
ArqMCM - fenix.tecnico.ulisboa.pt · The tool is able to generate synthesizable VHDL description of...
110
ArqMCM Estudo de arquitecturas para sistemas multiplicadores por múltiplas constantes Carlos Alexandre Marvão Lavadinho Dissertação para obtenção do Grau de Mestre em Engenharia Electrotécnica e de Computadores Júri Presidente: Prof. Marcelino Bicho dos Santos Orientador: Prof. Paulo Ferreira Godinho Flores Co-Orientador: Prof. José Carlos Alves Pereira Monteiro Vogal: Prof. Horácio Cláudio de Campos Neto Abril 2011
Transcript of ArqMCM - fenix.tecnico.ulisboa.pt · The tool is able to generate synthesizable VHDL description of...

ArqMCM
Estudo de arquitecturas para sistemas multiplicadores por múltiplas constantes
Carlos Alexandre Marvão Lavadinho
Dissertação para obtenção do Grau de Mestre em
Engenharia Electrotécnica e de Computadores
Júri
Presidente: Prof. Marcelino Bicho dos Santos
Orientador: Prof. Paulo Ferreira Godinho Flores
Co-Orientador: Prof. José Carlos Alves Pereira Monteiro
Vogal: Prof. Horácio Cláudio de Campos Neto
Abril 2011

ii

iii
Agradecimentos
Queria aproveitar a oportunidade para a agradecer a todas aquelas pessoas que possibilitaram, facilitaram e ajudaram à execução desta dissertação, e todos os outros trabalhos e projectos que surgiram ao longo do mestrado. Foi um grande prazer, ter sido a ajudado por todos vós.
Queria dedicar um especial agradecimento ao meu orientador, professor Paulo Ferreira Godinho Flores, pela total disponibilidade e prontidão na ajuda prestada sem a qual não teria sido possível a realização desta dissertação.
Aos meus amigos um muito Obrigado, pela ajuda, pelos risos, pelo apoio, pelo conforto e pela vida que me proporcionaram até hoje.
À minha família, em especial aos meus pais, sem eles não teria sido possível! Aos quais privei de muito tempo e atenção nestes últimos dias e anos da minha vida académica.

iv

v
Abstract
This work presents a study on different architectures, with multiple constant multipliers, for FIR filters. The filters are automatically generated by a tool G2FIR developed for this work.
The tool is able to generate synthesizable VHDL description of FIR filter for three different architecture: serial architecture with accumulator, parallel architecture with multipliers and parallel architecture with multiple constant multiply (MCM).
In order to evaluate the different architecture a set of benchmark filter were synthesized (with design_vision from Synopsis), using the AMS 0,35 µm technology, for a range of input bit witch size (8, 16 and 32 bits). By comparing the area, power and operation frequency (max delay), obtained after synthesis, we conclude that the serial architecture has a reduce area but the parallel architecture with MCM has a better performance researching operating frequency and power dissipated.
Keywords FIR architectures, MCM, area, power, frequency.

vi

vii
Resumo Esta dissertação para a obtenção de Mestre propõe um estudo de diferentes arquitecturas para sistemas multiplicadores por múltiplas constantes, para filtros FIR. Os filtros são gerados automaticamente pela ferramenta G2FIR, desenvolvida neste estudo. A ferramenta gera automaticamente ficheiros, em VHDL, com a descrição de três arquitecturas FIR distintas: arquitectura série com acumulador e multiplicador, arquitectura paralela com multiplicadores e arquitectura paralela com MCM. Foram geradas arquitecturas para diferentes filtros de referência, sintetizadas (design_vision, Synopsis) com a tecnologia AMS 0,35 µm, para diferentes larguras do sinal de entrada (8, 16 e 32 bits). Com os resultados da síntese será possível fazer a comparação dos resultados de área, potência e frequência, para as diferentes condições referidas anteriormente.
Palavras-chave Arquitecturas FIR; MCM; área; potência; frequência.

viii

ix
Índice Lista de Figuras ....................................................................................................................... xi
Lista de Tabelas...................................................................................................................... xv
Lista de acrónimos .................................................................................................................xvii
1 Capítulo 1 – Introdução ..................................................................................................... 1
1.1 Enquadramento ......................................................................................................... 1
1.2 Objectivos .................................................................................................................. 2
1.3 Estrutura .................................................................................................................... 2
2 Capítulo 2 – Filtros FIR -Arquitecturas .............................................................................. 3
2.1 Introdução ................................................................................................................. 3
2.2 Arquitecturas FIR ....................................................................................................... 4
2.3 Arquitectura série com acumulador e multiplicador ..................................................... 5
2.4 Arquitectura paralela com multiplicadores .................................................................. 6
2.5 Arquitectura paralela com MCM ................................................................................. 7
3 Capítulo 3 Gerador de VHDLpara Filtros FIR ................................................................. 11
3.1 Introdução ............................................................................................................... 11
3.2 Funcionalidades e características do gerador........................................................... 11
3.3 Opções básicas da linha de comandos .................................................................... 12
3.4 Biblioteca de elementos básicos .............................................................................. 13
3.5 Formato do ficheiro com os coeficientes dos filtros FIR ............................................ 16
3.6 Arquitectura série com Acumulador e Multiplicador .................................................. 17
3.6.1 Bloco com FIFO e Memória .............................................................................. 18
3.6.2 Bloco com Acumulador Multiplicador ................................................................ 20
3.6.3 Bloco da unidade de controlo ........................................................................... 21
3.7 Arquitectura paralela com multiplicadores ................................................................ 24
3.7.1 Unidade com multiplicadores em paralelo ........................................................ 25
3.7.2 Unidade de Registos e somadores ................................................................... 27
3.8 Arquitectura paralela com MCM ............................................................................... 29
3.8.1 Bloco com o MCM ............................................................................................ 30
3.9 Resultado e simulação das diferentes arquitecturas geradas ................................... 31
4 Capítulo 4 Resultados..................................................................................................... 35
4.1 Introdução ............................................................................................................... 35
4.2 Características dos filtros gerados ........................................................................... 35
4.3 Resultados de síntese sem limitação do sinal de saída ............................................ 37
4.3.1 Resultados de área .......................................................................................... 37
4.3.2 Resultados de potência .................................................................................... 44
4.3.3 Resultados de Atraso ....................................................................................... 50
4.4 Resultados de síntese com limitação do sinal de saída ............................................ 57

x
4.4.1 Resultados de área .......................................................................................... 58
4.4.2 Resultados de potência .................................................................................... 60
4.4.3 Resultados de atraso ....................................................................................... 63
4.5 Comparação de resultados para as diferentes arquitecturas .................................... 66
4.5.1 Comparação de área........................................................................................ 66
4.5.2 Comparação de potência ................................................................................. 69
4.5.3 Comparação de atraso ..................................................................................... 71
5 Capítulo 5 Conclusões .................................................................................................... 73
5.1 Conclusões gerais ................................................................................................... 73
5.2 Trabalhos futuros ..................................................................................................... 75
Anexo A .................................................................................................................................. 79
Anexo B .................................................................................................................................. 85
Anexo B.1 – Resultados de área ocupada ........................................................................... 85
Anexo B.2- Resultados de potência consumida ................................................................... 87
Anexo B.3- Resultados de atraso do caminho crítico ........................................................... 89
Anexo C .................................................................................................................................. 91

xi
Lista de Figuras Figura 2.1 Representação de um filtro digital não recursivo na sua Forma Directa. .................... 4 Figura 2.4 Diagrama de blocos da arquitectura acumulador e multiplicador. ............................ 6 Figura 2.5 Diagrama de blocos da arquitectura com multiplicadores em paralelo. ...................... 7 Figura 2.6 Diagrama de blocos de uma multiplicação 3x. Utilizando um multiplicador genérico à esquerda e utilizando uma deslocações e uma soma à direita. .................................................. 8 Figura 2.7 Diagrama de blocos com partilha de recursos do MCM............................................. 9 Figura 2.8 Diagrama de blocos da arquitectura MCM. ............................................................... 9 Figura 3.1 Arquitectura do software G2FIR. ............................................................................. 11 Figura 3.2 Exemplo da linha de comandos para chamar o programa com o ficheiro de coeficientes pretendido. .......................................................................................................... 12 Figura 3.3 Linha de comandos com a opção de arquitectura MCM. ......................................... 12 Figura 3.4 Exemplo da linha de comandos onde se definiu o sinal de entrada com dimensão de 8 bits em cima, e a linha de comandos onde se definiu o sinal de saída com dimensão de 16 bits. ......................................................................................................................................... 13 Figura 3.5 Exemplo que permite utilizar um somador genérico diferente do gerado por omissão. ............................................................................................................................................... 14 Figura 3.6 Formato do cabeçalho a cumprir do somador genérico. .......................................... 14 Figura 3.7 Formato do cabeçalho a cumprir do subtractor genérico. ........................................ 15 Figura 3.8 Formato do cabeçalho a cumprir do multiplicador genérico ..................................... 15 Figura 3.9 Formato do cabeçalho a cumprir do registo com reset genérico. ............................. 15 Figura 3.10 Exemplo da representação dos coeficientes e dos termos, retirados do ficheiro exemplo.fir .............................................................................................................................. 16 Figura 3.11 Diagrama de blocos da arquitectura acumulador e multiplicador. .......................... 18 Figura 3.12 (a) Diagrama de blocos da FIFO e (b) podemos ver o conteúdo da memória para o exemplo.fir. ............................................................................................................................. 19 Figura 3.13 Troço de código em VHDL que descreve a unidade FIFO. .................................... 20 Figura 3.14 Diagrama de blocos da unidade Acumulador e multiplicador. ................................ 21 Figura 3.15 Descrição em VHDL da arquitectura com acumulador. ......................................... 21 3.16 Diagrama de estados da maquina de estados da unidade de controlo (alterar). ............... 23 Figura 3.17 Cabeçalho VHDL que descreve a unidade de controlo para o exemplo.fir. ............ 24 Figura 3.18 Diagrama de blocos da arquitectura com multiplicadores em paralelo. .................. 24 Figura 3.19 Diagrama de fluxo de dados dos multiplicadores em paralelo do exemplo sem optimizações. .......................................................................................................................... 25 Figura 3.20 Diagrama de fluxo de dados dos multiplicadores em paralelo do exemplo com optimizações. .......................................................................................................................... 26 Figura 3.21 Cabeçalho da unidade com multiplicadores em paralelo. ...................................... 27 Figura 3.22 Troço do código em VHDL do ficheiro exemplo_mull_parallel.vhdl, para a implementação dos multiplicadores em paralelo. ..................................................................... 27 Figura 3.23 Diagrama de blocos da unidade de registos do exemplo.fir. .................................. 28 Figura 3.24 Cabeçalho da unidade de registos com somadores. ............................................. 28 Figura 3.25 Troço de código em VHDL, responsável pela descrição da unidade de registos e somadores. ............................................................................................................................. 29 Figura 3.26 Diagrama de blocos da arquitectura MCM. ........................................................... 29 Figura 3.27 Diagrama de fluxo de dados da unidade MCM. ..................................................... 30 Figura 3.28 Cabeçalho do ficheiro VHDL coma descrição da unidade MCM. ........................... 31 Figura 3.29 Troço do código em VHDL do ficheiro exemplo_mcm.vhdl, para a implementação do MCM. ................................................................................................................................. 31

xii
Figura 3.30 Simulação da resposta ao escalão, da arquitectura série com acumulador e multiplicador. ........................................................................................................................... 32 Figura 3.31 Simulação da ao escalão, da arquitectura paralelo com multiplicadores. ............... 32 Figura 3.32 Simulação da resposta ao escalão, da arquitectura paralelo com MCM. ............... 32 Figura 3.33 Simulação da resposta ao impulso, da arquitectura série com acumulador e multiplicador. ........................................................................................................................... 33 Figura 3.34 Simulação da resposta ao impulso, da arquitectura paralela com multiplicadores. 33 Figura 3.35 Simulação da resposta a um escalão unitário, da arquitectura paralela com MCM. ............................................................................................................................................... 33 Figura 4.1 Gráfico da área para a arquitectura para a arquitectura série acumulador e multiplicador, para diferente número de bits no sinal de entrada. ............................................. 38 Figura 4.2 Gráfico com as diferentes áreas da arquitectura paralelo com multiplicadores para os diferentes filtros gerados, para 8 bits. ...................................................................................... 39 Figura 4.3 Gráfico com as diferentes áreas da arquitectura paralela com multiplicadores para os diferentes filtros gerados, para 16 bits. .................................................................................... 39 Figura 4.4 Gráfico com as diferentes áreas da arquitectura paralelo com multiplicadores para os zdiferentes filtros gerados, para 32 bits. .................................................................................. 40 Figura 4.5 Gráfico com as áreas totais para a arquitectura paralela com multiplicadores dos diferentes filtros para sinais de entrada com diferentes larguras. ............................................. 41 Figura 4.6 Gráfico com as diferentes áreas da arquitectura paralelo com MCM para os diferentes filtros gerados, para 8 bits. ...................................................................................... 42 Figura 4.7 Gráfico com as diferentes áreas da arquitectura paralelo com MCM para os diferentes filtros gerados, para 16 bits. .................................................................................... 42 Figura 4.8 Gráfico com as diferentes áreas da arquitectura paralelo com MCM para os diferentes filtros gerados, para 32 bits. .................................................................................... 43 Figura 4.9 Gráfico de área da unidade MCM, para diferente número de bits na entrada. ......... 44 Figura 4.10 Gráfico de potência para a arquitectura série com acumulador e multiplicador, para diferente número de bits no sinal de entrada. .......................................................................... 45 Figura 4.11 Gráfico de potência total para a arquitectura série com acumulador e multiplicador, para diferente número de bits no sinal de entrada. .................................................................. 45 Figura 4.12 Gráfico com as diferentes potências da arquitectura paralelo com multiplicadores para os diferentes filtros gerados, para 8 bits. ......................................................................... 46 Figura 4.13 Gráfico com as diferentes potências da arquitectura paralelo com multiplicadores para os diferentes filtros gerados, para 16 bits. ....................................................................... 46 Figura 4.14 Gráfico com as diferentes potências da arquitectura paralelo com multiplicadores para os diferentes filtros gerados, para 32 bits. ....................................................................... 47 Figura 4.15 Gráfico da potência da arquitectura paralela com multiplicadores para diferentes larguras do sinal de entrada: 8, 16, 32 bits. ............................................................................. 48 Figura 4.16 Gráfico com as diferentes potências da arquitectura paralelo com MCM para os diferentes filtros gerados, para 8 bits. ...................................................................................... 48 Figura 4.17 Gráfico com as diferentes potências da arquitectura paralelo com MCM para os diferentes filtros gerados, para 16 bits. .................................................................................... 49 Figura 4.18 Gráfico com as diferentes potências da arquitectura paralelo com MCM para os diferentes filtros gerados, para 32 bits. .................................................................................... 49 Figura 4.19 Gráfico da potência da unidade MCM para diferentes larguras do sinal de entrada. ............................................................................................................................................... 50 Figura 4.20 Gráfico dos tempos de atraso parcial para a arquitectura série com acumulador e multiplicador, para diferentes larguras do sinal de entrada. ..................................................... 51 Figura 4.21 Gráfico com o atraso total para o cálculo de cada saída do filtro da arquitectura série com acumulador e multiplicador, para diferentes larguras do sinal de entrada. ............... 52

xiii
Figura 4.22 Gráfico do tempo de atraso para a arquitectura paralelo com multiplicadores para 8 bits. ......................................................................................................................................... 53 Figura 4.23 Gráfico do tempo de atraso para a arquitectura paralelo com multiplicadores para 16 bits. .................................................................................................................................... 53 Figura 4.24 Gráfico do tempo de atraso para a arquitectura paralelo com multiplicadores para 32 bits. .................................................................................................................................... 54 Figura 4.25 Gráfico do tempo de atraso total para a arquitectura paralelo com multiplicadores para diferente número de bits no sinal de entrada. .................................................................. 55 Figura 4.26 Gráfico do tempo de atraso para a arquitectura paralela com MCM para 8 bits. .... 55 Figura 4.27 Gráfico do tempo de atraso para a arquitectura paralela com MCM para 16 bits. .. 56 Figura 4.28 Gráfico do tempo de atraso para a arquitectura paralela com MCM para 32 bits. .. 56 Figura 4.29 Gráfico do atraso do caminho crítico da arquitectura paralela com MCM para diferentes bits no sinal de entrada ........................................................................................... 57 Figura 4.30 Gráfico de área para a arquitectura série com o sinal limitado a 32 bits. ............... 58 Figura 4.31 Gráfico da área total e das diferentes unidades da arquitectura paralelo com multiplicadores. Para entrada e saída limitada a 32 bits........................................................... 59 Figura 4.32 Gráfico da área total e das diferentes unidades da arquitectura paralela com MCM. Para entrada e saída limitada a . ............................................................................................. 60 Figura 4.33 Gráfico com a potência consumida para a arquitectura série com acumulador e multiplicador para os diferentes filtros com o sinal de entrada e saída limitada a 32 bits. ......... 61 Figura 4.34 Gráfico de potência total para a arquitectura série com acumulador e multiplicador, para a entrada e saída limita a 32 bits. .................................................................................... 61 Figura 4.35 Gráfico da potência total e das diferentes unidades da arquitectura paralelo com multiplicadores. Para entrada e saída limitadas a 32. .............................................................. 62 Figura 4.36 Gráfico da potência total e das diferentes unidades da arquitectura paralelo MCM. Para entrada e saída limitadas a 32 bits. ................................................................................. 63 Figura 4.37 Gráfico dos tempos de atraso parcial para a arquitectura série com acumulador e multiplicador, para entrada e saída limitada a 32 bits. .............................................................. 64 Figura 4.38 Gráfico com o atraso total para o cálculo de cada saída do filtro da arquitectura série com acumulador e multiplicador, para entrada e saída limitada a 32 bits......................... 64 Figura 4.39 Gráfico com o atraso total e das diferentes unidades da arquitectura paralelo com multiplicadores. Para 32 bits como entrada e limitação da saída. ............................................ 65 Figura 4.40 Gráfico com o atraso total e das diferentes unidades da arquitectura paralelo MCM. Para 32 bits como entrada e limitação da saída....................................................................... 66 Figura 4.41 Gráfico da área total para as diferentes arquitecturas com sinal de entrada a 16 bits. ............................................................................................................................................... 67 Figura 4.42 Gráfico da área total para as diferentes arquitecturas com sinal de entrada a 32 bits. ............................................................................................................................................... 67 Figura 4.43 Gráfico de área para as diferentes arquitecturas com sinal de entrada e limitado a 32 bits. .................................................................................................................................... 68 Figura 4.44 Gráfico da potência para as diferentes arquitecturas com sinal de entrada de 16 bits. ......................................................................................................................................... 69 Figura 4.45 Gráfico da potência para as diferentes arquitecturas com sinal de entrada de 32 bits. ......................................................................................................................................... 69 Figura 4.46 Gráfico de potência para as diferentes arquitecturas com sinal de entrada e saído limitado a 32 bits. .................................................................................................................... 70 Figura 4.47 Gráfico do tempo de atraso para as diferentes arquitecturas com sinal de entrada a 16 bits. .................................................................................................................................... 71 Figura 4.48 Gráfico do tempo de atraso para as diferentes arquitecturas com sinal de entrada a 32 bits. .................................................................................................................................... 71

xiv
Figura 4.49 Gráfico do tempo de atraso para as diferentes arquitecturas com sinal de entrada e saída é limitado a 32 bits. ........................................................................................................ 72

xv
Lista de Tabelas Tabela 3.1 Tabela com as diferentes opções de arquitectura. ................................................. 13 Tabela 3.2 Tabela com as diferentes opções da largura (bits) do sinal de entrada e saída. ..... 13 Tabela 3.3 Ficheiros genéricos por omissão da biblioteca de elementos básicos. .................... 14 Tabela 3.4 Tabela com as opções para as diferentes unidades genéricas. .............................. 14 Tabela 3.5 Tabela com os ficheiros gerados para cada uma das diferentes arquitecturas. ....... 15 Tabela 3.6 Tabela com o significado de cada campo dos coeficientes no ficheiro. ................... 16 Tabela 3.7 Tabela com o significado de cada campo dos termos parciais no ficheiro. .............. 17 Tabela 3.8 Sinais de saídas da máquina de estados ............................................................... 22 Tabela 4.1 Tabela com as características dos filtros FIR gerados. ........................................... 36 Tabela 4.2 Tabela com as características dos filtros FIR gerados. ........................................... 36 Tabela 4.3 Dimensão do sinal de saída para cada filtro consoante a largura do sinal de entrada. ............................................................................................................................................... 37

xvi

xvii
Lista de acrónimos
FIR Finite impulsive response
MCM Multiple Constant Multiplier VHDL Very High Speed Integrated Circuits Hardware Description Language
FIFO Frist in, Frist out
DSP Digital signal processing

xviii

1
1 Capítulo 1 – Introdução Introdução
1.1 Enquadramento
Existem várias aplicações que recorrem a um dado tipo de operações matemáticas, em que um sinal de entrada é multiplicado por um conjunto de coeficientes. A este tipo de operações é dado o nome de multiplicadores por múltiplas constantes, MCM (“Multiple Constant Multiplier”). Estes tipos de operações são muito comuns para o cálculo de filtros FIR e para o cálculo da transformada de Fourier, por exemplo. Para realizar o processamento deste tipo de operações, é comum serem usados processadores digitais de sinais (DSP), podendo também ter-se uma outra abordagem, em que é usado hardware com arquitecturas dedicadas de multiplicadores por múltiplas constantes, MCM por exemplo. Com esta abordagem consegue-se uma maior simplificação dos multiplicadores, conseguindo-se um desempenho maior e um consumo de energia menor.
As arquitecturas dedicadas podem ser realizadas de diferentes formas, uma das arquitecturas que tem particular interesse, consiste em utilizar somas e/ou subtracções com deslocamentos do sinal de entrada a fim de se conseguirem realizar multiplicações [1][2], pois os coeficientes dos filtros são constantes. Com as operações referidas anteriormente, pode se conseguir implementar unidades de multiplicadores por múltiplas constantes, MCM, a fim de se conseguir utilizar um hardware dedicado que possa substituir as funcionalidades de um processador digital de sinal (DSP).
Podem-se utilizar diferentes algoritmos [2] para gerar as diferentes unidades de multiplicadores por múltiplas constantes. Ao se ter um sinal entrada multiplicado por um conjunto de coeficientes constantes, pode-se conseguir obter reduções significativas de hardware. A redução pode ser conseguida através da partilha dos produtos parciais do sinal de entrada por um conjunto de multiplicações. Assim com diferentes algoritmos podem-se obter diferentes optimizações e partilha de recursos (que têm sido objecto de diversas pesquisas), afim de se conseguir diferentes objectivos na implementação do hardware dedicado.
Os projectos em que são utilizados processadores digitais de sinal (DSP), o desempenho dos mesmos são considerados um parâmetro crítico. Assim, a área do circuito é geralmente um parâmetro de segunda ordem, face ao seu desempenho, ou seja, o atraso é normalmente um parâmetro crítico [1]. As diferentes arquitecturas com multiplicadores por múltiplas constantes, MCM, com hardware dedicado pode conseguir realizar diferentes implementações afim de se conseguirem atrasos máximos menores, e consequentemente frequências de funcionamento maiores [3].

2
1.2 Objectivos
O objectivo deste trabalho consiste, em criar uma aplicação que gera de forma automática diferentes arquitecturas de multiplicadores por múltiplas constantes, para implementação digital de filtros FIR. As diferentes arquitecturas realizarão as multiplicações por múltiplas constantes de diferentes modos, tais como: uma arquitectura série e arquitecturas paralelas com multiplicadores ou com somas/subtracções e deslocamentos.
Um outro objectivo deste trabalho é fazer um estudo comparativo das diferentes arquitecturas, para as quais serão apresentados os resultados das diferentes arquitecturas propostas e geradas de forma automática. Serão comparadas as áreas ocupadas, as potências consumidas e frequências máximas de funcionamento (atraso máximo) para as diferentes arquitecturas implementadas, e para diferentes dimensões de número de bits do sinal de entrada.
1.3 Estrutura
A dissertação encontra-se dividida em cinco capítulos. O primeiro capítulo, a Introdução, faz um enquadramento sobre multiplicadores por múltiplas constantes. Fala sobre os objectivos trabalho e de como este vai estar organizado ao longo da dissertação.
O capítulo dois, Filtros FIR - Arquitecturas, apresenta as principais características da implementação dos filtros digitais FIR. São também apresentadas as diferentes arquitecturas que serão desenvolvidas ao longo da dissertação.
O capítulo três, Gerador de VHDL para filtros FIR, fala sobre as características do gerador para os diferentes filtros e das diferentes arquitecturas implementadas. Explica-se ainda as várias opções tomadas para cada uma das arquitecturas geradas e os parâmetros que podem ser configurados com este gerador.
No capítulo quatro, Resultados, são exibidos os resultados para cada uma das arquitecturas para sinais de entrada com diferentes números de bits. Neste capítulo faz-se a comparação entre as diferentes arquitecturas implementadas. São explicados os motivos que levaram aos resultados de área ocupada, potência dissipada e frequência máxima para cada uma das arquitecturas implementadas.
No capítulo cinco, Conclusões, são apresentadas as conclusões sobre o trabalho desta dissertação e são apresentados possíveis trabalhos futuros.

