
Brains & Brawn: the Logic and Implementation of a Redesigned Advertising Marketplace (Sponsor Talk)
54
The Brains and the Brawn: The Logic and Implementation of a Redesigned Advertising Marketplace pydata 2015 stephanie tzeng salvatore rinchiera
-
Upload
pydata -
Category
Data & Analytics
-
view
113 -
download
0
Transcript of Brains & Brawn: the Logic and Implementation of a Redesigned Advertising Marketplace (Sponsor Talk)

The Brains and the Brawn: The Logic and Implementation of a Redesigned Advertising Marketplace
pydata 2015 stephanie tzeng
salvatore rinchiera

what is online advertising?
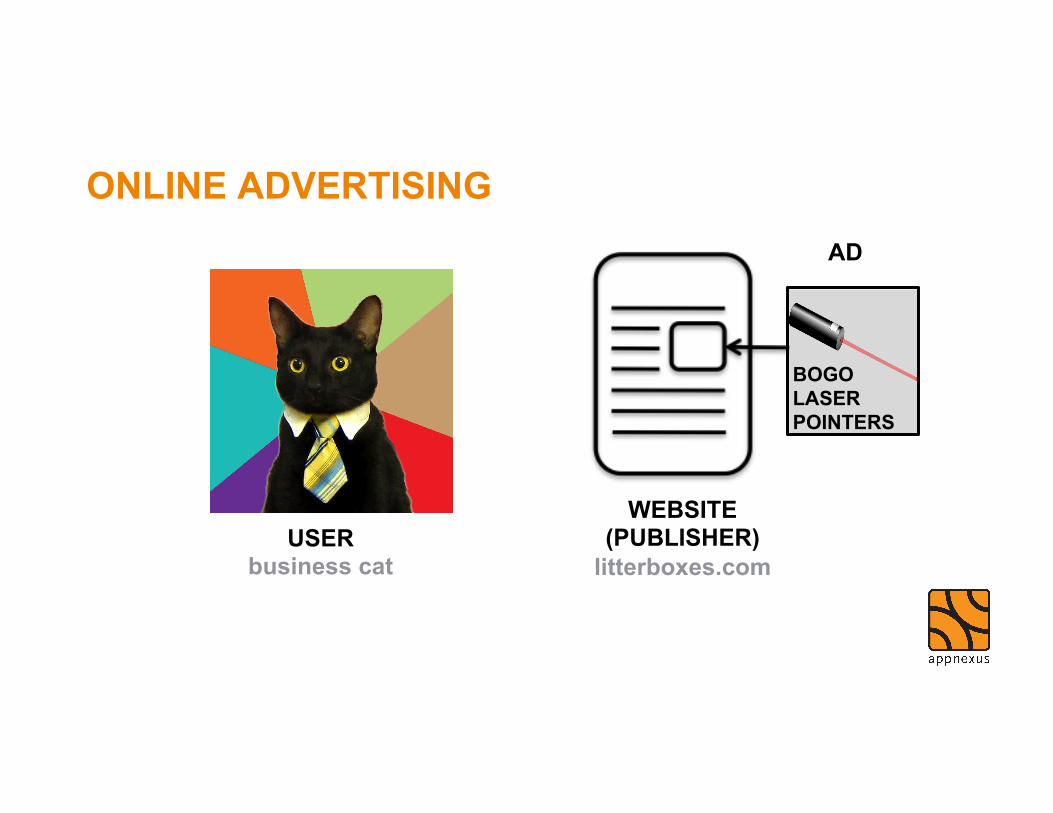
ONLINE ADVERTISING
USER business cat
WEBSITE (PUBLISHER)
litterboxes.com
AD
BOGO LASER POINTERS

APPNEXUS • Platform that connects advertisers and websites • Daily Volume:
• 120+ Billion Auctions • 44 Billion Ads Served • 170+ TB • Fill human brain capacity in 12 days • 700 billion pages of printed information
• 40,000 miles of printed material • Reaches moon in 6.5 days • $273,000,000,000 in printing costs

