
Big Data Analytics using Amazon Elastic MapReduce and Amazon Redshift
55
Big Data Analy,cs Using EMR and Redshi6 Sandesh Deshmane Talen,ca So6ware, Pune
-
Upload
indicthreads -
Category
Software
-
view
309 -
download
2
Transcript of Big Data Analytics using Amazon Elastic MapReduce and Amazon Redshift

Big Data Analy,cs Using EMR and Redshi6
Sandesh Deshmane Talen,ca So6ware, Pune

Case Study:
• Ad server generates 6 TB user logs daily
• The logs files are stored in Amazon S3 in compressed format • Expected processed data is 150 GB per day
• Need to support daily reports up to 6 months
• We need to process one day data in less than 2 hours
2

Case Study:
• No Hadoop Administrators
• Our data grows very fast ( In 2013, 2 TB daily)
• No need of 24*7 Hadoop Cluster
• Need to Run mul,ple Jobs ( Algorithms) on daily data at same ,me
• On demand data processing requests
3

What we did
4

5
Amazon Elas,c Map Reduce-‐ EMR

Agenda
• Introduc,on to Amazon EMR
• Amazon EMR Design Pa]erns
• Amazon EMR Best Prac,ces
Amazon EMR Design Patterns
6

7
Amazon Elas,c Map Reduce-‐ EMR

Amazon Elas,c Map Reduce-‐ When • We have big data and/or very long, embarrassingly parallel computa,on
• Our data may grow fast
• We want to try and implement Hadoop ASAP • We do not have our own infrastructure • We do not have Hadoop administrators • We have limited funds
8

HDFS
Analytics languages Data management
Amazon RedShift
Amazon EMR Amazon RDS
Amazon S3 Amazon DynamoDB
Data Pipeline
9

10
How to use EMR

Benefits of EMR
11

Agenda
• Introduc,on to Amazon EMR
• Amazon EMR Design Pa]erns
• Amazon EMR Best Prac,ces
R Design Patterns
12
Amazon EMR Design Pa]erns
• Transient vs. Alive Cluster
• Core Nodes and Task Nodes
• Amazon S3 and HDFS
13

Amazon EMR Best Prac,ces
Transient vs. Alive Clusters
14
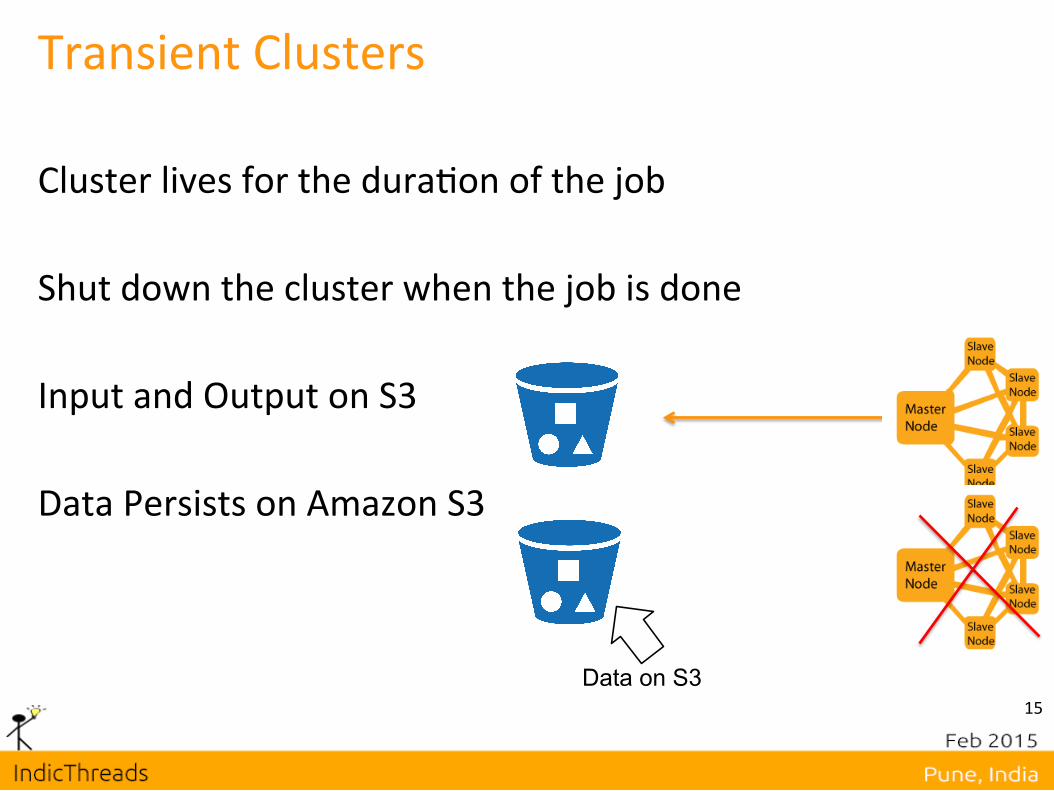
Transient Clusters Data persist on Cluster lives for the dura,on of the job Shut down the cluster when the job is done Input and Output on S3 Data Persists on Amazon S3
Data on S3 15

