
Association Analysis (7) (Mining Graphs). Frequent Subgraph Mining Extend association rule mining to...
23
Association Analysis (7) (Mining Graphs)
-
date post
18-Dec-2015 -
Category
Documents
-
view
223 -
download
2
Transcript of Association Analysis (7) (Mining Graphs). Frequent Subgraph Mining Extend association rule mining to...

Association Analysis (7)(Mining Graphs)

Frequent Subgraph Mining• Extend association rule mining to finding frequent subgraphs
• Useful for Web Mining, computational chemistry, spatial data sets, etc
Databases
Homepage
Teaching
Data Mining

Bio/Chem-Informatics• Each year, new chemical
compounds are designed.
• We know that structure of a compound plays a big role in its chemical properties.
• However, it is difficult to establish their exact relationship.
• Frequent subgraph mining can aid by identifying the substructures commonly associated with certain properties of known compounds.

Web mining• E.g. Mining the DBLP Web Graph
Garcia-Molina
Widom
Jeff Ullman
Alfred Aho
Lenzerini
Calvanese
Vardi
Kuperferman
A mined subgraph Two examples of matches

Graph Definitions
a
b a
c c
b
(a) Labeled Graph
pq
p
p
rs
tr
t
qp
a
a
c
b
(b) Subgraph
p
s
t
p
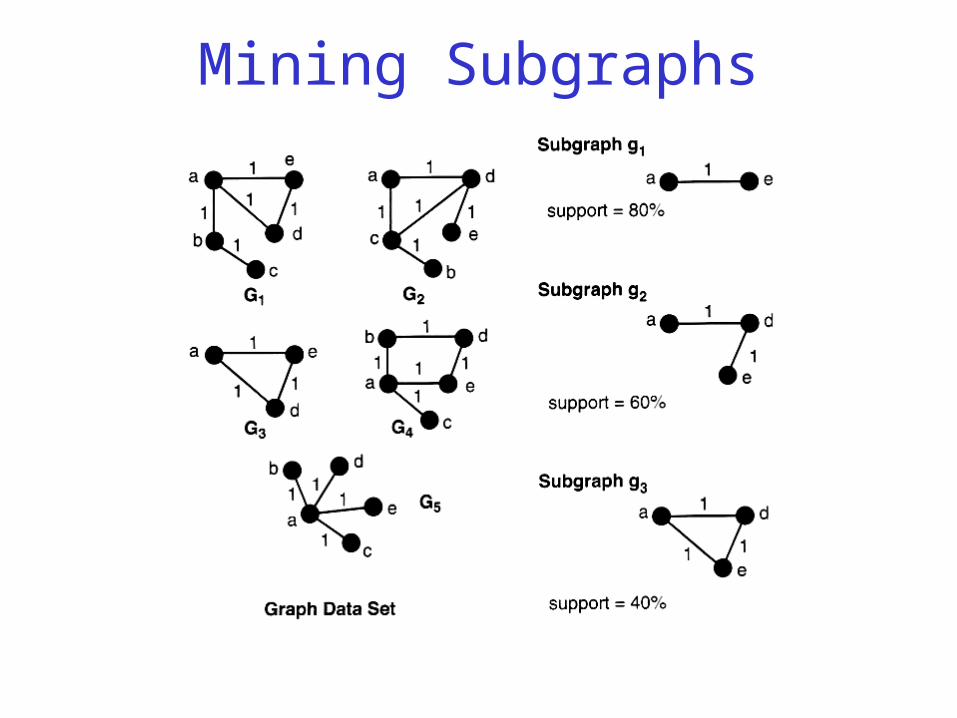
Mining Subgraphs
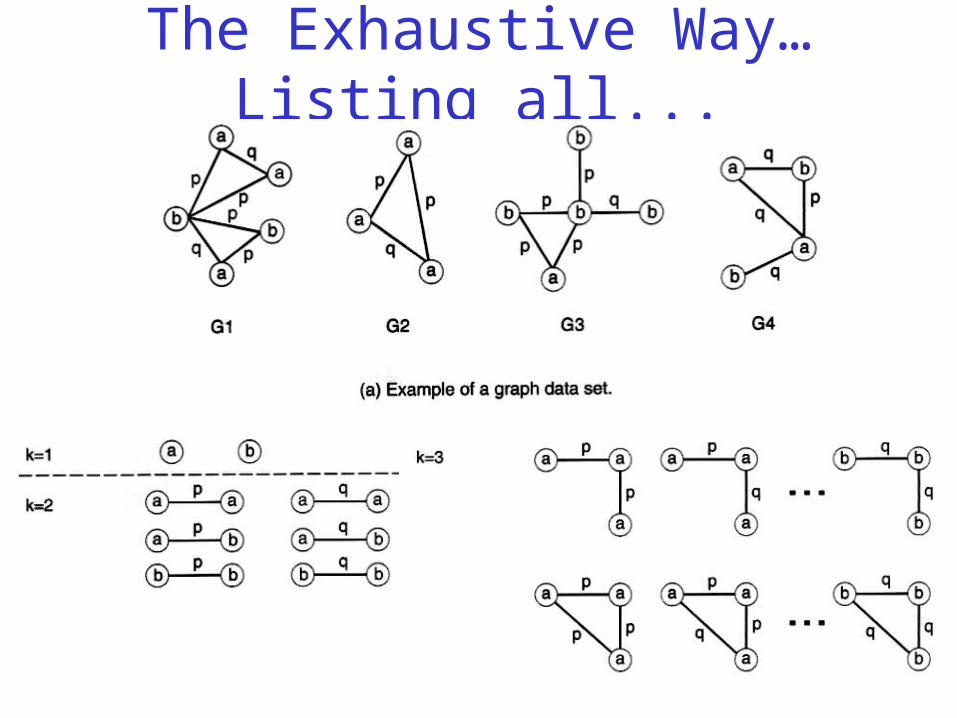
The Exhaustive Way…Listing all...

