
Fosdem how you can benefit from redis, javier ramirez @ teowaki
Upload
javier-ramirezCategory
view
254download
1
Everything you always wanted to know about Highly Available Distributed Databases
javier ramirez - @supercoco9
AMSTERDAM 11-12 MAY 2016
https://teowaki.com

IBM Data Centerin Japan duringand after an earthquake
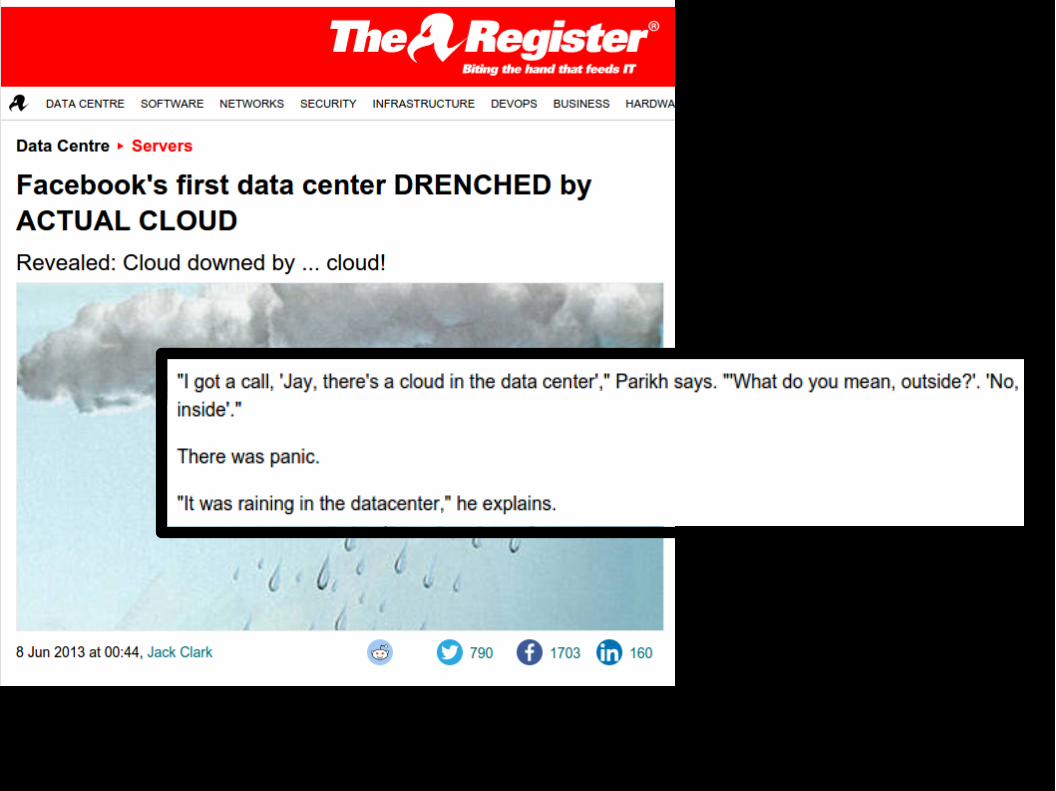

