

BUKU ACUAN : · Web viewTeknik / prosedur apa saja yang ada di dalam statistik? PENGERTIAN...
108
Statistik Bisnis BUKU ACUAN : Anderson, Sweeney, and Williams. 2002. Statistiks for Business and Economics. 8th edition. South-Western/Thomson LearningTM Algifari. 1997. STATISTIKA EKONOMI. Bagian penerbitan dan percetakan YKPN. Edisi ke empat Drs. Noegroho Boedijoewono. 2001. PENGANTAR STATISTIK EKONOMI BISNIS. Unit penerbitan dan percetakan AMP YKPN, Edisi keempat Santoso, Singgih. Pengolahan Data dengan SPSS. Penerbit Andi, Yogyakarta. Supramono, SE dan Ir. Sugiarto. 1993. STATISTIKA. Penerbit Andi Offset Yogyakarta. Edisi pertama PERTANYAAN MENDASAR Apa yang dimaksud dengan “ Statistik”? Kapan dan dimana kita bisa menggunakan “ Statistik”? Mengapa perlu “ Statistik”? Bagaimana menggunakan “ Statistik”? Teknik / prosedur apa saja yang ada di dalam statistik? PENGERTIAN STATISTIK Asal kata “Statistik”: Statia = catatan administrasi pemerintahan di US Stochos = “anak panah” (bahasa Yunani), sesuatu yang mengandung ketidak pastian Pengertian Statistik: Dalam arti sempit = Data ringkasan berbentuk angka (kuantitatif) Contoh : statistik Penduduk yaitu mengenai data atau ringkasan mengenai penduduk (jumlahnya, rata-rata umur, distribusinya, dsb) [email protected] 1
Transcript of BUKU ACUAN : · Web viewTeknik / prosedur apa saja yang ada di dalam statistik? PENGERTIAN...

Statistik Bisnis
BUKU ACUAN :
Anderson, Sweeney, and Williams. 2002. Statistiks for Business and Economics. 8th edition. South-Western/Thomson LearningTM
Algifari. 1997. STATISTIKA EKONOMI. Bagian penerbitan dan percetakan YKPN. Edisi ke empat
Drs. Noegroho Boedijoewono. 2001. PENGANTAR STATISTIK EKONOMI BISNIS. Unit penerbitan dan percetakan AMP YKPN, Edisi keempat
Santoso, Singgih. Pengolahan Data dengan SPSS. Penerbit Andi, Yogyakarta.
Supramono, SE dan Ir. Sugiarto. 1993. STATISTIKA. Penerbit Andi Offset Yogyakarta. Edisi pertama
PERTANYAAN MENDASAR
Apa yang dimaksud dengan “Statistik”?
Kapan dan dimana kita bisa menggunakan “Statistik”?
Mengapa perlu “Statistik”?
Bagaimana menggunakan “Statistik”?
Teknik / prosedur apa saja yang ada di dalam statistik?
PENGERTIAN STATISTIK
Asal kata “Statistik”:
Statia = catatan administrasi pemerintahan di US
Stochos = “anak panah” (bahasa Yunani), sesuatu yang mengandung ketidak pastian
Pengertian Statistik:
Dalam arti sempit = Data ringkasan berbentuk angka (kuantitatif)
Contoh: statistik Penduduk yaitu mengenai data atau ringkasan mengenai penduduk
(jumlahnya, rata-rata umur, distribusinya, dsb)
Statistik personalia (jumlahnya, rata-rata masa kerja, rata-rata jumlah keluarga)
Dalam arti luas = Ilmu yang mempelajari cara pengumpulan data, pengolahan data,
analisis data serta penyajian data sehingga menjadi suatu informasi
yang berguna bagi pengambilan keputusan
Contoh : Seorang pemilik pabrik susu kaleng ingin mengetahui berapa kaleng rata-rata
konsumsi susu perrumah tangga per rumah tangga dari suatu kota tertentu.

Statistik Bisnis
Di kota tersebut ada 1000 rumah tangga (N : 1000, yaitu banyaknya elemen
populasi), untuk menghemat tenaga, biaya dan waktu maka hanya 100 rumah tangga
yang akan di pilih sebagai sempel (n : 10, banyaknya elemen sempel). Dari 100
rumah tangga tersebut di peroleh rata-rata konsumsi antara 55 kaleng dan 65 kaleng.
Oleh karena setiap rumah tangga tidak di selidiki, maka hasil penyelidikan ini
merupakan suatu perkiraan atau pendugaan (estimate). Dari rata-rata berdasarkan
sempel di simpulkan, bahwa rata-rata sebenarnya terletak antara 55-65 kaleng
dengan tingkat keyakinan 95% misalnya. Keyakinan ini mengandung ketidakpastian,
jadi bisa jadi salah. Kesalahan yang mungkin timbul disebabkan karena tidak semua
rumah tangga di selidiki, dari contoh di atas tingkat kesalahan yang bisa di tolirir
sebesar 5%.
Definisi : ilmu statistik adalah kumpulan dari cara-cara atau aturan-aturan mengenai pengumpulan,
pengolahan, penafsiran dan penarikan kesimpulan dari data berupa angka-angka.
STATISTIK DESKRIPTIF DAN STATISTIK INDUKTIF
Menurut tingkat pekerjaan yang dapat dilakukan Statistik di bagi menjadi dua bagian. Kedua bagian
dari ilmu Statistik ialah Statistik deskriptif dan Statistik induktif.
1. Statistik Deskriptif
Adalah bagian dari Statistik yang membicarakan mengenai penyusunan data ke dalam daftar-daftar
atau jadwal, pembuatan grafik-grafik dan lain-lain yang tidak menyangkut penarikan kesimpulan.
2. Statistik Induktif
Adalah bagian lain dari Statistika yaitu semua aturan-aturan dan cara-cara yang di pakai sebagai
alat didalam mencoba menarik kesimpulan yang berlaku umum dari data yang sudah tersusun dan
telah di olah sebelumnya.
Contoh :
Misalkan seorang peneliti ingin mengetahui tingkat mahasiswa polsa yang mendapat nilai mata
pelajaran statistik. Tingkat tersebut di bagi menjadi golongan pagi dan golongan sore, yaitu mereka
yang masuk golongan pagi dan sore hari. Misalkan peneliti tersebut mengambil 10 orang dari golongan
pagi dan 10 orang dari golongan sore dan mengamati angka-angka ujian yang mereka peroleh,
misalkan angka yang di peroleh sbb :
Golongan 1 2 3 4 5 6 7 8 9 10
Pagi 60 54 70 66 70 80 45 75 60 70
Sore 63 80 74 53 90 89 75 66 64 36
Catatan : angak di nyatakan dalam presentase, bahwa ujian di nilai dari 0 sampai 100
Dari angka tersebut dapat di dapat jumlah rata-rata dari 2 golongan tersebut, yaitu 65 untuk
golongan pagi dan 69 untuk golongan sore. Jika peneliti tersebut menghentikan penyelidikannya dan
perhitungannya sampai di sini, maka pekerjaanya masih di dalam bidang statistik Deskriptif.
Akan tetapi, bukanlah tidak mungkin peneliti tersebut ingin membandingkan kedua golongan
mahasiswa tadi. Di atas telah kita ketahui bahwa angka ujian rata-rata golongan pagi adalah lebih

Statistik Bisnis
rendah dari golongan sore, jika 10 orang mahasiswa itu dapat dianggap sebagai wakil dan gambaran
yang representative dari golongan masing-masing. Maka peneliti tersebut dapat mengambil kesimpulan
bahwa golongan sore lebih pandai dari golongan pagi. Jika peneliti menjawab pertanyaan memakai
data yang di kumpulkan 20 orang mahasiswa tersebut di atas maka pekerjaan ini termasuk di dalam
Statistik Induktif
Mahasiswa-mahasiswa yang nilainya di amati itu adalah anggota-anggota sample (sample).
Sampel adalah sebagian dari anggota-anggota suatu golongan yang di pakai sebagai dasar untuk
mendapatkan keterangan mengenai golongan tadi. Golongan yang lebih besar itu di namakan Populasi
atau universe di dalam ilmu statistik. Dari contoh di atas population adalah sekumpulan dari seluruh
mahasiswa yang mengikuti mata kuliah statistik, sedang sempel ialah gologan dari mahasiswa yang
beberapa puluh orang itu, yang benar-benar di amati.
Nilai rata-rata yang di peroleh dari sempel itu di namakan statistik, tentu juga nilai rata-rata dari
seluruh mahasiswa di dalam population di namakan parameter. Jika statistik merupakan bilangan yang
menerangkan sifat dari sample, maka parameter adalah bilangan yang menerangkan sifat dari
population.
Cara Pengambial Sampel
1. Cara Acak (Random)
Adalah cara pemilihan sejumlah elemen dari populsai untuk menjadi sample, pemilihan dilakukan
sedemikian rupa sehingga setiap elemen mendapat bagian yang sama untuk di pilih menjadi
anggota sample. Pemilihan bisa di gunakan dengan lotre/ undian atau kalau data elemenya ribuan
perlu di gunakan tabel angka acak. Angka acak yaitu suatu daftar angka yang sudah di buat
sedemikian rupa sehimgga kalau digunakan akan menjamin pemilihan secara acak. Samplingnya di
sebut probability sampling
2. Cara Bukan Acak (Non Random)
Yaitu suatu cara pemilihan elemen-elemen dari populasi untuk menjadi anggota sample kalau setiap
elemen tidak mendapat kesempatan yang sama untuk dipilih, artinya setiap elemen tidak
mempunyai probabilitas yang sama untuk dipilih.
Contoh Penggunaan Statistika
Seorang Wirasuasta, dengan mengumpulkan data pendapatan dan biaya dan membandingkan
ukuran tersebut untuk mengetahui rata-rata hasil pengembalian atas investasi.
Keuangan (Finance) Penasehat keuangan menggunakan berbagai jenis informasi statistik, termasuk
price-earnings ratio dan hasil dividen, untuk membantu dalam memberikan rekomendasi investasi.
Pemasaran (Marketing) Pengambilan sampel masyarakat sebagai calon konsumen untuk diminta
pendapat tentang produk yang akan diluncurkan oleh suatu perusahaan seringkali menggunakan
kaidah Statistik
Ekonomi Para ahli ekonomi menggunakan prosedur statistik dalam melakukan peramalan tentang
kondisi perekonomian pada masa yang akan datang.

Statistik Bisnis
STATISTIK DI DALAM PEYELIDIKAN ILMIAH
Penelitian secara umum dapat di bagi menjadi beberapa tingkatan yaitu :
1. Observasi (pengamatan)
Seorang peneliti mengamati apa yang sudah kejadian, keterangan-keterangan apa yang dapat
dikumpulkan mengenai persoalan yang hendak ditelit, data mana yang sudah tersedia dan data
mana yang belum tersedia.
2. Penyusunan Hipotesa
Yaitu penyusunan berdasarkan pengamapat tadi diimbangi oleh perasaan dan pertimbangan si
peneliti. Hipotesa adalah suatu jawab (penyelesaian) sementara bagi persoalan yang di hadapi, yang
menurut perasaan peneliti merupakan keterangan atau jawaban terbaik atau keterangan yang dapat
diterima dari persoalan tersebut.
3. Verifikasi
Yaitu penyelidikan apakah peramalan yang di buat baik atau tidak. Baiknya peramalan dengan
membandingkan hasil penelitian dengan kenyataan (fakta).
Metodologi Pemecahan Masalah Secara Statistik
Langkah-langkah dasar dalam masalah secara statistik adalah :
1. Mengidentifikasi masalah atau peluang
Peneliti pertama-tama harus memahami dan mendefinisikan masalah atau peluang yang dihadapi
secara tepat. Informasi secara kualitatif yang bermanfaat dalam hal ini, mencakup data yang
menggariskan sifat dan luas permasalahan.
Contoh : Kurangnya produksi dan pesanan yang belum di penuhi, Fakta tentang populasi perlu di
pelajari . dampak terhadap sumber daya seperti personalia, material, dana dan waktu
2. Pengumpulan fakta yang tersedia
Data yang di kumpulkan harus benar, tepat waktu, selengkap mungkin dan relevan terhadap
masalah yang ditelaah. Sumber data bisa intern dan ekstern
3. Mengumpulkan data orisinil yang baru
4. Mengklasifikasikan data mengikhtisarkan data
Yaitu mengelompokan data untuk tujuan penelaahan.
5. Menyajikan Data
Bisa berbentuk tabel, grafik dan ukuran kuantitatif yang penting menyediakan sarana pemahaman
masalah.
6. Menganalisa data
Yaitu menarik kesimpulan secara statistic yang mungkin bernilai.

Statistik Bisnis
DATA
Data adalah sekumpulan datum yang berisi fakta-fakta serta gambaran suatu fenomena yang
dikumpulkan, dirangkum, dianalisis dan selanjutnya diinterpretasikan.
Data merupakan bahan baku atau komponen utama dalam statistika sarat data yang baik dan berguna :
1. Harus obyektif (bisa mewakili)
Misalnya produksi yang turun di laporkan naik, ini tidak obyektif
2. Harus Representatif
Misalnya hasil produksi padi dari satu daerah hanya didasarkan atas hasil sawah-sawah yang
subur saja, ini jelas tidak mewakili.
3. Variasinya kecil (standard error) harus kecil
Suatu perkiraan (estimate) dikatakan baik jika kesalahan bakunya kecil.
4. Harus tepat waktu
5. Harus relevan
Data yang dikumpulkan harus ada hubungannya dengan masalah yang akan dipecahkan.
Misalnya : Pemerintah mengetahui adanya kemerosotan produksi padi selama beberapa tahun
terakhir.
Untuk mencegah agar produksi padi jangan terus merosot, maka perlu diketahui
faktor-faktor apa saja yang menyebabkannya. Untuk itu di perlukan data yang
relevan misalnya data mengenai pupuk yang kurang, penyaluran kurang lancer
dsb.
Dikaitan dengan masalah manajemen, maka data bisa dipergunakan untuk :
1. Dasar suatu perencanaan
Agar perencanaan sesuai dengan kemampuan yang ada, kemampuan yang di maksud adalah
kemampuan personil, kemampuan pembiayaan (keuangan) serta kemampuan material.
2. Alat pengendalian
Sebagai alat terhadap pelaksanaan atau implementasi perencanaan tersebut agar diketahui dengan
segera kesalahan – kesalahan atau penyimpangan-penyimpangan yang terjadi agar segera
dilaksanakan perbaikan atau koreksi.
3. Dasar Evaluasi
Sebagai hasil kerja akhir. Apakah hasil kerja akhir yang telah diterapkan bisa dicapai 100%, 90%
atau kurang dari itu.
Jenis Data berdasarkan 4 kriteria :
1. Sifatnya 1. Kualitatif a. Berupa label/nama-nama yang digunakan untuk
mengidentifikasikan atribut suatu elemen
b. Skala pengukuran: Nominal atau Ordinal
c. Data bisa berupa numeric atau nonnumeric
Contoh : warna, status perkawinan, jenis kelamin dll

Statistik Bisnis
2. Kuantitatif a. Mengindikasikan seberapa banyak (how
many/diskret atau how much/kontinu)
b. Data selalu numeric
c. Skala pengukuran: Interval dan Rasio
Contoh : 30 tahun, 3 juta dan sebagainya
2. Sumbernya 1. Internal
2. Eksternal
Data yang menggambarkan keadaan/kegiatan
didalam suatu organisasi.
Contoh : data personalia, data keuangan.
Data yang menggambarkan keadaan/kegiatan diluar
suatu organisasi.
Contoh : data yang menggambarkan tingkat daya
beli masyaraka, data permintaan, data konsumsi
3. Cara
memperolehnya
1. Primer
2. Sekunder
data yang langsung dapat diperoleh dari tempat
obyek penelitian
data yang di peroleh dari tempat obyek penelitian
secara tidak langsung
4. Waktu
pengumpulan
1. Cross
section
2. Time
series
yaitu data yang dikumpulkan pada waktu tertentu
yang sama atau hampir sama
Contoh : Jumlah mahasiswa STEKPI TA 2005/2006,
Jumlah perusahaan go public tahun 2006
yaitu data yang dikumpulkan selama kurun
waktu/periode tertentu
Contoh: Pergerakan nilai tukar rupiah dalam 1 bulan,
Produksi Padi Indonesia tahun 1997-2006
VARIABEL
Variabel merupakan sifat yang di miliki oleh individu contoh yang berbeda antara satu individu dengan
individu yang lain
Misal : 1. Pada perusahaan : Upah pegawai
2. Pada tanaman : tinggi tanaman, panjang daun, jumlah daun
Metode Pengumpulan Data :
1. Data Primer : data yang langsung dapat diperoleh dari tempat obyek penelitian
Contoh : wawancara, observasi langsung, wawancara melalui telephon.
2. Data Sekunder : data yang di peroleh dari tempat obyek penelitian secara tidak langsung yaitu
dengan cara mempelajari buku / berkas-berkas
Contoh : BPS, mas media, lembaga pemerintah / swasta.
Data Menurut Skala Pengukuran

Statistik Bisnis
Nominal : digunakan untuk mengklasifikasikan objek amatan dalam katagori yang terpisah untuk
menunjang perbedaan/kesamaan, sifatnya hanya untuk membedakan antar kelompok.
Contoh: Jenis kelamin, Jurusan dalam suatu sekolah tinggi (Manajemen, akuntansi).
Ordinal : Obyek-obyek amatan dapat digolongkan ke dalam katagori tertentu, selain memiliki sifat
nominal, juga menunjukkan peringkat.
Contoh: Tingkat pendidikan (SD, SMP, SMA),
Skala perusahaan (besar, sedang).
PENYAJIAN DATA
CARA PENYAJIAN DATA
1. Tabel
– Tabel satu arah (one-way table)
– Tabulasi silang (lebih dari satu arah (two-way table)
– Tabel Distribusi Frekuensi
2. Grafik
– Batang (Bar Graph), untuk perbandingan/pertumbuhan
– Lingkaran (Pie Chart), untuk melihat perbandingan (dalam persentase/proporsi)
– Grafik Garis (Line Chart), untuk melihat pertumbuhan
– Grafik Peta, untuk melihat/menunjukkan lokasi
MANFAAT TABEL DAN GRAFIK
Hal-hal yang perlu diperhatikan dalam membuat tabel :
1. Tabel hendaknya yang mempunyai judul untuk membedakan tabel yang satu dengan tabel yang
lain.
2. Unit pengukuran angka-angka dalam baris dan kolom tabel harus di jelaskan secara eksplisit.
3. Katagori kelas dalam tabel harus jelas, jangan sampai terjadi tumpang tindih antara kelas yang satu
dengan kelas yang lain.
4. Sumber data keterangan perlu dicantumkan untuk mempermudah pengecekan bila terjadi keraguan.
Ada beberapa cara untuk membuat sajian data lebih mudah dipahami :
1. Tabel distribusi frekuensi : susunan data dalam suatu tabel yang telah diklasifikasikan menurut
kelas-kelas atau kategori tertentu.
Ada 2 macam :
Tabel distribusi frekuensi kualitatif : distribusi frekuensi yang pembagian kelasnya berdasarkan
kategori tertentu yang umum digunakan masyarakat.
Tabel distribusi frekuensi kuantitatif : distribusi frekuensi yang pembagian kelasnya dinyatalan
dalam angka.

