

Brian Rogers †‡ , Anil Krishna †‡ , Gordon Bell ‡ , Ken Vu ‡ , Xiaowei Jiang † , Yan...
23
Scaling the Bandwidth Wall: Challenges in and Avenues for CMP Scalability 36th International Symposium on Computer Architecture Brian Rogers †‡ , Anil Krishna †‡ , Gordon Bell ‡ , Ken Vu ‡ , Xiaowei Jiang † , Yan Solihin † NC STATE UNIVERSITY † ‡
-
Upload
erica-king -
Category
Documents
-
view
26 -
download
2
description
Scaling the Bandwidth Wall: Challenges in and Avenues for CMP Scalability 36th International Symposium on Computer Architecture. Brian Rogers †‡ , Anil Krishna †‡ , Gordon Bell ‡ , Ken Vu ‡ , Xiaowei Jiang † , Yan Solihin †. †. ‡. NC STATE UNIVERSITY. As Process Technology Scales …. P. - PowerPoint PPT Presentation
Transcript of Brian Rogers †‡ , Anil Krishna †‡ , Gordon Bell ‡ , Ken Vu ‡ , Xiaowei Jiang † , Yan...

Scaling the Bandwidth Wall:Challenges in and Avenues for
CMP Scalability
36th International Symposium on Computer Architecture
Brian Rogers†‡, Anil Krishna†‡, Gordon Bell‡,
Ken Vu‡, Xiaowei Jiang†, Yan Solihin†
NC STATE UNIVERSITY
† ‡
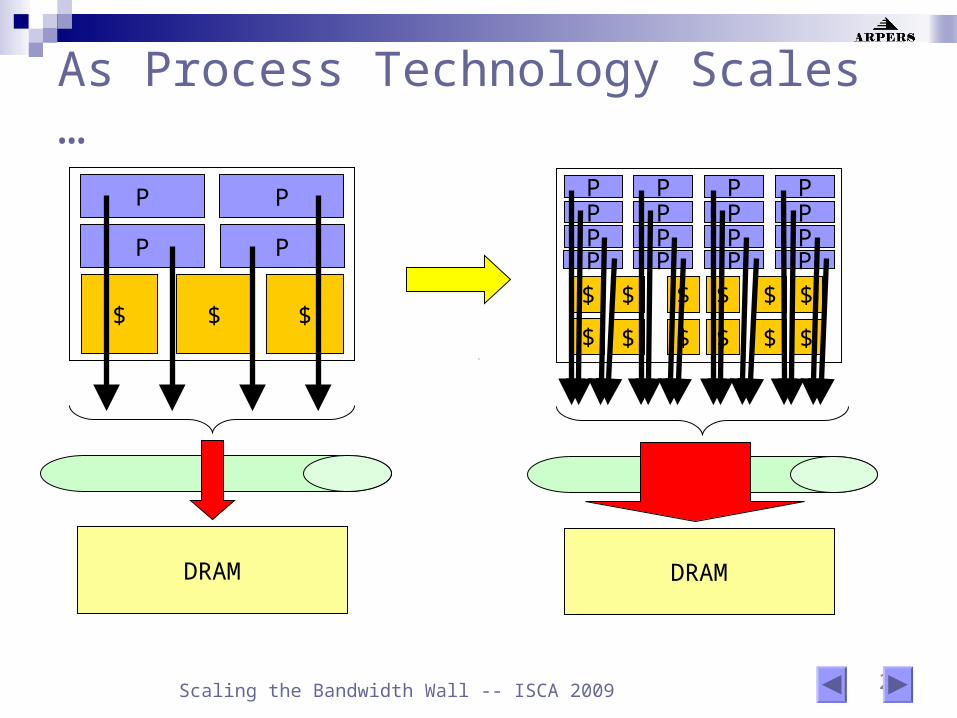
2 Scaling the Bandwidth Wall -- ISCA 2009
As Process Technology Scales …
P
P P
P
$ $ $
DRAM
P
DRAM
PP
PP
PP
PP
PP
PP
PP
P
$
$
$
$
$
$ $
$ $
$$
$

