
Basics of Data Compression Paolo Ferragina Dipartimento di Informatica Università di Pisa.
17
Basics of Data Compression Paolo Ferragina Dipartimento di Informatica Università di Pisa
-
Upload
adam-cummings -
Category
Documents
-
view
224 -
download
1
Transcript of Basics of Data Compression Paolo Ferragina Dipartimento di Informatica Università di Pisa.

Basics of Data Compression
Paolo FerraginaDipartimento di Informatica
Università di Pisa

Uniquely Decodable Codes
A variable length code assigns a bit string (codeword) of variable length to every symbol
e.g. a = 1, b = 01, c = 101, d = 011
What if you get the sequence 1011 ?
A uniquely decodable code can always be uniquely decomposed into their codewords.

Prefix Codes
A prefix code is a variable length code in which no codeword is a prefix of another one
e.g a = 0, b = 100, c = 101, d = 11Can be viewed as a binary trie
0 1
a
b c
d
0
0 1
1

Average Length
For a code C with codeword length L[s], the average length is defined as
p(A) = .7 [0], p(B) = p(C) = p(D) = .1 [1--]
La = .7 * 1 + .3 * 3 = 1.6 bit (Huffman achieves 1.5 bit)
We say that a prefix code C is optimal if for all prefix codes C’, La(C) La(C’)
Ss
a sLspCL ][)()(

Entropy (Shannon, 1948)
For a source S emitting symbols with probability p(s), the self information of s is:
bits
Lower probability higher information
Entropy is the weighted average of i(s)
Ss sp
spSH)(
1log)()( 2
)(
1log)( 2 sp
si
s s
s
occ
T
T
occTH
||log
||)( 20
0-th order empirical entropy of string T
i(s)
0 <= H <= log ||H -> 0, skewed distributionH max, uniform distribution
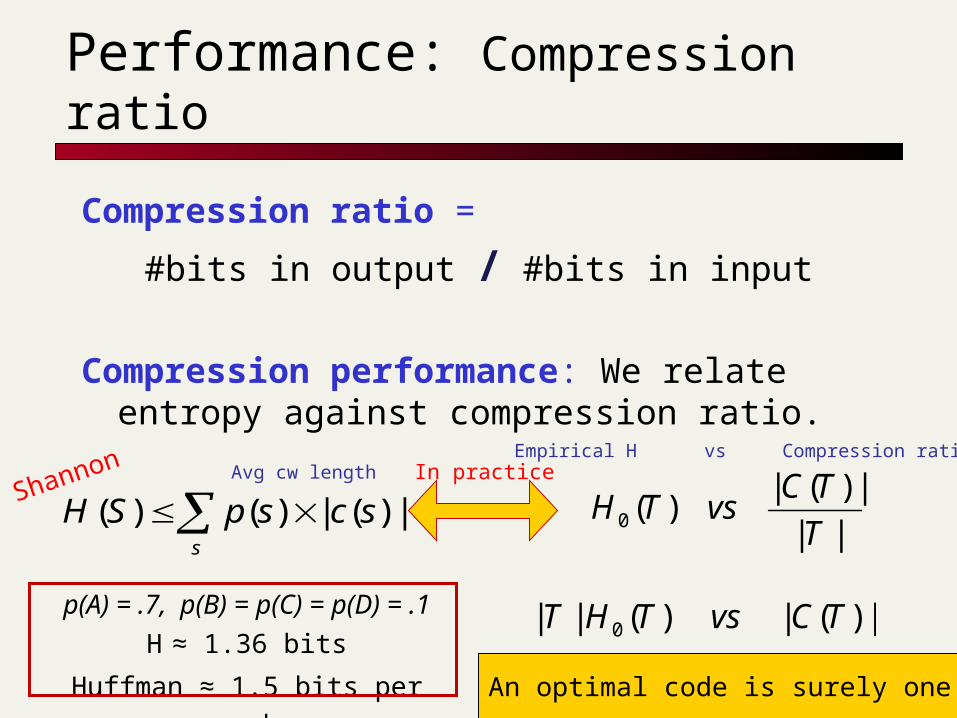
Performance: Compression ratio
Compression ratio =
#bits in output / #bits in input
Compression performance: We relate entropy against compression ratio.
p(A) = .7, p(B) = p(C) = p(D) = .1
H ≈ 1.36 bits
Huffman ≈ 1.5 bits per symb
||
|)(|)(0 T
TCvsTH
s
scspSH |)(|)()(Shannon In practiceAvg cw length
Empirical H vs Compression ratio
|)(|)(|| 0 TCvsTHT
An optimal code is surely one that…

Index construction:Compression of postings
Paolo FerraginaDipartimento di Informatica
Università di Pisa
Reading 5.3 and a paper

code for integer encoding
x > 0 and Length = log2 x +1
e.g., 9 represented as <000,1001>.
code for x takes 2 log2 x +1 bits (ie. factor of 2 from optimal)
Length-1
Optimal for Pr(x) = 1/2x2, and i.i.d integers

