
Automatic Paraphrase Collection and Identification in Twitter · Automatic Paraphrase Collection...
135
Automatic Paraphrase Collection and Identification in Twitter Wuwei Lan, Siyu Qiu, Hua He, Wei Xu
-
Upload
trinhduong -
Category
Documents
-
view
235 -
download
0
Transcript of Automatic Paraphrase Collection and Identification in Twitter · Automatic Paraphrase Collection...

Automatic Paraphrase Collection and Identification in Twitter
Wuwei Lan, Siyu Qiu, Hua He, Wei Xu
What is paraphrase?

What is paraphrase?
Willy Wonka was famous for his delicious candy. Children and adults loved to eat it.

What is paraphrase?
Willy Wonka was famous for his delicious candy. Children and adults loved to eat it.
Willy Wonka was known throughout the world because people enjoyed eating the tasty candy he made.

What is paraphrase?
Willy Wonka was famous for his delicious candy. Children and adults loved to eat it.
Willy Wonka was known throughout the world because people enjoyed eating the tasty candy he made.
famous
known throughout the world

What is paraphrase?
Willy Wonka was famous for his delicious candy. Children and adults loved to eat it.
Willy Wonka was known throughout the world because people enjoyed eating the tasty candy he made.
deliciousfamous
known throughout the worldtasty

What is paraphrase?
Willy Wonka was famous for his delicious candy. Children and adults loved to eat it.
Willy Wonka was known throughout the world because people enjoyed eating the tasty candy he made.
deliciousfamousloved to eat
known throughout the worldenjoyed eating tasty

Paraphrase Application: duplicate question identification

Paraphrase Application: duplicate question identification
Paraphrase Application: duplicate question identification
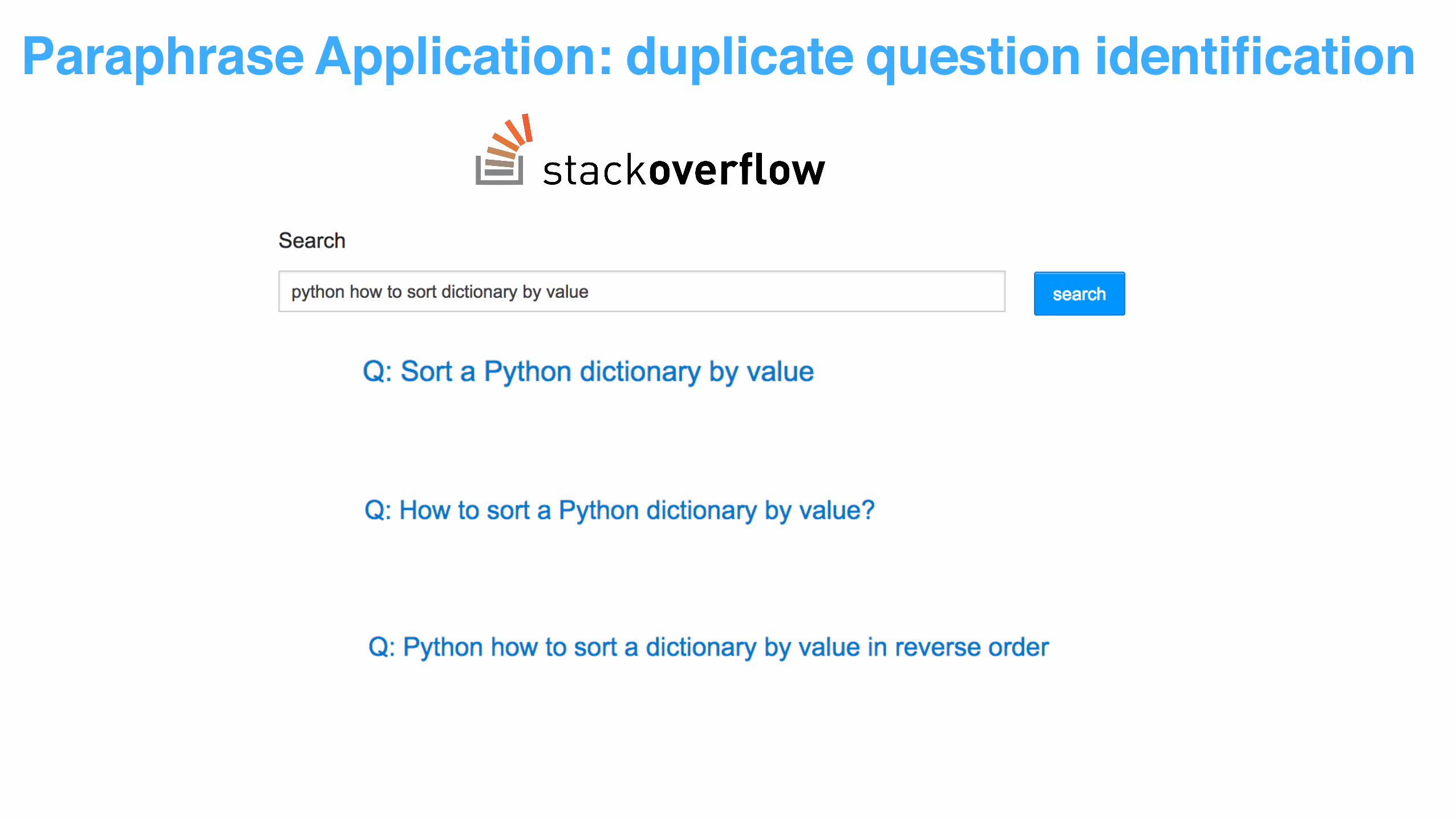
Paraphrase Application: duplicate question identification
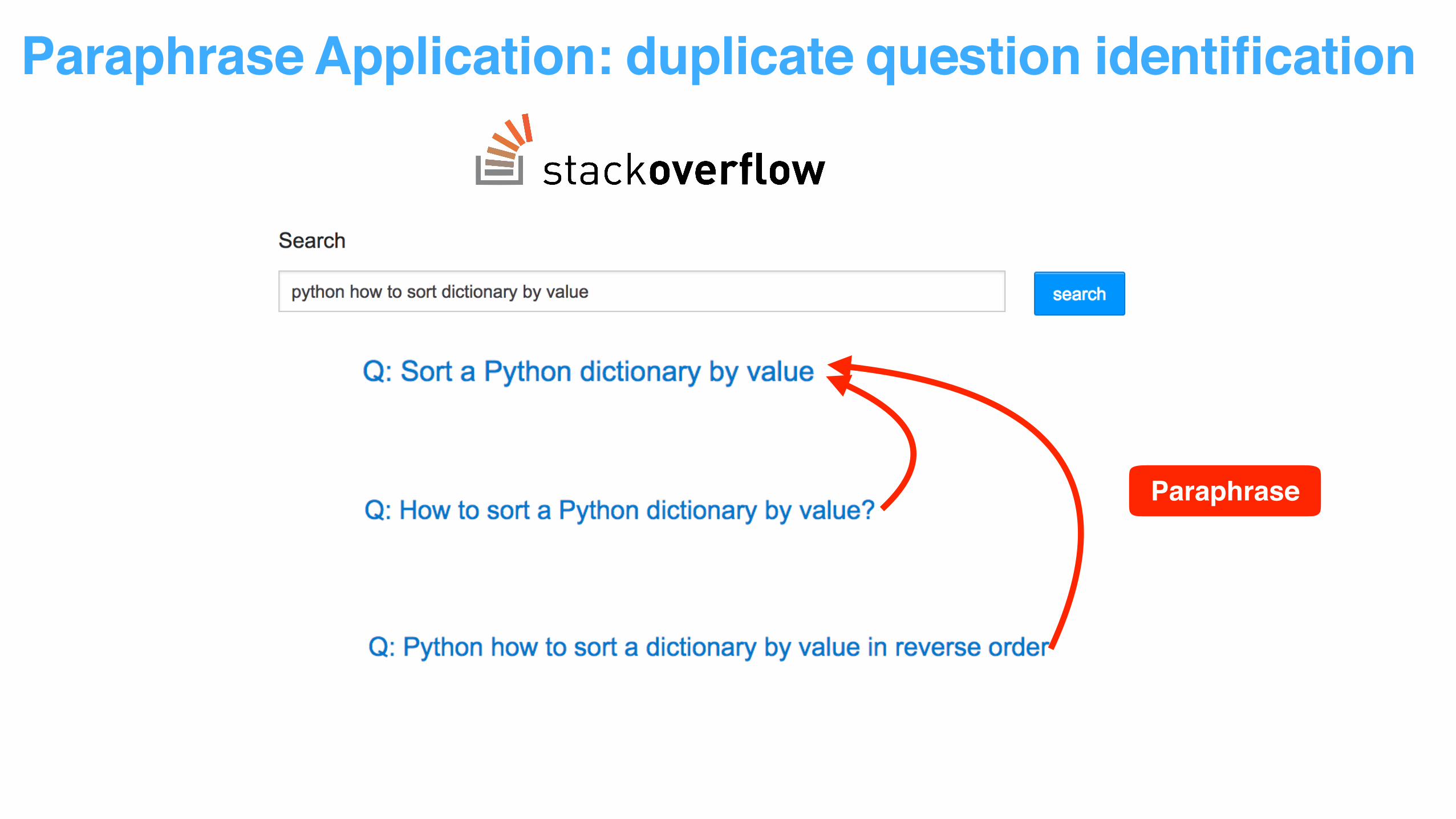
Paraphrase Application: duplicate question identification
Paraphrase
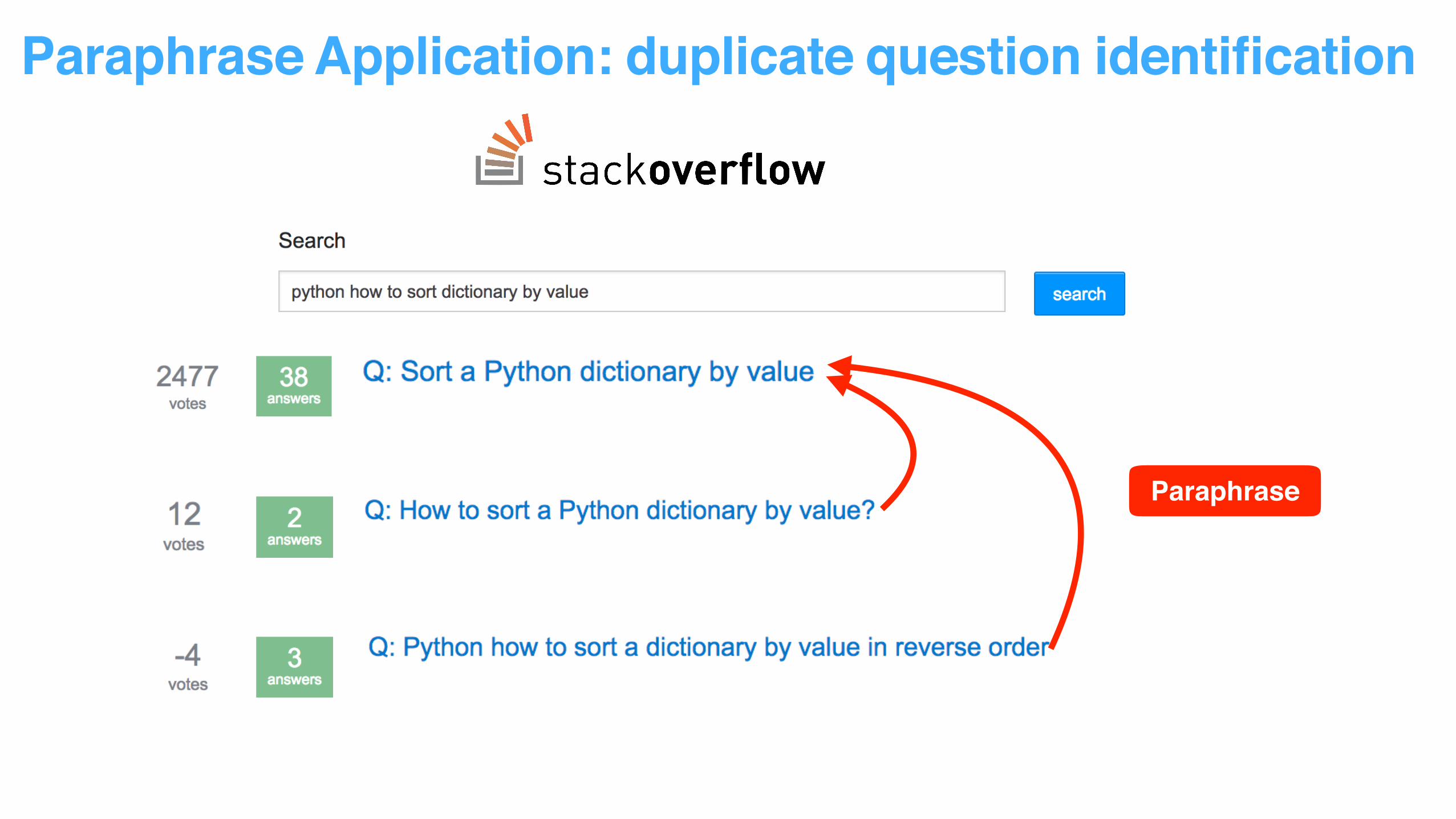
Paraphrase Application: duplicate question identification
Paraphrase
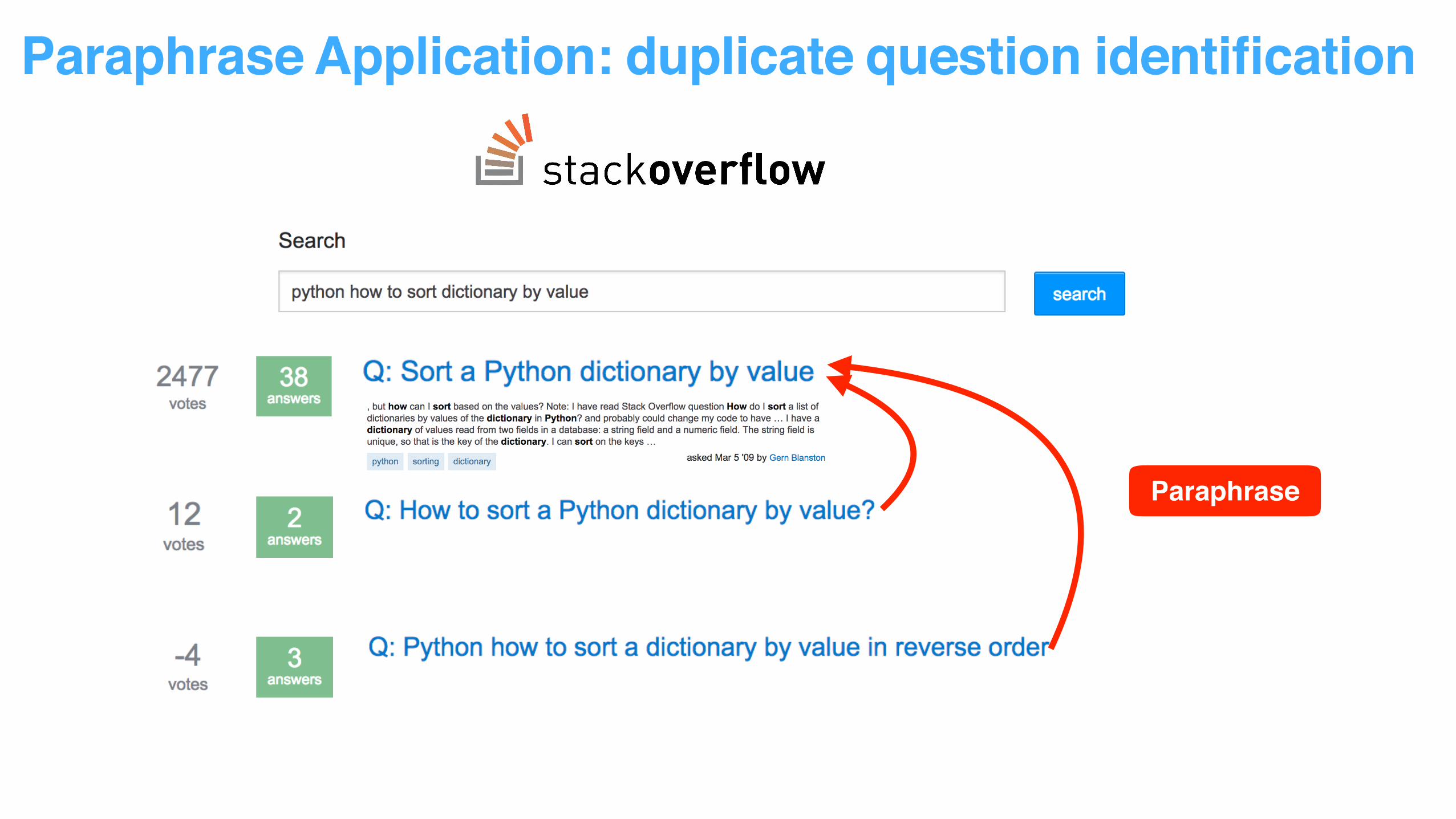
Paraphrase Application: duplicate question identification
Paraphrase

Paraphrase Application: question answering

Paraphrase Application: question answering

Paraphrase Application: question answering
[Question]
In May 1898 Portugal celebrated the 400th anniversary of this explorer’s arrival in India

Paraphrase Application: question answering
[Question] [Supporting Evidence]
In May 1898 Portugal celebrated the 400th anniversary of this explorer’s arrival in India
On the 27th of May 1498, Vasco da Gama landed in Kappad Beach
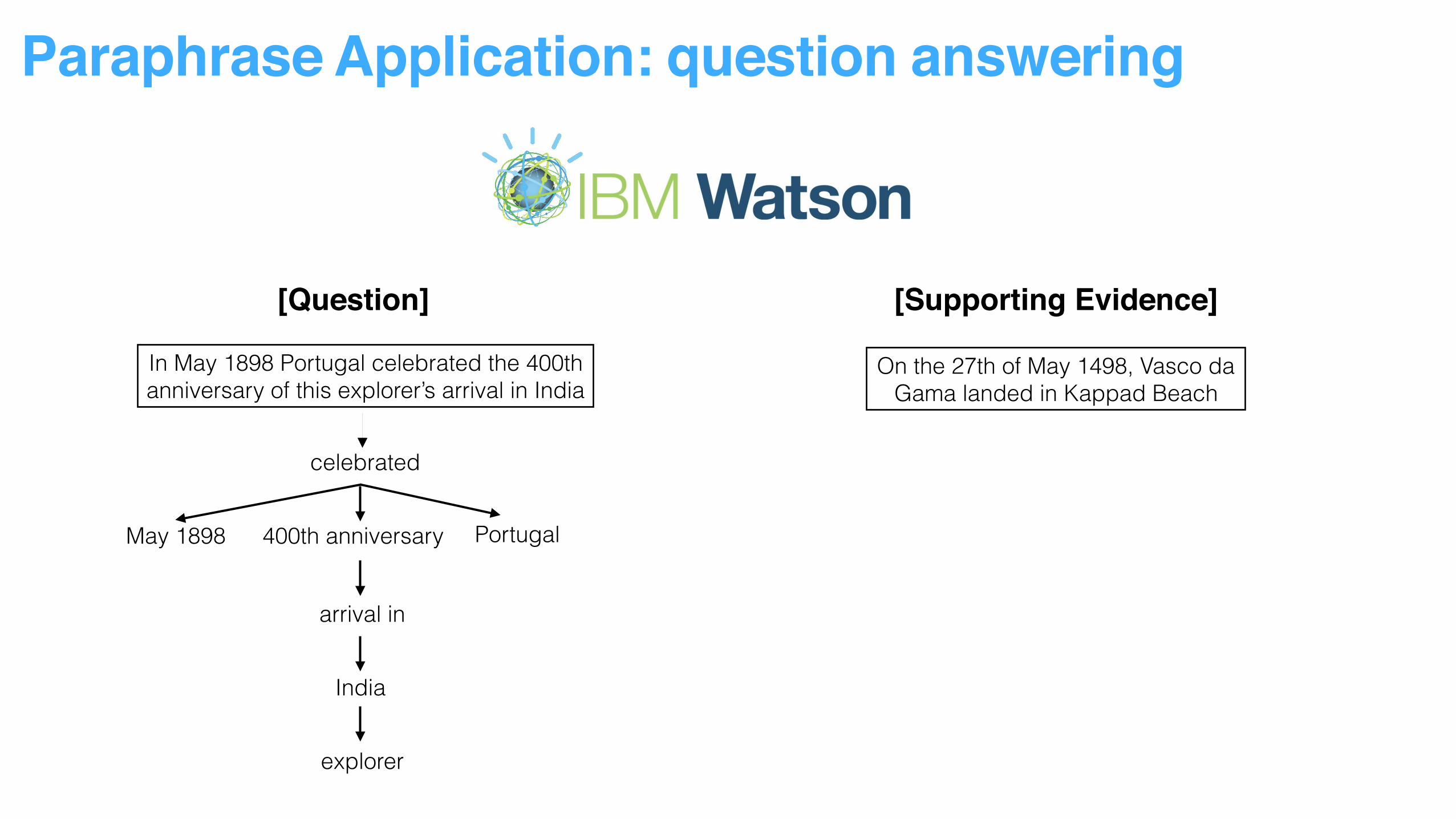
Paraphrase Application: question answering
[Question] [Supporting Evidence]
In May 1898 Portugal celebrated the 400th anniversary of this explorer’s arrival in India
On the 27th of May 1498, Vasco da Gama landed in Kappad Beach
celebrated
Portugal400th anniversaryMay 1898
arrival in
India
explorer
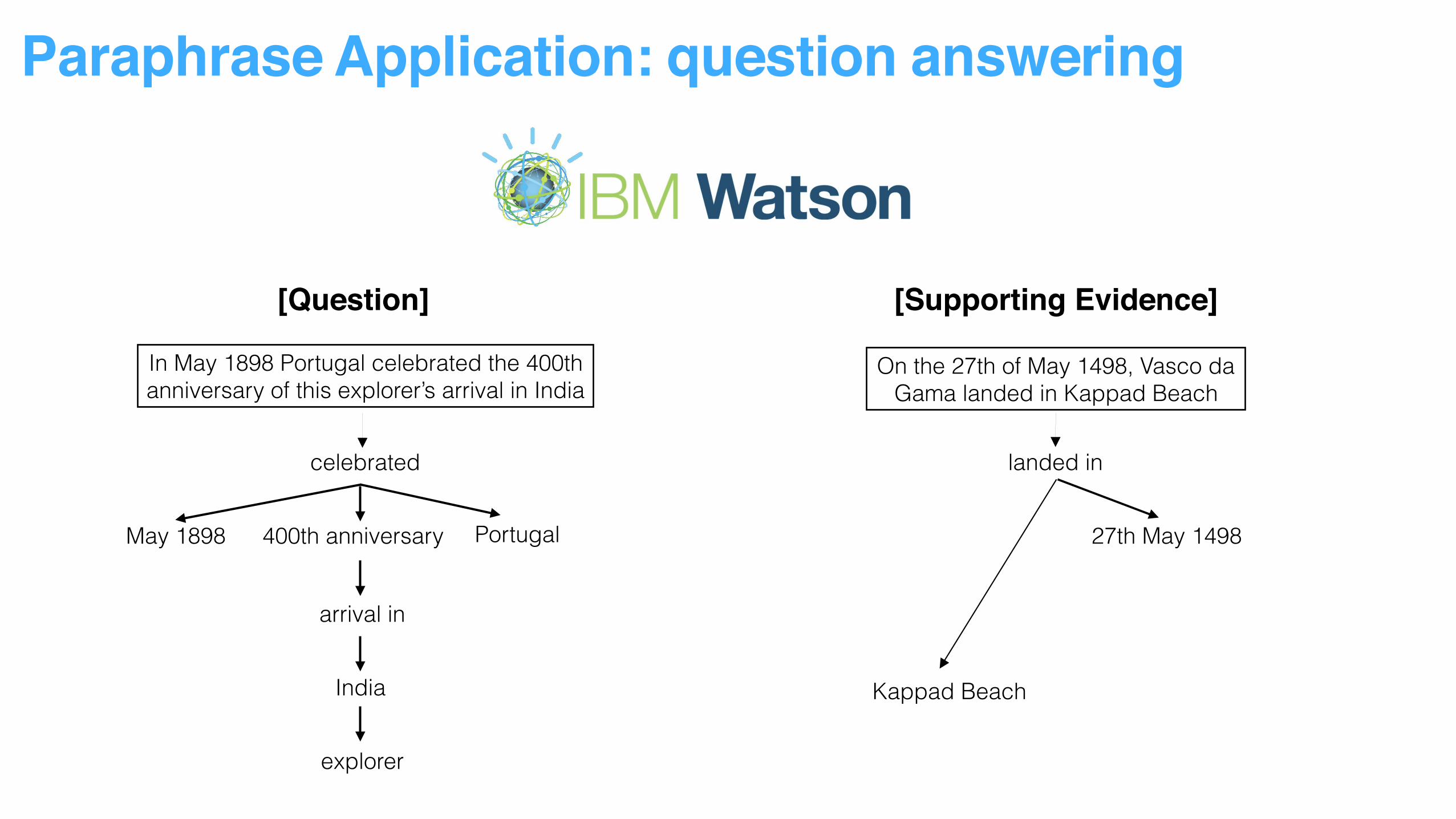
Paraphrase Application: question answering
[Question] [Supporting Evidence]
In May 1898 Portugal celebrated the 400th anniversary of this explorer’s arrival in India
On the 27th of May 1498, Vasco da Gama landed in Kappad Beach
celebrated
Portugal400th anniversaryMay 1898
arrival in
India
explorer
landed in
27th May 1498
Kappad Beach
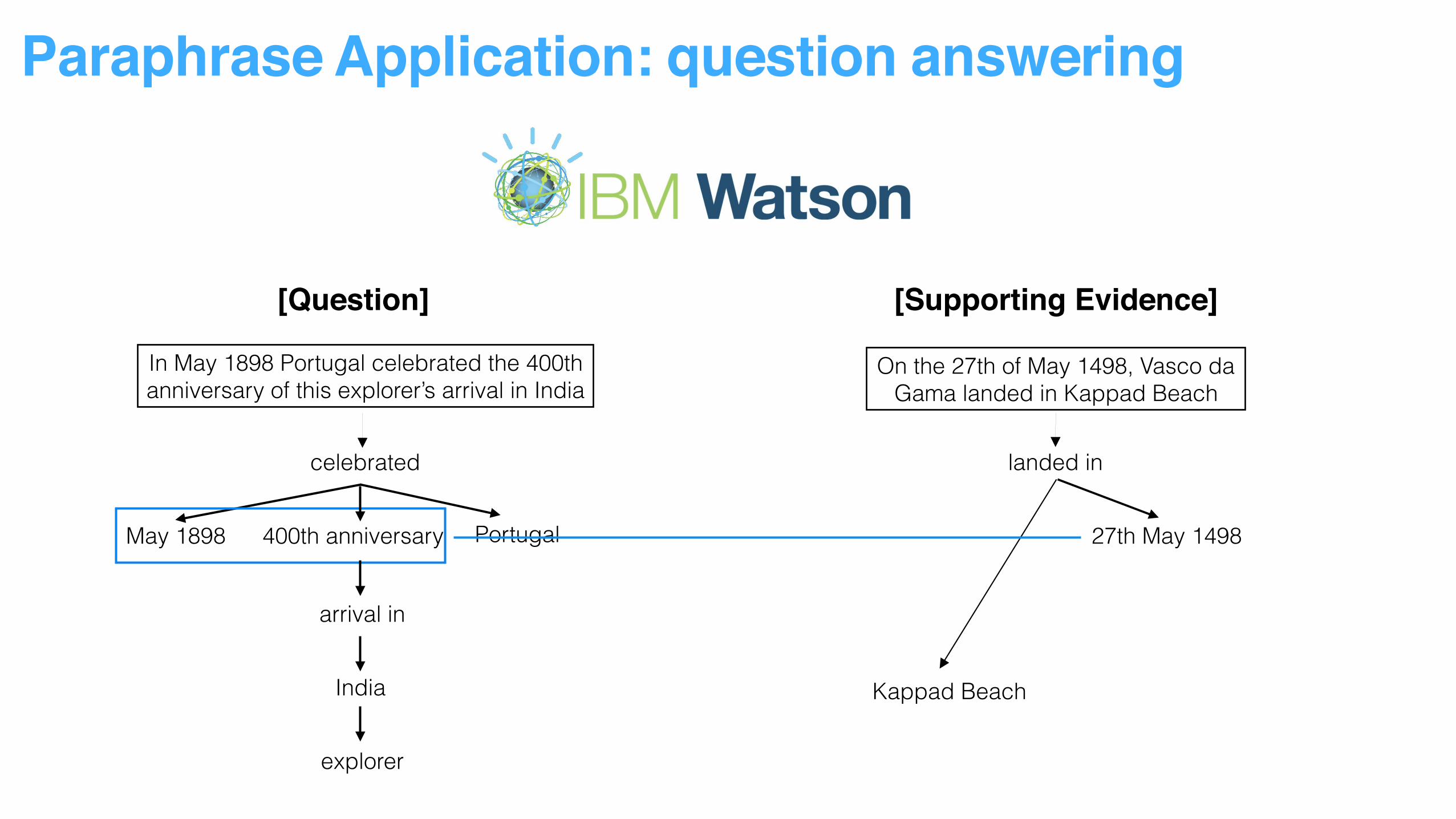
Paraphrase Application: question answering
[Question] [Supporting Evidence]
In May 1898 Portugal celebrated the 400th anniversary of this explorer’s arrival in India
On the 27th of May 1498, Vasco da Gama landed in Kappad Beach
celebrated
Portugal400th anniversaryMay 1898
arrival in
India
explorer
landed in
27th May 1498
Kappad Beach
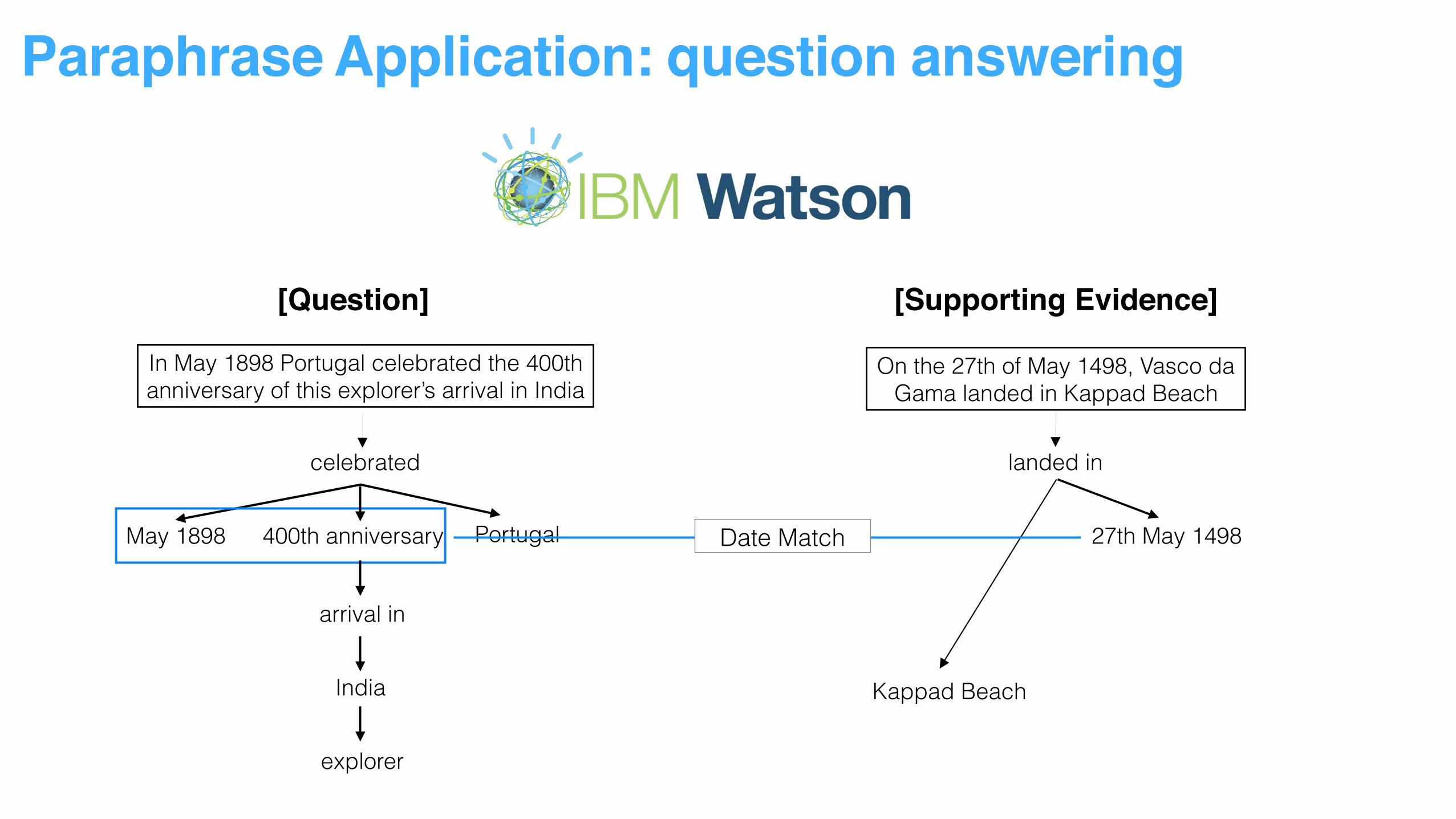
Paraphrase Application: question answering
[Question] [Supporting Evidence]
In May 1898 Portugal celebrated the 400th anniversary of this explorer’s arrival in India
On the 27th of May 1498, Vasco da Gama landed in Kappad Beach
celebrated
Portugal400th anniversaryMay 1898
arrival in
India
explorer
landed in
27th May 1498
Kappad Beach
Date Match
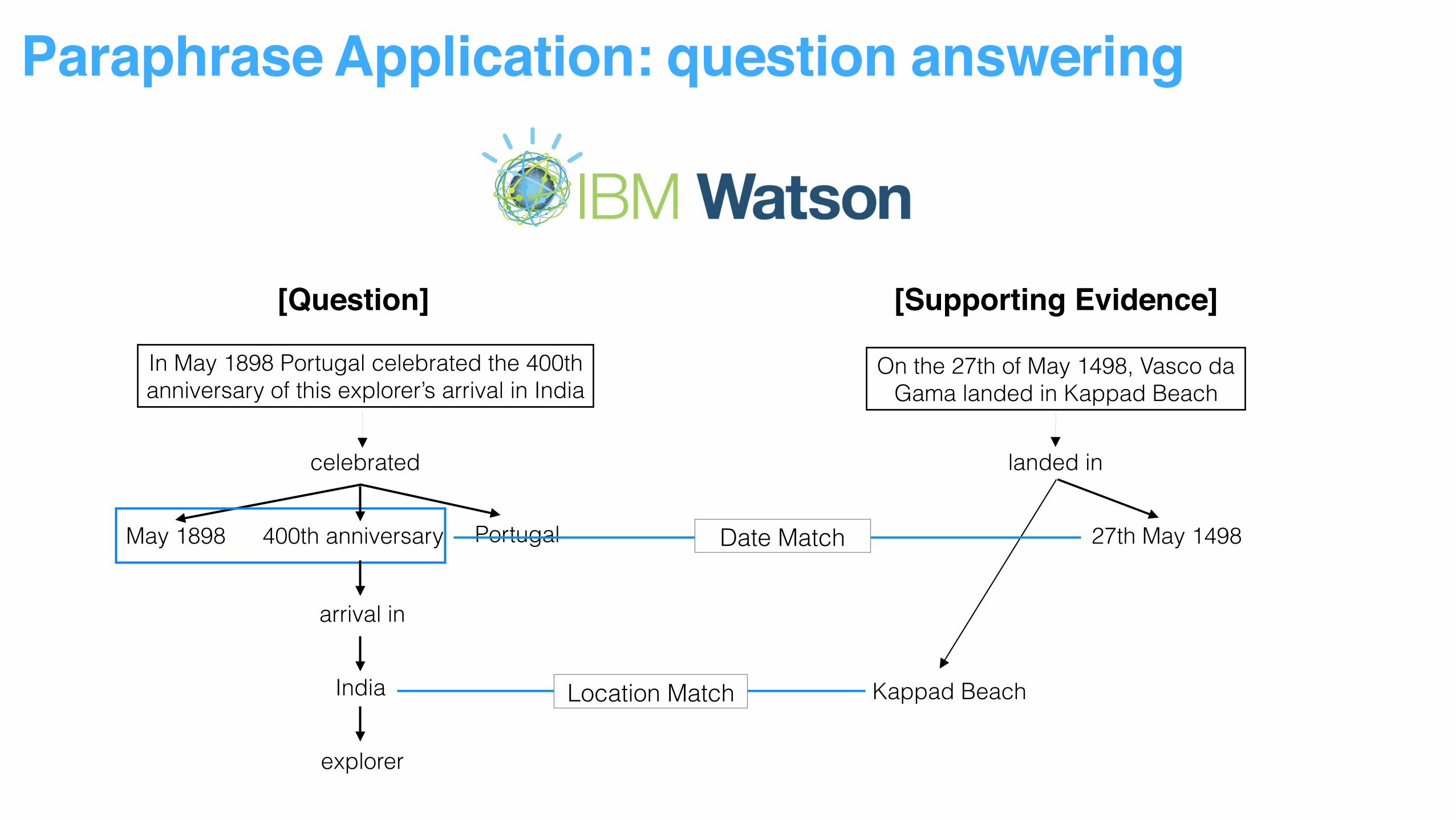
Paraphrase Application: question answering
[Question] [Supporting Evidence]
In May 1898 Portugal celebrated the 400th anniversary of this explorer’s arrival in India
On the 27th of May 1498, Vasco da Gama landed in Kappad Beach
Location Match
celebrated
Portugal400th anniversaryMay 1898
arrival in
India
explorer
landed in
27th May 1498
Kappad Beach
Date Match
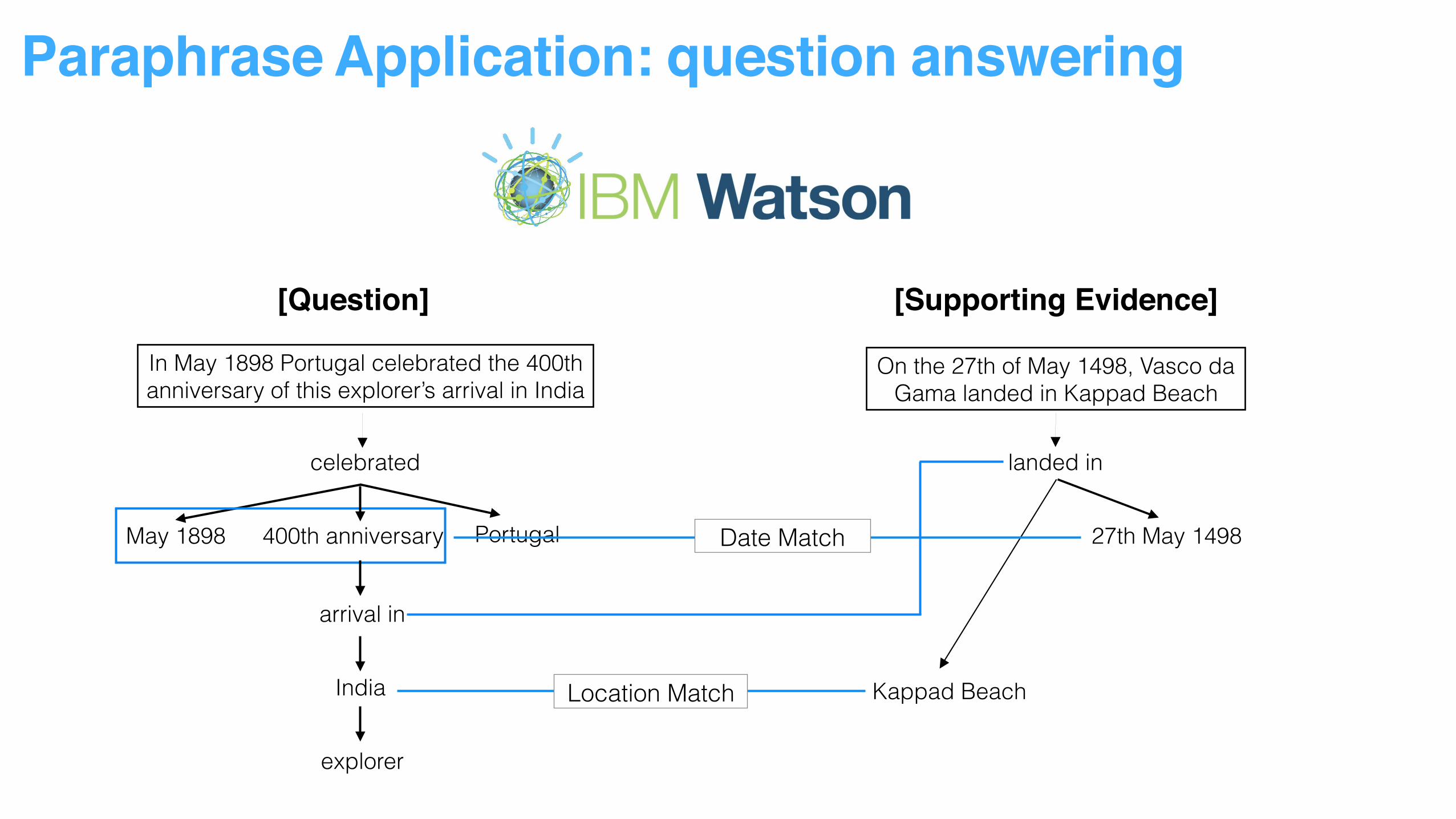
Paraphrase Application: question answering
[Question] [Supporting Evidence]
In May 1898 Portugal celebrated the 400th anniversary of this explorer’s arrival in India
On the 27th of May 1498, Vasco da Gama landed in Kappad Beach
Location Match
celebrated
Portugal400th anniversaryMay 1898
arrival in
India
explorer
landed in
27th May 1498
Kappad Beach
Date Match
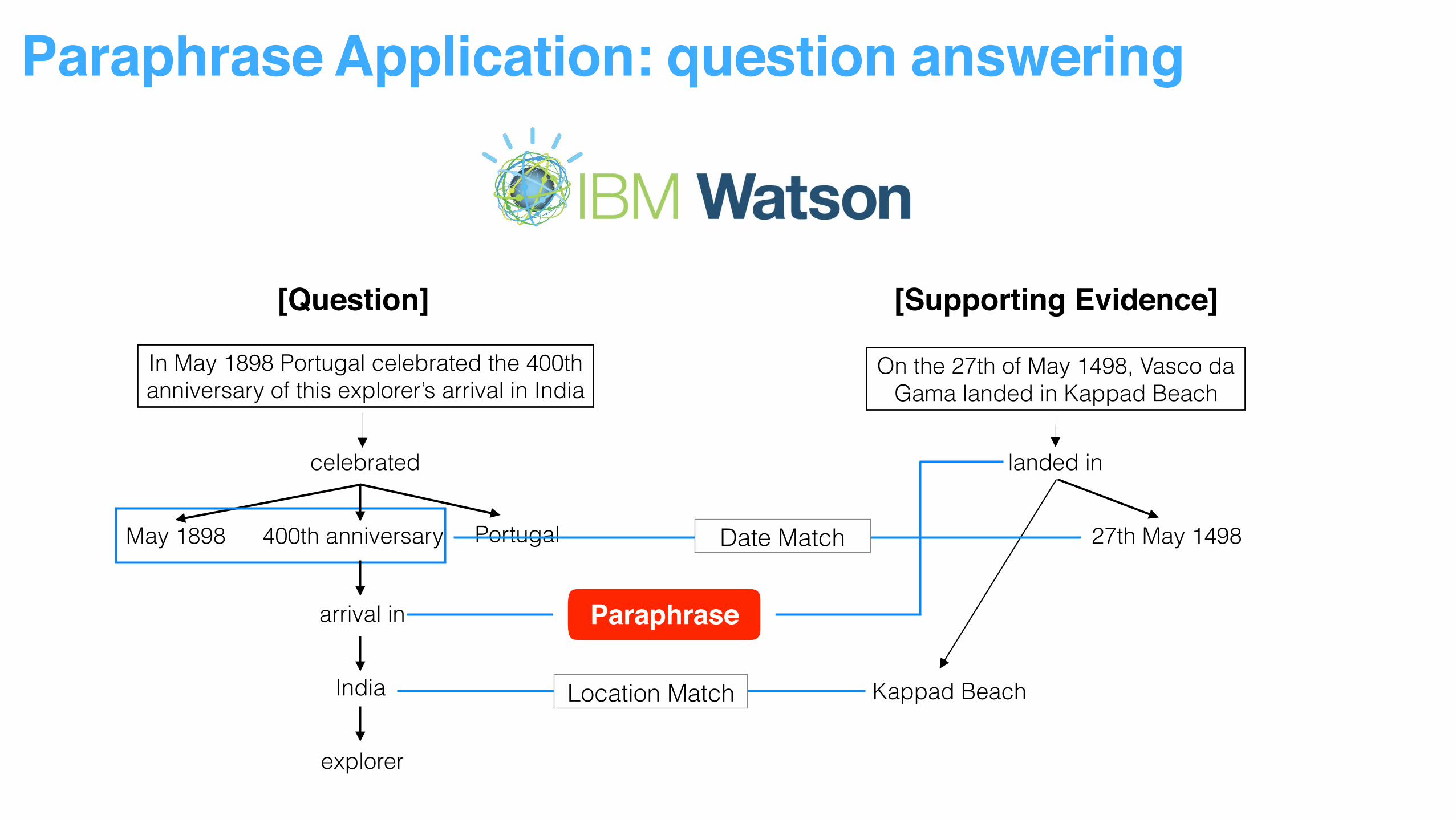
Paraphrase Application: question answering
[Question] [Supporting Evidence]
In May 1898 Portugal celebrated the 400th anniversary of this explorer’s arrival in India
On the 27th of May 1498, Vasco da Gama landed in Kappad Beach
Location Match
celebrated
Portugal400th anniversaryMay 1898
arrival in
India
explorer
landed in
27th May 1498
Kappad Beach
Date Match
Paraphrase