A squirrel did take out half of our Santa Clara data centre two years backMike Christian, Yahoo Director of Engineering
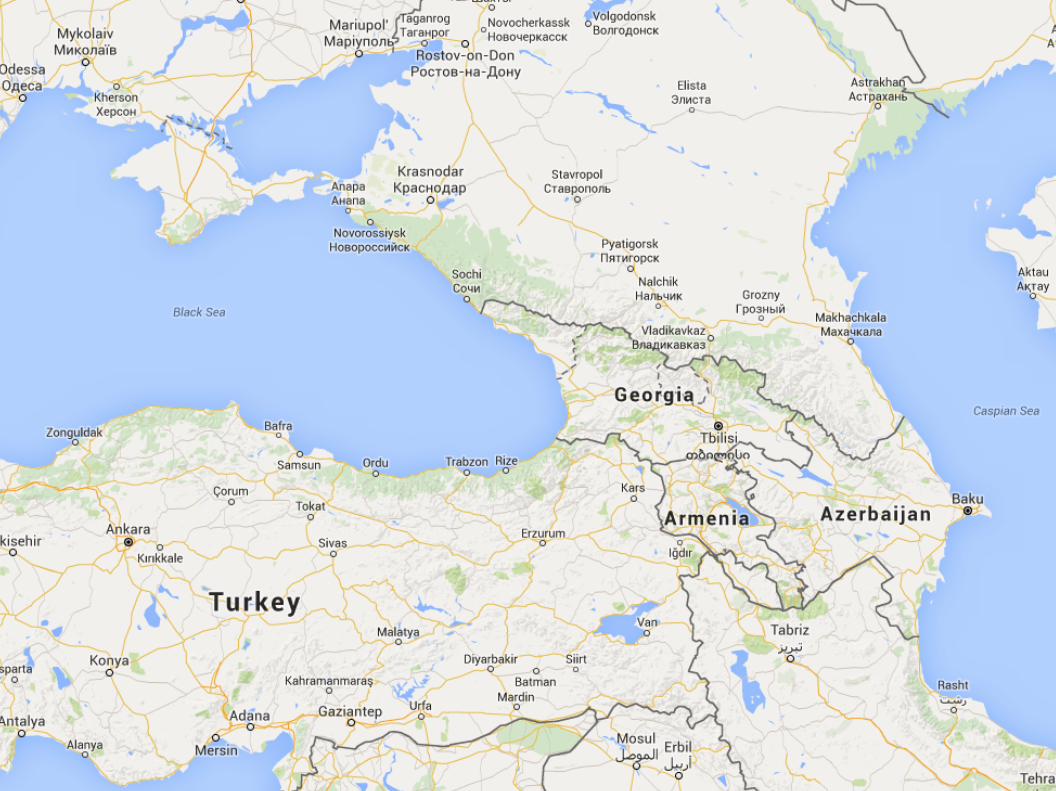

Hayastan Shakarian
a.k.a.The SpadeHacker

Cut-offArmeniafrom the Internetfor almostone day*
* By accident, while scavenging copper

I have no idea what the internet is

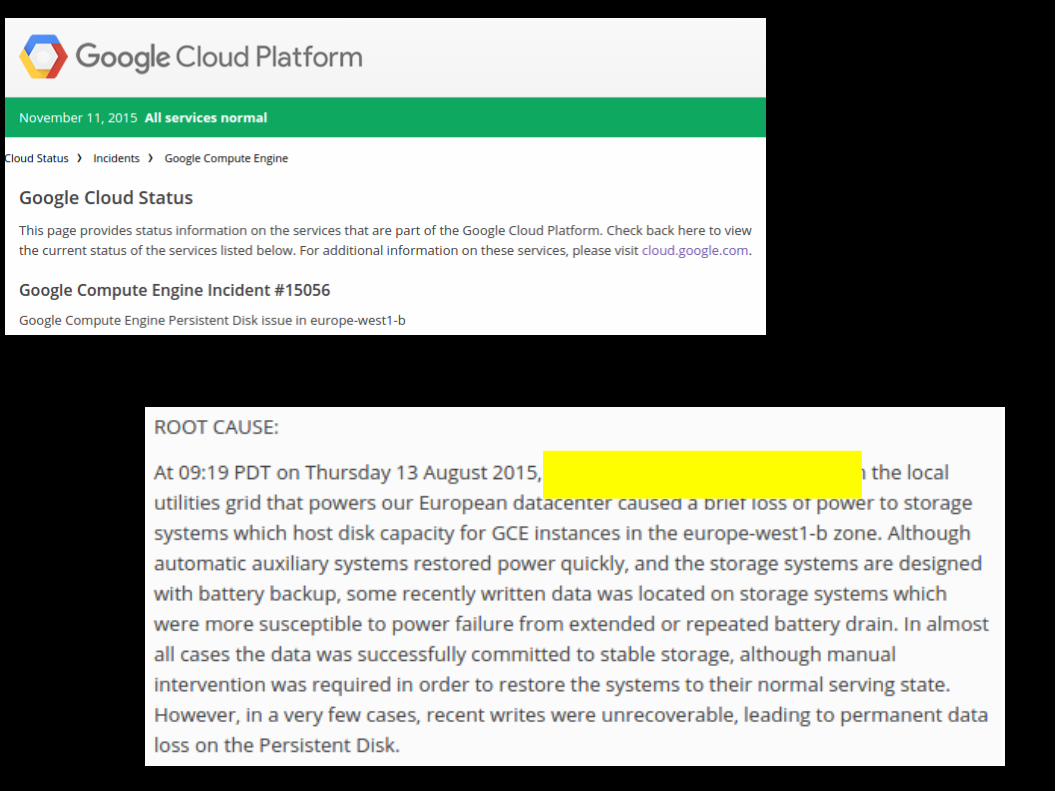
Some data center outages reported in 2015:
* Amazon Web Services* Apple iCloud* Microsoft Azure* IBM Softlayer* Google Cloud Platform
* And of course every hosting with scheduled maintenance operations (rackspace, digitalocean, ovh...)