Apriori-Like Approach• Support:
– number of graphs that contain a particular subgraph
• Apriori principle still holds
• Level-wise (Apriori-like) approach:– Vertex growing:
• k is the number of vertices
– Edge growing:• k is the number of edges

Apriori-Like Algorithm• Generate candidate
– Merge pairs of frequent (k - 1)-subgraphs to obtain a candidate k-subgraphs.
• Prune candidates – Discard all candidate k-subgraphs that contain infrequent (k - l)-
subgraphs.
• Count support – Counting the number of graphs in DB that contain each candidate.
– Discard all candidate subgraphs whose support counts are less than minsup.

Vertex Growing
The resulting matrix is the first matrix, appended with the last row and last column of the second matrix. The remaining entries of the new matrix are either zero or replaced by all valid edge labels connecting the pair of vertices.
r

Edge growing inserts a new edge to an existing frequent subgraph during candidate generation.
Doesn’t necessarily increase the number of vertices in the original graphs.
Edge Growing

Topological equivalenceTwo vertexes are topologically equivalent if they have:
1. The same label and
2. The same number and label of edges incident to them.
v1,v2,v3,v4 are topologically equivalent
v1,v4 are topologically equivalentv2,v3 are topologically equivalent
No topologically equivalentvertexes

Multiplicity of Candidates
Case 1a: v v’ , v1v2 (Topologically in the (k-2)-graphs)
ea
bd
cq
q
p
r
p
Core: The (k-2)-edge subgraph that is common between the joint graphs
We try to map the cores.
+
a
bd
cq
q
p
r
v
v’
a
be
c
pq
p
r
v1 v2

Multiplicity of Candidates
Case 1b: v v’ , v1=v2 (Topologically in the (k-2)-graphs)
a
be
cq
q
p
r
p
ea
be
cq
q
p
r
p
+
a
be
cq
q
p
r
v
v’
a
be
c
pq
p
r
v1
v2

