
bIoTope D4.1 Edge Data Storage and Intelligent Filtering...
53
DELIVERABLE This project has received financial support from the European Union Horizon 2020 Programme under grant agreement no. 688203. D4.1 Edge Data Storage and Intelligent Filtering Project Acronym: bIoTope Project title: Building an IoT Open Innovation Ecosystem for Connected Smart Objects Grant Agreement No. 688203 Website: www.bIoTope-project.org Version: 1.0 Date: 30 August 2016 Responsible Partner: UL Contributing Partners: UL, Cityzendata, eccenca, CSIRO, Opendatasoft, Holonix, ControlThings, Aalto, Grand Lyon, Brussels Region, BIBA Dissemination Level: Public X Confidential – only consortium members and European Commission Services
Transcript of bIoTope D4.1 Edge Data Storage and Intelligent Filtering...

DELIVERABLE
ThisprojecthasreceivedfinancialsupportfromtheEuropeanUnionHorizon2020Programmeundergrantagreementno.688203.
D4.1EdgeDataStorageandIntelligentFiltering
ProjectAcronym: bIoTopeProjecttitle: BuildinganIoTOpenInnovationEcosystemforConnectedSmartObjectsGrantAgreementNo. 688203Website: www.bIoTope-project.orgVersion: 1.0Date: 30August2016ResponsiblePartner: ULContributingPartners: UL,Cityzendata,eccenca,CSIRO,Opendatasoft,Holonix,ControlThings,Aalto,
GrandLyon,BrusselsRegion,BIBADisseminationLevel: Public X
Confidential–onlyconsortiummembersandEuropeanCommissionServices

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 2 30August2016
RevisionHistory
Revision Date Author Organization Description
0.1 29/03/2016 SylvainKubler UL Initialdraft
0.2 19/05/2016 SylvainKubler UL Draftinprogress
0.3 05/06/2016 AndreyBoystov UL ContributiontoSection2.3(BigDataAnalytics)
0.4 05/06/2016 MatthiasHerbert CityzenData ContributiontoSection2.3(BigDataAnalytics)
0.5 11/06/2016 SylvainKubler UL Section2.1completed
0.6 14/06/2016 SylvainKubler UL ContributiontoSection2.2
0.7 23/06/2016 AndreyBoystov UL InitialdraftofSection4(bIoTopeplatformsdesignedforBigDatamgmt)
0.8 25/06/2016 AndreyBoystov UL ContributionofSection4.2(KMF-relatedcontent)
0.9 04/07/2016 SylvainKubler UL Section2.2completed+FirstdraftSection3
0.10 08/07/2016 DavidThoumas Opendatasoft,eccenca
ContributiontoSection3.2(partner’splatformdescription)
0.11 11/07/2016 AnnetteWeilandt,SebastianNuck
eccenca ContributiontoSection3.2(partner’splatformdescription)
0.12 11/07/2016 SimoneParrotta,KristianBäckström
Holonix,ControlThings
ContributiontoSection3.2(partner’splatformdescription)
0.13 15/07/2016 SylvainKubler UL Section3.1completed
0.14 17/07/2016 SimoneParrottaKaryFrämling
Holonix,Aalto
ContributiontoSection3.2(partner’splatformdescription)
0.15 21/07/2016 EmmanuelGastaud,MarieWouter
GrandLyon,BrusselsRegion
ContributiontoSection3.2(partner’splatformdescription)
0.16 22/07/2016 ArkadyZaslavsky,AlexeyMedvedev
CSIRO ContributiontoSection3.2(partner’splatformdescription)
0.17 27/07/2016 AndreyBoystov UL ContributiontoSection2.3
0.18 27/07/2016 JeremyRobert UL ContributiontoSection3.3(IoTBnB-relatedstorage)
0.19 01/08/2016 RobertHellbach BIBA ContributiontoSection3.2(partner’splatformdescription)
0.20 02/08/2016 AndreyBoystov UL Contributiontosection4.2
0.20 03/08/2016 SylvainKubler UL ConsolidationofSection2,3and4
0.21 03/08/2016 AndreyBoystov UL Contributiontosections2.3.*,3.2.9and4.2
0.22 04/08/2016 MatthiasHerbert Cityzendata Contributiontosections2.3.4
0.23 04/08/2016 SylvainKubler UL Consolidationofthewholedocument

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 3 30August2016
0.24 05/08/2016 SylvainKubler UL DeliverablesenttobIoTope’sreviewers(internalreviewround1)
0.25 05/08/2016 AndreyBoystov UL UpdatingandformattingReferencesection+Acronymtable
0.26 05/08/2016 MatthiasHerbert Cityzendata ContributiontoSection4.1
0.27 04/08/2016 SylvainKubler UL FinalizationofSection4+StartingSection5
0.28 06/08/2016 SylvainKubler UL Versionsentforinternalreviewing(HervéRannou,JérémyMorel,and
KristianBäckström0.29 15/08/2016 Bäckström,K. CT Reviewofthewholedeliverable
0.3 25/08/2016 ArkadyZaslavsky CSIRO Comments&Formatting
0.31 26/08/2016 SylvainKubler UL IntegrationofReviews
0.32 29/08/2016 AndreyBoystov UL Styleadjustments;improvingsection5
0.33 29/08/2016 SylvainKubler UL IntegrationofReviews
1.0 30/08/2016 SylvainKubler UL Fewdetailsfixedup

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 4 30August2016
TableofContents
1. Introduction.........................................................................................................................10
2. BigDataas-a-Service............................................................................................................112.1. BigDataInfrastructure-as-a-Service–BDIaaS.............................................................................12
2.1.1. ContentFormat............................................................................................................................132.1.2. Datastores...................................................................................................................................132.1.3. Datastaging.................................................................................................................................14
2.2. BigDataPlatform-as-a-Service–BDPaaS....................................................................................142.2.1. Batchprocessing..........................................................................................................................152.2.2. Stream/Real-time.........................................................................................................................16
2.3. BigDataAnalytics-as-a-Service–BDAaaS....................................................................................172.3.1. BigDataAnalyticsinInternetofThings–theroadahead...........................................................172.3.2. BatchDataProcessing..................................................................................................................182.3.1. StreamDataProcessing...............................................................................................................192.3.2. Mini-BatchDataProcessing.........................................................................................................192.3.3. Edge-computing...........................................................................................................................192.3.4. BDAaaSVendors..........................................................................................................................20
3. StoragecapabilitiesofferedbyandrequiredforasuccessfulIoTecosystem.........................243.1. bIoTopeecosystemoverview......................................................................................................24
3.1.1. TowardsaunifiedIoTecosystem.................................................................................................243.1.2. Needforanecosystemservicecatalogue–IoTBnB....................................................................26
3.2. Cloud&Edge-datastorage/analyticscapabilities........................................................................273.2.1. eccenca Linked Data Suite......................................................................................................283.2.2. OpendatasoftSaaS.......................................................................................................................283.2.3. Semantic Mediator (SEMed)...................................................................................................293.2.4. VirtualObeya-iLike.....................................................................................................................293.2.5. OpenIoT......................................................................................................................................303.2.6. BMW ConnectedDrive..............................................................................................................303.2.7. City-relatedplatforms..................................................................................................................303.2.8. Storage-independentplatforms:DIALOG&Mist........................................................................313.2.9. BigData-focusedplatforms:Warp10&KMF...............................................................................31
3.3. Storagerequirementsforrequiredecosystembuildingblocks....................................................323.3.1. Serviceregistry/repositorymanagement....................................................................................333.3.2. Context-aware-as-a-Service.........................................................................................................35
4. bIoTopeplatformsdesignedforBigDatamanagement........................................................384.1. Warp10:Management&ManipulationofGeoTimeSeries.........................................................38
4.1.1. Platformscopeandgoal..............................................................................................................384.1.2. Underlyingcomponents,modules&technologies......................................................................38
4.2. KMF:LiveModel-DrivenAnalyticsattheEdge–TimeSeries.......................................................404.2.1. Platformscope&goal..................................................................................................................404.2.2. Underlyingcomponents,modulesandtechnologies...................................................................40
4.3. IntegrationofBigDataplatformstothebIoTopeecosystem.......................................................424.3.1. Warp10integrationtotheO-MI/O-DFreferenceimplementation............................................424.3.2. KMFintegrationtoexposeanalyticsresultsand/orfeedanalytics.............................................44

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 5 30August2016
5. BigDatascenariosinthebIoTopecitypilots.........................................................................455.1. Overviewofdatasourcestobeintegratedinthecitypilots........................................................45
5.1.1. BrusselsRegion............................................................................................................................455.1.2. GrandLyon&CoaaSasfoundationforadvancedanalytics........................................................465.1.3. RequirementsandNeedsformatchingwithexistingBigDatasolutions....................................47
6. Conclusion............................................................................................................................49
7. References...........................................................................................................................50

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 6 30August2016
ListofTables
Table1:Ataglanceoverviewoftoday'sBDIaaStechnologies.........................................................................15Table2:SummaryofBDAaaSplatforms&infrastructures...............................................................................20Table3:BDAaaSvendorlandscape...................................................................................................................21Table4:bIoTopepartner-relatedplatforms&storage/processingcapabilities...............................................28Table5:InitialobjectivesandspecificfocusesofeachPlatform......................................................................32Table6:Summaryofcontextrepresentationapproaches................................................................................37Table7:ListofdatasourcesinBrusselsRegionthatneedtobeintegratedtothebIoTopeecosystem..........46Table8:ListofdatasourcesinGrandLyonthatneedtobeintegratedtothebIoTopeecosystem................47
ListofFigures
Figure1:BigDataprinciplesanddisciplines.....................................................................................................12Figure2:BDaaSstack........................................................................................................................................12Figure3:BDIaaStaxonomy...............................................................................................................................13Figure4:BDPaaStaxonomy..............................................................................................................................16Figure5:BDPaaS-relatedconcepts&underlyingtechnologies........................................................................17Figure6:TypicalVerticalSilomodelcomposingtoday'sIoT(e.g.,Cloud-basedsolution)...............................25Figure7:bIoTopepartnerplatformstobeintegrated–asafirststage–tothebIoTope’secosystem...........27Figure8:PinciplesunderlyingIoTBnB&Designchoicesforstoring/searchingforO-MI-relatedservices.......33Figure9:BMWcar-relatedO-DFservice/datatree...........................................................................................34Figure10:Warp10underlyingsoftwarecomponents/modulesandtechnologies...........................................39Figure11:KMFunderlyingsoftwarecomponents/modulesandtechnologies................................................41Figure12:TimetoReadrandomly–classicDiscreteTimeSeriesvs.PolynomialKMFStorage........................41Figure13:TimetoWriterandomly–classicDiscreteTimeSeriesvs.PolynomialKMFStorage.......................42Figure14:Warp10integrationtothenewversionoftheO-MI/O-DFreferenceimplementation..................43Figure15:ExampleofO-DFpayload(includingornotlocationdata)thatisstoredinWarp10.......................43Figure16:KMFintegrationtothebIoTopeecosystem:inwhichcontextend-userscanbenefitfromKMF....44Figure17:WasteManagementscenariotakingadvantageofCoaaS-basedanalytics.....................................47Figure 18: BDaaS state-of-the-art used formapping city pilot’s needswith existing solutions/technologies
(eitherbasedonplatformsinternalorexternaltothebIoTopeconsortium)...........................................48

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 7 30August2016
AcronymsandDefinitions
Acronym DefinitionABS Anti-lockBrakingSystemACID Atomicity,Consistency,IsolationandDurabilityACL AccessControlListAPI ApplicationProgrammingInterfaceARM AdvancedRISC(ReducedInstructionSetComputing)MachineAWS AmazonWebServicesBDaaS BigDataasaServiceBDAaaS BigDataAnalyticsasaServiceBDIaaS BigDataInfrastructureasaServiceBDPaaS BigDataPlatformasaServiceBDXaaS BigDataEverythingasaServiceBIBA BremerInstituteforProductionandLogisticbIoTope BuildinganIoTOpeninnovationEcosystemforconnectedsmartobjectsBMW BayerischeMotorenWerkeAGCoaaS ContextasaServiceCAGR CompoundAnnualGrowthRateCAP Consistency/Availability/PartitiontoleranceCDH ClouderaDistributionincludingHadoopCEP ComplexEventProcessingCIRB Centred'InformatiquepourlaRégionBruxelloiseCoAP ConstrainedApplicationProtocolaCPU CentralProcessingUnitCSIRO CommonwealthScientificandIndustrialResearchOrganisationCST ContextSpacesTheoryCSV CommaSeparatedValuesCT ControlThingsDaaS DataasaServiceDIALOG DistributedInformationArchitecturesforcoLlaborativeloGisticsEJDB EmbeddableJSONDataBaseeLDS eccencaLinkedDataSuiteEMF EclipseModellingFrameworkEPSG EuropeanPetroleumSurveyGroupGeodesyETL Extraction,Transform,LoadingGM GeneralManagerGML GeographyMarkupLanguageGNU GNUisNotUnixGPL GNUGeneralPublicLicenseGUI GraphicalUserInterfaceHDF HortonworksDataFlowHDFS HadoopDistributedFileSystemsHDP HortonworksDataPlatformHTML HyperTextMarkupLanguage

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 8 30August2016
HTTP HyperTextTransferProtocolIaaS InformationasaServiceIBM InternationalBusinessMachinesCorporationICT InformationandCommunicationTechnologyICT30 InternetofThingsandPlatformsforConnectedSmartObjectsI/O Input/OutputIoAT InternetofAnythingIoT InternetofThingsIoTBnB IoTservicepuBlicationaNdBillingISO InternationalOrganizationforStandardizationIT InformationTechnologyJS JavaScriptJSON JavaScriptObjectNotationJSON-LD JavaScriptObjectNotationforLinkedDataJVM JavaVirtualMachineKMF KevoreeModellingFrameworkKML KeyholeMarkupLanguageLGPL GNULesserGeneralPublicLicenseM2M Machine-to-MachineMQTT MessageQueueingTelemetryTransportO-DF OpenDataFormatO-MI OpenMessagingInterfaceOpenTSDB OpenTimeSeriesDataBaseOWL WebOntologyLanguagePaaS PlatformasaServicePDF PortableDocumentFormatRDBMS RelationalDatabaseManagementSystemRDD ResilientDistributedDatasetREST RepresentationalStateTransferRPM RevolutionsPerMinuteRDF ResourceDescriptionFrameworkSaaS SoftwareasaServiceSIAMU LeServiced'Incendieetd'AideMédicaleUrgentedelaRégiondeBruxelles-CapitaleSPARQL SPARQLProtocolAndRDFQueryLanguageSPoF SinglePointofFailureSTIB SociétédesTransportsIntercommunauxdeBruxellesSQL StructuredQueryLanguageTCP/IP TransmissionControlProtocol/InternetProtocol(ProtocolStack)UI UserInterfaceUL UniversityofLuxembourgVP VicePresidentWGS WorldGeodeticSystemWP3 WorkPackage3WP4 WorkPackage4XMI XMLMetadataInterchangeXML eXtensibleMarkupLanguage

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 9 30August2016
ExecutiveSummary
ThisdeliverablefallswithinthescopeofWP4(Context-AwareServiceProvisioningforIoT),whichaddresseschallengesof context representation, validationand reasoningabout context, aswell asdata storageandperformance.
TheprimaryobjectiveofthisdeliverableistoprovideinsightintoBigDatatechnologiesandframeworksthatshape today’sBigData landscape. This state-of-the-art reviewcould serveas a reference study for futuredesignchoicesduringbIoTopedevelopmentandimplementationstages,andevenbeyondtheprojectitself.
Thesecondobjectiveis(i)toprovideanoverviewofthestorageandanalyticscapabilitiesthatarecurrentlysupported/offered by the platforms of the different partners involved in bIoTope, along with (ii) firstdiscussionsaboutadditionalkeybuildingblocksthatneedtobedevelopedtofosterthecreationofatrulyunifiedIoTecosystem.
ThethirdobjectiveistoprovideamoredetailedoverviewofBigDataplatformsthathavebeendevelopedby two distinct bIoTope partners, namely Cityzendata andUniversity of Luxembourg, and towhat extent(i.e.,inwhichcontexts)theyarerelevanttobeused.Firstproofs-of-conceptabouttheirintegrationwiththeO-MI/O-DFmessaging standards,ormoregenerallywith theoverall bIoTopeecosystemareprovidedanddiscussed.
Finally, some preliminary elements about the conceptual framework to be developed and set up in thedifferentbIoTopeusecasesarepresented,althoughitisstilldifficulttohaveacompleteoverviewofwhatstoragetechnologieswillberequiredon-site,asthecitieshavenotyetidentifiedalltheinformationsourcesthat need to be integrated to the bIoTope servicemarketplace/ecosystem (or how to access them to bemore accurate), meaning that we do not necessarily have an complete view of how much data will begeneratedinthecities(frequency,formats…).

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 10 30August2016
1. Introduction
“Bigdata”technologieshavereceivedconsiderablemediaattentioninthepastfewyears.RogerMagoulas,fromO’ReillyMedia,coinedthetermBigDatain2005,onlyayearaftertheycreatedthetermWeb2.0.Theyear2005isalsowhenHadoopwascreated(byYahoo)builtontopofGoogle’sMapReduce.Theobjectivewas to index the entire World Wide Web and nowadays the open-source Hadoop is used by manyorganizations to crunch through huge amounts of data. In 2010, Eric Schmidt speaks at the TechonomyconferenceinLakeTahoeinCaliforniaandsaysthat:
“Therewere5exabytesofinformationcreatedbytheentireworldbetweenthedawnofcivilizationand2003.Nowthesameamountiscreatedeverytwodays.”
Expertsnowpointtoanestimated4300%increaseinannualdatagenerationby2020[1].Driversincludetheswitch from analog to digital technologies and the rapid increase in data generation by individuals andcorporationsalike.WhileitlookslikeBigDataisaroundforalongtimealready,infactBigDataisasfarasthe Internet was in 1993. The large Big Data revolution is still ahead of us. Big data essentially meansdatasets that are too large for traditional data processing systems, and therefore require newprocessingtechnologies.Becauseof itssizeandassociatednumbers,BigDataishardtocapture,store,search,share,analyze and visualize, while working under space and time constraints. The phenomenon came about inrecent years due to the sheer amount ofmachinedata being generated today (smart connectedobjects,socialnetworks…),coupledwiththeadditionalinformationderivedbyanalyzingallthisinformation,whichonitsowncreatesanotherenormousdataset.CompaniespursueBigDatabecauseitcanberevelatoryinspottingbusiness trends, improving researchquality, and gaining insights in a varietyof fields, from IT tomedicinetolawenforcementandeverythinginbetweenandbeyond.
Thepastfifteenyearshaveseenextensiveinvestmentsinbusinessinfrastructures,whichhaveimprovedtheability to collect data throughout the enterprise. Virtually every aspect of business is now open to datacollection and often even instrumented for data collection: operations, manufacturing, supply-chainmanagement,customerbehavior,marketingcampaignperformance,etc.At thesametime, information isnow widely available on external events such as market trends, competitor’s movements, and industrynews.Withvastamountsofdatanowavailable,companiesinalmosteveryindustryfocusonexploitingdataforcompetitiveadvantage.Inthepast,firmscouldemployteamsofstatisticians,modelers,andanalyststoexploredatasetsmanually,butthevolumeandvarietyofdatahavefaroutstrippedthecapacityofmanualanalysis.Atthesametime,computershavebecomefarmorepowerful,networkinghasbecomeubiquitous,andalgorithmshavebeendevelopedthatcanconnectdatasetstoenablebroaderanddeeperanalysesthanpreviously possible. The convergence of these phenomena has given rise to the increasing widespreadbusinessapplicationofDataScienceprinciples,layingthefoundationofthe“BigData”.
Chapter2providesastate-of-the-artofexisting technologiesand frameworks thatshapetoday’sBigDatalandscape, while discussing their characteristics, pros and cons. Chapter 3 provides an overview of thestorageandanalyticscapabilitiesofthedifferentplatformsofthedifferentbIoTopepartners,eveniftheydonot necessarily claim or aim to manage “data lakes”. It is nonetheless important to be aware of suchcapabilitiesinordertodecideandidentifywhichplatform(s)canbenefitoneormorecitypilots;and,evenifoneplatformisnotconsideredinoneormorepilots,thesameplatformmayprovetoberelevant/usefulinother contexts (e.g., by ecosystem stakeholders, external to the project, who have specific applicationsneeds). Chapter 3 also discusses key storage building blocks thatmust be developed – in addition of thebIoTopepartnerplatforms–tofosterthecreationofatrulyunified IoTecosystem(particularly forservicepublication, discovery and consumption). Chapter 4 described two Big Data platforms, developed andsupportedbytwobIoTopepartners (Cityzendata&UniversityofLuxembourg),andinwhichcontextstheyarerelevanttobeused.Chapter5mainlydiscussestheinformationsources(dataflows)thatwillneedtobetackled in thedifferent citypilots, alongwithappropriate storage solutions (basedon the state-of-the-artreviewcarriedoutinChapter2);conclusionsanddiscussionsfollow.

