
Big data – an introduction
28
Making Sense out of Big Data Peter Morgan - July 2013
-
Upload
peter-morgan -
Category
Technology
-
view
58 -
download
4
Transcript of Big data – an introduction

Making Sense out of Big Data
Peter Morgan - July 2013

Table of Contents
1. Definition and Overview
2. Data Sources
3. Databases
4. Data Analytics
Glossary
References
2

1. Definition and Overview
3

What is big data?
More and more data is being collected and stored each day
4

Four main components
• Data
– Structured and unstructured
• Databases
– Proprietary and open source
• Query language
– Querying the database
• Analytics
– Analysing the data
5

How big is big?
• Large data sets – Greater than 1,000 Terabytes? (1 Petabyte) – 1,000,000 Terabytes? (1 Exabyte)
• Excel 2013 can have 1,048,576 rows by 16,384 columns – About 10 Gigabyte of data
• Only going to get bigger – 90% of all data produced in the past two years ! – Rate is increasing
• Recall – Giga = 10⁹ – Tera = 10¹² – Peta = 10¹⁵ – Exa = 10¹⁸
6

Big Data Evolution
7

2. Data Sources
8

Where does the data come from? • Science – particle, astrophysics
• Industry – oil, finance, telecom
– Actually all verticals
• Social – Facebook, LinkedIn, Twitter
• Medicine – genome, neuroscience
• Government – census, education, police
• Sports – statistics
• Environment – weather, sensors
9

Unstructured Data • 80% of data is unstructured
• NoSQL • Document based
– Documents – Texts, tweets – Emails – Machine logs – Blogs – Web pages – Photos – Videos (YouTube)
• Graph based – Social media sites – Facebook has 1.1billions users (Microstrategy, July 27, 2013)
10

Why do we need to use big data?
Use in public and private sector to: • Make faster and more accurate business decisions • Make accurate predictions • Gain competitive advantage • Implement smarter marketing – CRM • Discover new opportunities • Enhance Business Intelligence • Enable fraud detection • Reduce crime • Improve scientific research • Quicken analysis (up to real time)
– Weeks, days minutes, seconds
11

Big Data Startup - Case Study
• Rocket Fuel • No. 4 on Forbes' 2013 Most Promising Companies In
America list • Digital advertising startup • Screens over 26 billion ads per day • “Advertising that learns” big data platform • Distributed planet-scale computing engine • Hadoop implementation • Founders from Yahoo!, Salesforce.com, DoubleClick • Targeting algorithms use lifestyle, purchase intent and
social data
12

Some big statistics
13

3. Databases
14

Database Timeline
15
Relational databases – SQL
Proprietary
• Oracle DB
• IBM DB2
• Microsoft SQL
• SAP
• EMC
Open Source
• MySQL
• PostgresQL
• Drizzle
• Firebird
16

Non-relational databases – NoSQL
• BigTable – Google
• Cassandra – Facebook
• Eucalyptus – Amazon
• Hbase – Hadoop
• MongoDB – 10Gen
• Neo4j - NeoTechnologies
• CouchDB - Apache
• CouchBase
• Riak - Basho
• Redis - Pivotal
17

4. Big Data Analytics
18

Big Data Analytics - Incumbents
• Oracle – Exadata, Exalytics • Microsoft – HDInsight, xVelocity • IBM – Netezza, Cognos, BigInsights • SAP – HANA, Business Objects • EMC – Pivotal (Greenplum) • HP – Vertica, HAVEn • All run on Hadoop
19

Big Data Analytics – Pure Plays
• Pure plays – definition:
– Been around more than 20 years
– Purely data analytic companies
• Teradata - Aster
• SAS
• Microstrategy
20

Big Data Analytics – New Entrants
• Hortonworks
• Cloudera
• MapR
• Acunu
• Pentaho
• Tableau
• Talend
• Splunk
21

