centers
Introduction vii
and other Informix technical information such as technotes, white papers, and IBMRedbooks publications online at http://www.ibm.com/software/data/sw-library/.
Compliance with industry standardsIBM Informix products are compliant with various standards.
IBM Informix SQL-based products are fully compliant with SQL-92 Entry Level(published as ANSI X3.135-1992), which is identical to ISO 9075:1992. In addition,many features of IBM Informix database servers comply with the SQL-92Intermediate and Full Level and X/Open SQL Common Applications Environment(CAE) standards.
The IBM Informix Geodetic DataBlade® Module supports a subset of the data typesfrom the Spatial Data Transfer Standard (SDTS)—Federal Information ProcessingStandard 173, as referenced by the document Content Standard for GeospatialMetadata, Federal Geographic Data Committee, June 8, 1994 (FGDC MetadataStandard).
Syntax diagramsSyntax diagrams use special components to describe the syntax for statements andcommands.
Table 3. Syntax Diagram Components
Component represented in PDF Component represented in HTML Meaning
>>---------------------- Statement begins.
-----------------------> Statement continues on nextline.
>----------------------- Statement continues fromprevious line.
----------------------->< Statement ends.
--------SELECT---------- Required item.
--+-----------------+---’------LOCAL------’
Optional item.
---+-----ALL-------+---+--DISTINCT-----+’---UNIQUE------’
Required item with choice.Only one item must bepresent.
---+------------------+---+--FOR UPDATE-----+’--FOR READ ONLY--’
Optional items with choiceare shown below the mainline, one of which you mightspecify.
viii IBM Informix Warehouse Accelerator Administration Guide

Table 3. Syntax Diagram Components (continued)
Component represented in PDF Component represented in HTML Meaning
.---NEXT---------.----+----------------+---
+---PRIOR--------+’---PREVIOUS-----’
The values below the mainline are optional, one ofwhich you might specify. Ifyou do not specify an item,the value above the line isused by default.
.-------,-----------.V |---+-----------------+---
+---index_name---+’---table_name---’
Optional items. Several itemsare allowed; a comma mustprecede each repetition.
>>-| Table Reference |->< Reference to a syntaxsegment.
Table Reference
|--+-----view--------+--|+------table------+’----synonym------’
Syntax segment.
How to read a command-line syntax diagramCommand-line syntax diagrams use similar elements to those of other syntaxdiagrams.
Some of the elements are listed in the table in Syntax Diagrams.
Creating a no-conversion job
�� onpladm create job job-p project
-n -d device -D database �
� -t table �
� �(1)
Setting the Run Mode-S server -T target
��
Notes:
1 See page Z-1
This diagram has a segment named “Setting the Run Mode,” which according tothe diagram footnote is on page Z-1. If this was an actual cross-reference, youwould find this segment on the first page of Appendix Z. Instead, this segment isshown in the following segment diagram. Notice that the diagram uses segmentstart and end components.
Introduction ix

Setting the run mode:
-fdpa
lc
u n N
To see how to construct a command correctly, start at the upper left of the maindiagram. Follow the diagram to the right, including the elements that you want.The elements in this diagram are case-sensitive because they illustrate utilitysyntax. Other types of syntax, such as SQL, are not case-sensitive.
The Creating a No-Conversion Job diagram illustrates the following steps:1. Type onpladm create job and then the name of the job.2. Optionally, type -p and then the name of the project.3. Type the following required elements:
v -n
v -d and the name of the devicev -D and the name of the databasev -t and the name of the table
4. Optionally, you can choose one or more of the following elements and repeatthem an arbitrary number of times:v -S and the server namev -T and the target server namev The run mode. To set the run mode, follow the Setting the Run Mode
segment diagram to type -f, optionally type d, p, or a, and then optionallytype l or u.
5. Follow the diagram to the terminator.
Keywords and punctuationKeywords are words reserved for statements and all commands exceptsystem-level commands.
When a keyword appears in a syntax diagram, it is shown in uppercase letters.When you use a keyword in a command, you can write it in uppercase orlowercase letters, but you must spell the keyword exactly as it appears in thesyntax diagram.
You must also use any punctuation in your statements and commands exactly asshown in the syntax diagrams.
Identifiers and namesVariables serve as placeholders for identifiers and names in the syntax diagramsand examples.
You can replace a variable with an arbitrary name, identifier, or literal, dependingon the context. Variables are also used to represent complex syntax elements thatare expanded in additional syntax diagrams. When a variable appears in a syntaxdiagram, an example, or text, it is shown in lowercase italic.
x IBM Informix Warehouse Accelerator Administration Guide

The following syntax diagram uses variables to illustrate the general form of asimple SELECT statement.
�� SELECT column_name FROM table_name ��
When you write a SELECT statement of this form, you replace the variablescolumn_name and table_name with the name of a specific column and table.
How to provide documentation feedbackYou are encouraged to send your comments about IBM Informix userdocumentation.
Use one of the following methods:v Send email to [email protected] In the Informix information center, which is available online at
http://www.ibm.com/software/data/sw-library/, open the topic that you wantto comment on. Click the feedback link at the bottom of the page, fill out theform, and submit your feedback.
v Add comments to topics directly in the information center and read commentsthat were added by other users. Share information about the productdocumentation, participate in discussions with other users, rate topics, andmore!
Feedback from all methods is monitored by the team that maintains the userdocumentation. The feedback methods are reserved for reporting errors andomissions in the documentation. For immediate help with a technical problem,contact IBM Technical Support at http://www.ibm.com/planetwide/.
We appreciate your suggestions.
Introduction xi

xii IBM Informix Warehouse Accelerator Administration Guide

Chapter 1. Overview of Informix Warehouse Accelerator
Informix Warehouse Accelerator is a product that you use to improve theperformance of your warehouse queries.
Informix Warehouse Accelerator processes warehouse queries significantly morequickly than the Informix database server. The accelerator improves performancewhile at the same time reduces administration. There are only a few configurationparameters that you need to set to tune query performance. You can install theaccelerator on same computer as the Informix database server, as shown in thefollowing figure. You can also install the Informix Warehouse Accelerator on aseparate computer.
You can use Informix Warehouse Accelerator with an Informix database server thatsupports a mixed workload (online transactional processing (OLTP) database and adata warehouse database), or use it with a database server that supports only adata warehouse database. However, before you use Informix WarehouseAccelerator you must design and implement a dimensional database that uses astar or snowflake schema for your data warehouse. This design includes selectingthe business subject areas that you want to model, determining the granularity ofthe fact tables, and identifying the dimensions and hierarchies for each fact table.Additionally, you must identify the measures for the fact tables and determine theattributes for each dimension table.
The following figure shows a sample snowflake schema with a fact table andmultiple dimension tables.
Clientapplication
Clientapplication
Clientapplication
Clientconnectivity
Informix serverInformix WarehouseAccelerator
Figure 1-1. Informix Warehouse Accelerator installed on the same computer as the Informixdatabase server.
© Copyright IBM Corp. 2010, 2011 1-1

Administration interface
Informix Warehouse Accelerator includes an Eclipse-based administration interface,IBM Smart Analytics Optimizer Studio. You use this interface to administer theaccelerator, and the data contained within the accelerator. The administration tasksare performed using a set of stored procedures in the Informix database server. Thestored procedures are called through the administration interface.
Accelerator utilities
You also use utilities that are supplied with Informix Warehouse Accelerator tocreate the files and subdirectories that are required to run an accelerator instanceand start the accelerator nodes. By default, the Informix Warehouse Acceleratoruses one coordinator node and one worker node. The coordinator node is a processthat manages the query tasks, such as load query and run query. The Informixdatabase server and the ondwa utility connect to the coordinator node. The workernode is a process that communicates only with the coordinator node. The workernode has all of the data in main memory, compresses the data, and processes thequeries.
Accelerator samples
Informix Warehouse Accelerator also includes a sample set of Java classes that youcan use from the command line or in an application. You use these classes toperform many of the same tasks that you can perform with the administrationinterface.
Tip: One reason that you might use these classes is to automate the steps requiredto refresh the data stored in the data marts. Instead of dropping and recreating thedata marts manually through the administration interface, you can create anapplication that runs whenever it is convenient for your organization.See the dwa_java_reference.txt file in the dwa/example/cli/ directory for more
DAILY_SALESfact table
STORE
CUSTOMER
CONTACT
PRODUCT
PERIOD
CITY
REGION
ADDRESS
DEMOGRAPHICS PROMOTION
BRAND
QUARTER
PRODUCT_LINE
MONTH
Figure 1-2. A sample snowflake schema that has the DAILY_SALES table as the fact table.
1-2 IBM Informix Warehouse Accelerator Administration Guide

information about these sample Java classes.
Accelerator architecture
The following figure shows that the database server communicates with theworker nodes through the coordinator node, and describes the roles of thedatabase server, the coordinator node, and the worker nodes.
Informix Warehouse Accelerator must have its own copy of the data. The data isstored in logical collections of related data, or data marts. After you create a datamart, information about the data mart is sent to the database server in the form ofa special view referred to as an accelerated query table or AQT.
The architecture that is implemented with Informix Warehouse Accelerator isoptimal for processing data warehouse queries. The demands of data warehousequeries are substantially different than OLTP queries. A typical data warehousequery requires the processing of a large set of data and returns a small result set.
The overhead required to accelerate a query and return a result set is negligiblecompared with the benefits of using Informix Warehouse Accelerator:v The accelerator uses a copy of the data.v To expedite query processing, the copy of the data is kept in memory in a
special compressed format. Advances in compression techniques, queryprocessing on compressed data, and hybrid columnar organization ofcompressed data enable the accelerator to query the compressed data.
v The data is compressed and stored with the accelerator to maximize parallelquery processing.
In addition to the performance gain of the warehouse query itself, the resources onthe database server can be better utilized for other types of queries, such as OLTPqueries, which perform more efficiently on the database server.
Accelerator architecture optionsThere are several approaches that you can use to integrate the accelerator into yourcurrent system architecture.
Informix database server Informix Warehouse Accelerator
Performs the query parsingand AQT matching.
The Optimizerroutes the query blocks.
Coordinator node Worker nodes
Manages the distributiontasks such as loadingdata and and query
processing.
Store the data in mainmemory spread across all ofthe nodes. Perform the data
compression and queryprocessing.
Figure 1-3. A sample accelerator node architecture with one coordinator node and fourworker nodes.
Chapter 1. Overview of Informix Warehouse Accelerator 1-3

You can install Informix Warehouse Accelerator on the same computer as yourInformix database server, on a separate computer, or on a cluster. There must be aTCP/IP connection between the database server and the accelerator. If theaccelerator is installed on the same computer as the database server, the connectionmust be a local loop-back TCP/IP connection.
The query optimizer on the database server identifies which data warehousequeries can be accelerated and sends those queries to the accelerator. The result setis sent back to the database server, which passes the result set back to the client. Ifthe query cannot be processed by the accelerator, the query is processed on thedatabase server.
You use an administration tool called IBM Smart Analytics Optimizer Studio toperform the administration tasks that are required on the accelerator. The IBMSmart Analytics Optimizer Studio is commonly referred to as the administrationinterface. The administration tasks are implemented as a set of stored proceduresthat are called through the administration interface.
You can install the administration interface on the same computer as the Informixdatabase server or on a separate computer.
The accelerator and database server on the same computer
The following figure shows the accelerator and the database server installed on thesame computer with the administration interface installed on a separate computer.
The accelerator and database server on different computers
The following figure shows the accelerator and the database server installed ondifferent computers, with the administration interface installed on a separatecomputer.
SQL query
Informix database server
Optimizer
No
Result set
Yes
Administrator interface
UseAccelerator?
Informix WarehouseAccelerator
Local loopbackTCP/IP
connection
Client
Symmetric multiprocessing system
Acceleratoradministrator
interface
Figure 1-4. The accelerator and the database server installed on the same computer.
1-4 IBM Informix Warehouse Accelerator Administration Guide

The accelerator installed on a cluster system
The following figure shows the accelerator installed on a cluster and the databaseserver and administration interface installed on separate computers.
SQL query
Informix database server
Optimizer
No
Result set
YesUseAccelerator?
Linux 64-bit Intelprocessor
TCP/IPconnection
Client
Symmetricmultiprocessing system
Acceleratoradministratorinterface
InformixWarehouseAccelerator
Administratorstored
procedures
Figure 1-5. The accelerator and the database server installed on different computers.
Chapter 1. Overview of Informix Warehouse Accelerator 1-5
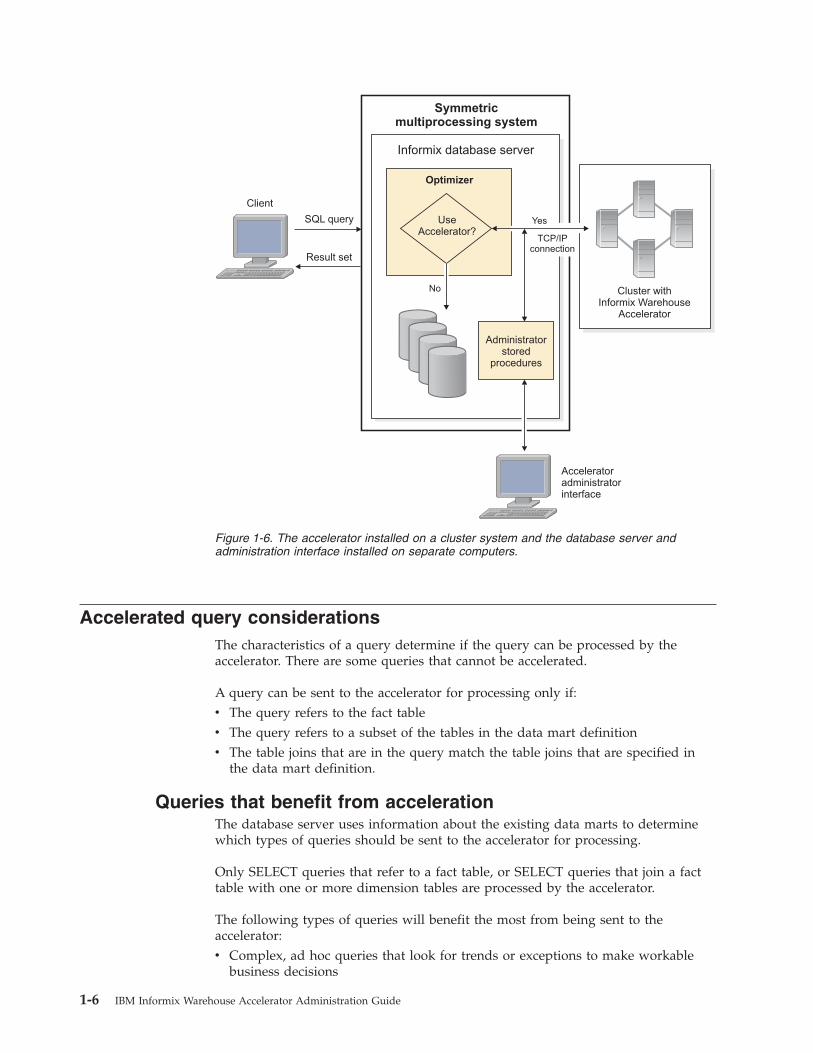
Accelerated query considerationsThe characteristics of a query determine if the query can be processed by theaccelerator. There are some queries that cannot be accelerated.
A query can be sent to the accelerator for processing only if:v The query refers to the fact tablev The query refers to a subset of the tables in the data mart definitionv The table joins that are in the query match the table joins that are specified in
the data mart definition.
Queries that benefit from accelerationThe database server uses information about the existing data marts to determinewhich types of queries should be sent to the accelerator for processing.
Only SELECT queries that refer to a fact table, or SELECT queries that join a facttable with one or more dimension tables are processed by the accelerator.
The following types of queries will benefit the most from being sent to theaccelerator:v Complex, ad hoc queries that look for trends or exceptions to make workable
business decisions
SQL query
Informix database server
Optimizer
No
Result set
UseAccelerator?
TCP/IPconnection
Client
Symmetricmultiprocessing system
Yes
Acceleratoradministratorinterface
Cluster withInformix Warehouse
Accelerator
Administratorstored
procedures
Figure 1-6. The accelerator installed on a cluster system and the database server andadministration interface installed on separate computers.
1-6 IBM Informix Warehouse Accelerator Administration Guide

v Queries that access a large subset of the database, often by using sequentialscans
v Queries that involve aggregation functions such as COUNT, SUM, AVG, MAX,MIN, and VARIANCE
v Queries that often create reports that group data by time, product, geography,customer set, or market
v Queries that involve star joins or snowflake joins of a large fact table withseveral dimension tables
Related concepts:“Analyze queries for acceleration” on page 4-7“Types of queries that are not accelerated” on page 1-8
Query Example: Quantity, revenue, and cost by itemThis example shows, for a given category, all of the items including quantity sold,revenue, and cost.SELECT ITEM_DESC,
SUM(QUANTITY_SOLD),SUM(EXTENDED_PRICE),SUM(EXTENDED_COST)
FROM PERIOD, DAILY_SALES,PRODUCT, STORE, PROMOTIONWHEREPERIOD.PERKEY=DAILY_SALES.PERKEY ANDPRODUCT.PRODKEY=DAILY_SALES.PRODKEY ANDSTORE.STOREKEY=DAILY_SALES.STOREKEY ANDPROMOTION.PROMOKEY=DAILY_SALES.PROMOKEY ANDCALENDAR_DATE BETWEEN ’2011/01/01’ AND ’2011/01/31’ ANDSTORE_NUMBER=01 ANDPROMODESC IN (’Advertisement’, ’Coupon’, ’Weekly Special’,
’Overstocked Items’) ANDCATEGORY=42
GROUP BY ITEM_DESC;
Query Example: Profit by storeThis example shows the profit by store for a given category on a given day.SELECT T1.STORE_NUMBER,T1.CITY,T1.DISTRICT,SUM(AMOUNT) AS SUM_PROFITFROM
(SELECT STORE_NUMBER,STORE.CITY,DISTRICT, EXTENDED_PRICE-EXTENDED_COSTFROM PERIOD, PRODUCT,STORE, DAILY_SALESWHERE
PERIOD.CALENDAR_DATE=3/1/2011 ANDPERIOD.PERKEY=DAILY_SALES.PERKEY ANDPRODUCT.PRODKEY=DAILY_SALES.PRODKEY ANDSTORE.STOREKEY=DAILY_SALES.STOREKEY ANDPRODUCT.CATEGORY=42 ) AS T1(STORE_NUMBER,CITY,DISTRICT,AMOUNT)
GROUP BY DISTRICT,CITY, STORE_NUMBERORDER BY DISTRICT,CITY, STORE_NUMBER DESC;
Query Example: Revenue by store for each brandThis example takes the revenue for each brand and calculates the revenue by store.
Products are grouped by store, current week, prior week, and prior month totals.SELECT STORE_NUMBER,
SUM(CASE WHEN ((CALENDAR_DATE >= 8/8/2010)AND (CALENDAR_DATE < 8/14/2010))
THEN EXTENDED_PRICE ELSE 0 END) AS CURR_PERIOD,SUM(CASE WHEN ((CALENDAR_DATE >= 8/1/2010)
AND (CALENDAR_DATE <= 8/7/2010))THEN EXTENDED_PRICE ELSE 0 END) AS PRIOR_WEEK,
SUM(CASE WHEN ((CALENDAR_DATE >= 7/1/2010)AND (CALENDAR_DATE <= 7/28/2010))
Chapter 1. Overview of Informix Warehouse Accelerator 1-7

