
Black Box and Generalized Algorithms for Planning in Uncertain Domains
51
1 Black Box and Generalized Algorithms for Planning in Uncertain Domains Thesis Proposal, Dept. of Computer Science, Carnegie Mellon University H. Brendan McMahan
-
Upload
reese-fletcher -
Category
Documents
-
view
26 -
download
2
description
Black Box and Generalized Algorithms for Planning in Uncertain Domains. Thesis Proposal, Dept. of Computer Science, Carnegie Mellon University H. Brendan McMahan. Outline. The Problem and Approach Motivating Examples Goals and Techniques MDPs and Uncertainty Example Algorithms - PowerPoint PPT Presentation
Transcript of Black Box and Generalized Algorithms for Planning in Uncertain Domains

1
Black Box and Generalized Algorithms for
Planning in Uncertain Domains
Thesis Proposal, Dept. of Computer Science, Carnegie Mellon University
H. Brendan McMahan

2
Outline
The Problem and Approach Motivating Examples Goals and Techniques MDPs and Uncertainty
Example Algorithms Proposed Future Work

3
Mars Rover Mission Planning
Human control not realistic
Collect data while conserving power and bandwidth
First Experiments in the Robotic Investigation of Life in the Atacama Desert of Chile. D. Wettergreen, et al. 2005.
Recent Progress in Local and Global Traversability for Planetary Rovers. S. Singh, et al. 2000.

4
Autonomous Helicopter Control
6+ continuous state dimensions
Complex, non-linear dynamics
High failure cost
Inverted Autonomous Helicopter Flight via Reinforcement LearningA. Ng, et al.
Autonomous Helicopter Control using Reinforcement Learning Policy Search MethodsJ. Bagnell and J. Schneider

5
Online Shortest Path Problem
Getting from my (old) house to CMU each day:

6
Other Domains

7
Goal
Planning multiple decisions over time to achieve
goals or minimize cost
in Uncertain Domains NOT deterministic, fully observable,
perfectly modeled

8
The Black Box Approach
Fast ExistingAlgorithm
New Algorithm
HardPlanningProblem
EasierProblems
Solutions
Solution

9
The Generalization Approach
HardPlanningProblem
Solution
Generalization of ExistingAlgorithm
Fast ExistingAlgorithm

10
Two Examples
Black Box Approach
MDP Alg(e.g., value iteration)
Used as a Black BoxOracle Algorithms
(MDPs with unknown costs)
Generalize ToAlgorithms for
Stochastic Shortest Paths
Dijkstra’s Alg(Shortest Paths)
Generalization Approach

11
Benefits of using Black Boxes
Use fast/optimized/mature implementations
Pick implementation for specific domain
Will be able to use algorithms not even invented yet
Theoretical advantages
12
Benefits of Generalization
New intuitions Some performance guarantees for free

13
Markov Decision Processes
An MDP (S, A, P, c) … S is a finite set of states A is a finite set of actions dynamics P(y | x, a) costs c(x,a)
Goal:New idea!
No New Ideas
Hungry
A = {eat, wait, work}
0.1
0.8
0.1
0.01
0.99
1.0
1.0
$1.00 $1.00
$0.10
$4.75A Research MDP

14
Simple Example Domain
Robot path planning problem: Actions = {8 neighbors} Cost: Euclidean Distance Prob. p of random action

15
Types of Uncertainty
Outcome Uncertainty (MDPs) Partial Observability (POMDPs) Model Uncertainty (families of MDPs, RL)
Modeling Other Agents
(Agent Uncertainty?)

16
The Curse of Dimensionality
The size of |S| is exponential in the number of state variables:
<x,y, vx, vy, battery_power, door_open, another_door_open, goal_x, goal_y, bob_x, bob_y, …
>

17
Outline
The Problem and Approach Example Algorithms
MDPs with Unknown Costs Generalizing Dijkstra’s Algorithm
Proposed Future Work

18
Unknown Costs, Offline Version
A game with two players: The Planner chooses a policy for a
MDP with known dynamics
The Sentry chooses a cost function from a set K = {c1,…,ck} of possible cost functions.

