
Bag-of-features models - cs.gmu.edukosecka/cs482/lect-bag-of-features.pdf · • Random sampling...
44
Bag-of-features models Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
Transcript of Bag-of-features models - cs.gmu.edukosecka/cs482/lect-bag-of-features.pdf · • Random sampling...

Bag-of-features models
Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba

Overview: Bag-of-features models
• Origins and motivation • Image representation
• Feature extraction • Visual vocabularies
• Discriminative methods • Nearest-neighbor classification • Categorization on instance based retrieval
• Extensions: incorporating spatial information

Origin 1: Texture recognition
• Texture is characterized by the repetition of basic elements or textons
• For stochastic textures, it is the identity of the textons, not their spatial arrangement, that matters
Julesz, 1981; Cula & Dana, 2001; Leung & Malik 2001; Mori, Belongie & Malik, 2001; Schmid 2001; Varma & Zisserman, 2002, 2003; Lazebnik, Schmid & Ponce, 2003
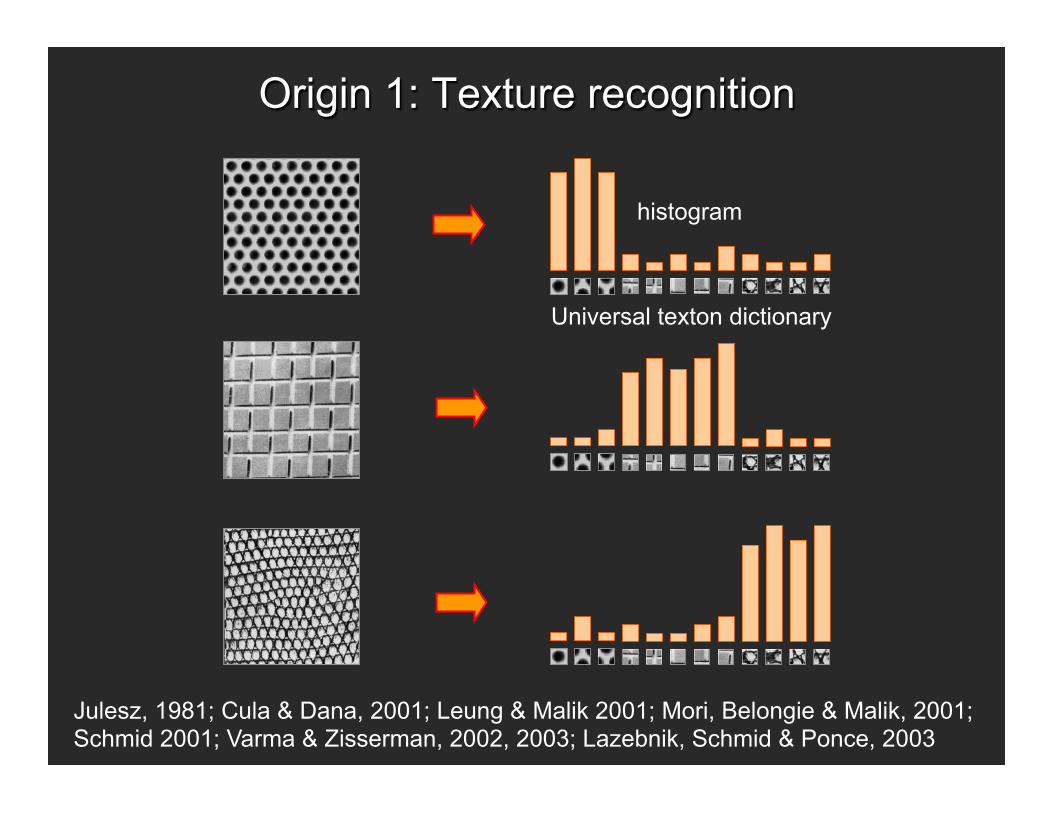
Origin 1: Texture recognition
Universal texton dictionary
histogram
Julesz, 1981; Cula & Dana, 2001; Leung & Malik 2001; Mori, Belongie & Malik, 2001; Schmid 2001; Varma & Zisserman, 2002, 2003; Lazebnik, Schmid & Ponce, 2003

Origin 2: Bag-of-words models
• Orderless document representation: frequencies of words from a dictionary Salton & McGill (1983)

Origin 2: Bag-of-words models
US Presidential Speeches Tag Cloud http://chir.ag/phernalia/preztags/
• Orderless document representation: frequencies of words from a dictionary Salton & McGill (1983)

