
Assessing the Performance of Computational...
26
Assessing the Performance of Computational Engineering Codes Omkar Deshmukh Simulation Based Engineering Laboratory Department of Electrical and Computer Engineering 5/13/2015 University of Wisconsin–Madison 1
Transcript of Assessing the Performance of Computational...

Assessing the Performance of
Computational Engineering Codes
Omkar Deshmukh
Simulation Based Engineering Laboratory
Department of Electrical and Computer Engineering
5/13/2015 University of Wisconsin–Madison 1

Acknowledgments
• Advisor
• Associate Professor Dan Negrut
• Committee member
• Associate Professor Krishnan Suresh
• Assistant Professor Eftychios Sifakis
• Lab members
• Dr. Radu Serban, Hammad Mazhar, Andrew Seidl, Ang Li, Naveen
Subramaniam, Vennila Megavannan
5/13/2015 University of Wisconsin–Madison 2

Overview
• Motivation and Background
• Systems Under Test
• Libraries and Benchmarks
• Benchmarking Results
• Performance Database (PerfDB)
• Live Demo
• Conclusions and Future Work
5/13/2015 University of Wisconsin–Madison 3

Motivation
• Why benchmark?
• How to benchmark?
• How to analyze results?
• Project contributions:
• Benchmarking state-of-the-art hardware platforms
• Creating infrastructure for performance benchmarking
5/13/2015 University of Wisconsin–Madison 4

Hardware – The CPUs
• AMD Opteron 6274
• 64 cores, 4 sockets, 128GB DDR3 RAM.
• Intel Core i7-5960X
• Haswell-E, 16 virtual cores, 32GB DDR4 RAM
• Intel Xeon E5-2690 v2
• Ivy Bridge-EP, 2 sockets 40 virtual cores, 64GB DDR3 RAM
• Intel Xeon Phi Coprocessor 5110P
• MIC, 60 cores / 240 threads, 512-bit VPU, 8 GB GDDR5 RAM
5/13/2015 University of Wisconsin–Madison 5

Hardware – The GPUs
• NVidia Tesla K40c
• Kepler, 12GB GDDR5 RAM, 2880 scalar processors
• NVidia Tesla K20Xm
• Kepler, 6GB GDDR5 RAM, 2688 scalar processors
• NVidia GeForce GTX 770
• Kepler, 4GB GDDR5 RAM, 1536 scalar processor
• AMD A10-7850K
• Kaveri APU, 16GB DDR3 RAM, 4 + 8 HSA cores, 512 GPU SPs
5/13/2015 University of Wisconsin–Madison 6

The Benchmarks
• Reduction
• Output = 𝑥𝑖𝑛𝑖=0
• Streaming access, O(N)
• SAXPY
• 𝑦𝑖 ← α 𝑥𝑖 + 𝑦𝑖
• Streaming access, 2 Reads + 1 Write per element
• Prefix Scan
• 𝑥𝑛 = 𝑥𝑖𝑛𝑖=0
• Streaming access, O(N log(N))
• Sorting
• Performance depends upon implementation
• Random access
5/13/2015 University of Wisconsin–Madison 7

Numerical Computing Libraries
• Thrust
• STL-like, commercially developed by Nvidia
• Supports OpenMP, CUDA
• VexCL
• Vector expression template library for GPGPU programming
• Support OpenCL, CUDA
• Intel Math Kernel Library (MKL)
• BLAS and LAPACK interfaces
• Blaze
• Dense and sparse arithmetic
• Supports OpenMP, C++11 and Boost threads
5/13/2015 University of Wisconsin–Madison 8

Results – Reduction
Intel Xeon Phi
• H/W with best performance
• Scales up
• Thrust Outperforms VexCL
Intel Xeon E5-2690v2
• Compute → Memory bound
transition
5/13/2015 University of Wisconsin–Madison 9

Results – Reduction
NVidia Tesla K20Xm
• Thrust scales up
• VexCL saturated
AMD A10 7850K
• GPU only implementation works
similar to CPU+GPU
5/13/2015 University of Wisconsin–Madison 10

