ARTIFICIAL NEURAL NETWORK … NEURAL NETWORK • A network of artificial neurons Characteristics...
49
Teny Handhayani ARTIFICIAL NEURAL NETWORK (JARINGAN SYARAF TIRUAN)
Transcript of ARTIFICIAL NEURAL NETWORK … NEURAL NETWORK • A network of artificial neurons Characteristics...

Teny Handhayani
ARTIFICIAL NEURAL NETWORK(JARINGAN SYARAF TIRUAN)
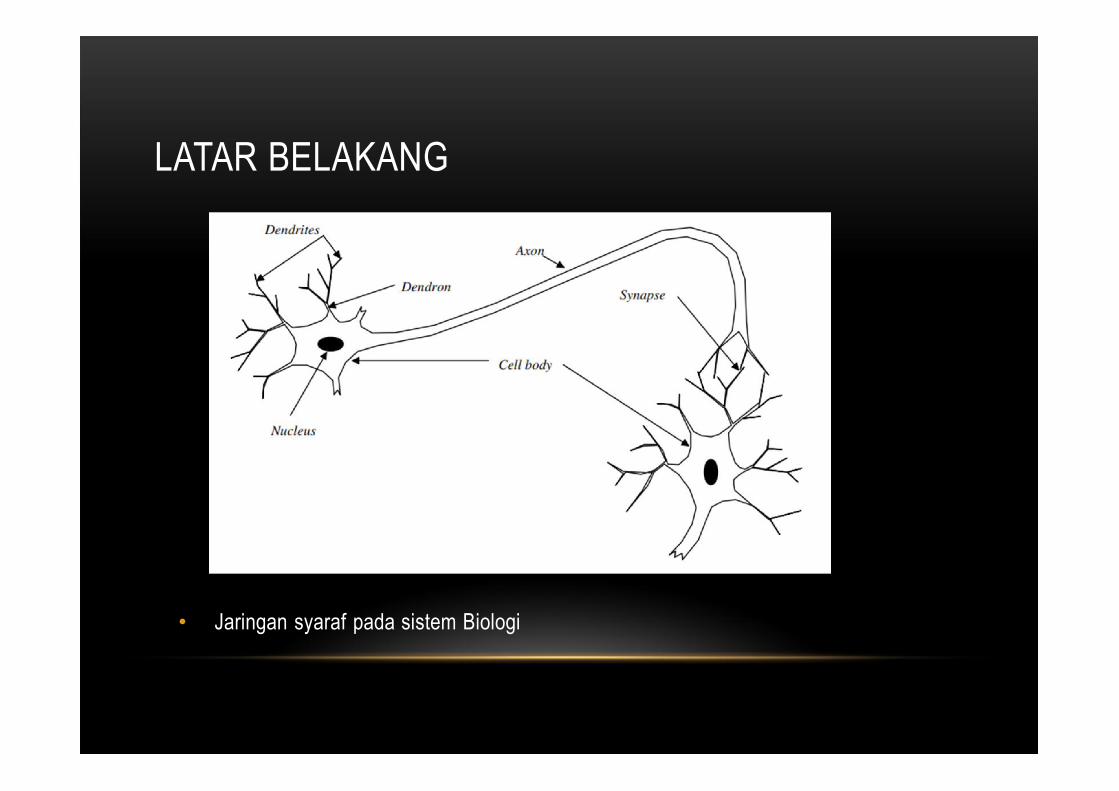
LATAR BELAKANG
• Jaringan syaraf pada sistem Biologi
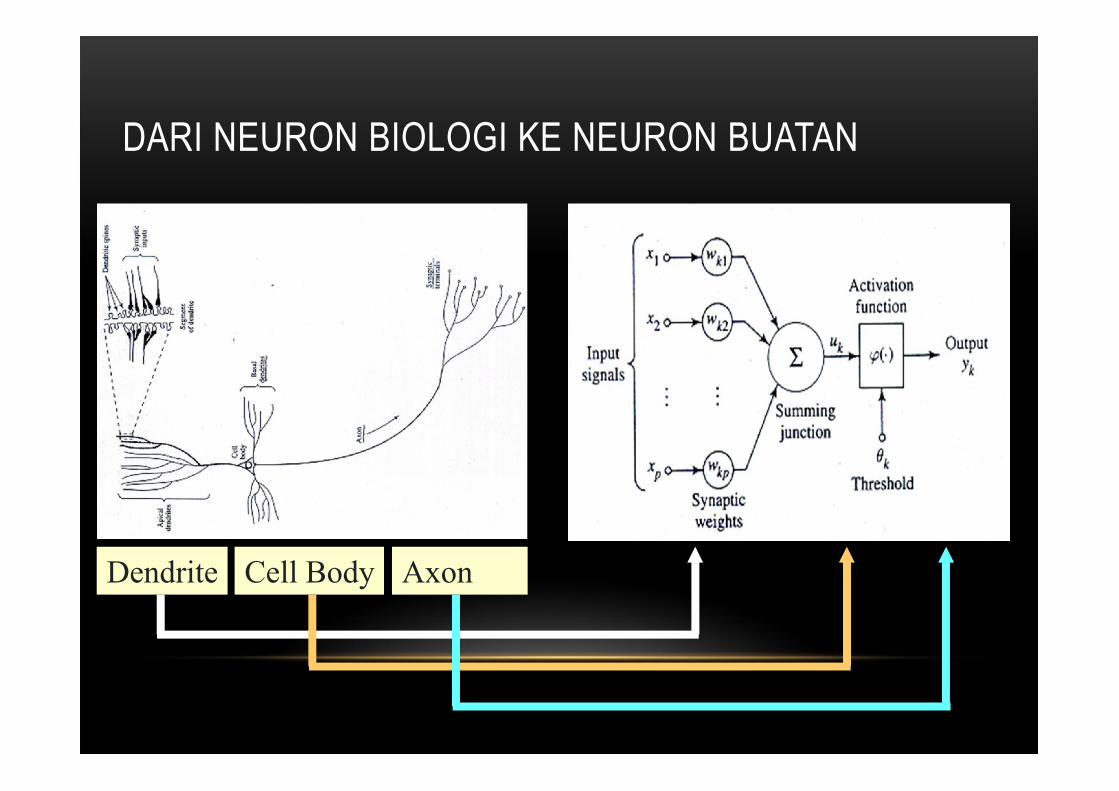
DARI NEURON BIOLOGI KE NEURON BUATAN
Dendrite Cell Body Axon
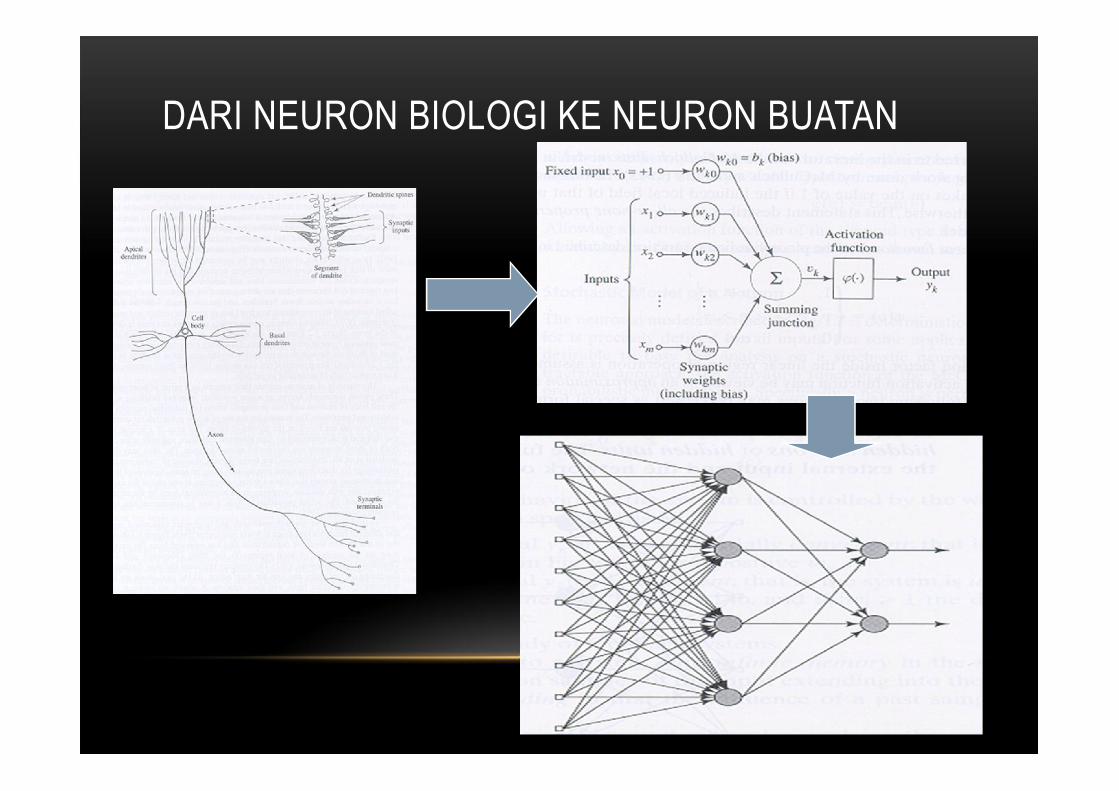
DARI NEURON BIOLOGI KE NEURON BUATAN
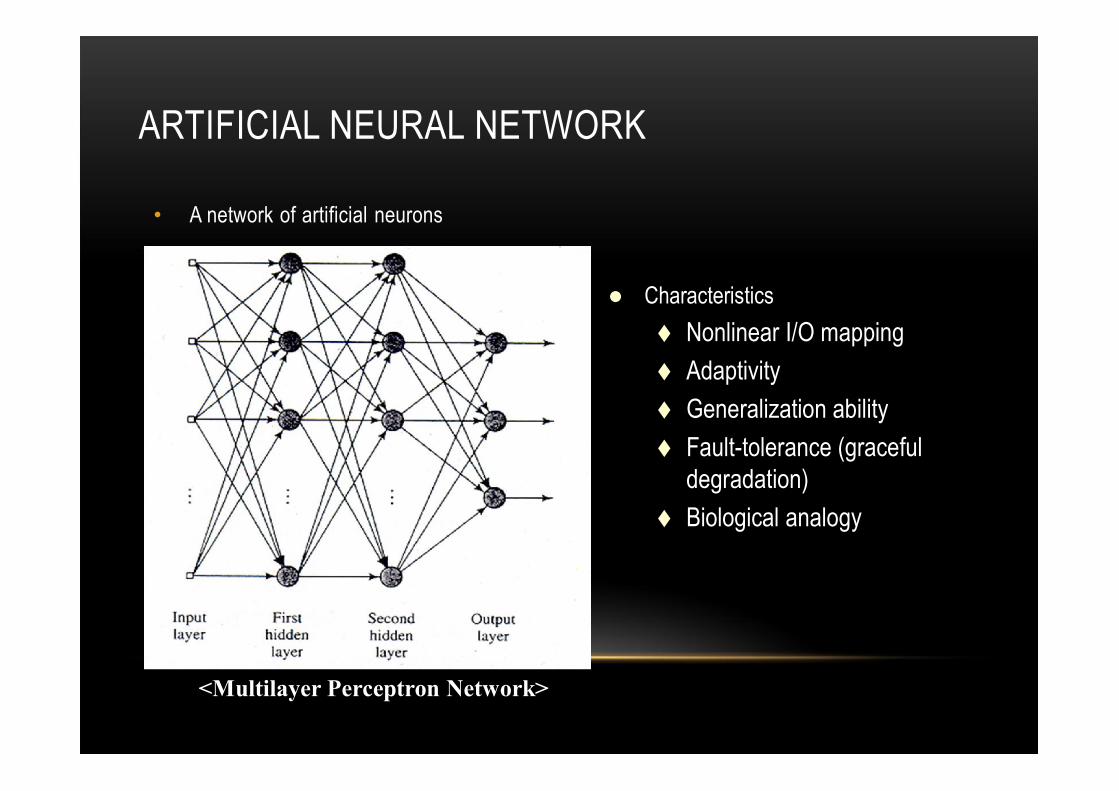
ARTIFICIAL NEURAL NETWORK
• A network of artificial neurons
Characteristics
Nonlinear I/O mapping
Adaptivity
Generalization ability
Fault-tolerance (graceful degradation)
Biological analogy
<Multilayer Perceptron Network>