THEN EXTENDED_PRICE ELSE 0 END) AS PRIOR_MONTHFROM PERIOD,PRODUCT,DAILY_SALES,STOREWHERE PRODUCT.PRODKEY=DAILY_SALES.PRODKEY
AND PERIOD.PERKEY=DAILY_SALES.PERKEYAND STORE.STOREKEY=DAILY_SALES.STOREKEYAND CALENDAR_DATE BETWEEN 7/1/2010 and 8/14/2010AND ITEM_DESC LIKE ’NESTLE%’
GROUP BY STORE_NUMBERORDER BY STORE_NUMBER;
Query Example: Week to day profitsThis example shows the week to day profits for a given category within region.SELECT FIRST 100 SUB_CATEGORY_DESC,
SUM(CASE REGION WHEN ’North’THEN EXTENDED_PRICE-EXTENDED_COST ELSE 0END) AS NORTHERN_REGION,
SUM(CASE REGION WHEN ’South’THEN EXTENDED_PRICE-EXTENDED_COST ELSE 0END) AS SOUTHERN_REGION,
SUM(CASE REGION WHEN ’East’THEN EXTENDED_PRICE-EXTENDED_COST ELSE 0END) AS EASTERN_REGION,
SUM(CASE REGION WHEN ’West’THEN EXTENDED_PRICE-EXTENDED_COST ELSE 0END) AS WESTERN_REGION,
SUM(CASE WHEN REGION IN (’North’, ’South’, ’East’, ’West’)THEN EXTENDED_PRICE-EXTENDED_COST ELSE 0END) as ALL_REGIONS
FROM PERIOD per, PRODUCT prd, STORE st, DAILY_SALES sWHERE
per.PERKEY=s.PERKEY ANDprd.PRODKEY=s.PRODKEY ANDst.STOREKEY=s.STOREKEY ANDper.CALENDAR_DATE BETWEEN ’07/01/2010’ AND ’09/30/2010’ANDCATEGORY<>88
GROUP BY SUB_CATEGORY_DESCORDER BY SUB_CATEGORY_DESC;
Types of queries that are not acceleratedThere are characteristics of queries that either will not benefit from being sent tothe accelerator, or will not be considered for acceleration.
Queries that will not benefit from being accelerated
Queries that only refer to a single, small dimension table do not benefit from beingsent to the accelerator for processing as much as queries that also refer to a facttable.
Queries that return a large result set should be processed by the database server toavoid the overhead of sending the large result set from the accelerator over theconnection to the database server. If a query returns millions of rows, the totalresponse time of the query is influenced by the maximum transfer rate of theconnection. For example, the following query might return a very large result set:SELECT * FROM fact_table ORDER BY sales_date;
Queries that search only a small number of rows of data should be processed bythe database server to avoid the overhead of sending the query to the accelerator.
Queries that are not considered for acceleration
There are some queries that will not be processed by the accelerator.
1-8 IBM Informix Warehouse Accelerator Administration Guide

Queries that would change the data cannot be processed by the accelerator andmust be processed by the database server. The data in the accelerator is a snapshotview of the data and is read only. There is no mechanism to change the data in thedata marts and replicate those changes back to the source database server.
Other queries that are not processed by the accelerator include queries that containINSERT, UPDATE, or DELETE statements, queries that contain subqueries, andother OLTP queries.Related concepts:“Queries that benefit from acceleration” on page 1-6
Supported data typesThe Informix Warehouse Accelerator supports specific data types.
The following data types are supported:v BIGINTv BIGSERIALv CHARv CHARACTERv CHARACTER VARYINGv DATEv DATETIME YEAR TO FRACTIONv DECIMALv DOUBLE PRECISIONv FLOATv INTv INT8v INTEGERv LVARCHARv MONEYv NUMERICv SMALLFLOATv SMALLINTv SERIALv SERIAL8v REALv VARCHAR
Supported functions and expressionsThe accelerator supports specific functions and expressions.
Aggregate functions and expressions
The following aggregate functions are supported by the accelerator:v AVGv STDEVv SUM
Chapter 1. Overview of Informix Warehouse Accelerator 1-9

v VARIANCE
User-defined functions
User-defined functions are not supported.
Scalar functions
The following scalar functions are supported by the accelerator:v ABSv ADD_MONTHSv CASEv CEILv CONCATv COUNTv DATEv DAYv DECODEv FLOORv LAST_DAYv LOWERv LPADv LTRIMv MAXv MINv MODv MONTHv MONTHS_BETWEENv NEXT_DAYv NVLv POWv POWERv RANGEv ROUNDv RPADv RTRIMv TRUNCv UPPERv WEEKDAY
Supported and unsupported joinsSpecific join types, join predicates, and join combinations are supported by theaccelerator.
1-10 IBM Informix Warehouse Accelerator Administration Guide

Supported joins
Equality join predicates, INNER joins, and LEFT OUTER joins are the supportedjoin types.
The fact table referenced in the query must be on the left side of the LEFT OUTERjoin.
Unsupported joins
The following joins are not supported:v RIGHT OUTER joinsv FULL OUTER joinsv Informix outer joinsv Joins that do not use an equality predicatev Subqueries
Software prerequisitesThere are separate software prerequisites for the Informix Warehouse Acceleratorand the administration interface, IBM Smart Analytics Optimizer Studio.
Informix Warehouse Accelerator must be installed on a computer that uses a LinuxIntel x86 64-bit operating system. Informix Warehouse Accelerator can be installedon the same computer as the Informix database server, on a separate computer, oron a cluster.
If you install the accelerator on a separate computer, then the Informix databaseserver must be installed on a computer that uses one of the following operatingsystems:v AIX® 64-bitv HP IA 64-bitv Solaris SPARC 64-bitv Linux Intel x86 64-bit
For a detailed list of the operating systems supported by the current version ofInformix and by other IBM Informix products, download the platform availabilityspreadsheet from http://www.ibm.com/software/data/informix/pubs/roadmaps.html. Search for the product name, or sort the spreadsheet by name.
The accelerator and database server on the same computer
You must have the following installed:v IBM Informix 11.70.xC2, or laterv A Linux Intel x86 64-bit operating systemv One of the supported Linux distributions: Red Hat Enterprise Linux (RHEL 5
update 3 or above) or SUSE Linux Enterprise Server (SLES 11). You might needto adjust the SHMMAX Linux Kernel parameter. SHMMAX is a shared memoryparameter that controls the maximum size, in bytes, of a shared memorysegment.
v Telnet client programv Expect utility (expect-5)
Chapter 1. Overview of Informix Warehouse Accelerator 1-11

v su command
The accelerator and database server on different computers
You must have the following installed on the Linux computer where theaccelerator is installed:v A Linux x86 64-bit operating system.v One of the supported Linux distributions: Red Hat Enterprise Linux (RHEL) 5 or
SUSE Linux Enterprise Server (SLES). You might need to adjust the SHMMAXLinux Kernel parameter. SHMMAX is a shared memory parameter that controlsthe maximum size, in bytes, of a shared memory segment.
v Telnet client programv Expect utility (expect-5)v su command
The accelerator installed on a cluster system
Following are additional requirements for installing the accelerator on a clustersystem:v You must have a shared-disk cluster file system. For example, IBM General
Parallel File System (GPFS™).v The user root must be able to connect to all cluster nodes using the Secure Shell
(SSH) network protocol without a password.v If user informix is used for accelerator administration, then user informix must
be able to connect to all cluster nodes using the Secure Shell (SSH) networkprotocol without a password.
The administration interface
You can install the administration interface, IBM Smart Analytics Optimizer Studio,on the same computer as the Informix database server or on a separate computer.
If you install the administration interface on a separate computer, that computercan use either Linux or Windows operating systems.Related concepts:“Hardware prerequisites”
Hardware prerequisitesMake certain that you have the appropriate hardware to support the InformixWarehouse Accelerator and the administration interface.
Informix Warehouse Accelerator can be installed on the same computer as theInformix database server, on a separate computer, or on a cluster.
You can install the administration interface on the same computer as the Informixdatabase server or on a separate computer.
Important: The accelerator caches compressed data in memory. It is essential thatthe computer where the accelerator is installed is configured with a large amountof memory.
1-12 IBM Informix Warehouse Accelerator Administration Guide

The computer on which you install Informix Warehouse Accelerator must have aCPU with the Streaming SIMD Extensions 3 (SSE3) instruction set. To verify whatis installed on the computer, you can run the cat /proc/cpuinfo command and lookat the flags that are returned.
For example, you can use the configuration that is shown in the following table:
Component Capacity / Size
System IBM System x3850 X5
Processor Intel Xeon CPU X7560 @ 2.26GHz (8-core)
Number of processors 4
Memory 512 GB
For additional information about the IBM System x3850 X5, see the specificationsat http://www.ibm.com/systems/x/hardware/enterprise/x3850x5/specs.html.
Hardware prerequisites for cluster configurations
Following are the hardware prerequisites if you install the accelerator on a clustersystem:v The number of CPUs and the amount of memory must be the same on each
cluster node.v You must have at least two cluster nodes. The maximum number of cluster
nodes is 256.Related concepts:“Software prerequisites” on page 1-11
Chapter 1. Overview of Informix Warehouse Accelerator 1-13

1-14 IBM Informix Warehouse Accelerator Administration Guide

Chapter 2. Accelerator installation
You can install Informix Warehouse Accelerator on the same computer as theInformix database server, on a separate computer, or on a cluster.
Important: Only one instance of Informix Warehouse Accelerator can be installedon a computer.
Informix Warehouse Accelerator includes an administration client called IBM SmartAnalytics Optimizer Studio. IBM Smart Analytics Optimizer Studio is anEclipse-based program. IBM Smart Analytics Optimizer Studio is included withInformix Warehouse Accelerator. You can install IBM Smart Analytics OptimizerStudio on the same computer as the accelerator or on a separate computer,including a Windows computer.
Before you install the accelerator, ensure that your computers meet the softwareand hardware prerequisites, and that you have decided which architecture youwant to implement.
Accelerator directory structureWhen you install and setup Informix Warehouse Accelerator there are severaldirectories that are needed.
Installation directory
The accelerator is installed in the directory that is specified by the INFORMIXDIRenvironment variable, if the variable is set in the environment in which theinstaller is launched. If the variable is not set, the default installation directory is/opt/IBM/informix. Whenever there is a reference to the file path for the acceleratorinstallation directory, the file path appears as $IWA_INSTALL_DIR.
Storage directory
The accelerator instance resides in its own directory, referred to as the acceleratorstorage directory. This directory stores the accelerator catalog, data marts, logs,traces, and so forth. You create this directory when you configure the accelerator.The file path for this directory is stored in the DWADIR parameter in thedwainst.conf file.
Administration interface directory
You specify the path to this directory when you install the administration interface.For example you might use $IWA_INSTALL_DIR/dwa_gui as the administrationinterface directory.
Sample directory for Java classes
The Java classes that are included with the command line sample are located in thedwa/example/cli directory.
Tip: Information about the Java classes is located in the dwa_java_reference.txtfile in the dwa/example/cli directory.
© Copyright IBM Corp. 2010, 2011 2-1

Documentation directory
Before you install the accelerator, you can access the accelerator documentation inthe following directories:v The Release Notes file is in the $IWA_ROOT_DIR/doc directoryv The Quick Start Guide is in the $IWA_ROOT_DIR/quickstart directory
After you install the accelerator, you can access the accelerator documentation inthe following directories:v The release notes file is in the $IWA_INSTALL_DIR/release/en_us/0333/doc
directoryRelated tasks:“Configuring the accelerator (non-cluster installation)” on page 3-1Related reference:“dwainst.conf configuration file” on page 3-3
Preparing the Informix database serverBefore you install the accelerator, you need to configure the database server.
To configure the Informix database server:1. Ensure that the user Informix has write access to the sqlhosts file and the
directory that the file is in.2. To use the administration interface, you must define a SOCTCP network
connection type in the $INFORMIXSQLHOSTS environment variable or in theONCONFIG file by using the NETTYPE configuration parameter.
3. If you do not already have a default sbspace created and configured, create thedefault sbspace:a. In the ONCONFIG file, set the SBSPACENAME parameter to the name of
your default sbspace. For example, to name the default sbspace sbsp1:SBSPACENAME sbspace1 # Default sbspace name
You must update the ONCONFIG file before you start the database server.b. Use the onspaces command to create the sbspace.
The following example creates an sbspace named sbspace1:onspaces -c -S sbspace1 -p $INFORMIXDIR/tmp/sbspace1 -o 0 -s 30000
Note: The size of the sbspace can be relatively small, for example between30 and 50 MB.
c. Restart the Informix database server.
2-2 IBM Informix Warehouse Accelerator Administration Guide

Related concepts:“Missing sbspace” on page 6-1Related tasks:
Setting up the sqlhosts file (UNIX) (Administrator's Guide)Related reference:
NETTYPE Configuration Parameter (Administrator's Reference)
Installing the acceleratorYou can use the graphical mode, console mode, or silent mode to install InformixWarehouse Accelerator.
Prerequisites
v You must have an Informix warehouse edition installed before you can installInformix Warehouse Accelerator.
v Only one instance of Informix Warehouse Accelerator can be installed on acomputer.
v If you are installing on a cluster system, ensure that the file paths for theInformix Warehouse Accelerator installation files are the same on each clusternode.
You can install Informix Warehouse Accelerator on the same computer as yourInformix database server, on a separate computer, or on a cluster system.
Informix Warehouse Accelerator is included in any warehouse edition of theInformix database server. You can install the accelerator from the providedinstallation media, or you can install it after you download a warehouse edition ofInformix from Passport Advantage®
1. On the computer where you want to run the Informix Warehouse Acceleratorinstallation program, log in as user root.
2. From the product media or the download site, locate the IBM Informixwarehouse edition bundle and unpack the iif.version.tar file.
3. Select the installation mode that you want to use:v For the graphical or console mode:
a. Issue the install command to start the installation program:
Installation mode Installation command
Graphical ./iwa_install -i gui
Console ./iwa_install -i console
b. Read the license agreement and accept the terms.c. Respond to the prompts in the installation program as the program
guides you through the installation.v For the silent mode:
a. Make a copy of the response file template that is located in the samedirectory as the Informix Warehouse Accelerator installation program. Thename of the template is iwa.properties.
b. In the response file change the value for license from FALSE to TRUE, toindicate that you accept the license terms. For example:DLICENSE_ACCEPTED=TRUE
Chapter 2. Accelerator installation 2-3

c. Issue the installation command for the silent mode. The command for thesilent mode installation is:./iwa_install -i silent -f "file_path"
Tip: Specify the absolute path for the response file.For example, to use the silent mode with a response file calledinstaller.properties that is located in the /usr3/iwa/ directory, thecommand is:./iwa_install -i silent -f "/usr3/iwa/installer.properties"
After you complete the installation, there are additional steps if you want to installthe administration interface.v The accelerator is installed in the directory that is specified by the
INFORMIXDIR environment variable, if the INFORMIXDIR environmentvariable is set in the environment in which the installer is launched. Otherwise,the default installation directory is /opt/IBM/informix.
v The configuration file, $IWA_INSTALL_DIR/dwa/etc/dwainst.conf, is generatedduring the installation. This configuration file is required to start the accelerator.
v The installation log file, $IWA_INSTALL_DIR/IBM_Informix_Warehouse_Accelerator_InstallLog.log, is generated during theinstallation. This log file provides information on the actions performed duringinstallation and success or failure status of those actions.
You must configure and start the accelerator before you can use it.Related tasks:“Installing the administration interface”Chapter 3, “Accelerator configuration,” on page 3-1“Uninstalling the accelerator” on page 2-5
Installing the administration interfaceYou can install the administration interface, IBM Smart Analytics Optimizer Studio,on the same computer as the Informix database server or on a separate computer.v You must have an Informix warehouse edition and Informix Warehouse
Accelerator installed before you can install the administration interface.v You must have write permission on the directory where you plan to install IBM
Smart Analytics Optimizer Studio.
To install the administration interface:1. Locate the IBM Smart Analytics Optimizer Studio installation programs. On the
computer where you unpacked the IBM Informix warehouse edition .tar file,the installation programs are in the IBM_Smart_Analytics_Optimizer_Suitedirectory. There is one installation program for Linux and UNIX computers,and another installation program for Windows computers. The names of theinstallation programs are:IBM_Smart_Analytics_Optimizer_Suite/install.binIBM_Smart_Analytics_Optimizer_Suite/install.exe
2. If you are installing the administration interface on a separate computer, youcan insert the provided media or FTP the installation program to the separatecomputer.
3. Run the installation program to install the administration interface. Theadministration interface is installed in the path that you specify in the installer,for example $IWA_INSTALL_DIR/dwa_gui.
2-4 IBM Informix Warehouse Accelerator Administration Guide

Tip: Linux and UNIX only - You can use the -i swing command for graphicalinstallation or the -i silent command for silent installation. The -i consolecommand is not supported.
4. Ensure that the interface opens without any errors.
After you complete the installation, open the directory where the administrationinterface is installed and run the ./datastudio command to start theadministration interface.
You must configure and start the accelerator before you can use it.Related tasks:“Installing the accelerator” on page 2-3Chapter 3, “Accelerator configuration,” on page 3-1“Uninstalling the accelerator”
Uninstalling the acceleratorIf you need to reinstall the accelerator or if you no longer want to use theaccelerator, you must uninstall the accelerator.
You must be logged on as user root to run the uninstaller.
To uninstall the accelerator:1. Stop the accelerator using the ondwa stop command.2. Uninstall the accelerator:
a.
b. Run the uninstaller program, uninstall_iwa, which is located in the$INFORMIXDIR/uninstall/uninstall_iwa/ directory
To reinstall the accelerator install the accelerator again. Then start the acceleratorusing the ondwa start command.Related tasks:“Installing the accelerator” on page 2-3“Installing the administration interface” on page 2-4Related reference:“ondwa start command” on page 3-11“ondwa stop command” on page 3-14
Chapter 2. Accelerator installation 2-5

2-6 IBM Informix Warehouse Accelerator Administration Guide

Chapter 3. Accelerator configuration
You must configure the accelerator to work with the Informix database server.
After you install Informix Warehouse Accelerator, there are several configurationsteps that you must complete before you can use the accelerator.1. “Configuring the accelerator (non-cluster installation)” or “Configuring the
accelerator (cluster installation)” on page 3-22. “Connecting the database server to the accelerator” on page 3-63. “Enabling and disabling query acceleration” on page 3-7Related tasks:“Installing the accelerator” on page 2-3“Installing the administration interface” on page 2-4
Configuring the accelerator (non-cluster installation)You must configure the Informix Warehouse Accelerator before you can enablequery acceleration and set up the connection between the accelerator and thedatabase server. Configure the accelerator by identifying the network interface,creating a storage directory, and editing the dwainst.conf configuration file.
Configuring the accelerator sets up the files and directories that you will need touse the accelerator:1. On the computer where the accelerator is installed, log on to the computer as
user root.2. Determine the correct network interface value to use for the connection from
the Informix database server to the accelerator.a. Run the Linux ifconfig system command to retrieve the information about
the network devices on your system.b. Review the output with your system administrator and network
administrator and select the appropriate value to use. Examples of networkinterface values are: eth0, lo, peth0. The default value is lo.
Note: If the accelerator is installed on a separate computer than theInformix database server, you cannot use the local loopback value.
3. Create a directory to use as the accelerator storage directory. Create this directorywith enough space to store the accelerator catalog, data marts, logs, traces, andso on. For example:$ mkdir $IWA_INSTALL_DIR/dwa/demo
Because the amount of data in the accelerator storage directory might increasesignificantly, do not create the accelerator storage directory in the acceleratorinstallation directory.You will specify the file path for this directory in the valuefor the DWADIR parameter in the dwainst.conf file.
4. Open the $IWA_INSTALL_DIR/dwa/etc/dwainst.conf configuration file. Reviewand edit the values in the “dwainst.conf configuration file” on page 3-3.
Important: Specify the network interface value for the DRDA_INTERFACEparameter in the dwainst.conf file.
© Copyright IBM Corp. 2010, 2011 3-1