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 11 30August2016
2. BigDataas-a-Service
The chapter is intended to be “descriptive” in the sense that it carries out a state-of-the-art review ofsolutionsandtechnologiescurrentlyavailableonthemarket,highlightingsomekeycharacteristics,prosandconsofeachsolution.Thisstate-of-the-artreviewcouldserveasareferencestudyforfuturedesignchoicesduringbIoTopedevelopmentandimplementationstages(andevenbeyondtheproject),aswillbediscussedingreaterdetailinthecitypilotsection(i.e.,insection5).
Big data is an increasingly important paradigm that is driven by the pervasive diffusion and adoption ofsmartconnectedobjects,mobiledevices,socialmediatools,andotherformsof informationsystems.ThisIDCstudyhavepresentedtheworldwide2015-2019forecastforstoragesystems,software,andservicesinBig Data, whose findings show that: (i) revenue for storage hardware (and software) used for Big DatadeploymentsisestimatedtogrowrespectivelyataCAGRof20.4%(and26.6%)from2014to2019andreach$8.51 billion (and $3.51) in 2019; (ii) revenue for Big Data–related storage serviceswill grow at CAGR of29.8%, largely driven by a skills shortage in many enterprise IT organizations and the need to procureexternalservicesorganizationstoquicklydeploynewBigDatadeployments.BigDatawillthereforeformthefoundationasbusinessestransformthemselvesintodata-drivenentities,andwillthereforecontributetolaythe foundationsof the ‘Web3.0' also knownas the SemanticWeb, and the ‘Web4.0' also knownas theMetaWeb.
Afirstdefinitionof“BigData”wasproposedbyDougLaney[2],introducingthe3Vsdefinition(standingfor"Volume,VelocityandVariety”).Itbasicallyinterpretedbigdataasbeingalotofdatathatisinascatteredform and needs to be processed quickly for proper interpretation. A decade later, Gantz and Reinsel [3]specifiedthatbigdata isnotonlycharacterizedbythe3Vsdefinitionbutmayalsoextendto4Vs,namely:"Volume,Velocity,Variety,Value”,asdetailedbelow.With thisnewdefinition,bigdatanowseemtonotonlydescribe itself according to itsamount,but furtherwasenhancedaccording to its interpretationandusability:
• Volume:referstotheamountofalltypesofdatageneratedfromdifferentsourcesandcontinuetoexpand.Thebenefitofgatheringlargeamountsofdataincludesthecreationofhiddeninformationandpatternsthroughdataanalysis;
• Variety:referstothedifferenttypesofdatacollectedviasensors,socialnetworks,mobiles,andsoon. Such data types include video, image, text, audio, and data logs,which can be structured orunstructureddata (e.g.,mostof thedatagenerated frommobileapplicationsare inunstructuredformat),makingitpossibletoexplorenewinsightswhenanalyzingthesedatatogether.;
• Velocity: refers to thespeedofdata transfer.Thecontentsofdataconstantlychangebecauseofthe absorption of complementary data collections, introduction of previously archived data orlegacycollections,andstreameddataarrivingfrommultiplesources;
• Value:oneof themost important aspect of big data since it refers to theprocess of discoveringhugehiddenvaluesfromlargedatasetswithvarioustypesandrapidgeneration
In order to properly address these four “Vs”, it is necessary to understand the different principles anddisciplinesthatshapetheBigData’s landscape. Inthisrespect,themodelpresentedbyD.Winters[4] (re-usedinFigure1)offersaninterestingviewpointofsuchdisciplines,howtheyareinterwoven,whethertheyare more theoretical/experimental in nature, or still Descriptive (i.e. description of a language) orPrescriptive(i.e.,setofrulesandexamplesdealingwiththesyntaxandwordstructuresofalanguage).
It has become common to talk about Big Data-as-a-Service (BDaaS). Technological tools delivered as aservicearenotnew.SoftwareasaService(SaaS),PlatformasaService(PaaS),andDataasaService(DaaS)

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 12 30August2016
area fewof themanydata solutionsofferedby thirdpartybigdatavendors.Weshould take things toawholenew level, combining these tools andapplying them tomassively largedata sets tohelp largeandsmallorganizationsmeettoday’sbigdatademandsinacost-effectivemanner.Today,BDaaScanbeseenasatwofoldbusinessprocess:(i)theownerofbigdataconductsdatastorage,management,andanalysisandprovideWebAPIsforuserstoaccesstheservice-generatedbigdataortheanalyzedresults;(ii)theownerofbigdataoutsources thebigdataprocessing (orpartof it) toa thirdparty. It consumes theBigData-as-a-Serviceprovidedbythirdpartyandallowstheserviceprovidertoworkonittoextractvalues.Eitherinthefirstorsecondmodel,similarchallengesmustbeaddressedstartingfromdataacquisition,datastaging(i.e.,BigDataInfrastructure-as-a-Service–BDIaaS),dataextraction&transformation(i.e.,BigDataPlatform-as-a-Service – BDPaaS), up to data analytics/analysis processing and visualization (i.e., BigData Analytics-as-a-Service–BDAaaS,asdepicted inFigure2),whichcanbereferredtoasdatascienceworkflows [5,6,7]. Itshould be noted that the “bigness” of big data depends on its location in the overall BDaaS stack. ThetakeawayisthatthehigheryougointheBDaaSstack,thelessdatayouneedtomanage.Toputitanotherway,at the topof thestack, size is considerably less relevant thanspeed formaking factdecisionsat theoperational and strategic levels. This is the reason why we highlight in Figure 1 that the potential ofinnovationinthecontextoftheIoT–wherewearedealingwithreal-timeapplications–comesessentiallyfromthetopofthestack.
In this section,a state-of-theart literature reviewof the threeBDXaaS layers ispresented in sections2.1,2.2,2.3respectively,whichwillhelpustobothpositionbIoTope’sworkandchooseappropriatesolutions/technologieswhendevelopingthebIoTope’susecasesdepending.
2.1. BigDataInfrastructure-as-a-Service–BDIaaSUpon the completion of raw data collection, data is transferred to a data storage infrastructure forprocessingandanalysis.Inthisrespect,differenttypesofinformationsourcesmustbetackled,especiallyinIoTsettingswhereawiderangeof smartconnectedobjectsandheterogeneous informationsystemstakeplace (i.e.,where informationsuchassensorreadings,alarms,assembly,disassembly,shippingevent,andotherinformationneedtobeexchangedbetweendifferentproducts,systemsoforganizations)[8].Areportfrom Intel confirmed the above statement by pointing out that big data in IoT has three features thatconformtothebigdataparadigm:
i. Abundantterminalsgeneratingmassesofdata;
ii. DatageneratedbyIoTisusuallysemi-structuredorunstructured;
Figure1:BigDataprinciplesanddisciplines
Figure2:BDaaSstack

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 13 30August2016
iii. DataofIoTisusefulonlywhenitisanalyzed[9].
Thestrategy tobeadopted forstoringdatasourcesdependonvariousaspects,whichareall summarizedthroughthetaxonomyproposedinFigure3,andintroducedinthefollowing.
2.1.1. ContentFormat
First,the“contentformat”ofthedatasourcesrangesfromunstructuredtohighlystructureddata/formats.StructureddataisoftenmanagedusingSQLinRDBMS(relationaldatabasemanagementsystem).Structureddataareeasytoinput,query,store,andanalyze(examplesofstructureddataincludenumbers,words,anddates).Semi-structureddataaredatathat donotresideinarelationaldatabasebutthatdoeshavesomeorganizational properties that make it easier to analyze (CSV butXML and JSON documents are semistructureddocuments).Therefore,capturingsemi-structureddatarequirestheuseofrulesthatdynamicallydecide the next process after capturing the data [9].Unstructured data, such as textmessages, locationinformation,videos,andsocialmediadata,aredatathatdonotfollowaspecifiedformat.Consideringthatthesizeofthistypeofdatacontinuestoincreasethroughtheuseofsmartphones,theneedtoanalyzeandunderstandsuchdatahasbecomeaveryimportantchallenge.
2.1.2. DatastoresKey-Value store databases are some of the least complex NoSQL options, designed for storing data in aschema-lessway. Inakey-valuestore,allofthedatawithinconsistsofan indexedkeyandavalue,hencethe name. Examples of this type of database include: DynamoDB [10], Redis [11] and Voldemort [12].Document-orienteddatabasesareoneofthecategoriesofNoSQLdatabasesthatareappropriateforweb-applications, which involve storing semi-structured data and execution of dynamic queries. Document-orienteddatastoresaremainlydesignedtostoreandretrievecollectionsofdocumentsorinformationandsupportcomplexdataforms inseveralstandardformats,suchasJSON,XML,andbinaryforms(e.g.,PDF).Examplesinclude:MongoDB[13],SimpleDB[14]andCouchDB[15].Column-oriented(alsoknownasWide-table data stores) are designed to tackle huge number of columns, sparse nature of data, and frequentchanges in schema. Unlike RDBMS where rows are stored contiguously, column values are storedcontiguously, thus resulting in better performance for some operations like aggregations and dynamicqueries[16].Popularopensourcecolumn-orienteddatabasesareHBase[17],Cassandra[18]andHypertable[19]. Finally,Graph databases are specialized on efficientmanagement of heavily linked data. Use casesusing graph databases are location-based services; knowledge representation and path finding problemsraised in navigation systems; recommendation systems and all other use cases that involve complex
Figure3:BDIaaStaxonomy

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 14 30August2016
relationships.Propertygraphdatabasesaremoresuitableforlargerelationshipsovermanynodes,whereasRDFisusedforcertaindetailsinagraph.Examplesofthistypeofdatabaseinclude:Ne04j[20]andGraphDB[21],whichbotharebasedondirectedandmulti-relationalpropertygraphs.
2.1.3. DatastagingPreparingdata isacrucial step fordataanalysis, themain reasonbeing that thequalityof the inputdatastrongly influences the quality of the analysis results. In datawarehouses,we talk about ETL (Extraction,Transformation, and Loading) process that consists of three main steps, as highlighted in Figure 3 anddescribedbelow:
1. Data Profiling: data is analyzed to determine its correct structure, content, and quality. Dataprofilingusesrulestodeterminewhatconstitutesacceptableorvaliddata,alsoknownasmetadata.Theusergathersthemetadatathatisavailableforanapplicationasastartingpointthenprocessesitagainsttherulestofinddifferences,whichgenerallyoccurduetotheexistenceofincorrectdata.This step helps find the correct structure and data attributes thatwill bemodeled in the stagingprocess.Thisstepiskeytodeterminewhichdataattributesareneededinthedatawarehouseandwhichcanbeleftbehindonthesourcesystem;
2. DataStaging:Inthestagingstep,thedatathatwasdeterminedtobeessentialtothedata-profilingstepisextractedandloadedinrawformintotheinitialdataprocessingareaofthedatawarehouse.This step is useful because data can be extracted quickly from the source systems, ensuring datawarehousinganddataprocessesdon'tbogdownoperationalsystems.
3. Transform/Load: this step is where data is aggregated and formatted in ways that are useful foransweringbusinessqueries;thedataispreparedwithinstagingtobeinsertedintothewarehouse.
In an effort to provide an “at a glance” summary of the BDIaaS-related taxonomy aspects, we refer thereader to Table 1, where we report themost widely utilized platforms that fulfill one or more of theseaspects. Regarding the ETL category, we rather focused on whether the reported platforms provide anenvironmentfor“queryexecution”soastobeabletocarryoutthecomparisonanalysis.
2.2. BigDataPlatform-as-a-Service–BDPaaS
Thereare reallyonly twoparadigms fordataprocessing,ashighlighted inFigure4,namely: (i)Batch thatenablesad-hocqueriesonhistoricaldataand(ii)Streamthatenabledtoprocessdataandmakedecisionoutofitinreal-time.Batchprocessingisfundamentallyhigh-latency,takingafewminutesandsometimeshours(withlargedatasets)togenerateanoutput.However,therearelotsofusecaseswhereitismuchusefultoknow results faster. Let us consider, for example, the scenario of traffic data collected from countingvehiclesateach traffic light.Batchprocessingcanbeused toanalyze thisdataandoffer relevant insightssuch as “traffic hotspots”, “traffic trendsover time”, and soon (e.g., to discover traffic patterns).On theotherhand,itisalsoveryusefulandvaluabletoknowandlearninreal-timeaboutthetrafficstatesothatonemayreactaccordingly(e.g.,avoidingbusyareas).Thisiswheretherealmof“Streamprocessing”begins,whichlooksatsmalleramountsofdataastheyarrive,whereintensecomputationslikeparallelsearchandmergequeriesontheflycanbeperformed.
In the following, we discuss these two paradigms, their pros, cons, and limitations with regard to IoTapplicationsandpeculiarities.Wealsoreviewexistingplatforms,ormorepreciselyexistingframeworksthataddressthesetwoparadigms,whichmightbeusefulduringtheprojecttochooseappropriatetechnologieson-sitetomeettheusecaserequirementsifdatahastobestored(e.g.,inthedifferentcityusecases).

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 15 30August2016
Table1:Ataglanceoverviewoftoday'sBDIaaStechnologies
E(TL) Data ContentFormat
Que
ryExtraction
Documen
t-oriented
Column-oriented
Grap
h-ba
sed
Key-value
Unstructured
Semi-structured
Structured
DynamoDB ✔ ✔
Redis ✔ ✔
Voldemort ✔ ✔
MongoDB ✔ ✔ ✔ ✔
SimpleDB ✔ ✔ ✔ ✔
CouchDB ✔ ✔ ✔ ✔
Hbase ✔ ✔ ✔ ✔
Cassandra ✔ ✔ ✔ ✔ ✔
Neo4j ✔ ✔ ✔
GraphDB ✔ ✔ ✔
mwDB ✔ ✔ ✔ ✔
AzureTableStorage(ATS) ✔ ✔ ✔
Riak ✔ ✔ ✔ ✔ ✔
2.2.1. BatchprocessingBatchprocessingisappliedtoprocesslargedatasets,where(I/O)operationsonmultipledata-itemscanbebatched for efficiency. In the context of big-data analytics, Google’s MapReduce is the first major data-processing paradigm.Dean andGhemawat proposedMapReduce [22] to facilitate development of highlyscalable, fault-tolerant, large-scale distributed applications. The MapReduce runtime system divestsprogrammersoflow-leveldetailsofscheduling,loadbalancing,andfaulttolerance,whichisoneofthekeyreasonswhyithasbeenwidelyadoptedinthebig-dataanalyticscommunity.MapReduceisattheheartofHadoop,whichwas initiallydesignedasa single-purpose system– to runMapReduce jobs tobuildawebindex— and that is expected to touch half of theworld’s data by 2020 (Gartner’s prediction). AlthoughHadoopgetsmuchofthebigdatacredit, thereality isthattheexpansionofNoSQLdatabases(MongoDB,ElasticSearch…)hasplayedaprominentroleinthecreationofMapReduce-bndexedStorage”inFigure5).Tocomeback toHadoop, it isworthnoting that it hasnowevolved intoa catchall for awide rangeofdataanalytics platforms proposing higher-level abstractions atopMapReduce, examples ofwhich are Pig [23],Cascading[24]orHive[25],asemphasizedinFigure5.Suchplatformssped-uptheadoptionofHadoop,butled to some inefficiencies and poor performance [26]. These limitations and the pressure towardsmoreflexibility and efficiency led to the refactoring of Hadoop into a general purpose, OS-like resourcemanagementlayer,namelyYARN[27],andanapplicationframeworklayerallowingforarbitraryexecutionengines. This enabled different applications to share a cluster, and made MapReduce just anotherapplicationintheHadoopecosystem.Importantexamplesofapplicationsthatbreak-freeoftheMapReducemodel(andruntime)areSpark[28],Impala[29]andApacheFlink[30].Thishasacceleratedinnovation,butalso led to a less efficient ecosystem, where common functionalities were being replicated acrossframeworks (e.g., MapReduce and Spark independently developed mechanisms to implement delayscheduling). In conclusion,Batchprocessesare the rightapproach for some jobs.But inmanycases,data

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 16 30August2016
mustbeanalyzedrapidly(in“near”real-time)wherewedonothavetheluxuryoflengthyETLprocessestocleandataforlaterpurposes.ThisiswheretherealmofStreamorReal-timebigdatabegins.
2.2.2. Stream/Real-time
“Real-timebigdataisnotjustaprocessforstoringpetabytesorexabytesofdatainadatawarehouse,”asquotedbyMichaelMinelli[31].“It’sabouttheabilitytomakebetterdecisionsandtakemeaningfulactionsat the right time. It’s aboutdetecting fraudwhile someone is swipinga credit card, or triggeringanofferwhilea shopper is standingona checkout line,orplacinganadonawebsitewhile someone is readingaspecificarticle. It’saboutcombiningandanalyzingdatasoyoucantaketherightaction,attherighttime,andattherightplace.”Real-timebigdata,or“Real-TimeAnalytics”asmentionedinFigure5,isattheheartofany IoTapplication,where live IoTdata is collected fromawide rangeof smartconnectedobjectsanddisparateinformationsystemsinandacrossorganizations,cities,andsoforth.Whilereal-timeanalyticsisattheheartofanyIoTapplication,therearestillchallengesaheadtobeaddressedinordertoofferinnovativeprovisionsforon-lineanalytics,andparticularlyforedgeanalyticsthatmakeitpossibletoingestandprocessdataascloseaspossibletotheinformationsources(e.g.,connecteddevices)[32].
Thebreakthrough thatenabledReal-timebigdata togoa step forward– toget ridof someperformancebottlenecks–wastheintroductionof“In-MemoryComputing”capabilitiesandframeworksasemphasizedinFigure5.AsdescribedinthesurveycarriedoutbyZhangetal.[33],in-memorydatamanagementsystemscanbeclassifiedintotwomaincategoriesdependingontheirfunctionality,suchas:
(i) Storage:designedpurely forefficientstorageservice,suchas in-memoryrelationaldatabasesonlyforOLTP(e.g.,NoSQLdatabaseswithoutanalyticssupport,cf.“indexedstorage”inFigure5);
(i) In-memory analytics systems: designed for large-scale data processing and analytics, such as in-memory big data analytics systems (Mammoth, Spak/RDD) and real-time in-memory processingsystems(Storm[34],Yahoo!S4[35],SparkStreaming[36],ApacheFlink[30]).Themainoptimizationobjectiveofthesesystemsistominimizetheruntimeofananalyticsjob.Allthesesystemsarefastand reliable large-scale data processing engines, which provide in-memory data sets, querylanguage,machinelearningsupportandmachineinterfaceshandlingstreamingdata.
Froman IoT standpoint, the second category isof theutmost importance since it lays the foundation formore advanced and low latency big data analytics, enabling IoT systems to handle Complex EventProcessing.
Figure5actsasasummaryofthedifferentrealmsthatBDPaaSiscomposedof,includingBatchprocessing,Stream (orReal-time)processing, In-MemoryComputing, InteractiveProcessingand IndexedStorage. Theobjectiveofthisdeliverable isnottodiscuss indetaileachpotentialunderlyingtechnologyandassociatedspecificities (pros/cons),but rather toposition relevant solutionsand technologies in termsof “what theyhavebeendesignedfor”sothat itcanbeused/serveasadefinitivesetofguidelineswhendevelopingthebIoTope’sbuildingblocks (e.g., regarding thebIoTope’s servicemarketplace/catalog,Context-as-a-Servicecomponents, etc.) aswell as the city use cases (i.e., dependingon the city needs/requirements, use casesettingsandotherexternalparametersthatmightinfluenceonthefinalchoices).
Figure4:BDPaaStaxonomy

