
By David Anderson SZTAKI (Budapest, Hungary) WPI D2009
42
By David Anderson SZTAKI (Budapest, Hungary) WPI D2009
Transcript of By David Anderson SZTAKI (Budapest, Hungary) WPI D2009

ByDavidAndersonSZTAKI(Budapest,Hungary)WPID2009

1997,DeepBluewonagainstKasparov AverageworkstationcandefeatbestChessplayers
ComputerChessnolonger“interesting” Goismuchharderforcomputerstoplay
Branchingfactoris~50‐200versus~35inChess Positionalevaluationinaccurate,expensive Gamecannotbescoreduntiltheend
BeginnerscandefeatbestGoprograms

Two‐player,totalinformation Playerstaketurnsplacingblackandwhitestonesongrid
Boardis19x19(13x13or9x9forbeginners) Objectistosurroundemptyspaceasterritory Piecescanbecaptured,butnotmoved Winnerdeterminedbymostpoints(territorypluscapturedpieces)

Imagefromhttp://ict.ewi.tudelft.nl/~gineke/
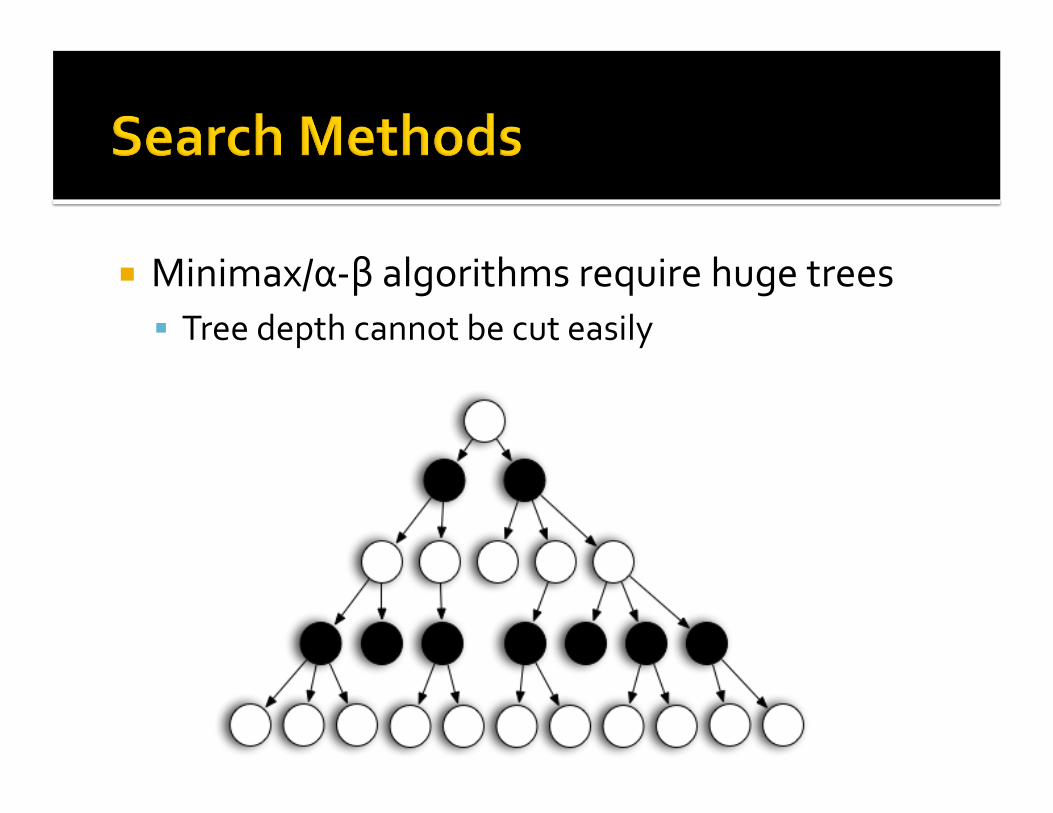
Minimax/α‐βalgorithmsrequirehugetrees Treedepthcannotbecuteasily

Monte‐Carlonowmorepopular Simulaterandomgamesfromthegametree Useresultstopickbestmove
Twoareasofoptimization Discoveryofgoodpathsinthegametree Intelligenceofrandomsimulations▪ Randomgamesareusuallybogus

Needtobalancebetweenexploration… Discoveringandsimulatingnewpaths
Andexploitation… Simulatingthemostoptimalpath
BestmethodiscurrentlyUCTgivenbyLeventeKocsisandCsabaSzepesvári.