5. Run the “ondwa setup command” on page 3-10 to create the files andsubdirectories that are required to run the accelerator instance.
6. Run the “ondwa start command” on page 3-11 to start all of the acceleratornodes.
Related concepts:“Accelerator directory structure” on page 2-1Related reference:“The ondwa utility” on page 3-9“ondwa setup command” on page 3-10“ondwa start command” on page 3-11“dwainst.conf configuration file” on page 3-3
Configuring the accelerator (cluster installation)You must configure the Informix Warehouse Accelerator before you can enablequery acceleration and set up the connection between the accelerator and thedatabase server. Configure the accelerator by identifying the network interface,creating a storage directory, editing the parameters in the dwainst.confconfiguration file, and creating a cluster.conf file. In a cluster system, onecoordinator node uses the first cluster node, and then each cluster node that youadd to the cluster becomes a worker node.
Prerequisite: Test that user root or user informix can run the Secure Shell (SSH)network protocol without a password between all cluster nodes.
Configuring the accelerator sets up the files and directories that you will need touse the accelerator.1. On one of the cluster nodes where the accelerator is installed, log on as user
root.2. Determine the correct network interface value to use for the connection from
the Informix database server to the accelerator.a. Run the Linux ifconfig system command to retrieve the information about
the network devices on your system.b. Review the output with your system administrator and network
administrator and select the appropriate value to use. Examples of networkinterface values are eth0 or peth0.
3. On the shared cluster file system, create a directory to use as the acceleratorstorage directory. The storage directory must be accessible with the same path onall cluster nodes. Create this directory with enough space to store theaccelerator catalog, data marts, logs, traces, and so on. For example:$ mkdir $IWA_INSTALL_DIR/dwa/demo
Because the amount of data in the accelerator storage directory might increasesignificantly, do not create the accelerator storage directory in the acceleratorinstallation directory.
4. Open the $IWA_INSTALL_DIR/dwa/etc/dwainst.conf configuration file. Reviewand edit the values in the “dwainst.conf configuration file” on page 3-3:a. For the DRDA_INTERFACE parameter, specify the network interface value
that you identified in step 2.b. For the DWADIR parameter, specify the file path for the storage directory
that you created in step 3. On all cluster nodes, the DWADIR parametermust be the same file path.
3-2 IBM Informix Warehouse Accelerator Administration Guide

c. For the CLUSTER_INTERFACE parameter, specify the network device namefor the connection between the cluster nodes. For example, eth0.
d. If only one coordinator node or one worker node will run on each clusternode, add the following additional parameters and values:CORES_FOR_SCAN_THREADS_PERCENTAGE=100CORES_FOR_LOAD_THREADS_PERCENTAGE=100CORES_FOR_REORG_THREADS_PERCENTAGE=25
5. In the $IWA_INSTALL_DIR/dwa/etc directory, create a file named cluster.conf tostore the cluster nodes’ host names or IP addresses. In the cluster.conf file,enter one cluster node per line. For example:node0001node0002node0003node0004
The order that you list the cluster nodes’ hosts names (or their IP addresses) isthe order that the cluster nodes are started or stopped with the ondwa startand ondwa stop commands.
6. Use the ondwa commands to set up and start the accelerator. You can run theondwa commands from any node in the cluster. The ondwa commands applyto all the nodes listed in the cluster.conf file.a. Run the “ondwa setup command” on page 3-10 to create the files and
subdirectories that are required to run the accelerator instance. Exampleoutput:Checking for DWA_CM_node0 on node0001: stoppedChecking for DWA_CM_node1 on node0002: stoppedChecking for DWA_CM_node2 on node0003: stoppedChecking for DWA_CM_node3 on node0004: stopped
b. Run the “ondwa start command” on page 3-11 to start all of the clusternodes. Example output:Starting DWA_CM_node0 on node0001: startedStarting DWA_CM_node1 on node0002: startedStarting DWA_CM_node2 on node0003: startedStarting DWA_CM_node3 on node0004: started
Related reference:“dwainst.conf configuration file”
dwainst.conf configuration fileThe dwainst.conf configuration file contains the parameters that are used toconfigure the accelerator.
The dwainst.conf configuration file is added to the $IWA_INSTALL_DIR/dwa/etcdirectory when you run the installation program for the Informix WarehouseAccelerator.
Open the dwainst.conf configuration file and edit the parameter values before yourun the ondwa setup command.
Important: After initial setup, if you update any of the parameters in thedwainst.conf configuration file, you must run the following ondwa commandsagain for the updated parameters to take effect:v ondwa stop
v ondwa reset
v ondwa setup
Chapter 3. Accelerator configuration 3-3

v ondwa start
The dwainst.conf file contains the following parameters.
Table 3-1. Parameters in the dwainst.conf file
Parameter Description Guidance
CLUSTER_INTERFACE For cluster installations: Thenetwork device name for theconnection between thecluster nodes.
Common examples are eth0,eth1, or eth2.
COORDINATOR_SHM The shared memory on thecoordinator node.
You can specify the value asa percentage, such as .70, ora value in Megabytes.
The total of the sharedmemory on the coordinatornode and worker nodesshould not exceed the freememory on the computerwhere the accelerator isinstalled.Tip: The coordinator nodedoes not need as muchshared memory as theworker nodes. A valuebetween 5 to 10 % of thetotal memory set aside forthe accelerator is a goodestimate for this parameter.
CORES_FOR_LOAD_THREADS_PERCENTAGE
Used in cluster installations. If only one coordinator nodeor one worker node will runon each cluster node, set thisvalue to 100.
CORES_FOR_REORG_THREADS_PERCENTAGE
Used in cluster installations. If only one coordinator nodeor one worker node will runon each cluster node, set thisvalue to 25.
CORES_FOR_SCAN_THREADS_PERCENTAGE
Used in cluster installations. If only one coordinator nodeor one worker node will runon each cluster node, set thisvalue to 100.
DRDA_INTERFACE The network device namethat you will use for theconnection from the Informixdatabase server to theaccelerator.
The default value is lo.
Ask your systemadministrator and networkadministrator which networkinterface to use for theDRDA_INTERFACE value.
If the accelerator is installedon a separate computer thanthe Informix database server,you cannot use the localloopback value.
DWADIR The name and file path foraccelerator storage directory.
Create the directory first andthen specify the directory inthe dwainst.conf file.Note: Specify the directorybefore you run the ondwasetup command.
3-4 IBM Informix Warehouse Accelerator Administration Guide
Table 3-1. Parameters in the dwainst.conf file (continued)
Parameter Description Guidance
NUM_NODES The number of nodes(DWA_CM processes)
The number of acceleratornodes should not overloadthe computer where theaccelerator is installed.
The number of worker nodesis the value of theNUM_NODES parameter - 1.
START_PORT The starting port number forthe coordinator node and theworker nodes.
The accelerator instanceassigns the port numbersthat immediately follow thestarting port number to thecoordinator node and theworker nodes. These portnumbers should not alreadybe used by other processes.
Each accelerator node needsto be configured with fourdifferent port numbers.Beginning with the startingport number, the nodes areassigned incremental portnumbers. For example, ifyour instance has five nodesand you specify theSTART_PORT number as21020, the acceleratorinstance will use ports 21020– 21039 because each nodeuses four port numbers.
WORKER_SHM The shared memory on theworker nodes. This value isthe total shared memory,combined, on all the workernodes.
You can specify the value asa percentage, such as .70, ora value in Megabytes.
The combined total sharedmemory on the workernodes and the coordinatornode should not exceed thefree memory on thecomputer where theaccelerator is installed.Tip: The data marts, with alltheir data in the compressedformat, must fit into theshared memory on theworker nodes. Plan on usingapproximately two-thirds ofthe total memory for theaccelerator as worker nodesshared memory.
The following example shows parameters and their values in a dwainst.confconfiguration file:DWADIR=$IWA_INSTALL_DIR/dwa/demoSTART_PORT=21020NUM_NODES=2WORKER_SHM=500COORDINATOR_SHM=250DRDA_INTERFACE="eth0"
Chapter 3. Accelerator configuration 3-5

Related concepts:“Accelerator directory structure” on page 2-1“Memory issues for the coordinator node and the worker nodes” on page 6-1Related tasks:“Configuring the accelerator (non-cluster installation)” on page 3-1“Configuring the accelerator (cluster installation)” on page 3-2Related reference:“ondwa setup command” on page 3-10
Connecting the database server to the acceleratorSet up the connection between the Informix database server and the acceleratorand using the ondwa getpin command to retrieve the IP address, port number,and PIN from the accelerator. You then use the IBM Smart Analytics OptimizerStudio to create the connection to the database server.1. On the computer where the accelerator is installed, log on as user root.2. Run the “ondwa getpin command” on page 3-13 to retrieve the IP address, port
number, and PIN from the accelerator. This information is needed to establishthe initial connection from the Informix database server to the accelerator.
3. On the computer where the IBM Smart Analytics Optimizer Studio is installed,start the administration interface:v On Linux and UNIX, open the directory where the administration interface is
installed and run the ./datastudio command. When the administrationinterface is installed on the same computer as Informix, the directory is$IWA_INSTALL_DIR/dwa_gui.
v On Windows, select Start > Programs > IBM Smart Analytics OptimizerStudio 1.1
4. In the Workspace Launcher window you can use the default workspace, selectan existing workspace, or create a new workspace:v The file path and name of default workspace appears in the Workspace
drop-down box. To accept the default workspace, click OK.v To select an existing workspace, choose a workspace from the drop-down list
and click OK.v To create a new workspace, click Browse. Navigate to the directory location
where you want to create the workspace and click Make New Folder. Typethe name for the workspace and click OK. Then click OK again.
5. The first time a workspace is created, a Welcome screen appears. Close theWelcome screen. The newly created blank workspace appears.
6. Add the accelerator and connect to the Informix database server:a. In the Data Source Explorer window, open the Database Connections folder.b. Create a new connection. You must use the Informix JDBC driver for the
connection.
Restriction: The Informix Warehouse Accelerator does not support usingthe IBM Data Server Driver for JDBC for the connection between Informixand the accelerator.
c. To add a new accelerator to the database, right-click on the DatabaseConnection folder. Right-click on the Accelerators folder and choose AddAccelerator.
3-6 IBM Informix Warehouse Accelerator Administration Guide

d. Using the information you gathered in Step 2 on page 3-6, type the nameand pairing information for the accelerator. In the Pairing code field, typethe PIN number.
e. Click OK.
A connection between the accelerator and the database server is established,and the sqlhosts file on the Informix database server is updated with theconnection information. An example of the sqlhosts file is:FLINS2 group - - c=1,
a=4b3f3f457d5f552b613b4c587551362d2776496f226e714d75217e22614742677b424224FLINS2_1 dwsoctcp 127.0.0.1 21022 g=FLINS2
7. Use the SET EXPLAIN statement to see the query plan. If the query isaccelerated, the Remote SQL Request section appears in the query plan. Forexample:QUERY: (ISAO-Executed)(OPTIMIZATION TIMESTAMP: 02-20-2011 01:05:57)
------select sum(units) from salesfact
Estimated Cost: 242522Estimated # of Rows Returned: 1Maximum Threads: 0
1) sk@FLINS2:dwa.aqt0f957100-cca1-406b-93cc-cae2117122ae:
Remote SQL Request:{QUERY {FROM dwa.aqt0f957100-cca1-406b-93cc-cae2117122ae}{SELECT {SUM {SYSCAST COL10 AS BIGINT} } } }
QUERY: (ISAO-FYI) (OPTIMIZATION TIMESTAMP: 02-20-2011 01:05:57)------select sum(units) from salesfact
Estimated Cost: 242522Estimated # of Rows Returned: 1Maximum Threads: 0
1) informix.salesfact: SEQUENTIAL SCAN
Query statistics:-----------------
Table map :----------------------------Internal name Table name----------------------------
type rows_prod est_rows time est_cost-------------------------------------------------remote 1 0 00:00.00 0
Enabling and disabling query accelerationBefore queries can be routed to the accelerator for processing, you must update thedatabase server statistics and set several session variables.1. On the Informix database server, run the UPDATE STATISTICS LOW statement.
The Informix query optimizer uses the statistics when evaluating a query to
Chapter 3. Accelerator configuration 3-7

determine the fact table in the query. If the fact table in the query is not the facttable in the AQT, the query is sent to Informix for processing
Tip: Run the statistics again if the distribution of the data in the databasechanges.
2. Set the PDQPRIORITY session variable. This variable needs to be set so that a starjoin plan is considered by the optimizer and the right fact table is chosen.
3. Set the use_dwa session variable. Setting this variable enables the Informixquery optimizer to consider using the accelerator to process the query when theoptimizer generates the query plans. If the variable is set to use_dwa ’0’ or isnot set at all, queries are not accelerated. You can specify that the variable is setautomatically or you can set the variable manually:v To have this variable set when you connect to the Informix database, add the
use_dwa session variable to the sysdbopen() stored procedure on yourInformix database server. Specifying the variable in the procedure will avoidchanging your applications or recompiling.
v To set the use_dwa variable manually, from the Informix database client setthe use_dwa session variable. For example:SET ENVIRONMENT use_dwa ’1’;
Valid values are:
Value Action Description
0 Turns acceleration OFF. Queries are not sent to theaccelerator even if thequeries meet the requiredcriteria.
The default value for theuse_dwa variable is ’0’.
1 Turns acceleration ON. Thisis the recommended setting.
Queries that match one ofthe accelerated query tables(AQTs) are sent to theaccelerator for processing.
3 Turns acceleration ON andsends debugging informationto a LOG file.
Queries that match one ofthe accelerated query tables(AQTs) are sent to theaccelerator for processing.Debugging information issaved to the Informixmessage log file.
The following example shows the information in the log file:14:08:54 Explain file for session 281 : /work3/andreasb/test.new/sqexplain.out14:08:54 Identified one candidate AQT for matching.14:08:54 Trying to match query with AQT aqta77d004f-7fc1-444e-87d6-380aef1617fd14:08:54 select MIN(s_suppkey)from par14:08:54 AQT aqta77d004f-7fc1-444e-87d6-380aef1617fd is a potential syntacticalmatch for query.14:08:54 Successfully generated query plan to offload query to AQTaqta77d004f-7fc1-444e-87d6-380aef1617fd14:08:55 Matching succesful. Took 383 ms.
3-8 IBM Informix Warehouse Accelerator Administration Guide

Related concepts:
The query plan (Performance Guide)
Statistics held for the table and index (Performance Guide)Related reference:
Configure session properties (Administrator's Guide)
PDQPRIORITY environment variable (SQL Reference)
The ondwa utilityUse the ondwa utility is to set up and work with the Informix WarehouseAccelerator instance.
Prerequisites
The ondwa utility is a Bash shell script. Because the accelerator is supported onlyon Linux operating systems, the ability to run Bash shell scripts is built into theoperating system. The following prerequisites must be installed on the machinewhere you installed the accelerator:v Telnet client programv Expect utilityv su command
The ondwa utility directory
The ondwa utility is located in the $IWA_INSTALL_DIR/bin directory.
Running the ondwa utility in a cluster system
If you have installed Informix Warehouse Accelerator on a cluster system, you canrun the ondwa command from any cluster node. The ondwa command will run onall cluster nodes listed in the $IWA_INSTALL_DIR/dwa/etc/cluster.conf file.Related tasks:“Configuring the accelerator (non-cluster installation)” on page 3-1
Users who can run the ondwa commandsEither user root or user informix can run the ondwa commands. To run the ondwacommands as user informix requires setup steps. It is recommended that youdetermine which user will run the ondwa commands and to use the same userconsistently.
To run ondwa commands as user informix, the following restrictions apply:v The directory specified in the DWADIR parameter in the dwainst.conf file must
be owned by user informix.v If you have a DWA_watchdog.log file, it must be writable for user informix. The
DWA_watchdog.log file is in the directory specified by the DWADIR parameter.v The following shell soft and hard limits must be set to unlimited prior to
running ondwa commands. For example, you can use the built-in Linux Bashshell ulimit command to change the resource availability.
Chapter 3. Accelerator configuration 3-9

Table 3-2. Resources that must be set to unlimited for user informix to run ondwacommands.
Resource Bash sell ulimit command
max locked memory ulimit -l
max memory size ulimit -m
virtual memory ulimit -v
If you installed Informix Warehouse Accelerator on a cluster system with userinformix, you can set the following equivalent parameters to unlimited in the/etc/security/limits.conf file on each cluster node:
memlockmax locked-in-memory address space
rss max resident set size
as address space limit
For example:informix soft memlock unlimitedinformix hard memlock unlimitedinformix soft rss unlimitedinformix hard rss unlimitedinformix soft as unlimitedinformix hard as unlimited
ondwa setup commandThe ondwa setup command creates the files and subdirectories that are required torun an accelerator instance.
To run this command, you must log on to the computer as either user root or asuser informix. To run the command as user informix, your Linux administratormust make specific memory resources available. See “Users who can run theondwa commands” on page 3-9.
Usage:$ ondwa setup
The ondwa setup command uses a file named dwainst.conf in the$IWA_INSTALL_DIR/dwa/etcdirectory to configure the accelerator instance.
Using the dwainst.conf file, the ondwa setup command creates the followingstructure in the accelerator storage directory:v The directory shared between the accelerator nodes (shared)v The directory containing the accelerator node private directories (local)v For each accelerator node:
– The accelerator node private directory: local/node– The accelerator node configuration file: node.conf– A link to the DWA_CM executable file: DWA_CM_node
The ondwa utility automatically determines the role of the coordinator node or aworker node. The first node is the coordinator node, whereas the remaining nodesare worker nodes. The number of worker nodes is determined by the followingcalculation: NUM_NODES - 1.
3-10 IBM Informix Warehouse Accelerator Administration Guide

Tip: If you have the accelerator installed on the same symmetric multiprocessing(SMP) system as your Informix database server, edit the dwainst.conf file andchange the NUM_NODES to 5. This will generate one coordinator node and fourworker nodes on the accelerator.
Each accelerator node needs to be configured with four different port numbers.These port numbers are listed in the configuration file for the accelerator node. Thestarting port number is taken from the dwainst.conf file, and incremented in turn.For example, if your instance has five accelerator nodes and you specify theSTART_PORT number as 21020, the accelerator instance will use ports 21020 –21039 because each accelerator node uses four port numbers.
When a accelerator node is started, the corresponding link to the accelerator binaryDWA_CM_node is used. The ondwa setup command creates a symbolic link foraccelerator each node to the DWA_CM binary. The link makes it easier to find theprocesses of your accelerator instance in a ps output because the ps commandshows the symbolic links and not the DWA_CM binary itself.Related tasks:“Configuring the accelerator (non-cluster installation)” on page 3-1Related reference:“ondwa start command”“dwainst.conf configuration file” on page 3-3
ondwa start commandThe ondwa start command starts all of the accelerator nodes. If the accelerator isinstalled on a cluster system, and if some of the cluster nodes are stopped, theondwa start command starts the offline cluster nodes.
To run this command, you must log on to the computer as either user root or asuser informix. To run the command as user informix, your Linux administratormust make specific memory resources available. See “Users who can run theondwa commands” on page 3-9.
Usage:$ ondwa start
The output of a accelerator node is recorded in the log file for the node, forexample: node0.log, node1.log, and so forth. These files are located in theaccelerator storage directory. After the ondwa start command has finished, youraccelerator instance is ready to use.
After you run ondwa start, you should run the ondwa status command to checkthat status of the accelerator.
Chapter 3. Accelerator configuration 3-11