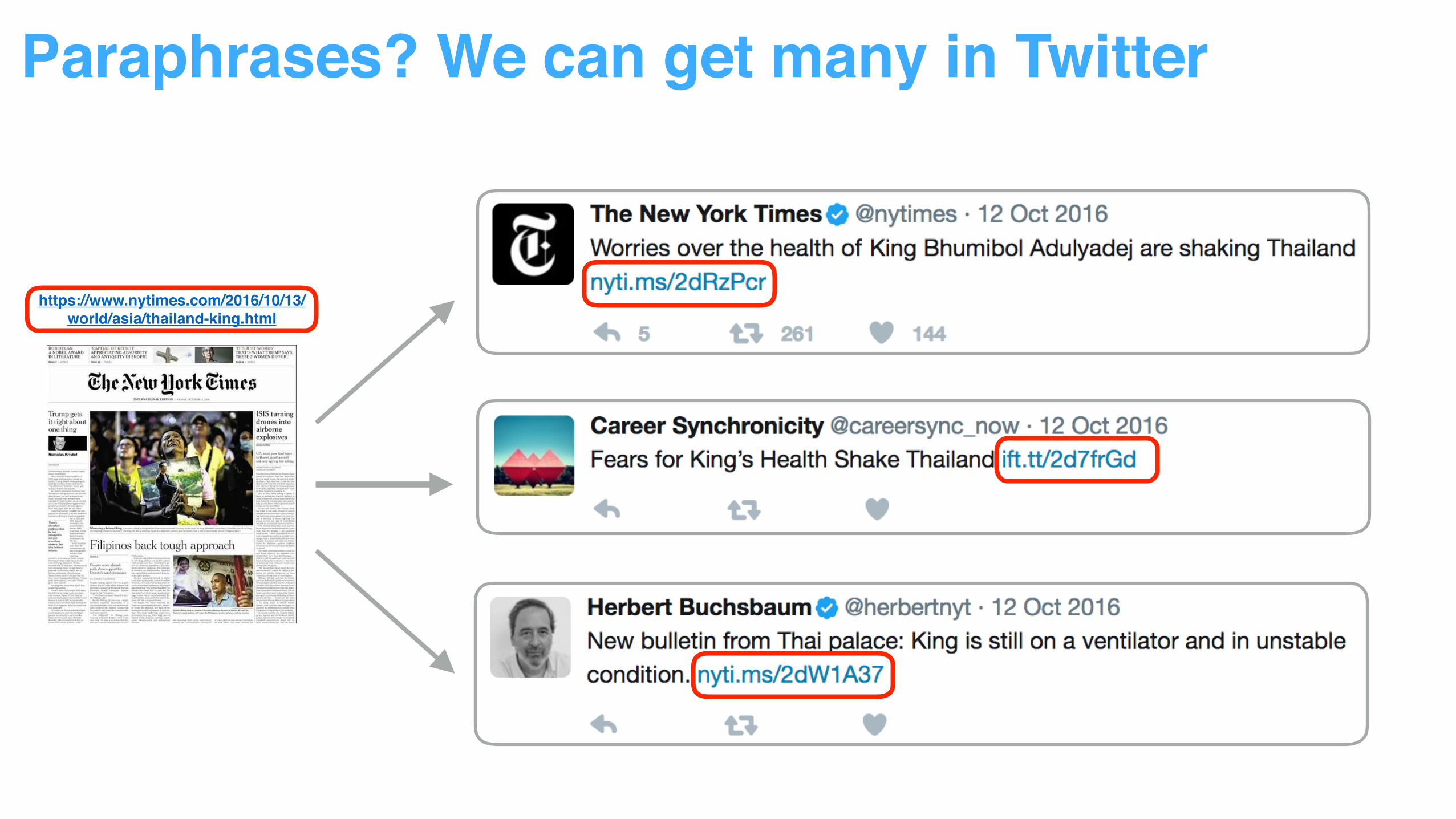
Paraphrases?
https://www.nytimes.com/2016/10/13/world/asia/thailand-king.html

Paraphrases?
https://www.nytimes.com/2016/10/13/world/asia/thailand-king.html

Paraphrases?
https://www.nytimes.com/2016/10/13/world/asia/thailand-king.html

Paraphrases?
https://www.nytimes.com/2016/10/13/world/asia/thailand-king.html

Paraphrases?
https://www.nytimes.com/2016/10/13/world/asia/thailand-king.html
Paraphrase

Paraphrases?
https://www.nytimes.com/2016/10/13/world/asia/thailand-king.html
Paraphrase

Paraphrases?
https://www.nytimes.com/2016/10/13/world/asia/thailand-king.html
Paraphrase

Paraphrases?
https://www.nytimes.com/2016/10/13/world/asia/thailand-king.html
Paraphrase
Non-Paraphrase

Paraphrases? We can get many in Twitter
https://www.nytimes.com/2016/10/13/world/asia/thailand-king.html
Paraphrases? We can get many in Twitter
https://www.nytimes.com/2016/10/13/world/asia/thailand-king.html
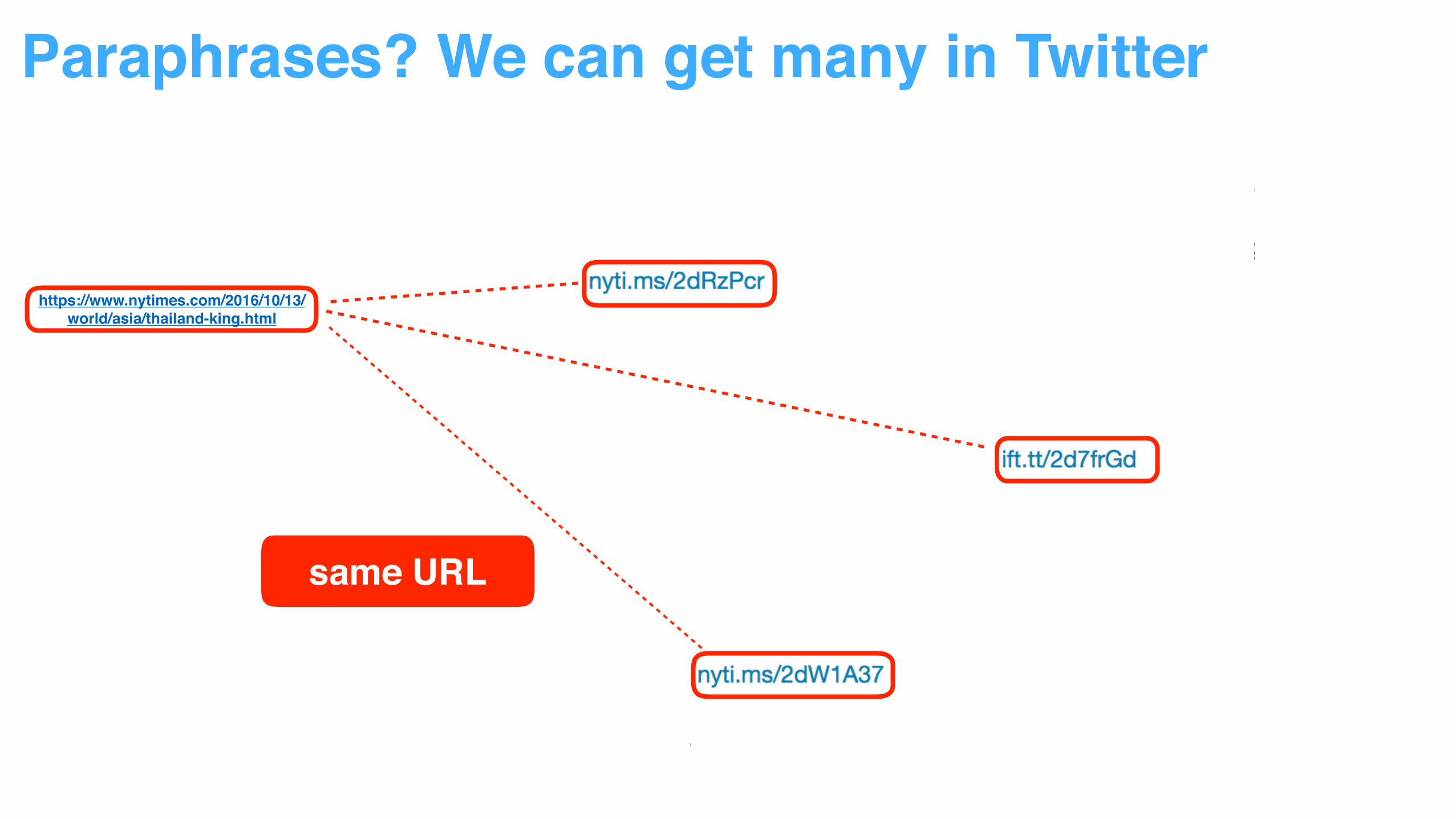
Paraphrases? We can get many in Twitter
https://www.nytimes.com/2016/10/13/world/asia/thailand-king.html
same URL

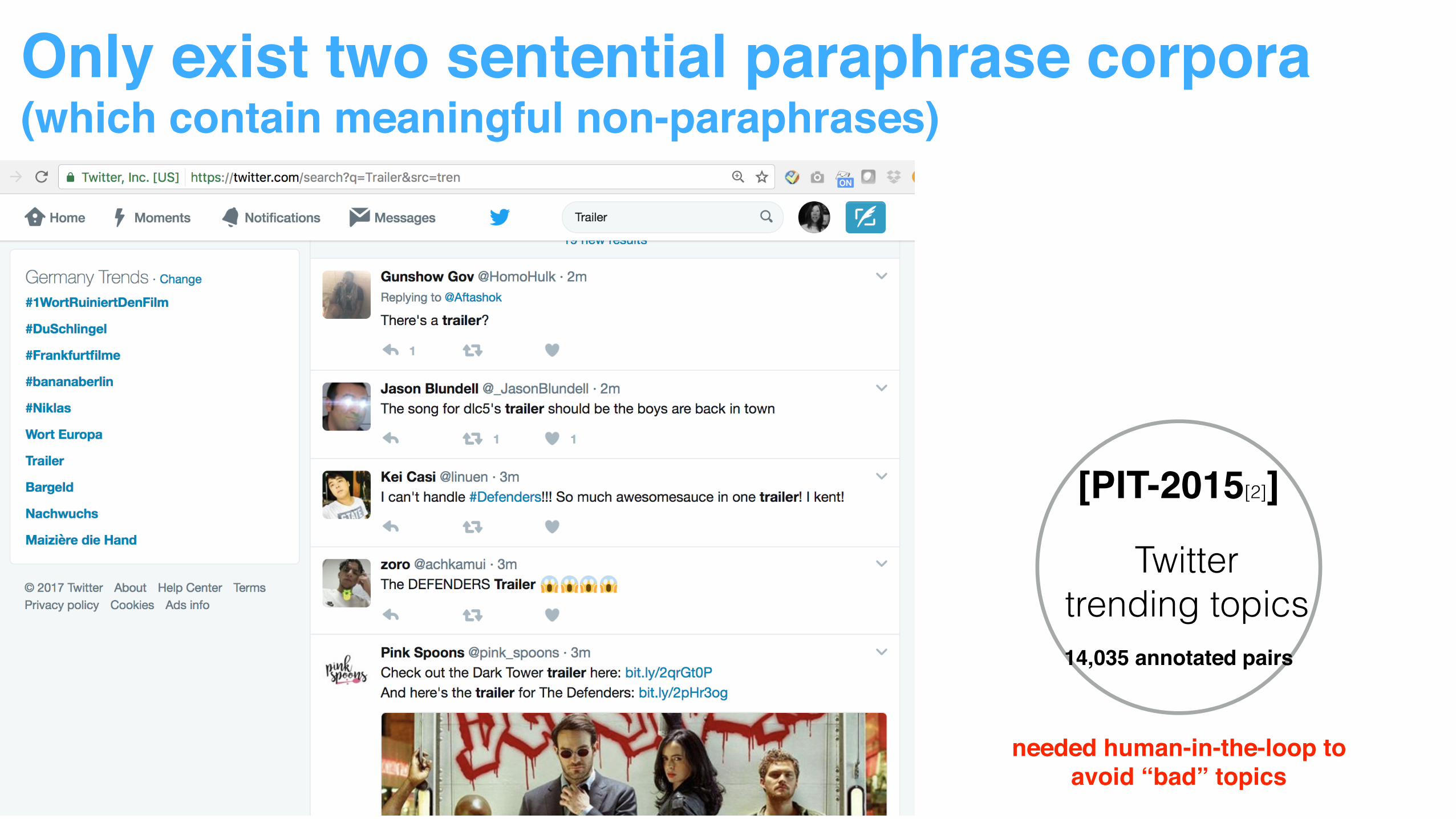
Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP[1]]
clustered news articles
[1] Dolan et al., 2004 [2] Xu et al., 2014
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs5,801 annotated pairs

Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP[1]]
clustered news articles
Key for success:
[1] Dolan et al., 2004 [2] Xu et al., 2014
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs5,801 annotated pairs

Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP[1]]
clustered news articles
Key for success:• narrow the search space
[1] Dolan et al., 2004 [2] Xu et al., 2014
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs5,801 annotated pairs

Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP[1]]
clustered news articles
Key for success:• narrow the search space • ensure diversity among sentences
[1] Dolan et al., 2004 [2] Xu et al., 2014
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs5,801 annotated pairs

Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP[1]]
clustered news articles
Key for success:• narrow the search space • ensure diversity among sentencesAlso Pitfalls …
[1] Dolan et al., 2004 [2] Xu et al., 2014
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs5,801 annotated pairs

Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP[1]]
clustered news articles
needed a SVM classifier to select sentences before data annotation
Key for success:• narrow the search space • ensure diversity among sentencesAlso Pitfalls …
[1] Dolan et al., 2004 [2] Xu et al., 2014
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs5,801 annotated pairs

Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP[1]]
clustered news articles
needed a SVM classifier to select sentences before data annotation
Key for success:• narrow the search space • ensure diversity among sentencesAlso Pitfalls …
needed human-in-the-loop toavoid “bad” topics
[1] Dolan et al., 2004 [2] Xu et al., 2014
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs5,801 annotated pairs
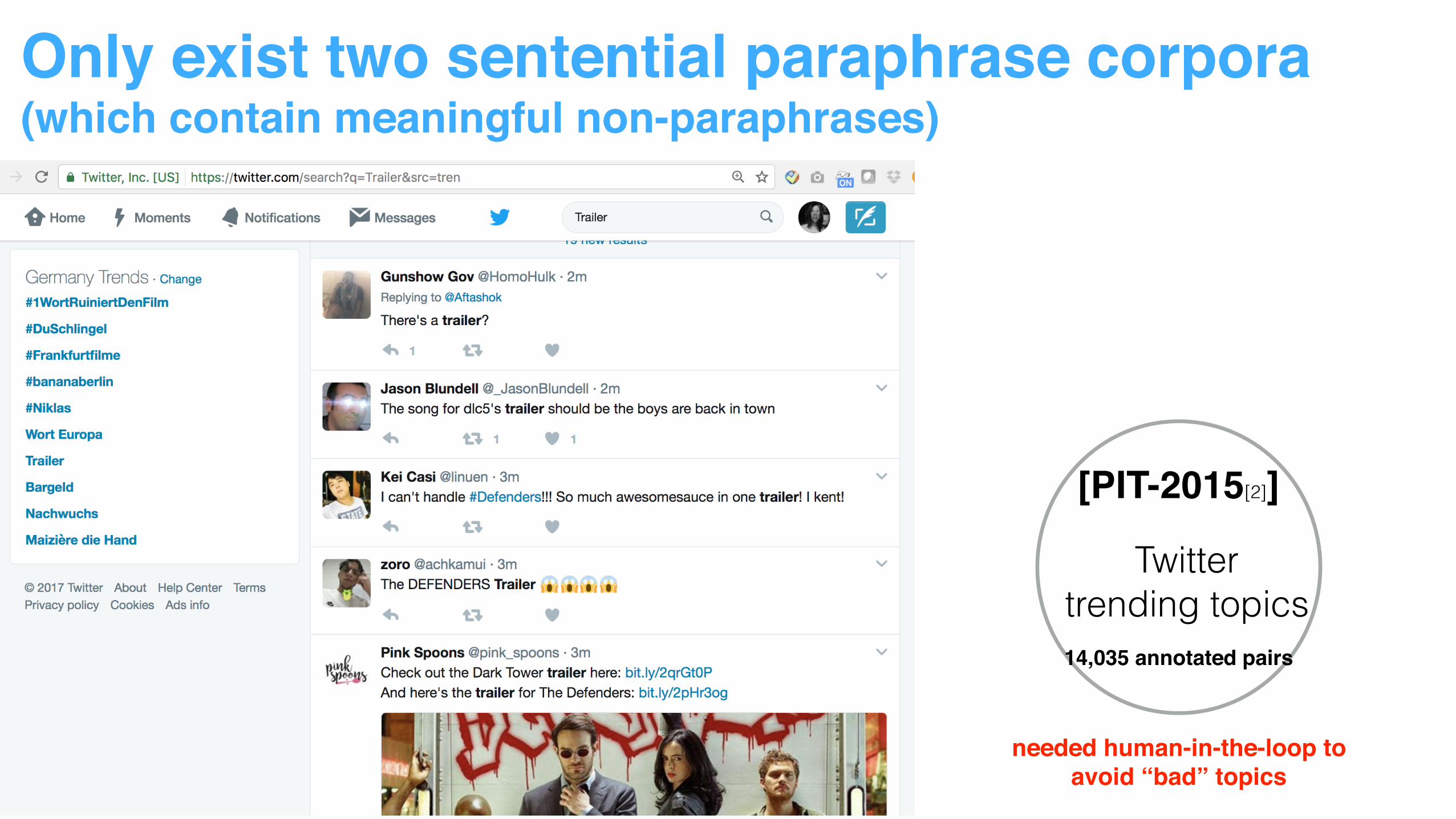
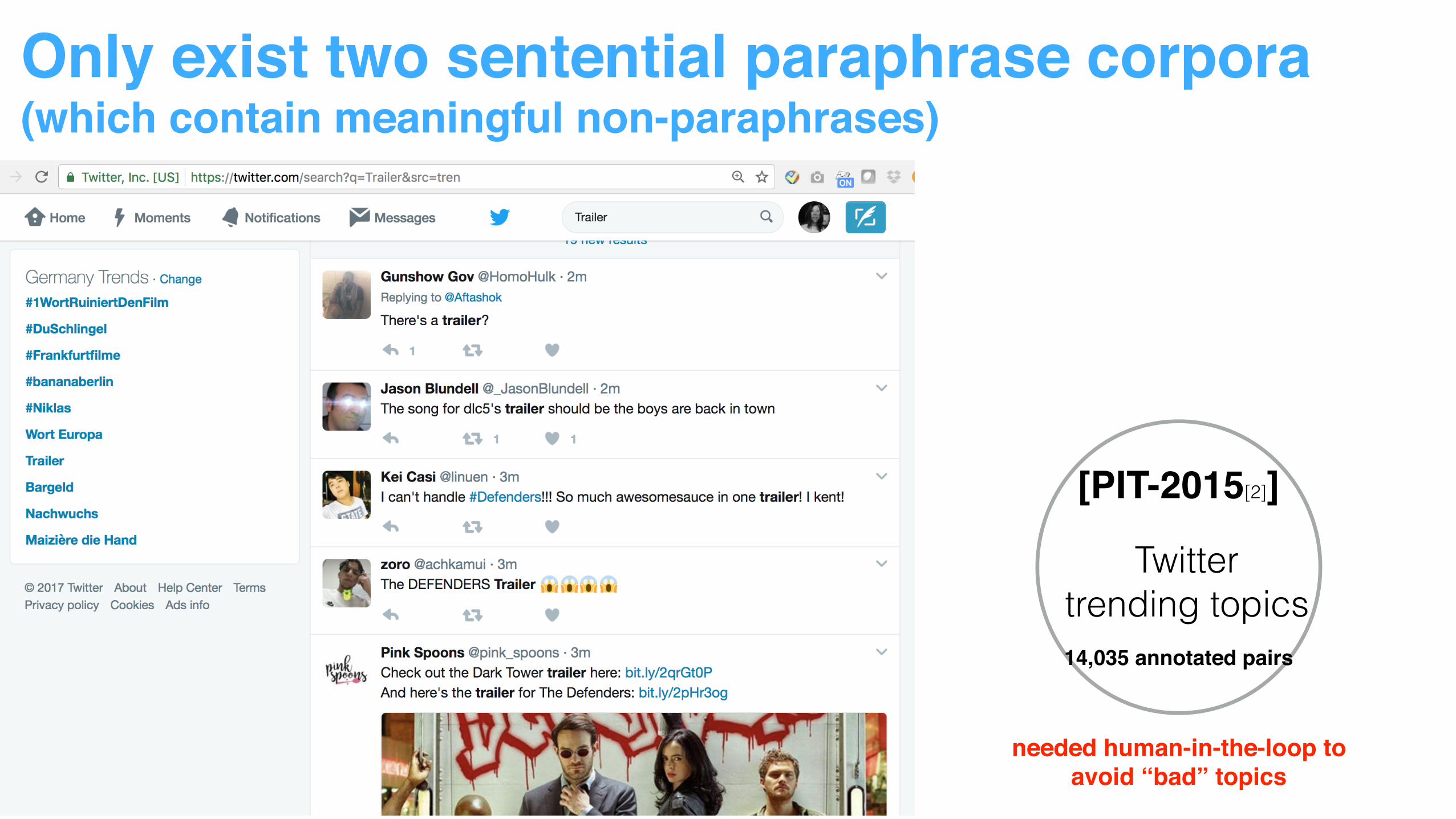
Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP]
clustered news articles5801 sentence pairs
needed human-in-the-loop toavoid “bad” topics
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs
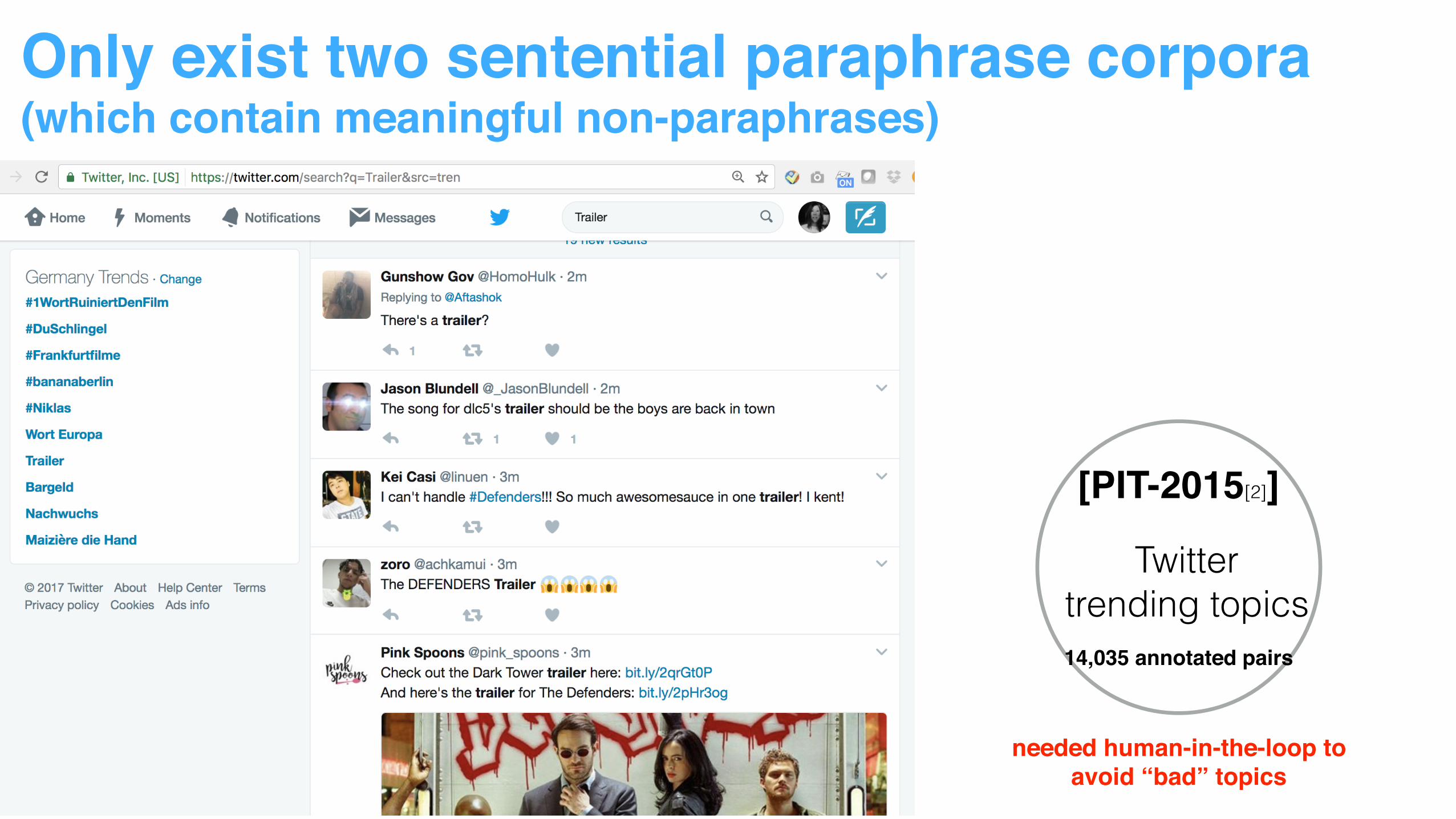
Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP]
clustered news articles
Key for success:
5801 sentence pairs
needed human-in-the-loop toavoid “bad” topics
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs
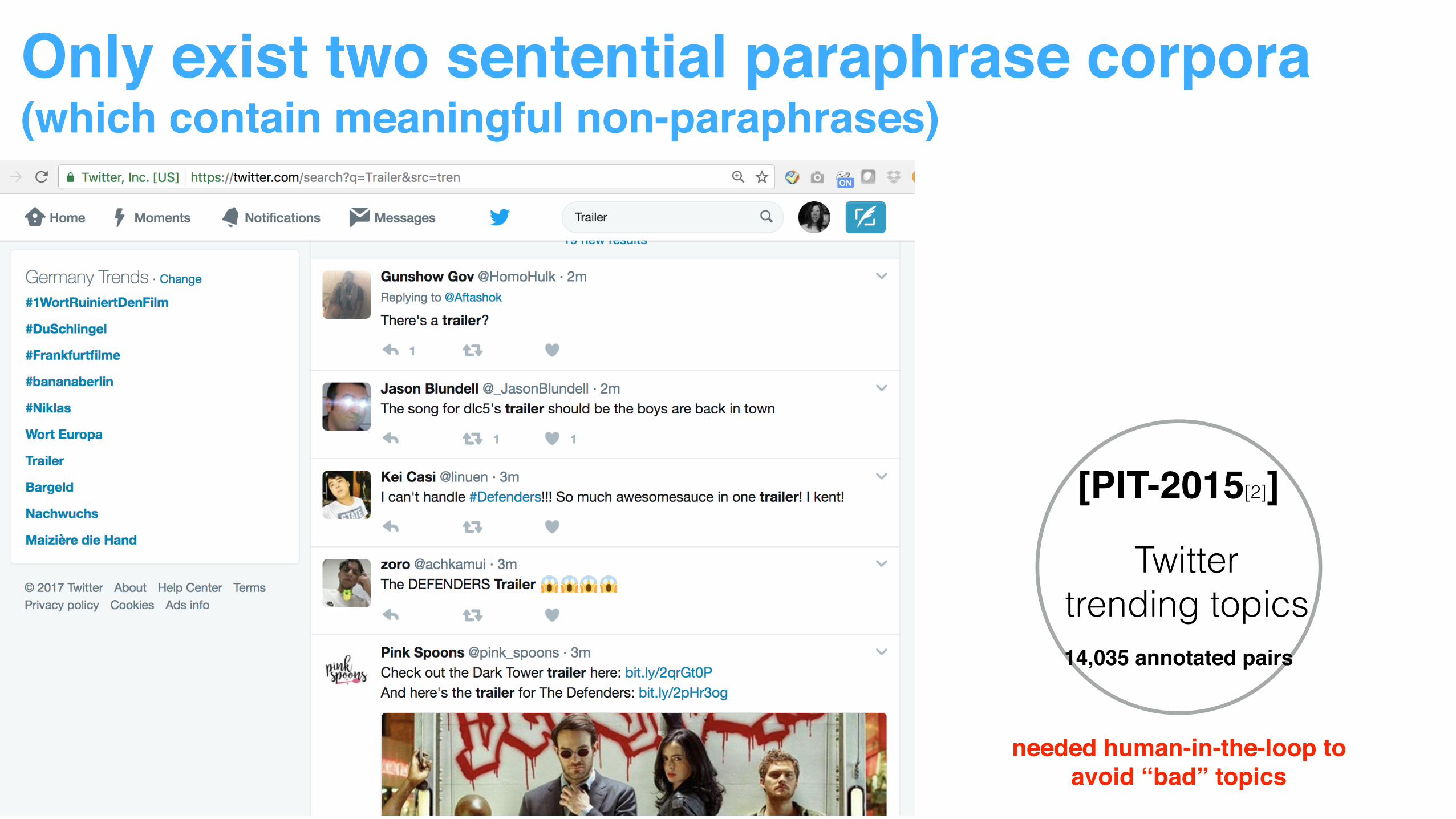
Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP]
clustered news articles
Key for success:• narrow the search space
5801 sentence pairs
needed human-in-the-loop toavoid “bad” topics
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs
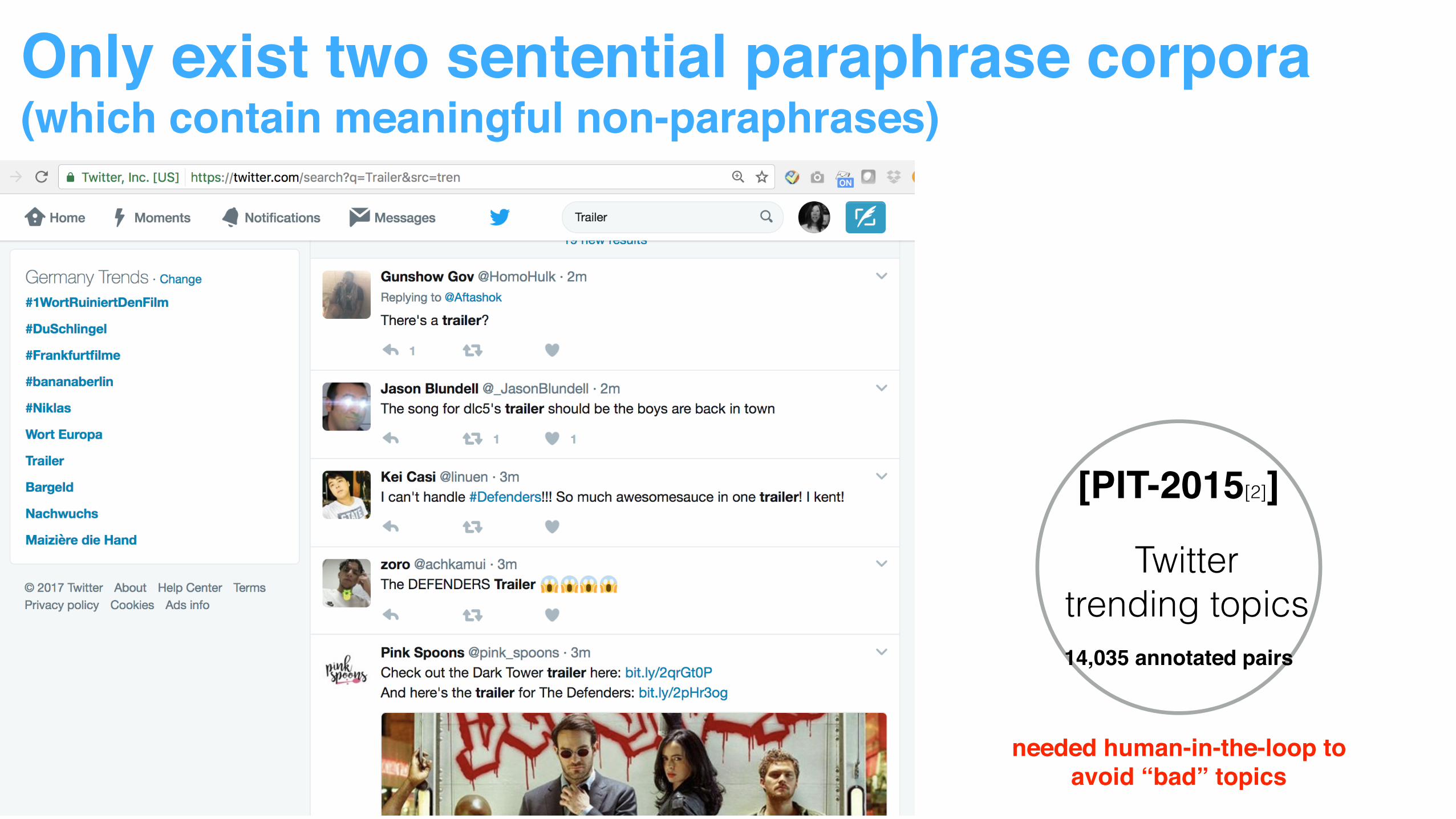
Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP]
clustered news articles
Key for success:• narrow the search space • ensure diversity among sentences
5801 sentence pairs
needed human-in-the-loop toavoid “bad” topics
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs
Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP]
clustered news articles
Key for success:• narrow the search space • ensure diversity among sentencesAlso Pitfalls …
5801 sentence pairs
needed human-in-the-loop toavoid “bad” topics
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs
Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP]
clustered news articles
needed a SVM classifier to select sentences before data annotation
Key for success:• narrow the search space • ensure diversity among sentencesAlso Pitfalls …
5801 sentence pairs
needed human-in-the-loop toavoid “bad” topics
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs

Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP[1]]
clustered news articles
needed a SVM classifier to select sentences before data annotation
needed human-in-the-loop toavoid “bad” topics
Key for success:• narrow the search space • ensure diversity among sentences Also Pitfalls:
[1] Dolan et al., 2004 [2] Xu et al., 2014
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs5,801 annotated pairs

Only exist two sentential paraphrase corpora(which contain meaningful non-paraphrases)
[MSRP[1]]
clustered news articles
needed a SVM classifier to select sentences before data annotation
needed human-in-the-loop toavoid “bad” topics
Key for success:• narrow the search space • ensure diversity among sentences Also Pitfalls: cause over-identification when applied to unlabeled data
[1] Dolan et al., 2004 [2] Xu et al., 2014
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs5,801 annotated pairs

[MSRP[1]] [PIT-2015[2]]
clustered news articles
Twitter trending topics
[Twitter URL Corpus]
no clustering or topic detection neededno data selection steps needed
Key for success:• narrow the search space • ensure diversity among sentences • the simpler the better!
URL-linked Tweets
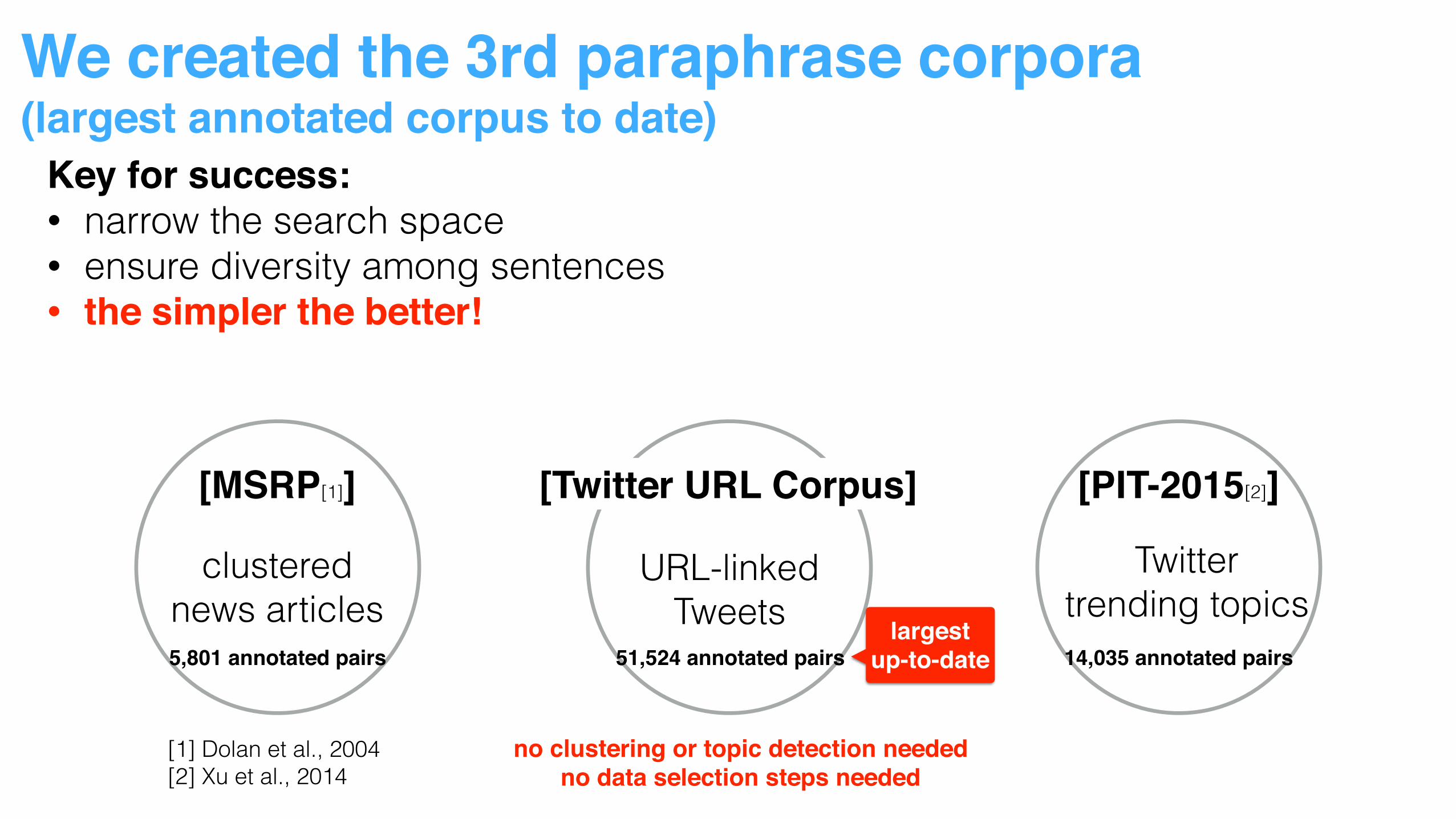
We created the 3rd paraphrase corpora (largest annotated corpus to date)
[1] Dolan et al., 2004 [2] Xu et al., 2014
14,035 annotated pairs5,801 annotated pairs 51,524 annotated pairs
[MSRP[1]] [PIT-2015[2]]
clustered news articles
Twitter trending topics
[Twitter URL Corpus]
no clustering or topic detection neededno data selection steps needed
Key for success:• narrow the search space • ensure diversity among sentences • the simpler the better!
URL-linked Tweets
We created the 3rd paraphrase corpora (largest annotated corpus to date)
[1] Dolan et al., 2004 [2] Xu et al., 2014
largest up-to-date 14,035 annotated pairs5,801 annotated pairs 51,524 annotated pairs

We created the 3rd paraphrase corpora (which also dynamically updates!)
Key for success:• narrow the search space • ensure diversity among sentences • the simpler the better! more effective automatic paraphrase identification
URL-linked Tweets
30,000 new sentential paraphrases every month
[Twitter URL Corpus][MSRP[1]]
clustered news articles
[1] Dolan et al., 2004 [2] Xu et al., 2014
[PIT-2015[2]]
Twitter trending topics14,035 annotated pairs5,801 annotated pairs 51,524 annotated pairs

Once we have a lot of up-to-date sentential paraphrases(we can, for example, learn name variations fully automatically)

Donald Trump, DJT, Drumpf, Mr Trump, Idiot Trump, Chump, Evil Donald, #OrangeHitler, Donald @realTrump, D*nald Tr*mp, Comrade #Trump, Crooked #Trump, CryBaby Trump, Daffy Trump, Donald KKKrump, Dumb Trump, GOPTrump, Incompetent Trump, He-Who-Must-Not-Be-Named, Pres-elect Trump, President-Elect Trump, President-elect Donald J . Trump, PEOTUS Trump, Emperor Trump
Once we have a lot of up-to-date sentential paraphrases(we can, for example, learn name variations fully automatically)

FBI Director backs CIA finding FBI agrees with CIA FBI backs CIA view FBI finally backs CIA view FBI now backs CIA view FBI supports CIA assertion FBI Clapper back CIA’s view The FBI backs the CIA’s assessment FBI Backs CIA …
Once we have a lot of up-to-date sentential paraphrases(we can, of course, learn other synonyms in large quantity via word alignment)

How different from existing paraphrase corpora?
Model Performance Dataset Difference

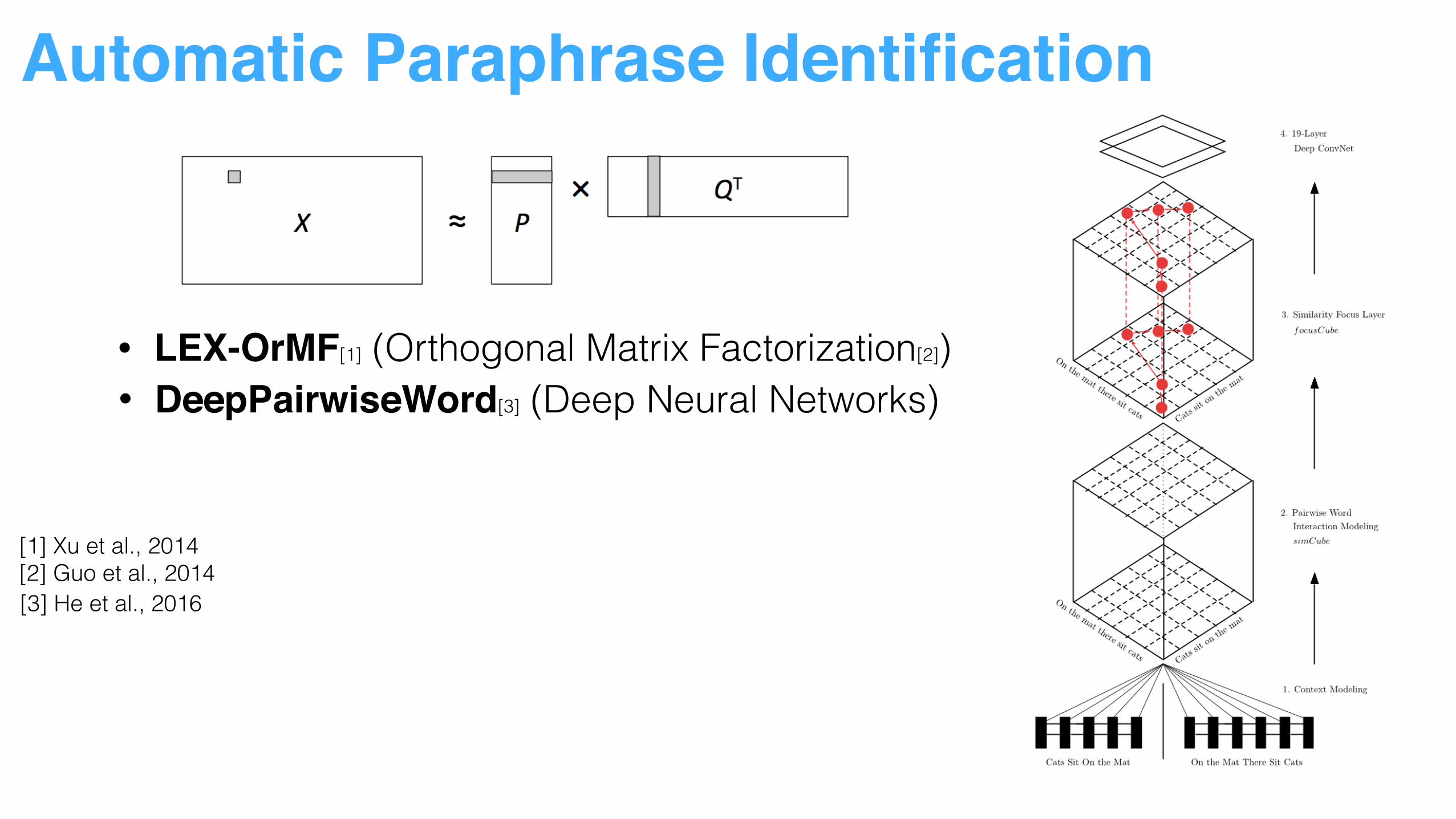
Automatic Paraphrase Identification

Automatic Paraphrase Identification
• LEX-OrMF[1] (Orthogonal Matrix Factorization[2])
[1] Xu et al., 2014 [2] Guo et al., 2014
Automatic Paraphrase Identification
• LEX-OrMF[1] (Orthogonal Matrix Factorization[2])• DeepPairwiseWord[3] (Deep Neural Networks)
[1] Xu et al., 2014 [2] Guo et al., 2014[3] He et al., 2016
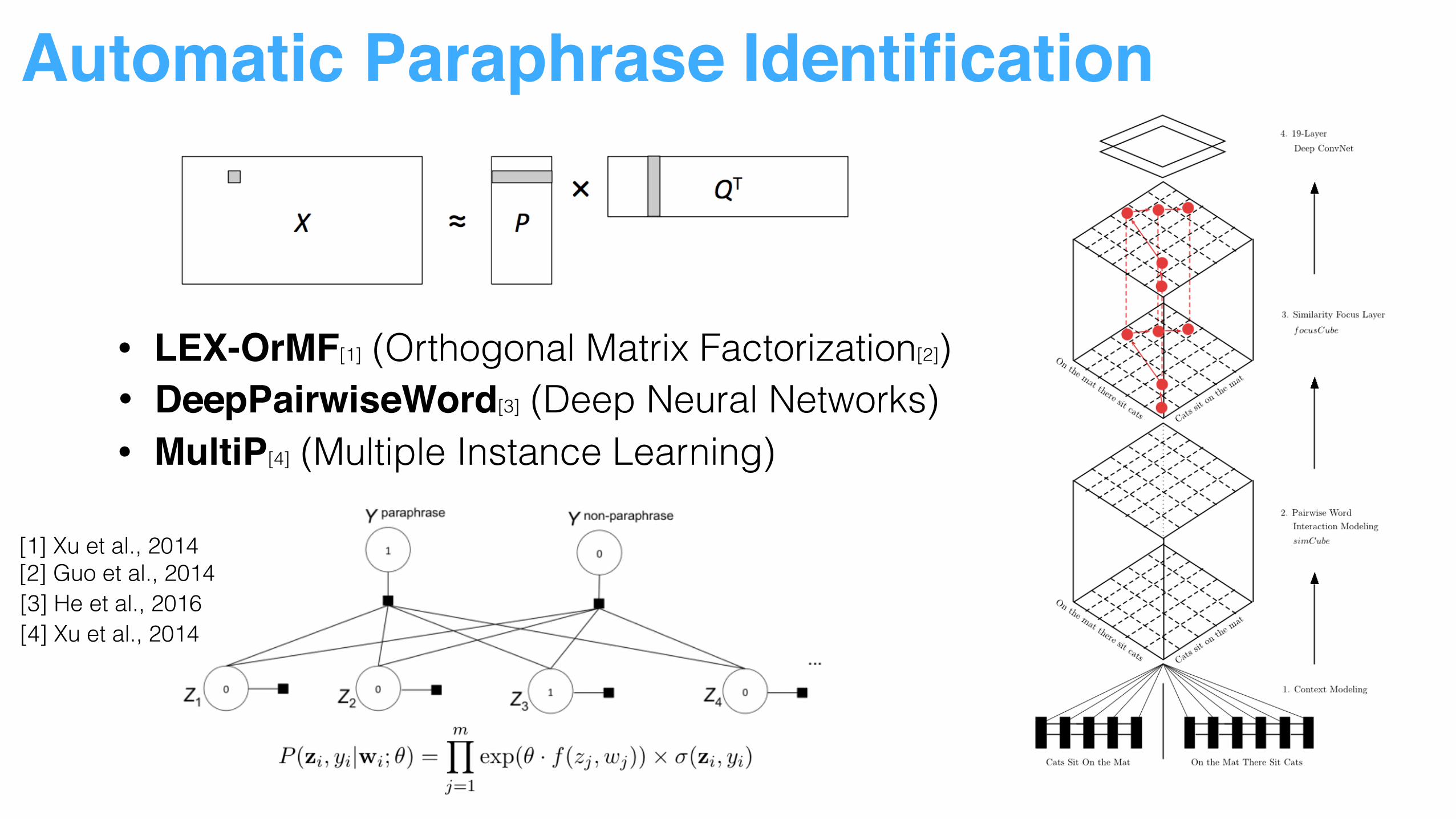
Automatic Paraphrase Identification
• LEX-OrMF[1] (Orthogonal Matrix Factorization[2])• DeepPairwiseWord[3] (Deep Neural Networks)• MultiP[4] (Multiple Instance Learning)
[1] Xu et al., 2014 [2] Guo et al., 2014[3] He et al., 2016[4] Xu et al., 2014
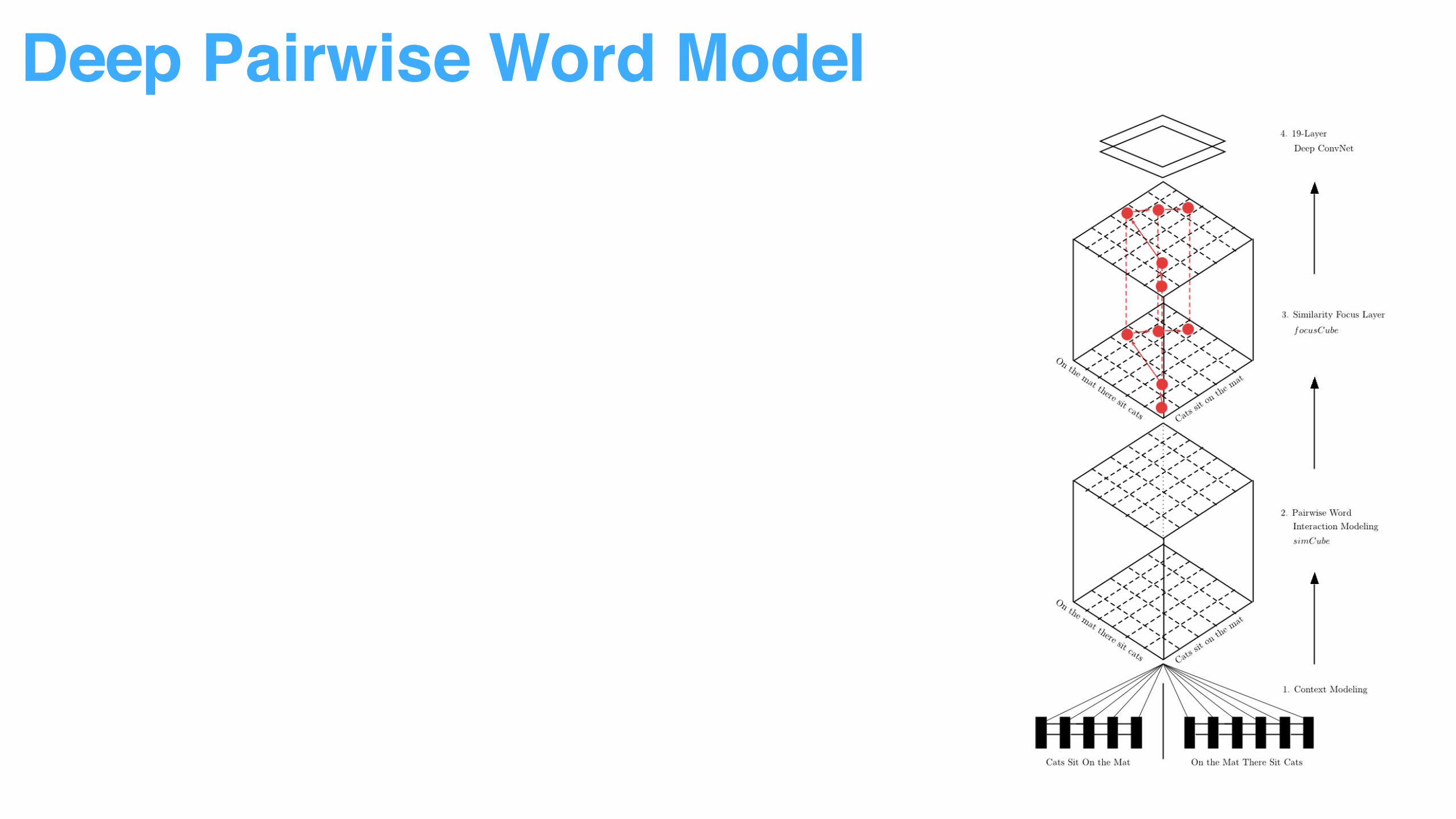
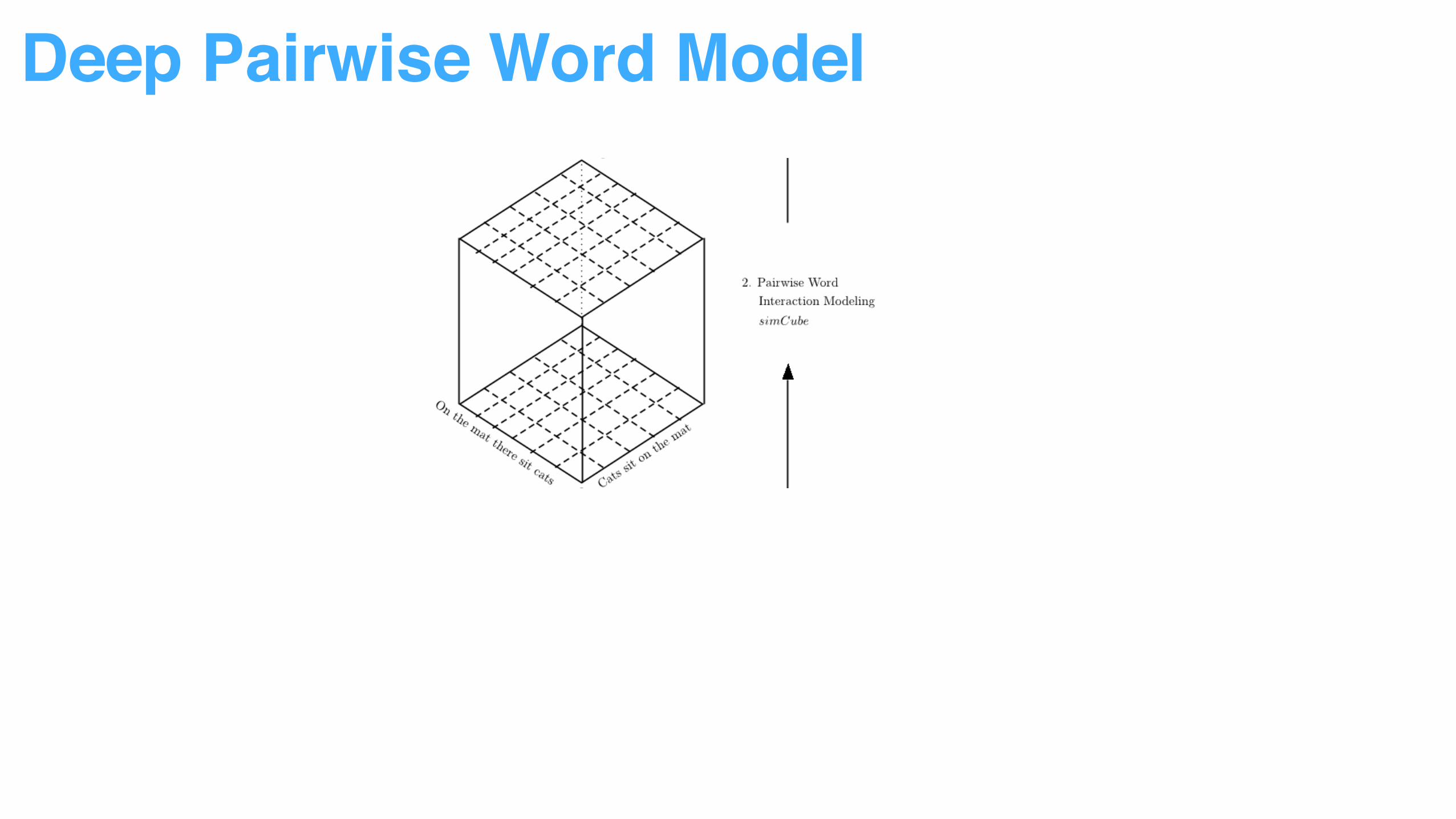
Deep Pairwise Word Model
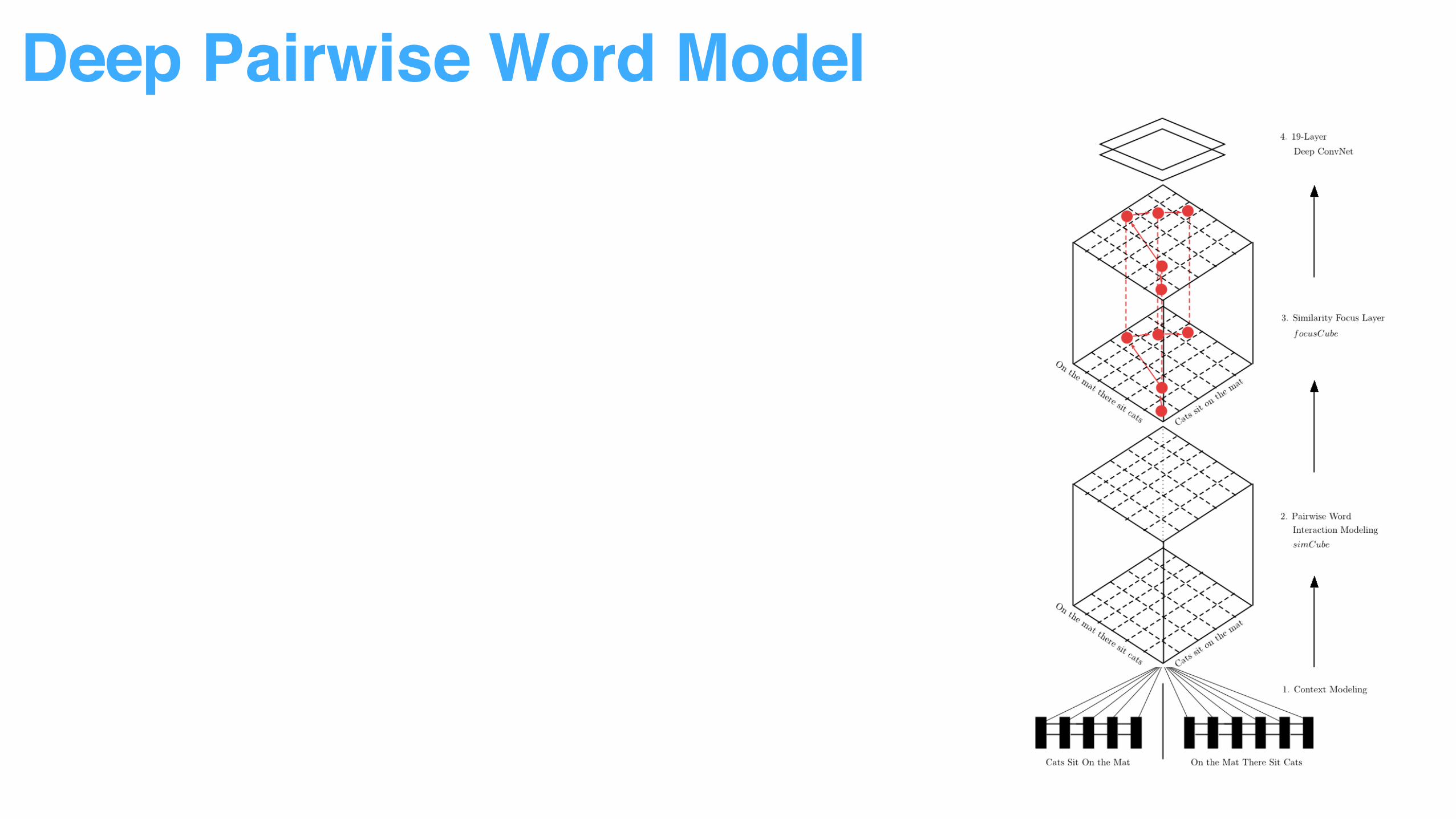
Deep Pairwise Word Model

