
Building a Recommendation Engine Using Diverse Features by Divyanshu Vats
37
BUILDING A RECOMMENDATION ENGINE USING DIVERSE FEATURES Divyanshu Vats Sailthru
-
Upload
spark-summit -
Category
Data & Analytics
-
view
1.251 -
download
0
Transcript of Building a Recommendation Engine Using Diverse Features by Divyanshu Vats

BUILDING A RECOMMENDATION ENGINE USING DIVERSE FEATURES
Divyanshu VatsSailthru

Joint work with
Max Sperlich(Sailthru)
David Glueck(Sailthru)
Alex Gaudio(Alluvium)
Jeremy Stanley(Instacart)

Customer Retention Cloud

users
items
users
items
Buy?
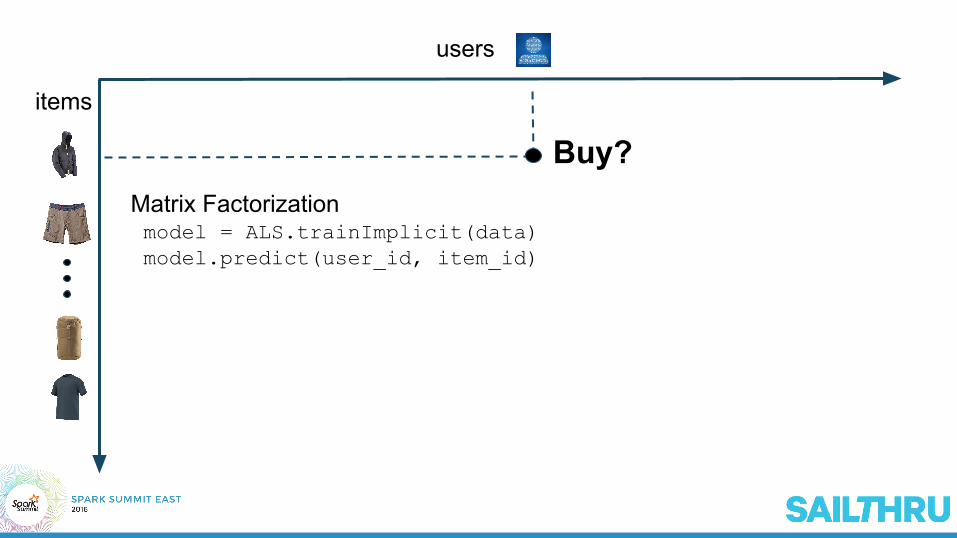
users
items
Buy?Matrix Factorization model = ALS.trainImplicit(data) model.predict(user_id, item_id)

users
items
Buy?Matrix Factorization model = ALS.trainImplicit(data) model.predict(user_id, item_id)
Other Methods- Item-Item Similarity- Content Based- Nearest neighbor based methods

users
items
Buy?Matrix Factorization model = ALS.trainImplicit(data) model.predict(user_id, item_id)
Other Methods- Item-Item Similarity- Content Based- Nearest neighbor based methods
Open source scalableimplementations
Easily Incorporate additional features?

Additional Features?

