
Artificial Neural Networks Lecture Noteslucci/notes/lecture11.pdfArtificial Neural Networks Lecture...
19
Part 11 About this file: l This is the printer-friendly version of the file "lecture11.htm". In case the page is not properly displayed, use IE 5 or higher. l Since this is an offline page, each file "lecture nn .htm" (for instance "lecture11.htm") is accompanied with a "img nn " folder (for instance "img11") containing the images which make part of the notes. So, to see the images, Each html file must be kept in the same directory (folder) as its corresponding "img nn " folder. l If you have trouble reading the contents of this file, or in case of transcription errors, email [email protected] l Acknowledgments: Background image is from http://www.anatomy.usyd.edu.au/online/neuroanatomy/tutorial1/tutorial1.html (edited) at the University of Sydney Neuroanatomy web page. Mathematics symbols images are from metamath.org 's GIF images for Math Symbols web page. Some images are scans from R. Rojas, Neural Networks (Springer-Verlag, 1996), as well as from other books to be credited in a future revision of this file. Some image credits may be given where noted, the remainder are native to this file. Contents l Associative Memory Networks ¡ A Taxonomy of Associative Memories ¡ An Example of Associative Recall ¡ Hebbian Learning ¡ Hebb Rule for Pattern Association ¡ Character Recognition Example ¡ Autoassociative Nets ¡ Application and Examples ¡ Storage Capacity l Genetic Algorithms ¡ GA's Vs. Other Stochastic Methods ¡ The Metropolis Algorithm ¡ Bit-Based Descent Methods ¡ Genetic Algorithms ¡ Neural Nets and GA Artificial Neural Networks Lecture Notes Stephen Lucci, PhD Stephen Lucci, PhD Artificial Neural Networks Part 11 Page 1 of 19
Transcript of Artificial Neural Networks Lecture Noteslucci/notes/lecture11.pdfArtificial Neural Networks Lecture...

Part 11
About this file:
l This is the printer-friendly version of the file "lecture11.htm". In case the page is not properly displayed, use IE 5 or higher.
l Since this is an offline page, each file "lecturenn.htm" (for instance "lecture11.htm") is accompanied with a "imgnn" folder (for instance "img11") containing the images which make part of the notes. So, to see the images, Each html file must be kept in the same directory (folder) as its corresponding "imgnn" folder.
l If you have trouble reading the contents of this file, or in case of transcription errors, email [email protected]
l Acknowledgments: Background image is from http://www.anatomy.usyd.edu.au/online/neuroanatomy/tutorial1/tutorial1.html (edited) at the University of Sydney Neuroanatomy web page. Mathematics symbols images are from metamath.org's GIF images for Math Symbols web page. Some images are scans from R. Rojas, Neural Networks (Springer-Verlag, 1996), as well as from other books to be credited in a future revision of this file. Some image credits may be given where noted, the remainder are native to this file.
Contents
l Associative Memory Networks ¡ A Taxonomy of Associative Memories ¡ An Example of Associative Recall ¡ Hebbian Learning ¡ Hebb Rule for Pattern Association ¡ Character Recognition Example ¡ Autoassociative Nets ¡ Application and Examples ¡ Storage Capacity
l Genetic Algorithms ¡ GA's Vs. Other Stochastic Methods ¡ The Metropolis Algorithm ¡ Bit-Based Descent Methods ¡ Genetic Algorithms ¡ Neural Nets and GA
Artificial Neural Networks Lecture Notes
Stephen Lucci, PhD
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 1 of 19

Associative Memory Networks
l Remembering something: Associating an idea or thought with a sensory cue.
l Human memory connects items (ideas, sensations, &c.) that are similar, that are contrary, that occur in close proximity, or that occur in close succsession - Aristotle
l An input stimulus which is similar to the stimulus for the association will invoke the associated response pattern.
¡ A woman's perfume on an elevator... ¡ A song on the radio... ¡ An old photograph...
l An Associative Memory Net may serve as a highly simplified model of human memory.
l These associative memory units should not be confused with Content Addressable Memory Units.
A Taxonomy of Associative Memories
The superscripts of x and y are all i
l Heteroassociative network Maps n input vectors 1, 2, ..., n, in n-dimensional space to m output vectors 1, 2, ..., m, in m-dimensional space,
i i
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 2 of 19

if || - i||2 < then i
l Autoassociative Network A type of heteroassociative network. Each vector is associated with itself; i.e.,
i = i , i = 1, ..., n.
Features correction of noisy input vectors.
l Pattern Recognition Network A type of heteroassociative network. Each vector i is associated with the scalar i. [illegible - remainder cut-off in photocopy]
An Example of Associative Recall
To the left is a binarized version of the letter "T".
The middle picture is the same "T" but with the bottom half replaced by noise. Pixels
have been assigned a value 1 with probability 0.5 Upper half: The cue Bottom half: has to be recalled from memory.
The pattern on the right is obtained from the original "T" by adding 20% noise. Each pixel is inverted with probability 0.2. The whole memory is available, but in an imperfectly recalled form ("hazy" or inaccurate memory of some scene.)
(Compare/contrast the following with database searches) In each case, when part of the pattern of data is presented in the form of a sensory cue, the rest of the pattern (memory) is associated with it.
Alternatively, we may be offered an imperfect version of the... [illegible - remainder cut-off in photocopy]
Hebbian Learning
Donald Hebb - psychologist, 1949.
Two neurons which are simultaneously active should develop a degree of interaction higher than those neurons whose activities are uncorrelated.
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 3 of 19

