
Audio Music Monitoring: Analyzing Current Techniques for ... · Audio Music Monitoring: Analyzing...
12
Audio Music Monitoring: Analyzing Current Techniques for Song Recognition and Identification E.D. Nishan W. Senevirathna and Lakshman Jayaratne Abstract—when people are attaching or interesting in something, usually they are trying to interact with it frequently. Music is attached to people since the day of they were born. When music repository grows, people faced lots of challenges such as finding a song quickly, categorizing, organizing and even listening again when they want etc. Because of this, people tend to find electronic solutions. To index music, most of the researchers use content based information retrieval mechanism since content based classification doesn’t need any additional information rather than audio features embedded to it. As well as it is the most suitable way to search music, when user don’t know the meta data attached to it, like author of the song. The most valuable application of this audio recognition is copyright infringement detection. Throughout this survey we will present approaches which were proposed by various researchers to detect, recognize music using content base mechanisms. And finally we will conclude this by analyzing the current status of this era. Keywords— Audio fingerprint; features extraction; wavelets; broadcast monitoring; Audio classification; Audio identification. I. INTRODUCTION usic repositories in the world are increasing exponentially. New artist can come to the field easily with new technologies. Once we listen a new song, we can’t get it again easily if we don’t know the meta data of that song like author or singer. However the most common method of accessing music is through textual meta-data but this is no longer function properly against huge music collection. When we come to the audio music recognition era, followings are the key considerations. Can we find an unknown song using a small part of it or humming the melody? Can we organize, index songs without meta data like singer of the song? Can we detect copyright infringement? For an example after a song was broadcasted in a radio channel. Can we identify a cover song when multiple versions exist? Can we obtain a statistical report about broadcasted songs in a radio channel without a manual monitoring process? Above considerations motivate researches to find proper solutions for these challenges. As of now, so many ideas have been proposed by researches as well as some of them have been implemented, Shazam is one of example for that. However still this is a challenging research area since there is no optimal solution. This problem become even more complex when, Audio signal is altered by noise. Audio signal is polluted by adding unnecessary audio object like advertisement in radio broadcasting. When multiple versions are existed. Only a small part of a song is available. At any of above situations, human auditory system can recognize music but providing an automated electronic solution is very challenging task since similarity between original music and querying music could be very few or these similar features may not be possible to model mathematically. It means researches need to consider perceptual features also, in order to provide a proper solution. Feature extraction can be considered as the heart of any of these approaches since the accuracy and all are depended on the way of feature extraction. Rest of this survey, will provide broader overview and comparisons of proposed feature extractions, searching algorithms and overall solutions architectures. M DOI: 10.5176/2251-3043_4.3.328 GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015 ©The Author(s) 2015. This article is published with open access by the GSTF 23 Received 20 Jul 2015 Accepted 13 Aug 2015 DOI 10.7603/s40601-014-0015-7
Transcript of Audio Music Monitoring: Analyzing Current Techniques for ... · Audio Music Monitoring: Analyzing...

Audio Music Monitoring: Analyzing Current
Techniques for Song Recognition and Identification
E.D. Nishan W. Senevirathna and Lakshman Jayaratne
Abstract—when people are attaching or interesting in something, usually they are trying to interact with it frequently. Music is attached to people since the day of they were born. When music repository grows, people faced lots of challenges such as finding a song quickly, categorizing, organizing and even listening again when they want etc. Because of this, people tend to find electronic solutions. To index music, most of the researchers use content based information retrieval mechanism since content based classification doesn’t need any additional
information rather than audio features embedded to it. As well as it is the most suitable way to search music, when user don’t
know the meta data attached to it, like author of the song. The most valuable application of this audio recognition is copyright infringement detection. Throughout this survey we will present approaches which were proposed by various researchers to detect, recognize music using content base mechanisms. And finally we will conclude this by analyzing the current status of this era.
Keywords— Audio fingerprint; features extraction; wavelets; broadcast monitoring; Audio classification; Audio identification.
I. INTRODUCTION
usic repositories in the world are increasing exponentially. New artist can come to the field easily
with new technologies. Once we listen a new song, we can’t
get it again easily if we don’t know the meta data of that song
like author or singer. However the most common method of accessing music is through textual meta-data but this is no longer function properly against huge music collection. When we come to the audio music recognition era, followings are the key considerations.
Can we find an unknown song using a small part of it or humming the melody?
Can we organize, index songs without meta data like singer of the song?
Can we detect copyright infringement? For an example after a song was broadcasted in a radio channel.
Can we identify a cover song when multiple versions exist?
Can we obtain a statistical report about broadcasted songs in a radio channel without a manual monitoring process?
Above considerations motivate researches to find proper solutions for these challenges. As of now, so many ideas have been proposed by researches as well as some of them have been implemented, Shazam is one of example for that. However still this is a challenging research area since there is no optimal solution. This problem become even more complex when,
Audio signal is altered by noise.
Audio signal is polluted by adding unnecessary audio object like advertisement in radio broadcasting.
When multiple versions are existed.
Only a small part of a song is available.
At any of above situations, human auditory system can recognize music but providing an automated electronic solution is very challenging task since similarity between original music and querying music could be very few or these similar features may not be possible to model mathematically. It means researches need to consider perceptual features also, in order to provide a proper solution. Feature extraction can be considered as the heart of any of these approaches since the accuracy and all are depended on the way of feature extraction.
Rest of this survey, will provide broader overview and comparisons of proposed feature extractions, searching algorithms and overall solutions architectures.
