
arallel Lossless Compression Using...
42
Parallel lossless compression using GPUs Eva Sitaridi* Rene Mueller Tim Kaldewey Columbia University IBM Almaden IBM Almaden [email protected] [email protected] [email protected] *Work done while interning in IBM Almaden, partially funded from NSF Grant IIS-1218222
Transcript of arallel Lossless Compression Using...

Parallel lossless compression using GPUs
Eva Sitaridi* Rene Mueller Tim Kaldewey
Columbia University IBM Almaden IBM Almaden
[email protected] [email protected] [email protected]
*Work done while interning in IBM Almaden, partially funded from NSF Grant IIS-1218222

Agenda
• Introduction
• Overview of compression algorithms
• GPU implementation – LZSS compression
– Huffman coding
• Experimental results
• Conclusions
2

Why compression? • Data volume doubles every 2 years*
– Data retained for longer periods
– Data retained for business analytics
• Make better utilization of available storage resources
– Increase storage capacity
– Improve backup performance
– Reduce bandwidth utilization
•Compression should be seamless •Decompression important for Big Data workloads
*Sybase Adaptive Server Enterprise Data Compression, Business white paper 2012
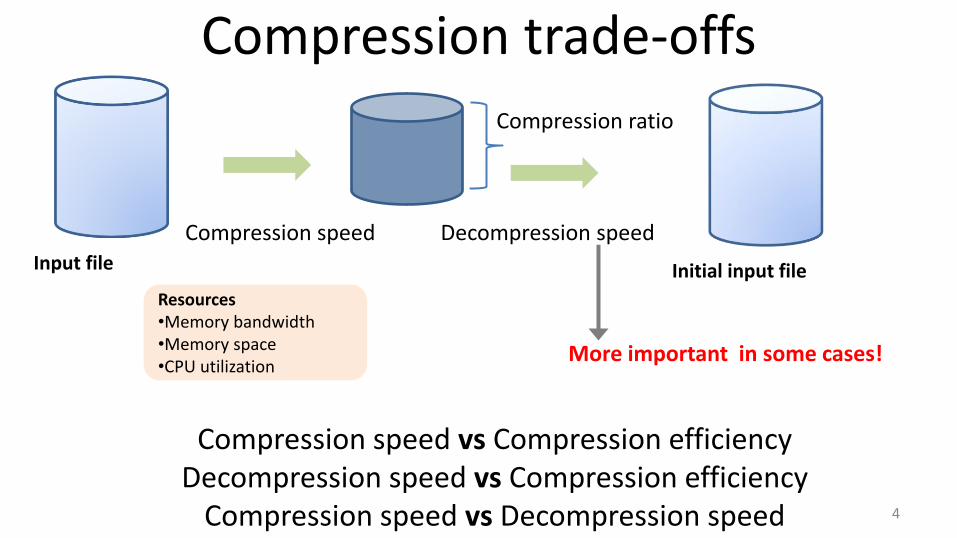
Compression trade-offs
Compression ratio
Compression speed
Decompression speed
More important in some cases!
