![Recognizing Food Places in Egocentric Photo-Streams Using Multi … · 2019. 11. 14. · places datasets, Places2 [30] and SUN397 [31] with millions of labeled images. The combination](https://static.fdocuments.in/doc/165x107/6012fe757146ac11a608f790/recognizing-food-places-in-egocentric-photo-streams-using-multi-2019-11-14.jpg)
Beyond datasets: Learning in a fully-labeled real world Thesis proposal Alexander Sorokin.
65
Beyond datasets: Learning in a fully-labeled real world Thesis proposal Alexander Sorokin
-
Upload
elijah-smith -
Category
Documents
-
view
220 -
download
0
Transcript of Beyond datasets: Learning in a fully-labeled real world Thesis proposal Alexander Sorokin.

Beyond datasets: Learning in a fully-labeled real world
Thesis proposal
Alexander Sorokin

Research projects

Research projects

Thesis

Thesis

Motivation
Task
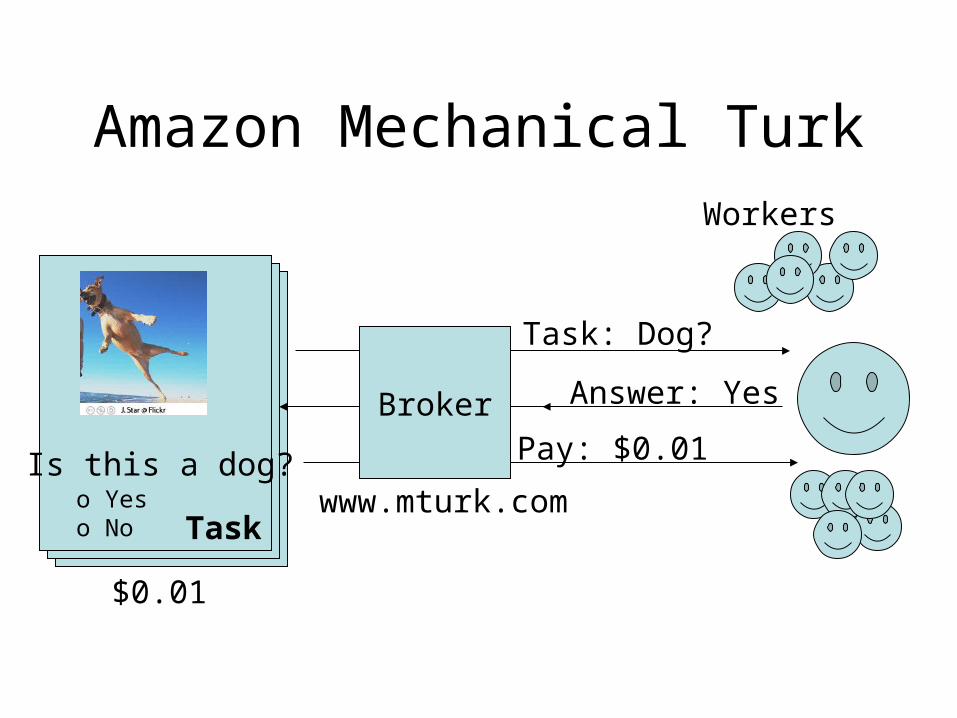
Amazon Mechanical Turk
Is this a dog?o Yeso No
Workers
Answer: Yes
Task: Dog?
Pay: $0.01Broker
www.mturk.com
$0.01

Select examples
Joint work with Tamara and Alex Berghttp://vision.cs.uiuc.edu/annotation/data/simpleevaluation/html/horse.html

Click on landmarks
$0.01http://vision-app1.cs.uiuc.edu:8080/mt/results/people14-batch11/p7/

Outline something
$0.01http://vision.cs.uiuc.edu/annotation/results/production-3-2/results_page_013.html
Data from Ramanan NIPS06

Mark object attributes
$0.03

Teach a robot

How do we define the task?

Annotation specification

Annotation language
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.