M
DOI: 10.5176/2251-3043_4.3.328
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
23
Received 20 Jul 2015 Accepted 13 Aug 2015
DOI 10.7603/s40601-014-0015-7

II. CLASSIFICATIONS (RECOGNITION) VS. IDENTIFICATIONS
What is the different between audio recognition (classification) and identification? In audio classification, audio object will be classified into pre-defined sets like song, advertisement, vocals etc. but they are not identified further. Ultimately we know that this is a song or advertisement but we don’t know what that song is! Audio classification is less
complex than recognition. Most of the time, we can see that these two things are combined each other in order to get better result. For an example, in audio song recognition system, first we can extract only songs among collection of other audio objects using audio classifier and output will be fed in to the audio recognition system. Using that kind of approach we can get better result by narrow downing the search space. There are more proposed audio classification approaches. Some of them will be discussed in next sub section.
A. Audio classifications
1) Overview
There are considerable amount of real world applications for audio classification. For an example it will be very helpful to be able to search sound effects automatically from a very large audio database in films post processing, which contains sounds of explosion, windstorm, earthquake, animals and so on[1]. As well as audio content analysis and classification is also useful for audio-assisted video classifications. For an example, all video of gun fight scenes should include the sound of shooting and or explosions, but image content may vary significantly from one scene to another.
When classifying an audio content into different sets, different classes have to be considered. Most of the researches have started this classifying speech and music. However these classes are depended on the situations. For example, “music”,
“speech” and “others” can be considered for the parsing of
news stories whereas audio recording can be classified into “speech”, ”laughter”, ”silences” and “non speech” for the
purpose of segmenting discussions recording in meetings[1]. In any cases above, we have to consider, extract some sort of audio features. This is the challenging part as well as past researches are differed from this point. But we can consider “feature extraction of audio classification” and “feature
extraction of audio identification” separately since most of the
times these two cases consider disjoin feature sets [7].
2) Feature extraction of audio classification
Actually, most of the time output of the audio classification is the input of the audio identification. This will reduce the searching space and speed up the process and help to retrieve better results. Most of the researchers, audio
classification will be broken down into further steps. In [1] they used two steps, in the first stage, audio signal is segmented and classified into basic types, including speech, music, several types of environmental sounds, and silence. They called it as the coarse-level classification. In the second stage, further classification is conducted within each basic type. For speech, they differentiated it into voices of man, woman, child as well as speech with a music background and so on. For music, it is classified according to the instruments or types (for example, classics, blues, jazz, rock and roll, music with singing and the plain song). For environmental sounds, they classified them into finer classes such as applause, bell ring, footstep, windstorm, laughter, birds' cry, and so on. They called this as the fine-level classification. Overall idea was reducing the searching space step by step in order to get better results. As well as we can use proper feature extraction mechanism for each finer level classes based on its basic type. For an example, due to differences in the origination of the three basic types of audio, i.e. speech, music and environmental sounds, different approaches can be taken in their fine classification. Most of the researches have used low-level (physical, acoustic) features such as Spectral Centroid or Mel-frequency Coefficients but end users may prefer to interact with a higher semantic level [2]. For an example they may need to find dog barking sound instead of environmental sounds. However low-level features can be easily extract using signal processing than high-level (perceptual) features.
Most of the researchers have used Hidden Markov Model (HMM) and Gaussian Mixture Model (GMM) as the pattern recognition tool. Those are the widely used very powerful statistical tools in pattern recognition. To use those tools we have to extract unique features. Any audio feature can be grouped into two or more sets. Most of the researches grouped all audio features into two group, physical (or mathematical) features and conceptual features. Physical features are directly extracted from the audio wave such as energy of the wave, frequency, peaks, average zero crossings and so on. These features cannot be identified by the human auditory system. But perceptual features are the features human can understand like loudness, pitch, timbre, rhythm and so on. Perceptual features cannot easily be model by mathematical functions but those are the very important audio features since human uses those features to differentiate audios.
However sometime we can see that audio features classified into hierarchical groups with similar characteristics [12]. They divide all audio features into six main categories, refer the Figure 1.
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
24

Figure 1. High level, Audio Feature Classification[12].
However no one can define audio feature and its
category exactly since there is no broad consensus on the allocation of features to particular groups. We can see that same feature may be classified into two different groups by two different researchers. It is depended on the different viewpoints of the authors. Features defined in the figure 1 can be further classified into several groups considering the structure of each feature.
Considering the structure of the temporal domain feature, in [12], they classified it into three sub groups of features: amplitude-based, power-based, and zero crossing-based features. Each of these features related to one or more physical property of the wave, refer the Figure 2.
Figure 2. The organization of features in Temporal Domain [12].
In here, some researches had defined zero crossings
rate (ZCR) as a physical feature. Frequency domain signals are the very important features. Most of the researches consider only the frequency domain features. Next we will look at the frequency domain feature classification done by [12] refer the Figure 3.
Sometime we can see that some researches had further classified other four main features as well. But those are not very important. Next we will see the main characteristics of major features.
Figure 3. The organization of features in Frequency Domain [12]
a) Temporal (Raw) Domain features
Most of the time, we can’t extract features without
altering the native audio signal. But there are several features which can be extracted from native audio signal those features are known as temporal features. Since we don’t want to alter
the native signal it is very law cost feature extraction methodology. But only using this feature we can’t uniquely
identify audio music.
Zero crossing rate is a main temporal domain feature. This is very helpful but low cost feature which is often used in audio classification. Usually we define is as the number of zero crossings in the temporal domain within one second. It is a rough estimation of dominant frequency and the spectral centroid [12]. Sometime we obtain ZCR by altering the audio signal bit. In this case we extract frequency information and corresponding intensities scaled sub bands from time domain zero crossings. It gives more stable measurement for us and it is very helpful in noisy environment. Since noises are always spread around zero axes but this is not creating considerable amount of peaks therefore peak related zero crossing rate will remain unchanged.
