
Automatic Summarization Team Final report JHU Summer Workshop August 16, 2001.
97
Automatic Summarization Team Final report JHU Summer Workshop August 16, 2001
-
Upload
rodger-west -
Category
Documents
-
view
214 -
download
0
Transcript of Automatic Summarization Team Final report JHU Summer Workshop August 16, 2001.

Automatic Summarization TeamFinal report
JHU Summer WorkshopAugust 16, 2001

The summarization problem space
• Single-document summarization
• Cross-lingual summarization
• Multi-document summarization
• Query-based summarization
• Evaluation

The summarization problem space
• Single-document summarization– 18,146 English-language documents
• Cross-lingual summarization– Chinese translations of the documents
• Multi-document summarization– Clusters of related documents
• Query-based summarization– Queries and their translations
• Evaluation– agreement between humans
– performance of automatic summaries

Technical objectives
• Develop a summarization toolkit including a modular state-of-the art summarizer: single-document, multi-document, generic, query-based
• Develop a summarization evaluation toolkit allowing comparisons between extractive and non-extractive summaries
• Produce an annotated corpus for further research in text summarization

Sample scenarios
• Evaluate an existing summarizer
• Build a summarizer from scratch
• Test a summarization feature
• Test a new evaluation metric
• Test a machine translation system

Resources
• manual summaries (extracts and abstracts)
• baseline summaries
• automatic summaries
• manual and automatic relevance judgements
• XREF, lemmatized, tagged versions of the corpus
• manual and automatic query translations
• sentence segmentation
• sentence alignments
• XML DTDs, converters
• subsumption judgements
• guidelines for judges
• guidelines for building summarizers
• evaluation software
• modular, trainable summarizer

Participants• Non-students
– Dragomir Radev, University of Michigan
– Wai Lam, Chinese University of Hong Kong
– Simone Teufel, Columbia University
– Horacio Saggion, University of Sheffield
• Students– John Blitzer, Cornell University
– Arda Celebi, Bilkent University
– Elliott Drabek, Johns Hopkins University
– Danyu Liu, Chinese University of Hong Kong
– Hong Qi, University of Michigan

Data annotation
• Linguistic Data Consortium– Stephanie Strassel, LDC
– Chris Cieri, LDC
– Dave Graff, LDC
• Bilingual Corpus• Queries• Judgements of relevance of documents and
sentences• Manual summaries

Information Retrieval Architecture
IR Engine
retrievalmodulequery
ranked listof documents
documentsindexingmodule
documentrepresentation(index)
(English)
English /Chinese)(
summaries
summaries

Cross-lingual retrieval
• Bilingual IR engine– Based on Smart, an IR engine developed at
Cornell University• Extend Smart to handle both Chinese and English
documents (XSmart)– Handle double-byte Chinese characters Query
Translation
– Phrasal Translation Module
– Term Disambiguation Module

Phrasal Translation
• Translation process begins for each sentence
• Detecting phrases in a sentence– Construct a phrase/word English-Chinese
lexicon– Maximal matching algorithm

Term Disambiguation
Make use of a cohesion model and corpus statistics– Cooccurrence of translation terms in the corpus
– Correct translations of terms tend to cooccur
,...,,: 321 iiii CCCE
,...,: 2,11,11 iii CCE
,...,: 2,11,11 iii CCE

Sample English Query<?xml version='1.0'?><!DOCTYPE QUERY SYSTEM "../../../dtd/query.dtd" ><QUERY QID="Q-241-E" QNO="241" TRANSLATED="NO"><TITLE>Fire safety, building management concerns</TITLE></QUERY>
<?xml version='1.0'?><!DOCTYPE QUERY SYSTEM “../../../dtd/query.dtd" ><QUERY QID="Q-241-C" QNO="241" TRANSLATED="NO"><TITLE>¨¾¤õ·NÃÑ,¤j·HºÞ²z</TITLE></QUERY>
Sample Chinese Query

Sample Retrieval Result for Full-length Documents
<?xml version='1.0'?><!DOCTYPE DOC-JUDGE SYSTEM "/export/ws01summ/dtd/docjudge.dtd" ><DOC-JUDGE QID="Q-241-E" SYSTEM="SMART" LANG="ENG"> <D DID="D-20000126_008.e" RANK="1" SCORE="135.0000" CORR-DOC="D-20000126_012.c"/> <D DID="D-19980625_007.e" RANK="2" SCORE="99.0000" CORR-DOC="D-19980625_006.c"/> <D DID="D-19990126_017.e" RANK="3" SCORE="98.0000" CORR-DOC="D-19990126_018.c"/> <D DID="D-19981007_018.e" RANK="4" SCORE="91.0000" CORR-DOC="D-19981007_023.c"/> <D DID="D-19980121_004.e" RANK="5" SCORE="78.0000" CORR-DOC="D-19980121_009.c"/> <D DID="D-19971016_004.e" RANK="6" SCORE="72.0000" CORR-DOC="D-19971016_005.c"/>
Sample Retrieval Result for Lead-Based Summary (5%)
<?xml version='1.0'?><!DOCTYPE DOC-JUDGE SYSTEM"/export/ws01summ/dtd/docjudge.dtd" ><DOC-JUDGE QID="Q-241-E" SYSTEM="SMART" LANG="ENG"> <D DID="D-20000126_008.e" RANK="1" SCORE="14.0000" CORR-DOC="D-20000126_012.c"/> <D DID="D-19991214_002.e" RANK="2" SCORE="11.0000" CORR-DOC="D-19991214_001.c"/> <D DID="D-19980810_006.e" RANK="3" SCORE="10.0000" CORR-DOC="D-19980810_003.c"/> <D DID="D-19990505_028.e" RANK="4" SCORE="9.0000" CORR-DOC="D-19990505_034.c"/> <D DID="D-19980115_009.e" RANK="4" SCORE="9.0000" CORR-DOC="D-19980115_013.c"/>:

querySMART
LDC Judges
Rankeddocumentlist
Rankeddocumentlist
IR results
document
Summarycomparison
Correlation
Summarizer
Baselines
Single-document situation
Extract
1. Co-selection2. Similarity

LDC Judges
Summarycomparison
Manual sum.
Summarizer
Baselines
documentcluster
Multi-document situation
1. Co-selection2. Similarity
Extracts

QueriesTRAINING:Group_125 Narcotics RehabilitationGroup_241 Fire safety, building management concernsGroup_323 Battle against disc piracyGroup_551 Natural disaster victims aidedGroup_112 Autumn and sports carnivalsGroup_199 Intellectual Property RightsGroup_398 Flu results in Health ControlsGroup_883 Public health concerns cause food-buisness closingsGroup_1014 Traffic Safety EnforcementGroup_1197 Museums: exhibits/hours
DEV-TEST:Group_447 Housing (Amendment) Bill Brings Assorted Improvements Group_827 Health education for youngstersGroup_885 Customs combats contraband/dutiable cigarette operationsGroup_2 Meetings with foreign leadersGroup_46 Improving Employment OpportunitiesGroup_54 Illegal immigrants Group_60 Customs staff doing good job.Group_61 Permits for charitable fundraisingGroup_62 Y2K readinessGroup_1018 Flower shows
TEST: 20 more queries

Summaries produced
• Single-document extracts– automatic (135 runs on 18,146 documents each): 10
compression rates, Word/Sentence, English/Chinese/Xlingual, 10 summarization methods
– manual (80 runs on 200 documents each): 10 compression rates, Word/Sentence, (3 judges + average)

Summaries produced
• Multi-document summaries– 3 lengths, 3 judges, 14 queries (out of 40)
• Multi-document extracts– automatic (160 extracts) = 8 compression rates (5-
40%,50-200AW) x 20 clusters
– manual (320 extracts) = 8 compression rates x 10 clusters x (3 judges + average)

List of summarizers
• MEAD, Websumm, Summarist, LexChains, Align
• English, Chinese
• Single-document, Multi-document