Results – SAXPY
Intel Xeon Phi
• Performance of libraries
• Flat profiles
AMD Opteron 6274
• Performance at 10M and 25M
• Transition to I/O intensive workload
5/13/2015 University of Wisconsin–Madison 11
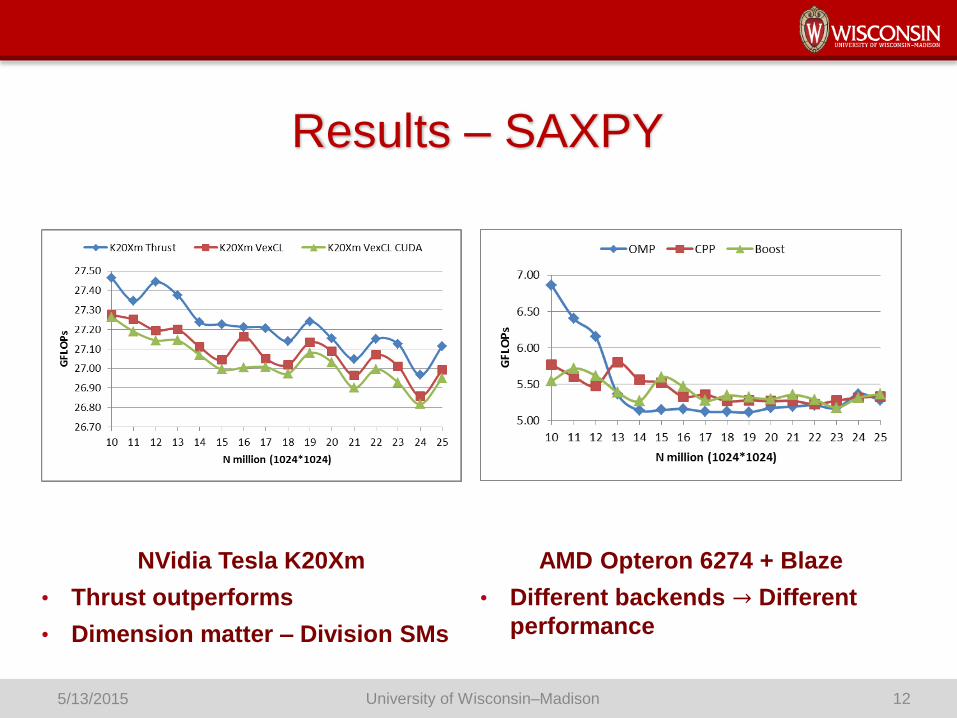
Results – SAXPY
NVidia Tesla K20Xm
• Thrust outperforms
• Dimension matter – Division SMs
AMD Opteron 6274 + Blaze
• Different backends → Different
performance
5/13/2015 University of Wisconsin–Madison 12
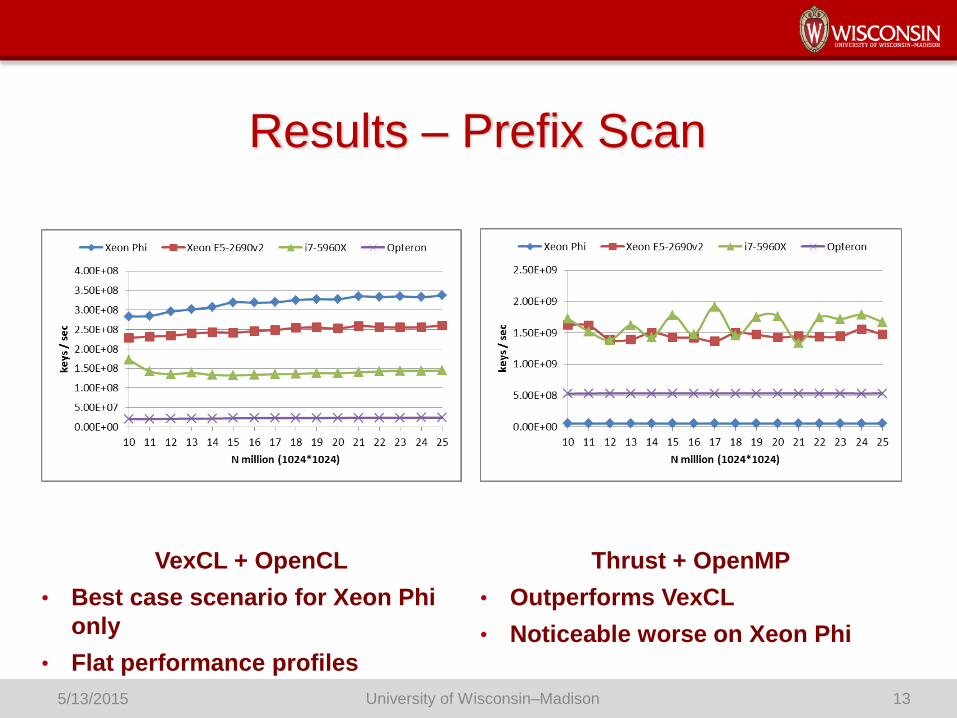
Results – Prefix Scan
VexCL + OpenCL
• Best case scenario for Xeon Phi
only
• Flat performance profiles
Thrust + OpenMP
• Outperforms VexCL
• Noticeable worse on Xeon Phi
5/13/2015 University of Wisconsin–Madison 13
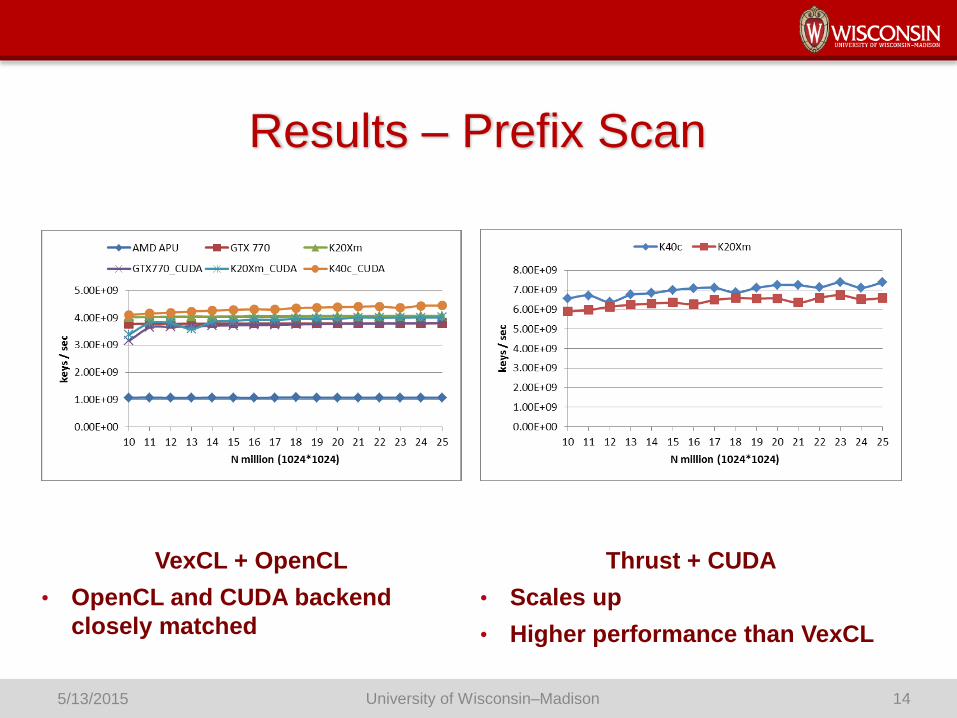
Results – Prefix Scan
VexCL + OpenCL
• OpenCL and CUDA backend
closely matched
Thrust + CUDA
• Scales up
• Higher performance than VexCL
5/13/2015 University of Wisconsin–Madison 14