Amplitude-Based Features are another example for temporal domain features. We can obtain this feature by directly computing the frequency of audio signal. It is again good measurement but subject to change even audio signal is alter little bit by noise like unwanted affects.
Power measurement is also a raw domain signal which is almost same as the amplitude based features. The power or the energy of a signal is the square of the amplitude represented by the waveform. Volume is well known power measurement feature it is widely used in silence detection and speech/music segmentation.
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
25

b) Physical features
Most of the audio features are obtain from frequency domain since almost all features live in this domain. Before extracting frequency domain features we have to transform the base signal into some other formats. To do that, we can use several methods. The most popular methods are the Fourier transform and the autocorrelation. Other popular methods are the Cosine transform, Wavelet transform, and the constant Q transform [12]. Frequency domain signal can be categorized into two major class, physical features and perceptual features. Physical domain features are defined using physical characteristics of audio signal which have not semantic meanings. Next we will discuss mainly used physical features and then perceptual features.
Auto-regression-Based Features: In statistics and signal processing, an autoregressive (AR) model is a representation of a type of random process; as such, it describes certain time-varying processes in nature, economics, etc.[18]. This is widely used standard techniques for speech/music discrimination. This can be used to extract basic parameters of a speech signal, such as formant frequencies and the vocal tract transfer function [18]. Sometime we can see that this feature group is divided further into two group, linear predictive coding (LPC) and Line spectral frequencies (LSF). But in here we are not going to discuss about these sub group in detailed.
Short-Time Fourier Transform-Based Features (STFT): this is another widely used audio feature based on the audio spectrum. STFT can be used to obtain characteristics of both frequency component and phase component. There are several features under STFT such as Shannon entropy, Renyi entropy, spectral centroid, spectral bandwidth, spectral flatness measure, spectral crest factor and Mel-frequency cepstral coefficients [15].
Short-time energy function: Energy of an audio signal is measured by amplitude of that signal. When we represent amplitude variation over time it is called energy function of that signal. For speech signals, it is a basis for distinguishing voiced speech components from unvoiced speech components, as the energy function values for unvoiced components are significantly smaller than those of the voiced components [1].
Short-time average zero-crossing rate (ZCR): This feature is another measurement to classify voiced speech components and unvoiced speech components. Usually voice component have much smaller ZCR than unvoiced component [1].
Short-time fundamental frequency (FuF): Using this feature we can find harmonic properties. Usually most
musical instrument sounds are harmonic. Sometime some sound can be mixer of harmonic and non-harmonic. However this feature also can be used to classify audio objects [1].
Spectral Flatness Measure (SFM): which is an estimation of the tone-like or noise-like quality for a band in the spectrum [1]. Really used for audio classifications.
There are some other widely used physical features like, Mel-Frequency Cepstrum Coefficients (MFCC),Papaodysseuset al. (2001) presented the “band
representative vectors”, which are an ordered list of indexes
of bands with prominent tones (i.e. with peaks with significant
amplitude). Energy of each band is used by Kimura et al. (2001). Normalized spectral sub-band centroids are proposed by Seo et al. (2005). Haitsma et al. use the energies of 33 bark-scaled bands to obtain their “hash string”, which is the sign of
the energy band differences (both in the time and the frequency axis) and so on.
Most of the time silent audio frames are identified earlier and those are not directed to further processing. There are several approaches to identify/define a silent frame. Some researched have used ZCR property. In [4], they have used something like below to define silent frames.
Before feature extraction, an audio signal (8-bit ISDN μ-law encoding) is pre-emphasized with parameter 0.96 and then divided into frames. Given the sampling frequency of 8000 Hz, the frames are of 256 samples (32ms) each, with 25% (64 samples or 8ms) overlap in each of the two adjacent frames. A frame is hamming-windowed by, wi = 0.54 – 0.46 * cos(2πi/256). It is marked as a silent frame if,
∑(𝑤𝑖 𝑠𝑖)2 <
256
𝑖=1
4002
Where si is the pre-emphasized signal magnitude at i and 4002 is an empirical threshold. Even most of the researches have used physical features, in order to give better result we have to consider perceptual features as well since those are the features recognize by human auditory system.
Spectral peaks: this is very important feature since it is noise robust representation of audio wave. Noises are spread across zero axes therefore noises are not affected on peaks. This feature is mainly used to create a unique finger print from a small segment of audio clip captured by mobile phone or some other device. The strength of the technique is that it solely relies on the salient frequencies (peaks) and rejects all other spectral content [12].
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
26

c) Perceptual features
How can human beings recognize an audio? Using some sort of audio features which are sensitive to human auditory system, those features are known as perceptual features. Usually these features cannot be easily extracted, since those cannot easily be model mathematically. However there are number of research attempts in this era, the final goal of those researches is to model perceptual features mathematically. In [5], statistical values (including means, variances, and autocorrelations) of several time- and frequency-domain measurements were used to represent perceptual features, such as loudness, brightness, bandwidth, and pitch. This method is only suitable for sounds with a single timbre. Other than that following are the mostly used perceptual features. According to the past researches perceptual features can be grouped into six groups, refer the Figure 4.
Figure 4: The organization of features in Frequency Domain perceptual[12].
Brightness: The word “Brightness” is more familiar
in “illumination” context. Usually we measure brightness of illumination surfaces like LCD monitors. What is meant by “brightness” of that context? If illumination is very high then
we define it as the high brightness otherwise law brightness. Likewise we can define audio brightness using its frequency instead of “illumination”. A sound becomes brighter as the
high-frequency content becomes more dominant and the low-frequency content becomes less dominant [12].