WEBSUMM:
Some of them are taking temporary shelter at Lung Hang Estate Community Centre in Sha Tin, and Shek Lei Estate Community Centre and Princess Alexandra Community Centre in Tsuen Wan.
Emergency relief by SWD
The Social Welfare Department has provided relief articles and hot meals to 114 people who were affected by the rainstorm or mudslip throughout the territory. The people, comprising adults and children, come from 30 families. Some of them are taking temporary shelter at Lung Hang Estate Community Centre in Sha Tin, and Shek Lei Estate Community Centre and Princess Alexandra Community Centre in Tsuen Wan. The Regional Social Welfare Officer (New Territories East), Mrs Lily Wong, visited victims at Lung Hang State Community Centre this (Thursday) afternoon to offer any necessary assistance. Six victims have so far requested for Comprehensive Social Security Allowance and the applications are being processed. Social workers also escorted an 88-year old man who was feeling unwell to the Prince of Wales hospital for medical checkup.
MEAD:
The Social Welfare Department has provided relief articles and hot meals to 114 people who were affected by the rainstorm or mudslip throughout the territory. The Regional Social Welfare Officer (New Territories East), Mrs Lily Wong, visited victims at Lung Hang State Community Centre this (Thursday) afternoon to offer any necessary assistance.
RANDOM:
The Social Welfare Department has provided relief articles and hot meals to 114 people who were affected by the rainstorm or mudslip throughout the territory. Some of them are taking temporary shelter at Lung Hang Estate Community Centre in Sha Tin, and Shek Lei Estate Community Centre and Princess Alexandra Community Centre in Tsuen Wan.
LEAD:
The Social Welfare Department has provided relief articles and hot meals to 114 people who were affected by the rainstorm or mudslip throughout the territory. The people, comprising adults and children, come from 30 families.
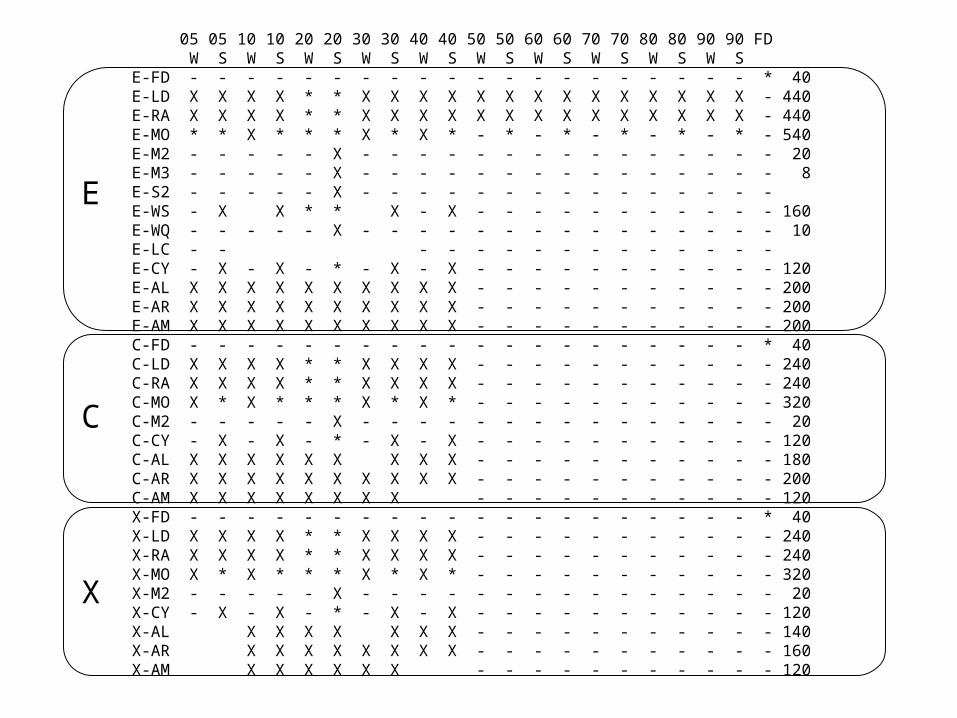
05 05 10 10 20 20 30 30 40 40 50 50 60 60 70 70 80 80 90 90 FD W S W S W S W S W S W S W S W S W S W S E-FD - - - - - - - - - - - - - - - - - - - - * 40E-LD X X X X * * X X X X X X X X X X X X X X - 440E-RA X X X X * * X X X X X X X X X X X X X X - 440E-MO * * X * * * X * X * - * - * - * - * - * - 540E-M2 - - - - - X - - - - - - - - - - - - - - - 20E-M3 - - - - - X - - - - - - - - - - - - - - - 8E-S2 - - - - - X - - - - - - - - - - - - - - - E-WS - X X * * X - X - - - - - - - - - - - 160E-WQ - - - - - X - - - - - - - - - - - - - - - 10E-LC - - - - - - - - - - - - - - - E-CY - X - X - * - X - X - - - - - - - - - - - 120E-AL X X X X X X X X X X - - - - - - - - - - - 200E-AR X X X X X X X X X X - - - - - - - - - - - 200E-AM X X X X X X X X X X - - - - - - - - - - - 200C-FD - - - - - - - - - - - - - - - - - - - - * 40C-LD X X X X * * X X X X - - - - - - - - - - - 240C-RA X X X X * * X X X X - - - - - - - - - - - 240C-MO X * X * * * X * X * - - - - - - - - - - - 320C-M2 - - - - - X - - - - - - - - - - - - - - - 20C-CY - X - X - * - X - X - - - - - - - - - - - 120C-AL X X X X X X X X X - - - - - - - - - - - 180C-AR X X X X X X X X X X - - - - - - - - - - - 200C-AM X X X X X X X X - - - - - - - - - - - 120 X-FD - - - - - - - - - - - - - - - - - - - - * 40X-LD X X X X * * X X X X - - - - - - - - - - - 240X-RA X X X X * * X X X X - - - - - - - - - - - 240X-MO X * X * * * X * X * - - - - - - - - - - - 320X-M2 - - - - - X - - - - - - - - - - - - - - - 20X-CY - X - X - * - X - X - - - - - - - - - - - 120X-AL X X X X X X X - - - - - - - - - - - 140X-AR X X X X X X X X - - - - - - - - - - - 160X-AM X X X X X X - - - - - - - - - - - 120
E
C
X

The MEAD Summarizer
• Extractive summarization as a classification task
– How can we deal with the combinatorial problem?
• Approximate by classifying individual sentences
• MEAD’s classification function– Give each sentence a score based on a linear
combination of features (Position, Centroid, First sentence similarity)
}1,0{2: Sf
}1,0{: sf
)()()()(Score sFwsCwsPws FCP

The Redundancy Problem
• Sentences with duplicate information content– Solemn ceremony marks handover.
– A solemn historic ceremony has marked the resumption of the exercise of sovereigntyover Hong Kong.
• MEAD’s method for combating redundancy• Do until # of sentences = max num for
summary:– Foreach sentence si in order of score
– if si too similar to sentences, skip
– else add si

Modular MEAD Architecture
• Feature Extractor– Sentences become feature vectors
• Classifier– Feature vectors become sentence scores
• Reranker– Sentence scores become other sentence scores

Uses of the architecture
• Current– Query-based features (textual similarity with query)
– SVMs and MaxEnt for classification
• Future– Advanced features
• Named entities, semantic similarity with query
– Generalized re-ranking algorithms
– Learned re-ranking preferences• Co-reference, subsumption, rhetorical relations

Sentence alignment
• Based on a statistical model of character lengths (Gale & Church)
• Makes use of the fact that longer sentences in one language tend to be translated into longer sentences in the other language
• Adapt to English-Chinese bilingual corpus
– Compute the length ratio between English and Chinese character
– Mean number of Chinese characters generated by each English character is c=0.6502 , with a standard deviation σ=0.008

0.30%8012=>2
11.04%29,0562=>1
6.60%17,4121=>2
81.65%215,2961=>1
0.28%7511=>0
0.13%357 0=>1
PercentageNumber of Pairs
Total number of sentence pairs = 312,544

