

AWS Summit Berlin 2013 - Tadaa - HD Camera and Photo Community
Upload
aws-germanyCategory
view
453download
6
Big Data AnalyticsConstantin Gonzalez
Solutions Architect, Amazon Web Services
Berlin

1. Introducing Big Data
2. From data to actionable information
3. Analytics and Cloud Computing
Overview

Introducing Big Data
1
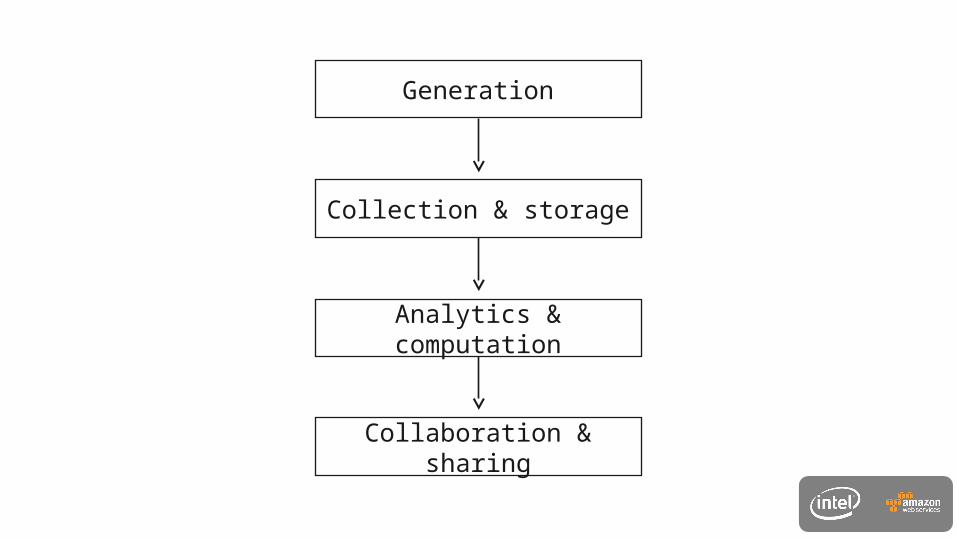
Generation
Collection & storage
Analytics & computation
Collaboration & sharing

The cost of data generation is falling

Generation
Collection & storage
Analytics & computation
Collaboration & sharing
Lower cost,higher throughput

Generation
Collection & storage
Analytics & computation
Collaboration & sharing
Lower cost,higher throughput
Highlyconstrained
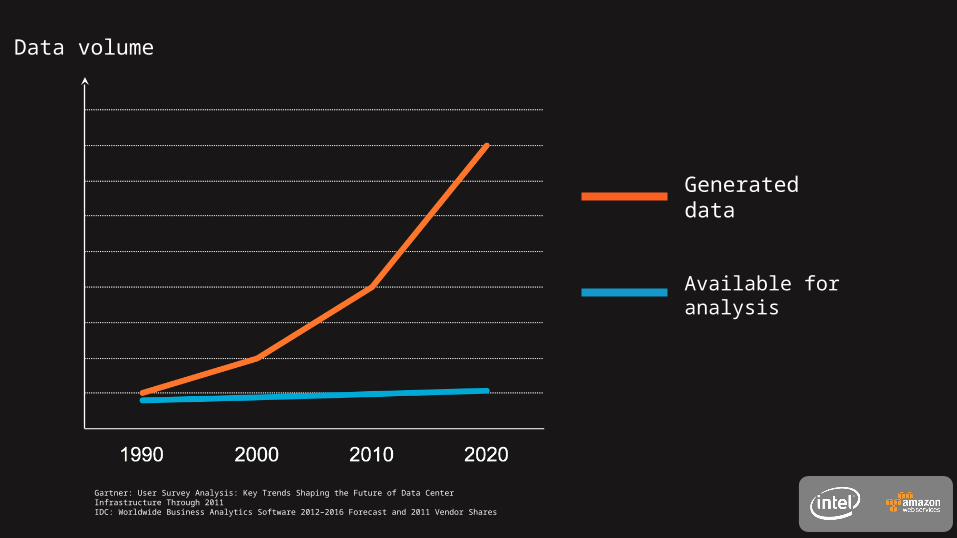
Generated data
Available for analysis
Data volume
Gartner: User Survey Analysis: Key Trends Shaping the Future of Data Center Infrastructure Through 2011 IDC: Worldwide Business Analytics Software 2012–2016 Forecast and 2011 Vendor Shares

Elastic and highly scalable
No upfront capital expense
Only pay for what you use+
+
Available on-demand+
=Remove
constraints

Generation
Collection & storage
Analytics & computation
Collaboration & sharing
Lower cost,higher throughput
Highlyconstrained

Generation
Collection & storage
Analytics & computation
Collaboration & sharing
Accelerated

Technologies and techniques for working productively with data,
at any scale.
Big Data

From data to
actionable information
2

“Who buys video games?”