Origin 2: Bag-of-words models
US Presidential Speeches Tag Cloud http://chir.ag/phernalia/preztags/
• Orderless document representation: frequencies of words from a dictionary Salton & McGill (1983)

Origin 2: Bag-of-words models
US Presidential Speeches Tag Cloud http://chir.ag/phernalia/preztags/
• Orderless document representation: frequencies of words from a dictionary Salton & McGill (1983)

Bags of features for object recognition
Csurka et al. (2004), Willamowski et al. (2005), Grauman & Darrell (2005), Sivic et al. (2003, 2005)
face, flowers, building
• Works pretty well for image-level classification

Bags of features for object recognition
Caltech6 dataset
bag of features bag of features Parts-and-shape model

Bag of features: outline
1. Extract features

Bag of features: outline
1. Extract features 2. Learn “visual vocabulary”

Bag of features: outline
1. Extract features 2. Learn “visual vocabulary” 3. Quantize features using visual vocabulary

Bag of features: outline
1. Extract features 2. Learn “visual vocabulary” 3. Quantize features using visual vocabulary 4. Represent images by frequencies of
“visual words”

Regular grid • Vogel & Schiele, 2003 • Fei-Fei & Perona, 2005
1. Feature extraction

Regular grid • Vogel & Schiele, 2003 • Fei-Fei & Perona, 2005
Interest point detector • Csurka et al. 2004 • Fei-Fei & Perona, 2005 • Sivic et al. 2005
1. Feature extraction

Regular grid • Vogel & Schiele, 2003 • Fei-Fei & Perona, 2005
Interest point detector • Csurka et al. 2004 • Fei-Fei & Perona, 2005 • Sivic et al. 2005
Other methods • Random sampling (Vidal-Naquet & Ullman, 2002) • Segmentation-based patches (Barnard et al. 2003)
1. Feature extraction

Normalize patch
Detect patches [Mikojaczyk and Schmid ’02]
[Mata, Chum, Urban & Pajdla, ’02]
[Sivic & Zisserman, ’03]
Compute SIFT
descriptor [Lowe’99]
Slide credit: Josef Sivic
1. Feature extraction

…
1. Feature extraction
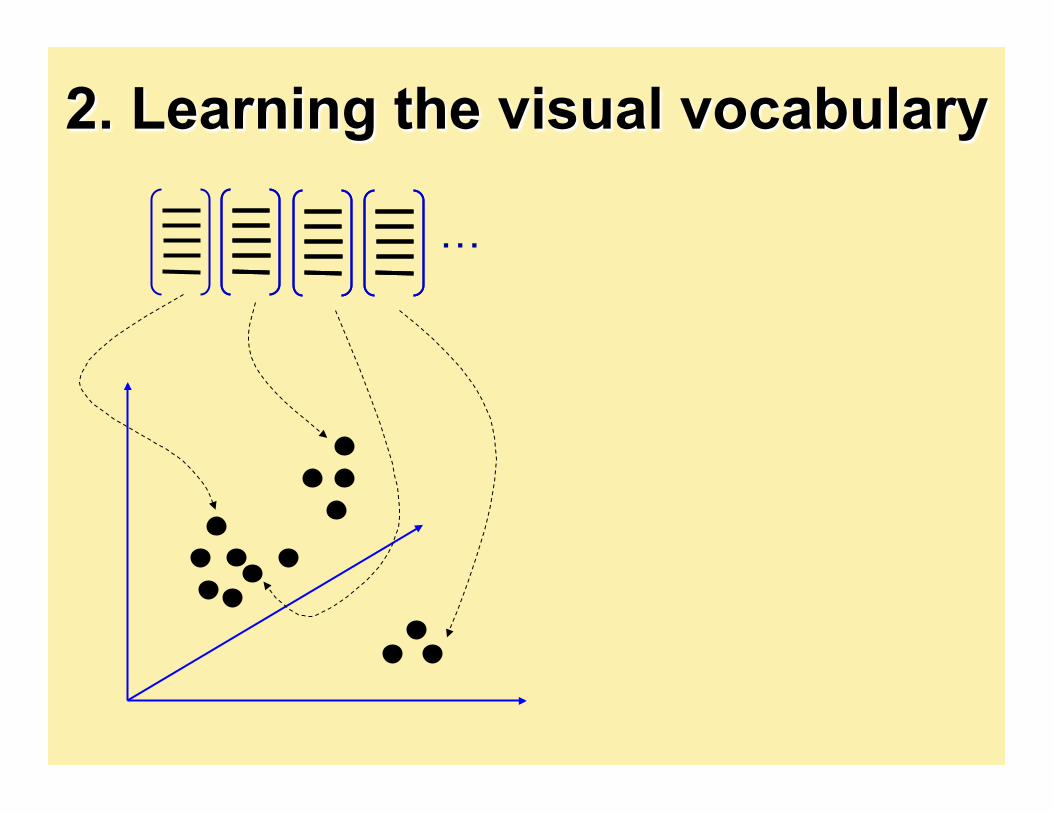
2. Learning the visual vocabulary
…

