
February 11, 20041 Hand Geometry BIOM 426 Instructor: Natalia A. Schmid.
date post
20-Dec-2015Category
view
221download
0
(c) Maria Indrawan 2004 1
Distributed Information Retrieval

(c) Maria Indrawan 2004 2
Challenges in Managing Distributed Information
• No topology of the data organisation.• Dynamic data.• The size of the collection.• No control over quality of the data.• Multimedia data.

(c) Maria Indrawan 2004 3
Challenges-Human Factor
• Diversity of users– Expert to novice
• Ill-formed queries.• Specific behaviour
– Favour precision over recall (85% users only look at the first screen – Lan Huang A survey on Web Information Technology)

(c) Maria Indrawan 2004 4
Types of Distributed IR
• Directory– Yahoo
• Search Engine– Google, AskJeeves, Yahoo, Teoma
• Meta Search– Metacrawler, Dogpile
• Distributed Broker– Harvest

(c) Maria Indrawan 2004 5
Directory Listing
• Manually created– Yahoo, Google, MSN
– Open Directory Project
• www.dmoz.org

(c) Maria Indrawan 2004 6
Directory Listing
• Automatic classification• TERENA.
– http://www.terena.nl/tech/projects/portal/isir/reisnews9908seac.html
• Scorpion– http://orc.rsch.oclc.org:6109/

(c) Maria Indrawan 2004 7
Search Engine Architecture
• Crawler (robots)– Collecting the pages from the WEB.
• Indexer– Indexing pages collected by the crawler and represent
them in an efficient data structure.
• Query Server– Accepting, process and return the results of the query
from the user.

(c) Maria Indrawan 2004 8
Crawler – Design Considerations
• Crawling algorithm– Breadth-first vs Depth first
• How do we handle URL-aliases?• How do we reduce server load? • How do we detect a duplicate page or a mirror-
site?• How often we need to revisit a site?

(c) Maria Indrawan 2004 9
Update Ratewww.searchengineshowdown.com (May 2003)
Search Engine Newest page Found
Rough Average Oldest Page Found
Google 2 days 1 month 165 days
MSN (Ink) 1 day 4 weeks 51 days
HotBot (Ink) 1 day 4 weeks 51 days
AlltheWeb 1 day 1 month 599 days
Gigablast 45 days 7 months 381 days
Teoma 41 days 2.5 months 81 days
WiseNut 133 days 6 months 183 days

(c) Maria Indrawan 2004 10
Indexer - Design Considerations
• How do we handle typing mistakes?• Do we use stop list and stemming algorithm?• How much do we want to index in a given web
page?– Google index only the first 101 KB of a web page and
120 KB of PDF file.
• How big do we want the database indexed to be?– response time vs coverage
• Do we want to index PDF, PS files?
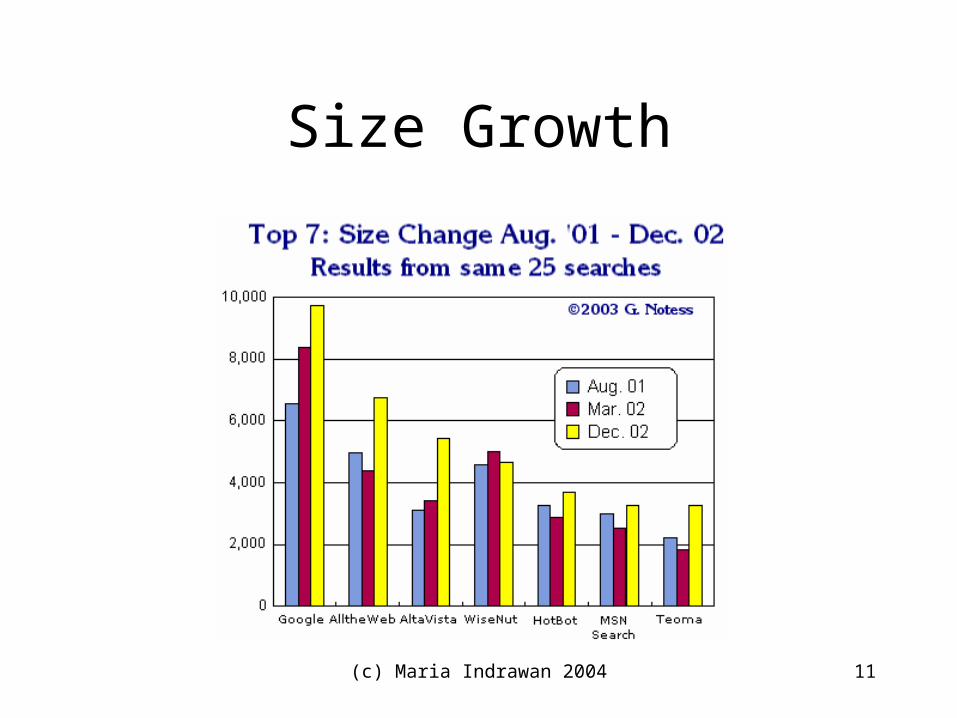
(c) Maria Indrawan 2004 11
Size Growth