Additional Features?
titleimage
description
item
location
browser
# clicks
user
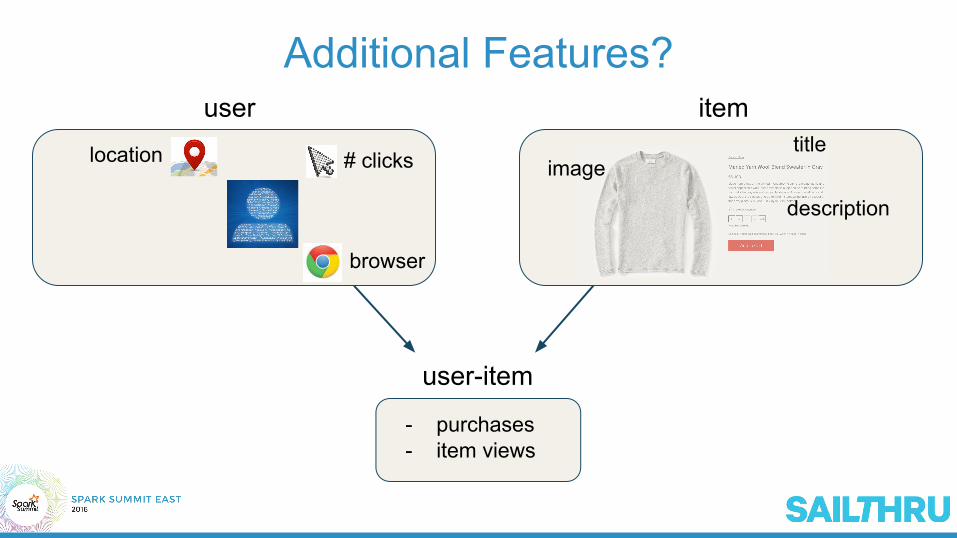
Additional Features?
titleimage
description
item
location
browser
# clicks
user
user-item
- purchases- item views

Goal: Framework to easily integrate user, item, and user-item interactions for meaningful recommendations
prediction interval response
