
Boosting Shai Raffaeli Seminar in mathematical biology freund
64
Boosting Shai Raffaeli Seminar in mathematical biology http:// www1.cs.columbia.edu/ ~freund /
-
date post
19-Dec-2015 -
Category
Documents
-
view
218 -
download
2
Transcript of Boosting Shai Raffaeli Seminar in mathematical biology freund

Boosting
Shai Raffaeli
Seminar in mathematical biology
http://www1.cs.columbia.edu/~freund/

Toy Example
• Computer receives telephone call
• Measures Pitch of voice
• Decides gender of caller
HumanVoice
Male
Female

Generative modeling
Voice Pitch
Pro
babi
lity
mean1
var1
mean2
var2

Discriminative approach
Voice Pitch
No.
of
mis
take
s

Ill-behaved data
Voice Pitch
Pro
babi
lity
mean1 mean2
No.
of
mis
take
s

Traditional Statistics vs. Machine Learning
DataEstimated world state
PredictionsActionsStatistics
Decision Theory
Machine Learning


A weighted training set
Feature vectors
Binary labels {-1,+1}
Positive weights
x1,y1,w1 , x2 ,y2 ,w2 ,, xm ,ym ,wm

A weak learner
weak learner
A weak rule
hWeighted
training set
(x1,y1,w1),(x2,y2,w2) … (xn,yn,wn)
instances
x1,x2,x3,…,xnh
labels
y1,y2,y3,…,yn
The weak requirement:
Feature vectorB
inary labelN
on-negative weights
sum to 1

The boosting process
weak learner h1
(x1,y1,1/n), … (xn,yn,1/n)
weak learner h2(x1,y1,w1), … (xn,yn,wn)
h3(x1,y1,w1), … (xn,yn,wn) h4
(x1,y1,w1), … (xn,yn,wn) h5(x1,y1,w1), … (xn,yn,wn) h6
(x1,y1,w1), … (xn,yn,wn) h7(x1,y1,w1), … (xn,yn,wn) h8
(x1,y1,w1), … (xn,yn,wn) h9(x1,y1,w1), … (xn,yn,wn) hT
(x1,y1,w1), … (xn,yn,wn)
Final rule: Sign[ ]h1 h2 hT

Adaboost
• Binary labels y = -1,+1
• margin(x,y) = y [ttht(x)]
• P(x,y) = (1/Z) exp (-margin(x,y))
• Given ht, we choose t to minimize
(x,y) exp (-margin(x,y))

t ln wit
i:ht xi 1,yi1 wi
t
i:ht xi 1,yi 1
wit exp yiFt 1(xi )
Adaboost
F0 x 0
Ft1 Ft tht
Get ht from weak learner
for t 1..T
Freund, Schapire 1997

Main property of adaboost
• If advantages of weak rules over random guessing are: T then in-sample error of final rule is at most

Adaboost as gradient descent
• Discriminator class: a linear discriminator in the space of “weak hypotheses”
• Original goal: find hyper plane with smallest number of mistakes – Known to be an NP-hard problem (no algorithm that
runs in time polynomial in d, where d is the dimension of the space)
• Computational method: Use exponential loss as a surrogate, perform gradient descent.

Margins view
}1,1{;, yRwx n )( xwsign Prediction =
+
- + +++
+
+
-
--
--
--
w
Correc
t
Mist
akes
Project
Margin
Cumulative # examples
Mistakes Correct
Margin = xw
xwy
)(

Adaboost et al.
Loss
Correct
MarginMistakes
Brownboost
LogitboostAdaboost = )( xwye
0-1 loss

One coordinate at a time
• Adaboost performs gradient descent on exponential loss• Adds one coordinate (“weak learner”) at each iteration.• Weak learning in binary classification = slightly better
than random guessing. • Weak learning in regression – unclear.• Uses example-weights to communicate the gradient
direction to the weak learner• Solves a computational problem

What is a good weak learner?
• The set of weak rules (features) should be flexible enough to be (weakly) correlated with most conceivable relations between feature vector and label.
• Small enough to allow exhaustive search for the minimal weighted training error.
• Small enough to avoid over-fitting.• Should be able to calculate predicted label very
efficiently.• Rules can be “specialists” – predict only on a small
subset of the input space and abstain from predicting on the rest (output 0).