2. Learning the visual vocabulary
Clustering
…
Slide credit: Josef Sivic

2. Learning the visual vocabulary
Clustering
…
Slide credit: Josef Sivic
Visual vocabulary

K-means clustering
• Want to minimize sum of squared Euclidean distances between points xi and their nearest cluster centers mk
Algorithm: • Randomly initialize K cluster centers • Iterate until convergence:
• Assign each data point to the nearest center • Recompute each cluster center as the mean of all points
assigned to it
∑ ∑ −=k
ki
ki mxMXDcluster
clusterinpoint
2)(),(

From clustering to vector quantization
• Clustering is a common method for learning a visual vocabulary or codebook • Unsupervised learning process • Each cluster center produced by k-means becomes a
codevector • Codebook can be learned on separate training set • Provided the training set is sufficiently representative, the
codebook will be “universal”
• The codebook is used for quantizing features • A vector quantizer takes a feature vector and maps it to the
index of the nearest codevector in a codebook • Codebook = visual vocabulary • Codevector = visual word

Example visual vocabulary
Fei-Fei et al. 2005

Image patch examples of visual words
Sivic et al. 2005

Visual vocabularies: Issues
• How to choose vocabulary size? • Too small: visual words not representative of all patches • Too large: quantization artifacts, overfitting
• Generative or discriminative learning? • Computational efficiency
• Vocabulary trees (Nister & Stewenius, 2006)
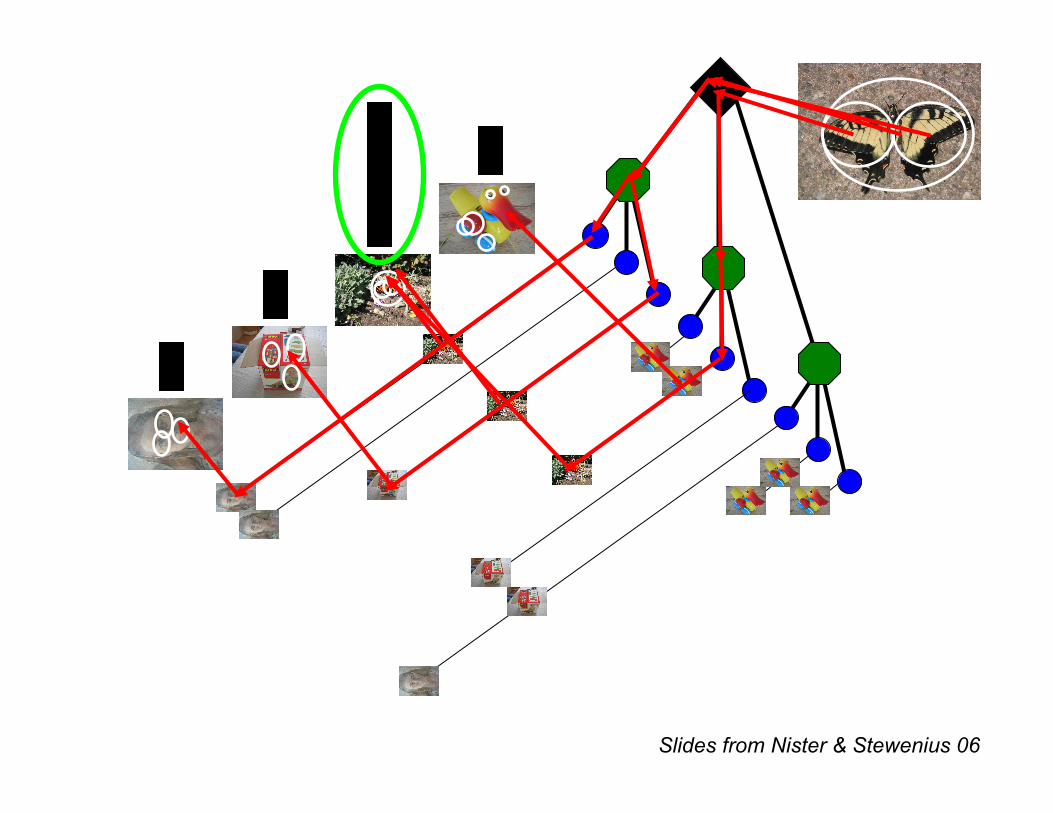
Slides from Nister & Stewenius 06