Benefits of Transient Clusters 1. Control your cost
2. Minimum maintenance • Cluster goes away when job is done
3. Prac,ce cloud architecture • Pay for what you use • Data processing as a workflow
16

Alive Clusters Data persist on • Very similar to tradi,onal Hadoop deployments • Cluster stays around a6er the job is done • Data persistence model:
• Amazon S3 • Amazon S3 Copy To HDFS • HDFS and Amazon S3 as backup
17

Alive Clusters • Always keep data safe on Amazon S3 even if you’re using
HDFS for primary storage • Design your data processing workflow to account for failure • You can use workflow managements such as AWS Data
Pipeline
18

Amazon EMR Design Pa]ern
Core Nodes & Task Nodes
19

Core Nodes
Master Node
Master instance group
Amazon EMR cluster
Core Instance GroupCore instance group
HDFS HDFS
Run TaskTrackers (Compute) Run DataNode (HDFS)
Master Instance Group
20

Core Nodes
Master Node
Master instance group
Amazon EMR cluster
Core instance group
HDFS HDFS
Can add core nodes More HDFS space More CPU/memory Can not Remove Nodes because of HDFS
HDFS
Core Instance GroupCore instance group
Master Instance Group
21
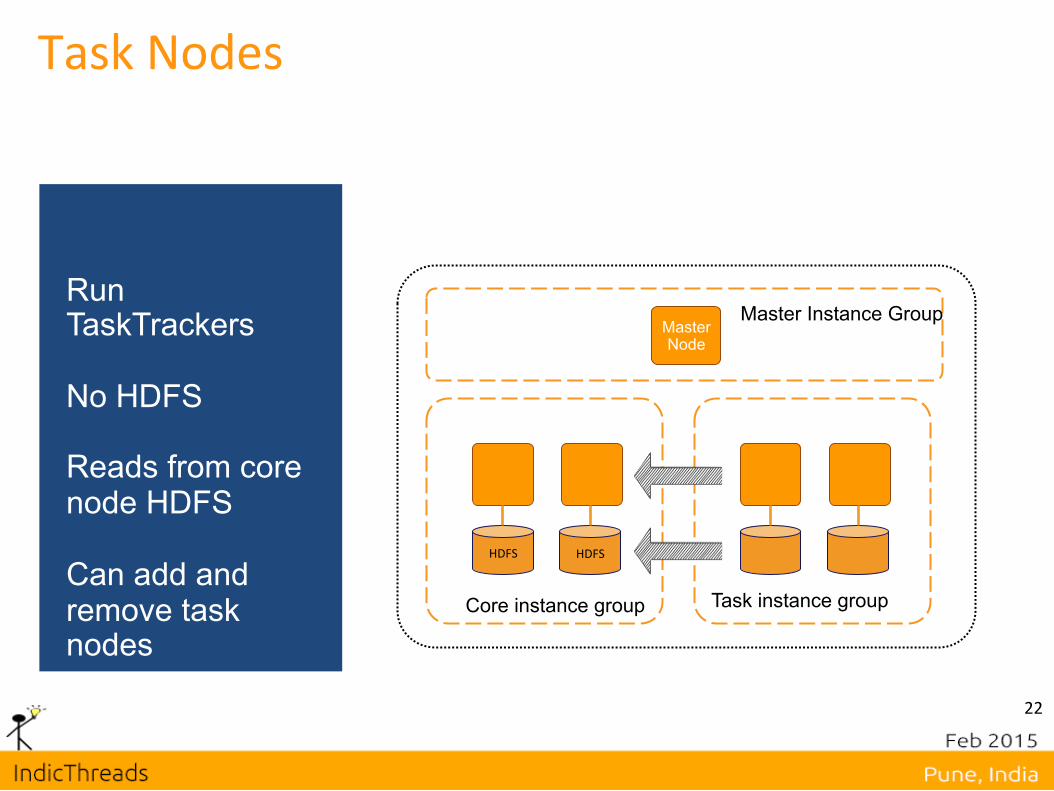
Task Nodes
Master Node
Amazon EMR cluster
Core instance group
HDFS HDFS
Run TaskTrackers No HDFS Reads from core node HDFS Can add and remove task nodes
Task instance group
22
Master Instance Group

