
August 30, 2007 RC Device Characterizations & Tradeoff Analysis Jason Williams.
36
August 30, 2007 RC Device RC Device Characterizations & Characterizations & Tradeoff Analysis Tradeoff Analysis Jason Williams
-
Upload
gervase-woods -
Category
Documents
-
view
213 -
download
0
Transcript of August 30, 2007 RC Device Characterizations & Tradeoff Analysis Jason Williams.

August 30, 2007
RC Device RC Device Characterizations & Characterizations & Tradeoff AnalysisTradeoff Analysis
Jason Williams

2
Introduction Reconfigurable Computing
(RC) is an emerging field that utilizes devices with a programmable fabric allowing the hardware to be configured and adapted to solve changing problems
RC systems have typically been built using Field Programmable Gate Arrays (FPGAs) but there are other architectures that could implement RC systems such as Field Programmable Object Arrays (FPOAs) and Field Programmable Compute Arrays (FPCA, e.g. MONARCH)

3
Subject & Purpose Subject
To survey the landscape of various RC devices Characterize these devices using various metrics
(performance, price, power) Create a comparison framework using the
characterizations Purpose
Will give the end user a quantitative framework to aid in the selection of an appropriate RC device to meet their application needs
Lays groundwork for understanding performance impacts of architectural components

4
Problem Definition
RC devices differ from traditional microprocessors Typically slower clock rates Potential for massive parallelism Different power consumption trends Different on-die memory configurations
All of these differences make direct device comparisons difficult
Problems RC devices can be vastly different from one
another Various architectural differences and very few
standard/common parameters Memory Example: Xilinx BRAM vs. Altera M-
RAM/M4K/M512 vs. FPOA RF/IRAM vs. CPU cache

5
Problem Background Users have a variety of requirements/concerns –
What key parameters do we need to compare? Computational performance (integer/fixed point, floating
point, fine grained/bit level) On-chip memory performance (latency, bandwidth) Off-chip communications and I/O Power consumption Price

6
Scope Statement Devices to be included in study
Xilinx Virtex 4 LX200, LX100, SX55 Altera Stratix II S180 Freescale PowerPC MPC7447 +
AltiVec MathStar Arrix FPOA (1 GHz) Raytheon Monarch PCA Sony/Toshiba/IBM Cell

7
Methods Literature review
Apply and extend characterizations and metrics to devices under study
Datasheet analysis Experiments using vendor development
tools/simulation environments Example: Utilization and timing analysis results from
post place and route for common ALU/FP structures Combine characterization study results into a QFD
style matrix

8
FPGA Theoretical Floating Point Performance
Methodology Adapted from Jeff Mason’s (Xilinx) presentation at RSSI
’07 “FPGA HPC – The road beyond processors” with input from Dave Strenski (Cray). Similar methodology also reported in An overview of FPGAs and FPGA programming; Initial experiences at Daresbury, Richard Wain, Ian Bush, Martyn Guest, Miles Deegan, Igor Kozin and Christine Kitchen. November 2006. Distributed Computing Group at Daresbury Laboratory.
Using datasheet information, Altera and Xilinx Floating Point cores, ISE and Quartus, estimate FP add and FP multiply performance.

9
FPGA Floating Point Performance Xilinx Example
Data from Virtex 4 Family Overview (DS112) and Coregen Floating Point Operator v3.0 (DS335)
Assumptions: 15% slice overhead (routing, I/O, etc.) Use DSP resources first, then logic only implementation to fill
device. Use lower of the two clock speeds for all calculations (DSP vs.
Logic only). Assume 2 storage elements (BRAM) per operation (operands,
overwrite with result). Limit the number of operations if there is not enough BRAM to support.
Use speed optimized, highest effort for Synthesis, Map, PAR.