Decision Trees
X>3
Y>5-1
+1-1
no
yes
yesno
X
Y
3
5
+1
-1
-1
-0.2
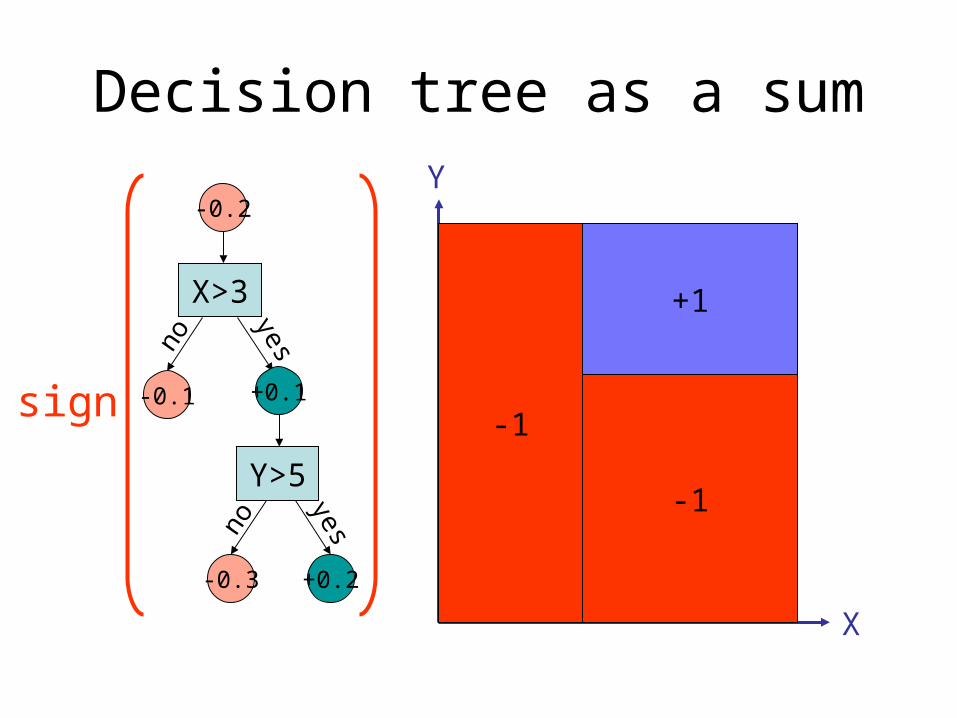
Decision tree as a sum
X
Y-0.2
Y>5
+0.2-0.3
yesno
X>3
-0.1
no
yes
+0.1
+0.1-0.1
+0.2
-0.3
+1
-1
-1sign

An alternating decision tree
X
Y
+0.1-0.1
+0.2
-0.3
sign
-0.2
Y>5
+0.2-0.3yesno
X>3
-0.1
no
yes
+0.1
+0.7
Y<1
0.0
no
yes
+0.7
+1
-1
-1
+1

Example: Medical Diagnostics
•Cleve dataset from UC Irvine database.
•Heart disease diagnostics (+1=healthy,-1=sick)
•13 features from tests (real valued and discrete).
•303 instances.

Adtree for Cleveland heart-disease diagnostics problem

Cross-validated accuracy
Learning algorithm
Number of splits
Average test error
Test error variance
ADtree 6 17.0% 0.6%
C5.0 27 27.2% 0.5%
C5.0 + boostin
g446 20.2% 0.5%
Boost Stumps
16 16.5% 0.8%


Curious phenomenon
Boosting decision trees
Using <10,000 training examples we fit >2,000,000 parameters

Explanation using margins
Margin
0-1 loss

Explanation using margins
Margin
0-1 loss
No examples with small margins!!

