
Cassandra Summit 2014: Cassandra Compute Cloud: An elastic Cassandra Infrastructure

WHITE PAPER
BENEFITS OF EMC XTREMIO ICDM FOR
CASSANDRA DATABASE
Using EMC XtremIO Virtual Copies (XVC) to create Cassandra database replicas for various use cases
ABSTRACT
This white paper details the benefits of EMC XtremIO integrated copy data
management (iCDM) for Cassandra database deployments. It explains how to create
and manage database replicas through XtremIO iCDM features. It also explains the
Cassandra database data path and identifies key database structures and files. Finally,
this white paper compares and contrasts how both Cassandra snapshots and XtremIO
XVC work in support of various use cases.
March, 2016

2
To learn more about how EMC products, services, and solutions can help solve your business and IT challenges, contact your local
representative or authorized reseller, visit www.emc.com, or explore and compare products in the EMC Store
Copyright © 2016 EMC Corporation. All Rights Reserved.
EMC believes the information in this publication is accurate as of its publication date. The information is subject to change without
notice.
The information in this publication is provided “as is.” EMC Corporation makes no representations or warranties of any kind with
respect to the information in this publication, and specifically disclaims implied warranties of merchantability or fitness for a
particular purpose.
Use, copying, and distribution of any EMC software described in this publication requires an applicable software license.
For the most up-to-date listing of EMC product names, see EMC Corporation Trademarks on EMC.com.
Part Number H14983

3
TABLE OF CONTENTS
EXECUTIVE SUMMARY .............................................................................. 4
AUDIENCE ......................................................................................................... 4
CASSANDRA ARCHITECTURE .................................................................... 5
COMMITLOG ...................................................................................................... 5
MEMTABLE ........................................................................................................ 6
SSTABLE AND COMPACTION................................................................................ 6
XTREMIO INTEGRATED COPY DATA MANAGEMENT ................................... 7
XTREMIO VIRTUAL COPY ..................................................................................... 7
CRASH-CONSISTENT COPY ................................................................................. 7
APPLICATION-CONSISTENT COPY ........................................................................ 8
CASSANDRA ICDM USE CASES .................................................................. 9
LOGICAL DATA PROTECTION ............................................................................... 9
PREREQUISITES ......................................................................................................... 9
AUTOMATING SCRIPT (THROUGH A LINUX SCHEDULER) ................................................. 9
RESTORE ................................................................................................................ 10
BACKUP TO SECONDARY MEDIA ........................................................................ 11
PREREQUISITES ....................................................................................................... 11
AUTOMATING SCRIPT (THROUGH A LINUX SCHEDULER) ............................................... 11
DATABASE REPURPOSING ................................................................................. 12
PREREQUISITES ....................................................................................................... 12
WORKFLOW ............................................................................................................. 12
CONCLUSION .......................................................................................... 13
APPENDIX A “TABLE/COLUMN-FAMILY EXAMPLES” ............................... 14
REFERENCES ........................................................................................... 15

4
EXECUTIVE SUMMARY With the growing popularity of Cassandra database, customers are deploying large-scale, mission-critical applications on the
distributed database platform. As a Cassandra database scales to tens and hundreds of nodes, issues start to arise with traditional
deployment methods using direct-attached storage (DAS). DAS may initially be perceived as a low-cost, simple, and quick storage
solution. However, as the system scales, issues can arise around the complexity and inefficiency of managing performance, capacity,
and availability across storage silos—increasing risk and cost to the organization. Customers running Cassandra on DAS commonly
face the following challenges:
Inability to protect database from user error—if a user accidentally deletes data from a production database, it can take hours to
manually recover the data
High risk of product quality issues due to the inability to test and develop on the production data set
Non-scalable storage—the limited performance and capacity of DAS frequently causes fire drills during the compacting process
Long backup times
This white paper examines Cassandra DB’s internal mechanism to create immutable database files and durable log entries across
distinct nodes in a Cassandra cluster. It also discusses how EMC® XtremIO® integrated copy data management (iCDM) can be used
to create point-in-time replicas of the database, shared and/or replicated across all nodes comprising the cluster, for various use
cases such as local protection, staging for remote or off-line backup, database re-purposing, and others.
AUDIENCE
Cassandra DB administrators
Developers
Operators
Architects
Storage and Linux administrators
IT strategists and decision makers