3.5 billion records
13 TB of click stream logs
71 million unique cookies
Per day:



500% return on ad spend
From 2 months procurement timeto a few minutes
Results:

“Who is using our service?”

Identified early mobile usage
Invested heavily in mobile development
Finding signal in the noise of logs

9,432,061 unique mobile devices used the Yelp mobile app.
4 million+ calls. 5 million+ directions.
In January 2013

Speaking of mobile devicesand social networks…

You Are What You Tweet: Analyzing Twitter for Public Health. M. J. Paul and M. Dredze, 2011
Tweets about the Flu

Analytics and
Cloud Computing
3

Generation
Collection & storage
Analytics & computation
Collaboration & sharing

Generation
Collection & storage
Analytics & computation
Collaboration & sharing
S3, Glacier,Storage Gateway,
DynamoDB, Redshift, RDS,
HBase

Generation
Collection & storage
Analytics & computation
Collaboration & sharing
EC2 &Elastic MapReduce

Generation
Collection & storage
Analytics & computation
Collaboration & sharing
EC2, S3, RDSCloudFormation,
Elastic MapReduce, DynamoDB, Redshift

Generation
Collection & storage
Analytics & computation
Collaboration & sharing
EC2 &Elastic MapReduce
S3, Glacier,Storage Gateway,
DynamoDB, Redshift, RDS,
HBaseAWS Data Pipeline
EC2, S3, RDSCloudFormation,
Elastic MapReduce, DynamoDB, Redshift

Elastic MapReduce

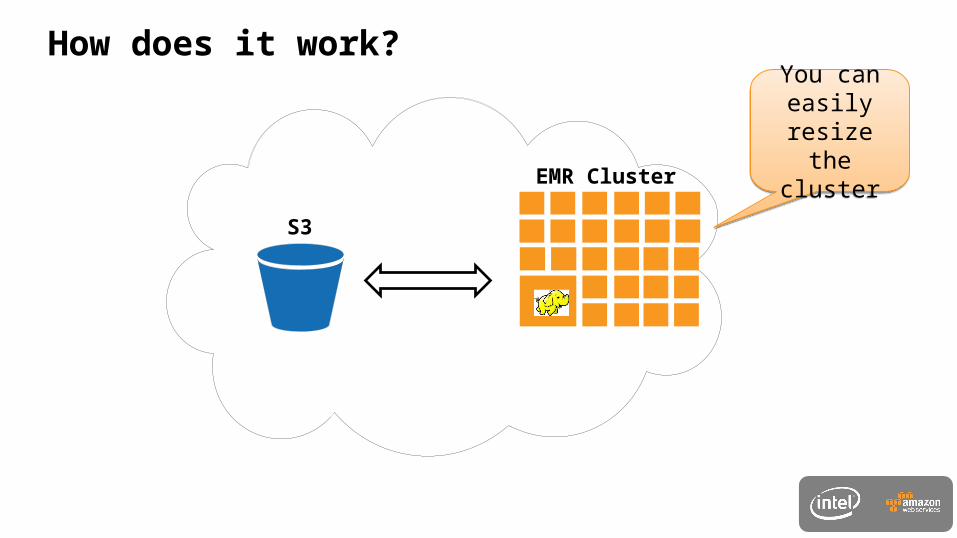
How does it work?
EMR
EMR ClusterS3
1. Put the data into S3 (or HDFS)
1. Put the data into S3 (or HDFS)
3. Get the results3. Get the results
2. Launch your cluster. Choose:•Hadoop distribution•How many nodes•Node type (hi-CPU, hi-memory, etc.)•Hadoop apps (Hive, Pig, HBase)
2. Launch your cluster. Choose:•Hadoop distribution•How many nodes•Node type (hi-CPU, hi-memory, etc.)•Hadoop apps (Hive, Pig, HBase)
EMR
EMR Cluster
How does it work?
S3
You can easily resize the cluster
You can easily resize the cluster