10
FPGA Floating Point Performance Xilinx Example Continued (LX200 –10)
Double Precision Floating Point Multiply
96 / 16 = 6 DSP Multipliers 151449 – (774 * 6) = 146805 remaining LUT for Logic Multipliers 146805 / 2457 = ~59 Logic Only Multipliers 65 total multipliers in 1 context @ 185 MHz = ~12 Gflop/s Limit total number of multipliers to 85 due to BRAM limitation = ~11.1 Gflop/s LX100 has 336 18Kb dual port BRAM. For 64-bit (DP), ((336 * 2) / 4) / 2 = 85 function units
Per Instance DSP Implementation Logic Only Implementation
Device Maximum (less 15% LUT for overhead)
Max Frequency (MHz) 303 185 500
DSPs Used 16 0 96
LUTs Used 550 2311 178176 (151449)
FF Used 774 2457 178176 (151449)

11
Theoretical Floating Point Performance
Methodology FPOA floating point performance is reported as 0. This
device could have a floating point core designed for it, but its architecture (16 bit ALUs) would not implement FP efficiently.
PowerPC, AltiVec, MONARCH, and Cell floating point performance numbers are available/derivable from their respective datasheets

12
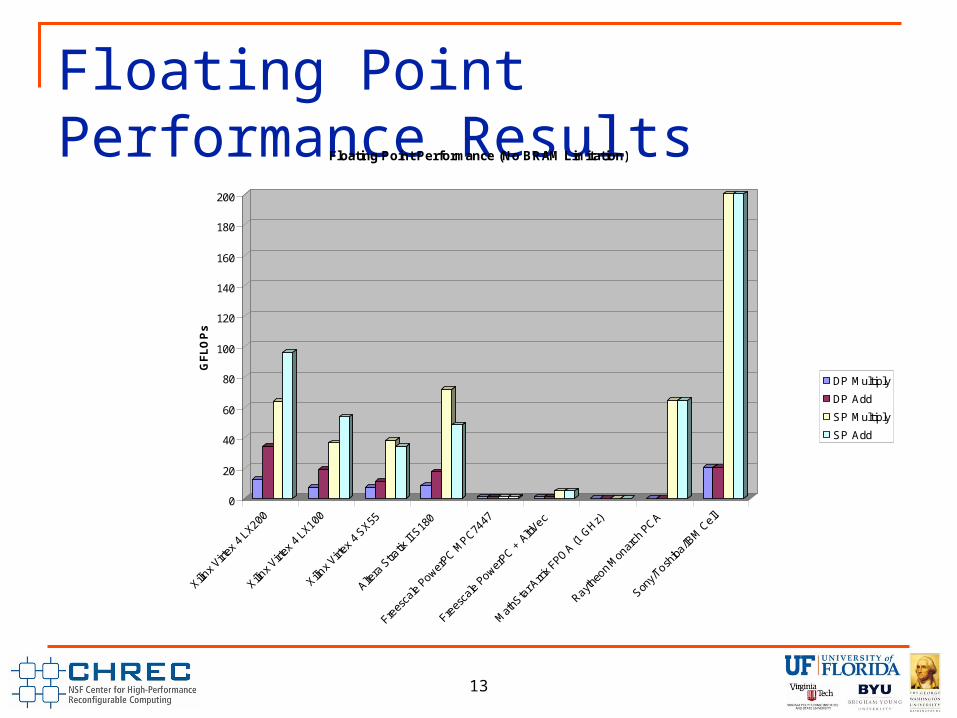
Floating Point Performance Results
0
20
40
60
80
100
120
140
160
180
200G
FL
OP
s
Xilinx V
irtex
4 L
X200
Xilinx V
irtex
4 L
X100
Xilinx V
irtex
4 S
X55
Altera
Stra
tix II
S180
Frees
cale
PowerPC M
PC7447
Frees
cale
PowerPC +
AltiV
ec
Mat
hSta
r Arri
x FPO
A (1 G
Hz)
Raytheo
n Mon
arch
PCA
Sony/T
oshiba
/IBM C
ell
Floating Point Performance (BRAM Limitation)
DP Multiply
DP Add
SP Multiply
SP Add
13
Floating Point Performance Results
0
20
40
60
80
100
120
140
160
180
200G
FL
OP
s
Xilinx V
irtex
4 L
X200
Xilinx V
irtex
4 L
X100
Xilinx V
irtex
4 S
X55
Altera
Stra
tix II
S180
Frees
cale
PowerPC M
PC7447
Frees
cale
PowerPC +
AltiV
ec
Mat
hSta
r Arri
x FPO
A (1 G
Hz)
Raytheo
n Mon
arch
PCA
Sony/T
oshiba
/IBM C
ell
Floating Point Performance (No BRAM Limitation)
DP Multiply
DP Add
SP Multiply
SP Add