3 Scaling the Bandwidth Wall -- ISCA 2009
Problem Core growth >> Memory bandwidth growth
Cores: ~ exponential growth (driven by Moore’s Law) Bandwidth: ~ much slower growth (pin and power limitations)
At each relative technology generation (T): (# Cores = 2T) >> (Bandwidth = BT)
Some key questions (Our contributions): How constraining is increasing gap between # of cores and
available memory bandwidth? How should future CMPs be designed; how should we
allocate transistors to caches and cores? What techniques can best reduce memory traffic demand?
Build Analytical CMP Memory Bandwidth Model

4 Scaling the Bandwidth Wall -- ISCA 2009
Agenda Background / Motivation Assumptions / Scope CMP Memory Traffic Model Alternate Views of Model Memory Traffic Reduction Techniques
Indirect Direct Dual
Conclusions

5 Scaling the Bandwidth Wall -- ISCA 2009
Assumptions / Scope
Homogenous cores Single-threaded cores (multi-threading adds to problem) Co-scheduled sequential applications
Multi-threaded apps with data sharing evaluated separately
Enough work to keep all cores busy Workloads static across technology generations Equal amount of cache per core Power/Energy constraints outside scope of this study

6 Scaling the Bandwidth Wall -- ISCA 2009
Agenda Background / Motivation Assumptions / Scope CMP Memory Traffic Model Alternate Views of Model Memory Traffic Reduction Techniques
Indirect Direct Dual
Conclusions
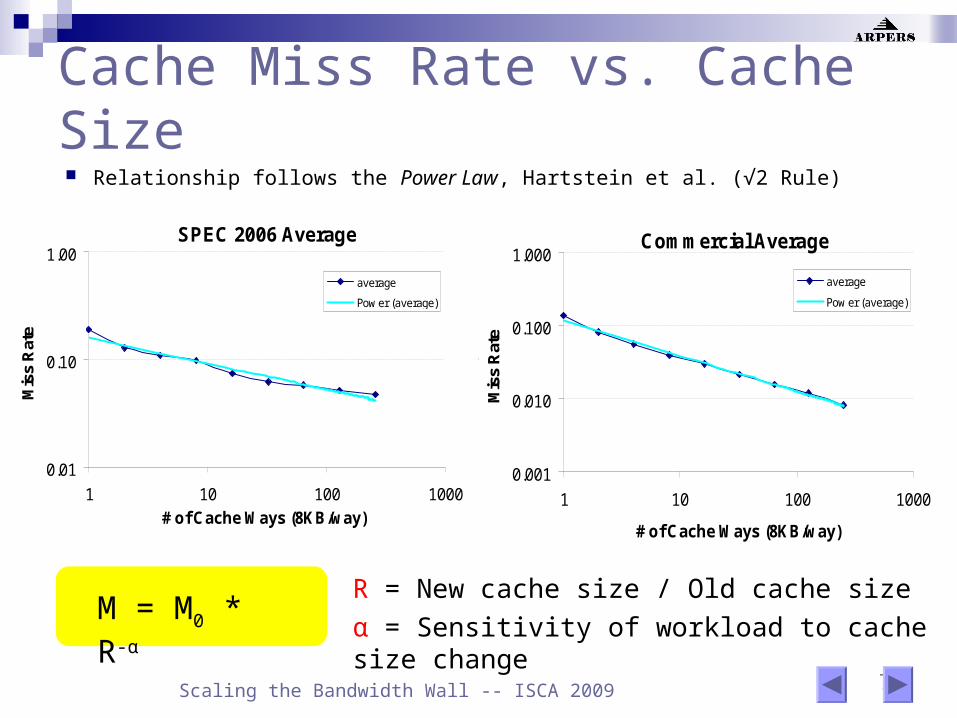
7 Scaling the Bandwidth Wall -- ISCA 2009
SPEC 2006 Average
0.01
0.10
1.00
1 10 100 1000# of Cache Ways (8KB/way)
Mis
s R
ate
average
Pow er (average)
Commercial Average
0.001
0.010
0.100
1.000
1 10 100 1000
# of Cache Ways (8KB/way)
Mis
s R
ate
average
Pow er (average)
Cache Miss Rate vs. Cache Size Relationship follows the Power Law, Hartstein et al. (√2 Rule)
M = M0 * R-αR = New cache size / Old cache size
α = Sensitivity of workload to cache size change