BIG data
Have you tried
atkins?
medium data

I M P B U S
AN Bidder
log
HDFS
Data Pipeline
Vertica
MySQL
impression
Bidder Bidder Bidder Other Bidders
Optimization

PERFORMANCE BUYING
Advertiser only pays website when someone buys lasers
Website accepts CPA payment
BOGO LASER POINTERS
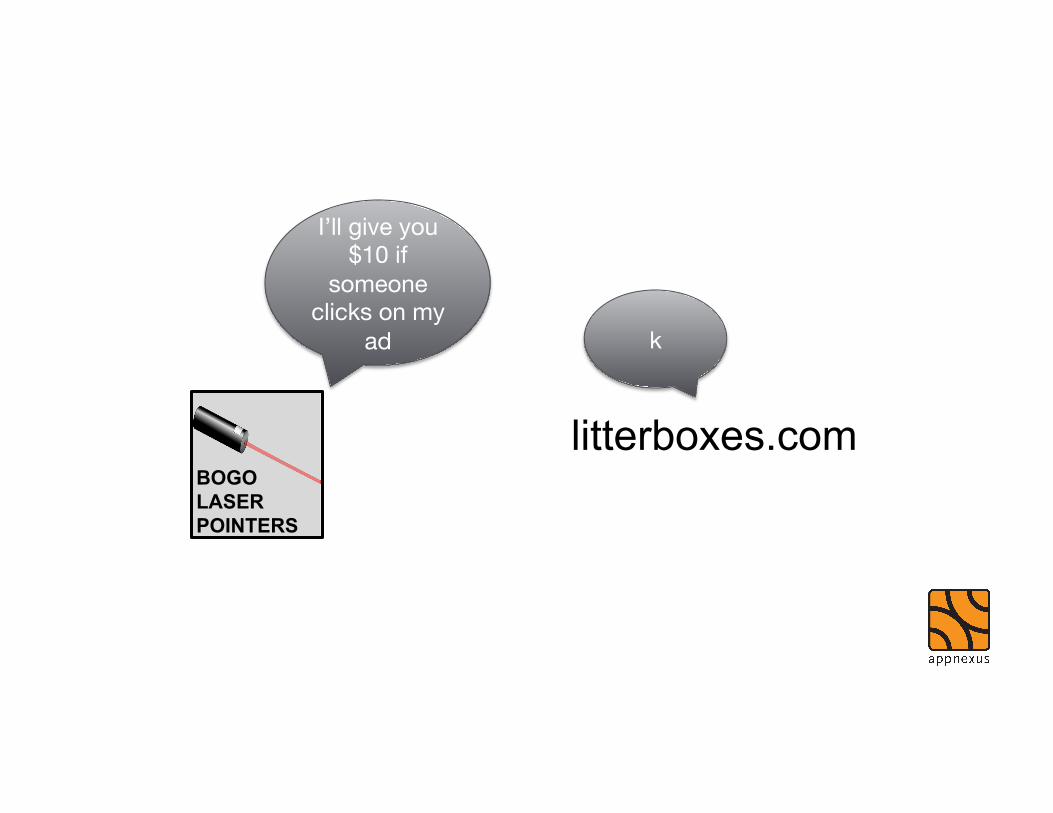
I’ll give you $10 if
someone clicks on my
ad k
BOGO LASER POINTERS
litterboxes.com

9
$5 / click
$50/ purchase
$3 / click
$7 / click
$10 / subscription
$9 / click
$100/ purchase
$10/ purchase
$4 / click
$.5 / click
$13 / click
$8/ purchase $5 /
click
$3 / click
Uhhh…
litterboxes.com

OFFERS -> BID VALUES
• Cost Per Click (CPC) = $10
• Pr(Click) = 0.1
• E(Imp) = $10 x 0.1 = $1
Pr(Click) = # of clicks / # of impressions
What happens when we have no data?