Compression speed vs Compression efficiency Decompression speed vs Compression efficiency
Compression speed vs Decompression speed 4
Input file Initial input file
Resources •Memory bandwidth •Memory space •CPU utilization
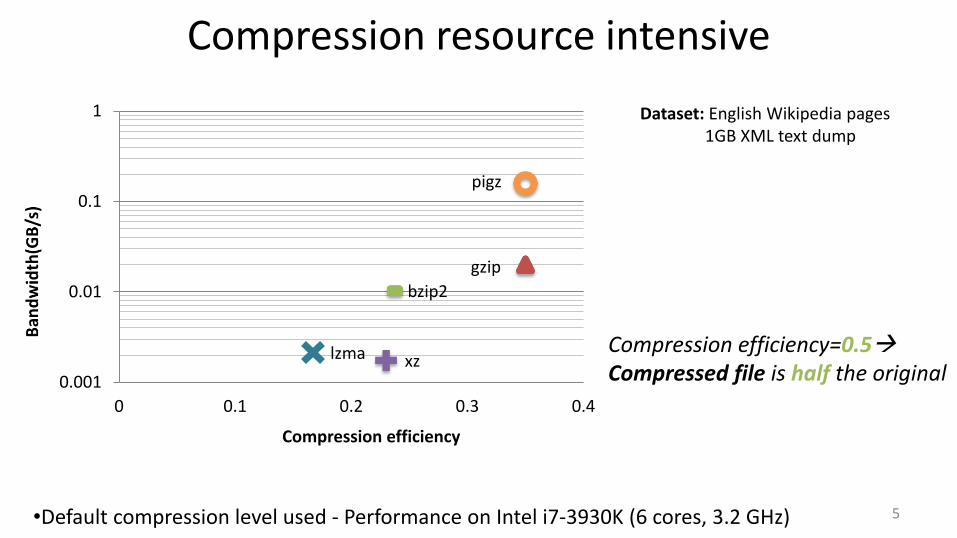
Compression resource intensive
Dataset: English Wikipedia pages 1GB XML text dump
5 •Default compression level used - Performance on Intel i7-3930K (6 cores, 3.2 GHz)
Compression efficiency
pigz
lzma
bzip2
gzip
xz 0.001
0.01
0.1
1
0 0.1 0.2 0.3 0.4
Compression efficiency=0.5 Compressed file is half the original

Compression libraries
6
snappy
All use LZ-variants
XZ
Deflate format
– LZ77 compression
– Huffman coding
– Single threaded
Parallel gzip