5
CASSANDRA ARCHITECTURE Cassandra is designed as a distributed database with peer-to-peer communication. A Cassandra database cluster contains a number
of nodes and Cassandra automatically distributes data across all of these nodes that participate in a ring or database cluster. In
addition, each node contains a partitioned row store database. Cassandra built-in replication ensures redundant copies of data are
stored across nodes. Replication can be configured to work within one data center, across multiple data centers, or across multiple
cloud availability zones to provide high availability protection, as well as scalability.
Cassandra uses a log-structured storage engine, which groups inserts/updates to be made, and sequentially writes only the updated
parts of a row in append mode. In addition, Cassandra never re-writes or re-reads existing data, and never overwrites the rows in
place.
Important terms:
Memtables: Tables in memory pertaining to Cassandra Query Table (CQL) tables with indexes
CommitLog: Append-only log where log entries are replayed to reconstruct Memtables
SSTables: Memtable copies periodically flushed to disk to free up heap
Compaction: Periodic process to merge and streamline SSTables
The following is a reenactment of a write path flow on a node in a Cassandra Cluster for a sample table (or column-family) called
“Player” that has three fields—FirstName, LastName, and Level. Assume this Memtable (table in memory) corresponds to a CQL
table that has two entries or partitions (partitions are analogous to rows).
Partition Key 1 FirstName: Rose LastName: Colorado Level: 2
Partition Key 2 FirstName: Adam LastName: Washington Level: 1
Now, a new write comes in (3, Johnny, Utah, 10). It immediately goes to two places: the Memtable (in memory) and the CommitLog
(disk). At this point, the write is durable. The data is then sorted via the clustering column and the write request is acknowledged.
This is a very fast write operation. From time to time, the Memtable is flushed to disk (SSTable) to be read friendly. Once durable on
disk, the memtable, along with the entries in the Commitlog, can now be released.
If the data is modified a few times—for example, “Johnny Utah’s level has progressed/increased a few times”—and flushed a few
times then there would be equal number of versions of the data on disk, representing each state of the data. But the only data that
matters is the most recent one. So from time to time, all of these SSTables on disk are combined or compacted into a new file. Once
this is achieved, all of the previous files that contributed to the new one are deleted. The important point is that the files are never
modified or edited. A new one is created that supersedes a former one. This is a very important point because if compaction is not
performed at some point, then a read request would have to traverse through all previous versions of the data on disk to arrive to
the current view.
Compaction is expensive with high updates. All iterations of the data have to be streamed to memory and filtered to find the newest
values. The data is also evicted and streamed back to disk. This is an expensive read/write operation that XtremIO does very well.
COMMITLOG
As previously mentioned, CommitLog is an append-only log. In the event of a downed node, the CommitLog will automatically
rebuild the Memtables when a node is restarted. Memtables are flushed to disk when CommitLog sizes reach certain thresholds.
These parameters have default values and are configurable in cassandra.yaml (Cassandra configuration file):
“commitlog_total_space_in_mb” size at which oldest Memtable log segment will be flushed to disk (default is 1024 for 64-bit
JVMs)
“commitlog_segment_size_in_mb” max size of individual log segments (default: 32)
Entries in CommitLog are marked as flushed when corresponding Memtable entries are flushed to disk as an SSTable. Entries accrue
in memory and are synced to disk in either batch or periodic manner. The following parameters affect these:

6
“commitlog_sync” – either periodic or batch (default: periodic)
o “batch” writes are not acknowledged until log syncs to disk
- “commit_log_sync_batch_window_in_ms” how long to wait for more writes before fsync (default: 50)
o “periodic” writes are acknowledged immediately while sync happens periodically
- “commitlog_sync_period_in_ms how long to wait between fsync log to disk (default:10000 or 10 seconds)
Note: By default, for Cassandra’s performance optimization, the writes are acknowledged before writes are durable on disk. For ten
seconds, data may not be flushed or persistent to the durable CommitLog. But this is okay since the proper implementation of
Cassandra DB requires replication to other DB servers. Thus, careful consideration should be taken when deploying these servers to
ensure redundant power supplies or grids are in place.
MEMTABLE
Memtables are in-memory representations of a CQL table. Each node has a Memtable for each CQL table in the keyspace
(counterpart of a Microsoft SQL DB or an Oracle Tablespace). Each Memtable accrues writes and provides reads for data not yet
flushed. Updates to Memtables mutate the in-memory partition (a partition is a physical unit of data that consists of a collection of
sorted cells and is identified by a partition key). See Appendix A for examples depicting table with single-row and multi-row
partitions.
When a Memtable flushes to disk, current Memtable data is written to a new immutable SSTable on disk, JVM heap space is
reclaimed from the flushed data, and corresponding CommitLog entries are marked as flushed.
A Memtable flushes the oldest CommitLog segments to a new corresponding SSTable on disk when:
“memtable_total_space_in_mb” is reached (default: 25 percent of JVM heap)—typically 2 GB out of 8 GB, the recommended
heap size
Or “commitlog_total_space_in_mb” is reached (default: 1 GB)
Or a “nodetool flush” command is issued
SSTABLE AND COMPACTION
An SSTable, sorted string table, is an immutable file of sorted partitions written to disk through fast, sequential I/O. It contains the
state of a Memtable when flushed. The current data state of a CQL table is comprised of its corresponding Memtable plus all current
SSTables flushed from that Memtable. SSTables are periodically compacted from many to one.
For each SSTable, two important structures are created among other structures:
Partition index: A list of its primary keys and row start positions
Partition summary: In-memory sample of its partition index
See “Writing and Reading” section of this introduction by rschumacher https://academy.datastax.com/demos/brief-introduction-
apache-cassandra to read about a brief interaction with other structures during read operation. More elaborate training modules are
available from DataStax.com.
Updates do mutate Memtable partitions, but its SSTables are immutable. SSTables are never modified or over-written. SSTables just
accrue new time-stamped updates. Therefore, SSTables must be compacted periodically. The most recent version of each column is
compiled to one partition in one new SSTable. Partitions marked for deletion are evicted, and old SSTables are deleted. Compaction
will impact the physical makeup of files and file system, but will not affect the integrity of data content assigned.