An Event = Information
• Pr(Click) is crucial to expected value of an offer
• Rare events like clicks hold much more information than having impressions with no clicks
• 0 / 10 imps = 0 …
• 0 / 1000 imps = 0 …
• 0 / 10000 imps = 0 … still??
• 1 / 10000 … now we’re getting somewhere!

OFFER STATES Offers are allocated into 2 different auction states per website
• Optimized State = Exploit. Capitalizing on known information
• Learn State = Explore. Acquiring new information
In learn, there is no data. We estimate an initial click or conversion probability to “buy” information.
IMPRESSIONS
learn auctions
optimized auctions

OLD WORLD
• Compute a predicted probability for all offer:website combinations
• Update this prediction as you gain information
• Store all prediction combinations in memory
• Problem: Elaborate probability prediction schemes are not accurate enough, and you end up collecting real data very slowly for all offers

A SINGLE BID IN LEARN
WEBSITE
offer learn valuation instant ramen subscription 3 quest bars 3.5 bh farms carrot juice 0.8 cholula hot sauce 0.00001 starbucks oprah chai lattes 2 justin bieber fanny pack 0.000005 … … recorder midi file download 1.9
bidder memory

OFFER QUICK TEST APPROACH

THE HYPOTHESIS
For information gathering, it is more cost effective to test out “enough” impressions for a concentrated number of offers than buying impressions for all offers based off a flawed prediction. RECALL: when working with rare events, the event holds the key to your information.
You can use this event with limited impressions to classify an offer as good or bad.
CLICK GOOD! NO CLICK BAD!
QUICK-TEST

WHAT IS “ENOUGH”?
N impressions = the minimal amount of impressions you need to deem an offer is bad (given no events).
Compute N impressions based on the offer’s payout (Goal), desired conversion rate (p0), and our tolerance for false negatives (λ).
For each website, set
If p represents the “true” click through rate for offer:website, then N = min(n) such that
QUICK-TEST

THE MATH
Bayes theorem tells us So given an intelligent prior H(p) for p, we can solve for N from
QUICK-TEST

LAMBDA VS N
QUICK-TEST
lam
bda
(fa
lse
nega
tive
rate
)
N
1
0.5
Stop buying! As you decrease your threshold for false negatives, you are more confident that this offer is not good.

CHOOSING LAMBDA ROC Curve
sens
itivi
ty
1 - specificity
Sensitivity = = True Positive Rate
1 – Specificity = 1 – True Negative
Rate =
= False Positive Rate
ideal