Sayyouhaveaslotmachinewithaprobabilityofgivingyoumoney.Youcaninferthisprobabilitythroughexperimentation.

Whatiftherearethreeslotmachines,andeachhasadifferentprobability?

Youneedtochoosebetweenexperimenting(exploration)andgettingthebestreward(exploitation).

UCBalgorithmbalancestheseproblemstominimizelossofreward.

UCTappliesUCBtogameslikeGo,decidingwhichmovetoexplorenextbytreatingitlikethebanditproblem.
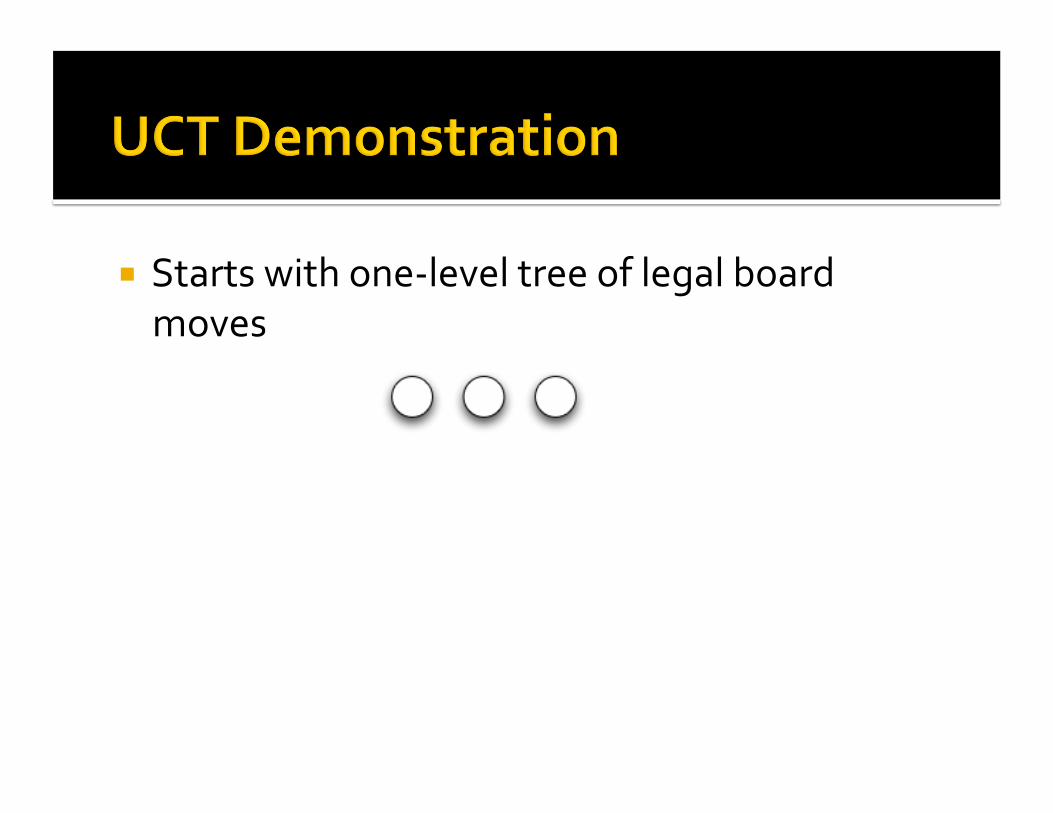
Startswithone‐leveltreeoflegalboardmoves
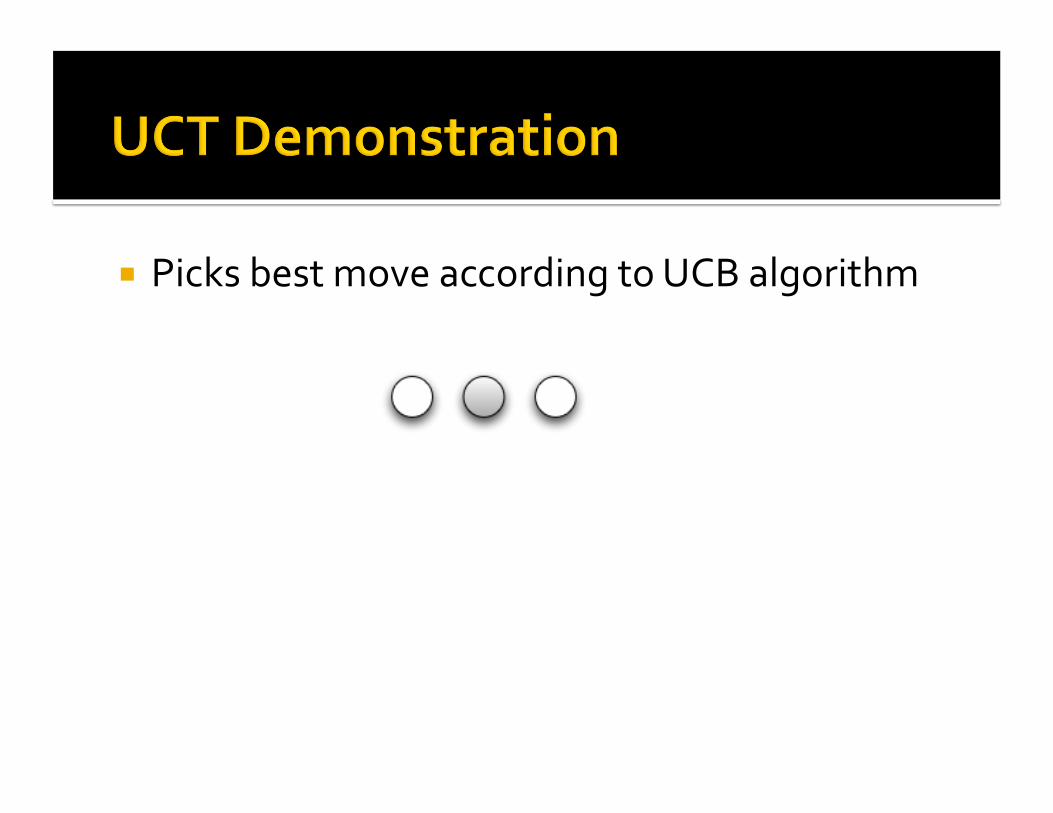
PicksbestmoveaccordingtoUCBalgorithm