Experimental Evidence

Theorem
For any convex combination and any threshold
Probability of mistake
Fraction of training example with small margin
Size of training sample
VC dimension of weak rules
No dependence on numberNo dependence on number of weak rules of weak rules that are combined!!!that are combined!!!
Schapire, Freund, Bartlett & LeeAnnals of stat. 98

Suggested optimization problem
Margin
m
d

Idea of Proof


Applications of Boosting
• Academic research
• Applied research
• Commercial deployment

Academic research
Database Other BoostingError reduction
Cleveland 27.2 (DT) 16.5 39%
Promoters
22.0 (DT) 11.8 46%
Letter 13.8 (DT) 3.5 74%
Reuters 4 5.8, 6.0, 9.8 2.95 ~60%
Reuters 8 11.3, 12.1, 13.4 7.4 ~40%
% test error rates

Applied research
• “AT&T, How may I help you?”• Classify voice requests• Voice -> text -> category• Fourteen categories
Area code, AT&T service, billing credit, calling card, collect, competitor, dial assistance, directory, how to dial, person to person, rate, third party, time charge ,time
Schapire, Singer, Gorin 98

• Yes I’d like to place a collect call long distance please
• Operator I need to make a call but I need to bill it to my office
• Yes I’d like to place a call on my master card please
• I just called a number in Sioux city and I musta rang the wrong number because I got the wrong party and I would like to have that taken off my bill
Examples
collect
third party
billing credit
calling card

Calling card
Collect
call
Third party
Weak Rule
Category
Word occursWord does not occur
Weak rules generated by “boostexter”

Results
• 7844 training examples– hand transcribed
• 1000 test examples– hand / machine transcribed
• Accuracy with 20% rejected– Machine transcribed: 75%– Hand transcribed: 90%

Commercial deployment
• Distinguish business/residence customers
• Using statistics from call-detail records
• Alternating decision trees– Similar to boosting decision trees, more
flexible– Combines very simple rules– Can over-fit, cross validation used to stop
Freund, Mason, Rogers, Pregibon, Cortes 2000

Summary
• Boosting is a computational method for learning accurate classifiers
• Resistance to over-fit explained by margins• Underlying explanation –
large “neighborhoods” of good classifiers• Boosting has been applied successfully to a
variety of classification problems

DNA
Measurable quantity
Gene Regulation• Regulatory proteins bind to non-coding regulatory
sequence of a gene to control rate of transcription
regulators
mRNAtranscript
bindingsites

From mRNA to Protein
mRNAtranscript
Nucleus wall
ribosomeProteinfolding
Protein sequence

Protein Transcription Factors
regulator

Genome-wide Expression Data

• Microarrays measure mRNA transcript expression levels for all of the ~6000 yeast genes at once.
• Very noisy data• Rough time slice over all
compartments of many cells.• Protein expression not observed

Partial “Parts List” for YeastMany known and putative – Transcription factors– Signaling molecules
that activate transcription factors– Known and putative binding site “motifs” – In yeast, regulatory sequence = 500 bp
upstream region
TFSM
MTF
TF
MTF

Predict target gene regulatory response from regulator activity and binding site data
MicroarrayImage
R1 R2 RpR4R3 …..“Parent” gene expression G1
…
Target gene expression
G2
G3
G4
Gt
GeneClass: Problem Formulation
G1G2G3G4
Gt
Binding sites (motifs)in upstream region
…
M. Middendorf, A. Kundaje, C. Wiggins, Y. Freund, C. Leslie.Predicting Genetic Regulatory Response Using Classification. ISMB 2004.

Role of quantization
-1 +10
By Quantizing expression into three classesWe reduce noise but maintain most of signal
Weighting +1/-1 examples linearly with Expression level performs slightly better.