3
2 Capítulo 2 – Filtros FIR -Arquitecturas Filtros FIR - Arquitecturas
Nesta secção são apresentadas as principais características da implementação dos filtros digitais FIR. São também apresentadas as diferentes arquitecturas que serão desenvolvidas ao longo do estudo.
2.1 Introdução
Um filtro de resposta impulsiva finita, FIR (“finite impulse response”), do tipo digital, é caracterizado por ter uma resposta ao impulso que se torna nula após um tempo finito. Os filtros FIR não recursivos têm uma implementação em hardware simples e eficaz. Na equação abaixo (2.1), podemos observar a expressão matemática de um filtro FIR, visto no tempo [4]:
푦(푛) = 푎 푥(푛 − 푖)
= 푎 푥(푛) + 푎 푥(푛 − 1) + … + 푎 푥(푛 −푁 + 1) (2.1)
a que corresponde a seguinte função de transferência, na Equação 2.2, se analisarmos a sua resposta na frequência [5]:
ℎ(푧) =푦(푧)푥(푧) = 푧 ℎ (2.2)
Estes filtros são caracterizados por serem sempre estáveis, e por serem os únicos que podem ter fases lineares [4]. Os filtros FIR possuem um conjunto de N coeficientes (푎 ), onde N pode ser ímpar ou par. Estes filtros quando tem a sua fase linear apresentam simetria face ao coeficiente central, ou seja, 푎 = 푎 , 푎 = 푎 , 푎 = 푎 , etc. Ao longo do trabalho serão sempre considerados os filtros FIR de fase linear, pois estes têm uma implementação em hardware mais simples e eficaz, sendo uma das principais vantagens que leva à utilização de filtros FIR, sendo também a implementação com fase linear as mais comuns para a implementação de filtros FIR.
Para a implementação em hardware de um filtro FIR, serão necessárias realizar um conjunto de operações básicas tais como: adições, multiplicações e forçar atrasos do sinal de entrada. Existem várias arquitecturas que podem ser usadas para implementar os filtros FIR, como veremos na próxima secção.

4
2.2 Arquitecturas FIR
Os filtros FIR tanto podem ser implementados com uma arquitectura série ou paralela [5]. As arquitecturas paralelas ainda têm duas formas diferentes de serem implementadas, sob a sua forma directa ou sob a forma transposta que consistem numa representação gráfica das arquitecturas para implementação dos filtros, como pode ser observada nas Figuras 2.1 e 2.2. As formas referidas anteriormente são conseguidas através da inspecção da função de transferência, Equação 2.2.
Figura 2.1 Representação de um filtro digital não recursivo na sua Forma Directa.
Figura 2.2 Representação de um filtro digital não recursivo na sua Forma Transposta.
Nas Figuras em cima representadas, as setas horizontais com o nome 푧 , representam o
atraso do sinal de entrada; as setas verticais com o nome 푎(푁), representam os diferentes coeficientes do filtro. Assim através da inspecção das imagens anteriores, podemos chegar a um diagrama de blocos que represente a implementação digital do filtro.
A implementação série da arquitectura de um filtro FIR, consiste em utilizar um multiplicador, que realize o produto das amostras atrasadas do sinal de entrada pelos respectivos coeficientes, e um somador em conjunto com um registo, a funcionar como um acumulador. Ou seja, é uma arquitectura série com acumulador e multiplicador que realiza todas as operações em série com um só multiplicador e somador. Sendo necessário N+1, onde N é o número de coeficientes, ciclos de relógio para obter uma saída da amostra.
Numa implementação paralela, um novo valor de saída do filtro é obtido a cada ciclo de relógio. A implementação paralela da arquitectura de um filtro FIR, como já foi referido, pode ser sob a sua forma directa ou transposta, pois ambas apresentam um grau de complexidade semelhante, no que à sua implementação diz respeito. Mas a implementação na forma transposta apresenta maior eficiência energética, uma vez que vão existir menos transições o que faz com seja consumida menos potência para um mesmo filtro [6]. O cominho crítico
푧 푧 푧
푧 푧 푧

5
também é mais curto, o que faz com que a frequência de funcionamento do filtro seja maior. Assim a implementação dos filtros na arquitectura paralela será sempre realizada sob a sua forma transposta.
Serão consideradas neste trabalho, duas arquitecturas paralelas semelhantes na forma transposta e uma arquitectura série. Tendo como comum a ambas as arquitecturas paralelas uma unidade de registos, que contém somadores ligados em série com os de registos. O que distingue as duas arquitecturas paralelas, é a forma como são feitos os produtos dos coeficientes do filtro pelo sinal de entrada. Num dos casos adoptar-se um conjunto de multiplicadores em paralelo, a outra situação que se estudará, é substituir todos os multiplicadores, por multiplicadores por múltiplas constantes, MCM (“Multiple Constant Multiplier”) ou seja somas/subtracções e deslocamentos do sinal de entrada.
Nas próximas secções descrevem-se com mais detalhe as arquitecturas que irão ser estudadas: arquitectura série com acumulador e multiplicador, arquitectura paralela com multiplicadores e arquitectura paralela com MCM.
2.3 Arquitectura série com acumulador e multiplicador
A implementação de filtros FIR usando uma arquitectura série com Acumulador e Multiplicador [4], consiste na utilização de um multiplicador que faça o produto das sucessivas amostras do sinal de entrada pelo respectivo coeficiente e no armazenamento da soma parcial do resultado num registo, até obter o valor final. Para se armazenar as sucessivas amostras do sinal de entrada, utiliza-se uma FIFO, e para armazenar os coeficientes uma memória. Utiliza-se um acumulador para realizar as somas, o armazenamento dos resultados parciais é feito no registo acumulador. Para controlar o endereçamento da memória e do acesso à FIFO, será necessário implementar uma unidade de controlo.
Na Figura 2.4 é apresentado um diagrama de blocos, da implementação de um FIR, usando a arquitectura série com acumulador e com três coeficientes, onde os coeficientes são: 1,7,11.

6
2.3 Diagrama de blocos da arquitectura acumulador e multiplicador.
Nesta arquitectura as áreas ocupadas e potências consumidas, são menores face às outras arquitecturas que iremos estudar, pois são usados menos operadores. Em contrapartida demorar-se há mais tempo para o processamento do resultado final do filtro, quando comparado com as outras arquitecturas, pois todas as operações necessárias para determinar um valor na saída final do filtro são executadas em série.
2.4 Arquitectura paralela com multiplicadores
Esta arquitectura como já foi referida anteriormente, esta dividida em dois grandes blocos, um para realizar multiplicações e outro com os registos e somadores/subtracções para armazenar os resultados parciais e fazer as somas parciais [6] [7]. O bloco de multiplicação consiste num conjunto de multiplicadores em paralelo, que faz a multiplicação em simultâneo do sinal de entrada por cada um dos coeficientes. Este bloco encontra-se ligado ao bloco de registos com somadores/subtractores.

7
O bloco de registos com somadores/subtractores, consiste numa cadeia de registos ligados em série por somadores. Os somadores recebem como operador o conteúdo do registo anterior, somando-o ao produto do coeficiente pelo sinal de entrada. Desta forma consegue-se ir realizando as somas parciais e armazenar as mesmas, nos registos de forma sucessiva.
Na Figura 2.5 é apresentado um diagrama de blocos, para implementação de um FIR com três coeficientes, onde os coeficientes são: 1,7,11.
Figura 2.4 Diagrama de blocos da arquitectura com multiplicadores em paralelo.
A arquitectura paralela com multiplicadores consegue funcionar com uma velocidade de processamento do filtro seja maior que a arquitectura anterior, com acumulador e multiplicador. Quanto a área e potência, espera-se que esta arquitectura seja a que obtenha piores resultados, de todas as arquitecturas, dado que vai existir pelo menos um multiplicador e registo por constante. Note-se no entanto que, dados os operadores do multiplicadores serem constantes (coeficientes do filtro), a ferramenta de síntese pode fazer optimizações de forma a reduzir as áreas dos multiplicadores utilizados.
2.5 Arquitectura paralela com MCM
A implementação de filtros FIR usando uma arquitectura MCM [8], consiste em substituir os multiplicadores por somas, subtracções e deslocamentos criando uma unidade MCM que vai substituir todos os multiplicadores em paralelo [7]. Esta arquitectura e a arquitectura paralela com multiplicadores, acabam por ser muito semelhantes do ponto de vista da utilização de registos. A diferença reside na unidade que se responsabiliza pelo produto do sinal de entrada pelos coeficientes.
Os filtros FIR ao terem coeficientes constantes, permitem que se substituíam todos os multiplicadores por um conjunto de somadores/subtractores e deslocamentos [9], afim de se conseguir uma redução do hardware utilizado e melhorando o atraso total do caminho crítico do multiplicador. Através de diferentes algoritmos podem-se conseguir substituir os multiplicadores por um conjunto de somadores/subtractores e deslocamentos, conseguindo-se fazer partilha para diferentes coeficientes, que utilizem os mesmos operadores (termos auxiliares) [10]. Com a partilha de recursos referida anteriormente ainda se consegue uma maior optimização da área ocupada, mantendo o desempenho temporal.

8
Por exemplo, para fazer a multiplicação de três pelo sinal de entrada, ou seja 3x, será necessário deslocar o sinal de entrada para a esquerda uma vez e somá-lo com ele próprio. Para ser mais fácil perceber o exemplo, em seguida é exibida a fórmula matemática do exemplo referido.
3푥 = 2 푥 + 2 푥
= 2 푥 + 푥 (2.3)
Figura 2.5 Diagrama de blocos de uma multiplicação 3x. Utilizando um multiplicador genérico à esquerda e utilizando uma deslocações e uma soma à direita.
Como se observa na Figura 2.6 podemos verificar, que uma multiplicação, pode ser substituída por uma soma e um deslocamento. Isto tem especial interesse porque, um deslocamento não tem qualquer custo de área ou potência, e por regra geral um somador também consegue ocupar menos área, consumir menos potência e ter menos atraso que um multiplicador. Salienta-se ainda que para coeficientes múltiplos de dois, a multiplicação consegue ser realizada apenas deslocando o sinal de entrada o número de vezes necessário.
Ao pensar-se num filtro FIR, a arquitectura com MCM ganha um interesse ainda maior, devido a poderem ser partilhados recursos para diferentes coeficientes, como já foi referido. Ou seja, muitos coeficientes dos filtros, poderão ter em comum muitos termos auxiliares comuns para a sua implementação. Por exemplo, nas equações seguintes é ilustrada a forma de como se pode conseguir substituir a multiplicação de, 7x e 11x, por adições e somas.
⎩⎪⎨
⎪⎧
7푥 = 3푥 + 4푥 = (2 푥 + 2 푥) + 2 푥
11푥 = 3푥 + 8푥 = (2 푥 + 2 푥) + 2 푥
(2.6)
Ao se observar as equações anteriores, conclui-se que ambas utilizam o termo auxiliar 3x, para obter o produto de 7x e 11x. A existência de termos auxiliares comuns torna possível a partilha de recursos, conseguindo-se assim reduzir o número de somadores, o que vai fazer com que também se diminua a área e a potência consumida, por um filtro que utilize esta arquitectura. Na Figura 2.7 apresenta-se o diagrama de blocos onde se evidência a partilha de um somador para o calculo de 7x e 11x.

9
Figura 2.6 Diagrama de blocos com partilha de recursos do MCM.
Na Figura 2.8 é apresentado um diagrama de blocos, da implementação de um filtro FIR com três coeficientes, onde os coeficientes são: 1,7,11.
Figura 2.7 Diagrama de blocos da arquitectura MCM.
Existem vários algoritmos para encontrar os termos parciais [2] [11], que podem ser partilhados no MCM. Note-se que para além de somas, também se pode utilizar subtracções para o cálculo dos termos auxiliares ou dos próprios coeficientes. Os diferentes algoritmos existentes podem ter objectivos, no entanto a maioria deles tenta reduzir o número de operadores necessários, o que implica uma redução na área ocupada, na potência dissipada e no tempo de cálculo.

10
Esta arquitectura consome mais área e potência que a arquitectura com acumulador e multiplicador, mas apresenta uma velocidade de processamento maior que esta. Talvez o que tenha mais interesse, seja comparar esta arquitectura com a arquitectura com multiplicadores em paralelo. Será de esperar que esta arquitectura com MCM consuma menos potência, ocupe menos área e tenha com uma velocidade de processamento maior que a arquitectura com multiplicadores em paralelo.

11
3 Capítulo 3 Gerador de VHDLpara Filtros FIR Gerador de VHDL para Filtros FIR
Esta secção apresenta as características do gerador para os diferentes filtros e das diferentes arquitecturas geradas. Explica-se ainda as várias opções tomadas para cada uma das arquitecturas geradas e os parâmetros que podem ser configurados com este gerador.
3.1 Introdução
A fim de se conseguir implementar de forma automática as diferentes arquitecturas FIR referidas no capítulo anterior, foi realizado um programa gerador dessas arquitecturas, a partir de um ficheiro com as características do filtro pretendido. Este programa foi desenvolvido na linguagem de programação C e permite gerar diferentes ficheiros com a descrição do filtro, em VHDL sintetizavel, para as arquitecturas pretendidas.
3.2 Funcionalidades e características do gerador
O gerador enunciado anteriormente foi desenvolvido com a perspectiva de poder ser configurado facilmente com diferentes parâmetros que possam ter interesse para o utilizador, a fim de se gerarem filtros com as diferentes arquitecturas e com diferentes características.
Um dos dados necessários e imprescindíveis para o funcionamento do gerador, é um ficheiro com os coeficientes do filtro. O nome do ficheiro com os coeficientes deve ser indicado, na linha de comandos depois do nome do programa G2FIR. Este ficheiro, que pode ter qualquer nome ou extensão, apenas necessita estar colocado na mesma directoria que o programa e seguir um formato especifico (formato este será descrito na secção 3.3). O nome do ficheiro servirá também de base para o nome dos ficheiros VHDL de saída do programa e para as entidades VHDL que serão criadas. Na Figura 3.1, podemos ver um exemplo de como chamar o programa, de forma a gerar o filtro para o ficheiro exemplo.fir.
C:\FIR>G2FIR exemplo.fir
Figura 3.1 Arquitectura do software G2FIR.

12
Figura 3.2 Exemplo da linha de comandos para chamar o programa com o ficheiro de coeficientes pretendido.
O modo de funcionamento do gerador dos filtros FIR em VHDL, G2FIR, encontra-se representado na Figura 3.2. O programa lê um ficheiro de coeficientes que descreve o filtro com as características pretendidas. Na linha de comandos podem ser passadas várias opções que, permitem parametrizar o funcionamento do gerador e consequentemente as características e o tipo da arquitectura do filtro gerado.
Na geração dos ficheiros com a descrição VHDL do filtro o programa G2FIR recorre a uma biblioteca de componentes básicos pré-definida, esta biblioteca está armazenada numa directoria de nome G2FIR, armazenada na directoria do gerador. Esta biblioteca corresponde aos elementos básicos (operadores e registos) que vão ser usados nas várias arquitecturas.
Na secção seguinte descreve-se cada uma das componentes necessárias para o funcionamento do G2FIR assim como as descrições detalhadas das arquitecturas implementadas. No Anexo A, pode se observar o código VHDL com a descrição das unidades genéricas e das diferentes unidades necessárias para as diferentes arquitecturas, com os coeficientes: -2,0,5,10,5,0,-2, armazenados no exemplo.fir.
3.3 Opções básicas da linha de comandos
As diferentes arquitecturas podem ser escolhidas através de uma opção na linha de comandos, após o nome do ficheiro de coeficientes. Por exemplo, na Figura 3.3 é indicada a opção –t:c para indicar a selecção da arquitectura MCM. Na Tabela 3.1 são indicadas as diferentes opções existentes, para a escolha de arquitectura do filtro FIR. Caso esta opção não seja indicada a arquitectura assumida por opção é a correspondente à arquitectura MCM.
C:\FIR>G2FIR exemplo.fir –t:c
Figura 3.3 Linha de comandos com a opção de arquitectura MCM.

13
Tabela 3.1 Tabela com as diferentes opções de arquitectura.
Opção Arquitectura: -t:a Acumulador e multiplicador -t:b Multiplicador paralelo -t:c MCM (por omissão)
Outra característica que se pode configurar na linha de comandos é a dimensão do sinal de entrada. Para se conseguir fazer variar o sinal de entrada, basta escrever na linha de comandos a opção que permite variar a dimensão do sinal, -b:8, assim consegue-se que o sinal de entrada tenha a dimensão de 8 bits, como podemos ver na Figura 3.4. Caso esta opção não seja activa o programa assumira que o sinal de entrada tem dimensão de 16 bits, por omissão.
A dimensão do sinal de saída é outra das características que se pode configurar na linha de comandos. À imagem do sinal de entrada o sinal de saída também utiliza um comando como, -o:16, desta forma faz-se com que a dimensão do sinal de saída tenha 16 bits, como podemos ver na Figura 3.4 e na Tabela 3.2. Caso esta opção não seja seleccionada, o sinal de saída tem por omissão uma dimensão variável, que depende da dimensão do sinal de entrada e dos coeficientes do filtro. Ou seja, terá a dimensão mínima necessária para que não existam erros de truncatura.
C:\FIR>G2FIR exemplo.fir –b:8
C:\FIR>G2FIR exemplo.fir –o:16
Figura 3.4 Exemplo da linha de comandos onde se definiu o sinal de entrada com dimensão de 8 bits em cima, e a linha de comandos onde se definiu o sinal de saída com dimensão de 16 bits.
Tabela 3.2 Tabela com as diferentes opções da largura (bits) do sinal de entrada e saída.
Opção Função
–b:8 Define o sinal de entrada com uma largura de 8 bits
-o:16 Define o sinal de saída com uma largura de 16 bits
3.4 Biblioteca de elementos básicos
As diferentes arquitecturas implementadas vão necessitar de vários componentes genéricos tais como: registos, somadores, multiplicadores e subtractores. Como podemos observar na Figura 3.2, as diferentes unidades genéricas utilizadas, descritas em ficheiros VHDL, estão armazenadas numa biblioteca de elementos básicos.
Assim, sempre que na implementação de uma dada arquitectura for necessário utilizar um operador ou registo, estes serão instanciados da biblioteca básica. Desta forma é possível controlar a arquitectura de cada um destes elementos básicos. Existe portanto a opção da linha

14
de comandos extra que permite seleccionar diferentes unidades genéricas, armazenada em diferentes ficheiros na biblioteca.
Para conseguir utilizar diferentes unidades para além das genéricas, o utilizador do gerador de filtros FIR deverá colocar os ficheiros VHDL com as entidades e arquitecturas pretendidas na biblioteca. Após ter colocado os ficheiros na biblioteca, deverá escrever na linha de comandos a opção -a:uni_somador, por exemplo, esta opção permite-nos utilizar uma entidade com o nome uni_somador para a entidade do somador, em vez do gen_add, utilizado por omissão na biblioteca do gerador. Na Tabela 3.2 podemos observar os nomes dos ficheiros VHDL das várias unidades genéricas e as funções que realizam. Na Tabela 3.3 podemos observar o nome das varias opções para seleccionar as diferentes unidades e o nome por omissão que o gerador utiliza.
Tabela 3.3 Ficheiros genéricos por omissão da biblioteca de elementos básicos.
Ficheiros genéricos da biblioteca Função realizada gen_add.vhd Somador gen_subb.vhd Subtractor gen_mul.vhd Multiplicador gen_reg.vhd Registo com reset
Tabela 3.4 Tabela com as opções para as diferentes unidades genéricas.
Opção Unidades Nome das unidades por omissão -a:nome_somador Somador gen_add -s:nome_subtractor Subtractor gen_sub -m:nome_multiplicador Multiplicador gen_mul -r:nome_registo Registo gen_reg
C:\FIR>G2FIR exemplo.fir –a:somador_generico
Figura 3.5 Exemplo que permite utilizar um somador genérico diferente do gerado por omissão.
Para o correcto funcionando dos filtros gerados para as diferentes arquitecturas, o utilizador terá de ter em conta o formato dos cabeçalhos das entidades que introduz na biblioteca e a sua chamada na linha de comandos. O nome e a ordem dos portos de entrada terá de ser a mesma, de forma a garantir o mesmo interface, mas as entidades poderão ter o nome que o utilizador pretender. Nas Figuras 3.6 a 3.9, são exibidos os formatos dos cabeçalho dos ficheiros de VHDL, que o utilizador tem de seguir para o correcto funcionamentos dos filtros gerados (exemplos apresentados para a as entidades genéricas, pré-definidas na biblioteca).
entity gen_add is generic( dim :integer:=16); Port ( OperA : in signed (dim-1 downto 0); OperB : in signed (dim-1 downto 0); RES : out signed (dim-1 downto 0)); end gen_add;
Figura 3.6 Formato do cabeçalho a cumprir do somador genérico.

15
entity gen_subb is generic( dim :integer:=16); Port ( OperA : in signed (dim-1 downto 0); OperB : in signed (dim-1 downto 0); RES : out signed (dim-1 downto 0)); end gen_subb;
Figura 3.7 Formato do cabeçalho a cumprir do subtractor genérico.
entity gen_mul is generic( dim :integer:=16); Port ( OperA : in signed (dim-1 downto 0); OperB : in signed (dim-1 downto 0); RES : out signed (dim+dim-1 downto 0)); end gen_mul;
Figura 3.8 Formato do cabeçalho a cumprir do multiplicador genérico
entity gen_reg is generic(dim : integer := 64); -- top bit port (clk : in std_logic; clear : in std_logic; data_in : in signed (dim downto 0); data_out: out signed (dim downto 0)); end gen_reg;
Figura 3.9 Formato do cabeçalho a cumprir do registo com reset genérico.
Como podemos observar na Figura 3.2, o gerador vai gerar diferentes ficheiros em linguagem VHDL, com a arquitectura do filtro FIR a implementar. Os ficheiros gerados pelo G2FIR, são dependentes da arquitectura escolhida e do nome do ficheiro dos coeficiente do filtro a implementar. Na Tabela 3.4 é exibido o nome dos ficheiros gerados para cada uma das arquitecturas, para o ficheiro exemplo.fir.
Tabela 3.5 Tabela com os ficheiros gerados para cada uma das diferentes arquitecturas.
Arquitecturas Ficheiros VHDL
Acumulador Multiplicador
exemplo_arq_acum.vhd exemplo_memory.vhd exemlo_uc.vhd exemplo_fifo.vhd
Multiplicador paralelo exemplo_arq_multiplier.vhd exemplo_reg_uni.vhd exemplo_multiplier.vhd
MCM exemplo_arq_mcm.vhd exemplo_reg_uni.vhd exemplo_mcm.vhd
O primeiro ficheiro é onde está armazenada a descrição da unidade de topo, nas secções seguintes são exibidas imagens com a organização de cada uma das arquitecturas e com suas descrições.