Input x i
Output yj
weight update wij = xiyj
Hebb Rule for Pattern Association
It can be used with patterns that are represented as either binary or bipolar vectors.
l Training Vector Pairs : l Testing Input Vector (which may or may not be the same as one of the
training input vectors.)
In this simple form of Hebbian Learning, one generally employs outer product calculations instead.
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 4 of 19

Architecture of a Heteroassociative Neural Net
A simple example (from Fausett's text) Heteroassociative network. Input vectors - 4 components Output vectors - 2 components
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 5 of 19

The input vectors are not mutually orthogonal (i.e., the dot product 0,) - in which case the response will include a portion of each of their target values - cross-talk.
Note: target values are chosen to be related to the input vectors in a simple manner. The cross-talk between the first and second input vectors does not pose any difficulties (since these target values... [Illegible - cut off in photocopy]
The training is accomplished by the Hebb rule:
l wij(new) = wij(old) + s itj
ie, wij = s itj , = 1.
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 6 of 19

testing - cont'd:
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 7 of 19

We can employ vector-matrix rotation to illustrate the testing process.
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 8 of 19

l A bipolar representation would be preferable. More robust in the presence of
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 9 of 19

noise.
l The weight matrix obtained from the previous examples would be:
with two "mistakes". Trouble remains: ie, (-1, 1, 1, -1) w = (0,0) (0,0).
l However, the net can respond correctly when given an input vector with two components missing . e.g., X = (0, 1, 0, -1) formed from S = (1, 1,-1, -1) with the first and third components missing rather than wrong. (0, 1, 0, -1) w = (6,-6) = (1,1) which is the ... [illegible - cut off in photocopy]
Character Recognition Example
(Example 3.9) A heteroassociative net for associating letters from different fonts
A heteroassociative neural net was trained using the Hebb rule (outer products) to associate three vector pairs. The x vectors have 63 components, the y vectors 15. The vectors represent patterns. The pattern
is converted to a vector representation that is suitable for processing as follows: The #'s are replaced by 1's and the dots by -1's, reading across each row (starting with the top row). The pattern shown becomes the vector
(-1,1,-1 1,-1,1 1,1,1 1,-1,1 1,-1,1).
The extra spaces between the vector components, which separate the different rows of the original pattern for ease of reading, are not necessary for the network. The figure below shows the vector pairs in their original two-dimensional form.
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 10 of 19

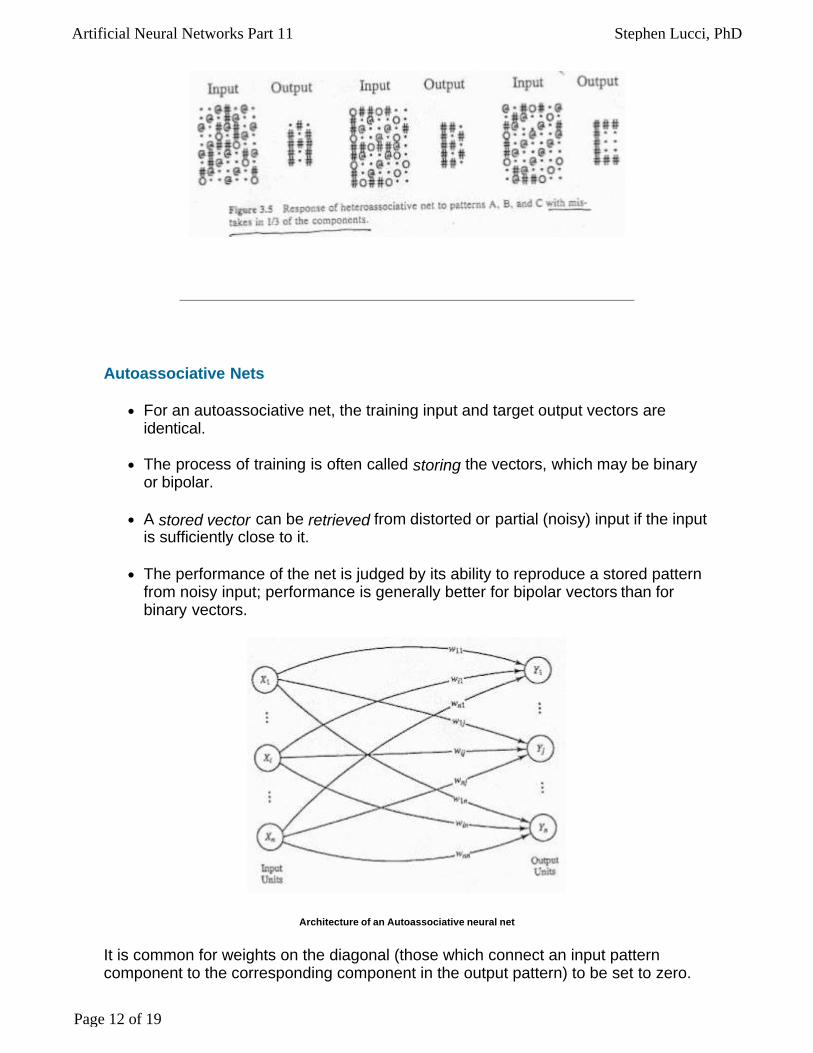
After training, the net was used with input patterns that were noisy versions of the training input patterns. The results are shown in figures 3.4 and 3.5 (below). The noise took the form of turning pixels "on" that should have been "off" and vice versa. These are denoted as follows:
@ Pixel is now "on", but this is a mistake (noise). O Pixel is now "off", but this is a mistake (noise).
Figure 3.5 (below) shows that the neural net can recognize the small letters that are stored in it, even when given input patterns representing the large training patterns with 30% noise.
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 11 of 19
Autoassociative Nets
l For an autoassociative net, the training input and target output vectors are identical.
l The process of training is often called storing the vectors, which may be binary or bipolar.
l A stored vector can be retrieved from distorted or partial (noisy) input if the input is sufficiently close to it.
l The performance of the net is judged by its ability to reproduce a stored pattern from noisy input; performance is generally better for bipolar vectors than for binary vectors.
Architecture of an Autoassociative neural net
It is common for weights on the diagonal (those which connect an input pattern component to the corresponding component in the output pattern) to be set to zero.
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 12 of 19