Deep Pairwise Word Model
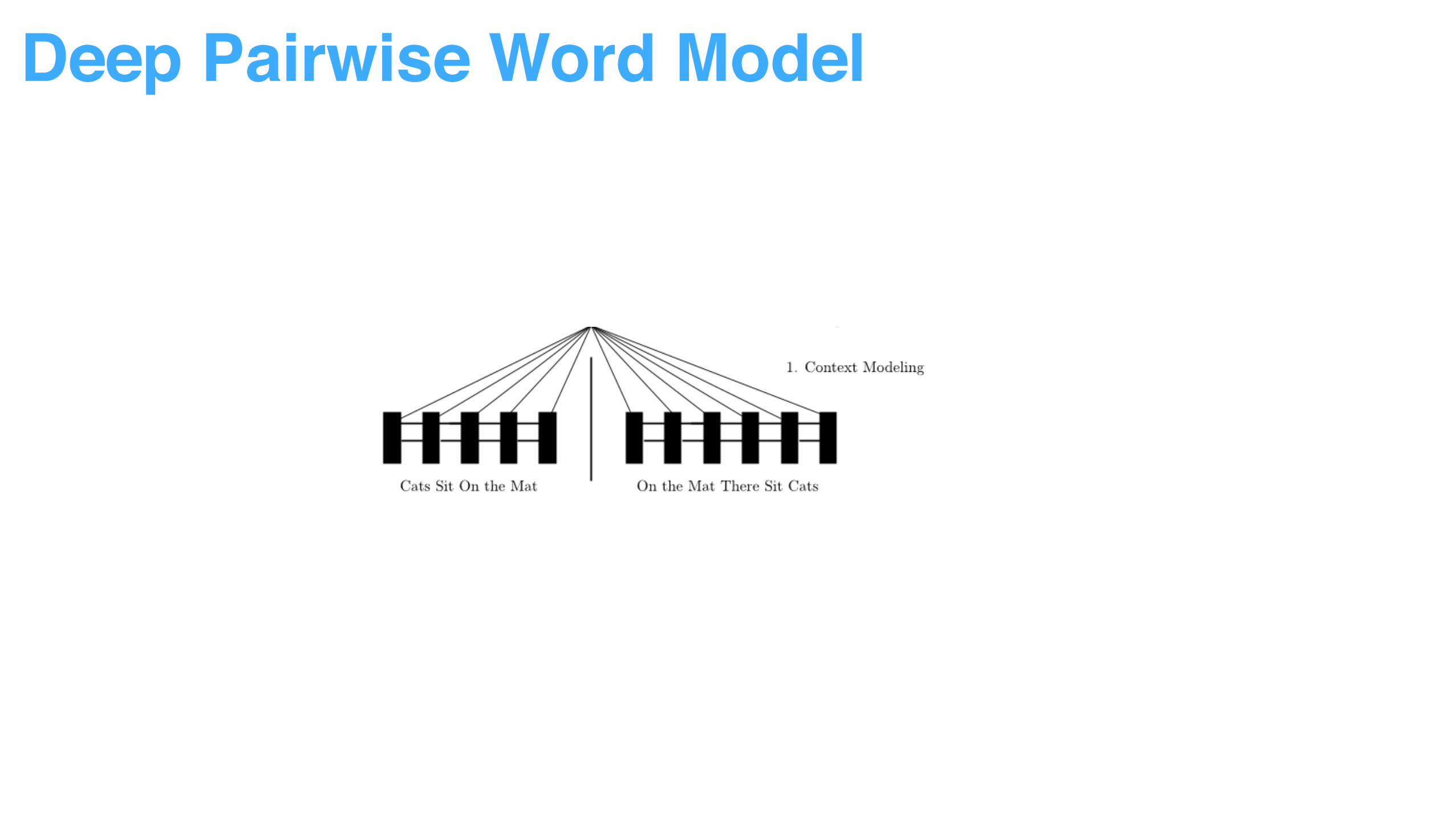
Deep Pairwise Word Model
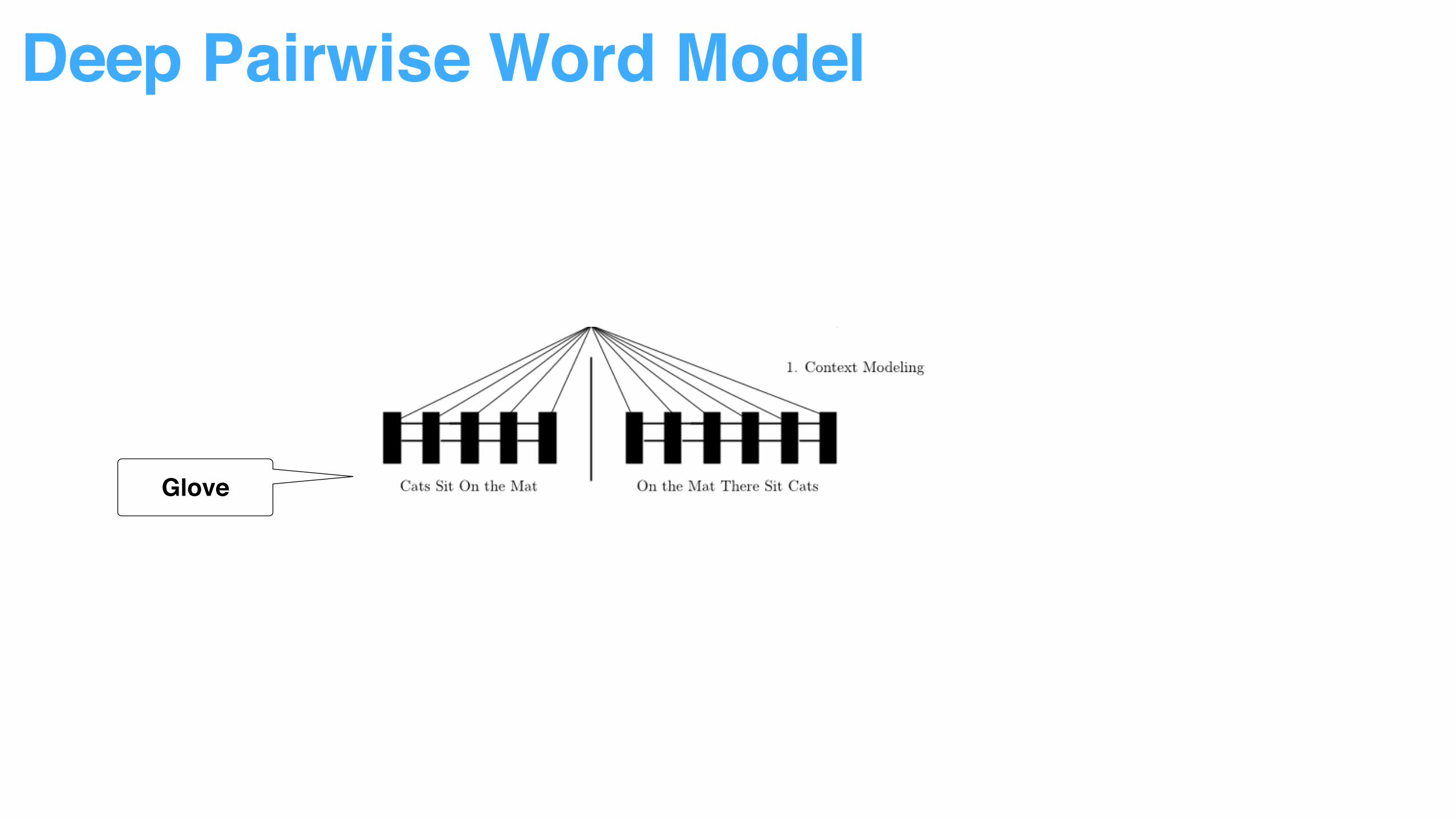
Deep Pairwise Word Model
Glove
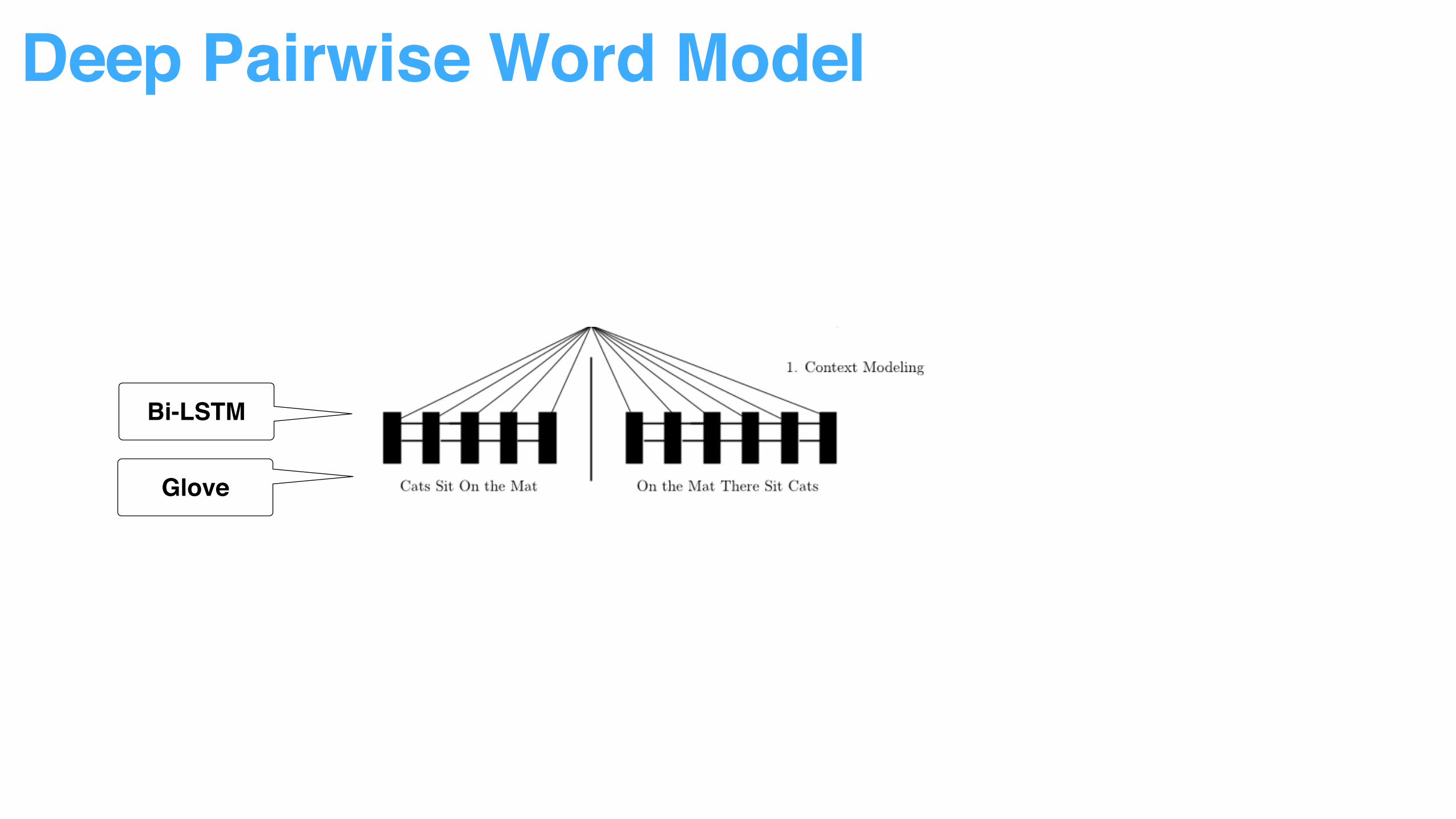
Deep Pairwise Word Model
Bi-LSTM
Glove
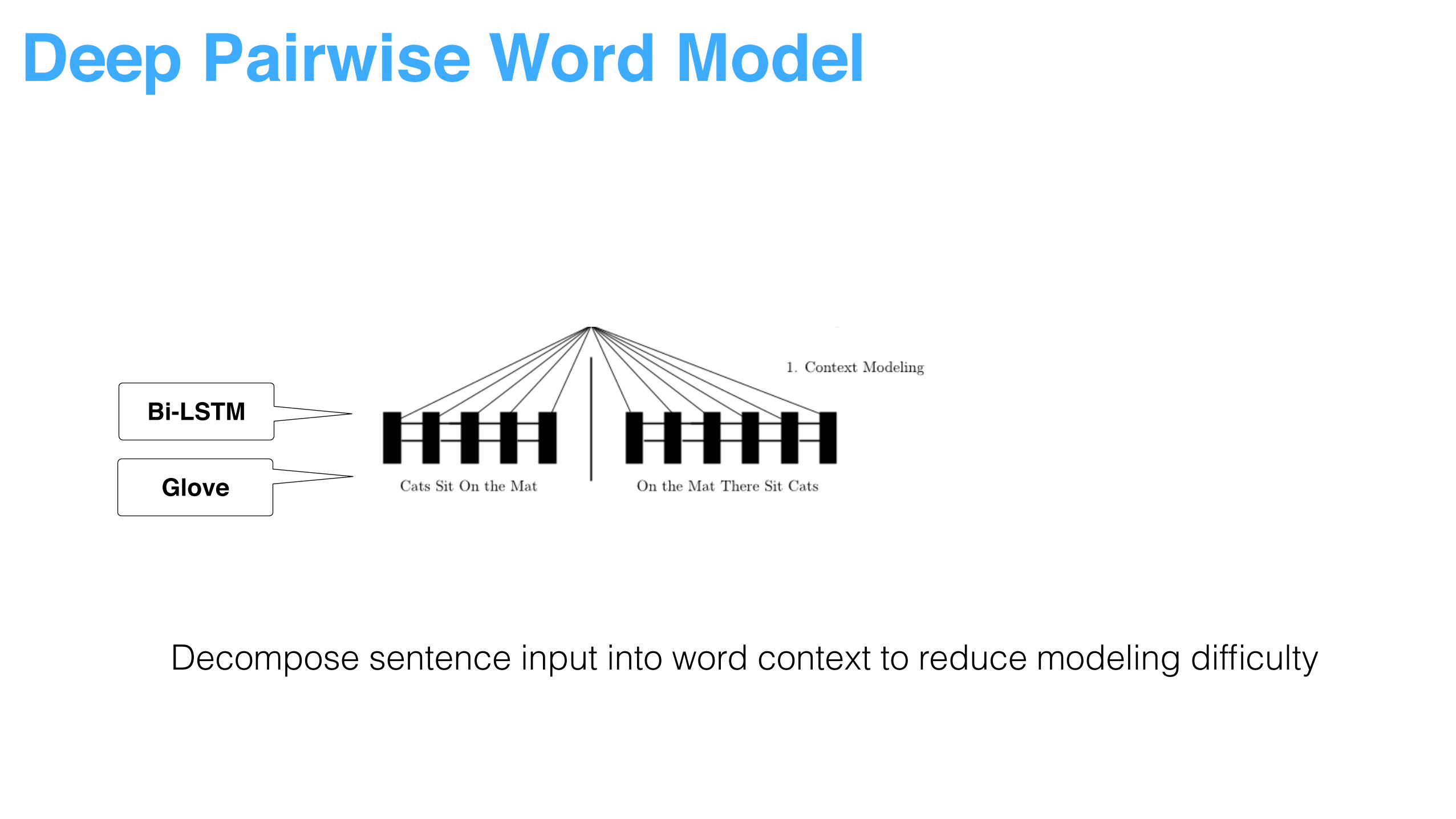
Deep Pairwise Word Model
Bi-LSTM
Glove
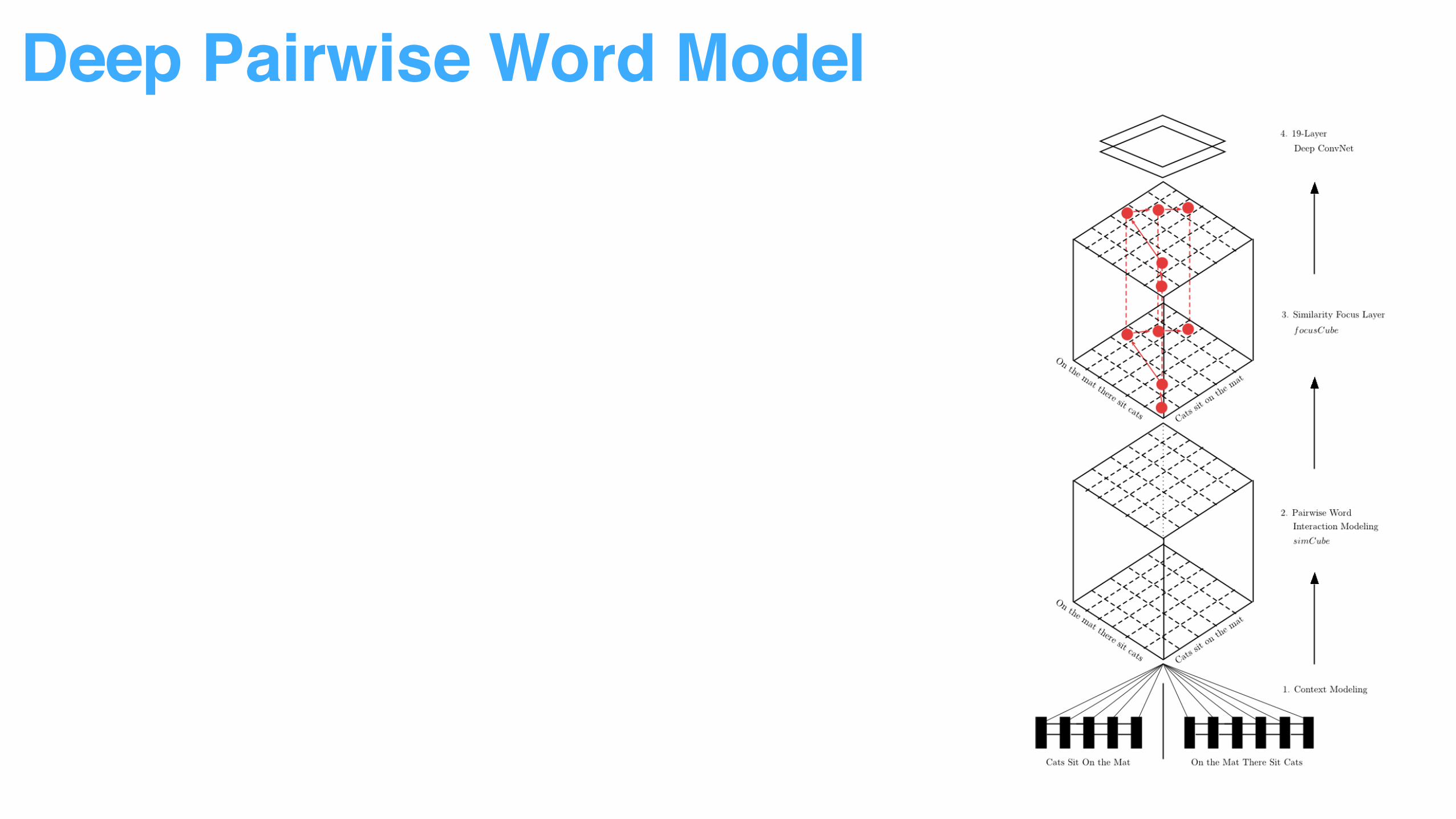
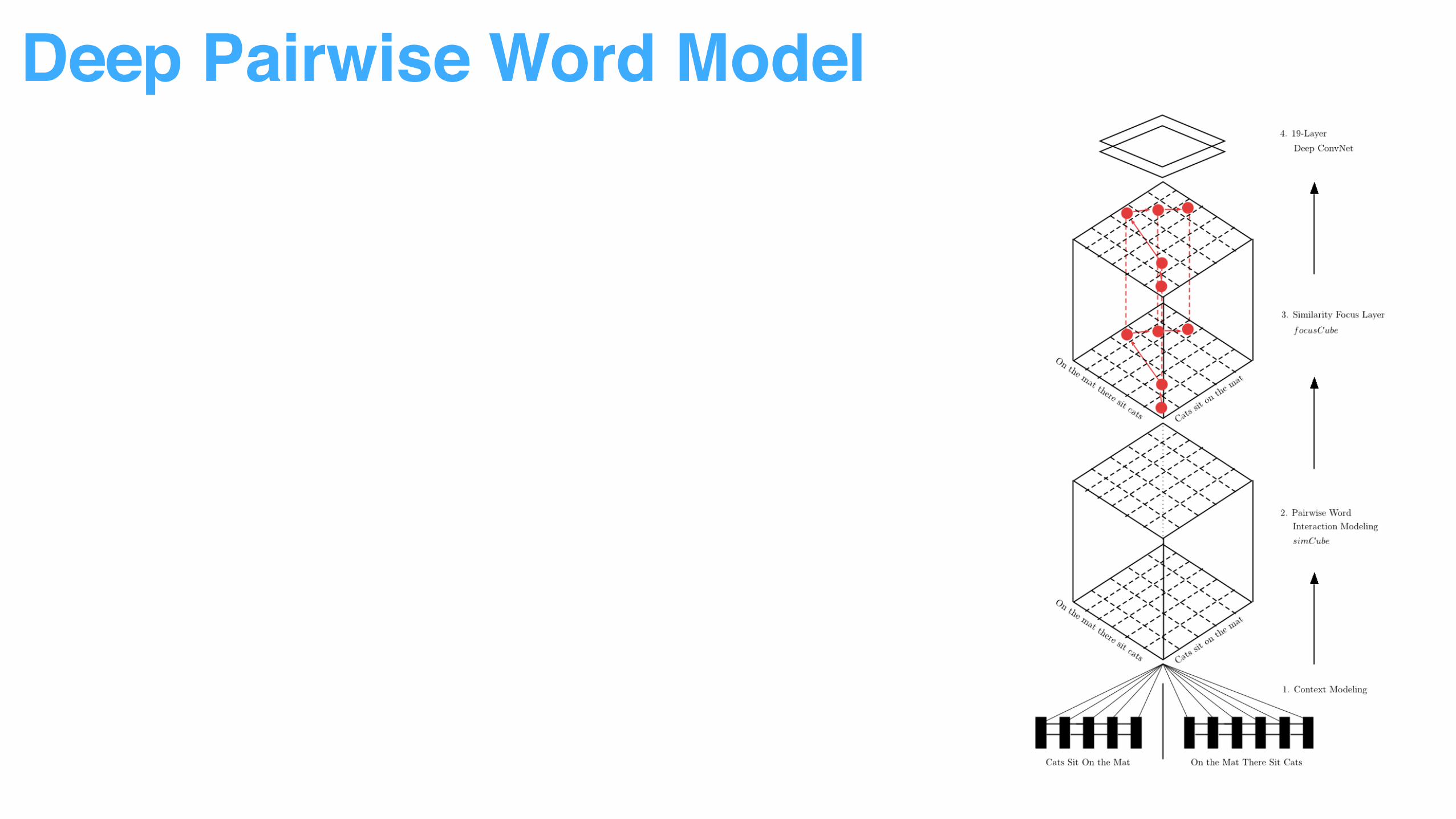
Decompose sentence input into word context to reduce modeling difficulty
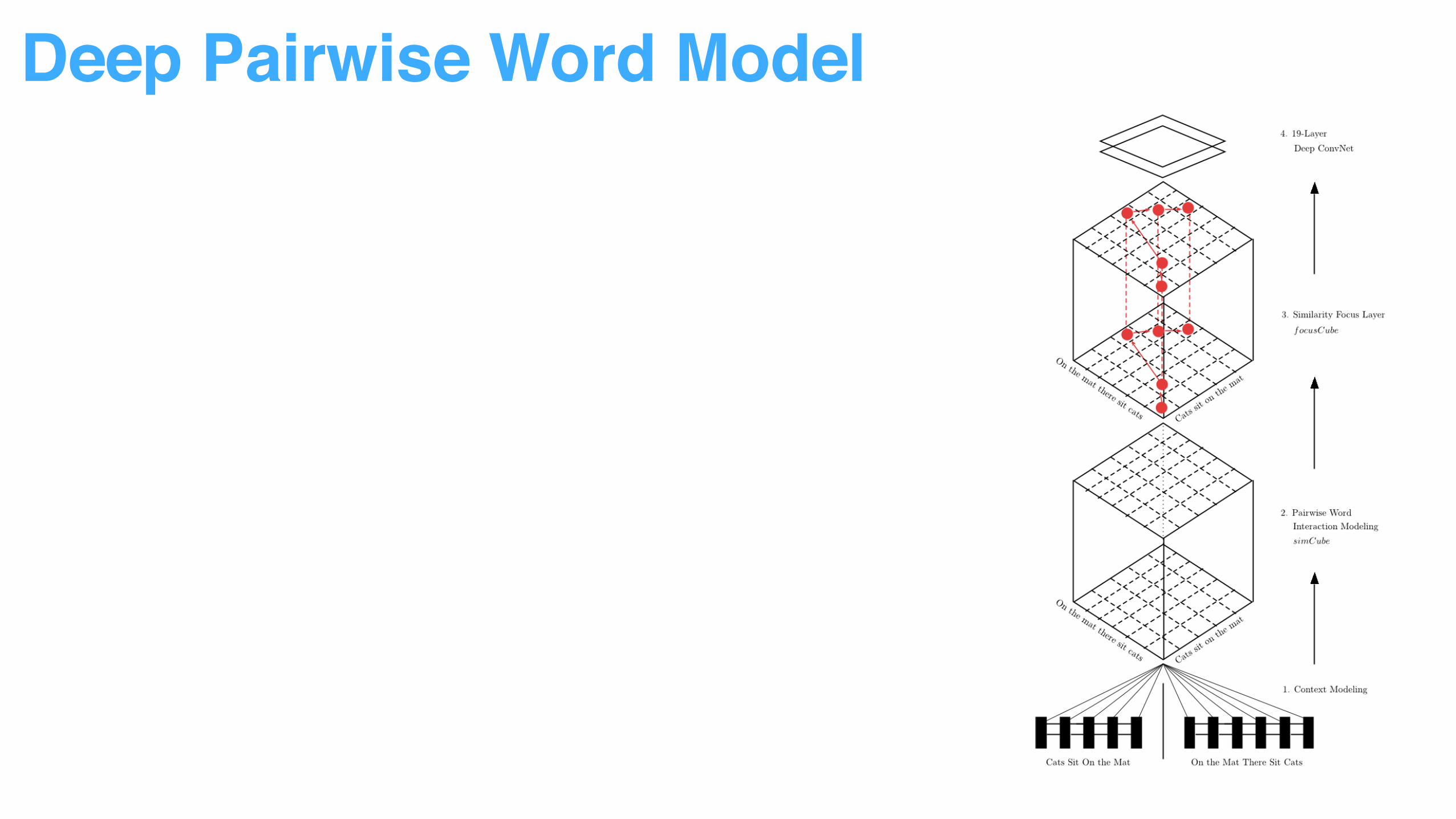
Deep Pairwise Word Model
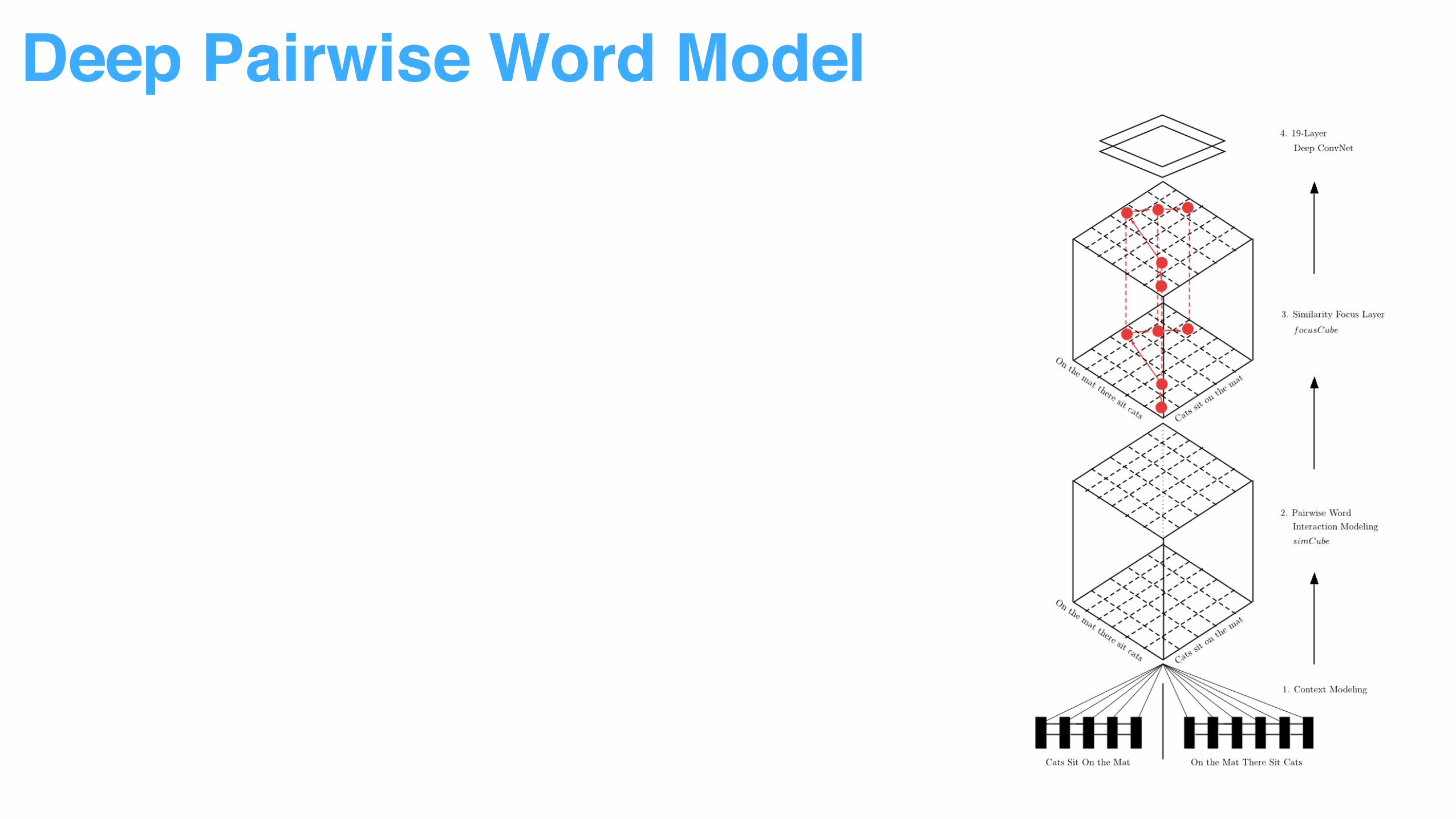
Deep Pairwise Word Model