Complex systems can and will fail

You better distribute your data, or else...
Also, distributed databases can perform better and run on cheaper hardware thancentralised ones

Most basic level:Backup

And keep the copyon a separate data centre*
* Vodafone once lost one yearof data on a fire because of this

Next Level:
Replicas(master-slave)

A main server sends a binary log of changes to one or more
replicas
* Also known as Write Ahead Log or WAL

Master-slave is good but
* All the operations are replicated on all slaves
* Good scalability on reads, but not on writes
* Cannot function during a network partition
* Single point of failure (SPOF)

Next Level:Multi-Master Cluster(master-master)

Every server can accept reads or writes, and send its binary log to all the other servers
* also referred as update-anywhere

Multi-master is great, but:* All the operations are replicated on all masters.
* When synchronous, high latency (Consistency achieved via locks, coordination and serializable transactions)
* When asynchronous, typically poor conflict resolution
*Hard to scale up or down automatically

The system I want:* Always ON, even with network partitions
* Scales out both reads and writes. Doesn't need to keep all the data in all the servers
* Runs on cheap commodity diverse hardware
* Runs locally to my users (low latency)
* Grows/shrinks elastically and survives server failures

Then you need to let go ofmany convenient things you take for granted in databases
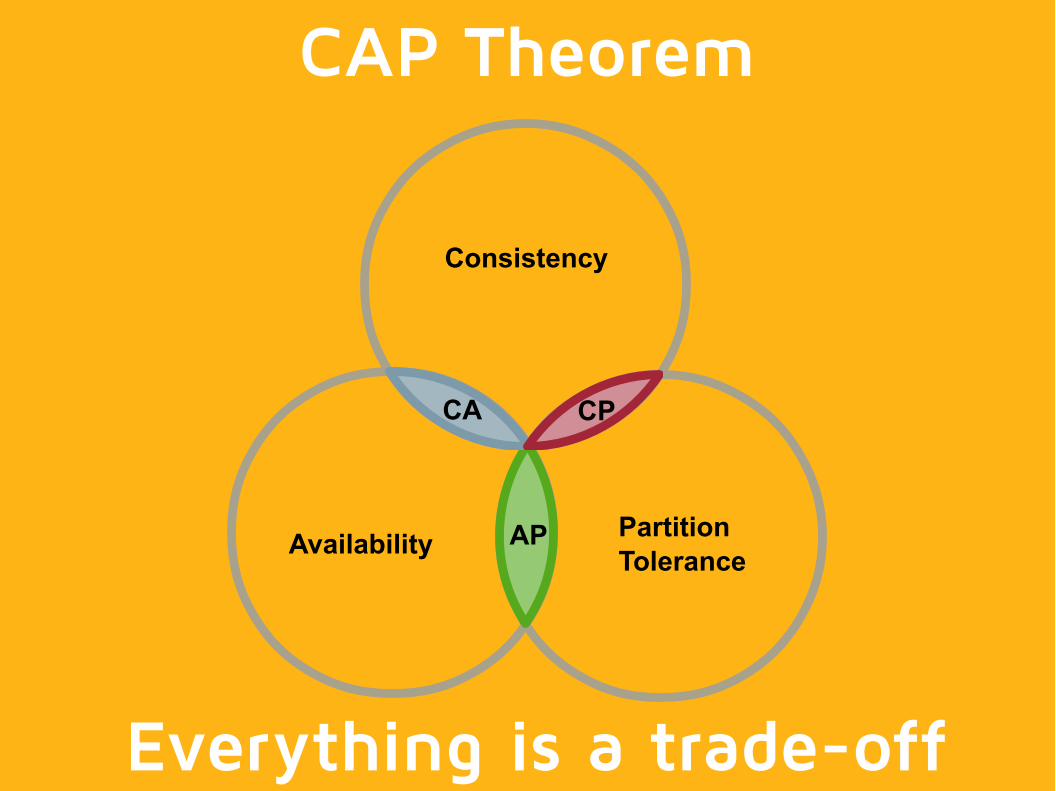
AvailabilityPartition Tolerance
Consistency
CA
AP
CP
CAP Theorem
Everything is a trade-off