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 17 30August2016
2.3. BigDataAnalytics-as-a-Service–BDAaaSBDAaaS,sometimesreferredtoas“DataandAnalytics"-as-a-Service(DAaaS)[37],aimstoenableend-userstoeasilyandfastlybrowsethelake’sdatacatalog(aDatapedia)tofindandselecttheavailabledataandfillametaphorical “shopping cart” (effectively an analytics sandbox) with data to work with. Once access isprovisioned, users can use the analytics tools of their choice to develop models and gain insights.Subsequently,userscanpublishanalyticalmodelsorpushrefinedor transformeddataback into theDataLake to sharewith the larger community. Fromour perspective, BDAaaS providers aremostly concernedwith infrastructure for data analysis workflow, whose exact business model may vary depending on theapplication domain and user needs. Some companies provide BDAaaS software solutions, along withtraining,supportandcustomizationfortheusers(seee.g.Cloudera[38],Hortonworks[39]orMapR[40]).Some of these solutions offer a full BDAaaS infrastructure in the cloud (e.g. AmazonWeb Services [41],GoogleCloud[42]orMicrosoftAzure[43]),providingboththehardwareandsoftwareforbigdataanalyticsonuser’sdata.All thiswillbediscussed in this section, inwhichwewillprovideanoverviewof themostpopularBDAaaSsolutionsfromanIoTperspective,implyingspecificchallengessuchasthefactthatcurrentBDAaaSsolutionsarenotyetfullymaturetocopewiththeIoTpeculiarities(eveniftheyclaimtheyare),aswillbediscussedin2.3.1.Sections2.3.2to2.3.3discussthedifferentparadigmsforachievingBDAaaS(batchdata processing, mini-batch data processing, stream data processing and edge-computing), while section2.3.4 ratherdiscusses themain vendorofBDAaaS solutions, the scope/paradigm theyareaddressingandsupportedsoftware.
2.3.1. BigDataAnalyticsinInternetofThings–theroadaheadBig Data for the IoT comeswith a set of additional challenges that need to be addressed specifically bytechnology solutions targeting this sector.When it comes to data, the IoT can be considered as a set ofobjectsequippedwithbothsensors,actuators,oreven–fromaproductlifecyclemanagementperspective–manufacturerdatabasesthatcontainuseful informationrelatedtothatobject(e.g.,billofmaterial…)[44].Eachofthesedevicesandback-endsystemsproduceandconsumedata,openingupopportunitiestohavea
Figure5:BDPaaS-relatedconcepts&underlyingtechnologies

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 18 30August2016
completeandaccuratephotographofthedevicestateaswellasof itssurrounding.Thedataproducedbythesesystemsareanorderofmagnitudelargerthandataoriginatinginuserinteractionwithsystems,mostofthosesensorsproducingdataroundtheclockwithveryfewinterruptions.Theproduceddataalsoneedstoberetainedforlongerperiodsinordertobeabletocreatemodelsthataccuratelyreflecttheseasonalityoftheevolutionoftheobject’sbehaviorandenvironment.ABSAaaSplatformfortheIoTthereforeneedstoscale inboth ingestionand storage capacity.However, data analysis paradigm in IoT settingsdiffers fromthatweusuallyencounterwithintheBigDatalandscape.
IoT data is used by data scientists to create models (e.g., for describing trends, seasonal behaviors,correlationwithothervariables),butthenthesemodelsneedtobeappliedataverylargescale,ontheflyonincomingdata,butalsoondeephistoricaldata.ABigDataplatformfortheIoTthereforeneedstoenabletheindustrializationofthedataanalysis.Byindustrialization,wemeanthatdataanalysismustbeconductedwithouttheneedforhumanintervention,eitherasthedatacomesin,periodically,orwhenanapplicationrequires it.Theanalysiscan involvedata frommultipledevicesorconcentrateonasingleone,aBigDataplatform for the IoT must adapt to both cases. Also, given the sheer amount of data involved in IoTapplications,BigDataplatformmustenablethestorageofhistoricaldatatobemanipulatedinbatchmodetocreate theaforementionedmodels, aswillbediscussed in sections2.3.2and2.3.2. Anotherdifferencewith the Big Data landscape lies in the type of analysis that need to be performed. Signal processingtechniques are very often used when dealing with sensor data, this means that the components madeavailable by an IoT Big Data platformmust allow to use such techniques in an industrializedway. In thisrespect,whendoingmachinelearningtoconstructamodel,greatcaremustbetakentoensurethatfeatureextraction can be done within the IoT Big Data platform so model utilization can be industrialized too,meaning that the platformmust offer tools for such feature computation along with data cleansing andpreparation.Lastly,theIoTbringstheneedforwhatiscallededgeanalytics,whichistheexecutionofdataanalysis as close as possible to the objects, as will be discussed in section 2.3.3. This need fulfills twopurposes:(i)allowdevicestofunctioninamostlyautonomousway,analyzingthecollecteddataanddrivingthevariousactuatorsaccording to the resultsof theanalysis;and (ii)enable toperformpre-processingofdataclosetothedevicestosimplifyandoptimizethedatathatispushedtotheIoTBigDataplatform,ortocomputeadditionaldatathatwillbepushedjointlywiththerawsensormeasurements.ThisdualityofIoTBigDataplatforms,havingbothcentralandedgecomponents,makethemratheruniqueintheBigDatalandscape.Forefficiencyoftheiruse,thosetwocomponentsmustasmuchaspossibleusethesameanalyticsapproachsothattrainingeffortsdoneononecomponentcanbeleveragedontheother.FormaximumefficiencyandcompatibilitywithotherBigDatapipelines,suchplatformsshouldbebasedonor easily integrate with standard Big Data tools such as those found in the Hadoop ecosystem or theplethoraoftoolsusedbydatascientistssuchasZeppelin[45],R[46],orstillJupyter[47]tonameafew.Aswehavejustdescribed,IoTBigDataplatformcomewithratherspecificfeatures,nevertheless,astheymustinteract with external tools, they should support some standards for data ingestion or query. As thosestandards usually focus on a very limited area of what covers IoT Big Data platforms, they should beprovidedviaintermediaryservicesandnotbedirectlysupportedbytheplatformsthemselves.
2.3.2. BatchDataProcessingBatchdataprocessingassumesthatalldataisalreadycollectedandstored,andthenthewholebulkofdataisprocessed.BatchdataprocessingcannotcoveralltheIoTusecases,althoughitcanbeusedforanalyticsovercollecteddata.ApacheSpark[28]ismaybethemostwellknownsolutiontoday,whichcanrunontopofmultiplebigdataplatforms(includingApacheHadoop[48])aswasalreadydiscussedinprevioussections.The computational structure, which goes beyond map-reduce paradigm along with efficient caching inmemory,makesSparksuitableforiterativealgorithms(e.g.,multipleofmachinelearningapproaches).IthasAPI provisions for a wide variety of programming languages, including Python, Java, Scala and R. Alsomultiple analytic toolshave connectors toApacheSpark. ExactperformanceofApacheSparkdependsonthe system architecture, although some benchmarks can be found in the literature [49]. Apache Spark

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 19 30August2016
Streaming,theextensionofApacheSpark,allowsmini-batchdataprocessing,aswillbediscussedinsection2.3.2.Otheralternativesinclude(i)AzureMachineLearning[50],whichisabatchdataprocessingsolutionfromMicrosoft (offered as a part of IoT suite in Azure cloud) that provides tools to build pipeline thatincludesdatapreprocessing,applyingmachinelearningalgorithmstolearnthemodel,andthedeployingthelearntmodel; (ii)Google Dataflow [42, 51], IBMWatson IoT platform [52],Apache Flink,which all offerbothbatchandstreamdataprocessing,aswillbediscussedinthenextsection.
2.3.1. StreamDataProcessing
Streamdataprocessingsystemsassumeconstantflowofdataintothesystem,andprocess incomingdataone at a time. The concept of stream processing is one of the most important components for IoTapplications. Current big data stream processing systems include: (i) Apache Storm [34], which is adistributed stream processing and computation framework specifically tuned for real-time data analytics.SomeBDAaaSproviders, likeHortonworks [39], integrateStormaspartof theirBDAaaSplatform.ApacheStorm processes one event at a time, unlike Apache Spark Streaming that uses mini-batches, as will bediscussedinthenextsection.Itallowsformuchlower(sub-second)latency;(ii)ApacheFlink,whichenablesbothstreamandbatchanalyticstobecombinedinsingleruntime;(iii)IBMWatsonIoTPlatform,whichisacore analytics component of IBM IoT solution focusing on machine learning and image, video and textanalytics (e.g., for interactingwith humans naturally by using both text and voice, understanding images,recognizing scenes, learning from sensory inputs to find meaningful patterns, etc.); (iv) Azure StreamAnalytics [53],which isastreamdataprocessingtool fromMicrosoft (aspartofAzureCloud IoTsolution)intended to achieve anomaly detection, transformation of incoming data, alerting of a specific error orconditioninthestream,andreal-timedatadisplayusingthedashboard(apparentlysupportingathroughputofmillionsofeventspersecond);(v)GoogleCloudDataflow,whichprovidesaunifiedprogrammingmodelforstreamandbatchdataanalytics.
2.3.2. Mini-BatchDataProcessing
Mini-batchcombinesbatchandstreamdataprocessingtechniques.Streamofdataiscomposedintosmallbatches of data,wheremini-batches are processed using batch data processing techniques. Perhaps, themostwell-knownmini-batchdataprocessing tool isApache Spark Streaming [36],amini-batchextensionoverApacheSpark.ApacheSparkStreamingcomposesDStream(discretizedstream)outof incomingdata.DStream isa sequenceofRDDs (ResilientDistributedDatasets), thusmaking itpossible toeffectively turnstreams intomini-batchesofdata. Thereexist libraries to connect Spark Streaming to inputdata streamsfrommanysourcesincludingApacheKafka,Twitter,ApacheFlume,AmazonKinesis,andmore.Zahariaetal.compare1theperformanceofApacheStormandApacheSparkStreamingonvariousbenchmarks,showingthatApacheSparkStreamingachievedathroughputof25-60MBspersecondpernode,andatotalclusterthroughputofseveralGBspersecondunder1-2slatencybound.
2.3.3. Edge-computing
Edgecomputing,alsoreferredtoasFogcomputing,arealternativesolutionstodataanalyticsinthecloud.As already mentioned, these concept move computation, data and services from central nodes of thenetwork (the “core”) to the peripheral nodes likemobile devices or even sensors (the “edge”) [54]. Thisinevitably results in a less centralized architecture,which is very beneficial for IoT applications aswell ascomplexSystems-of-Systemsenvironmentssuchassmartcities.
Intoday’s IoT landscape,wecancitetheOpenFogConsortium[55],wasformed–foundedbyARM,Cisco,Dell, Intel,MicrosoftandPrincetonUniversity–todefineandpromotefogcomputing,aimingatdefiningaOpenFogarchitectureaddressingsecurityissuesandplanningindustrytestbeds.InthebIoTopeconsortium,one partner, ControlThings, is focusing on providing an authentication solution that fits edge computing,1http://www.eecs.berkeley.edu/Pubs/TechRpts/2012/EECS-2012-259.pdf

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 20 30August2016
whiletwootherpartners,UL(academic)andCityzendata(privatecompany),proposeplatformstosupportdifferentedgecomputingaspects,notablyWarp10[56]developedbyCityzendatathatprimarilyfocusesonedge data storage aspects andKevoreeModelling Framework (KMF) developed by UL [57] that focusesmoreondatamining/reasoning.Bothplatformsarepresentedingreaterdetailinsection4.
An “at a glance” summary of the main big data analytics platforms discussed in the previous section isprovidedinTable2.Overall,existingBDaaSvendorscombineexistingsoftwaresolutionstobuildacoherentbig data analytics platform,wheremost of them today rely on theApache family of products. Those areopensourceproductswithaverypermissiveApachelicense.Theproductsareusedasabackboneformanyvendors(aswillbeshowninfurthersections).Moreover,theycanbeinstalledonexistingcloudplatforms,even ifnotprovidedatonce.Someplatformsuseproprietary software (Azure solutions, IBMWatson IoT,Google Dataflow) as an alternative or in combinationwith Apache products. Edge computing software issomewhat separatephenomenon, and it is oftenopen source.Next sectiondiscussesBDaaS vendors andmentionshowexactlytheycomposebigdataplatformoutofmentionedinfrastructurecomponents.
Table2:SummaryofBDAaaSplatforms&infrastructures
Solution DevelopedBy Type LicenseType
ApacheHadoop ApacheSoftwareFoundation;Google;Yahoo
Batch OpenSource(Apache)
ApacheSpark Apache Software Foundation;UCBerkeley;Databricks
Batch OpenSource(Apache)
ApacheSparkStreaming Apache Software Foundation;UCBerkeley;Databricks
Mini-batch OpenSource(Apache)
ApacheFlink ApacheSoftwareFoundation Stream OpenSource(Apache)ApacheStorm Twitter(Backtype) Stream OpenSource(Apache)
GoogleDataflow Google Stream;Batch ProprietaryAzureMachineLearning Microsoft Batch ProprietaryAzureStreamProcessing Microsoft Stream ProprietaryIBMWatsonIoTPlatform IBM Stream;Batch ProprietaryKMF UniversityofLuxembourg Edge OpenSource(GPL)Warp10 Cityzendata Edge OpenSource(Apache)
2.3.4. BDAaaSVendorsToday, perhaps the most well-known software providers for big data processing are Cloudera [38],Hortonworks[39]andMapR[41],althoughnewplayersandsolutionshaveenteredthebigdatamarketsuchas Cityzendata, Predix, IBM, and so forth. In Table 3, we tried to roughly summarize the main BDAaaSsolutionprovidersbyreportingwhethertheirprovideend-userswithaspecificsoftware,aCloud-basedorEdge-basedoffer,orboth,andwhattypesofanalyticsframeworksaresupportedbyeachvendor,althoughend-usersarenotlimitedtothislist.Inthefollowing,wediscussingreaterdetaileachofthesesolutions.
Cloudera[38]isoneofthemostpopularprovidersofbigdatasoftwareandservices.ThecompanyprovidesCDH(ClouderaDistributionincludingHadoop)opensourcestackforbigdataprocessing,aswellasvariousbigdataprocessingservices.Analyticsasaserviceisoneoftheirbusinessdirections.ClouderarecognizesIoTasanimportantusecase,althoughatthemomentClouderahasnospecificIoT-relatedproposals.Clouderadistribution(CDH)usesHadoopasacore,andalsoprovidesmultipleothertoolsincludingApacheSparkwithApache Spark Streaming (for advanced analytics), Apache Kafka (for processing of data streams), Impala,ApacheHBASEandApacheHive(forstorageandqueryofdata)andmultipleothertools.AllthesetoolscanbeveryrelevantforIoTscenarios.So,althoughClouderadoesnothave–atthetimeofwriting–aturnkey

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 21 30August2016
IoT-relatedproduct,theiroffersshouldbecloselyfollowed.Hortonworks[39]providestwomainsolutions:Hortonworks Data Platform (HDP) and Hortonworks Data Flow (HDF), which focuses on real-time datacollection, delivery and analysis, as well as on real-time data-driven decisions, mentioning Internet ofAnything (IoAT)as itsusecase.Amongother toolsHDF includesApacheKafka fordatacollection,ApacheStorm fordistributed real-timedataprocessing, andApacheNiFi fordata visualization.HortonworksDataPlatform(HDP)isbasedonApacheHadoopopensourcedistributionasacoreandincludesApacheSparkforadvanceddataprocessingandvarioustoolsfordatastorageandquery(ApacheHive,ApacheHBASE,ApacheAccumuloandmore).MapR [40]providesthreemainplatformservices:MapR-Streamforeventstreaming(IoT is explicitlymentionedas a supporteduse case),MapR-DB fordatabasewith real-timeanalytics, andMapR-FSforbigdatastorage.MapRecosystemusesApacheHadoopasitscoreandprovideswidevarietyofothertoolsincludingApacheSparkwithApacheSparkStreamingforadvanceddataprocessing,ImpalaandApacheDrillforSQLqueries,andApacheHBASEasadatabasesolution.
Cloud infrastructure providers usually offer BDAaaS solutions and often include specific offers for IoTscenarios. Main cloud infrastructure providers are Amazon Web Services [41], Google Cloud [42] andMicrosoft Azure [43]. Amazon Web Services (AWS) offers a wide range of cloud computing services,includingoffersforIoTscenarios[58]withaspecialfocusonauthenticationandauthorizationofIoTdevicesand smooth connection toAmazonWebServices cloud.Bigdata analytics solutions arebasedonApacheHadoop,butalsoprovidenativesupportforApacheSpark,aswellasPresto(forqueries),ApacheHBASE(forlargetables),ApacheZeppelin(fordatavisualizationandexploration)andmanymore.GoogleCloudoffersspecific solutions for IoT use cases, using its own toolchain on top of Hadoop and Spark frameworks.ProvidedanalyticstoolsincludeGoogleCloudDataFlow(basedonopensourceprojectJupyter[47])forETLtasks, Google BigQuery for SQL-like queries, Google Dataproc for managing Spark and Hadoop for dataprocessing,andCloudDatalabforbigdataexploration.CloudBigTabletoolcanalsoprovidethedashboardforadditionalmonitoringandexploration.MicrosoftAzure[43]offersspecificIoTsuite,includinge.g.“AzureIoT Hub” for secure and reliable communications between devices and the cloud, “Azure Storage” and“AzureDocumentDB” fordatastorage,“AzureWebApps”and“MicrosoftPowerBI” fordatavisualization.IntegrationwithAzureStreamAnalyticsandAzureMachineLearningservicesispossibleforadvanceddataprocessing.IBMBluemix[59]isalsoacloud-basedplatformthatoffersaspecialsuiteforIoTscenarios,the
Table3:BDAaaSvendorlandscape
Vendor Provides SupportedAnalyticsSoftwareCloudera Software (free, open source);
support,services,trainingApacheHadoop;ApacheSpark;ApacheSparkStreaming
Hortonworks Software (free, open source);support,services,training
ApacheHadoop;ApacheSpark;ApacheSparkStreaming;ApacheStorm
MapR Software(freemium),support,services,training
ApacheHadoop;ApacheSpark;ApacheSparkStreaming;ApacheStorm
Amazon WebServices
Cloudservices ApacheHadoop;ApacheSpark;ApacheSparkStreaming;
MicrosoftAzure Cloudservices AzureHDInsight(ApacheHadoopdistribution);AzureMachineLearning;AzureStreamAnalytics;ApacheSpark;ApacheStorm;
IBMBluemix Cloudservices IBMWatsonIoTPlatformGoogleCloud Cloudservices Apache Hadoop; Apache Spark; Apache Spark
Streaming;GoogleDataproc;GoogleDataflow;Predix CloudandEdgecomputing SASKevoree Edgecomputingsoftware KevoreeModellingFrameworkCityzenData Cloud&Edgeservices Warp10