Ideal task properties

Ideal task properties

How good are the annotations?
Submission is Volume Action Redo
Empty 6% Reject yes
Clearly bad 2% Reject yes
Almost good 4% Accept (pay) yes
Good 88% Accept (pay) no
Task: label people, box+14pts; Volume 3078 HITs

How do we make it better?

1. Average N annotations

2. Require qualification
Please read the detailed instructions to learn how to perform the task. Please confirm that you understand the instructions by answering the following questions:
Which of the following checboxes are correct for this annotation?
No people (there are people in the image)
> 20 people (there are less than 20 people of appropriate size)
Small heads (there are unmarked small heads in the image)
Task: Put a box around every head

2. Require qualification

3. Use task pipeline

4. Do grading

Grade conflicts
Total grades: 4410

5. Automatic grading

Learning to grade
Task Bottles People Hands Large objects
Accuracy 95.0% 83.8% 45.5% 29.5%

Quality control

Setting the pay

Annotation Method Comparison
Approach Cost Scale Setupeffort
Collaborative Quality Directed Central Elastic to $
MTurk $ +++ * no +/+++ Yes no +++++
GWAP ++++ *** no + Yes Yes +
LabelME ++ Yes ++ no Yes
ImageParsing $$ ++ ** no ++++ Yes Yes +++
In house $$$ + * no +++ Yes no ++

Is it useful?

Publications

Thesis

Thesis
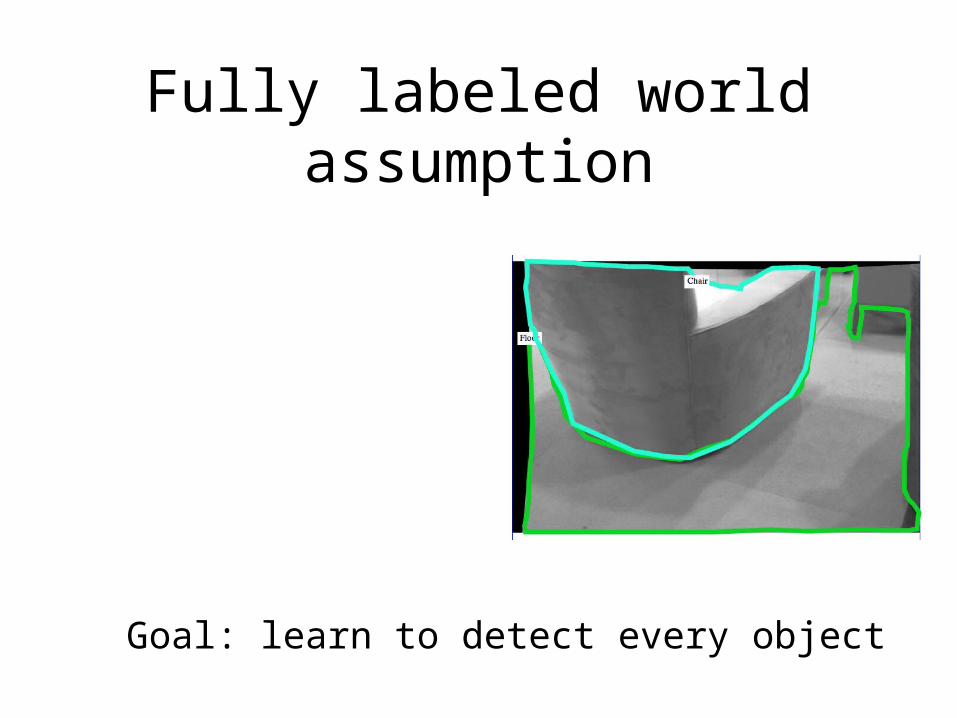
Fully labeled world assumption
Goal: learn to detect every object

Why is it important
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.

Computer vision task

Challenges

Challenges
Lighting conditions
Background clutter
Lighting and background are known
Within-class variability Viewpoint changesInternal deformations
100 000 categories How many instances?10s billions total10 000 locally
1000 examples per category 1-10 labels per object
Single image Rich sensor data

PR2 Sensing capabilities
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.