TIPE-TIPE ARTIFICIAL NEURAL NETWORKS
• Single Layer Perceptron
• Multilayer Perceptrons (MLPs)
• Radial-Basis Function Networks (RBFs)
• Hopfield Network
• Boltzmann Machine
• Self-Organization Map (SOM)
• Modular Networks (Committee Machines)
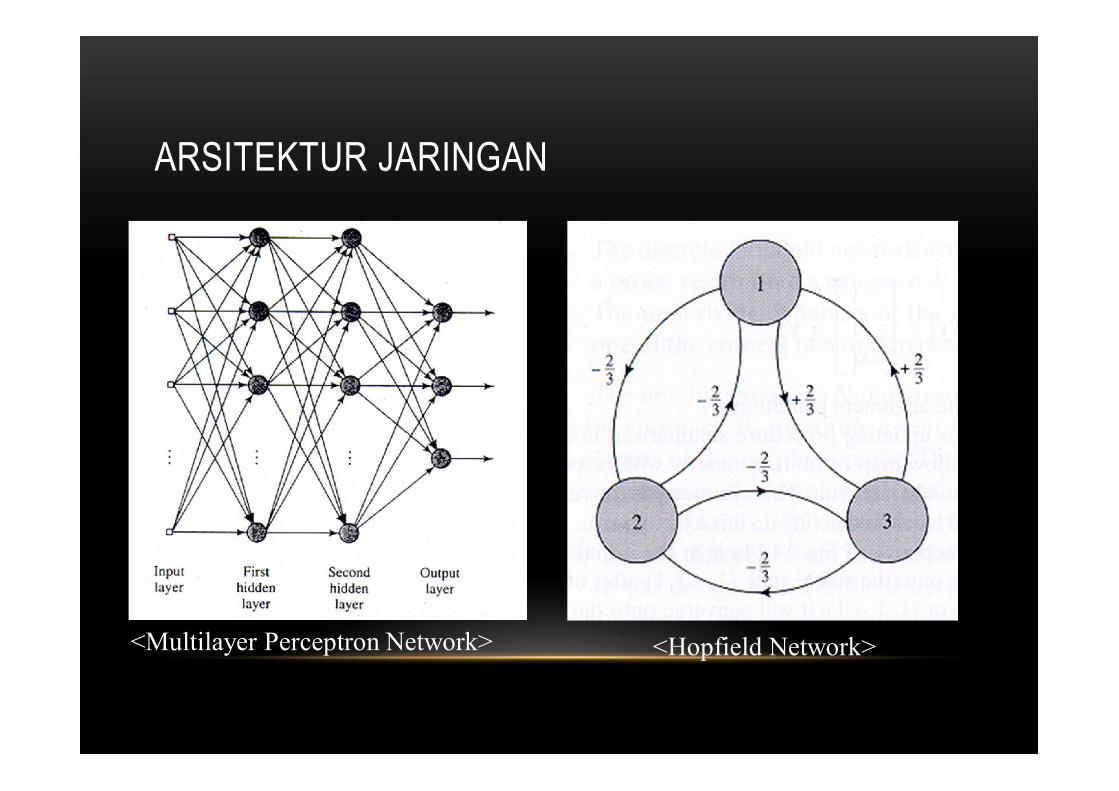
ARSITEKTUR JARINGAN
<Multilayer Perceptron Network> <Hopfield Network>

FITUR DARI ARTIFICIAL NEURAL NETWORKS
• Records (examples) need to be represented as a (possibly large) set of tuples of
<attribute, value>
• Nilai output direpresentasikan sebagai nilai diskrit, real, atau vektor
• Memiliki toleransi terhadap noise data input
• Time factor
• Membutuhkan waktu yang lama untuk pelatihan
• Sekali melalui pelatihan, ANN mampu memrpoduksi output dengan cepat
• Sulit untuk menginterpretasikan proses prediksi ANN