OFFER STATE DIAGRAM

IMPLEMENTATION
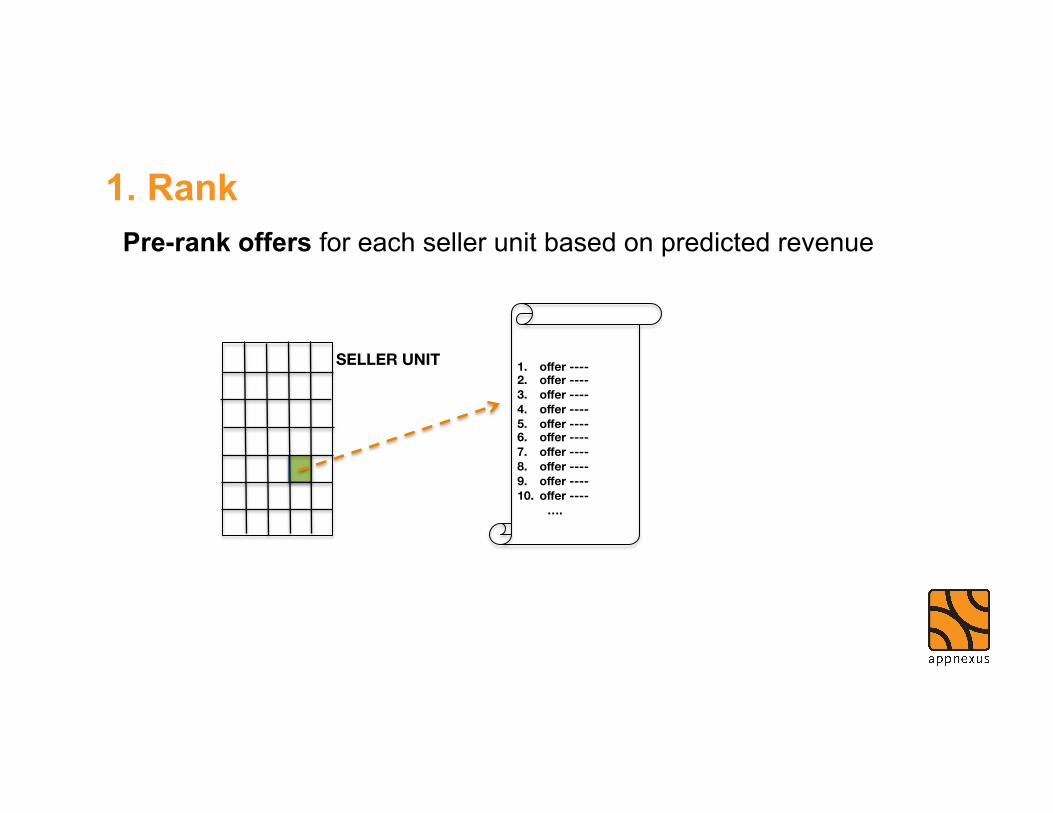
Pre-rank offers for each seller unit based on predicted revenue
1. Rank
1. offer ---- 2. offer ---- 3. offer ---- 4. offer ---- 5. offer ---- 6. offer ---- 7. offer ---- 8. offer ---- 9. offer ---- 10. offer ---- ….
SELLER UNIT
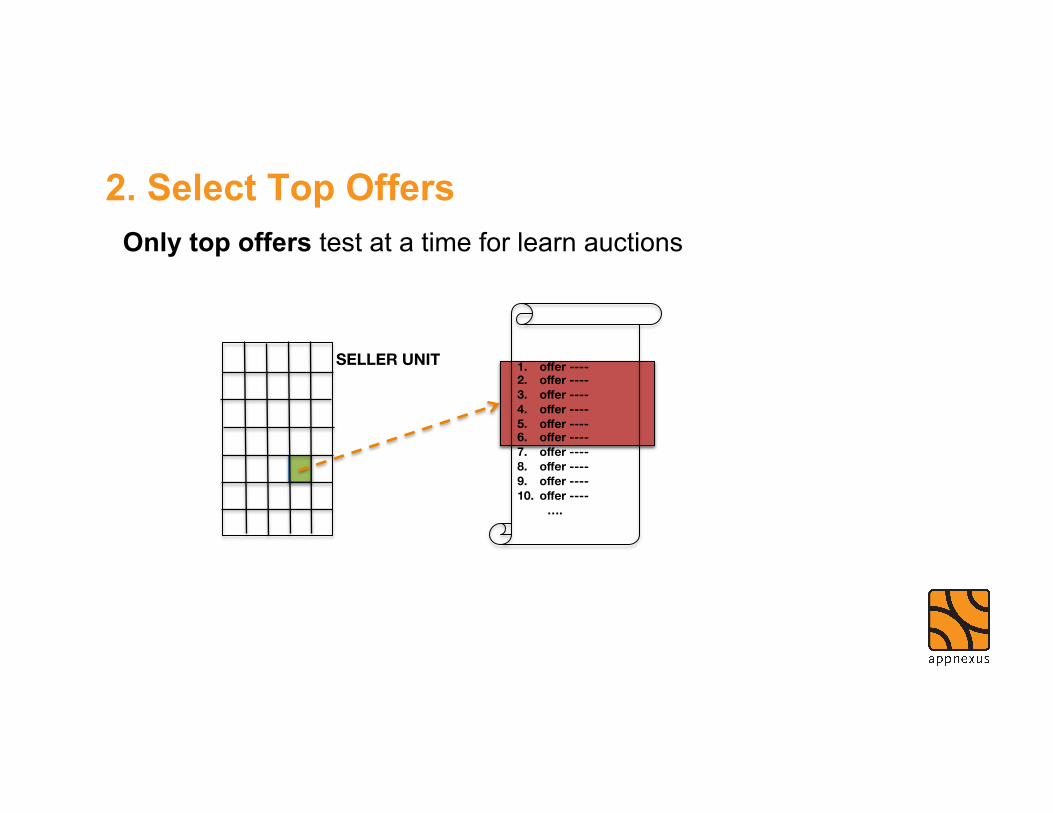
Only top offers test at a time for learn auctions
2. Select Top Offers