RunsMonte‐Carlosimulation,updatenode’swin/loss.
ThisisoneiterationoftheUCTprocess.

Ifnodegetsvisitedenoughtimes,startlookingatitschildmoves

UCTdivesdeeper,eachtimepickingthemost“interesting”move.
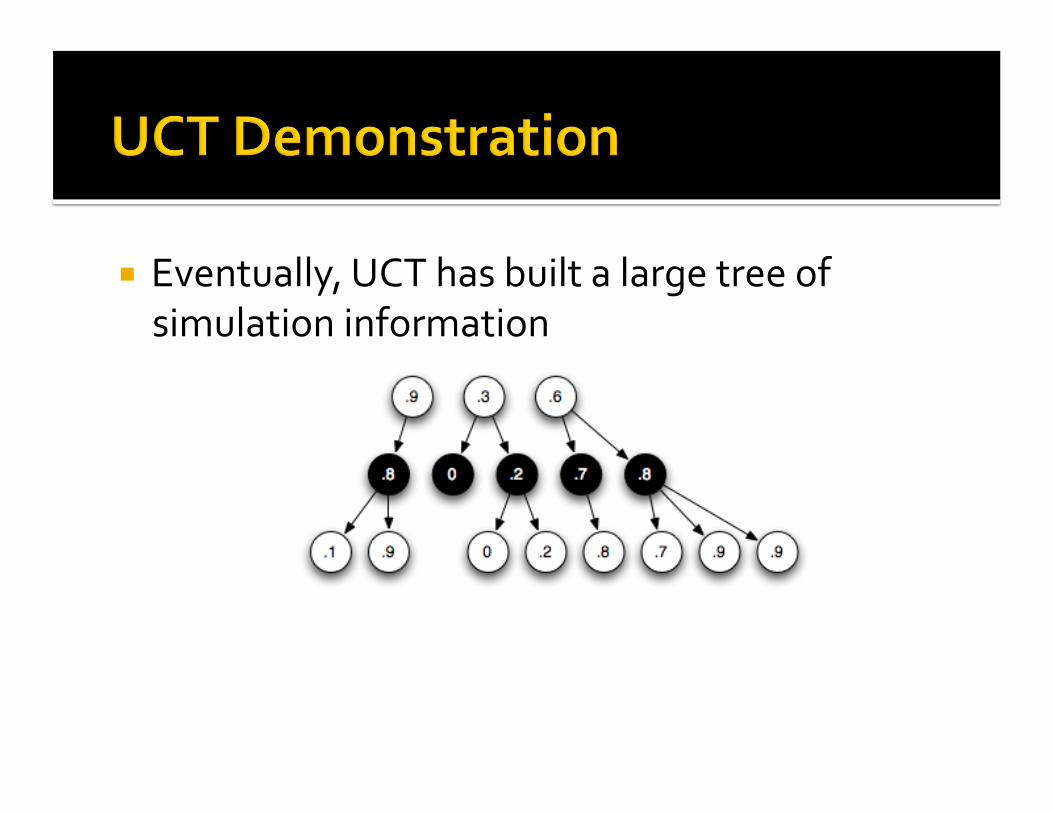
Eventually,UCThasbuiltalargetreeofsimulationinformation

UCTisnowinmostmajorcompetitiveprograms
“MoGo”usedUCTtodefeataprofessional Used800‐nodegridanda9stonehandicap
Muchresearchnowfocusedonimprovingsimulationintelligence

Policydecideswhichmovetoplaynextinarandomgamesimulation
HighstochasticitymakesUCTlessaccurate Takeslongertoconvergetocorrectmove
ToomuchdeterminismmakesUCTlesseffective DefeatspurposeofMonte‐Carlosearch Mightintroduceharmfulselectionbias

CertainshapesinGoaregood “Hane”hereisastrongattackonB
Othersarequitebad! B’s“emptytriangle”istoodenseandwasteful

MoGousespatternknowledgewithUCT Hand‐crafteddatabaseof3x3interestingpatterns Doubledsimulationwin‐rateaccordingtoauthors
Canpatternknowledgebetrainedautomaticallyviamachinelearning?

Paper“Monte‐CarloSimulationBalancing” (byDavidSilverandGeraldTesauro) Policiesaccumulateerrorwitheachmove Strongpoliciesminimizethiserror,butnotthewhole‐gameerror
Proposesalgorithmsforminimizingwhole‐gameerrorwitheachmove
Authorstestedon5x5Gousing2x2patterns Foundthatbalancingwasmoreeffectiveoverrawstrength
Implementedpattern‐learningalgorithmsin“Monte‐CarloSimulationBalancing” Strength:Apprenticeship Strength:PolicyGradientReinforcement Balance:PolicyGradientSimulationBalancing Balance:Two‐StepSimulationBalancing
Used9x9Gowith3x3patterns

Usedamateurdatabaseof9x9gamesfortraining
Mention‐worthymetrics: Simulationwinrateagainstpurelyrandom UCTwinrateagainstUCTpurelyrandom UCTwinrateagainstGNUGo