Most of the times, we measure brightness as the spectral centroid (SC). It indicates where the "center of mass" of the spectrum is. Perceptually, it has a robust connection with the impression of "brightness" of a sound. It is calculated as the weighted mean of the frequencies present in the signal, determined using a Fourier transform, with their magnitudes as the weights [19].
Tonality: this is more important audio feature to distinguish noise-like sound from other sounds. Tonal sounds typically have line spectra whereas noise-like sound have
continues spectrum. Usually tonality is measured by bandwidth and/or flatness.
Bandwidth is usually defined as the magnitude-weighted average of the differences between the spectral components and the spectral centroid. As we already know tonal sounds typically have line spectrum therefore component variation related to the SC is law it means tonal sounds have law bandwidth than noise like sounds. There are several other feature classes which measure tonality of audio signal such as Spectral dispersion, Spectral roll-off point, Spectral crest factor, Sub-band spectral flux (SSF) and Entropy. More details of each feature can be found in [12].
Loudness: We use this feature in our day to day life, is the characteristic of a sound that is primarily a psychological correlate of physical strength (amplitude). More formally, it is defined as "that attribute of auditory sensation in terms of which sounds can be ordered on a scale extending from quiet to loud" [20]. In other words, Loudness is “that attribute of auditory sensation in terms of which sounds may be ordered on a scale extending from soft to loud”
[12]. According to the definition, this is widely used perceptual feature as well as this feature can be extracted easily than other perceptual features.
Pitch: Again this is much closed audio feature to the human auditory system like loudness. Pitch is a basic dimension of audio and this is defined together with loudness, duration, and timbre. In the past researches, this feature was widely used to genre classification and audio identification. Pitches are compared as "higher" and "lower" in the sense associated with musical melodies, which require sound whose frequency is clear and stable enough to distinguish from noise [21].
Chroma: this feature is an interesting and powerful representation of audio. We know that any tone is belongs to one of musical octaves. To classify tone into musical octaves we used tone height i.e. if tone height is less then it may belongs to class “C” and if it is very high then it could belongs
to class “B”. But there is another measurement of a tone class which is called “Chroma”. The entire spectrum is projected onto 12 bins representing the 12 distinct semitones (or chroma) of the musical octave. Since, in music, notes exactly one octave apart are perceived as particularly similar, knowing the distribution of chroma even without the absolute frequency (i.e. the original octave) can give useful musical information about the audio [14].
Harmonicity: is a property that distinguishes periodic signals (harmonic sounds) from non-periodic signals (inharmonic and noise-like sounds). Harmonics are frequencies at integer multiples of the fundamental frequency
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
27
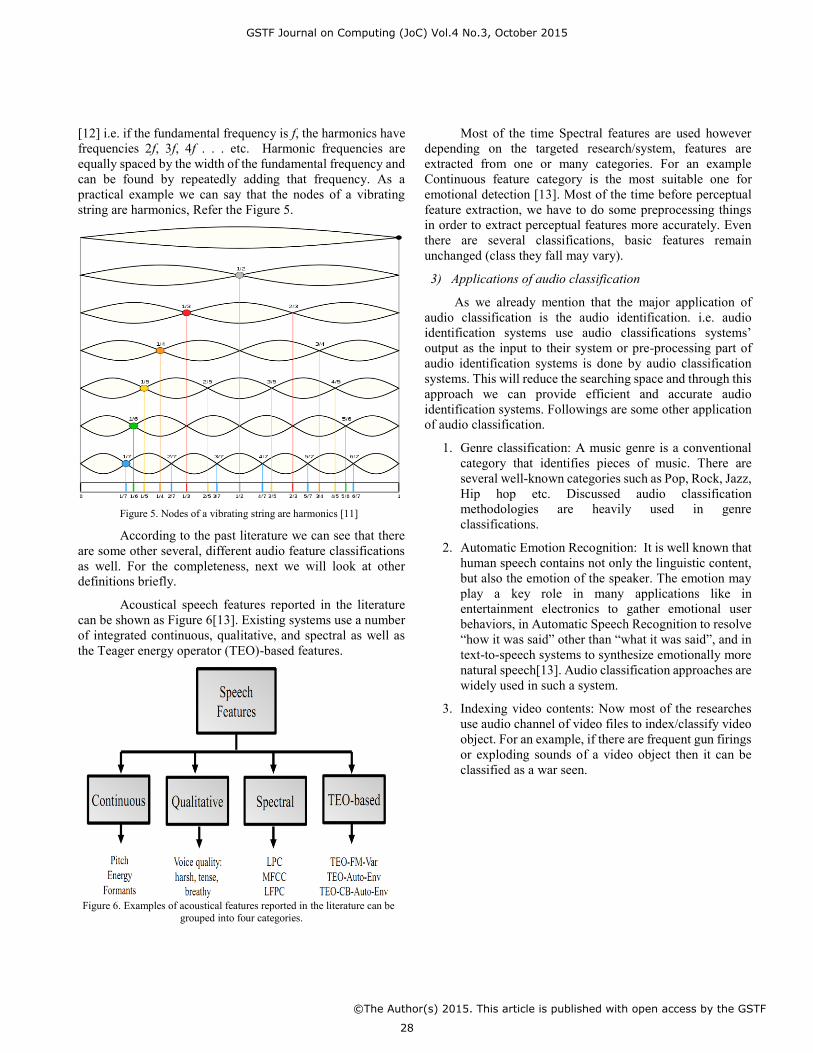
[12] i.e. if the fundamental frequency is f, the harmonics have frequencies 2f, 3f, 4f . . . etc. Harmonic frequencies are equally spaced by the width of the fundamental frequency and can be found by repeatedly adding that frequency. As a practical example we can say that the nodes of a vibrating string are harmonics, Refer the Figure 5.