1. offer ---- 2. offer ---- 3. offer ---- 4. offer ---- 5. offer ---- 6. offer ---- 7. offer ---- 8. offer ---- 9. offer ---- 10. offer ---- ….
SELLER UNIT
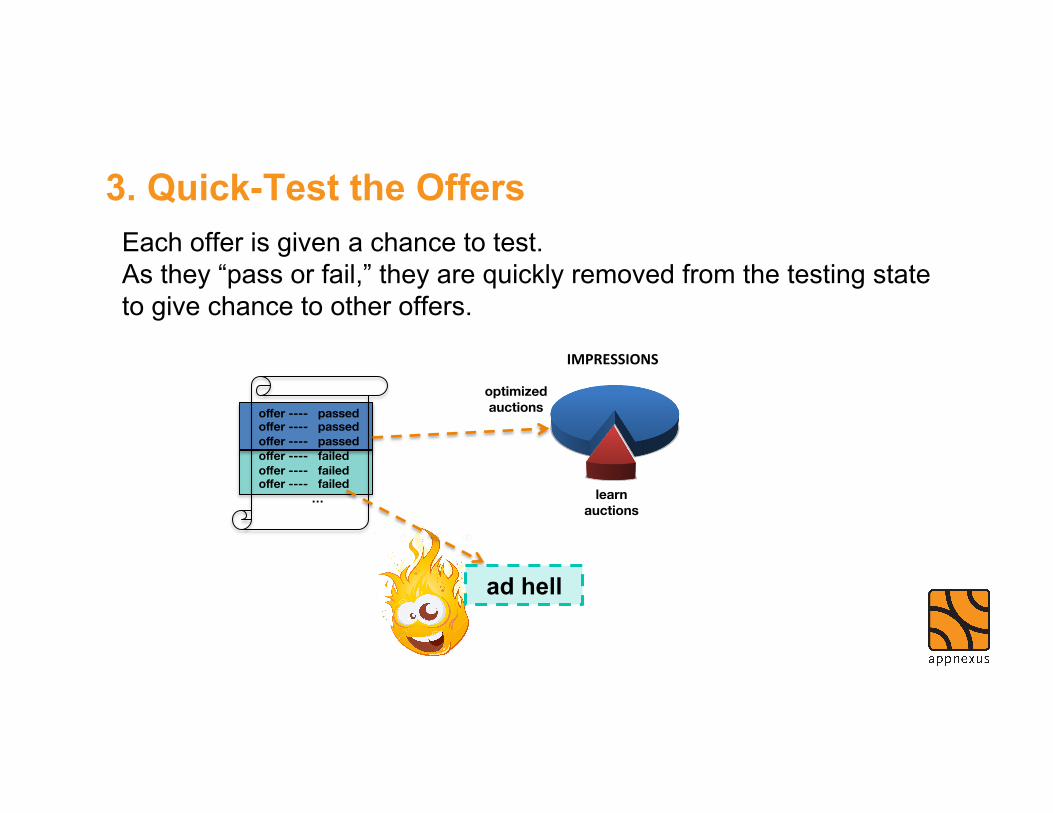
Each offer is given a chance to test. As they “pass or fail,” they are quickly removed from the testing state to give chance to other offers.
3. Quick-Test the Offers
offer ---- passed offer ---- passed offer ---- passed offer ---- failed offer ---- failed offer ---- failed
…
IMPRESSIONS
learn auctions
optimized auctions
ad hell