Deep Pairwise Word Model
Deep Pairwise Word Model
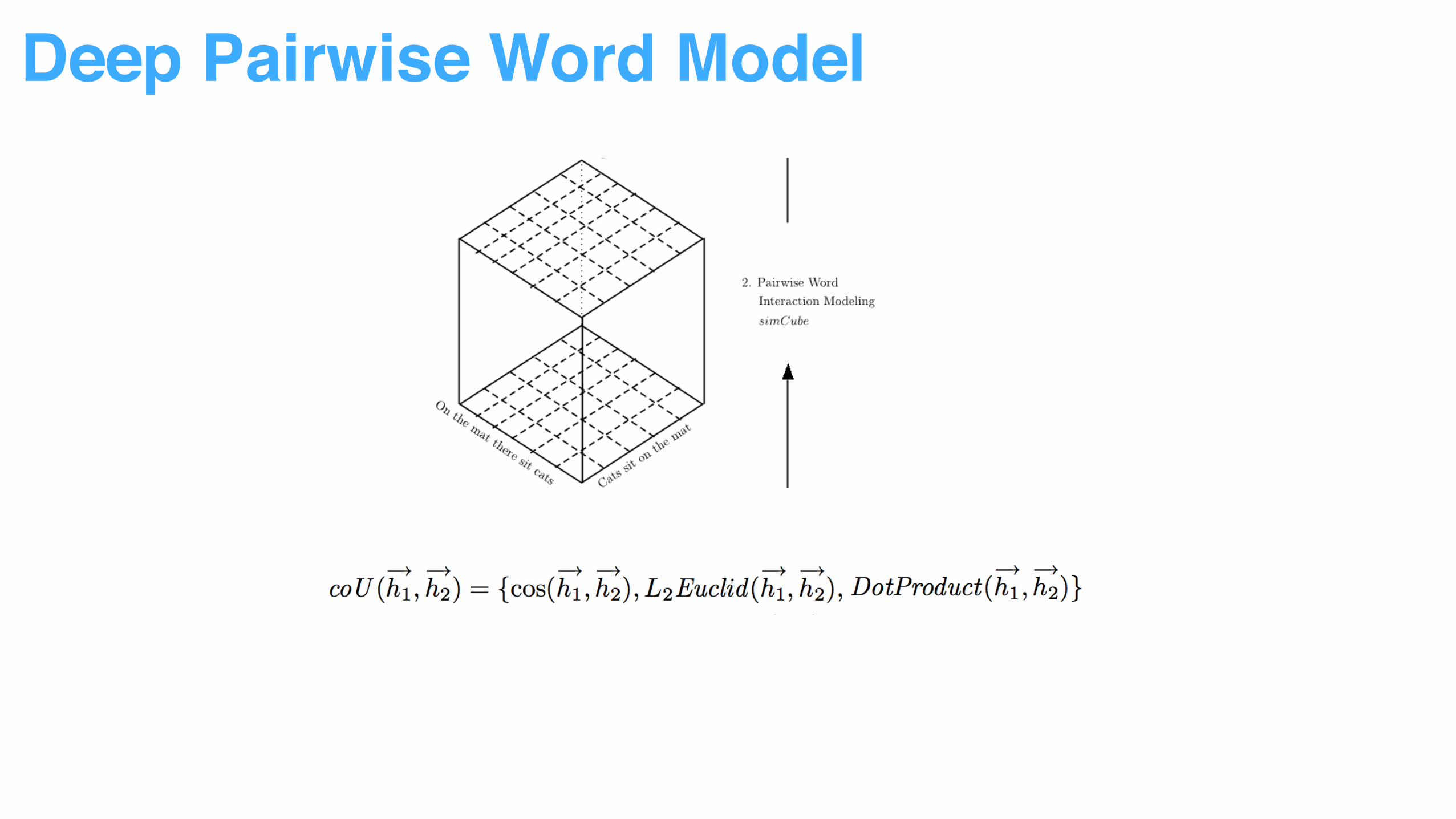
Deep Pairwise Word Model
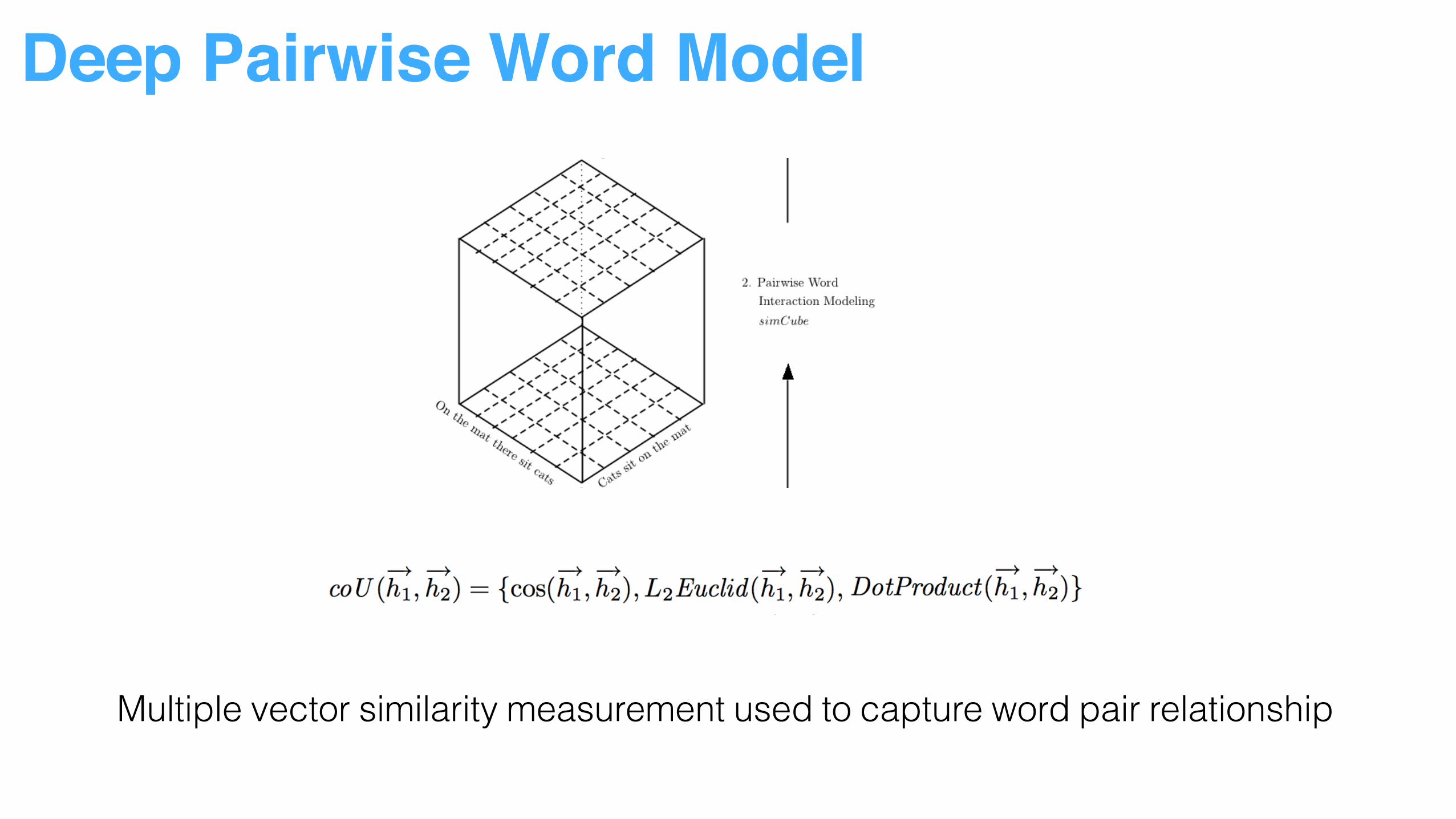
Deep Pairwise Word Model
Multiple vector similarity measurement used to capture word pair relationship
Deep Pairwise Word Model
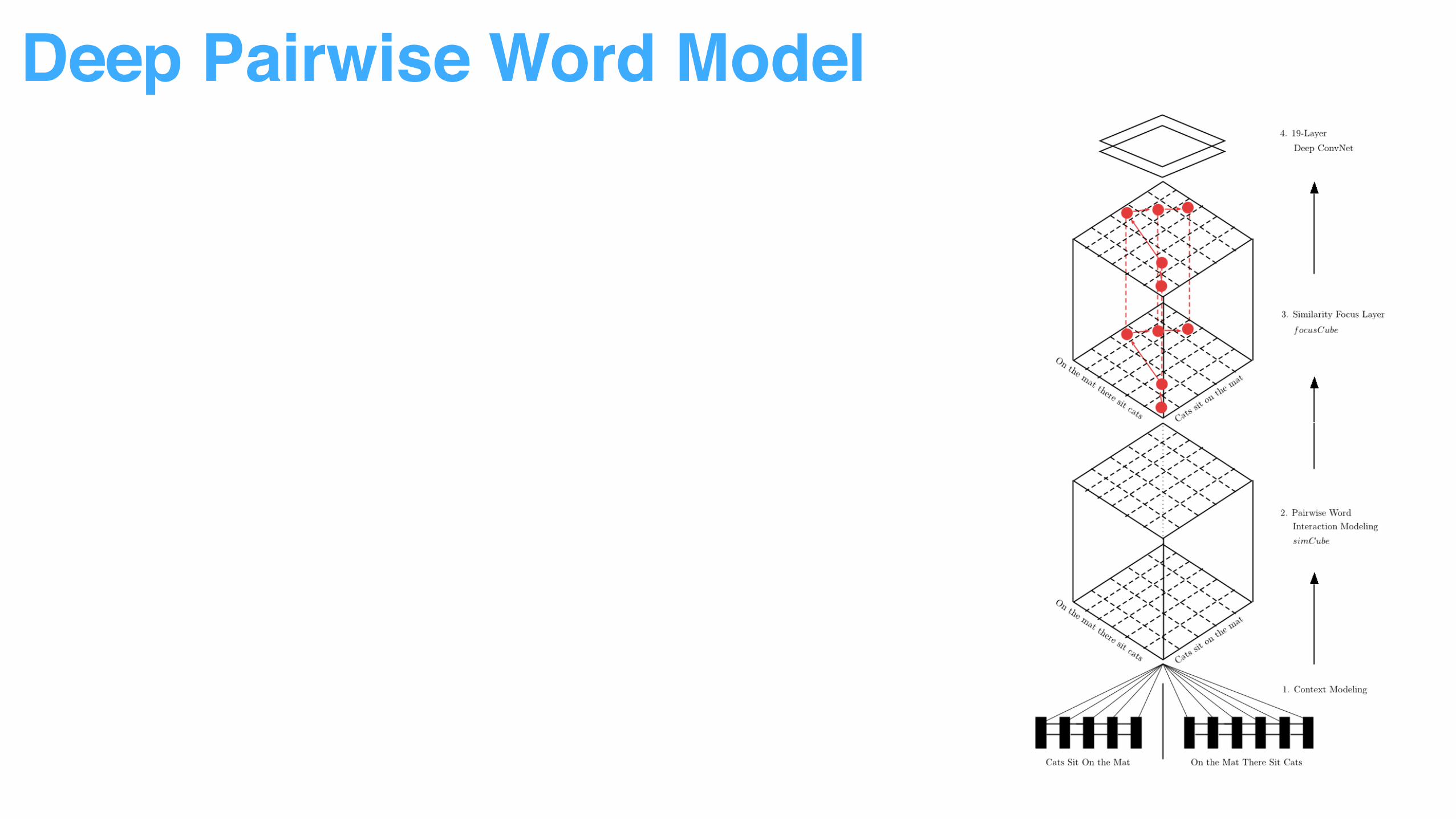
Deep Pairwise Word Model
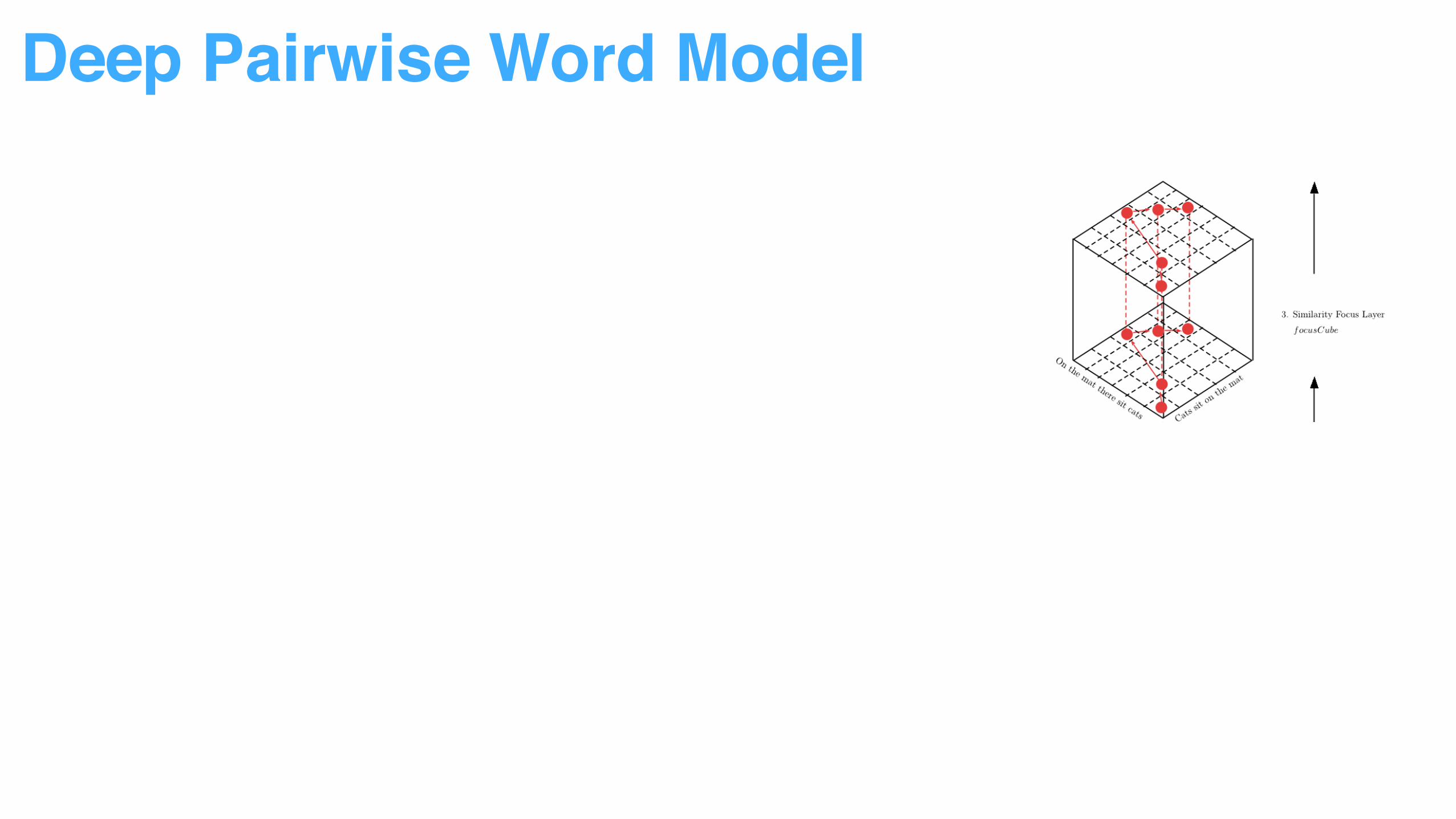
Deep Pairwise Word Model
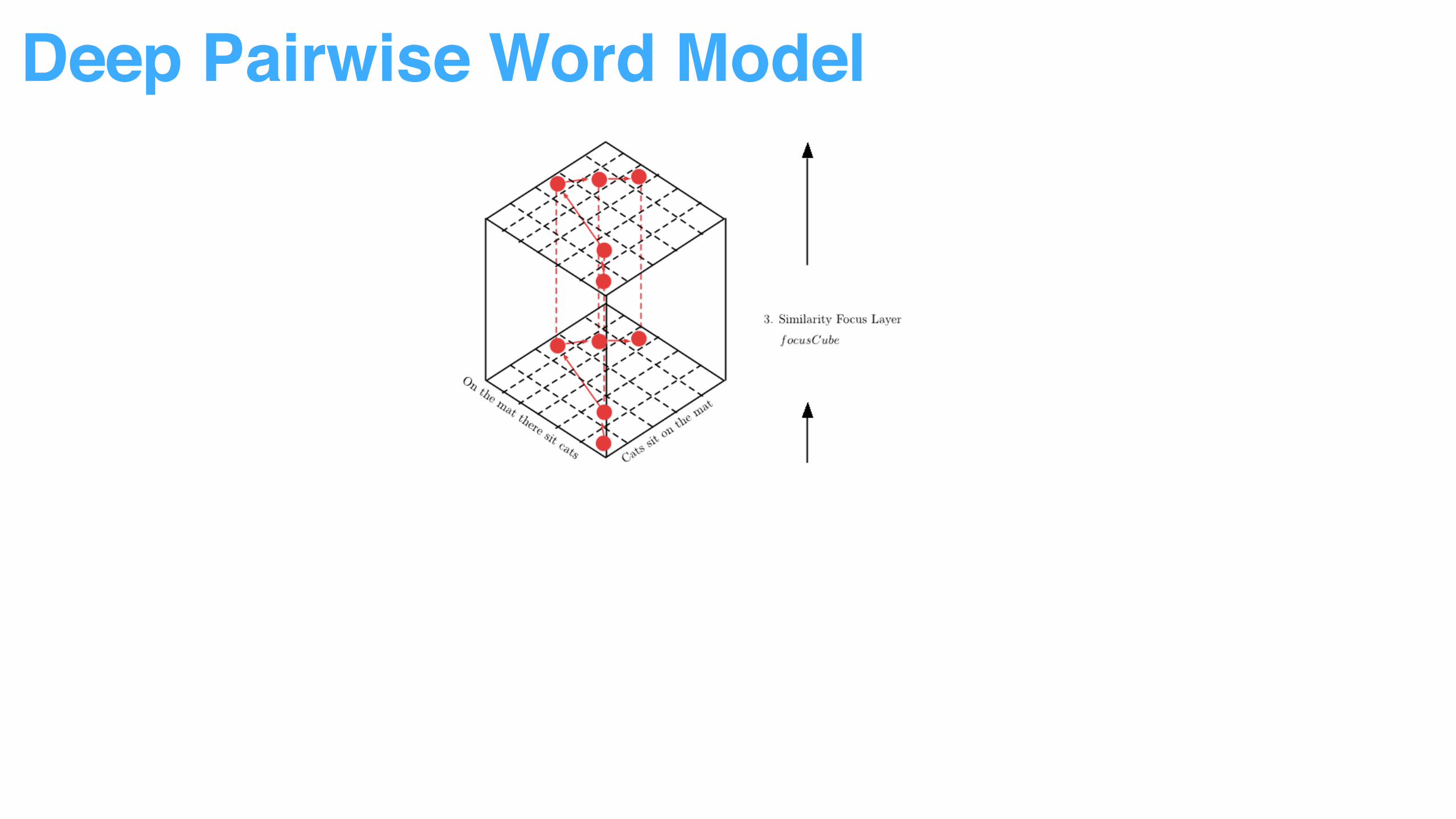
Deep Pairwise Word Model
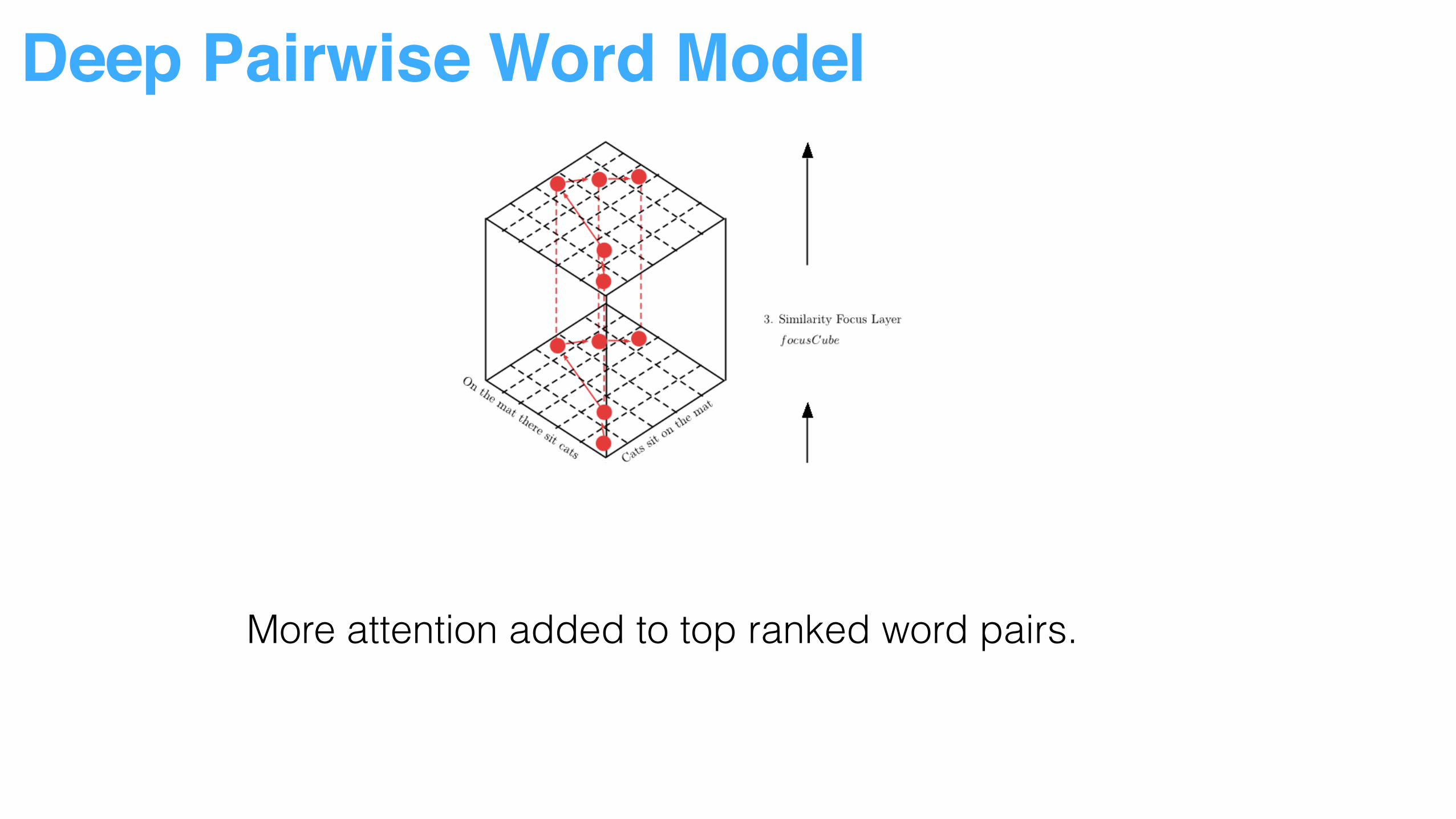
Deep Pairwise Word Model
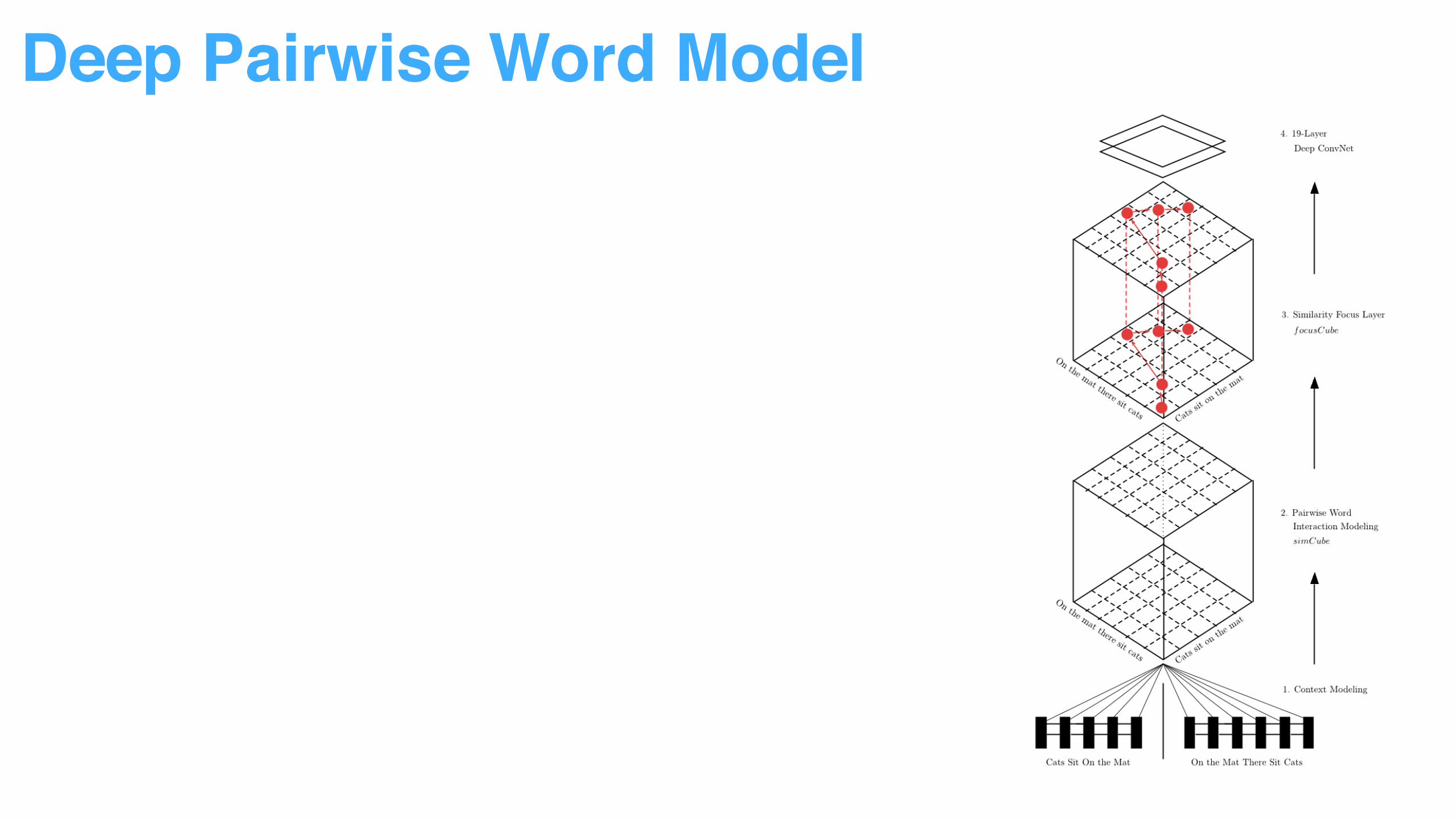
More attention added to top ranked word pairs.
Deep Pairwise Word Model
Deep Pairwise Word Model

Deep Pairwise Word Model
Deep Pairwise Word Model
Deep Pairwise Word Model
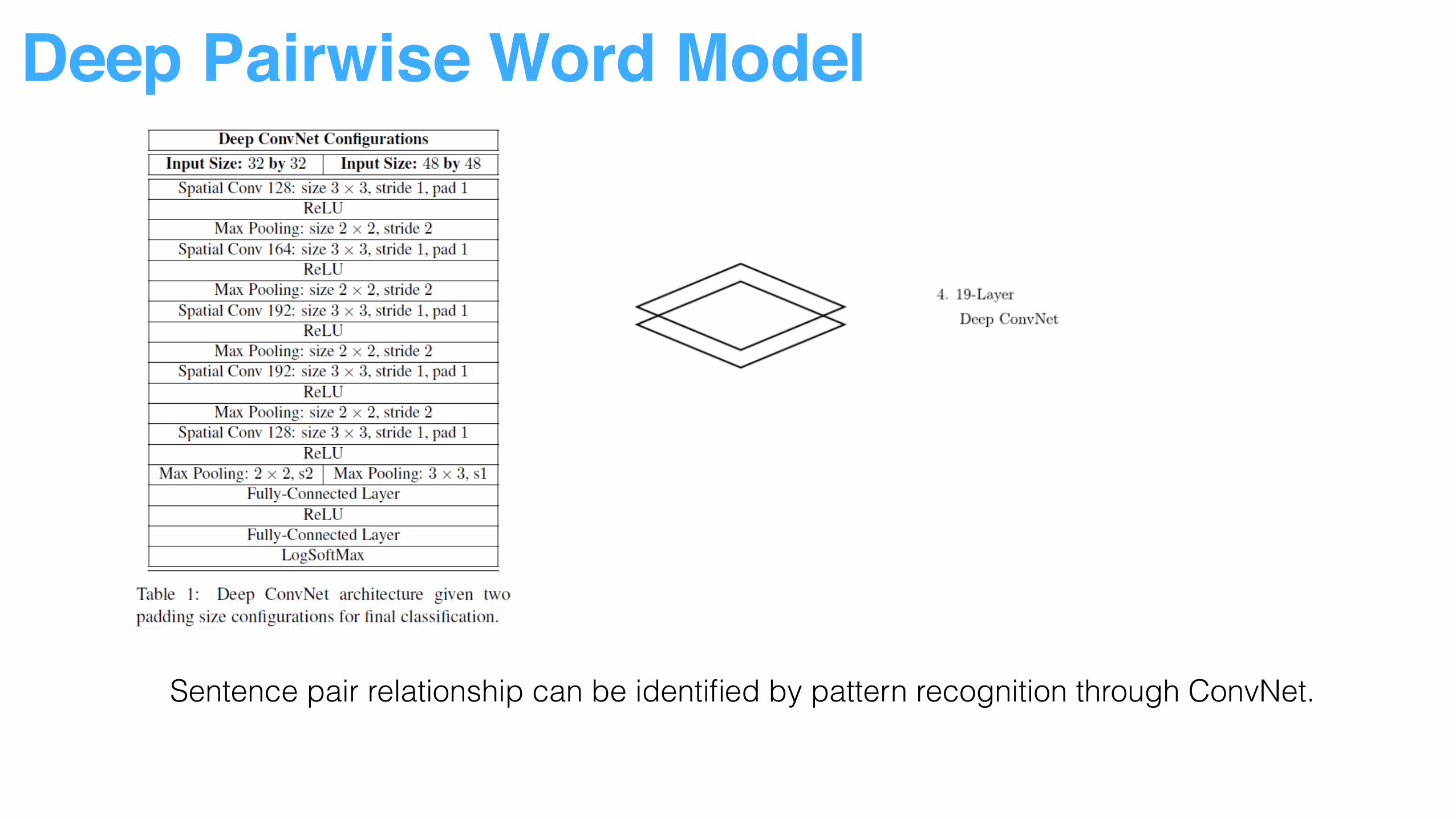
Deep Pairwise Word Model
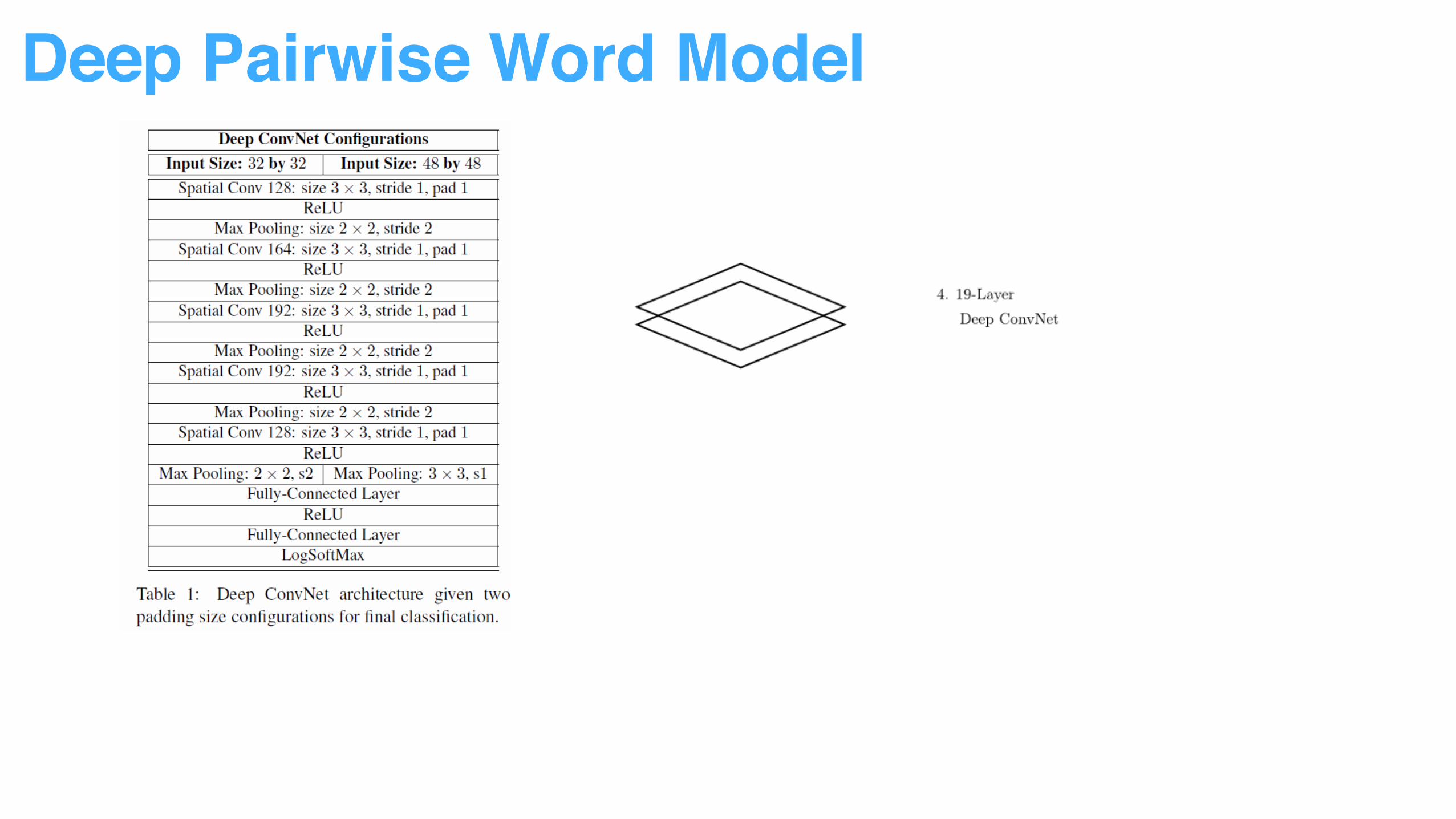
Sentence pair relationship can be identified by pattern recognition through ConvNet.
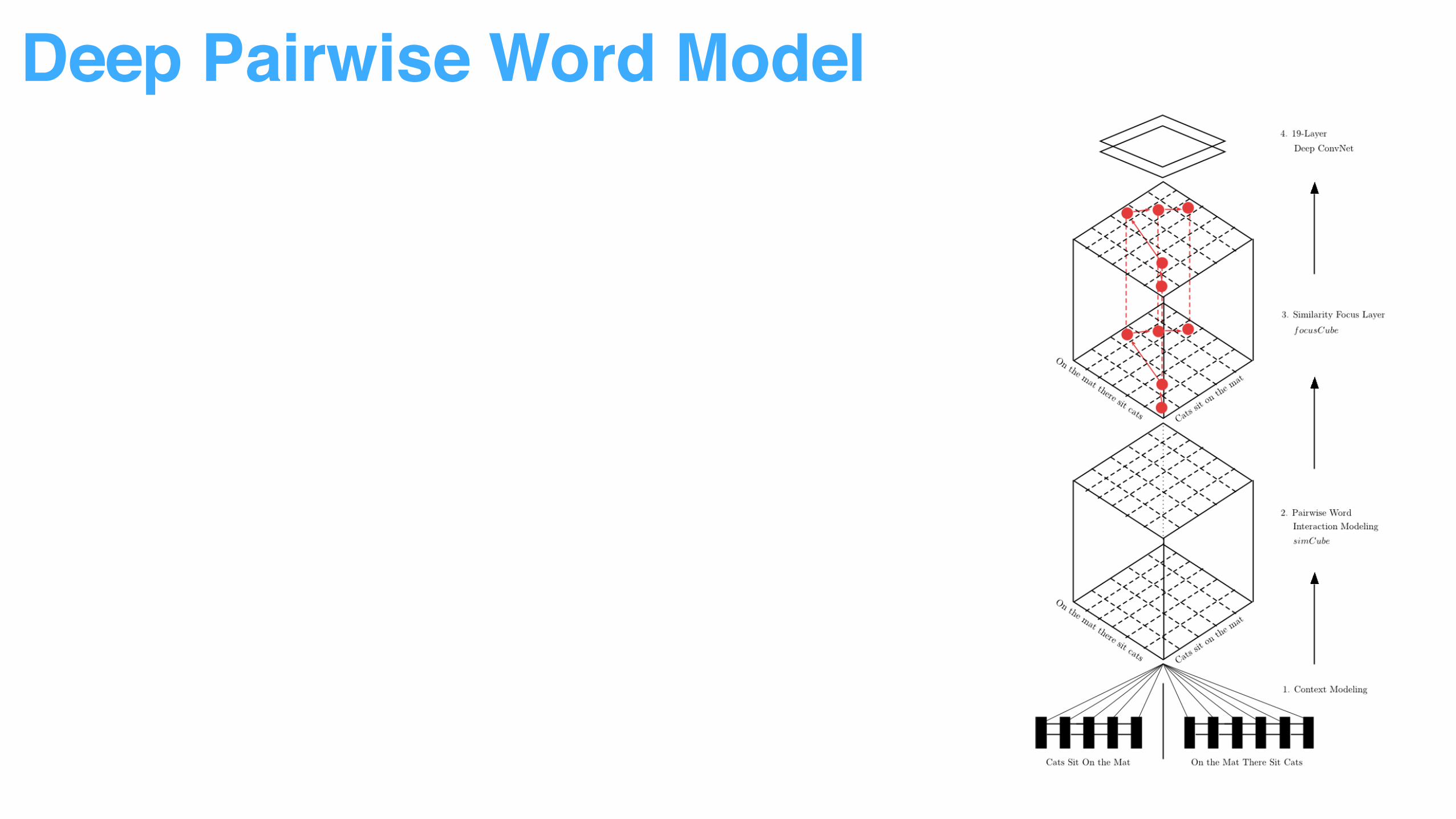
Deep Pairwise Word Model
Deep Pairwise Word Model
• From Sentence Representation to Word Representation
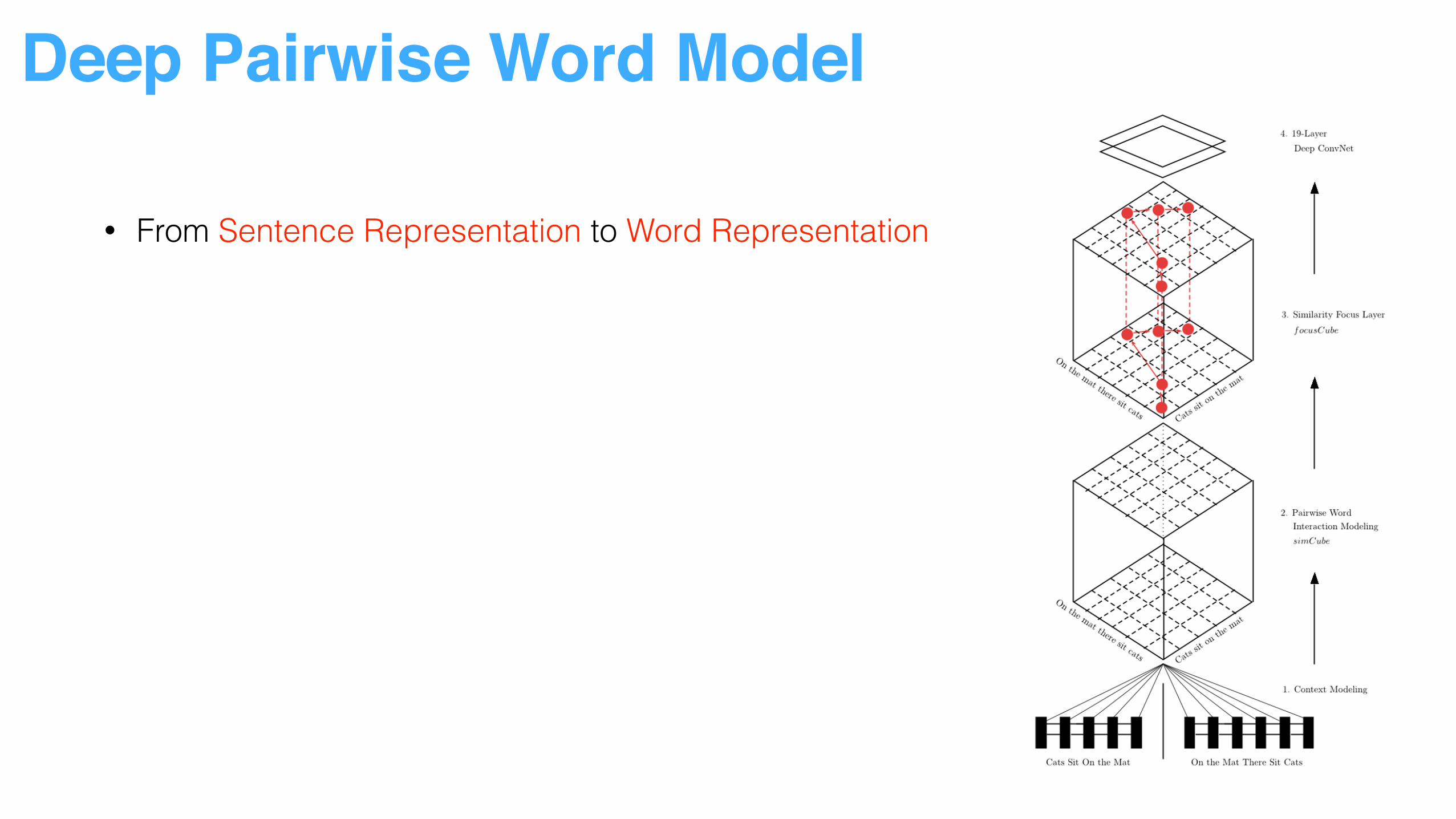
Deep Pairwise Word Model
• From Sentence Representation to Word Representation
• From Word Representation to Word Pair Interaction
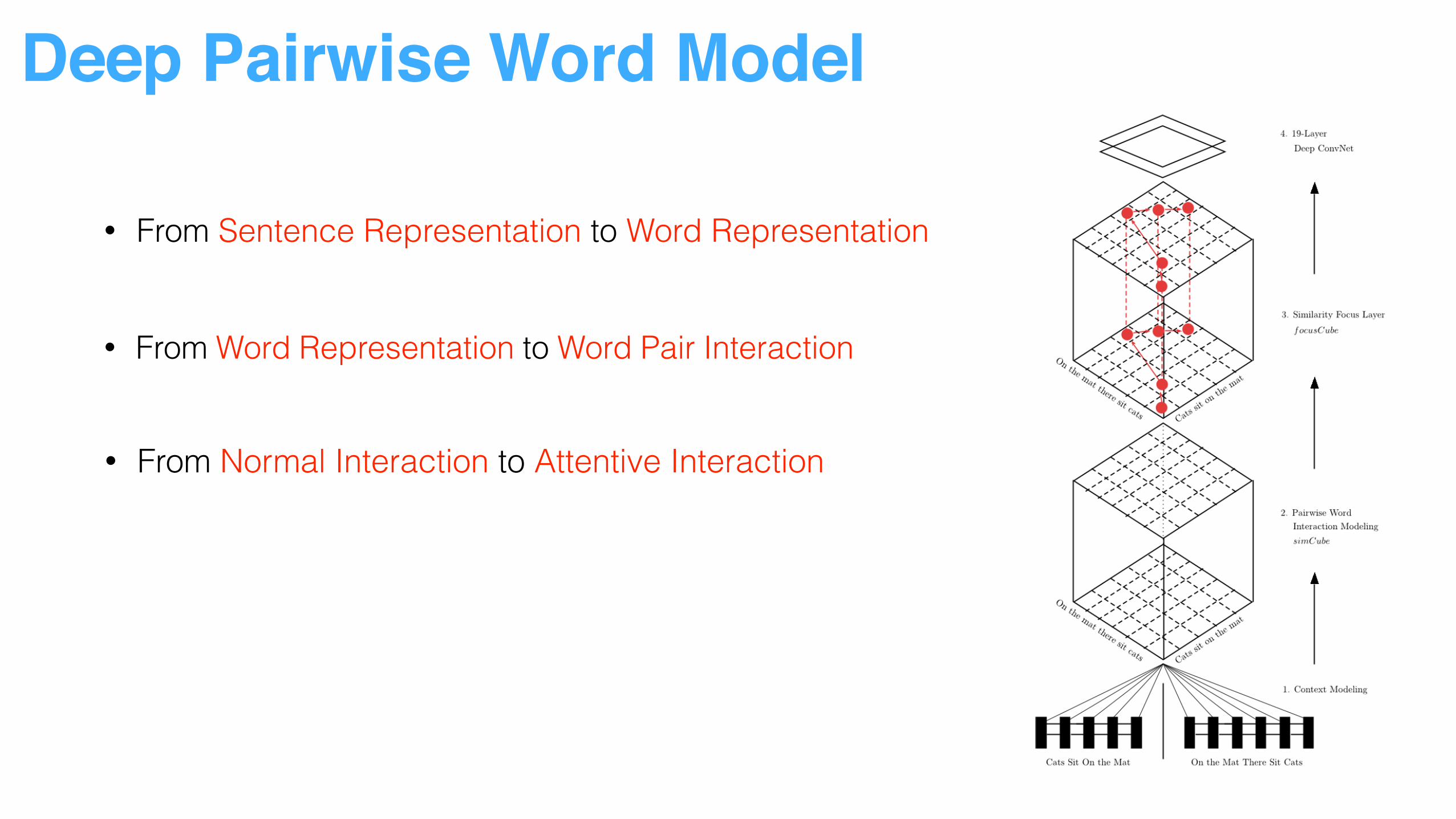
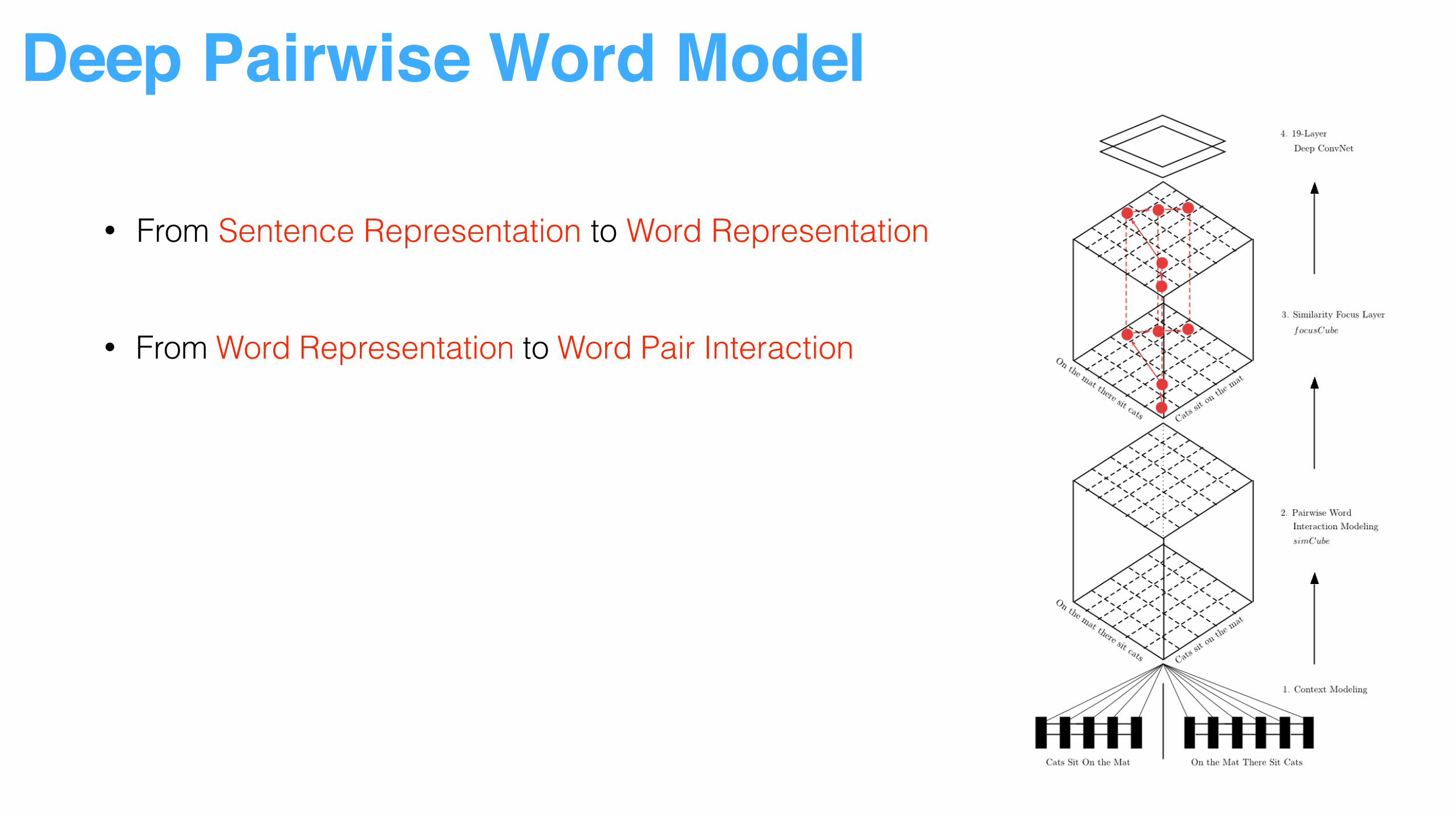
Deep Pairwise Word Model
• From Sentence Representation to Word Representation
• From Normal Interaction to Attentive Interaction
• From Word Representation to Word Pair Interaction
Deep Pairwise Word Model
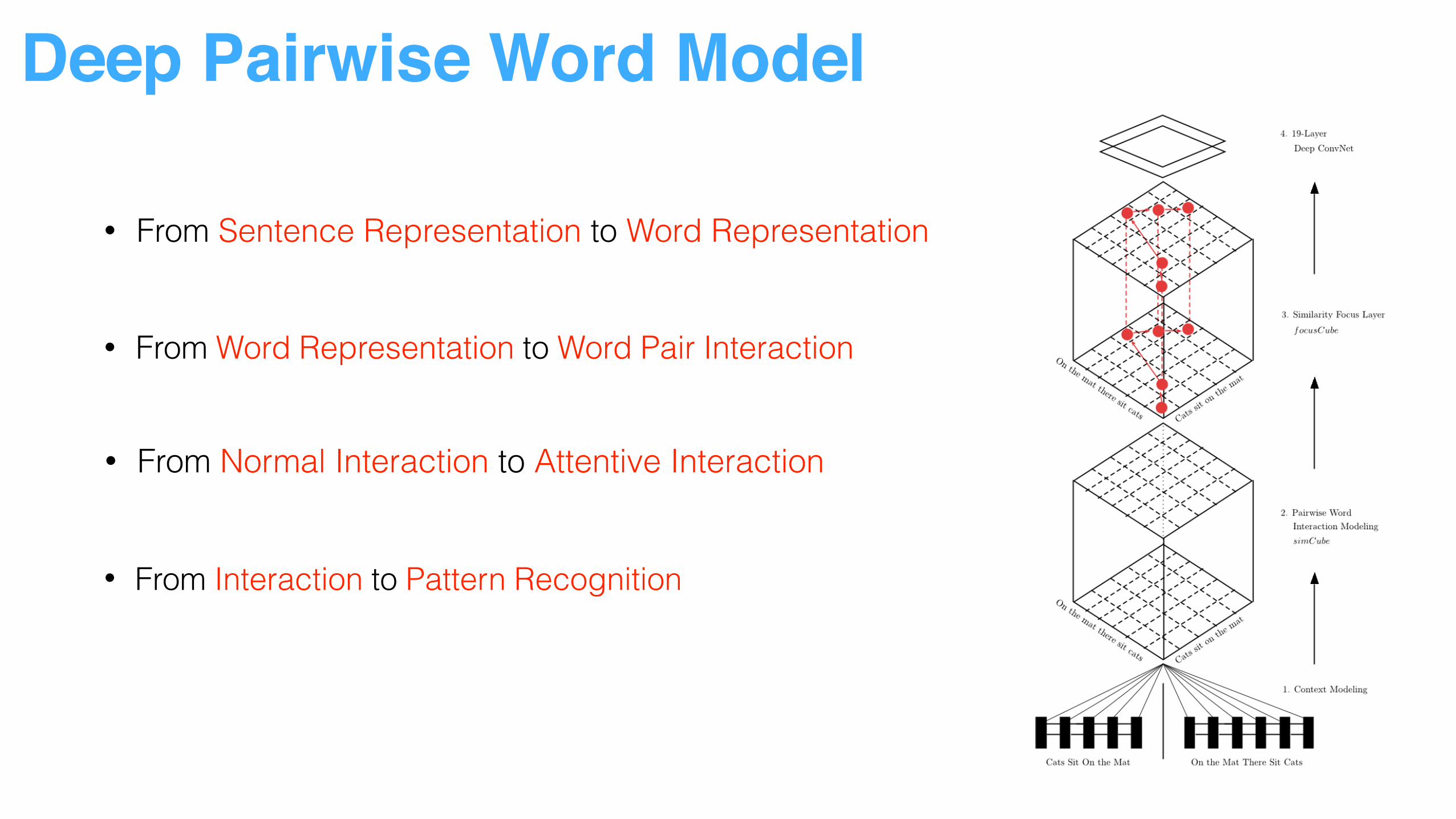
• From Sentence Representation to Word Representation
• From Normal Interaction to Attentive Interaction
• From Word Representation to Word Pair Interaction
• From Interaction to Pattern Recognition