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 22 30August2016
coreanalyticscomponentbeingtheIBMWatsonIoTPlatform.Predix[60]providesasimilarofferforstreamprocessing,theproposedframeworkbeingbasedonSASstatisticssoftware[61].
AlthoughallthebigandsmallbigdataplayersseizedtheimportancetorapidlycomeupwithplatformofferstosupportIoTusecases,theiroffersarenotyetmatureenoughtobeeasilydeployedand/orintegratedtoexisting IoT environments due to (for most of them) the need to acquaint with complex programminglanguages.Indeed,dataanalysisfortheInternetofThingsdiffersfromotherkindsofdataanalysissuchascustomer behavior or IT logs analysis. Typical questions asked in the IoT field will involve multi-stepscomputationsonseveralsensordatastreams.SuchcomputationscannotbeexpressedinsimplisticSQL-likequerylanguages,thereforeifthestoragetechnologyusedformanagingthesensordatadoesnotprovidearichenvironmenttomanipulatetheseriesofreadings,theneededcomputationswillhavetobedevelopedasanexternalclientcomponentusingastandardprogramminglanguage.Doingsousuallyleadstocomplexapplications, longdevelopment timesandpossible technicaldebtswhenalgorithmsordatastructuresarenot fully optimized.All those added together also lead to explodingbudgets.On the contrary, expressingsuch analysis in a language designed specifically for handling sensor data will lead to conciseness,performanceandcontrolledcosts.Asanexample,let’sconsideratypicalanalysisinthefieldofautomotive:
“WhatistheaverageRPM2(RevolutionsPerMinute)whentheABSisused?”
Performing such an analysis using a simple storage platform will mean coding all the needed steps in adedicated program, including the retrieval of data from the storage platform, the re-alignment of themeasurements so we can guarantee we have an RPM and an ABS reading at identical timestamps, theselectionof instantswhen theABS is actually triggered, the selectionof theRPM readingsat those sameinstants and then finally the computation of their average. This is obviously something that will requireseveral hours of development.On the other hand, using a specialized platform such asWarp 10 and itsWarpScriptlanguage,makesallthisverysimpletobecoded,asillustratedbelow:
// Load the raw abs/rpm data ‘TOKEN’ ‘~(abs|rpm)’ {} NOW 24 h FETCH
// Align the ticks on second boundaries [ SWAP bucketizer.last 0 STU 0 ] BUCKETIZE
// Select the instants when abs is triggered DUP ‘abs’ filter.byclass FILTER [ SWAP true mapper.eq 0 0 0 ] MAP
// Select the rpm series SWAP ‘rpm’ filter.byclass FILTER
// Put the two series in a map APPEND
// Retain only the common ticks where we have both an RPM and an ABS reading
COMMONTICKS // Retain only the ‘rpm’ series
‘Rpm’ filter.byclass FILTER // Compute the average
MUSIGMA DROP
So, all in all, 9 lines of code (if we exclude the comments) is undoubtedly less than similar codes in anytraditionalprogramminglanguages.Toconcludethischapter,wedonotclaimthatonesolutionstandsoutwithrespecttoothers.Therearemultiplebigdatainfrastructureprovidersonthemarket,allacknowledgingthe importance of providing solutions fine-tuned for IoT use cases. However, there is stillmuch to do toprovide easy-to-use and flexible programming languages, particularly for edge nodes as illustrated aboveusingWarp10.InbIoTope,accordingtotheusecaseneedsandenvironments,someoftheBDIaaS,BDPaaSand BDAaaS solutions reviewed throughout section 2 will potentially be selected for implementationpurposes,e.g. ina specific cityuse case for storingorprocessing specificdata, coming fromoneormore
2Howfastthecar’sengineisturningi.e.howmanytimesthecrankshaftrotatesinoneminute.

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 23 30August2016
platforms.Nonetheless,at this stageof theproject, it is stilldifficult tobeawareof theexactquantityofdata thatwill need tobe stored/processedper city, adding that someof thesedata sets arealreadywellstored, processed, and just need to be exposed to the IoT (or bIoTope) ecosystem through an open andstandardizedRESTAPI,aswillbediscussedingreaterdetailinthenextsection.

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 24 30August2016
3. Storage capabilities offered by and required for a successful IoTecosystem
The chapter provides an overview of the storage and analytics capabilities that are currently supported/offered by the platforms of the different bIoTope partners, thus forming the initial “service kernel” of theecosystem.ThischapteralsodiscussesadditionalkeybIoTopebuildingblocksthatneedtobedevelopedtofosterthecreationofatrulyunifiedIoTecosystemforservicepublicationanddiscoveryacrossthesedifferentplatforms,whichareeitherdomain-specificortool-specific.
Theobjectiveofthischapteristwo-fold.First,itdiscusses(section3.1)thekeybIoTopebuildingblocksthatfoster the creation of a truly unified IoT ecosystem for service publication and discovery across variousplatformsanddomains.Withinthiscontext,itprovidesinsightintothesetofplatformsheldbythebIoTopepartners that will take part in the initial bIoTope ecosystem to offer various types of services (e.g., formobility, open data, smart building services, ormore generic ones such as storage services). Section 3.2provides a more in-depth overview of the storage and analytics capabilities offered by each of theseplatforms, while section 3.3 rather describes fundamental services that are needed for the properfunctioningofthebIoTopeecosystem(e.g.,serviceregistry/repository).
3.1. bIoTopeecosystemoverview
3.1.1. TowardsaunifiedIoTecosystem
All ICT30 projects are looking to offer new capabilities for enhanced connectivity and device/servicemanagement across disparate IoT platforms/domains (e.g., across transportation, energy,manufacturing,healthcareandcity serviceproviders). In thisquest foravoiding thecontinualemergenceof vertical silos,which hamper developers to produce disruptive and added value services across multiple platforms,interoperabilitychallengesatdifferentlevelsmustbeaddressed.Inthisproject,wemaketheassumptionsthatthefollowingprinciplesarefundamentalforsuccessfulopenIoTecosystems:
1) The web is the IoT platform: no single organization or company is in control, thus removing thethreatofasinglepointoffailure.Everyoneisabletoprovideanytypeofserviceandpossiblymakemoneyoutofitwithoutanyforcedintermediary.Itincludestakingintoconsiderationthefollowingaspects:
a) MakingavailableadisruptiveIoTservicemarketplacetoenableanyonetopublishhis/herservices,while helping him/her to leverage the service quality (e.g., by enriching the service description,addingcontextualinformation,etc.);
2) WebService Interoperability&Visibility: thesuccessofan IoTecosystem iscloselybound-upwiththenumberof services that are available, andhoweasy it is tomake these services talk andunderstandeachother.Itincludestakingintoconsiderationthefollowingaspects:
a) Genericmessaginginterfaceprotocols(suchasO-MI)toexchangeIoTinformationaboutanykindofobjects;
b) Genericpayloads fordescribing IoT services,whichmustbe flexible enough tobeextendedusing“independent semantic models” (e.g., schema.org, SSN) and “dependent semantic models” (e.g.,Mobivoc,DATEX,etc.). Suchcontrolledvocabulariesorganized in taxonomiesorontologies shouldbeeasytoaccessandunderstoodbyservice/webcrawlerssoastoindextheIoT.InitiativesuchasJSON-LDarealreadyproposingsolutionsinthisdirection;

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 25 30August2016
Overall,a long-termgoal istobeabletoconnectcloudendpointsservingdata,whilereducingasmuchaspossibletheneedtodevelopcustomconnectorsand,fortheendusers,tomanuallyconnectoneservicetoanother.
3) Security& Data ownership: organizations and end-usersmust have the control over their data aswell as data generated by the devices they own (e.g., deciding sharing specific data with any otherpartner/serviceoftheecosystem).Itincludestakingintoconsiderationimportantaspectssuchas:
a) FrameworkstovalidateObject’sidentities(e.g.,usingAuth0,MyData,etc.);b) Authorization,forprovidingapossibilitytolimittheaccesstofeaturesandresources;c) Encryptedcommunicationtopreventeavesdroppingandspoofing.
Nonetheless,mostof current IoT solutions formvertical silos/platforms that look like theonedepicted inFigure6,usuallyconsistingofacompletepackageincludingoneormoresiloedsmartproducts(embeddingaspecifichardwareandoperatingsystem),whichareconnected–throughspecificM2MprotocolssuchasMQTT,CoAP,etc.–toaCloudsystemthatcollects,aggregatesandprocessesthedatageneratedbytheseproducts, andultimately returnsoneormore services toend-users (via a siloedApp). Just tounderstandhowcomplexitistomakealltheseverticalsilosinteroperableintoday’sIoT,somestudiesreportthatmorethan 250 IoT platforms are currently available on the market [62], whose number may be much higherdependingonhowanIoTplatformisdefined.LookingonlyatthebIoTopeconsortium,therearealready10differentplatforms–whetherproprietaryoropensource(seesection3.2)–providedbydifferentpartners.FromabIoTope viewpoint, the success of a unified IoT ecosystem (i.e., vendor-independent andopen) isclosely bound-upwith thenumber of services that aremade available, andhoweasy it is tomake these
Figure6:TypicalVerticalSilomodelcomposingtoday'sIoT(e.g.,Cloud-basedsolution)

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 26 30August2016
servicestalkandunderstandeachother3,asitisdiscussedinourthirdfundamentalprincipleforsuccessfulIoT ecosystems above. One vision that is increasingly shared by the IoT community, even by hardwaremanufacturers,isthat:“APIsareoneofthefundamentalbuildingblocksonwhichtheInternetofThingswillsucceed”,asquotedbyRaineBergstrom(VP/GMSoftwareandServicesProductsatIntel)[63].Atfirstsight,relating thisAPIphenomenonto IoTmightseemfar-fetched:manybelieve that IoT ismostly relatedwithtechnologiesattheNetworkandTransportlayer,and“stops”whenInternetinteroperability(namelyTCP/IPandHTTP) isachieved. InbIoTope,wedonot share this visionbecause interoperabilityeffortsgobeyondtechnicalissuesonly,andshouldaddressinteroperabilityattheSyntacticalandSemanticlevelsaswell[64].Havingsaidthat,muchremainstobedoneattheselevelstoenablethecreationofSystems-of-Systems(orPlatforms-of-Platforms) integration.At the timeofwriting thispaper,programmableweb.com–apopularAPIdirectoryservice–countsover15.000publicAPIs(roughlydoublingevery18months).Theadoptionofopen and preferably standardized APIs should play a key role in fostering the creation of unified IoTecosystems.
Given the above, bIoTope aims to provide an efficient, flexible and – importantly – user-friendly way to“align”or“makeuniform”anyplatform-relatedREST-API,thusempoweringthebIoTopeecosystemtomakeabstractionoftheplatform’sunderlyinginfrastructureandtechnologies.AsO-MI/O-DFarekeyenablerstoachievethisgoal4inbIoTope(ashighlightedthroughtheredelementsinFigure6),letusremindafewkeyfeatures/specificationsofbothstandards:O-MIprovidesagenericOpenAPIforanyRESTfulIoTinformationsystem,meaning that in the sameway thatHTTP canbeused for transportingpayloads in formatsotherthanHTML,O-MIcanbeusedfortransportingpayloadsinnearlyanyformat.Thecomplementary–butnotcompulsory–standard(O-DF)partlyfulfilsthesameroleintheIoTasHTMLdoesfortheInternet,meaningthat O-DF is a generic content descriptionmodel for Things in the IoT that can be extended with morespecific vocabularies (e.g., using domain-specific ontology vocabularies). As will be discussed in the nextsection, a common service catalog (referred to as IoTBnB in bIoTope)will beneeded so as to enable thepublicationanddiscoveryofservicespublishedbythedifferentnodes.
3.1.2. Needforanecosystemservicecatalogue–IoTBnB
bIoTopeisintendedtomakeawiderangeofIoTservicestalktoandunderstandeachother,acrossmultipleplatformsanddomains.Thisimpliestohaveauniversalwaytoboth(i)describeandshare/publishaservice,and(ii)discoverrelevantservicesdependingonthestakeholder’sneeds,context,role, location,activityorsituation.Overall,oneof the long-termgoals is tobeable toconnectcloudendpoints servingdata,whilereducingasmuchaspossibletheneedtodevelopcustomconnectorsand,fromanend-userperspective,toavoidmanuallyconnectingoneservicetoanother.Tothisend,aservicecatalog(i.e.,registry/repository)willbedevelopedinbIoTope,referredtoasIoTBnBstandingfor“IoTservicepuBlicationaNdBilling”,basedonwhichastrikingservicemarketwillbesetupsoastoenableanyoneto:
• RegisterandpublishservicestodifferentIoTstakeholders:PublishIoTservices,fromthepublicationof basic smart connected-related data such as sensor data, to more advanced services such as“discoverServices(<required parameters>)“,whileenablingpublisherstopotentiallymakemoneyoutofit(relatedto“Task3.C:Safemicro-billingforIoT”inWP3);
• Discover IoT services according to (i) the end-user needs, e.g. a developerwhowants todiscoversmartfridgesofaspecificbrandinthecity,or(ii)theend-usersituation,e.g.aBMWcarentersacityandwantstonotifythecitythatitprovidesspecificserviceprovisionsand, inreturn,wouldliketodiscover (or being notified) about potential relevant services that are available in the car’ssurrounding,suchas:“discoverServices(<required parameters>)”.
3Servicesrefertooneormoreservicesmadeavailableregardlessoftheunderlyingplatform.4O-MI/O-DFstandardsarefurtherdetailedinD3.2(InformationSourcePublicationandConsumptionFrameworkv1).

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 27 30August2016
Toachieve this, thecore idea tostartbuilding thebIoTopeecosystem is to“wrap” (usingO-MI/O-DF) thedifferentbIoTopepartnerplatforms,ortheirrespective(REST-)APIstobemoreprecise.ThisisillustratedinFigure7,whichprovidesanoverviewof thedifferentpartnerplatforms,whichallhavebeendesigned foroneormorespecificpurposes; letuscitee.g.BMWConnectedDriveplatformdesigned forsmartmobilitypurposes, Opendatasoft platform designed for open data management, Enervent platform designed forindoor air quality management, and so forth. Each of these platforms has different provisions for datastorage, access, and possibly processing, which are tightly coupled to the market they are respectivelyaddressing(respondingtospecificconsumer-ledneeds).Toputitsimply,notallplatformsarefacingbigdataissues depending on the type of services they provide, and obviously depending on how we define andunderstand“bigdata”!Nonetheless,theyallprovidestoragecapabilities(cloudoredge-based),whichareallrelevantfromanecosystemviewpoint(cf.thefirstfundamentalprinciplepreviouslyintroduced).
Figure7:bIoTopepartnerplatformstobeintegrated–asafirststage–tothebIoTope’secosystem
Inthefollowingsection,weprovideamorein-depthoverviewofthestorage,andpotentiallytheprocessinglayer(ifany),ofeachoftheseplatforms.Suchanoverviewwillalsohighlighthoweachplatformcontributestotheoverallecosystemfunctionalityandsustainability,andpotentiallytoeachbIoTopecityusecase.
3.2. Cloud&Edge-datastorage/analyticscapabilitiesInthissection,wedescribetheprovisionsfordatastorage,access,andprocessingofthedifferentplatformsthatwillbe (initially) integrated to thebIoTopeecosystem. Indeed,aspreviously stated, there shouldnothaveasingleorganizationorcompany incontrolof the IoT,everyonehavingthepossibilitytoexposeanytype of servicewithout any forced intermediary. An IoT ecosystem consists of a number of independent

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 28 30August2016
stakeholderssharingacommoninterestinparticularkindsofinformationandobtainingoverallbenefitfromparticipation.StakeholdersinanIoTecosystemmaytakeoneormoreroles.Theseincludeinformationandplatformproviders,applicationdevelopers,analyticsserviceproviders,aswellasusersof informationandapplications;informationprovidersandusersbeingeitherindividualororganisational.Withinthiscontext,itisimportanttodescribewhataretheplatformsandassociatedserviceseachbIoTopepartnerisfeedingthebIoTope ecosystemwith. Table 4 provides a first “at a glance” overview of each platform characteristics(e.g., designed for edge- and/or cloud-based analytics, type of License, etc.). A greater insight into eachplatformisgiveninthefollowingsections.
3.2.1. eccenca Linked Data Suite
eccencaGmbHoffersmarket-leading solutions for search infrastructures and LinkedDataapplications. Toachieve this goal, eccenca is providing the eccenca Linked Data Suite (eLDS),which is an enterprise datamanagement, integration and provisioning software for semantic web and linked data applications. Itprovides common features for the storage, processing, integration, and provisioning of RDF data. eLDSconsistsofthreecomponents,namely:
• eccencaDataPlatform:astorageabstractionandvirtualizationplatformservingasbackendtoeLDS.Itsmainfunctionistoserveasanauthenticationandauthorizationmediatorbetweenthesoftwarecomponents. DataPlatform also provides a state of the art RDF versioning system and graphmanagementabstractionfortriple/quadstores;
• eccenca DataManager: a knowledge graph creation, management and browsing frontendapplicationbasedonJavaScript,featuringanumberofdataviews,inlineeditingandqueryinterface.It serves as visual interface for users to add, remove, browse, edit and query RDF data andontologies.ItcommunicateswiththeDataPlatformthatmanagesthedatainthetriple/quadstore,soDataManageritselfstoresnodata;
• eccencaDataIntegration: a data linking,mapping and transformation application.,which supportsthe creation of linkage rules and ETLworkflows using an integrated visual editor. DataIntegrationprojectsandotherdataarepersistedinthetriple/quadstore,mediatedbyDataPlatform.
3.2.2. OpendatasoftSaaSOpenDataSoftisaFrench-basedprovideroftoolstopublishopendataontheweb.OpenDataSoftcustomerslike the City of Paris use the OpenDataSoft Software-as-a-Service (SaaS) platform to share data withpartners,developersandthegeneralpublic.OpenDataSoftprovidesastandarddataportal,aswellasAPIsthatenabledeveloperstointegratethedataintotheirapplications.Asinglecustomercanhavehundredsofmillionsofrecords,sosearchisakeyfunctionalityofthesolution,enablingtheend-userstofindtheright
Table4:bIoTopepartner-relatedplatforms&storage/processingcapabilities
Partner Platformname Storage/processingtype LicensetypeCities(Lyon,Helsinki,Brussels)
Opendataportals,existingcityplatforms(publicorproprietary)
Cloud-based -
Aalto DIALOG Cloud- & Edge-based LGPLCityzendata Warp10 Cloud- & Edge-based Apache 2.0UL KMF (Kevoree Modeling Framework) Edge-based GPL (AL2)Opendatasoft Opendatasoft SaaS Cloud-based CommercialHolonix Virtual Obeya - iLike Cloud-based CommercialCT Mist Cloud- & Edge-based Commercialeccenca Eccenca Linked Data Suite Cloud-based Commercial CSIRO OpenIoT Cloud-based LGPL 3.0 BMW BMW ConnectedDrive Cloud- & Edge-based Commercial BIBA Semantic Mediator (SEMed) Cloud- & Edge-based GPL v3