14
Floating Point Performance Results
Device DP Multiply DP Add SP Multiply SP AddXilinx Virtex 4 LX200 12.025 24.14 46.032 61.824Xilinx Virtex 4 LX100 7.03 17.04 32.88 44.16Xilinx Virtex 4 SX55 7.03 11.016 38.36 33.998Altera Stratix II S180 8.14 17.304 71.68 48.334Freescale PowerPC MPC7447 1 1 1 1Freescale PowerPC + AltiVec 1 1 5 5MathStar Arrix FPOA (1 GHz) 0 0 0 0Raytheon Monarch PCA 0 0 64 64Sony/Toshiba/IBM Cell 20 20 200 200
Device DP Multiply DP Add SP Multiply SP AddXilinx Virtex 4 LX200 12.025 34.08 63.568 95.68Xilinx Virtex 4 LX100 7.03 18.744 36.716 53.36Xilinx Virtex 4 SX55 7.03 11.016 38.36 33.998Altera Stratix II S180 8.14 17.304 71.68 48.334Freescale PowerPC MPC7447 1 1 1 1Freescale PowerPC + AltiVec 1 1 5 5MathStar Arrix FPOA (1 GHz) 0 0 0 0Raytheon Monarch PCA 0 0 64 64Sony/Toshiba/IBM Cell 20 20 200 200
Theoretical Floating Point Performance (GFlops, BRAM Limitation)
Theoretical Floating Point Performance (GFlops, No BRAM Limitation)

15
Floating Point Conclusions For FPGAs, floating point performance dependent on FP
core implementation. This impacts resource utilization and maximum achievable frequency.
For Xilinx devices, available on-chip memory also greatly impacts performance if we assume there has to be enough on-chip memory to buffer operands and results. Stratix II S180 has more on chip RAM (1.5x V4LX200) and a more flexible memory hierarchy (a larger number of smaller blocks to support more individual registers, higher device memory bandwidth) and does not have this issue.
Xilinx adder cores can use on-chip DSP resources, Altera adder cores do not.
MONARCH only supports single precision floating point. Cell is the clear leader in theoretical floating point
performance (using all processing elements).

16
Theoretical Integer Performance Utilize same basic methodology as
Floating Point Performance Comparison 15% slice overhead (routing, I/O, etc.). Use DSP resources first, then logic only
implementation to fill device. Use lower of the two clock speeds for all calculations
(DSP vs. Logic only). Use vendor software (Quartus, ISE) to find resource utilization for 1 functional unit.
Calculate the number of parallel functional units that fit in 1 context using datasheet values.
Assume 2 storage elements (BRAM) per functional unit (operands, overwrite with result). Limit the number of parallel functional units if there is not enough BRAM to support 2 storage elements per functional unit.
Use speed optimized, highest effort for Synthesis, Map, PAR.
Use standard integer widths (32 bit and 16 bit). Analyze Addition and Multiplication operations separately.

17
Theoretical Integer Performance Methodology
FPOA 32 bit integer performance is reported as 0. This device could have a 32 bit ALU core designed for it, but it is natively a 16 bit device.
PowerPC, AltiVec, MONARCH, and Cell integer performance numbers are available/derivable from their respective datasheets

