Citizen Science - Insights, opportunities and approaches for biomedical research

Biomedical knowledge engineering approaches
driven by processing the primary
experimental literature
Gully Burns 1*, Eduard Hovy 1 and Tommy Ingulfsen 1
1 USC Information Sciences Institute, USA, [http://bmkeg.isi.edu/]
Poster for INCF 2008

IntroductionNeuroinformatics databases derived from the literature tend to be much smaller than their bioinfor-matics counterparts. One neuroinformatics system, CoCoMac, describes roughly 4x104 neuroana-tomical connections from 413 papers; by way of constrast, the Mouse Genome Informatics (‘MGI’) system, contains nucleotide sequences from ~105 papers. The resources needed to support a large-scale database are extraordinary (MGI supports a team of 30+ professsional biocurators), and even then, it is still highly challenging to maintain a complete, up-to-date account of large-scale portions of the literature. Curating knowledge from Neuroscientific papers is is made even more difficult because: (A) the information is largely unstructured (occuring either as natural language text or tables) and (B) the information is semantically complex: typically more so than genomic studies where individual genes are linked to ontologies of phenotype or function. Thus, we need to (A) provide tools to acceler-ate the process of biocuration and (B) we need to define a general-purpose Knowledge Representa-tion (KR) that can capture the semantics of neuroscientific knowledge in a mathematically tractable format that is also intuitively understandable to bench-scientists.Here we present an approach for the construction of knowledge bases from the biomedical literature based on a relatively-simple, generally-applicable KR for scientific observations called ‘Knowledge Engineering from Experimental Design’ (’KE-f-ED’). This approach is based on the experimental vari-ables being studied and provides a way to represent data, significance relations and correlations in a generalized informatics framework. We describe the basic theory behind the model, and demonstrate a sample implementation in the domain of neuroendocrinology. We also describe how this approach provides a framework suitable for text mining that leverages information extraction (IE) technology. In collaboration with Elsevier Science, we downloaded 39,643 full-text articles as XML documents (and 117,602 as PDFs) from multiple neuroanatomically-focused journals. We used a Conditional Random Fields (CRF) model to extract individual mentions of variables from text based on a generic model of a specific experiment type (tract-tracing experiments) and are extending this approach to construct text-mining systems for other experimental types.

p = 0.001
dependent-variablevalues
independent-variable-2
independent-variable-1
independent-
variable
-3a
b
c
d
0
20
40
60
80
100
EDCBA
*
Independent Variable (IV1)
Dep
ende
nt V
aria
ble
(DV1
)
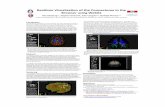
Figure 1: The basic premise of the KE-f-ED model. (A) The foundation of many scientific arguments is based on ‘experimentally measurable effect’ where it is possible to observe a statistically- significant difference in the value of a dependent variable (a measurement) when changes are made in an independent variable (a constraint). (B) Conceptually, each dependent variable is represented in the KE-f-ED model as a ‘coordinate space’ where each dimension is determined by the values of independent variables. Significance relations correspond to links between points in this space.
A
B
Knowledge Engineering from Experimental Design

By focusing only on variables involved in experiments, we simplify our KR task enormously. Firstly, we partition the literature into domains based on different ‘types’ of experiment. Cru-cially, these types are defined by con-sidering the variables that pertain only to the primary observations (rather than attempting to model how an experiment is interpreted or to capture every tiny detail of the protocol). A suitable rule-of-thumb is to include only those details needed to interpret results correctly (see Fig. 2).Following Fig. 1B, the linkage between dependent and independent variables is key to this representation. This linkage is directly provided by consid-eration of the scientific protocol. Given that computer programs and a scien-tific protocols are both sets of proce-dural instructions, we use the Unified Modeling Language (UML, a software engineering industry standard) to provide a modeling framework. A schema for tract-tracing experiments is shown in Fig. 3. Each dependent vari-able is indexed by all independent vari-ables that precede them in the flow-chart. Thus, this representation of a tract-tracing experiment has the follow-ing structure of variables:
Independent Variables: species, tracer-chemical, injection-location, labeling-location
Dependent Variables:
labeling-type, labeling-density
Example (from Gerfen & Sawchenko 1984): labeling-type[rat][PHAL][CA3][LS] = fiberslabeling-density[rat][PHAL][CA3][LS] = dense
Given that PHAL is an anterograde tracer, this information is enough to infer that a neuroanatomical projection exists from CA3 to LS in the rat. Note that careful ontology engineering must be used to correctly define all variables being defined and used within the system. We anticipate automating this sort of interpretive reason-ing in the future.
labeling-type
labeling-densitylabeling-location
injection-location
tracer-chemical
species
neuroanatomical mapping analysis
immuno-histochemistry
perfusion and tissue handling
neuroanatomical tracer injection
animal selection and handling
An example: connections & tract-tracing experiments
Dependent Variables
Parameters and Independent
Variables
Protocol
Figure 3: A simplified KE-f-ED model for tract-tracing experiments illustrates the basic components of this approach.
e.g. lesion experiments
e.g. tract-tracing experiments
e.g. activation experiments
high-level interpretations
('punchline')
primary experimental observations
'brain region A projects to
brain region B'
'tracer A was injected into region B and labeling of type C was observed in regions D, E & F
Partitioning the literature by Experimental Type
all details of methods &
results
nuances + reliability
number of rats, type of injection, handling protocol, methods of
data analysis, etc.
quality of histology, reputation of authors, etc.
Figure 2: Partitioning the primary research literature in two dimensions: ‘Experimental Type’ and ‘Depth of Representation’. Note that our approach specifically targets primary experimental observations rather than high-level interpretations.
Dep
th o
f Rep
rese
nta
tio
n