23
Task Node Use-‐Cases Speed up job processing using Spot market
• Run task nodes on Spot market • Get discount on hourly price • Nodes can come and go without interrup,on to your cluster
When you need extra horsepower for a short amount of ,me Example: Need to pull large amount of data from Amazon S3

Amazon EMR Design Pa]erns
Amazon S3 & HDFS
24

Amazon S3 as HDFS Use Amazon S3 as your permanent data store HDFS for temporary storage data between jobs No addi,onal step to copy data to HDFS
Core instance group
HDFS HDFS
Task instance group
Amazon EMR Cluster
Amazon S3
25

Benefits of Amazon S3 as HDFS Ability to shut down your cluster
HUGE Benefit!! Use Amazon S3 as your durable storage No need to scale HDFS Capacity Replica,on for durability
26

Benefits of Amazon S3 as HDFS Amazon S3 scales with your data Ability to share data between mul,ple clusters Hard to do with HDFS
Build elas,c clusters Add nodes to read from S3 Remove nodes with Data Safe in S3
27

When HDFS is be]er Choice Iterative workloads
If you’re processing the same dataset more than once
Disk I/O intensive workloads
28

Op,mize Latency with HDFS 1. Data Persisted on Amazon S3
29

Op,mize Latency with HDFS 1. Data Persisted on Amazon S3
2. Launch EMR and copy data to HDFS using S3distcp
sS3D
istC
p
30

Op,mize Latency with HDFS 1. Data Persisted on Amazon S3
2. Launch EMR and copy data to HDFS using S3distcp 3. Start Processing data on HDFS
sS3D
istC
p
31

Agenda
• Introduc,on to Amazon EMR
• Amazon EMR Design Pa]erns
• Amazon EMR Best Prac,ces
R Design Patterns
32

Amazon EMR Nodes and Size
• Use M1.medium Instances for func,onal tes,ng
• Use Xlarge + nodes for produc,on workloads
• Use CC2,C3 for memory and CPU intensive jobs
• HS1, HI1, I2 instances for HDFS workloads
33

The Holy Grail?
How many nodes do I need ?
34

Instance Resource Alloca,on
Hadoop 1 – Sta,c Number of Mappers/Reducers configured for the Cluster Nodes
Hadoop 2 – Variable Number of Hadoop Applica,ons based on File Splits and Available Memory
35

Cluster Sizing Calcula,on 1. Es,mate the number of tasks your job requires. 2. Pick an instance and note down the number of tasks it can run in parallel
3. We need to pick some sample data files to run a test workload.
4. Run an Amazon EMR cluster with a single Core node and process your sample files from #3.
Note down the amount of ,me taken to process your sample files.
36