Figure 5. Nodes of a vibrating string are harmonics [11]
According to the past literature we can see that there are some other several, different audio feature classifications as well. For the completeness, next we will look at other definitions briefly.
Acoustical speech features reported in the literature can be shown as Figure 6[13]. Existing systems use a number of integrated continuous, qualitative, and spectral as well as the Teager energy operator (TEO)-based features.
Figure 6. Examples of acoustical features reported in the literature can be
grouped into four categories.
Most of the time Spectral features are used however depending on the targeted research/system, features are extracted from one or many categories. For an example Continuous feature category is the most suitable one for emotional detection [13]. Most of the time before perceptual feature extraction, we have to do some preprocessing things in order to extract perceptual features more accurately. Even there are several classifications, basic features remain unchanged (class they fall may vary).
3) Applications of audio classification
As we already mention that the major application of audio classification is the audio identification. i.e. audio identification systems use audio classifications systems’
output as the input to their system or pre-processing part of audio identification systems is done by audio classification systems. This will reduce the searching space and through this approach we can provide efficient and accurate audio identification systems. Followings are some other application of audio classification.
1. Genre classification: A music genre is a conventional category that identifies pieces of music. There are several well-known categories such as Pop, Rock, Jazz, Hip hop etc. Discussed audio classification methodologies are heavily used in genre classifications.
2. Automatic Emotion Recognition: It is well known that human speech contains not only the linguistic content, but also the emotion of the speaker. The emotion may play a key role in many applications like in entertainment electronics to gather emotional user behaviors, in Automatic Speech Recognition to resolve “how it was said” other than “what it was said”, and in
text-to-speech systems to synthesize emotionally more natural speech[13]. Audio classification approaches are widely used in such a system.
3. Indexing video contents: Now most of the researches use audio channel of video files to index/classify video object. For an example, if there are frequent gun firings or exploding sounds of a video object then it can be classified as a war seen.
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
28

Figure 7. General flow of the audio identification process.
B. Audio Identification
1) Overview
Audio identification is very challenging task compared to audio classification since we have to specifically match unknown audio object with thousands of pre-installed audio objects whereas in audio classification we classify any audio object into small number of pre-defined classes. As we discussed earlier most of the researches have joined these two together in order to get better result. First we classify unknown audio object and identify its class then we can match this unknown audio object among other pre install object in the same class. By doing this we can speed up the process by omitting the unrelated class of audio objects as well as obtain better results.
In this section we focus only on the identification part. According to the past literature, we can provide high level overview of overall process done by most of the researches. Look at the Figure 7. In here feature extraction part is exactly same as the feature extraction of audio classifications which we have already discussed. The key thing is to discuss here is that how to create audio archives and searching mechanisms. Thesetwo things we will discuss later in detail.Apart from that almost all researches have framed audio object into sets of overlapping frames. The reason for doing it is a very important thing. Usually we have to identify audio object like a song when a small part of it is presented.
This small part can be come from any place from the original track. In this case we don’t know the offset of that part. To
address this problem we can use framing thing. Look at the Figure 8.
Figure 8. Diving audio object into set of overlapping frames. This
approach facilitates to identify any small part of unknown audio object which is extracted from anywhere of the original source.
Refer the Figure 8, we can see that there are sets of frames and overlapping areas. According to the past researches we can interpret this image as this. Parameters for sampling frequency and frame size can be different from one research to another but most of the researches have used following parameter values. Given the sampling frequency of 8000 Hz, the frames are of 256 samples (32 ms) each, with 25% (64 samples or 8 ms) overlaps in each of the two adjacent frames. A frame is Hamming-windowed by [9],
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
29

2) Audio identification methodologies
This is the most important part of the audio identification. In here we will discuss, what are the proposed mechanisms used to create an archives of audio. In other words, now we have various audio features which should be store in a database. What are the proposed approaches used to convert a sets of audio features to an audio fingerprint?
a) Audio fingerprint
Audio fingerprinting is best known for its ability to link unlabeled audio to corresponding meta-data (e.g. artist and song name), regardless of the audio format. This is very powerful and widely used method, the main advantage is that this is independent from the audio format. What is mean by fingerprint? It is a unique representation of an object for an example human fingerprint can be used to identify a human likewise we can use audio fingerprint to identify an audio uniquely. Audio file is just a binary file nothing more than that. If we use this digital file as the fingerprint we may face several problems. Usually unknown audio object can be a part of original one or it may corrupt partially. In such a case we can’t get unique fingerprint. Therefore, the direct comparison
of the digitalized waveform is neither efficient nor effective. To alleviate mentioned issues we usually split audio object into sets of overlapping frames as we discussed earlier and generate sets of fingerprint for each and every frame. But again we can’t use the digitalized waveform of a frame as the
fingerprint. First we extract one or more desired audio features as we discussed in section 2.2. Then we join those feature values according to some specific manner this is changed from one research to another. At the end of this we can obtain some sort of string representation of several features. A more efficient implementation of this approach could use a hash method, such as MD5 (Message Digest 5) or CRC (Cyclic Redundancy Checking), to obtain a compact representation of the combined features [2]. Downside of this presentation is that, hash value is fragile i.e. even a single bit is change it is enough to get completely different hash value. Therefore we can’t use fingerprint method as it is for robust
implementation. As a whole we can represent fingerprinting model as the Figure 9.