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 29 30August2016
data. Opendatasoft has now an extensive experience using Elasticsearch for achieving such search anddiscoveryfunctionalities.ThecompanyswitchedtoElasticsearchasthesearchengineforboththestandarddataportal–asimpletoolenablinganyonetoexplorethedataprovidedbyOpenDataSoft'scustomers–andtheAPIsfordevelopers.Theend-userscansearchforthedatasetbythemetadata.Oncetheyfindtherightdataset, they go to a dataset-landing pagewhere they can search by the fields. Or they can navigate byElasticsearchfacets.OpenDataSoftSaaSprovidesgeo-searchinadditiontobasicsearchfeatures.Ifadatasetcontainsgeographicalinformation,theendusercandisplaytheresultsofthequeryonamap.Ontopofthebasic geo-search, a geo-clustering algorithm is implemented to make it possible for anyone to displaymillionsofpointsonasinglemap.
Fordevelopers,threeAPIsareprovided,allbuiltontopofElasticsearch.First,theCatalogsearchAPIallowsdevelopersforsearchingadatasetcatalog.Second,theGeoAPIisusedtobuildclusteredresultsthatcanbedisplayed on a map. Third, the Analytics API is used to retrieve time series data. The way Elasticsearchprovides near real-time indexing is a very important aspect for both developers and end-users.With itslightweight indexing approach, Elasticsearch is a good technology for data preparationwhile still keepingnear-real-time latency. Furthermore, there is a range of business logic available as Elasticsearch plug-ins(e.g., as geo-clusteringAPIoranalytics tool supports). Forexample, Elasticsearchmakes itpossible to rungeo-clustering queries on 3 million points of interest in less than one second (based on Opendatasoft’sexperience). In conclusion, Opendatasoft is a key partner with a valuable expertise in designing andimplementingElasticsearch-basedsystems,onwhichwewill likely relyupontodesignkeycomponentsofthebIoTopeecosystemsuchastheservicecatalog(discussedinfurtherdetailinsection3.3).
3.2.3. Semantic Mediator (SEMed)
TheSemanticMediator(SEMed)canbeconnectedtoseveralheterogeneousdatasourcesviawrappersandhas the capabilities to calculate a logical view, giving insight into all the connected data sources. For thispurpose,itdoesnotneedafederatedschemaorsingledatamodeltooperate,asnewdatasourcescanbeintegratedorremovedquicklyandflexibly.AtypicalinformationflowstartsfromthewrapperviatheSEMedto a front-end component, which could be an integration service or a forwarding service. To start theinformationflow,aninformationrequestisrequired.ThisrequestisrepresentedasanSPARQLqueryandistriggeredbyonefront-endmodule.Themediatorfollowsavirtualdataintegrationapproach,meaningthatdataisnotstoredorholdforlateraccess,onlytemporaryintheRAM.TheSEMedgathersdatafromoneorseveraldistinctdatasourcesandaggregatesthisdatatoaholisticlogicalview.Thedataisrepresentedasanontology,morepreciselytheunderlyingT-box(likeaschemeinaDB)andthedataasA-box(liketuplesinaDB). This output could be used to forward the ontology directly for storing or transformation (post-processingbytheSEMed)intoadataschemaofthetargetsystem,e.g.SQL,databasesorO-MInodes.ThemainobjectivesoftheSEMedservicesandunderlyingfunctionalitiesare:
• Enableapplicationsindynamicenvironmentsthroughusingnofixeddeployedontology;
• Enableastrictseparationbetweendataandinformationviewthroughaddingasemanticdescriptionofthedatabeyondadatasource;
• Enabletheaggregationofinformationovertheboundariesofdatasources
• Enableasimplifiedanddynamicmethodsforaddingdatasources;• SupportasubsetofSPARQLastheleadingontologyquerylanguage
3.2.4. VirtualObeya-iLikeThei-LiKe(intelligentLifecycledataandKnowledge)platformprovidedbyHolonixisacommercialproduct-centric,modularplatformforitem-levelProductLifecycleManagement.Itenablesthecollection,integrationand interlinking of data across different stages of the product lifecycle, supporting product virtualization,continuous improvement, product reengineering and design improvements, product traceability,maintenance activities and design of services aswell as end of life process decisions as remanufacturing,

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 30 30August2016
recycling or disposal. It is composed by cross-sectorial suites and verticalmodules. It runswithin ApacheTomcat,allowsforlaunchingwebapplicationsdevelopedinJava,whosemainmodulesarethefollowing:
• BusinessLogic:includestheintelligenceandlogicbehindtheplatform;
• Application Framework: used to interconnect together manymodules providing security aspects,relationsandlogicswithdatastored;
• UIFramework:allowstodevelopuserinterfaceinaweb-basedformat;
• RestAPI:allowstoexchangeinformationwiththirdapplications;
I-Like uses MySQL as database management system to store data. The Virtual Obeya is a dynamicenvironmentthatallowsimprovingcollaborationandinformationsharingbetweentwoormoreactorsinaphysicalcontext(ameetingroom)and/orinavirtualway(betweentwoorseveralmeetingroomsorsinglecomputers). The Virtual Obeya allows the creation of virtual roomswith dedicated topics. Each of theseroomscanhavespecificparticipantseachwithdifferentaccessrights.Withineachroom,manyapplicationscanbeembeddedtoprovideawidesetofservices. Inaddition,web-basedtoolsprovidedbythirdpartiescanbeembedded into rooms setupusing theVirtualObeya. TheVirtualObeya supports concurrent andasynchronous work in the same virtual rooms, and collaboration with teammembers both in the samephysical place and at a distance. Users can customize how tools and applications are visualized in theirindividual rooms (removingobjects, addingnew tools andapplications, changing thepositionof availabletoolsbysimpledraganddropactions,andinvitingnewparticipantstojointheroom.
3.2.5. OpenIoT
TheOpenIoTarchitectureiscomprisedbysevenmainelementsthatbelongtothreedifferentlogicalplanes,namely: (i) Utility/Application Plane; (ii) Virtualized Plane; and (iii) Physical Plane, each one includingdifferent modules among which storage modules. At the physical layer/plane, OpenIoT uses the SensorMiddleware(ExtendedGlobalSensorNetwork,X-GSN)tocollect,filter,combine,andsemanticallyannotatedatastreamsfromvirtualsensorsorphysicaldevices(actingasahubbetweentheOpenIoTplatformandthephysical world). Then, data streams stemming from the sensor middleware (the hub) are stored at the“Virtualized” layer using the Linked Stream Middleware Light (LSM-Light), thereby acting as a clouddatabase. The cloud infrastructure stores also the metadata required for the operation of the OpenIoTplatform(functionaldata),provideprovisionsforRDFCloudstorage,annotationandprocessing.
3.2.6. BMW ConnectedDrive
ConnectedDriveisasuiteofin-carservicesthatmotoristscanusetogivethemupdatedtrafficinformation,internet-based searches, productivity functions, information to help improve the car’s efficiency,emergency-callservices,theabilitytocontrolsomeofthecar’sfunctionsremotely,usingconnectedmobiledevicesandawide rangeofApps thatcanoffer the likesof streamingmusicandsocialmedia.The in-carnetworkoftheBMWcarisconnectedviatheBMWbackendwithsuchacloudsystem,allowingthevehicletoexchangedatawithconnecteddevices.ThismodelfitsperfectlywiththevisiondepictedanddiscussedinFigure6.
3.2.7. City-relatedplatforms
Mostofthecities,atleasttheonesinvolvedinthebIoTope’sproject(GrandLyon,Helsinki,BrusselsRegion),have implementedovertheyearsvarioustypesof ICTplatforms inthecity, forvariouspurposes includingthe management of transportation-related data, city public parking-related data, environmental-relateddata,smartbuilding-relateddata,governmentaldata,andsoforth.Allthismakessmartcitiesverycomplexecosystems, consisting of awide range of stakeholders and service providers (network operators, energyproviders,logisticsandtransportationcenters,etc.)whomustworktogethertooptimizevariousaspectsofthecityaswellasthecitizens’ life.Section5willprovidean“ataglance”overviewofthesetofplatformsand systems that are currently in place/running inBrussels and LyonRegion to collect, store andprocess

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 31 30August2016
varioustypesofcityinformation,fromthedescriptionofstaticinformationsuchas“schoolzones”,“greenspaces”,parkinglocation,crossroadswithredlights,etc.,tothecollectionofreal-time/streamdatasuchastheflowsofcars,cyclists,pedestrian,ofthereal-timetraveltimeofpublictransportationvehicles
3.2.8. Storage-independentplatforms:DIALOG&Mist
Somepartner’splatformsarenottypical“monolithic”IoTplatformsinthesensethattheyratherdefineandprovideamessagingarchitecturewherethe“application-level”functionalityisprovidedby“softwareagentsor components”. DIALOG (developed by Aalto) [65] and Mist (developed by CT) are examples of suchstorage-independent platforms, where different instances (nodes) can have completely differentfunctionalitiesdependingonwhat“agents”havebeenloadedandaresupported.Moreconcretely,DIALOGandMistdonotstrictlyspecifyhigher-levelAPIslikebufferingandqueryingoflogs.
Mist can instead provide an assortment of such higher-level APIs alongwith generic implementations fordifferent purposes. In other words, Mist provides several convenient abstraction layers below theapplicationlayer,abovethesecuredtrustnetworkcommunication.Mistcanbeperceivedasaconnectivityandsecurityframework,forbeingembeddedintootherIoTplatforms,althoughitcanrunindependentlyasanownplatform.Overall, if the end-userwants to log data, he/shemay choose tomap thedata-relatedendpointtotheinputendpointofagenericofftheshelfloggernode(i.e.,usingaspecificstoragesolution),oralternativelyimplementtheloggingfeaturefromtheMistapplicationlayerdirectly(asinothersystems).TheAPIforaccessingtheloggeddataofthegenericloggernodecanbeexposedtotheMistnetwork,aswellas other O-MI/O-DF ecosystems. Complex event processing can be broken down in more simple taskorientedMistnodes,whichexposesinputsandoutputsasMistendpoints,towhichsignalsfromdevicescanbeconnected.Thesenodescanevenbeconfiguredasahierarchyofprogramlogicunits, inordertoavoidtoomuchmonolithiccomplexity.TheinternalfunctionalityofaMistnodeisnotpredefined,asthatbelongstotheApplicationlevel.TheMistprinciplesfollowstheO-MI/O-DFphilosophy(peer-to-peerinsteadofcloudonly),exceptthatMistcanbeseenasasub-ecosystemofthebIoTope’sone,whichcanachieveadvancededge-servicessuchas:
• Authentication
• Addressingwhichsupportsnetworkroaming
• End-to-endencryption(nothird-partytrustrequired);
• Endpointlevelaccesscontrol(indeviceACL)
• Privacyandsecurity(workswithoutsendingdatatocloud)
• Internetconnectionnotrequired(worksonlocalnetworks)
ThereadercanrefertodeliverableD3.1toobtainmoredetailsabout“Mist”,and[65]formoredetailsaboutDIALOGmiddleware.
3.2.9. BigData-focusedplatforms:Warp10&KMF
AsitcanbeobservedinTable4,twoofthelistedplatforms–Warp10(developedbyCityzenData)andKMF(developedbyUL)–havebeendesignedforBigDatamanagement,eachonehavingbeendesignedbasedondifferentrequirements.
TheWarp10platformaimstounifyandsimplifytraditionalinteractive,batchandstreamingapproachesbyproviding a data model and an associated set of tools that take care of the heavy lifting and let thedevelopers focusoncreatingbusinessvalue fromthedata rather thanon implementation issues.Warp10wasinitiallydesignedasaCloudplatform,butanedge-basedversionasbeenrecentlyreleased,enablingthestorageandmanagementofdata lakesattheedgenode(runningonRasperryPIsorsimilarboards).KMF(Kevoree Modelling Framework) is specifically designed to support the distributed Models@Runtimeparadigm[66],thereforetargetingruntimemodels.Runtimemodelsofcomplexsystemsusuallyhavehighrequirements regarding memory usage, runtime performance, and thread safety. KMF was specifically

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 32 30August2016
designed with these requirements in mind. Distributed computing on a graph and edge computingcapabilitiesmakeKMFa very suitable candidate for BigData scenarioswhere environment attributes arelinkedwitheachother,eitherphysically(e.g.,apowertransmissionanddistributionnetwork insmartgridusecases)orvirtually(e.g.,datafromdistinctsensors).
A more detailed view of the main concepts and components underpinning both Warp10 and KMF isprovided inSection4.Obviously,othertypesofdatabasesforedgenodesexistandcanbeconsideredforsomeusecases,suchasthe“RoundRobinDatabase”(RRD)technologyforself-awareedgenodes[67].Thistechnologyisabletostoretimeseriesofsensordatawithaconstant,fairlysmall,diskfootprint,achievedbyreducingtheprecisionovertime.Toputitsimply,theclosesthistoryhashighgranularity,whileolderdatahaslessgranularity.
DuetothenumberofplatformsincludedinthebIoTopeconsortium,Table5givesan“at-a-glance”overviewof themain,or initialobjective(s),pursuedbyeachplatform(i.e.,why theyhavebeen“initially”designedfor,althoughmostofthemevolvedoveryears).
Table5:InitialobjectivesandspecificfocusesofeachPlatform
Linked
Data(SPA
RQL,RDF
)
Ope
nDa
taPortals
Large-scaleETL
Messaging(A
gent)a
rchitecture
Prod
uctLife
cycleMan
agem
ent
SmartM
obility-spe
cific
Smarth
ome-specific
IoTplatform
-agnostic
P2PSecurity
City-relatedinfrastructures ✔ ✔ ✔ DIALOG ✔ ✔ ✔
Warp10 ✔ KMF ✔ OpendatasoftSaaS ✔ VirtualObeya(iLikeSuite) ✔ Mist ✔ ✔ ✔
EccencaLinkedDataSuite ✔ OpenIoT ✔ ✔
BMWConnectedDrive ✔ SemanticMediator(SEMed) ✔ ✔ Enervent ✔
3.3. Storagerequirementsforrequiredecosystembuildingblocks
Inthissection,weintroducefundamentalservicesandrelatedinfrastructuresthatareneededfortheproperfunctioningofthebIoTopeecosystem,namelyforserviceregistry/repositorypurposes(tolaythefoundationofamarketplace),aswellasforcontext-awareprovisioningandmanagementoffered“as-a-service”.Thesetwopointsarediscussedinsections3.3.1and3.1.2respectively.

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 33 30August2016
3.3.1. Serviceregistry/repositorymanagement
Letusrememberthatthemainobjectiveoftheservicecatalogue(IoTBnB)willbetoenablepersonand/orsystemto:
• PublishIoTservicestodifferent IoTstakeholders–offeringdifferentserviceviewsaccordingtothestakeholder–whileenablingthepublishertopotentiallymakemoneyoutofit;
• DiscoverIoTservicesaccordingtoseveralcriteria(e.g.,end-userneeds,end-usersituation,typesofdigitalcurrenciesacceptedbypublishers,andsoforth).
These objectives can be fulfilled only if the service catalogue is able to store all the IoT services, andeventuallypublishers’profile-related information,whileenablingend-users toefficientlyandeasily searchforoneormoreservicesaccordingtotheir“context”,roles,needs,preferences,etc.Havingsaidthat,itdoesraise broader questions about the usage of the amount of “service-related information” that need to beingested/stored/searched. It is important tounderstand that IoTBnBdoesnotactasaClouddata storagecentre where the data related to smart connected objects is stored, but rather as a platform ormarketwherethe“description”ofwhatdata/servicesoneormoresmartconnectedobjectscanprovide(whetherforrewardorfreeofcharge).Then,onlyoncetheconsumerwantsandisallowedtoaccessit,IoTBnBplaysthe role of intermediary, putting the publisher and consumer in relation with each other so that the
Figure8:PinciplesunderlyingIoTBnB&Designchoicesforstoring/searchingforO-MI-relatedservices
Wallet description (access information…)$
Smart City
●!
●✇ ●●
●!
●✇ ●● ●!
"●●
ABot
tle
Bank
●● ●●
###
Shopping Center
$$$
%&&%
✈
'❍
●!"!!!
!School
%&&
%●School Bus
●●
Manufacturer
●✇ ●●
●✇ ●●
●✇ ●●
✙
✚●● ●●
H
●●●
ALandfill site
Phys
ical
Cou
nter
part
Virtu
al C
ount
erpa
rt
Charging Station-related Data
…power outlet type
Charging Station-related Wallet(s)
Charging Station-related Goods
0291733kWh
Station location
Energy supplied to the EV …
BMW car-related DataCar’s Co2
Charging Station-related Wallet(s)
BMW car-related Goods
Car’s location
Wallet technology supported by the
BMW car or driver
CO2
Car’s temperature …
Car renting options
BMW car setting/profile
Charging Station setting/profile
Charging Station-related Data
…power outlet type Station
location
BMW car-related DataCar’s Co2 Car’s
locationCO2
Car’s temperature … …
Wallet description (access information…)$
Wallet description (access information…)$
Wallet technology supported by the
BMW car or driver
Wallet description (access information…)$
Web service directory/repository
O-MI node
O-MI node
Web
App
REST API
Read/Search
Write
Web
App
HTTP RequestHTTP Response
Thing/Service Decription (O-MI/O-DF)Domain Independent Semantic Models (e.g., schema.org, SSN…)
Domain Dependent Semantic Models (e.g., DATEX, eCl@ss, Mobivoc, Smart City…)
11
Car publishes its services (using O-DF) when entering the city
Charging station service provider publishes its services using O-DF

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 34 30August2016
exchangeofdata/servicescanbeachievedinapeer-to-peermanner(withouttransitingthroughIoTBnB).
Letusconsider,forexample,aBMWcarthat–whenenteringacity–wantstoexpose/publishitspresenceand the set of information/services (if any) that it can offers (e.g., car’s Co2, car’s temperature, car’s
location,poweroutlet type,etc.),and inreturntobeawareofservicesavailable in thecity (e.g.,onecitymay have a service to find the best charging station or parking spot). To this end, it is assumed that thedifferentscenariostakeholders(e.g.,theBMWcarandthedifferentchargingstationprovidersand/orcities)have installed/set up their own O-MI node to expose, and most importantly described the set ofinformation/services they can make available in the city, or more generally in the bIoTope ecosystem(whether for rewardor freeof charge). This is illustrated in Figure8,whereboth the car (owner) andonechargingstationproviderhavepublishedadescriptionoftheirrespectiveserviceportfolioandregisteredtopotentiallyto IoTBnBtomakethemmorevisibleortoobtainsupporttosell/buyservices(seethe“virtualcounterpart”view). Itmustbenoted,even ifnot thoroughlydiscussed in thedeliverable, that theservicedescription should rely on both domain independent semanticmodels (e.g., SSN) and domain dependentsemanticmodels(e.g.,schema.org),asemphasizedinFigure8,soastoimproveservicediscoveryinIoTBnB.In this respect, each Thing (end-user/object) can either submit digitally signed service descriptions to thecatalogueweb application, or they authenticate to theweb application (with login-password, or popularsocialproviderssuchasFacebook,Google,Twitter…)andprovidestheirownO-MInode’ssetofURIs(http,websocket,Mist,etc.).TheIoTBnBwebapplicationthereforeprovidestheend-userswiththepossibilitytodecidewhatpartoftheirservicetree(i.e.,theO-DFtree)theywanttoexpose,towhom,whataccessrightstheywanttodefinedforanindividualoragroupofend-users,andshouldprovidemeanstobecompliantwith semanticmodels, asmentioned above. IoTBnB can request thewholeO-DF service tree and relateddescriptionsusingtheRESTful“discovery”mechanismsupportedbytheO-MI/O-DFstandards.OneexampleofabasicservicetreerelatedtotheBMWcarisdepictedinFigure9(orsee[8]foramoredetailedview),regardlessofthesemanticmodelaspect.Thechargingstationproviderisassumedtopublishasimilartree,includingservicessuchasthe“poweroutlettype”,“stationlocation”,“price”,etc.Giventheseservicetreeexamples, the challenge is to properly store all theseO-DF trees considering that thousand of thousandspublisherscanpotentiallyjointheecosystemandpublishtheirownservicetree.Asaresult, it isthereforeimportanttoanswerthefollowingquestion:
"How the different O-DF service trees must be stored so as to enable fast and efficient search ofservicesacrosstheallservicecatalogue?"
Thechoiceofanarchitecturetostore,explore/searchforandqueryhugenumberofO-DFservicetrees,inthe fastest possible way, depends on what functionalities are intended to be supported by the IoTBnBserviceregistry/repository,whatthroughputofdata isexpected,andsoforth.Atthisstageoftheproject,
Figure9:BMWcar-relatedO-DFservice/datatree