Evaluation with 20 randomly selected document pairs containing 263 sentence pairs
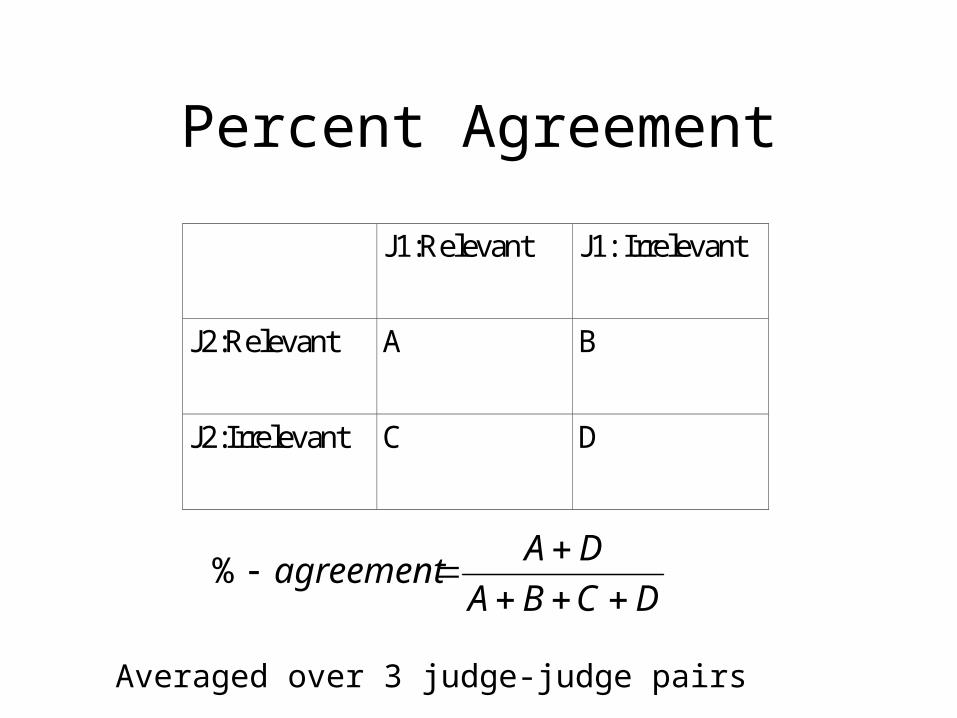
Percent Agreement
J1:Relevant J1: Irrelevant
J2:Relevant A B
J2:Irrelevant C D
DCBA
DAagreement
%
Averaged over 3 judge-judge pairs

510
2030
4050
6070
8090
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
% agreement
compression
Humans: Percent Agreement (20-cluster average) and compression

Precision and recall
J1:Relevant J1: Irrelevant
J2:Relevant A B
J2:Irrelevant C D
Precision(J1)=
Recall(J2)=
Recall(J1)=
Precision(J2)=
CA
A
BA
A
CA
A
BA
A

510
2030
4050
6070
8090
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p/r
compression
Random
Humans
Humans: precision/recall (cluster average) and compression

2 46 54 60 61 62 112 125 199 323 398 447 551 827 883 885 1014 1197 241 1018
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p/r
cluster no.
5%
10%
20%
30%
40%
50%
60%
70%
80%
90%
Precision and recall, human agreement

Kappa
• N: number of items (index i)
• n: number of categories (index j)
• k: number of annotators
)(1
)()(
EP
EPAP
N
i
n
jij k
mkNk
AP1 1
2
1
1
)1(
1)(
2
1
1
)(
Nk
mEP
N
iijn
j

510
2030
4050
6070
8090
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
K
compression
Humans: Kappa and compression

2 46 54 60 61 62 112 125 199 323 398 447 551 827 883 885 1014 1197 241 1018
5%
20%
40%
60%
80%-0.2
0
0.2
0.4
0.6
0.8
1
K
cluster no.
5%
10%
20%
30%
40%
50%
60%
70%
80%
90%
Kappa, human agreement

2 46 54 60 61 62 112 125 199 323 398 447 551 827 883 885 1014 1197 241 1018
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
K
cluster no
Kappa, human agreement, 40%

2 46 54 60 61 62 112 125 199 323 398 447 551 827 883 885 1014 1197 241 1018
-0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Random
Websum
MEAD
Humans
LEAD
Kappa, different systems in annotator pool, 20%

0.097
0.1460.168
0.1940.213
0
0.05
0.1
0.15
0.2
0.25
K
Random Websum MEAD Humans Lead
Kappa, different systems in annotator pool, avg, 20%

112125
199241
323398
551883
10141197
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
K
cluster no
MEAD
Humans
Multi-document summaries of length 50 words, kappa on 10 clusters

Content Based Evaluation
• Precision and Recall
F({S1,S2},{S3,S4}) = 0
S1 “The US President visited China”
S4 “The visit of the President of the US to China”
• Vocabulary Overlap
• Text Representation: Bag, Sequence, Vector
• Units: Words, Lemmas, Phrases, Verbs, Nouns, etc.
TEXT1
TEXT2F 0..1

Content Based Evaluation Mono Lingual
HUMAN EXTRACTS MULTI-DOC SUMMARIES
AUTOMATIC EXTRACTS
SINGLE MULTI
FULL DOCUMENT

Content Based Evaluation Cross Lingual
HUMAN EXTRACTS (CH)
AUTOMATIC EXTRACTS (CH)
SINGLE MULTI
FULL DOCUMENT (CH)HUMAN EXTACT (EN)

Text Representation for Content Based Similarity
<S PAR='4' RSNT='1' SNO='4'> <W C='DT' L='a'>A</W> <W C='NNP' L='council'>Council</W> <W C='NN' L='spokesman'>spokesman</W> <W C='VBD' L='say'>said</W> <W C='IN' L='that'>that</W> <W C='DT' L='the'>the</W> <W C='JJ' L='five-storey'>five-storey</W> <W C='NN' L='market'>market</W> <W C=',' L=','>,</W> <W C='RB' L='conveniently'>conveniently</W> <W C='VBN' L='locate'>located</W> <W C='IN' L='at'>at</W>…
a council spokesman said that the five-storey market , conveniently located at 43 - 47 centre street , occupied an area of about 1,200 square metres and accommodated a total of 102 stalls providing a wide range of fresh goods including vegetables , fish , meat and poultry (words)
a council spokesman say that the five-storey market , conveniently locate at 43 - 47 centre street , occupy an area of about 1,200 square metre and accommodate a total of 102 stall provide a wide range of fresh goods include vegetable , fish , meat and poultry (lemmas )
• Words, Lemmas, Nouns, Verbs, …• Term Frequency (word/lemma) • Inverted Document Frequency (word/lemma)

Similarity Measures
• Cosine
• Overlap
t
ii
t
ii
t
iii
ww
wwtt
1
22
1
21
121
21
)()(
*),cos(
||||||||
),(2121
2121
tttttt
ttoverlap

Similarity Measures
• Longest Common Subsequence
),(),(*2 yxeditllyxlcs diyx
21
)max()max(),( 21
tt
i j jiijtext
ll
lcslcsttlcs

¬ü°ê Á`²Î ©M ²Ä¤@ ¤Ò¤H
¬ü°ê Á`²Î ©M ²Ä¤@ ¤Ò¤H
THE US PRESIDENT AND THE FIRST LADY
THE PRESIDENT OF US AND THE 1ST LADY

MONO LINGUAL EVALUATION HUMAN EXTRACTS (COSINE,LEMMAS,NOUNS)
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
C_125
C_241
C_323
C_551
C_125 0.50 0.74 0.85 0.91 0.75
C_241 0.59 0.75 0.81 0.90 0.76
C_323 0.48 0.57 0.69 0.75 0.62
C_551 0.28 0.75 0.74 0.75 0.63
10S 20S 30S 40S AVERAGE