Related tasks:“Uninstalling the accelerator” on page 2-5“Configuring the accelerator (non-cluster installation)” on page 3-1Related reference:“ondwa setup command” on page 3-10“ondwa status command”
ondwa status commandThe ondwa status command shows information about the status of the acceleratornodes, the cluster status, and the expected node count.
To run this command, you must log on to the computer as either user root or asuser informix. To run the command as user informix, your Linux administratormust make specific memory resources available. See “Users who can run theondwa commands” on page 3-9.
Usage:$ ondwa statusID | Role | Cat-Status | HB-Status | Hostname | System ID---+-------------+------------+-----------+----------+------------0 | COORDINATOR | ACTIVE | Healthy | leo | 11 | WORKER | ACTIVE | Healthy | leo | 2Cluster is in state : Fully OperationalExpected node count : 1 coordinator and 1 worker nodes
If one accelerator node is shut down, the status shows:$ ondwa statusID | Role | Cat-Status | HB-Status | Hostname | System ID---+-------------+-------------+-----------+----------+------------0 | COORDINATOR | ACTIVE | Healthy | leo | 11 | WORKER | DEACTIVATED | Shutdown | leo | 2Cluster is in state : RecoveringExpected node count : 1 coordinator and 1 worker nodes
The following example output shows the status of a cluster system:ID | Role | Cat-Status | HB-Status | Hostname | System ID-----+-------------+-------------+--------------+------------------+------------0 | COORDINATOR | ACTIVE | Healthy | node0001 | 11 | WORKER | ACTIVE | Healthy | node0002 | 22 | WORKER | ACTIVE | Healthy | node0003 | 33 | WORKER | ACTIVE | Healthy | node0004 | 4
Cluster is in state : Fully OperationalExpected node count : 1 coordinator and 3 worker nodes
Columns in ondwa status command output
The Cat-Status column shows the status of all nodes in the accelerator catalog.The Cat-Status column can have one of the following values:
ACTIVEThe accelerator node is active. For a cluster system, ACTIVE indicates thatthe cluster node participates in the cluster.
DEACTIVATEDThe accelerator node is shut down or the accelerator is not running.
FAILOVERA failed accelerator node that was set in ERROR state.
3-12 IBM Informix Warehouse Accelerator Administration Guide

The HB-Status (heartbeat status) column can have one of the following values:
InitializingThe accelerator node is initializing and loading data into memory.
HealthyThe initialization is complete and the accelerator node is ready for queries.
QuiescePendThe accelerator node is waiting to go into a quiesced state.
QuiescedThe accelerator node is in a quiesced state.
ResumingThe accelerator node is resuming after a quiesced or a maintenance state.
MaintenanceThe accelerator node is in maintenance state.
MaintPendThe accelerator node is waiting to go into a maintenance state.
MissingThe accelerator node has a missing heartbeat.
ShutdownThe accelerator node is shutting down.
Related reference:“ondwa start command” on page 3-11
ondwa getpin commandThe ondwa getpin command retrieves the IP address, port number, and PIN thatare required for Informix to connect to your accelerator instance.
To run this command, you must log on to the computer as either user root or asuser informix. To run the command as user informix, your Linux administratormust make specific memory resources available. See “Users who can run theondwa commands” on page 3-9.
Usage:$ ondwa getpin
The following shows examples of the values that are returned:127.0.0.1 21022 1234
ondwa tasks commandThe ondwa tasks command shows information about that tasks that are currentlyrunning, memory used, and resources.
To run this command, you must log on to the computer as either user root or asuser informix. To run the command as user informix, your Linux administratormust make specific memory resources available. See “Users who can run theondwa commands” on page 3-9.
Usage:$ ondwa tasks
TaskManager tracking 2 task(s):
Chapter 3. Accelerator configuration 3-13

------------------+--------------------+---------+---------+--------+------------Task 316822777484 (of type ’QUERY’ with name Query execution @ coordinator - 0:00)------------------+--------------------+---------+---------+--------+------------Location | Status | Progr. | Upd. ms | Memory | Monitor------------------+--------------------+---------+---------+--------+------------Primary Node 0 | OPNQRY | 0 | 10 | 17K | Fine
-> Node 1 | Fact | 0 | 3 | 22M | Fine(Total Memory) | | | | 22M |------------------+--------------------+---------+---------+--------+------------Used Resources | Mart ID: 2 on node 0------------------+--------------------+---------+---------+--------+------------Task 437785070080 (of type ’DAEMON’ with name DRDADaemon - 4:48)------------------+--------------------+---------+---------+--------+------------Location | Status | Progr. | Upd. ms | Memory | Monitor------------------+--------------------+---------+---------+--------+------------Primary Node 0 | Running | 2 | 30 | 0 | Fine(Total Memory) | | | | 0 |------------------+--------------------+---------+---------+--------+------------Used Resources | DRDA device: ’lo’ address: ’127.0.0.1:21022’ on node 0
| Unbound on node 0------------------+--------------------+---------+---------+--------+------------- End of Tasklist -
ondwa stop commandThe ondwa stop command stops the accelerator instance.
To run this command, you must log on to the computer as either user root or asuser informix. To run the command as user informix, your Linux administratormust make specific memory resources available. See “Users who can run theondwa commands” on page 3-9.
Usage:$ ondwa stop
$ ondwa stop -f
The ondwa stop action ends when all of the DWA_CM_* processes on youraccelerator instance are completed.
Use the -f option to stop the full set of DWA_CM processes. Use this option if theondwa stop action is not able to shut down one or more of the processes.Related tasks:“Uninstalling the accelerator” on page 2-5
ondwa reset commandThe ondwa reset command removes all of the files from the accelerator storagedirectory that were created by the accelerator instance under the shared andlocal/* subdirectories.
To run this command, you must log on to the computer as either user root or asuser informix. To run the command as user informix, your Linux administratormust make specific memory resources available. See “Users who can run theondwa commands” on page 3-9.
Important: Before using this command, you must drop all data marts on theaccelerator.
Usage:
3-14 IBM Informix Warehouse Accelerator Administration Guide

$ ondwa reset
The ondwa reset command also removes all of the entries of your acceleratorinstance under the /dev/shm directory.
This command does not remove the log files for the accelerator node and the filescreated by the ondwa setup command. After you run the ondwa reset command,you can initialize the accelerator instance by using the ondwa start command.
ondwa clean commandThe ondwa clean command cleans the accelerator instance directory.
To run this command, you must log on to the computer as either user root or asuser informix. To run the command as user informix, your Linux administratormust make specific memory resources available. See “Users who can run theondwa commands” on page 3-9.
Important: Before using this command, all of the data marts must be dropped onthe accelerator and the accelerator instance must be removed from the computer.
Usage:$ ondwa clean
The ondwa clean command removes the following files and directories:v All of the files created by the ondwa setup commandv The complete shared and local directory trees in the accelerator storage directoryv The log files for the accelerator node
After you run the ondwa clean command, you can run the ondwa setup commandto set up the accelerator instance again.
Chapter 3. Accelerator configuration 3-15

3-16 IBM Informix Warehouse Accelerator Administration Guide

Chapter 4. Accelerator data marts and AQTs
For efficient query processing, the Informix Warehouse Accelerator must have itsown copy of the data. The data is stored in logical collections of related data, ordata marts.
A data mart specifies the collection of tables that are loaded into an accelerator andthe relationships, or references, between these tables.
Before the data mart can be created, information about the tables used by yourwarehouse queries must be assembled into a data mart definition.
A data mart definition is an XML file that contains information about the data mart.The information includes the tables and columns within the table that are includedin the data mart. The information also specifies how the tables and columns arerelated to each other. The XML file that contains the data mart definition does notcontain any actual user data.
When a data mart is created, information about the data mart is sent to theInformix database server in the form of a special view referred to as an acceleratedquery table or AQT.
The information in the AQTs is used by the database server to determine whichqueries can be processed by the accelerator. The database server attempts to matcha query with an AQT.
Creating data martsAfter you configure the accelerator instance and set up the connection between theaccelerator and the database server, you need to create the data marts.
A data mart is an object in the accelerator and is actually created when youcomplete the step to deploy the data mart. When you load the data mart, the datamart is filled with the actual user data. The query optimizer can then use the datamart when the optimizer generates the query access plans.
Before the data mart can be created, information about the tables used by yourwarehouse queries must be assembled into a data mart definition.
The key tasks in creating data marts are:1. Designing effective data marts2. Creating data mart definitions. There are several methods you can use to create
the data mart definitions:v “Creating data mart definitions by using the administration interface” on
page 4-8This method is a good choice when you have detailed knowledge about theschema of the database and the queries that applications are sending to thedatabase server.
v “Creating data mart definitions by using workload analysis” on page 4-10This method is a good choice when you are not familiar with the databaseschema and the application queries, or when your database schema has a
© Copyright IBM Corp. 2010, 2011 4-1

very large number of tables. The data mart definitions are created after yourun a series of statements, stored procedures, and functions that analyze yourschema and queries.
3. “Deploying a data mart” on page 4-204. “Loading data into data marts” on page 4-21Related tasks:“Creating data mart definitions by using the administration interface” on page 4-8“Creating data mart definitions by using workload analysis” on page 4-10
Designing effective data martsPlanning is an essential part of creating data marts that are effective at acceleratingqueries.
Before you create the data marts, you should learn more about data marts, AQTs,queries that are accelerated, and analyze your query workload.1. Understand how data marts are created from your fact tables and dimension
tables.2. Understand how AQTs work with the Optimizer to accelerate queries.3. Determine the query workload that should be accelerated. If you do not know
which queries you want to accelerate, you can identify the queries that havethe longest elapsed time or cause the highest CPU cost by following thesesteps:a. On the computer where the Informix database server is installed, log on as
user informix.b. Enable the SQLTRACE configuration parameter in the onconfig file in the
$INFORMIXDIR/etc directory. For example:SQLTRACE level=high,ntraces=1000,size=4,mode=global
Or you can activate SQLTRACE by using the SQL Administration APIFunctions. For example:EXECUTE FUNCTION task("set sql tracing on","1500","4","high","global");
c. Restart the database server to activate the configuration parameters.d. Run the query workload.e. Review the results of the workload by using one of the following methods:
v Run the onstat -g his commandv Use information from the syssqltrace table in the sysmaster database. For
example in dbaccess run this SQL statement:SELECT sql_runtime, sql_statement FROM syssqltraceWHERE sql_stmtname matches "SELECT" ORDER BY sql_runtime DESC
4. Analyze the queries that you want to accelerate.5. From the query information, exclude the OLTP queries. Analyze the remaining
queries to determine which columns in the dimension tables are being used bythe queries.
6. If you have large dimension tables, identify specific columns in the tables toload into the data mart instead of loading all of the columns from each table.
4-2 IBM Informix Warehouse Accelerator Administration Guide

Related reference:
Enable SQL tracing (Administrator's Guide)
set sql tracing argument: Set global SQL tracing (SQL administration API)(Administrator's Reference)
EXPLAIN_STAT Configuration Parameter (Administrator's Reference)
SQLTRACE Configuration Parameter (Administrator's Reference)
Data martsFor efficient query processing, the Informix Warehouse Accelerator must have itsown copy of the data. The data is stored in logical collections of related data, ordata marts.
A data mart specifies the collection of tables that are loaded into an accelerator andthe relationships, or references, between these tables. Typically, the data martscontain a subset of the tables in your database. The data marts can also contain asubset of the columns within a table.
To improve query processing, limit the number of dimension tables, and columnswithin the dimension tables, in the data mart. By identifying only those columnsthat are necessary to respond to your queries.
However, the data marts do not need to be a duplication of the design of yourwarehouse fact and dimension tables. For example, you can designate a dimensiontable in your warehouse schema as a fact table in a data mart.
When you create a data mart you use the accelerator administrator interface tospecify the fact table, the dimension tables, and the references between the tables.
A newly created data mart has all of the necessary structures defined but is emptyand must be filled with a snapshot of the data from the Informix database server.When the data from the database server is loaded in the data mart on theaccelerator, the data is compressed. After the data is loaded in the data mart, thedata mart becomes operational.
Data marts must be based on a snowflake or star schema
The following figure shows a sample schema with two fact tables, DAILY_SALESand DAILY_FORECAST. These fact tables are linked to several dimension tables:STORE, CUSTOMER, PROMOTION, PERIOD, and PRODUCT. There are severalkey references in the fact tables that are used to link to the dimension tables. Forexample in the DAILY_SALES fact table, the PRODKEY column is linked to thePRODKEY column in the PRODUCT dimension table.
Chapter 4. Accelerator data marts and AQTs 4-3

Using the schema in Figure 4-1, you can create two data marts. The first data martis based on the DAILY_SALES fact table and the dimension tables that it links to,as shown in Figure 4-2 on page 4-5. A second data mart is based on theDAILY_FORECAST fact table and the dimension tables that it links to, as shown inFigure 4-3 on page 4-6.
PERKEY
PRODKEY
STOREKEY
CUSTKEY
PROMOKEY
QUANTITY_SOLDEXTENDED_PRICEEXTENDED_COSTSHELF_LOCATIONSHELF_NUMBERSTART_SHELF_DATESHELF_HEIGHTSHELF_WIDTH…
DAILY_SALESfact table
DAILY_FORECASTfact table
PERKEY
STOREKEY
PRODKEY
QUANTITY_FORECASTEXTENDED_PRICE_FORECASTEXTENDED_COST_FORECAST
STORE
STOREKEY
STORE_NUMBERCITYSTATEDISTRICTREGION
CUSTOMER
CUSTKEY
NAMEADDRESSC_CITYC_STATEZIPPHONEAGE_LEVEL…
PROMOTION
PROMOKEY
PROMOTYPEPROMODESCPROMOVALUEPROMOVALUE2PROMO_COST
PRODUCT
PRODKEY
BRANDKEY
PRODLINEKEY
UPC_NUMBERP_PRICEP_COSTITEM_DESCPACKAGE_TYPECATEGORYSUB_CATEGORYPACKAGE_SIZE…
PERIOD
PERKEY
CALENDAR_DATEWEEKWEEK_ENDING_DATEMONTHPERIODYEARHOLIDAY_FLAG…
Figure 4-1. A sample star schema with two fact tables
4-4 IBM Informix Warehouse Accelerator Administration Guide
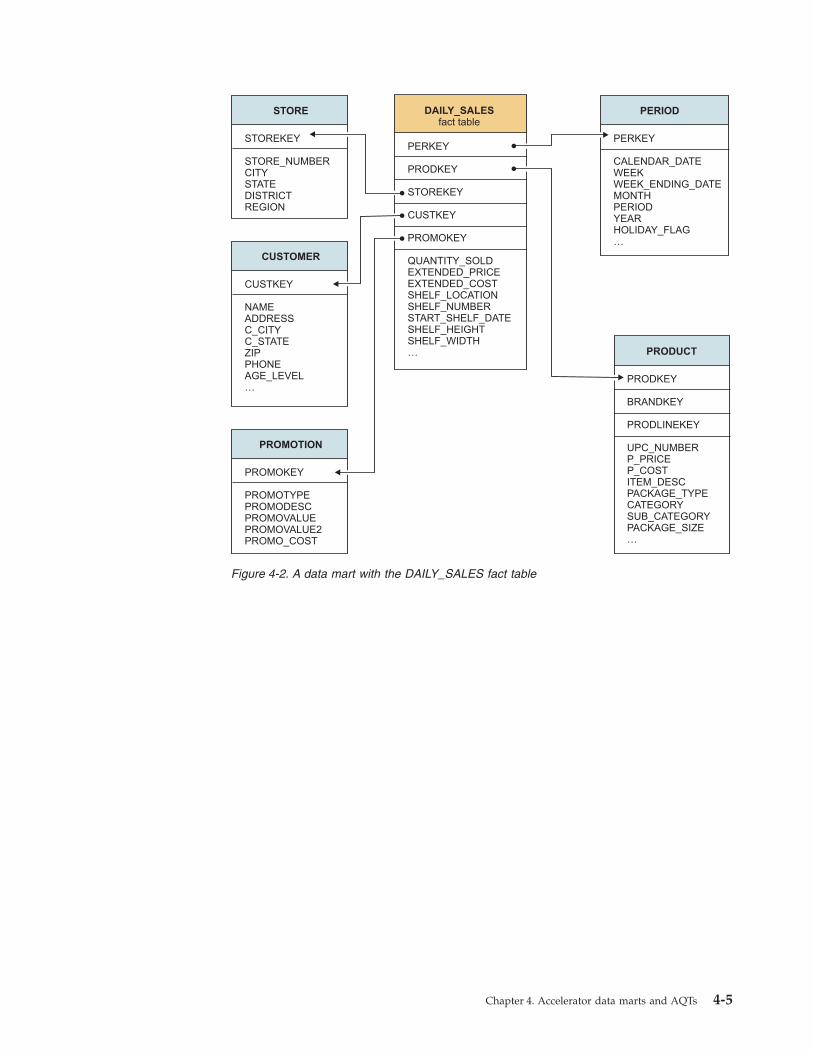
PERKEY
PRODKEY
STOREKEY
CUSTKEY
PROMOKEY
QUANTITY_SOLDEXTENDED_PRICEEXTENDED_COSTSHELF_LOCATIONSHELF_NUMBERSTART_SHELF_DATESHELF_HEIGHTSHELF_WIDTH…
DAILY_SALESfact table
STORE
STOREKEY
STORE_NUMBERCITYSTATEDISTRICTREGION
CUSTOMER
CUSTKEY
NAMEADDRESSC_CITYC_STATEZIPPHONEAGE_LEVEL…
PROMOTION
PROMOKEY
PROMOTYPEPROMODESCPROMOVALUEPROMOVALUE2PROMO_COST
PRODUCT
PRODKEY
BRANDKEY
PRODLINEKEY
UPC_NUMBERP_PRICEP_COSTITEM_DESCPACKAGE_TYPECATEGORYSUB_CATEGORYPACKAGE_SIZE…
PERIOD
PERKEY
CALENDAR_DATEWEEKWEEK_ENDING_DATEMONTHPERIODYEARHOLIDAY_FLAG…
Figure 4-2. A data mart with the DAILY_SALES fact table
Chapter 4. Accelerator data marts and AQTs 4-5