CONTOH APLIKASI
• NETtalk [Sejnowski]
• Inputs: English text
• Output: Spoken phonemes
• Phoneme recognition [Waibel]
• Inputs: wave form features
• Outputs: b, c, d,…
• Robot control [Pomerleau]
• Inputs: perceived features
• Outputs: steering control
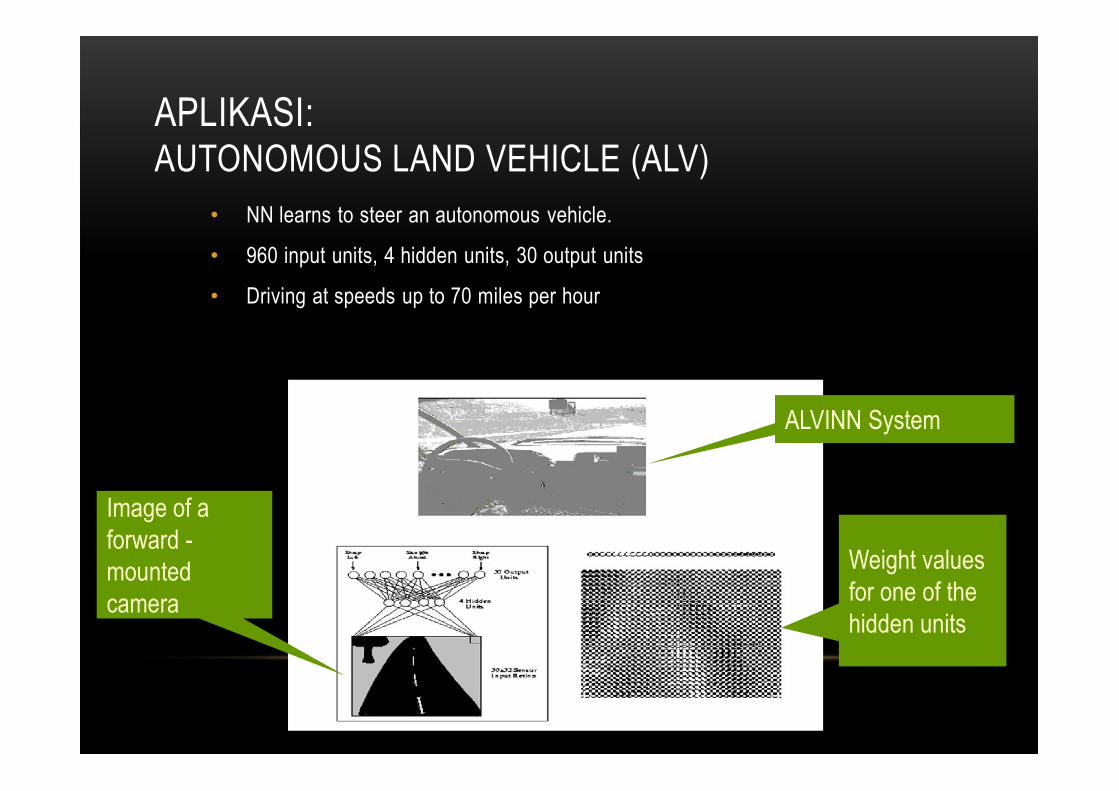
APLIKASI:AUTONOMOUS LAND VEHICLE (ALV)
• NN learns to steer an autonomous vehicle.
• 960 input units, 4 hidden units, 30 output units
• Driving at speeds up to 70 miles per hour
Weight valuesfor one of the hidden units
Image of aforward -mountedcamera
ALVINN System
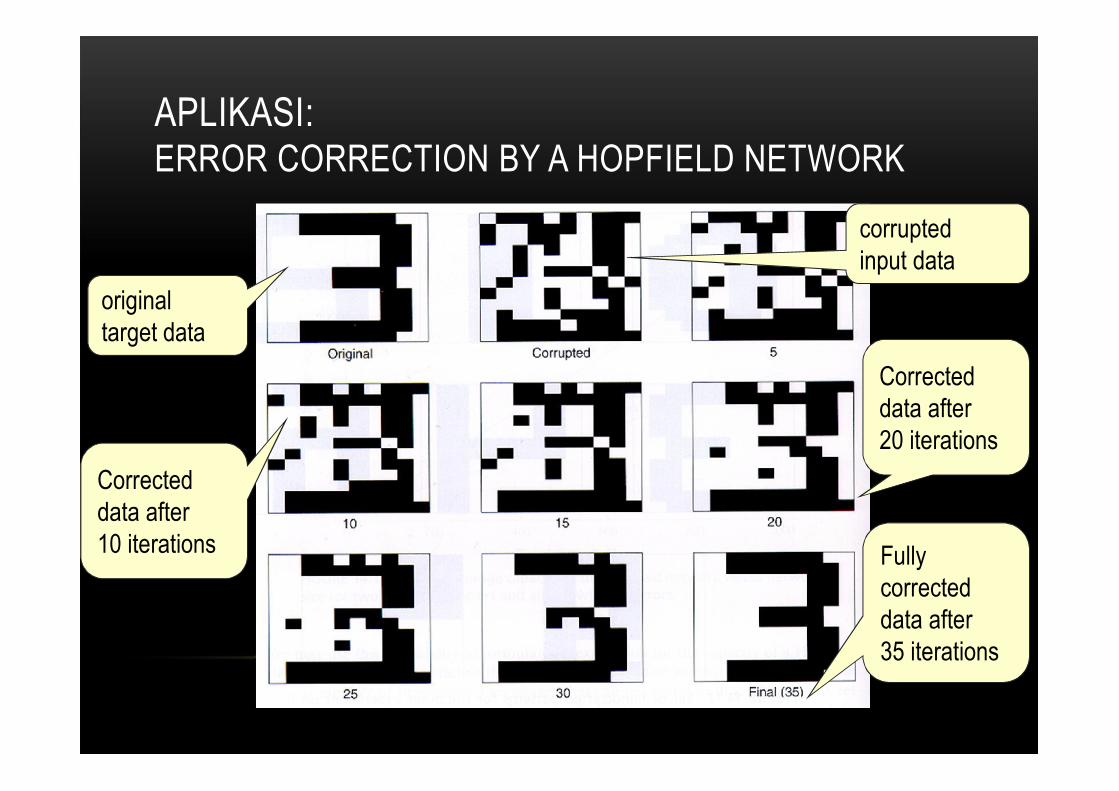
APLIKASI:ERROR CORRECTION BY A HOPFIELD NETWORK
original target data
corrupted input data
Corrected data after 10 iterations
Corrected data after 20 iterations
Fullycorrected data after 35 iterations

PERCEPTRON AND
GRADIENT DESCENT ALGORITHM
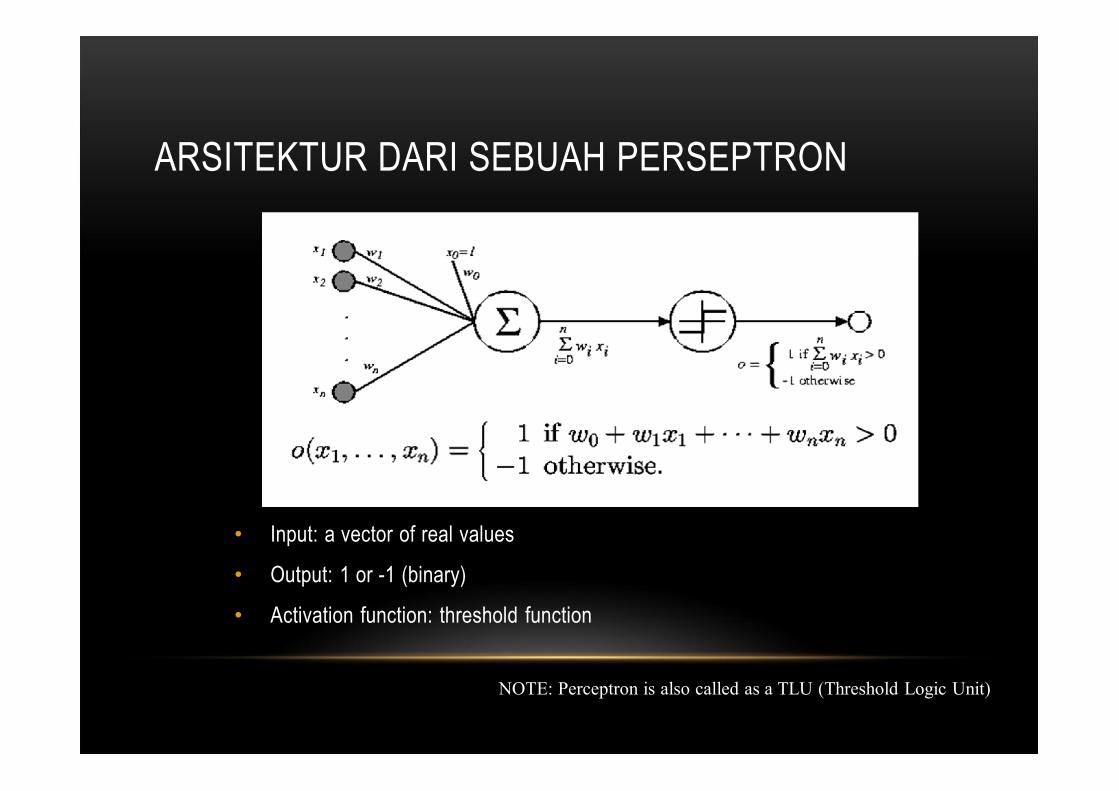
ARSITEKTUR DARI SEBUAH PERSEPTRON
• Input: a vector of real values
• Output: 1 or -1 (binary)
• Activation function: threshold function
NOTE: Perceptron is also called as a TLU (Threshold Logic Unit)

HYPOTHESIS SPACE OF PERCEPTRONS
• Free parameters: weights (and thresholds)
• Learning: choosing values for the weights
• Hypotheses space of perceptron learning
• n: dimension of the input vector
• Linear function
}|{ )1( nwwH
nn xwxwwf 110)(x

PERCEPTRON AND DECISION HYPERPLANE
• Perceptron merepresentasikan sebuah ‘hyperplane’ pada n-dimensional space dari instance (misalnya titik)
• Output perceptron 1 untuk instance yang terletak pada satusisi hyperplane dan output -1 untuk instance yang terletak di sisi lainnya
• Equation for the decision hyperplane: wx = 0.
• Data positif dan negatif tidak dapat dipisahkan dengansembarang hyperplane
• Sebuah perceptron tidak dapat melatih permasalahan padadata linearly nonseparable

LINEARLY SEPARABLE V.S. LINEARLY NONSEPARABLE
(a) Decision surface for a linearly separable set of examples (correctly classified by a straight line)
(b) A set of training examples that is not linearly separable.