8 Scaling the Bandwidth Wall -- ISCA 2009
CMP Traffic Model Express chip area in terms of Core Equivalent Areas
(CEAs) Core = 1 CEA, Unit_of_Cache = 1 CEA P = # cores, C = # cache CEAs, N = P+C, S = C/P
Assume that non-core and non-cache components require constant fraction of area
Add # of cores term for CMP model:
α
SSMPM
00

9 Scaling the Bandwidth Wall -- ISCA 2009
CMP Traffic Model (2)
Going from CMP1=<P1,C1> to CMP2=<P2,C2>
Remove common terms, express M2 in terms of M1
0
101
0
202
1
2
SSMP
SSMP
M
M
11
2
1
22 M
S
S
P
PM
11
2
1
22 M
S
S
P
PM
P = # cores, C = # cache CEAS N = P+C, S = C/P
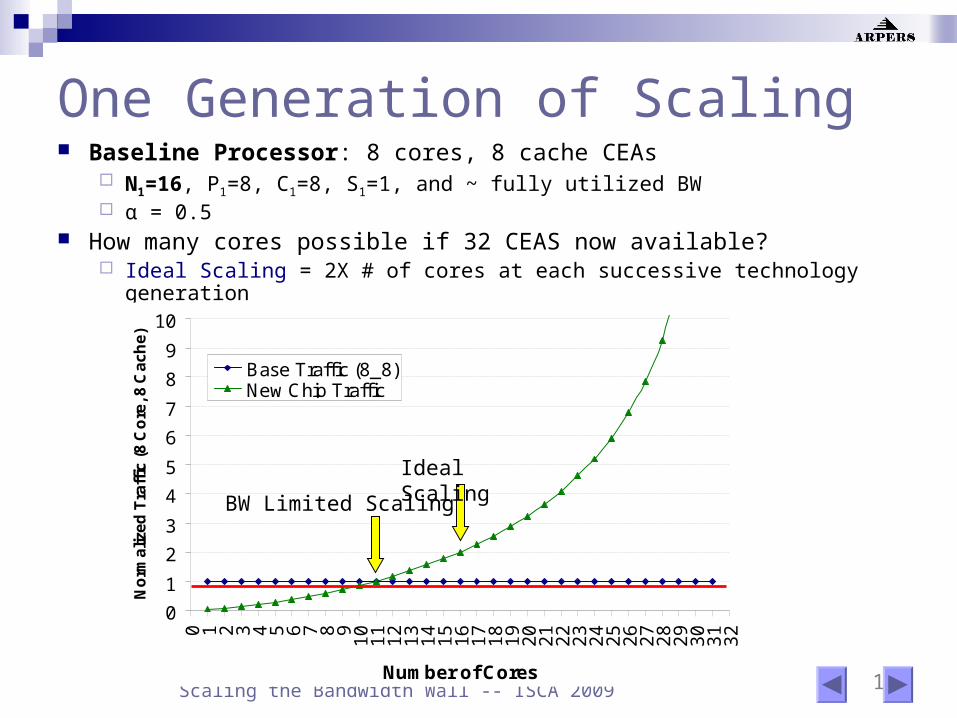
10 Scaling the Bandwidth Wall -- ISCA 2009
One Generation of Scaling Baseline Processor: 8 cores, 8 cache CEAs
N1=16, P1=8, C1=8, S1=1, and ~ fully utilized BW α = 0.5
How many cores possible if 32 CEAS now available? Ideal Scaling = 2X # of cores at each successive technology generation
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 91
01
11
21
31
41
51
61
71
81
92
02
12
22
32
42
52
62
72
82
93
03
13
2
Number of Cores
No
rma
lize
d T
raff
ic (
8 C
ore
, 8 C
ac
he
)
Base Traffic (8_8)New Chip Traffic
Ideal Scaling
BW Limited Scaling