It is a prefix-free encoding…
Given the following sequence of coded integers, reconstruct the original sequence:
0001000001100110000011101100111
8 6 3 59 7

code for integer encoding
Use -coding to reduce the length of the first field
Useful for medium-sized integers
e.g., 19 represented as <00,101,10011>.
coding x takes about log2 x + 2 log2( log2 x ) + 2 bits.
(Length) x
Optimal for Pr(x) = 1/2x(log x)2, and i.i.d integers

Variable-bytecodes [10.2 bits per TREC12]
Wish to get very fast (de)compress byte-align
Given a binary representation of an integer Append 0s to front, to get a multiple-of-7 number of bits Form groups of 7-bits each Append to the last group the bit 0, and to the other
groups the bit 1 (tagging)
e.g., v=214+1 binary(v) = 10000000000000110000001 10000000 00000001
Note: We waste 1 bit per byte, and avg 4 for the first byte.
But it is a prefix code, and encodes also the value 0 !!

PForDelta coding
10 11 11 …01 01 11 11 01 42 2311 10
2 3 3 …1 1 3 3 23 13 42 2
a block of 128 numbers = 256 bits = 32 bytes
Use b (e.g. 2) bits to encode 128 numbers or create exceptions
Encode exceptions: ESC or pointers
Choose b to encode 90% values, or trade-off: b waste more bits, b more exceptions
Translate data: [base, base + 2b-1] [0,2b-1]
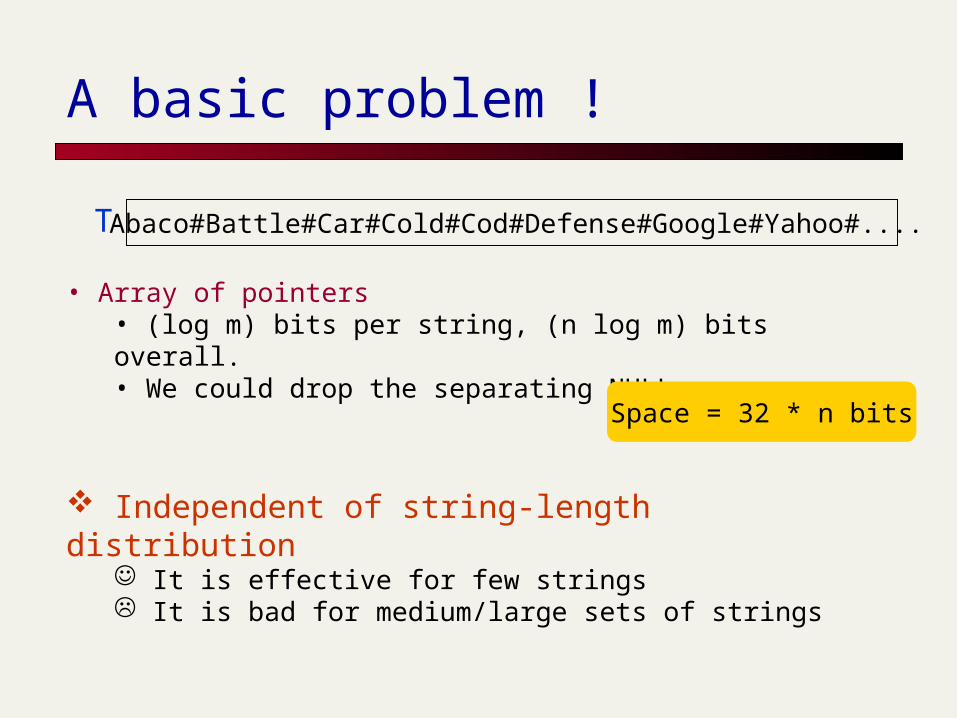
A basic problem !
Abaco#Battle#Car#Cold#Cod#Defense#Google#Yahoo#....T
• Array of pointers• (log m) bits per string, (n log m) bits overall.• We could drop the separating NULL
Independent of string-length distribution It is effective for few strings It is bad for medium/large sets of strings
Space = 32 * n bits
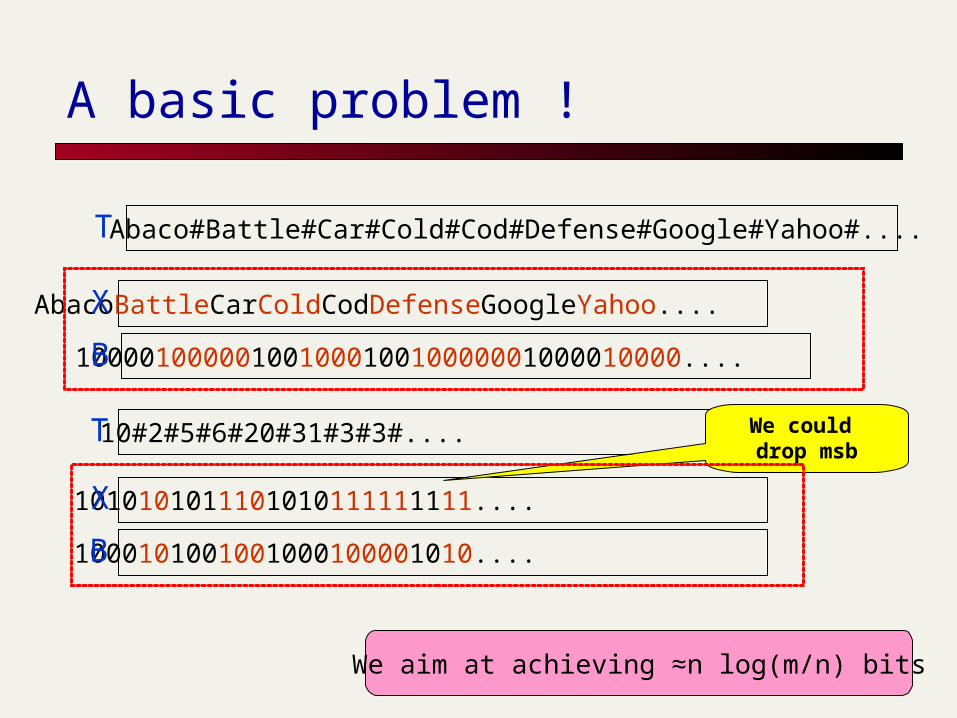
A basic problem !
10000100000100100010010000001000010000....B
Abaco#Battle#Car#Cold#Cod#Defense#Google#Yahoo#....T
10#2#5#6#20#31#3#3#....T
1010101011101010111111111....X
AbacoBattleCarColdCodDefenseGoogleYahoo....X
1000101001001000100001010....B
We could drop msb
We aim at achieving ≈n log(m/n) bits