MONO LINGUAL EVALUATION HUMAN EXTRACTS (LCS,LEMMAS,NOUNS)
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
C_125
C_241
C_323
C_551
C_125 0.38 0.59 0.72 0.81 0.62
C_241 0.36 0.54 0.63 0.76 0.57
C_323 0.33 0.40 0.55 0.59 0.47
C_551 0.17 0.55 0.52 0.53 0.44
10S 20S 30S 40S AVERAGE
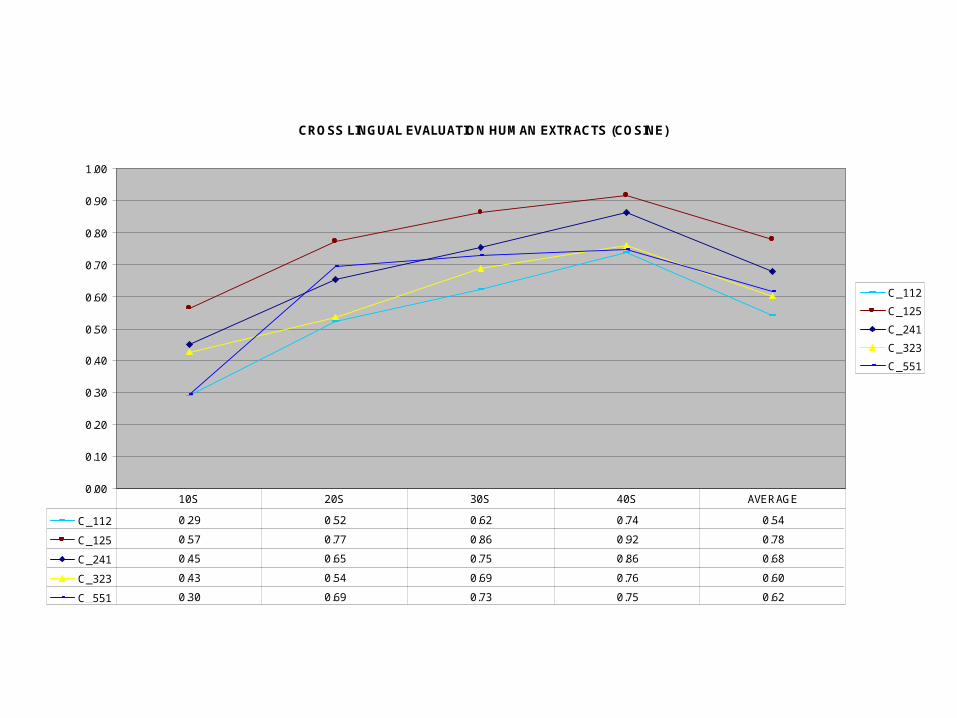
CROSS LINGUAL EVALUATION HUMAN EXTRACTS (COSINE)
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
C_112
C_125
C_241
C_323
C_551
C_112 0.29 0.52 0.62 0.74 0.54
C_125 0.57 0.77 0.86 0.92 0.78
C_241 0.45 0.65 0.75 0.86 0.68
C_323 0.43 0.54 0.69 0.76 0.60
C_551 0.30 0.69 0.73 0.75 0.62
10S 20S 30S 40S AVERAGE
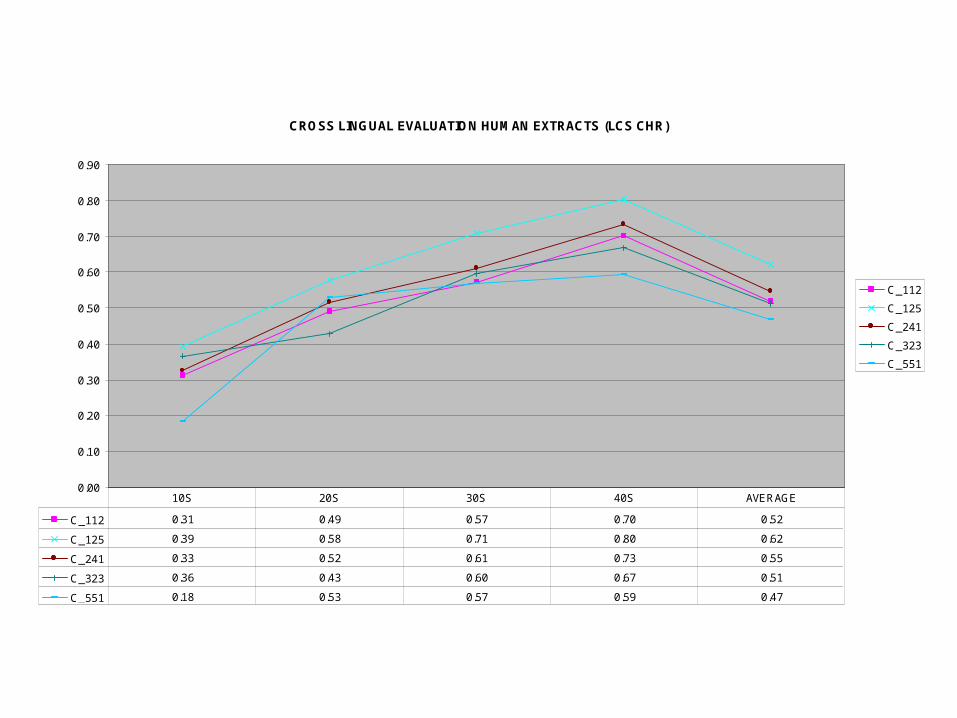
CROSS LINGUAL EVALUATION HUMAN EXTRACTS (LCS CHR)
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
C_112
C_125
C_241
C_323
C_551
C_112 0.31 0.49 0.57 0.70 0.52
C_125 0.39 0.58 0.71 0.80 0.62
C_241 0.33 0.52 0.61 0.73 0.55
C_323 0.36 0.43 0.60 0.67 0.51
C_551 0.18 0.53 0.57 0.59 0.47
10S 20S 30S 40S AVERAGE

MONO LINGUAL (COSINE) C_112
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
SUMM
LEAD
MEAD
RANDOM
WEBSUMM
SUMM 0.01 0.12 0.19 0.24
LEAD 0.27 0.47 0.55 0.72
MEAD 0.37 0.58 0.70 0.81
RANDOM 0.22 0.45 0.60 0.63
WEBSUMM 0.35 0.48 0.62 0.69
10S 20S 30S 40S

MONO LINGUAL EVALUATION (COSINE, LEMMAS, NOUNS) Q112
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
LEAD
MEAD
RANDOM
WEBSUMM
LEAD 0.31 0.52 0.60 0.76
MEAD 0.42 0.63 0.74 0.84
RANDOM 0.27 0.50 0.66 0.69
WEBSUMM 0.42 0.53 0.68 0.75
10S 20S 30S 40S

MONO LINGUAL ALL CLUSTERS (COSINE)
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
CYL
LEAD
MEAD
RANDOM
LEXCHAIN
WEBSUMM
CYL 0.14 0.33 0.41 0.47 0.48 0.366
LEAD 0.71 0.68 0.57 0.65 0.66 0.654
MEAD 0.63 0.61 0.64 0.69 0.62 0.638
RANDOM 0.45 0.5 0.51 0.57 0.5 0.506
LEXCHAIN 0.41 0.52 0.53 0.64 0.42 0.504
WEBSUMM 0.54 0.67 0.75 0.66 0.75 0.674
C_112 C_125 C_241 C_323 C_551 AVERAGE

MONO LINGUAL ALL CLUSTERS (LCS)
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
CYL
LEAD
LEXCHAIN
MEAD
RANDOM
WEBSUMM
CYL 0.26 0.48 0.37 0.47 0.29 0.37
LEAD 0.44 0.58 0.45 0.63 0.71 0.56
LEXCHAIN 0.47 0.56 0.45 0.62 0.60 0.54
MEAD 0.55 0.58 0.56 0.53 0.49 0.54
RANDOM 0.44 0.43 0.43 0.46 0.48 0.45
WEBSUMM 0.48 0.48 0.55 0.46 0.63 0.52
C_112 C_125 C_241 C_323 C_551 AVERAGE