EMR
EMR Cluster
How does it work?
S3
Use Spot nodes to save time
and money
Use Spot nodes to save time
and money
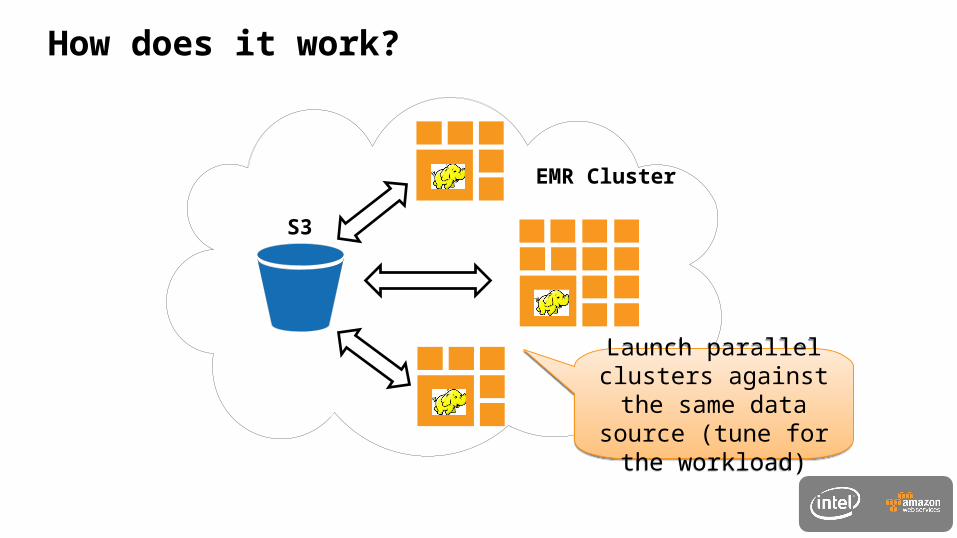
EMR
EMR Cluster
How does it work?
S3
Launch parallel clusters against the same data source (tune for the
workload)
Launch parallel clusters against the same data source (tune for the
workload)
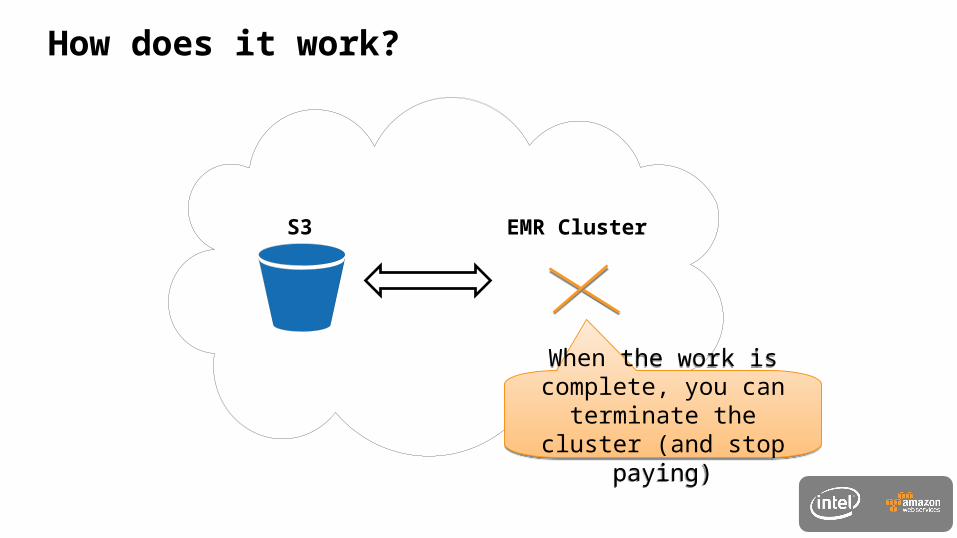
How does it work?
EMR ClusterS3
When the work is complete, you can terminate the
cluster (and stop paying)
When the work is complete, you can terminate the
cluster (and stop paying)

EMR Cluster
How does it work?
You can store everything in HDFS
(local disk)
You can store everything in HDFS
(local disk)
High Storage nodes = 48 TB/node
High Storage nodes = 48 TB/node

EMR Cluster
How does it work?
Launch in a Virtual Private Cloud for
extra security
Launch in a Virtual Private Cloud for
extra security
Thousands of Customers, 5+ Million Clusters

Give it a try:aws.amazon.com/elasticmapreduce
Cost to run a 100-node EMR cluster:EUR 5.75/hour
($7.50/h)

Photos: renee_mcgurk https://www.flickr.com/photos/51018933@N08/5355664961/in/photostream/Calgary Reviews https://www.flickr.com/photos/calgaryreviews/6328302248/in/photostream/
+