18
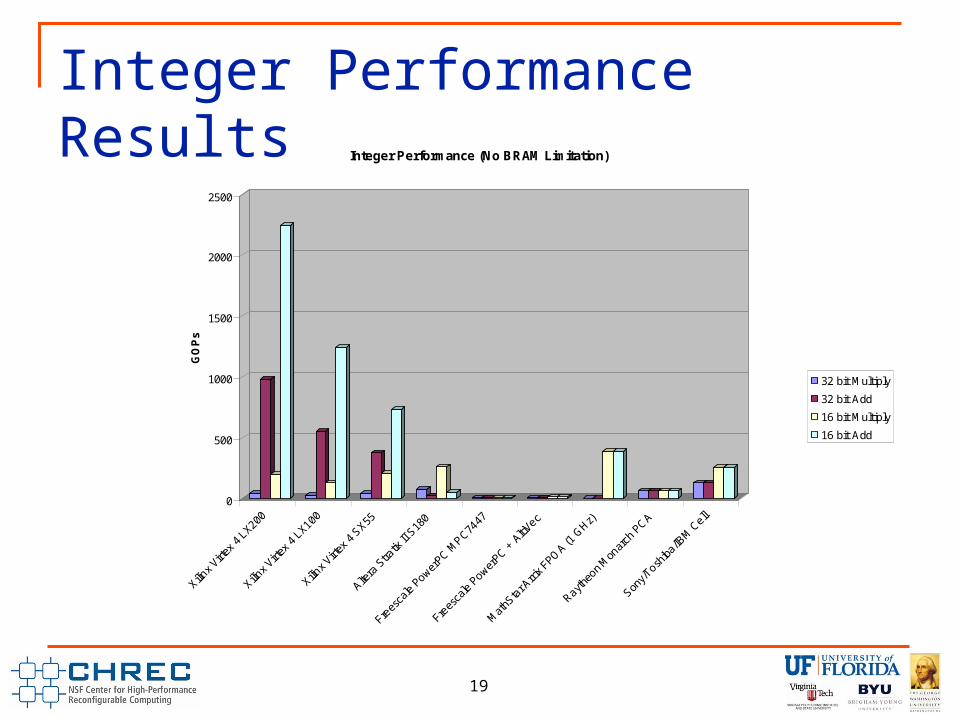
Integer Performance Results
0
50
100
150
200
250
300
350
400G
OP
s
Xilinx V
irtex
4 L
X200
Xilinx V
irtex
4 L
X100
Xilinx V
irtex
4 S
X55
Altera
Stra
tix II
S180
Frees
cale
PowerPC M
PC7447
Frees
cale
PowerPC +
AltiV
ec
Mat
hSta
r Arri
x FPO
A (1 G
Hz)
Raytheo
n Mon
arch
PCA
Sony/T
oshiba
/IBM C
ell
Integer Performance (BRAM Limitation)
32 bit Multiply
32 bit Add
16 bit Multiply
16 bit Add
19
Integer Performance Results
0
500
1000
1500
2000
2500G
OP
s
Xilinx V
irtex
4 L
X200
Xilinx V
irtex
4 L
X100
Xilinx V
irtex
4 S
X55
Altera
Stra
tix II
S180
Frees
cale
PowerPC M
PC7447
Frees
cale
PowerPC +
AltiV
ec
Mat
hSta
r Arri
x FPO
A (1 G
Hz)
Raytheo
n Mon
arch
PCA
Sony/T
oshiba
/IBM C
ell
Integer Performance (No BRAM Limitation)
32 bit Multiply
32 bit Add
16 bit Multiply
16 bit Add

20
Integer Performance ResultsDevice 32 bit Multiply 32 bit Add 16 bit Multiply 16 bit AddXilinx Virtex 4 LX200 37.848 979.736 198.144 2243.04Xilinx Virtex 4 LX100 23.406 549.608 122.464 1238.88Xilinx Virtex 4 SX55 38.346 371.624 201.928 733.92Altera Stratix II S180 74.5 17.304 257.07 48.334Freescale PowerPC MPC7447 3 3 3 3Freescale PowerPC + AltiVec 7 7 11 11MathStar Arrix FPOA (1 GHz) 0 0 384 384Raytheon Monarch PCA 64 64 64 64Sony/Toshiba/IBM Cell 125 125 250 250
Device 32 bit Multiply 32 bit Add 16 bit Multiply 16 bit AddXilinx Virtex 4 LX200 37.848 69.216 115.584 161.28Xilinx Virtex 4 LX100 23.406 49.44 82.56 115.2Xilinx Virtex 4 SX55 38.346 65.92 110.08 153.6Altera Stratix II S180 74.5 17.304 257.07 48.334Freescale PowerPC MPC7447 3 3 3 3Freescale PowerPC + AltiVec 7 7 11 11MathStar Arrix FPOA (1 GHz) 0 0 384 384Raytheon Monarch PCA 64 64 64 64Sony/Toshiba/IBM Cell 125 125 250 250
Theoretical Integer Performance (GOPs, BRAM Limitation)
Theoretical Integer Performance (GOPs, No BRAM Limitation)