RESULTS Number of Offers
Bid Type −− Learn −− Optimized
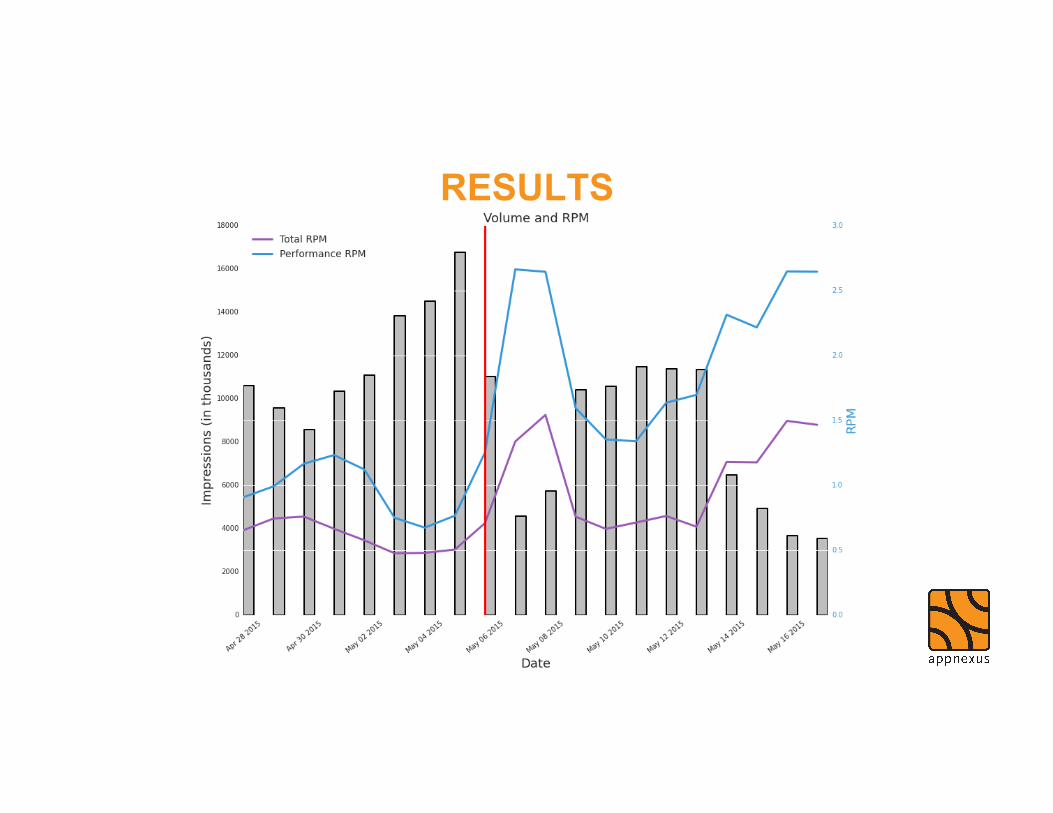
RESULTS