11 Scaling the Bandwidth Wall -- ISCA 2009
Agenda Background / Motivation Assumptions / Scope CMP Memory Traffic Model Alternate Views of Model Memory Traffic Reduction Techniques
Indirect Direct Dual
Conclusions

12 Scaling the Bandwidth Wall -- ISCA 2009
CMP Design Constraint If available off-chip BW grows by factor of B:
Total memory traffic should grow by at most a factor of B each generation
Write S2 in terms of P2 and N2:
New technology: N2 CEAs, B bandwidth => solve for P2 numerically
12 MBM
1
2
1
2
S
S
P
PB
1
222
1
2
S
PPN
P
PB
P2 is # of cores that can be supported
P = # cores, C = # cache CEAS N = P+C, S = C/P

13 Scaling the Bandwidth Wall -- ISCA 2009
Scaling Under Area Constraints
With an increasing # of CEAs available, how many cores can be supported at constant BW requirement
0
10
20
30
40
50
60
1x 2x 4x 8x 16x 32x 64x 128x
Scaling Ratio
Nu
mb
er
of
Co
res
0%
10%
20%
30%
40%
50%
60%
Po
rtio
n o
f C
hip
Are
a
# of Cores% of Chip Area for Cores • 2x die area: 1.4x cores
• 4x die area: 1.9x cores
• 8x die area: 2.4x cores
• 16x die area: 3.2x cores
• …

14 Scaling the Bandwidth Wall -- ISCA 2009
Agenda Background / Motivation Assumptions / Scope CMP Memory Traffic Model Alternate Views of Model Memory Traffic Reduction Techniques
Indirect Direct Dual
Conclusions
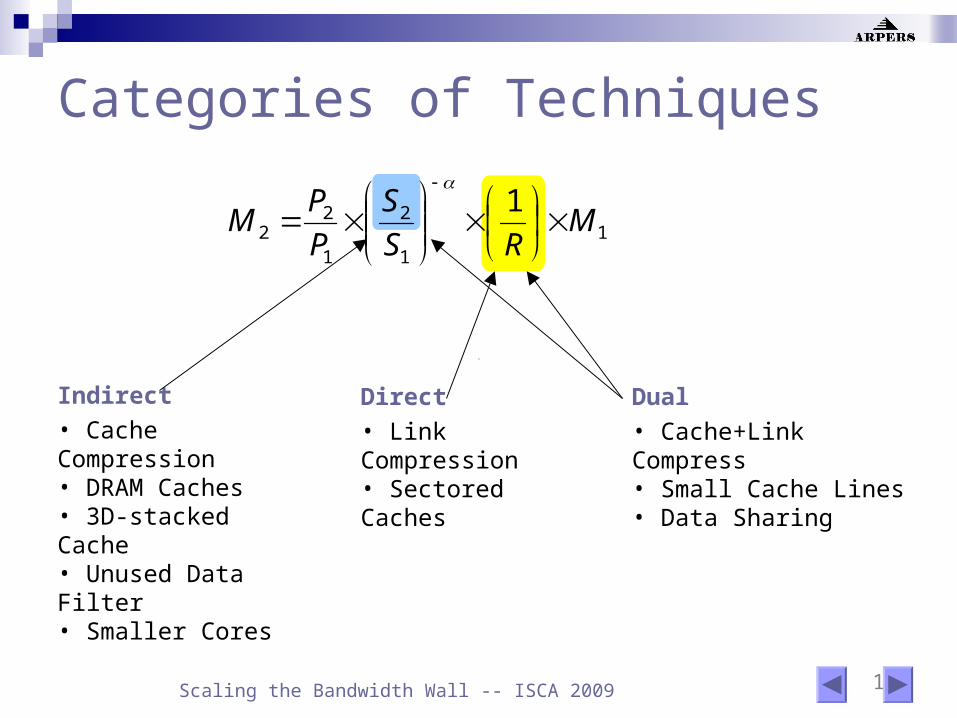
15 Scaling the Bandwidth Wall -- ISCA 2009
Categories of Techniques
Indirect
• Cache Compression• DRAM Caches• 3D-stacked Cache• Unused Data Filter• Smaller Cores
Direct
• Link Compression• Sectored Caches
Dual
• Cache+Link Compress• Small Cache Lines• Data Sharing
11
2
1
22
1M
RS
S
P
PM