Cluster Sizing Calcula,on Estimated Number Of Nodes: Total Tasks * Time To Process Sample Files Instance Task Capacity * Desired Processing Time
37

File Best Prac,ces Avoid Small files at any costs ( Smaller than 100 MB) Use compression
38

The second Holy Grail?
What if I have small file issues ?
39

Dealing with small files
Use S3DistCP to combine smaller files together S3DistCP takes a pa]ern and target file to combine smaller input files to larger ones
./elas,c-‐mapreduce –jar /home/hadoop/lib/emr-‐s3distcp-‐1.0.jar \
-‐-‐args '-‐-‐src,s3://myawsbucket/cf,\ -‐-‐dest,hdfs:///local,\ -‐-‐groupBy,.*XABCD12345678.([0-‐9]+-‐[0-‐9]+-‐ [0-‐9]+-‐[0-‐9]+).*,\ -‐-‐targetSize,128,\
40

In Summary • Prac,ce Cloud Architecture with Transient Clusters
• U,lize S3 as the system of record for durability
• U,lize Task Nodes on Spot for Increased performance and Lower Cost
• Move to new Instance Families for Be]er Performance/$
41

What's next ? • Processed data using EMR
• Data processed size is in Gigabytes
• Bo]le neck for tradi,onal RDBS-‐Loading and Query
• Data management problem for historic Data
42

43

Amazon Redshi6 Fast, simple, petabyte-‐scale data warehousing for less than $1,000/TB/Year
44

Why Redshi6? Easy Provision and scale up massively
No upfront cost , pay as you use
Really fast performance at a really low price
Open and flexible with support for popular BI tools
x
45

Amazon Redshi6 Architecture Leader Node -‐ SQL endpoint
-‐ Stores metadata -‐ Coordinates query execu,on
Compute Nodes -‐ Local, columnar storage
-‐ Execute queries in parallel -‐ dedicated CPU, memory ,a]ached
Storage -‐par,,oned into node slices
Single node version available
46

Amazon Redshi6 Internal Architecture
• Query
• Load
• Backup/Restore
• Resize
47

Amazon Redshi6 Internal Architecture
• Query
• Load
• Backup/Restore
• Resize
• Load in parallel from Amazon S3
• Data Automa,cally distributed and Stored as per DDL
• Scale linearly with number of nodes
48

Amazon Redshi6 Internal Architecture
• Query
• Load
• Backup/Restore
• Resize
• Backups to Amazon S3 are automa,c, con,nuous and incremental • Configurable system snapshot reten,on period • Take user snapshots on-‐demand • Streaming restores enable you to resume querying faster 49

Amazon Redshi6 Internal Architecture
• Query
• Load
• Backup/Restore
• Resize
• Resize while remaining online • Provision a new cluster in the background • Copy data in parallel from node to node • Only charged for source cluster
50

Amazon Redshi6 Internal Architecture
• Query
• Load
• Backup/Restore
• Resize
• Automa,c SQL endpoint switchover via DNS • Decommission the source cluster • Simple opera,on via Console or API
51

Manages data replica,on and Hardware Failure
• Replica,on within the cluster and backup to Amazon S3 to
maintain mul,ple copies of data at all ,mes
• Backups to Amazon S3 are con,nuous, automa,c, and incremental
• Con,nuous monitoring and automated recovery from failures of drives and nodes
• Able to restore snapshots to any Availability Zone within a region
52

Simple Integra,on with exis,ng BI tools
53

Ques,ons?
54

55










![PerfEnforce: A Dynamic Scaling Engine for Analytics with ... · able as cloud services today, including Amazon Elas-tic MapReduce (EMR), Amazon Redshift [2], Azure’s HDInsight [4],](https://static.fdocuments.in/doc/165x107/5f68b5657096a059ed25417a/perfenforce-a-dynamic-scaling-engine-for-analytics-with-able-as-cloud-services.jpg)