Putting the Py in PyData

OFFER STATE DIAGRAM

Getting in the flow


• Distribute computation across several machines • A large unit of work is called a job • Jobs are split into smaller units of work called tasks • Scheduler is responsible for kicking off job and splitting jobs into tasks • Task computation is carried out by worker machines
Distributed Work Queue
Job
task
task
task
task

• In-house system implemented in Python • Scheduler and worker machines are listening on RabbitMQ
• Similar to celery
• Scheduler begins job when it receives notification on the exchange • Store job history and current status in MySQL • 23 worker machines
Distributed Work Queue

RabbitMQ
1. Your data is ready! 2.
3.
4.
worker
worker
worker
Scheduler Data Pipeline
5.

RabbitMQ • Not interested in pushing broker service to the limit
• 10’s messages / second
• Lots of flexibility with regard to routing rules • Fault tolerant
• Clustering, federation, mirroring, message durability
• Fantastic Python support with pika • Built in features that make it ideal for a work queue
• Acking • Auto re-routing on failure

Vertica
Redis
HDFS raw log
data
1. a
ggre
gate
3. transition
MySQL
Data flow
Bidder Memory
4. sync

• Stores log level data on every single impression • 170+ TB / day
• Great for large data sets • Fault tolerant • ~1400 machines
• 2 datacenters, NYM & LAX
Distributed Filesystem

Vertica
Redis
HDFS raw log
data
1. a
ggre
gate
3. transition
MySQL
You are here.
Bidder Memory
4. sync
\

Aggregate into Vertica • HP column store database
• Fast aggregations!
• Horizontally scaling • Supports frequent querying • ~150 Vertica nodes
Aggregation (Java)

Vertica • 331,813,174,897 rows

Vertica
Redis
HDFS raw log
data
1. a
ggre
gate
3. transition
MySQL
You are here.
Bidder Memory
4. sync
\

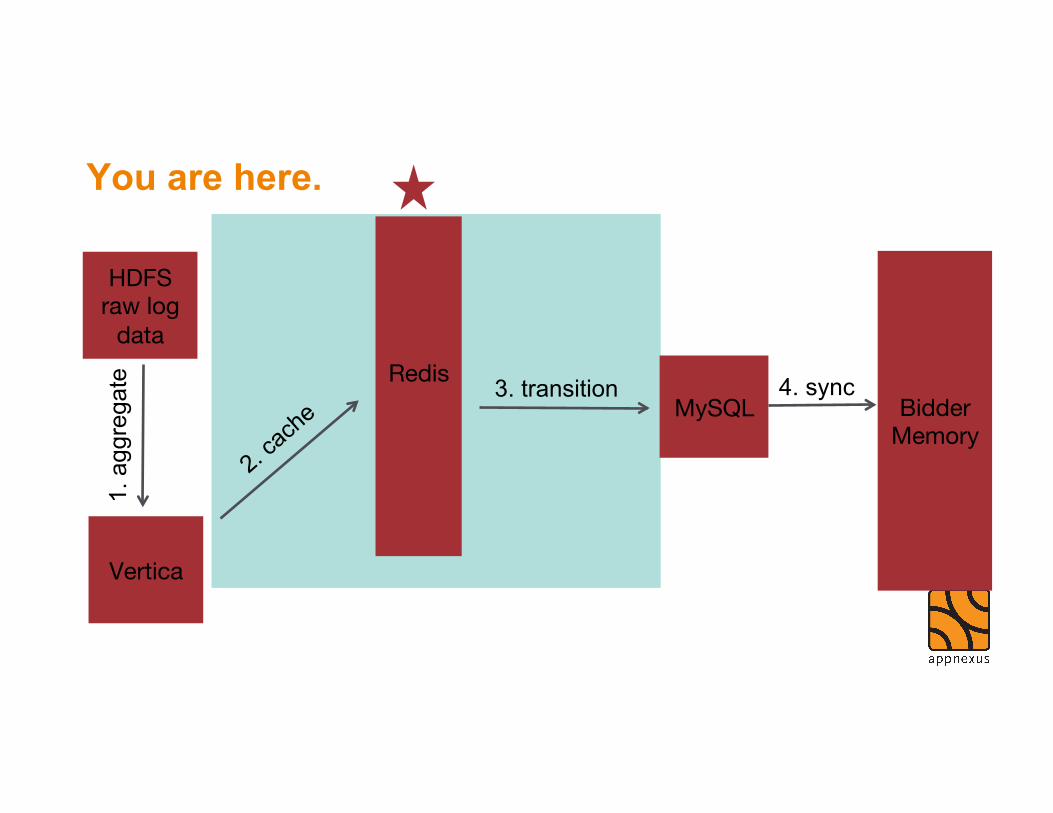
$$$ing • Many processes need to access the same aggregated data • Can’t be querying Vertica constantly

Slicing + Dicing with Pandas • Represent rows and columns in memory • API supports complex row manipulation • Let pandas worry about performance for you! (mostly) • pyodbc + iopro under the hood