21
Integer Performance Conclusions In some cases, BRAM limitation is again an important performance limiter for
Xilinx devices. Stratix II S180 has more on chip RAM (1.5x V4LX200) and a more flexible memory hierarchy (a larger number of smaller blocks to support more individual registers, higher device memory bandwidth) and does not .
Quartus II 6.0 typically reports higher maximum achievable frequency for post place and route timing analysis versus ISE 9.2. Used speed grade –10 for Virtex 4 devices. Used speed grade –3 for Stratix II device. 32 bit multiply example: Quartus reports 500 MHz for both DSP and Logic Only
implementations, ISE reports 421 MHz for DSP, 249 MHz for Logic Only. Xilinx adder cores can use on-chip DSP resources, which could improve add
performance if there was enough memory support. Altera adder cores do not support DSP utilization and therefore suffer a performance hit compared to Xilinx devices.
Without the BRAM limitation, Xilinx devices show the highest performance for Integer Add operations.
With the BRAM limitation, the FPOA has the highest 16 bit integer performance.
Cell has the highest 32 bit integer performance (using all processing elements).

22
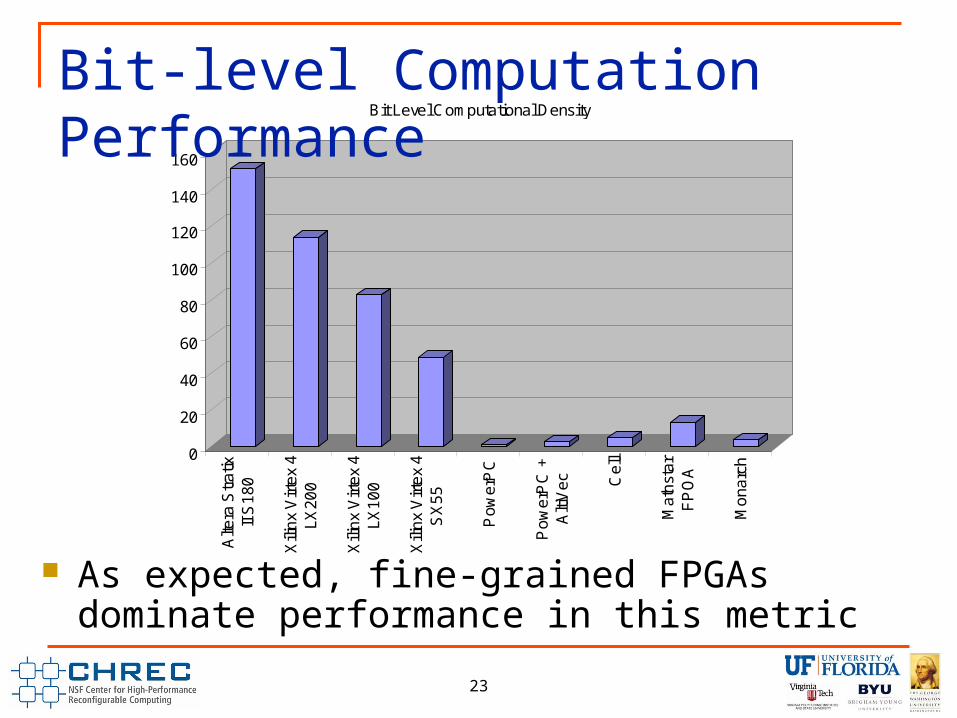
Bit-level Computational Performance Methodology
Based off of Dehon’s Computational Density calculations Computational Density
Normalizes performance by die (or package) area and minimum feature size/process technology
Bit operations for FPGAs are number of 4 input LUTs Bit operations for GPP and other “hybrid” devices based
on number of cores, number of issued instructions, and width of ALU/Functional Units
2
area Diefrequency/cycleoperationsbit ALU
23
0
20
40
60
80
100
120
140
160
Alte
ra S
tra
tixII
S1
80
Xili
nx
Vir
tex
4L
X2
00
Xili
nx
Vir
tex
4L
X1
00
Xili
nx
Vir
tex
4S
X5
5
Po
we
rPC
Po
we
rPC
+A
ltiV
ec Ce
ll
Ma
thst
ar
FP
OA
Mo
na
rch
Bit Level Computational Density
As expected, fine-grained FPGAs dominate performance in this metric
Bit-level Computation Performance