We present preliminary data concerning our efforts to implement a text-mining application based on the assumption that an individual experiment is essentially a collection of independent and depen-dent variables. We use Natural Language Processing to identify named entities corresponding to these variables and their values in the results sections of the full-text articles. Preliminary results show performance is quite high for automatically reproducing annotations of text based on our tract-tracing model (Fig. 4): Precision = 0.80, Recall = 0.78, F-Score = 0.79. [Burns et al. SOBDAT ‘07]. Other work concerned with identifying the span of experiments within text yields Precision = 0.85, Recall = 0.93, F-Score = 0.89 when used to extract text passages describing a single experiment [Feng et al. EMNLP-CoNLL ‘07]. Therefore, the KE-f-ED model provides a general frameork for text-mining of experimental observations.
Figure 4: Annotated text from Gerfen CR, et al. (1982) J Comp Neurol 207(3):283-303. Yellow = injection-location; Grey = tracer-chemical; Purple = labeling-type; Red = labeling-location; Dotted line = text from one experiment. Developing annotation schema must also be tailorted to language usage within domains.
Challenge 1: scaling up biocuration with text mining

Challenge 2: a general KR for scientific argumentation
saccharine-consumed
sucrose-consumed
saline-consumed
optical-density
food-consumed
fat-pad-mass
concentration
labeling-density
day 1, day 2, day 3,day 4, day 5, time
CORT, Leptin, Insulin, Trigyceride, Free Fatty Acid, Glucose chemical
PVN, CeA, LC, A2/C2
CRF mRNA, DBA mRNA
sucrose, saline, saline & sucrose,saline & saccharine
ADX,sham-ADX
rat
labeling-location
probe
species
surgery
diet
fat pad measurements
bloodmeasurements
analysis
in-situhybridization
perfusion and tissue processing
feeding
surgery
animal selection and handling
optical-density[ADX][sucrose][*][CRF mRNA][PVN] > (P = 0.05)[sham-ADX][saline & sucrose][*][CRF mRNA][PVN]
Relation
optical-density[ADX][sucrose][day 5][CRF mRNA][PVN] = [r2=0.97] a – b * sucrose-consumed[ADX][sucrose][day 5]
Correlation
Datumoptical-density [sham-ADX][saline] [*][CRF mRNA][PVN] = 25
A) Interpretative Statement: “Finally, recent intriguing data from Dallman's lab have raised the possibility that at least part of these inhibitory effects are mediated by altering energy metabolism [Laugero, et al. (2001) Endocrinology, 142(7): 2796-804].”
B) KE-f-ED model: C) Capture of Data, Relations and Correlations
Figure 5: Conceptual demonstration of the KE-f-ED model. (A) A typical ‘citance’ or ‘citation sentence’ (attrib. Marti Hearst, UC Berkeley) providing a statement based on a cited experimental paper. (B) The design of the relevant experiment from the cited paper showing a computationally tractable representation of a complex physiological experiment. (C) This computational representation can capture and represent three essential elements of scientific knowledge: data, statistically-significant relations between data points and correlations between variables. The inset graphs are taken from Fig. 4 of Laugero, et al. (2001), showing that, after adrenalectomy, expression of CRF mRNA in the Paraventricular Hypothalamic Nucleus is almost perfectly correlated to sucrose intake in day 5 of the experiment.
The goal of the KE-f-ED model is to be able to represent the primary observations from any study. In order to test this idea, we examined a short passage of text from a typical scientific narrative (a colleagues’ grant pro-posal of 6 statements citing 11 studies) and represented the experimental evidence supporting each state-ment as a separate KE-f-ED model (Fig. 5).

- protocol steps- variables
KE-f-EDModel
KE-f-ED enabled database
1
2
Scientist data
spread-
sheets
3
4
fill in spreadsheets
5
6
User
Version ‘zero’, software implementation
buildmodelin UML
uploadmodel
uploaddata / relations / correlationsgenerate
excelspreadsheet
browse
Figure 6: Left: Flowchart of initial bare-bones, proof-of-concept build using UML model files and Excel spreadsheets; Right: Summary view of the populated system in a browser.
Acknowledgements: This work was funded by grant R01 GM-083871 from NIGMS and support from the Center for Health Informatics (CHI) at ISI. We are grateful to Alan Watts and Arshad Khan for their support in developing the basic ideas of the KE-f-ED model, as well as many of our colleagues at ISI and USC for their ongoing contributions and ideas.