What do we cache? • Websites with new data
• If a website has new data, we’ll need to reevaluate which offers it is testing
• How many offers should be testing on each website at a time • AKA – Max Testing Offer
• Which offers allowed to serve on which countries / sizes? • How many impressions / clicks / conversion on a website / offer combination

• Key-value store • Rich feature set
• Sets • Hash set • Ordered set
• Enforce best practices • Common layer to handle
serialization + deserialization
• Defined namespaces
• redis-py API

Beware! Resource starvation • Apache Zookeeper + Kazoo to the rescue!
pls help, I’m so hungry
Vertica
Redis
HDFS raw log
data
1. a
ggre
gate
3. transition
MySQL
You are here.
Bidder Memory
4. sync

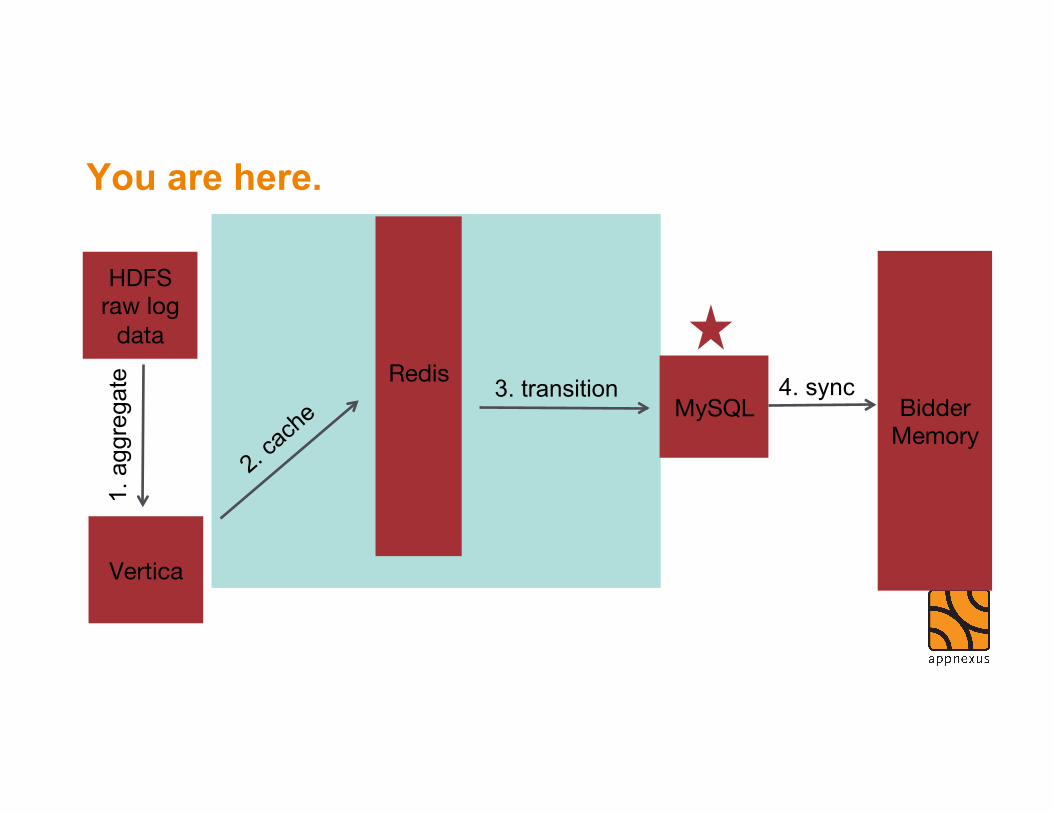
Load to MySQL with SqlAlchemy • After transition computation we write data to MySQL
• SqlAlchemy to do writes

Vertica
Redis
HDFS raw log
data
1. a
ggre
gate
3. transition
MySQL
You are here.
Bidder Memory
4. sync

I M P B U S
AN Bidder
log
HDFS
Data Pipeline
Vertica
MySQL
impression
Bidder Bidder Bidder Other Bidders
Optimization

WE’RE HIRING

THANK YOU


