7
XTREMIO INTEGRATED COPY DATA MANAGEMENT The benefits of copy data management (CDM) to traditional databases (shared-everything architecture) is well understood in the
storage and database community. Methodologies for integrating copies of primary volumes with traditional databases on legacy
storage were well entrenched in the storage industry long before the advent of EMC XtremIO. But XtremIO, through iCDM, has taken
it to the next level.
Using the XtremIO iCDM technology stack, you can create crash consistent copies of the Cassandra database without invoking the
Cassandra application process using XtremIO Virtual Copy (XVC). Or you can create application consistent copies of the database by
coordinating the copy creation process between the Cassandra application and XtremIO.
XTREMIO VIRTUAL COPY
At the heart of iCDM is XtremIO Virtual Copy (XVC). XVC is space-efficient, point-in-time copy of a volume. Methodologies to
integrate primary volume copies with databases that have been established for many years need not change and are compatible with
XVC, a differentiator of XVC. Furthermore, XtremIO provides a built-in scheduler for automation, a rich set of REST APIs, and simple
XMCLI calls to refresh images in various directions.
The process to invoke XVC is all about metadata manipulation in memory on XtremIO. The process is metadata efficient, space-
capacity efficient, seamless, and fast with no degradation in terms of performance against the source volumes or the virtual copies of
the source volumes. A solution overview on iCDM can be retrieved here.
XVC can be created, deleted, restored (to source volumes), and refreshed with point-in-time images from source volumes or other
XVCs created from the same source volumes. In addition, they can be managed via the GUI, CLI, or REST API. The built-in scheduler
via the XtremIO GUI not only automatically schedules the creation of XVC, but also manages the expiration of XVC, which is essential
for achieving a hands-free, crash-consistent copy-creation policy.
XVC can be associated to a set of volumes, a consistency group (CG), comprising an application (a database for example), or
associated individually to a source volume. The relationship is one-to-many—one source volume to many snapshots or XVCs, or one
source CG to many snapshot CGs (snapshot sets). Relevant documents authenticating and managing XtremIO through REST are
downloadable from support.emc.com.
CRASH-CONSISTENT COPY
The process to create crash-consistent database replicas using the XtremIO GUI XVC Scheduler is fairly straightforward. The process
is comprised of the following simple steps:
Using the GUI, right-click on the consistency group and select “Create Scheduler”
The next step is comprised of entering the following parameters:

8
Note: A crash-consistent Cassandra DB is acceptable as long as it is understood that there is a possibility that the copy on the XVC
can be up to 10 seconds behind from the source Cassandra cluster when the database image is captured on XVCs. There is a 10-
second delay before “fsync” can flush the active entries to the CommitLog by default for optimization reasons. This is certainly
configurable, but it is the default for a reason. However, you can schedule an hourly or every 30 minute interval using the XtremIO
GUI. This is much easier to implement and offers a longer protection window than what can be achieved natively utilizing “nodetool
snapshot.” This is because the native implementation carries the potential for a build-up of wasted space in the “snapshots” directory
of each node.
The database replicas can be read-only and can be restored quickly and directly to the production database. The image can also be
writeable and can be mounted, modified, tested, and validated before refreshing the image to the production database.
The scheduler not only automatically schedules the creation of XVCs but also manages the expiration of XVCs. It is a hands-free,
crash-consistent copy-creation policy.
APPLICATION-CONSISTENT COPY
Switching the process for creating snapshots from a file-system-based process to a storage-based one utilizing XVC is very
streamlined. The process is comprised of the following simple steps:
Using “parallel ssh tool”, issue “nodetool flush” on every node in the cluster
Using “parallel ssh tool”, flush the page file (OS Layer) on every node in the cluster