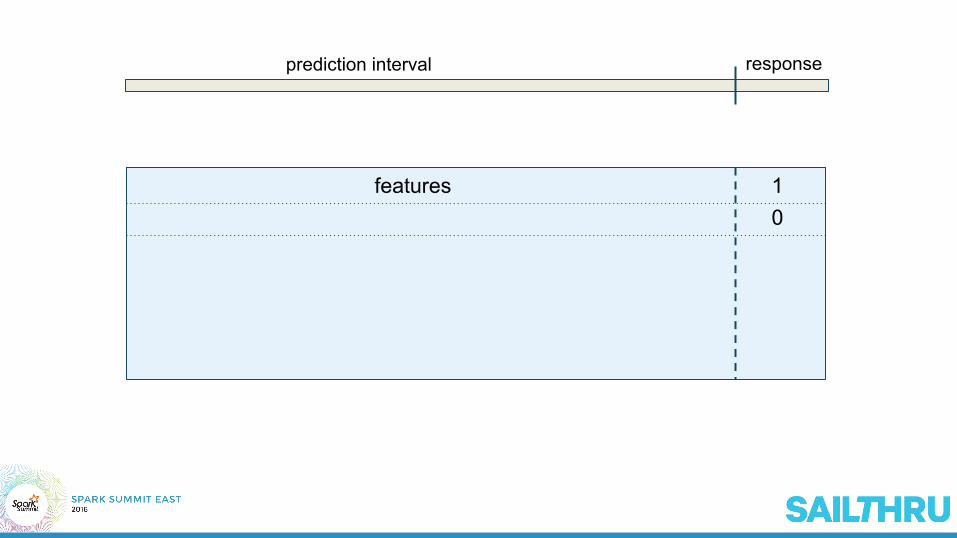
prediction interval response
1features0
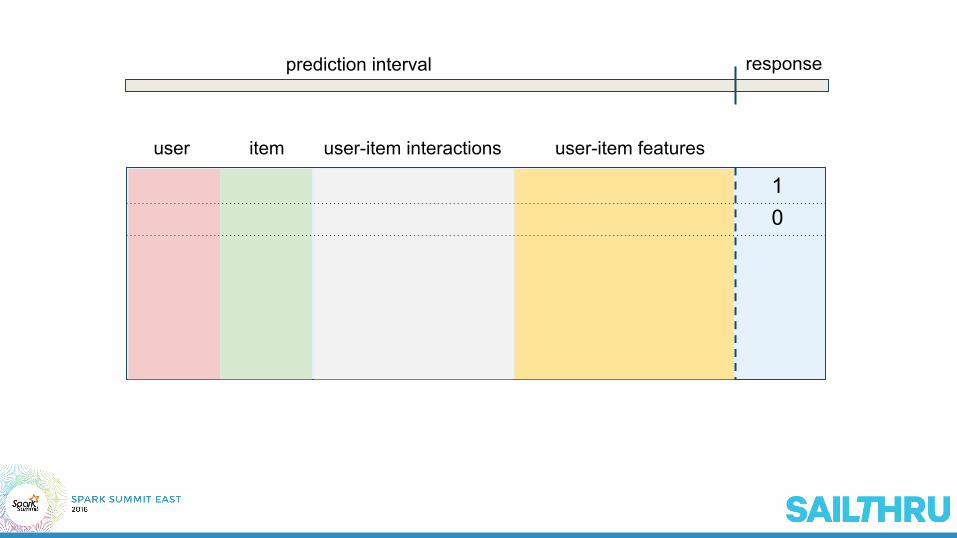
prediction interval response
user item user-item interactions user-item features
10
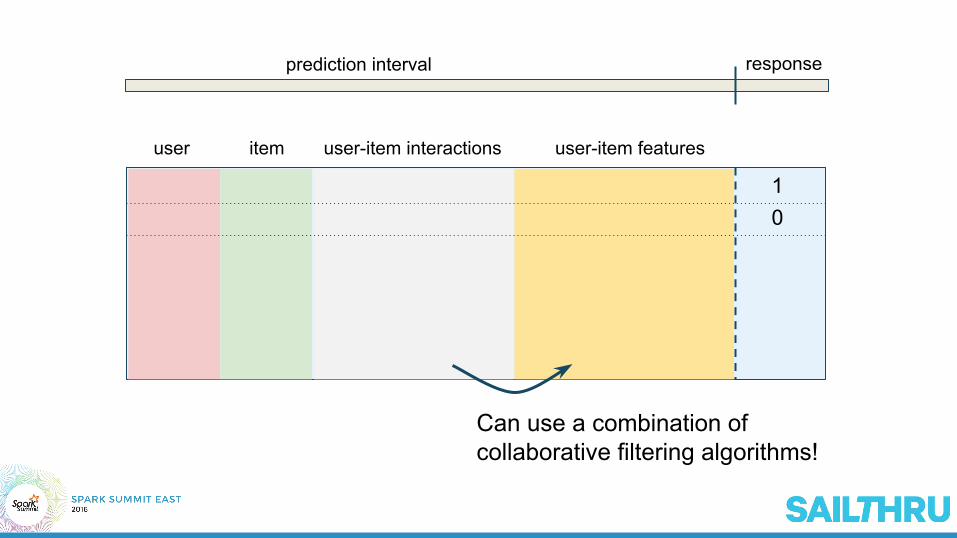
prediction interval response
Can use a combination of collaborative filtering algorithms!
user item
10
user-item interactions user-item features