REPRESENTATIONAL POWER OF PERCEPTRONS
• Perceptron tunggal dapat digunakan untuk merepresentasikan banyak fungsiboolean
• AND function: w0 = -0.8, w1 = w2 = 0.5
• OR function: w0 = -0.3, w1 = w2 = 0.5
• Perceptron dapat merepresentasikan semua fungsi boolean primitif : AND, OR, NAND dan NOR
• Catatan: Beberapa fungsi tidak dapat direpresentasikan dengan perceptron tunggal contohnya XOR
• Setiap fungsi boolean dapat direpresentasikan dengan beberapa jaringanperceptron hanya dengan dua level kedalaman
• One way merepresentasikan fungsi boolean pada bentuk DNF (OR of ANDs)

PERCEPTRON TRAINING RULE
• Note: output value o is +1 or -1 (not a real)
• Perceptron rule: a learning rule for a threshold unit.
• Conditions for convergence
• Training examples are linearly separable.
• Learning rate is sufficiently small.

CONTOH
• Jika diketahui xi = 0.8, = 0.1, t = 1 dan o = -1
maka
wi = (t - o) xi
= 0.1 * ( 1 – (-1)) * 0.8
= 0.1 * 2 * 0.8 = 0.16

LEAST MEAN SQUARE (LMS) ERROR
• Note: output value o is a real value (not binary)
• Delta rule: learning rule for an unthresholded perceptron (i.e. linear unit).
• Delta rule is a gradient-descent rule.
• Also known as the Widrow-Hoff rule
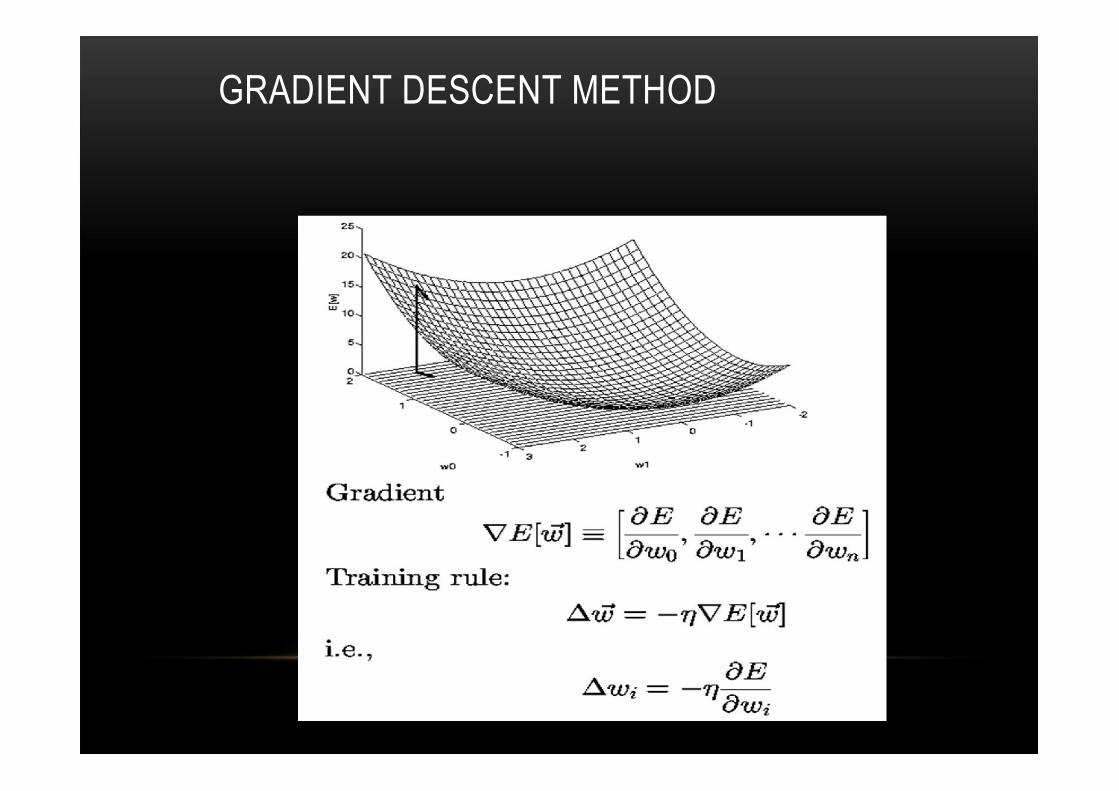
GRADIENT DESCENT METHOD

DELTA RULE FOR ERROR MINIMIZATION
i
iiiiw
Ewwww
,
Dd
idddi xotw )(

GRADIENT DESCENT ALGORITHM FOR PERCEPTRON LEARNING

PROPERTIES OF GRADIENT DESCENT
• Because the error surface contains only a single global minimum, the gradient descent algorithm will converge to a weight vector with minimum error, regardless of whether the training examples are linearly separable.
• Condition: a sufficiently small learning rate
• If the learning rate is too large, the gradient descent search may overstep the minimum in the error surface.
• A solution: gradually reduce the learning rate value.

CONDITIONS FOR GRADIENT DESCENT
• Gradient descent adalah strategi umum yang penting untukmencari hipotesis space yang besar atau infinite
• Kondisi untuk gradient descent search
• Hypothesis space terdiri atas parameter hipotesis yang kontinue, contohnya bobot pada unit linear
• Error dapat dibedakan w.r.t parameter hipotesis

DIFFICULTIES WITH GRADIENT DESCENT
• Konvergensi ke local minimum bersifat lambat
• Jika terdapat banyak local minima pada error surfae, makatidak ada jaminan bahwa prosedur akan menemukan global minimum

PERCEPTRON RULE V.S. DELTA RULE
• Perceptron rule
• Thresholded output
• Konvergen setelah melalui sejumlah iterasi terbatas terhadap hipotesis yang dapat mengklasifikasi data latih dengan benar,data latih linear separable.
• Hanya dapat digunakan pada data linearly separable
• Delta rule
• Unthresholded output
• .Konvergen hanya secara asymtitic menuju error minimum, mungkinmembutuhkan waktu yang tak terbatas, tetapi tidak terpaku pada data linearly separable
• Dapat digunakan untuk data linearly nonseparable