Results – Sort
VexCL + OpenCL
• Drop in sort rate for Xeon Phi
Thrust + OpenMP
• 4 to 5 times faster than VexCL
5/13/2015 University of Wisconsin–Madison 15

Software Setup for PerfDB
• The need for database
• Information archival and retrieval
• Deluge of data. Bound to increase fast
• Easy to collaborate
• Use Github to keep track of:
• Source code + makefiles
• Results and reports
• SQLite3 – Embedded database
5/13/2015 University of Wisconsin–Madison 16

Database Schema
5/13/2015 University of Wisconsin–Madison 17

Interacting with PerfDB
Semi-automated process →
• Manual pre-runs setup – Uses
config.json
• Automated benchmark reporting
{
"db_url": "sqlite:///perfdb",
"host_id": "3",
"accl_id": "6",
"system_id": "30",
"source_id": "1",
"perf_id": "1"
} Config.json
5/13/2015 University of Wisconsin–Madison 18
name = 'test name' input = 'vector or matrix name' datatype = 'float/double' dim_x = #int dim_y = #int NNZ = #int value_type = 'GFLOPS or keys/sec' value = #float
Benchmark Output

Interacting with PerfDB
• Web based interface
• Get existing data
• Insert new configurations
• Query results
• Command line interface
• Access to SQLite3 shell
• Python utilities for similar functionality
• Usage of script “insert.py” common to both workflows
5/13/2015 University of Wisconsin–Madison 19

PerfDB Demo
5/13/2015 University of Wisconsin–Madison 20

Conclusions
• Benchmarking:
• Performance dependent on application requirements
• Understand the context of vendor-advertised performance metrics
• Numerical Computing Libraries:
• Thrust – Consistent and fast
• VexCL – GPU performance lower than Thrust
• MKL – Not always the best option
• Software Setup
• Pro and cons of embedded SQLite3 database
5/13/2015 University of Wisconsin–Madison 21

Future Work
• Current version – Functional and ready to use
• In short term:
• Use CMake for portable cross-platform builds
• Move to database server, e.g. PostgreSQL
• Long term goals:
• Incorporate software profiling
• Extend web-based interface
• Widen the user and/or contributor base
5/13/2015 University of Wisconsin–Madison 22