Simplestalgorithm Looksateverymoveofeverygameinthetrainingset Highpreferenceforchosenmoves Lowpreferenceforunchosenmoves
Stronglyfavoredgoodpatterns Over‐training;poorerrorcompensation
Valuesconvergetoinfinity
0
10
20
30
40
50
60
70
80
Playout UCTvslibEGO UCTvsGNUGo
Winrate(%
)
GameType
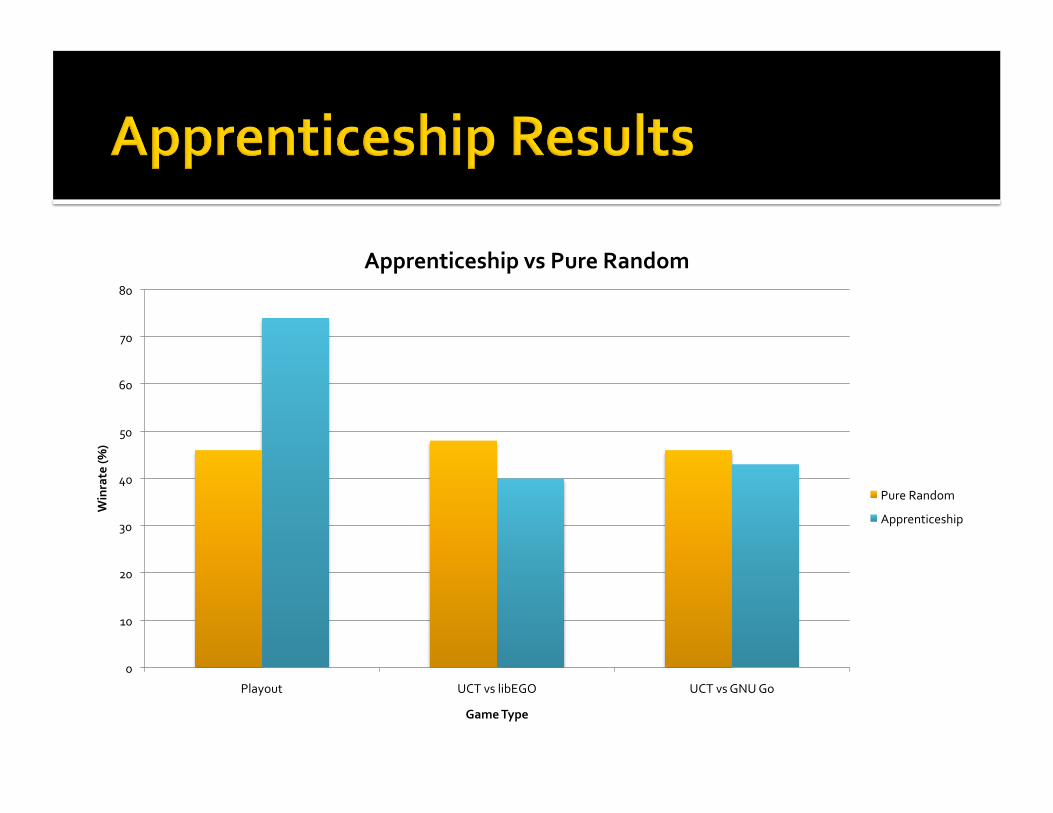
ApprenticeshipvsPureRandom
PureRandom
Apprenticeship