Multiplicity of Candidates
Case 2a: v v’ , v1v2 (Topologically in the (k-2)-graphs)
ea
bd
c
p
r
p
+
a
bd
c
p
r
v v’
a
be
c
pq
p
r
v2v1
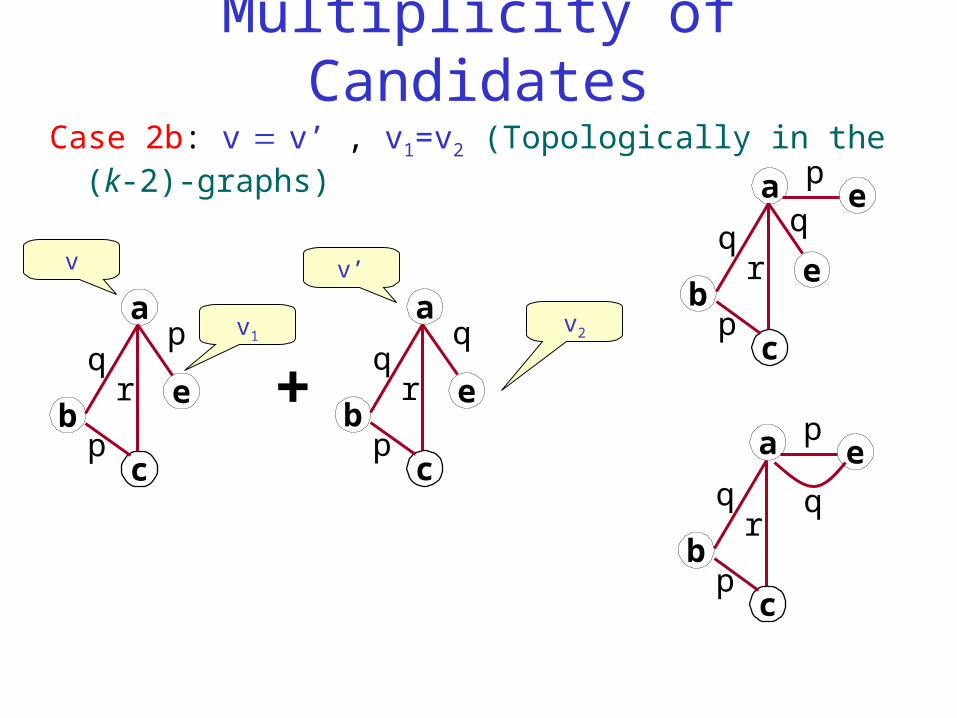
Multiplicity of Candidates
Case 2b: v v’ , v1=v2 (Topologically in the (k-2)-graphs)
ea
be
c
p
r
p
ea
b
c
p
r
p+
a
be
c
p
r
v v’
a
be
c
pq
p
r
v1v2

Multiplicity of Candidates
Case 2c: v v’ (Topologically in the (k-2)-graphs)
+
a
bd
a
q
q
q
r
v
v’
a
be
a
pq
q
r
ea
bd
a
q
r
p
ea
bd
a
q
q
q
r
p
We try to map the cores, and there two ways to do this.
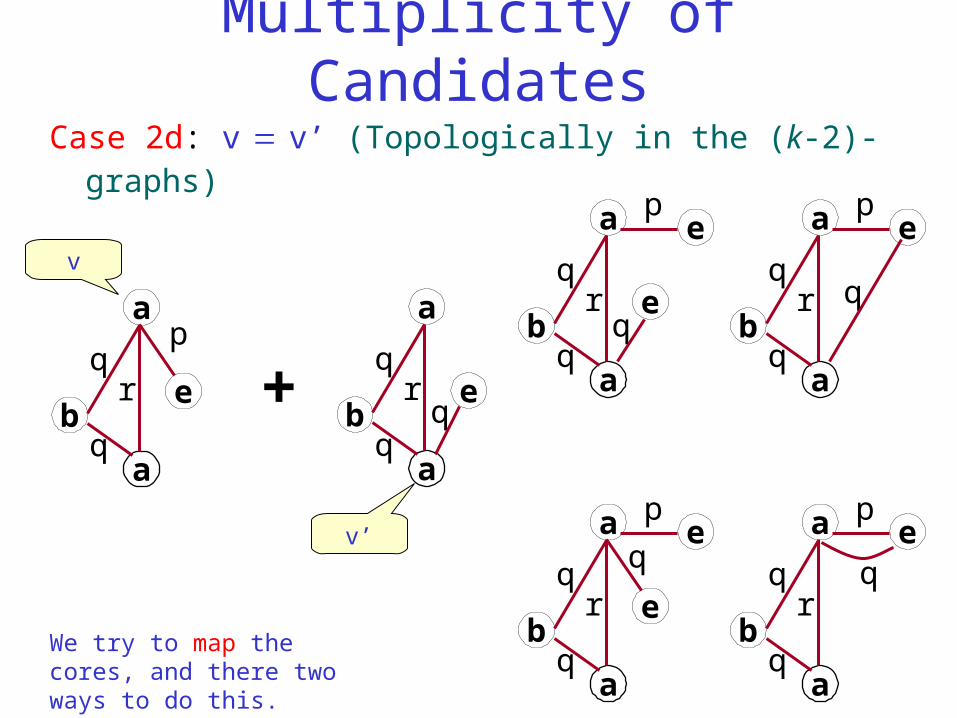
Multiplicity of Candidates
Case 2d: v v’ (Topologically in the (k-2)-graphs)
+
a
be
a
q
q
q
r
v
v’
a
be
a
pq
q
r
We try to map the cores, and there two ways to do this.
ea
be
a
q
q
q
r
pea
b
a
q
r
p
ea
be
a
q
r
pea
b
a
q
r
p