CROSS LINGUAL EVALUATION (LCS, CHR) Q112
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
CYL
LEAD
MEAD
RANDOM
CYL 0.22 0.47 0.56 0.64
LEAD 0.26 0.38 0.47 0.62
MEAD 0.37 0.53 0.63 0.70
RANDOM 0.26 0.38 0.47 0.47
10S 20S 30S 40S
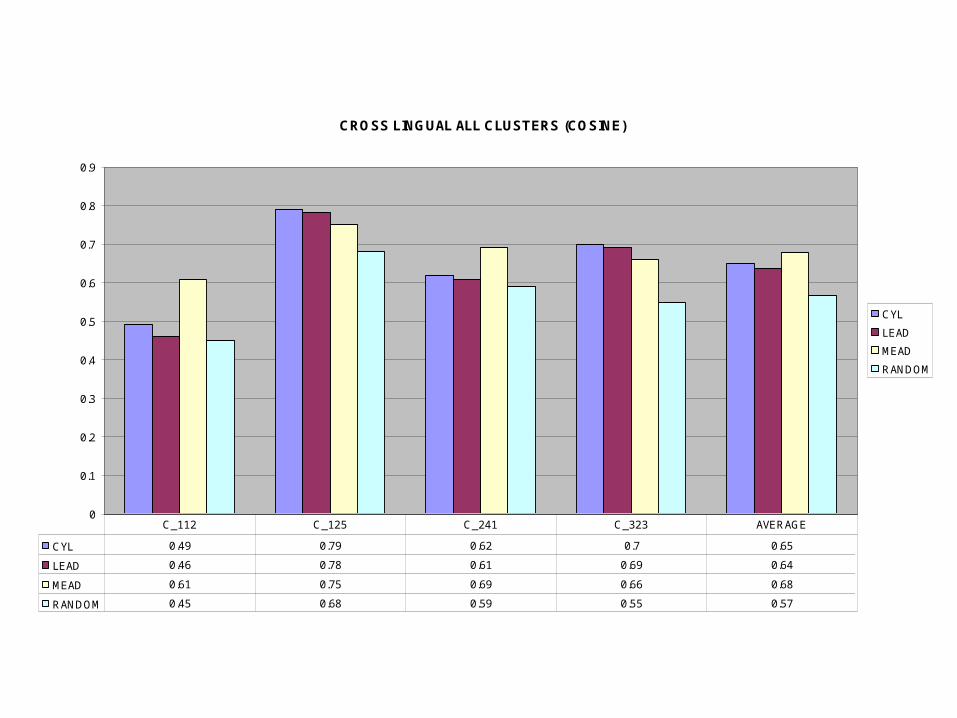
CROSS LINGUAL ALL CLUSTERS (COSINE)
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
CYL
LEAD
MEAD
RANDOM
CYL 0.49 0.79 0.62 0.7 0.65
LEAD 0.46 0.78 0.61 0.69 0.64
MEAD 0.61 0.75 0.69 0.66 0.68
RANDOM 0.45 0.68 0.59 0.55 0.57
C_112 C_125 C_241 C_323 AVERAGE

CROSS LINGUAL ALL CLUSTERS (LCS)
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
CYL
LEAD
MEAD
RANDOM
CYL 0.43 0.56 0.43 0.60 0.51
LEAD 0.40 0.56 0.42 0.57 0.49
MEAD 0.52 0.53 0.50 0.57 0.53
RANDOM 0.36 0.45 0.36 0.44 0.40
C_112 C_125 C_241 C_323 AVERAGE
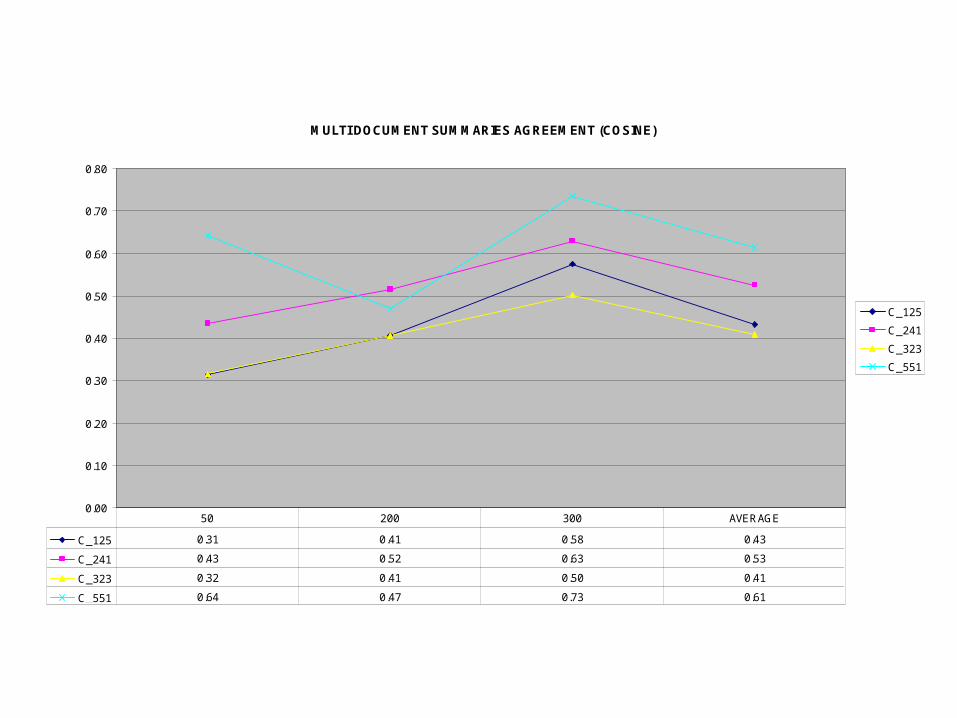
MULTI DOCUMENT SUMMARIES AGREEMENT (COSINE)
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
C_125
C_241
C_323
C_551
C_125 0.31 0.41 0.58 0.43
C_241 0.43 0.52 0.63 0.53
C_323 0.32 0.41 0.50 0.41
C_551 0.64 0.47 0.73 0.61
50 200 300 AVERAGE

BIG COS01 COSINE WRD50 0.039854 0.278973 0.171477 0.198361
100 0.043703 0.277186 0.219399 0.210311200 0.067433 0.334611 0.429588 0.227994
BIG COS01 COSINE WRD50 0.063069 0.334818 0.356008 0.233835
100 0.068872 0.322049 0.436582 0.250311200 0.079958 0.330042 0.500884 0.253613
Multi-document summary evaluation (4 queries)
Summary vs. automatic extract
Summary vs. manual extract

Relative Utility
---S10
---S9
---S8
---S7
---S6
---S5
+--S4
---S3
+++S2
-++S1
System 2System 1Ideal
RU = % of ideal utility covered by system summary
--3S10
--3S9
--4S8
--7S7
--6S6
--7S5
+-7S4
--2S3
++8(+)S2
-+10(+)S1
System 2System 1Ideal

A B C D E FG H
I J
R
J
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
Relative utility (upper and lower bounds), Q125, 5%
R
J
R 0.648 0.65 0.652 0.465 0.626 0.727 0.509 0.497 0.644 0.566
J 0.715 0.666 0.859 0.726 0.876 0.944 0.909 0.776 0.71 0.869
A B C D E F G H I J

A B C D E FG H
I J
R
J
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
Relative utility (upper and lower bounds), Q125, 20%
R
J
R 0.69 0.685 0.679 0.523 0.642 0.741 0.541 0.553 0.699 0.595
J 0.827 0.73 0.866 0.828 0.838 0.913 0.861 0.876 0.736 0.874
A B C D E F G H I J