Statistik Bisnis
2. Tabel distribusi frekuensi relatife : besaran yang menunjukan presentase obyek yang termasuk
dalam kelas yang bersangkutan.
3. Tabel distribusi frekuensi kumulatif : besaran yang menunjukan jumlah obyek yang termasuk kelas
yang bersangkutan dan kelas-kelas yang sebelumnya atau kelas-kelas berikutnya.
4. Grafik : merupakan gambar-gambar yang menunjukan data secara visual yang dibuat berdasarkan
nilai pengamatan aslinya ataupun dari tabel-tabel yang dibuat sebelumnya.
Keuntungan penyajian data menggunakan grafik :
1. Grafik lebih mudah diingat daripada tabel.
2. Grafik lebih menarik bagi orang-orang yang tidak menyukai angka dan tabel
3. Dengan grafik dapat diperoleh informasi secara visual dan dapat digunakan untuk melakukan
perbandingan secara visual.
4. Grafik dapat menunjukan perubahan satu bagian rangka data dengan bagian yang lainnya.
Kelemahan penyajian data dengan grafik
1. Penyajian jenis grafik harus disesuaikan dengan tujuan penyajian data.
2. Penyajian data dalam bentuk grafik hanya memberi gambaran secara garis besar.
3. Tampilkan grafik sangat dipengaruhi oleh skala yang dipergunakan.
PANCARAN FREKUENSI
Di dalam pembentukan pancaran frekuensi, data yang berupa deretan atau kumpulan bilangan-bilangan
itu kita bagi kedalam beberapa golongan, dan kita menentukan aturan tertentu bilangan mana yang
masuk kedalam setiap golongan.
Ada 2 macam pancaran frekuensi menurut jenis data yang digolongkan didalamnya :
1. Pancaran Frekuensi Bilangan (numerical frequency distribution)
2. Pancaran Frekuensi Katagories (categorical Frequency distribution)
Misalnya disuatau Fakultas terdapat 50 orang mahasiswa mengambil ujian di dalam suatu mata
pelajaran. Angka-angka ujian tersebut ditunjukan oleh daftar 2.1.
Daftar 2.1Pancaran Frekuensi Bilangan
Angka ujian Jumlah mahasiswa
0.00 – 19.99
20.00 – 39.99
40.00 – 59.99
60.00 – 79.99
80.00 atau lebih
3
10
20
12
5
Jumlah 50
Penggolongan di dalam pancaran frekuensi katagoris atau pancaran kualitatif itu berdasarkan sifat-
sifatnya.
Missalnya : Dari penduduk wanita suatu kampung kecil, di kampung tinggal 100 orang wanita dengan
jumlah dari masing-masning terdapat dalam daftar 2.2
Pancaran Frekuensi Katagoris
Katagori Frekuensi
Anak-anak 30

Statistik Bisnis
Gadis
Bersuami
Janda
35
25
10
Jumlah 100
Membentuk Pancaran Frekuensi
Contoh :
Berikut ini data mengenai laba selama 30 hari pada bulan januari 2007 yang di peroleh PT. Bandung
(data dalam ribuan rupiah)
60 55 61 72 59 49
57 65 78 66 41 52
42 47 50 65 74 68
88 68 90 63 79 56
87 65 85 95 81 69
Dari kumpulan angka terebut diatas kita sulit untuk mengetahui berapa laba tertinggi, laba terrenda,
laba yang sebagian besar diperoleh bulan januari dan sebagainya. Oleh karena itu laba tersebut perlu
disusun untuk mendapatkan informasi yang dibutuhkan.
Langkah-langkah yang harus dilakukan untuk membuat tabel distribusi frekuensi adalah sebagai
berikut :
1. Urutkan data dari nilai tertinggi ke nilai terendah
2. Tentukan jumlah kelas yang akan digunakan
Cara menentukan jumlah kelas menurut Sturges (1926)
K = 1 + 3.33 log n
Dengan K : jumlah kelas
n : banyaknya data observasi
3. Menentukan interval kelas
Cara menentukan interval kelas :
I : interval kelas
H : nilai data tertinggi + 1/2 unit pengamat terkecil
L : nilai data terendah - 1/2 unit pengamat terkecil
4. Menyusun data observasi ke dalam tabel distribusi frekuensi
Untuk menjawab kasus tersebut buat tabel distribusi frekuensi mengenai laba selama 30 hari pada
bulan April 2006 (dalam ribuan rupiah).
1. Urutan laba dari terendah sampai tertinggi
H - LI = K

Statistik Bisnis
41 52 60 65 72 85
42 55 61 66 74 87
47 56 63 68 78 88
49 57 65 68 79 90
50 59 65 69 81 95
2. Menentukan jumlah kelas pada pada tabel distribusi frekuensi
K = 1 + 3.33 log n
= 1 + 3.33 log (30)
= 1 + 4.91
= 5.91 dibulatkan 6
3. Menentukan interval kelas
95.5 – 40.5 I = =9.167 di bulatkan 10
64. Menyusun data observasi pada tabel distribusi frekuensi
Tabel 3.1
LABA SCORE BANYAKNYA DATA
40 – 49 IIII 4
50 – 59 IIII I 660 – 69 IIII IIII 10
70 – 79 IIII 4
80 – 89 IIII 4
90 – 99 II 2
Dari tabel tersebut diperoleh informasi :
1. Laba terendah : antara Rp 40.000 – 49.000
Banyaknya hari : 4
2. Laba tertinggi : antara Rp 90.000 – 99.000
Banyaknya hari : 2
3. Sebagian besar diperoleh laba antara Rp Rp 60.000 – 69.000
Banyaknya hari : 10
Batas kelas
Ada 2 macam :
1. Batas kelas bawah : nilai terendah dalam kelas tersebut
2. Batas kelas atas : nilai tertinggi pada kelas tersebut
H - LI = K

Statistik Bisnis
Batas kelas tabel 3.1 sebagai berikut :
1. Kelas pertama
Batas kelas bawah : 40
Batas kelas atas : 49
2. Kelas kedua
Batas kelas bawah : 50
Batas kelas atas : 59 dan seterusnya
Tepi Kelas
Ada 2 macam
1. Tepi kelas bawah
Batas kelas bawah tersebut dikurangi 1/2 dari selisih antara batas atas suatu kelas dengan batas kelas
sesudahnya.
Contoh :
Kelas kedua :
Tepi kelas bawah : 50 - 1/2 (60-59)
: 49.5
Kelas ketiga
Tepi kelas bawah : 60-1/2 (70-69)
: 59.5
2. Tepi kelas atas
Batas kelas tersebut ditambah 1/2 dari selisih antara batas atas suatu kelas dengan batas bawah kelas
sesudahnya.
Contoh :
Kelas kedua :
Tepi kelas atas : 59 +1/2 (60-59)
: 59.5
Kelas ketiga:
Tepi kelas atas : 69+1/2 (70-69)
Nilai Tengah
Adalah nilai uang berada di tengah antara batas kelas bawah suatu kelas dengan batas kelas atas kelas
tersebut.
Nilai tengah = B1+B2
2
B1 = Batas kelas bawah
B2 = Batas kelas atas
Contoh :
Kelas pertama

Statistik Bisnis
Nilai tengah = 40+49
2
= 44.5
Kelas kedua
Nilai tengah = 50+59
2
Frekuensi Relative
Adalah presentase frekuensi suatu kelas terhadap frekuensi total
FR1 = 40+49 X 100%
f
Dimana FR1 = frekuensi relatife kelas ke i
Fi = frekuensi kelas ke i
i = 1,2,3…….
Contoh :
Kelas pertama :
FR = 4 X 100% = 13,3% = 13% 30Kelas kedua :
FR = 6 X 100% = 20% 30
Frekuensi Kumulatif Ada 2 macam :1. Frekuensi kumulatif kurang dari satu kelas : jumlah frekuensi semua kelas sebelum kelas tersebut.2. Frekuensi kumulatif lebih dari satu kelas : jumlah frekuensi semua kelas sesudah kelas tersebut.
Contoh :
LABA BANYAK DATA
NILAI TENGAH
TEPI KELAS
LABA KURANG
DARIFREK.
KUMULATIF
LABA LEBIH DARI
FREK. KUMULATIF
39.5 0 39.5 3040 - 49 4 44.5 39.5 - 49.5
49.5 4 49.5 2650 - 59 6 54.5 49.5 - 59.5
59.5 10 59.5 2060 - 69 10 64.5 59.5 - 69.5
69.5 20 69.5 1070 - 79 4 74.5 69.5 - 79.5
79.5 24 79.5 680 - 89 4 84.5 79.5 89.5
89.5 28 89.5 290 - 99 2 94.5 89.5 - 99.5
99.5 30 99.5 0
Tabel distribusi frekuensi
Dalam tabel distribusi frekuensi terdapat beberapa kelas yang masing-masing kelas berisi data
observasi
Statistik Bisnis
Masing-masing kelas mempunyai interval yang besarnya sama untuk suatu kelas dalam suatu tabel
distribusi frekuensi.
Ada beberapa hal yang perlu diperhatikan agar tabel distribusi frekuensi dapat memberikan informasi
yang terbaik :
1. Jumlah kelas pada tabel distribusi frekuensi jangan terlalu banyak dan jangan terlalu sedikit.
2. Hindari adanya suatu kelas yang tidak dapat menampung data observasi (frekuensi kelasnya nol)
3. Semua data harus dapat ditampung dalam tabel distribusi frekuensi tersebut.
Frekuensi : banyaknya data yang terdapat dalam suatu kelas pada distribusi frekuensi
DISTRIBUSI FREKUENSI
Merupakan tabel ringkasan data yang menunjukkan frekuensi/banyaknya item/obyek pada setiap
kelas yang ada.
Tujuan: mendapatkan informasi lebih dalam tentang data yang ada yang tidak dapat secara cepat
diperoleh dengan melihat data aslinya.
DISTRIBUSI FREKUENSI RELATIF
Merupakan fraksi atau proporsi frekuensi setiap kelas terhadap jumlah total.
Distribusi frekuensi relatif merupakan tabel ringkasan dari sekumpulan data yang menggambarkan
frekuensi relatif untuk masing-masing kelas.
GRAFIK BATANG (BAR GRAPH)
Bermanfaat untuk merepresentasikan data kuantitatif maupun kualitatif yang telah dirangkum
dalam frekuensi, frekuensi relatif, atau persen distribusi frekuensi.
Cara:
– Pada sumbu horisontal diberi label yang menunjukkan kelas/kelompok.
– Frekuensi, frekuensi relatif, maupun persen frekuensi dinyatakan dalam sumbu vertikal yang
dinyatakan dengan menggunakan gambar berbentuk batang dengan lebar yang sama/tetap.
GRAFIK LINGKARAN (PIE CHART)
Digunakan untuk mempresentasikan distribusi frekuensi relatif dari data kualitatif maupaun data
kuantitatif yagn telah dikelompokkan.
Cara:
– Gambar sebuah lingkaran, kemudian gunakan frekuensi relatif untuk membagi daerah pada
lingkaran menjadi sektor-sektor yang luasnya sesuai dengan frekuensi relatif tiap
kelas/kelompok.
– Contoh, bila total lingkaran adalah 360o maka suatu kelas dengan frekuensi relatif 0,25 akan
membutuhkan daerah seluas (0,25)(360) = 90o dari total luas lingkaran
CONTOH DISTRIBUSI FREKUENSI
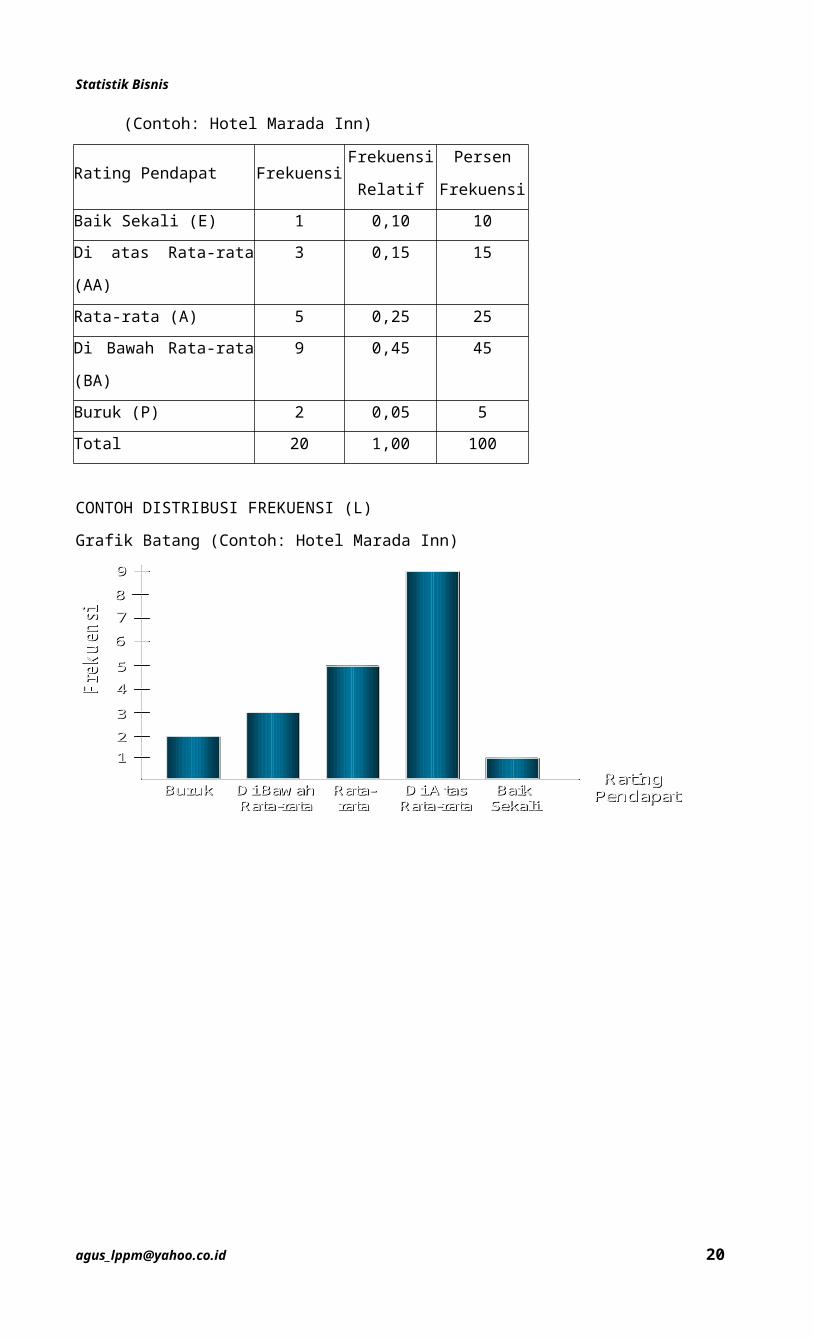
Data Kualitatif
– Tamu yang menginap di Hotel Marada Inn ditanya pendapat mereka tentang akomodasi yang
tersedia. Jawaban dikategorikan menjadi baik sekali (E), diatas rata-rata (AA), rata-rata (A),

Statistik Bisnis
di bawah rata-rata (BA), dan buruk (P). Data dari 20 tamu yang menginap diperoleh sebagai
berikut:
BA A AA AA AA
AA AA BA BA A
P P AA E AA
A AA A AA A
CONTOH DISTRIBUSI FREKUENSI (L)
Tabel Distribusi Frekuensi
(Contoh: Hotel Marada Inn)
Rating Pendapat FrekuensiFrekuensi
Relatif
Persen
Frekuensi
Baik Sekali (E) 1 0,10 10
Di atas Rata-rata (AA) 3 0,15 15
Rata-rata (A) 5 0,25 25
Di Bawah Rata-rata (BA) 9 0,45 45
Buruk (P) 2 0,05 5
Total 20 1,00 100
CONTOH DISTRIBUSI FREKUENSI (L)
Grafik Batang (Contoh: Hotel Marada Inn)
112233445566778899
BurukBuruk Di BawahRata-rataDi BawahRata-rata
Rata-rata
Rata-rata
Di AtasRata-rataDi Atas
Rata-rataBaik
SekaliBaik
Sekali
Frek
uens
iFr
ekue
nsi
Rating PendapatRating
Pendapat
112233445566778899
BurukBuruk Di BawahRata-rataDi BawahRata-rata
Rata-rata
Rata-rata
Di AtasRata-rataDi Atas
Rata-rataBaik
SekaliBaik
Sekali
Frek
uens
iFr
ekue
nsi
Rating PendapatRating
Pendapat

Statistik Bisnis
CONTOH DISTRIBUSI FREKUENSI (L)
Data Kuantitatif
– Manajer Bengkel Hudson Auto berkeinginan melihat gambaran yang lebih jelas tentang
distribusi biaya perbaikan mesin mobil. Untuk itu diambil 50 pelanggan sebagai sampel,
kemudian dicatat data tentang biaya perbaikan mesin mobilnya ($). Berikut hasilnya:
CONTOH DISTRIBUSI FREKUENSI (L)
Petunjuk Penentuan Jumlah Kelas
– Gunakan ukuran banyaknya kelas (k) antara 5 s.d. 20, atau menggunakan formula
k = 1 + 3,3 log n.
n = banyaknya sampel
– Data dengan jumlah besar memerlukan kelas yang lebih banyak, dan sebaliknya.
Petunjuk Penentuan Lebar Kelas
– Gunakan kelas dengan lebar sama.
– Lebar kelas dapat didekati dengan rumus berikut:
CONTOH DISTRIBUSI FREKUENSI (L)
Contoh: Bengkel Hudson Auto
– Jika banyaknya kelas 6, maka lebar kelas = 9,5 ≈ 10
– Tabel distribusi frekuensi diperoleh:
Biaya ($) Frekuensi Frekuensi Frekuensi Frek. Relatif
CONTOH DISTRIBUSI FREKUENSI (L)
Grafik Lingkaran (Contoh: Hotel Marada Inn)Grafik Lingkaran (Contoh: Hotel Marada Inn)
25%
Di bawahRata-rata
10%
45%
Baik Sekali
Kategori Rating Pendapat
5%5%BurukBuruk
15%15%
Rata-rata
Di atasRata-rata

Statistik Bisnis
relatif kumulatif Kumulatif
50 – 59 2 0,04 2 0,04
60 – 69 13 0,26 15 0,30
70 – 79 16 0,32 31 0,62
80 – 89 7 0,14 38 0,76
90 – 99 7 0,14 45 0,90
100 – 109 5 0,10 50 1,00
Total 50 1,00
ANALISIS TABEL DISTRIBUSI FREKUENSI
Contoh: Bengkel Hudson Auto
– Hanya 4% pelanggan bengkel dengan biaya perbaikan mesin $50-59.
– 30% biaya perbaikan mesin berada di bawah $70.
– Persentase terbesar biaya perbaikan mesin berkisar pada $70-79.
– 10% biaya perbaikan mesin adalah $100 atau lebih.
HISTOGRAM
Contoh: Bengkel Hudson Auto
Biaya($)
Biaya($)
22
44
66
88
1010
1212
1414
1616
1818
Frek
uens
iFr
ekue
nsi
50 60 70 80 90 100 11050 60 70 80 90 100 110
OGIVE
Merupakan grafik dari distribusi frekuensi kumulatif.
Nilai data disajikan pada garis horisontal (sumbu-x).
Pada sumbu vertikal dapat disajikan:
– Frekuensi kumulatif, atau
– Frekuensi relatif kumulatif, atau
– Persen frekuensi kumulatif
Frekuensi yang digunakan (salah satu diatas)masing-masing kelas digambarkan sebagai titik.
Setiap titik dihubungkan oleh garis lurus.
OGIVE
Contoh: Bengkel Hudson Auto

Statistik Bisnis
Biaya($)
BiayaBiaya($)($)
2020
4040
6060
8080
100100
Pers
enfre
kuen
siku
mul
atif
Pers
enPe
rsen
freku
ensi
freku
ensi
kum
ulat
ifku
mul
atif
50 60 70 80 90 100 11050 60 70 80 90 100 11050 60 70 80 90 100 110
DIAGRAM BATANG-DAUN (Steam and Leaf)
Contoh: Bengkel Hudson Auto
5 2 7
6 2 2 2 2 5 6 7 8 8 8 9 9 9
7 1 1 2 2 3 4 4 5 5 5 6 7 8 9 9 9
8 0 0 2 3 5 8 9
9 1 3 7 7 7 8 9
10 1 4 5 5 9
Kegunaan:
– Data tersusun secara berurutan
– Dapat menunjukkan bentuk distribusi data
– Seperti Histogram, namun sekaligus menunjukkan data sebenarnya
TABULASI SILANG
Tabulasi silang (Crosstabulation) merupakan metode tabulasi untuk merangkum data dengan
dua atau lebih variabel secara bersamaan / sekaligus.
Tabulasi silang dapat digunakan jika:
– Salah satu variabel bersifat kualitatif dan lainnya kuantitatif
– Kedua variabel berupa variabel kualitatif
– Kedua variabel berupa variabel kuantitatif
Sisi (kolom) sebelah kiri dan baris atas menyatakan kelas untuk kedua variabel yang digunakan.
DIAGRAM SCATTER
Diagram scatter (scatter diagram) merupakan metode presentasi secara grafis untuk
menggambarkan hubungan antara dua variabel kuantitatif.
Salah satu variabel digambarkan pada sumbu horisontal dan variabel lainnya digambarkan pada
sumbu vertikal.
Pola yang ditunjukkan oleh titik-titik yang ada menggambarkan hubungan yang terjadi antar
variabel.
POLA HUBUNGAN PADA DIAGRAM SCATTER

Statistik Bisnis
UKURAN NILAI PUSAT
Suatu kumpulan data biasanya mempunyai kecenderungan untuk memusat pada nialai tertentu. Nilai
tertentu tersebut berupa nilai tunggal atau nilai tendensi pusat yang diangkat dengan Nilai Pusat.
UKURAN-UKURAN STATISTIK
1. Ukuran Tendensi Sentral (Central tendency measurement):
– Rata-rata (mean)
– Nilai tengah (median)
– Modus
2. Ukuran Lokasi (Location measurement):
– Persentil (Percentiles)
– Kuartil (Quartiles)
– Desil (Deciles)
UKURAN-UKURAN STATISTIK
3. Ukuran Dispersi/Keragaman (Variability measurement):
– Jarak (Range)
– Ragam/Varian (Variance)
– Simpangan Baku (Standard deviation)
– Rata-rata deviasi (Mean deviation)
1. RATA – RATA ( MEAN)
xx
yy
xx
yy
xx
yy
xx
yy
xx
yy
xx
yy
Hubungan PositifJika X naik, maka Y juga naik dan
jika X turun, maka Y juga turun
Hubungan NegatifJika X naik, maka Y akan turun dan jika X turun, maka
Y akan naik
Tidak ada hubunganantara X dan YY