Problem setup
• Data point = Target gene X Microarray
• Input features:– Parent state {-1,0,+1}– Motif Presence {0,1}
• Predict output:– Target Gene {-1,+1}

Boosting with Alternating Decision Trees (ADTs)
• Use boosting to build a single ADT, margin-based generalization of decision tree
Splitter NodeIs MotifMIG1 presentAND ParentXBP1 up?Prediction Node
F(x) given by sum of prediction nodes alongall paths consistent with x

Statistical Validation• 10-fold cross-validation experiments, ~50,000
(gene/microarray) training examples • Significant correlation between prediction score and true
log expression ratio on held-out data.• Prediction accuracy on +1/-1 labels: 88.5%

Biological InterpretationFrom correlation to causation
• Good prediction only implies Correlation.• To infer causation we need to integrate additional knowledge.• Comparative case studies: train on similar conditions
(stresses), test on related experiments• Extract significant features from learned model
– Iteration score (IS): Boosting iteration at which feature first appearsIdentifies significant motifs, motif-parent pairs
– Abundance score (AS): Number of nodes in ADT containing featureIdentifies important regulators
• In silico knock-outs: remove significant regulator and retrain.

Case Study: Heat Shock and Osmolarity
Training set: Heat shock, osmolarity, amino acid starvation
Test set: Stationary phase, simultaneous heat shock+osmolarity
Results: Test error = 9.3% Supports Gasch hypothesis: heat shock and osmolarity
pathways independent, additive– High scoring parents (AS): USV1 (stationary phase and
heat shock), PPT1 (osmolarity response), GAC1 (response to heat)

Case Study: Heat Shock and Osmolarity
Results: High scoring binding sites (IS):
MSN2/MSN4 STRE element Heat shock related: HSF1 and RAP1 binding sitesOsmolarity/glycerol pathways: CAT8, MIG1, GCN4Amino acid starvation: GCN4, CHA4, MET31
– High scoring motif-parent pair (IS):TPK1~STRE pair (kinase that regulates MSN2 via
cellular localization) – indirect effect
TFMTF
PPMp
PMMp
Direct binding Indirect effect Co-occurrence

Case Study: In silico knockout
• Training and test sets: Same as heat shock and osmolarity case study
• Knockout: Remove USV1 from regulator list and retrain
• Results:– Test error: 12% (increase from 9%)– Identify putative downstream targets of USV1: target
genes that change from correct to incorrect label– GO annotation analysis reveals putative functions:
Nucleoside transport, cell-wall organization and biogenesis, heat-shock protein activity
– Putative functions match those identified in wet lab USV1 knockout (Segal et al., 2003)

Conclusions: Gene Regulation
• New predictive model for study of gene regulation– First gene regulation model to make quantitative
predictions. – Using actual expression levels - no clustering.– Strong prediction accuracy on held-out
experiments– Interpretable hypotheses: significant regulators,
binding motifs, regulator-motif pairs• New methodology for biological analysis:
comparative training/test studies, in silico knockouts

Summary
• Boosting is an efficient and flexible method for constructing complex and accurate classifiers.
• Correlation -> Causation : still a hard problem, requires domain specific expertise and integration of data sources.

Improvement suggestions...
• Use of binary labels simplify the algorithm, but doesn’t reflect reality.
• “Confusion table”.

The End.

Large margins
marginFT(x,y) Ý y
tht x t1
Ttt1
Ty
FT x
1
marginFT(x,y) 0 fT (x)y
Thesis:large margins => reliable predictions
Very similar to SVM.

Experimental Evidence

TheoremSchapire, Freund, Bartlett & Lee / Annals of statistics 1998
H: set of binary functions with VC-dimension d
C
ihi | hi H ,i 0, i 1
c C, 0, with probability1 w.r.t. T ~ Dm
P x ,y ~D sign c(x) y P x,y ~T marginc x,y
˜ O d / m
O log
1
T x1,y1 , x2 ,y2 ,..., xm ,ym ; T ~ Dm
No dependence on no. of combined functions!!!

Idea of Proof








![A Tutorial on Boosting Yoav Freund Rob Schapiregroups.di.unipi.it/~cardillo/AA0304/fabio/boosting.pdf · [Kearns & Valiant ’88]: does weak learnability imply strong learnability?](https://static.fdocuments.in/doc/165x107/5f9d1b37db2d123477402b2c/a-tutorial-on-boosting-yoav-freund-rob-cardilloaa0304fabioboostingpdf-kearns.jpg)