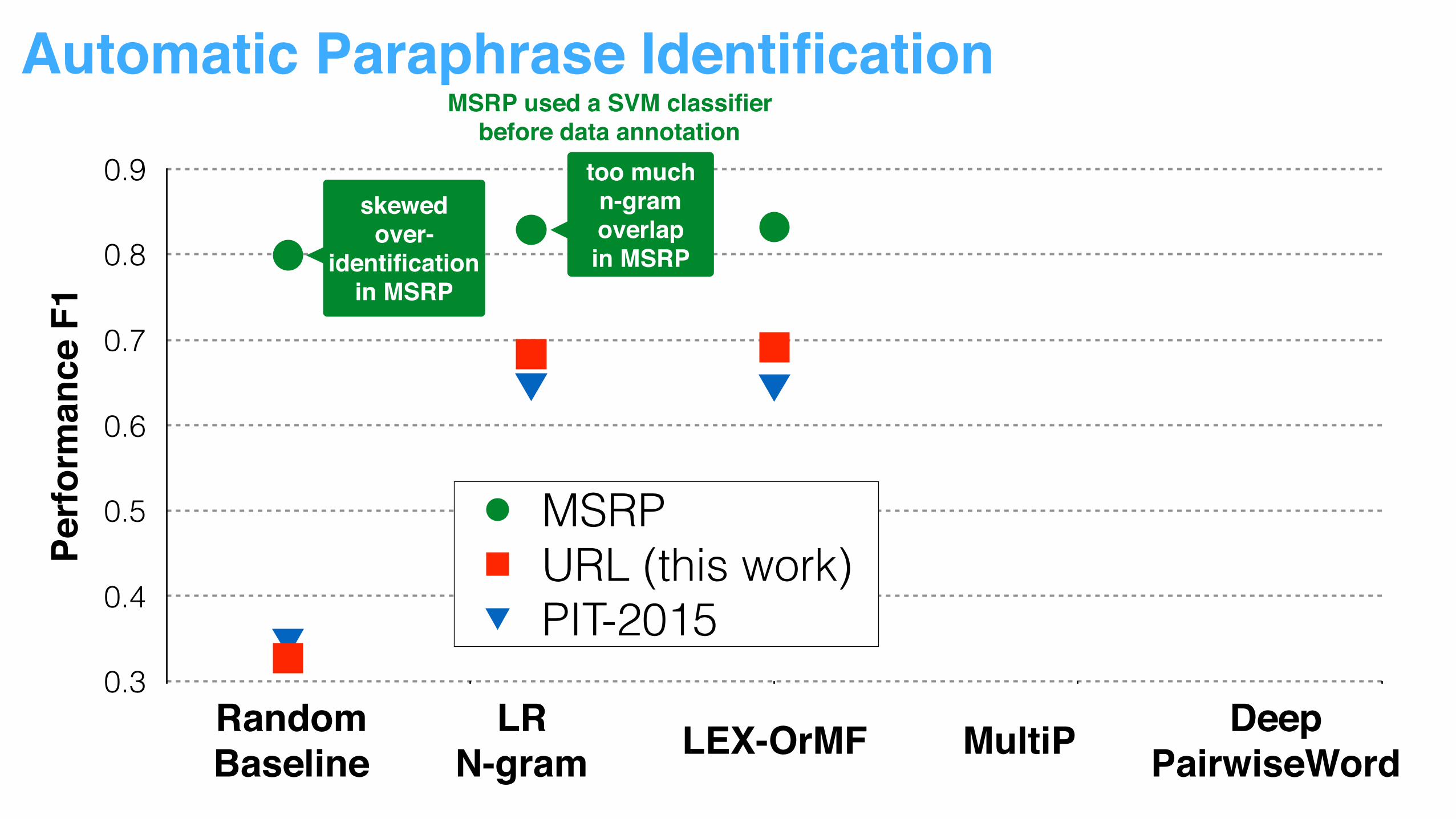
Automatic Paraphrase Identification Pe
rfor
man
ce F
1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
MSRPURL (this work)PIT-2015
LR N-gram LEX-OrMF MultiP Deep
PairwiseWordRandomBaseline

Automatic Paraphrase Identification Pe
rfor
man
ce F
1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
MSRPURL (this work)PIT-2015
LR N-gram LEX-OrMF MultiP Deep
PairwiseWordRandomBaseline
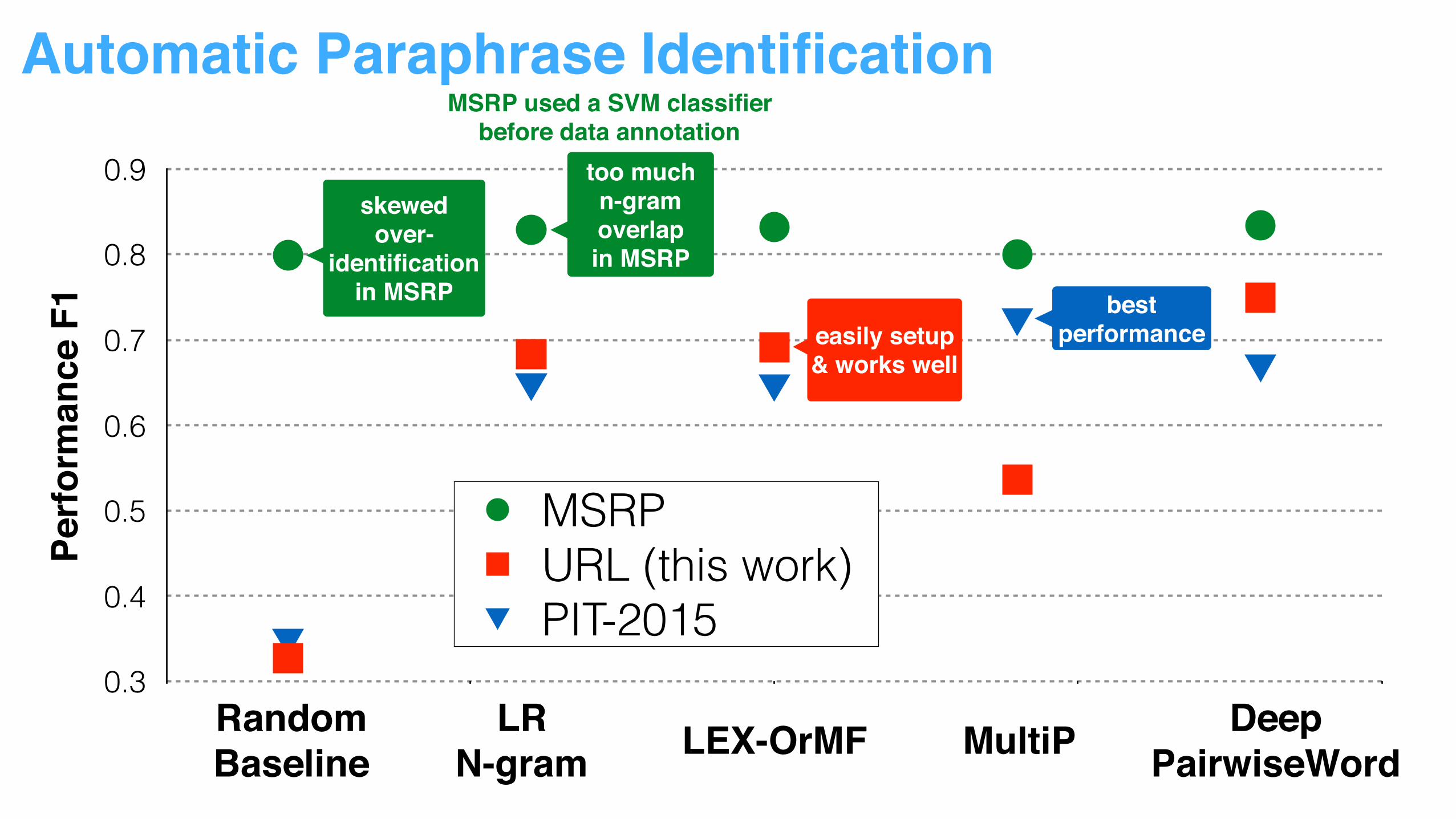
skewedover-
identification in MSRP
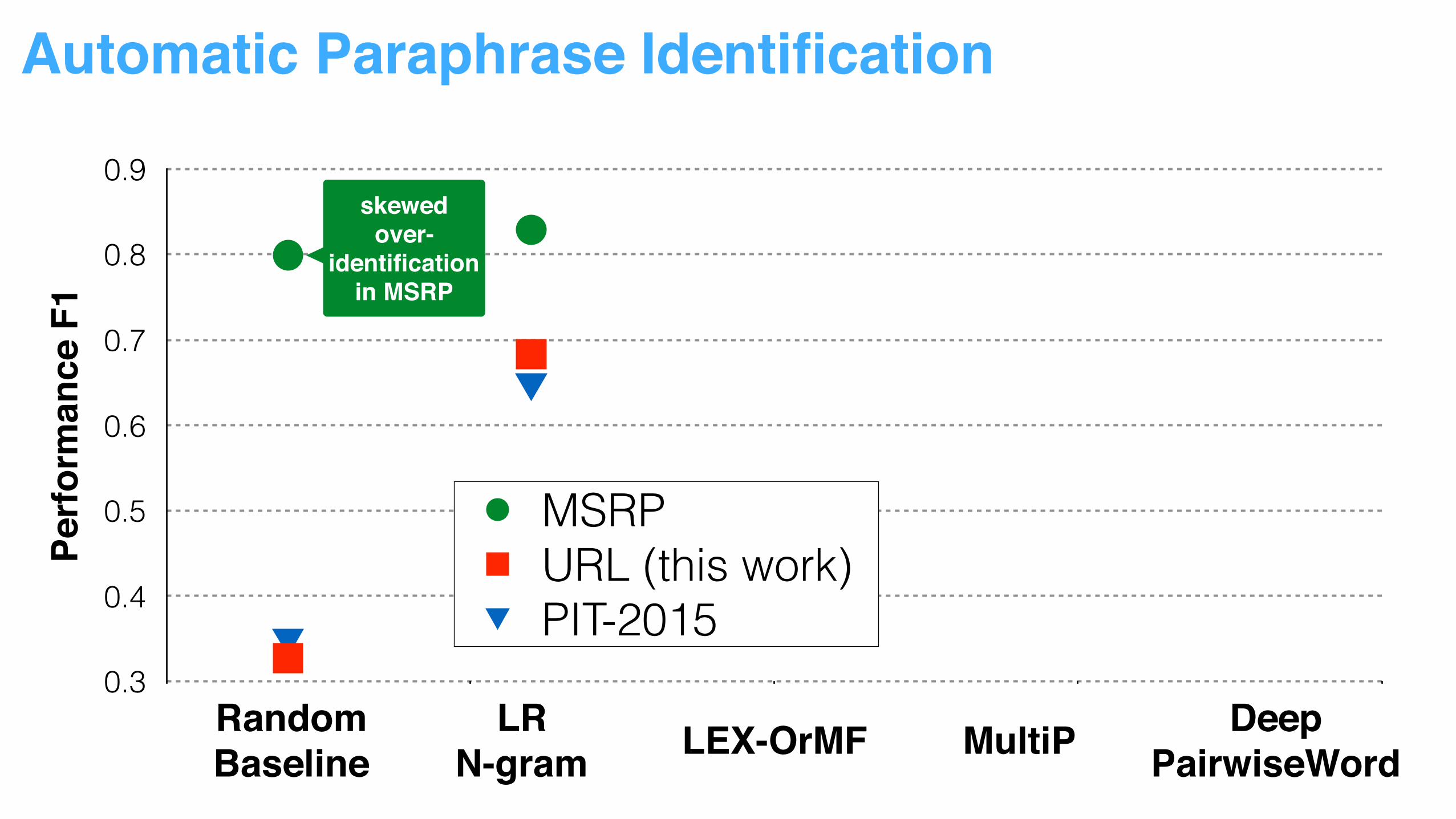
Automatic Paraphrase Identification Pe
rfor
man
ce F
1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
MSRPURL (this work)PIT-2015
LR N-gram LEX-OrMF MultiP Deep
PairwiseWordRandomBaseline
skewedover-
identification in MSRP
Automatic Paraphrase Identification Pe
rfor
man
ce F
1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
MSRPURL (this work)PIT-2015
LR N-gram LEX-OrMF MultiP Deep
PairwiseWordRandomBaseline
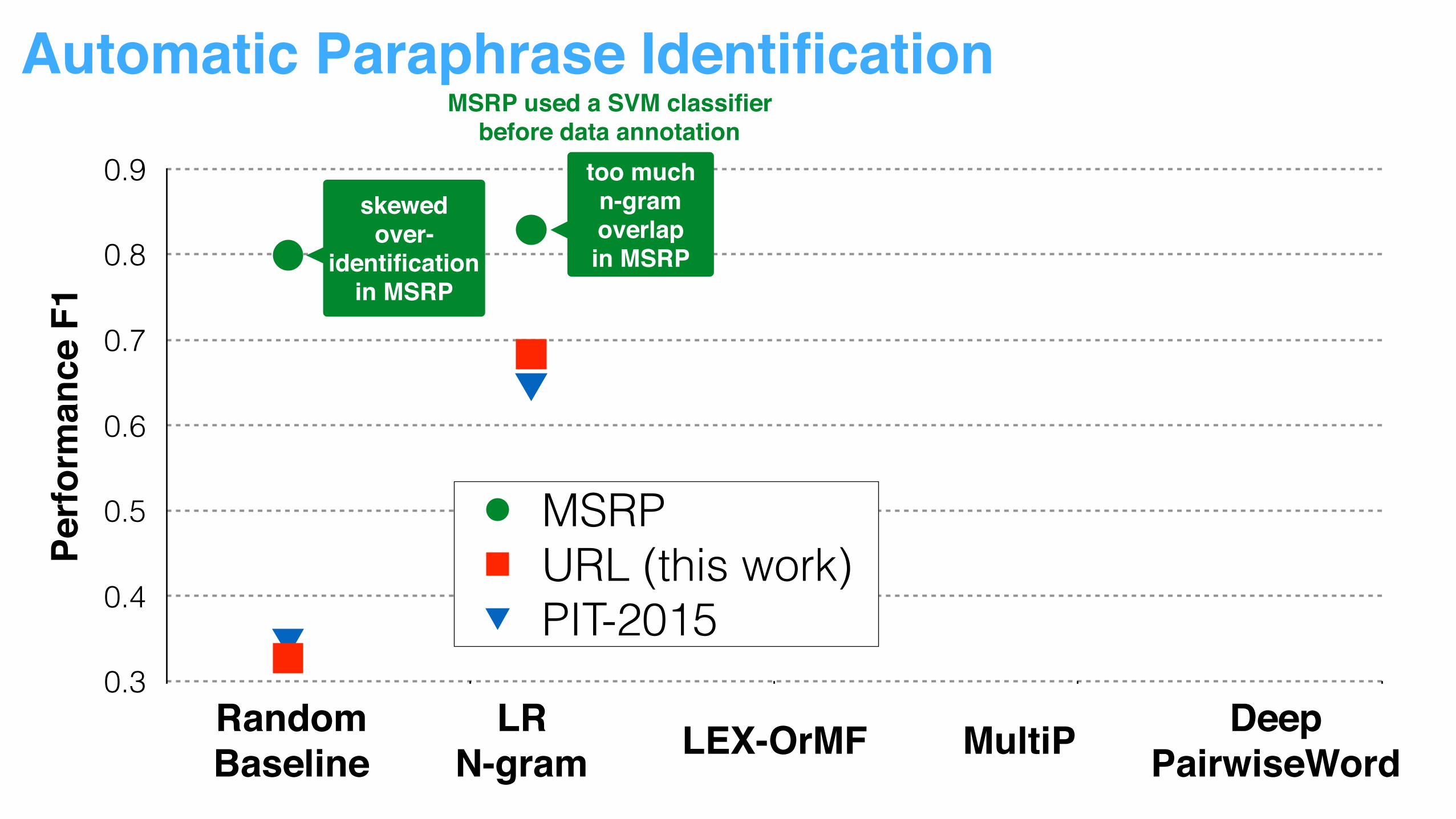
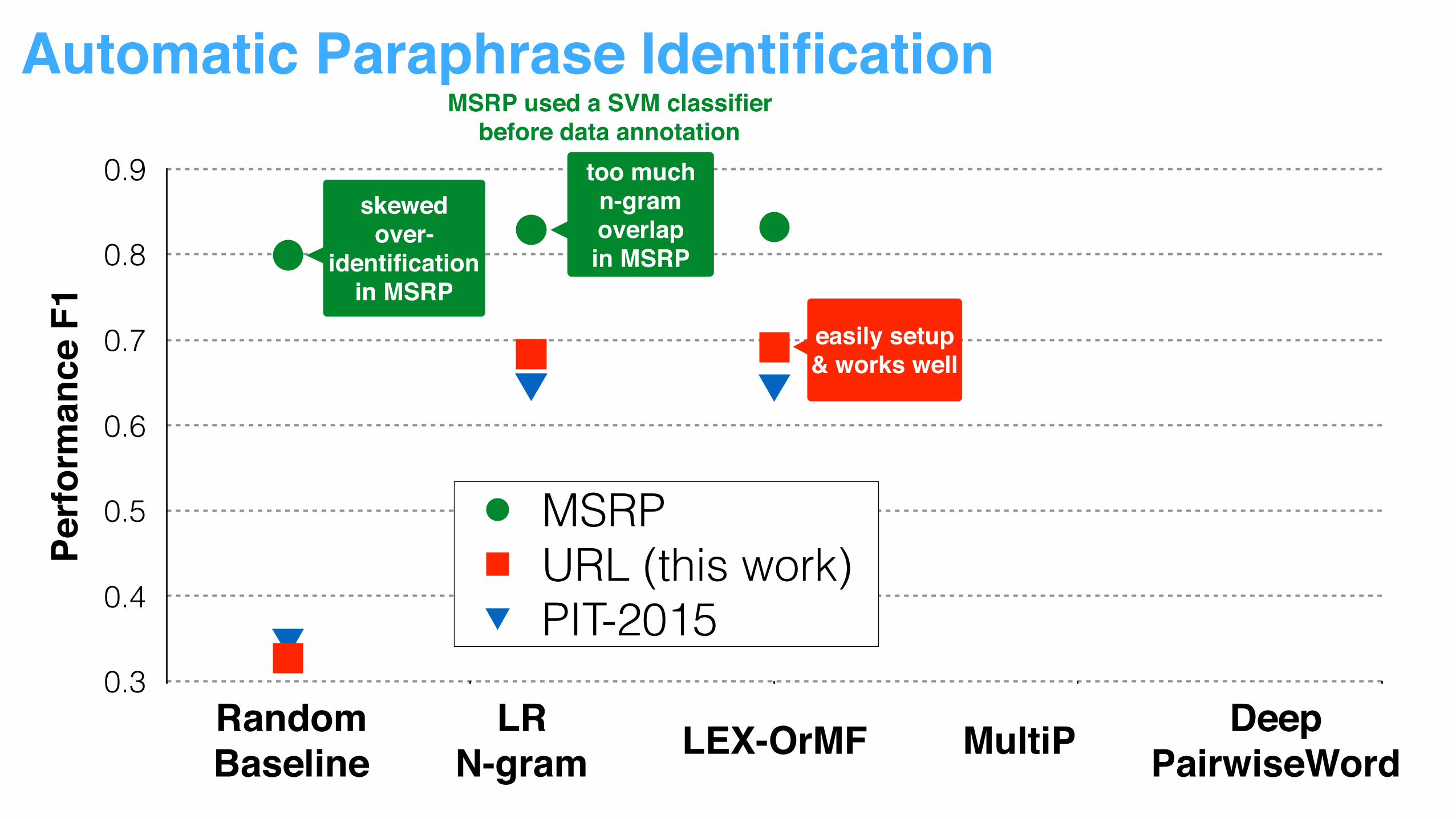
too muchn-gram overlapin MSRP
skewedover-
identification in MSRP
MSRP used a SVM classifier before data annotation
Automatic Paraphrase Identification Pe
rfor
man
ce F
1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
MSRPURL (this work)PIT-2015
LR N-gram LEX-OrMF MultiP Deep
PairwiseWordRandomBaseline
too muchn-gram overlapin MSRP
skewedover-
identification in MSRP
MSRP used a SVM classifier before data annotation
Automatic Paraphrase Identification Pe
rfor
man
ce F
1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
MSRPURL (this work)PIT-2015
LR N-gram LEX-OrMF MultiP Deep
PairwiseWordRandomBaseline
too muchn-gram overlapin MSRP
skewedover-
identification in MSRP
MSRP used a SVM classifier before data annotation
easily setup & works well
Automatic Paraphrase Identification Pe
rfor
man
ce F
1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
MSRPURL (this work)PIT-2015
LR N-gram LEX-OrMF MultiP Deep
PairwiseWordRandomBaseline
too muchn-gram overlapin MSRP
skewedover-
identification in MSRP
MSRP used a SVM classifier before data annotation
easily setup & works well
Automatic Paraphrase Identification Pe
rfor
man
ce F
1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
MSRPURL (this work)PIT-2015
LR N-gram LEX-OrMF MultiP Deep
PairwiseWordRandomBaseline
too muchn-gram overlapin MSRP
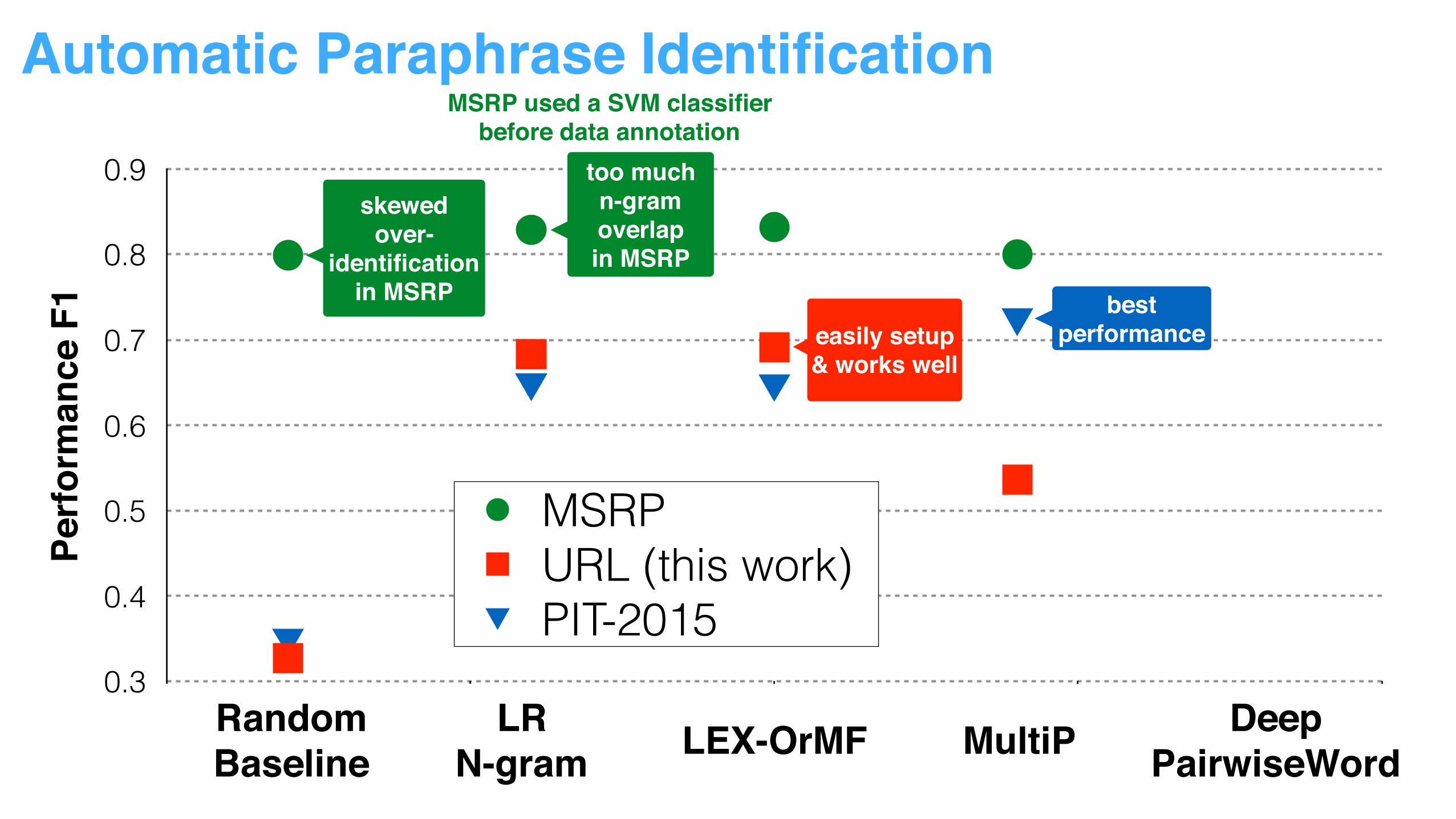
skewedover-
identification in MSRP best
performance
MSRP used a SVM classifier before data annotation
easily setup & works well
Automatic Paraphrase Identification Pe
rfor
man
ce F
1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
MSRPURL (this work)PIT-2015
easily setup & works well
LR N-gram LEX-OrMF MultiP Deep
PairwiseWordRandomBaseline
too muchn-gram overlapin MSRP
skewedover-
identification in MSRP best
performance
MSRP used a SVM classifier before data annotation