16
3.5 Formato do ficheiro com os coeficientes dos filtros FIR
Os ficheiros com os coeficientes dos filtros FIR, têm de seguir um formato predefinido, para que seja possível ao programa fazer a leitura correcta da informação necessária. O ficheiro deve ter duas secções, uma que indica os coeficientes do filtro, outra que indica os termos para a arquitectura MCM. Note-se que para as arquitecturas série com acumulador e multiplicador e paralela com multiplicadores, esta secção deve existir, podendo estar vazia pois não vai ser utilizada.
A primeira secção do ficheiro, começa uma linha com a frase, ***Implementation of coefficeinets***, a anteceder os coeficientes do filtro. A segunda secção do ficheiro, começa uma linha com a frase, ***Implementation of Partial Terms ***, a anteceder os coeficientes parciais, utilizados pela arquitectura MCM. Deve-se respeitar a ordem com que as secções surgem no ficheiro. De seguida passamos a explicar o significado de cada elemento de cada uma das linhas dos coeficientes, com auxílio de uma das linhas do ficheiro exemplo.fir, que podemos ver na Figura 3.10.
*** Implementation of Coefficients *** -2 = -1<<1 0 = +0<<0 5 = +5<<0 10 = +5<<1 5 = +5<<0 0 = +0<<0 -2 = -1<<1 *** Implementation of Partial Terms *** 5>>0 = +1<<0 +1<<2
Figura 3.10 Exemplo da representação dos coeficientes e dos termos, retirados do ficheiro exemplo.fir
Cada linha de especificação de um coeficiente é composta por cinco elementos como se descreve em seguida.
coef = coef_parcial≪
≫n_desloc
Onde o significado de cada elemento se encontra descrito na Tabela 3.5
Tabela 3.6 Tabela com o significado de cada campo dos coeficientes no ficheiro.
coef Coeficiente do filtro
coef_parcial Termo parcial associado ao coeficiente do filtro
<< ou >> Deslocamento à esquerda ou direita, respectivamente
n_deslocaçoes Representa o número de deslocamentos do termo parcial

17
Cada linha de especificação de um coeficiente é composta por dez elementos, como se descreve em seguida.
coef ≪
≫n_desloca = coef_parcial
≪
≫ n_desloca
+
−coef_parcial
≪
≫n_desloca
Onde o significado de cada elemento se encontra descrito na Tabela 3.6.
Tabela 3.7 Tabela com o significado de cada campo dos termos parciais no ficheiro.
coef Coeficiente do filtro
coef_parcial Termo parcial associado ao coeficiente do filtro
<< ou >> Representa um deslocamento à esquerda ou direita, respectivamente
+ ou − Operação necessária para a implementação do coeficiente MCM
n_desloca Representa o número deslocamento do termo parcial
3.6 Arquitectura série com Acumulador e Multiplicador
Para a implementação da arquitectura série dos filtros FIR com acumulador e multiplicador, considerou-se a utilização de quatro grandes entidades diferentes. Um acumulador multiplicador onde se realizam as operações aritméticas (somas e multiplicações) e o armazenamento dos sucessivos resultados parciais. Uma memória onde são armazenados os coeficientes do filtro; uma FIFO para guardar as sucessivas amostras do sinal de entrada; e uma unidade de controlo, para fazer o controlo da memória e do funcionamento do filtro. Para a implementação desta arquitectura utilizam-se quatro ficheiros VHDL, como se observou na Tabela 4.3, com a descrição de cada um das unidades. Na Figura 3.13, podemos observar o diagrama de blocos das diferentes unidades, para a implementação do filtro FIR. A descrição da arquitectura série com acumulador e multiplicador é feita no ficheiro arq_acum.vhd.

18
Figura 3.11 Diagrama de blocos da arquitectura acumulador e multiplicador.
3.6.1 Bloco com FIFO e Memória
Na arquitectura série com acumulador e multiplicador, vão existir três unidades de armazenamento, as quais são: uma FIFO, uma memória e um acumulador; nesta secção vão se estudar apenas a FIFO e a memória, deixando o acumulador para a secção 3.4.3. Para cada uma das unidades foi criado um ficheiro em VHDL com a descrição de cada uma das unidades, com os nomes fifo.vhd e memory.vhd, para além dos ficheiros genéricos armazenados na biblioteca para o gerador de filtros.
A FIFO, consiste numa bateria de registos ligados em série, onde o número de registos é definido pelo número de coeficientes do filtro gerado. A FIFO possui uma ligação do último registo até um multiplexer que faz a selecção entre esta e o sinal de entrada. Ao se ter a esta ligação, vai se conseguir guardar as sucessivas amostras do sinal de entrada, descartando a que já não será necessária e adquirindo uma nova amostra a cada N ciclos, onde N representa o número de coeficientes do filtro.
A memória vai ter sempre metade da dimensão do número de coeficientes, pois como já foi referido anteriormente os filtros são simétricos face ao seu coeficiente central, assim não será necessário repetir o conteúdo em duplicado na memória, cabendo à unidade de controlo fazer o correcto endereçamento da memória.
A dimensão da largura da memória é feita através da análise dos coeficientes do filtro a implementar, ou seja, o número de bits de dados é dimensionado para o maior coeficiente, o pior caso. Os coeficientes são armazenados com sinal de forma a só ser utilizado um somador no acumulador.

19
Na Figura 3.12 é exibido o diagrama de blocos para a FIFO para o exemplo.fir, e o diagrama de blocos da memória com os seguintes coeficientes: -2,0,5,10,5,0,-2.
Figura 3.12 (a) Diagrama de blocos da FIFO e (b) podemos ver o conteúdo da memória para o exemplo.fir.
Para a implementação da FIFO é utilizado um registo genérico, o qual tem a sua arquitectura descrita no ficheiro, gen_reg.vhd, armazenado na biblioteca de ficheiros genéricos do gerador. Os registos são dimensionados com o tamanho do sinal de entrada, na Figura 3.13 podemos observar um troço de código para a implementação da FIFO para o exemplo.fir.

20
--Cabeçalho da FIFO entity fifo is Port ( clk : in STD_LOGIC; clear : in STD_LOGIC; mux_sel: in STD_LOGIC; x_in : in signed (7downto 0); x_n: inout signed (7downto 0)); end fifo; --Descrição da FIFO --MUX if mux_sel = '0' then mux_out<= x_in; else mux_out<= reg_un; end if; --Registos reg0:gen_reg generic map(dim =>7)port map(load,clk,clear,x_in,out_0); … reg6:gen_reg generic map(dim =>7)port map(load,clk,clear,out_5,x_n); reg_un<=x_n;
Figura 3.13 Troço de código em VHDL que descreve a unidade FIFO.
3.6.2 Bloco com Acumulador Multiplicador
A arquitectura série com acumulador e multiplicador é descrita no ficheiro de VHDL, com o nome arq_acum.vhd, como se pode observar na Tabela 3.2. Nesta unidade existirão um multiplicador, um somador e um registo, ligados entre si.
O multiplicador terá como operadores o sinal proveniente da FIFO e da memória. Afim de não se usarem mais bits que o necessário para a multiplicação, vê-se qual dos sinais é maior, se o proveniente da memória ou da FIFO, fazendo-se o dimensionamento do tamanho do multiplicador para o pior caso. Isto é feito para se poder instanciar um multiplicador genérico, como os da Figura 3.8 em que ambos os operadores tem o mesmo tamanho. Espera-se que o sintetizador faça a optimização de recursos, afim de não serem usados mais bits que o necessário.
O somador terá como operadores o conteúdo do registo de saída e o sinal proveniente do multiplicador. O dimensionamento para o somador, que será uma instancia genérica, como a referida Figura 3.9, é feito através da inspecção do pior caso, ou seja, vê-se qual o número de bits necessários para representar o máximo do produto do sinal pelo somatório do modulo de todos os coeficientes.
O registo de saída tem como sinal de entrada de dados o resultado proveniente do somador. Será feito um reset ao conteúdo do registo de saída a cada N ciclos, onde N representa o número de coeficientes do filtro implementado, como foi explicado na secção 3.4.1. Na Figura 3.14 e 3.15 podemos observar o diagrama de blocos da unidade do acumulador com o multiplicador e o troço de código com a sua descrição. O código a apresentado é para o caso em que são necessários 8 bits para o coeficiente e para a palavra de dados na entrada, mas apenas serão necessários 12 bits para representar a saída do multiplicador, fazendo-se o

21
redimensionamento do sinal do multiplicador para 12 bits para ser utilizado no somador e no registo.
Figura 3.14 Diagrama de blocos da unidade Acumulador e multiplicador.
--aritmetica aux_coef<=resize(coef,8); aux_x_fifo<=resize(x_fifo,8); mult_out<=resize(aux_mult_out,12); uni_mult: gen_mul generic map(dim =>8) port map (aux_coef,aux_x_fifo,aux_mult_out); uni_summ: gen_add generic map(dim =>12) port map (mult_out,feedback,summ_out); --registo saída uni_reg: gen_reg generic map(dim =>12) port map (clk,aux_reset,summ_out,feedback); y_out<=feedback
Figura 3.15 Descrição em VHDL da arquitectura com acumulador.
3.6.3 Bloco da unidade de controlo
Para a implementação da arquitectura acumulador e multiplicador como foi referido na secção anterior será necessário uma unidade de controlo, cuja descrição em VHDL desta unidade é armazenada no ficheiro com o sufixo uc.vhd. A unidade de controlo descrita, terá como função fazer o controlo da FIFO, do acumulador e da memória com os coeficientes do filtro.

22
A unidade de controlo implementada, consiste numa máquina de Moore com quatro estados, que têm a função de percorrer de forma ascendente a memória com os coeficientes, num primeiro momento, e de forma descendente num segundo momento. À máquina de estados está associada um contador, que permite percorrer as várias posições da memória. A unidade de controlo também será responsável por controlar as diferentes amostras do sinal de entrada a serem guardadas na FIFO e por limpar o conteúdo do acumulador a cada N ciclo, onde N é o número de coeficientes do filtro. A esta máquina de estados está associado um contador, responsável por percorrer as posições da memória.
Para a implementação da máquina de estados foram considerados quatro estados, que teriam como função gerar cinco sinais de controlo. Os sinais gerados são: o endereço da memória, sinal reset parcial (limpa o conteúdo do registo do acumulador), e o sinal de controlo do multiplexer responsável pela selecção entre as amostras do sinal de entrada a serem guardados na FIFO. Na Tabela 3.8 podemos observar os sinais de saída da Figura 3.18 podemos observar o diagrama de estados da maquina de estados e na Figura 3.16 podemos observar o troço de código da entidade da unidade de controlo.
Tabela 3.8 Sinais de saídas da máquina de estados
Estados Limpar acumulador Endereço Mux
RESET Limpa Primeira posição Sinal de entrada
START Limpa Primeira posição Sinal de entrada
DEC Não Limpa Incrementa uma posição
Sinal proveniente da FIFO
INC Não Limpa Decrementa uma posição
Sinal proveniente da FIFO
COEF_PAR Não Limpa Mantêm última posição Sinal proveniente da FIFO

23
Coefic
iente = 0
Coeficie
nte < N
º_Coefi
ciente
/2
Nº de C
oeficie
nte = P
arCoeficiente =
Nº_Coeficiente/2
3.16 Diagrama de estados da maquina de estados da unidade de controlo (alterar).
O estado START, é um estado inicial ao que se pode aceder a partir do estado RESET ou DEC, tendo como principal característica estar sempre a apontar para a primeira posição de memória, e é o responsável por limpar o conteúdo do registo de saída do acumulador.
O estado com o nome INC, é um estado que faz o incremento das sucessivas posições de memória. A saída deste estado difere caso o número de coeficientes seja par ou ímpar, caso seja par vai para o estado COEF_PAR e repete a última posição da memória, no caso de ser ímpar, apenas a percorre uma vez esta última posição. Indo para o estado seguinte da máquina, estado DEC.
O estado com o nome DEC, é um estado que faz o decremento das sucessivas posições de memória até à posição zero, ou seja a primeira posição da memória, passando de seguida para o estado START.
A unidade de armazenamento FIFO também necessita ser controlada, de forma a guardar e descartar as sucessivas amostras do sinal de entrada. A FIFO tem um multiplexer que é controlado pela unidade de controlo, cujo funcionamento (FIFO) é explicado na Secção 3.4.2. Assim sempre que se estiver no estado START, da unidade de controlo, é feito o armazenamento de uma nova amostra do sinal de entrada. Ou seja a FIFO funciona como um registo de deslocamento.

24
entity UC is Port ( clk : in STD_LOGIC; clear : in STD_LOGIC; reset_out: out STD_LOGIC; mux_select: out STD_LOGIC; addr_mem : out STD_LOGIC_VECTOR (1 downto 0)); end UC;
Figura 3.17 Cabeçalho VHDL que descreve a unidade de controlo para o exemplo.fir.
3.7 Arquitectura paralela com multiplicadores
Para a implementação da arquitectura com multiplicadores em paralelo, considerou-se a utilização de duas grandes entidades diferentes, uma onde se realizam as multiplicações, outro onde se realizam as somas e o armazenamento dos vários resultados parciais. Na Figura 3.19, podemos observar o diagrama de blocos desta arquitectura.
A descrição VHDL da arquitectura com multiplicadores em paralelo vai utilizar três ficheiros, para além dos ficheiros genéricos armazenados na biblioteca do gerador de filtros. No ficheiro com o sufixo arq_parallel.vhd descreve a unidade com o nome “Multiplicadores Paralelo” da Figura 3.20; o ficheiro com o sufixo reg_uni.vhd descreve a cadeia de registos e somadores da Figura 3.20 com o nome “Unidade de Registos e Somadores”. O terceiro ficheiro com o sufixo, arq_multiplier.vhd, é utilizado para fazer a junção das unidades anteriormente referidas.
Figura 3.18 Diagrama de blocos da arquitectura com multiplicadores em paralelo.

25
3.7.1 Unidade com multiplicadores em paralelo
Os filtros FIR com fase linear, para além de terem como característica a simetria em relação ao coeficiente central, como foi referido na secção 2.1, também é comum apresentarem coeficientes repetidos, muitos coeficientes com valor de zero ou um e coeficientes simétricos, o que faz com que se consiga reduzir grandemente o número de multiplicadores necessários à implementação do filtro.
Assim, para a implementação dos multiplicadores em paralelo, os coeficientes repetidos são implementados apenas uma única vez. Para os coeficientes que são zero (elemento absorvente da multiplicação) ou um (elemento neutro da multiplicação) não é necessário implementar multiplicadores para estes coeficientes. Tratam-se também todos os coeficientes em módulo, desta forma consegue-se reduzir o número de multiplicações, porque para todos os coeficientes que forem iguais em módulo é apenas necessário implementar um multiplicador, o sinal negativo dos coeficientes é obtido na unidade de registos e somadores. Desta forma diminui-se o número de multiplicadores que necessitam ser implementados, resultado de serem feitas as optimizações e partilhas de recurso referidas anteriormente, e que têm como consequência a redução da área e da potência consumida, pelo bloco de multiplicadores em paralelo.
Na Figura 3.21, pode-se observa a implementação da unidade de multiplicadores em paralelo do exemplo.fir, sem ter em contas quaisquer optimizações, enquanto que na Figura 3.22 é exibido os multiplicadores em paralelo com as diferentes optimizações. Recordando que os coeficientes do filtro do exemplo.fir são: -2,0,5,10,5,0, -2.
Figura 3.19 Diagrama de fluxo de dados dos multiplicadores em paralelo do exemplo sem optimizações.

26
Figura 3.20 Diagrama de fluxo de dados dos multiplicadores em paralelo do exemplo com optimizações.
Na Figura 3.19 com um mapeamento directo das operações, à partida seriam necessários 7 multiplicadores para a implementação do filtro, mas com as optimizações implementadas serão necessária apenas 3 multiplicadores, como podemos observar na Figura 3.20.
Para implementar a estrutura referida anteriormente em VHDL, vão ser utilizados multiplicadores genéricos que façam o produto do sinal de entrada por constantes, que representam os coeficientes. Os multiplicadores como já foi referido anteriormente terão uma interface genérica que pode ser observada na Figura 3.8.
O multiplicador genérico tem como características: ter duas entradas, o operA e o operB com a largura dim e uma saída RES com a largura de 2dim. O dimensionamento do valor dim é feito através da identificação do pior caso, ou seja, é verificado qual dos sinais de entrada do multiplicador necessita de maior número de bits para a sua representação, ou seja, dim = max {coe iciente , sinal de entrada}.
Ao estarem a ser usados multiplicadores em que as entradas têm a mesma largura e a saída o dobro da largura do sinal de entrada, leva a que muitas vezes sejam declarados mais bits que o necessário na saída do multiplicador. Assim deve-se a fazer o redimensionamento do sinal de saída para a dimensão prevista e suficiente do sinal, ou seja, o número de bits que suporte o máximo do produto do coeficiente pelo sinal de entrada. Caso seja a activa a opção que limita a dimensão do sinal de saída, caso o máximo do produto seja superior à limitação, a saída do multiplicador é feita para a dimensão seleccionada, utilizando os bits menos significativos da multiplicação. Espera-se que o sintetizador de VHDL utilizado, faça a optimização dos recursos para a síntese das arquitecturas genéricas dos filtros FIR.
Na Figura 3.21 podemos observar o cabeçalho da unidade de multiplicadores paralelo para o filtro exemplo.fir, por sua vez na Figura 3.22, podemos observar um troço de código em VHDL da implementação de o coeficiente 2 do filtro. Para este coeficiente de valor 2 e para um sinal de entrada de 8 bits, é o sinal de entrada que tem maior número de bits para a sua representação, logo faz-se um redimensionamento do sinal do coeficiente para 8 bits. O sinal de saída do multiplicador genérico, será de 16 bits, mas no pior caso serão necessários apenas 9 bits para representar o sinal de saída, deste modo faz-se um redimensionamento do sinal de saída para os 9 bits.

27
entity multiplier is Port (x_n : in signed (7 downto 0); sin2: out signed (8 downto 0); sin5: out signed (9 downto 0); sin10: out signed (10 downto 0)); end multiplier;
Figura 3.21 Cabeçalho da unidade com multiplicadores em paralelo.
s2s<="00000010"; mul_0: generic_mul generic map(dim =>8) port map(x_in,s2s,aux_out_0); sin2<=resize(aux_out_0,9);
Figura 3.22 Troço do código em VHDL do ficheiro exemplo_mull_parallel.vhdl, para a implementação dos multiplicadores em paralelo.
3.7.2 Unidade de Registos e somadores
O bloco de registos e somadores é uma unidade comum às arquitecturas com multiplicadores em paralelo e MCM, sendo descrita no ficheiro reg_uni.vhd. Esta unidade, tem como função fazer as somas dos sucessivos resultados parciais e ir armazenando os mesmos nos sucessivos registos. Esta unidade é também responsável corrigir o sinal de cada coeficiente, pois quer para unidade com multiplicadores como para a MCM, os coeficientes são tratados em módulo. É nesta unidade que se transformam os coeficientes positivos em negativos implementando subtractores entre cada registo em vez de somadores. Assim, quando o sinal do coeficiente é positivo implementa-se um somador, quando o coeficiente é negativo é implementado um subtractor.
Os coeficientes que sejam zero, são tratados de forma especial, não serão implementados nem somadores nem subtractores, existindo apenas uma linha a ligar os registos. Quando o primeiro coeficiente é zero, não será implementado o registo do respectivo coeficiente, este processo é repetido caso o segundo coeficiente seja também zero e assim sucessivamente, até encontrar um coeficiente diferente de zero.
Uma outra situação considerada pelo gerador, é quando o primeiro coeficiente é Negativo. Nesse caso o sinal dos coeficientes mantêm-se trocado até encontrar um coeficiente positivo maior que zero e nesse caso em vez de se implementar um somador é implementado um subtractor. Na Figura 3.30 podemos observar o diagrama de blocos da unidade de registos com somadores/subtractores para o filtro exemplo.fir.

28
Figura 3.23 Diagrama de blocos da unidade de registos do exemplo.fir.
Esta unidade utiliza os somadores, subtractores e registos genéricos da biblioteca de componentes na sua descrição em VHDL. Os somadores, subtractores genéricos tem como característica ter um número de bits na entrada igual ao número de bits na saída, assim estas unidades terão as entradas com operA e operB, uma saída com o nome RES, todos estes sinais terão dim bits. Não é utilizado o carry dos somadores/subtractores, pois ao serem utilizados unidades genéricas, todos os sinais terão de utilizar a mesma dimensão de número de bits.
As unidades genéricas referidas anteriormente tais como: somadores, subtractores e registos vão sendo redimensionados consoante a necessidade, ou seja, para cada resultado parcial a dimensão das várias entidades genéricas é ou não actualizada para o pior caso, que consiste no somatório dos sucessivos resultados parciais com a soma do produto do coeficiente actual com o sinal de entrada. Caso a opção que permite dimensionar a largura do sinal de saída esteja activa, nenhum sinal passará a ter mais bits que o valor da opção seleccionada, para esta situação apenas serão utilizados os bits menos significativos para a representação dos diferentes sinais.
entity reg_uni is Port (y_n : out signed (11 downto 0); clear : in STD_LOGIC; clk: in STD_LOGIC; coef2 : in signed (8 downto 0); coef5 : in signed (9 downto 0); coef10 : in signed (10 downto 0)); end REG_UNI
Figura 3.24 Cabeçalho da unidade de registos com somadores.
coef_reg0: gen_reg generic map(dim =>8) port map (clk,clear, coef2, scoef_0); coef_reg1: gen_reg generic map(dim =>8) port map (clk,clear, scoef_0, scoef_1); --Somador entre registos subb2: gen_subb generic map(dim=>10) port map (aux_coef_2,aux_scoef_1, ecoef_2); aux_scoef_1<=resize(scoef_1,10);

29
aux_coef_2<=resize(coef5,10); coef_reg2: gen_reg generic map(dim =>10) port map (clk,clear, ecoef_2, scoef_2);
Figura 3.25 Troço de código em VHDL, responsável pela descrição da unidade de registos e somadores.
3.8 Arquitectura paralela com MCM
Para a implementação da arquitectura MCM, considerou-se a utilização de duas entidades diferentes, uma onde se realizam as multiplicações com arquitectura MCM, outra onde se realizam as somas e o armazenamento dos vários resultados parciais. Na Figura 3.26, podemos observar o diagrama de blocos desta arquitectura.
A arquitectura paralela com MCM vai ser descrita utilizando três ficheiros, para além de utilizar os ficheiros genéricos, presentes na biblioteca do gerador. O ficheiro como o sufixo mcm.vhd representa a unidade com o nome MCM da Figura 3.26, o ficheiro com o sufixo reg_uni.vhd representa a cadeia de registos da Figura 3.25. O terceiro ficheiro com o sufixo, arq_MCM.vhd, é utilizado para fazer a junção das unidades anteriormente referidas.
Note-se que o bloco de registos e somadores é uma unidade comum às arquitecturas MCM e com multiplicadores em paralelo, no ficheiro reg_uni.vhd, assim as opções tomadas foram as mesmas para ambas as arquitecturas, assim as características desta unidade encontra-se descrita na secção 3.7.2.
Figura 3.26 Diagrama de blocos da arquitectura MCM.

30
3.8.1 Bloco com o MCM
A arquitectura FIR com MCM, vai possuir uma unidade (MCM) para realizar as multiplicações, através de somas, subtracções e deslocamentos. A construção da unidade MCM é feita com recurso à informação armazenada no ficheiro com os coeficientes do filtro a ser gerado. Assim através da informação armazenada vai ser possível construir a sequência de somas e/ou subtracções e deslocamentos do sinal de entrada de forma a gerar os termos auxiliares necessários e por fim os coeficientes do filtro multiplicado pelo sinal de entrada.
Tal como na arquitectura anterior os coeficientes de valor zero e repetidos não serão implementados. Dos coeficientes resultantes apenas são considerados para implementação o módulo dos coeficientes ímpares sem haver repetição. Os coeficientes pares serão sucessivamente divididos por dois até encontrar um número ímpar. A implementação de coeficientes múltiplos de dois é feita sem recurso a qualquer tipo de operação, apenas utilizando deslocamentos, e os coeficientes pares com índice diferente de dois, são conseguidos através do deslocamento de um dos termos parciais ímpares do MCM. Para o exemplo.fir de 7 coeficientes, será necessário fazer um deslocamento de um bit de forma a se conseguir obter o coeficiente 2 (os coeficientes são considerados em modulo), para se conseguir o coeficiente 5, é feita a soma de sinal de entrada com o deslocamento de 2 bits do sinal de entrada, para o coeficiente 10, é feito o deslocamento de um bit do termo parcial 5x. Na Figura 3.27 mostra-se o diagrama de fluxo de dados da unidade MCM para o exemplo.
Figura 3.27 Diagrama de fluxo de dados da unidade MCM.
A unidade MCM utiliza somadores e subtractores genéricos baseados na biblioteca genérica para a sua descrição em VHDL. Como podemos observar na Figura 3.7 e na Figura 3.8, os somadores e subtractores genéricos, têm dois sinais de entrada de nome OperA e OperB e têm um sinal de saída com o nome RES. Os sinais de entrada e saída terão o mesmo número de bits, ou seja, todos os sinais têm dim bits. Desta forma os sinais de entrada dos somadores e dos subtractores são redimensionados para a dimensão necessária do máximo do produto do sinal de entrada pelo coeficiente.
Os deslocamentos à direita e à esquerda são feitos através do redimensionamento do sinal e concatenando a zero o número de bits que foram deslocados. Assim, para o exemplo.fir o coeficiente 2 é feito através do deslocamento de um bit para a esquerda e concaténando com um zero no bit menos significativo, redimensionado o sinal original de oito para nove bits. Caso a opção que selecciona a largura máxima do sinal de saída esteja activa, o sinal não pode ser

31
redimensionado para um sinal maior dimensão que o máximo permitido, todo o processo restante funciona da mesma forma. Apenas serão aproveitados os bits menos significativos.
Nas Figura 3.31 é exibido um troço de código, onde podemos observar a unidade MCM e a implementação dos coeficientes. Na Figura 3.30 é exibido a entidade da unidade MCM definindo o seu interface para o exemplo apresentado.
entity MCM is Port ( x_in : in signed (7 downto 0); sin2: out signed (8 downto 0); sin5: out signed (9 downto 0); sin10: out signed (10 downto 0)); end MCM;
Figura 3.28 Cabeçalho do ficheiro VHDL coma descrição da unidade MCM.
--MCM s1s <= signed(x_in); aux_s1s_5_1 <= resize((s1s),10); aux_s1s_5_2 <= resize((s1s&"00"),10); add5: gen_reg generic map(dim=>10) port map (aux_s1s_5_1, aux_s1s_5_2,s5s ); --Coeficients sin2 <= signed(resize(s1s &"0",9)); sin5 <= signed(resize(s5s, 10)); sin10 <= signed(resize(s5s &"0",11));
Figura 3.29 Troço do código em VHDL do ficheiro exemplo_mcm.vhdl, para a implementação do MCM.
3.9 Resultado e simulação das diferentes arquitecturas geradas
Os filtros gerados pelo G2FIR foram simulados e testados numa fase inicial com recurso da ferramenta Xilinx® ISE Design Suite 10.1, a fim de se verificar a correcta implementação de cada uma das arquitecturas. As simulações foram do tipo Behavorial Model, tendo sido simulada a resposta do filtro FIR a um impulso e a um escalão unitário.
A resposta ao escalão unitário de um filtro FIR será igual á soma de todos os coeficientes. Após N ciclos, onde N é o número de ciclos de relógio, para o exemplo.fir o resultado final do filtro FIR implementado será, −2 + 0 + 5 + 10 + 5 + 0 − 2 = 16.
Nas Figuras 3.32, 3.33 e 3.34 podemos observar a simulação de cada uma das arquitecturas implementadas. Onde o sinal de nome x_n com 8 bits, representa o sinal de entrada do filtro, o sinal de saída do filtro surge nas Figuras com o nome de y_n com 12 bits.