Statistik Bisnis
Adalah suatu nilai rata-rata dari semua nilai data observasi. Nilai rata-rata data observasi di beri
simbul u (miyu)
Ada 2 macam Mean :
a. Rata – rata data observasi tidak berkelompok
Merupakan nilai yang diperoleh dari penjumlahan semua data observasi dibagi dengan
banyaknya data.
u = X
N
u = Rata-rata data observasi
= Jumkah
X = nilai data obervasi
N = banyaknya data observasi
Contoh :
Berikut ini adalah skor tes prestasi 10 tenaga sales PT. Probo :
70 56 66 94 48 82 80 70 76 50
Rata – rata skor tes tersebut adalah :
N = 10
X= 78+56+66+…..+50= 700
maka u = X
N = 700 10 = 70
b. Rata – rata data observasi berkelompok
Merupakan jumlah hasil kali antara frekuensi dengan nilai tengah semua kelas jumlah
frekuensi.
u = FM F
u = rata-rata data observasi
= Jumlah
F = Frekuensi
M = nilai tengah
Contoh :
Berikut ini data observasi mengenai laba setiap hari yang diperoleh PT Probo selama 30 hari
pada bulan april 2006
Tabel 4.1.
Laba Frekuensi (f) Nilai Tengah (M) f.M
Statistik Bisnis
40 - 49 4 44.5 178
50 – 59 6 54.5 327
60 – 69 10 64.5 645
70 – 79 4 74.5 298
80 – 89 4 84.5 338
90 – 99 2 94.5 189
f : 30 fM : 1975
Rata-rata laba setiap hari :
fM = 1975
f = 30
u = FM F
= 1975 = 65. 83 30
2. MEDIAN
Adalah nilai data observasi yang berada di tengah-tengah urutan data tersebut, atau data observasi
yang membagi data observasi yang sudah diurutkan menjadi 2 bagian yang sama banyak.
Nilai median data observasi diberi symbol Md
Ada 2 macam Median :
a. Median data observasi tidak berkelompok, dapat ditentukan dengan langkah-langkah sebagai
berikut :
o Urutkan data observasi dari kecil ke yang besar
o Tentukan letak median dengan rumus
N + 1 2o Tentukan nilai median
Contoh :
Data Ganjil
Berikut ini adalah skor tes prestasi 9 karyawan PT. Probo :
78 56 66 94 48 82 80 70 76
Median skor tes 9 karyawan tersebut ditentukan dengan cara :
No urut 1 2 3 4 5 6 7 8 9
Nilai 48 56 66 70 76 78 80 82 94
Letak Median : 9 + 1
2
: 5
jadi letak median pada urutan data ke 5
Data Genap
Berikut ini adalah skor tes prestasi 10 karyawan PT probo

Statistik Bisnis
78 56 66 94 48 82 80 70 76 96
Median skor tes 10 karyawan tersebut ditentukan dengan 2 cara :
No urut 1 2 3 4 5 6 7 8 9 10
Nilai 48 56 6 70 76 78 80 82 94 96
Letak median : 10 + 1
2
: 5.5
Jadi letak median pada urutan data 5.5 atau terletak di antara no urut 5 dan 6 kemudian di
bagi 2
Median (Md) = 76 + 78 = 77
2
b. Median data observasi berkelompok, dapat ditentukan dengan langkah-langkah :
o Tentukan kelas median dengan rumus
Kelas Median : N
2
o Tentukan median dengan rumus
N - CF 2
Md : BMd + fMd X i
Md : Median
BMd : Tepi kelas bawah dari kelas yang mengandung median
N : Banyaknya data observasi
Cf : Frekuensi kumulatif kelas sebelum kelas median
FMd : Frekuensi kelas median
i : Interval
Contoh berikut ini data mengenai laba PT Probo bulan April 2006
LABA FREKUENSI (f) TEPI KELAS FREK. KUM
40 – 49
50 – 59
60 – 69
70 – 79
80 – 89
90 - 99
4
6
10
4
4
2
39.5
49.5
59.5
69.5
79.5
89.5
99.5
4
10
20
24
28
30Langkah untuk menentukan median :
o Letak median = N = 30 = 15 2 2
Jadi kelas median adalah kelas yang ditempati oleh frekuensi kumulatif 15
Frekuensi kumulatif berada di kelas no 3
o Menentukan Median dengan rumus
N - CF

Statistik Bisnis
2Md : BMd + fMd X i
30 - 10 2
Md : BMd + 10 X 10
3. MODUS (Mo)
a. Merupakan suatu nilai yang paling sering muncul (nilai dengan frekuensi muncul terbesar)
b. Jika data memiliki dua modus, disebut bimodal
c. Jika data memiliki modus lebih dari 2, disebut multimodal
Ada 2 macam modus :
a. Modus data observasi tidak berkelompok
Contoh :
o Berikut ini skor tes prestasi PT Probo :
70 56 66 70 48 82 80 70 76 70
frekuensi terbesar adalah 70 yaitu ada 3 orang
jadi modus skor prestasi karyawan PT. Probo : 70
o Berikut adalah data sampel tentang nilai sewa bulanan untuk satu kamar apartemen ($).
Berikut adalah data yang berasal dari 70 apartemen di suatu kota tertentu:
Rata-rata Hitung (Mean)
Median
Karena banyaknya data genap (70), maka median merupakan rata-rata nilai ke-35 dan ke-36,
yaitu
(475 + 475)/2 = 475
Modus = 450 (muncul sebanyak 7 kali)
b. Modus data observasi berkelopok, dapat ditentukan sebagai berikut :

Statistik Bisnis
o Tentukan kelas modus yaitu yang mempunyai frekuensi terbesar.
o Tentukan modus dengan rumus.
Mo : Modus
BMo : Tepi kelas bawah dari kelas yang mengandung modus
d 1 : Selisih antara frekuensi kelas modus dengan frekuensi kelas sebelumnya
d 2 : selisih antara frekuensi kelas modus dengan frekuensi kelas sebelumnya
i : Interval kelas
contoh :Berikut ini data mengenai laba PT. Probo bulan April 2006
Tabel 4.3
LABA FREKUENSI (f) TEPI KELAS
40 – 49
50 – 59
60 – 69
70 - 79
80 – 89
90 - 99
4
6
104
4
2
39.5
49.5
59.5
69.5
79.5
89.5
99.5
= 63.5
Dari contoh Bengkel Hudson Auto
Biaya ($)Frekuensi
(fi)xi
Frekuensi
kumulatif
Lower
Boundaryfixi
50 – 59 2 54,5 2 49,5 109,0
60 – 69 13 64,5 15 59,5 838,5
70 – 79 16 74,5 31 69,5 1192,0
80 – 89 7 84,5 38 79,5 591,5
90 – 99 7 94,5 45 89,5 661,5
100 – 109 5 104,5 50 99,5 522,5
Total 50 3915,0
DATA BERKELOMPOK (L)
Rata-rata Hitung (Mean)
Median
Xidd
dBMoMo21
1
Xidd
dBMoMo21
1
1064
45.59 XMo

Statistik Bisnis
Modus
Rata-rata Hitung (Mean)
– Kelebihan:
Melibatkan seluruh observasi
Tidak peka dengan adanya penambahan data
Contoh dari data :
3 4 5 9 11 Rata-rata = 6,4
3 4 5 9 10 11 Rata-rata = 7
– Kekurangan:
Sangat peka dengan adanya nilai ekstrim (outlier)
Contoh: Dari 2 kelompok data berikut
Kel. I : 3 4 5 9 11 Rata-rata = 6,4
Kel. II : 3 4 5 9 30 Rata-rata = 10,2
Median
– Kelebihan:
Tidak peka terhadap adanya nilai ekstrim
Contoh: Dari 2 kelompok data berikut
Kel. I : 3 4 5 13 14
Kel. II : 3 4 5 13 30
Median I = Median II = 5
– Kekurangan:
Sangat peka dengan adanya penambahan data (sangat dipengaruhi oleh
banyaknya data)
Contoh: Jika ada satu observasi baru masuk ke dalam kelompok I, maka median
= 9
Modus
– Kelebihan:
Tidak peka terhadap adanya nilai ekstrim
Contoh: Dari 2 kelompok data berikut
Kel. I : 3 3 4 7 8 9
Kel. II : 3 3 4 7 8 35
Modus I = Modus II = 3
– Kekurangan:
Peka terhadap penambahan jumlah data
Cohtoh: Pada data

Statistik Bisnis
3 3 4 7 8 9 Modus = 3
3 3 4 7 7 7 8 9 Modus = 7
1. Persentil (Percentiles)
– Persentil merupakan suatu ukuran yang membagi sekumpulan data menjadi 100 bagian
sama besar.
– Persentil ke-p dari sekumpulan data merupakan nilai data sehingga paling tidak p persen
obyek berada pada nilai tersebut atau lebih kecil dan paling tidak (100 - p) percent
obyek berada pada nilai tersebut atau lebih besar.
2. Persentil (Percentiles) (Lanjutan)
– Cara pencarian persentil
Urutkan dari dari yang terkecil ke terbesar.
Cari nilai i yang menunjukkan posisi persentil ke-p dengan rumus:
i = (p/100)n
Jika i bukan bilangan bulat, maka bulatkan ke atas. Persentil ke-p merupakan
nilai data pada posisi ke-i.
Jika i merupakan bilangan bulat, maka persentil ke-p merupakan rata-rata nilai
pada posisi ke-i dan ke-(i+1).
Berdasarkan kasus sewa kamar apartemen
Persentil ke-90
– Yaitu posisi data ke-(p/100)n = (90/100)70 = 63
– Karena i=63 merupakan bilangan bulat, maka persentil ke-90 merupakan rata-rata nilai
data ke 63 dan 64
– Persentil ke-90 = (580 + 590)/2 = 585
425 430 430 435 435 435 435 435 440 440440 440 440 445 445 445 445 445 450 450450 450 450 450 450 460 460 460 465 465465 470 470 472 475 475 475 480 480 480480 485 490 490 490 500 500 500 500 510510 515 525 525 525 535 549 550 570 570575 575 580 590 600 600 600 600 615 615
2. Kuartil (Quartiles)– Kuartil merupakan suatu ukuran yang membagi data menjadi 4 (empat) bagian sama
besar– Kuartil merupakan bentuk khusus dari persentil, dimana
Kuartil pertama = Percentile ke-25 Kuartil kedua = Percentile ke-50 = Median Kuartil ketiga = Percentile ke-75
Berdasarkan kasus sewa kamar apartemen Kuartil ke-3
– Kuartil ke-3 = Percentile ke-75– Yaitu data ke-(p/100)n = (75/100)70 = 52.5 = 53– Jadi kuartil ke-3 = 525

Statistik Bisnis
425 430 430 435 435 435 435 435 440 440
440 440 440 445 445 445 445 445 450 450
450 450 450 450 450 460 460 460 465 465
465 470 470 472 475 475 475 480 480 480
480 485 490 490 490 500 500 500 500 510
510 515 525 525 525 535 549 550 570 570
575 575 580 590 600 600 600 600 615 615
3. Desil (Deciles)– Merupakan suatu ukuran yang membagi sekumpulan data menjadi 10 bagian sama besar– Merupakan bentuk khusus dari persentil, dimana:
Desil ke-1 = persentil ke-10 Desil ke-2 = persentil ke-20 Desil ke-3 = persentil ke-30 … Desil ke-9 = persentil ke-90
Berdasarkan kasus sewa kamar apartemen Desil ke-9
– Desil ke-9 = Percentile ke-90 = 585
425 430 430 435 435 435 435 435 440 440
440 440 440 445 445 445 445 445 450 450
450 450 450 450 450 460 460 460 465 465
465 470 470 472 475 475 475 480 480 480
480 485 490 490 490 500 500 500 500 510
510 515 525 525 525 535 549 550 570 570
575 575 580 590 600 600 600 600 615 615
UKURAN KERAGAMAN/ DISPERSI (Variability measurement)
Mengukur seberapa besar keragaman data Bersama-sama dengan ukuran sentral, ukuran ini berguna untuk membandingkan 2 atau lebih
kelompok data.
Contoh: Dalam pemilihan 2 suplier A atau B, umumnya kita tidak cukup hanya dengan melihat lamanya
rata-rata waktu pengiriman barang yang dilakukan masing-masing suplier, namun juga variasi/keragaman lamanya waktu pengiriman barang.
1. Jarak (Range)– Range = selisih nilai terbesar dan nilai terkecil– Range merupakan ukuran keragaman yang paling sederhana– Sangat peka terhadap data dengan nilai terbesar dan nilai terkecil
Contoh: Kasus sewa kamar apartemenRange = 615 - 425 = 190
2. Varian (Variance)– Merupakan ukuran keragaman yang melibatkan seluruh data– Didasarkan pada perbedaan antara nilai tiap observasi (xi) dan rata-ratanya ( untuk
sampel, untuk populasi)

Statistik Bisnis
– Rumus HitungSample: Populasi: Varian = Varian =
2. Varian (Variance) – (Lanjutan)– Untuk Data Berkelompok, rumus hitung:
Sample: Populasi: Varian = Varian =
dimanak = banyaknya kelasfi = frekuensi kelas ke-Ixi = nilai tengah kelas ke-i
3. Simpangan baku (Standard deviation)– Merupakan akar positif dari varian– Diukur pada satuan data yang sama, sehingga mudah untuk diperbandingkan– Rumus Hitung
Sample: Simpangan baku =
Populasi: Simpangan baku =
4. Koefisien Variasi (Coefficient of Variation)– Mengindikasikan seberapa besar nilai simpangan baku relatif terhadap rata-ratanya– Rumus Hitung
Sample: Koefisien Variasi =
Populasi: Koefisien Variasi =
DATA TIDAK BERKELOMPOK Contoh Kasus Sewa Kamar Apartemen
– Varian
– Simpangan Baku
– Koefisien Variasi
DATA BERKELOMPOK Contoh Kasus Bengkel Hudson Auto
– Varian
1
)(1
2
2
n
xxs
n
ii
1
)(
1
1
2
2
k
ii
k
iii
f
xxfs
k
ii
k
iii
f
xf
1
1
2
2)(
2ss
100xscv

Statistik Bisnis
UKURAN KEMENCENGAN
o Ukuran kemencengan digunakan untuk menunjukan simetris tidaknya bentuk kurva yang dihasilkan dari distribusi suatu gugus data.
o Kemencengan suatu kurva dapat dilihat dari perbedaan letak antara Mean, Median dan Modus.o Distribusi dari kumpulan data dikatakan simetris bila Mean, Median, dan Modus terletak dalam
suatu titik atau dengan kata lain ketiga ukuran nilai pusat tersebut mempunyai nilai yang sama.
Formula yang digunakan untuk menentukan koefisien kemencengan :
Sk : Koefesien kemencenganU : mean / nilai rata-rataMd : median
: deviasi standar
Ketentuan :1. Apakah koefisien kemencengan negatife (Sk < 0), berarti distribusinya tidak simetris dan bentuk
kurva polygon menceng ke kiri.2. Apabila koefisien kemencengan nol (Sk = 0), berarti distribusinya simetris dan bentuk kurva
polygon simetris.3. Apabila koefisien kemencengan positif (Sk>0), berarti distribusinya tidak simetris dan bentuk
kurva poligon menceng ke kanan.Gambar berikut menunjukan kurva poligon dengan 3 macam bentuk kemencengan :
0 U Md Mo 0 U Md Mo 0 M0 Md U
Contoh :U : 65,83Md : 64,5
: 14,08Maka koefisien kemencengan dapat dihitung sebagai berikut :
= 3.99 14.8= 0.28
o Kemencengan negativeo Distribusi menceng ke kirio Data cenderung
terkonsentrasi pada nilai yang tertinggi
o Kemencengan nolo Distribusi Simetris
o Kemencengan Positifo Distribusi Menceng ke
kanano Data cenderung
terkonsentrasi pada nilai yang terendah

Statistik Bisnis
Dengan nilai Sk>0 berarti distribusi menceng ke Kaman dan data cenderung terkonsentrasi pada nilai yang rendah,
63.5 64.5 14.08 Mo Md U
UKURAN KERUNCINGANo Adalah Suatu ukuran yang digunakan untuk menentukan runcing tidaknya suatu kurva distribusi
sehingga dapat diketahui apakah kumpulan data terkonsentrasi di sekitar mean atau menyebar.o Untuk menentukan keruncingan suatu distribusi maka digunakan formulir
0 Platikurtik 0 Mesokurtik 0 LeptokurtikDistribusi ini menunjukan frekuensi menyebar ke seluruh daerah kurva
Distribusi ini menunjukan distribusinya simetris sehingga dianggap menggambarkan distribusi normal
Distribusi ini menunjukan frekuensi menumpuk pada interval tertentu sekitar mean, sedikit yang tersebar lebih jauh dari mean.
ANGKA INDEKSAngka indeks merupakan presentase relatife ukuran suatu vareabel pada waktu tertentu
terhadap ukuran variable tersebut pada waktu dasar (pereode waktu yang digunakan sebagai dasar perbandingan).Angka indeks dapat diukur melalui harga, kuantitas atau nilai dari variable dan sebagainya.
Misal :Indeks harga beras di banjarmasin tahun 1991 adalah 110 dengan tahun dasar 1980, ini mengandung makna bahwa dari tahun 1980 – tahun 1991 harga beras dibanjarmasin naik 10%.
ANGKA INDEKS RELATIF SEDERHANA1. Indeks harga
menunjukan perkembangan relatife harga suatu barang pada waktu tertentu dari pereode waktu dasar.Rumus :
IHn : Indeks harga pada tahun ke n

Statistik Bisnis
Pn : Harga pada tahun ke nPo : Harga pada tahun dasarContoh :Tahun 1988 harga beras A di kota Kebumen Rp 800 perliter. Kemudian tahun 1989-tahun 1993 harga beras tersebut berturut-turut Rp 880, 1000, 1080, 1200, 1240 perliter. Perbandingan harga beras :
Tahun (n)
1989 880 x 100 = 110800
1990 1000 x 100 = 125800
1991 1080 x 100 = 135800
1992 1200 x 100 = 150800
1993 1240 x 100 = 155800
2. Indeks Harga rata-rata dari relatifeAngka indeks yang diperoleh dari jumlah harga rata-rata dibagi banyaknya tahun yang digunakan dakali 100Rumus :
Contoh :Berdasarkan contoh dan perhitungan pada indeks harga maka indeks harga rata-rata dari relatife (I r) :
Tahun (n) PnP1988
19891990199119921993
1.101.251.351.501.55
= (6.75) x 100 5= 135
3. Indeks KuantitasPresentase relatife perubahan kuantitas suatu barang selama pereode tertentuRumus :

Statistik Bisnis
IKn = Indeks kuantitas pada tahun nqn = kuantitas pada tahun nqo = kuantitas pada tahun dasar
contoh :Tahun 1988 Jumlah telur bebek yang dihasilkan diKutoarjo sebanyak 800 Ton. Kemudian tahun 1989-tahun 1993 jumlah telur itu berturut-turut 880 ton, 1000, 1080, 1200, 1240. Perbandingan jumlah (kuantitas) telur :
Tahun (n)
1989 880 x 100 = 110800
1990 1000 x 100 = 125800
1991 1080 x 100 = 135800
1992 1200 x 100 = 150800
1993 1240 x 100 = 155800
4. Indeks NilaiDiukur dengan mengalikan antara kuantitas dengan harga pada periode tertentu dibagi dengan kuantitas dikali harga tahun dasar.Rumus
Inn : Indeks nilai pada thm nPn : Harga pada tahun ke nP0 : Harga pada tahun dasarqn : Kuantitas pada tahun nq0 : Kuantitas pada tahun dasar
Contoh : Tabel berikut menunjukan harga dan jumlah gabah yang dihasilkan kecamatan Purworejo :
Keterangan 1990 1991Harga (Ribu Rp) 80 85Kuantitas (ton) 100 124
Maka indeks nilai gabah tahun 1991 dengan tahun dasar 1990 :
= 131.75
ANGKA INDEKS AGREGATIF TIDAK TERTIMBANG1. Indeks Harga Agregatif
Presentase relatife jumlah harga barang-barang pada tahun tertentu terhadap jumlah harga barang-barang tersebut pada tahun dasar.Rumus :

Statistik Bisnis
IHn : Indeks harga agregatif pada tahun n: Jumlah harga barang pada tahun n: Jumlah harga barang pada tahun dasar
Contoh :Tabel berikut ini data mengenai harga-harga jumlah 3 macam barang konsumsi pada tahun 1990 dan tahun 1991.
Barang Harga1990 (Po) 1991 (P1)
Beras (liter) 800 800Telur (Kg) 2000 2400Susu (kg) 1400 1600
1990: 4200 1991: 4800
=114.29
2. Indeks Kuantitas AgregartifPresentase relatife jumlah kuantitas barang-barang pada tahun tertentu terhadap jumlah kuantitas barang tersebut pada tahun dasar.Rumus :
IKn = Indeks kuantitas pada tahun n= Jumlah kuantitas barang pada tahun n= Jumlah kuantitas barang pada tahun dasar
Contoh :Tabel berikut data mengenai harga-harga jumlah barang konsumsi pada tahun 1990 dan tahun 1991.
Barang Kuantitas1990 (qo) 1991 (q1)
Beras (liter) 15 12Telur (Kg) 2 2.8Susu (kg) 6 8
1990: 23 1991: 22.8
= 99.133. Indeks nilai agregatif
Presentase relatife nilai (harga dikali kuantitas) barang-barang pada tahun tertentu terhadap nilai barang-barang tersebut pada tahun dasar.Rumus :
INn : Indeks nilai pada tahun n

Statistik Bisnis
Pn : Harga barang-barang pada tahun nPo : Harga barang-barang pada tahun dasarqn : Kualitas barang-barang pada tahun nqo : Kuantitas barang-barang pada tahun dasar
Contoh :Tabel berikut data mengenai harga-harga jumlah 3 macam barang konsumsi pada tahun 1990 dan tahun 1991 :
BarangHarga Kuantitas
Poqo Pnqn1990(P0)
1991(Pn)
1990(qo)
1991(qn)
Beras (liter) 800 800 15 12 12.000 9.600Telur (Kg) 2000 2400 2 2.8 4.000 6.720Susu (kg) 1400 1560 6 8 8.400 12.480
24.400 28.800
= 118.03
ANGKA INDEKS AGREGATIF TERTIMBANG1. Formulasi Laspeyres
Angka indeks yang menggunakan kuantitas tahun dasar (q0) sebagai penimbang.Rumus :
IL : Indeks LaspeyresPn : Harga pada tahun nPo : Harga pada tahun dasarq0 : Kuantitas pada tahun dasar
Contoh :
BarangHarga Kuantitas
Pnqo Poqo1990(P0)
1991(Pn)
1990(qo)
1991(qn)
Beras (liter) 800 800 15 12 12.000 12.000Telur (Kg) 2000 2400 2 2.8 4.800 4.000Susu (kg) 1400 1560 6 8 9.360 8.400
26.160 24.400
= 107.21
2. Formulasi Passche Angka indeks yang menggunakan kuantitas tahun tertentu (qn) sebagai penimbang.