24
External Memory Bandwidth Methodology
Methodology varies by platform due to available information and architecture differences.
In all cases, choose maximum throughput available based on vendor IP for memory controllers.
Saturated Case uses maximum amount of I/O for external memory interface, Balanced Case assumes a balance of I/O and memory interface.
Altera Stratix II Influenced by speed grade, number of I/O Used new high performance ALTMEMPHY core (vs. legacy memory
interface core) Support for 333 MHz DDR2 RAM Number of controllers limited by the number of on-chip delay-locked loops
(2)

25
External Memory Bandwidth Methodology Xilinx Virtex 4
Influenced by speed grade, number of I/O Memory Interface Generator v1.73 (Coregen) forces use of slower “Direct
Clocking” to support multiple banks vs. SERDES strobe implementation, for -10 speed grade maximum frequency is 220 – 240 MHz (depending on bus width)
Mathstar FPOA Datasheet information for total external memory interface bandwidth
(RLDRAM II) Cell
External Memory Bandwidth (Rambus XDRAM) reported in presentation “Introduction to the Cell Processor” from Dr. Michael Perrone (IBM)
MONARCH External Memory Bandwidth (DDR2) reported in presentation “World’s First
Polymorphic Computer – MONARCH” from K. Prager, L. Lewis, M. Vahey, G. Groves (Raytheon)

26
External Memory Bandwidth Results
0
5
10
15
20
25
GB/s
Stratix IIS180
Virtex 4LX200
Virtex 4LX100
Virtex 4SX55
Cell FPOA MONARCH
External Memory Bandwidth
Saturated
Balanced

27
External Memory Bandwidth Conclusions External Memory Bandwidth important to prevent data bottleneck into
the device. For FPGAs, the type and speed of external memory supported
depends on the family and speed grade of the device. In this study, non-FPGA devices have separate I/O and memory
controllers/interfaces, so there is not a distinction between saturated and balanced.
Stratix II S180 and Virtex 4 SX55 configurations support 2 simultaneous controllers, Virtex 4 LX100 and LX200 support 3 simultaneous controllers which is shown in the performance difference for the saturated case.
Although Stratix II controller supports faster DDR2 RAM (333 MHz vs. 220 MHz in this configuration), Virtex 4 SX55 has higher bandwidth due to support for a wider bus.
Xilinx claims higher bandwidth on website, assumes wider bus than existing memories.
For the balanced case, Cell is the performance leader, primarily due to specialized RAM format (XDRAM).

28
I/O Bandwidth Methodology Methodology varies by platform due to available information and
architecture differences. In all cases, choose maximum throughput available protocol/signaling
level. Saturated Case uses maximum amount of I/O for I/O interface,
Balanced Case assumes a balance of I/O and 1 memory interface. Altera Stratix II
Datasheet information for concurrent receive pairs and transmit pairs @ 1.040 Gb/s per pair.
Xilinx Virtex 4 Datasheet information for concurrent receive pairs and transmit pairs @ 1
Gb/s per pair. Mathstar FPOA
Datasheet information for concurrent total transmit and receive bandwidth.

29
I/O Bandwidth Methodology Cell
I/O Bandwidth reported in presentation “Introduction to the Cell Processor” from Dr. Michael Perrone (IBM)
MONARCH I/O Bandwidth reported in presentation “World’s First
Polymorphic Computer – MONARCH” from K. Prager, L. Lewis, M. Vahey, G. Groves (Raytheon)

30
I/O Bandwidth Results
0
10
20
30
40
50
60
70
80
GB/s
Altera Stratix II S180 Xilinx Virtex 4 SX55 Xilinx Virtex 4 LX100 Xilinx Virtex 4 LX200 Cell Mathstar FPOA MONARCH
I/O Bandwidth
Saturated
Balanced

31
I/O Bandwidth Conclusions I/O Bandwidth is important to prevent I/O and data
bottleneck. In this study, non-FPGA devices have separate I/O and
memory controllers/interfaces, so there is not a distinction between saturated and balanced.
All devices except for FPOA have at least 40 GB/s throughput.
FPGAs are shown in both fully utilized and balanced cases. Stratix II uses separate I/O for single ended memory
interface and differential pairs so there is no distinction between saturated and balanced cases.
Cell has the highest I/O performance for both cases.