Next Level:Distributed Data stores


Distributed DB design decisions
* data (keys) distribution* data replication/durability* conflict resolution* membership* status of the other peers* operation under partitions and during unavailability of peers* incremental scalability

Data distribution
Consistent hashing based on the key
Usually implies operations work on single keys. Somesolutions, like Redis, allow the clients to group related keys consistently. Some solutions, like BigTable, allow tocollocate data by group or family.
Queries are frequently limited to query by key or by secondary indexes (say bye to the power of SQL)

Data distribution. The Ring

Data ReplicationHow many replicas of each? Typically at least 3, so in case of conflicts there can be a quorum
Often, the distribution of keys is done taking into account the physical location of nodes, so replicas live in different racks or different datacentres

Replication: durabilityIf we want to have a durable system, we need at least to make sure the data is replicated in at least 2 nodes beforeconfirming the transaction to the client.
This is called the write quorum, and in many cases it can be configured individually.
Not all data are equally important, and not all systems have thesame R/W ratio.
Systems can be configured to be “always writable” or “always readable”.

Conflicts
I see a record that I thought was deleted
I created a record but cannot see it
I have different values in two nodes
Something should be unique, but it's not

No-Conflict strategies
Quorum-based systems: Paxos, RAFT. Require coordinationof processes with continuous electionsof leaders and consensus. Worse latency
Last Write Wins (LWW): Doesn't require coordination. Good latency

But, what does “Last” mean?
* Google spanner uses atomic clocks and servers with GPS clocks to synchronize time
* Cassandra tries to sync clocks and divides updates in small parts to minimize conflict
* Dynamo-like use vector clocks

Conflict resolution
Can be done at Write time or at Read time.

Conflict resolution
Can be done at Write time or at Read time.
As long as R + W > N it's possible to reach a quorum

Vector clocks
* Don't need to sync time
* There are several versions of a same item
* Need consolidationto prune size
* Usually client needs tofix the conflict and update

Alternatives to conflict resolution
* Conflict-Free-Replicated-Datatypes(CRDT).Counters, Hashes, Maps
* Allowing for strong consistency on keys from the same family
* The Uber solution with serialized tokens
* Some solutions are implementing immutability, so no conflicts
* Peter David Bailis paper on Coordination Avoidance usingRead Atomic Multi-Partition transactions (Nov/15)

membership
gossip
infection-likeprotocols

Gossip
A centralised server is a SPOF
Communicating state with each node is very time consumingand doesn't support partitions
Gossip protocols communicate pairs of random nodes atregular frequent intervals and exchange information.
Based on that information exchange, a new status is agreed

Gossip example

Incremental scalabilityWhen a new node enters the system, the rest of nodes noticevia gossip.
The node claims a partition of the ring and asksthe replicas of the same partition to send data to it.
When the rest of nodes decide (after gossiping) that a nodehas left the system and it's not a temporary failure, the dataassigned to the partitions of that node is copied to more replicas to reach the N copies.
All the process is automatic and transparent.