(Some of) IBM’s Big Data Acquisitions
• Algorithmics – Oct 2011, $400million
• OpenPages – Oct 2010, ?
• Netezza – Sept 2010, $1.7billion
• SPSS – Jan 2010, $1.2billion
• Cognos – Jan 2008, $4.9billion
• About $10billion in four years
http://en.wikipedia.org/wiki/List_of_mergers_and_acquisitions_by_IBM
22

Big Data Science Tools
• Hadoop
• NoSQL
• MapReduce
• R
• Matlab
• Python
• Statistics
23
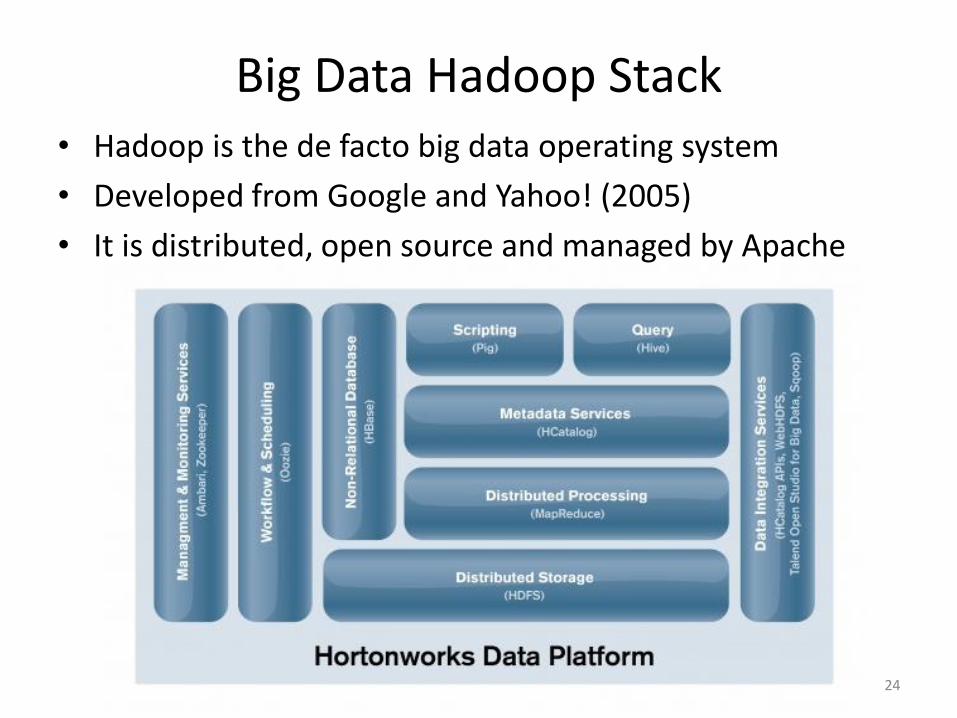
Big Data Hadoop Stack • Hadoop is the de facto big data operating system
• Developed from Google and Yahoo! (2005)
• It is distributed, open source and managed by Apache
24

Analytic Technologies
• A/B testing
• Genetic algorithms
• Machine learning
• Natural language processing
• Neural networks
• Pattern recognition
• Anomaly detection
• Decision tree
• Predictive modeling
• Regression testing
• Sentiment analysis
• Signal processing
• Simulations
• Time series analysis
• Visualization
• Multivariate analysis
• Text analytics
25

Glossary
• OLTP = On Line Transactional Processing
• OLAP = On Line Analytic Processing
• ODBC = Open DataBase Connectivity
• IMDB = In Memory DataBase
• CRUD = Create, Read, Update, Delete
• ETL = Extract, Transform and Load
• CDO = Chief Data Officer
• NLP = Natural Language Processing
• GQL = Graph Query Language
• AaaS = Analytics as a Service
• EDW = Enterprise Data Warehouse
26

References
• Microstrategy website, 27 July, 2013, Michael Saylor Presentation at Microstrategy World 2013, http://www.microstrategy.com/
• Teradata website www.teradata.com
• Wikipedia http://en.wikipedia.org/wiki/
• Google images www.google.co.uk
• IBM website www.ibm.com
• Youtube www.youtube.com
• Hadoop www.hortonworks.com
27

Any Questions?
28


