Automatic Paraphrase Identification Pe
rfor
man
ce F
1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
MSRPURL (this work)PIT-2015
easily setup & works well
best performance
LR N-gram LEX-OrMF MultiP Deep
PairwiseWordRandomBaseline
too muchn-gram overlapin MSRP
skewedover-
identification in MSRP
bestperformance
bestperformance
MSRP used a SVM classifier before data annotation
Automatic Paraphrase Identification Pe
rfor
man
ce F
1
0.3
0.4
0.5
0.6
0.7
0.8
0.9
MSRPURL (this work)PIT-2015
easily setup & works well
best performance
LR N-gram LEX-OrMF MultiP Deep
PairwiseWordRandomBaseline
too muchn-gram overlapin MSRP
skewedover-
identification in MSRP
bestperformance
bestperformance
MSRP used a SVM classifier before data annotation
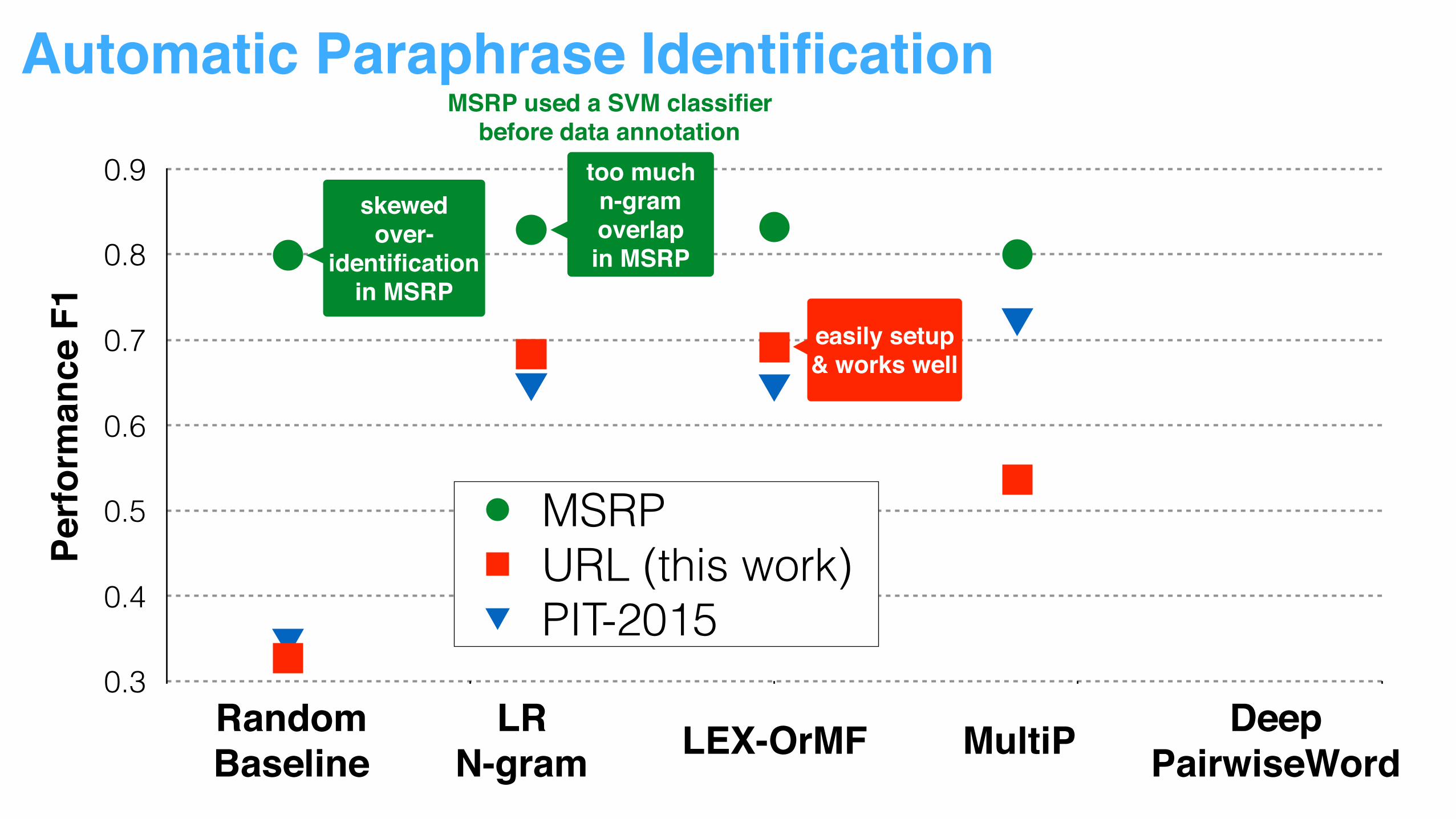
too less n-gram overlap
in PIT-2015PIT-2015 covered too broad
content under the topic

System Performance v.s. Human Upper-bound
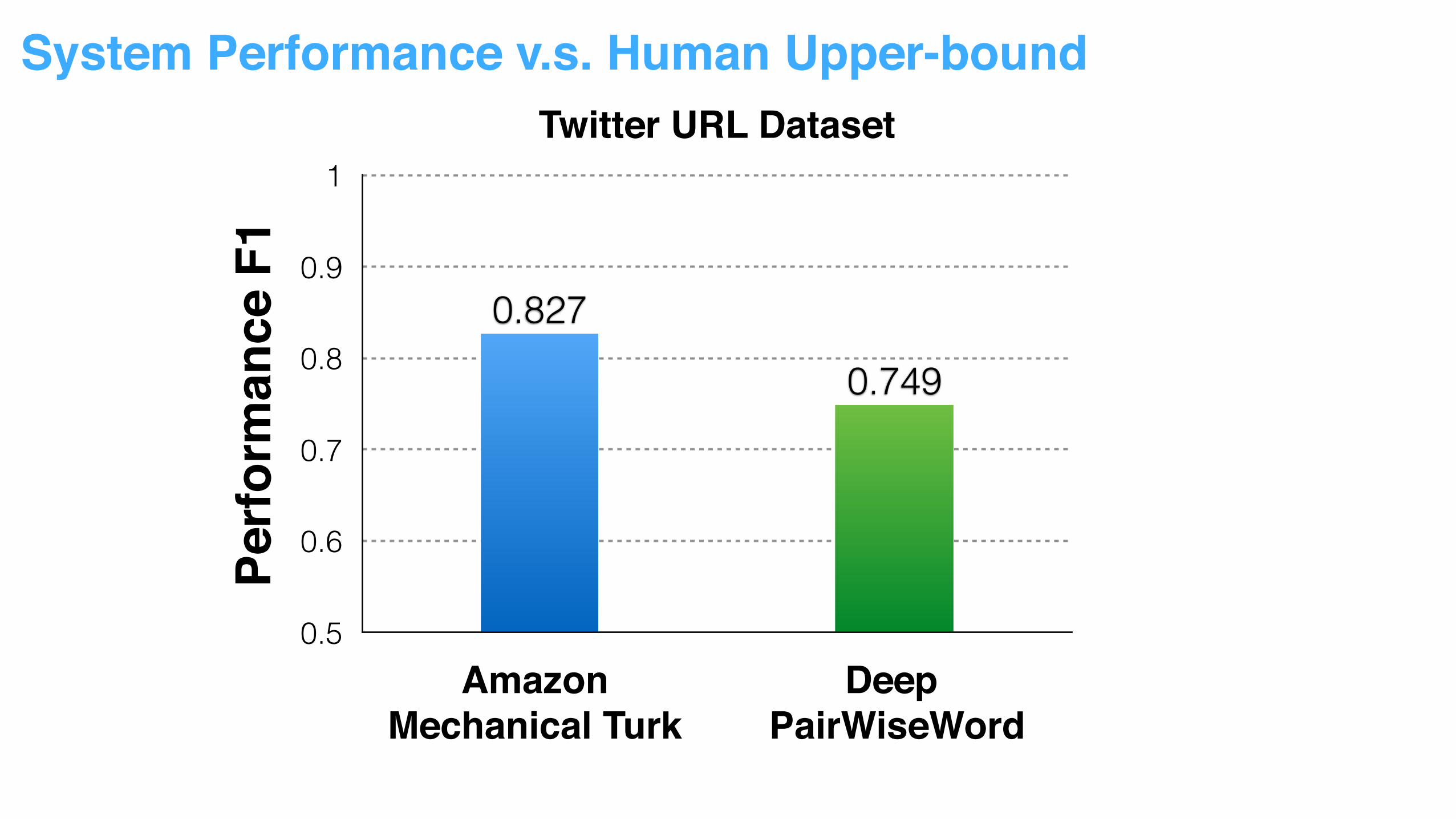
System Performance v.s. Human Upper-boundTwitter URL Dataset
Perf
orm
ance
F1
0.5
0.6
0.7
0.8
0.9
1
0.749
0.827
Amazon Mechanical Turk
Deep PairWiseWord

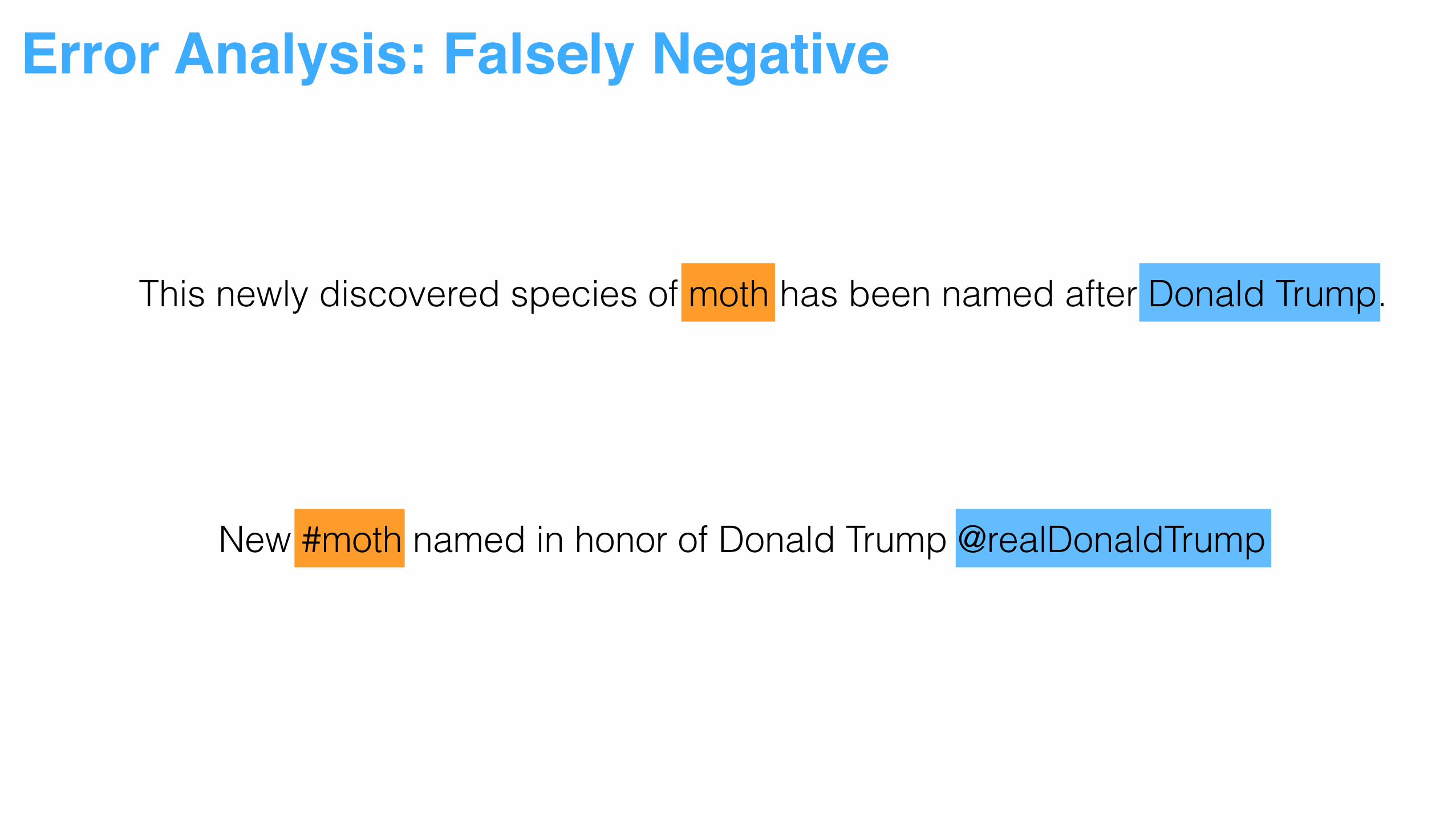
This newly discovered species of moth has been named after Donald Trump.
Error Analysis: Falsely Negative
New #moth named in honor of Donald Trump @realDonaldTrump

This newly discovered species of moth has been named after Donald Trump.
Error Analysis: Falsely Negative
New #moth named in honor of Donald Trump @realDonaldTrump
This newly discovered species of moth has been named after Donald Trump.
Error Analysis: Falsely Negative
New #moth named in honor of Donald Trump @realDonaldTrump

Out-of-Vocabulary Word Problem
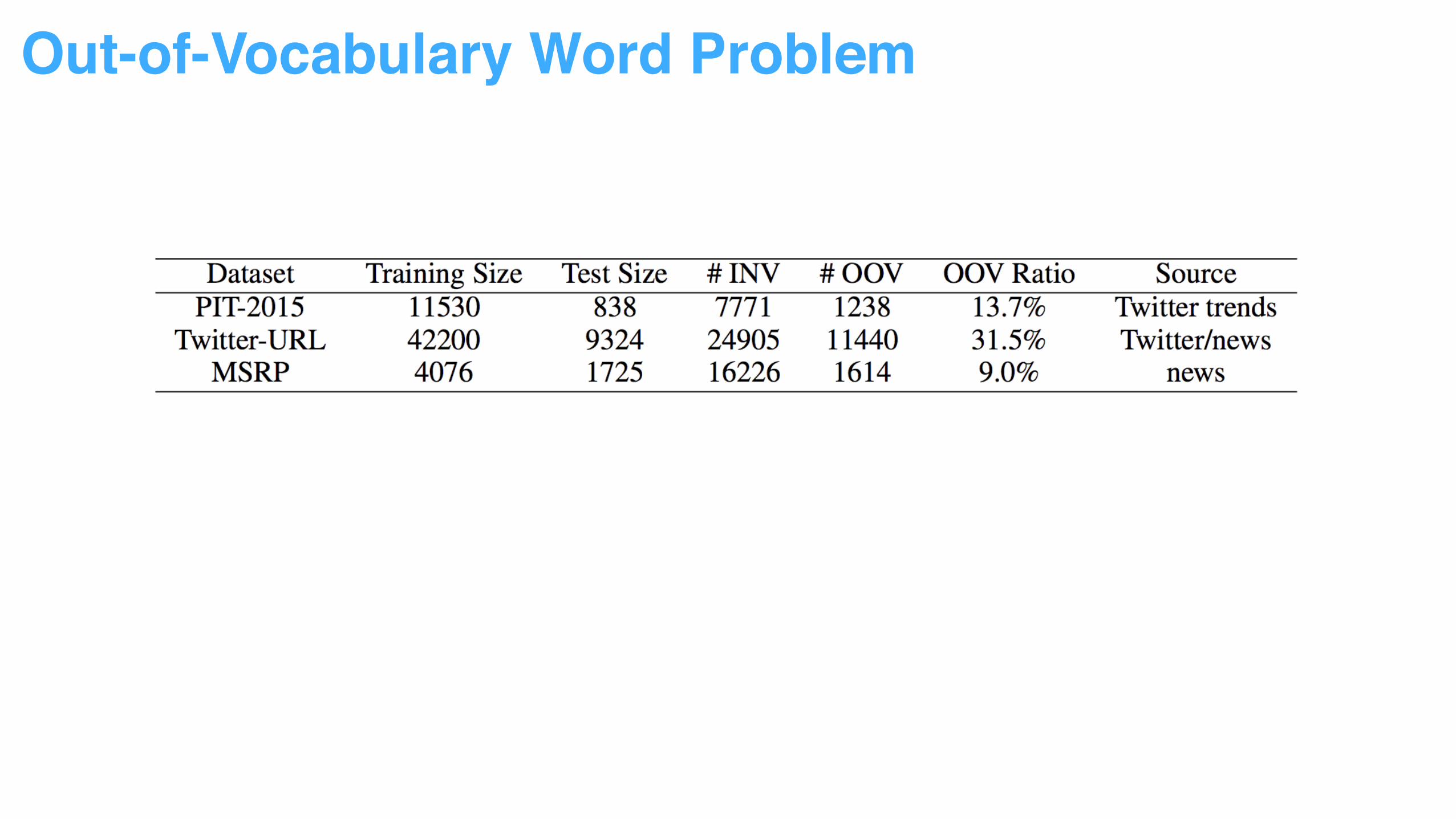
Out-of-Vocabulary Word Problem
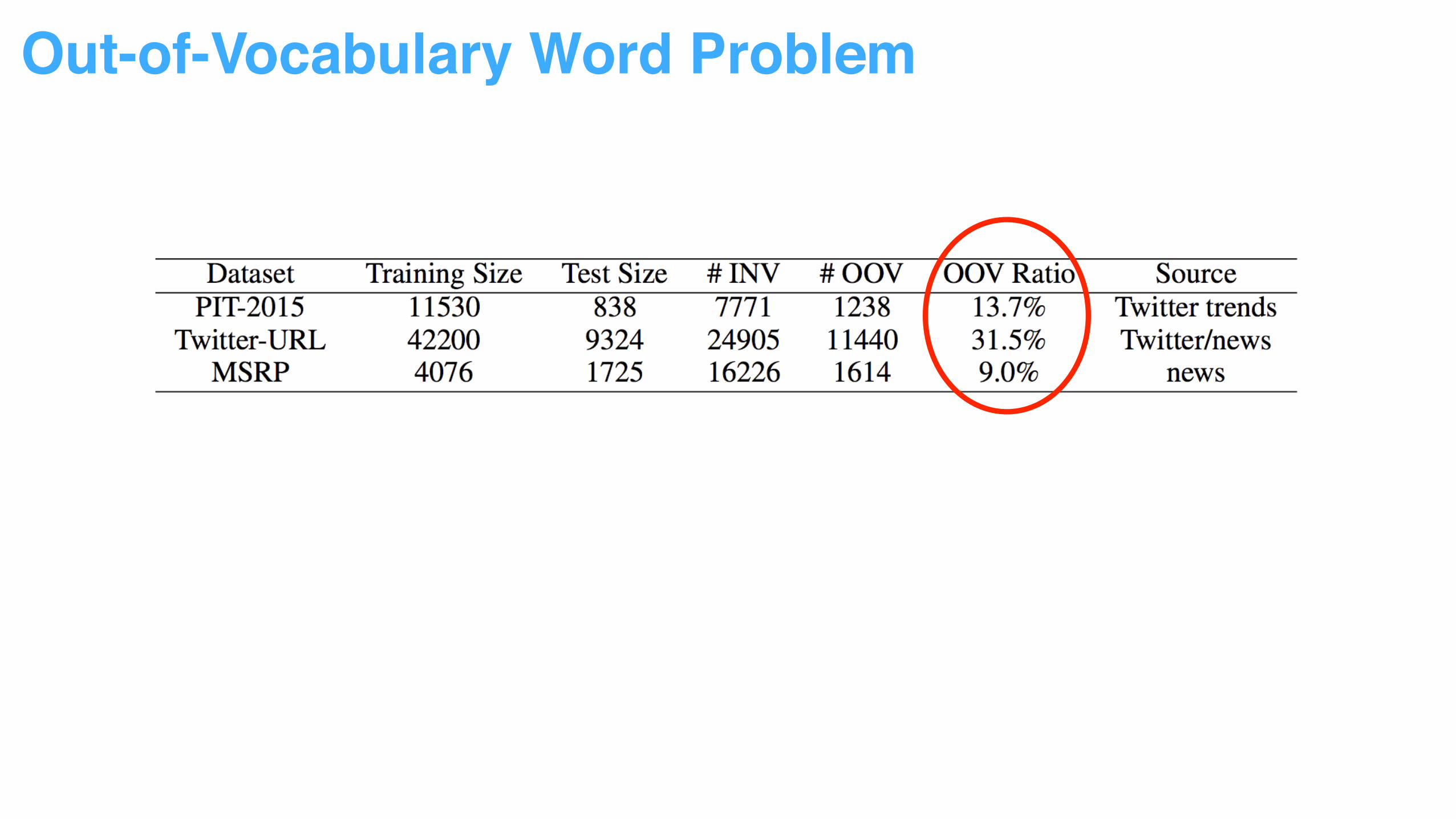
Out-of-Vocabulary Word Problem
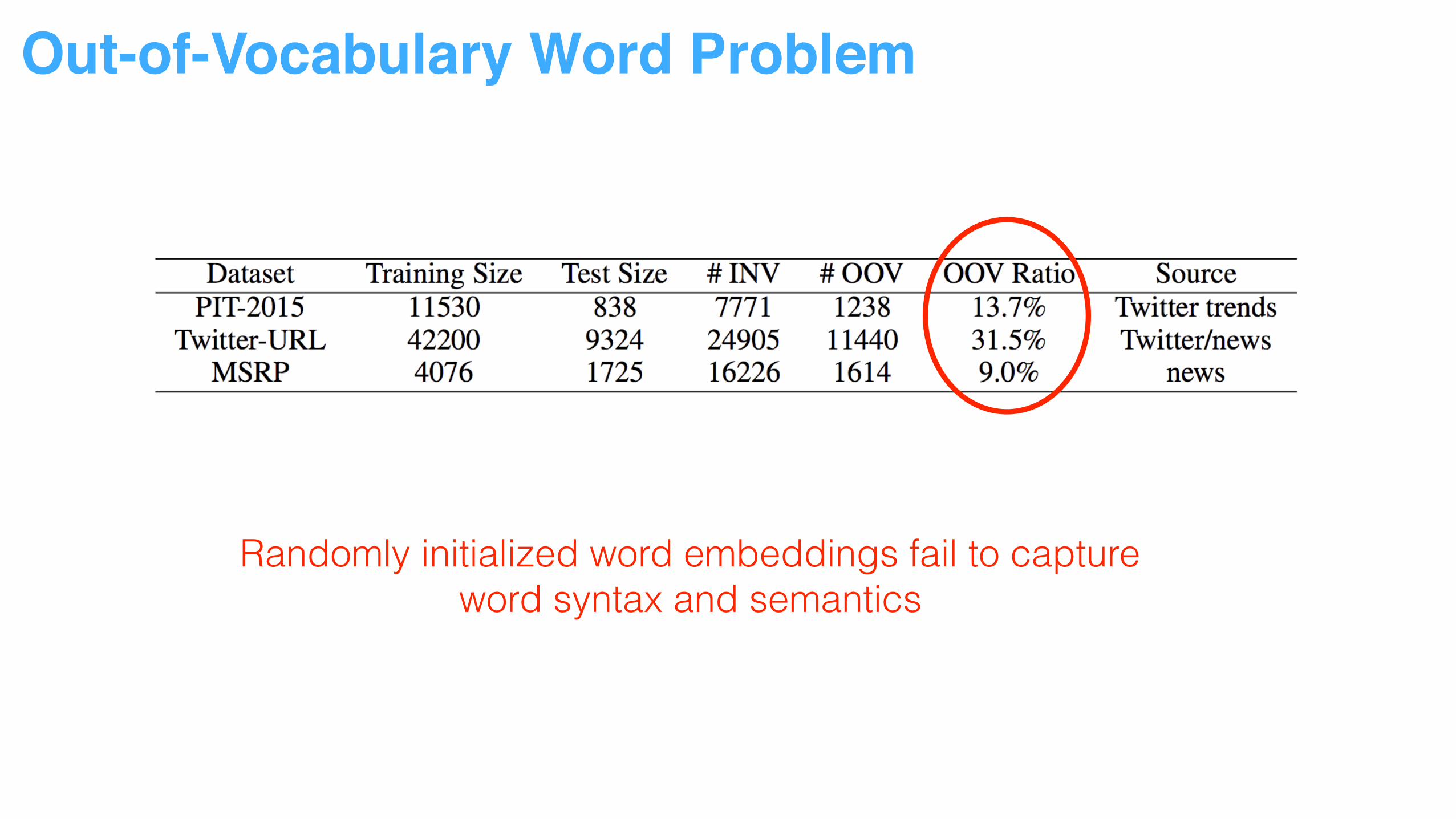
Out-of-Vocabulary Word Problem
Randomly initialized word embeddings fail to capture word syntax and semantics

Representing Word with Smaller Units

Representing Word with Smaller Units

LSTM Based Character Embedding (C2W)[1]

LSTM Based Character Embedding (C2W)[1]
[1] Ling et al., 2015
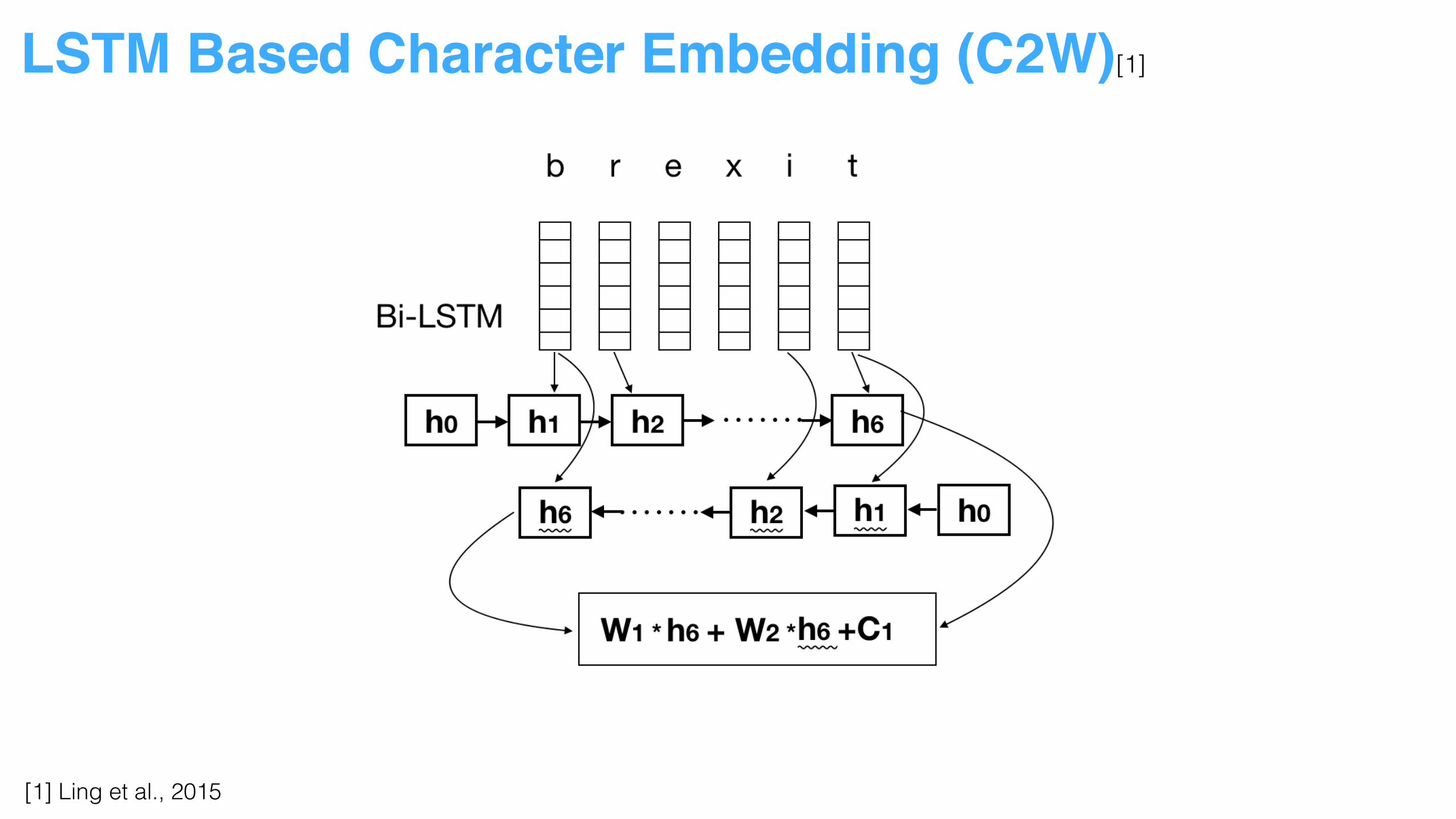
LSTM Based Character Embedding (C2W)[1]
[1] Ling et al., 2015

CNN Based Character Embedding[1]