So far….users
items
Buy?
- Easily integrate user, item, and user-item features
- Recommendation → Binary classification
- Next: Implementation and use of Spark!

Structured Tables: e.g. url views, purchases
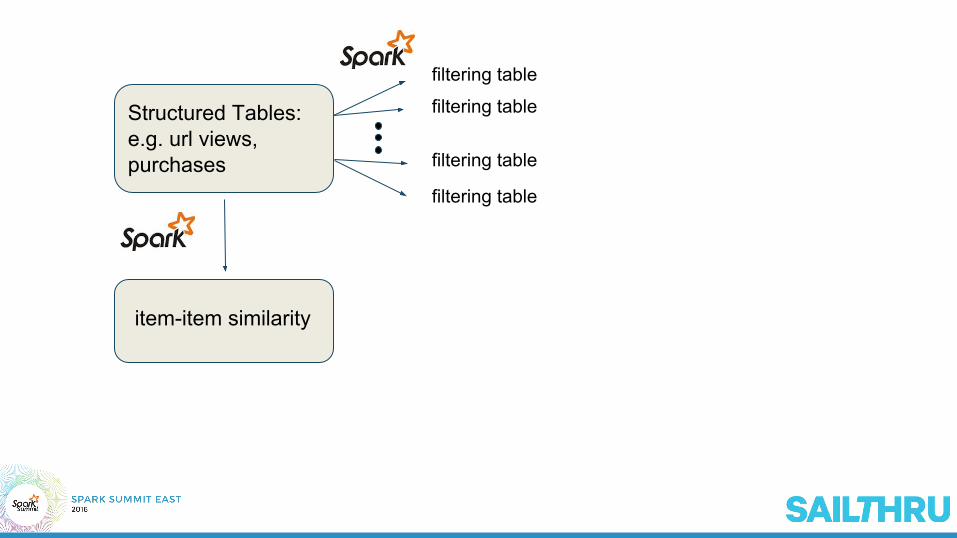
Structured Tables: e.g. url views, purchases
item-item similarity
filtering table
filtering table
filtering table
filtering table
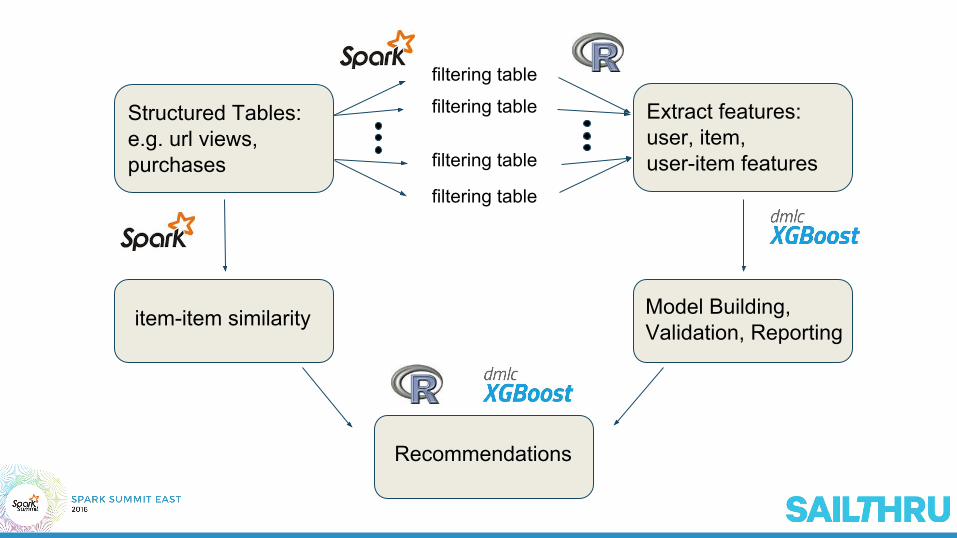
Structured Tables: e.g. url views, purchases
filtering table
filtering table
filtering table
filtering table
Extract features:user, item,user-item features
Model Building,Validation, Reporting
item-item similarity
Recommendations

Know Thy Partitions!
data.select(‘user_id’, ‘url’)data.groupBy(‘user_id’)data.count()data.filter(count > 10)