19
Avoiding Detection by Sensors
The Planner (robot) picks policies (paths):
The Sentry picks cost functions (sensor placements):

20
Matrix Game Formulation
Matrix game M: Planner (rows) selects a policy Sentry (columns) selects a cost c M(, c) =
[total cost of under costs c]
Goal: Find a minimax solution to M
An optimal mixed strategy for the planner is a distribution over deterministic polices
(paths).

21
Interpretations
Model Uncertainty:
→ unknown cost function Partial Observability:
→ fixed, unobservable cost function Agent Uncertainty:
→ an adversary picks the cost function

22
How to Solve It
Problem: Matrix M is exponentially big Solution: Can be represented compactly as a
Linear Program (LP)
Problem: LP still takes much too long to solve Solution: The Single Oracle Algorithm, taking
advantage of fast black box MDP algorithms

23
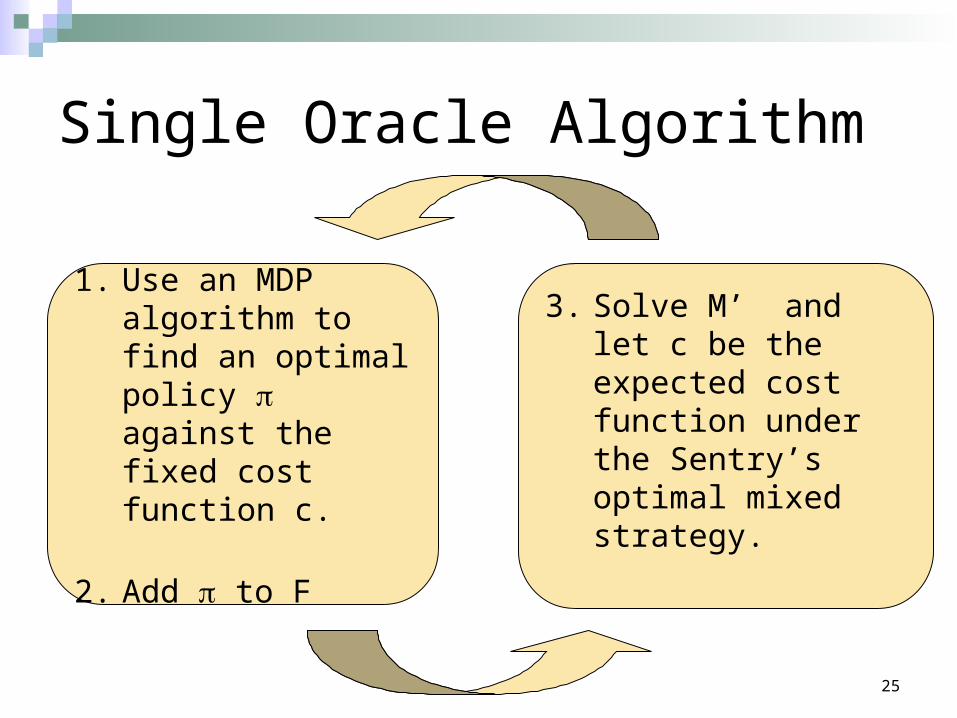
Single Oracle Algorithm
F is a small set of policies M’ is the matrix game
where the Planner must play from F.
We can solve M’ efficiently, it is only |F| x |K| in size!
|F| = 2

24
Single Oracle Algorithm
If only … we knew it was sufficient for
the Planner to randomize among a small set of strategies
and we could find that set of strategies.
25
Single Oracle Algorithm
1. Use an MDP algorithm to find an optimal policy against the fixed cost function c.
2. Add to F
3. Solve M’ and let c be the expected cost function under the Sentry’s optimal mixed strategy.