Figure 9. The flow of the Audio Fingerprint model
The ideal fingerprints should have following properties.
1. Should be able to accurately identify an audio object.
2. Robust representation against the distortion or interference in the transmission channel.
3. Generate powerful fingerprint using only few seconds of the audio object.
4. It should be computationally efficient. 5. Size of the fingerprints should be small. 6. Less complexity of the fingerprint extraction.
This method is less vulnerable to attack since changing the fingerprint means alteration of the quality of the sound. Usually fingerprint data base will be very huge one since we have to extract many finger prints from an audio object. Therefore we can’t use traditional bruit-force like searching mechanism for this. Instead of it, many researchers have used indexed look-up tables which give result very fast.
b) Audio water marking
Audio water marking is some sort of massage which is embedded to the audio object when it is recording. According to [16] watermarking is the addition of some form of identifying mark that can be used to prove the authenticity or ownership of a candidate item. Embedding a water mark will not alter the perception of the song. Finally Identification of a song title is possible by extracting the message embedded in the audio. Actually this is not a content based audio identification mechanism since we don’t worry about the
audio properties because of this nature sometime audio watermarking identification mechanism is known as “blind
detection” method. Dual Tone Multi-Frequency (DTMF) is the origin point
of this water marking approach. DTMF used in touch-tone and mobile telephony. There are two frequencies in DTMF for bit 1 and 0 [16].
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
30

DTMF 1 tone: 697Hz and 1209Hz combined DTMF 0 tone: 941Hz and 1336Hz combined
To reduce the data to be watermarked we can use series of bit-representations of its ASCII codes. Every character has a unique ASCII code. According to that we can represent any character as a pattern of pure sine waves using the combined DTMF frequencies for 1 and 0. This approach can be represented as Figure 10.
However audio water marking can be tampered since this is not an audio property itself. As well as we don’t have
any option to already released legacy audio objects like songs. Other thing is that using this method we can’t identify two
songs/audio object with same perception but one without watermark.
c) Using Neural Network/SVM
Support Vector Machine (SVM) is also a widely used approach for audio identification. Actually SVM is widely used for audio classification instead of identification for completeness we will discuss it here. It is a statistical learning algorithm for classifiers. SVM is used to solve many practical problems such as face detections, three-dimensional (3-D) objects recognition and so on.
Again, features are extracted using methods which we discussed earlier and those features use to train the classifier. Most of the time we can see that perceptual features like composed of total power, sub-band powers, brightness, bandwidth and pitch and mel-frequency cepstral coefficients (MFCCs) are used. Then means and standard deviations of the feature trajectories over all frames are computed and these statistics are considered as feature sets for the audio sound. After that we create training vector data and train the SVM classifier. In here we are not going to discuss about SVM in detail you can find more information in [4][8][9][13].
There are some other widely used neural networks based methods like Nearest neighbor(NN), Nearest Feature Line(NFL)[5] and so on.
d) Auditory Zernike moment
All of the discussed methods so far consist with a major drawback i.e. they are working on raw (uncompressed) audio formats like wav. But we all know that, nowadays compressed audio format like MP3 music, has grown into the dominant way to store music on personal computers and/or transmit it over the Internet [17]. Therefore it will be very nice if we can directly recognize compressed audio without decompressing it, and definitely, it will be more efficient and more accurate. There is very few attempts works on compressed audio domain; this method is one of them. As most of the identification methods, this approach also creates a fingerprint at the end. But the way we used in this method is considerably different from the others.
Actually “Zernike moment” feature is used by image
processing techniques such as image recognition, image watermarking, human face recognition and image analysis, due to its prominent property of strong robustness and rotation, scale, and translation (RST) invariance. Because of these things, researches have motivated to use Zernike moment for audio information retrievals as well.
According to the past researches, we can see that there are four kind of compressed domain features, i.e., modified discrete cosine transform (MDCT) spectral coefficients, MFCC, MPEG-7, and chroma vectors from the compressed MP3 bit stream. Actually Zernike moment define using very complex sets of polynomials. We are not going to discuss about this in very detail. You can find more information in [17]. For completeness we will show how to grab Zernike moment in image. Following are extracted from [17].
We already mentioned that Zernike moment is defined using sets of polynomials which form a complete orthogonal basis set defined on the unit disk x2 + y2 ≤ 1. These
polynomials have the form,
Figure 10: The flow of the initial water marking system
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
31

Where n is a non-negative integer, m is a non-zero integer subject to the constraints that (n − |m|) is non negative
and even, ρ is the length of vector from the origin to the pixel
(x, y), and θ is the angle between the vector and x-axis in counter-clockwise direction. Rnm(ρ) is the Zernike radial polynomials in (ρ, θ) polar coordinates defined as,
Note that, Rn,m(ρ) = Rn,-m(ρ), so Vn,-m(ρ,θ) = V*
n,m(ρ ,θ).
Zernike moments are the projection of a function onto these orthogonal basis functions. The Zernike moment of order n with repetition m for a continuous two-dimensional (2D) function f(x, y) that vanishes outside the unit disk is defined as,
For 2D signal-like digital image, the integrals are replaced by summations to,
“Zernike moment” features can only be extracted from
2D space but audio data is time variant 1D data. Therefore we have to map 1D audio data to 2D space somehow. We can see that there are several ways to do this according to the past researches. For example some we can construct a series of consecutive granule-MDCT 2D images [17].