Know Thy Partitions!
data.select(‘user_id’, ‘url’)data.groupBy(‘user_id’)data.count()data.filter(count > 10)
Inefficient!
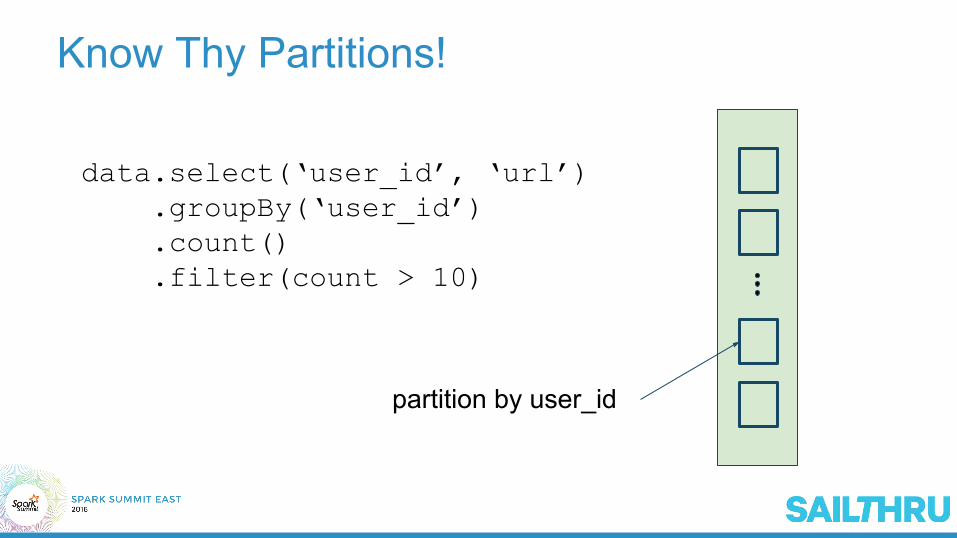
Know Thy Partitions!
partition by user_id
data.select(‘user_id’, ‘url’)data.groupBy(‘user_id’)data.count()data.filter(count > 10)
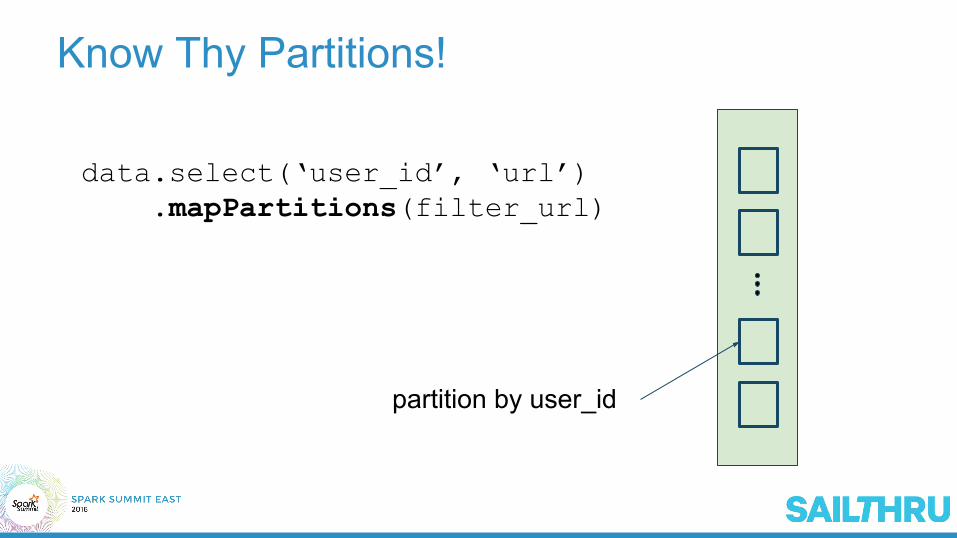
Know Thy Partitions!
data.select(‘user_id’, ‘url’)data.mapPartitions(filter_url)da
partition by user_id

Break up application into small chunks!
users = data.select(‘user_id’, ‘url’) .mapPartitions(filter_url)
.collect()
BigData.filter(lambda x: x.user_id in users)

Break up application into small chunks!
users = data.select(‘user_id’, ‘url’) .mapPartitions(filter_url)
.collect()
BigData.filter(lambda x: x.user_id in users)