Playsrandomgamesfromthetrainingset Ifthesimulationmatchestheoriginalgameresult,patternsgethigherpreference
Otherwise,lowerpreference Resultswerepromising
0
10
20
30
40
50
60
70
Playout UCTvslibEGO UCTvsGNUGo
Winrate(%
)
GameType
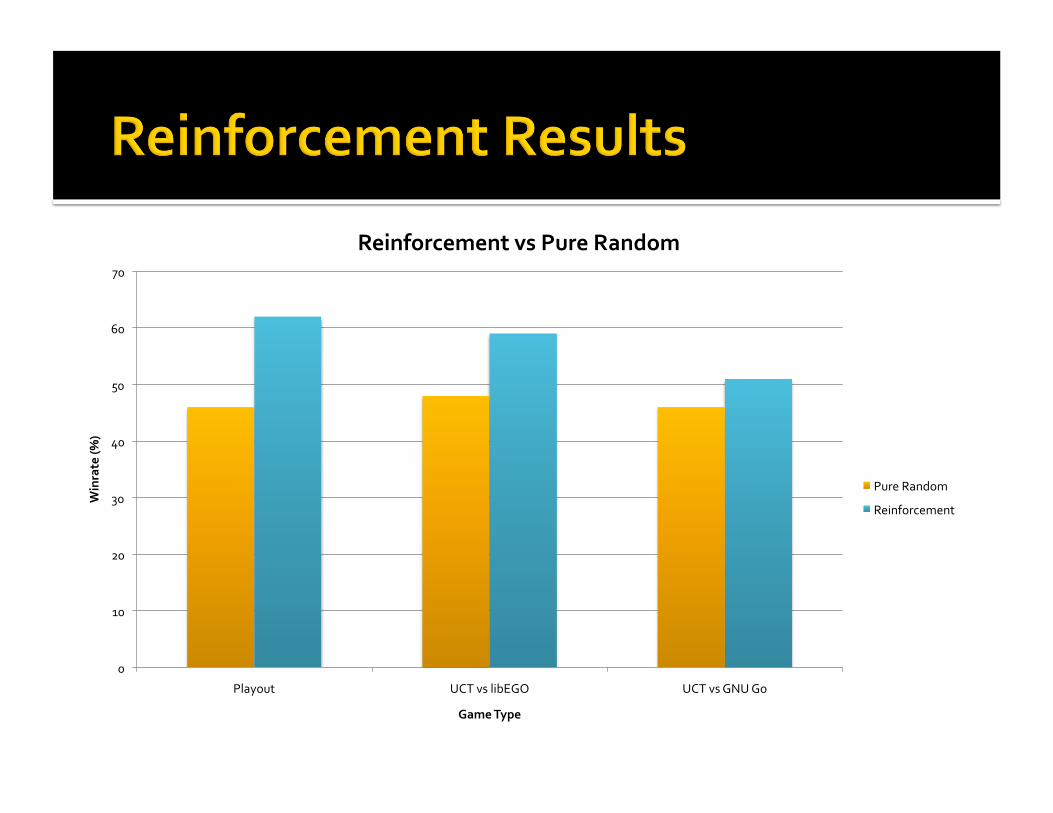
ReinforcementvsPureRandom
PureRandom
Reinforcement

Foreachtraininggame… Playsrandomgamestoestimatewinrate Playsmorerandomgamestodeterminewhichpatternswinandlose