32
Internal Device Memory Bandwidth Methodology
FPGAs Xilinx – all BRAMs are the same,
calculation = number of BRAMS * port width * number of ports * memory access frequency
Altera – 3 levels of internal memory hierarchy, calculation similar to above for all levels of hierarchy
FPOA – similar to above with 2 levels of memory hierarchy (Register File and Internal RAM)
GPP – bus width * frequency * ports

33
0
500
1000
1500
2000
2500
3000G
B/s
Alte
ra S
tra
tixII
S1
80
Xili
nx
Vir
tex
4 L
X2
00
Xili
nx
Vir
tex
4 L
X1
00
Xili
nx
Vir
tex
4 S
X5
5
Po
we
rPC
Po
we
rPC
+A
ltiV
ec Ce
ll
Ma
thst
ar
FP
OA
Mo
na
rch
Internal Memory Bandwidth
Internal Memory Bandwidth
Large amount of parallel accesses give FPGAs the advantage in this metric

3434
Device Characterization Matrix Goal: enable comparison of
different devices on key parameters Tie all device characterizations into
unifying framework User weights allow adjustment to
specific application needs Scores quickly show comparison
results based on input weights Approach:
Scale each characterization study from 1 to 10
Generate weighted average score for each device taking into account user weights
Justification Significant architectural differences
have historically made these devices difficult to compare
DeviceSP FP Multiply Throughput (GFlops)
Scaled SP FP Multiply Performance
Altera Stratix II S180 71.68 4Xilinx Virtex 4 LX200 46.03 3Xilinx Virtex 4 LX100 32.88 2Xilinx Virtex 4 SX55 38.36 3PowerPC 1 1PowerPC + AltiVec 5 1Cell 200 10Monarch 64 4
min 1 1max 200 10
}10 ,1{
)}(max ),(min{
)(*)(
maxmin
1max
1min
minmax
minmaxminmin
scalescale
andxxxxwhere
scalescale
xxxxscalezationCharacteri
j
N
jj
N
j
ii
Single-Precision Floating-Point scaling example Use min and max values to scale
from 1 to 10

3535
Device Characterization Matrix
weightnegative-non a is w
*
1
1
where
w
zationcharacteriwScore N
i i
i
N
i i
Sin
gle
-Pre
cisi
on
Flo
atin
g-P
oin
t A
dd
Co
mp
uta
tio
nal
P
erfo
rman
ce
Sin
gle
-Pre
cisi
on
Flo
atin
g-P
oin
t M
ult
iply
Co
mp
uta
tio
nal
P
erfo
rman
ce
Do
ub
le-P
reci
sio
n F
loat
ing
-Po
int
Ad
d C
om
pu
tati
on
al
Per
form
ance
Do
ub
le-P
reci
sio
n F
loat
ing
-Po
int
Mu
ltip
ly C
om
pu
tati
on
al
Per
form
ance
32-b
it I
nte
ger
Ad
d
Co
mp
uta
tio
nal
Per
form
ance
32-b
it I
nte
ger
Mu
ltip
ly
Co
mp
uta
tio
nal
Per
form
ance
16-b
it I
nte
ger
Ad
d
Co
mp
uta
tio
nal
Per
form
ance
16-b
it I
nte
ger
Mu
ltip
ly
Co
mp
uta
tio
nal
Per
form
ance
Bit
-Lev
el C
om
pu
tati
on
al
Den
sity
Inte
rnal
Mem
ory
Ban
dw
idth
Ext
ern
al M
emo
ry B
and
wid
th
I/O
Ban
dw
idth
Po
wer
Co
nsu
mp
tio
n
User Weight 10 10 10 10 10 10 10 10 10 10 10 10 10PPC 1 1 1 1 1 1 1 1 1 1 1 1 10AltiVec 1 1 1 1 1 2 1 1 1 1 1 1 10Xilinx Virtex-4 LX100 3 3 6 4 6 3 6 4 6 4 3 6 8Xilinx Virtex-4 SX55 2 3 4 4 4 4 4 6 4 5 3 4 8Xilinx Virtex-4 LX200 5 4 10 6 10 4 10 6 8 6 3 6 8Altera Stratix-II S180 3 4 6 5 8 6 6 7 10 10 3 6 8Cell 10 10 6 10 2 10 2 7 1 3 10 10 1Mathstar FPOA 0 0 0 0 0 0 3 10 2 3 2 2 7MONARCH 4 4 1 1 2 6 1 2 1 1 4 6 6
Examples with other weights: A. Power & cost (10), internal & external
memory BW (5), 16-bit integer performance (7): FPOA & V4SX55 lead
B. DP FP performance (5), power (10) Stratix-II S180 and V4LX200 lead
C. External & I/O BW (10), power (10), cost (10) MONARCH and Cell lead
Examples with other weights: A. Power & cost (10), internal & external
memory BW (5), 16-bit integer performance (7): FPOA & V4SX55 lead
B. DP FP performance (5), power (10) Stratix-II S180 and V4LX200 lead
C. External & I/O BW (10), power (10), cost (10) MONARCH and Cell lead