AWS Data Pipeline
Data-intensive orchestration and automation
Reliable and scheduled
Easy to use, drag and drop
Execution and retry logic
Map data dependencies
Create and manage temporary compute resources
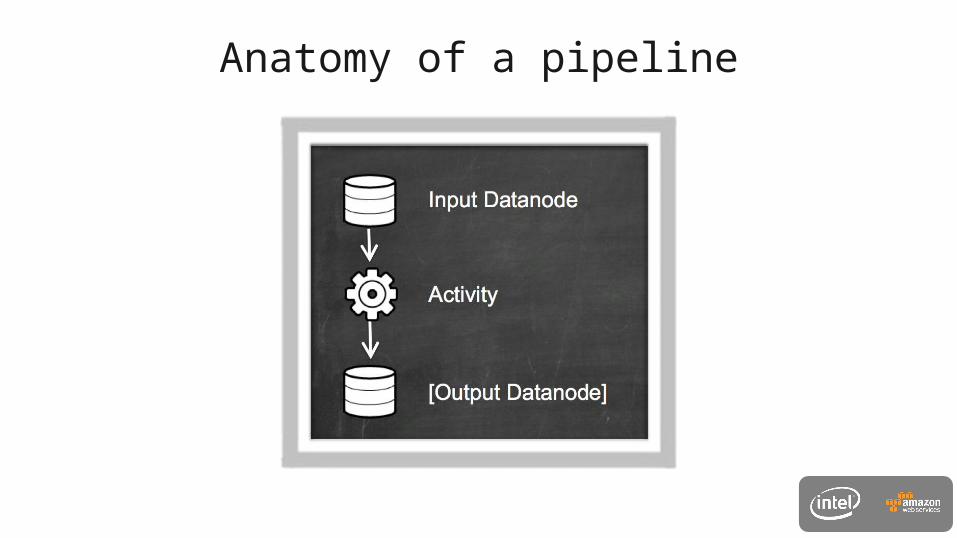
Anatomy of a pipeline

Additional checks and notifications

Arbitrarily complex pipelines

Alan PriestleyStrategic Marketing Director
Intel Corporation

Analysis of Data Can Transform Society
Create new business models and improve
organizational processes.
Enhance scientific understanding,
drive innovation, and accelerate medical cures.
Increase public safety and improve
energy efficiency with smart grids.
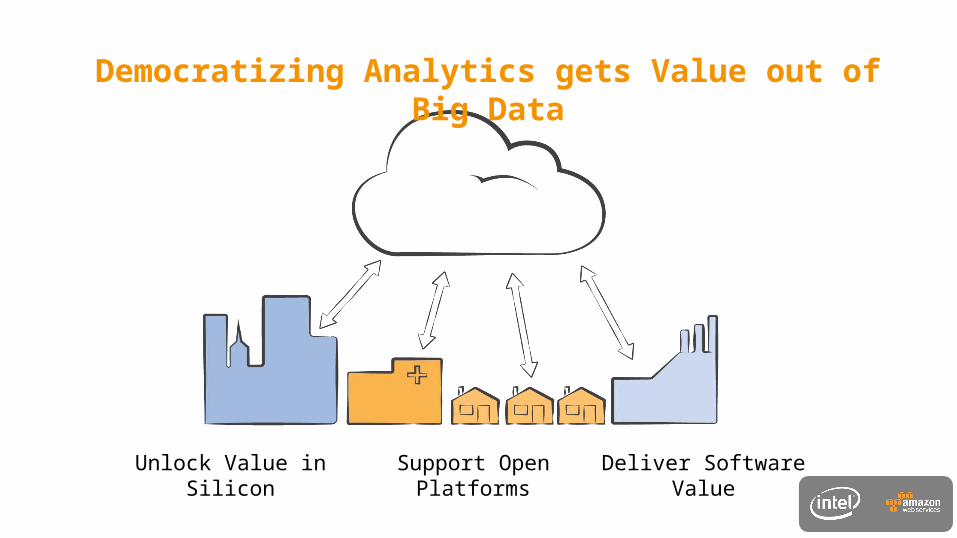
Democratizing Analytics gets Value out of Big Data
Unlock Value in Silicon
Support Open Platforms
Deliver Software Value
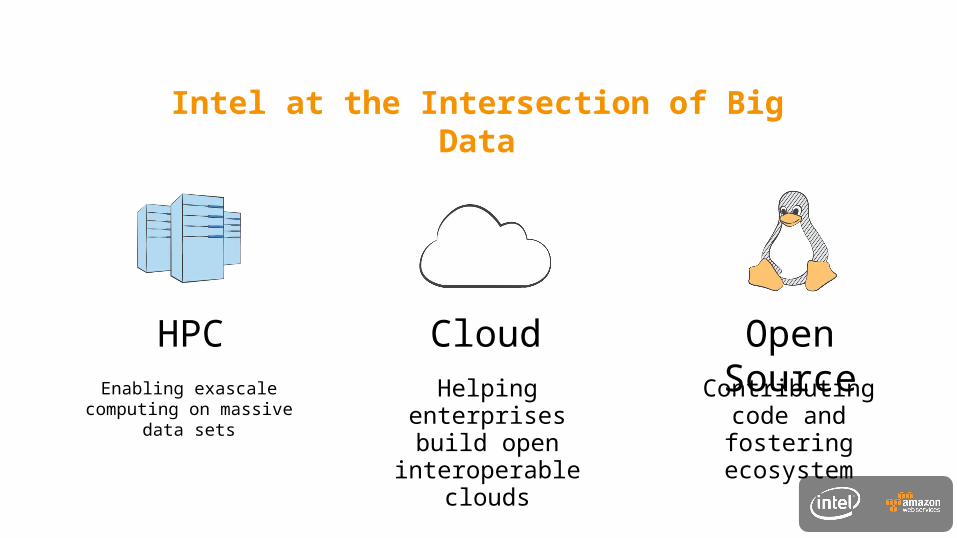
Intel at the Intersection of Big Data
Enabling exascale computing on massive
data sets
Helping enterprises build open
interoperable clouds
Contributing code and fostering ecosystem
HPC Cloud Open Source