Thank you!
5/13/2015 University of Wisconsin–Madison 23

Comparison - Reduction
5/13/2015 University of Wisconsin–Madison 25
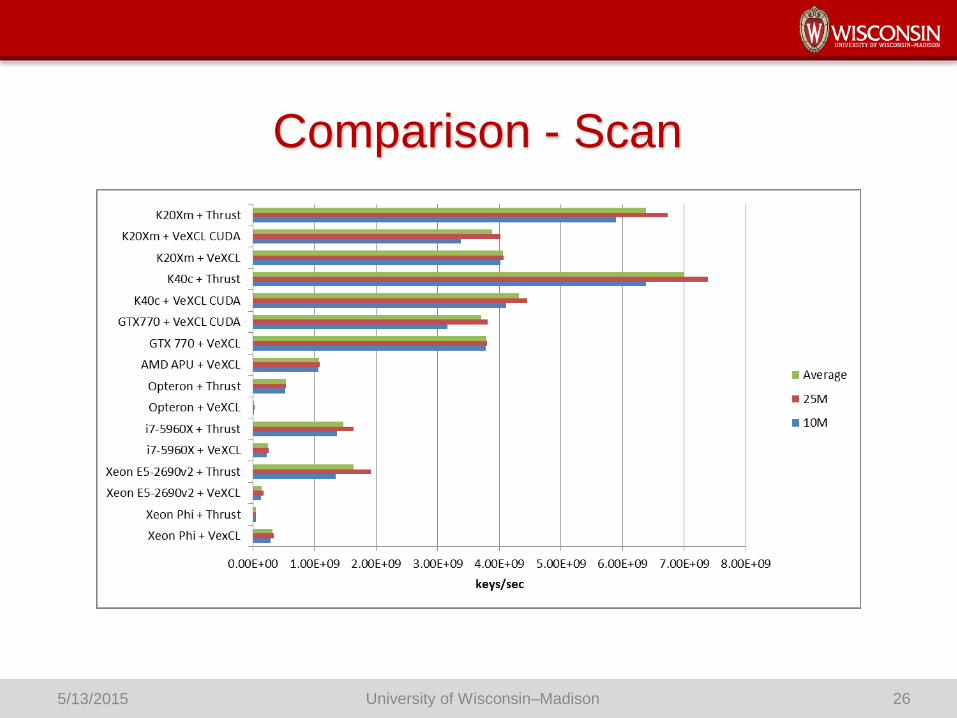
Comparison - Scan
5/13/2015 University of Wisconsin–Madison 26
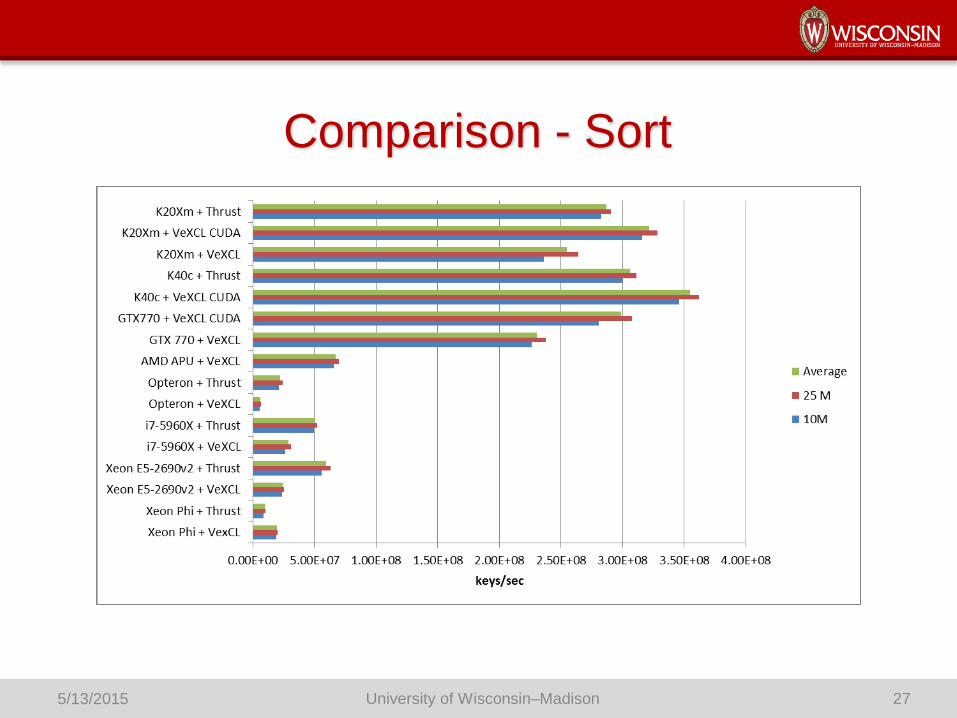
Comparison - Sort
5/13/2015 University of Wisconsin–Madison 27


