Statistik Bisnis
Rumus :
IP : Indeks PasschePn : Harga pada tahun nPo : Harga pada tahun dasarqn : Kuantitas pada tahun nContoh :Tabel berikut merupakan data mengenai harga dan kuantitas :
BarangHarga Kuantitas
Poqn Pnqn1990(P0)
1991(Pn)
1990(qo)
1991(qn)
Beras (liter) 800 800 15 12 9.600 9.600Telur (Kg) 2000 2400 2 2.8 5.600 6.720Susu (kg) 1400 1560 6 8 11.200 12.480
26.400 28.800
= 109.09
3. Formulasi FisherAngka indeks yang menggunakan Indeks Laspeyres dan Indeks Paasche dalam perhitungan.Indeks Fisher disebut sebagai Indeks karena merupakan penyempurnaan dari Formulasi Laspeyres dan Passche.Rumus :
IF : Indeks FisherIL : Indeks LaspeyresIP : Indeks PaascheContoh :Berdasarkan perhitungan dalam contoh formulasi laspeyres dan formulasi passche tersebut maka :
= 108.15
4. Formulasi Marshal-EdgeworthAngka indeks yang menggunakan jumlah kuantitas tahun dasar (qo) dan kuantitas tahun yang akan ditentukan angka indeksnya (qn) sebagai penimbang.Rumus :
IME = Indeks Marshal-EdPo,qo = Harga dan kuantitas tahun dasarPn,qn = Harga dan kuantitas tahun yang akan ditentukan angka indeknya Contoh :Data pada table sebelumnya diolah sebagai berikut :
BarangHarga Kuantitas
Po(qo+qn) Pn(qo+qn)1990(Po)
1991(Pn)
1990(qo)
1991(qn)
Beras (liter) 800 800 15 12 21.600 21.600Telur (Kg) 2000 2400 2 2.8 9.600 11.520Susu (kg) 1400 1560 6 8 19.600 21.840

Statistik Bisnis
50.800 54.960
= 108.19
5. Formulasi WalshAngka indeks yang menggunakan akar dari hasil kali antara kuantitas tahun dasar (qn) dan kuantitas tahun yang akan ditentukan angka indeksnya (qn) sebagai penimbang.Rumus :
IW = Indeks WaleshPo,qo = harga dan kuantitas tahun dasarPn,qn = harga dan kuantitas tahun yang akan ditentukan angka indeknyaContoh :Data pada tabel sebelumnya diolah sebagai berikut :
BarangHarga Kuantitas
1990(Po)
1991(Pn)
1990(qo)
1991(qn)
Beras (liter) 800 800 15 12 4.156.92 4.156.92Telur (Kg) 2000 2400 2 2.8 4.381.78 5.258.14Susu (kg) 1400 1560 6 8 5.238.32 5.836.99
13.677.02 15.252.05
= 111.526. Formulasi Drobisch
Angka indeks yang digunakan apabila selisih antara angka indeks dengan Formulasi Laspeyres dan Formulasi Paasche terlalu besar.Rumus :
ID = Indeks DrobischIL = Indeks LaspeyresIP = Indeks Paasche
Contoh : berdasarkan perhitungan dalam contoh Formulasi Laspeyres dan formulasi Paasche tersebut maka :

Statistik Bisnis
ANALISA DERET BERKALA
Yaitu alat analisis yang dapat digunakan untuk mempelajari perubahan nilai variable dari waktu ke waktu.
Analisis deret berkala dapat digunakan untuk :1. Mengetahui kecenderungan nilai suatu variable dari waktu ke waktu2. Meramal ninlai suatu variable pada suatu waktu tertentu
Deret berkala (time series) merupakan susunan nilai data observasi secara berurutan dari waktu ke waktu
Angka perkembangan niali variable mudah diketahui maka pola perubahannya digambarkan dengan ebuah grafik (garis)
Dalam analisis ekonomi dan bisnis, analisis deret berkala biasanya digunakan untuk meramal nilai suatu variable pada masa lalu dan masa yang akan datang dengan berdasarkan pada kecenderungan dari perubahan nilai variable tersebut dari waktu ke waktu.
Perubahan nilai suatu variable dipengaruhi oleh :1. Trend Sekuler (secular trend)
Adalah perubahan nilai variable yang relative stabil dari waktu ke waktu.Arah perubahan ini dapat digambarkan dengan suatu garis linier yang halus.
2. Variasi musiman (seasonal variations)Merupakan perubahan nilai suatu variable dari waktu ke waktu sebagai akibat dari adanya musim tertentu
3. Fluktuasi siklis (cyclical fluctuations)Adalah perubahan nilai suatu variable dari waktu ke waktu yang biasanya disebabkan oleh factor-faktor ekonomi
4. gerak tak beraturan (irregular movements)merupakan perubahan variable dari waktu ke waktu yang bergerak tak menentu, tidak mengikuti pola trend, fluktuasi siklis maupun variasi musiman.
TREND SEKULERBentuk umum persamaan linier trend :
y = a + b x
agar persamaan trend yang diperoleh memenuhi krtiteria persamaan garis linier yang baik maka untuk menentukan persamaan tersebut (a dan b) di gunakan formula :
a = n
b = 2
Yang menyatakan :n : banyaknya tahun yang digunakany : nilai variable deret berkalax : kode waktu masing-masing tahuncomtoh :Trend data produksi padi di Dlangu dari tahun 1986-1992
Tahun Produksi(y)
Kode waktu(x) XY X2
1986 10 -3 -30 91987 8 -2 -16 41988 10 -1 -10 11989 12 0 0 01990 16 1 16 11991 12 2 24 41992 16 3 48 9
=84 =0 =32 2=28
Persamaan linier trens :

Statistik Bisnis
a = = =12 n 7
b = = 32 =1.143 2 28
Maka yt = 12+1.143xyt menunjukan ramalan produksi pada tahun t.Misalkan persamaan garis linier trend untuk membuat ramalan tahun 1995, maka ramalan produksi padi berdasarkan persamaan tersebut :Y1995 = 12+1.143 (6)
= 18.858
Banyaknya waktu menunjukan bilangan genap, perhatikan contoh berikut :
Tahun Produksi(y)
Kode waktu(x) XY X2
1986 10 -3.5 -30 91987 8 -2.5 -16 41988 10 -1.5 -10 11989 12 -0.5 -6 0.25
- - 0 - -1990 16 0.5 16 11991 12 1.5 24 41992 16 2.5 48 91993 14.86 3.5 52 12.25
=98.86 =42 2=42
Persamaan linier trend :
a = = 98.86 =12.36 n 8
b = = 42 =1 2 42
yt = 12.36+1x

Statistik Bisnis
REGRESI DAN KORELASI SEDERHANA
Analisa regresi dan korelasi ;Analisis mengenai perubahan suatu nilai variable yang diakibatkan oleh perubahan nilai variable lain yang dapat mempengaruhi variable tersebut.
Sederhana:Di dalam analisis hanya melibatkan 2 buah variable yang mempengaruhi (independent variable) dan variable yang dipengaruhi (dependent variable).
Hubungan antara 2 atau lebih variable ada 2 macam analisis : Regresi
Menunjukan bentuk hubungan antara variable independent dan variable dependent. Korelasi
Menjelaskan keeratan hubungan antara variable yang satu dengan variable dependent
Contoh :Hubungan antara nilai test masuk dan IP mahasiswa :Mahasiswa : A B C D E F G HNilai test: 74 69 85 63 82 60 79 91IP (y) : 2.6 2.2 3.4 2.3 3.1 2.1 3.2 3.1Dari informasi maka test masuk merupakan variable independent dan indeks prestasi sebagai variable dependent.Apabila dibuat dalam gambar sebagai berikut : y3.5
3.25
3.0
2.75
2.50
2.25
60 65 70 75 80 85 90 95 X
Dengan diagram tersebut dapat diberikan beberapa penjelasan: Bentuk hubungan kedua variable tersebut adalah positif karena meningkatnya nilai y (searah) Derajat atau tingkat hubungan kedua variable sangat erat, titil-titik yang menunjukan pertemuan x
dan y mendekati garis lurus. Hubungan kedua variable adalah linier karena titik-titik yang menunjukan pertemuan nilai x dan y
menggambarkan garis lurus.
KONSTANTA DAN KOOFISIEN REGRESIAnalisis regresi bertujuan menentukan persamaan regresi yang baik yang dapat digunakan untuk menaksir nilai variable dependen.Bentuk persamaan :
Y = a + bx
Yang menyatakan bahwa a : konstanta (nilai y apabila x = 0)

Statistik Bisnis
b : Koefisien regresi (kenaikan atau penurunan taksiran nilai y apabila x berubah 1 unit)y : niali variable yang dipengaruhi variable lain(dependent variable)x : nilai variable yang mempengaruhi variable lain (independent variable)Nilai konstanta (a) dan koefisien regresi (b) dapat dihitung dengan formula :
n = jumlah data observasidana = y – bxy = nilai rata-ratax = nilai x rata-rata
Nilai y rata-rata dan nilai x rata-rata dapat ditentukan :
y = dan x n ncontoh :
Perusahaan batik Angreani ingin mengetahui hubungan fungsional antara biaya produksi dengan jumlah yang diproduksi.
Biaya Prodk(y)
Jml Prodk(x)
XY X2 Y2
64 20 1280 400 409661 16 976 256 372184 34 2856 1156 705670 23 1610 529 490088 27 2376 729 774492 32 2944 1024 846472 18 1296 324 518477 22 1694 484 5929
=608 =192 =15032 2=4902 2=47094
a =Y - BX = 608 = 78 n 8
X = = 192 = 24 n 8
a = 76 – 1.5 –(24) = 40sehingga diperoleh persamaan regresi :y = a + bx = 40 + 1.5x
KOEFISIEN KORELASI

Statistik Bisnis
Adalah untuk mengetahui keeratan antara 2 macam variableBesarnya r antara 0 sampai dengan +1 Apabila r=0 berarti antara 2 variabel tak ada hubungannya. Apabila r=1 berarti antara 2 variabel mempunyai hubungan sempurna dan menunjukan hubungan
yang searah Apabila r=-1 berarti antara 2 variabel mempunyai hubungan yang sempurna tetapi menunjukan
hubungan yang berlawanan arah.
Sempurna tinggi nilai korelasi antara 2 buah variable (semakin mendekati satu) maka tingkat keeratan hubungan antara 2 variabel tersebut semakin tinggi dan sebaliknya.Misalnya :2 buah variable mempunyai koefisien korelasi R = 0.7 menunjukan bahwa tingkat keeratan hubungan searah antara 2 variabel tersebut adalah 0,7atau 70%
koefisien korelasi dapat dihitung dengan formula:
contoh :temukan keeratan hubungan antara biaya produksi dengan jumlah yang diproduksi berdasarkan pada tabel perusahaan batik anggraeniuntuk menentukan koefisien korelasi ®, maka masukan nilai pada tabel tersebut ke dalam formula :
keeratan hubungan antara biaya produksi gengan jumlah yang diproduksi adalah 0.86 atau 86%

Statistik Bisnis
KOEFISIEN DETERMINASI (R2)Adalah ukuran yang menunjukan besarnya variasi variable dependen yang dapat dijelaskan oleh persamaan yang diperoleh.Dalam persamaan regresi, koefisien determinasi menunjukan presentase pengaruh semua variable independent yang terdapat dalam persamaan terhadap variable dependennya.Contoh :Jika suatu persamaan regresi mempunyai koefisien korelasi (r)= 0.86 atau 86% maka besarnya koefisien determinasi (r2)=(0.86)2 = 0,74 atau 74%.Artinya besarnya variasi variable dependen yang dapat dipengaruhi oleh variable independent adalah 74%, sedangkan sisanya 26% dipengaruhi oleh variable lain di luar persamaan regresi tersebut.
Penaksiran Nilai Variabel DependenCaranya adalah dengan memasukan nilai variable independenya ke dalam persamaan regresi yang diperoleh, maka dapat ditentukan taksiran nilai variable independennya.Contoh :Buatlah taksiran biaya total pada tingkat produksi 100 unit dengan menggunakan persamaan regresi :
Y = 40 + 1,5x
Dengan memasukan jumlah out put (x=100) ke dalam persamaan tersebut, maka biaya produksi taksiran (y) dapat ditentukan sebagai berikut :
Y = 40 + 1.5 (100) = 40 + 150 = 190jadi biaya produksi yang harus dikeluarkan untuk memproduksi sebanyak 100 unit ditaksir sebesar 190.

Statistik Bisnis
UKURAN VARIASI(Measure of Variation)
Ukuran Variasi adalah ukuran yang menyatakan seberapa jauh nilai pengamatan yang sebenarnya menyimpang atau beberapa dengan nilai pusatnya.
Ukuran yang termasuk dalam ukuran variasi1. Range (R) : selisih antara tepi kelas atas kelas yang terakhir dengan kelas bawah pertama
Contoh : LABA BANYAKNYA HARI40 – 4950 – 5960 – 6970 – 7980 – 8990 - 99
4610442
Range (R)laba dari data tersebut adalah :R : B2 – B1
R : Range data observasiB1 : Nilai terendahSehingga besernya range : R : 99,5 – 39,5 : 60
2. Deviasi Rata-rata (MD) : suatu ukuran yang menunjukkan deviasi rata-rata data observasi terhadap rata-ratanya
MD : Deviasi rata-rataf : Frekuensi Kelasu : nilai rata-rata data observasi : Tanda aljabar yang menunjukan nilai absolut N : Banyaknya data observasi
Contoh :
Laba F M M-u F M-u
40 – 4950 – 5960 – 6970 – 7980 – 8990 - 99
4610442
44.554.564.574.584.594.5
21.3311.331.338.6718.6728.67
85.3267.9813.334.6874.6857.34
= 333.3
Diketahui u = 65.83
Sehingga besarnya
= 333.3 30= 11.11

Statistik Bisnis
3. Deviasi Standar Suatu ukuran yang menunjukan standar data observasi terhadap rata-ratanya
2
N 2
N
= 14.08
ANGKA INDEKSCakupan:
1. Harga Relatif (Price Relatives)2. Indeks Harga Agregat (Aggregate Price Indexes)3. Berbagai Indeks Penting4. Indeks Kuantitas (Quantity Indexes)
HARGA RELATIF (PRICE RELATIVES) Bermanfaat dalam memahami dan menginterpretasikan perubahan kondisi ekonomi dan bisnis
dari waktu ke waktu. Harga relatif menunjukkan bagaimana harga per unit untuk komoditas tertentu saat ini
dibandingkan dengan harga per unit komoditas yang sama pada tahun dasar. Harga relatif memperlihatkan harga per unit pada setiap periode waktu sebagai persentase dari
harga per unit pada tahun dasar.HARGA RELATIF (PRICE RELATIVES) (L)
Periode dasar merupakan waktu/titik awal (starting point) yang telah ditentukan.
Harga relatif dirumuskan:
CONTOH: PRODUK BESCO
Berikut adalah biaya iklan melalui surat kabar dan televisi pada tahun 1992 dan 1997 yang telah dikeluarkan oleh Besco. Dengan menggunakan tahun dasar 1992, hitung indes harga pada tahun 1997 untuk biaya iklan melalui surat kabar dan televisi.
1992 1997Surat kabar $14,794 $29,412Televisi $11,469 $23,904
CONTOH: PRODUK BESCO
Harga Relatif Surat kabar Televisi
Kenaikan biaya iklan melalui televisi lebih besar dibandingkan melalui surat kabar.
Indeks Harga Agregat dibuat untuk mengukur perubahan harga dari berbagai jenis barang secara bersama-sama.
Indeks Harga Agregat Tak Tertimbang pada periode t, dinotasikan dengan I, dirumuskan sebagai berikut:
199)100(794,14412,29
1997 I 2 0 8)1 0 0(4 6 9,119 0 4,2 3
1 9 9 7 I
)( Mf
7,946.5
7,946.5

Statistik Bisnis
dimanaPit = harga per unit jenis barang i pada periode tPi0 = harga per unit jenis barang i pada tahun dasar
Pada Indeks Harga Agregat Tertimbang, masing-masing jenis barang diberi bobot/penimbang sesuai dengan pentingnya barang tersebut. Biasanya digunakan kuantitas barang sebagai penimbang.
Misal Qi = kuantitas barang i, maka Indeks Harga Agregat Tertimbang pada period t dirumuskan:
Jika penimbang (bobot) menggunakan kuantitas pada tahun dasar, maka indeks ini disebut sebagai Indeks Laspeyres (Laspeyres index).
Jika penimbang menggunakan periode t, maka indeks ini disebut Indeks Paasche (Paasche index).
CONTOH: KOTA NEWTON Berikut adalah data konsumsi dan pengeluaran energi menurut sektor di Kota Newton. Hitung
Indeks harga Agregat untuk pengeluaran energi pada tahun 2000 dengan tahun dasar 1985.
Quantity (BTU) Unit Price ($/BTU)
Sektor 1985 2000 1985 2000Tempat Tinggal 9,473 8,804 2.12 10.92Komersil 5,416 6,015 1.97 11.32Industri 21,287 17,832 0.79 5.13Transportasi 15,293 20,262 2.32 6.16
CONTOH: KOTA NEWTON Indeks Harga Agregat Tak Tertimbang I2000 = 10.92 + 11.32 + 5.13 + 6.16 (100) = 466
2.12 + 1.97 + .79 + 2.32 Indeks Harga Agregat Tertimbang (Laspeyres) I2000 = 10.92(9473) + . . . + 6.16(15293) (100) = 443
2.12(9473) + . . . + 2.32(15293) Indeks Harga Agregat Tertimbang (Paasche) I2000 = 10.92(8804) + . . . + 6.16(20262) (100) = 415
2.12(8804) + . . . + 2.32(20262)
BERBAGAI INDEKS PENTING Indeks Harga Konsumen (IHK) Indeks Harga Produsen (IHP) Indeks Harga Perdagangan Besar (IHPB) Indeks Biaya Hidup (IBH)
Pemilihan Komoditas– Jika banyaknya kelompok komoditas sangat besar, maka cukup dipilih kelompok yang
dianggap mewakili (secara purposive).– Dalam Indeks Harga Agregat kelompok komoditas harus dikaji ulang dan direvisi secara teratur
untuk mengetahui apakah kelompok yang dipilih mewakili seluruh kelompok yang ada atau tidak.
BEBEBAPA HAL PENTING TENTANG INDEKS HARGA (L)