Summary or aggregate tables in data marts
To summarize the granular data in the fact tables and dimension tables, sometimesother tables are created which are referred to as summary tables or aggregate tables.For example, a summary table might contain sales information for an entire monthor quarter that is consolidated from fact and dimension tables.
One reason to use summary tables is to improve query performance by queryingthe summary table instead of the underlying fact and dimension tables.
Because Informix Warehouse Accelerator is designed to significantly speed upquery processing, it is not necessary for you to use summary tables to improvequery performance. Using Informix Warehouse Accelerator you can query the facttable and dimension tables directly and still experience improvements in queryperformance.
Tip: If you want to query a summary table and use the accelerator, you mustinclude the summary table in the data mart.
Accelerated query tablesWhen a data mart is created, information about the data mart is sent to thedatabase server in the form of a special view referred to as an accelerated query tableor AQT.
DAILY_FORECASTfact table
PERKEY
STOREKEY
PRODKEY
QUANTITY_FORECASTEXTENDED_PRICE_FORECASTEXTENDED_COST_FORECAST
STORE
STOREKEY
STORE_NUMBERCITYSTATEDISTRICTREGION
PRODCUT
PRODKEY
BRANDKEY
PRODLINEKEY
UPC_NUMBERP_PRICEP_COSTITEM_DESCPACKAGE_TYPECATEGORYSUB_CATEGORYPACKAGE_SIZE…
PERIOD
PERKEY
CALENDAR_DATEWEEKWEEK_ENDING_DATEMONTHPERIODYEARHOLIDAY_FLAG…
Figure 4-3. A data mart with the DAILY_FORECAST fact table
4-6 IBM Informix Warehouse Accelerator Administration Guide

The information stored in the catalog tables of the Informix database server is thesame information that is stored in the catalog tables for other types of views.
The information in the AQTs is used by the database server to determine whichqueries can be processed by the accelerator. The database server attempts to matcha query with an AQT. If a query matches an AQT, the query is sent to theaccelerator.
There can be many AQTs. If the first AQT is not able to satisfy a query, then thesearch for a match continues until the query has been checked against all of theAQTs. If a match is found, the query is sent to the accelerator for processing. If nomatch is found, the query is processed by Informix.
To be sent to the accelerator, the query must meet the following criteria:v The query must refer to a subset of the tables in the AQT.v The table references, or joins, specified in the query must be the same as the
references in the data mart definition.v The query must include only one fact table.v The query must have an INNER JOIN or LEFT JOIN with the fact table on the
left dominant side.v The scalar and aggregate functions in the query must be supported by the
accelerator.
A data mart can be in different states such as: LOAD PENDING, ENABLED,DISABLED. The associated AQTs reflect the basic states to facilitate correct querymatching and have only two states: active and inactive.
When the administrator drops a data mart from the accelerator, the associatedAQTs are removed automatically from the database server.Related concepts:“Analyze queries for acceleration”
Analyze queries for accelerationBy analyzing your queries you will have a better understanding of which queriescan be accelerated.
If a query matches an AQT, the query is sent to the accelerator. This process iscalled acceleration. The results are then returned from the accelerator to Informix.Different types of queries are more or less suitable for acceleration. Knowing thecharacteristics of these query types helps to understand which queries are eligiblefor offloading and which queries are not.
Although you do not need to redesign your queries to use the accelerator,understanding why some queries are not accelerated will help you design yourqueries to take advantage of the accelerator.
Consideration Description
Does the query reference only the tables andcolumns that are included in the data martdefinition?
Only queries that include the supported datatypes are loaded into the accelerator.
Does the query reference a table that ismarked as a fact table in the data martdefinition?
Chapter 4. Accelerator data marts and AQTs 4-7

Consideration Description
Is the query a long-running analytical queryand not a transactional query that shouldnot be processed by the accelerator? Forexample, a query that returns only a fewrows by using a selective condition on anindexed column.
Does the query use only supported jointypes?
Do the join sequence and the join predicatesof the query match the definition of theaccelerated query table (AQT)?
Equality join predicates, INNER joins, andLEFT OUTER joins are the supported jointypes.
The fact table referenced in the query mustbe on the left side of the LEFT OUTER join.
You need to know the joins that aresupported and unsupported.
Does the query use only supportedaggregate and scalar functions?
Only queries that include the supportedfunctions are sent to the accelerator forprocessing.
Related concepts:“Accelerated query tables” on page 4-6“Queries that benefit from acceleration” on page 1-6
Creating data mart definitions by using the administrationinterface
Use the IBM Smart Analytics Optimizer Studio to create the data mart definitionswhen you are familiar with the database schema and the application queries thatare sent to the database server.
The administration interface estimates how large the data mart might become anddetermines if there is sufficient space on the accelerator for the proposed datamart.
To create a data mart definition using the administration interface, use thefollowing steps:1. On the computer where the IBM Smart Analytics Optimizer Studio is installed,
start the administration interface:v On UNIX, open the $IWA_INSTALL_DIR/dwa_gui directory and run the
./datastudio command.v On Windows, select Start > Programs > IBM Smart Analytics Optimizer
Studio 1.1
2. Create a new accelerator project. Right-click the Accelerators folder and selectNew Accelerator or choose File > New > Accelerator project.
3. Use the New Data Mart wizard to create a data mart definition. Choose File >New > Data Mart to start the New DataMart Wizard. The New Data Martwizard uses the existing database connection to read the catalog tables in thedatabase and to retrieve information about the objects in the database, such asthe tables, constraints, and so on. The wizard uses this information to createresources in the workspace on your computer.
4. Add database tables to the data mart definition.v A single data mart definition can have a maximum of 255 tables or 750
columns
4-8 IBM Informix Warehouse Accelerator Administration Guide

v If you add a table to your data mart definition that includes a data typecolumn that is not supported, you must remove that column from the datamart definition
5. Create references, or joins, between tables in the data mart definition (ifnecessary).
6. Designate the fact table for the data mart definition.7. Specify the table columns to load into the accelerator. Select the table in the
Canvas and look at the Properties view. Click on the Columns page to view alist of the columns in that table. By default all of the columns in the table areincluded in the data mart. Uncheck the columns that you do not wantincluded.
8. Check the size of a data mart definition before it is deployed. You can comparea size estimate of the data mart definition with the memory that is available onyour accelerator. If necessary, you can change the join type of table referencesor omit specific columns that are rarely or never needed to reduce requiredmemory.
9. Validate the integrity of the data mart definition. Ensure that the syntax andstructure of a data mart definition are correct and that the data mart can besafely deployed to the accelerator.
After you create the data mart definition, you need to deploy and load data intothe data mart.Related tasks:“Creating data marts” on page 4-1“Deploying a data mart” on page 4-20
Specify references in data martsA reference is a join between two database tables that indicates how the tables inthe data mart are related to each other.
One-to-many joins
A one-to-many join connects the columns of a primary key, unique constraint orunique, nonnullable index of the parent table with columns of the child table. Anyrow or tuple in the child table is related to a maximum of one row or tuple in theparent table. If the table has a primary key, the corresponding key columns areselected automatically. You can override this automatic selection by selectinganother unique constraint or unique index.
If the parent table does not have a primary key, select one of the unique keys. Atleast one unique constraint or unique nonnullable index is required, otherwise theone-to-many reference cannot be created.
Important: One-to-many joins lead to a better query performance thanmany-to-many joins. If one of the tables that you want to use has a uniqueconstraint, unique index, or primary key on the join columns, use a one-to-manyjoin.
Many-to-many joins
In a many-to-many join, one or more columns of the parent table are joined withan equal number of columns in the child table. The values of these columns do nothave to be unique and you do not have to enforce uniqueness through theselection of a constraint. This means that any row or tuple in the child table can
Chapter 4. Accelerator data marts and AQTs 4-9

relate to multiple tuples in the parent table.
Join tables at run-time:
When you specify that the tables are joined at run time, the tables are joined in thesystem memory of the accelerator when the query is run.
Runtime joins require less system memory to hold the data mart.
Fact table for the data martTypical queries against a data mart join the fact table with the dimension tablesand group information by a specific criteria.
When you specify the tables to use for the data mart, the administrator interfaceautomatically identifies the fact table in the warehouse on the Informix databaseserver. The fact table is partitioned across the worker nodes of the data warehouseaccelerator to reach a maximum degree of parallel processing.
The fact table for the data mart does not necessarily need to be the fact table in thewarehouse that you created on the Informix database server.
By default, the largest table that you identify for the data mart is designated as thefact table by the administrator interface. However, you can specify any table that ispart of a star or snowflake schema as the fact table for a data mart.
Creating data mart definitions by using workload analysisUse this method to create data marts when you are not familiar with the databaseschema and the application queries, or when your database schema contains manytables.v To use workload analysis, the database must be a local database of the server
that you are connected to.v A default smart blob space must exist.
Workload analysis involves two main steps, query probing and data analysis.Query probing is gathering information about your query workload. The probingdata and database schema are then analyzed and the end result is a data martdefinition.
To create a data mart definition by using workload analysis, use the followingsteps:1. Connect to the database that contains the data warehouse tables.2. Update database statistics using the LOW option to generate a minimum
amount of statistics for the database. For example UPDATE STATISTICS LOW.Query probing needs to determine the fact table of a query. If paralleldatabase query (PDQ) is active, you can specify the fact table with the FACToptimizer directive. If the FACT optimizer directive is not set, and for innerjoin queries, the fact table is identified as the table with the most number ofrows.
3. Enable query probing. Run the following command to activate query probingfor the current user session:SET ENVIRONMENT use_dwa ’probe start’;
You can run this command through an application or with the sysdbopen()procedure.
4-10 IBM Informix Warehouse Accelerator Administration Guide

4. Optional. You can enable SQL tracing. With SQL tracing on, you can identifythe probing data that resulted from a specific SQL statement because eachquery statement is assigned an individual number, a statement ID.
SQL Tracing Results
On You can identify specific statements, forexample statements that took a certainlength of time to process, or statements thataccessed specific tables. With thatinformation, you can include the probingdata that resulted from only thesestatements in the mart definition.
Off (default setting) The probing data is collected into one singleset of data. When you create the data martdefinition, the entire set of probing datamust be used.
To turn SQL tracing on, use the following steps:a. On the computer where the Informix database server is installed, log on as
user informix.b. Enable the SQLTRACE configuration parameter in the onconfig file in the
$INFORMIXDIR/etc directory. For example:SQLTRACE level=low,ntraces=1000,size=4,mode=global
Or you can activate SQLTRACE by using the SQL Administration APIFunctions. For example:EXECUTE FUNCTION task("set sql tracing on","1000","4","low","global");
c. If you changed the onconfig file, restart the database server to activate theconfiguration parameter.
5. Optional. To run the query probing more quickly, issue the SET EXPLAIN ONAVOID_EXECUTE statement before you run your query workload. When youissue this statement, the queries are optimized and the probing data iscollected, but a result set is not determined or returned.
Important: If you want to process the probing data based on the runtime ofthe queries then turn on SQL tracing and do not use the AVOID_EXECUTEoption of the SET EXPLAIN statement. If you avoid running the queries, youwill not know how long it takes to really run the queries.
6. Run the query workload. The probing data is stored in memory.7. If you want to view the SQL trace information about the workload, use one of
the following methods:v Run the onstat -g his command.v Use information from the syssqltrace table in the sysmaster database. For
example, in dbaccess run this SQL statement:SELECT sql_runtime, sql_statement FROM syssqltraceWHERE sql_stmtname matches "SELECT" ORDER BY sql_runtime DESC
8. If you want to view the probing data, use one of the following methods:v Run the onstat -g probe command.v Query the system monitoring interface (SMI) pseudo tables that contain
probing data.9. Create a separate logging database. Even though your warehouse database
might be configured for logging, you should create a separate database. Thisseparate database is used to store the data mart definition.
Chapter 4. Accelerator data marts and AQTs 4-11

10. Convert the probing data into a data mart definition using the probe2mart()stored procedure. You can create a data mart definition from all of the probingdata or from the data from specific queries (if SQL tracing is ON).
11. Use the genmartdef() function to generate the data mart definition. Thisfunction returns a CLOB that contains the data mart definition in XML format.Store the data mart definition in a file.
12. Import the file into the administration interface.a. On the computer where the IBM Smart Analytics Optimizer Studio is
installed, start the administration interface:v On UNIX, open the $IWA_INSTALL_DIR/dwa_gui directory and run the
./datastudio command.v On Windows, select Start > Programs > IBM Smart Analytics
Optimizer Studio 1.1
b. Create a new accelerator project. Right-click on the Accelerators folder andselect New Accelerator or choose File > New > Accelerator project.
c. Right-click on the new accelerator project in the Project Explorer window.Select Import. The value Data Mart Import is selected by default. ClickNext.
d. Locate the generated file. Verify that Import into existing project and thename of the current project is selected. Click Finish.
After you create the data mart definition, you need to deploy and load data intothe data mart.Related tasks:“Creating data marts” on page 4-1“Deploying a data mart” on page 4-20Related reference:
UPDATE STATISTICS statement (SQL Syntax)
Star-Join Directives (SQL Syntax)“Contents of query probing data” on page 4-18“The probe2mart stored procedure” on page 4-18Appendix B, “Sysmaster interface (SMI) pseudo tables for query probing data,” onpage B-1
Example: Create data mart definitions using workload analysisUse this step-by-step example as a guide when you create data mart definitionsusing workload analysis.
This example uses the stores_demo database that is created by the commanddbaccessdemo.
The workload is from the following query:SELECT {+ FACT(orders)} first 5 fname,lname,sum(ship_weight)
FROM customer c,orders oWHERE c.customer_num=o.customer_numand state=’CA’ and ship_date is not nullGROUP BY 1,2ORDER BY 3 desc;
The query selects the names of the top five customers from the state CA and thetotal ship weight of their already shipped orders. The query is an inner join. Theorders table is the fact table. The customer table is the dimension table. Since the
4-12 IBM Informix Warehouse Accelerator Administration Guide

orders table has fewer rows than the customer table, the {+ FACT(orders)}optimizer hint is required. Otherwise the customer table would be considered asthe fact table.
The following commands correspond to steps in the task “Creating data martdefinitions by using workload analysis” on page 4-10.
The SQL statements used in this example were executed using dbaccess, and areprompted by ">". Commands executed from the shell are prompted by "$".
Step 1: Connect to the database
Connect to the database. This example uses the stores_demo database:> connect to ’stores_demo’;Connected.
Step 2: Update statistics
Update the statistics on the database:> update statistics low;Statistics updated.
Step 3: Start probing
Set the environment variable to activate probing:> SET ENVIRONMENT use_dwa ’probe start’;Environment set.
Step 4: Optional - Enable SQL tracing
In a separate session, connect as user informix to the sysadmin database andactivate SQL tracing:> execute function task("set sql tracing on","1500","4","low", "global");(expression) SQL Tracing ON: ntraces=1500, size=4056, level=Low,mode=Global.1 row(s) retrieved.
Step 5: Optional - Skip running the query workload
When you issue this statement, the queries are optimized and probed but a resultset is not determined or returned.
Important: If you want to process the probing data based on the runtime of thequeries, then turn on SQL tracing and do not use the AVOID_EXECUTE option ofthe SET EXPLAIN statement. If you avoid running the queries, you will not knowhow long it takes to really run the queries.> set explain on avoid_execute;Explain set.
Step 6: Run the query workload
Using this example, the SQL statements are:> SELECT {+ FACT(orders)} first 5 fname,lname,sum(ship_weight)
FROM customer c,orders oWHERE c.customer_num=o.customer_num and state=’CA’and ship_date is notnull
Chapter 4. Accelerator data marts and AQTs 4-13

GROUP BY by 1,2ORDER BY by 3 desc;fname lname (sum)
No rows found.
The reason no rows are returned in this example is that the SET EXPLAIN ONAVOID_EXECUTE statement has been used.
Step 7: Optional - View the SQL trace information
You can use the onstat command or query the SMI tables to view the SQL traceinformation.
To use the onstat command:$ onstat -g his
IBM Informix Dynamic Server Version 11.70.FC3 -- On-Line -- Up 00:53:06 --182532 Kbytes
Statement history:
Trace Level LowTrace Mode GlobalNumber of traces 1500Current Stmt ID 2Trace Buffer size 4056Duration of buffer 42 SecondsTrace Flags 0x00001611Control Block 0x4dd51028
Statement # 2: @ 0x4dd51058
Database: 0x100153Statement text:select {+ FACT(orders)} first 5 fname,lname,sum(ship_weight)from customer c,orders owhere c.customer_num=o.customer_num and state=’CA’ andship_date is not null group by 1,2 order by 3 desc
Statement information:Sess_id User_id Stmt Type Finish Time Run Time TX Stamp PDQ51 29574 SELECT 10:39:09 0.0000 33f4e 0
Statement Statistics:Page Buffer Read Buffer Page Buffer WriteRead Read % Cache IDX Read Write Write % Cache0 0 0.00 0 0 0 0.00
Lock Lock LK Wait Log Num Disk MemoryRequests Waits Time (S) Space Sorts Sorts Sorts0 0 0.0000 0.000 B 0 0 0
Total Total Avg Max Avg I/O Wait Avg RowsExecutions Time (S) Time (S) Time (S) IO Wait Time (S) Per Sec1 0.0000 0.0000 0.0000 0.000000 0.000000 678122.8357
Estimated Estimated Actual SQL ISAM Isolation SQLCost Rows Rows Error Error Level Memory10 2 0 0 0 NL 25304
To query the SMI tables to view the SQL trace information:
4-14 IBM Informix Warehouse Accelerator Administration Guide

> SELECT sql_id,sql_runtime, sql_statementFROM sysmaster:syssqltraceWHERE ql_stmtname=’SELECT’ORDER BY sql_runtime desc;
sql_id 2sql_runtime 1.47450285e-06sql_statement select {+ FACT(orders)} first 5 fname,lname,sum(ship_weight)
from customer c,orders o where c.customer_num=o.customer_numand state=’CA’ and ship_date is not null group by 1,2 order by 3 desc
Step 8: Optional - View the probing data
To see the data that was gathered from running the query workload, you can runan onstat command or query the SMI tables.
To use the onstat -g probe command:$ onstat -g probe
DWA probing data for database stores_demo:
statement 2:columns: tabid[colno,...]
100[1,2,3,8]102[3,7,8] f
joins: tabid[colno,...] = tabid[colno,...] (type) {u:unique}102[3] = 100[1] (inner) u
Output description:v Statement 2 accesses tables: the customer table with tabid 100 and the orders
table with tabid 102v In the customer table, columns 1, 2, 3, and 8 are accessedv In the orders table, columns 3, 7, and 8 are accessedv The orders table is the fact tablev Column 3 in the orders table is joined with column 1 in the customers tablev The join is an inner joinv The customers table has a unique index on column 1
You can verify that the probing data was gathered by connecting to the sysmasterdatabase and querying the SMI tables:> SELECT * FROM sysprobetables;
dbname stores_demosql_id 2tabid 100fact n
dbname stores_demosql_id 2tabid 102fact y
2 row(s) retrieved.
> SELECT * FROM sysprobecolumns;
dbname stores_demosql_id 2tabid 100colno 1
Chapter 4. Accelerator data marts and AQTs 4-15

dbname stores_demosql_id 2tabid 100colno 2
dbname stores_demosql_id 2tabid 100colno 3
dbname stores_demosql_id 2tabid 100colno 8
dbname stores_demosql_id 2tabid 102colno 3
dbname stores_demosql_id 2tabid 102colno 7
dbname stores_demosql_id 2tabid 102colno 8
7 row(s) retrieved.
> SELECT * FROM sysprobejds;
dbname stores_demosql_id 2jd 1ctabid 102ptabid 100type iuniq y
1 row(s) retrieved.
> SELECT * FROM sysprobejps;
dbname stores_demosql_id 2jd 1jp 1ccolno 3pcolno 1
1 row(s) retrieved.
Step 9: Create a logging database
The stores_demo database is not a logging database. A different database isrequired to store the data mart information generated by running the probe2mart()stored procedure:> CREATE DATABASE stores_marts WITH LOG;Database created.
4-16 IBM Informix Warehouse Accelerator Administration Guide