MULTILAYER PERCEPTRON
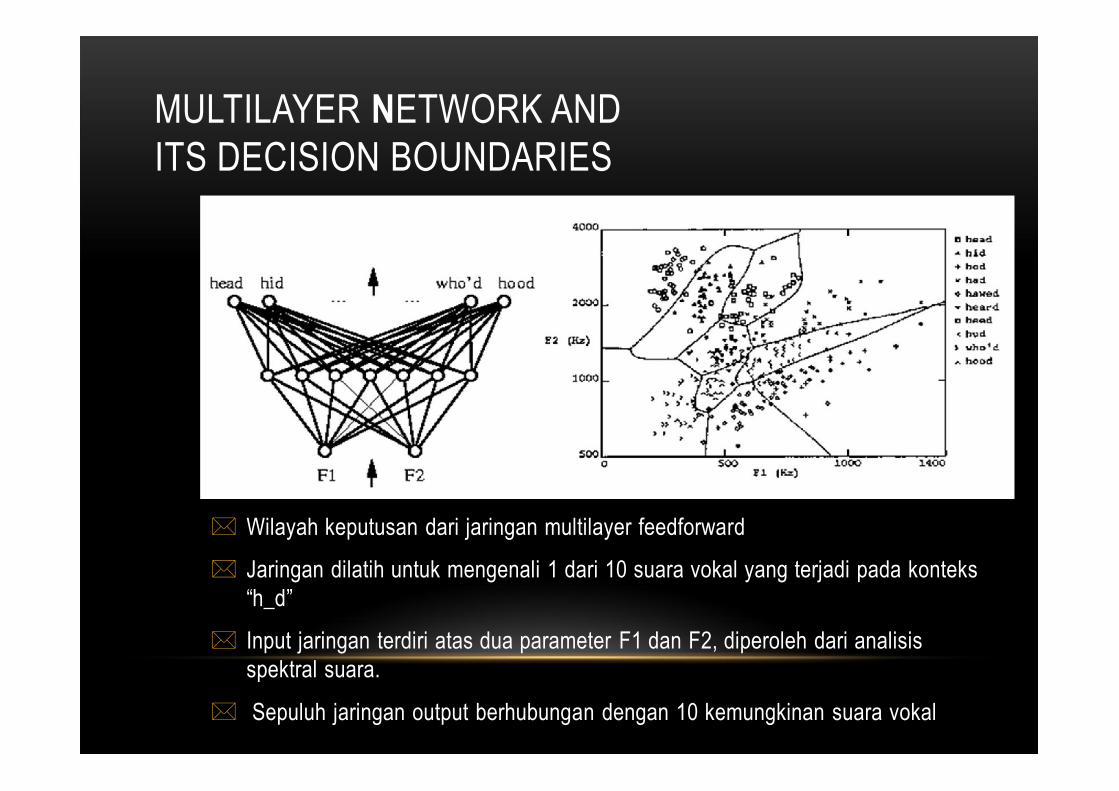
MULTILAYER NETWORK AND ITS DECISION BOUNDARIES
Wilayah keputusan dari jaringan multilayer feedforward
Jaringan dilatih untuk mengenali 1 dari 10 suara vokal yang terjadi pada konteks“h_d”
Input jaringan terdiri atas dua parameter F1 dan F2, diperoleh dari analisisspektral suara.
Sepuluh jaringan output berhubungan dengan 10 kemungkinan suara vokal

DIFFERENTIABLE THRESHOLD UNIT
• Sigmoid function: nonlinear, differentiable

BACKPROPAGATION (BP) ALGORITHM
• BP mempelajari bobot untuk jaringan multilayer, diberikan sebuah jaringandengan sekumpulan unit tetap dan interkoneksi
• BP memperkerjakan gradien descent untuk mencoba meminimalkan error kuadrat antara jaringan output dan nilai target
• Dua tahapan pembelajaran:
• Forwad stage: menghitung output yang diberikan oleh pola x.
• Backward stage: mengupdate bobot dengan menghitung delta

FUNGSI ERROR UNTUK BP
Dd outputsk
kdkd otwE 2)(2
1)(
• E defined as a sum of the squared errors over all the output units k for all the training examples d.
• Error surface can have multiple local minima
• Guarantee toward some local minimum
• No guarantee to the global minimum

BACKPROPAGATION ALGORITHM FOR MLP
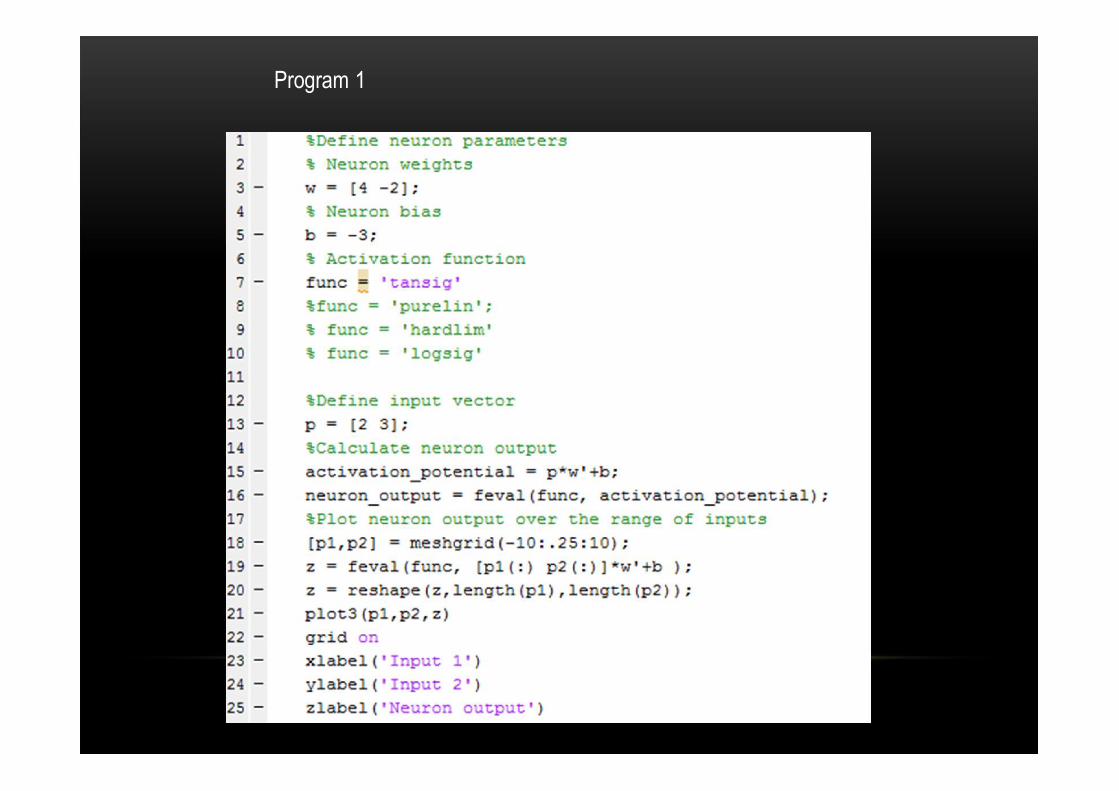
Program 1