32
Figura 3.30 Simulação da resposta ao escalão, da arquitectura série com acumulador e multiplicador.
Figura 3.31 Simulação da ao escalão, da arquitectura paralelo com multiplicadores.
Figura 3.32 Simulação da resposta ao escalão, da arquitectura paralelo com MCM.
A resposta ao impulso unitário de um filtro FIR também foi testada, afim de se verificar o correcto funcionamento de cada um dos filtros. A resposta ao impulso tem como características ser igual aos coeficientes do filtro. Apresentará na saída uma sequência de valores que corresponderá aos coeficientes do filtro. No caso do exemplo.fir teremos:−2, 0,5,10,5,0,−2.
Nas Figuras 3.35, 3.36 e 3.37 podemos observar a simulação de cada uma das arquitecturas implementadas. Onde o sinal de nome x_n com 8 bits, representa o sinal de entrada do filtro, o sinal de saída do filtro surge nas Figuras com o nome de y_n com 12 bits

33
Figura 3.33 Simulação da resposta ao impulso, da arquitectura série com acumulador e multiplicador.
Figura 3.34 Simulação da resposta ao impulso, da arquitectura paralela com multiplicadores.
Figura 3.35 Simulação da resposta a um escalão unitário, da arquitectura paralela com MCM.
Ao se observarem as figuras com as simulações do filtro, exemplo.fir, pode-se concluir que as várias arquitecturas estão a funcionar de forma correcta para os dois exemplos. Ainda se pode observar que a arquitectura série com acumulador e multiplicador tem uma latência muito superior, pois apenas gera um valor correcto a cada N ciclos+1. Ainda se observa que os primeiros N +1 ciclos a arquitectura série com acumulador e multiplicador, apenas preenche a FIFO com as sucessivas amostras do sinal de entrada. Através desta análise pode se concluir que a arquitectura série com acumulador e multiplicador vai demorar mais que qualquer uma das arquitecturas paralelo.

34

35
4 Capítulo 4 Resultados
Resultados
Nesta secção são exibidos os resultados para cada uma das arquitecturas geradas para sinais de entrada com diferentes números de bits. Nesta secção faz-se a comparação entre as diferentes arquitecturas implementadas
4.1 Introdução
Para se compararem as características das diferentes arquitecturas geradas pelo G2FIR, foi feita a síntese das mesmas para vários filtros para sinais de entrada com diferentes larguras. Ao longo desta secção será feita a análise dos resultados de síntese para 8, 16 e 32 bits. A síntese destes filtros será feita com recurso à ferramenta design_vision do software Synopsys (versão V3.70), com a biblioteca c35_corelib da tecnologia AMS. A síntese considerada para as diferentes arquitecturas foi: compile -exact_map, esta síntese mantém a integridades das diferentes unidades geradas. Foram deixadas as diferentes opções de síntese utilizadas por defeito pelo programa. Foi considerado um relógio com um período de 50ns, esta especificação de relógio é mais que suficiente para todos os filtros gerados.
4.2 Características dos filtros gerados
Os filtros sintetizados para as diferentes arquitecturas, foram gerados a partir de 9 filtros com diferentes características, como se pode observar na Tabela 4.1. As características dos filtros tais como: número de coeficientes, diversidade de coeficientes, número de operadores do MCM e o número de bits máximo para a representação de cada coeficiente, pode ser observado na Tabela 4.2. Na Tabela 4.3 podemos observar a dimensão dos bits de saída necessários para não haver erros de truncatura, para a entrada com 8, 16 e 32 bits.

36
Tabela 4.1 Tabela com as características dos filtros FIR gerados.
Filtro Banda de passagem Banda de paragem Nº coeficientes
1 0,2 0,25 121
2 0,10 0,25 101
3 0,15 0,25 30
4 0,20 0,25 81
5 0,24 0,25 121
6 0,15 0,25 60
7 0,15 0,20 60
8 0,10 0,15 60
9 0,10 0,15 100
Tabela 4.2 Tabela com as características dos filtros FIR gerados.
Filtro Nº coeficientes
Nº Coeficientes
diferentes
Nº operadores
MCM
Nº operadores em série do MCM Nº bits máx
coeficientes
1 121 19 10 2 8
2 101 24 17 4 10
3 30 16 15 5 12
4 81 38 28 6 12
5 121 47 34 5 12
6 60 22 20 3 14
7 60 28 29 3 14
8 60 29 28 3 14
9 100 49 45 3 16

37
Tabela 4.3 Dimensão do sinal de saída para cada filtro consoante a largura do sinal de entrada.
Filtro Número de bits de saída para 8 bits
Número de bits de saída para 16 bits
Número de bits de saída para 32 bits
1 18 26 42
2 20 28 44
3 21 29 45
4 22 30 46
5 22 30 46
6 23 31 47
7 23 31 48
8 24 32 49
9 26 34 50
4.3 Resultados de síntese sem limitação do sinal de saída
Nesta secção podemos observar o resultados de área, potência e tempo de atraso máximos para os diferentes filtros, nas arquitecturas geradas pelo G2FIR, sem limitação da dimensão de bits de saída.
4.3.1 Resultados de área
A partir dos resultados da área dos diferentes filtros e arquitecturas, foram construídas Tabelas a partir das quais se obtiveram diferentes gráficos. As Tabelas respectivas aos gráficos apresentadas nas secções seguintes podem ser encontradas no AnexoB.1. Os valores de área foram obtidos através do relatório Report area (que nos permite saber a área total ocupada pelo filtro) e o relatório Report reference (que nos permite saber a área ocupada por cada uma das unidades do filtro gerado).

38
4.3.1.1 Arquitectura série com acumulador e multiplicador
Na Figura 4.1, podemos observar o gráfico com a representação da área total da arquitectura série com acumulador e multiplicador para os filtros gerados. O eixo vertical representa a área do filtro, em µm² e no eixo horizontal são representados os diferentes filtros gerados, para sinais de entradas de 8, 16 e 32 bits.
Figura 4.1 Gráfico da área para a arquitectura para a arquitectura série acumulador e multiplicador, para diferente número de bits no sinal de entrada.
Através da análise das Figura 4.1 podemos concluir que a área ocupada pela arquitectura série com acumulador e multiplicador, está fortemente relacionada com o número de coeficientes de cada filtro, ou seja, podemos observar que os filtros 1 e 5 são os filtros com maior número de coeficientes e consequentemente com a maior área, por sua vez o filtro 3 tem a menor área, pois é o filtro que tem um número menor de coeficientes.
A arquitectura série com acumulador e multiplicador é composta por um único acumulador e multiplicador, para além da memória onde são armazenados os diferentes coeficientes e a FIFO. Para o mesmo filtro independentemente do número de bits utilizados, para a representação do sinal de entrada, a memória terá sempre a mesma dimensão. O que faz com que a FIFO seja a principal responsável pelo aumento da área em função do número de bits do sinal de entrada. Note-se que as memórias são sintetizadas pela ferramenta de síntese como um banco de registos, onde são armazenados os diferentes coeficientes. (no total de N/2 registos onde N é o número de coeficientes).
Assim, podemos concluir que o número de coeficientes é fundamental para dimensão da área final, pois a FIFO e a memória estão directamente relacionadas com o número de coeficientes e na FIFO é usado um registo por cada coeficiente. A memória irá implementar N/2 registos, onde N representa o número de coeficientes do filtro. Esta arquitectura tem um crescimento linear da área ocupada, com o aumento do número de bits do sinal de entrada.
0
500000
1000000
1500000
2000000
2500000
1 2 3 4 5 6 7 8 9 média
Área ( µm²)
8 bits 16 bits 32 bits

39
4.3.1.2 Arquitectura paralela com multiplicadores
Na Figura 4.2, 4.3 e 4.4 podemos observar o gráfico com a representação da área total e de cada uma das unidades (unidade de registos e da unidade de multiplicadores) da arquitectura paralela com multiplicadores para os filtros gerados com 8,16 e 32 bits respectivamente. Ao se ter duas arquitecturas paralelas (com multiplicadores ou com MCM), que tem uma unidade comum a ambas (unidade de registo), existe o interesse em se poder observar a área das distintas unidades, para se poder comparar mais facilmente as duas arquitecturas. O eixo vertical representa a área, em µm² e no eixo horizontal são representados os diferentes filtros gerados.
Figura 4.2 Gráfico com as diferentes áreas da arquitectura paralelo com multiplicadores para os diferentes filtros gerados, para 8 bits.
Figura 4.3 Gráfico com as diferentes áreas da arquitectura paralela com multiplicadores para os diferentes filtros gerados, para 16 bits.
0
500000
1000000
1500000
2000000
2500000
3000000
3500000
4000000
4500000
1 2 3 4 5 6 7 8 9 média:
Área (µm²) 8 bits
total unidade Multiplicadores unidade registos
0
1000000
2000000
3000000
4000000
5000000
6000000
7000000
8000000
1 2 3 4 5 6 7 8 9 média:
Área (µm²) 16 bits
total unidade Multiplicadores unidade registos

40
Figura 4.4 Gráfico com as diferentes áreas da arquitectura paralelo com multiplicadores para os zdiferentes filtros gerados, para 32 bits.
Através da análise do gráfico da Figura 4.2, 4.3 e 4.4 podemos observar que a unidade multiplicadores tem geralmente um maior peso na área ocupada que a unidade de registos. Também podemos observar que o aumento relativo da área ocupada pela unidade de multiplicadores, aumenta com o número de bits utilizados para a representação do sinal de entrada. Para sinais de entrada com 8 e 16 bits, os multiplicadores têm um peso de 45% e 60% respectivamente, para 32 bits o seu peso é 73%.
Isto deve-se ao facto do sinal de entrada passa ter um peso maior no sinal de saída, como podemos observar através das equações 4.1, 4.2 e 4.3, para o filtro 1:
푆푖푛푎푙 푑푒 푒푛푡푟푎푑푎 = 8 푏푖푡푠 푆푖푛푎푙 푑푒 푠푎푖푑푎 = 18 푏푖푡푠
푃 =
= = 0,44 (4.1)
푆푖푛푎푙 푑푒 푒푛푡푟푎푑푎 = 16 푏푖푡푠 푆푖푛푎푙 푑푒 푠푎푖푑푎 = 26 푏푖푡푠
푃 =
= = 0,62 (4.2)
푆푖푛푎푙 푑푒 푒푛푡푟푎푑푎 = 32 푏푖푡푠 푆푖푛푎푙 푑푒 푠푎푖푑푎 = 42 푏푖푡푠
푃 =
= = 0,76 (4.3)
Assim através da análise das equações que relacionam a dimensão do sinal de entrada e de saída, para o filtro 1, verifica-se que o sinal de entrada passa a ser cada vez mais, o dominante, face aos coeficientes do filtro. O filtro necessita no máximo de 10 bits para a representação dos coeficientes, o que faz com que o peso do multiplicador passe a ser cada vez maior na área final, à medida que o número de bits para a representação do sinal de entrada aumenta.
0
5000000
10000000
15000000
20000000
25000000
1 2 3 4 5 6 7 8 9 média:
Área (µm²) 32 bits
total unidade Multiplicadores unidade registos
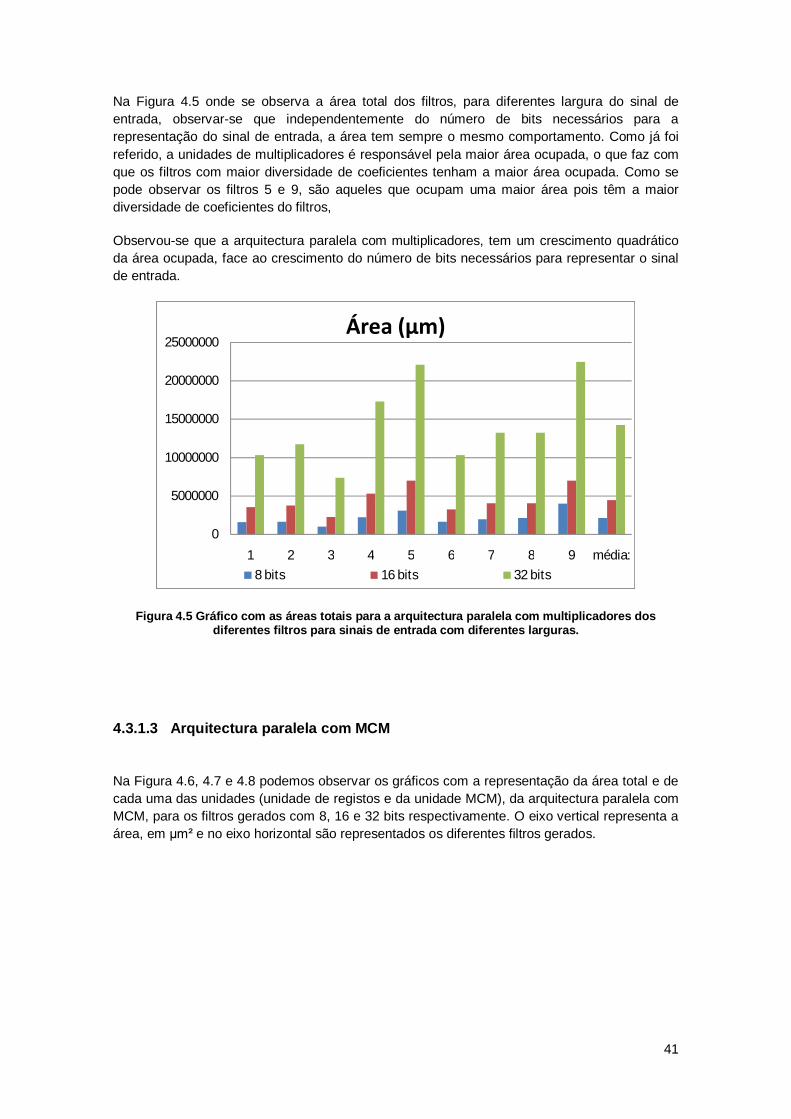
41
Na Figura 4.5 onde se observa a área total dos filtros, para diferentes largura do sinal de entrada, observar-se que independentemente do número de bits necessários para a representação do sinal de entrada, a área tem sempre o mesmo comportamento. Como já foi referido, a unidades de multiplicadores é responsável pela maior área ocupada, o que faz com que os filtros com maior diversidade de coeficientes tenham a maior área ocupada. Como se pode observar os filtros 5 e 9, são aqueles que ocupam uma maior área pois têm a maior diversidade de coeficientes do filtros,
Observou-se que a arquitectura paralela com multiplicadores, tem um crescimento quadrático da área ocupada, face ao crescimento do número de bits necessários para representar o sinal de entrada.
Figura 4.5 Gráfico com as áreas totais para a arquitectura paralela com multiplicadores dos diferentes filtros para sinais de entrada com diferentes larguras.
4.3.1.3 Arquitectura paralela com MCM
Na Figura 4.6, 4.7 e 4.8 podemos observar os gráficos com a representação da área total e de cada uma das unidades (unidade de registos e da unidade MCM), da arquitectura paralela com MCM, para os filtros gerados com 8, 16 e 32 bits respectivamente. O eixo vertical representa a área, em µm² e no eixo horizontal são representados os diferentes filtros gerados.
0
5000000
10000000
15000000
20000000
25000000
1 2 3 4 5 6 7 8 9 média:
Área (µm)
8 bits 16 bits 32 bits

42
Figura 4.6 Gráfico com as diferentes áreas da arquitectura paralelo com MCM para os diferentes filtros gerados, para 8 bits.
Figura 4.7 Gráfico com as diferentes áreas da arquitectura paralelo com MCM para os diferentes filtros gerados, para 16 bits.
0200000400000600000800000
100000012000001400000160000018000002000000
1 2 3 4 5 6 7 8 9 média:
Área (µm²) 8 bits
total unidade MCM unidade registos
0
500000
1000000
1500000
2000000
2500000
3000000
1 2 3 4 5 6 7 8 9 média:
Área (µm²) 16 bits
total unidade MCM unidade registos
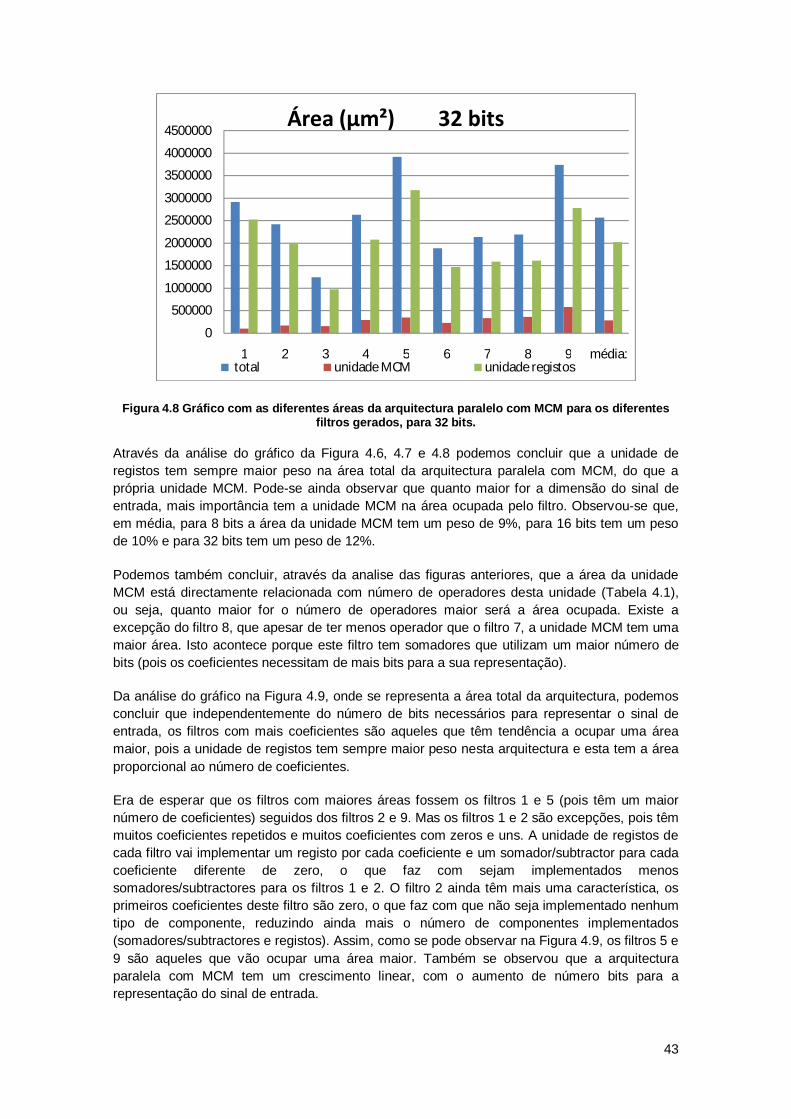
43
Figura 4.8 Gráfico com as diferentes áreas da arquitectura paralelo com MCM para os diferentes filtros gerados, para 32 bits.
Através da análise do gráfico da Figura 4.6, 4.7 e 4.8 podemos concluir que a unidade de registos tem sempre maior peso na área total da arquitectura paralela com MCM, do que a própria unidade MCM. Pode-se ainda observar que quanto maior for a dimensão do sinal de entrada, mais importância tem a unidade MCM na área ocupada pelo filtro. Observou-se que, em média, para 8 bits a área da unidade MCM tem um peso de 9%, para 16 bits tem um peso de 10% e para 32 bits tem um peso de 12%.
Podemos também concluir, através da analise das figuras anteriores, que a área da unidade MCM está directamente relacionada com número de operadores desta unidade (Tabela 4.1), ou seja, quanto maior for o número de operadores maior será a área ocupada. Existe a excepção do filtro 8, que apesar de ter menos operador que o filtro 7, a unidade MCM tem uma maior área. Isto acontece porque este filtro tem somadores que utilizam um maior número de bits (pois os coeficientes necessitam de mais bits para a sua representação).
Da análise do gráfico na Figura 4.9, onde se representa a área total da arquitectura, podemos concluir que independentemente do número de bits necessários para representar o sinal de entrada, os filtros com mais coeficientes são aqueles que têm tendência a ocupar uma área maior, pois a unidade de registos tem sempre maior peso nesta arquitectura e esta tem a área proporcional ao número de coeficientes.
Era de esperar que os filtros com maiores áreas fossem os filtros 1 e 5 (pois têm um maior número de coeficientes) seguidos dos filtros 2 e 9. Mas os filtros 1 e 2 são excepções, pois têm muitos coeficientes repetidos e muitos coeficientes com zeros e uns. A unidade de registos de cada filtro vai implementar um registo por cada coeficiente e um somador/subtractor para cada coeficiente diferente de zero, o que faz com sejam implementados menos somadores/subtractores para os filtros 1 e 2. O filtro 2 ainda têm mais uma característica, os primeiros coeficientes deste filtro são zero, o que faz com que não seja implementado nenhum tipo de componente, reduzindo ainda mais o número de componentes implementados (somadores/subtractores e registos). Assim, como se pode observar na Figura 4.9, os filtros 5 e 9 são aqueles que vão ocupar uma área maior. Também se observou que a arquitectura paralela com MCM tem um crescimento linear, com o aumento de número bits para a representação do sinal de entrada.
0
500000
1000000
1500000
2000000
2500000
3000000
3500000
4000000
4500000
1 2 3 4 5 6 7 8 9 média:
Área (µm²) 32 bits
total unidade MCM unidade registos

44
Figura 4.9 Gráfico de área da unidade MCM, para diferente número de bits na entrada.
4.3.2 Resultados de potência
A partir dos resultados da potência consumida estimados pela ferramenta de síntese, dos filtros com as diferentes arquitecturas, foram construídas Tabelas a partir das quais foram construídos os gráficos desta secção. As respectivas Tabelas podem ser encontradas no AnexoB.2. Os valores de potência foram obtidos através do relatório Report power, gerados pela ferramenta após a síntese do circuito para cada unidade do filtro.
4.3.2.1 Arquitectura série com acumulador e multiplicador
Na Figura 4.10, podemos observar o gráfico com a representação da potência total consumida da arquitectura série com acumulador e multiplicador para os filtros gerados. O eixo vertical representa a potência do filtro, em mW e no eixo horizontal são representados os diferentes filtros gerados, para entradas de 8, 16 e 32 bits.
0
500000
1000000
1500000
2000000
2500000
3000000
3500000
4000000
4500000
1 2 3 4 5 6 7 8 9 média:
Área (µm²)
8 bits 16 bits 32 bits