Givespreferencestopatternsbasedonerrorbetweenactualgameresultandobservedwinrate

Usually,stronglocalmoves Seemedtolearngoodpatterndistribution Aggressivelyplayeduselessmoveshopingforanopponentmistake
Poorconsiderationofthewholeboard

0
10
20
30
40
50
60
Playout UCTvslibEGO UCTvsGNUGo
Winrate(%
)
GameType
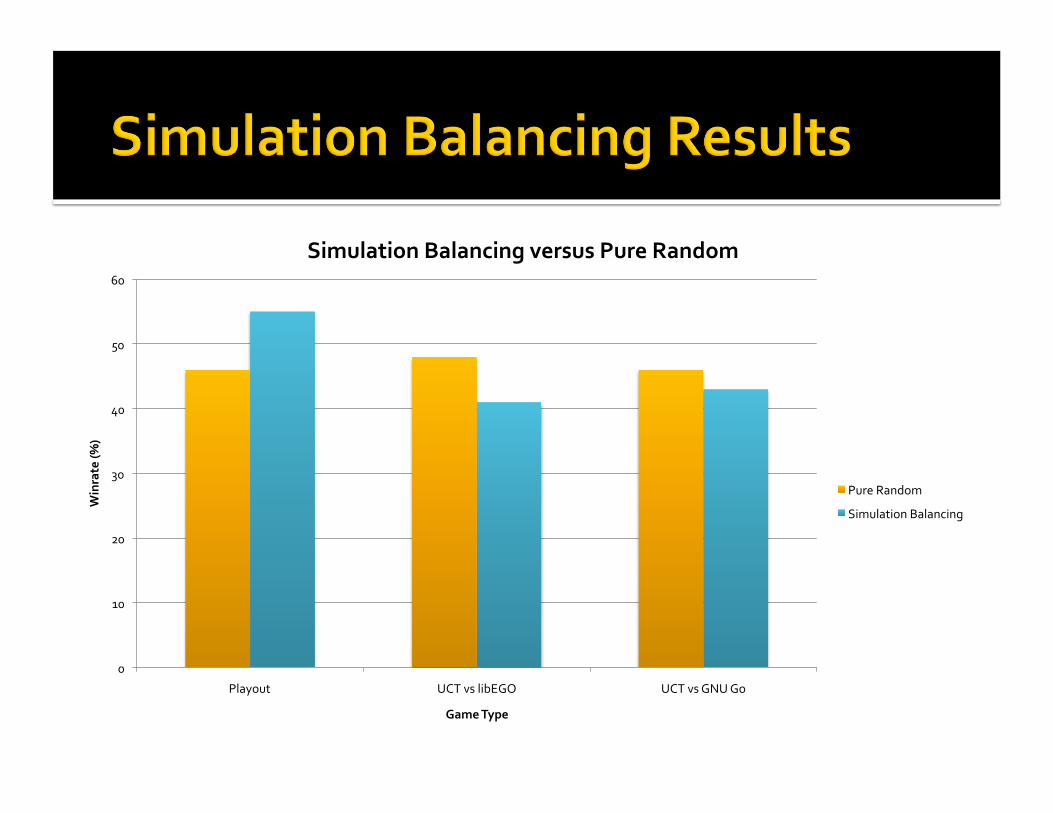
SimulationBalancingversusPureRandom
PureRandom
SimulationBalancing