(c) Maria Indrawan 2004 12
Estimated Sizewww.searchengineshowdown.com, Dec 31, 2002
Estimated Database Total Size
0
500
1000
1500
2000
2500
3000
3500
Goggle AlltheWeb AltaVista WiseNut Hotbot MSN Teoma NLResearch Gigablast
mil
lio
ns
Estimated
Claim

(c) Maria Indrawan 2004 13
Query Server- Design Considerations
• Retrieval model.• Complexity of the query syntax.• HCI – human computer interface.• Output display.

(c) Maria Indrawan 2004 14
Retrieval Model
• Traditional approach:– Keywords matching returns to many low quality
matches – low precision.
• Search engines need a VERY high precision output – even on the expense of RECALL.
• How can we achieve this?

(c) Maria Indrawan 2004 15
Google Retrieval Model
• Utilise the popularity of a page– If a page has many other pages pointed to this page, the
page must be very important. We can assign a high weight to this page during search.
– If a page is pointed by a popular page, this page can be considered as important because it is referred by a reputable source (a popular page).
– PageRank Function.

(c) Maria Indrawan 2004 16
PageRank Example
3
3
100 53
950
50
50
3

(c) Maria Indrawan 2004 17
Google Retrieval Model
• Utilise the anchor text.– Anchors often provide more accurate descriptions of
web pages than the pages themselves.
– Anchors may exist for documents which cannot be indexed by a text-based search engine.
• Utilise the appearance of the text.– Larger and bolder font text are weighted higher than
other words.

(c) Maria Indrawan 2004 18
Results Overlap

(c) Maria Indrawan 2004 19
Metasearch
• Meta searches do not build their own index.• They use the index of the existing search engines. • When user posted a query to a meta search, the
meta search sends the query to a number of search engines and collates the results.
• A list of metacrawler:– http://www.searchenginewatch.com/links/article.php/21
56241

(c) Maria Indrawan 2004 20
Meta Search
• metacrawler, www.metacrawler.com– uses google, yahoo,askJeeves, About, Looksmart,
Teoma, Overture, FindWhat.
• dogpile, www.dogpile.com– uses google, yahoo,askJeeves, About, Looksmart,
Teoma, Overture, FindWhat

(c) Maria Indrawan 2004 21
Metasearch Design Issue
• Potential problems:– Translating the user query into a different query in a
different search engine.– Query time is bounded by the least powerful (slowest)
underlying system.– Combining results into a single ranked list is difficult.
Effectiveness depend on heuristics and information passed back from underlying search engines.
• detecting overlap in the query results• different scoring schemes (some do not use)

(c) Maria Indrawan 2004 22
Distributed Broker • Information is indexed locally by geographical
locations or institutional boundaries.– Suitable for supporting community that to have a
common search database.
• Local indexes are combined to provide wider coverage.
• Document scoring is performed locally by each index server.

(c) Maria Indrawan 2004 23
Distributed Broker
broker
CSSE
broker
SIMS
broker
ACC
broker
MGM
broker
FIT
broker
F. Bussiness
broker
Monash

(c) Maria Indrawan 2004 24
Distributed Broker
• Example: Harvest– http://www.ncsa.uiuc.edu
/SDG/IT94/Proceedings/Searching/schwartz.harvest/schwartz.harvest.html

(c) Maria Indrawan 2004 25
General architecture• Hierarchical vs Flat • Hierarchical: underlying index servers are
connected through a hierarchy of brokers.– broker hierarchy provides efficient and global
coverage.
– brokers can be geographical, institutional or subject based. broker
query
brokerquery
broker
index server index server
. . .
. . .
. . .

(c) Maria Indrawan 2004 26
Flat Graph Modelbroker
index server
brokerindex server
brokerindex server
brokerindex server
. . .
. . .
queryquery

(c) Maria Indrawan 2004 27
Useful site
• www.searchenginewatch.com– Provides links to most of the information discovery
tools.

(c) Maria Indrawan 2004 28
Summary
• Type of Distributed Information Discovery– Directory Listing
• yahoo
– Search Engines.
• Google, AskJeeves, Teoma
– Metasearch
• metacrawler, dogpile
– Distributed Broker
• Harvest


