45
Figura 4.10 Gráfico de potência para a arquitectura série com acumulador e multiplicador, para diferente número de bits no sinal de entrada.
Ao analisarmos a Figura 4.10, podemos concluir que a potência tem um comportamento semelhante ao da área, ou seja, a potência está directamente relacionadas com o número de coeficientes do filtro. Assim podemos concluir que quanto maior for o número de coeficientes de um filtro, maior será a potência dissipada pelo filtro.
A potência dissipada pela arquitectura série com multiplicador estimada pela ferramenta, só tem em conta um ciclo de relógio, mas a arquitectura série com acumulador e multiplicador vai necessitar de N+1 ciclos de relógio para produzir o valor de saída correcto, onde N representa o número de coeficientes. O cálculo da potência total necessária para os diferentes filtros e para diferentes larguras do sinal de entrada (8, 16 e 32 bits), é exibido no gráfico da Figura 4.11. Como se pode observar a energia gasta para calcular a saída de um valor do filtro é tanto maior quanto maior for o número de coeficientes, para um número fixo de bits de entrada.
Figura 4.11 Gráfico de potência total para a arquitectura série com acumulador e multiplicador, para diferente número de bits no sinal de entrada.
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 média
Potência (mW)
8 bits 16 bits 32 bits
0
500
1000
1500
2000
2500
3000
3500
1 2 3 4 5 6 7 8 9 média
Potência equivalente (mW)
8 bits 16 bits 32 bits

46
4.3.2.2 Arquitectura paralela com multiplicadores
Na Figura 4.12, 4.13 e 4.14 podemos observar o gráfico com a representação da potência total e de cada uma das unidades (unidade de registos e da unidade de multiplicadores) da arquitectura paralela com multiplicadores para os filtros gerados. Ao se ter duas arquitecturas paralelas, que tem uma unidade comum a ambas (unidade de registos), existe o interesse em se poder observar a potência das distintas unidades, para serem mais facilmente comparáveis. O eixo vertical representa a potência, em mW, e no eixo horizontal são representados os diferentes filtros gerados para 8,16 e 32 bits.
Figura 4.12 Gráfico com as diferentes potências da arquitectura paralelo com multiplicadores para os diferentes filtros gerados, para 8 bits.
Figura 4.13 Gráfico com as diferentes potências da arquitectura paralelo com multiplicadores para os diferentes filtros gerados, para 16 bits.
0
10
20
30
40
50
60
70
1 2 3 4 5 6 7 8 9 média:
Potência (mw) 8 bits
total unidade multiplicadores unidade registos
0
10
20
30
40
50
60
7080
90
100
1 2 3 4 5 6 7 8 9 média:
Potência (mw) 16 bits
total unidade multiplicadores unidade registos

47
Figura 4.14 Gráfico com as diferentes potências da arquitectura paralelo com multiplicadores para os diferentes filtros gerados, para 32 bits.
Através da análise do gráfico da Figura 4.12, 4.13 e 4.14 podemos concluir que a potência dissipada pela unidade de registos tem sempre o maior peso da potência total consumida pela arquitectura paralela com multiplicadores. Observa-se que mesmo variando o número de bits necessários para a representação do sinal de entrada, a potência tem sempre o mesmo comportamento. No entanto com aumentado do número de bits do sinal de entrada, cada vez é maior o peso da unidade de multiplicadores na potência consumida, pois como já foi referido anteriormente, existe um maior peso do sinal de entrada no sinal de saída (푃 ). Para um sinal com a entrada de 8 bits a unidade de multiplicadores tem um peso 12%, para 16 bits tem um peso de 15% e para 32 bits tem peso de 17%. Também podemos observar que a potência total consumida é diferente da soma das potências de cada unidade, isto deve-se à perda de potência nas interligações das unidades, que também aumenta com o número de bits necessários para a representação do sinal de entrada.
Assim é de esperar que os filtros com maior consumo de potência sejam aqueles que têm maior número de coeficientes. São excepção os filtros 1 e 2, que têm muitos coeficientes a zero, o que faz com que não sejam implementados os somadores/subtractores (para o filtro 2 chegam mesmo a não ser implementados registos) como já foi referido anteriormente. Ainda se deve considerar o facto de estes filtros terem elevadas perdas devido às elevadas capacidades das interligações. Como a área tem um crescimento quadrático com o número de bits da entrada, o número e o tamanho dos fios também aumenta e assim também aumentará, relativamente, a potência dissipada devido às interligações. O que faz que os filtros com relativamente poucos coeficientes, como os filtros 7 e 8, mas com muita diversidade de coeficientes (Tabela 4.1), tenham consumos de potência nos fios relativamente mais elevados que os filtros 1 e 2, com pouca diversidade. Assim filtros com muita diversidade de coeficientes podem chegar a consumir mais potência, que os filtros com maior número de coeficientes mas menos diversidade, como se pode observar na Figura 4.15.
0
20
40
60
80
100
120
140
160
180200
1 2 3 4 5 6 7 8 9 média:
Potência (mw) 32 bits
total unidade multiplicadores unidade registos

48
Figura 4.15 Gráfico da potência da arquitectura paralela com multiplicadores para diferentes larguras do sinal de entrada: 8, 16, 32 bits.
4.3.2.3 Arquitectura paralela com MCM
Na Figura 4.16, 4.17 e 4.18, podemos observar o gráfico com a representação da potência total e de cada uma das unidades (bloco de registos e bloco MCM) da arquitectura paralela com MCM para os filtros gerados. O eixo vertical representa a potência, em mW e no eixo horizontal são representados os diferentes filtros gerados para 8, 16, 32 bits.
Figura 4.16 Gráfico com as diferentes potências da arquitectura paralelo com MCM para os diferentes filtros gerados, para 8 bits.
0
50
100
150
200
1 2 3 4 5 6 7 8 9 média:
Potência (mw)
8 bits 16 bits 32 bits
0
5
10
15
20
25
30
35
4045
50
1 2 3 4 5 6 7 8 9 média:
Potência (mw) 8 bits
total undidade MCM unidade registos

49
Figura 4.17 Gráfico com as diferentes potências da arquitectura paralelo com MCM para os diferentes filtros gerados, para 16 bits.
Figura 4.18 Gráfico com as diferentes potências da arquitectura paralelo com MCM para os diferentes filtros gerados, para 32 bits.
Através da análise do gráfico da Figura 4.16, 4.17 e 4.18, podemos concluir que a unidade MCM tem sempre um peso relativamente baixo, na potência consumida pela arquitectura paralela com MCM. Também se observa, que existe um aumento do peso da potência consumida pela unidade MCM, com o aumento do número de bits necessários para a representação do sinal de entrada. Isto acontece porque o sinal de entrada passa a ter um maior peso no sinal de saída, como se viu anteriormente. Assim para 8 bits tem um peso de 4%, para 16 bits tem um peso de 5% e para 32 bits tem um peso de 6%.
0
10
20
30
40
50
60
70
80
1 2 3 4 5 6 7 8 9 média:
Potência (mw) 16 bits
total undidade MCM unidade registos
0
20
40
60
80
100
120
140
1 2 3 4 5 6 7 8 9 média:
Potência (mw) 32 bits
total unidade MCM unidade registos
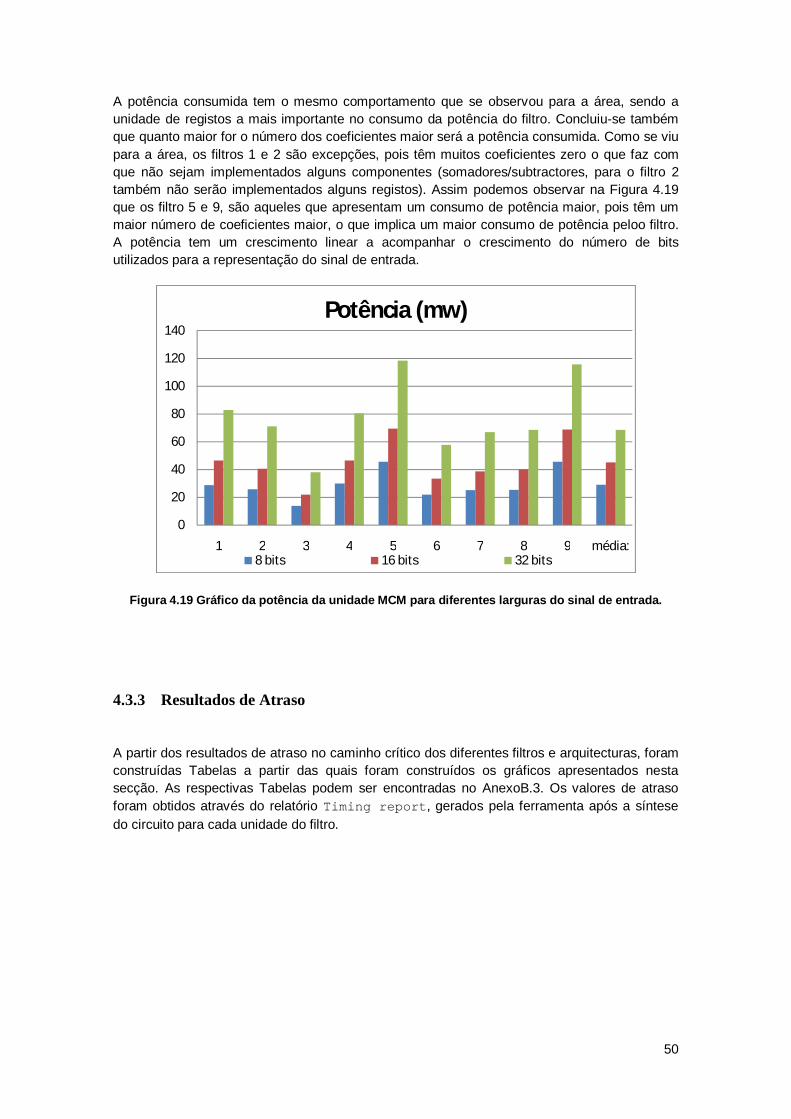
50
A potência consumida tem o mesmo comportamento que se observou para a área, sendo a unidade de registos a mais importante no consumo da potência do filtro. Concluiu-se também que quanto maior for o número dos coeficientes maior será a potência consumida. Como se viu para a área, os filtros 1 e 2 são excepções, pois têm muitos coeficientes zero o que faz com que não sejam implementados alguns componentes (somadores/subtractores, para o filtro 2 também não serão implementados alguns registos). Assim podemos observar na Figura 4.19 que os filtro 5 e 9, são aqueles que apresentam um consumo de potência maior, pois têm um maior número de coeficientes maior, o que implica um maior consumo de potência peloo filtro. A potência tem um crescimento linear a acompanhar o crescimento do número de bits utilizados para a representação do sinal de entrada.
Figura 4.19 Gráfico da potência da unidade MCM para diferentes larguras do sinal de entrada.
4.3.3 Resultados de Atraso
A partir dos resultados de atraso no caminho crítico dos diferentes filtros e arquitecturas, foram construídas Tabelas a partir das quais foram construídos os gráficos apresentados nesta secção. As respectivas Tabelas podem ser encontradas no AnexoB.3. Os valores de atraso foram obtidos através do relatório Timing report, gerados pela ferramenta após a síntese do circuito para cada unidade do filtro.
0
20
40
60
80
100
120
140
1 2 3 4 5 6 7 8 9 média:
Potência (mw)
8 bits 16 bits 32 bits
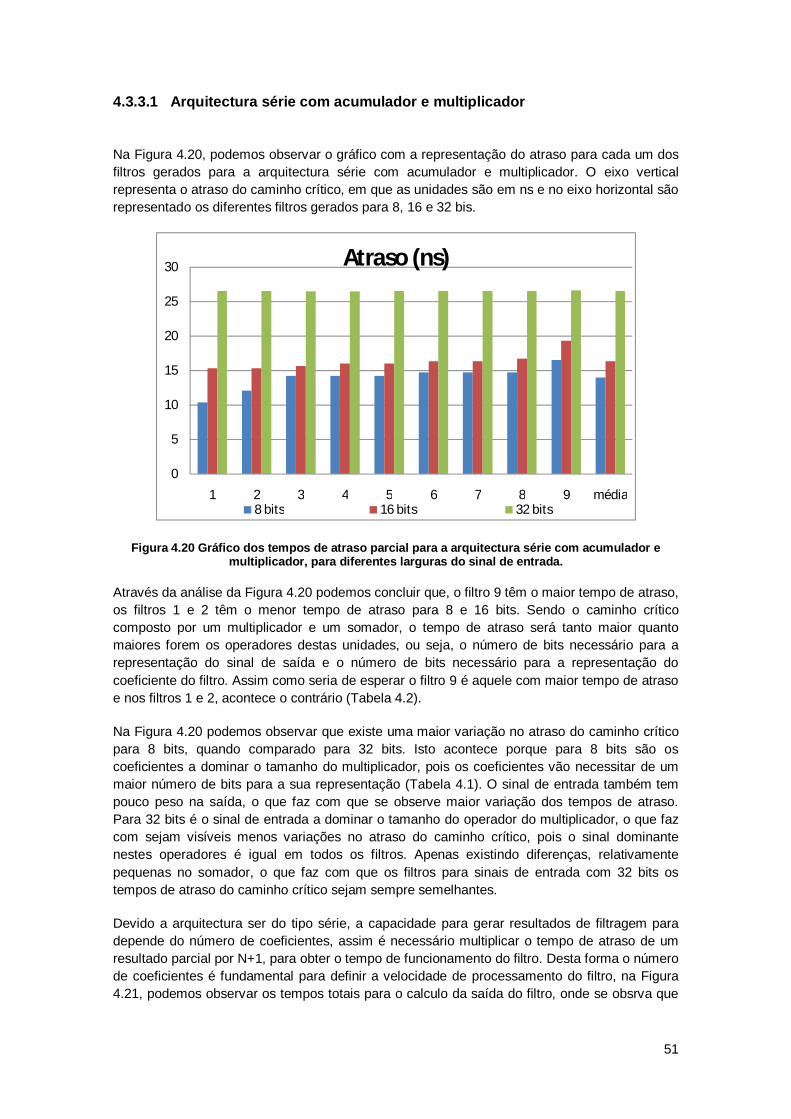
51
4.3.3.1 Arquitectura série com acumulador e multiplicador
Na Figura 4.20, podemos observar o gráfico com a representação do atraso para cada um dos filtros gerados para a arquitectura série com acumulador e multiplicador. O eixo vertical representa o atraso do caminho crítico, em que as unidades são em ns e no eixo horizontal são representado os diferentes filtros gerados para 8, 16 e 32 bis.
Figura 4.20 Gráfico dos tempos de atraso parcial para a arquitectura série com acumulador e multiplicador, para diferentes larguras do sinal de entrada.
Através da análise da Figura 4.20 podemos concluir que, o filtro 9 têm o maior tempo de atraso, os filtros 1 e 2 têm o menor tempo de atraso para 8 e 16 bits. Sendo o caminho crítico composto por um multiplicador e um somador, o tempo de atraso será tanto maior quanto maiores forem os operadores destas unidades, ou seja, o número de bits necessário para a representação do sinal de saída e o número de bits necessário para a representação do coeficiente do filtro. Assim como seria de esperar o filtro 9 é aquele com maior tempo de atraso e nos filtros 1 e 2, acontece o contrário (Tabela 4.2).
Na Figura 4.20 podemos observar que existe uma maior variação no atraso do caminho crítico para 8 bits, quando comparado para 32 bits. Isto acontece porque para 8 bits são os coeficientes a dominar o tamanho do multiplicador, pois os coeficientes vão necessitar de um maior número de bits para a sua representação (Tabela 4.1). O sinal de entrada também tem pouco peso na saída, o que faz com que se observe maior variação dos tempos de atraso. Para 32 bits é o sinal de entrada a dominar o tamanho do operador do multiplicador, o que faz com sejam visíveis menos variações no atraso do caminho crítico, pois o sinal dominante nestes operadores é igual em todos os filtros. Apenas existindo diferenças, relativamente pequenas no somador, o que faz com que os filtros para sinais de entrada com 32 bits os tempos de atraso do caminho crítico sejam sempre semelhantes.
Devido a arquitectura ser do tipo série, a capacidade para gerar resultados de filtragem para depende do número de coeficientes, assim é necessário multiplicar o tempo de atraso de um resultado parcial por N+1, para obter o tempo de funcionamento do filtro. Desta forma o número de coeficientes é fundamental para definir a velocidade de processamento do filtro, na Figura 4.21, podemos observar os tempos totais para o calculo da saída do filtro, onde se obsrva que
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 média
Atraso (ns)
8 bits 16 bits 32 bits

52
os filtro 1 e 5 são os mais lentos e o filtro 3 é o mais rápido, essencialmente devido ao número reduzido de coeficientes que têm de ser calculados em sequência.
Figura 4.21 Gráfico com o atraso total para o cálculo de cada saída do filtro da arquitectura série com acumulador e multiplicador, para diferentes larguras do sinal de entrada.
4.3.3.2 Arquitectura paralela com multiplicadores
Na Figura 4.22, 4.23 e 4.24 podemos observar o gráfico com a representação do atraso caminho crítico total e do caminho crítico para as unidade de multiplicadores. Ao se ter duas arquitecturas paralelo, que tem uma unidade comum a ambas (unidade de registos), existe o interesse em se poder observar o atraso dos caminhos críticos das unidades de multiplicadores em separado, para serem mais facilmente comparáveis. O eixo vertical representa o atraso do caminho crítico, em ns e no eixo horizontal são representados os diferentes filtros gerados para 8, 16 e 32 bits.
0
500
1000
1500
2000
2500
3000
3500
1 2 3 4 5 6 7 8 9 média
Velocidade do filtro (ns)
8 bits 16 bits 32 bits
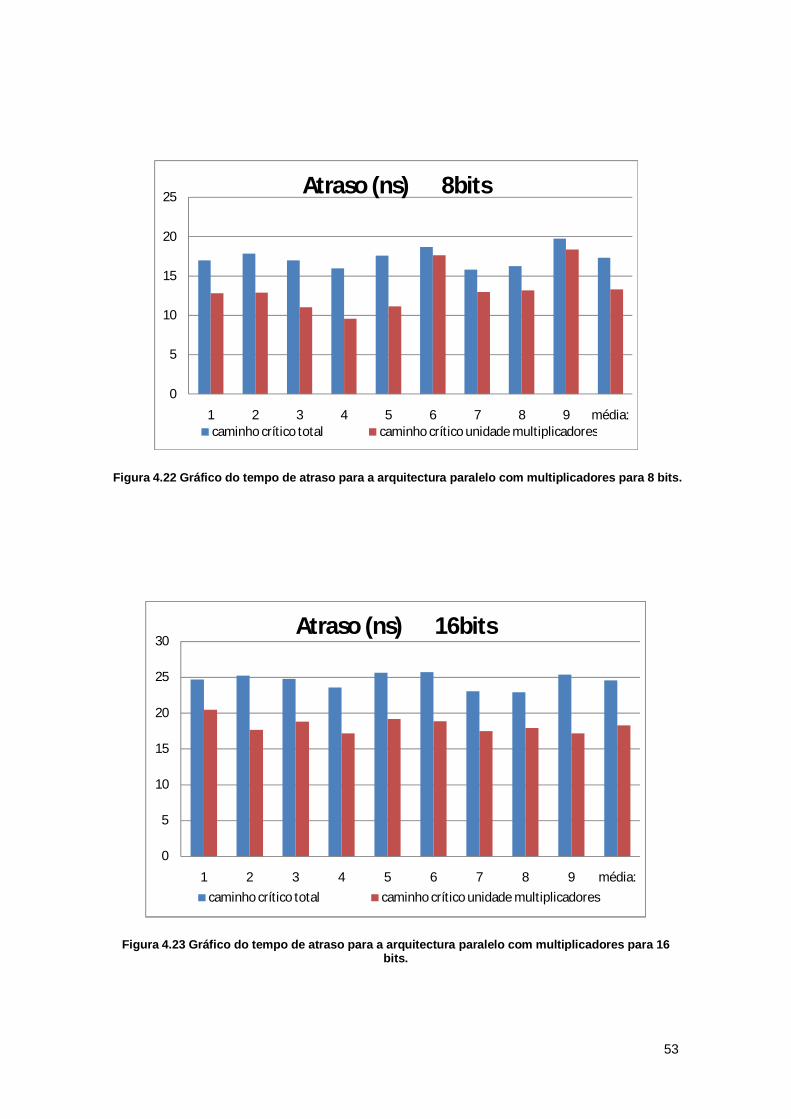
53
Figura 4.22 Gráfico do tempo de atraso para a arquitectura paralelo com multiplicadores para 8 bits.
Figura 4.23 Gráfico do tempo de atraso para a arquitectura paralelo com multiplicadores para 16 bits.
0
5
10
15
20
25
1 2 3 4 5 6 7 8 9 média:
Atraso (ns) 8bits
caminho crítico total caminho crítico unidade multiplicadores
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 média:
Atraso (ns) 16bits
caminho crítico total caminho crítico unidade multiplicadores

54
Figura 4.24 Gráfico do tempo de atraso para a arquitectura paralelo com multiplicadores para 32 bits.
Através da análise das Figuras 4.22, 4.23 e 4.24 podemos concluir que o caminho crítico tem a tendência em ter menos variações em função do aumento do número de bits necessário para a representação do sinal de entrada, e que também aumenta a importância do multiplicador no atraso total do caminho crítico.
Para 32 bits, observa-se na Figura 4.24, que o atraso varia menos entre os diferentes filtros. O atraso do caminho crítico do multiplicador tem um maior peso no atraso do caminho crítico total, para 32 bits que para sinais de entrada com menor número de bits. Isto acontece porque o sinal de entrada vai ser o sinal dominante na definição do tamanho do multiplicador tendo portanto o sinal de entrada um maior peso no sinal de saída. O caminho crítico ao ser composto pelo multiplicador e pelo somador, tendo estes componentes sensivelmente o mesmo tamanho e consequentemente o mesmo tempo de atraso (multiplicadores genéricos de 32 bits). Para 32 bits também se observou que filtros com menor diversidade de coeficientes e consequentemente com maiores fan-out, também tem tendências em ter atrasos maiores nos caminhos críticos maiores.
Na Figura 4.22 também se observou que para 8 bits existe uma maior variação dos caminhos críticos, pois são os coeficientes a dominar o operando dos multiplicadores, o que faz com que exista uma maior variação da dimensão dos multiplicadores e consequentemente do seu atraso máximo.
0
5
10
15
20
25
30
35
40
45
1 2 3 4 5 6 7 8 9 média:
Atraso (ns) 32bits
caminho crítico total caminho crítico unidade multiplicadores

55
Figura 4.25 Gráfico do tempo de atraso total para a arquitectura paralelo com multiplicadores para diferente número de bits no sinal de entrada.
4.3.3.3 Arquitectura paralela com MCM
Na Figura 4.28, 4.29 e 4.30, podemos observar o gráfico com a representação do atraso total do circuito e da unidade MCM da arquitectura paralela com MCM para os filtros gerados. O eixo vertical representa o atraso do caminho crítico, em ns, e no eixo horizontal são representados os diferentes filtros gerados para 8, 16 e 32 bits.
Figura 4.26 Gráfico do tempo de atraso para a arquitectura paralela com MCM para 8 bits.
0
5
10
15
20
25
30
35
40
45
1 2 3 4 5 6 7 8 9 média:
Atraso (ns)
8 bits 16 bits 32 bits
0
2
4
6
8
10
12
14
16
18
20
1 2 3 4 5 6 7 8 9 média:
Atraso (ns) 8bits
caminho crítico total caminho crítico unidade MCM