Rank/Select
00101001010101011111110000011010101....B
• Rankb(i) = number of b in B[1,i]
• Selectb(i) = position of the i-th b in B
Rank1(6) = 2
Select1(3) = 8
m = |B|n = #1
Do exist data structures that
solve this problem in O(1) query time
and n log(m/n) + o(m) bits of space
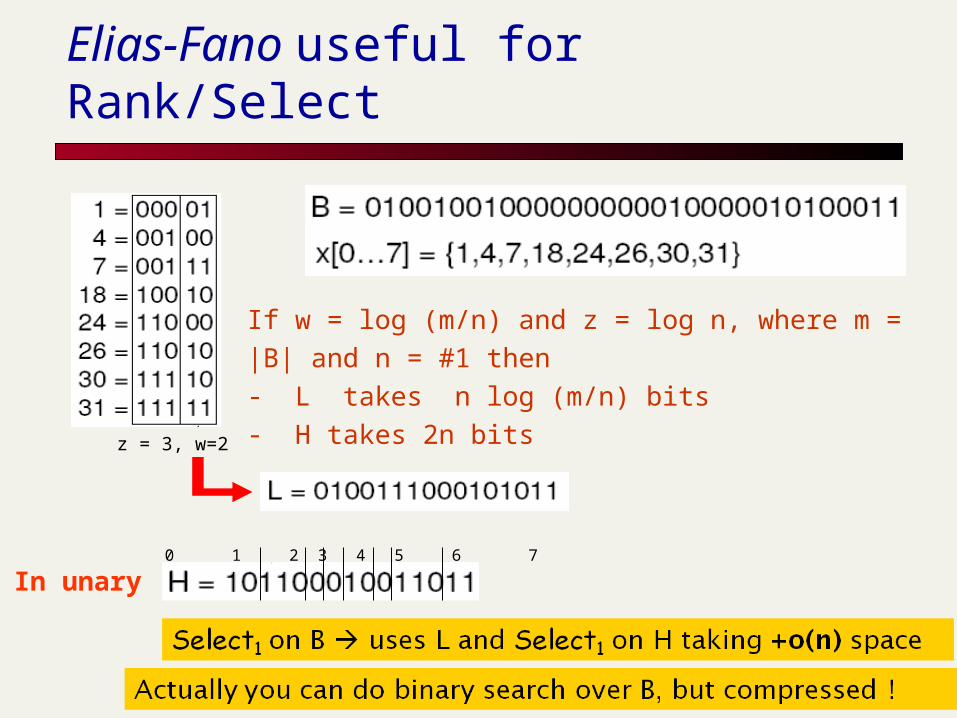
z = 3, w=2
Elias-Fano useful for Rank/Select
If w = log (m/n) and z = log n, where m = |B| and n = #1 then - L takes n log (m/n) bits- H takes 2n bits
0 1 2 3 4 5 6 7
In unary

If you wish to play with Rank and Select
A next lecture…
m/10 + n log m/nRank in 0.4 sec, Select in < 1 sec
For binary search cfr 2n + n log (m/n) only select
vs 32n bits of explicit pointers


