16 Scaling the Bandwidth Wall -- ISCA 2009
Indirect – DRAM Cache
F – Influenced by Increased Density
0
5
10
15
20
25
SRAM L2 DRAM L2 (4x) DRAM L2 (8x) DRAM L2 (16x)
L2 Cache Configuration
Nu
mb
er
of
CM
P C
ore
s Pessimistic
Realistic
Optimistic
Ideal Scaling
11
2
1
22 M
S
SF
P
PM

17 Scaling the Bandwidth Wall -- ISCA 2009
Direct – Link Compression
R – Influenced by Compression Ratio11
2
1
22
1M
RS
S
P
PM
0
5
10
15
20
25
NoCompress
1.25x 1.50x 1.75x 2.0x 2.5x 3.0x 3.5x 4.0x
Compression Effectiveness
Nu
mb
er
of
CM
P C
ore
s
Pessimistic
Realistic
Optimistic
Ideal Scaling
18 Scaling the Bandwidth Wall -- ISCA 2009
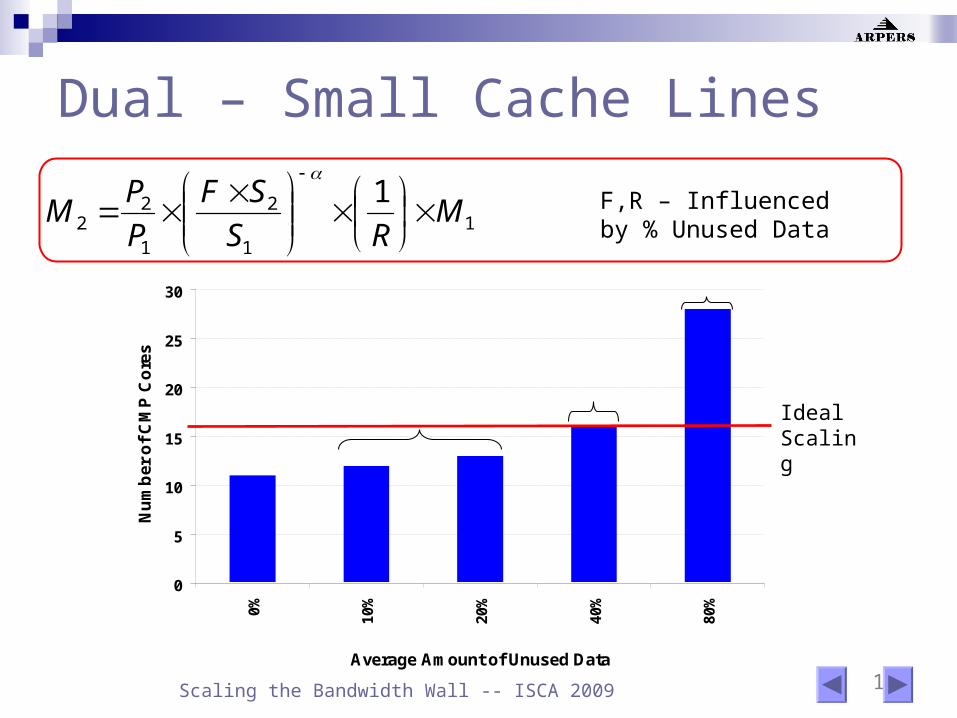
Dual – Small Cache Lines
F,R – Influenced by % Unused Data1
1
2
1
22
1M
RS
SF
P
PM
0
5
10
15
20
25
30
0% 10%
20%
40%
80%
Average Amount of Unused Data
Nu
mb
er
of
CM
P C
ore
s
Pessimistic