56
Figura 4.27 Gráfico do tempo de atraso para a arquitectura paralela com MCM para 16 bits.
Figura 4.28 Gráfico do tempo de atraso para a arquitectura paralela com MCM para 32 bits.
Como podemos observar nas Figuras 4.27, 4.28 e 4.29, o atraso do caminho crítico tem sensivelmente o mesmo comportamento independentemente do número de bits do sinal de entrada. Nesta situação o caminho crítico é composto pelo número operadores em série do MCM (Tabela 4.1) e pelo somador da unidade de registos. Podemos concluir que o número de operadores em série é importante para definir o atraso total do caminho crítico. Note-se que independentemente do sinal de entrada, os filtros 4 e 5 encontram-se sempre entre os filtros com maior tempo de atraso sendo também dos filtros que tem maior número de operadores em série (6 e 5 operadores em série respectivamente, Tabela 4.1), como se observa nos gráficos. O filtro 1 com apenas 2 operadores em série é sempre o filtro com o menor tempo de atraso, como se pode observar nas Figuras 4.27, 4.28 e 4.29. Também se observou que independentemente do número de bits necessários para representar o sinal de entrada, é sempre a unidade MCM a principal responsável pelo atraso global do filtro.
0
5
10
15
20
25
1 2 3 4 5 6 7 8 9 média:
Atraso (ns) 16bits
caminho crítico total caminho crítico unidade MCM
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 média:
Atraso (ns) 32bits
caminho crítico total caminho crítico unidade MCM
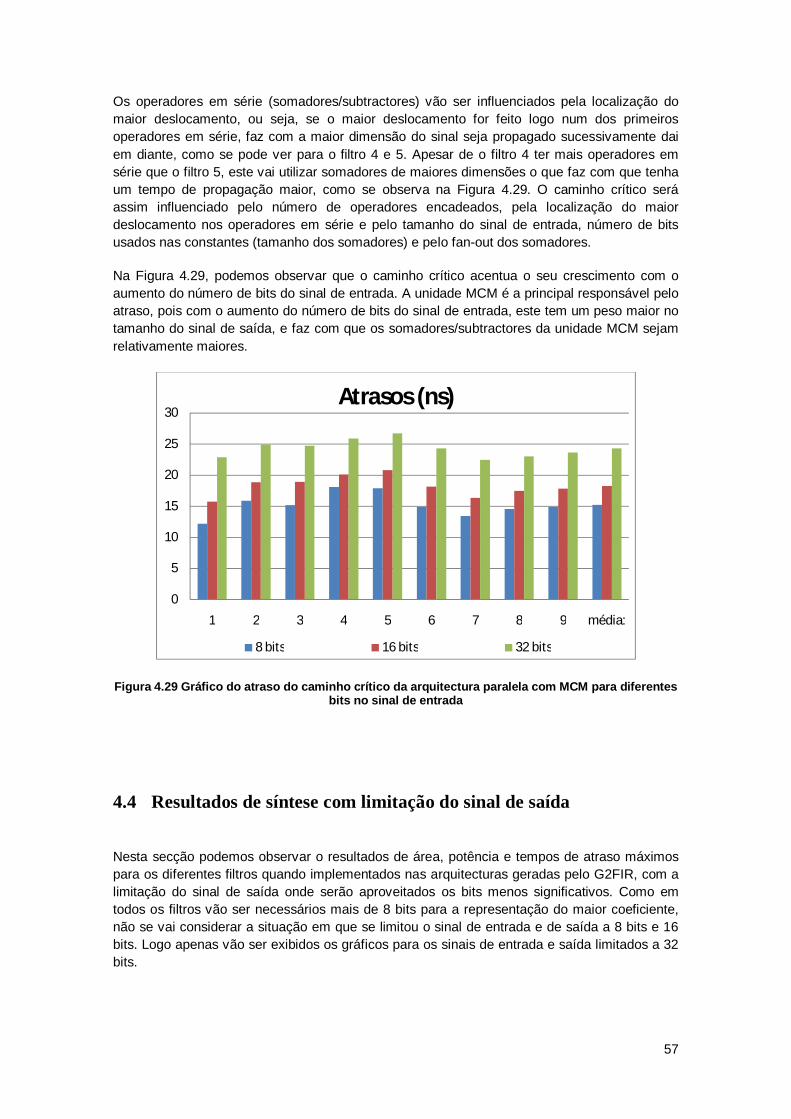
57
Os operadores em série (somadores/subtractores) vão ser influenciados pela localização do maior deslocamento, ou seja, se o maior deslocamento for feito logo num dos primeiros operadores em série, faz com a maior dimensão do sinal seja propagado sucessivamente dai em diante, como se pode ver para o filtro 4 e 5. Apesar de o filtro 4 ter mais operadores em série que o filtro 5, este vai utilizar somadores de maiores dimensões o que faz com que tenha um tempo de propagação maior, como se observa na Figura 4.29. O caminho crítico será assim influenciado pelo número de operadores encadeados, pela localização do maior deslocamento nos operadores em série e pelo tamanho do sinal de entrada, número de bits usados nas constantes (tamanho dos somadores) e pelo fan-out dos somadores.
Na Figura 4.29, podemos observar que o caminho crítico acentua o seu crescimento com o aumento do número de bits do sinal de entrada. A unidade MCM é a principal responsável pelo atraso, pois com o aumento do número de bits do sinal de entrada, este tem um peso maior no tamanho do sinal de saída, e faz com que os somadores/subtractores da unidade MCM sejam relativamente maiores.
Figura 4.29 Gráfico do atraso do caminho crítico da arquitectura paralela com MCM para diferentes bits no sinal de entrada
4.4 Resultados de síntese com limitação do sinal de saída
Nesta secção podemos observar o resultados de área, potência e tempos de atraso máximos para os diferentes filtros quando implementados nas arquitecturas geradas pelo G2FIR, com a limitação do sinal de saída onde serão aproveitados os bits menos significativos. Como em todos os filtros vão ser necessários mais de 8 bits para a representação do maior coeficiente, não se vai considerar a situação em que se limitou o sinal de entrada e de saída a 8 bits e 16 bits. Logo apenas vão ser exibidos os gráficos para os sinais de entrada e saída limitados a 32 bits.
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 média:
Atrasos (ns)
8 bits 16 bits 32 bits

58
4.4.1 Resultados de área
A partir dos resultados de área ocupada dos diferentes filtros e arquitecturas, foram construídas Tabelas a partir das quais foram construídos os diferentes gráficos. As respectivas Tabelas podem ser encontradas no AnexoC, para a arquitectura série com multiplicador e acumulador, e para as arquitecturas paralelas com MCM e para a arquitectura paralela com multiplicadores para 32 bits
4.4.1.1 Arquitectura série com acumulador e multiplicador
Na Figura 4.30, podemos observar o gráfico com a representação da área total da arquitectura série com acumulador e multiplicador para os filtros gerados. O eixo vertical representa a área do filtro, em µm² e no eixo horizontal são representados os diferentes filtros gerados, para entradas e saídas limitadas a 32 bits.
Figura 4.30 Gráfico de área para a arquitectura série com o sinal limitado a 32 bits.
Através da análise do gráfico da Figura 4.30, verificamos que a área ocupada por cada um dos filtros está directamente relacionada com o número de coeficientes do filtro. A memória (mapeada com registos) e a FIFO estão directamente relacionadas com o número de coeficientes, pois vão ser implementados N registos para a FIFO e N/2 registos para a memória, onde N representa o número de coeficientes do filtro. Como foi referido numa secção anterior, a FIFO e a memória serão as unidades mais importantes em termos de área ocupada, o que faz concluir que quanto maior for o número de coeficientes maior será a área total do filtro gerado.
0
500000
1000000
1500000
2000000
2500000
1 2 3 4 5 6 7 8 9 média
Área (µm²)

59
4.4.1.2 Arquitectura paralela com multiplicadores
Na Figura 4.31, podemos observar o gráfico com a representação da área total e de cada uma das unidades (unidade de registos e da unidade de multiplicadores) da arquitectura paralela com multiplicadores, para os filtros gerados com 32 bits. Ao se ter duas arquitecturas paralelas, que têm uma unidade comum a ambas (unidade de registo), existe o interesse em se poder observar a área das distintas unidades, para se poder comparar mais facilmente as duas arquitecturas. O eixo vertical representa a área, em µm² e no eixo horizontal são representados os diferentes filtros gerados com a entrada e a saída limitada a 32 bits.
Figura 4.31 Gráfico da área total e das diferentes unidades da arquitectura paralelo com multiplicadores. Para entrada e saída limitada a 32 bits
Através dos gráficos da Figura 4.31 verificamos que é a unidade de multiplicadores que tem maior peso para 32 bits. A área desta arquitectura está directamente relacionada com a diversidade de coeficientes do filtro, pois a unidade de multiplicadores é a mais preponderante para a área final, como já se tinha visto quando não se tinha limitado o sinal de saída, tendo em média um peso de 76%. Assim podemos observar que os filtros 9 e 5, são aqueles que ocupam uma maior área, pois têm um maior diversidade de coeficientes (Tabela 4.1), como já se tinha visto para quando não se limitou a saída.
4.4.1.3 Arquitectura paralela com MCM
Na Figura 4.32, podemos observar o gráfico com a representação da área total e de cada uma das unidades (unidade de registos e da unidade MCM) da arquitectura paralela com MCM para os filtros gerados. O eixo vertical representa a área, em µm² e no eixo horizontal são representados os diferentes filtros gerados com o sinal de entrada e saída limitada a 32 bits.
0
5000000
10000000
15000000
20000000
25000000
1 2 3 4 5 6 7 8 9 média
Área (µm²) 32 bits
total unidade Multiplicadores unidade registos

60
Figura 4.32 Gráfico da área total e das diferentes unidades da arquitectura paralela com MCM. Para entrada e saída limitada a .
Através da análise dos gráficos na Figura 4.32, podemos concluir que os filtros com maior área são os filtros 5 e 9. Na arquitectura paralela com MCM, como já se tinha observado a quando da não limitação do sinal de saída, a unidade de registos é aquela que apresenta um maior peso na área final de cada filtro, onde em média a unidade de registos tem um peso de 80% da área total ocupada. O que nos leva a concluir que os filtros com maior número de coeficientes são aqueles que vão ocupar uma maior área, como os filtros 5 e 9, como já foi referido. Existe a excepção do filtro 1 e 2, que ao terem muitos coeficientes repetidos e zero, faz com que sejam implementados menos componentes (registos, somadores e subtractores) como já foi explicado anteriormente.
4.4.2 Resultados de potência
A partir dos resultados do consumo de potência dos diferentes filtros e arquitecturas, foram construídas Tabelas a partir das quais foram construídos os diferentes gráficos. As respectivas Tabelas podem ser encontradas no AnexoC, para a arquitectura série com multiplicador e acumulador, e para as arquitecturas paralelas com MCM e para a arquitectura paralela com multiplicadores para 32 bits
4.4.2.1 Arquitectura série com acumulador e multiplicador
Na Figura 4.33, podemos observar o gráfico com a representação da potência consumida da arquitectura série com acumulador e multiplicador para os filtros gerados. O eixo vertical representa a potência do filtro, em mW e no eixo horizontal são representados os diferentes filtros gerados, para entradas e saídas limitadas a 32 bits.
0
500000
1000000
1500000
2000000
2500000
3000000
1 2 3 4 5 6 7 8 9 média
Área (µm²) 32 bits
área total área MCM área unidade registos

61
Figura 4.33 Gráfico com a potência consumida para a arquitectura série com acumulador e multiplicador para os diferentes filtros com o sinal de entrada e saída limitada a 32 bits.
Através da análise do gráfico da Figura 4.33, podemos concluir que os filtros com maior número de coeficientes, como o filtro 1 e 5, são aqueles têm um maior consumo de potência. Como já tínhamos visto anteriormente, a potência nesta arquitectura tem um comportamento semelhante com o dá área, o que faz com os filtros com o maior número de coeficientes tenham o maior consumo de potência.
Esta potência estimada só tem em conta um ciclo de relógio, no entanto, esta arquitectura vai necessitar de N+1 ciclos de relógio para produzir o valor de saída correcto, onde N representa o número de coeficientes. O cálculo da potência total necessária para os diferentes filtros é exibido no gráfico da Figura 4.34. Como se pode observar a potência gasta para calcular a saída de um valor do filtro é tanto maior quanto maior for o número de coeficientes.
Figura 4.34 Gráfico de potência total para a arquitectura série com acumulador e multiplicador, para a entrada e saída limita a 32 bits.
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 média
Potência(mW)
0
500
1000
1500
2000
2500
3000
3500
121 101 30 81 121 60 60 60 100 média:
Potência equivalente (mW)

62
4.4.2.2 Arquitectura paralela com multiplicadores
Na Figura 4.35, podemos observar o gráfico com a representação da potência total consumida e de cada uma das unidades da arquitectura paralela com multiplicadores para os filtros gerados. O eixo vertical representa a área, em mW e no eixo horizontal são representados os diferentes filtros gerados com a entrada e a saída limitada a 32 bits.
Figura 4.35 Gráfico da potência total e das diferentes unidades da arquitectura paralelo com multiplicadores. Para entrada e saída limitadas a 32.
Através da análise da Figura 4.35, podemos concluir que são as unidades de registos são as mais importantes no consumo total de potência para a arquitectura paralela com multiplicadores. Como também se tinha observado a quando da não limitação do sinal de saída, são os filtros 5 e 9 são aqueles que consomem uma maior potência, pois também são eles que têm um maior número de coeficientes. Assim os filtros 1 e 2 continuam a ser excepções, pois as suas características (coeficientes repetidos e muitos zeros), não são influenciadas com os sinais limitados a uma representação de 32 bits.
4.4.2.3 Arquitectura paralela com MCM
Na Figura 4.36, podemos observar o gráfico com a representação da potência consumida total e de cada uma das unidades (unidade de registos e da unidade MCM) da arquitectura paralela com MCM para os filtros gerados. O eixo vertical representa a área, em mW e no eixo horizontal são representados os diferentes filtros gerados com o sinal de entrada e saída limitada a 32 bits.
0
20
40
60
80
100
120
140
160
1 2 3 4 5 6 7 8 9 média
Potência(mW) 32 bits
total unidade Multiplicadores unidade registos

63
Figura 4.36 Gráfico da potência total e das diferentes unidades da arquitectura paralelo MCM. Para entrada e saída limitadas a 32 bits.
Através da análise dos gráficos na Figura 4.36, observa-se que os filtros 5 e 9 com maior consumo de potência. A unidade de registos é a que representa maior peso no consumo total de potência, como também se viu na a área, podemos concluir que os filtros com maior consumo de potência está relacionado com o maior número de coeficientes, ou seja, quanto maior for esse número maior será o consumo de potência.
4.4.3 Resultados de atraso
A partir dos resultados do tempo do atraso do caminho crítico dos diferentes filtros e arquitecturas, foram construídas Tabelas a partir das quais foram construídos os diferentes gráficos, as respectivas Tabelas podem ser encontradas no Anexo C. Para as arquitecturas paralelas com MCM e para a arquitectura paralela com multiplicadores, apenas são apresentados os gráficos para 32 bits.
4.4.3.1 Arquitectura série com acumulador e multiplicador
Na Figura 4.37, podemos observar o gráfico com a representação do atraso do caminho crítico da arquitectura série com acumulador e multiplicador para os filtros gerados. O eixo vertical representa o atraso do filtro, em ns e no eixo horizontal são representados os diferentes filtros gerados, para entrada e saídas limitadas a 32 bits.
0
10
20
30
40
50
60
70
80
90
100
1 2 3 4 5 6 7 8 9 média
Potência(mW) 32 bits
potência total potência MCM unidade registos

64
Figura 4.37 Gráfico dos tempos de atraso parcial para a arquitectura série com acumulador e multiplicador, para entrada e saída limitada a 32 bits.
Através da análise da Figura 4.37, podemos observar que existem pequenas variações no caminho crítico dos diferentes filtros para a arquitectura série com acumulador. Como o caminho crítico dos multiplicadores é composto por multiplicador e um somador, limitados a 32 bits, logo os caminhos críticos para os diferentes filtros vão ser sensivelmente os mesmos, pois o número de bits máximo para a representação dos coeficientes não influência o caminho crítico.
Devido à arquitectura ser do tipo série, vai ter uma velocidade para gerar resultados para cada filtro, diferente de um ciclo de relógio. Assim como para a potência, é necessário de a multiplicar por N+1 para calcular a energia gasta pelo filtro. Também temos que multiplicar o tempo de atraso por N+1 de para obter o tempo de funcionamento do filtro, logo o número de coeficientes é fundamental para definir a velocidade do filtro. Na Figura 4.38, podemos observar os tempos totais para o calculo da saída do filtro em que os filtro 1 e 5 são os mais lentos e o filtro 3 é o mais rápido, devido ao número de coeficientes que têm de calcular.
Figura 4.38 Gráfico com o atraso total para o cálculo de cada saída do filtro da arquitectura série com acumulador e multiplicador, para entrada e saída limitada a 32 bits.
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 média
Atraso(ns)
0
500
1000
1500
2000
2500
3000
3500
1 2 3 4 5 6 7 8 9 média
Velocidade do filtro (ns)

65
4.4.3.2 Arquitectura paralela com multiplicadores
Na Figura 4.39, podemos observar o gráfico com a representação do tempo de atraso do caminho crítico total e de cada uma das unidades da arquitectura paralela com multiplicadores para os filtros gerados com 32 bits. O eixo vertical representa o atraso, em ns e no eixo horizontal são representados os diferentes filtros gerados com a entrada e a saída limitada a 32 bits.
Figura 4.39 Gráfico com o atraso total e das diferentes unidades da arquitectura paralelo com multiplicadores. Para 32 bits como entrada e limitação da saída.
Podemos ver através das Figuras 4.39 que o multiplicador é maior responsável pelo atraso do caminho crítico, onde o atraso do mesmo representa cerca de 97% do atraso total. Como se está a limitar os sinais de saída, faz com que todos os multiplicadores sejam sensivelmente da mesma dimensão, o que faz com que exista pouca variação do tempo total de atraso do caminho crítico, como se observou na Figura 4.39. As diferenças que se observaram podem dever-se à influência do tamanho dos fios e do fan-out no cálculo dos tempos de atraso.
4.4.3.3 Arquitectura paralela com MCM
Na Figura 4.40, podemos observar o gráfico com a representação do tempo de atraso do caminho crítico total e de cada uma das unidades da arquitectura paralela com MCM para os filtros gerados com 32 bits. O eixo vertical representa o atraso, em ns e no eixo horizontal são representados os diferentes filtros gerados com a entrada e a saída limitada a 32 bits.
0
5
10
15
20
25
30
35
1 2 3 4 5 6 7 8 9 média
Atraso(ns) 32 bits
caminho crítico total caminho crítico unidade multiplicadores

66
Figura 4.40 Gráfico com o atraso total e das diferentes unidades da arquitectura paralelo MCM. Para 32 bits como entrada e limitação da saída.
Através da análise das Figuras 4.40, podemos concluir que em média 80% do atraso total se deve à unidade MCM. Os operadores com maior número de operadores em série (Tabela 4.2) são aqueles que têm um maior atraso. Existe a excepção do filtro 1 que apesar de só ter 2 operadores em série vai ter um maior tempo de atraso do que os filtros 6, 7 e 8, com 3 coeficientes em série. Isto acontece porque o filtro 2 tem uma menor diversidade de coeficientes que os outros filtors, o que faz com que este filtro tenham um maior fan-out, influenciado assim o caminho crítico. Pode se ver o mesmo nos filtros 6, 7 e 8, os três com o mesmo número de coeficientes, em que o filtro 6 tem um menor diversidade de coeficientes e um maior tempo de atraso, pois este filtro tem um fan-out maior que os outros dois.
4.5 Comparação de resultados para as diferentes arquitecturas
As arquitecturas com sinais de entrada de 8 bits, não serão consideradas nas comparações, pois os resultados têm em geral o mesmo comportamento que para 16 bits.
4.5.1 Comparação de área
Nas Figuras 4.41 e 4.42, podemos observar as áreas ocupadas pelas várias arquitecturas geradas sem a limitação do sinal de entrada para 16 e 32 bits. Como nos gráficos anteriores, o eixo vertical representa a área, em µm² e no eixo horizontal são representados os diferentes filtros gerados.
0,00
5,00
10,00
15,00
20,00
25,00
1 2 3 4 5 6 7 8 9 média
Atraso(ns) 32 bits
caminho crítico total caminho crítico MCM
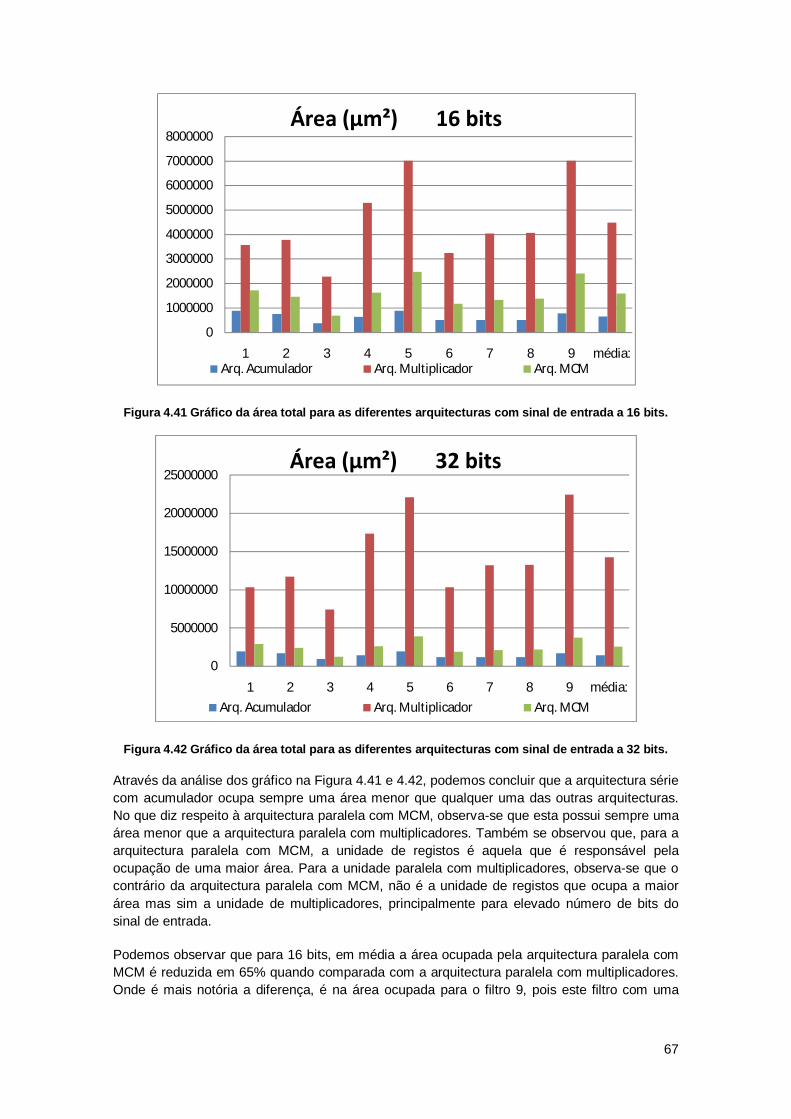
67
Figura 4.41 Gráfico da área total para as diferentes arquitecturas com sinal de entrada a 16 bits.
Figura 4.42 Gráfico da área total para as diferentes arquitecturas com sinal de entrada a 32 bits.
Através da análise dos gráfico na Figura 4.41 e 4.42, podemos concluir que a arquitectura série com acumulador ocupa sempre uma área menor que qualquer uma das outras arquitecturas. No que diz respeito à arquitectura paralela com MCM, observa-se que esta possui sempre uma área menor que a arquitectura paralela com multiplicadores. Também se observou que, para a arquitectura paralela com MCM, a unidade de registos é aquela que é responsável pela ocupação de uma maior área. Para a unidade paralela com multiplicadores, observa-se que o contrário da arquitectura paralela com MCM, não é a unidade de registos que ocupa a maior área mas sim a unidade de multiplicadores, principalmente para elevado número de bits do sinal de entrada.
Podemos observar que para 16 bits, em média a área ocupada pela arquitectura paralela com MCM é reduzida em 65% quando comparada com a arquitectura paralela com multiplicadores. Onde é mais notória a diferença, é na área ocupada para o filtro 9, pois este filtro com uma
0
1000000
2000000
3000000
4000000
5000000
6000000
7000000
8000000
1 2 3 4 5 6 7 8 9 média:
Área (µm²) 16 bits
Arq. Acumulador Arq. Multiplicador Arq. MCM
0
5000000
10000000
15000000
20000000
25000000
1 2 3 4 5 6 7 8 9 média:
Área (µm²) 32 bits
Arq. Acumulador Arq. Multiplicador Arq. MCM