Autonomous data collection

Data labeling

Learning

QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.
Preliminary learning results
UChicago-VOC2008-person

Expected outcome

Thesis

Detect-Sample-Label

Sampling based estimation

Standard deviation tableAccuracy Sigma
% % 10 40 100 300 100099 9.95 3.15 1.57 0.99 0.57 0.3190 30.00 9.49 4.74 3.00 1.73 0.9560 48.99 15.49 7.75 4.90 2.83 1.5550 50.00 15.81 7.91 5.00 2.89 1.5830 45.83 14.49 7.25 4.58 2.65 1.4510 30.00 9.49 4.74 3.00 1.73 0.951 9.95 3.15 1.57 0.99 0.57 0.31
Sigma(%) at N samples

Estimating recall

Experimental results
Detector confidence levelNumber of detects
Number of samplesPrecision
3 sigmaRecall 0.1464 0.09774 0.2482 0.16565 0.3861 0.2577 0.6144 0.41008 0.8216 0.54834
Estimate for number of positives
@78K @118K @78K @118K @78K @118K @78K @118K @78K @118K
0.0234 0.0327 0.0275 0.0305
20%-50%
2000
50%-100%14000 14000 28011 84033 140055
5% 5%-10% 10%-20%
0.0126
9960.8239 0.5724 0.3878 0.214 0.11658278 4008 1996

What are the errors?

Timeline

Timeline

Timeline




Acknowledgments
Special thanks to:David Forsyth
Nicolas Loeff, Ali Farhadi, Du Tran, Ian Endres Tamara Berg, Pushmeet KohliDolores Labs (Lukas Biewald)Willow Garage (Gary Bradsky, Alex Teichman, Daniel Munos, …)
All workers at Amazon Mechanical Turk
This work was supported in part by the National Science Foundation under IIS - 0534837 and in part by the Office of Naval Research under N00014-01-1-0890 as part of the MURI program.
Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect those of the National Science Foundation or the Office of Naval Research.

Thank you

What is an annotation task?

PR2 Platform
• 2 Laser scannersFixed and Tilting
• 7 cameras2 stereo pairs,1 hires (5mpx)2 in the arms
• Structured light• 16 cores, 48 GB RAM• 2 Arms
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.

What are datasets good for?
• Training– The data is fully labeled
• Evaluation
• Tweaking the parameters– Performance is computed automatically
• Comparing algorithms– “They run on exact same data”

Why are datasets bad?
• Data sampling and labeling bias
• Small changes in performance are insignificant
• Parameter tweaking doesn’t generalize
• Overfitting to the datasets
• Datasets should be discarded after performance is measured












![arXiv:1802.07856v1 [cs.CV] 22 Feb 2018 · ings, all using different (and sometimes custom collected and labeled) datasets [13, 4, 1]. The uti-lization of different datasets makes](https://static.fdocuments.in/doc/165x107/5b704b277f8b9a66338d035f/arxiv180207856v1-cscv-22-feb-2018-ings-all-using-dierent-and-sometimes.jpg)


![SoundNet: Learning Sound Representations from Unlabeled …vondrick/soundnet.pdfthe emergence of massive labeled datasets [31, 42, 10] and learned deep representations [17, 33, 10,](https://static.fdocuments.in/doc/165x107/5f17725fcae7a5753e7d38fa/soundnet-learning-sound-representations-from-unlabeled-vondricksoundnetpdf-the.jpg)



![One-Shot Metric Learning for Person Re-Identification · 2017. 5. 31. · learn the model using large labeled datasets (e.g. fashion photography datasets [49]) and transfer the discriminative](https://static.fdocuments.in/doc/165x107/5fc148e2380c4d1c9834952a/one-shot-metric-learning-for-person-re-identification-2017-5-31-learn-the-model.jpg)