9
Using XMCLI or REST API, create snapshots (if none exist) or refresh image of snapshots (if existing) with the production cluster
image in unison
Note: The immutable nature of Cassandra DB files (SSTables), the durability of commit log in conjunction with the consistency of the
XVC comprising snapshot set, and the simplicity of the process on XtremIO to invoke and manage XVC make the solution robust,
simple, and effective.
CASSANDRA ICDM USE CASES
LOGICAL DATA PROTECTION
While the Cassandra distributed architecture provides built-in redundancy to protect from node failure, proper backup of the
database is still critical to protect the application from logical data corruption, accidental data deletion, and other user errors.
Native Cassandra backup uses Linux hardlinks for creating snapshots. During snapshot operation, Cassandra creates hardlinks for
each SSTable in a designated snapshot directory. As SSTables are immutable, there are numerous SSTables over a period of time.
During compaction or merge operation, the file system makes a copy of SSTable to perform compaction and merging of these files to
consolidate and free up storage. The copies require the same amount of free space on the system as the SSTables. The process of
copy creation is time-consuming as well as resource-intensive.
The XtremIO iCDM stack provides an alternate way of backing up the Cassandra cluster for logical data protection that is
instantaneous and space efficient. The following provides a combination of commands (script) that can be automated using a Linux
scheduler (such as crontab) to create a nightly Cassandra DB Cluster replica on XVCs for online backup. The goal is to refresh these
XVCs with a timely production image nightly at 23:00 PM as an example.
PREREQUISITES
For this setup, there are four nodes in the Cassandra DB Cluster. Each node has a data and log volume. These are DATA1, DATA2,
DATA3, DATA4, LOG1, LOG2, LOG3 and LOG4. Node1 has DATA1 (mounted as /data) and LOG1 (mounted as /datalog), Node2 has
DATA2 (mounted as /data) and LOG2 (mounted as /datalog) and so forth. All of the volumes are contained in a consistency group
called “Cassandra_Cluster_CG” as defined on XtremIO.
A Linux jump box has been selected to manage automation for this task. It has the Cassandra binaries installed. Parallel SSH (pssh)
is installed on this Linux box as well. An admin Linux user has the required privilege to execute nodetool and communicate to all of
the nodes in parallel over IP. The IP addresses of each node are contained in a configuration file called “ipcx.txt”. A user named
cassandra, privileged to execute the following XMCLI commands, has been created on XtremIO:
“create-snapshot”
“create-snapshot-and-reassign”
“rename”
The XtremIO user has been provided with the public key (id_rsa.pub) from the admin Linux user. This allows the Linux user to
authenticate to XtremIO (XMS) without requiring a password or executing XMCLI commands.
The snapshot set for Monday has been pre-created using the following XMCLI command:
create-snapshot consistency-group-id="Cassandra_Cluster_CG" snapshot-set-name="Monday_Cassandra_Cluster_CG" snap-
suffix="Snap_Monday"
After execution, a new Snapshot set with the name “Monday_Cassandra_Cluster_CG” is created. The snapshot set is comprised of
eight snapshots named DATA1.Snap_Monday, DATA2.Snap_Monday, etc. pertaining to a consistent point-in-time for each source
volume in the CG.
AUTOMATING SCRIPT (THROUGH A LINUX SCHEDULER)
Automating the refresh of the DB replicas on XtremIO is fairly easy. The following shows a simple implementation utilizing crontab as
an example:

10
00 23 * * * </Path/script_name>
At 23:00 PM, cron initiates the script.
The simple script has the following lines of code:
pssh -h ./ipcs.txt -o /tmp/foo nodetool flush;cat /tmp/foo/* #Flushes Memtables to SSTables
pssh -h ./ipcs.txt -o /tmp/foo free && sync && echo 3 > /proc/sys/vm/drop_caches && free;cat /tmp/foo/* # Flushes file system
buffer cache/page file
ssh cassandra@xbricksc108 create-snapshot-and-reassign no-backup from-consistency-group-id=\"Cassandra_Cluster_CG\"
snapshot-set-name=\"Temp_Monday_Cassandra_Cluster_CG\" to-snapshot-set-id=\"Monday_Cassandra_Cluster_CG\" #Refreshes
image of snapshots associated to the source volumes comprising the CG, and these new snapshots are associated to a new snapshot
set id
ssh cassandra@xbricksc108 rename snapshot-set-id=\"Temp_Monday_Cassandra_Cluster_CG\" new-
name=\"Monday_Cassandra_Cluster_CG\" #Renames the snapshot set id to the designated snapshot set name
cqlsh <IP Address of Node1> -f cquery_schema.cql > Monday_Schema.txt #Creates a script to recreate schema if necessary
Note: The file “cquery_schema.cql” contains a single command: “DESCRIBE SCHEMA”. The output is directed to
“Monday_Schema.txt”.
The script itself could be computing the actual day of the week through a variable, for example, Day=`date +%A`. The idea is that a
single script can be scheduled to run every night. Nightly online backup creation is just an example. This can be changed easily to an
hourly schedule if so desired to extend the protection window.
With XtremIO, there is no need to invoke “nodetool snapshot” although it is recommended to leave “auto_snapshot” set to true since
this protects from inadvertent delete or truncate. Cassandra snapshots resulting from these triggers would still need to be cleaned up
if no longer needed. As a result, there is more space from the actual file system dedicated to data versus leftover SSTables (in the
“snapshots” directory) that may take time to offload.
RESTORE
Restore from an online backup to production is just as fast and efficient since the process consists of in-memory meta-data
manipulation on XtremIO. Unlike a typical restore process in Cassandra, there is no need to delete the current SSTables in the data
directory. Also, there is no need to copy the SSTables from the “snapshots” directory to the data directory, and certainly there is no
need to clean up the “snapshots” directory except from events triggering creation of Cassandra Snapshots due to truncate or delete.
On XtremIO, the actual restore steps are composed of the following:
Stopping dse service on all nodes #pssh -h ./ipcs.txt -o /tmp/foo service dse stop;cat /tmp/foo/*
Stopping datastax-agent service on all nodes #pssh -h ./ipcs.txt -o /tmp/foo service datastax-agent stop;cat /tmp/foo/*
Unmounting “/data” and “/datalog” on all nodes #pssh -h ./ipcs.txt -o /tmp/foo umount /data /datalog;cat /tmp/foo/*
On XtremIO, it might be wise to create another snapshot set to preserve the current state of the Cassandra DB cluster. Call it
“Old_Cassandra_Cluster_CG” if you will just in case.
Restoring desired online copy from the inventory (for example “Monday_Cassandra_Cluster_CG” or from the last hour if hourly
interval is implemented)
From the XtremIO authenticated Linux admin user, this can be done by issuing a single XMCLI command:
o ssh cassandra@xbricksc108 create-snapshot-and-reassign from-snapshot-set-id=\"Monday_Cassandra_Cluster_CG\"
to-consistency-group-id=\"Cassandra_Cluster_CG\" no-backup

11
Note: The above command allows for the point-in-time image from an online backup (database replica) to replenish the former
production database image, but the SCSI device name remains intact. As a result, there is no need to rediscover new devices on the
channel from the host/node perspective or to modify the “/etc/fstab” with the new block device names to be mounted.
Rebooting all nodes #Or perform the following: Mount “/data” and “/datalog” on all nodes; Start “dse” and “datastax-agent” on
all nodes
Automatically, nodes will perform recovery on restart. If there are entries in the CommitLog, these will convert to Memtables after
the cluster comes up. If that is not the desired result, delete the entries in the CommitLog before starting the “dse” service on each
node.
BACKUP TO SECONDARY MEDIA
A complete backup strategy involves first backing up the local SAN, and copying backups to secondary media for longer term
retention. XtremIO iCDM technology can be used to enhance the backup to secondary media process.
XtremIO XVCs are autonomous and can be mounted directly to a backup server. Once mounted, they can be streamed to a
secondary media (disk or tape). There are a few advantages of doing it this way:
Eliminates file-system contention compared to traditional backup effort in Cassandra
Alleviates the actual nodes from exerting or spending any resources streaming the backup
Eliminates the build-up of wasted space in the “snapshots” directory
PREREQUISITES
Resuming from the previous setup, the designated Linux server also functions as the backup server. The XVCs from the nightly
online backup job are presented (mapped) to the backup server. There would be a total of 8 * seven (days) XVCs. These virtual
copies would be unmounted by default and only mounted for the duration of the backup. XVCs would be unmounted right after.
Appropriate directories or mount points will be pre-created: /data1, /data2, /data3.. /datalog1, datalog2, etc., on the Linux server.
AUTOMATING SCRIPT (THROUGH A LINUX SCHEDULER)
Automating the backup of the database replicas to a secondary media is fairly easy. The following shows a simple implementation
utilizing crontab as an example:
30 23 * * * </Path/script_name>
At 23:30 PM, cron initiates the script.
The simple script has the following pseudo codes:
Depending on the day of the week (Day=`date +%A`), mount the corresponding XVCs; for example if Monday:
“ mount <block device pertaining to DATA1.Snap_Monday> as /data1”
“ mount <block device pertaining to LOG1.Snap_Monday> as /datalog1”
“ mount <block device pertaining to DATA2.Snap_Monday> as /data2”
“ mount <block device pertaining to LOG2.Snap_Monday> as /datalog2”
..
Streaming to tape for example using “xfsdump”
xfsdump -l 0 -f <media object> /data1
xfsdump -l 0 -f <media object> /datalog1
Unmount /data1, /data2, etc.