TF-IDF scoring
• TF-IDF term frequency – inverse document frequency • Used in the information retrieval and text mining • To evaluate how important is a word to document
• Importance depends on how many times the word appears in document – offset by number of occurrence of that word in the whole document corpus

3. Image representation
…..
frequ
ency
codewords

Image classification
• Given the bag-of-features representations of images from different classes, how do we learn a model for distinguishing them?
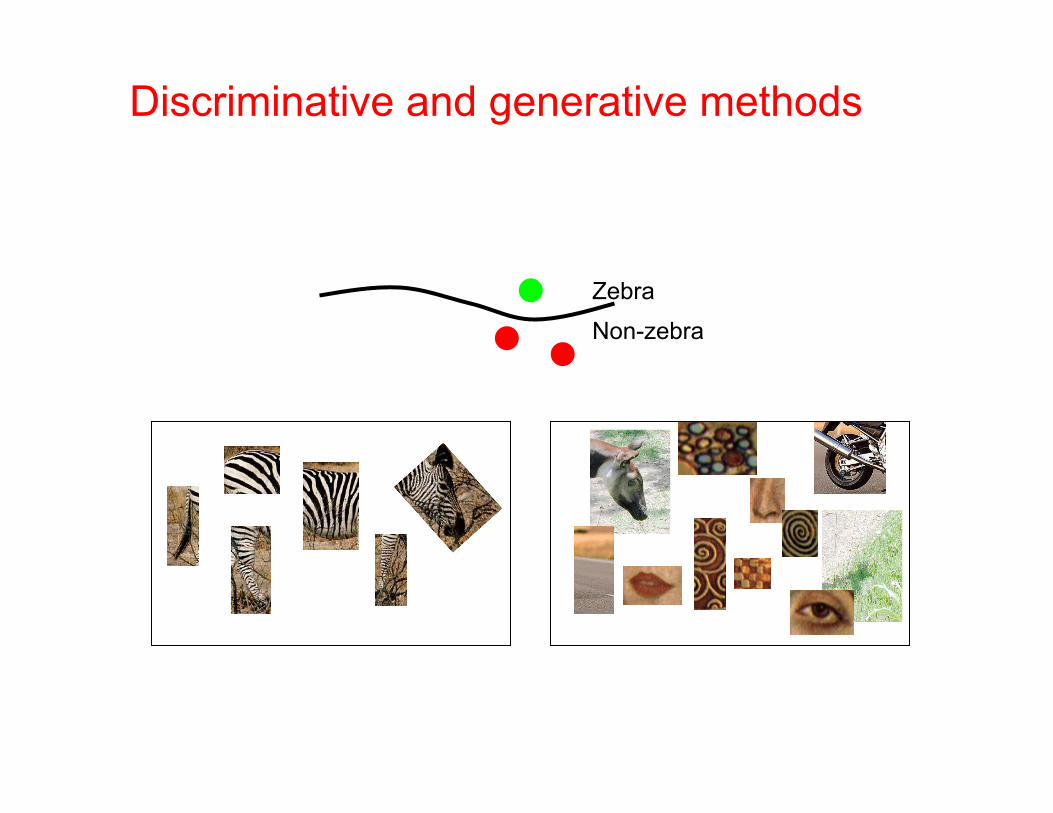
Discriminative and generative methods
Zebra
Non-zebra

Image classification
• Given the bag-of-features representations of images from different classes, how do we learn a model for distinguishing them?

Nearest Neighbor Classifier
• Assign label of nearest training data point to each test data point
Voronoi partitioning of feature space for 2-category 2-D and 3-D data
from Duda et al.
Source: D. Lowe

• For a new point, find the k closest points from training data • Labels of the k points “vote” to classify • Works well provided there is lots of data and the distance function is
good
K-Nearest Neighbors
k = 5
Source: D. Lowe

Functions for comparing histograms
• L1 distance
• χ2 distance
• Quadratic distance (cross-bin)
∑=
−=N
iihihhhD
12121 |)()(|),(
Jan Puzicha, Yossi Rubner, Carlo Tomasi, Joachim M. Buhmann: Empirical Evaluation of Dissimilarity Measures for Color and Texture. ICCV 1999
( )∑= +
−=
N
i ihihihihhhD
1 21
221
21 )()()()(),(
∑ −=ji
ij jhihAhhD,
22121 ))()((),(