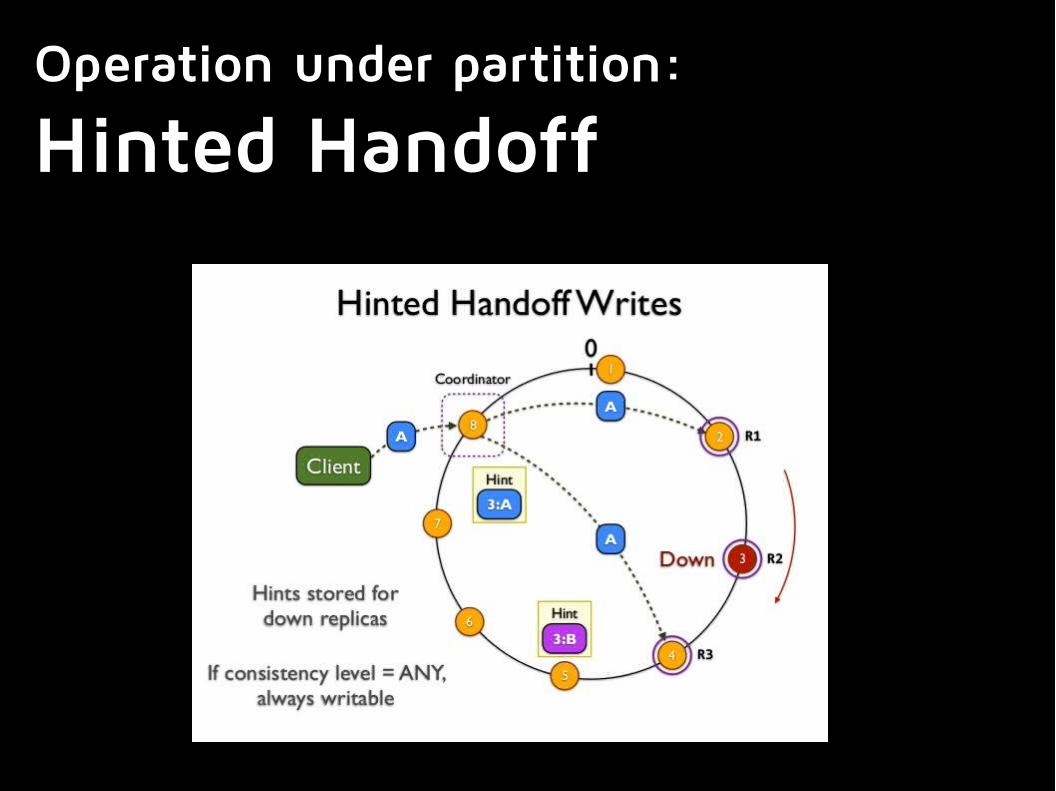
Operation under partition:
Hinted HandoffOn a network partition, it can happen that we have less than W nodes of the same segment in the current partition.
In this case, the data is replicated to W nodes, even if thatnode wasn't responsible for the segment. The data is keptwith a “hint”, and stored in a special area.
Periodically, the server will try to contact the original destination and will “hand off” the data to it.
Operation under partition:
Hinted Handoff

Anti Entropy
A system with handoffs can be chaotic and not veryeffective
Anti Entropy is implemented to make sure hints arehanded off or synchronized to other nodes
Anti entropy is usually achieved by using Merkle Trees, ahash of hashes structure very efficient to compare differences between nodes

All this features mean your clients need tobe aware of some internals of the system

Clients must * Know which close nodes are responsible for each segment of the ring, and hash locally**
* Be aware of when nodes become available or unavailable**
* Decide on durability
* Handle conflict resolution, unless under LWW
** some solutions offer a load balancer proxy to abstract the client from that complexity, but trading off latency

now you know how it works
* A system that always can work, even with network partitions
* That scales out both reads and writes
* On cheap commodity diverse hardware
* Running locally to your users (low latency)
* Can grow/shrink elastically and survive server failures

Extra level: Build yourown distributed database
Netflix dynomite, built in Java
Uber ringpop, built in JavaScript

Not ScaredOf YouAnymore

Dank jeJavier Ramírez@supercoco9
All pictures belongto their respective authors
AMSTERDAM 9-12 MAY 2016
Find related links at
http://bit.ly/teowaki-distributed-systems(https://teams.teowaki.com/teams/javier-community/link-categories/distributed-systems)
need help with cloud, distributed systems or big data?
https://teowaki.com


