12
Note: The “xfsrestore” command may be used to restore the files back from the media. Once on the XVCs, a simple XMCLI refresh
from the XVCs can be performed to replenish the source volumes with images from the XVCs. Obviously, the former database image
can be preserved using XVCs prior to over-writing, demonstrating the remarkable flexibility provided by iCDM on XtremIO.
EMC Data Domain® offers certain advantages for consolidating backup and archive data on the Data Domain system. Through inline
deduplication, the storage requirement for storing backup or archive data is remarkably reduced. In addition, the restore operation is
much simpler.
DATABASE REPURPOSING
Copies of production environment are critical to many downstream processes. For example, the ability to test and develop on a
production copy of data would significantly reduce risk of rolling out new features. In industries like financial, different teams run
different reports/analysis on the data, so it is essential for them to get access to a point-in-time copy of production data.
The following sections describe processes of using XtremIO iCDM technology to create instant copies of Cassandra database for
downstream consumption with storage efficiency.
The Cassandra cluster utilizes vnodes for this setup in the lab. A token is an “integer value generated by a hashing algorithm” that
identifies the partition location (which node) within a Cassandra cluster. The number of tokens used per node is 256 (num_tokens:
256 in cassandra.yaml). It has certain advantages over single-node token implementation if the goal is to have flexibility when
adding or removing nodes as automatic data redistribution kicks in and data is rebalanced among nodes. With single-node, you have
to double the number of nodes every time you want to add nodes to achieve balanced data redistribution among the nodes.
Each partition in a given column-family is associated to a token. The node partitioner makes it so. Each node has 256 tokens per
setup disclosed above. These tokens are associated to a given node, host id. These tokens persist on the data thus preventing chaos.
When nodes are added or a node is removed, the association between partitions and tokens is reorganized throughout the cluster.
Since stale data is not removed during rebalancing, it is recommended to run the “nodetool cleanup” operation to remove stale data
not previously deleted.
After the primary volumes are cloned, the clones (XVCs) containing data and log will be mapped to another cluster (new). The
tokens for the new cluster being repurposed must match the tokens from the source cluster (original). Furthermore, the data and log
XVCs must be presented to the correct node with the matching tokens. To recover the database in its entirety, there has to be a
matching number of cluster nodes between the source and the target cluster. Consider enforcing Replication Factor (RF) on all
keyspaces to be able to restart the cluster with a smaller number of nodes. Otherwise, consider recreating the schema and using the
“sstableloader” procedure documented in “Apache Cassandra 2.1 Documentation, November 10, 2015”.
PREREQUISITES
Resuming from the original setup, there will be four new nodes with identical setup as the nodes comprising the original cluster.
These new nodes (CLONES of the original) are exactly alike in every aspect with the exception of the hostnames (host IDs) and IP
addresses. These new nodes (C_NODE1, C_NODE2, C_NODE3, and C_NODE4) will contain a similar matching “cassandra.yaml” file
as their counterpart (original cluster- NODE1, NODE2, NODE3, and NODE4), but the settings in the “cassandra.yaml” requiring IP
addresses will be replaced with that of C_NODE1, C_NODE2, C_NODE3, and C_NODE4, respectively. Essentially, the C_NODEs are
contained separately in their own cluster. The “cassandra.yaml” files on the new nodes again will be modified at a later time to add
the tokens from the original nodes. A new snapshot set will be forged from "Cassandra_Cluster_CG". Call this snapshot set
“Snap_Cassandra_Cluster_CG” if you will. The XVCs are named DATA1.XVC, DATA2.XVC, LOG1.XVC, LOG2.XVC, etc. Similar to the
setup on the source nodes, DATA1.XVC (mounted as “/data”) and LOG1.XVC (mounted as “/datalog”) are mapped to C_NODE1.
DATA2.XVC (mounted as “/data”) and LOG2.XVC (mounted as “/datalog”) are mapped to C_NODE2, and so forth.
WORKFLOW
Generate the tokens for NODE1 using the following command:
nodetool ring | grep <ip_address_of_NODE1> | awk ' {print $NF ","}' | xargs
Collect the result from the above output and append it to the “cassandra.yaml” file for C_NODE1 just like the following: #This is
a onetime process unless the source cluster is recreated
initial_token: -9181203603096949228, -9086097857848777132, -9064540780373956006, -9014128871795450441, -
8979487920106982487, -8939973617398573175, -8887063701687856121, -8855931846083367083, -
8852105983478641008. #Remove the trailing comma from the above output