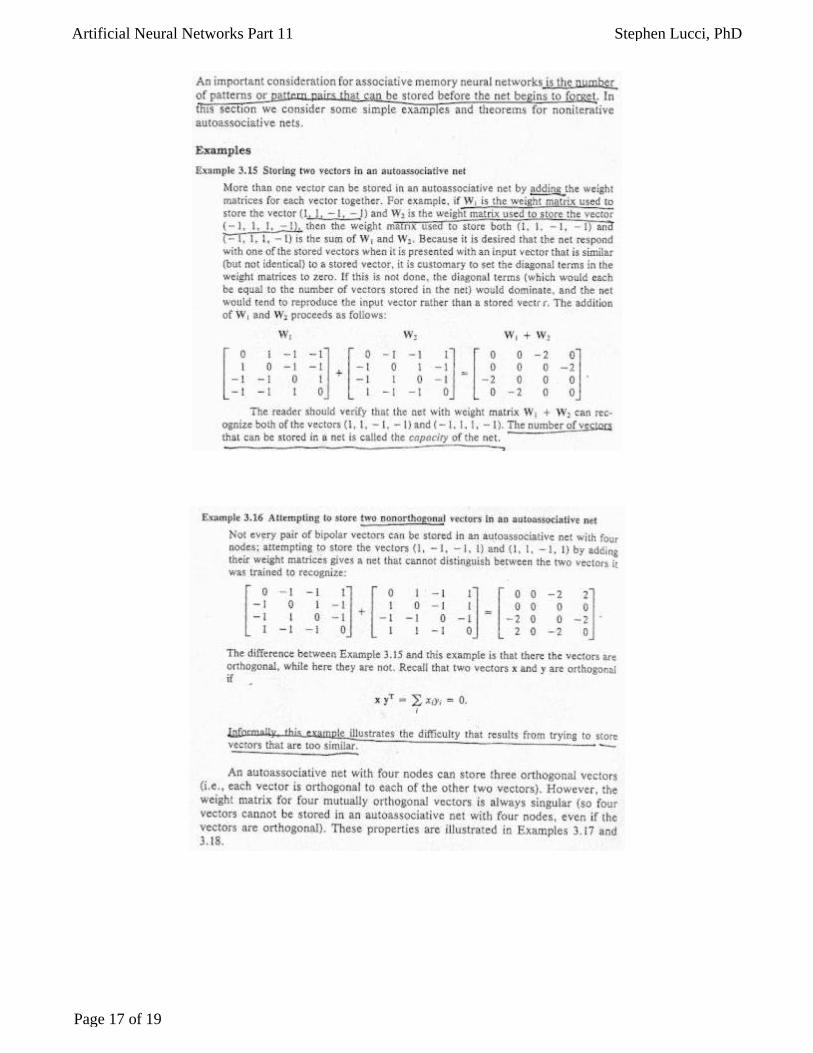
Application and examples of Autoassociative Nets
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 13 of 19

Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 14 of 19

Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 15 of 19

Storage Capacity
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 16 of 19
Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 17 of 19

Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 18 of 19

Stephen Lucci, PhDArtificial Neural Networks Part 11
Page 19 of 19





![Deep Parametric Continuous Convolutional Neural Networks€¦ · Graph Neural Networks: Graph neural networks (GNNs) [25] are generalizations of neural networks to graph structured](https://static.fdocuments.in/doc/165x107/5f7096c356401635d36dbe30/deep-parametric-continuous-convolutional-neural-networks-graph-neural-networks.jpg)