68
maior diversidade de coeficientes utiliza um maior número de operadores (multiplicadores e somadores/subtractores).
Para 32 bits, observamos que existe uma maior diferença entre as arquitecturas paralelas, enquanto que para a arquitectura paralela com MCM é a unidade de registos a mais preponderante, na arquitectura paralela com multiplicadores em paralelo é a unidade de multiplicadores a mais preponderante para a área final, como já se referiu anteriormente. Assim devido ao crescimento quadrático dos multiplicadores, a diferença entre as áreas ocupadas pelas arquitecturas paralelas será maior. Conseguindo-se em média, uma redução de 82% da área final da arquitectura paralela com MCM. Esta diferença é mais notória em filtros com maior diversidade nos coeficientes, como se pode observar para os filtros 5 e 9 na Figura 4.42.
Quando se limitou o sinal de saída para 32 bits, Figuras 4.43, observa-se o mesmo tipo de comportamento para a área de quando não se limitou o sinal de saída a 32 bits. Existe uma redução de 70% da área ocupada pela arquitectura paralela com MCM em relação à arquitectura paralela com multiplicadores.
Figura 4.43 Gráfico de área para as diferentes arquitecturas com sinal de entrada e limitado a 32 bits.
Concluímos que independentemente da limitação da dimensão do sinal de saída ou não, a arquitectura série com acumulador é sempre aquela que ocupa menos área. No que diz respeito à arquitectura paralela com MCM, podemos concluir que ocupa sempre menos área que a arquitectura paralela com multiplicadores, sendo mais visível esta redução em filtros com a maior diversidade de coeficientes. Para 32 bits independentemente da limitação da dimensão do sinal de saída ou não, a arquitectura paralelo com MCM é sempre muito mais pequena que a arquitectura paralela com multiplicadores. Isto acontece porque a área da unidade de multiplicadores tem um crescimento quadrático com o número de bits de entrada. A arquitectura paralela com multiplicador ao ter a unidade de multiplicadores como principal responsável pela área ocupada, vai fazer com que está cada vez se distancie mais das restantes, pois esta unidade tem um crescimento quadrático com o aumento do número de bits do sinal de entrada.
0
5000000
10000000
15000000
20000000
25000000
1 2 3 4 5 6 7 8 9 média
Área (µm²) 32 bits
Arq. Acumulador Arq. Multiplicador Arq. MCM
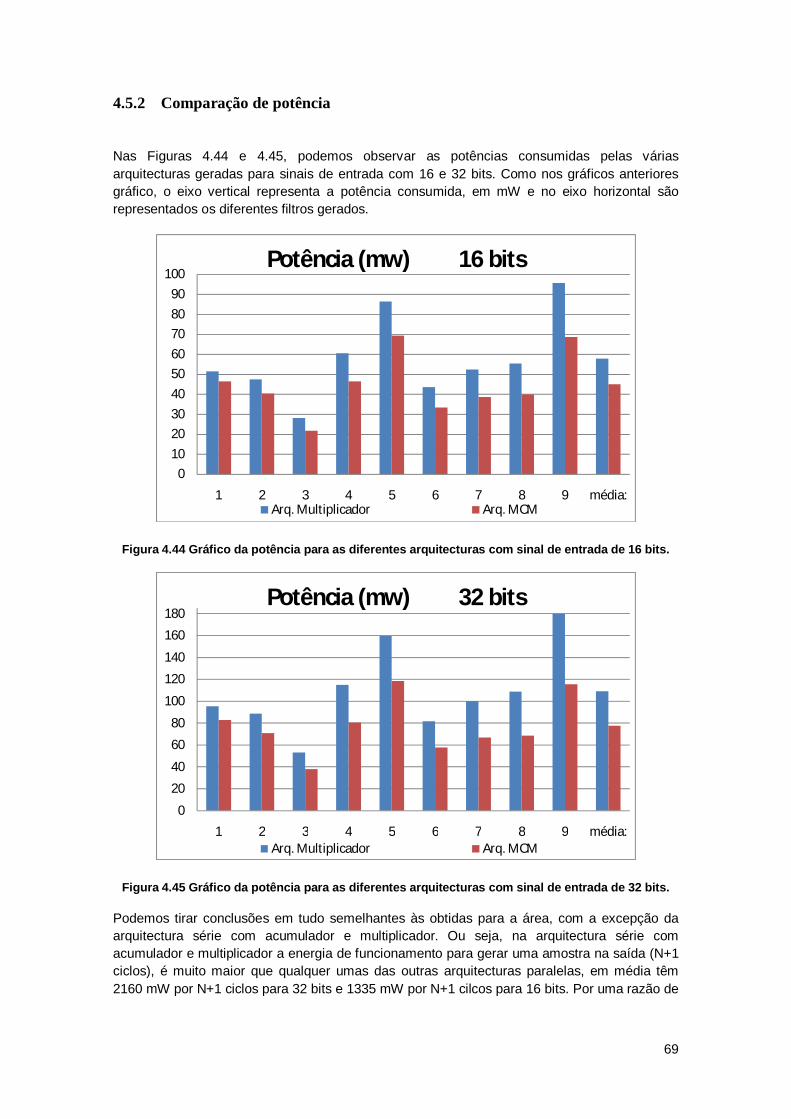
69
4.5.2 Comparação de potência
Nas Figuras 4.44 e 4.45, podemos observar as potências consumidas pelas várias arquitecturas geradas para sinais de entrada com 16 e 32 bits. Como nos gráficos anteriores gráfico, o eixo vertical representa a potência consumida, em mW e no eixo horizontal são representados os diferentes filtros gerados.
Figura 4.44 Gráfico da potência para as diferentes arquitecturas com sinal de entrada de 16 bits.
Figura 4.45 Gráfico da potência para as diferentes arquitecturas com sinal de entrada de 32 bits.
Podemos tirar conclusões em tudo semelhantes às obtidas para a área, com a excepção da arquitectura série com acumulador e multiplicador. Ou seja, na arquitectura série com acumulador e multiplicador a energia de funcionamento para gerar uma amostra na saída (N+1 ciclos), é muito maior que qualquer umas das outras arquitecturas paralelas, em média têm 2160 mW por N+1 ciclos para 32 bits e 1335 mW por N+1 cilcos para 16 bits. Por uma razão de
0
10
20
30
40
50
60
70
80
90
100
1 2 3 4 5 6 7 8 9 média:
Potência (mw) 16 bits
Arq. Multiplicador Arq. MCM
0
20
40
60
80
100
120
140
160
180
1 2 3 4 5 6 7 8 9 média:
Potência (mw) 32 bits
Arq. Multiplicador Arq. MCM

70
escala optou-se por não se incluir a potência da arquitectura série com acumulador e multiplicador em nenhum dos gráficos.
A potência consumida pela arquitectura paralela com MCM tem em média uma redução de 22% para 16 bits em relação à arquitectura paralela com multiplicadores, para 32 bits observa-se uma redução de 30%. A redução acentua-se porque, as unidades de multiplicadores têm uma importância na potência consumida pelo filtro assim como as interligações, quando comparadas e a unidade MCM que consome menos potência que a de multiplicadores e as suas interligações também.
Como já se referiu anteriormente a área da unidade de multiplicadores, da arquitectura paralela com multiplicadores, tem um crescimento quadrático. O crescimento quadrático desta unidade, provoca um aumento drástico da área total para 32 bits, isto provoca que a potência perdida nos fios do circuito seja relativamente cada vez maior, se para 16 ou 8 bits em média 75% da potência é gasta nas células e 25% nos fios, para 32 bits passamos a ter 55% e 45% respectivamente. Enquanto que para a arquitectura paralela com MCM, se para 16 ou 8 bits em média 75% da potência é gasta nas células e 25%, para 32 bits passa a ser de 65% e 35% respectivamente. Estes efeitos no consumo de potência vão acentuar mais a diferença no consumo total de potência para as diferentes arquitecturas paralelas.
Quando se limitou o sinal de saída a 32 bits, como podemos observar nas Figuras 4.46 observamos o mesmo tipo de comportamento da potência consumida, para 32 bits observa-se em média uma redução de 36% da potência consumida da arquitectura paralela com MCM em relação à arquitectura paralela com multiplicadores.
Figura 4.46 Gráfico de potência para as diferentes arquitecturas com sinal de entrada e saído limitado a 32 bits.
Concluímos que independentemente da limitação da dimensão do sinal de saída ou não, a arquitectura série com acumulador é sempre aquela que consome mais potência para o cálculo de uma saída do filtro. Para as arquitecturas paralelas, observou-se que a potência tinha o mesmo comportamento que a área, ou seja, a arquitectura paralela com MCM consome sempre menos potência que a arquitectura paralela com multiplicadores.
0
20
40
60
80
100
120
140
160
1 2 3 4 5 6 7 8 9 média:
Potência (mw) 32 bits
Arq. Multiplicador Arq. MCM
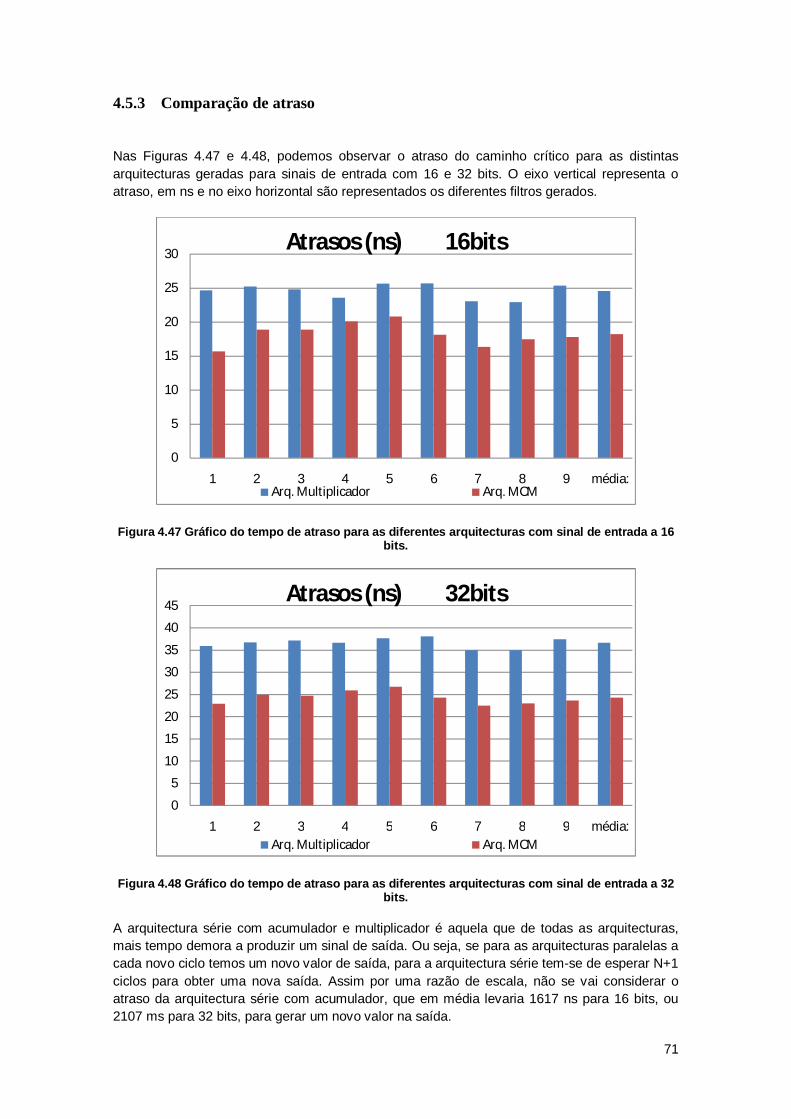
71
4.5.3 Comparação de atraso
Nas Figuras 4.47 e 4.48, podemos observar o atraso do caminho crítico para as distintas arquitecturas geradas para sinais de entrada com 16 e 32 bits. O eixo vertical representa o atraso, em ns e no eixo horizontal são representados os diferentes filtros gerados.
Figura 4.47 Gráfico do tempo de atraso para as diferentes arquitecturas com sinal de entrada a 16 bits.
Figura 4.48 Gráfico do tempo de atraso para as diferentes arquitecturas com sinal de entrada a 32 bits.
A arquitectura série com acumulador e multiplicador é aquela que de todas as arquitecturas, mais tempo demora a produzir um sinal de saída. Ou seja, se para as arquitecturas paralelas a cada novo ciclo temos um novo valor de saída, para a arquitectura série tem-se de esperar N+1 ciclos para obter uma nova saída. Assim por uma razão de escala, não se vai considerar o atraso da arquitectura série com acumulador, que em média levaria 1617 ns para 16 bits, ou 2107 ms para 32 bits, para gerar um novo valor na saída.
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 média:
Atrasos (ns) 16bits
Arq. Multiplicador Arq. MCM
0
5
10
15
20
25
30
35
40
45
1 2 3 4 5 6 7 8 9 média:
Atrasos (ns) 32bits
Arq. Multiplicador Arq. MCM

72
Quando não se limitou o sinal de saída a 16 e 32 bits, observou-se que o atraso do caminho crítico da arquitectura paralela com MCM é sempre menor que o da arquitectura paralela com multiplicadores. Como se pode observar na Figuras 4.48, o filtro com mais operadores em série da unidade MCM, como o filtro 5, também continua a ter um tempo de atraso menor, no seu caminho crítico que para a arquitectura paralela com multiplicadores. Conseguiu-se me média uma redução de 25% para 16 bits e de 35% para 32 bits.
Quando se limita o sinal de entrada e de saída a 32 bits, observa-se que para a arquitectura paralela com MCM tem sempre um tempo de atraso menor que a arquitectura paralela com multiplicadores, como se observa na Figura 4.49. Com a limitação do sinal de saída consegue-se em média uma redução de 45% da arquitectura paralela com MCM face à arquitectura paralela com Multiplicadores.
Figura 4.49 Gráfico do tempo de atraso para as diferentes arquitecturas com sinal de entrada e saída é limitado a 32 bits.
Podemos concluir que quanto maior for a entrada, maior a tendência da arquitectura com MCM se tornar mais rápida que a arquitectura paralela com MCM. Quando se fez limitar as saídas continuou-se a observar que a unidade MCM tem sempre tempos de atraso menores que a arquitectura paralela com multiplicadores, sendo que nesta situação, observa-se uma redução relativamente superior.
0
5
10
15
20
25
30
35
1 2 3 4 5 6 7 8 9 média:
Atrasos (ns) 32bits
Arq. Multiplicador Arq. MCM

73
5 Capítulo 5 Conclusões
Conclusões
5.1 Conclusões gerais
Nesta dissertação estudaram-se três arquitecturas possíveis para a implementação digital de filtros FIR. As três arquitecturas estudadas podem ser dívidas em dois grupos, arquitecturas série e arquitecturas paralelas. A arquitectura série consiste em utilizar apenas um somador e um multiplicador, onde o cálculo de cada coeficiente é feito em série, sendo sucessivamente armazenados os produtos parciais, de forma a se obter o resultado final do filtro. As arquitecturas paralelas fazem todos os cálculos em paralelo, gerando o valor final do filtro num único ciclo, sendo o cálculo dos coeficientes, o que distingue as duas arquitecturas. A arquitectura paralela com multiplicadores utiliza multiplicadores genéricos de forma a realizar o produto do sinal de entrada pelos coeficientes. Por sua vez, a arquitectura paralela com MCM utiliza um conjunto de somas/subtracções e deslocamentos do sinal de entrada, para obter os mesmos resultados.
Para criar de forma automática as distintas arquitecturas referidas anteriormente, realizou-se um gerador, G2FIR, que através de um ficheiro com os coeficientes dos filtros e os seus termos parciais gera ficheiros, em VHDL, com a descrição das diferentes arquitecturas: série com acumulador e multiplicador, paralela com multiplicadores e paralela com MCM. Para além das arquitecturas o gerador também permite alterar diferentes componentes (somadores, subtractores, multiplicadores e registos). Assim como definir o número de bits necessários para a representação do sinal de entrada. O gerador também permite definir ou não o número máximo de bits para representar o sinal de saída. Nesta dissertação foram gerados filtros com sinais de entrada de 8, 16 e 32 bits e também se utilizou a opção em que se limitou o número de bits do sinal de saída a 32 bits.
Neste trabalho concluiu-se que a arquitectura série com acumulador e multiplicador é aquela que ocupa uma menor área, independentemente do número de bits entrada e quer se limite ou não o número de bits do sinal de saída, a área tem um crescimento linear com o número de bits do sinal de entrada. No que diz respeito à potência, esta arquitectura é aquela que vai necessitar de consumir menos potência num ciclo de relógio, mas como esta arquitectura realiza os cálculos em série, vão ser necessários N+1 ciclos para obter a saída do filtro. Assim podemos dizer que apesar de ser a arquitectura que gasta menos potência, é também aquela que gasta muito mais energia no cálculo do sinal filtrado. No que diz respeito aos tempos de atraso do caminho crítico, podemos concluir que independentemente do número de bits do sinal de entrada, esta é a arquitectura que apresentou maiores tempos de atraso.

74
A arquitectura paralela com multiplicadores é, de todas as arquitecturas, aquela que ocupa a maior área, e é a única que têm um crescimento quadrático com o número de bits do sinal de entrada. Esta arquitectura consome uma maior potência que a arquitectura paralela com MCM, mas tem um menor consumo de energético quando comparada com a arquitectura serie com acumulador e multiplicador. Esta arquitectura ainda apresenta outra peculiaridade, no consumo de potência, devido ao crescimento quadrático da área com o número de bits do sinal de entrada (devido aos multiplicadores genéricos). O tamanho das interligações e consequentemente das suas perdas de potência é maior nas interligações. Por exemplo, esta perda pode ser 45% da potência total consumida para um sinal de entrada de 32 bits. O tempo de atraso no caminho crítico da arquitectura paralela é maior que a arquitectura paralela com MCM, mas é menor que na arquitectura série com acumulador e multiplicador.
A arquitectura paralela com MCM tem um crescimento linear da área, com o aumento do número de bits do sinal de entrada. Esta arquitectura ocupa menos área que a outra arquitectura paralela com multiplicadores, mas ocupa uma maior área que a arquitectura série com acumulador e multiplicador. De todas as arquitecturas estudadas, é a que consome menos energia, sendo mesmo o consumo da unidade MCM residual, quando comparado com a unidade de registos ou as perdas nas interligações (35% para 32 bits). A arquitectura paralela com MCM é a mais rápida das estudadas, ou seja, a que apresenta o atraso total do caminho crítico menor.
Quando o sinal de saída foi limitado a 32 bits, sendo apenas aproveitados os bits menos significativos, pôde-se tirar as mesmas conclusões de quando não se limitou a saída, aumentadas ainda mais as diferenças entre arquitecturas paralelas. Conclui-se também, com a limitação do sinal de saída, que a arquitectura paralela com MCM ainda se torna mais vantajosas, em todos os aspectos estudados (potência, frequência máxima de funcionamento área), que a arquitectura paralela com multiplicadores.
Concluiu-se que quando a área é um factor decisivo, deve-se optar pela arquitectura série com acumulador e multiplicador. Pondo de parte a hipótese da arquitectura paralela com multiplicadores, pois o seu crescimento quadrático, torna esta arquitectura pouco interessante para circuito VLSI.
Pelos dados observados pode-se também concluir que a arquitectura paralela com MCM, é a melhor das arquitecturas estudadas quando as prioridades são o consumo energético e a frequência de funcionamento. Para estas prioridades, principalmente na energética, a arquitectura série com acumulador e multiplicador é muito pior que todas as outras. Assim podemos dizer que de uma forma geral a arquitectura paralela com MCM apresenta-se como a melhor das arquitecturas estudadas.

75
5.2 Trabalhos futuros
No desenvolvimento deste trabalho foi criada uma ferramenta, que permite utilizar outras unidades que não as genéricas. Assim no trabalho futuro pretende-se estudar o uso de diferentes arquitectura genéricas, a fim de se poderem tirar mais resultados dos benefícios de cada uma das arquitecturas, no que diz respeito a área, potência e frequência de funcionamento.
Uma extensão deste trabalho, constitui em adaptar as arquitecturas geradas pelo, G2FIR, às arquitecturas internas das FPGAS. Por exemplo adaptando as arquitecturas dos filtros e respectivos operadores às unidades já existentes nas FPGAS, tais como: multiplicadores, memórias e unidades DSP’s.
Um trabalho futuro, é implementar uma ferramenta para o gerador, G2FIR, que permita seleccionar entre a linguagem VHDL ou Verilog, com a descrição dos filtros.

76

77
Referências
1. L. Aksoy, E. Costa, P. Flores, and J. Monteiro, “Exact and Approximate Algorithms for the Optimization of Area and Delay in Multiple Constant Multiplications,” IEEE TRANSACTIONS
ON COMPUTER-AIDED DESIGN OF INTEGRATED CIRCUITS AND SYSTEMS, VOL. 27, NO. 6, JUNE 2008.
2. L. Aksoy, E. Costa, P. Flores, and J. Monteiro, “Optimization Algorithms for Multiple Constant
Multiplications”, Chapter in book “Advanced Topics on VLSI Design ”, pages 71-99. Nº2 in innovation series, January 2009.
3. Kang, H.J., Park, I.C.: FIR Filter Synthesis Algorithms for Minimizing the Delay and the Number of Adders. IEEE Transactions on Circuits and Systems II: Analog and Digital Signal Processing 48, 2001.
4. M. de Medeiros Silva e J. A. Beltran Gerald "Filtros Analogicos e Digitais", Setembro 2002.
5. Oppenheim, A., Shafer, R.: Discrete-Time Signal Processing. Signal Processing Series. Prentice
Hall, 1989.
6. Erdogan, A., Arslan, T.: High Throughput FIR Filter Design for Low Power SoC Applications. In: 13th Annual IEEE International ASIC/SoC Conference, 2000.
7. Nannarelli, A., Re, M., Cardarilli, G.: Tradeoffs between Residue Number System and
Traditional FIR Filters. In: Proceedings of the International Symposium on Circuits and Systems, 2001.
8. Nguyen, H., Chatterjee, A.: Number-Splitting with Shift-and-Add Decomposition for Power and
Hardware Optimization in Linear DSP Synthesis. IEEE Transactions on VLSI 8, 2000.
9. Kang, H.J., Park, I.C.: FIR Filter Synthesis Algorithms for Minimizing the Delay and the Number of Adders. IEEE Transactions on Circuits and Systems II: Analog and Digital Signal Processing 48, 2001.
10. Flores, P., Monteiro, J., Costa, E.: An Exact Algorithm for the Maximal Sharing of Partial Terms in Multiple Constant Multiplications. In: Proceedings of Interna-tional Conference on Computer-Aided Design. 2005.
11. Hosangadi, A., Fallah, F., Kastner, R.: Simultaneous Optimization of Delay and Number of Operations in Multiplierless Implementation of Linear Systems. In:International Workshop on Logic Synthesis, 2005.