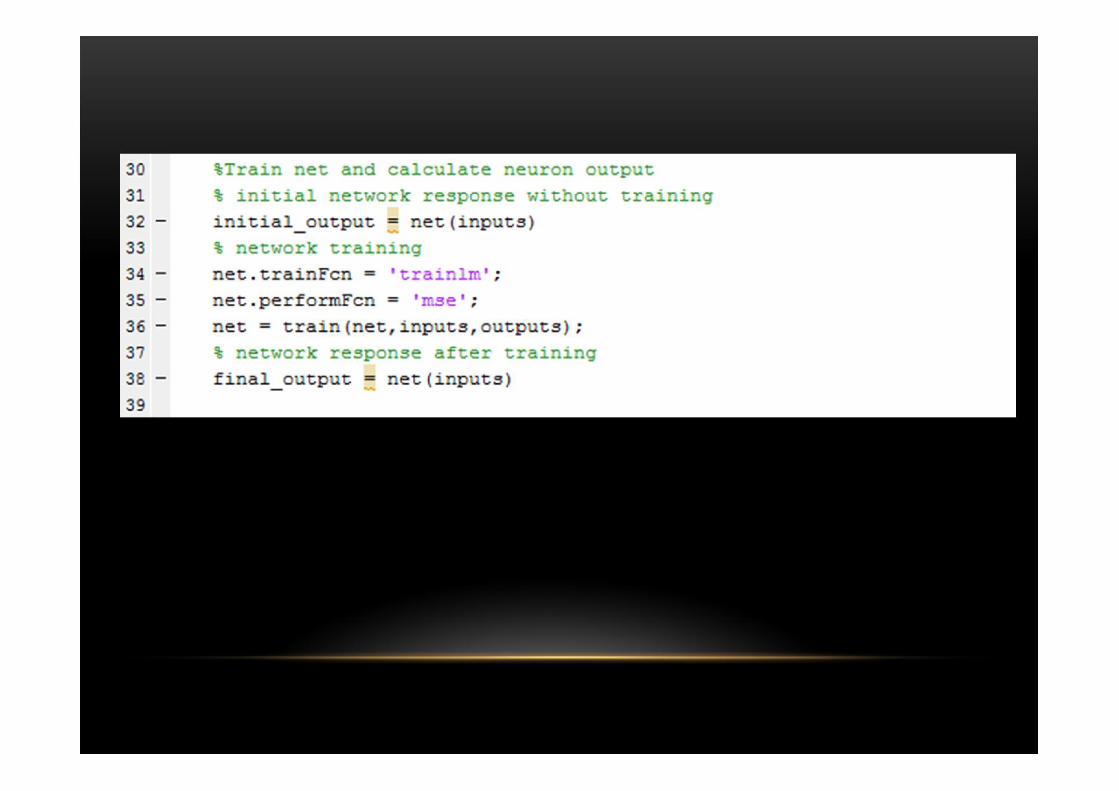
Program 2PROBLEM DESCRIPTION: Create and view custom neural networks
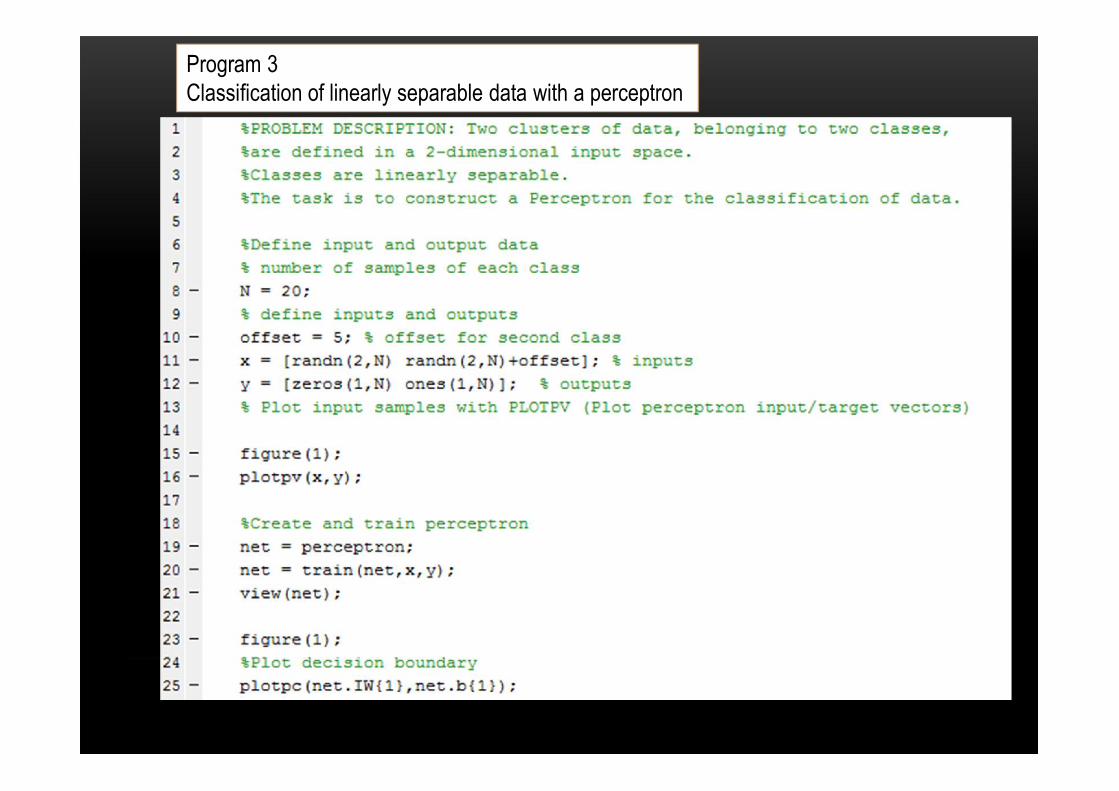
Program 3Classification of linearly separable data with a perceptron
TUGAS
• Ketikkan kode program berikut kemudian cari keluaran program, misalnya:
1. Data input
2. Neural Network Training
3. Feed-forward Neural Network
4. Output
5. Dsb
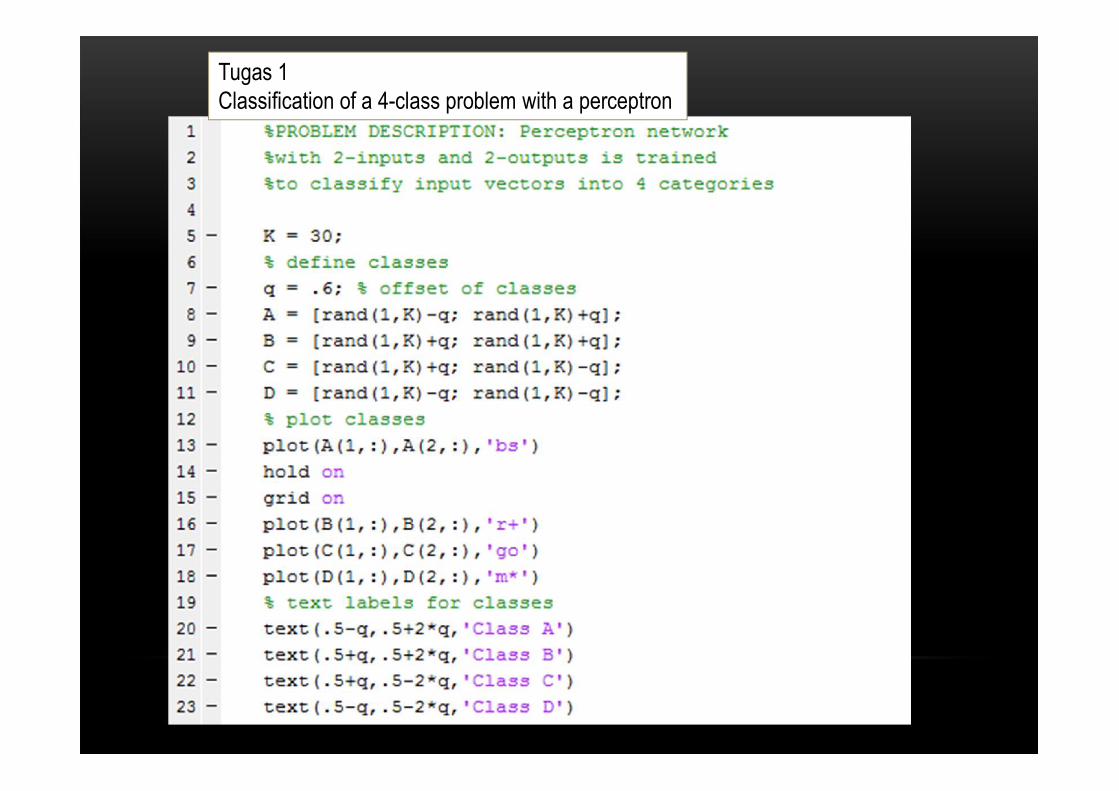