Break up application into small chunks!
users = data.select(‘user_id’, ‘url’) .mapPartitions(filter_url)
.collect()
BigData.filter(lambda x: x.user_id in users)
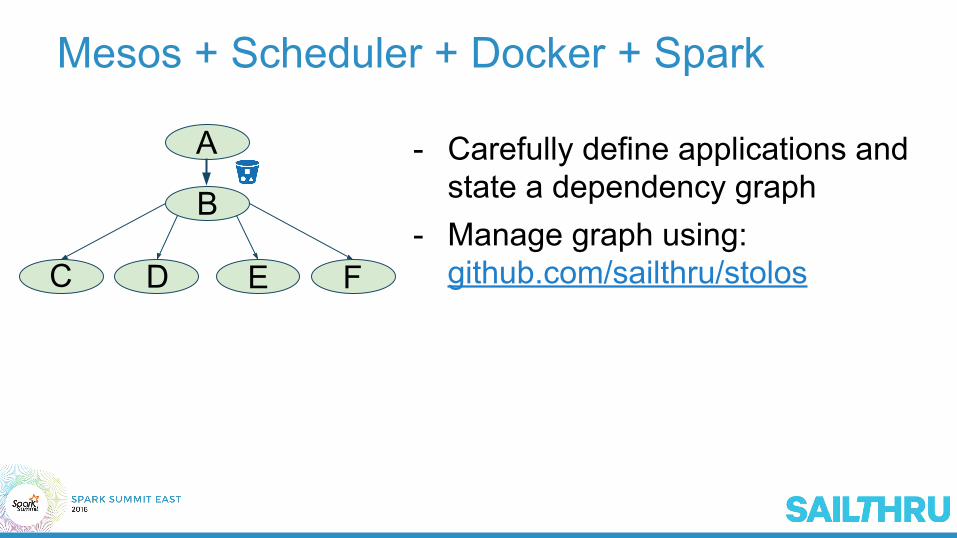
Mesos + Scheduler + Docker + Spark
A
B
C D E F
- Carefully define applications and state a dependency graph
- Manage graph using:github.com/sailthru/stolos

Mesos + Scheduler + Docker + Spark
A
B
C D E F
- Carefully define applications and state a dependency graph
- Manage graph using:github.com/sailthru/stolos

Item-Item Similaritiesusers
items
P(Buy) = 0.002

users
items
P(Buy) = 0.002
500 items
1000 items
> 5000 items
Item-Item Similarities

users
items
P(Buy) = 0.002
RowMatrix.computeSimilarites
item-item similarities
Item-Item Similarities

users
items
P(Buy) = 0.002
RowMatrix.computeSimilarites
item-item similarities
filter and score items for each user
Item-Item Similarities
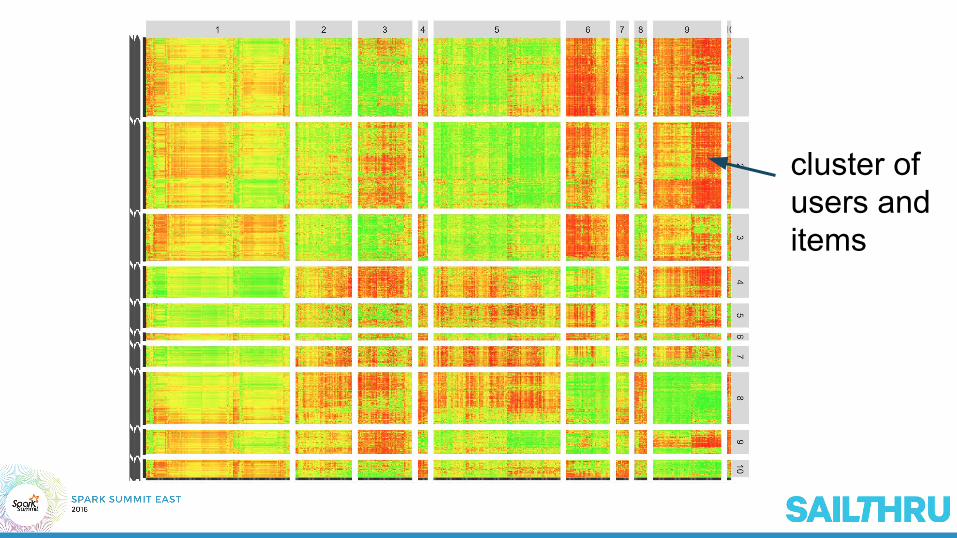
cluster of users and items

To Summarize..users
items
Buy?
- Recommendations using diverse features
- Carefully designed spark apps connected using a graph
- Future work:- More spark apps + spark-mesos cluster manager

THANK YOU.email: [email protected]




![Divyanshu 9-c Economics[Project]Urban Area and Rural Area](https://static.fdocuments.in/doc/165x107/577ce08f1a28ab9e78b396b4/divyanshu-9-c-economicsprojecturban-area-and-rural-area.jpg)