Multiplicity of CandidatesMore than two topologically equivalent vertexes
+
a
aa
a
c
b
a
aa
a
c
a
aa
a
c
b
b
a
aa
a
b a
aa
a
c
Core: The (k-2) subgraph that is common between the joint graphs

Adjacency Matrix RepresentationA(1) A(2)
B (6)
A(4)
B (5)
A(3)
B (7) B (8)
A(2) A(1)
B (6)
A(4)
B (7)
A(3)
B (5) B (8)
• The same graph can be represented in many ways
A(1) A(2) A(3) A(4) B(5) B(6) B(7) B(8)A(1) 0 1 1 0 1 0 0 0A(2) 1 0 0 1 0 1 0 0A(3) 1 0 0 1 0 0 1 0A(4) 0 1 1 0 0 0 0 1B(5) 1 0 0 0 0 1 1 0B(6) 0 1 0 0 1 0 0 1B(7) 0 0 1 0 1 0 0 1B(8) 0 0 0 1 0 1 1 0
A(1) A(2) A(3) A(4) B(5) B(6) B(7) B(8)A(1) 0 1 0 1 0 1 0 0A(2) 1 0 1 0 0 0 1 0A(3) 0 1 0 1 1 0 0 0A(4) 1 0 1 0 0 0 0 1B(5) 0 0 1 0 0 0 1 1B(6) 1 0 0 0 0 0 1 1B(7) 0 1 0 0 1 1 0 0B(8) 0 0 0 1 1 1 0 0

Graph Isomorphism• A graph G1 is isomorphic to another graph G2, if G1 is
topologically equivalent to G2
• Test for graph isomorphism is needed:– During candidate generation, to determine whether a candidate can
be generated
– During candidate pruning, to check whether its (k-1)-subgraphs are frequent
– During candidate counting, to check whether a candidate is contained within another graph, we should use more specialized algorithms (possibly using indexes with each frequent (k-1) sub-graph)

CodesA(1) A(2)
B (6)
A(4)
B (5)
A(3)
B (7) B (8)
A(1) A(2) A(3) A(4) B(5) B(6) B(7) B(8)A(1) 0 1 1 0 1 0 0 0A(2) 1 0 0 1 0 1 0 0A(3) 1 0 0 1 0 0 1 0A(4) 0 1 1 0 0 0 0 1B(5) 1 0 0 0 0 1 1 0B(6) 0 1 0 0 1 0 0 1B(7) 0 0 1 0 1 0 0 1B(8) 0 0 0 1 0 1 1 0
A(2) A(1)
B (6)
A(4)
B (7)
A(3)
B (5) B (8)
A(1) A(2) A(3) A(4) B(5) B(6) B(7) B(8)A(1) 0 1 0 1 0 1 0 0A(2) 1 0 1 0 0 0 1 0A(3) 0 1 0 1 1 0 0 0A(4) 1 0 1 0 0 0 0 1B(5) 0 0 1 0 0 0 1 1B(6) 1 0 0 0 0 0 1 1B(7) 0 1 0 0 1 1 0 0B(8) 0 0 0 1 1 1 0 0
Code =1 10 011 1000 01001 001010 0001011
Code =1011010010100000100110001110

Graph Isomorphism• Use canonical labeling to handle isomorphism
– Map each graph into an ordered string representation (known as its code) such that two isomorphic graphs will be mapped to the same canonical encoding
• Example: – Choose the string representation with the lowest
Lexicographical value
• Then, the graph isomorphism problem can be solved by string matching.











![Scalable Topical Phrase Mining from Text Corpora[Mining frequent patterns] without candidate generation: a [frequent pattern] tree approach. Title 2. [Frequent pattern mining] : current](https://static.fdocuments.in/doc/165x107/5e9b8030d4570c75907f97b4/scalable-topical-phrase-mining-from-text-mining-frequent-patterns-without-candidate.jpg)