A B C D E FG H
I J
R
J
0.45
0.55
0.65
0.75
0.85
0.95
Relative utility (upper and lower bounds), Q125, 40%
R
J
R 0.74 0.738 0.724 0.653 0.695 0.77 0.647 0.679 0.764 0.664
J 0.836 0.754 0.878 0.954 0.91 0.952 0.919 0.954 0.811 0.904
A B C D E F G H I J
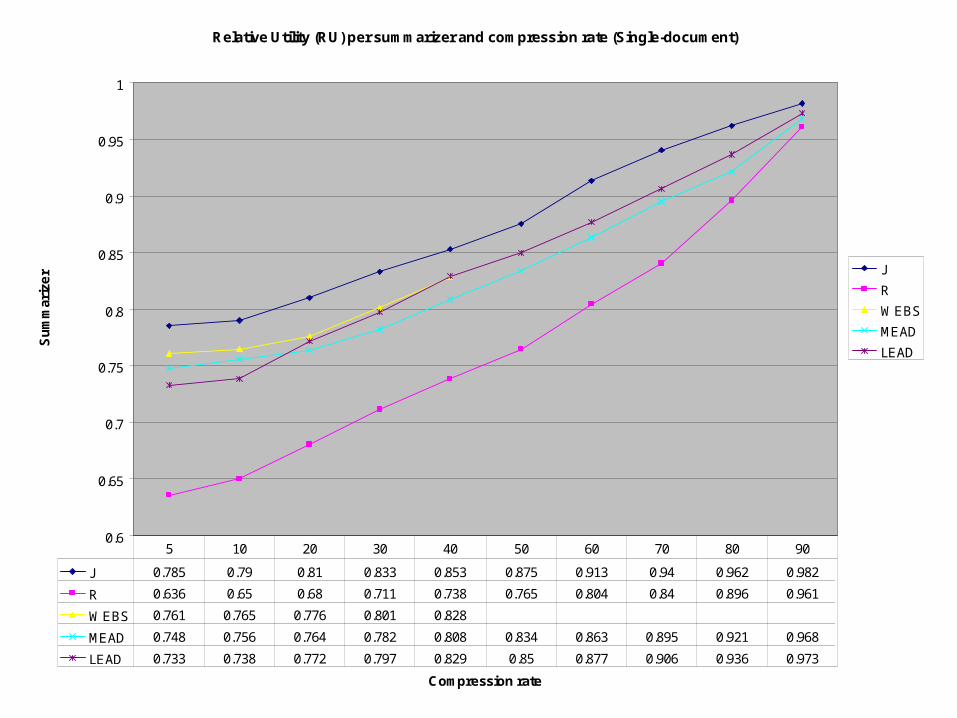
Relative Utility (RU) per summarizer and compression rate (Single-document)
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
Compression rate
Su
mm
ariz
er J
R
WEBS
MEAD
LEAD
J 0.785 0.79 0.81 0.833 0.853 0.875 0.913 0.94 0.962 0.982
R 0.636 0.65 0.68 0.711 0.738 0.765 0.804 0.84 0.896 0.961
WEBS 0.761 0.765 0.776 0.801 0.828
MEAD 0.748 0.756 0.764 0.782 0.808 0.834 0.863 0.895 0.921 0.968
LEAD 0.733 0.738 0.772 0.797 0.829 0.85 0.877 0.906 0.936 0.973
5 10 20 30 40 50 60 70 80 90

Relative Utility (RU) per compression rate (Multi-document)
0.61
0.63
0.65
0.67
0.69
0.71
0.73
0.75
0.77
0.79
0.81
Compression rate
RU
R
S
J
R 0.6116 0.6302 0.6614 0.6894
S 0.6928 0.7246 0.7476 0.766
J 0.6886 0.7296 0.7582 0.7904
5 10 20 30

Relevance correlation (RC)
22)()(
))((
ii
ii
iii
yyxx
yyxxr

Relevance Preservation Value (RPV) as a function of compression rate (RANDOM)
0.44
0.54
0.64
0.74
0.84
0.94
Summary length (%)
RPV
Query 112
Query 125
Query 241
Query 323
Query 551
AVERAGE (10 queries)
Query 112 0.5 0.64 0.8 0.86 0.91 0.93 0.95 0.97 0.98 0.99
Query 125 0.44 0.66 0.78 0.87 0.91 0.91 0.96 0.97 0.98 0.99
Query 241 0.68 0.77 0.87 0.91 0.94 0.96 0.97 0.98 0.99 1
Query 323 0.63 0.78 0.85 0.9 0.93 0.95 0.97 0.98 0.99 1
Query 551 0.52 0.69 0.79 0.88 0.92 0.94 0.95 0.97 0.98 0.99
AVERAGE (10 queries) 0.553 0.687 0.8 0.874 0.912 0.932 0.956 0.973 0.984 0.992
5 10 20 30 40 50 60 70 80 90

FD
ME
AD
WE
BS
LEA
D
RA
ND
SU
MM
Q12
5
Q55
1
AV
G(1
0Q)
Q11
2
Q24
1
Q32
3
0.77
0.82
0.87
0.92
0.97
RPV
Summarizer
Query
Relevance Preservation Value (RPV) for different summarizers (English, 20%)
Q125
Q551
AVG(10Q)
Q112
Q241
Q323
Q125 1 0.92 0.82 0.8 0.78 0.79
Q551 1 0.9 0.88 0.81 0.79 0.81
AVG(10Q) 1 0.903 0.843 0.802 0.8 0.775
Q112 1 0.91 0.88 0.8 0.8 0.77
Q241 1 0.93 0.89 0.84 0.87 0.85
Q323 1 0.92 0.91 0.85 0.85 0.88
FD MEAD WEBS LEAD RAND SUMM

FD
ME
AD
SU
MM
ALG
N
LEA
D
RA
ND
Q11
2
Q32
3
Q55
1
AV
G(1
0Q)
Q12
5
Q24
1
0.58
0.63
0.68
0.73
0.78
0.83
0.88
0.93
0.98
RPV
Summarizer
Query
Relevance Preservation Value (RPV) for different summarizers (Chinese, 20%)
Q112
Q323
Q551
AVG(10Q)
Q125
Q241
Q112 1 0.87 0.76 0.74 0.72 0.71
Q323 1 0.66 0.84 0.59 0.58 0.6
Q551 1 0.91 0.75 0.72 0.75 0.74
AVG(10Q) 1 0.85 0.755 0.738 0.733 0.744
Q125 1 0.87 0.75 0.72 0.71 0.75
Q241 1 0.93 0.85 0.83 0.83 0.85
FD MEAD SUMM ALGN LEAD RAND
FDMEAD
WEBSLEAD
SUMMRAND 5%
10%20%
30%40%
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
RPV
Summarizer
Compression rate
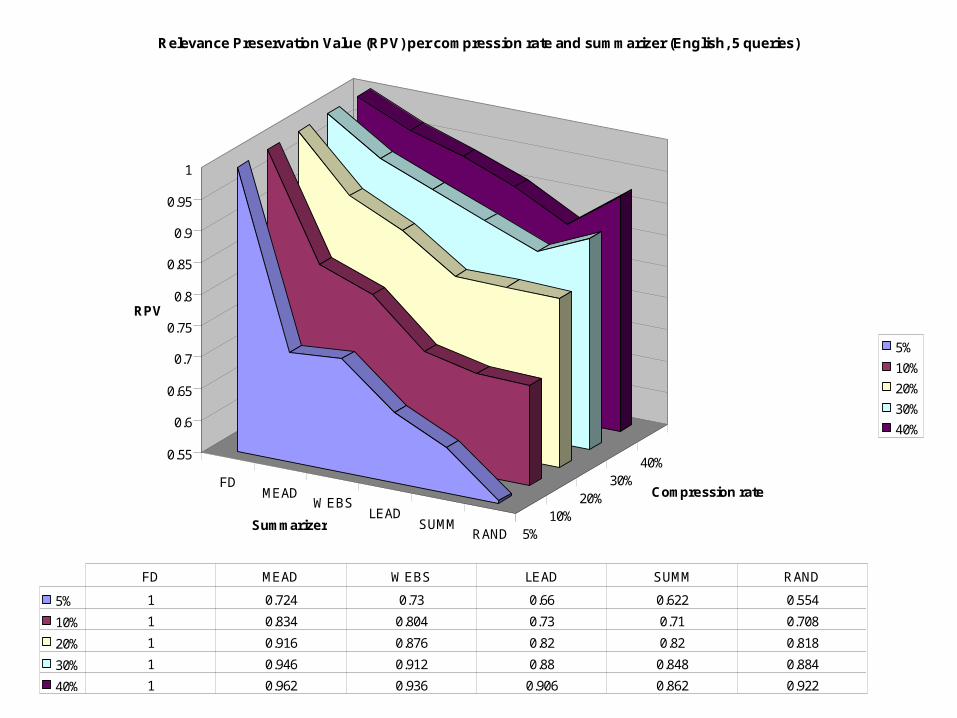
Relevance Preservation Value (RPV) per compression rate and summarizer (English, 5 queries)
5%
10%
20%
30%
40%
5% 1 0.724 0.73 0.66 0.622 0.554
10% 1 0.834 0.804 0.73 0.71 0.708
20% 1 0.916 0.876 0.82 0.82 0.818
30% 1 0.946 0.912 0.88 0.848 0.884
40% 1 0.962 0.936 0.906 0.862 0.922
FD MEAD WEBS LEAD SUMM RAND