26
Example Run: Initialization
Fix policy (blue path)
Solve M’ to find red sensor field (cost vector), fix this as c

27
Iteration 1: Best Response
Solve for the best response policy (new blue line)
Add to F
Red: Fixed cost vector (expected field of view)Blue: Shortest path given costs

28
Iteration 1: Solve the Game
Solve M’
Minimax Equilibrium:Red: Mixture of CostsBlue: Mixture of Paths from F

29
Iteration 2: Best Response
Solve for the best response policy (new blue line)
Add to F
Red: Fixed cost vector (expected field of view)Blue: Shortest path given costs

30
Iteration 2: Solve the Game
Solve M’
Minimax Equilibrium:Red: Mixture of CostsBlue: Mixture of Paths from F

31
Iteration 6: ConvergenceSolution to M’ Best Response

32
Unknown Costs, Online Version
Go from my house to CMU each day Model as a graph

33
A Shortest Path Problem?
If we knew all the edge costs, it would be easy! But, traffic, downed trees → uncertainty

34
Limited Observations
Each day, observe the total length of the path we actually took to get to CMU
BGA Algorithm:
Keep estimates of edge lengths
• Most days, follow FPL1 algorithm: pick shortest path with respect to estimated lengths plus a little noise.
• Occasionally, play a “random” path in order to make sure we have good estimates of the edge lengths.
1 [Kalai and Vempala, 2003]

35
Dijkstra's Algorithm
G
x1
x2
x3
x4
v'= 0
v'=∞
v'=∞
v'= ∞
v'=∞
v'=3
v'=2v'=1
v'=5
v'=6v'=7
v'=2
Keeps states on a priority queue
Pops states in order of increasing distance, updates predecessors
Prioritized Sweeping1,2 has a similar structure, but doesn’t reduce to Dijkstra’s algorithm
1 [A. Moore, C. Atkeson 1993] 2 [D. Andre, et al. 1998]

36
Prioritized Sweeping
When we pop a state x, backup x, update priorities of predecessors w
y1
y2
y3
w1
w2
x1
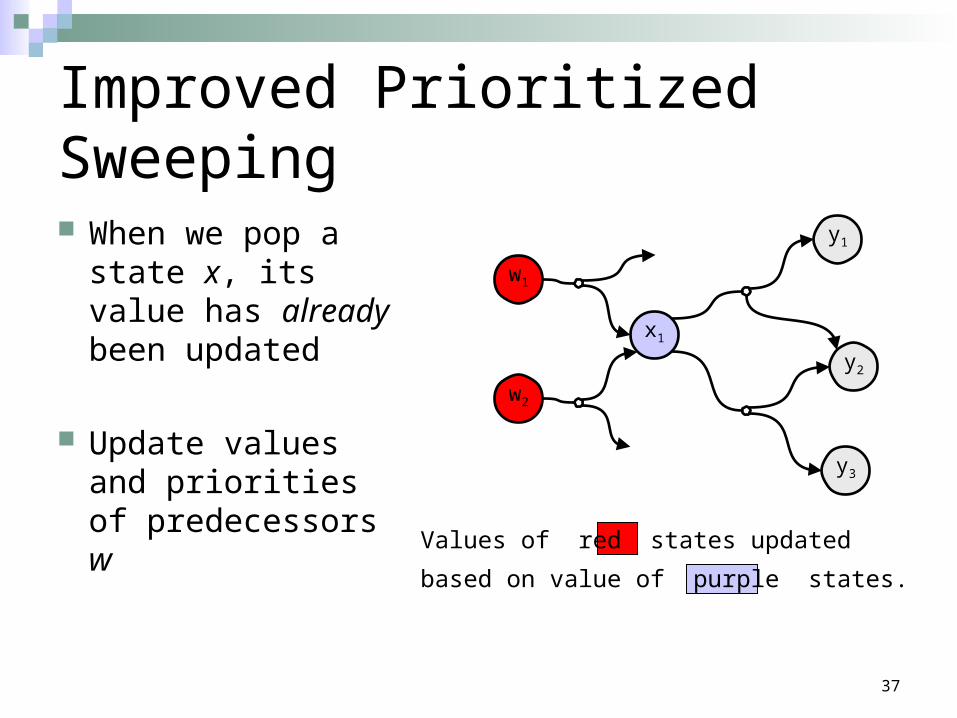
Values of red states updated
based on value of purple states.
37
Improved Prioritized Sweeping
When we pop a state x, its value has already been updated
Update values and priorities of predecessors w
y1
y2
y3
w1
w2
x1
Values of red states updated
based on value of purple states.