Realistic
Optimistic
Ideal Scaling
19 Scaling the Bandwidth Wall -- ISCA 2009
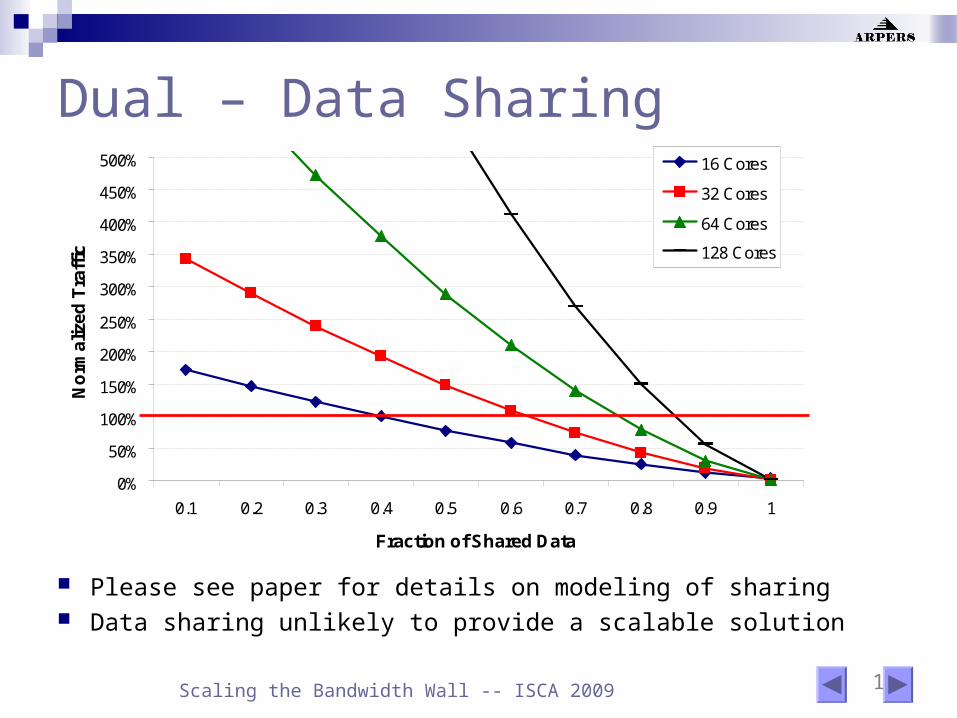
Dual – Data Sharing
0%
50%
100%
150%
200%
250%
300%
350%
400%
450%
500%
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Fraction of Shared Data
No
rma
lize
d T
raff
ic
16 Cores
32 Cores
64 Cores
128 Cores
Please see paper for details on modeling of sharing Data sharing unlikely to provide a scalable solution
20 Scaling the Bandwidth Wall -- ISCA 2009
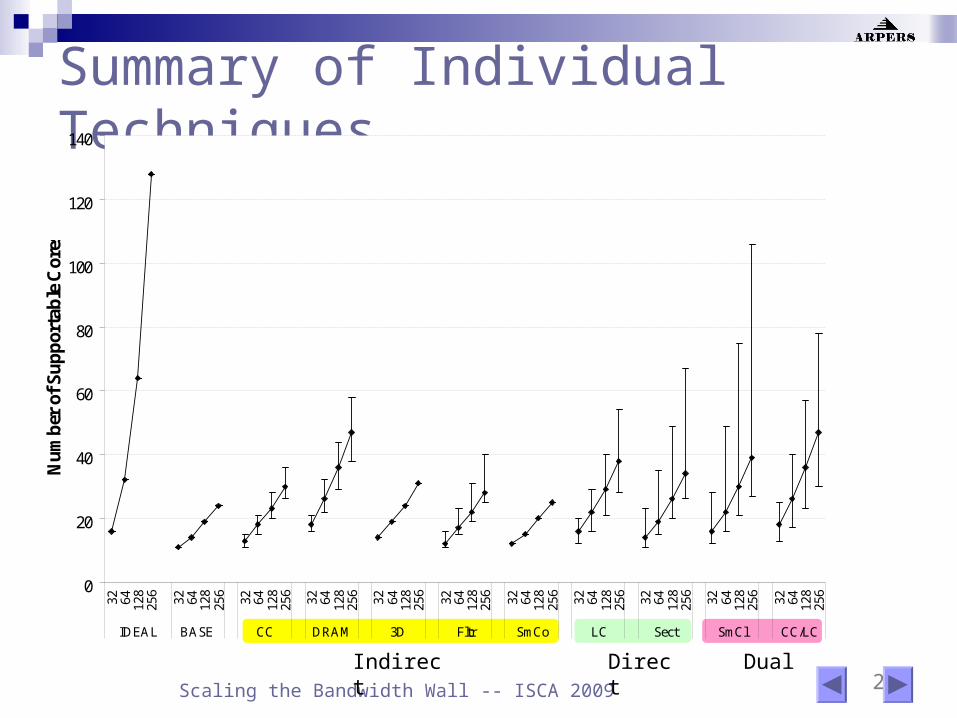
Summary of Individual Techniques
0
20
40
60
80
100
120
140
32 64 128
256
32 64 128
256
32 64 128
256
32 64 128
256
32 64 128
256
32 64 128
256
32 64 128
256
32 64 128
256
32 64 128
256
32 64 128
256
32 64 128
256
IDEAL BASE CC DRAM 3D Fltr SmCo LC Sect SmCl CC/LC
Nu
mb
er o
f S
up
por
tab
le C
ores
Indirect Direct Dual