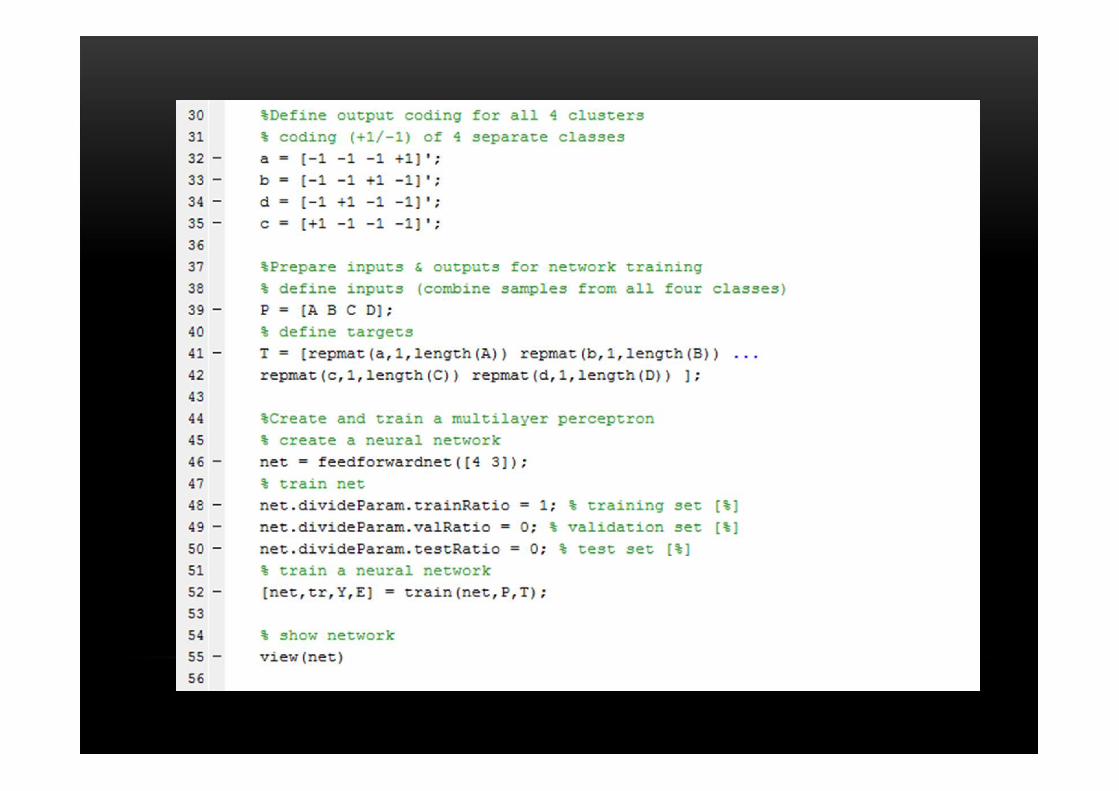
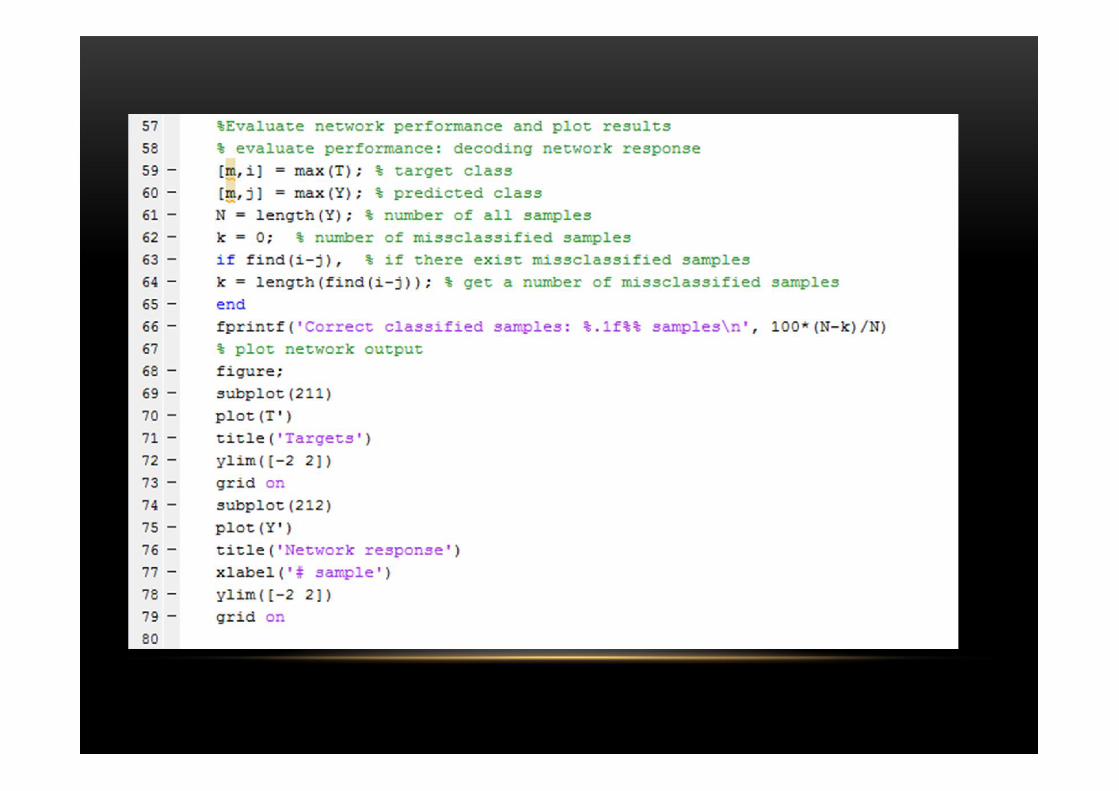
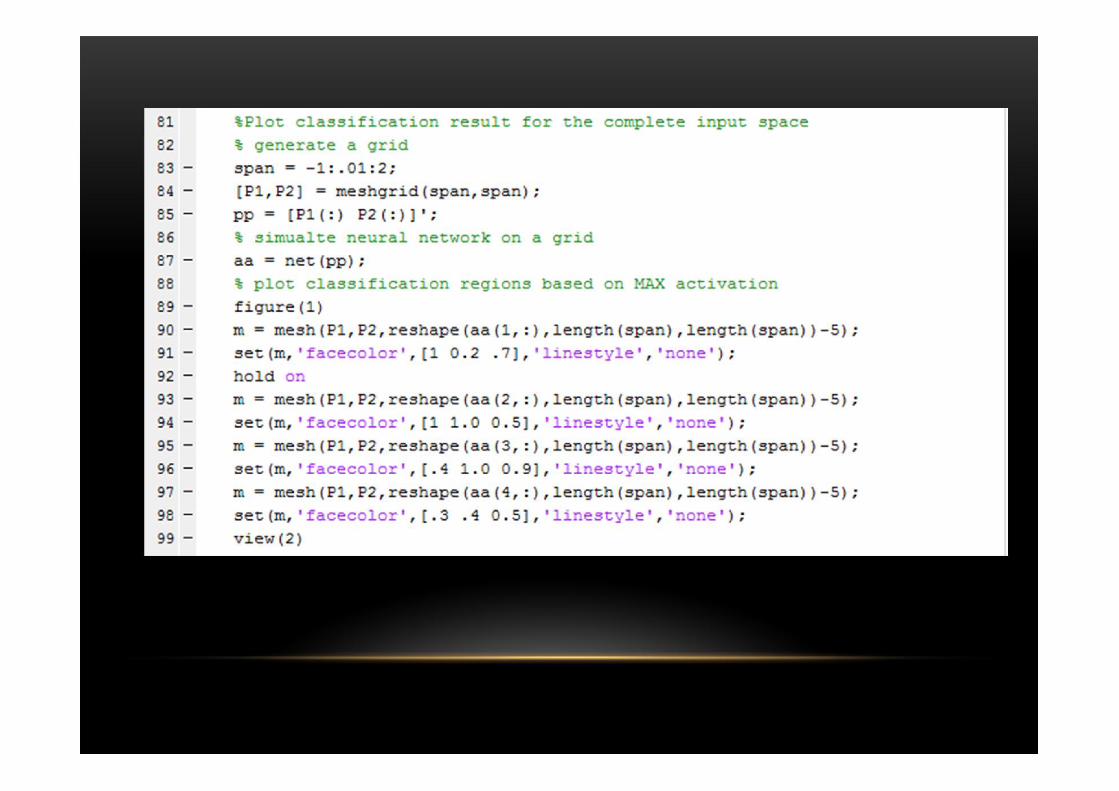
Tugas 1Classification of a 4-class problem with a perceptron
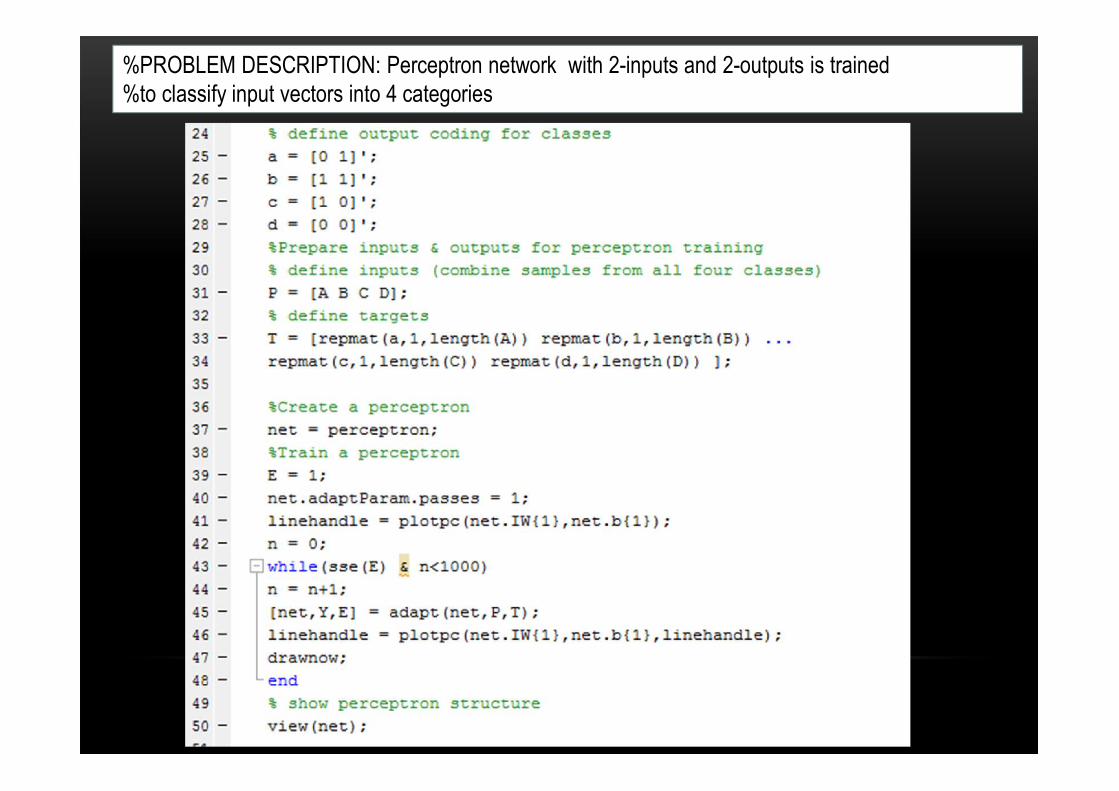
%PROBLEM DESCRIPTION: Perceptron network with 2-inputs and 2-outputs is trained %to classify input vectors into 4 categories
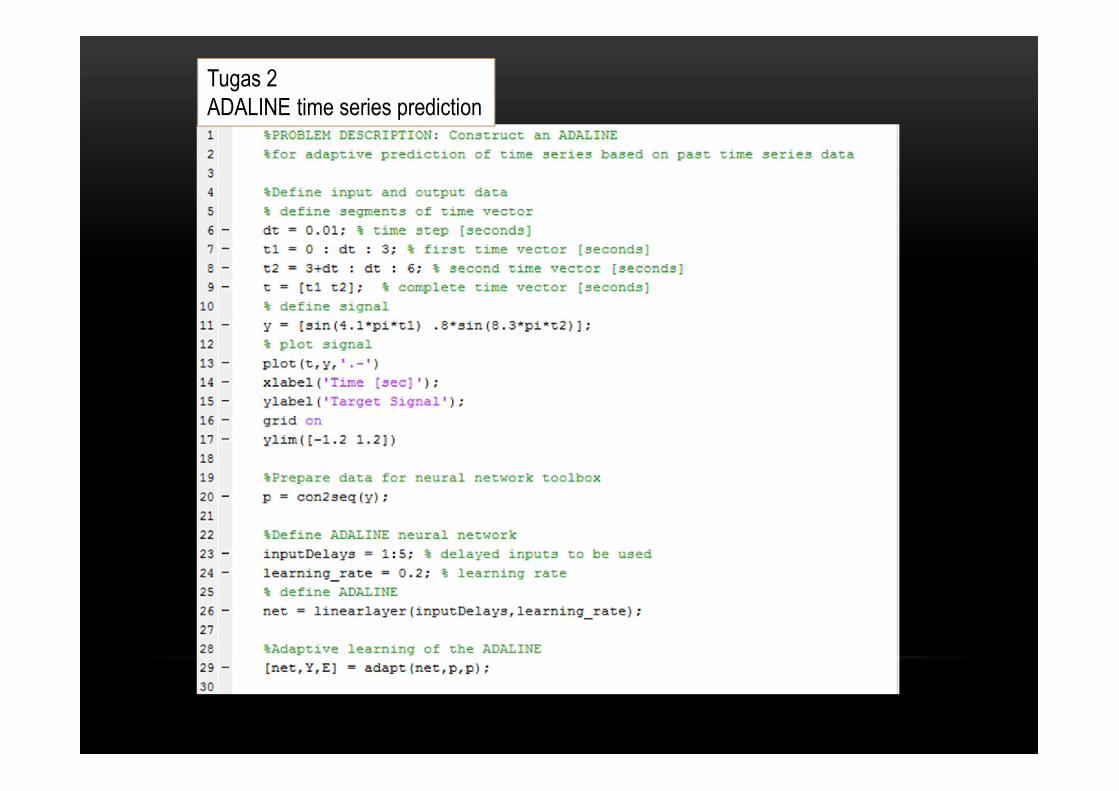
Tugas 2ADALINE time series prediction