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 35 30August2016
wedonot have a clear viewon this usageor on the exact volumeof service data thatwill bemanaged,althoughafirstinvestigationandstudywascarriedoutin[68]toidentifythekeyfunctionalitiesthatneedtobe covered by IoTBnB, and its boundaries. Based on such an analysis, it seemed that Elasticsearch couldcater for this requirement, since it provides a (full-text) search engine that is designed to be distributed,scalable, highly available and near real-time capable. However, there is disagreement about whetherElasticsearchisornotadatabase,whichhasresultedinvariousElasticsearch-basedframeworkssuchas:
1. Elasticsearchasprimary/maindatabaseandsearchengine;
2. ElasticsearchassearchengineandaNoSqldatabaselikeMongoDB;
3. ElasticsearchassearchengineandaRDBMSlikeMySQL;
4. ElasticsearchassearchengineandaHDFS
Framework3wasconsidered,duringalongtime,thebestframeworkforstoringandsearchingdata.Withthe embracing of schema-less database systems, the second frameworkwas then strongly backed by bigdatapractitionersandscholars.However,newextensionsanddevelopmentsofElasticsearch,especiallythetwo last years regarding document-based storage capabilities, have made Elasticsearch a very relevantsolutionasastand-alonestorageproduct.Recently,framework4hasemerged,enablingtoconnectspeedysearchengineswithbigdataanalytics.Giventhis,weconsiderthatElasticsearchusedasprimarydatabaseandsearchengineistodayaviabletechnologyforsupportingourservicecatalogue(repository/registry).Allthemore so as bIoTope can benefit from the OpenDataSoft expertise who, as previously described (seeSection 3.2.2), have an extensive know-how inmanaging, cataloguing and valorizing heterogeneous databasedonanElasticsearchsmartindexing.
IoTBnB will therefore likely store the different O-DF service tree using Elasticsearch as a stand-alonesolution,asemphasized inFigure8,thusenablingthesearchofservicesthankstoaRESTAPIprovidedbytheIoTBnBserver.ItisworthnothingthatthewaytheO-DFdatawillbestoredintheElasticsearchdatabasewilldependhowservice-relateddescriptionwillbedisplayedandfilteredfromanend-userviewpoint(e.g.location-basedmap,servicetype,domain-specific,metadata-based,andsoforth).
3.3.2. Context-aware-as-a-ServiceInbIoTope,aworkpackage isdedicatedtothe investigationandprovisionofContext-as-a-Service(CoaaS)brokers,orContextBrokerfollowingtheGartner’sdefinition5,meaningsoftwarecomponentsthatareabletodiscover,predict,validateandsupplyrelevant‘Context(s)’toapplicationsand/orentitiesrequestingit.Itis important tounderstand that thiswill beone serviceamong the setof servicesavailable in theoverallecosystem(i.e.,searchableandavailableinIoTBnB).Suchcomponentsshouldoffercost-efficientadaptationand optimisation services at run-time through adaptation services, metric computation, environmentmonitoring and adaptive learning. In this respect, this section identifies and discusses requirements of acontextstoragemiddleware.
These requirements can have sufficient differences with context representation that is optimal inubiquitous/mobilecomputingscenariosbecauseofthesignificantdifferenceincomputingpower,valueandveracity of data streams and durability expectations. Endpoint applications need to acquire context fromvarious sources. The only way for these applications to get context(s) about the outside world is tocommunicatewithsomemiddleware,ascommunicationwithenormousnumbersofsensorsisnotfeasibledue tomany restrictions, suchasnetworkbandwidth, energyefficiency, access control and complexityoftask.Themiddleware receives requests forcontext fromclientsand tries to fulfil these requests.For this,themiddleware platform should either store all the information inside or query some other systems forretrieving the needed data. The first approach is disk space consuming, but may however improve theperformance(e.g.,modernsearchenginesuseindexedinformationforprovidingsearchresults).Thesecondapproachistime-consuming,asqueryingothersystemsandespeciallymobilesensorsanddevicescanbea
5https://www.gartner.com/doc/2967518/context-brokers-smarter-business-decisions

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 36 30August2016
time-consuming process due to networks delays and slow response timeor inaccessibility ofmobile datasources.TheIoTmiddlewaremaycombinebothapproachesthatwillresultinabetterbalanceofdiskspaceconsumption, performance and data relevance. Given this observation, the following requirements havebeenidentifiedasimportanttodevelopanefficientcontextstoragemiddleware:
• Disk based: although in-memory systems are gettingmore attention nowadays, the amount andvarietyofdatamakeprocessingnotpossiblewithoutkeepingdatapersistentlyondisk;
• Scalability:itishardtopredicttheamountofstoredinformation,butincaseofaSmartCityitwouldnot be possible to provide the storage service by one server node. This means that proposedsolutionmustbehorizontallyscalable;
• HighAvailability:thestorageshouldnothaveasinglepointoffailure(SPoF);
• Structural freedom:storagemustbeabletostorestructureddatawithoutapplyingrestrictionsonitsstructure.
• Interconnected entities: in some cases storage must facilitate the means for storing highlyinterconnected data (e.g. relations of people, organisations, transport, infrastructure etc.) andeffectivelyrunningqueriesoversuchdata;
• Veracity: different sources can supply information that can be conflicting or uncertain and thereshouldbeawaytostoreallvariantsofincomingdatawithannotationsabouttheidentityandtrustlevel of the originator and rank of the suggestion. Context of the querying sidemust be treatedrespectivelyduringrespondingtothequery;
• Largeamountsofsensorydata:sensorsandotherInternetenableddevicesgeneratelargenumberoftimeserieseventsofsimilarbutnotthesamestructure.
• Ontology support:anumberof researchprojectsmodeldatausingontologicalprinciplesas it isagoodway formodelling thedomain interconnectionsand facilitating reasoningoverdata (seee.g.[9]).However,thisapproachdoesnotseemtobesuitableforstoringlargeamountsofrawdataandlow-levelcontext;
• Fast information retrieval & rich indexing capabilities: performance is the key requirement forcontextdeliveryinsmartcitiesapplications.Thishighlightstheneedforefficientindexingofstoredcontext;
• Fastwrites:streamsofsensorreadingsmustbewrittenondiskwithoutlongqueuesandexpensiverebuildingofindexes;
• Geospatialdata:manyofSmartCityapplicationsarehighlydependableofgeospatialcontext,sothemiddlewarestoragemustbeabletoprovideeffectiveindexingpossibilitiesforthistypeofcontext;
• Various approaches to CAP theorem. Traditionally, one of the main principles of databasemanagement systems is ACID (Atomicity, Consistency, Isolation and Durability). According to thistheorem,we cannothave consistency, availability andpartitioning tolerance inone systemat thesame time. Indeed, the context coming from different sources can already be uncertain andconflicting, which means the middleware solution in some cases can afford lack of transactionalsupport and consistency in favour of high availability and partitioning, as the requirements forhorizontalscalabilityandavailabilityhavehigherpriority.
Afteranalysingtheaboverequirementsforthemiddlewarestoragesystemitbecomesclearthatfulfillingalltherequirementswithoneexistingsolutionisnotfeasible.Thevarietyofdataprocessingapproachesleadsustotheideaofhybridstoragearchitecture.Oneoftherecenttrendsinsoftwaredevelopmentispolyglotpersistence[69],wheresystemsnolongertrytoaccomplishalltasksusingonedatastorage,butratherusedifferent technologies to store datawhere each technology provides certain capabilities. Existing contextrepresentationandstoragetechnologieshavebeenintroducedanddiscussedinTable1,exceptmaybe(i)“Ontology-based modelling” that provides a way of organizing context into ontologies using semantic

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 37 30August2016
technologieslikeRDForOWL,and(ii)Object-basedmodellingthatfocusesoncontext-awarenesscommonobject-orientedprogramminglanguagestechniqueofmodellingcontextasobjects(seee.g.[70,71]).
Based on the above discussion, we carry out in Table 6 a quantitate analysis based on the list ofrequirements previously introduced. We use the following designations: Disk based (D); Relations (R);Veracity (C); Geospatial data indexing (GSI); Storage of Sensory Data (SD); Schemaless/Structural datafreedom (SL); Horizontal Scalability (HS); Fast Writes (FW); Strong/native support (++); Supported (+);Limitedsupport (+/-);Notsupported(-).Accordingtothisanalysis,document-orientedapproachseemstobethemostappropriateforcontextrepresentationandstoragepurposes.
Table6:Summaryofcontextrepresentationapproaches
D R V GSI SD SL HS FWRelational + + - + +/- - - +/-Ontology + + + - - + - -Key-Value + - + - +/- ++ ++ ++Document + +/- + + ++ ++ ++ +Wide-Column + - + + + + ++ +Graph + ++ + + - ++ +/- -Object - + - - - ++ - +
One theoretical foundation of the context representation and reasoning about situation awareness inbIoTopewillbethe[71],whichusesgeometricmetaphorsforrepresentingcontextattributesandbuildingmultidimensional spaces. Special context situations algebra is used for situationdetection andprediction.CST proposes steps to a generic framework for context-aware applications and provides a model andconcepts for context description and operations over context. This theory is implemented in twoframeworks ECORA [71] and ECSTRA [70] and has been extended in Fuzzy Situation Inference (FSI) forsituation modelling and reasoning under uncertainty and other advanced reasoning capabilities. Theseframeworksuse theaforementionedobject-basedmodellingapproachanddonot focuson issuessuchasscalability or persistence. Developingmethods formapping context spaces theory approaches to scalableandefficienthybridstoragecanhelptoimplementthesemethodsinlarge-scaleSmartCityscenarios.
Accordingto[72],document-orientedstorageisthemostsuitabletechnologyforstoringrawcontextasthe“nature” of raw context is based on XML or JSON formats. Moreover, JSON documents are the moststraightforwardwayforserializingin-memoryobjects,whichmakesdocument-orientedapproachthemostsuitable for facilitating scalable datastore for CST reasoning algorithms. Initially, MongoDB as beenconsidered as a primary raw context storage because of its horizontal scalability and native compatibilitywith JSON-LD. However, some issues with indexing nested objects has been identified, which cansignificantlyspoiltheperformance[73].Asmentionedbefore,thereisnoinformationatthesystemdesigntimeastowhatdocumentstructuresexactlywillbestoredcausingalackofindexesonunexpectedfields.Toencompassthisproblem,weproposetouseanexternalsearchenginebasedonfulltextsearchtechnologyand,inthisrespect,Elasticsearchseemsoncemorethemostappropriatetechnologyonthatday.

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 38 30August2016
4. bIoTopeplatformsdesignedforBigDatamanagement
Thechapterprovidesadetailedviewofthemaingoals,concepts,andcomponentsunderlyingWarp10andKMFplatforms–developedbytwobIoTopepartners(CityzendataandUL)–andhowtheseplatformscanbeintegratedtothebIoTopeecosystem,soastopotentiallybenefitoneormorecitypilotsandfutureend-usersofthatecosystem.
Inthischapter,werespectivelypresenttheWarp10andKMFplatformsthatcanbenefitoneormoreofthebIoTopecitypilots.Themaingoals,concepts,andcomponentsthatunderpinbothplatformsaredescribedinSections4.1and4.2respectively.Section4.3providesfirstproofs-of-conceptonhowsuchplatformscanbeintegratedtothebIoTopeecosystem,whosepresentedapproachcanobviouslybefollowedtointegrateanyotherBigData-likeplatform(i.e., theecosystem isNOTLIMITEDtoWarp10andKMFtodealwithBigData,butarejustinitialplatformsthatarepartofthatecosystemandcanbeused/solicited,whenneeded).
4.1. Warp10:Management&ManipulationofGeoTimeSeries
4.1.1. Platformscopeandgoal
TheWarp10platformisasuiteoftoolsdesignedspecificallyforworkingwithIoT(sensor)data.Thosedatadifferfromothermoretraditionalbigdatasetsatdifferentlevels.Firstofall,dataproducedbymachinesarefarmoremassive thandata related to human interactionwith IT systems. It is not uncommon in the IoTspacetohaveasingleequipmentthatproducesseveralhundredthousandsmeasurementspersecond,allthose measurements being useful to analyze and predict the behavior of the said equipment. An IoTplatform must therefore be in capacity of ingesting and storing such a data deluge/lake. Secondly, theanalysisthatmustbeperformedonthosedatasetsmustmanipulatedeephistoricaldatainaninteractivewaywith short response time even in the case of a large number of parallelmanipulations. Thirdly, thatanalysis go beyond simple summary statistics and often include complex computations, filtering and joinoperations,allwithspecificdatamanipulationpatternsrepeatedoverandover.Andlastly,moreelaborateanalysisneedtoapplymachine learningmodels inbatchoronstreams.Thetrainingof thosemodelsalsoinvolves feature extraction techniques relying on similarmanipulation patterns. The goal of theWarp 10platform is to unify and simplify all those approaches (interactive, batch, streaming) by providing a datamodel and an associated set of tools that take care of the heavy lifting and let the developers focus oncreatingbusinessvaluefromthedata.
4.1.2. Underlyingcomponents,modules&technologies
An overview of themain components,modules and technologies supported/usedbyWarp 10 is given inFigure 10.Warp10 offers a universal datamodel to represent sensor data, which is based on Geo TimeSeries,eachonebeingthefusionofasequenceofmeasurementsfromasensorwiththeoptionalposition(latitude, longitude, elevation) of the sensor at the time of each reading. Each Geo Time Serie ischaracterized by a class (representing the type of measurement) and two sets of key/value pairs, oneimmutable(calledlabels)andonemutable(calledattributes),whichcanbearthesemanticsofanyverticalinwhich the platform is being used. The readings themselves can be numeric (floating point or integer),boolean,orUTF-8textstrings,thussupportinganytypeofdataasvaluesforitsGeoTimeSeries.Ontopofthisdatamodel,Warp10providesasetoftoolstobothmanageandmanipulatethoseGeoTimeSeries.Thefirst tool provides is a storage layer that can be used to ingest and persist massive amounts ofmeasurementsfromaverylargenumberofGeoTimeSeries.Twoversionsofthistoolareavailable:

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 39 30August2016
• Astandaloneversion(Edgenode):designedtobedeployedonasinglemachine(Edge-node),fromanembeddedcomputersuchasaRaspberryPitolargermulti-CPU/multi-coreservers.SuchaversionisusableuptotensofmillionofGeoTimeSeriesandafewhundredbillionmeasurements.
• Adistributedversion (Cloud): for largerneeds,thedistributedversionreliesonHadoopHBase(cf.Figure10),whichcanbescaledoverbillionsofGeoTimeSeriesandtrillionsofmeasurements.
ThesecondtoolprovidedbyWarp10isafeaturerichdatamanipulationenvironmentbasedonalanguage(calledWarpScript) that is specificallydesigned forefficientlydealingwithGeoTimeSeries. This languagecontains over 700 functions andprovides 5 high level frameworks (BUCKETIZE,MAP,REDUCE,APPLY andFILTER),whichencompass themostoftenperformedGeoTimeSeries transformations. The languagealsocontains constructs such as loops, conditionals and asynchronous transfer of control, which makeWarpScriptTuringcompleteandsuitable forexpressinganykindofcomputation.The700 functionscoverfeaturesfromsimplesummarystatisticstomoreadvancedmanipulationssuchassignalprocessing(WaveletandFouriertransforms)orbinaryframedecoding.WarpScriptalsohasprovisionforcallingexternallibrariesor tools thusmaking it compatiblewithexisting,possiblyproprietary,analysisenvironment.The languageapproach offered byWarp 10 is meant to become the lingua franca of (Geo) Time Series manipulation.Beyondenabling themanipulationofdata storedwithinWarp10,WarpScript canalsobeput toworkondata residing in any storage layer forwhich a retrieval function canbewrittenand runon the JVM (JavaVirtualMachine). Successful integrationwith solutions such asRiak-TS, InfluxDB,OpenTSDB, ElasticSearchandMySQLhasbeenachieved.WarpScripthasalsobeen integrated indistributedcomputing frameworksfor both batch analysis (Spark, Pig, Flink) and for stream analysis (Flink, Storm), users of Warp 10 andWarpScript can therefore capitalizeon their trainingbyhaving a single set of tools they canuse in thosevarious scenarii. Overall, Warp 10 – distributed under an Open Source license (Apache 2.0) – makes itpossibletoeasilyandefficiently:
• IngesthugeamountofGeoTimeSeries;
• Manipulatethestoredseriesthroughastack-basedlanguagecalledWarpScript(includingmorethan700functionsand5high-levelframeworks);
• DefinesecurityandprivacypoliciesoveroneormoreGeoTimeSeries;
• Visualize(processed)GeoTimeSeriesscriptsthrougheasy-to-usescripts(usingWarpScript);
Figure10:Warp10underlyingsoftwarecomponents/modulesandtechnologies