Step 10: Run the probe2mart () stored procedure
Connect to the logging database stores_marts and run the stored procedure:$ dbaccess stores_marts -> execute procedure probe2mart(’stores_demo’,’orders_customer_mart’);Routine executed.
Step 11: Run the genmartdef() function and store the result in a file
Connect to the logging database stores_mart, where the probing data that wasgenerated by the probe2mart stored procedure is stored:$ dbaccess stores_marts -> execute function lotofile(genmartdef(’orders_customer_mart’),’orders_customer_mart.xml!’,’client’);(expression) orders_customer_mart.xml1 row(s) retrieved.
To view the contents of the data mart definition file:$ cat orders_customer_mart.xml<?xml version="1.0" encoding="UTF-8" ?><dwa:martModel xmlns:dwa="http://www.ibm.com/xmlns/prod/dwa" version="1.0">
<mart name="orders_customer_mart"><table name="customer" schema="informix" isFactTable="false" >
<column name="customer_num"/><column name="fname"/><column name="lname"/><column name="state"/>
</table><table name="orders" schema="informix" isFactTable="true" >
<column name="customer_num"/><column name="ship_date"/><column name="ship_weight"/>
</table><reference
referenceType="LEFTOUTER"isRuntimeJoin="true"parentCardinality="1"dependentCardinality="n"dependentTableSchema="informix"dependentTableName="orders"parentTableSchema="informix"parentTableName="customer"><parentColumn name="customer_num"/><dependentColumn name="customer_num"/>
</reference></mart>
</dwa:martModel>
Step 12: Import the file into a project in the administration interface
The detailed instructions for importing the file into the administration interface arealready documented in the task.
Alternatively, you can also use the Java classes that are included with theaccelerator to deploy and load the data mart.
To deploy the data mart:$ java createMart <accelerator name> orders_customer_mart.xml
To load the data mart:$ java loadMart <accelerator name> orders_customer_mart NONE
Chapter 4. Accelerator data marts and AQTs 4-17

See the dwa_java_reference.txt file in the dwa/example/cli/ directory for moreinformation about these sample Java classes.
Contents of query probing dataThe query probing data contains a set of records when SQL tracing is used, or asingle record when SQL tracing is not used.
Each record is identified by a statement ID. A record contains:v The database name the user was connected tov A list of tables, identified by their table id (tabid)v A list of columns for each table, identified by their column number (colno)v A list of references between each pair of tables, also known as the join
descriptorsv A list of column pairs for each join descriptor, also known as the join predicates
A join predicate in the probing data corresponds to an equality join predicatebetween columns of different tables in the query. For example:table_1.col_a = table_2.col_x
A join descriptor is comprised of:v All of the join predicates of the same pair of tables. For example:
table_1.col_a = table_2.col_x andtable_1.col_b = table_2.col_y andtable_1.col_c = table_2.col_z
v The type of the join - an inner join or left outer join.v Information about any unique indexes on the dimension table of the join. The
dimension table is the right table in case of a left outer join. The unique indexmust be on the complete set of columns contained in this join descriptor.
Related tasks:“Creating data mart definitions by using workload analysis” on page 4-10
The probe2mart stored procedureThe probe2mart stored procedure is used to convert the data that is gathered fromprobing into a data mart definition.
Syntax
The syntax of the stored procedure is:
�� probe2mart ( ' database ' , ' mart_name ' ) ;, sqlid
��
databaseThe name of the database that contains the data warehouse. This is thewarehouse database on which the workload queries are run. See Usage.
mart_nameThe name that you want to use for the data mart definition. The name isalso the name of the data mart that is created later, based on the data martdefinition. If the name you specify is an existing data mart definition, theprobing data is merged into the already existing data mart definition. If thedata mart definition you specify does not exist, the data mart definition iscreated.
sqlid Optional. The ID of the query SQL statement, which identifies the probing
4-18 IBM Informix Warehouse Accelerator Administration Guide

data from that query. If the sqlid is not provided, all of the probing datafrom the specified database is added to the data mart definition.
Usage
The probe2mart stored procedure should be run from a different database than thewarehouse database. This separate database must be a logging database. You canuse a test database, if the test database is already a logging database, or you cancreate a different database that keeps these tables separated from your other tables.
Note: Create a separate logging database to use with the probe2mart storedprocedure. Using a separate makes it much easier to revert from Informix 11.70 toan earlier version of Informix.
When the stored procedure is run, the probing data is processed and stored in thelogging database in a set of permanent tables.
The tables keep the data mart definition in a relational format. The tables areautomatically created when the probing data is processed into a data martdefinition for the first time.
The probe2mart stored procedure creates a data mart definition by converting theprobing data and inserting rows into the following tables.
Table 4-1. Tables created by the probe2mart stored procedure
Table Description
'informix'.iwa_marts Names of the data mart definitions
'informix'.iwa_tables All of the tables used in any data martdefinition
'informix'.iwa_columns All columns used in any data martdefinition
'informix'.iwa_mtabs Tables for a specific data mart definition
'informix'.iwa_mcols Columns for a specific data mart definition
'informix'.iwa_mrefs References (join descriptors) of a specificdata mart definition
'informix'.iwa_mrefcols Reference columns (join predicates) of aspecific data mart definition
Examples
To convert, or merge, all of the probing data into a data mart definition, use thisform of the syntax:EXECUTE PROCEDURE probe2mart(’database’, ’mart_name’);
For example, to generate a data mart definition named salesmart from all ofprobing data that is available for the database sales, use this statement:EXECUTE PROCEDURE probe2mart(’sales’, ’salesmart’);
You can also merge the probing data from a specific query into a data martdefinition. You need to look up the SQL ID number of the query which wascaptured by SQL tracing. SQL tracing must be ON to designate data from specificqueries. Queries are identified by a statement ID.
Chapter 4. Accelerator data marts and AQTs 4-19

For example, to merge the probing data from SQL statement 8372 into the datamart definition salesmart, run this command:EXECUTE PROCEDURE probe2mart(’sales’, ’salesmart’, 8372);
To create a data mart definition from queries that run longer than 10 seconds, usethis SQL statement:SELECT probe2mart(’sales’,’salesmart’,sql_id)
FROM sysmaster:syssqltraceWHERE sql_runtime > 10;
Related tasks:“Creating data mart definitions by using workload analysis” on page 4-10Related reference:Chapter 5, “Reversion requirements for an Informix warehouse edition server andInformix Warehouse Accelerator,” on page 5-1
The genmartdef() functionThe genmartdef() function returns a CLOB that contains the data mart definition inan XML format.
Syntax
The syntax of the function is:genmartdef(’mart name’);
You can either issue the genmartdef() function by itself, or incorporate it as aparameter within the LOTOFILE() function. Using the genmartdef() function withthe LOTOFILE() function places the CLOB into an operating system file.
Examples
Use the genmartdef() function as a parameter within the LOTOFILE() function:EXECUTE FUNCTION LOTOFILE(genmartdef(’salesmart’),
’salesmart.xml!’,’client’));
The following example generates the data mart definition for salesmart. Theresulting CLOB is used as a parameter within the LOTOFILE() function. TheLOTOFILE() function stores the resulting CLOB in an operating system file namedsalesmart.xml on the client computer.SELECT lotofile(genmartdef(’salesmart’),’salesmart.xml!’,’client’)
FROM iwa_marts WHERE martname=’salesmart’;
Related reference:
LOTOFILE Function (SQL Syntax)
Deploying a data martWhen a data mart is initially deployed, the data mart is in the LOAD PENDINGstate and is disabled until you load data into the data mart.
As part of creating a data mart definition, IBM Smart Analytics Studio estimatesthe amount of space required for the data mart and the data mart definition isvalidated.
When you use the administration interface to deploy the data mart, the data martdefinition is imported from an XML file into an accelerator project in the IBMSmart Analytics Optimizer Studio.
4-20 IBM Informix Warehouse Accelerator Administration Guide

1. On the computer where the IBM Smart Analytics Optimizer Studio is installed,start the administration interface:v On UNIX, open the$IWA_INSTALL_DIR/dwa_gui directory and run the
./datastudio command.v On Windows, select Start > Programs > IBM Smart Analytics Optimizer
Studio 1.1
2. You can deploy the data mart from either the Data Source Explorer or from theProperties view of the data mart.
Related tasks:“Loading data into data marts”“Creating data mart definitions by using the administration interface” on page 4-8“Creating data mart definitions by using workload analysis” on page 4-10
Loading data into data martsWhen you load a data mart, the related data is unloaded from the Informix tablesand transferred to the accelerator.
When data is loaded into the data mart, it is enabled automatically and is in theActive state. You can disable or enable a loaded data mart to switch the queryacceleration for the data mart on or off.
For most data marts, the data is gathered from several different Informix tables.
Important: Loading data into a data mart can take several hours, depending onthe size and the amount of data that is contained in the tables.
To load the data into the data marts:1. On the computer where the IBM Smart Analytics Optimizer Studio is installed,
start the administration interface:v On UNIX, open the$IWA_INSTALL_DIR/dwa_gui directory and run the
./datastudio command.v On Windows, select Start > Programs > IBM Smart Analytics Optimizer
Studio 1.1
2. You can start the load process from either the Data Source Explorer or from theProperties view of the data mart.
3. Right-click on the data mart and select Load.4. Choose the level of consistency that you want for the loaded data by specifying
a value for the locking parameter for the data load. The values that you canchoose from are:
Option Description
NONE No locking is done during the load. Thedata is read from the different tables similarto a dirty read. Other user sessions canchange the data during the load operation.As a result the loaded data might beinconsistent.
The data inconsistencies might be acceptableif the primary goal of the data mart is tocreate statistics and discover trends ratherthan to find the exact values of specific datarows.
Chapter 4. Accelerator data marts and AQTs 4-21

Option Description
TABLE Each table is locked for the duration it takesto gather the load data from the table. Theloaded data is consistent within each table,but not necessarily across different tables.
MART All of the tables in the data mart are lockedfor the duration of the load. The loaded datais consistent from all of the tables. However,all of the other user sessions are blockedfrom changing the data in the tables that areinvolved in the load.
Related tasks:“Deploying a data mart” on page 4-20
Refreshing the data in a data martBy creating a new data mart, you can refresh the data in the Informix WarehouseAccelerator while queries are being accelerated. You do not need to suspend queryacceleration in order to drop and re-create the original data mart.
Prerequisite: Confirm that you have enough memory to create the new data mart.During the load phase, you need approximately twice as much memory as theoriginal data mart has. You can drop the original data mart after the new datamart has successfully loaded.
To refresh the data-mart data that is used by the accelerator, create a new datamart. As soon as the new data mart is loaded, the database server uses the newdata mart for matching new queries to AQTs. New candidate queries that are sentto the accelerator will use the new data mart.
Use either IBM Smart Analytics Optimizer Studio or the Java classes that areincluded with the accelerator to create and load the new data mart. The new andold data marts must have the same data mart definition, but different names.
In this example, datamart_1 has been loaded and sent to the accelerator forprocessing. The data for datamart_1 has changed. You want any new queries thatare sent to the database server to use the new data.1. Create a data mart that has the same definition as datamart_1, but name the
data mart datamart_2.2. Load datamart_2. When the data loading for datamart_2 completes, the
accelerator will use datamart_2 with the refreshed data for incoming queries.3. Disable datamart_1.4. Optional: Drop datamart_1. If multiple data marts use the same tables,
Informix will use latest data mart to accelerate the queries.
4-22 IBM Informix Warehouse Accelerator Administration Guide

Related concepts:“Updating the data in a data mart”Related tasks:“Creating data marts” on page 4-1
Updating the data in a data martWhen you want to update the data in a data mart with the most recentinformation in your database, you can drop and deploy the same data mart again.You cannot update the data in a data mart directly.
You can drop and deploy the same data mart again, for example, if you do nothave a enough memory to refresh the data in the Informix Warehouse Acceleratorwhile queries are being accelerated.
Fast path: Instead of using the Administrator interface to redeploy the data mart,you can deploy the data mart directly from an XML file. The advantage is that theentire process to deploy requires only one step and you do not need a local copyof the data mart definition in your IBM Smart Analytics Optimizer Studioworkspace. When you deploy a data mart, the XML file is created. You can savethe XML file on your computer. If you forget to save the XML file locally, you canretrieve the file from the Informix Warehouse Accelerator only if the data martdefinition has not been deleted from the accelerator. You must retrieve a copy ofthe XML file before the data mart is dropped.Related tasks:“Refreshing the data in a data mart” on page 4-22
Drop a data martYou can drop a data mart if you no longer need the data mart or if you need toupdate the data in a data mart.
The data mart can be dropped from either the Data Source Explorer folder or theProperties view in the administrator interface.
Handling schema changesWhen you modify the schema for the tables on the database server, the data martsthat refer to those tables are impacted. Errors are returned when you run queriesthat refer to those tables.
Examples of schema modification operations include:v Renaming tablesv Renaming columnsv Altering tables to add or drop columnsv Changing the datatype of the columnsv Adding or dropping constraints
Use the following steps to refresh the data marts:1. Drop the data marts from the accelerator that are impacted by the schema
changes.2. Recreate the data mart definitions that were impacted by the schema changes.
Chapter 4. Accelerator data marts and AQTs 4-23

3. Validate the data marts.4. Deploy the data marts.5. Load the data into the data marts again.
After you refresh the data marts, rerun the queries to confirm that no processingerrors are returned.
Removing probing data from the databaseAfter you no longer need the probing data, you can use a SET ENVIRONMENTstatement to remove it from the database that contains the warehousing data.
To remove all of the probing data from the database:1. Connect to the database where the warehousing data resides.2. Run the SET ENVIRONMENT use_dwa ’probe cleanup’ statement.
For example:$ dbaccess stores_demo -> set environment use_dwa ’probe cleanup’;Environment set.
To check if the probing data is removed, run the onstat -g probe command.
Important: The probing data is stored in memory. The data is automaticallyremoved when the database server is shut down.
Monitoring AQTsYou can use the onstat -g aqt command to view information about the data martsand the associated accelerated query tables (AQTs).Related reference:
onstat -g aqt command: Print data mart and accelerated query tableinformation (Administrator's Reference)
4-24 IBM Informix Warehouse Accelerator Administration Guide

Chapter 5. Reversion requirements for an Informix warehouseedition server and Informix Warehouse Accelerator
If you need to revert from the Informix 11.70 instance to an earlier version, thereare some reversion tasks you need to perform.
Reversion of the database server that contains data marts thatwere created with Informix Warehouse Accelerator
Before you use the onmode -b command to revert the database server, you mustdrop all of the data marts associated with that database server. You can drop thedata marts by using the administration interface, Informix Smart AnalyticsOptimizer Studio, or by using the command line interface.
If you do not drop the data marts and the reversion succeeds, the system databasesmight be rebuilt and the AQTs will disappear. As a result, the data martsassociated with the reverted databases are orphaned and consume space andmemory.
Reversion of the database server that performed workloadanalysis to create data mart definitions
If you created the data mart definitions using workload analysis, the tables that arecreated by the probe2mart stored procedure must be dropped before starting thereversion:v If you created a separate logging database to use with the probe2mart stored
procedure, all of the data mart definition information will be in tables in thatseparate database. You can simply drop that database without impacting yourother databases.
v If you used your warehousing database as the logging database with theprobe2mart stored procedure, you must manually drop each of the permanenttables that were created by the probe2mart stored procedure.
If you do not drop the tables before you start reversion, the reversion will fail.Related reference:“The probe2mart stored procedure” on page 4-18
© Copyright IBM Corp. 2010, 2011 5-1

5-2 IBM Informix Warehouse Accelerator Administration Guide

Chapter 6. Troubleshooting
Missing sbspaceIf you do not have a default sbspace created in the Informix database server andattempt to install the accelerator an error is returned.
You must create and configure a default sbspace in the Informix database server,set the name of the default sbspace in the SBSPACENAME configurationparameter, and restart the Informix database server.Related tasks:“Preparing the Informix database server” on page 2-2
Memory issues for the coordinator node and the worker nodesIf you do not have sufficient memory assigned to the coordinator node and to theworker nodes, you might receive errors when you load data from the databaseserver or when you run queries.
The more worker nodes that you designate, the faster the data will be loaded fromthe database server. However, the more worker nodes you designate the morememory you will need because each worker node stores a copy of the data in thedimension tables.
You specify the memory in the dwainst.conf configuration file.Related reference:“dwainst.conf configuration file” on page 3-3
Ensuring a result set includes the most current dataOccasionally you want a specific query to access the most current data, which isstored on the database server. You can turn off the accelerator temporarily to runthe query.
The data that is stored on the accelerator is a snap-shot of the data on the databaseserver. If you need to ensure that a query result set includes the most current data,turn off the accelerator, run the query, and turn the accelerator on again:1. Specify the SET ENVIRONMENT use_dwa ’0’ statement at the beginning of the
query to turn off acceleration. Setting this variable ensures that the query isprocessed by the Informix query optimizer and not processed by theaccelerator.
2. Add the statement SET ENVIRONMENT use_dwa ’1’ at the end of the query toactivate acceleration again.
3. Run the query.
© Copyright IBM Corp. 2010, 2011 6-1

6-2 IBM Informix Warehouse Accelerator Administration Guide

Appendix A. Sample warehouse schema
The Informix Warehouse Accelerator examples use this sample warehouse schema.
SQL statements
The following SQL statements create the tables, indexes, and key constraints for thesample warehouse schema.CREATE TABLE DAILY_FORECAST (
PERKEY INTEGER NOT NULL ,STOREKEY INTEGER NOT NULL ,PRODKEY INTEGER NOT NULL ,QUANTITY_FORECAST INTEGER ,EXTENDED_PRICE_FORECAST DECIMAL(16,2) ,EXTENDED_COST_FORECAST DECIMAL(16,2) );
CREATE TABLE DAILY_SALES (PERKEY INTEGER NOT NULL ,STOREKEY INTEGER NOT NULL ,CUSTKEY INTEGER NOT NULL ,PRODKEY INTEGER NOT NULL ,PROMOKEY INTEGER NOT NULL ,QUANTITY_SOLD INTEGER ,EXTENDED_PRICE DECIMAL(16,2) ,EXTENDED_COST DECIMAL(16,2) ,SHELF_LOCATION INTEGER ,SHELF_NUMBER INTEGER ,START_SHELF_DATE INTEGER ,SHELF_HEIGHT INTEGER ,SHELF_WIDTH INTEGER ,SHELF_DEPTH INTEGER ,SHELF_COST DECIMAL(16,2) ,SHELF_COST_PCT_OF_SALE DECIMAL(16,2) ,BIN_NUMBER INTEGER ,PRODUCT_PER_BIN INTEGER ,START_BIN_DATE INTEGER ,BIN_HEIGHT INTEGER ,BIN_WIDTH INTEGER ,BIN_DEPTH INTEGER ,BIN_COST DECIMAL(16,2) ,BIN_COST_PCT_OF_SALE DECIMAL(16,2) ,TRANS_NUMBER INTEGER ,HANDLING_CHARGE INTEGER ,UPC INTEGER ,SHIPPING INTEGER ,TAX INTEGER ,PERCENT_DISCOUNT INTEGER ,TOTAL_DISPLAY_COST DECIMAL(16,2) ,TOTAL_DISCOUNT DECIMAL(16,2) ) ;
CREATE TABLE CUSTOMER (CUSTKEY INTEGER NOT NULL ,NAME CHAR(30) ,ADDRESS CHAR(40) ,C_CITY CHAR(20) ,C_STATE CHAR(5) ,ZIP CHAR(5) ,PHONE CHAR(10) ,AGE_LEVEL SMALLINT ,AGE_LEVEL_DESC CHAR(20) ,INCOME_LEVEL SMALLINT ,
© Copyright IBM Corp. 2010, 2011 A-1