36
References DeHon, A. The Density Advantage of Configurable Computing. Computer , vol.33, no.4, pp.41-49, Apr 2000. DeHon, A. Reconfigurable Architectures for General-Purpose Computing. A.I. Technical Report No. 1586, Massachusetts Institute of
Technology, 1996. Compton, K. and Hauck, S. Reconfigurable computing: a survey of systems and software. ACM Comput. Surv. 34, 2 (Jun. 2002), 171-210. Memory Bandwidth, http://en.wikipedia.org/wiki/Memory_bandwidth. Mason, J. FPGA HPC – The road beyond processors, Xilinx Corporation. RSSI 2007. Wain, R., Bush, I., Guest, M., Deegan, M., Kozin, I. and Kitchen, C. An overview of FPGAs and FPGA programming; Initial experiences at
Daresbury,. November 2006. Distributed Computing Group at Daresbury Laboratory. Bolsens, I. Programming Modern FPGAs. Xilinx Corporation. MPSOC August, 2006. Underwood, K. 2004. FPGAs vs. CPUs: trends in peak floating-point performance. In Proceedings of the 2004 ACM/SIGDA 12th international
Symposium on Field Programmable Gate Arrays (Monterey, California, USA, February 22 - 24, 2004). FPGA '04. ACM Press, New York, NY, 171-180.
HPEC Challenge Benchmarks. http://www.ll.mit.edu/HPECchallenge. Xilinx Corporation. 2100 Logic Drive, San Jose, CA 95124-3400. Virtex-4 Family Overview (DS112), January 23, 2007. Xilinx Corporation. 2100 Logic Drive, San Jose, CA 95124-3400. Floating-Point Operator v3.0 (DS335). September 28, 2006. “Introduction to the Cell Processor” from Dr. Michael Perrone (IBM) “World’s First Polymorphic Computer – MONARCH” from K. Prager, L. Lewis, M. Vahey, G. Groves (Raytheon) Strenski, Dave. “FPGA Floating Point Performance – a pencil and paper evaluation”. http://www.hpcwire.com/hpc/1195762.html. Strenski, Dave. 2006. Computational Bottlenecks and Hardware Decisions for FPGAs. FPGA and Structured ASIC Journal. Altera Corporation. 101 Innovation Drive, San Jose, CA 95134. Stratix II Device Handbook v 4.3, May 2007. Freescale Semiconductor Inc. 6501 William Cannon Drive West, Austin, TX 78735. MPC7450 RISC Microprocessor Family Reference Manual,
Rev. 5. January 2005. Freescale Semiconductor Inc. 6501 William Cannon Drive West, Austin, TX 78735. AltiVec Technology Programming Environments Manual,
Rev. 3. April 2006. MathStar Corporation. 19075 NW Tanasbourne Dr. Suite 200, Hillsboro, OR 97124. Arrix Family Product Brief, August 2006.


