Statistik Bisnis
Pemilihan Tahun Dasar– Tahun dasar sebaiknya tidak jauh jaraknya dari periode saat ini (current period).– Penentuan tahun dasar sebaiknya dilakukan penyesuaian/pembaruan secara teratur.
Perubahan Kualitas– Asumsi dasar Indeks Harga : harga dihitung untuk komoditas yang sama pada setiap
periode.– Perbaikan kualitas secara substansial akan berakibat meningkatnya harga sebuah produk.
INDEKS KUANTITAS (QUANTITY INDEXES) Indeks Kuantitas merupakan indeks yang mengukur perubahan kuantitas produk pada kurun
waktu tertentu. Penghitungan Indeks Kuantitas Agregat Tertimbang memiliki cara yang sama dengan Indeks
Harga Agregat Tertimbang. Rumus Indeks Kuantitas Agregat Tertimbang pada periode t adalah
DERET BERKALA (TIME SERIES) Suatu deret berkala merupakan suatu himpunan observasi dimana variabel yang digunakan
diukur dalam urutan periode waktu, misalnya tahunan, bulanan, triwulanan, dan sebagainya. Tujuan dari metode deret berkala adalah untuk menemukan pola data secara historis dan
mengekstrapolasikan pola tersebut untuk masa yang akan datang. Peramalan didasarkan pada nilai variabel yang telah lalu dan atau peramalan kesalahan masa
lalu.
KOMPONEN DERET BERKALA Komponen Tren (Trend Component)
– Merepresentasikan suatu perubahan dari waktu ke waktu (cenderung naik atau turun).– Tren biasanya merupakan hasil perubahan dalam populasi/penduduk, faktor demografi,
teknologi, dan atau minat konsumen.
Komponen Siklis (Cyclical Component)– Merepresentasikan rangkaian titik-titik dengan pola siklis (pergerakan secara siklis/naik-
turun) di atas atau di bawah garis tren dalam kurung waktu satu tahun.KOMPONEN DERET BERKALA (L)
Komponen Musim (Seasonal Component)– Merepresentasikan pola berulang dengan durasi kurang dari 1 tahun dalam suatu deret
berkala.– Pola durasi dapat berupa jam atau waktu yang lebih pendek.
Komponen Tak Beraturan (Irregular Component)– Mengukur simpangan nilai deret berkala sebenarnya dari yang diharapkan berdasarkan
komponen lain.– Hal tersebut disebabkan oleh jangka waktu yang pendek (short-term) dan faktor yang tidak
terantisipasi yang dapat mempengaruhi deret berkala.
AKURASI PERAMALANAkurasi peramalan dapat diukur dari nila berikut:
1. Mean Squared Error (MSE)– Merupakan rata-rata jumlah kuadrat kesalahan peramalan.
2. Mean Absolute Deviation (MAD)– Merupakan rata-rata nilai absolut kesalahan peramalan.
METODE PENGHALUSAN DALAM PERAMALAN1. Rata-rata Bergerak (Moving Averages - MA)
– Menggunakan n nilai data terbaru dalam suatu deret berkala untuk meramalkan periode yang akan datang.
– Rata-rata perubahan atau pergerakan sebagai observasi baru.– Penghitungan rata-rata bergerak adalah sebagai berikut:

Statistik Bisnis
METODE PENGHALUSAN DALAM PERAMALAN (L)2. Rata-rata Bergerak Tertimbang (Weighted Moving Averages)
– Melibatkan penimbang untuk setiap nilai data dan kemudian menghitung rata-rata penimbang sebagai nilai peramalan.
– Contoh, rata-rata bergerak terimbang 3 periode dihitung sebagai berikut
Ft+1 = w1(Yt-2) + w2(Yt-1) + w3(Yt)
dimana jumlah total penimbang (nilai w) = 1.
METODE PENGHALUSAN DALAM PERAMALAN (L)3. Penghalusan Eksponensial (Exponential Smoothing)
– Merupakan kasus khusus dari metode Rata-rata Bergerak Tertimbang dimana penimbang dipilih hanya untuk observasi terbaru.
– Penimbang yang diletakkan pada observasi terbaru adalah nilai konstanta penghalusan, α.– Penimbang untuk nilai data lain dihitung secara otomatis dan semakin lama periode waktu
suatu observasi nilainya akan lebih kecil.
4. Penghalusan Eksponensial (Exponential Smoothing) (Lanjutan)
Rumus:Ft+1 = αYt + (1 - α)Ftdimana Ft+1 = nilai peramalan untuk periode t+1Yt = nilai sebenarnya untuk periode t+1Ft = nilai peramalan untuk periode tα = konstanta penghalusan (0 < α < 1)
CONTOH : EXECUTIVE SEMINARS, INC.
Executive Seminars bergerak dalam manajemen penyelenggaraan seminar. Untuk keperluan perencanaan pendapatan dan biaya pada masa mendatang yang lebih baik, pihak manajemen ingin membangun model peramalan untuk seminar “Manajemen Waktu”. Pendaftar pada 10 seminar “MW” terakhir adalah:
Seminar 1 2 3 4 5 6 7 8 9 10Pendaftar 3440 35 39 41 36 33 38 43 40
METODE PENGHALUSAN DALAM PERAMALAN (L)CONTOH : EXECUTIVE SEMINARS, INC.
Penghalusan Eksponensial (Exponential Smoothing)Misal α = 0.2, F1 = Y1 = 34F2 = α Y1 + (1 - α)F1
= 0.2(34) + 0.8(34) = 34 F3 = α Y2 + (1 - α)F2 = 0.2(40) + 0.8(34) = 35.20 F4 = α Y3 + (1 - α)F3
= 0.2(35) + 0.8(35.20) = 35.16 dst

Statistik Bisnis
CONTOH : EXECUTIVE SEMINARS, INC.
Seminar Pendaftar Ramalan dg Exp. Smoothing 1 34 34.002 40 34.003 35 35.204 39 35.165 41 35.936 36 36.947 33 36.768 38 36.009 43 36.4010 40 37.7211 Ramalan untuk seminar y.a.d = 38.18
Persamaan Tren Linier: Tt = b0 + b1t dimana Tt = nilai tren pada periode t (sebagai variabel tak
bebas/dependent variabel) b0 = intercept garis tren b1 = slope/kemiringan garis tren t = waktu (sebagai variabel bebas/independent
variable) Penghitungan Slope (b1) dan Intercept (b0)
Dan
dimanaYt = nilai sebenarnya pada periode t n = banyaknya periode dalam deret berkala
CONTOH : PENJUALAN PRODUK “X”
Manajemen perusahaan penghasil produk “X” ingin membuat metode peramalan yang dapat mengontrol stok produk mereka dengan baik. Penjualan tahunan (banyaknya produk “X” terjual) dalam 5 tahun terakhir adalah sebagai berikut:
Tahun 1 2 3 4 5Penjualan 11 14 20 26 34
CONTOH : PENJUALAN PRODUK “X” (Lanjutan) Menggunakan rumus penghitungan untuk b0 dan b1 diperoleh:
sehingga Tt = 3,6 + 5,8 t
Perkiraan penjualan pada tahun ke-6 =
T6 = 3,6 + (5,8)(6) = 38,4

Statistik Bisnis
TEORI PELUANG
PENGERTIAN PELUANG1. Salah satu tujuan statistik adalah menarik kesimpulan mengenai populasi berdasarkan informasi
yang didapat dari sample2. Sample hanya menyediakan sebagian informasi tentang populasi sehingga dibutuhkan metode
untuk menarik kesimpulan dengan memanfaatkan sifat-sifat peluang.3. Nilai peluang dari satu kejadian (P) berkisar antara 0 dan 1
P = 0 menunjukan suatu peristiwa tidak mungkin terjadiP = 1 menunjukan suatu peristiwa yang pasti terjadi
4. Peristiwa adalah suatu atau lebih hasil yang mungkin dari satu kegiatan.5. Ruang sample adalah himpunan dari seluruh terjadinya peristiwa atau jumlah seluruh frekuensi
PENDEKATAN PELUANG1. Pendekatan Klasik
Menurut pendekatan klasik terjadinya suatu peristiwa (P) adalah rasio antara peristiwa yang menguntungkan dengan seluruh peristiwa yang mungkin dimana setiap peristiwa mempunyai kesempatan yang sama.Rumus :
P (A) = N
P (A) = Peluang terjadinya peristiwa A
X = Peristiwa yang menguntungkan
N = Jumlah seluruh peristiwa
2. Pendekatan Frekuensi RelatifAdalah pendekatan yang menggunakan perhitungan frekuensi relatife yang didasarkan pada terjadinya peristiwa masa lalu sebagai suatu peluang.Pendekatan frekuensi relatife didasarkan pada : Pengamatan frkuensi relatife dari suatu peristiwa dalam percobaan yang dilakukan beberapa
kali Proposi waktu dari suatu peristiwa dalam jangka panjang bila kondisi stabil.Pendekatan frekuensi relatife ini menunjukan seringnya sesuatu terjadi pada masa lalu dan digunakan untuk memprediksikan peluang bahwa sesuatu tersebut akan terjadi lagi di masa datang.
3. Pendekatan SeubyektifAdalah pendekatan yang didasarkan pada tingkat kepercayaan individu yang membuat dugaan terhadap suatu peluang.Kepercayaan individu tersebut bisa berasal dari pengalaman terjadinya suatu peristiwa pada masa lalu atau terkaan saja.Tingkat kepercayaan individu dalam membuat dugaan peluang suatu peristiwa dapat dikelompokan menjadi 2 (dua):– Pandangan yang optimis bahwa peristiwa itu akan terjadi sehingga peluangnya mendekati 1,
misal P=0.90– Pandangan yang pesimis bahwa peristiwa itu akan terjadi sehingga peluangnya mendekati 1,
misal P=0.20
TEORI PENGAMBIL KEPUTUSANSetiap individu, kelompok maupun perusahaan akan selalu menghadapi masalah untuk bertindak berdasarkan berbagai alternatife tindakan.Pemilihan alternatife tindakan ini didasarkan karena adanya masalah ketidakpastian.
Ada 2 macam pengambilan keputusan :Teori Pengambilan Keputusan Berdasar Pendekatan Klasik
Teori ini didasarkan atas pertimbangan ekonomi secara tidak langsung yang merupakan pengambilan kesimpulan terhadap populasi berdasarkan pada informasi sampel
Teori Pengambilan Keputusan Berdasar Pendekatan BayersPengambilan keputusan berdasar pendekatan ini dititikeratkan pada pengguna pertimbangan ekonomi secara langsung, yaitu dengan menggunakan tabel hasil.

Statistik Bisnis
Dasar-dasar pengambilan keputusan ada 4 : Alternatif cara bertindakDalam mengambil keputusan kita dihadapkan pada berbagai alternatife pilihan, oleh sebab itu perlu adanya evaluasi terhadap berbagai alternatife tindakan. Peristiwa atau keadaan duniaApabila di dalam pengambilan keputusan kita hanya menghadapi suatu peristiwa atau keadaan maka kita tidak akan menjumpai kesulitan dalam pengambil keputusan ini tetapi apabila kita menghadapi berbagai macam peristiwa atau keadaan dalam dunia ini maka pengambilan keputusan menjadi sulit sehingga perlu mengadakan pendugaan berdasar informasi yang ada agar pengambilan keputusan mendekati keadaan yang sebenarnya.
HasilAgar suatu peristiwa atau keadaan sebagai hasil suatu tindakan dapat dievaluasi maka hasil tindakan ini dinyatakan dalam bentuk nilai/hasil.Dalam perusahaan hasil ini disebut keuntungan atau dapat dirumuskan sebagai biaya meskipun ada berbagai bentuk lain berupa manfaat atau kepuasan. Kriteria Pengambilan KeputusanPengambilan keputusan harus menentukan bagaimana memilih alternatife terbaik dalam cara bertindak.Suatu kriteria yang banyak dipergunakan dalam pengambilan keputusan mengambil alternatife yang dapat mendatangkan keuntungan besar.
PERMUTASI DAN KOMBINASI
PERMUTASI Permutasi suatu obyek adalah penyusunan obyek tersebut dalam urutan yang teratur.
Macam-macam permutasi : Permutasi dari seluruh obyek
Rumus :
nPn = n!
P = permutasin = jumlah obyekn! = n factorial adalah pengadaan dari 1 sampai nn! = n(n-1)(n-2)…..contoh :3P3 = 3!
= 3 (3-1) (3-2)= 3 x 2 x 1= 6
Permutasi sebanyak r dari n obyekRumus :
nPr = ! (n-r)!
P = Permutasin = jumlah seluruh obyekr = jumlah obyek yang dipermutasikan! = Faktorialcontoh :
3P2 = 3! (3-2)!
= 3x2x1 = 6 1

Statistik Bisnis
permutasi kelilingpermutasi suatu kelompok obyek yang membentuk suatu lingkaran.Rumus :P=(n-1)!Contoh : 5 orang mahasiswa duduk mengelilingi sebuah meja yang bulat. Ada beberapa permutasi untuk menyusun tempat duduk tersebut?P = (5-1)! = 4! = 4(4-1)(4-2)(4-3)
= 4 x 3 x 2 x 1= 24
KOMBINASI Kombinasi dari sejumlah obyek merupakan cara pemilihan obyek yang bersangkutan tanpa
menghiraukan urutan obyek tersebut.Rumus :
atau nCr =
r!(n-r)!
Dengan ketentuan 0 < r < nContoh :
Dalam berapa carakah sebuah panitia yang beranggotakan 5 orang dapat dibentuk dari 6 pria dan 3 wanita jika paling sedikit panitia itu harus beranggotakan 3 orang pria:Jawab :
Panitia yang beranggotakan 3 orang pria. Pemilihan 3 pria dari 6 orang adalah :
=
3!(6-3)!= 6 x 5 x 4 x 3 x 2 x 1 =20 (3 x 2 x 1) (3 x 2 x 1)
Pemilihan 2 wanita dari 3 orang wanita adalah :
= 3!
2!(3-2)!
= 3 x 2 x 1 = 3 (2x1) (1)
jadi kombinasinya
x = 20 x 3
= 60Panitia yang beranggotakan 4 orang pria
Pemilihan 4 pria dari 6 orang pria adalah:
= 6!
4!(6-4)!
= 6 x 5 x 4 x 3 x 2 x 1 = 15 (4 x 3 x 2 x 1) (2 x 1)
Pemilihan 1 wanita dari 3 orang wanita adalah :
= 3!
3!(3-1)!

Statistik Bisnis
= 3 x 2 x 1 = 3 1(2 x 1)
jadi lombinasinya
x = 15 x 3
= 45
Panitia yang beranggotakan 5 orang pria dari 6 orang pria
= 6!
5!(6-5)!
= 6 x 4 x3 x 2 x 1 = 6
(5 x 4 x 3 x 2 x 1)
Pemilihan pada wanita tidak dilakukan karena panitia sudah terisi sebanyak 5 orang.Jadi panitia yang beranggotakan 5 orang dari 6 pria dan 3 wanita dengan anggota paling sedikit 3 orang pria adalah :
+ + =60+45+6 = 111 cara
DISTRIBUSI PELUANG
PENGERTIANFrekuensi dalam distribusi frekuensi diperoleh berdasarkan hasil percobaan atau hasil observasi.Frekuensi dalam distribusi peluang merupakan hasil yang diharapkan jika percobaan atau pengamatan dilakukan.

Statistik Bisnis
Berikut ini contoh bila dilakukan percobaan pelemparan uang logam sebanyak dua kali, maka hasil yang mungkin terjadi sebagai berikut :Kemungkinan muncul sisi angka dari 2x lemparan uang logam muncul angka :
Lemparan Pertama Lemparan Kedua Jumlah Sisi AngkaAngka (A)Angka (A)Gambar (G)Gambar (G)
Angka (A)Gambar (G)Gambar (G)Angka (A)
2101
Dengan hasil tersebut maka :Peluang kemungkinan hasil dari 2x lemparan uang logam muncul angka:
Lemparan Pertama Lemparan Kedua Jumlah Sisa
AngkaPeluang
Angka (A)Angka (A)Gambar (G)Gambar (G)
Angka (A)Gambar (G)Gambar (G)Angka (A)
2101
0.5x0.5 =0.250.5x0.5 =0.250.5x0.5 =0.250.5x0.5 =0.25
1.00Dari tabel tersebut dapat diketahui :Distribusi peluang dari kemungkinan munculnya sisa angka dalam 2x lemparan uang logam :
Jumlah Sisa Angka Lemparan Peluang012
(G,G)(A,G) +(G+A)
(A,A)
0.250.500.25
Kegunaan mempelajari distribusi peluang :Contoh :
Pengusaha toko sepatu perlu mengetahui pola permintaan dari para konsumen, bagaimana distribusi dari nomor-nomor sepatu yang diminta para konsumen.Pengusaha rumah makan perlu mengetahui pola selera makanan yang digemari para pelanggannya.
Dengan mengetahui pola permintaan yang didasarkan pada pelanggan dimasa lalu pengusaha tersebut akan dapat menyelesaikan persediaan barang-barangnya. Dengan kata lain apabila kita dapat mengetahui distribusi peluangnya maka kita dapat mengetahui distribusi peluangnya maka kita dapat mengetahui pola distribusi frekuensinya.
MACAM DISTRIBUSI PELUANG DISTRIBUSI BINOMIAL (Percobaan Bernoulli)Adalah distribusi peluang dari suatu variable acak yang bersifat diskrit, yaitu variable yang besarannya tidak sama nilai diantara 2 titik sehingga nilainya berupa bilangan bulat.Model dari percobaan binomial mengambil anggapan bahwa :
Setiap percobaan hanya menghasilkan 2 kemungkinan yang saling meniadakan yaitu sukses atau gagalPeluang peristiwa sukses dirumuskan dengan p dari satu percobaan ke percobaan berikutnya adalah tetap. Peluang gagal dirumuskan dengan q atau (1-p)Masing-masing percobaan merupakan peristiwa independent, artinya peristiwa yang satu tidak mempengaruhi terjadinya peristiwa yang lain.
Rumus Binomial :
PxQn-x
Dimana :n : Jumlah percobaanx : jumlah sukses yang diharapkanp : peluang suksesq : peluang gagalContoh :Peluang munculnya 2x sisi angka dalam 3 kali lemparan uang logam adalah :

Statistik Bisnis
N : 3X : 2P : 0.5Q : 1-P =0.5
PxQn-x
(0.5)2(0.5)3-2
(0.5)2(0.5)3-2
= 0.375DISTRIBUSI POISSON
Adalah suatu distribusi teoritis yang berhubungan dengan variable acak diskrit. Ada 2 cara kategori yang mungkin timbul pada populasi : Timbulnya tiap kejadian dalam Distribusi Poisson adalah independent dan setiap kejadian
mempunyai peluang yang tetap Jumlah individu yang dihadapi besar sekali sedangkan peluang timbulnya suatu individu
termasuk kategori tertentu kecil sekali. Syarat distribusi poisson : P < 0.05 dan n > 20
(n besar dan peluang untuk terjadi sangat kecil)Distribusi poisson digunakan untuk peristiwa yang jarang terjadi.Tujuan penggunaan Distribusi Poisson : Untuk menentukan peluang berbagai peristiwa dalam periode yang panjang atau dalam daerah yang spesifik.Rumus :
Dimana P(x;u) : peluang munculnya peristiwa Xu : rata-rata terjadinya suatu peristiwae : 2.71828
Contoh ;Menurut catatan polisi, dalam 1 bulan rata-rata terjadi 5 kali kecelakaan. Jumlah kecelakaan tersebut terdistribusi poisson. Kepala polisi ingin menghitung peluang terjadinya kecelakaan tiap bulan. Bila ternyata peluang terjadinya kecelakaan lebih dari 3x tiap bulan melebihi 65% akan diadakan perbaikan system pengamanan jalan raya.Poisson : Tidak terjadi kecelakaan
Terjadi kecelakaan
Terjadi 2 kecelakaan
Terjadi 3 kecelakaan