3) Applications of Audio Identification
Audio identification is very important real world problem therefore we can find many applications in this area. In this section we will discuss several important real world applications.
a) Copyright infringement detection
Music copyright enforcement is major problem when we are dealing with digital audio files. Digital audio file can easily be copied and distributed. Audio watermarking which we discussed earlier is one of solution to that problem. Before releasing a song, we can embed watermarks which will not affect to the audio quality. After that we can identify that audio object by extracting the watermark. This is working
fine for new releases, but there is no option for already released audio.
Another approach to the copyright-protection problem is audio fingerprint. In this method, as we discussed earlier, we can construct a fingerprint by analyzing an audio signal that is uniquely associated with the audio signal. After that we can identify a song by searching for its fingerprint in a previously constructed database. This kind of solution can be used tomonitor radio broadcasting and audio file sharing systems and so on.
b) Searching audio objects effectively
Sometime we need to download/find a song but we don’t know the lyrics exactly. In this case we can query audio
database by humming the melody or providing a part of that song. As an example, suppose an automated system organize a user’s music collection by properly naming each file
according to artist and song title. Another application could attempt to retrieve the artist and title of a song given a short clip recorded from a radio broadcast or perhaps even hummed into a microphone [10]. In such a case we can use content base audio identification methods to query the data base. Audible Magic and Shazam are examples of such systems which already used audio fingerprinting [6].
Sometime we may want to search, index and organize songs in our personal computer. Usually we may have same song with different names and in different locations. In such a case we can use content base audio identification methodologies to do these tasks.
c) Analyzing Audio objects for video indexing
Usually we identify videos by using image processing techniques. But it is very inefficient and low accurate method. Instead of it we can analyze audio which is attached to the video file to index it [1]. This is properly suited for commercial advertisement tracking systems.
d) Speech Recognition
Speech recognition (SR) is the translation of spoken words into text. It is also known as "automatic speech recognition" (ASR), "computer speech recognition", or just "speech to text" (STT). Additionally, research addresses the recognition of the spoken language, the speaker, and the extraction of emotions [13]. This is another major application of Audio Identification.
III. OPEN ISSUES
As we discussed earlier, this is still a growing research area. The reason is there are several and major
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
32

challengers/issues which are not addressed properly so far. In this section we will discussed about those open issues.
Most of the time, we can’t perform the major audio
analyzing task in a controlled environment. It is the major issue faced by researches. There are thousands of interruptions/interference such as unwanted noise effects, audio alterations, playback speed, tempo and beat like audio characteristics variations, variations of the signal source and so on. We can divide those issues into two major groups i.e. psychoacoustic and technical.
Psychoacoustics focuses on the mechanisms that process an audio signal in a way that sensations in our brain are caused. Even if the human auditory system has been extensively investigated in recent years, we still do not fully understand all aspects of auditory perception [13]. Therefore modelingpsychological features in order to simulate human perceptionis not a trivial task but it is really important. This is a one of major overhead in this research area.
Normally humans recognize unknown audio using their historical knowledge. This is very important to identify a new version or cover copy of original audio object but we can easily model this historical knowledge mathematically. For an example is audio object masking. Masking is “the process
by which the threshold of hearing for one sound is raised by the presence of another (masking) sound”. Human auditory
system has especial capability to distinguish between simultaneous masking and temporal masking using frequency selectivity of human eye. This is model mathematically using the loudness of audio objects but it is not provided 100% accuracy compared to native auditory system.
Other than that there are several technical difficulties as well. An audio signal is usually exposed to distortions, such as interfering noise and channel distortions. Therefore modeling technically robust solution is very challenging task.
Noises, Sound pressure level, Tempo variations, concurrently presence of several audio objects and so on are affected on any audio recognition algorithm badly. Those are the major issues/challenges in this area. When we are introducing any new feature we have to think about these challenges.
IV. CONCLUSIONS AND FUTURE DIRECTIONS
Throughout this review, we discussed about digital audio classification and identification techniques done by various researches. As a conclusion we can summarize our findings as below.
Still this is a young research area hence there are lots of rooms for improvements. Finding, searching, indexing audio file using meta data attached to it is no longer functions properly. Audio repository is rapidly increasing, new songs are introduced frequently therefore we have to move to the content based audio identification mythologies. According to the past history, most of the researches have used audio fingerprinting concept to do that. The most important part is the feature extraction of any of these methods since it is the heart of the system. Still we don’t have rich robust features
against any kind of signal distortions and alterations. As well as most of the solutions can’t scale to fit current audio
repositories. Therefore now we have to think about robust and scalable solution.
Cover song identification or dealing with several versions of the same song is a very important research area when we discuss about audio identification approaches. This is even more important when we thinking about intellectual property of artists. There are several attempts on this area like [3], but this should be improved in the future.
ACKNOWLEDGEMENTS
I offer my sincerest gratitude to my supervisor, Dr. K.L. Jayaratne, who has supported me throughout my research. I would like to show my gratitude to Mr. Brian for supporting me. Finally thank everybody who contributed to the successful realization of my project.
REFERENCES
[1] T. Zhang and C.-C. J. Kuo, “Hierarchical system for content-based audio classification and retrieval,” in Photonics East (ISAM, VVDC, IEMB), 1998, pp. 398-409,International Society for Optics and Photonics, 1998.
[2] P. Cano, “Content-Based Audio Search from Fingerprinting to Semantic Audio Retrieval,” Ph.D. Dissertation. UPF, 2007.
[3] J. Serrà, E. Gómez, and P. Herrera, “Audio cover song identification
and similarity: background, approaches, evaluation, and beyond,” in Advances in Music Information Retrieval, vol. 274, Z. Ras and A. A. Wieczorkowska, Eds. Springer-Verlag Berlin / Heidelberg, 2010, pp. 307-332.