38
Priority Function Intuitions
Update the state: with lowest value (closest to goal) whose value is most accurately known
For Dijkstra’s algorithm, the updated (popped) state’s optimal value is known
This is the state whose value will change the least in the future.
whose value has changed the most since it was last updated.
39
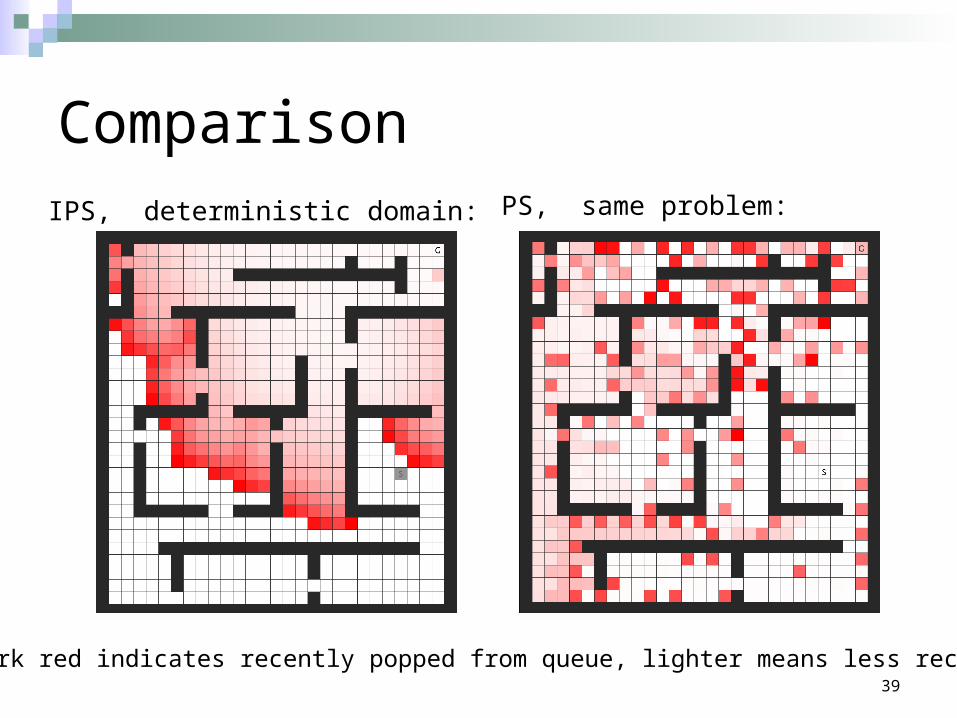
ComparisonIPS, deterministic domain: PS, same problem:
Dark red indicates recently popped from queue, lighter means less recently.

40
Outline
The Problem and Approach Example Algorithms Proposed Future Work
Bounded RTDP and extensions Large action spaces Details of proposed contributions

41
Bounded RTDP
RTDP: Fixed start state means many
states are irrelevant Sample, backup along start → goal trajectories
BRTDP adds: performance guarantees, much
faster convergence(often better than HDP, LRTDP,and LAO*)