INCOME_LEVEL_DESC CHAR(20) ,MARITAL_STATUS CHAR(1) ,GENDER CHAR(1) ,DISCOUNT DECIMAL(16,2) ) ;
ALTER TABLE CUSTOMERADD CONSTRAINT PRIMARY KEY( CUSTKEY );
CREATE TABLE PERIOD (PERKEY INTEGER NOT NULL ,CALENDAR_DATE DATE ,DAY_OF_WEEK SMALLINT ,WEEK SMALLINT ,PERIOD SMALLINT ,YEAR SMALLINT ,HOLIDAY_FLAG CHAR(1) ,WEEK_ENDING_DATE DATE ,MONTH CHAR(3) ) ;
ALTER TABLE PERIODADD CONSTRAINT PRIMARY KEY( PERKEY );
CREATE UNIQUE INDEX PERX1 ON PERIOD( CALENDAR_DATE ASC,PERKEY ASC );
CREATE UNIQUE INDEX PERX2 ON PERIOD( WEEK_ENDING_DATE ASC,
PERKEY ASC );
CREATE TABLE PRODUCT (PRODKEY INTEGER NOT NULL ,UPC_NUMBER CHAR(11) NOT NULL ,PACKAGE_TYPE CHAR(20) ,FLAVOR CHAR(20) ,FORM CHAR(20) ,CATEGORY INTEGER ,SUB_CATEGORY INTEGER ,CASE_PACK INTEGER ,PACKAGE_SIZE CHAR(6) ,ITEM_DESC CHAR(30) ,P_PRICE DECIMAL(16,2) ,CATEGORY_DESC CHAR(30) ,P_COST DECIMAL(16,2) ,SUB_CATEGORY_DESC CHAR(70) ) ;
ALTER TABLE PRODUCTADD CONSTRAINT PRIMARY KEY( PRODKEY );
CREATE UNIQUE INDEX PRODX2 ON PRODUCT( CATEGORY ASC,
PRODKEY ASC );
CREATE UNIQUE INDEX PRODX3 ON PRODUCT( CATEGORY_DESC ASC,
PRODKEY ASC );
CREATE TABLE PROMOTION (PROMOKEY INTEGER NOT NULL ,PROMOTYPE INTEGER ,PROMODESC CHAR(30) ,PROMOVALUE DECIMAL(16,2) ,PROMOVALUE2 DECIMAL(16,2) ,
A-2 IBM Informix Warehouse Accelerator Administration Guide

PROMO_COST DECIMAL(16,2) ) ;
ALTER TABLE PROMOTIONADD CONSTRAINT PRIMARY KEY( PROMOKEY );
CREATE UNIQUE INDEX PROMOX1 ON PROMOTION( PROMODESC ASC,
PROMOKEY ASC);
CREATE TABLE STORE (STOREKEY INTEGER NOT NULL ,STORE_NUMBER CHAR(2) ,CITY CHAR(20) ,STATE CHAR(5) ,DISTRICT CHAR(14) ,REGION CHAR(10) ) ;
ALTER TABLE STOREADD CONSTRAINT PRIMARY KEY( STOREKEY );
CREATE INDEX DFX1 ON DAILY_FORECAST ( PERKEY ASC);
CREATE INDEX DFX2 ON DAILY_FORECAST ( STOREKEY ASC);
CREATE INDEX DFX3 ON DAILY_FORECAST ( PRODKEY ASC);
CREATE INDEX DSX1 ON DAILY_SALES ( PERKEY ASC);
CREATE INDEX DSX2 ON DAILY_SALES ( STOREKEY ASC);
CREATE INDEX DSX3 ON DAILY_SALES ( CUSTKEY ASC);
CREATE INDEX DSX4 ON DAILY_SALES ( PRODKEY ASC);
CREATE INDEX DSX5 ON DAILY_SALES ( PROMOKEY ASC);
ALTER TABLE daily_sales ADD CONSTRAINT FOREIGN KEY (perkey)references period(perkey);
ALTER TABLE daily_sales ADD CONSTRAINT FOREIGN KEY (prodkey)references product(prodkey);
ALTER TABLE daily_sales ADD CONSTRAINT FOREIGN KEY(storekey) references store(storekey);
ALTER TABLE daily_sales ADD CONSTRAINT FOREIGN KEY (custkey)references customer(custkey);
ALTER TABLE daily_sales ADD CONSTRAINT FOREIGN KEY (promokey)references promotion(promokey);
ALTER TABLE daily_forecast ADD CONSTRAINT FOREIGN KEY (perkey)references period(perkey);
ALTER TABLE daily_forecast ADD CONSTRAINT FOREIGN KEY (prodkey)references product(prodkey);
ALTER TABLE daily_forecast ADD CONSTRAINT FOREIGN KEY (storekey)references store(storekey);
update statistics medium;
Appendix A. Sample warehouse schema A-3

A-4 IBM Informix Warehouse Accelerator Administration Guide

Appendix B. Sysmaster interface (SMI) pseudo tables forquery probing data
The SMI tables provide a way to access probing data in a relational form, which ismost convenient for further processing.
The sysmaster database provides the following pseudo tables for accessing probingdata:v For tables: sysprobetablesv For columns: sysprobecolumnsv For join descriptors: sysprobejdsv For join predicates: sysprobejps
The sysprobetables table
The schema for the sysprobetables table is:CREATE TABLE informix.sysprobetables(dbname char(128), { database name }sql_id int8, { statement id in syssqltrace }tabid integer, { table id }fact char(1) { table is fact table (y/n) });REVOKE ALL ON informix.sysprobetables FROM public AS informix;GRANT SELECT ON informix.sysprobetables TO public as informix;
The sysprobecolumns table
The schema for the sysprobecolumns table is:CREATE TABLE informix.sysprobecolumns(dbname char(128), { database name }sql_id int8, { statement id in syssqltrace }tabid integer, { table id }colno smallint { column number });REVOKE ALL ON informix.sysprobecolumns FROM public AS informix;GRANT SELECT ON informix.sysprobecolumns TO public AS informix;
The sysprobejds table
The schema for the sysprobejds table is:CREATE TABLE informix.sysprobejds(dbname char(128), { database name }sql_id int8, { statement id in syssqltrace }jd integer, { join descriptor sequence number }ctabid integer, { child table id }ptabid integer, { parent table id }type char(1), { join type: inner (i), left outer (l) }uniq char(1) { parent table has unique index (y/n) });REVOKE ALL ON informix.sysprobejds FROM public AS informix;GRANT SELECT ON informix.sysprobejds TO public AS informix;
© Copyright IBM Corp. 2010, 2011 B-1

The sysprobejps table
The schema for the sysprobejps table:CREATE TABLE informix.sysprobejps(dbname char(128), { database name }sql_id int8, { statement id in syssqltrace }jd integer, { join descriptor sequence number }jp integer, { join predicate sequence number }ccolno smallint, { child table column number }pcolno smallint { parent table column number });REVOKE ALL ON informix.sysprobejps FROM public AS informix;GRANT SELECT ON informix.sysprobejps TO public AS informix;
Related tasks:“Creating data mart definitions by using workload analysis” on page 4-10
B-2 IBM Informix Warehouse Accelerator Administration Guide

Appendix C. Supported locales
Informix Warehouse Accelerator supports a subset of the locales that IBM Informixsupports.
Some of the locales are not supported by the JDBC environment that is needed torun administrative commands for the accelerator. For these locales you must mapthe locale to a different locale or code set name, only for the connection throughJDBC, for example in the Java connection URL. See User-defined locales (JDBCDriver Guide) for information about how to map the locale in the Java connectionURL.
Locale 8859-1 and 8859-15
The following table lists the supported locales:
Table C-1. Information for locales 8859-1 and 8859-15
Locale 8859-1 Locale 8859-15
da_dk.8859-1de_at.8859-1de_at.8859-1@bun1de_at.8859-1@bundde_at.8859-1@dud1de_at.8859-1@dudede_ch.8859-1de_ch.8859-1@bun1de_ch.8859-1@bundde_ch.8859-1@dudede_de.8859-1de_de.8859-1@bun1de_de.8859-1@bundde_de.8859-1@dud1de_de.8859-1@dudeen_au.8859-1en_gb.8859-1en_us.8859-1en_us.8859-1@dicten_us.8859-1@dresen_us.8859-1@extnes_es.8859-1es_es.8859-1@ra94es_es.8859-1@raefi_fi.8859-1fr_be.8859-1fr_ca.8859-1fr_ch.8859-1fr_fr.8859-1is_is.8859-1it_it.8859-1nl_be.8859-1nl_nl.8859-1no_no.8859-1pt_br.8859-1pt_pt.8859-1sv_se.8859-1
da_dk.8859-15de_at.8859-15de_at.8859-15@bun1de_at.8859-15@dud1de_ch.8859-15de_ch.8859-15@bun1de_ch.8859-15@dud1de_de.8859-15de_de.8859-15@bun1de_de.8859-15@dud1en_gb.8859-15en_us.8859-15en_us.8859-15@dictes_es.8859-15es_es.8859-15@raefi_fi.8859-15fr_be.8859-15fr_ch.8859-15fr_fr.8859-15it_it.8859-15nl_be.8859-15nl_nl.8859-15no_no.8859-15pt_pt.8859-15sv_se.8859-15
© Copyright IBM Corp. 2010, 2011 C-1

Locales 8859-2, 8859-5, and 8859-6
The following table lists the supported locales:
Table C-2. Information for locales 8859-2, 8859-5, and 8859-6
Locale 8859-2 Locale 8859-5 Locale 8859-6
cs_cz.8859-2cs_cz.8859-2@sishr_hr.8859-2hu_hu.8859-2pl_pl.8859-2ro_ro.8859-2sh_hr.8859-2
(Needs mapping tohr_hr.8859-2for Java/JDBC)
sk_sk.8859-2sk_sk.8859-2@sn
bg_bg.8859-5ru_ru.8859-5uk_ua.8859-5
The following locales aresupported if mapped to thear_ae.8859-6 locale for theJava/JDBC connection:ar_dz, ar_eg, ar_jo, ar_lb,ar_ma, ar_sy, ar_tn, andar_ye.ar_ae.8859-6ar_ae.8859-6@gregar_ae.8859-6@islaar_bh.8859-6ar_bh.8859-6@gregar_bh.8859-6@islaar_kw.8859-6ar_kw.8859-6@gregar_kw.8859-6@islaar_om.8859-6ar_om.8859-6@gregar_om.8859-6@islaar_qa.8859-6ar_qa.8859-6@gregar_qa.8859-6@islaar_sa.8859-6ar_sa.8859-6@gregar_sa.8859-6@islaar_dz.8859-6ar_eg.8859-6ar_jo.8859-6ar_lb.8859-6ar_ma.8859-6ar_sy.8859-6ar_tn.8859-6ar_ye.8859-6
Locales 8859-7, 8859-8, and 8859-9
The following table lists the supported locales:
Table C-3. Information for locales 8859-7, 8859-8, and 8859-9
Locale 8859-7 Locale 8859-8 Locale 8859-9
el_gr.8859-7 iw_il.8859-8iw_il.8859-8@gregiw_il.8859-8@hebr
tr_tr.8859-9@ifix
C-2 IBM Informix Warehouse Accelerator Administration Guide

Locales utf-8
The following table lists the supported locales:
Table C-4. Information for locales utf-8
Locale utf-8 (ar_ae - hu_hu) Locale utf8 (ja_jp - zh_tw)
ar_ae.utf8ar_bh.utf8ar_kw.utf8ar_om.utf8ar_qa.utf8ar_sa.utf8cs_cz.utf8da_dk.utf8de_at.utf8de_ch.utf8de_de.utf8en_au.utf8en_gb.utf8en_us.utf8es_es.utf8fi_fi.utf8fr_be.utf8fr_ca.utf8fr_ch.utf8fr_fr.utf8hr_hr.utf8hu_hu.utf8
ja_jp.utf8ko_kr.utf8nl_be.utf8nl_nl.utf8no_no.utf8pl_pl.utf8pt_br.utf8pt_pt.utf8ro_ro.utf8ru_ru.utf8sh_hr.utf8
(Needs mapping tohr_hr.utf8for Java/JDBC)
sk_sk.utf8sv_se.utf8th_th.utf8tr_tr.utf8tr_tr.utf8@ifixzh_cn.utf8zh_hk.utf8
(Needs mapping tozh_tw.utf8 for Java/JDBC)
zh_tw.utf8
Locales PC-Latin-1, PC-Latin-2, and 858
The PC-Latin codesets need to be replaced with the following codesets:v Replace PC-Latin-1 with 850
v Replace PC-Latin-2 with 852
v Replace PC-Latin-1 w_euro with 858
For the Java/JDBC connection, the codeset name 858 then needs to be mapped toLatin9.
Note: The sh_hr locale must be mapped to hr_hr for the Java/JDBC connection.
The following table lists the supported locales:
Appendix C. Supported locales C-3

Table C-5. Information for locales PC-Latin-1, PC-Latin-2, and 858
Locale PC-Latin-1 Locale PC-Latin-2 Locale 858
da_dk.PC-Latin-1de_at.PC-Latin-1de_at.PC-Latin-1@bundde_at.PC-Latin-1@dudede_ch.PC-Latin-1de_ch.PC-Latin-1@bundde_ch.PC-Latin-1@dudede_de.PC-Latin-1de_de.PC-Latin-1@bun1de_de.PC-Latin-1@bundde_de.PC-Latin-1@dud1de_de.PC-Latin-1@dudeen_au.PC-Latin-1en_gb.PC-Latin-1en_us.PC-Latin-1en_us.PC-Latin-1@dictes_es.PC-Latin-1es_es.PC-Latin-1@raefi_fi.PC-Latin-1fr_be.PC-Latin-1fr_ca.PC-Latin-1fr_ch.PC-Latin-1fr_fr.PC-Latin-1is_is.PC-Latin-1it_it.PC-Latin-1nl_be.PC-Latin-1nl_nl.PC-Latin-1no_no.PC-Latin-1pt_pt.PC-Latin-1sv_se.PC-Latin-1
cs_cz.PC-Latin-2hr_hr.PC-Latin-2hu_hu.PC-Latin-2pl_pl.PC-Latin-2ro_ro.PC-Latin-2sh_hr.PC-Latin-2sk_sk.PC-Latin-2
da_dk.858de_at.858de_at.858@bundde_at.858@dudede_de.858de_de.858@bun1de_de.858@bundde_de.858@dud1de_de.858@dudees_es.858fi_fi.858fr_be.858fr_fr.858it_it.858nl_be.858nl_nl.858pt_pt.858
C-4 IBM Informix Warehouse Accelerator Administration Guide
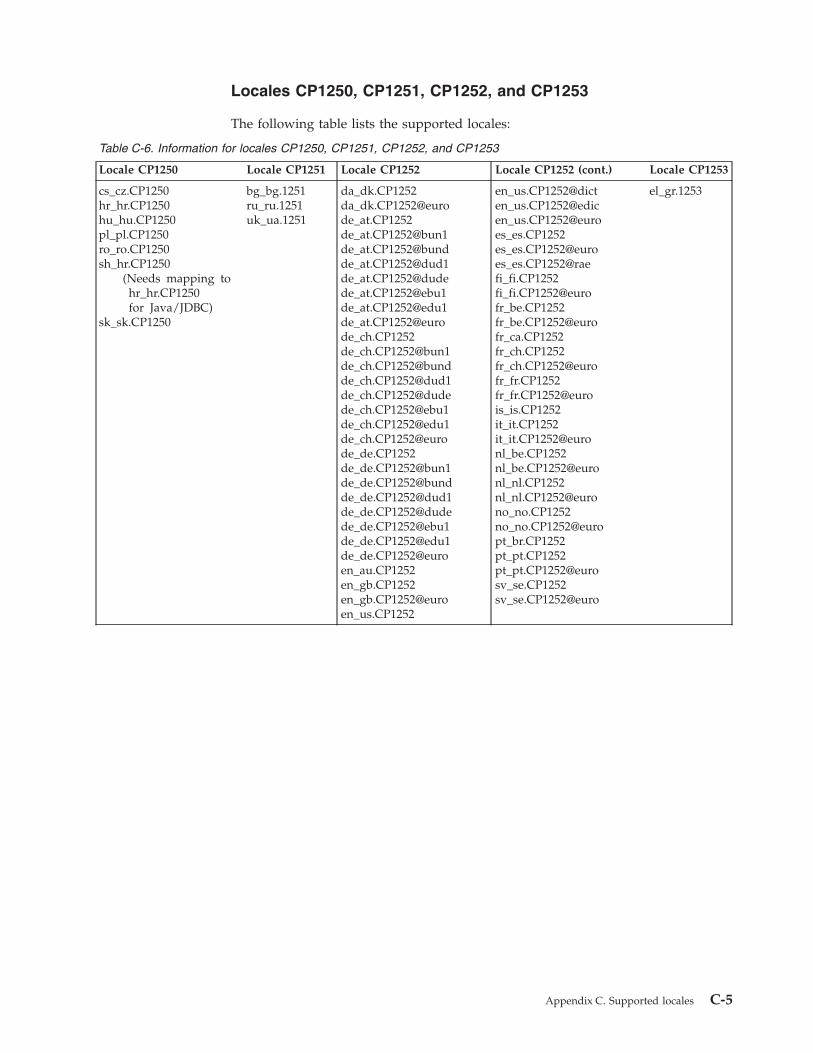
Locales CP1250, CP1251, CP1252, and CP1253
The following table lists the supported locales:
Table C-6. Information for locales CP1250, CP1251, CP1252, and CP1253
Locale CP1250 Locale CP1251 Locale CP1252 Locale CP1252 (cont.) Locale CP1253
cs_cz.CP1250hr_hr.CP1250hu_hu.CP1250pl_pl.CP1250ro_ro.CP1250sh_hr.CP1250
(Needs mapping tohr_hr.CP1250for Java/JDBC)
sk_sk.CP1250
bg_bg.1251ru_ru.1251uk_ua.1251
da_dk.CP1252da_dk.CP1252@eurode_at.CP1252de_at.CP1252@bun1de_at.CP1252@bundde_at.CP1252@dud1de_at.CP1252@dudede_at.CP1252@ebu1de_at.CP1252@edu1de_at.CP1252@eurode_ch.CP1252de_ch.CP1252@bun1de_ch.CP1252@bundde_ch.CP1252@dud1de_ch.CP1252@dudede_ch.CP1252@ebu1de_ch.CP1252@edu1de_ch.CP1252@eurode_de.CP1252de_de.CP1252@bun1de_de.CP1252@bundde_de.CP1252@dud1de_de.CP1252@dudede_de.CP1252@ebu1de_de.CP1252@edu1de_de.CP1252@euroen_au.CP1252en_gb.CP1252en_gb.CP1252@euroen_us.CP1252
en_us.CP1252@dicten_us.CP1252@edicen_us.CP1252@euroes_es.CP1252es_es.CP1252@euroes_es.CP1252@raefi_fi.CP1252fi_fi.CP1252@eurofr_be.CP1252fr_be.CP1252@eurofr_ca.CP1252fr_ch.CP1252fr_ch.CP1252@eurofr_fr.CP1252fr_fr.CP1252@eurois_is.CP1252it_it.CP1252it_it.CP1252@euronl_be.CP1252nl_be.CP1252@euronl_nl.CP1252nl_nl.CP1252@eurono_no.CP1252no_no.CP1252@europt_br.CP1252pt_pt.CP1252pt_pt.CP1252@eurosv_se.CP1252sv_se.CP1252@euro
el_gr.1253
Appendix C. Supported locales C-5