78

79
Anexo A Neste anexo é exibido o código VHDL com a descrição das diferentes arquitecturas (arquitectura série com acumulador e multiplicador, arquitectura paralela com multiplicadores, arquitectura paralela com MCM) geradas pelo G2FIR para o ficheiro exemplo.
Ficheiros VHDL com a descrição da arquitectura série____________________
exemplo_arq_acum.vhd
entity arq_acum is Port (clk : in STD_LOGIC;
clear: in STD_LOGIC; x_in: in signed(7 downto 0);
y_out : out signed (11 downto 0)); end arq_acum; … signal mult_out: signed (11 downto 0); signal aux_mult_out: signed (15 downto 0); signal x_fifo: signed (7 downto 0); signal aux_x_fifo: signed (7 downto 0); signal summ_out: signed(11 downto 0); signal feedback: signed(11 downto 0); signal addr_mem: STD_LOGIC_VECTOR(1 downto 0); signal coef:signed (4 downto 0); signal aux_coef:signed (7 downto 0); signal aux_reset: std_logic; signal mux_select: std_logic; begin
unidade_controlo: UC port map(clk, clear, aux_reset, mux_select, addr_mem); xin_fifo: fifo port map (clk,clear,mux_select,x_in,x_fifo); coef_mem: memory port map(addr_mem,clk,coef); aux_coef<=resize(coef,8); aux_x_fifo<=resize(x_fifo,8); mult_out<=resize(aux_mult_out,12); uni_mult: generic_mul generic map(dim =>7) port map (aux_coef,aux_x_fifo,aux_mult_out); uni_summ: adder generic map(dim =>11) port map(mult_out,feedback,summ_out);
uni_reg: registo generic map(dim =>11) port map (clk,aux_ reset,summ_out,feedback);
y_out<=feedback;
end Behavioral; ____________________
fifo.vhdl
entity fifo is Port (clk : in STD_LOGIC;
clear : in STD_LOGIC; mux_select: in STD_LOGIC;
x_in : in signed (7downto 0); fifo_output: inout signed (7downto 0));
end fifo; … signal out_0: signed (7 downto 0); signal out_1: signed (7 downto 0); signal out_2: signed (7 downto 0); signal out_3: signed (7 downto 0); signal out_4: signed (7 downto 0); signal out_5: signed (7 downto 0); signal mux_out: signed (7 downto 0); begin

80
process(mux_select, x_in,fifo_out) begin
if mux_select = '0' then mux_out<= ent;
else mux_out<= sai;
end if; end process;
reg0:gen_reg generic map(dim =>7) port map(clk,clear,mux_out,out_0); reg1:gen_reg generic map(dim =>7) port map(clk,clear,out_0,out_1); reg2:gen_reg generic map(dim =>7) port map(clk,clear,out_1,out_2); reg3:gen_reg generic map(dim =>7) port map(clk,clear,out_2,out_3); reg4:gen_reg generic map(dim =>7) port map(,clk,clear,out_3,out_4); reg5:gen_reg generic map(dim =>7) port map(clk,clear,out_4,out_5); reg6:gen_reg generic map(dim =>7) port map(clk,clear,out_5,sai);
end Behavioral; _________________ memory.vhd entity memory is
Port(addr : in STD_LOGIC_VECTOR (1 downto 0); clk : in STD_LOGIC; mem_out : out signed (4 downto 0));
end memory; … begin
process(addr,clk) begin
if CLK'event and CLK = '1' then
case addr is when "00" => mem_out <="11110"; when "01" => mem_out <="00000"; when "10" => mem_out <="00101"; when "11" => mem_out <="01010"; when others => mem_out<= (others => '0');
end case; end if;
end process; end Behavioral; _______________ uc.vhd entity UC is
Port(clk: in STD_LOGIC; clear: in STD_LOGIC; reset: out STD_LOGIC; mux_select: out STD_LOGIC; addr_mem : out STD_LOGIC_VECTOR (1 downto 0));
end UC; architecture Behavioral of UNI_CONTROL is type state is (start,inc,dec); signal next : start; signal aux_addr_mem : STD_LOGIC_VECTOR (1 downto 0); signal aux_cycle:STD_LOGIC; signal aux_cycle2:STD_LOGIC; signal aux_cycle3:STD_LOGIC; begin
process(clk,clear) begin
if clear = '1' then addr_mem<= (others => '0'); aux_addr_mem<= (others => '0');
aux_cycle2<='1'; aux_cycle<='0'; reset<='1'; mux_select<='0'; next<=start;

81
elsif CLK'event and CLK='1' then
case next is when start=> aux_addr_mem<= (others => '0'); addr_mem<= (others => '0');
if aux_cycle2 ='1' then reset<='1'; end if;
if aux_cycle = '1' then mux_select<='1';
next<=inc; else mux_select<='0'; aux_cycle<='1'; aux_cycle2<='1'; reset<='0'; next<=start; end if;
when dec => addr_mem<= aux_addr_mem; aux_addr_mem<= aux_addr_mem-1; reset<='0'; if aux_cycle = '1' then
mux_select<='1'; else
mux_select<='0'; end if;
if aux_addr_mem > 0 then next<=dec;
else aux_cycle2<='0'; next<=start;
end if;
when inc => addr_mem<= aux_addr_mem; aux_addr_mem<= aux_addr_mem+1; reset<='0';
if aux_cycle='1' then
mux_select<='1'; else mux_select<='0'; end if;
if aux_addr_mem < 2 then next<=inc;
else next<=dec;
end if;
end case; end if;
end process; end Behavioral; ________________________________________________________________________________________ Ficheiros VHDL com a descrição da arquitectura paralela com multiplicadores_
exemplo_arq_multiplier.vhd
entity arq_multiplier is Port (clear : in STD_LOGIC;
clk: in STD_LOGIC;

82
x_in : in signed (7 downto 0); y_out : out signed (11 downto 0));
end arq_multiplier; … signal aux_coef0: signed (8 downto 0); signal aux_coef2: signed (9 downto 0); signal aux_coef3: signed (10 downto 0); begin
unidade_armazenamento: reg_uni port map (y_out,clear,clk,aux_coef0,aux_coef2,aux_coef3);
unidade_aritemetica: multipliers port map (x_in,aux_coef0,aux_coef2,aux_coef3);
end Behavioral; ___________________
exemplo_multipliers.vhd
entity multipliers is Port (x_in : in signed (7 downto 0); sin2: out signed (8 downto 0); sin5: out signed (9 downto 0); sin10: out signed (10 downto 0));
end multipliers; architecture Behavioral of multiplier is component gen_mul
generic(dim : integer := 64); port (operA : in signed (dim downto 0); operB : in signed (dim downto 0); RES: out signed (2*dim+1 downto 0)); end component; signal s2s : signed (7 downto 0); signal aux_ent_0 : signed (7 downto 0); signal aux_out_0 : signed (15 downto 0); signal s5s : signed (7 downto 0); signal aux_ent_2 : signed (7 downto 0); signal aux_out_2 : signed (15 downto 0); signal s10s : signed (7 downto 0); signal aux_ent_3 : signed (7 downto 0); signal aux_out_3 : signed (15 downto 0); begin
s2s<="00000010"; aux_ent_0<=resize(x_in,8); mul_0: generic_mul generic map(dim =>7) port map(aux_ent_0, s2s, aux_out_0); sin2<=resize(aux_out_0,9);
s5s<="00000101"; aux_ent_2<=resize(ent,8); mul_2: generic_mul generic map(dim =>7) port map(aux_ent_2, s5s, aux_out_2); sin5<=resize(aux_out_2,10);
s10s<="00001010"; aux_ent_3<=resize(ent,8); mul_3: generic_mul generic map(dim =>7) port map(aux_ent_3, s10s, aux_out_3); sin10<=resize(aux_out_3,11);
end Behavioral; __________________
exemplo_reg_uni.vhd
entity REG_UNI is Port (y_reg: out signed (11 downto 0);

83
clear: in STD_LOGIC; clk: in STD_LOGIC; Coef2: in signed (8 downto 0); Coef5: in signed (9 downto 0); Coef10: in signed (10 downto 0));
end REG_UNI; … component gen_reg
generic(dim : integer := 64); port (clk : in std_logic; clear : in std_logic; data_in : in signed (dim downto 0); data_out: out signed (dim downto 0)); end component; … signal scoef_0: signed (8 downto 0); signal aux_scoef_0: signed (8 downto 0); signal scoef_1: signed (8 downto 0); signal aux_scoef_1: signed (9 downto 0);
signal ecoef_2: signed (9 downto 0); signal scoef_2: signed (9 downto 0); signal aux_coef_2: signed (9 downto 0); signal aux_scoef_2: signed (11 downto 0); signal ecoef_3: signed (11 downto 0); signal scoef_3: signed (11 downto 0); signal aux_coef_3: signed (11 downto 0); signal aux_scoef_3: signed (11 downto 0); signal ecoef_4: signed (11 downto 0); signal scoef_4: signed (11 downto 0); signal aux_coef_4: signed (11 downto 0); signal aux_scoef_4: signed (11 downto 0); signal scoef_5: signed (11 downto 0); signal aux_scoef_5: signed (11 downto 0); signal ecoef_6: signed (11 downto 0); signal aux_coef_6: signed (11 downto 0); begin
aux_coef_2<=resize(coef5,10); aux_coef_3<=resize(coef10,12); aux_coef_4<=resize(coef5,12); aux_coef_6<=resize(coef2,12); aux_coef_3<=resize(coef10,12); aux_coef_4<=resize(coef5,12); aux_coef_6<=resize(coef2,12);
coef_reg0: gen_reg generic map(dim =>8) port map(clk,clear, coef2, scoef_0);
coef_reg1: gen_reg generic map(dim =>8) port map(clk,clear, scoef_0, scoef_1);
subb2: subb generic map(dim=>9) port map(aux_coef_2,aux_scoef_1,ecoef_2); aux_scoef_1<=resize(scoef_1,10); coef_reg2: gen_reg generic map(dim =>9) port map(clk,clear, ecoef_2, scoef_2);
add3: adder generic map(dim=>11) port map(aux_scoef_2,aux_coef_3,ecoef_3); aux_scoef_2<=resize(scoef_2,12); coef_reg3: gen_reg generic map(dim =>11) port map(clk,clear, ecoef_3, scoef_3); add4: adder generic map(dim=>11) port map(aux_scoef_3,aux_coef_4,ecoef_4); aux_scoef_3<=resize(scoef_3,12); coef_reg4: gen_reg generic map(dim =>11) port map(clk,clear, ecoef_4, scoef_4);
coef_reg5: gen_reg generic map(dim =>11) port map(clk,clear, scoef_4, scoef_5);
subb6: subb generic map(dim=>11) port map(aux_scoef_5,aux_coef_6,ecoef_6); aux_scoef_5<=resize(scoef_5,12); coef_reg6: gen_reg generic map(dim =>11) port map(clk,clear, ecoef_6, y_reg);
end Behavioral; ________________________________________________________________________________________
Ficheiros VHDL com a descrição da arquitectura paralela com MCM_________

84
exemplo_arq_mcm.vhd
entity arq_mcm is Port (clear : in STD_LOGIC;
clk: in STD_LOGIC; x_in : in signed (7 downto 0); y_out : out signed (11 downto 0));
end arq_mcm; … signal aux_coef0: signed (8 downto 0); signal aux_coef2: signed (9 downto 0); signal aux_coef3: signed (10 downto 0); begin
unidade_armazenamento: REG_UNI port map (y_out,clear,clk,aux_coef0,aux_coef2,aux_coef3);
unidade_aritemetica: MCM port map (x_in,aux_coef0,aux_coef2,aux_coef3);
end Behavioral; ________________
exemplo_ mcm.vhd
entity MCM is Port ( x_in : in signed (7 downto 0); sin2: out signed (8 downto 0); sin5: out signed (9 downto 0); sin10: out signed (10 downto 0)); end MCM; architecture Behavioral of MCM is component gen_add generic(dim : integer := 64 port (operA: in signed (dim downto 0); operB: in signed (dim downto 0); RES: out signed (dim downto 0)); end component; component gen_subb generic(dim : integer := 64); port (operA : in signed (dim downto 0); operB : in signed (dim downto 0); RES: out signed (dim downto 0)); end component; signal s1s: signed (7 downto 0); signal s5s : signed (9 downto 0); signal aux_s1s_5_1 : signed (9 downto 0); signal aux_s1s_5_2 : signed (9 downto 0); begin
s1s <= signed(x_in); aux_s1s_5_1 <= resize((s1s),10); aux_s1s_5_2 <= resize((s1s&"00"),10); add5: adder generic map(dim=>9) port map (aux_s1s_5_1,aux_s1s_5_2,s5s); sin2 <= signed(resize(s1s &"0",9)); sin5 <= signed(resize(s5s, 10)); sin10 <= signed(resize(s5s &"0",11)); end Behavioral;

85
Anexo B Anexo B.1 – Resultados de área ocupada Tabelas para com os resultados de síntese de área para as diferentes arquitecturas (arquitectura série com acumulador e multiplicador, arquitectura paralela com multiplicadores, arquitectura paralela com MCM).
Tabela B. 1 Tabela com a área ocupada pela arquitectura série com acumulador e multiplicador.
Filtro
Área(µm²)
8 bits 16 bits 32 bits
1 442271 884436 1940371
2 397838 762787 1695139
3 225027 384093 935826
4 358910 643280 1446192
5 486333 892761 1948954
6 312373 511354 1185373
7 313825 512271 1186643
8 315205 513351 1187724
9 472249 779133 1692615
Média 369337 653719 1468760
Tabela B. 2 Tabela com a área ocupada pela arquitectura paralela com multiplicadores (8 bits).
Filtro
Área 8 bits(µm²)
Total Unidade Multiplicadores Unidade registos
1 1581640 434234 973627
2 1632497 602165 835908
3 1019343 477513 417253
4 2238411 1034652 924797
5 3094607 1263972 1446864
6 1642470 775684 663554
7 1986907 1005568 731422
8 2150801 1123268 756410
9 3995419 2145198 1345035
Média: 2149122 984695 899430

86
Tabela B. 3 Tabela com a área ocupada pela arquitectura paralela com multiplicadores (16 bits).
Filtro
Área 16 bits(µm²)
Total Unidade Multiplicadores Unidade registos
1 3571784 1648829 1490252
2 3776548 2082317 1228136
3 2278164 1388150 601874
4 5298729 3297057 1309872
5 7018196 4078292 2023840
6 3248130 1908962 931749
7 4046962 2516114 1016725
8 4073956 2516077 1041349
9 7019186 4273451 1823331
Média: 4481295 2634361 1274125
Tabela B. 4 Tabela com a área ocupada pela arquitectura paralela com multiplicadores (32 bits).
Filtro
Área 32 bits(µm²)
Total Unidade Multiplicadores Unidade registos
1 10334847 6508466 2523248
2 11731765 8220631 2009626
3 7402742 5480384 970369
4 17339357 13016149 2082317
5 22125487 16099119 3179704
6 10335212 7535783 1467721
7 13233208 9933323 1589060
8 13260446 9933214 1613667
9 22467581 16783931 2781470
Média: 14247849 10390111 2024131
Tabela B. 5 Tabela com a área ocupada pela arquitectura paralela com MCM (8 bits).
Filtro Área 8 bits(µm²)
Total Unidade MCM Unidade registos
1 1107408 33215 972899
2 985312 59150 836363
3 522782 56875 417399
4 1133656 104231 925816
5 1748670 124142 1447064
6 826103 87069 662808
7 945073 125325 732259
8 944937 125252 732204
9 1751068 233397 1345890
Média: 1107223 105406 896967

87
Tabela B. 6 Tabela com a área ocupada pela arquitectura paralela com MCM (16 bits).
Filtro Área 16 bits (µm²)
Total Unidade MCM Unidade registos 1 1719681 55929 1490635
2 1456524 96278 1228573
3 690030 89926 602511
4 1635983 166585 1311783
5 2472250 198398 2024950
6 1175053 135262 931949
7 1333346 193794 1017071
8 1381633 212194 1042332
9 2418968 349476 1823422
Média: 1587052 166427 1274803
Tabela B. 7 Tabela com a área ocupada pela arquitectura paralela com multiplicadores (32 bits).
Filtro
Área 32 bits (µm²) Total Unidade MCM Unidade registos
1 2918216 102102 2524504
2 2424732 170589 2011355
3 1240750 155992 971025
4 2636676 290035 2083026
5 3919222 346583 3181087
6 1891876 231631 1468594
7 2138504 332914 1589351
8 2196607 361325 1613776
9 3741642 582873 2780341
Média: 2567580 286005 2024784
Anexo B.2- Resultados de potência consumida Tabelas para com os resultados de síntese de potência para as diferentes arquitecturas (arquitectura série com acumulador e multiplicador, arquitectura paralela com multiplicadores, arquitectura paralela com MCM).
Tabela B. 8 Tabela com a potência dissipada pela arquitectura série com acumulador e multiplicador.
Filtro
Potência (mW) 8 bits 16 bits 32 bits
1 6,29 12,17 24,61 2 5,38 10,29 20,76 3 2,90 5,05 10,59 4 4,86 8,93 18,39 5 6,77 12,73 26,02 6 3,93 6,90 14,28 7 4,09 7,11 14,78 8 4,11 7,13 14,84
9 6,04 10,83 22,04
Média 4,93 9,02 18,48

88
Tabela B. 9 Tabela com a potência dissipada pela arquitectura paralela com multiplicadores.
Filtro Potência 8 bits (mW) Potência 16 bits (mW)
Total Unidade Multiplicadores
Unidade registos Total Unidade
Multiplicadores Unidade registos
1 31 1 22 51 3 36
2 29 2 19 48 5 29
3 17 2 10 28 4 15
4 36 4 21 61 9 32
5 53 5 33 86 11 49
6 27 4 16 44 7 23
7 32 5 17 52 9 25
8 35 6 18 55 11 26
9 61 10 31 96 18 45
Média: 36 4 21 58 9 31
Tabela B. 10 Tabela com a potência dissipada pela arquitectura paralela com MCM.
Filtro Potência 8 bits (mW) Potência 16 bits (mW)
Total Unidade MCM Unidade registos Total Unidade MCM Unidade
registos 1 29 0 23 47 1 36
2 26 1 20 40 1 30
3 14 1 10 22 1 15
4 30 1 22 46 2 33
5 46 1 34 69 2 49
6 22 1 16 33 2 23
7 25 1 18 39 3 26
8 25 1 18 40 3 26
9 46 2 32 69 5 45 Média: 29 1 21 45 2 32
Filtro Potência 32 bits (mW) Total Unidade Multiplicadores Unidade registos
1 95 6 63
2 89 10 50
3 53 10 25
4 115 20 53
5 160 24 80
6 82 15 38
7 100 21 42
8 109 24 42
9 180 40 72 Média: 109 19 52
Filtro Potência 32 bits (mW) Total Unidade MCM Unidade registos
1 83 1 64 2 71 2 51 3 38 2 25 4 81 4 54 5 118 5 82 6 58 4 38 7 67 5 42 8 69 5 43 9 116 9 72
Média: 78 4 52
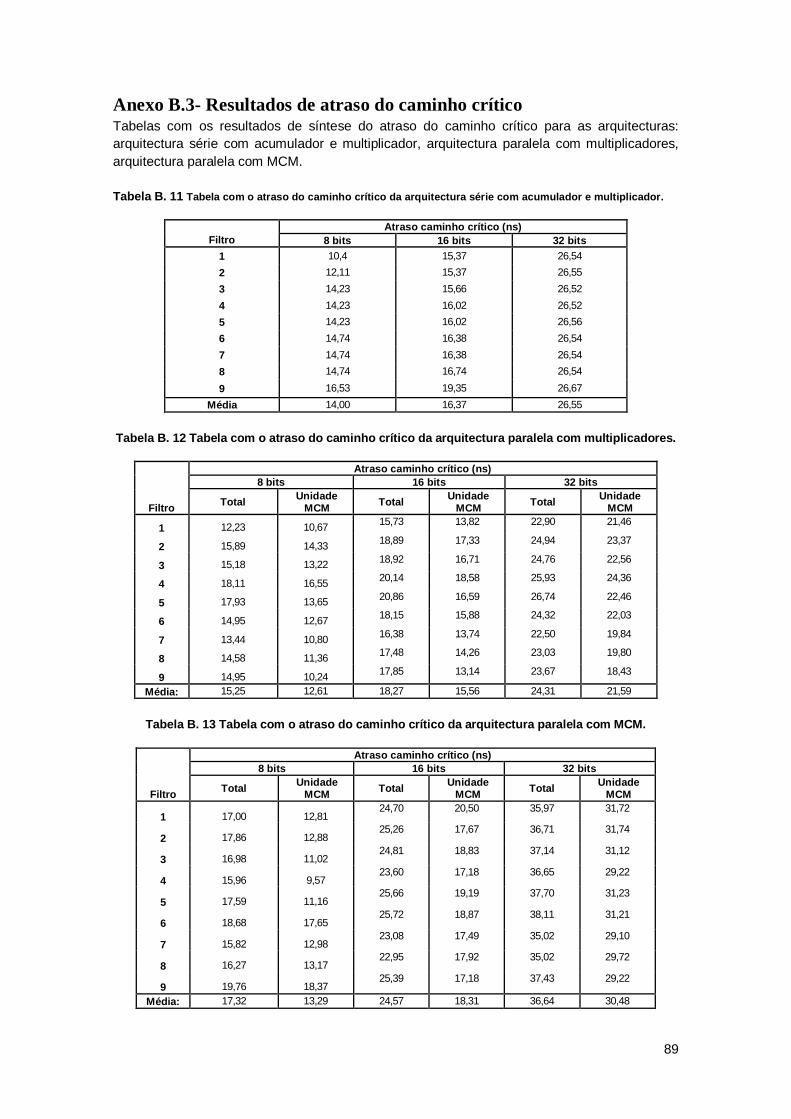
89
Anexo B.3- Resultados de atraso do caminho crítico Tabelas com os resultados de síntese do atraso do caminho crítico para as arquitecturas: arquitectura série com acumulador e multiplicador, arquitectura paralela com multiplicadores, arquitectura paralela com MCM.
Tabela B. 11 Tabela com o atraso do caminho crítico da arquitectura série com acumulador e multiplicador.
Filtro
Atraso caminho crítico (ns) 8 bits 16 bits 32 bits
1 10,4 15,37 26,54
2 12,11 15,37 26,55
3 14,23 15,66 26,52
4 14,23 16,02 26,52
5 14,23 16,02 26,56
6 14,74 16,38 26,54
7 14,74 16,38 26,54
8 14,74 16,74 26,54
9 16,53 19,35 26,67
Média 14,00 16,37 26,55
Tabela B. 12 Tabela com o atraso do caminho crítico da arquitectura paralela com multiplicadores.
Filtro
Atraso caminho crítico (ns) 8 bits 16 bits 32 bits
Total Unidade MCM Total Unidade
MCM Total Unidade MCM
1 12,23 10,67 15,73 13,82 22,90 21,46
2 15,89 14,33 18,89 17,33 24,94 23,37
3 15,18 13,22 18,92 16,71 24,76 22,56
4 18,11 16,55 20,14 18,58 25,93 24,36
5 17,93 13,65 20,86 16,59 26,74 22,46
6 14,95 12,67 18,15 15,88 24,32 22,03
7 13,44 10,80 16,38 13,74 22,50 19,84
8 14,58 11,36 17,48 14,26 23,03 19,80
9 14,95 10,24 17,85 13,14 23,67 18,43
Média: 15,25 12,61 18,27 15,56 24,31 21,59
Tabela B. 13 Tabela com o atraso do caminho crítico da arquitectura paralela com MCM.
Filtro
Atraso caminho crítico (ns) 8 bits 16 bits 32 bits
Total Unidade MCM Total Unidade
MCM Total Unidade MCM
1 17,00 12,81 24,70 20,50 35,97 31,72
2 17,86 12,88 25,26 17,67 36,71 31,74
3 16,98 11,02 24,81 18,83 37,14 31,12
4 15,96 9,57 23,60 17,18 36,65 29,22
5 17,59 11,16 25,66 19,19 37,70 31,23
6 18,68 17,65 25,72 18,87 38,11 31,21
7 15,82 12,98 23,08 17,49 35,02 29,10
8 16,27 13,17 22,95 17,92 35,02 29,72
9 19,76 18,37 25,39 17,18 37,43 29,22
Média: 17,32 13,29 24,57 18,31 36,64 30,48

90

91
Anexo C Neste anexo são exibidas as diferentes Tabelas, com a limitação do sinal de entrada e saída de 32 bits, de área ocupada potência consumida e atraso do caminho crítico para a síntese para as arquitecturas: arquitectura série com acumulador e multiplicador, arquitectura paralela com multiplicadores, arquitectura paralela com MCM).
Tabela C. 1 Tabela com a área, potência e tempos de atraso para a arquitectura série com acumulador e multiplicador, para um sinal de entrada e saída limitada a 32 bits.
Filtro
Arquitectura série com acumulador e multiplicador
Área (µm²) Potência (mW) Atraso caminho crítico (ns)
1 1936176 24,45 26,52
2 1690303 20,70 26,75
3 931045 10,60 26,52
4 1440847 18,32 26,52
5 1943893 25,95 26,56
6 1180037 14,27 26,54
7 1180826 14,67 26,54
8 1181561 14,72 26,54
9 1686765 22,02 26,61
Média 1463495 18,42 26,57
Tabela C. 2 Tabela com a área ocupada das arquitecturas paralelas com a entrada e a saída limitada a 32 bits.
Filtro
Área (µm²) da arquitectura Paralela com: Multiplicadores MCM
Total Unidade Registos
Unidade Multiplicadores Total Unidade
Registos Unidade MCM
1 9824332 2067956 6507937 2401702 2068484 91928
2 11233012 1564617 8220211 1906552 1565491 148748
3 7142084 736954 5480165 957424 736954 131731
4 16730486 1540120 13015293 1985136 1540447 245354
5 21149003 2310125 16097918 2899022 2310999 297042
6 9885288 1072580 7535273 1393240 1073090 191172
7 12723989 1141849 9932740 1560673 1141776 275165
8 12722487 1140630 9932740 1591830 1140739 295131
9 21489026 1910108 16782856 2640753 1910180 460496
Média: 13655524 1498327 10389460 1926260 1498685 237419

92
Tabela C. 3 Tabela da potência dissipada para as arquitecturas paralelas com a entrada e a saída limitada a 32 bits.
Filtro
Potência (mW) da arquitectura Paralela com: Multiplicadores MCM
Total Unidade Registos
Unidade Multiplicadores Total Unidade
Registos Unidade MCM
1 82,98 53,46 6,11 69,95 53,32 1,08
2 76,49 40,81 10,34 57,87 41,26 2,13
3 45,96 19,25 9,55 29,88 19,53 1,99
4 98,47 40,57 20,30 62,72 41,43 3,53
5 133,76 60,66 24,09 90,86 61,75 4,16
6 68,97 28,23 14,99 43,66 28,55 3,03
7 85,29 30,78 20,98 50,49 31,11 4,38
8 90,27 30,82 23,61 51,07 31,09 4,55
9 151,89 50,94 40,33 84,34 51,56 7,38
Média: 92,68 39,51 18,92 60,10 39,96 3,59
Tabela C. 4 Tabela com o atraso do caminho crítico das arquitecturas paralelas com a entrada e a saída limitada a 32 bits.
Filtro
Atraso do caminho crítico (ns) da arquitectura Paralela com: Multiplicadores MCM
Total Unidade Multiplicadores Total Unidade MCM
1 32,35 31,45 18,40 17,68
2 32,43 31,14 19,16 17,28
3 32,16 31,14 19,14 17,27
4 32,34 31,32 19,20 18,71
5 32,26 31,25 20,45 19,78
6 32,29 31,27 16,57 14,75
7 30,33 29,32 16,11 15,54
8 30,33 29,32 15,87 15,20
9 30,34 29,32 16,87 16,13
Média: 31,65 30,64 17,99 14,70


