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 40 30August2016
4.2. KMF:LiveModel-DrivenAnalyticsattheEdge–TimeSeries
4.2.1. Platformscope&goal
The primary goal of KMF (Kevoree Modelling Framework) [66] is to support the Models@Runtimeparadigm, therefore targeting runtime models that have high requirements regarding memory usage,runtimeperformance,andthreadsafety.KMFstartedasaresearchprojecttocreateanalternativetotheEclipseModellingFramework(EMF).LikeEMF,KMF isamodellingframeworkandcodegenerationfacilityforbuildingcomplexobject-orientedapplicationsbasedonstructureddatamodels.WhileEMFwasprimarilydesignedtosupportdesign-timemodels,KMFisspecificallydesignedtobeapplicableforthefollowingusecases[57]:
• Internet of Things: in IoT settings,models are used during the software execution to reflect theconfiguration of devices, their links to siblings or services. The intermittent presence of devicesrequires dynamic adaptations of the running system to install and remove pieces of software tocontrol each specific device present in the range of control. The models are very useful in thiscontexttodescribewhataretheservicesavailableoneachdevice,wherearethebinariestoconnectit,andsoon.Inaddition,modelstructuresareusefultoexpresscompositionofservicesoperations,inherentlynecessarytocomposedatacollectedasynchronously.Themainconcernhereisaboutthememory restrictions and time of adaptations. The kind of execution environment used in thisdomainisusuallyconstrainedintermsofmemoryandcomputationalpower;
• Cloud Computing: Cloud computing is characterized by a dynamic provisioning of services oncomputationresources.Alsocalledelasticity,thisintelligentprocessmustdynamicallyplaceseveralsoftware components to adapt the computation power to the real consumption of customers'software.However,constraintsoncostsimposedbycloudcustomersforcetheelasticitymechanismtomakeschoices,sometimescontradictoryones(e.g.,costandpowercannotbeoptimizedatsametime, because of their intrinsic dependency). This leads to multi-objective optimizations, whichconsider lotof information tocomputeaplacementof softwareoffering thebest tradeoff. In thiscontext,modelsareperfectcandidatestorepresentthestateofthecloud infrastructureandeasetheworkoftheseoptimizationalgorithms;
• SoftwareSystemSelf-Adaptation.Models@runtime isaparadigmaimingatmaking theevolutionprocess of applications more agile and dynamic, still leveraging the key benefits of modelling:simplicity, efficiency and safety. KMF leverages the Models@runtime paradigm to support thecontinuousdesignofcomplex,distributed,heterogeneousandadaptivesystems.
4.2.2. Underlyingcomponents,modulesandtechnologies
Fromanydomain-specificmeta-model,KMFcreatesaspecificmodellingenvironmentnativelysuppliedwithmodellingoperatorscompiled for JVMand JSand tuned foranefficientuseat runtime. It canbeused tosimplyhosttheconfigurationofsoftware,rationalizeandstoredataorhelpinthemanagementofcomplexdistributedsoftwaresystems.ItofferstheAPIinplainJava,andJavaScript,toeasethedevelopmentof,forinstance,aserver-sidestorageinJavaanditspresentationlayerinasimplebrowser.Tosummarize,andasillustratedthroughthehigh-levelarchitecturedepictedinFigure11,KMFgeneratesspecificAPIsandToolsfromaMetaModel,readyfordistributedmodellingactivities.KMFalsosuppliesruntime-orientedfeatures,suchas:
• Distributeddatastoreforbigdatamodels&amemoryoptimizedobjectorientedmodellingAPI;
• JS(Browser,NodeJS)andJVMcross-compiledmodels;
• Efficientvisitorsformodelstraversalandauniquepathforeachmodelelement;
• Anoptimizedquerylanguagetolookupmodelelements;
• Built-inload/saveoperationsinJSON/XMIformataswellasclonestrategies;

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 41 30August2016
• Persistencelayerforbigmodelswithlazyloadpolicy;
KMF uses multiple mechanisms to improve the performance of runtime operations, including optimizedpaths, polynomial approximation for storage compression, thread safety andmore. The performance ofKMFwas evaluated in several KMF-related publications, such as in [74] where the performance of basicoperationsread/writeoperationswereevaluatedandcomparedwithtraditional/classicdiscreteTimeSeries,consideringvarioustypesof informationsources(constant/lineardatasignals,temperatureandluminositysensordata signals, audio signals, etc.). Figure12andError! Reference source not found.provideanat aglanceoverviewon the results for readingandwriting thesedifferent typesof signals. It canbeobservedthat KMF allows speeding up reading operations 40x-60x and writing operations 5x. KMF also providesignificant performance improvement from a storage perspective (46% to 73% compared withtraditional/classic discrete TimeSeries, as presented in detail in [74]. To summarize, KMF provides a verypowerfulModels@Runtimeplatformtobothhandlelargeamountofdataatnearruntime,whilefacilitatingreasoningandcognitiveprocesses– integratingexpertknowledge thanks to themodeling framework –atnearruntime,too.
To summarize, KMFprovides a verypowerfulModels@Runtimeplatform tobothhandle largeamountofdata at near runtime,while facilitating reasoning and cognitive processes – integrating expert knowledge
thankstothemodelingframework–atnearruntime,too.
Figure11:KMFunderlyingsoftwarecomponents/modulesandtechnologies
Figure12:TimetoReadrandomly–classicDiscreteTimeSeriesvs.PolynomialKMFStorage
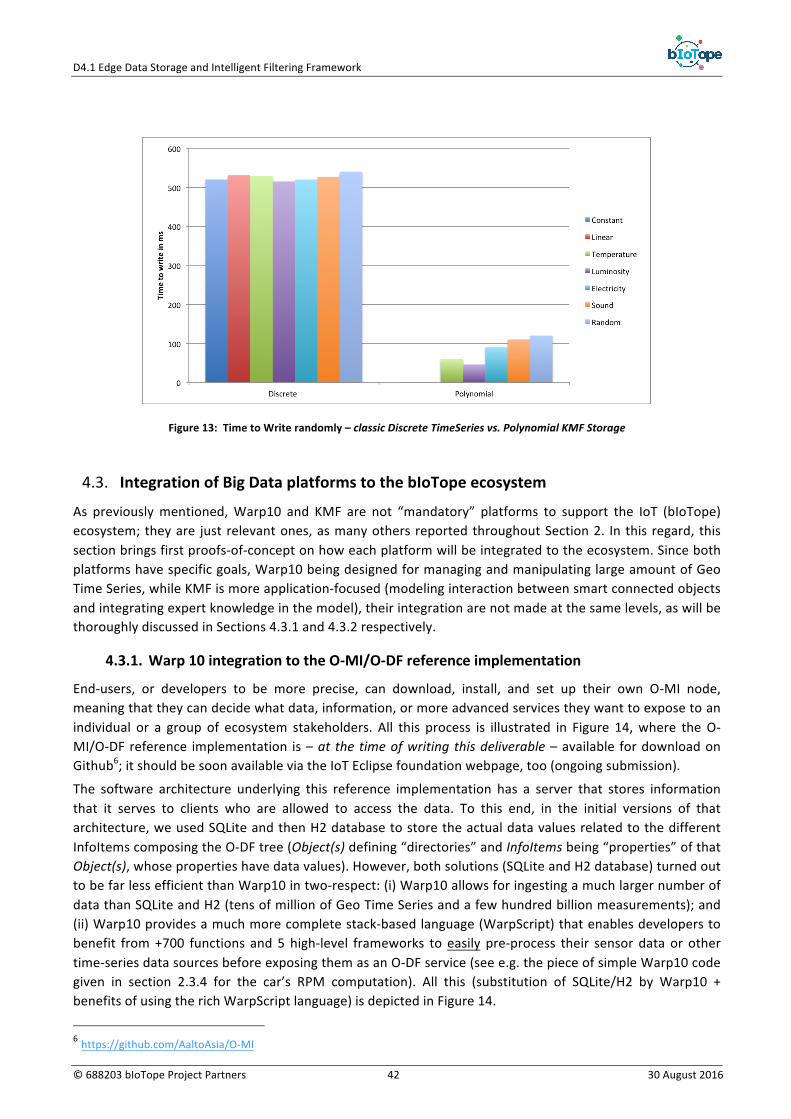
D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 42 30August2016
4.3. IntegrationofBigDataplatformstothebIoTopeecosystem
As previouslymentioned,Warp10 and KMF are not “mandatory” platforms to support the IoT (bIoTope)ecosystem;theyare just relevantones,asmanyothersreportedthroughoutSection2. In this regard, thissectionbringsfirstproofs-of-conceptonhoweachplatformwillbeintegratedtotheecosystem.Sincebothplatformshavespecificgoals,Warp10beingdesignedformanagingandmanipulatinglargeamountofGeoTimeSeries,whileKMFismoreapplication-focused(modelinginteractionbetweensmartconnectedobjectsandintegratingexpertknowledgeinthemodel),theirintegrationarenotmadeatthesamelevels,aswillbethoroughlydiscussedinSections4.3.1and4.3.2respectively.
4.3.1. Warp10integrationtotheO-MI/O-DFreferenceimplementation
End-users, or developers to be more precise, can download, install, and set up their own O-MI node,meaningthattheycandecidewhatdata,information,ormoreadvancedservicestheywanttoexposetoanindividual or a group of ecosystem stakeholders. All this process is illustrated in Figure 14,where theO-MI/O-DFreference implementation is–at thetimeofwritingthisdeliverable–available fordownloadonGithub6;itshouldbesoonavailableviatheIoTEclipsefoundationwebpage,too(ongoingsubmission).
The software architecture underlying this reference implementation has a server that stores informationthat it serves to clients who are allowed to access the data. To this end, in the initial versions of thatarchitecture,weusedSQLiteandthenH2databasetostoretheactualdatavaluesrelatedtothedifferentInfoItemscomposingtheO-DFtree(Object(s)defining“directories”andInfoItemsbeing“properties”ofthatObject(s),whosepropertieshavedatavalues).However,bothsolutions(SQLiteandH2database)turnedouttobefarlessefficientthanWarp10intwo-respect:(i)Warp10allowsforingestingamuchlargernumberofdatathanSQLiteandH2(tensofmillionofGeoTimeSeriesandafewhundredbillionmeasurements);and(ii)Warp10providesamuchmorecompletestack-basedlanguage(WarpScript)thatenablesdeveloperstobenefit from+700 functions and5 high-level frameworks to easily pre-process their sensor data or othertime-seriesdatasourcesbeforeexposingthemasanO-DFservice(seee.g.thepieceofsimpleWarp10codegiven in section 2.3.4 for the car’s RPM computation). All this (substitution of SQLite/H2 by Warp10 +benefitsofusingtherichWarpScriptlanguage)isdepictedinFigure14.
6https://github.com/AaltoAsia/O-MI
Figure13:TimetoWriterandomly–classicDiscreteTimeSeriesvs.PolynomialKMFStorage

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 43 30August2016
Warp10hasbeenintegratedastheinternal(edge)databasesolutioninthenewversionoftheO-MI/O-DFreferenceimplementation.Thisistransparentfromthedeveloper/downloaderperspective,meaningthatitdoes even have to know that the reference implementation usesWarp10 as database. We nonethelessexplaininthefollowinghowthisintegrationhasbeenmade:theWarp10APImodelhasbeenmappedtotheO-DF’sone,whereonesubtletyneededtobetackled,namelythefactthatWarp10takeslocationdataforeachvalue,whileO-DFdoesnothavethatkindoffield.Instead,weusethefollowingformat:
• Locationisstoredintheparent<Object>underInfoItemnamed“location”;
• Eachlocationvaluethattoawarp10sensorvalueshouldhavethesametimestamp(forsinglevaluessinglelocationandvaluewithouttimestampcanbeprovided);
• LocationsareconvertedfromISO6709standardtoWarp10(Warp10geo-locationformatandothersmightbesupportedinthefuture);
OneexampleofcorrectO-DFmessagepayloadisprovidedinFigure15,wheretheObject“SensorBox123”has an InfoItem named “location”, in which the locations of three distinct sensors are specified, and asecondInfoItemnamed“humidity”thatcorrespondstotherealsensordatavalues(humiditysensorsinthisexample).Incasetheend-userdoesnothavetospecifyanylocationrelatedtoasensororsmartconnectedobject,the“location”InfoItemcanberemoved(seeredframeinFigure15).Fromadeveloperperspective,functionswillbeavailabletospecifywhetherlocation-relateddataareneededornot.
Figure14:Warp10integrationtothenewversionoftheO-MI/O-DFreferenceimplementation
Figure15:ExampleofO-DFpayload(includingornotlocationdata)thatisstoredinWarp10
Optional “location”-related data

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 44 30August2016
4.3.2. KMFintegrationtoexposeanalyticsresultsand/orfeedanalytics
Asmentionedpreviously,KMFplatformismoreapplication-focused,offeringatoolfordeveloperstomodeltheir application, meaning the possible interactions between physical or virtual entities (e.g., sensors’correlation,humanbeings,etc.),expertknowledgeaboutsuch interactionsandotherbusinessknowledgethat can be integrated to the KMF model, all this helping to provide advanced model-driven analyticsincludingreasoning,learning,anddecisionmakingunderuncertainty.ComparedwithWarp10,KMFismoreacomplementarytooltotheoverallbIoTopeecosystemthatcanbedownloadedand“plugged”withtheO-MI/O-DFreferenceimplementationinordertoeither/both:
• Expose the analytics outcomes: for example, prediction outcomes about the probability that afailureoccursonaspecificdeviceinthecominghours;or/and,
• Integrateexternal information sources to theapplicationmodel: forexample, thedevelopercansearchforandfindrelevantinformationsourcesandknowledgethathavebeenexposed–byotherstakeholders(externaltotheapplication)–tothebIoTopeecosystem(servicemarketplace),whichcould be accessed by the application developer and integrated to the application-specificmodel,thusresultinginmoreefficientreasoning,learning,anddecisionmaking.
AllthishasbeenillustratedinFigure16,wherewestressthefactthatKMFshouldbeusedwhenthereisaneedtomodeltheapplicationtoperformadvancedmodel-drivenanalytics.ItshouldbenonethelessnotedthattheplugintomaptheKMFAPIwiththeO-MI/O-DFreferenceimplementation(tomakedevelopers’lifeeasy)hasnotbeendevelopedyet,butwillbeoneoftheobjectiveintheshortterm.Forexample,fromacityperspective,thiskindofmodel-drivenanalyticsapproachcanbeveryusefulforsmart-gridapplications–astargetede.g.inHelsinki–tomodelthegridnetwork,andperformreasoning,learningandpredictionontopofthatmodel@runtime.
Figure16:KMFintegrationtothebIoTopeecosystem:inwhichcontextend-userscanbenefitfromKMF

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 45 30August2016
5. BigDatascenariosinthebIoTopecitypilots
This chapter discusses the current state and progress of the city pilots, i.e. what types of informationsources/data flowswill need to be integrated to andmanaged in the bIoTope project, alongwith relatedcharacteristics(e.g.,dataformats,staticordynamic/livedata,platformowner,andsoon).Italsodiscussedhowweplan to use the state-of-the-art reviewoutcomes (cf. Chapter 2), aswell as the different bIoTopepartnerplatforms, to setup relevantandappropriate solutions to copewith the cityneeds, requirements,andconstraintsforefficientlystoring,accessingandprocessingdataflows.
Thischapteraimstoprovideabriefoverviewofthecurrentstatusesofthedataflowsthatwilllikelybeusedin the different city pilots, depending on whether cities obtain all the necessary agreements (from thedifferent city or government departments) to provide uswith a full or limited access. In Section 5.1, webrieflyexposethesetofdatasourcesthatbothBrusselsRegionandGrandLyonwouldliketoconsiderandintegratetothebIoTopeecosysteminordertocombinethemandcreateservicesontopofit.SectionError!Referencesourcenotfound.discusseshowwillplan–dependingonourneedstostoreandaccessthedata– to identify relevant back-end technologies based on the state-of-the-art review and set of platformsofferedbythebIoTopepartners.
5.1. OverviewofdatasourcestobeintegratedinthecitypilotsThis section aims to be as concise as possible to present the set of data flows and underlyingtechnologies/platformsthatneedtobeaccessedinoneormorecitypilotsinthecaseofBrusselsRegionandGrandLyon.ThelistofinformationsourcesindatasourcesinHelsinkiislessconsequentand,asaresult,isnot presented in detail in this deliverable, but the reader can refer to deliverable D2.1 (“EcosystemStakeholderRequirementsReport&PilotsDefinition”).
5.1.1. BrusselsRegionAs alreadymentioned, citiesmay be themost striking examples of complex ecosystems inwhich awiderange of stakeholders and service providers (network operators, energy providers, logistics andtransportation centers, etc.) must work/cooperate together, or at least must be “aligned” to foster thecreation of innovative and disruptive services. An overview of the set of platforms and systems that arecurrentlyinplace/runninginBrusselstocollect,storeandprocessvarioustypesofcityinformation,fromthedescriptionofstatic informationsuchas“schoolzones”,“greenspaces”,parkinglocation,crossroadswithredlights,etc.,tothecollectionofreal-time/streamdatasuchastheflowsofcars,cyclists,pedestrian,traveltimeofpublictransportationvehicles,etc.,isprovidedinTable7.
From a data management perspective, some of the listed platforms and service providers already offerprovisionsforstoringandprocessingvariousformatsofdata(see“Technicaldetails”columninprovidedinTable 7). Obviously, some of these systems might not be optimally configured to cope with the IoTpeculiarities,andparticularlywiththeobjectivesthecitywanttoachieve intermsofserviceandanalyticsprovisions in bIoTope. As a result, one of the objectives, during the project, is to implement, wheneverrequired,anappropriatestorageandqueryextractionlayerbetweenthecityback-endsystemandtheO-MInode (used for exposing anddescribing in a standardizedmanner – i.e., usingO-MI/O-DF– the back-endsystemresources/services).Forexample,intheBrusselscase,CIRBisinchargeofcollectingtheproceduresto enable us to access the different information sources in Brussels (i.e., the ones listed in Table 7).Dependingonthepossibilitiesandagreementswiththedifferentgovernmentdepartments,oneor–ideally–severalO-MInodeswillbesetuptoexposealltheseinformationsources,meaningthatinsomecasesCIRBmightbetheintermediarybetweentheinformationsourceproviderandthebIoTopeecosysteminorderto

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 46 30August2016
controlwhatshouldbeexposedandhowthedatashouldbeaccessedfromtheBrussels’back-endsystems.Thiswaytoproceedwillbethesamee.g.consideringHelsinkiorGrandLyoncities.
5.1.2. GrandLyon&CoaaSasfoundationforadvancedanalyticsSimilarly to Brussels, an initial list of platformproviders and associatedowners (althoughnot exhaustive)currentlyusedinGrandLyonisprovidedinTable8.Atthisstageoftheproject,theobjectiveisthustowrapall platform APIs (or similar access points) with the O-MI/O-DF reference implementation, so that moreadvancedservicesandanalyticscouldbecreatedontopofit.
As an example, let us consider themanagement of solidwaste collection thatwill be addressed in bothGrandLyonandSt-Petersburg (ITMObeingnowanofficialpartnerof thebIoTopeproject).Thehigh levelview of the whole data exchange process, and associated stakeholders, are depicted in Figure 17. InbIoTope, a Cloud-based CoaaS platform (developed in WP4) will take part in the bIoTope ecosystem,providing possibilities for city stakeholders (citizens, municipalities, truck owning companies, recyclingfactories, city administration and others as depicted in Figure 17) and other ecosystem stakeholders(startups, etc.) to use the developed analytics services taking advantage of the CoaaS platform. To put itsimply,theproposedCloud-basedCoaaSplatformwillbeableaccess(e.g.,usingsubscriptionmechanismsorotherinterfacesofferedbyO-MI)thenecessaryinformationsourcesinthecity(regardlessofthecityback-endarchitecture),whichwillenabletoturntheseinformationsourcesinto“contextinformation/attributes”thatareusedinthedosomereasoningaboutthecurrentcitysituation,thereforeenablingthedevelopmentofadvancedandreal-timeDecisionSupportSystems,forexampletooptimizeroutesthatwillhelptoreduce
Table7:ListofdatasourcesinBrusselsRegionthatneedtobeintegratedtothebIoTopeecosystemPlatformProvider Platformandrelatedcityinformation Technicaldetails
CIRB(bIoTope’spartner) Opendataportal(School,Entrypoints) -Opendatastore.brussels Greenspaces GeoJSONIbgebim.be Waterflows GML3.2.1
STIBDetailsaboutthestopsandTimetableoftrams,metrosandbuses
-
STIB Real-timetraveltimeoftrams,metros,buses -Opendatastore.brusselsBrusselsMobility(bIoTope’spartner)
RERallowing“bikes”Routesofcyclists
GeoJSON,EPSG
Opendatastore.brusselsIrisnet(bIoTope’spartner)
Parkingforbikes GeoJSON,Shapefile,KML
JCDecaux Thefree-servicebikestations api.jcdecaux.com- Thefree-servicebiketariff OrangeBE Realtimeflowofcyclists ?SIAMU Drivingdirections ?BrusselsMobility(bIoTope’spartner) 30km/hZones EPSGBrusselsMobility(bIoTope’spartner) Crossroadswithredlights ?Irisnet(bIoTope’spartner)BrusselsMobility(bIoTope’spartner)
Publicroadparking GeoJSON,EPSG
OrangeBE Real-timeflowofcarsReal-timeflowofpedestrians
?
BrusselsMobility(bIoTope’spartner) Roadworksandevents GeoJSONGoogle/Waze Congestionsofpublicroads -Ibgebim.be Sidewalks EPSG
BrusselsMobility(bIoTope’spartner) PedestriancrossroadsDangeroustrafficpoints
Irisnet(bIoTope’spartner) Trafficsigns HTML...