[4] S. Z. Li and G.-dong Guo, “Content-based audio classification and retrieval using SVM learning,” Invited Talk PCM, 2000.
[5] S. Z. Li, “Content-based audio classification and retrieval using the nearest feature line method,” Speech and Audio Processing, IEEE Transactions on, vol. 8, no. 5, pp. 619-625, 2000.
[6] T. Huang, Y. Tian, W. Gao, and J. Lu, “Mediaprinting: Identifying
multimedia content for digital rights management,” 2010.
[7] M. S. Lew, N. Sebe, C. Djeraba, and R. Jain, “Content-based multimedia information retrieval: State of the art and challenges,”
ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), vol. 2, no. 1, pp. 1-19, 2006.
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
33

[8] J. T. Foote, “Content-Based Retrieval of Music and Audio,” in
MULTIMEDIA STORAGE AND ARCHIVING SYSTEMS II, PROC. OF SPIE, 1997, pp. 138-147.
[9] G. Guo and S. Z. Li, “Content-based audio classification and retrieval by support vector machines,” Neural Networks, IEEE Transactions on, vol. 14, no. 1, pp. 209-215, 2003.
[10] M. Riley, E. Heinen, and J. Ghosh, “A text retrieval approach to
content-based audio retrieval,” in Int. Symp. on Music Information Retrieval (ISMIR), 2008, pp. 295-300.
[11] Wikipedia, “Harmonic --- Wikipedia, The Free Encyclopedia.”
http://en.wikipedia.org/w/index.php?title=Harmonic&oldid=657491925, 2015. [Online; accessed6-May-2015].
[12] D. Mitrović, M. Zeppelzauer, and C. Breiteneder, “Features for
content-based audio retrieval,” Advances in computers, vol. 78, pp. 71-150, 2010.
[13] M. C. Sezgin, B. Gunsel, and G. K. Kurt, “Perceptual audio features
for emotion detection,” EURASIP Journal on Audio, Speech, and Music Processing, vol. 2012, no. 1, pp. 1-21, 2012.
[14] M. A. Bartsch and G. H. Wakefield, “Audio thumbnailing of popular
music using chroma-based representations,” Multimedia, IEEE Transactions on, vol. 7, no. 1, pp. 96-104, Feb. 2005.
[15] A. Ramalingam and S. Krishnan, “Gaussian mixture modeling using
short time fourier transform features for audio fingerprinting,” in Multimedia and Expo, 2005. ICME 2005. IEEE International Conference on, 2005, pp. 1146-1149.
[16] R. Healy and J. Timoney, “Digital Audio Watermarking with Semi-Blind Detection for In-Car and Domestic Music Content Identification,” in Audio Engineering Society Conference: 36th International Conference: Automotive Audio, 2009.
[17] W. Li, C. Xiao, and Y. Liu, “Low-order auditory Zernike moment: a novel approach for robust music identification in the compressed domain,” EURASIP Journal on Advances in Signal Processing, vol. 2013, no. 1, 2013.
[18] D. Mitrović, M. Zeppelzauer, and C. Breiteneder, “Chapter 3 - Features for Content-Based Audio Retrieval,” in Advances in Computers: Improving the Web, vol. 78, Elsevier, 2010, pp. 71-150.
[19] B. Gajic and K. K. Paliwal, “Robust feature extraction using subband spectral centroid histograms,” in Acoustics, Speech, and Signal Processing, 2001. Proceedings. (ICASSP ’01). 2001 IEEE
International Conference on, 2001, vol. 1, pp. 85-88 vol.1.
[20] B. R. Glasberg and B. C. J. Moore, “A Model of Loudness Applicable
to Time-Varying Sounds,” J. Audio Eng. Soc, vol. 50, no. 5, pp. 331-342, 2002.
[21] K. Kondo, “Method of changing tempo and pitch of audio by digital signal processing.” Google Patents, 1999.
AUTHORS’ PROFIEL
Nishan Senevirathna (B.Sc. in Computer Science (SL)) obtained his B.Sc (Hons) in Computer Science from the University of Colombo School of Computing (UCSC), Sri Lanka in 2013. Currently working as a Senior Software Engineer at CodeGen International (Pvt) Ltd and following a M.Phil Degree program at UCSC. His research interests includes Multimedia Computing, Image Processing, High Performance Computing and Human Computer Interaction.
Dr. Lakshman Jayaratne-(Ph.D (UWS),B.Sc. (SL), MACS,MCS (SL), and MIEEE) obtained his B.Sc (Hons) in Computer Science from the University of Colombo (UCSC), Sri Lanka in 1992. He obtained his PhD degree in Information Technology in 2006 from the University of Western Sydney, Sydney, Australia. He is working as a Senior Lecturer at the UCSC, University of Colombo. He was the President of the IEEE Chapter of Sri Lankan in 2012. He has wide experience in actively engaging in IT consultancies for public and private sector organizations in Sri Lanka. He was worked as a Research Advisor to Ministry of Defense, Sri Lanka. He Awarded in Recognition of Excellence in Research in the year 2013 at Postgraduate Convocation of University of Colombo, Sri Lanka. His research interest includes Multimedia Information Management, Multimedia Databases, Intelligent Human-Web Interaction, Web Information Management and Retrieval, and Web Search Optimization. Also his research interest includes Audio Music Monitoring for Radio Broadcasting and Computational Approach to Train on Music Notations for Visually Impaired in Sri Lanka.
GSTF Journal on Computing (JoC) Vol.4 No.3, October 2015
©The Author(s) 2015. This article is published with open access by the GSTF
34
This article is distributed under the terms of the Creative Commons Attribution License whichpermits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.


