SUMMLEAD
MEADRAND
WEBS
with cutoff
no cutoff0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
RPV
Summarizer
Correlation method
Relevance Preservation Value (RPV) with and without cutoff (English, 5%)
with cutoff
no cutoff
with cutoff 0.48 0.55 0.61 0.29 0.6
no cutoff 0.61 0.59 0.74 0.44 0.63
SUMM LEAD MEAD RAND WEBS

SUMMLEAD
MEADRAND
WEBS
with cutoff
no cutoff0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
RPV
Summarizer
Correlation method
Relevance Preservation Value (RPV) with and without cutoff (English, 10%)
with cutoff
no cutoff
with cutoff 0.65 0.65 0.76 0.56 0.7
no cutoff 0.73 0.71 0.84 0.66 0.72
SUMM LEAD MEAD RAND WEBS

SUMMLEAD
MEADRAND
WEBS
with cutoff
no cutoff0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
RPV
Summarizer
Correlation method
Relevance Preservation Value (RPV) with and without cutoff (English, 20%)
with cutoff
no cutoff
with cutoff 0.71 0.74 0.88 0.72 0.8
no cutoff 0.79 0.8 0.92 0.78 0.82
SUMM LEAD MEAD RAND WEBS

AS
GE
ME
AD
ME
AD
OR
IG
ME
AD
002
ME
AD
003
ME
AD
S00
2
Q55
1
Q11
2
Q-A
VG Q12
5
Q32
3
Q24
1
0.85
0.86
0.87
0.88
0.89
0.9
0.91
0.92
0.93
RPV
MEAD policy
Query
Relevance Preservation Value (RPV) per MEAD policy (5 queries)
Q551
Q112
Q-AVG
Q125
Q323
Q241
Q551 0.88 0.9 0.89 0.89
Q112 0.86 0.91 0.9 0.9 0.9
Q-AVG 0.886 0.916 0.908 0.908 0.9125
Q125 0.87 0.92 0.91 0.91 0.91
Q323 0.89 0.92 0.91 0.91 0.91
Q241 0.93 0.93 0.93 0.93 0.93
ASGEMEAD MEADORIG MEAD002 MEAD003 MEADS002

BASE English Chinese-MonoChinese-XAVG-5 English 91.6 48.8 45.8
20% Chinese-Mono 61.4 84.8 34.6Chinese-X 63.2 36 69.4
RPV, E/C-Mono/C-Xlingual

Addressing redundancy
--3S10
--3S9
--4S8
--7S7
--6S6
--7S5
+-7S4
--2S3
++8(+)S2
-+10(+)S1
System 2System 1Ideal

Addressing redundancy
--3S10
--3S9
--4S8
--7S7
--6S6
--7S5
+-7S4
--2S3
++8(+)S2
-+10(+)S1
System 2System 1Ideal
RU1’ = (8+ 10 )/(8+10)
RU2’ = (8+ 7)/(8+10)RU2 = (8+7)/(8+10)
RU1 = (8+10)/(8+10)
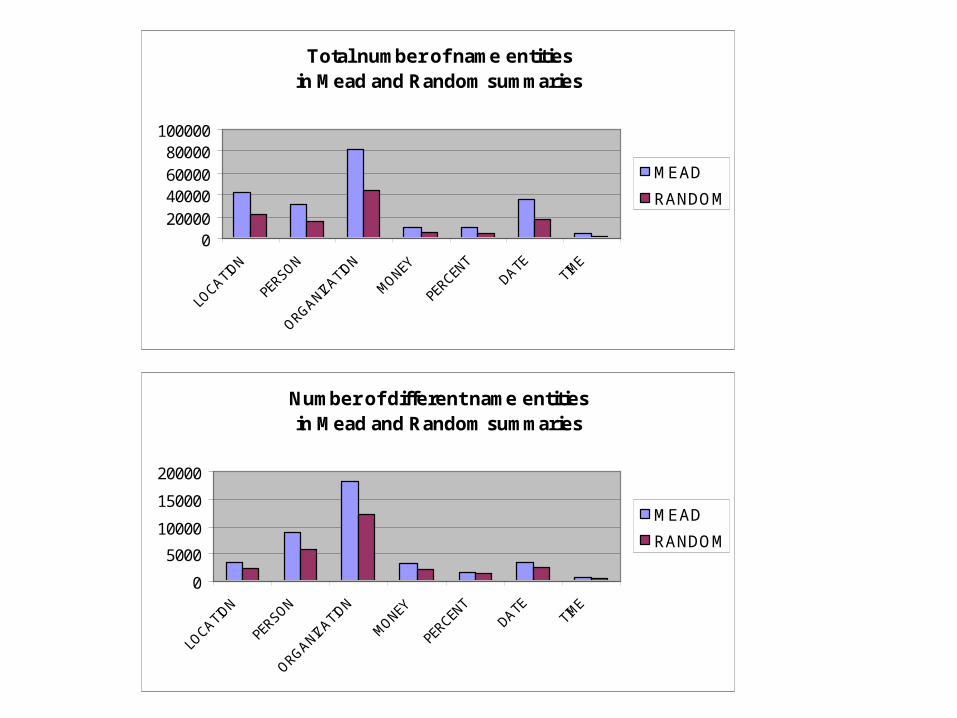
Total number of name entities in Mead and Random summaries
020000400006000080000
100000
MEAD
RANDOM
Number of different name entities in Mead and Random summaries
0
5000
10000
15000
20000
MEAD
RANDOM

43.5% name entities are kept in 20% Mead summaries
43.5%
22.6% name entities are kept in 20% random summaries
22.6%
59.3% different name entities are kept in 20% Mead summaries
59.3%
40.7% different name entities are kept in 20% Random summaries
40.7%

Narcotics rehabilitation translation ¬r«~ ±d´_
The study was commissioned to The Chinese University of Hong Kong, and aims to find out the underlying causes for the chronic abuse of illicit drugs and the relapse into drug addiction after detoxification and rehabilitation. Commenting on the research topic, a spokesman of the Narcotics Division said, "It is considered that there is a demonstrated need for such a project, as relapse into drug addiction following detoxification and rehabilitation has been an issue of great concern for policy-makers and workers in the anti-drug field." "It is hoped that the findings of the study will help the Government and ACAN develop effective treatment strategies for chronic or frequently relapsed drug abusers, and look into what modifications should be made to the existing methadone programme. "It is recognized in psychiatric field that, drug abuse cases which are identified early usually stand a better chance of recovering in full, while late ones normally have more severe or perhaps life-long psychiatric damage," the spokesman said.
Run mead on English document
Run mead on Chinese document
Sentence Alignment
Commenting on the research topic, a spokesman of the Narcotics Division said, "It is considered that there is a demonstrated need for such a project, as relapse into drug addiction following detoxification and rehabilitation has been an issue of great concern for policy-makers and workers in the anti-drug field." "It is hoped that the findings of the study will help the Government and ACAN develop effective treatment strategies for chronic or frequently relapsed drug abusers, and look into what modifications should be made to the existing methadone programme. "This coincide with the observation that relapse is an acute problem for those who have a long drug addiction history, in particular methadone patients," he added. "It is recognized in psychiatric field that, drug abuse cases which are identified early usually stand a better chance of recovering in full, while late ones normally have more severe or perhaps life-long psychiatric damage," the spokesman said.