Statistik Bisnis
Peluang terjadinya kurang dari atau sama dengan 3x kecelakaan perbulan diperoleh dengan menjumlah peluang terjadi kecelakaan 0,1,2,3P(X=0) = 0.00675P(X=1) = 0.03370P(X=2) = 0.08425P(X=3) = 0.14042
0.26511terjadinya kecelakaan kurang dari atau sama dengan 3x perbulan adalah sebesar 0.26511, maka terjadi kecelakaan lebih dari 3 kali kecelakaan adalah 1 – 0.26511 = 0.7389 atau 74%Nilai yang di peroleh melebihi 65% sehingga dengan demikian dibutuhkan system pengamanan jalan raya yang lebih baik.
DISTRIBUSI NORMALAdalah distribusi peluang yang bersifat kontinyu.Ada 2 pertimbangan pokok sehingga normal mempunyai peranan yang penting dalam statistik. Beberapa hal yang dimiliki distribusi normal memungkinkan distribusi ini dapat dipergunakan
untuk berbagai analisa dengan cara penarikan kesimpulan berdasar sample yang diambil. Distribusi normal sangat mendekati untuk menggambarkan frekuensi yang diperoleh dari hasil
observasi pada berbagai bidang baik yang bersifat human seperti tinggi, berat atau tingkat kecerdasan maupun ukuran-ukuran lain yang penting guna keperluan manajemen dibidang sosial dan ilmu pengetahuan alam.
Pengertian distribusi normal suatu distribusi yang simetris dan berbentuk lonceng yang menunjukan hubungan antara ordinat pada mean dengan berbagai ordinat pada berbagai jarak sigma yang diukur dari mean.
Mean ( ) Sifat-sifat dari distribusi normal :
Bentuk distribusi normal menyerupai bentuk lonceng dengan sebuah puncak. Nilai rata-rata (mean) pada distribusi normal akan terletak di tengah-tengah dari kurva normal Bentuk distribusi normal adalah simetris, oleh sebab itu nilai mean = median = modus Ujung masing-masing sisi kurva akan sejajar dengan sumbu horizontal dan tidak akan
memotong sumbu horizontal tersebut. Sebagian besar dari data ada sitengah dan sebagian kecil dari data ada pada masing-masing sisi 68% dari data akan berada dalam jarak + 1 standar deviasi95% dari data akan berada dalam jarak + 2 standar deviasi99% dari data akan berada dalam jarak + 3 standar deviasi
Rumus Distribusi Normal :
Yo = ordinat pada mean= standar deviasi
N = jumlah frekuensiCi = Interval kelas

Statistik Bisnis
Selanjutnya untuk masing masing masing nilai ordinat dapat dihitung dengan mengalikan hasil tersebut dengan tabel ordinatnya (lampiran III)
Contoh :Dari distribusi frekuensi penghasilan 50 karyawan perusahaan di Yogyakarta tahun 1985 (dalam ribuan rupiah) diperoleh data sebagai berikut :Nilai rata rata (mean) = 65.5
N = 50Ci = 10
Deviasi Standar = 16.78
Y0 = 0.39894 x 500/16.78= 11.9
untuk nilai ordinat yang lain dapat dihitung berdasar nilai tabel ordinat dengan dikalikan ordinat maksimum (11.9)Dengan tabel ordinat (lampiran III) kali N Ci diperoleh hasil :Nilai + 0.1 = 0.39695 x 29.8 = 11.8Nilai + 0.2 = 0.39104 x 29.8 = 11.7Nilai + 0.3 = 0.38139 x 29.8 = 11.4Nilai + 0.4 = 0.36827 x 29.8 = 10.9Nilai + 0.5 = 0.35207 x 29.8 = 10.5 dan seterusnya
Semua titik ordinat pada kurva dapat di hitung selanjutnya digambarkan dalam diagram berikut
Cara menggambarkan kurve normal
Mean (65.1 )
Y011.9

Statistik Bisnis
METODE SAMPLING
Dalam kehidupan sehari-hari sample mempunyai peranan yang penting. Hampir semua pengetahuan, sikap dan tindakan seseorang selalu berdasarkan kepada sample. Sampai saat ini masalah masalah yang dihadapi adalah bagaimana cara memilih sample yang baik. Masalah pemilihan sample yang baik ini akan penting apabila kita menghadapi masalah pemilihan sample dari data yang bersifat heterogen.
SAMPLINGAdalah metode yang dipergunakan untuk menyeleksi individu dari populasi yang dapat menghasilkan sample yang representative.POPULASIAdalah keseluruhan dari obyek yang akan ditelitiSAMPELAdalah sebagian anggota populasi yang terpilih.Tujuan utama dari diadakannya sampling adalah memberikan pedoman utuk memlih sample yang dapat mewakili populasi yang mendasarinya.
Alasan-alasan menggunakan sample : Di dalam hal kita menghadapi obyek yang mudah rusak, maka penelitian terhadap seluruh obyek
tidak mungkin dilakukan. Di dalam penelitian apabila kita menghadapi suatu obyek penelitian yang bersifat homogen, maka
kita tidak perlu mengadakan penelitian terhadap seluruh obyek atau populasi melainkan terhadap sample.
Penggunaan metode sample dapat menghemat biaya. Penelitian yang mempergunakan metode sample dapat cepat diselesaikan Penggunaan metode sample akan dapat memperluas lingkup informasi yang diperolehnya. Penggunaan metode sample memungkinkan dipergunakannya personal yang ahli dan terlatih
sehingga sample diharapkan akan lebih tinggi ketepatan hasilnya. Dengan makin berkembangnya teknik metode pengambilan dan perhitungan sample maka hasil-
hasil sample dapat menggambarkan hasil populasinya.
Secara matematis kita dapat mengukur suatu sample dan populasi seperti mean, median, modus dan sebagainya. Meskipun ukuran-ukuran ini mempunyai makna yang sama tetapi di dalam statistik dibedakan dengan penggunaan symbul-simbul yang berbeda. Ukuran-ukuran sample disebut dengan istilah statistik, sedang ukuran-ukuran untuk populasi disebut parameter.
Bila metode pengambilan sample yang dipakai tepat, diharapkan individu individu sample yang diobservasi mampu mewakili seluruh anggota populasi dan diperoleh statistik sebagai peduga yang baik. Statistik yang merupakan estimator yang baik harus memenuhi syarat berikut :
Tidak BiasSuatu estimator dikatakan tidak bias apabila yang diharapkan dari Statistik adalah sama dengan nilai parameternya EfisienSuatu estimator dikatakan efisien apabila estimator dapat menghasilkan standard error yang terkecil dibandingkan dengan standard error dari estimator yang lain. KonsistenSuatu estimator dikatakan konsisten apabila peluang untuk memperoleh perbedaan antara statistik dengan parameter mendekati nol jika individu sample bertambah. Artinya jika sampelnya diperbesar maka suatu nilai statistik tertentu mendekati nilai parameter yang diestimasi. Estimator yang tidak konsisten akan memboroskan waktu dan biaya yang dikeluarkan untuk memperbesar sampel SufficirntSuatu estimator yang Sufficirnt adalah bila mempunyai informasi yang lebih sempurna mengenai parameter yang diestimasi dibandingkan dengan estimator yang lain.
Penggunaan metode kompleks karena berkaitan erat dengan sifat dari populasinya. Kita dapat menyusun tahap tagap dalam penelitian yang menggunakan metode sample sebagai berikut :
Menentukan tujuan penelitian Perumusan populasi Menentukan jenis data yang akan dikumpulkan Penentuan metode pengumpulan

Statistik Bisnis
Pemilihan unit sampling Pemilihan Sampel Mengorganisir petugas lapangan atau pencacah Penyusunan atau analisis data
Tujuan dari teori sampling adalah membuat metode sampling menjadi lebih effisien. Teori sampling mengembangkan cara pemilihan sample serta perhitungan sample sebagai dasar pendugaan terhadap populasi yang setepat mungkin dengan biaya yang serendah rendahnya. Agar suatu prosedur pengambilan sample dan perhitungan sample dapat tepat maka diperlukan pengetahuan terhadap populasinya. Suatu cara yang ditempuh untuk penyederhanaan adalah kita selalu mengharap bahwa sample itu mempunyai distribusi yang normal.
TIPE TIPE SAMPLINGRandom Sampling atau Probability SamplingDalam probability sampling, pemilihan sample tidak dilakukan secara subyektif sehingga setiap anggota populsai mempunyai kesempatan yang sama untuk terpilih sebagai sample. Dengan demikian diharapkan sample yang terpilih dapat digunakan untuk menduga karakteristik populasi secara subyektif.
Simple Random SamplingAdalah metode yang digunakan untuk memilih sample dari populasi dengan cara sedemikian rupa sehingga setiap anggota populasi mempunyai peluang yang sama besar untuk diambil sebagai sample.Adapun cara cara mendapatkannya melalui :
UndianTabelOrdinal
Contoh :Suatu populasi yang terbatas terdiri dari 4 orang karyawan dan akan di pilih sample 2 orang guna keperluan wawancara, berdasarkan pada rumus kombinasi akan memperoleh kemungkinan sebanyak 6 kemungkinan. hasil undian ini merupakan sample yang terpilih.
Stratified Random SamplingAdalah metode pemilihan sampai dengan cara membagi populasi ke dalam kelompok kelompok yang homogen yang disebut starta dan kemudian sample diambil dari masing masing starta tersebut.Starta dapat didasarkan atas beberapa factor antara lain :
Kedudukan Umur Jenis Kelamin Tingkat pendidikan Suku Kepercayaan Lingkungan dan lain lain
Pada stratified random sampling yang proposional jumlah sample yang diambil tiap starta ditentukan oleh populasi jumlah anggota populasi tiap starta.Pada stratified random samping yang non proposional pengambilan sample tiap starta tidak ditentukan berdasarkan proposi tertentu dari anggota populasi tiap strata tetapi lebih didasarkan besar kecilnya anggota populasi tiap strata serta informasi yang diharapkan diperoleh.Contoh :Suatu populasi terdiri dari 1000 orang (200 (pedagang makanan, 100 (pedagang minuman, 400 pedagang kerajinan dan 300 pedagang rokok)Apabila kita akan mengambil sample 20 pedagang maka :Starta I = 200/1000 x 20 = 4 pedagangStarta II = 100/1000 x 20 = 2 pedagangStarta III = 400/1000 x 20 = 8 pedagangStarta IV= 300/1000 x 20 = 6 pedagangJumlah sample keseluruhan = 20 pedagang kaki lima

Statistik Bisnis
Cluster SamplingAdalah metode pemilihan sample yang dilalukan dengan terlebih dahulu membagi populasi dalam kelompok berdasarkan cluster-cluster/rumpun-rumpun/kelompok-kelompok dan selanjutnya pemilihan sample dilakukan secara acak pada cluster-cluster tersebut.Dalam hal ini yang dipilih adalah cluster cluster dan bukan individu, oleh karena itu kesimpulan hasil penelitian tidak berlaku bagi individu tetapi cluster.
Area SamplingSample tipe ini berkenan dengan dasar pengelompokan adalah wilayah administrasi pemerintahan dan kondisi geografis atau lokasi dimana sample harus diperoleh. Dapat diartikan pula bahwa daerah yang luas dibagi bagikan didalam daerah daerah yang lebih kecil.Misalnya :1. Propinsi dalam setiap sample daerah2. Kabupaten dalam setiap sample propinsi3. Kecamatan dalam setiap sample kabupaten4. Desa dalam setiap sample kecamatan
Multistage SamplingAdalah metode pengambilan sample yamg memadukan jenis random sampling dengan berbagai tipe sampling yang telah disebut pada bagian sebelumnya sehingga diharapkan sample yang terambil lebih dapat mewakili karakteristik populasi.
Non Probability SamplingPengetahuan, kepercayaan dan pengalaman seseorang seringkali dijadikan pertimbangan untuk menentukan anggota populasi yang akan dipilih sebagai sample. Pengambilan sample dengan memperhatikan factor factor tersebut menyebabkan tidak semua anggota populasi mempunyai kesempatan yang sama untuk dipilih secara acak sebagai sample.Accidental Sampling
Pemilihan sample terjadi secara kebetulan atau sembarangan pada saat diadakan pengumpulan data. Dengan kata lain yang dijadikan sample oleh peneliti adalah individu yang secara kebetulan pada saat pengumpulan data.
Judgement SamplingPemilihan sample yang diambil dari anggota populasi dipilih sekehendak hati peneliti.
Qouta SamplingPemilih sample dilakukan dengan membagi populasi dalam strata yang dibuat berdasarkan sifat sifat yang mempunyai pengaruh paling besar terhadap variable yang sedang diteliti. Jumlah anggota yang diambil dari setiap strata tersebut dilakukan secara penjatahan (quotum). Dasar penentuan quotum bias berupa alasan geografis, ekonomis dan sebagainya.
Expert SamplingPemilihan sample yang representative didasarkan atas pendapat ahli, sehingga siapa dan dalam jumlah berapa sample harus dipilih sangat tergantung pada pendapat ahli yang bersangkutan.
Purposive Pemilihan sample dengan cara ini bertitik tolak pada penilaian peneliti sendiri bahwa sample yang dipilih nantinya benar benar representative. Oleh karena itu untuk menggunakan metode ini peneliti harus menguasai bidangnya dan memiliki pengetahuan yang memadai tentang karakteristik anggota populasi.

Statistik Bisnis
ESTIMASI
Permasalahan dalam statistik inferensia muncul apabila kita ingin membuat generalisasi tentang populasi atas dasar sample yang terambil. Permasalahan tersebut muncul karena setiap inferansi tentang parameter populasi akan melibatkan ketidakpastian, mengingat hasil yang diperoleh didasarkan atas sample dan bukan atas populasi secara keseluruhan.
Statistik Inferensia merupakan bagian statistik yang membicarakan cara cara menganalisa data serta mengambil kesimpulan.Walaupun dengan menggunakan statistik inferensia kita bisa menarik kesimpulan, perlu diingat bahwa pada dasarnya dengan menggunakan statistika inferensia kita tidak membuktikan sesuatu.
Meskipun demekian dengan penggunaan metode ini dapat diketahui besarnya peluang untuk memperoleh kesimpulan yang sama bila penelitian tersebut diulang. Selain itu penggunaan metode yang tepat memungkinkan kita untuk mengukur besarnya error dalam menarik kesimpulan atau memberikan taraf kepercayaan tertentu terhadap suatu pernyataan.
Tipe Statistik Inferensia Adalah :3. Estimasi ParameterNilai parameter yang sebenarnya adalah konstatnta yang besarnya seringkali tidak diketahui kecuali bila seluruh anggota populasi diobservasi. Tujuan kita adalah memperoleh suatu dugaan atau estimasi mengenai niali parameter dari sample.
4. Pengujian HipotesisDibutuhkan bila kita memeriksa apakah data sample mendukung atau berlawanan dengan dugaan peneliti tentang nilai sebenarnya dari parameter.
Bila kita dapat mengobservasi keseluruhan individu anggota populasi, maka kita akan mendapatkan besaran yang menyatakan karakteristik populasi yang sebenarnya yang disebut parameter.
Sebagai anggota populasi yang diambil menurut prosedur tertentu sehingga dapat mewakili populasinya biasa dikenal dengan sample. Dari hasil pengambilan sample, kita mencoba menduga besaran populasi yang sebenarnya. Besaran yang kita peroleh dari sample ini dikenal dengan statistik.
Estimasi merupakan salah satu cara untuk mengemukakan pernyataan induktif (menyatakan karakteristik populasi dengan menggunakan karakteristik yang didapat dari sample).
Estimator adalah statistik yang digunakan untuk mengestimasi parameter populasi, misalnya mean sample dapat digunakan sebagai estimator untuk mean populasi.
Dalam statistik dikenal 2 macam estimasi :1. Estimasi Titik
Adalah suatu nilai tunggal yang dihitung berdasarkan pengukuran dari sample dan digunakan sebagai penduga terhadap nilai parameter populasi yang besarnya tidak diketahui.
2. Estimasi IntervalAdalah suatu estimasi terhadap parameter populasi dengan menggunakan nilai range (interval nilai)
Pada estimasi titik seringkali timbul pertanyaan sampai seberapa besar keyakinan nilai dugaan yang diperoleh tersebut benar.Pertanyaan tersebut berjarak dari kenyataan yang menunjukan bahwa :

Statistik Bisnis
1. Meskipun estimasi titik sangat sederhana dan mudah diperoleh namun sulit untuk mendapatkan hasil estimasi yang memadai.
2. Estimasi titik memberikan peluang untuk mengukur derajat kepercayaan terhadap kepastian kebenaran estimasi yang kita lakukan.
Karena itu ketepatan dari estimasi harus diindikasikan menggunakan standard deviasi pada distribusi sampling. Dengan cara tersebut dapat ditetapkan interval kepercayaan yang menampung derajat kepercayaan terhadap kepastian estimasi. Lembar interval yang terbentuk dengan demikian akan tergantung pada nilai estimasi titik yang diperoleh serta standard deviasi dari distribusi sampilngnya.Hasil estimasi interval ini diharapkan :
– Akan lebih obyektif karena memberikan dugaan nilai parameter dalam bentuk range (interval) sehingga menampung adanya ketidakpastian yang menyertai dalam estimasi.
– Dalam menggunakan estimasi interval kita dapat menyatakan berapa besar kepercayaan kita bahwa interval yang terbentuk benar benar menampung parameter yang diestimasi. Tingkat kepercayaan tersebut ditunjukan oleh peluang membuat kesalahan dalam menentukan interval.
Tingkat kepercayaan ini dalam statsitik dinyatakan dalam bentuk presentase. Besaran yang sering digunakan adalah 90%, 95% dan 99%. Semakin tinggi tingkat kepercayaan yang diberikan maka semakin tinggi pula tingkat kepercayaan bahwa parameter populasi yang diestimasi terletak dalam interval yang terbentuk.
Suatu interval nilai yang menunjukan berbagai peluang letak dari nilai parameter populasi yang diestimasi disebut Interval Kepercayaan.
Contoh :Jika hasil penelitian dengan tingkat kepercayaan 90% menunjukan bahwa rata rata orang Indonesia mengkonsumsi daging antara 5 kg sampai dengan 10 kg per tahun, maka range (5 kg – 10 kg) disebut interval kepercayaan.
Bila variance populasi diketahui maka dipergunakan distribusi normal sedangkan bila variance populasi tidak diketahui maka perlu dilihat jumlah sampelnya. Bila jumlah sample n > 30 dipergunakan distribusi normal, sedang untuk n < 30 dipergunakan distribusi t.Bila variance populasi diketahui atau bila ukuran sampelnya besar (>30) maka formula dari internal kepercayaan untuk mengestimasi mean populasi adalah X + Za/2 x
formula tersebut dapat diuraiakan sebagai berikut :

Statistik Bisnis
X + Za/2 x : batas atas interval kepercayaanX - Za/2 x : batas bawah interval
Dimana :X : mean sampleZ : nilai dalam tabel Z (distribusi normal) dengan tertentu : peluang estimasi interval tidak benar x : Standard error dari mean
Nilai x tergantung pada dan n. Bila semakin besar maka nilai x semakin kecil sehingga estimasi intervalnya semakin sempit.Besarnya nilai yang diperoleh juga berpengaruh terhadap lebar estimasi interval.Dengan 0.05 berarti tingkat kepercayaan yang dibuat adalah 95%, yang artinya 95% dari interval tersebut mengandung mean populasi dan 5% tidak mengandung mean populasi.Dengan melihat tabel di bawah ini dapat diketahui bahwa bila nya semakin kecil maka interval nilai yang terbentuk akan semakin lebar.Dengan tabel tersebut dapat diketahui pula bahwa mean sample yang digunakan sebagai estimasi parameter berada dalam suatu interval, bukan hanya dari satu titik tertentu saja.Pada tabel berikut dapat dilihat berbagai nilai z dengan yang umum dipakai.
Timgkat Kepercayaan (1 – a)
a Za/2 Interval Kepercayaan
0,90 0,10 1,645 X + 1,645 .
0,95 0,05 1,96 X + 1,96.
0,99 0,01 2,58 X + 2,58 .
Pendekatan dengan distribusi tDistribusi t digunakan dalam estimasi bila ukuran sample kecil yaitu < 30 dan standard deviasi populasi ( ) tidak diketahui dengan asumsi populasi menyebar normal atau mendekati normal.Untuk keperluan estimasi, kita membutuhkan tabel distribusi t. Pada tabel terlihat bahwa tabel distribusi t tidak disusun menurut besarnya sample (n) tetapi disusun menurut deret bebas. Dengan ukuran sample sebesar n maka derajat bebasnya (db) adalah n-1
n
n
n
n

Statistik Bisnis
db(1-a) = 90% a = 10%1 a/2 = 5%
(1-a) = 95% a = 5%t a/2 = 2.5%
(1-a) = 90% a = 1 %t a/2 = 0.5%
1 6.314 12.706 63.6572 2.920 4.303 9.9253 2.353 3.182 5.8414 2.132 2.776 4.6045 2.015 2.571 4.0326 1.943 2.447 3.7077 1.895 2.365 3.4998 1.860 2.306 3.3559 1.833 2.262 3.25010 1.812 2.228 3.16911 1.796 2.201 3.10612 1.782 2.179 3.05513 1.771 2.160 3.01214 1.761 2.145 2.97715 1.753 2.131 2.94716 1.746 2.120 2.92117 1.740 2.110 2.89818 1.734 2.101 2.87819 1.729 2.093 2.86120 1.725 2.086 2.84521 1.721 2.080 2.83122 1.717 2.074 2.81923 1.714 2.069 2.80724 1.711 2.064 2.79725 1.708 2.060 2.78726 1.706 2.056 2.77927 1.703 2.052 2.77128 1.701 2.048 2.76329 1.699 2.045 2.75630 1.697 2.042 2.750