Locales CP1254, CP1255, and CP1256
The following table lists the supported locales:
Table C-7. Information for locales CP1254, CP1255, and CP1256
Locale CP1254 Locale CP1255 Locale CP1256
tr_tr.CP1254@ifix iw_il.1255iw_il.1255@gregiw_il.1255@hebr
ar_ae.1256ar_ae.1256@gregar_ae.1256@islaar_bh.1256ar_bh.1256@gregar_bh.1256@islaar_kw.1256ar_kw.1256@gregar_kw.1256@islaar_om.1256ar_om.1256@gregar_om.1256@islaar_qa.1256ar_qa.1256@gregar_qa.1256@islaar_sa.1256ar_sa.1256@gregar_sa.1256@isla
Locales big5, gb, ksc, and cp949
The following table lists the supported locales:
Table C-8. Information for locales big5, and gb
Locale big5 Locale gb Locales ksc and cp949
zh_cn.big5zh_tw.big5zh_hk.big5-HKSCS
(needs to be mapped tozh_tw.Big5-HKSCS
for Java/JDBCconnection)
zh_cn.gbzh_tw.gb
ko_kr.kscko_kr.cp949
(Needs mapping toko_kr.windows-949for Java/JDBCconnection)
Locales 866, KOI-8, and thai620
The following table lists the supported locales:
Table C-9. Information for locales 866, KOI-8, thai620
Locale 866 Locale KOI-8 Locale thai620
ru_ru.866 ru_ru.KOI-8 th_th.thai620
C-6 IBM Informix Warehouse Accelerator Administration Guide

Appendix D. Accessibility
IBM strives to provide products with usable access for everyone, regardless of ageor ability.
Accessibility features for IBM Informix productsAccessibility features help a user who has a physical disability, such as restrictedmobility or limited vision, to use information technology products successfully.
Accessibility featuresThe following list includes the major accessibility features in IBM Informixproducts. These features support:v Keyboard-only operation.v Interfaces that are commonly used by screen readers.v The attachment of alternative input and output devices.
Tip: The information center and its related publications are accessibility-enabledfor the IBM Home Page Reader. You can operate all features by using the keyboardinstead of the mouse.
Keyboard navigationThis product uses standard Microsoft Windows navigation keys.
Related accessibility informationIBM is committed to making our documentation accessible to persons withdisabilities. Our publications are available in HTML format so that they can beaccessed with assistive technology such as screen reader software.
You can view the publications in Adobe Portable Document Format (PDF) by usingthe Adobe Acrobat Reader.
IBM and accessibilitySee the IBM Accessibility Center at http://www.ibm.com/able for more informationabout the IBM commitment to accessibility.
Dotted decimal syntax diagramsThe syntax diagrams in our publications are available in dotted decimal format,which is an accessible format that is available only if you are using a screen reader.
In dotted decimal format, each syntax element is written on a separate line. If twoor more syntax elements are always present together (or always absent together),the elements can appear on the same line, because they can be considered as asingle compound syntax element.
Each line starts with a dotted decimal number; for example, 3 or 3.1 or 3.1.1. Tohear these numbers correctly, make sure that your screen reader is set to readpunctuation. All syntax elements that have the same dotted decimal number (forexample, all syntax elements that have the number 3.1) are mutually exclusive
© Copyright IBM Corp. 2010, 2011 D-1

alternatives. If you hear the lines 3.1 USERID and 3.1 SYSTEMID, your syntax caninclude either USERID or SYSTEMID, but not both.
The dotted decimal numbering level denotes the level of nesting. For example, if asyntax element with dotted decimal number 3 is followed by a series of syntaxelements with dotted decimal number 3.1, all the syntax elements numbered 3.1are subordinate to the syntax element numbered 3.
Certain words and symbols are used next to the dotted decimal numbers to addinformation about the syntax elements. Occasionally, these words and symbolsmight occur at the beginning of the element itself. For ease of identification, if theword or symbol is a part of the syntax element, the word or symbol is preceded bythe backslash (\) character. The * symbol can be used next to a dotted decimalnumber to indicate that the syntax element repeats. For example, syntax element*FILE with dotted decimal number 3 is read as 3 \* FILE. Format 3* FILEindicates that syntax element FILE repeats. Format 3* \* FILE indicates thatsyntax element * FILE repeats.
Characters such as commas, which are used to separate a string of syntaxelements, are shown in the syntax just before the items they separate. Thesecharacters can appear on the same line as each item, or on a separate line with thesame dotted decimal number as the relevant items. The line can also show anothersymbol that provides information about the syntax elements. For example, the lines5.1*, 5.1 LASTRUN, and 5.1 DELETE mean that if you use more than one of theLASTRUN and DELETE syntax elements, the elements must be separated by a comma.If no separator is given, assume that you use a blank to separate each syntaxelement.
If a syntax element is preceded by the % symbol, that element is defined elsewhere.The string following the % symbol is the name of a syntax fragment rather than aliteral. For example, the line 2.1 %OP1 refers to a separate syntax fragment OP1.
The following words and symbols are used next to the dotted decimal numbers:
? Specifies an optional syntax element. A dotted decimal number followedby the ? symbol indicates that all the syntax elements with acorresponding dotted decimal number, and any subordinate syntaxelements, are optional. If there is only one syntax element with a dotteddecimal number, the ? symbol is displayed on the same line as the syntaxelement (for example, 5? NOTIFY). If there is more than one syntax elementwith a dotted decimal number, the ? symbol is displayed on a line byitself, followed by the syntax elements that are optional. For example, ifyou hear the lines 5 ?, 5 NOTIFY, and 5 UPDATE, you know that syntaxelements NOTIFY and UPDATE are optional; that is, you can choose one ornone of them. The ? symbol is equivalent to a bypass line in a railroaddiagram.
! Specifies a default syntax element. A dotted decimal number followed bythe ! symbol and a syntax element indicates that the syntax element is thedefault option for all syntax elements that share the same dotted decimalnumber. Only one of the syntax elements that share the same dotteddecimal number can specify a ! symbol. For example, if you hear the lines2? FILE, 2.1! (KEEP), and 2.1 (DELETE), you know that (KEEP) is thedefault option for the FILE keyword. In this example, if you include theFILE keyword but do not specify an option, default option KEEP is applied.A default option also applies to the next higher dotted decimal number. Inthis example, if the FILE keyword is omitted, default FILE(KEEP) is used.
D-2 IBM Informix Warehouse Accelerator Administration Guide

However, if you hear the lines 2? FILE, 2.1, 2.1.1! (KEEP), and 2.1.1(DELETE), the default option KEEP only applies to the next higher dotteddecimal number, 2.1 (which does not have an associated keyword), anddoes not apply to 2? FILE. Nothing is used if the keyword FILE is omitted.
* Specifies a syntax element that can be repeated zero or more times. Adotted decimal number followed by the * symbol indicates that this syntaxelement can be used zero or more times; that is, it is optional and can berepeated. For example, if you hear the line 5.1* data-area, you know thatyou can include more than one data area or you can include none. If youhear the lines 3*, 3 HOST, and 3 STATE, you know that you can includeHOST, STATE, both together, or nothing.
Notes:
1. If a dotted decimal number has an asterisk (*) next to it and there isonly one item with that dotted decimal number, you can repeat thatsame item more than once.
2. If a dotted decimal number has an asterisk next to it and several itemshave that dotted decimal number, you can use more than one itemfrom the list, but you cannot use the items more than once each. In theprevious example, you can write HOST STATE, but you cannot write HOSTHOST.
3. The * symbol is equivalent to a loop-back line in a railroad syntaxdiagram.
+ Specifies a syntax element that must be included one or more times. Adotted decimal number followed by the + symbol indicates that this syntaxelement must be included one or more times. For example, if you hear theline 6.1+ data-area, you must include at least one data area. If you hearthe lines 2+, 2 HOST, and 2 STATE, you know that you must include HOST,STATE, or both. As for the * symbol, you can repeat a particular item if it isthe only item with that dotted decimal number. The + symbol, like the *symbol, is equivalent to a loop-back line in a railroad syntax diagram.
Appendix D. Accessibility D-3

D-4 IBM Informix Warehouse Accelerator Administration Guide

Notices
This information was developed for products and services offered in the U.S.A.
IBM may not offer the products, services, or features discussed in this document inother countries. Consult your local IBM representative for information on theproducts and services currently available in your area. Any reference to an IBMproduct, program, or service is not intended to state or imply that only that IBMproduct, program, or service may be used. Any functionally equivalent product,program, or service that does not infringe any IBM intellectual property right maybe used instead. However, it is the user's responsibility to evaluate and verify theoperation of any non-IBM product, program, or service.
IBM may have patents or pending patent applications covering subject matterdescribed in this document. The furnishing of this document does not grant youany license to these patents. You can send license inquiries, in writing, to:
IBM Director of LicensingIBM CorporationNorth Castle DriveArmonk, NY 10504-1785U.S.A.
For license inquiries regarding double-byte (DBCS) information, contact the IBMIntellectual Property Department in your country or send inquiries, in writing, to:
Intellectual Property LicensingLegal and Intellectual Property LawIBM Japan Ltd.1623-14, Shimotsuruma, Yamato-shiKanagawa 242-8502 Japan
The following paragraph does not apply to the United Kingdom or any othercountry where such provisions are inconsistent with local law: INTERNATIONALBUSINESS MACHINES CORPORATION PROVIDES THIS PUBLICATION "AS IS"WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED,INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OFNON-INFRINGEMENT, MERCHANTABILITY OR FITNESS FOR A PARTICULARPURPOSE. Some states do not allow disclaimer of express or implied warranties incertain transactions, therefore, this statement may not apply to you.
This information could include technical inaccuracies or typographical errors.Changes are periodically made to the information herein; these changes will beincorporated in new editions of the publication. IBM may make improvementsand/or changes in the product(s) and/or the program(s) described in thispublication at any time without notice.
Any references in this information to non-IBM websites are provided forconvenience only and do not in any manner serve as an endorsement of thosewebsites. The materials at those websites are not part of the materials for this IBMproduct and use of those websites is at your own risk.
© Copyright IBM Corp. 2010, 2011 E-1

IBM may use or distribute any of the information you supply in any way itbelieves appropriate without incurring any obligation to you.
Licensees of this program who wish to have information about it for the purposeof enabling: (i) the exchange of information between independently createdprograms and other programs (including this one) and (ii) the mutual use of theinformation which has been exchanged, should contact:
IBM CorporationJ46A/G4555 Bailey AvenueSan Jose, CA 95141-1003U.S.A.
Such information may be available, subject to appropriate terms and conditions,including in some cases, payment of a fee.
The licensed program described in this document and all licensed materialavailable for it are provided by IBM under terms of the IBM Customer Agreement,IBM International Program License Agreement or any equivalent agreementbetween us.
Any performance data contained herein was determined in a controlledenvironment. Therefore, the results obtained in other operating environments mayvary significantly. Some measurements may have been made on development-levelsystems and there is no guarantee that these measurements will be the same ongenerally available systems. Furthermore, some measurements may have beenestimated through extrapolation. Actual results may vary. Users of this documentshould verify the applicable data for their specific environment.
Information concerning non-IBM products was obtained from the suppliers ofthose products, their published announcements or other publicly available sources.IBM has not tested those products and cannot confirm the accuracy ofperformance, compatibility or any other claims related to non-IBM products.Questions on the capabilities of non-IBM products should be addressed to thesuppliers of those products.
All statements regarding IBM's future direction or intent are subject to change orwithdrawal without notice, and represent goals and objectives only.
All IBM prices shown are IBM's suggested retail prices, are current and are subjectto change without notice. Dealer prices may vary.
This information is for planning purposes only. The information herein is subject tochange before the products described become available.
This information contains examples of data and reports used in daily businessoperations. To illustrate them as completely as possible, the examples include thenames of individuals, companies, brands, and products. All of these names arefictitious and any similarity to the names and addresses used by an actual businessenterprise is entirely coincidental.
COPYRIGHT LICENSE:
This information contains sample application programs in source language, whichillustrate programming techniques on various operating platforms. You may copy,
E-2 IBM Informix Warehouse Accelerator Administration Guide

modify, and distribute these sample programs in any form without payment toIBM, for the purposes of developing, using, marketing or distributing applicationprograms conforming to the application programming interface for the operatingplatform for which the sample programs are written. These examples have notbeen thoroughly tested under all conditions. IBM, therefore, cannot guarantee orimply reliability, serviceability, or function of these programs. The sampleprograms are provided "AS IS", without warranty of any kind. IBM shall not beliable for any damages arising out of your use of the sample programs.
Each copy or any portion of these sample programs or any derivative work, mustinclude a copyright notice as follows:
© (your company name) (year). Portions of this code are derived from IBM Corp.Sample Programs.
© Copyright IBM Corp. _enter the year or years_. All rights reserved.
If you are viewing this information softcopy, the photographs and colorillustrations may not appear.
TrademarksIBM, the IBM logo, and ibm.com are trademarks or registered trademarks ofInternational Business Machines Corp., registered in many jurisdictions worldwide.Other product and service names might be trademarks of IBM or other companies.A current list of IBM trademarks is available on the web at "Copyright andtrademark information" at http://www.ibm.com/legal/copytrade.shtml.
Adobe, the Adobe logo, and PostScript are either registered trademarks ortrademarks of Adobe Systems Incorporated in the United States, and/or othercountries.
Intel, Itanium, and Pentium are trademarks or registered trademarks of IntelCorporation or its subsidiaries in the United States and other countries.
Java and all Java-based trademarks and logos are trademarks or registeredtrademarks of Oracle and/or its affiliates.
Linux is a registered trademark of Linus Torvalds in the United States, othercountries, or both.
Microsoft, Windows, and Windows NT are trademarks of Microsoft Corporation inthe United States, other countries, or both.
UNIX is a registered trademark of The Open Group in the United States and othercountries.
Other company, product, or service names may be trademarks or service marks ofothers.
Notices E-3

E-4 IBM Informix Warehouse Accelerator Administration Guide

Index
AAccelerated query tables
described 1-1, 4-7states 4-7
Acceleratoradministrator interface 1-4architecture 1-4configuring 3-1, 3-2connecting to Informix 3-6installing 2-1, 2-3instance 2-1memory 1-12operating system 1-11reinstalling 2-5turning off acceleration 6-1uninstalling 2-5
Accessibility D-1dotted decimal format of syntax diagrams D-1keyboard D-1shortcut keys D-1syntax diagrams, reading in a screen reader D-1
Administration interfacecreating data marts 4-8installing 2-4operating system 1-11overview 1-4
Aggregate functions 1-9Aggregate tables 4-3AQTs
See Accelerated query tables
CCLUSTER_INTERFACE parameter 3-2, 3-3cluster.conf file 3-2compliance with standards viiiConfiguring
accelerator 3-1, 3-2dwainst.conf file 3-3overview 3-1sbspace 2-2SBSPACENAME configuration parameter 2-2
Coordinator node 1-1memory issues 6-1
COORDINATOR_SHM parameter 3-3
DData currency 4-22Data mart definitions
creating 4-10defined 4-1
Data martsaggregate tables 4-3creating 4-8defined 4-1deploying 4-20described 1-1, 4-3designing 4-2dimension table 4-3
Data marts (continued)dropping 4-23example, creating 4-12fact table 4-3key tasks, creating 4-1loading data 4-21overview 4-3refreshing data 4-22star schema 4-3summary tables 4-3updating data 4-23
Data typessupported 1-9
Database serverschema changes 4-23
Dimension tablessample 4-3
Directoriesadministration interface 2-1documentation 2-1installation 2-1instance 2-1samples 2-1storage 2-1, 3-1, 3-2
Disabilities, visualreading syntax diagrams D-1
Disability D-1Dotted decimal format of syntax diagrams D-1DRDA_INTERFACE parameter 3-3DWA_CM binary 3-10DWADIR parameter 3-3dwainst.conf file
ondwa setup command 3-10parameters 3-3
EEclipse tool 1-1Environment settings 3-7Examples
genmartdef function 4-20probe2mart stored procedure 4-18workload analysis 4-12
FFact tables 4-10
sample 4-3Functions
aggregate functions 1-9genmartdef 4-20scalar functions 1-9user-defined functions 1-9
GGenmartdef function
examples 4-20syntax 4-20
© Copyright IBM Corp. 2010, 2011 X-1

IIBM Smart Analytics Optimizer Studio
architecture 1-4described 1-1installing 2-1, 2-4
industry standards viiiInstalling
administration interface 2-4directory 2-1Informix Warehouse Accelerator 2-3overview 2-1
Instancedirectory 2-1
JJoin descriptors 4-18, B-1Join predicates 4-18, B-1Joins
join combinations 1-11join predicates 1-11many-to-many 4-9one-to-many 4-9supported 1-11unsupported 1-11
LLocales v, 1-1
supported C-1
MMany-to-many joins 4-9Memory
accelerator 1-12issues 6-1
NNUM_NODES parameter 3-3
Oondwa utility
clean command 3-15dwainst.conf file 3-10getpin command 3-13overview 3-9reset command 3-14running a cluster system 3-9setup command 3-10start command 3-11status command 3-12stop command 3-14tasks command 3-13users who can run the command 3-9
One-to-many joins 4-9onstat -g aqt command 4-24Operating systems
supported 1-11Overview 1-1
PPDQPRIORITY variable 3-7Prerequisites
hardware 1-12operating system 1-11software 1-11
Probe2martreversion requirements 5-1
Probe2mart stored procedureexamples 4-18syntax 4-18tables 4-18
Probing dataremoving 4-24
QQueries
acceleration considerations 1-6analyze 4-7not accelerated 1-8types accelerated 1-6
Query probingcreating data marts 4-10example 4-12removing data 4-24
RReinstalling
Informix Warehouse Accelerator 2-5Reversion
workload analysis tables 5-1
SSamples
queryprofit by store 1-7revenue by item 1-7revenue by store 1-7week to day profits 1-8
warehouse schema A-1sbspace
configuring 2-2SBSPACENAME configuration parameter 2-2Scalar functions 1-9Schemas
sample SQL A-1Screen reader
reading syntax diagrams D-1SET ENVIRONMENT
statement 4-24, 6-1Shortcut keys
keyboard D-1Snowflake schema 1-1standards viiiStar schema
sample 4-3START_PORT parameter 3-3Statistics
UPDATE STATISTICS LOW statement 3-7Stored procedures
probe2mart examples 4-18probe2mart syntax 4-18
X-2 IBM Informix Warehouse Accelerator Administration Guide

Summary tables 4-3Syntax
genmartdef function 4-20Syntax diagrams
reading in a screen reader D-1sysdbopen() procedure 3-7
TTroubleshooting
memory issues 6-1sbspace 6-1
UUninstalling
Informix Warehouse Accelerator 2-5UPDATE STATISTICS LOW statement 3-7use_dwa variable 3-7, 6-1User-defined functions 1-9
VVariables
PDQPRIORITY 3-7use_dwa 3-7
Visual disabilitiesreading syntax diagrams D-1
WWorker nodes 1-1
memory issues 6-1WORKER_SHM parameter 3-3Workload analysis
creating data marts 4-10
Index X-3

X-4 IBM Informix Warehouse Accelerator Administration Guide


����
Printed in USA
SC27-3851-00


