Tugas 3 :Solving XOR problem with a multilayer perceptron
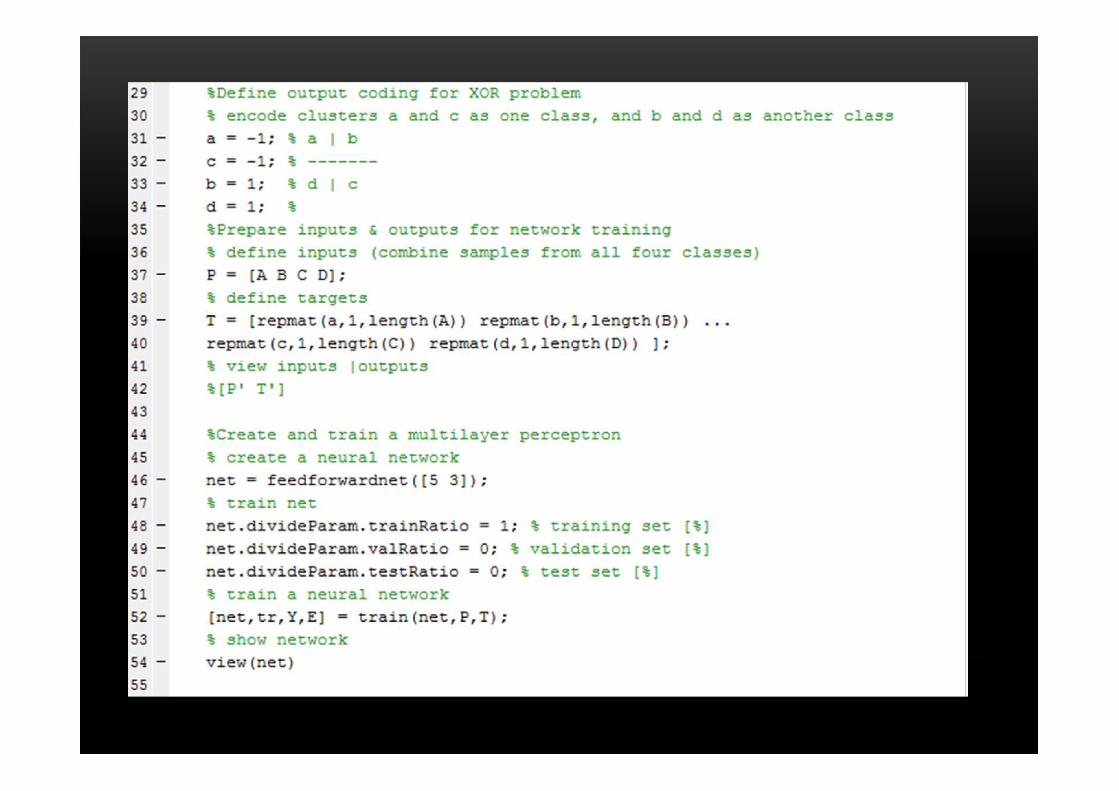
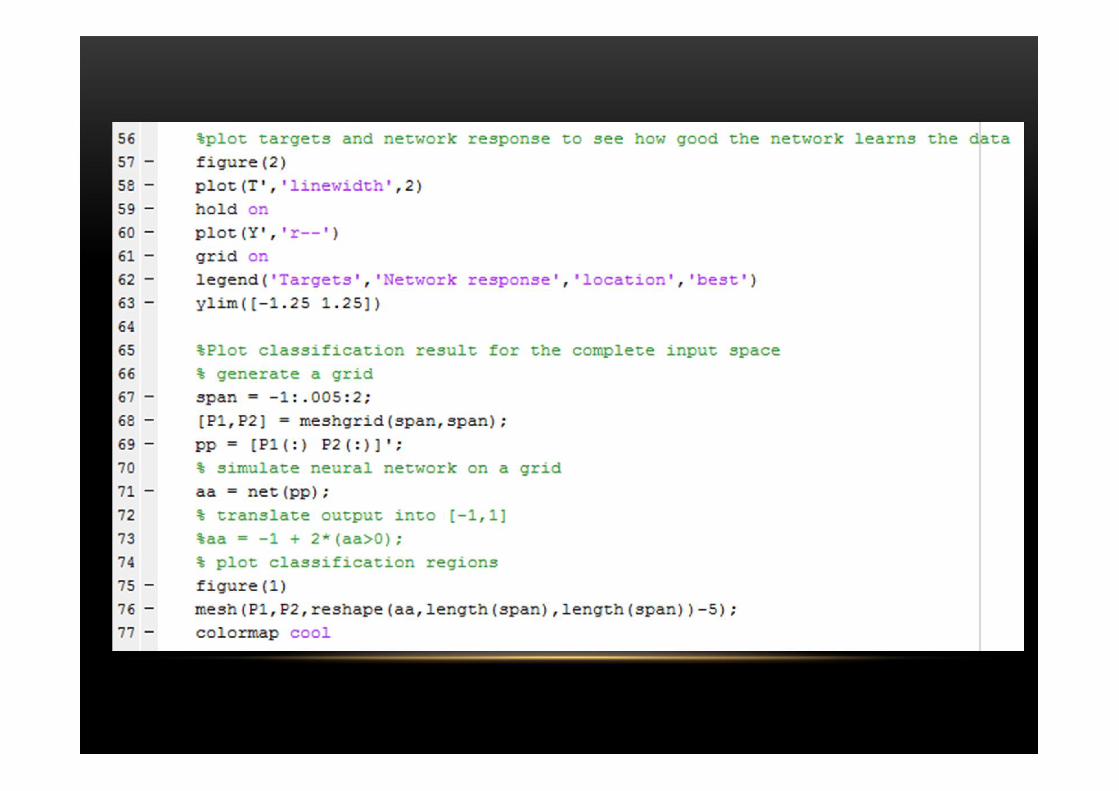

Tugas 4Classification of a 4-class problem with a multilayer perceptron