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 47 30August2016
fuel consumptionanddriverseffortswhilekeeping thequalityof serviceatahigh-level,or still topredictfuturewastemanagementproblemsandtakeappropriatepreventivedecisions.
Table8:ListofdatasourcesinGrandLyonthatneedtobeintegratedtothebIoTopeecosystemPlatformProvider Platformandrelatedcityinformation Technicaldetails
CIRB(bIoTope’spartner) Opendataportal(Bottlebankslocation) -Cybeel:MSAzureplatform(SigFox) Cybeelbottlebanksensorsexperimentation SpecificRESTAPIs
GrandLyon(bottlebankssensors)
Oneorseveraldatasetswillbecreatedtostorethefollowingcomingfrombottlebanksensors:(i)Fillingrate;(ii)Internaltemperature;(iii)Location(GPS);(iv)Acceleration(asanevent:whenbottlebankisemptied);(v)Timestamp
GeoJSON,KML,JSON,EPSG,etc.
GrandLyon(Trafficcondition)Real-timetrafficdensityontheroadsections,(refreshedeveryminute)
WMS,WFS,KMLGeoJSON,Shape-zip,JSON,XML
Infoclimat,Wunderground,Netatmo… Temperature&Humidityexternaldatas SpecificRESTAPIsFutureIoTplatformproviders(e.g.,Rainwatertank)
IoTplatformtobedeployedsoon(upto150sensorstobedeployedsoon) -
TensioManager(Greenspacesmaintenanceprovider) Soilhumiditysensors -
PEPIPIAF(INRA) Treesevapotranspirationsensors -...
5.1.3. RequirementsandNeedsformatchingwithexistingBigDatasolutions
AsexplainedthroughoutSection5,dependingontheusecase-relateddataflowsandexistinginfrastructuresinthedifferentcities, itwillbenecessarytosetuptheright infrastructuresusingeitherplatformsheldbybIoTopepartners, suchWarp10heldbyCityzendata thatenables to storeandmanipulategeo-timeseriesdata lakes (which isOpenSource). Then,BDIaaS,BDPaaSandBDAaaS layers canbe seeneither (i)at thelowerlevelsoftheecosystem:tostore,accessandprocessdatabeforeexposingthemtotheIoTecosystem(this iswhatwehave illustrated throughFigure18),orat theupper levels: forexample,CoaaSwillaccessservicesalreadyexposed,andwillprovideBDIaaS,BDPaaSandBDAaaStoprovidemoreadvancedservicesto various stakeholders (cf. Figure 17).Overall, and as highlighted in Figure 18, this deliverable canbeof
Figure17:WasteManagementscenariotakingadvantageofCoaaS-basedanalytics
CaaS-based analytics
bIoTope ecosystemService description, discovery & consumption

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 48 30August2016
greathelpforthebIoTopeconsortiumwhenalldataflowstobeintegratedtothedifferentusecaseswillbethoroughlydefined(i.e.,frequencyofaccessofeachdatastream,formatsofdata,etc.),asbrieflydiscussedintheprevioussections.
Figure18:BDaaSstate-of-the-artusedformappingcitypilot’sneedswithexistingsolutions/technologies(eitherbasedon
platformsinternalorexternaltothebIoTopeconsortium)

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 49 30August2016
6. Conclusion
In the quest for avoiding the continual emergence of vertical silos that hamper developers to producedisruptiveandaddedvalueservicesacrossmultipleplatforms,weclaiminbIoTopethatthreeprinciplesarefundamental for successful open IoT ecosystems, namely: (i) the web is the IoT platform: no singleorganization or company is in control; (ii)Web Service Interoperability & Visibility: the success of an IoTecosystem is closelybound-upwith thenumberof services thatareavailable,andhoweasy it is tomaketheseservicestalkandunderstandeachother;(iii)Security&Dataownership:organizationsandend-usersmust have the control over their data aswell as data generated by the devices they own (e.g., decidingsharingspecificdatawithanyotherpartner/serviceof theecosystem).Given theseprinciples,particularlythefirstone,itisclearthatanyecosystemstakeholder(e.g.,aplatformprovider)shouldbeabletojointheecosystem,exposehis/herservices,andpotentiallyconsumesservicesavailableontheservicemarketplace.Theexposedservices,obviously, can relyonvarious typesofplatforms,whichmayhavedifferentstorageandprocessingcapabilities.
Inthisregard,thisdeliverableoffersanoverviewofthestorageandanalyticscapabilitiesthatarecurrentlysupported/offered by the different platforms of the different partners involved in bIoTope. A particularemphasisisgiventotwoBigDataplatforms,developedbytwobIoTopepartners(Cityzendata&Universityof Luxembourg), which have been designed for and used to deal with Big Data requirements: KMF thatsupportstheModels@Runtimeparadigm,andWarp10thatenablestheingestionandaneasymanipulationof huge amount of Geo Time Series. In addition of the bIoTope platforms’ overview, we provide in thisdeliverable a state-of-the-art of existing technologies and frameworks that shape today’s Big Datalandscape,whilediscussingtheircharacteristics,prosandcons,whichcanbeusefulduringimplementationstages in the different city pilots. The deliverable also discusses key storage building blocks thatmust bedeveloped – in addition of the bIoTope partner platforms – to foster the creation of a truly unified IoTecosystem(asdiscussedabove).Thisstate-of-the-artshowsthattherearemultiplebigdata infrastructureproviders on themarket, all acknowledging the importance of providing solutions fine-tuned for IoT usecases, however, there is still much to do to provide easy-to-use and flexible programming languages,particularly for edge nodes. All this given that edge computingwill gainmomentum in the coming years,whichispartlyduetoagrowingawarenessofthesecurityandprivacyimplicationsofstoringalluser-relatedandsmart-connectedobject-relateddataintheCloud.
One importantconclusion is thatthebIoTopeecosystemisnotboundtoaspecificsetofplatformsand issufficiently“open”toenabletouseonespecifictechnology,platform,infrastructureorstillparadigm(edge,cloud…)aspartofthebIoTopeecosystem(e.g.,somechoiceswillbemadetosupportspecificservicessuchasCoaaS,whichwillnotimpactontherestoftheecosystem).

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 50 30August2016
7. References
[1] (CSC, n.d.). Big Data Just Beginning to Explode. CSC, accessed 03 August 2016<http://www.csc.com/big_data/flxwd/83638-big_data_just_beginning_to_explode_interactive_infographic>
[2] Laney,D.(2001).3Ddatamanagement:Controllingdatavolume,velocityandvariety,METAGroupResearchNote,6(70).
[3] Gantz,J.andReinsel,D.(2011).Extractingvaluefromchaos.IDCiView1-12.
[4] Mayer-Schönberger, V. & Cukier, K. (2013),Big Data : A Revolution ThatWill TransformHowWeLive,Work,andThink,HoughtonMifflinHarcourt,Boston.
[5] Taylor,I.J.,Deelman,E.,andGannonD.B.(2006).Workflowsfore-Science:ScientificWorkflowsforGrids.
[6] K.Park,M.C.Nguyen&H.Won(2015),Web-basedcollaborativebigdataanalyticsonbigdataasaservice platform,2015 17th International Conference on Advanced Communication Technology(ICACT),Seoul,pp.564-567.doi:10.1109/ICACT.2015.7224859
[7] Wang, J.; Crawl, D.; Altintas, I. & Li, W. (2014), 'Big Data Applications UsingWorkflows for DataParallelComputing.',ComputinginScienceandEngineering16(4),11-21.
[8] Främling,K.;Kubler,S.&Buda,A.(2014),UniversalMessagingStandardsfortheIoTFromaLifecycleManagementPerspective,IEEEInternetofThingsJournal1(4),319-327.
[9] Perera,C.,Zaslavsky,A.B.,Christen,P.&Georgakopoulos,D.(2014).ContextAwareComputingforTheInternetofThings:ASurvey,IEEECommunicationsSurveysandTutorials16(1),414-454.
[10] DeCandia,G.;Hastorun,D.;Jampani,M.;Kakulapati,G.;Lakshman,A.;Pilchin,A.;Sivasubramanian,S.; Vosshall, P. & Vogels,W. (2007), 'Dynamo: Amazon's highly available key-value store',SIGOPSOper.Syst.Rev.41(6),205--220.
[11] Redishomepage.Accessed03August2016<http://redis.io/>
[12] Voldemorthomepage.Accessed03August2016<http://www.project-voldemort.com/voldemort/>
[13] MongoDBhomepage.Accessed03August2016<http://mongodb.org/>
[14] SimpleDBhomepage.Accessed03August2016<https://aws.amazon.com/fr/simpledb/>[15] CouchDBhomepage.Accessed03August2016<http://couchdb.org>
[16] Kaur, K. & Rani, R. (2013),Modeling and querying data in NoSQL databases.,inXiaohuaHu; TsauYoung Lin; Vijay V. Raghavan; BenjaminW.Wah; Ricardo A. Baeza-Yates; Geoffrey C. Fox; CyrusShahabi;MatthewSmith;QiangYang;RayidGhani;WeiFan;RonnyLempel&RaghunathNambiar,ed.,'BigDataConference',IEEE,,pp.1-7.
[17] Hbasehomepage.Accessed03August2016<http://hbase.apache.org/>
[18] Cassandrahomepage.Accessed03August2016<http://cassandra.apache.org>
[19] Hypertablehomepage.Accessed03August2016<http://hypertable.org>
[20] Neo4jhomepage.Accessed03August2016<http://neo4j.com/>
[21] GraphDBhomepage.Accessed03August2016<http://ontotext.com/products/graphdb/>
[22] Dean, J. and Ghemawat, S. (2008). MapReduce: simplified data processing on largeclusters.CommunicationsoftheACM,51(1),pp.107-113.
[23] Olston, C., Reed, B., Srivastava, U., Kumar, R. and Tomkins, A., (2008). Pig latin: a not-so-foreignlanguagefordataprocessing.InProceedingsofthe2008ACMSIGMODinternationalconferenceonManagementofdata(pp.1099-1110).ACM.
[24] Cascading:Projectwebsite.Accessed03August2016<http://www.cascading.org>

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 51 30August2016
[25] Thusoo,A.,Sarma,J.S.,Jain,N.,Shao,Z.,Chakka,P.,Anthony,S.,Liu,H.,Wyckoff,P.andMurthy,R.,2009. Hive: a warehousing solution over a map-reduce framework.Proceedings of the VLDBEndowment,2(2),pp.1626-1629.
[26] Stonebraker,M., Abadi, D., DeWitt, D.J.,Madden, S., Paulson, E., Pavlo, A. and Rasin, A., (2010).MapReduceandparallelDBMSs:friendsorfoes?.CommunicationsoftheACM,53(1),pp.64-71.
[27] Vavilapalli, V.K.,Murthy, A.C., Douglas, C., Agarwal, S., Konar,M., Evans, R., Graves, T., Lowe, J.,Shah, H., Seth, S. and Saha, B., (2013). Apache hadoop yarn: Yet another resource negotiator.InProceedingsofthe4thannualSymposiumonCloudComputing(p.5).ACM.
[28] ApacheSpark:Projectwebsite.Accessed03August2016<http://spark.apache.org/>
[29] Kornacker, M., Behm, A., Bittorf, V., Bobrovytsky, T., Ching, C., Choi, A., Erickson, J., Grund, M.,Hecht,D.,Jacobs,M.andJoshi, I.,(2015).Impala:AModern,Open-SourceSQLEngineforHadoop.InCIDR.
[30] ApacheFlink:Projectwebsite.Accessed03August2016<http://flink.apache.org/>[31] Minelli, M., Chambers, M. and Dhiraj, A., 2012.Big data, big analytics: emerging business
intelligenceandanalytictrendsfortoday'sbusinesses.JohnWiley&Sons.
[32] 'Real-Time Analytics is Hard'. MongoDB project page. Accessed 03 August 2016<https://www.mongodb.com/use-cases/real-time-analytics>
[33] Zhang,H.,Chen,G.,Ooi,B.C.,Tan,K.L.andZhang,M.,(2015).In-memorybigdatamanagementandprocessing:Asurvey.IEEETransactionsonKnowledgeandDataEngineering,27(7),pp.1920-1948.
[34] ApacheStorm:ProjectWebsite.Accessed03August2016<http://storm.apache.org/>
[35] S4 distributed stream computing platform: Accessed 03 August 2016<http://storm.apache.org/>http://incubator.apache.org/s4/
[36] Spark Streaming programming guide. Accessed 03 August 2016<http://spark.apache.org/docs/latest/streaming-programming-guide.html>
[37] Liu, L., (2014). Editorial: ServiceComputing in theNext Seven Years.IEEE Transactions on ServicesComputing,7(4),pp.529-529.
[38] Cloudera: CDH Components. Accessed 03 August 2016<https://www.cloudera.com/products/apache-hadoop/key-cdh-components.html>
[39] Hortonworks:CompanyWebsite.Accessed03August2016<http://hortonworks.com/>
[40] MapR: Platform Services Overview. Accessed 03 August 2016<https://www.mapr.com/products/platform-services>
[41] AmazonWebServices:ProductWebsite.Accessed03August2016<http://aws.amazon.com/>
[42] Google Cloud: Overview of Internet of Things. Accessed 03 August 2016<https://cloud.google.com/solutions/iot-overview>
[43] Microsoft Azure IoT Suite: Product Website. Accessed 03 August 2016<https://azure.microsoft.com/en-us/solutions/iot-suite/>
[44] Främling,K.,Holmström,J.,Loukkola,J.,Nyman,J.andKaustell,A.,(2013).SustainablePLMthroughintelligentproducts.EngineeringApplicationsofArtificialIntelligence,26(2),pp.789-799.
[45] Apache Zeppelin: Project overview. Hortonworks company website. Accessed 03 August 2016<http://hortonworks.com/apache/zeppelin/>
[46] R:Projectwebsite.Accessed03August2016<https://www.r-project.org>
[47] Jupyter:Projectwebsite.Accessed03August2016<http://jupyter.org>[48] ApacheHadoop:ProjectWebsite.Accessed03/08/2016<http://hadoop.apache.org/>

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 52 30August2016
[49] Armbrust,M.,Das,T.,Davidson,A.,Ghodsi,A.,Or,A.,Rosen, J.,Stoica, I.,Wendell,P.,Xin,R.andZaharia,M., (2015). Scaling spark in the realworld: performance andusability.Proceedings of theVLDBEndowment,8(12),pp.1840-1843.
[50] Azure Machine Learning Tutorial. Accessed 03 August 2016<http://download.microsoft.com/download/3/b/9/3b9fba69-8aad-4707-830f-6c70a545c389/introducing_azure_machine_learning.pdf>
[51] GoogleDataflow:ServiceWebsite.Accessed03August2016<https://cloud.google.com/dataflow/>
[52] Knowles,G.,Melamed,A.,Fisher,A. (2015)Acceleratethedevelopmentofcognitivecomputing inyour IoT app. Accessed 03 August 2016 <http://www.ibm.com/developerworks/library/iot-cc-watson-iot-platform-trs/index.html>
[53] Azure Stream Analytics: Product Website. Accessed 03 August 2016<https://azure.microsoft.com/en-us/services/stream-analytics/>
[54] López,P.G.;Montresor,A.;Epema,D.H.J.;Datta,A.;Higashino,T.; Iamnitchi,A.;Barcellos,M.P.;Felber, P. & Rivière, E. (2015), 'Edge-centric Computing: Vision and Challenges.',ComputerCommunicationReview45(5),37-42
[55] Shi,W.andDustdar,S.(2016)ThePromiseofEdgeComputing,Computer,49(5),78-81.[56] Warp10:ProjectWebpage.Accessed03August2016<http://www.warp10.io>
[57] Fouquet, F., Nain, G., Morin, B., Daubert, E., Barais, O., Plouzeau, N., & Jézéquel, J. M. (2014).Kevoree Modeling Framework (KMF): Efficient modeling techniques for runtime use.CoRR,abs/1405.6817.
[58] Amazon Web Services for IoT: Getting Started Guide. Accessed 03 August 2016<https://aws.amazon.com/iot/getting-started/>
[59] IBM Bluemix: Product Webpage. Accessed 03 August 2016 <http://www.ibm.com/cloud-computing/bluemix/>
[60] PredixPlatformWebsite.Accessed03August2016https://www.predix.io[61] SASCompanyWebsite.Accessed03August2016<http://www.sas.com/>[62] IoT Analytics, List of 260+ IoT Platform Companies. Accessed 03 August 2016 <https://iot-
analytics.com/product/list-of-260-iot-platform-companies/>
[63] Deloitt University Press, Collins, G. & Sisk, D.: Accessed 03 August 2016<http://dupress.com/articles/tech-trends-2015-what-is-api-economy/>
[64] Serrano, M., Barnaghi, P. & Cousin, P. (2012-2014). IoT Semantic Interoperability: ResearchChallenges,BestPractices,SolutionsandNextSteps,IERCAC4.EuropeanCommission.
[65] Främling,K.,Harrison,M.,Brusey,J.andPetrow,J., (2007).Requirementsonuniqueidentifiersformanagingproductlifecycleinformation:comparisonofalternativeapproaches.InternationalJournalofComputerIntegratedManufacturing,20(7),pp.715-726.
[66] Kevoree Modelling Framework: Project Website. Accessed 03 August 2016<http://kevoree.org/kmf/>
[67] RoundRobinDatabases:https://jawnsy.wordpress.com/2010/01/08/round-robin-databases/[68] Robert, J., Kubler, S., & Le Traon, Y. (2016). Micro-billing framework for IoT: Research &
Technological foundations, In:4st InternationalConferenceonFuture InternetofThingsandCloud,(proceedingstoappearsoon).
[69] Kaur, K. & Rani, R., (2015). A Smart Polyglot Solution for Big Data in Healthcare. IT Professional,17(6),pp.48–55.
[70] Boytsov,A.,&Zaslavsky,A.(2011).ECSTRA–DistributedContextReasoningFrameworkforPervasiveComputing Systems. In Smart Spaces andNextGenerationWired/WirelessNetworking (pp. 1-13).SpringerBerlinHeidelberg.

D4.1EdgeDataStorageandIntelligentFilteringFramework
©688203bIoTopeProjectPartners 53 30August2016
[71] Padovitz, A., Loke, S.W. & Zaslavsky, A., (2008). The ECORA framework: A hybrid architecture forcontext-orientedpervasivecomputing.PervasiveandMobileComputing,4(2),pp.182–215.
[72] Santos, N., Pereira, O.M. & Gomes, D., (2011). Context Storage Using NoSQL. Conferência sobreRedes de Computadores, (November 2011). Accessed 03 August 2016<http://atnog.av.it.pt/publications/context-storage-using-nosql>
[73] Marechal, L., (2015).MongoDB vs. Elasticsearch: The Quest of the Holy Performances. 23March2015.Accessed03August2016<http://blog.quarkslab.com/mongodb-vs-elasticsearch-the-quest-of-the-holy-performances.html>
[74] Assad, M., Hartmann, T., Fouquet, F., Nain, G. Klein, J. & Le Traon, Y. (2015). Beyond DiscreteModeling: A Continuous and EfficientModel for IoT. InModel Driven Engineering Languages andSystems(MODELS),2015ACM/IEEE18thInternationalConferenceon,pp.90–99.


