42
Dijkstra and BRTDP
Dijkstra-style scheduling of backups for BRTDP
Sample multiple trajectories
Use priority queue to schedule backups of states on all trajectories
43
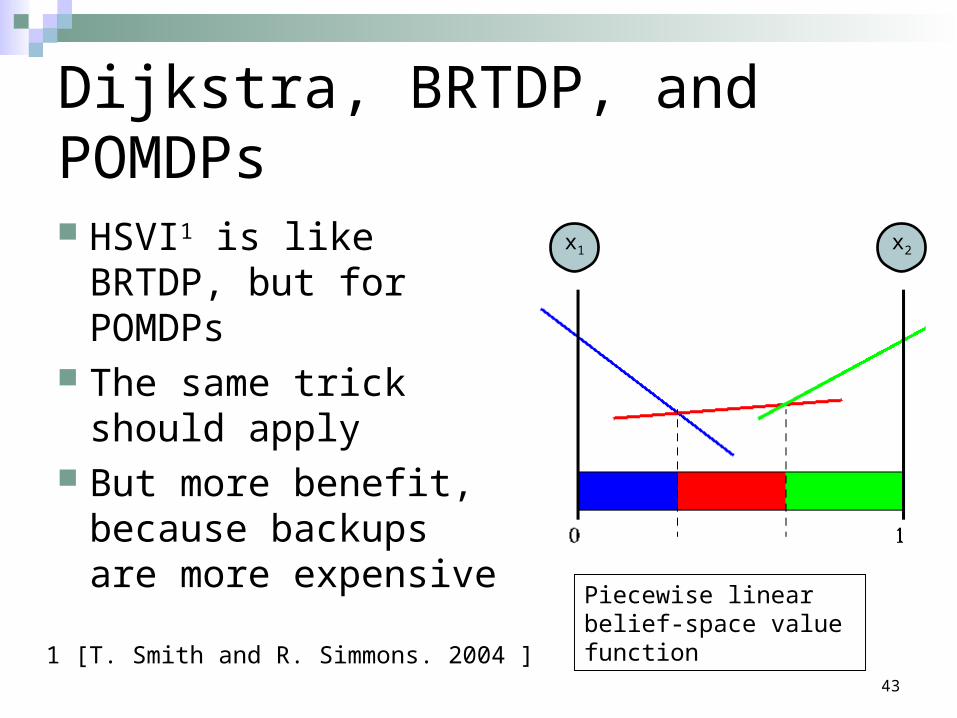
Dijkstra, BRTDP, and POMDPs
HSVI1 is like BRTDP, but for POMDPs
The same trick should apply
But more benefit, because backups are more expensive
Piecewise linear belief-space value function
x1 x2
1 [T. Smith and R. Simmons. 2004 ]

44
Large Action Spaces
(Prioritized) Policy Iteration already has an advantage
Better tradeoff between policy evaluation, policy improvement?
Structured sets of actions? Application of
Experts/Bandits algorithms?

45
Details: Proposed Contributions
Discussion of algorithms already developed: Oracle Algorithms, BGA, IPS, BRTDP, and several others.
At least two significant new algorithmic contributions: BRTDP + Dijkstra algorithm, extension to POMDPs Improved version of PPI to handle large action spaces Something else: generalizations of conjugate-gradient linear
solvers to MDPs, extensions of the technique for finding upper bounds introduced in the BRTDP paper, algorithms for efficiently
solving restricted classes of POMDPs...

46
Details: Proposed Contributions
At least one significant new theoretical contribution: Approximation algorithm for Canadian Traveler’s
Problem or Stochastic TSP Results connecting online algorithms / MDP
techniques to stochastic optimization New contributions on bandit-style online algorithms,
perhaps applications to MDPs

47
SummaryMotivating Problems
Black Boxes: MDPs with unknown Costs
Generalization:
Reducing to Dijkstra
Future Work:BRTDP + Dijkstra,Large action spaces

48
Questions?

49
Relationships of Algorithms Discussed

50
Iteration 3: Best Response
Solve for the best response policy (new blue line)
Add to F
Red: Fixed cost vector (expected field of view)Blue: Shortest path given costs

51
Representations, Algorithms
Simulation dynamics model
Factored Representation (DBNs, etc)
STRIPS-style languages
Policy Search, …
Generalizations of Value Iteration, …


















