
Auto encoding-variational-bayes
17
Transcript of Auto encoding-variational-bayes

Auto-encoding variational Bayes
Diederik P Kingma1 Max Welling2
Presented by : Mehdi Cherti (LAL/CNRS)
9th May 2015
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

Diederik P Kingma, Max Welling Auto-encoding variational Bayes

What is a generative model ?
A model of how the data X was generated
Typically, the purpose is to �nd a model for : p(x) or p(x , y)
y can be a set of latent (hidden) variables or a set of outputvariables, for discriminative problems
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

Training generative models
Typically, we assume a parametric form of the probabilitydensity :
p(x |Θ)
Given an i.i.d dataset : X = (x1, x2, ..., xN), we typically do :
Maximum likelihood (ML) : argmaxΘp(X |Θ)Maximum a posteriori (MAP) : argmaxΘp(X |Θ)p(Θ)
Bayesian inference : p(Θ|X ) = p(x|Θ)p(Θ)´Θp(x|Θ)p(Θ)dΘ
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

The problem
let x be the observed variables
we assume a latent representation z
we de�ne pΘ(z) and pΘ(x |z)
We want to design a generative model where:
pΘ(x) =´pΘ(x |z)pΘ(z)dz is intractable
pΘ(z |x) = pΘ(x |z)pΘ(z)/pΘ(x) is intractable
we have large datasets : we want to avoid sampling basedtraining procedures (e.g MCMC)
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

The proposed solution
They propose:
a fast training procedure that estimates the parameters Θ: fordata generation
an approximation of the posterior pΘ(z |x) : for data
representation
an approximation of the marginal pΘ(x) : for model
evaluation and as a prior for other tasks
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

Formulation of the problem
the process of generation consists of sampling z from pΘ(z) then xfrom pΘ(x |z).Let's de�ne :
a prior over over the latent representation pΘ(z),
a �decoder� pΘ(x |z)
We want to maximize the log-likelihood of the data(x (1), x (2), ..., x (N)):
logpΘ(x (1), x (2), ..., x (N)) =∑i
logpΘ(xi )
and be able to do inference : pΘ(z |x)
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

The variational lower bound
We will learn an approximate of pΘ(z |x) : qΦ(z |x) bymaximizing a lower bound of the log-likelihood of the data
We can write :logpΘ(x) = DKL(qΦ(z |x)||pΘ(z |x)) + L(Θ, φ, x) where:
L(Θ,Φ, x) = EqΦ(z|x)[logpΘ(x , z)− logqφ(z |x)]
L(Θ,Φ, x)is called the variational lower bound, and the goal isto maximize it w.r.t to all the parameters (Θ,Φ)
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

Estimating the lower bound gradients
We need to compute ∂L(Θ,Φ,x)∂Θ , ∂L(Θ,Φ,x)
∂φ to apply gradientdescent
For that, we use the reparametrisation trick : we samplefrom a noise variable p(ε) and apply a determenistic functionto it so that we obtain correct samples from qφ(z |x), meaning:
if ε ∼ p(ε) we �nd g so that if z = g(x , φ, ε) then z ∼ qφ(z |x)g can be the inverse CDF of qΦ(z |x) if ε is uniform
With the reparametrisation trick we can rewrite L:
L(Θ,Φ, x) = Eε∼p(ε)[logpΘ(x , g(x , φ, ε))− logqφ(g(x , φ, ε)|x)]
We then estimate the gradients with Monte Carlo
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

A connection with auto-encoders
Note that L can also be written in this form:
L(Θ, φ, x) = −DKL(qΦ(z |x)||pΘ(z)) + EqΦ(z|x)[logpΘ(x |z)]
We can interpret the �rst term as a regularizer : it forcesqΦ(z |x) to not be too divergent from the prior pΘ(z)
We can interpret the (-second term) as the reconstructionerror
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