Cosine similarity with human extracts
00.10.20.30.40.50.60.70.8
125 241 323 551 112
English Meadsummaries
Aligned Englishsummaries fromChinese Meadsummaries
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Q-125
Q-323
Q-112
Q-398Q-1014
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
precision
recall
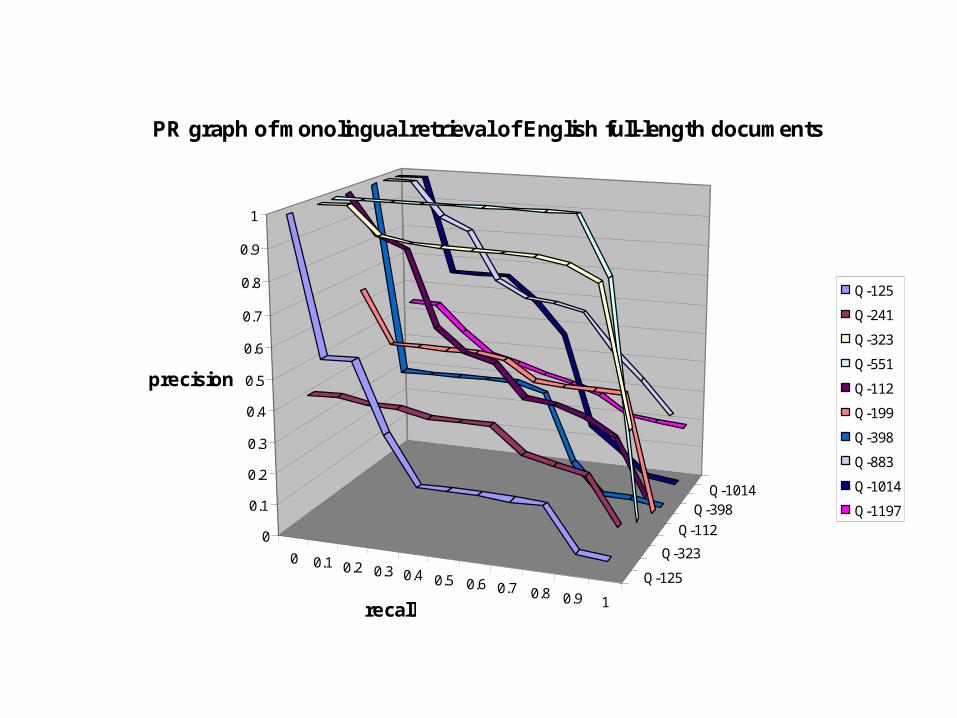
PR graph of monolingual retrieval of English full-length documents
Q-125
Q-241
Q-323
Q-551
Q-112
Q-199
Q-398
Q-883
Q-1014
Q-1197

1 2 3 4 5 6 7 8 9 10 11
Q-447
Q-2
Q-60
Q-1018
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
precision
recall
PR graph of monolingual retrieval of English full-length documents
Q-447
Q-827
Q-885
Q-2
Q-46
Q-54
Q-60
Q-61
Q-62
Q-1018

0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Q-125
Q-551
Q-398
Q-1197
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
precision
recall
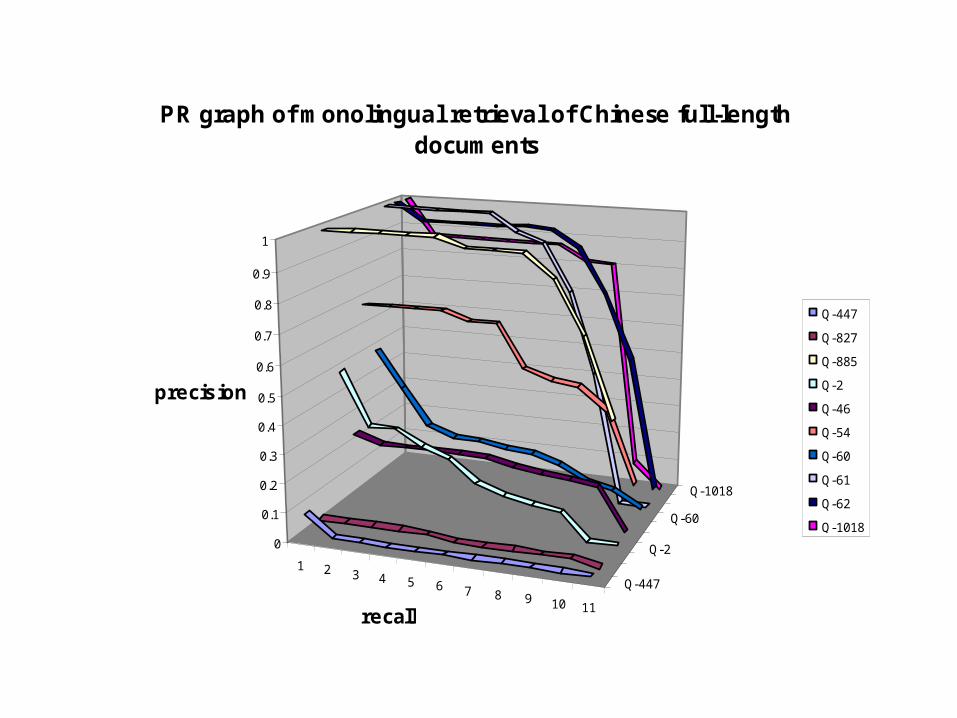
PR graph of monolingual retrieval of Chinese full-length documents
Q-125
Q-241
Q-323
Q-551
Q-112
Q-199
Q-398
Q-883
Q-1014
Q-1197
1 2 3 4 5 6 7 8 9 10 11
Q-447
Q-2
Q-60
Q-1018
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
precision
recall
PR graph of monolingual retrieval of Chinese full-length documents
Q-447
Q-827
Q-885
Q-2
Q-46
Q-54
Q-60
Q-61
Q-62
Q-1018

0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Chinese crosslingualChinese monolingual
English monolingual0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
precision
recall
PR graph of retrieval of English full-length documents (20 query average)

0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
RANDOM
Sent-Algn-MEAD
SUMM
WEBSUMM
LEAD
MEAD
full-length
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
precision
recall
PR graph of retrieval of English summaries (20%)
RANDOM
Sent-Algn-MEAD
SUMM
WEBSUMM
LEAD
MEAD
full-length
0.3298
Sent-Algn-MEAD
0.351
Summarist
0.29930.35360.38450.38920.4387Avg. Prec.
randomWebsummleadMEADFull-length

Precision at the first 30 retrieved documents/summaries (20%)
0.4
0.41
0.42
0.43
0.44
0.45
0.46
0.47
0.48
0.49
pre
cis
ion

Research contributions
• Relevance preservation value: compared to established evaluation metrics
• Relative utility: large-scale evaluation
• Comparison of query-based and generic summarization
• Comparison of manual extracts and manual summaries
• Cross-lingual summarization using alignment
• Evaluation of cross-lingual summaries

Properties of evaluation metricsKappa,P/R,accuracy
RU Wordoverlap,cosine, lcs
Relevancepreserv.
Agreement Humanextracts
X X X
Agreement humanextracts – automaticextracts
X X X
Agreement humansummaries/extracts
X
Non-binary decisions X X X
Full documents vs.extracts
X X
Systems with differentsentence segm.
X X
Multidocument extracts X X X
Full corpus coverage X X

Technical accomplishments
• Develop a summarization toolkit including a modular state-of-the art summarizer: single-document, multi-document, generic, query-based
• Develop a summarization evaluation toolkit allowing comparisons between extractive and non-extractive summaries
• Produce an annotated corpus for further research in text summarization

Future work
• Evaluate trainable framework
• Explore subsumption
• Fact-based evaluation
• Task-based evaluation
• Determine optimal compression rate

Acknowledgements
• Chin-Yew Lin, ISI• Inderjeet Mani, MITRE• Breck Baldwin, Coreference.com• Regina Barzilay, Columbia• Greg Silber, Delaware• Dan Melamed, NYU• Ralph Weischedel, Sean Boisen, BBN

Acknowledgements
• Stephanie Strassel, LDC
• Dave Graff, LDC
• Chris Cieri, LDC
• Donna Harman, NIST
• Paul Over, NIST
• Sasha Blair-Goldensohn, Michigan
• Sanjeev Khudanpur, JHU
• Bill Byrne, JHU
• Laura Graham, JHU
• Jacob Laderman, JHU
• Fred Jelinek, JHU
• The US government agencies who sponsored the research


![Automatic Text Summarization of Chinese Legal Informationceur-ws.org/Vol-2318/paper19.pdf · Automatic Text Summarization of Chinese Legal Information Dmitry 1[0000Lande-000339451178],](https://static.fdocuments.in/doc/165x107/5f8922188f8b97483771ea7d/automatic-text-summarization-of-chinese-legal-informationceur-wsorgvol-2318-.jpg)