13
Repeat the same procedure on C_NODE2, C_NODE3 and C_NODE4
Unmount “/data” and “/datalog” for each node (C_NODE1, C_NODE2, C_NODE3, C_NODE4)
Perform a coordinated “nodetool flush” on the source cluster
Perform a coordinated flush of each node’s buffer cache or page file (source cluster)
Perform “Snapshot Refresh” of source database image or source Cassandra cluster (“Cassandra_Cluster_CG”) to the target
database replica (“Snap_Cassandra_Cluster_CG”) or target Cassandra cluster
Reboot all nodes #Or perform the following Mount “/data” and “/datalog” on all nodes; Start “dse” and “datastax-agent” on all
nodes
Note: With the exception of the modification to the “cassandra.yaml” file on each C_NODE, which has to be done once, the entire
workflow can be automated. The steps mentioned in the workflow above are not new and can be automated from the same Linux
user. The “Snap_Cassandra_Cluster_CG” snapshot set does not have to be refreshed from the source CG. It could very well be
refreshed from existing snapshot sets such as the online nightly backup. This proves the versatility of iCDM on XtremIO.
CONCLUSION iCDM is a clear differentiator for Cassandra deployed on XtremIO for various use cases. XtremIO Virtual Copies provides the core
technology that enables the use of these space-efficient and no over-head copies of the source Cassandra cluster for different
purposes such as database re-purposing, local protection, and staging for off-line backups. As illustrated in this paper, using XVCs
drastically simplifies the operation complexity and increases the efficiency in deploying and managing Cassandra DB and copies at
large scale. Through the consistent and scale-out performance of XtremIO, the original/source database and replicas all can coexist
without impacting each other by utilizing easy-to-implement performance sizing methodologies. While the examples presented in this
paper used XMCLI as a way to illustrate the workflow automation, the XtremIO GUI XVC scheduler and REST API are all viable
options for automation based on the operational and business requirements, taking into consideration acceptable SLAs.
In summary, using agile instantaneous XtremIO Virtual Copies over native Cassandra snapshots provides the following benefits:
No Overhead Crash-Consistent Copies: Copies created through the XtremIO GUI scheduler can provide a longer protection
window than what can be achieved natively utilizing “nodetool snapshot” because the native implementation implies potential
build-up of wasted space in the “snapshots” directory of each node.
More efficient and frequent protection copies: Creating “flushed copies/Application Consistent copies” or backup compliant
copies through iCDM is more efficient and simpler to implement and maintain in comparison to capturing the database image
using “nodetool snapshot” command and taking into consideration the post-processing involved and management over-head
associated with it. iCDM provides a more efficient methodology of backing up to secondary media. You can also integrate this
with existing remote backup appliances such as EMC Data Domain for nightly full backups.
Efficient and instantaneous restore from copies: As previously illustrated, the restore and recovery process through iCDM
from online database replicas either from a crash-consistent copy or “flushed copy/Application Consistent copies” is
instantaneous and very easy to implement compared to the procedures that have to be performed natively recovering from the
“snapshots” and “backups” directories. Having many point-in-time copies from which to restore benefits the IT infrastructure
solutions tremendously.
Instant copies for database repurposing: Through iCDM, the administrators can make instant copies that can eliminate the
overall streaming and replication of Cassandra clusters. In addition, XVCs provide flexibility in terms of refreshing copies with
production images instantaneously. This is not the case with the native Cassandra process of streaming the data to replicas.
iCDM has many benefits such as the ability to apply and test patches on a copy before rolling out to production or being able to
instantly roll back in the event of a disaster or botched attempt at an upgrade or patch installation.
Instant space reclamation: Over time, space in XtremIO blocks consumed by the source Cassandra Cluster will deviate from a
replica (XVCs) created on a Monday (for example) as data in production is continuously modified. However, on the following
Monday, when the image is refreshed, the former referenced XtremIO blocks are invalidated and the delta reverts back to zero
capacity, providing instant space reclamation. Again, this cycle continues for Tuesday’s image and so forth. This automated
process implies no management overhead.
14
It is clear that the benefits of XtremIO iCDM can be used for Cassandra databases just as they are for traditional databases such as
Oracle and SQL Server.
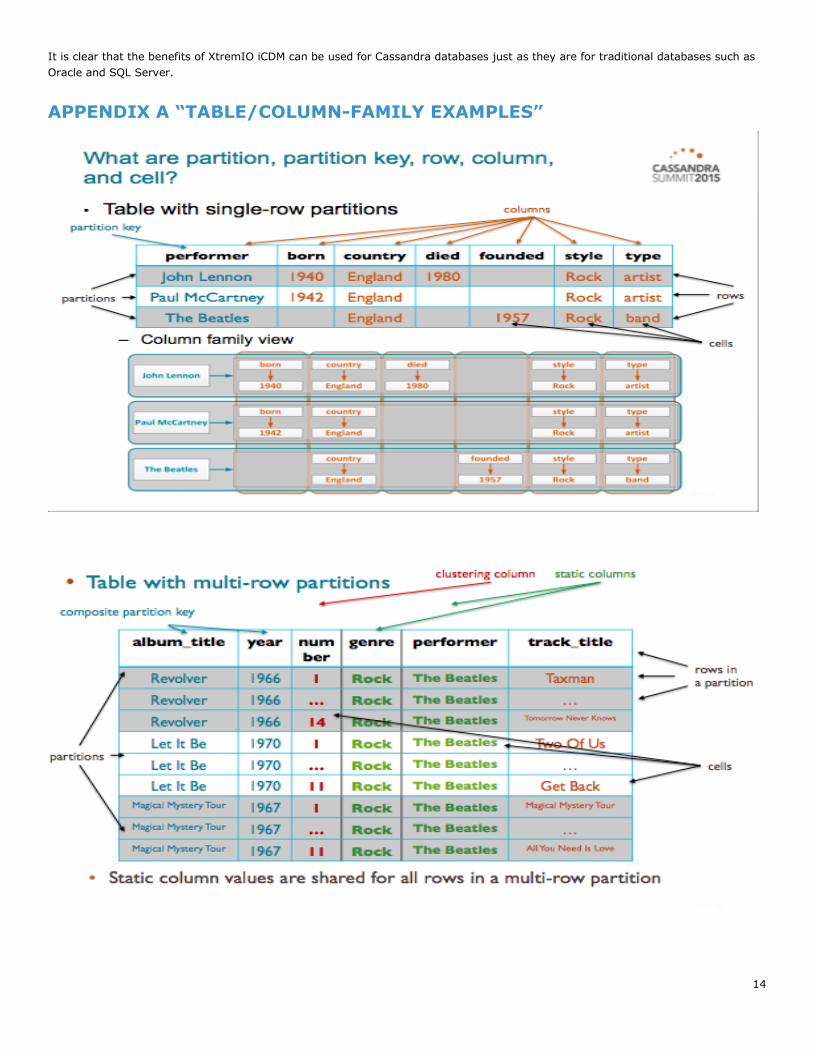
APPENDIX A “TABLE/COLUMN-FAMILY EXAMPLES”