The algorithm
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

Variational auto-encoders
It is a model example which uses the procedure describedabove to maximize the lower bound
In V.A, we choose:
pΘ(z) = N(0, I)pΘ(x |z) :
is normal distribution for real data, we have neural network
decoder that computes µand σ of this distribution from z
is multivariate bernoulli for boolean data, we have neural
network decoder that computes the probability of 1 from z
qΦ(z |x) = N(µ(x), σ(x)I) : we have a neural networkencoder that computes µand σ of qΦ(z |x) from x
ε ∼ N(0, I) and z = g(x , φ, ε) = µ(x) + σ(x) ∗ ε
Diederik P Kingma, Max Welling Auto-encoding variational Bayes
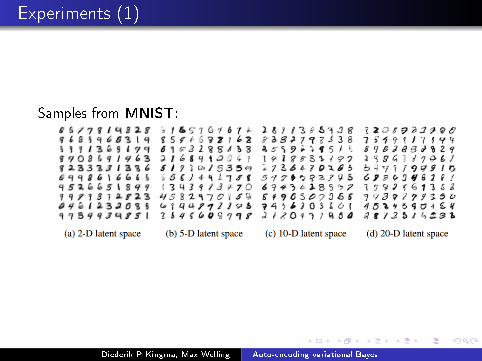
Experiments (1)
Samples from MNIST:
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

Experiments (2)
2D-Latent space manifolds from MNIST and Frey datasets
Diederik P Kingma, Max Welling Auto-encoding variational Bayes
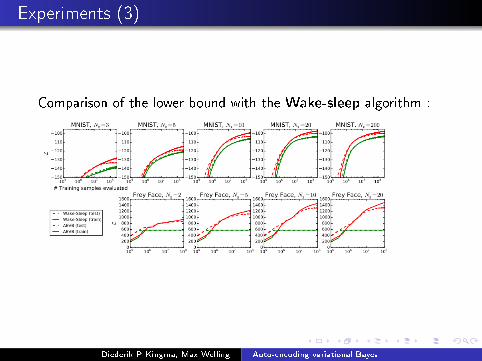
Experiments (3)
Comparison of the lower bound with the Wake-sleep algorithm :
Diederik P Kingma, Max Welling Auto-encoding variational Bayes
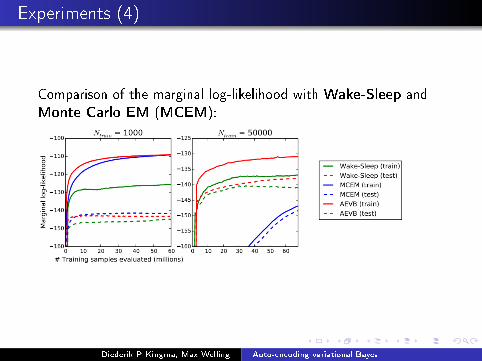
Experiments (4)
Comparison of the marginal log-likelihood with Wake-Sleep andMonte Carlo EM (MCEM):
Diederik P Kingma, Max Welling Auto-encoding variational Bayes

Implementation : https://github.com/mehdidc/lasagnekit
Diederik P Kingma, Max Welling Auto-encoding variational Bayes












![Extracting Interpretable Physical Parameters from Partial ...phys2018.csail.mit.edu/papers/57.pdf · [7] Diederik P Kingma and Max Welling. Auto-Encoding Variational Bayes, 2013.](https://static.fdocuments.in/doc/165x107/5ed408d78d46b66d226352b6/extracting-interpretable-physical-parameters-from-partial-7-diederik-p-kingma.jpg)

![The Thermodynamic Variational Objective · Auto-encoding variational Bayes. In International Conference on Learning Representations, 2014. [8] Danilo Jimenez Rezende, Shakir Mohamed,](https://static.fdocuments.in/doc/165x107/5ed408d88d46b66d226352b8/the-thermodynamic-variational-objective-auto-encoding-variational-bayes-in-international.jpg)