Picksrandomgamestates Computesscoreestimateofeverymoveat2‐plydepth
Updatespatternpreferencesbasedontheseresults,usingactualgameresulttocompensateforerror

Gamescoreishardtoestimate,usuallyinaccurate
Extremelyexpensive;10‐30sectoestimatescore
Gamescoredoesn’tchangemeaningfullyformanymoves
Probablydoesnotscaleasboardsizegrows
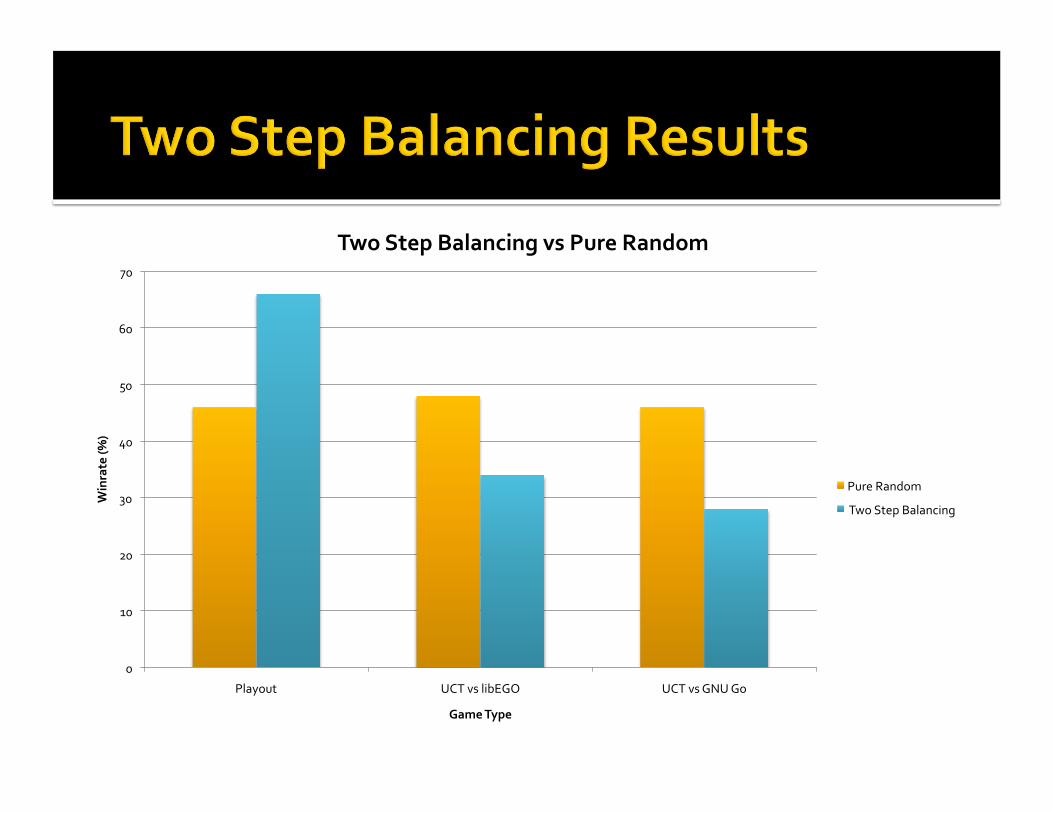
0
10
20
30
40
50
60
70
Playout UCTvslibEGO UCTvsGNUGo
Winrate(%
)
GameType
TwoStepBalancingvsPureRandom
PureRandom
TwoStepBalancing