Intel at the Heart of the Cloud
Server
Storage
Network

Scale-Out Platform Optimizations for Big Data
Cost-effective performance
•Intel® Advanced Vector Extension Technology•Intel® Turbo Boost Technology 2.0 •Intel® Advanced Encryption Standard New Instructions Technology

52
Intel® Advanced Vector Extensions Technology
• Newest in a long line of processor instruction innovations
• Increases floating point operations per clock up to 2X1 performance
1 : Performance comparison using Linpack benchmark. See backup for configuration details. For more legal information on performance forecasts go to http://www.intel.com/performance
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.

Intel® Turbo Boost Technology 2.0
More PerformanceHigher turbo speeds maximize performance for single and multi-threaded applications

Intel® Advanced Encryption Standard New
Instructions
•Processor assistance for performing AES encryption7 new instructions
•Makes enabled encryption software faster and stronger

Power of the Platform built by Intel
Richer user
experiences
4HRS
50%Reduction
10MIN
80%Reduction 50%
Reduction 40%Reduction
TeraSort for 1TB sort
Intel® Xeon® Processor E5 2600
Solid-State Drive 10G
Ethernet Intel® Apache Hadoop
Previous
Intel® Xeon® Process
or
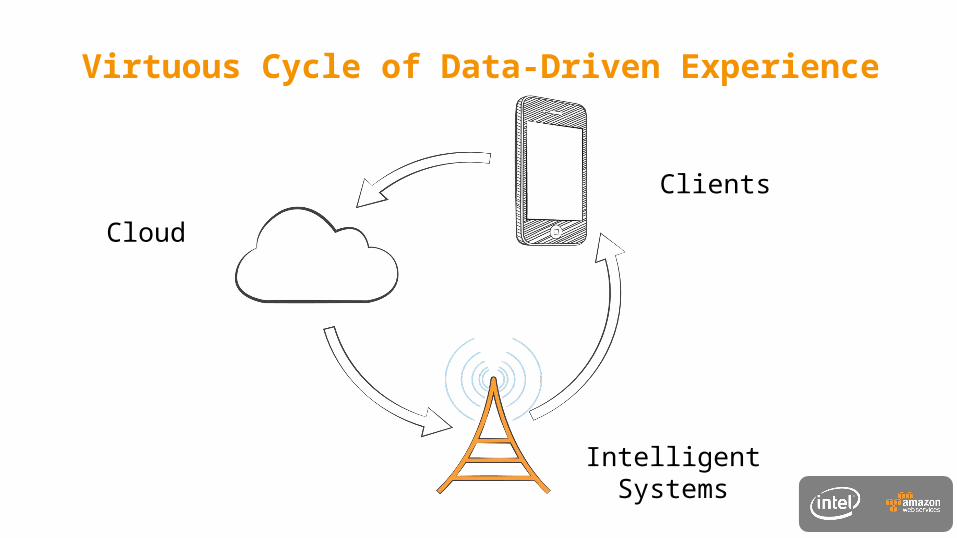
Cloud
Intelligent Systems
Clients
Virtuous Cycle of Data-Driven Experience

Get 600 Hours of free supercomputing time!
www.powerof60.com

Thank you!


