Statistik Bisnis
PENGUJIAN HIPOTESA
Arti dan Pentingnya Pengajuan HipotesaHipotesa adalah suatu anggapan atau pendapat yang diterima secara tenatip (a tentative statement) sesuatu yang belum pasti atau dapat berubah, untuk menjelaskan suatu fakta atau yang dipakai sebagai dasar bagi suatu penelitian.Beberapa contoh hipotesa dapat dikemukakan berikut ini :
– Seorang manager produksi menyatakan bahwa kerusakan produk dalam proses produksi hanya 10%
– Manager pemasaran suatu perusahaan menyatakan bahwa pemasaran produk-produk baru sangat tergantung pada iklan.
– Manager personalia menyatakan bahwa produktivitas perusahaan masih dapat ditingkatkan 10% dengan meningkatkan kondisi kerja.
– Seorang ekonom menyatakan bahwa resesi dunia sangat mempengaruhi penerimaan devisa Negara.
Hipotesa, anggapan atau pendapat di atas seringkali dipergunakan untuk mengambil keputusan, kalau hipotesa itu keliru dengan sendirinya keputusannya akan keliru.
Oleh karena itu, hipotesa harus diuji berdasarkan data empiris yaitu dara berdasar pada penelitian suatu sample.
Berdasarkan keadaan yang nyata ini, maka hasil pengujian hipotesa dapat dipergunakan sebagai dasar pengambilan keputusan. Kesalahan yang diakibatkan pengambilan keputusan agar suatu hipotea dapat diuji, hipotesa harus dirumuskan secara jelas dan bersifat operasional.
Menurut sifat dari hipotesa kita dapat membedakan yang bersifat kualitatif, misalnya seorang hakim menganggap seseorang bersalah atau kuantitatif yang disebut hipotesa statistik, misalnya rata rata pengeluaran sebulan Rp 200.000,-.Hipotesa statistik dirumuskan sebagai suatu pernyataan tentang nilai suatu parameter nisalnya rata-rata populasi, proporsi populasi, varians populasi dan sebagainya.
Prosedur Pengujian HipotesaPengujian hipotesa pada hakekatnya dapat disusun dalam beberapa tahap.Pentahapan di dalam pengujian hipotesa ini secara keseluruhan merupakan prosedur dari pengujian hipotesa.
Tahapan Pengujian Hipotesa adalah sebagai berikut : Perumusan hipotesa nol dan hipotesa alternative Penentuan tarif nyata (significant level) biasanya digunakan simbul a, misalnya 10%, 5%, 1%. Menentukan statistik uji atau kriteria uji yang akan dipergunakan, apakah dengan kurva normal,
distribusi t, distribusi X2 atau dengan distribusi F Pengambilan keputusan apakah hipotesa dapat di terima ataukah hipotesa ditolak
Selanjutnya masing-masing tahap didalam pengujian hipotesa ini kita bahas satupersatu sebagai berikut.Perumusan Hipotesa Nol dan Hipotesa AlternatifDi dalam paragraph di muka telah dijelaskan apa makna dari hipotesa, dalam paragraph ini kita akan membahas pengertian hipotesa nol (null hypotheses) yang biasanya di rumuskan dengan H0.
Hipotesa yang dirumuskan ini disebut hipotesa nol, karena hipotesa ini mempunyai perbedaan nol atau tidak mempunyai perbedaan dengan hipotesa yang sebenarnya.Contoh :
Apabila kita ingin membuktikan bahwa obat A lebih efektif terhadap penyakit daripada obat B, maka kita merumuskan hipotesanya, efektifitasnya obat A dan B sama.Demikian pola apabila kita ingin membuktikan bahwa mesin A lebih produktif dari mesin B, maka hipotesanya dirumuskan produktifitas mesin A sama dengan mesin B.
Hipotesa alternatife yang selanjutnya dirumuskan dengan Ha adalah hipotesa kerja yang dirumuskan sebagai kebalikan dari hipotesa nol.Contoh :
Pada hipotesa nol yang menyatakan bahwa efektifitas obat A sama dengan obat B, hipotesa alternatifenya dirumuskan sebagai berikut : Efektivitas obat A tidak sama dengan obat B Efektivitas obat A lebih baik dari obat B

Statistik Bisnis
Efektivtas obat A lebih jelek dari obat BKetiga macam hipotesa alternatife tersebut merupakan 3 alternatif yang dapat dipergunakan sebagai perumusan hipotesa alternatife. Setelah hipotesa nol dan hipotesa alternatifenya dirumuskan, maka selanjutnya kita mengadakan observasi sampling.
Atas dasar nilai statistik sample ini, maka keputusan diambil apakah hipotesa nol diterima atau ditolak. Apabila kita menerima hipotesa nol berarti hipotesa alternatife kita tolak atau kalau kita menolak hipotesa nol, maka hipotesa alternative kita terima.
Penentuan Tarif Nyata (Significant Level)Tujuan dari pengujian hipotesa tidaklah semata-mata untuk menghitung nilai statistik, melainkan untuk menentukan apakah perbedaan atara nilai statistik dan parameter sebagai proses hipotesa, cukup nyata ataupun tidak.Contoh :
Sebuah perusahaan pembuat pesawat terbang menyatakan bahwa penggunaan bahan aluminium mempunyai rata rata ketebalan 0.04 inci, sedang batas toleransi yang didapat diterima 5%
Di sini hipotesa nol (Ho) = 0,04 inciSedang batas toleransi 5% disebut tariff nyata atau significant level (tingkat kesalahan).Apabila hipotesa nol benar, maka taraf nyata ini menunjukan persentase dari rata rata sample atau nilai statistik yang terletak di luar batas kepercayaan atau confidence level.Diagram berikut menunjukan taraf nyata 5% yang didalam kurva normal terletak pada ujung kurva masing masing seluas 2,5%

Statistik Bisnis
Bagan Daearah Penerimaan dan PenolakanDengan Taraf Nyata (Significant Level) 5%
Menurut tabel daerah kurva normal, luas daerah kurva sebesar 95% akan terletak dalam jarak + 1.96 yang menunjukan bahwa di daerah ini tidak ada perbedaan yang nyata (significant) antara nilai statistik dan nilai parameter yang dinyatakan sebagai hipotesa.Daerah ini disebut daerah penerimaan hipotesa atau acceptance region. Sedang kedua ujung kurve dengan luas masing masing 2.5% merupakan daerah penolakan hipotesa, karena daerah ini menunjukkan adanya perbedaan yang nyata atau significant antara nilai statistik dengan nilai parameternya yang dijadikan hipotesa.5. Pemilihan Taraf Nyata (Significant Level)
Di dalam pemilihan taraf nyata atau significant level ini tidak ada standar ukuran yang pasti. Beberapa nilai taraf nyata yang banyak dipergunakan adalah 10%, 5%, atau 1%. Ada yang mengatakan bahwa taraf nyata 1% atau kurang dipergunakan di bidang kesehatan, 5% di bidang ekonomi, dan 10% untuk bidang pertanian
Sedang Richard I. Levin dalam bukunya Statistics For Management mengatakan bahwa taraf nyata 1% banyak dipergunakan untuk pengujian hipotesa hipotesa di dalam penelitian penelitian.
Selanjutnya dikatakan bahwa tidak mungkin mempergunakan semua kriteria taraf nyata melainkan harus ditetapkan salah satu nilai standar yang minimal. Semakin besar nilai taraf nyata akan semakin besar propabilitasnya umtuk menolak hipotesa nolSebagai penjelasan dapat dijelaskan diagram berikut ini :
Daerah Penerimaan(Acceptance Region)
Z = -1,96 Z = -1,96
Daerah Penolakan(Acceptance Region)
2,5%Tarif nyata
Daerah Penolakan(Acceptance Region)
2,5%Tarif nyata

Statistik Bisnis
Bagan Suatu Hipotesa Diuji Dengan 3 Macam Taraf Nyata Yaitu 1%, 5% dan 10%
1. Taraf Nyata 1%
X
2. Taraf Nyata 5%
X
3. Taraf Nyata 10%
XDari bagian A,B, dan C di atas menunjukan bahwa semakin besar nilai taraf nyata (significant level), maka semakin sempit daerah penerimaan hipotesa atau semakin besar probabilita untuk menolak hipotesa. Lihat titik X yang merupakan nilai sample, pada Bagian C semakin mendekati daerah penolakan hipotesa.
6. Pengajuan Dengan 2 Sisi dan Dengan 1 SisiDi dalam pengujian hipotesa kita dapat mempergunakan 2 sisi atau 1 sisi penguji.
Pengujian dengan 2 sisi adalah pengujian hipotesa yang akan menolak hipotesa nol, jika nilai statistik mempunyai perbedaan nyata lebih besar atau lebih kecil dari parameter populasi yang dijadikan hipotesa.Pengujian 2 sisi ini mempunyai 2 daerah penolakan :1. Pengujian dengan 2 sisi (two tailed test)
Pengujian hipotesa dengan 2 sisi dilakukan apabila hipotesa alternatifnya dirumuskan dengan :
Ha…………………u [email protected] 67
0.5% 0.5%
Luas daerah penerimaan99%
Luas daerah penerimaan95%
0.25% 0.25%
Luas daerah penerimaan90%
5% 5%

Statistik Bisnis
Contoh :Suatu perusahaan yang memproduksi lampu pijar hasil produksinya rata rata 1.000 jam. Perumusan hipotesa nol dan hipotesa alternatifnya adalah sebagai berikut :Ho…… 1.000 jamHo…… 1.000 jamPerumusan hipotesa alternatif yang demikian karena produsen tidak menghendaki hasil produksinya mempunyai daya tahan yang lebih kecil atau lebih besar dari rata rata daya tahan yang telah ditetapkan sebesar 1.000 jam.Jika daya tahan lebih kecil dari daya tahan rata rata yang telah ditetapkan, maka perusahan tersebut akan kehilangan pembeli atau konsumennya. Sebaliknya apabila daya tahan lampu pijar jauh di atas daya tahan rata rata yang telah ditetapkan, maka perusahaan akan menghadapi biaya yang tinggi.
2. Pengujian dengan 1 sisi (one tailed test)Dalam banyak hal kadang kadang kita tidak memerlukan pengujian dengan menggunakan 2 sisi, yaitu apabila kita menghadapi masalah berikut ini.Misalkan pemerintah ingin membeli bola lampu pijar dalam jumlah yang cukup besar untuk keperluan instansi instansinya. Dalam pembelian bola lampu ini, pemerintah menghendaki agar mutu produk cukup baik dengan daya tahan rata tata sebagaimana telah disebutkan di atas adalah 1.000 jam, sehingga pemerintah dapat memantau hasil pembeliannya dengan mengadakan penelitian sample dari bola lampu pijar yang diabilnya.Berdasar pertimbangan daya tahan rata rata dari bola lampu tersebut, pemerintah akan menolak apabila daya tahan bola lampu yang dibelinya di bawah 1.000 jam. Pemerintah akan merasa diuntungkan, sebab semakin besar daya tahan bola lampu pemerintah akan dapat menghemat pengeluaran.Dengan demikian hipotesa nol (Ho) adalah u = 1.000 jam, sedang hipotesa alternatifnya Ha < 1.000 jam. Jadi penolakan hipotesa nol di sini jika daya tahan bola lampu tersebut kurang dari 1.000 jam. Pengujian ini disebut pengujian dengan 1 sisi sebelah kiri.Hal ini dapat dilihat dalam diagram berikut ini :
Bagan Pengujian Dengan 1 Sisi di Sebelah Kiri
Pengujian dengan 1 sisi di sebelah kiri ini dipergunakan apabila hipotesa alternatife menyatakan lebih kecil dari hipotesa nolnya, Apabila nilai statistik menunjukan perbedaan yang nyata atau signifikan di bawah nilai parameter yang dijadikan hipotesa, maka hal ini akan mengarah kepada kesimpulan yang akan menolak hipotesa nolnya. Karena daerah penolakan hipotesa ini berada di sebelah kiri, maka kita mengatakan pengujian hipotesa ini pengujian dengan 1 sisi disebelah kiri.Pengujian hipotesa dengan 1 sisi di sebelah kanan dipergunakan apabila kita menghadapi masalah sebagai berikut :Seorang manager pemasaran alat alat kecantikan mengadakan penghematan dengan menentukan pengeluaran rata rata untuk setiap salesmen setiap hari dengan dana Rp 10.000,- setelah keadaan ini berjalan kemudian diperlakukan penelitian apakah ketentuan ini benar benar dapat ditepati dengan mengadakan penelitian terhadap sample. Karena kebijaksanaan penghematan ini, maka fokusdari manager tersebut adalah apabila pengeluaran lebih besar dari batas dari batas yang telah ditetapkan
o
Luas daerah penerimaan90%Daerah penolakan
5%
U = 1.000 jam

Statistik Bisnis
yaitu Rp 10.000,- perhari, sehingga hipotesa nol (Ho) dirumuskan u = Rp 10.000,- sedang hipotesa alternatifnya (Ha) dirumuskan > Rp 10.000,- Pengujian ini mempergunakan 1 sisi di sebelah kananKeadaan ini dapat dilihat dalam diagram berikut :

Statistik Bisnis
Bagan Pengujian dengan 1 sisi di sebelah kanan
Dari bagan diatas menunjukan bahwa daerah penolakan terletak di sebelah kanan atau sisi kanan.Pengujian hipotesa ini di sebut pengujian dengan 1 sisi di sebelah kanan.
Penentuan Statistik UjiPada umumnya statistik uji yang dipergunakan sebagai dasar pengambilan keputusan dalam pengujian hipotesa apabila sampelnya besar dalam hal ini n > 30. Penggunaan statistik uji Z ini tergantung pada ciri hipotesanya dan asumsi asumsi tentang populasinya yang dirumuskan sebagai berikut :
st - parameter st
st = statistik (nilai sample)parameter = Hipotesa parameternya st = Deviasi standar sample
sebaliknya apabila sampelnya kecil dalam hal ini n < 30, maka akan dipergunakan statistik uji t sebagai dasar pengujian hipotesa dirumuskan sebagai berikut :
st - parameter st
dimana :t = Distribusi t dengan derajat kebebasan sebesar n-1
Pengambilan KeputusanDidalam setiap proses pengambilan keputusan tenteng apakah kita akan menerima ataukah menolak suatu hipotesa, kita akan selalu dihadapkan pada 2 macam kesalahan, yakni dirumuskan dengan kesalahan jenis 1 atau type 1 error dan kesalahan jenis II atau type II error.Kesalahan jenis 1 akan kita jumpai apabila kita menolak suatu hipotesa yang benar (Ho benar), sedang kesalahan jenis II akan kita junpai apabila kita menerima suatu hipotesa yang keliru (Ho keliru sedang H1 benar)Secara skematis kedua jenis kesalahan tersebut dapat dilaksanakan dalam tabel berikut ini.
Tabel Beberapa Kemungkinan Hasil Pengujian HipotesaHipotesa Jika Ho Benar Jika Ho Palsu
(H1 Benar)KeputusanMenerima Ho Keputusan Betul
Probabilita = 1 - aKesalahan jenis IIProbabilita
Luas daerah penerimaan90%
Daerah penolakan5%
U = Rp 10.000,-

f
0 Daerah Penerimaan 15,99
Statistik Bisnis
Menolak Ho Kesalahan jenis IProbabilita = a(tariff nyata)
Keputusan betul Probabilita = (kuasa pengujian)
Pengujian hipotesa dapat dilakukan dengan 1 sisi yakni dengan nilai kritis atau daerah penolakan yang terdapat pada salah satu ujung kurve atau dengan mempergunakan 2 sisi dengan nilai kritis atau daerah penolakan pada kedua ujung kurve sebagaimana telah dijelaskan pada paragraph di muka.Misalkan kita mengadakan pengujian hipotesa dengan mempergunakan 1 sisi dengan a = 0.05 dan misalkan hipotesa nol (Ho) yang menyatakan pengeluaran rata rata setiap hari untuk salesmen Rp 10.000,- sedangkan statistik sample terletak pada daerah penolakan, maka secara konsekuen kita harus menolak Ho.Dengan demikian keputusan itu membuat resiko membuat kesalahan a sebesar 0.05. Sebaliknya apabila Ho yang menyatakan pengeluaran rata rata setiap hari untuk salesmen Rp 10.000,- tidak benar atau palsu, maka H1 yang benar, sedang statistik sample terletak pada daerah penerimaan, secara konsekuen kita harus menerima Ho dengan menbuat kesalahan menerima Ho palsu sebesar .Secara teoritis kedua jenis kesalahan di atas sedapat mungkin harus diusahakan sekecil mungkin dengan melalui pemilihan daerah kritis yang setepat tepatnya.Prosedur pengujian hipotesa yang baik seharusnya mengikuti suatu asas umum sebagai berikut. Bila terdapat beberapa daerah kritis yang memiliki probabilita kesalahan jenis I yang sama dan sudah ditentukan, maka pengujian hipotesa yang terbaik adalah yang memiliki probabilita kesalahan jenis II yang sekecil mungkin.
DISTRIBUSI KAI KUADRAT Dalam bab ini akan dibahas tentang pengujian hipotesa terhadap
perbedaan lebih dari 2 proporsi. Distribusi KAI Kuadrat (X2) merupakan pereode pengujian hipotesa
terhadap perbedaan lebih dari 2 proporsi.
Misalnya : Manager pemasaran suatu perusahaan ingin mengetahui apakah perbedaan proporsi penjualan produk baru dari perusahaannya pada 3 daerah pemasaran yang berbeda disebabkan karena faktor kebetulan atau faktor faktor lain, sehingga preferensi terhadap produk baru pada 3 daerah pemasaran tersebut berbeda.
Distribusi KAI Kuadrat (X2) mempunyai beberapa kelebihan pada penggunaanya :
– Pengujian terhadap persesuaian frekuensi hasil observasi dengan frekuensi teoritisnya, disebut Test Of Goodness Of Fit.
– Pengujian terhadap hubungan antara variable disebut Test Of Indefendence
– Pengujian terhadap homogenitis suatu variable disebut Test Of Homogenity
TABEL KAI KUADRAT (X2)Dapat dilihat dalam lampiran. Menurut tabel tersebut apakah derajat kebebasan = 10 dan taraf nyata (significant level) = 10%, maka akan diperoleh nilai X2 = 15,99.
Daerah Penerimaan dan Penolakan HipotesaPada Distribusi X2 dengan Taraf Nyata 10% dan Derajat Kebebasan 10

Luas sebesar 10%Daerah penolakan X2 10%
X2
Statistik Bisnis
Menurut diagram tersebut hipotesa akan ditolak untuk semua nilai yang lebih besar dari 15,99. Sedang untuk nilai-nilai kurang dari atau sama dengan 15,99 hipotesa diterima.
PENGGUNAAN DISTRIBUSI KAI KUADRAT7. Pengujian Tentang Kompatibilitas (Test Of Goodness Of Fit)Persoalan yang dihadapi adalah menguji apakah frekuensi yang diobservasi memang konsisten dengan frekuensi teoritisnya.1. Apabila konsisten atau tidak terdapat perbedaan yang nyata atau
signifikan maka hipotesa dapat diterima.2. Apabila tidak terdapat konsistensi maka hipotesa ditolak artinya
hipotesa teoritisnya tidak didukung oleh hasil observasi.Rumus :
Dengan derajat kebebasan sebesar k – 1Dimana :Oi = Frekuensi observasi (fo)Ei = Frekuensi teoritis (fe)
X2 merupakan ukuran perbedaan antara frekuensi observasi dengan frekuensi teoritis.
Apabila tidak ada perbedaan antara frekuensi observasi dengan frekuensi teoritis maka X2 = 0
Semakin besar perbedaan antara frekuensi observasi dengan frekuensi teoritis maka nilai X2 akan menjadi besar.
Selanjutnya nilai X2 akan dievaluasi dengan distribusi dengan distribusi kai kuadrat.
Prosedur pengujian hipotesa dilakukan dengan langkah langkah sebagai berikut :
1. Nyatakan hipotesa nol dan hipotesa alternatifnya.2. Tentukan taraf nyata dan derajat kebebasanya.3. Tentukan statistik uji X2
4. Pengambilan keputusanUntuk menjelaskan, diambil contoh :Sebuah lembaga manajemen ingin mengetahui pola konsumsi terhadap 5 macam merk ban mobil yang dominan dalam pemasaran ban. Untuk keperluan ini dipilih 1.000 orang konsumen.
Dari hasil observasi diperoleh informasi sebagai berikut :Preferensi Konsumen Terhadap 5 Macam Merk Ban Mobil
Dengan Sampel 1.000 Orang Konsumen
Preferensi Merk Mobil Jumlah KonsumenAB
210310

f
0
Daerah Penerimaan
9.488
134.750Daerah penolakan X2 10%
X2
Statistik Bisnis
CDE
17085225
Jumlah 1.000
Apabila proporsi, konsumen untuk setiap merk ban dinyatakan dengan PA, PB, PC, PD, dan PE maka rumusan hipotesa nol dan hipotesa alternatifnya :
1.
2. Tarif nyata 5% dengan derajat kebebasan k–1= 5–1 =4Menurut table, x2 = 9.488
3. Statistik Uji
Dimana : fo = frekuensi observasi Fe = frekuensi teoritis
Perhitungan Uji Statistik Preferensi Konsumen Terhadap5 Macam Merk Ban Mobil Di Suatu Kota Besar
Dengan Sampel 1.000 Orang Konsumen
Preferensi
Konsumen Ban
Frekuensi Observasi
(fo)
Frekuensi
Teoritis (fe)
(fo-fe) (fo-fe)2 (fo-fe) 2
fe
ABCDE
21031017085225
200200200200200
10110-30-11525
10012.100900
13.225625
0.50060.5004.50066.1253.125
Jumlah 1.000 1.000 0 26.950 134.750
4. Kesimpulan :Hasil uji statistik uji x2 = 134.750 lebih besar dari 9.488. berarti ada perbedaan yang signifikan antara frekuensi hasil observasi dengan frekuensi teoritis sehingga hipotesa yang mengatakan bahwa tidak ada perbedaan proporsi konsumsi ban untuk 5 merk ditolak Ho ditolak.