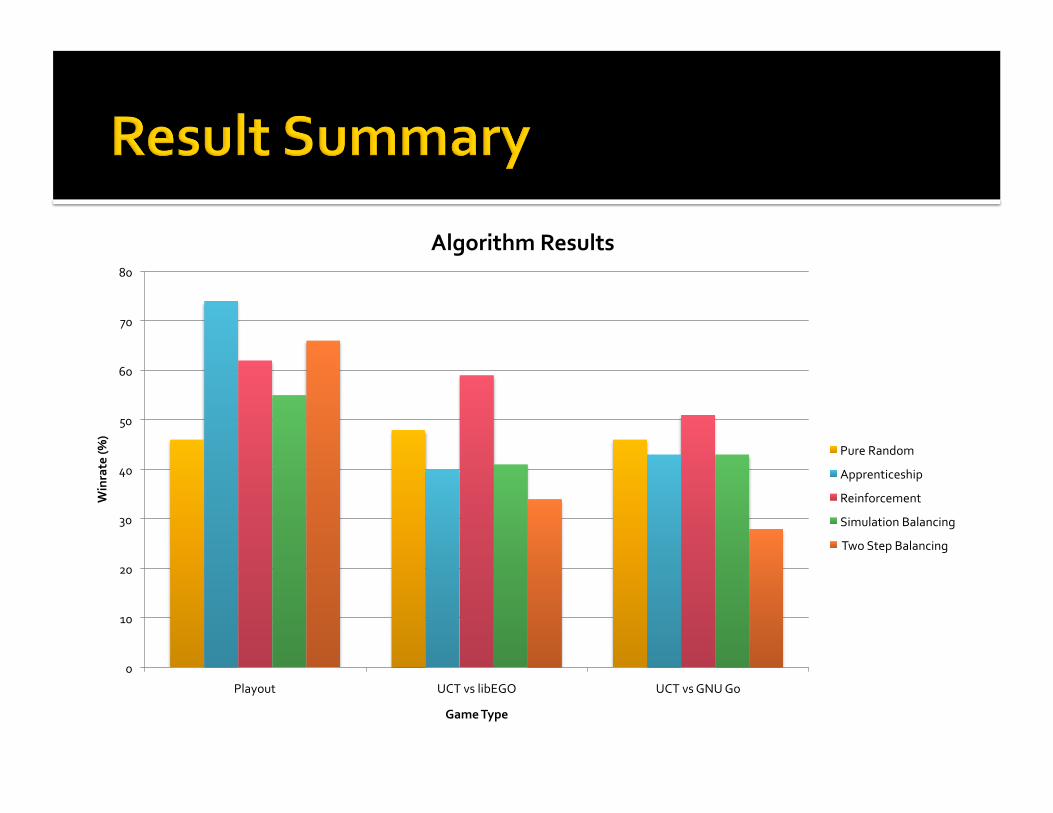
0
10
20
30
40
50
60
70
80
Playout UCTvslibEGO UCTvsGNUGo
Winrate(%
)
GameType
AlgorithmResults
PureRandom
Apprenticeship
Reinforcement
SimulationBalancing
TwoStepBalancing

Reinforcementstrongest Allalgorithmscapableofverydeterministicpolicies
HigherplayoutwinratesweretoodeterministicandthususuallybadwithUCT
Gomaybetoocomplexforthesealgorithms Optimizingself‐playdoesn’tguaranteegoodmoves

LeventeKocsis
SZTAKI
ProfessorsSárközyandSelkow


Algorithmgenerateslistofpatterns Eachpatternhasaweight/value Policylooksatopenpositionsontheboard Getsthepatternateachopenposition Usesweightsasaprobabilitydistribution


