15
REFERENCES
Gabriel, Kiyu (Present). DS201: Cassandra Core Concepts. Write Path: “Cassandra Write Path”. Retrieved from
https://academy.datastax.com/courses/ds201-cassandra-core-concepts/write-path-cassandra-write-path
Gabriel, Kiyu (Present). Cassandra Summig 2015: Cassandra Core Concepts Exam Review. “CQL Table with single row and multi-row
partitions”. Retrieved from PowerPoint Slides.
Rshumacher (2015). A Brief Introduction to Appache Cassandra. Retrieved from
https://academy.datastax.com/demos/brief-introduction-apache-cassandra
Kumar, Avishek (2015). Whiteboard Video for iCDM. Retrieved from
https://edutube.emc.com/html5/videoPlayer.htm?vno=GbocUPa592Tf4uDW7hLm3Q==
XtremIO 4.0.2 Storage Array Restful API Guide. Retrieved from
https://support.emc.com/docu62759_XtremIO-4.0.2-Storage-Array-RESTful-API-Guide.pdf?language=en_US
XtremIO 4.0.2 Storage Array User Guide
https://support.emc.com/docu62760_XtremIO-4.0.2-Storage-Array-User-Guide.pdf?language=en_US
Magic Quadrant for Operational Database Management Systems. Retrieved from
http://www.gartner.com/technology/reprints.do?id=1-2PO8Z2O&ct=151013&st=sb
Solution Overview: XtremIO Integrated Copy Data Management. Retrieved from
https://www.emc.com/collateral/solution-overview/solution-overview-xtremio-icdm-h14591.pdf
Oracle 12c: Making Backups with Third-Party Snapshot Technologies
https://docs.oracle.com/database/121/BRADV/osbackup.htm#BRADV90019

16


