CNN Based Character Embedding[1]
[1] Kim et al., 2016
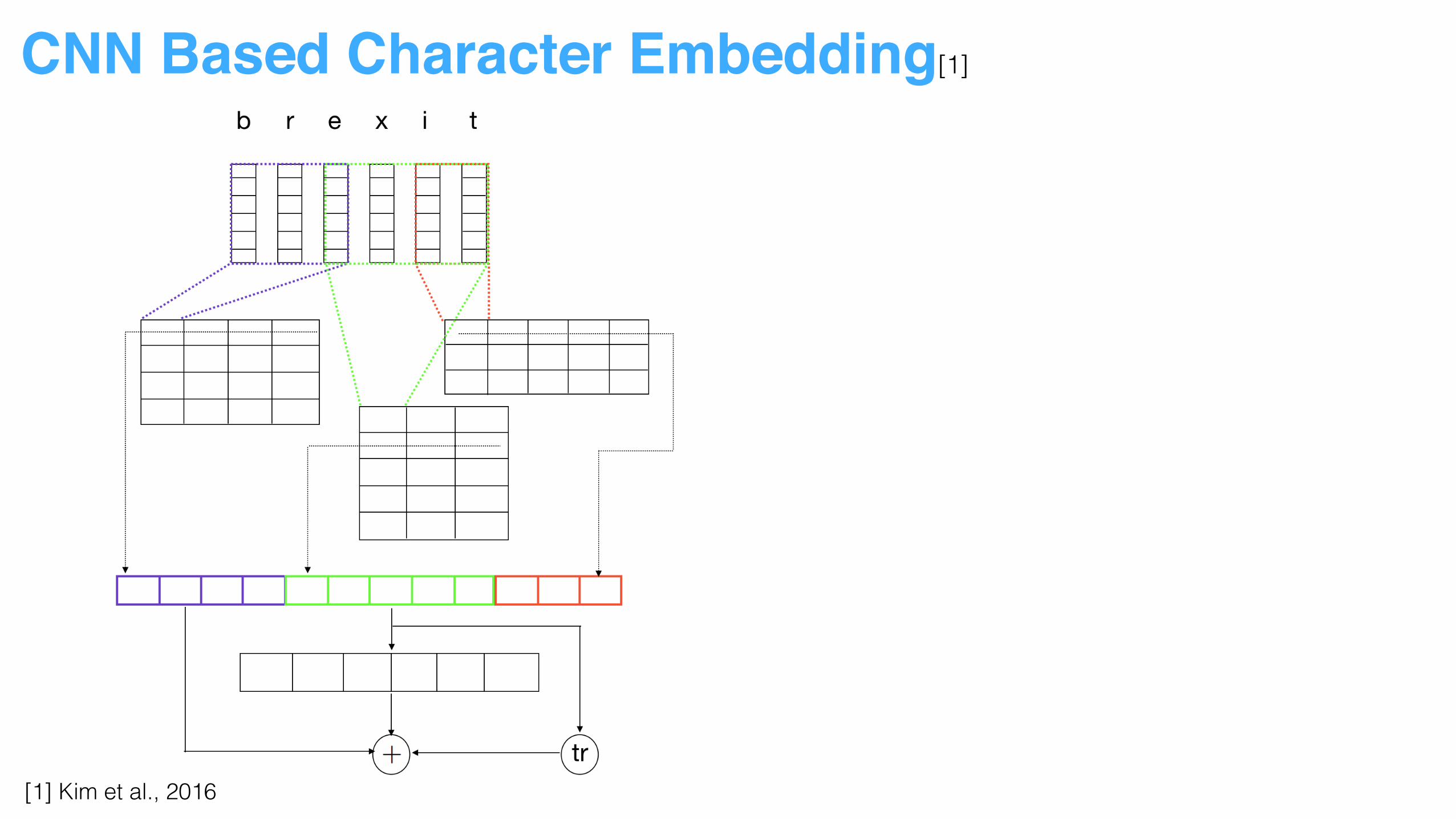
CNN Based Character Embedding[1]
[1] Kim et al., 2016
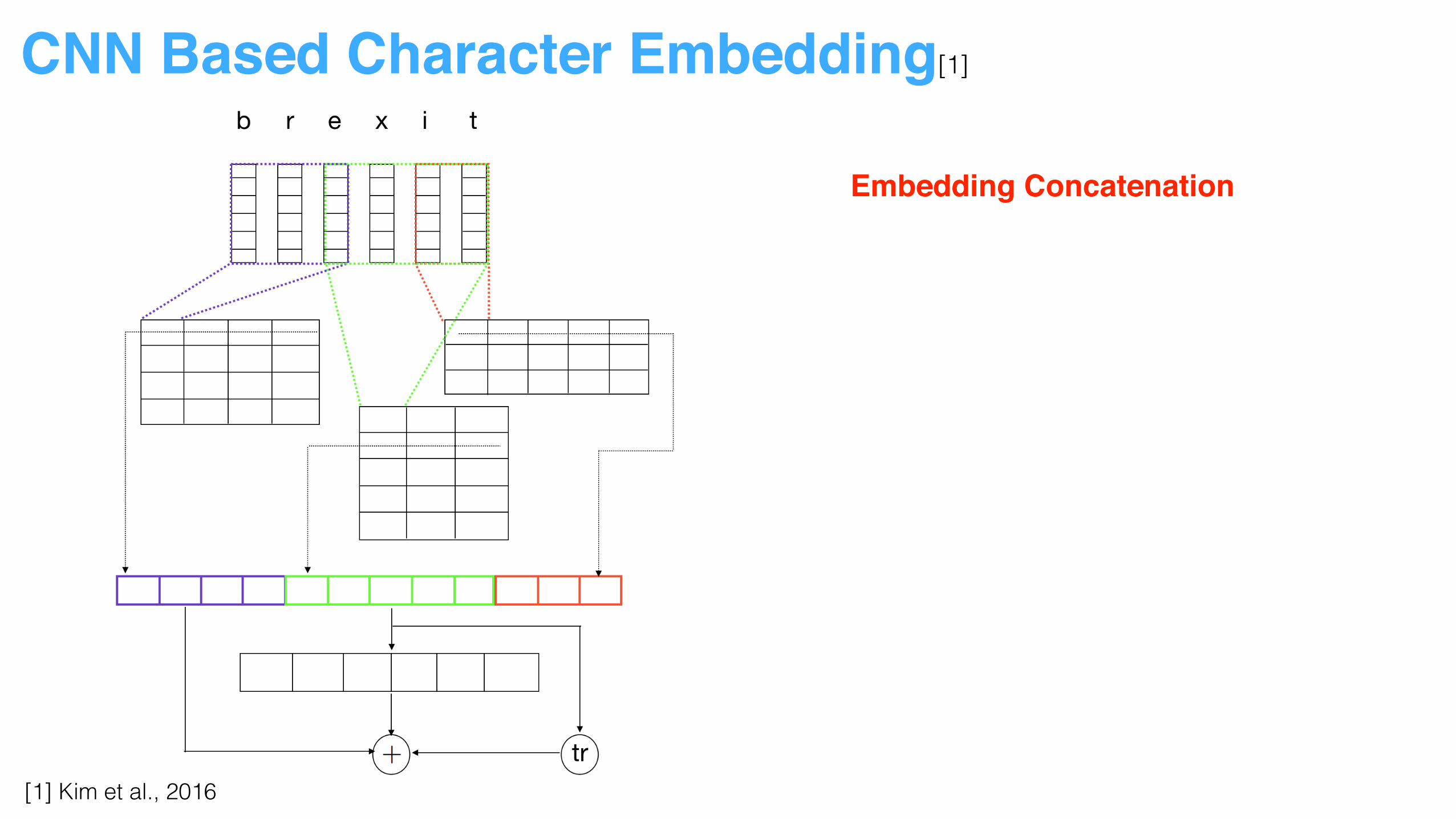
CNN Based Character Embedding[1]
Embedding Concatenation
[1] Kim et al., 2016
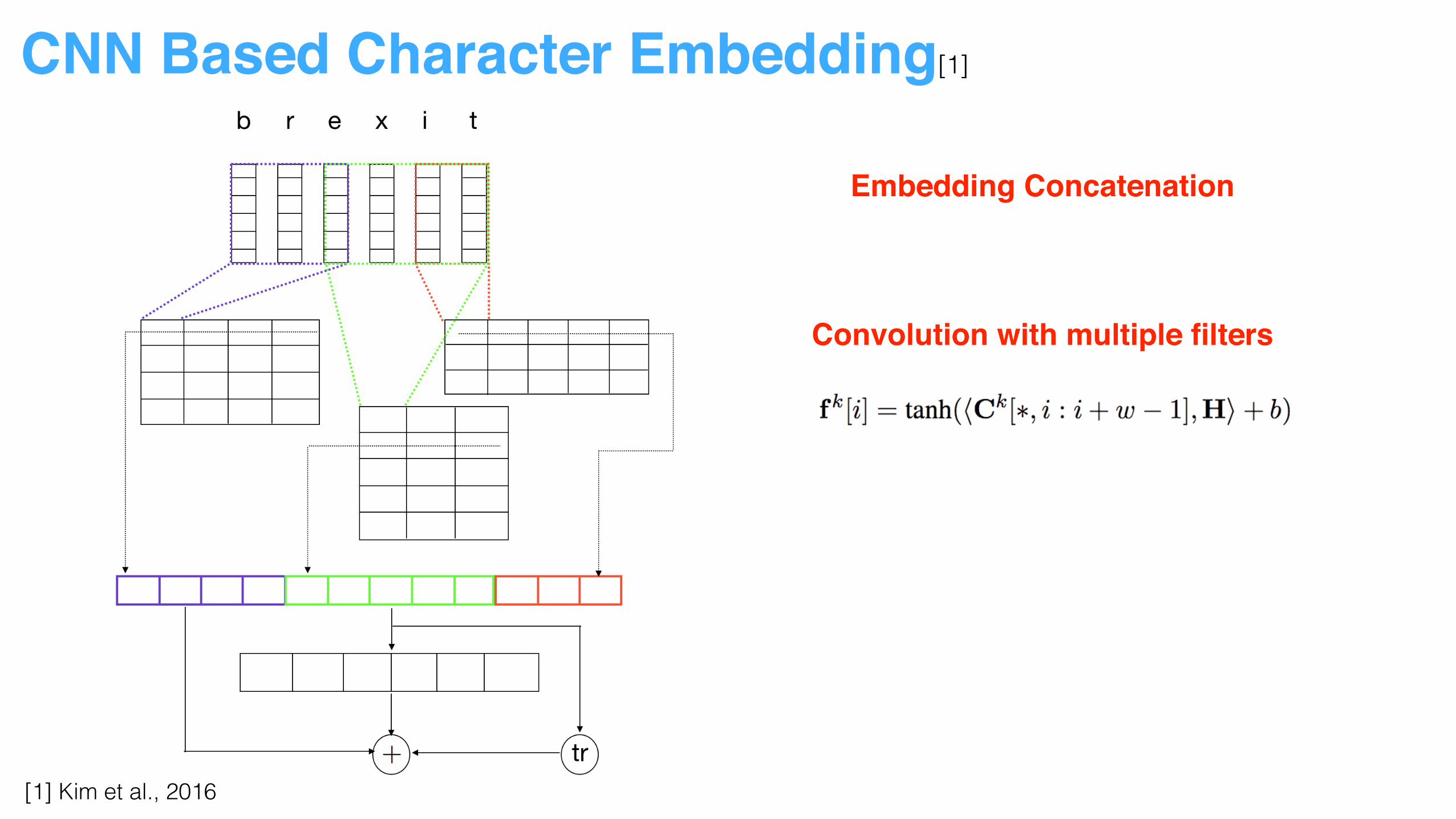
CNN Based Character Embedding[1]
Embedding Concatenation
Convolution with multiple filters
[1] Kim et al., 2016
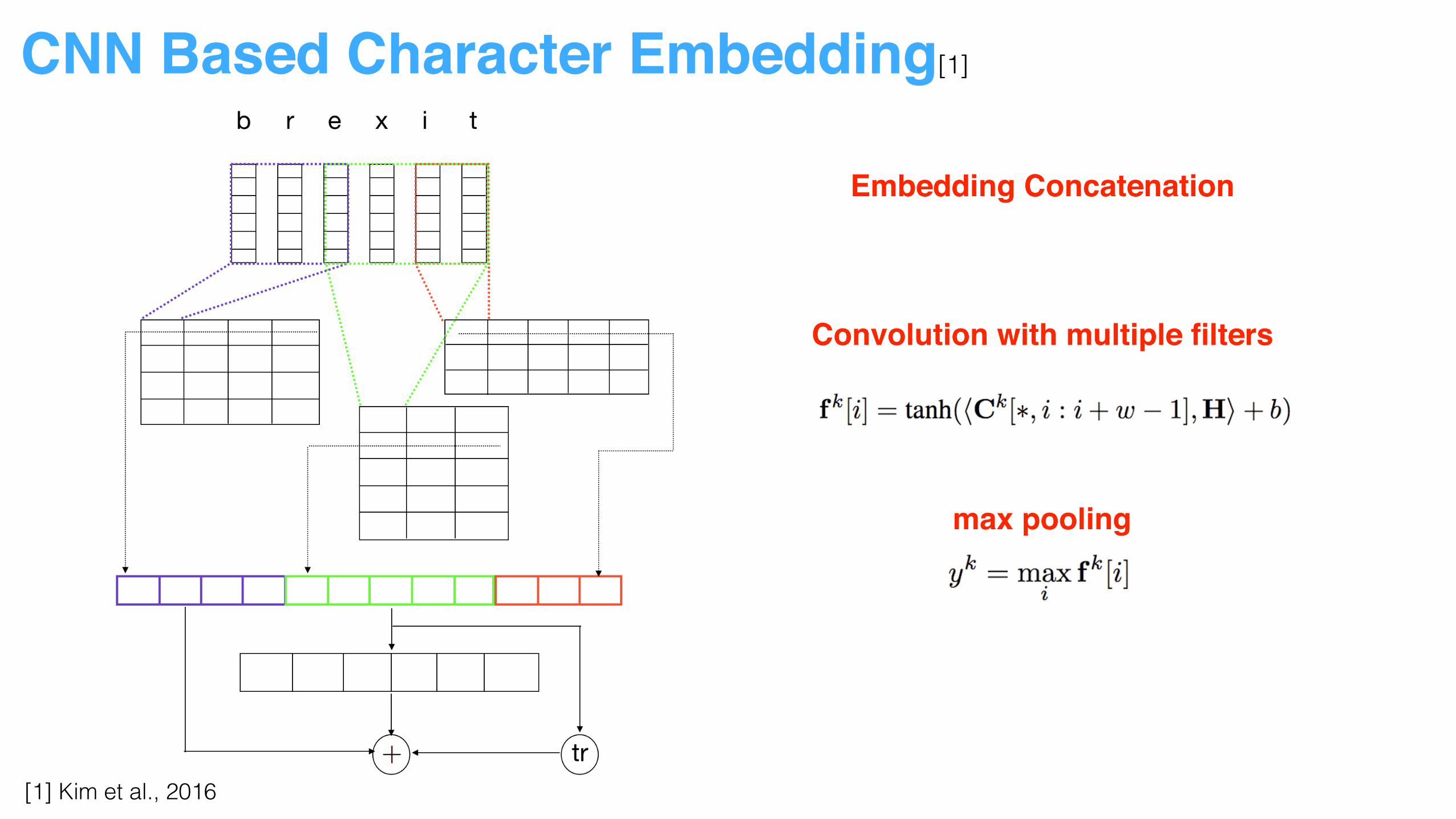
CNN Based Character Embedding[1]
Embedding Concatenation
Convolution with multiple filters
max pooling
[1] Kim et al., 2016
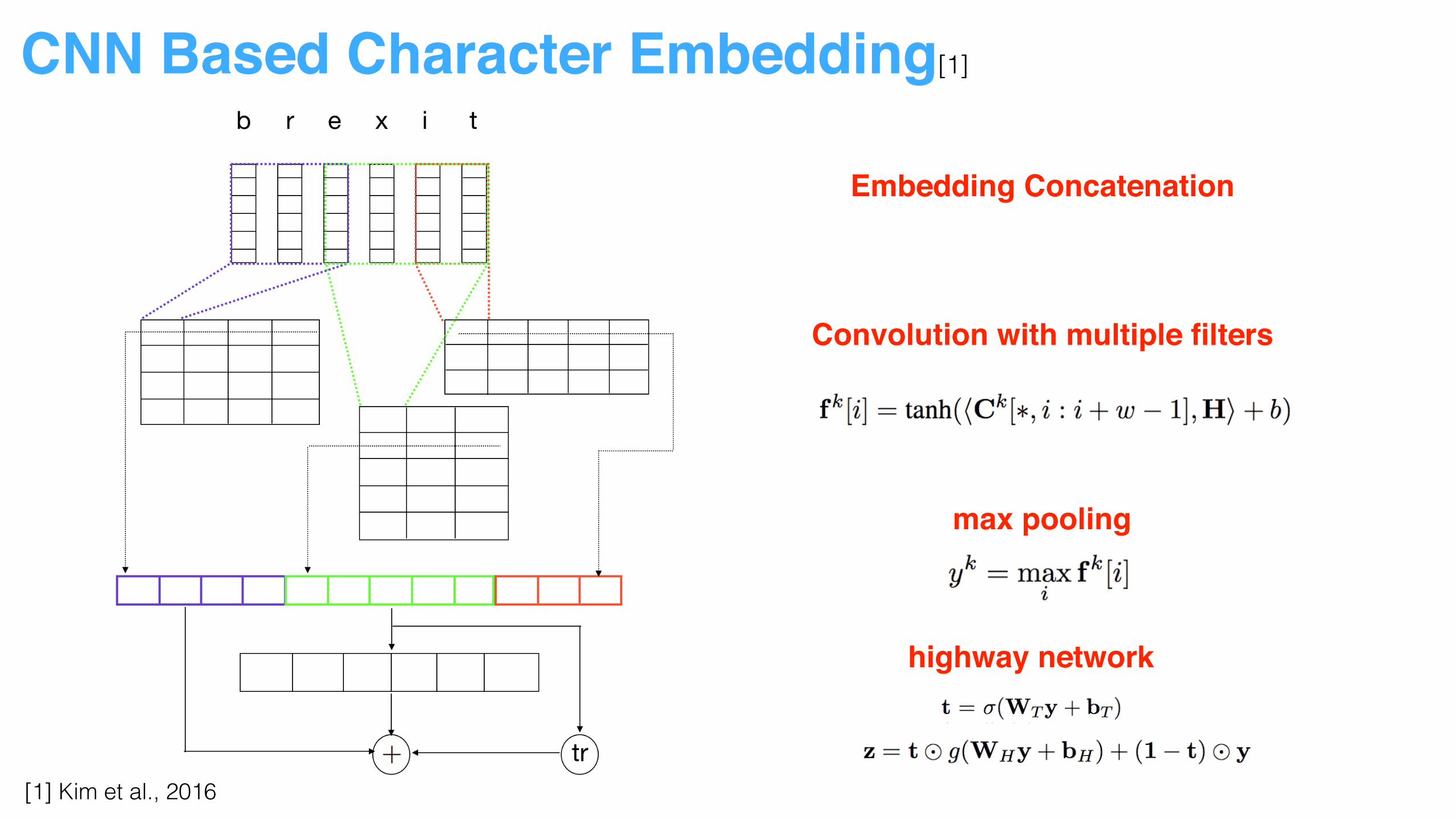
CNN Based Character Embedding[1]
Embedding Concatenation
Convolution with multiple filters
max pooling
highway network
[1] Kim et al., 2016

Subword Based Pairwise Word Interaction Model
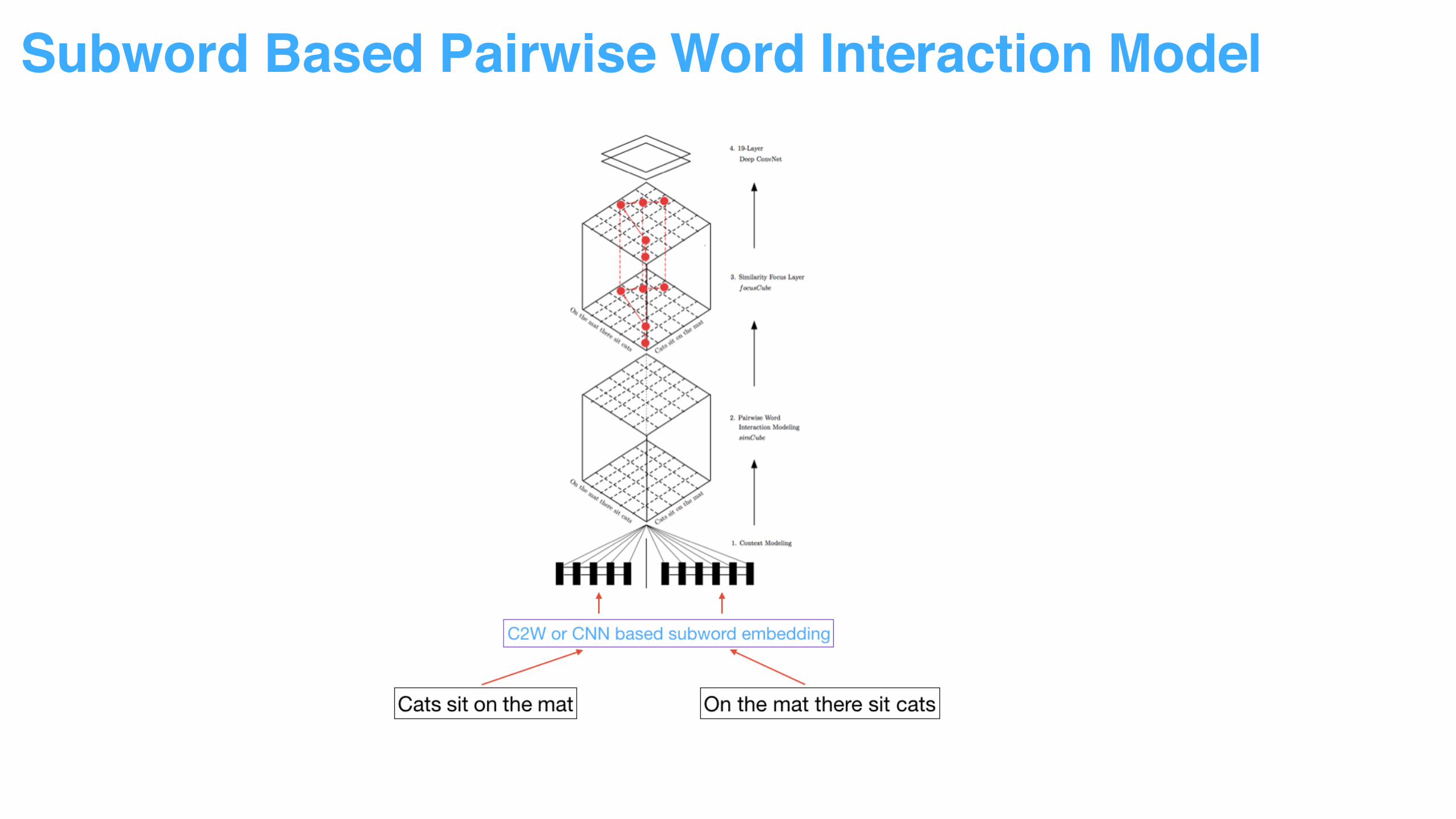
Subword Based Pairwise Word Interaction Model

Word Embedding v.s. Subword Embedding
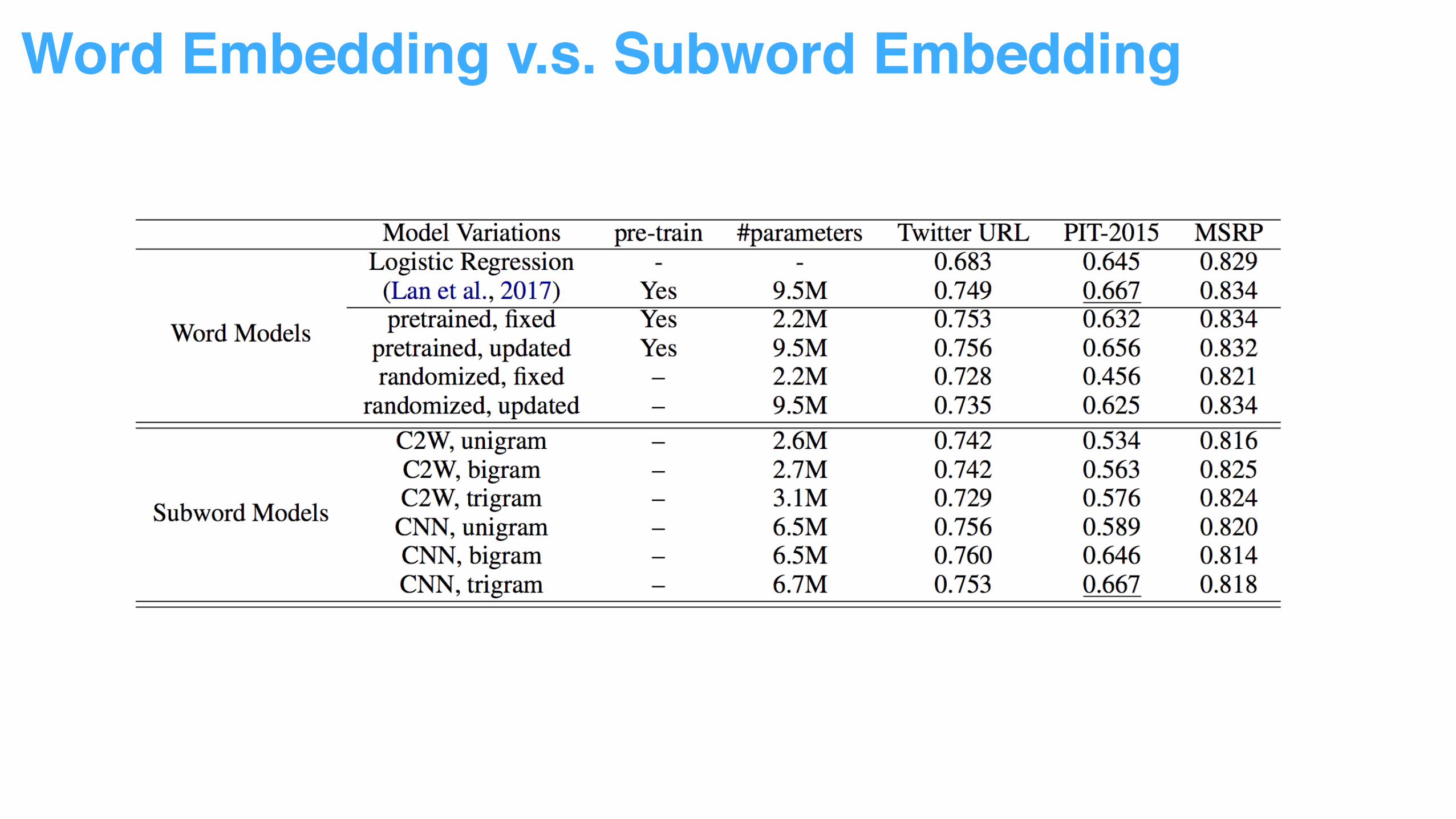
Word Embedding v.s. Subword Embedding

Multi-task Language Model
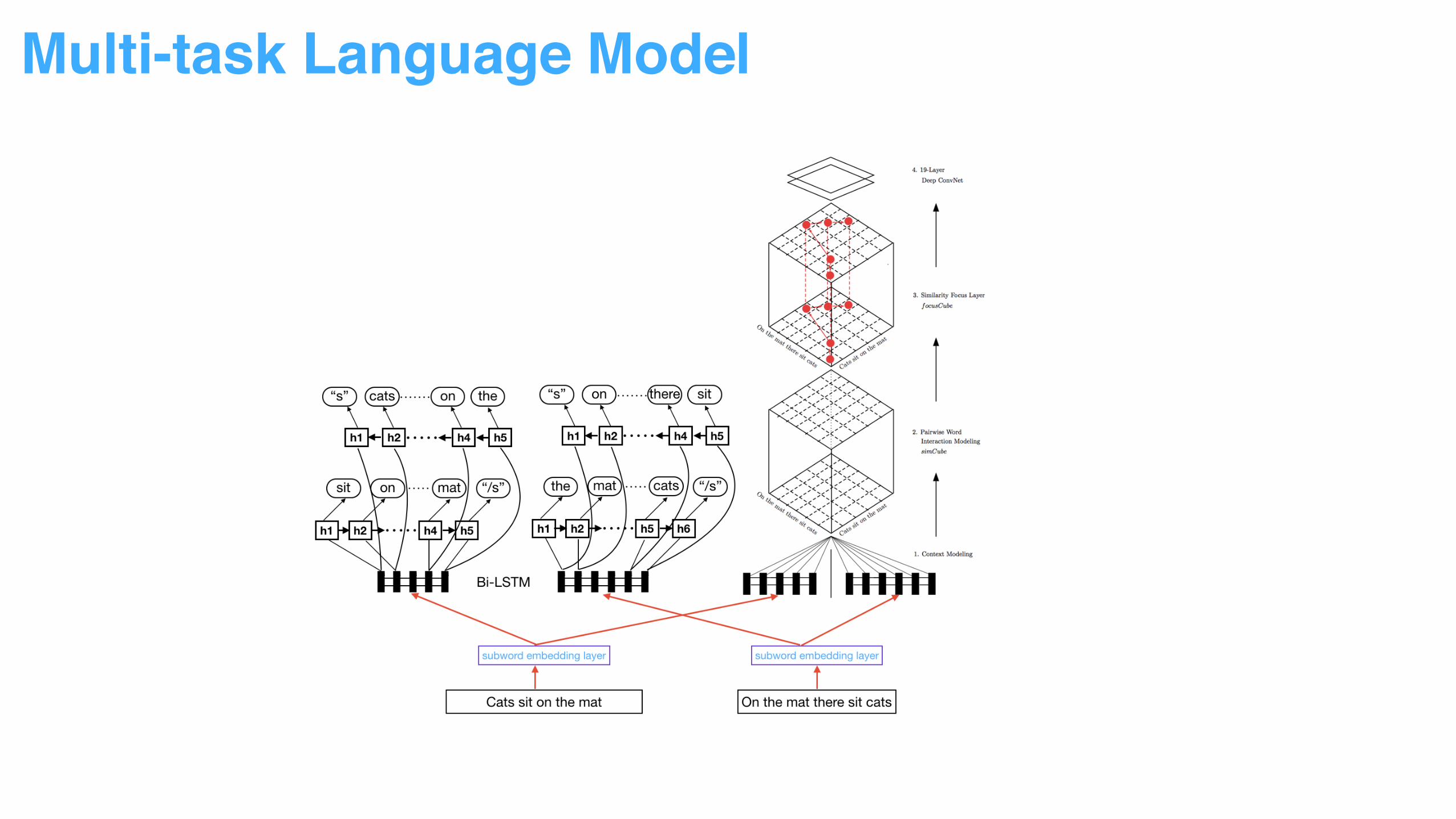
Multi-task Language Model
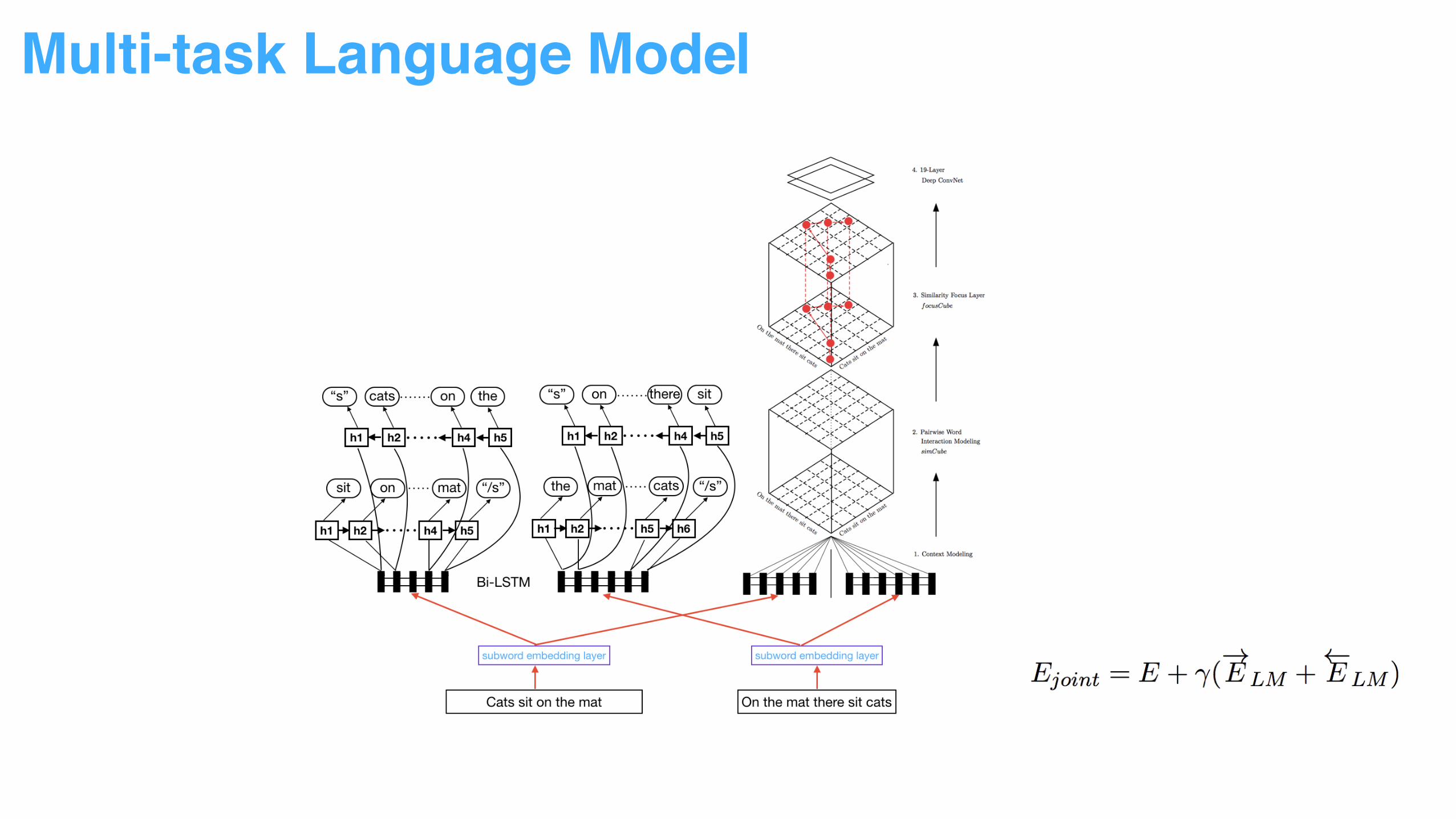
Multi-task Language Model

New State-of-the-art with Multi-task Language Model
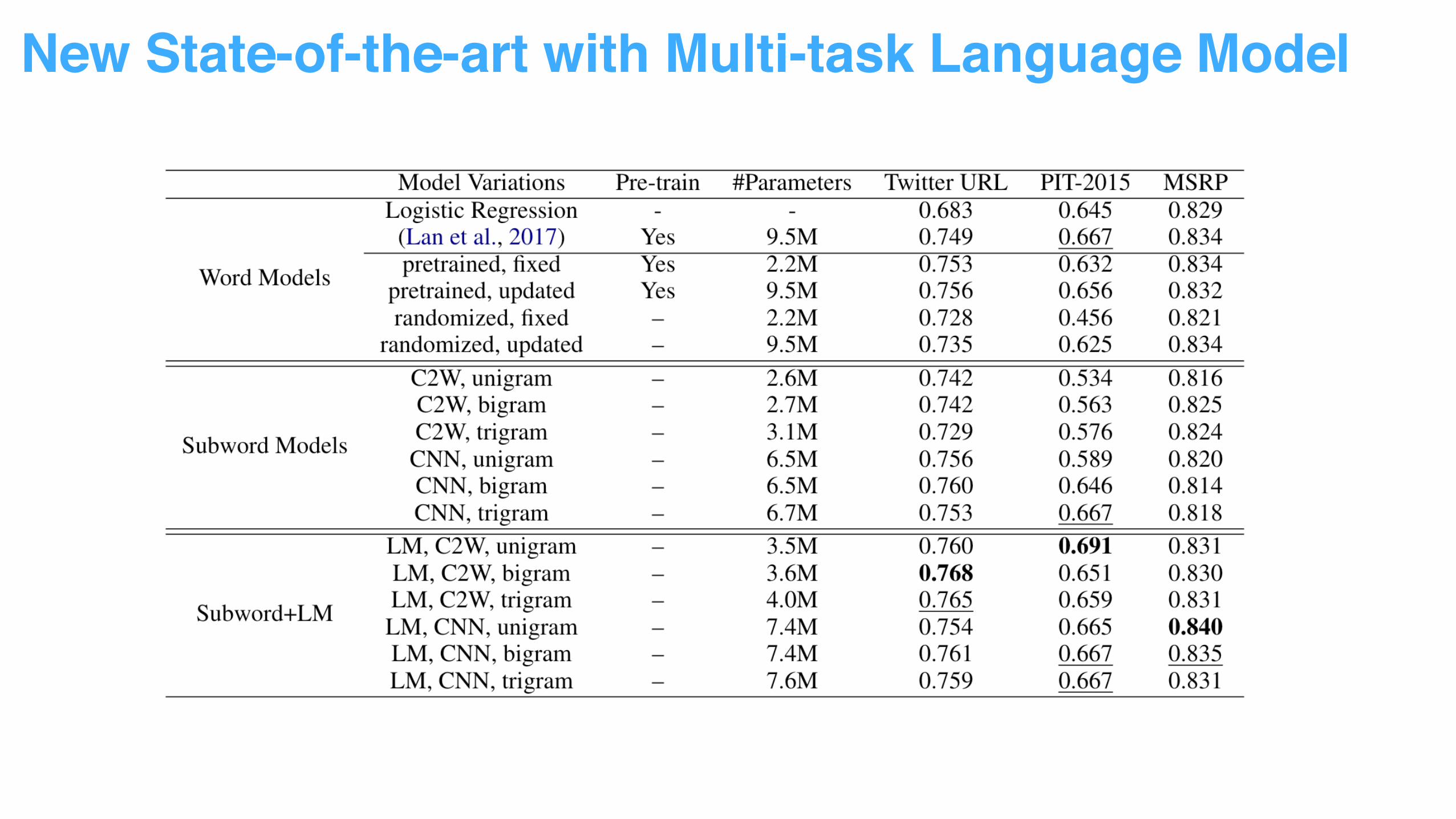
New State-of-the-art with Multi-task Language Model

Takeaways
• Simple but effective paraphrase collection method
• Largest annotated paraphrase corpora to date
• Continuously growing, providing up-to-date data
• Subword embedding for paraphrase identification
• Data and Code: https://github.com/lanwuwei/paraphrase-dataset

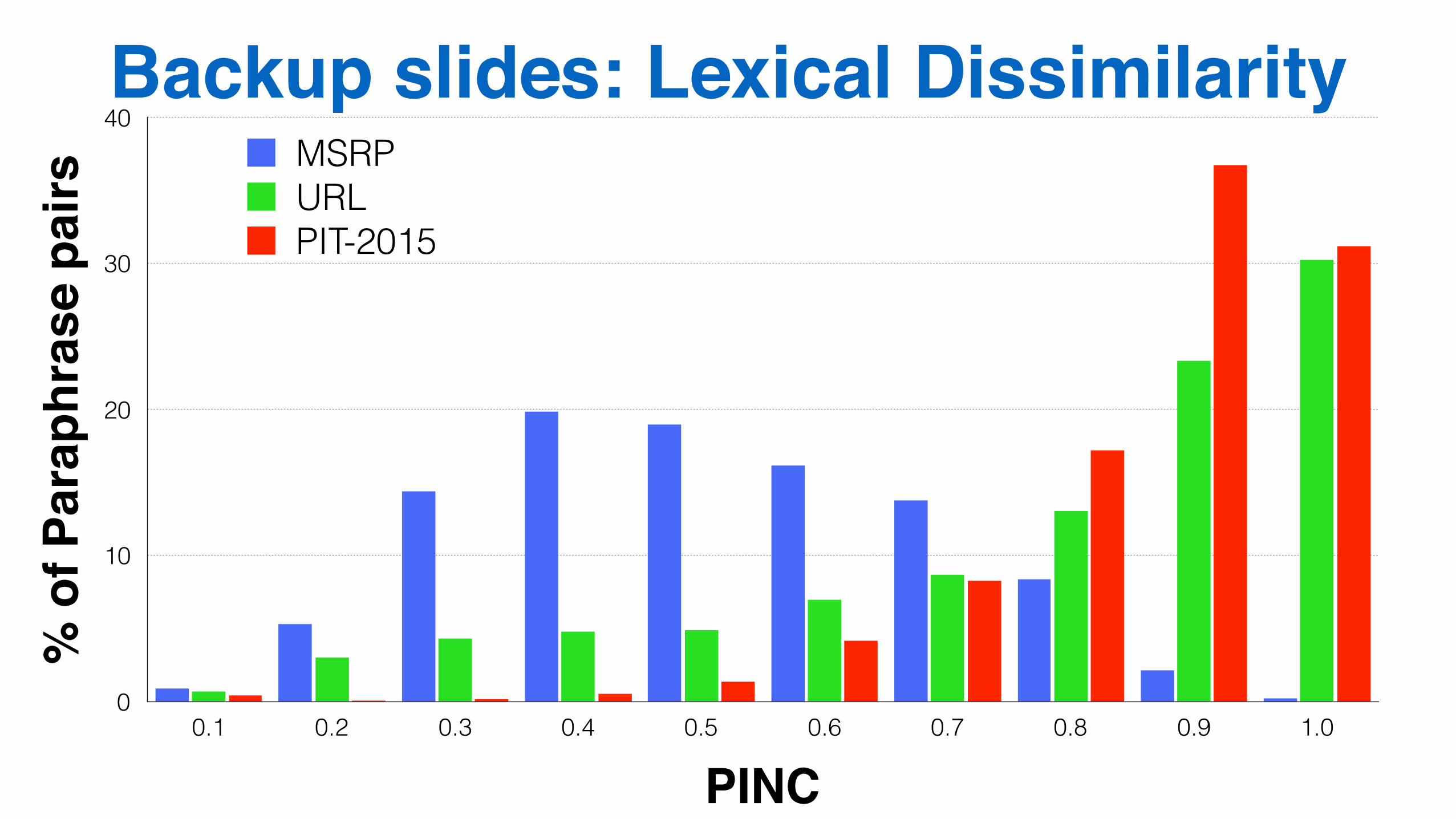
Backup slides: Lexical Dissimilarity%
of P
arap
hras
e pa
irs
0
10
20
30
40
PINC0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
MSRPURLPIT-2015


