21 Scaling the Bandwidth Wall -- ISCA 2009
Summary of Combined Techniques
0
50
100
150
200
250
300
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
2x
4x
8x
16x
IDEAL BASE CC +DRAM+ 3D
CC/LC+
DRAM
CC +3D +Fltr
CC/LC+ Fltr
DRAM+ 3D +
LC
DRAM+ Fltr +
LC
DRAM+ LC +Sect
3D +Fltr +LC
SmCl+ LC
CC/LC+ SmCl
DRAM+ 3D +SmCl
CC/LC+
DRAM+ SmCl
CC/LC+ 3D +SmCl
CC/LC+
DRAM+ 3D
CC/LC+
DRAM+ 3D +SmCl
Nu
mb
er
of
Su
pp
ort
ab
le C
ore
s

22 Scaling the Bandwidth Wall -- ISCA 2009
Conclusions Contributions
Simple, powerful analytical CMP memory traffic model Quantify significance of memory BW wall problem
10% chip area for cores in 4 generations if constant traffic req. Guide design (cores vs. cache) of future CMPs
Given fixed chip area and BW scaling, how many cores? Evaluate memory traffic reduction techniques
Combinations can enable ideal scaling for several generations
Need bandwidth-efficient computing: Hardware/Architecture level: DRAM caches, cache/link
compression, prefetching, smarter memory controllers, etc. Technology level: 3D chips, optical interconnects, etc. Application level: working set reduction, locality
enhancement, data vs. pipelined parallelism, computation vs. communication, etc.


