Invariant Local Features
Image content is transformed into local feature coordinates that are invariant to translation, rotation, scale, and other imaging parameters SIFT features covered previously For each query view – count how many features can be matched with each of the database objects
SIFT Features

Model verification
For each set of features matched to object O – verify whether they are geometrically consistent
Examine all clusters with at least 3 features
Perform least-squares affine fit to model.
Discard outliers and perform top-down check for additional features.
Evaluate probability that match is correct
! Use Bayesian model, with probability that features would arise by chance if object was not present (Lowe, CVPR 01)
Invariant Local Features

Solution for affine parameters
Affine transform of [x,y] to [u,v]: Rewrite to solve for transform parameters:

3D Object Recognition
Extract outlines with background subtraction

3D Object Recognition
Only 3 keys are needed for recognition, so extra keys provide robustness
Affine model is no longer as accurate

Test of illumination invariance
Same image under differing illumination
273 keys verified in final match
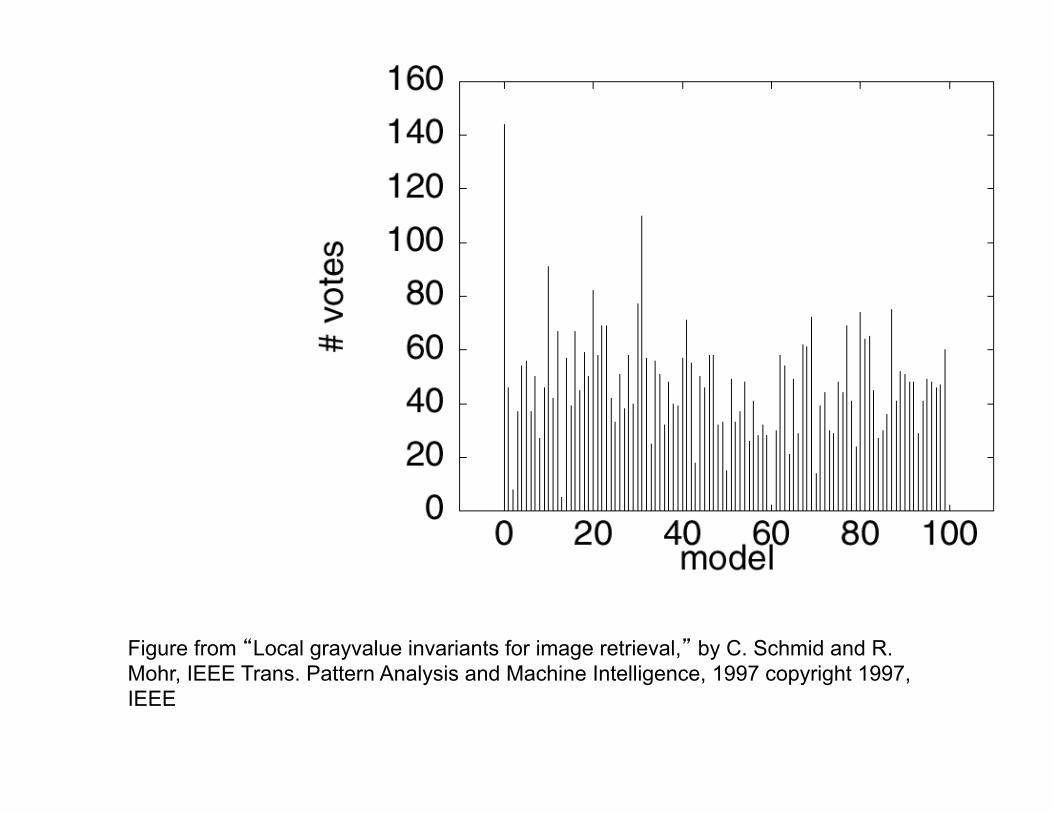
Figure from “Local grayvalue invariants for image retrieval,” by C. Schmid and R. Mohr, IEEE Trans. Pattern Analysis and Machine Intelligence, 1997 copyright 1997, IEEE

Applications: • Duplicated detection for image based retrieval • Oxford building dataset, Video Google • Instances based recognition • Google Goggles • This is often considered as baseline methods for many retrieval tasks • Many advances exploring the tradeoffs between accuracy and efficiency Drawbacks • The spatial relationships between features are not modeled


