Statistik Bisnis
8. Pengujian Sifat Independensi (Test Of Independence)Pengujian kompatibilitas digunakan jika data populasi maupun
sample diklasifikasikan menurut artibut tunggal (single atribut) maupun jika kita ingin menguji distribusi probabilita populasi hipotesa.
Apabila klasifikasi data sample maupun data populsai dalam beberapa artibut sedang distribusi probablilitasnya tidak diketahui, maka pengujian kompatibilitas sulit dipergunakan. Misalnya:setiap konsumen dapat diklasifikasikan menurut penghasilannya dan kualitas sabun mandi yang dipergunakan, sedang distribusi probabilitanya tidak diketahui, maka pengujian kompatibilitasnya sulit dipergunakan. Misalnya setiap konsumen dapat diklasifikasikan menurut penghasilannya dan kualitas sabun mandi yang dipergunakan, sedang proporsi tiap golongan dalam populasi tidak diketahui.
Persoalan yang ingin diketahui adalah apakah ada hubungan antara penghasilan dan kualitas sabun mandi yang dipergunakan. Pengujian yang demikian ini disebut pengujian sifat independensi.
Dalam pengujian hipotesa ini kita hanya sampai pada kesimpulan apakah kedua atribut tersebut mempunyai sifat independent atau tidak. Pengujian tidak akan menjawab sampai derajat asosianya.
Pengujian sifat independensi ini akan dijelaskan secara berturut turut mulai dari populasi, sampelnya, penyusunan table dwi kasta dan pengujian hipotesanya.
Misalkan sebuah sample n = 30 yang dipilih dari populasi, ternyata yang berpenghasilan tinggi n1 = 100, n2 = 200, n.1 = 150, dan n.2 = 150 maka table dwi kastanya, menjadi :
Tabel Dwikasta Tingkat Penghasilan dan JenisSabun Mandi yang Dikonsumir
Penghasilan Kualitas Sabun Mandi Jumlah Baris(n1)Baik (B1) Rendah (B2)
Tinggi (A1)Rendah (A2)
40110
6090
100200
Jumlah Kolom (n1)
150 150 300
Selanjutnya untuk masing masing baris dan kolom dapat dihitung frekuensi teoritisnya.
Baris 1 kolom 1,
Baris 1 kolom 2,
Baris 2 kolom 1,
Baris 2 kolom ,
Frekuensi Observasi dan Frekuensi Teoritis Data Tingkat Penghasilan dan
Jenis Sabun Mandi yang Dipergunakan dengan Sampel Sebesar n = 30

f
0
Daerah Penerimaan
3.841
Daerah penolakan6
X2
Statistik Bisnis
PenghasilanKualitas Sabun Mandi Jumlah
(n1)Baik (B1) Rendah (B2)fo fe fo Fe
Tinggi (A1)Rendah (A1)
40110
(50)(100)
6090
(50)(100)
100200
Jumlah Kolom (n1) 150 (150) 150 (150) 300
Tabel selengkapnya dapat disajikan sbb:Prosedur Pengujian hipotesa dilakukan dengan langkah langkah :
1. Ho ; tingkat penghasilan dan jenis sabun mandi yang dipergunakan adalah independent.
Ha ; tingkat penghasilan dan jenis sabun mandi yang dipergunakan tidak independent.
2. Tarif nyata dipergunakan 5% dengan derajat kebebasan (r-1) (c-1)= (2-1)(2-1) = 1 menurut x2 nilainya 3,841
3. Statistik uji yang dipergunakan adalah rumus:
4. KesimpulanHasil statistic uji 6 adalah lebih besar dari 3.841. Berarti perbedaanya signifikan atau cukup besar, sehingga hipotesa ditolak. Yang berarti bahwa tidak ada hubungan antara tingkat penghasilan dengan sabun mandi yang dipergunakan.
Daerah Penerimaan dan Penolakan HipotesaDengan Tarif Nyata 5%
Secara diagramatis dapat disajikan sebagai berikut :Apakah ada hubungan antara pria dan wanita dengan preferensinya terhadap pakaian?
Hubungan antara pria dan wanita Dalam pilihan warna pakaian dengan sample sebesar n= 100
Warna Pakaian
Pria Wanita Jumlah
Merah MudaPutihBiru
102030
201010
303040
Jumlah 60 40 100

0
Daerah Penerimaan
5.991
Daerah penolakan13.19
X2
Statistik Bisnis
Perhitungan Frekuensi Teoritis Hubungan Pria dan Wanita
Dalam Pilihan Warna Pakaian dengan Sampel Sebesar n=100
Warna Pakaian Pria WanitaMerah mudaPutihBiru
30/100x60 = 1830/100x60 = 1840/100x60 = 24
30/100x40 =1230/100x40 =1240/100x40 =16
Jumlah 60 40
Prosedur pengujian hipotesanya adalah :1. Ho : tidak ada hubungan antara pria dan wanita dengan pilihan warna
pakeannyaHa : ada hubungan antara pria dan wanita dengan pilihan warna
pakaian2. Tarif nyata 5% dengan derajat kebebasan (r-1)(c-1) = (3-1)(2-1) = 23. Statistik uji X2
4. KesimpulanHasil statistik uji 13.19 adalah lebih besar dari 5.991. jadi ada perbedaan yang signifikan, sehingga hipotesanya ditolak.
Daerah Penerimaan dan Penolakan HipotesaDengan Tarif Nyata 5%
9. Pengujian Terhadap Sifat Homogenitas (The of Homogenity)Dalam pengujian hipotesa kita kadang kadang dihadapkan pada
suatu masalah apakah dua sample atau lebih berasal dari satu populasi atau dengan perkataan lain apakah satu sample dengan sample yang lain mempunyai persamaan.
Pengujian untuk mengetahui apakah 2 sampel atau lebih bersifat homogen atau sama disebut pengujian sifat homogenitas (test homogeneity).
Nilai Seleksi ke Perguruan Tinggi yang Berasal dari2 Sekolah Lanjutan Atas Masing masing dengan Sampel
Sebesar 100 (n1 =100) dan (n2 =100)
Niali Sampel SLTA JumlahSampel 1 Sampel 2ABCDE
1020302020
1010403010
2030705030

Statistik Bisnis
n1=100 n2=100 n =200
Suatu penilaian terhadap hasil seleksi perguruan tinggi terhadap 2 sampel sekolah lanjutan tingkat atas yang masing masing dengan sample sebesar 100, menunjukan hasil nilai seleksi sebagai berikut :1. Hipotesa nol dapat dirumuskan kedua sample di atas mempunyai
distribusi probabilita yang sama yakni distribusi probablilita dari populasi.Hipotesa alternatifenya menyatakan bahwa kedua sample tersebut tidak memiliki distribusi probabilita yang sama.
2. Tarif 5% dengan derajat kebebasan (5-1) (2-1) =4 Menurut table X2 = 9.48
3. Statistik uji di pergunakan adalah X2
Sebelum kita menghitung nilai X2, kita menghitung frekuensi teoritisnya lebih dahulu dan membandingkan dengan frekuensi observasinya.
Fe11 = n1 x (n1/n) = 100 x 20/200 = 10Fe21 = n1 x (n1/n) = 100 x 30/200 = 15Fe31 = n1 x (n1/n) = 100 x 70/200 = 35Fe41 = n1 x (n1/n) = 100 x 50/200 = 25Fe51 = n1 x (n1/n) = 100 x 30/200 = 15
Frekuensi Observasi dan Frekuensi TeoritisDari Hasil Nilai 2 sampel SLTA
Nilai
Sampel SLTA sampel1 sampel 2 JumlahSampel Sampel 2
Fo Fe Fo feABCDE
1020302020
(10)(15)(35)(25)(15)
1010402010
(10)(15)(35)(25)(15)
0/10=0.025/15=1.625/35=0.725/25=1.025/15=1.6
0/10=0.025/15=1.625/35=0.725/25=1.025/15=1.6
0.03.21.42.03.2
Untuk fe21, fe22, fe23, fe24, dan fe25 nilainya sama dengan di atas.
4. KesimpulanHasil statistic uji 9,48 berarti ada perbedaan yang signifikan, sehingga hipotesa ditolak.
Daerah Penerimaan dan Penolakan HipotesaDengan Tarif Nyata 5%

Statistik Bisnis
ANALISA VARIAN Dipergunakan untuk mengadakan pengujian terhadap lebih dari 2 rata rata
sample Metode ini dapat digunakan untuk mengambil kesimpulan apakah sample
berasal dari populasi yang memiliki nilai rata rata yang sama.Misalnya : Membandingkan daya tahan 4 macam produksi ban, membandingkan 4 macam metode latihan yang diselenggarakan oleh suatu perusahaan dalam rangka peningkatan karir para karyawan.
PERUMUSAN MASALAHManajer pendidikan dan latihan suatu perusahaan perakitan radio kaset ingin mengadakan evaluasi terhadap 3 metode pendidikan dan latihan bagi karyawan karyawannya yang baru.ada 3 macam metode pendidikan dan latihan :
Pendidikan dan latihan terhadap para karyawan yang baru dengan cara mendidik dan melatih secara individual di dalam perusahaan.
Mendidik masing masing karyawan baru secara individual dan terpisah dengan bimbingan pelatih.
Mendidik dan melatih para karyawan baru dengan metode audio visual, film dengan belajar mandiri.
Setelah pendidikan dan latihan dapat diselesaikan, manajer produksi bersama dengan manajer pendidikan dan latihan mengadakan evaluasi terhadap hasilnya.Untuk keperluan penelitian ini diperoleh sampai 5 orang karyawan yang telah mengikuti masing masing metode dan dilakukan pencatatan terhadap hasil produksi setiap hari yang dapat diselesaikan oleh masing masing karyawan tersebut seperti disajikan dalam tabel berikut ini :
Produksi Radio Yang Dapat Dihasilkan Setiap HariDari 15 Orang Karyawan (Unit)
Metode I Metode II Metode III1518192211
2227182117
1824162215
PERUMUSAN HIPOTESAMetode analisa varians ini dipergunakan untuk mengetahui apakah rata rata produksi dari 3 sampel karyawan yang telah mengikuti pendidikan dan latihan dengan metode yang berbeda ini mempunyai perbedaan dalam produktivitas ataukah tidak. Dengan perkataan lain dapat dikatakan apakah 3 sampel yang masing masing berupa rata rata sample I,II, dan III berasal dari populasi yang sama.
Perumusan Hipotesa nol :
apabila di dalam pengujian hipotesa ini 3 rata rata sample sama, kita sampai pada kesimpulan bahwa 3 macam metode pendidikan dan latihan ini tidak mempengaruhi produktifitas karyawan.

Statistik Bisnis
Sebaliknya, apabila ke-3 rata rata sample tersebut menunjukan perbedaan yang nyata atau berarti (significant), maka berarti ketiga macam metode pendidikan dan latihan tersebut mempengaruhi produktifitas karyawan, sehingga perlu adanya peninjauan kembali terhadap ketiga macam metode pendidikan dan latihan tersebut.
KONSEP DASAR ANALISA VARIANSAnalisa varians berdasarkan pada perbandingan 2 macam nilai penduga terhadap varians populasi ( 2).2 nilai penduga varians populasi tersebut adalah :
Varians antar sample (Varians Among the Sample Means)Varians antar sample ini selanjutnya dinotasikan dengan Sa2.Dalam contoh di muka variana antar sample adalah varians di antara rata-rata sample 1 = 17; rata rata sample 2 = 21 dan rata rata 3 = 19 Varians dalam sample (Varians within the sample means)Varians dalam sample adalah varians di dalam ketiga sample. Dalam contoh dimuka yang dimaksud dengan varians dalam sample adalah data (15,18,19,22,11),(22,27,18,21,17), dan (18,24,16,22,15).
Perbandingan 2 nilai varians tersebut merupakan penduga terhadap varians populasi. Apabila nilai penduga ini sama atau mendekati sama maka hipotesa benar. Apabila kedua nilai perbandingan ini berbeda dengan varians populasi maka hipotesa keliru. Kesimpulan dalam analisa varians adalah sebagai berikut :
Tentukan penduga pertama dari varians populasi dari varians antar sample. Tentukan penduga kedua terhadap varians populasi dari varians dalam
sample. Bandingkan kedua nilai penduga ini. Jika hasilnya mendekati sama atau
hamper sama berarti hipotesanya benar.
CARA PERHITUNGAN VARIANS ANTAR SAMPELVarians antar sample dirumuskan sebagai berikut :
n yang di maksud adalah 3 sample atau 3 kolomperhitungan data menjadi sebagai berikut :
PERHITUNGAN VARIANS ANTAR SAMPEL2
172119
191919
17-19= -221-19= 219-19= 0
(-2)2 = 4(2)2 = 4(0)2 = 0
=8
Perumusan varians populasi yang diduga :
dimana Sa = standart deviasi antar sample = 4n = besarnya sample (jumlah karyawan) 5

Statistik Bisnis
sehingga = 20
CARA PERHITUNGAN VARIANS DALAM SAMPELVarians dalam sample dirumuskan sebagai berikut :
Sw2 = varians dalam sample S12+S22+….+Sn2 = Varians sample 1 sampai ke nn = Banyaknya kolom / sample
Peerhitungan Varians Dalam SampelModel 1
Rata rata sample = 17
Model IIRata rata sample =
21
Model IIIRata rata sample =
19X
2X
2X
2
1518192211
-2125-6
4142536
2227182117
16-30-4
1369016
1824162215
-15-33-4
1259916
=17 =21 =21

Statistik Bisnis
PENGUJIAN STATISTIK FStatistik F yang disingkat F merupakan rasio dari varians antara samples sebagai penduga varians populasi yang pertama dengan varians dalam sample sebagai panduga varians populasi yang kedua.Rumus :
Maka nilai F adalah :
Penafsiran nilai F :10. Pembilang (varians antar samples) sebagai penduga varians
populasi merupakan penduga yang terbaik11. Penyebut (varians dalam sample) sebagai penduga varians
populasi merupakan penduga yang baik juga.12. Dengan demikian apabila hipotesanya benar maka nilai
pembilang dan penyebut akan cenderung sama13. Jika nilai F semakin mendekati 1 semakin besar kemungkinan Ho
dapat diterima.14. Apabila nilai F besar semakin besar kemungkinan Ho di tolak dan
semakin besar kemungkinan Ha diterima.
DISTRIBUSI F Distribusi F ditandai dengan 2 macam derajat kebebasan yaitu derajat
kebebasan pembilang dan derajat kebebasan penyebut. Bentuk distribusi F sangat ditentukan oleh 2 nilai derajat kebebasan yaitu
derajat kebebasam dari pembilang dan penyebut.Bentuk umum dari kurva distribusi F adalah condong ke kanan dan akan cenderung menjadi berbentuk normal atau simetris apabila derajat kebebasan dari pembilang dan penyebut semakin besar.
DERAJAT KEBEBASAN DISTRIBUSI FDerajat kebebasan pembilang : jumlah sample – 1
: k – 1Derajat kebebasan penyebut : (jumlah data tiap sample – 1) x jumlah sample
: (n - 1) x kDari contoh di muka diketahui n = 5 dan k = 3
Derajat kebebasan besar
Derajat kebebasan sedang
Derajat kebebasan rendah

Statistik Bisnis
Maka :Nilai derajat kebebasan pembilang = 3 – 1 =2Nilai derajat kebebasan penyebut = (5 – 1) x 3
= 4 x 3 = 12
untuk pengujian hipotesa dengan distribusi F dipergunakan tabel F. dalam tabel F, kolom menunjukan derajat kebebasan pembilang baris menunjukan derajat kebebasan penyebut.Contoh :Pada taraf nyata 5% dengan derajat kebebasan pembilang = 2 dan derajat kebebasan penyebut = 12 maka tabel F = 3.89
KESIMPULAN DARI PENGUJIAN HIPOTESADalam pengujian hipotesa teradap 3 macam metode pendidikan dan latihan telah diperoleh hasil statistik uji dari distribusi F = 1,25. Hasil ini dibandingkan dengan nilai F=3.89.Karena hasil statistik uji lebih kecil maka Ho diterima.
Daftar Penerimaan Dan Penolakan HipotesaPada Taraf Nyata 5%
0 1.25 3.89
Karena statistik uji F = 1.25 terletak pada daerah penerimaan maka hipotesa diterima (Ho diterima).Kesimpulan yang dapat diambil adalah bahwa ketiga metode pendidikan dan latihan tersebut tidak menimbulkan perbedaan dalam produktifitas tenaga kerja.
ANALISA VARIANS DENGAN 2 KLASIFIKASI (Two Way Anova)Misalnya : Kita ingin mengetahui variasi yang timbul dengan adanya media promosi yang berbeda dari berbagai macam komoditi dagangan.Dua Klasifikasi ini meliputi :o Macam media promosio Macam komoditi daganganDalam pengamatan ini akan diteliti :[email protected] 82
Daerah PenerimaanDaerah Penolakan

Statistik Bisnis
apakah ada perbedaan 3 macam media promosi ? Apakah ada pengaruh dalam pengelompokan macam komoditi dagangan ?
Hasil Penelitian Terhadap 3 Macam Media Promosi Untuk3 Macam Komoditi Dagangan Dengan Sampel 180
Macam Komoditi
Dagangan
Macam Media PromosiJumlah (TI)Radio TV Surat
KabarABC
242325
191721
201417
635463
Jumlah (Tj) 72 57 51 180 (Tij)
Tiga macam komoditi dagangan dipromosikan dengan 3 media promosi yang berbeda yaitu :
Media Radio Media Televisi Media surat kabar
Dengan menggunakan tarif uji 5% maka ujilah :– Apakah efektifitas ketiga media promosi itu sama ?– Apakah pengelompokan menjadi 3 macam kelompok komoditi dagangan itu
tidak ada pengaruhnya?
Dalam uji hipotesa ini ada 2 macam hipotesa, yaitu :
(hipotesa berdasar baris/macam komoditi)
(hipotesa berdasar kolom/macam media promosi)
Beberapa notasi yang digunakan adalah :SSR : jumlah kuadrat barisSSC : Jumlah kuadrat kolomSSE : Jumlah kuadrat penyimpanganSST : Total dari jumlah kuadratMSS : Rata rata dari jumlah kuadratMSSR : Varians berdasar barisMSSC : Varians berdasar kolomMSSE : Varian berdasar penyimpangan
Tabel Analisa Varians (Anova)Varians Jumlah
Kuadrat
DerajatKebebas
an
Rata rata jumlah kuadrat
F
Baris (b) SSR (b-1)
Kolom (k) SSC (k-1)
Penyiapan
(error)SSE (b-1) (k-
1)
Jumlah SST (b-1) (k-1)
SSE=SST-SSR-SSC
Fb = F berdasar baris derajat kebebasan

Statistik Bisnis
2. Pembilang = (b-1)3. Penyebut = (b-1) (k-1)
Fk = F berdasar kolom derajat kebebasan Pembilang = (b-1) Penyebut = (b-1) (k-1)
Selanjutnya pengunaan Tabel F disesuaikan dengan tarif uji yang di pilih.Berdasar pada contoh data dimuka dapat dihitung sbb:
– SST =
= (24) 2 + (23) 2 + (19) 2 + (17) 2 + (21) 2 + (20) 2 + (14) 2 + (17) 2 3
= 3.706 – 3.600= 106
– =
= (24)2 + (23)2 + (19)2 + (17)2 + (21)2 + (20)2 + (14)2 + (17)2
= = 3618 – 3600= 18
MSSR = 18/2 = 9
– SSC =
= = 3678 – 3600 = 78
MSSC =
SSE = SST – SSR – SSC = 106 – 18 – 78 = 10
MSSE =
– Fb =
F 0,05 df 2/4 nilai table 6,94 (efek baris)
– Fb =


