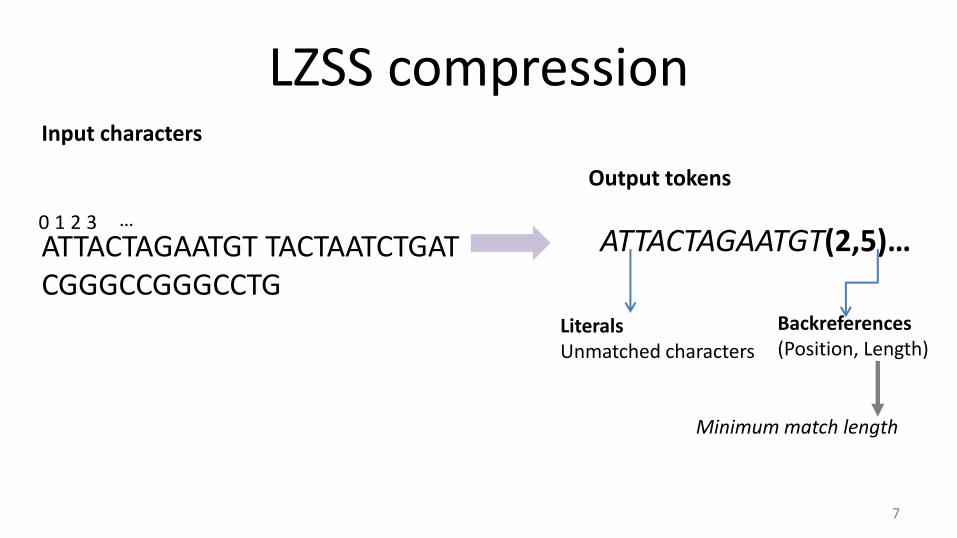
LZSS compression
Input characters
7
0 1 2 3 …
ATTACTAGAATGT TACTAATCTGAT CGGGCCGGGCCTG
Output tokens
ATTACTAGAATGT(2,5)…
Backreferences (Position, Length)
Literals Unmatched characters
Minimum match length
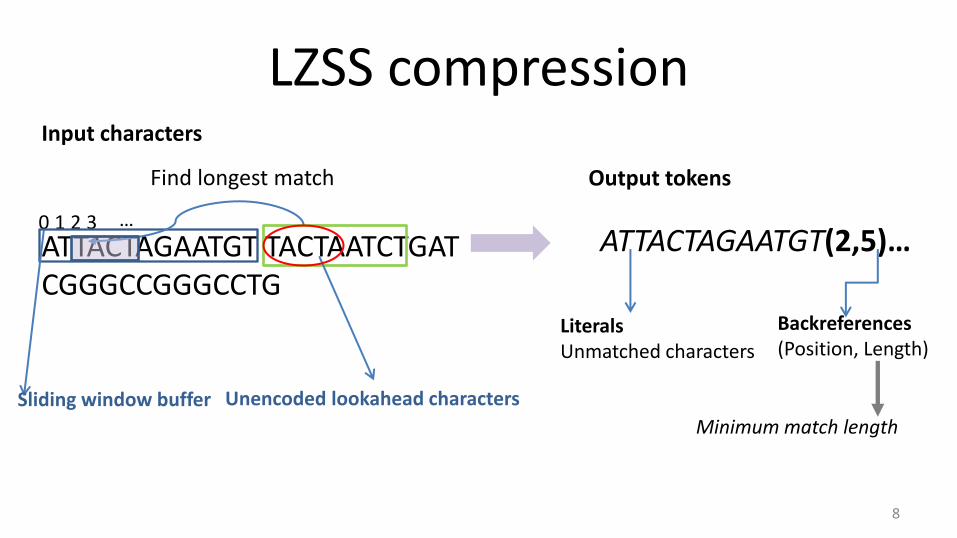
LZSS compression
Input characters
8
0 1 2 3 …
ATTACTAGAATGT TACTAATCTGAT CGGGCCGGGCCTG
Sliding window buffer Unencoded lookahead characters
Find longest match Output tokens
ATTACTAGAATGT(2,5)…
Backreferences (Position, Length)
Literals Unmatched characters
Minimum match length
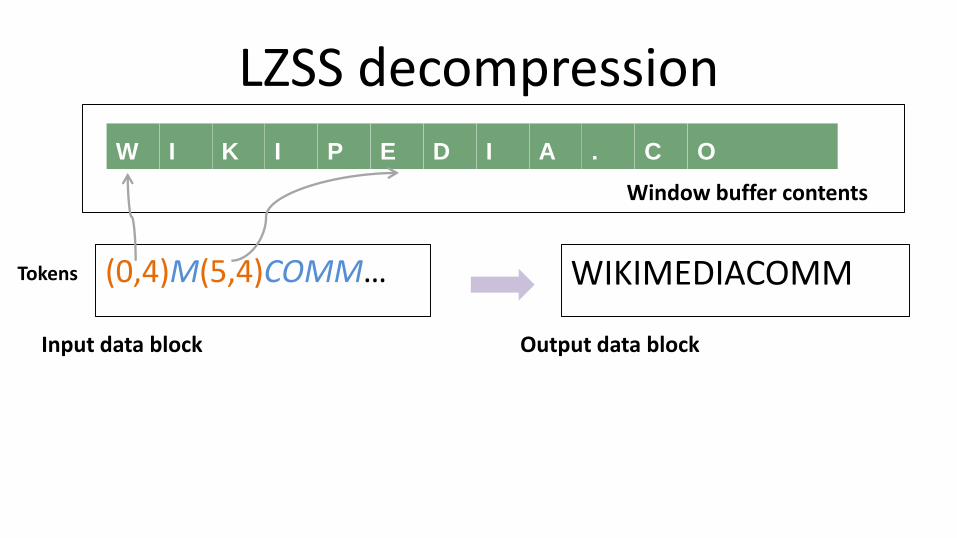
(0,4)M(5,4)COMM… Output data block
W I K I P E D I A . C O
WIKIMEDIACOMM
Window buffer contents
LZSS decompression
Input data block
Tokens
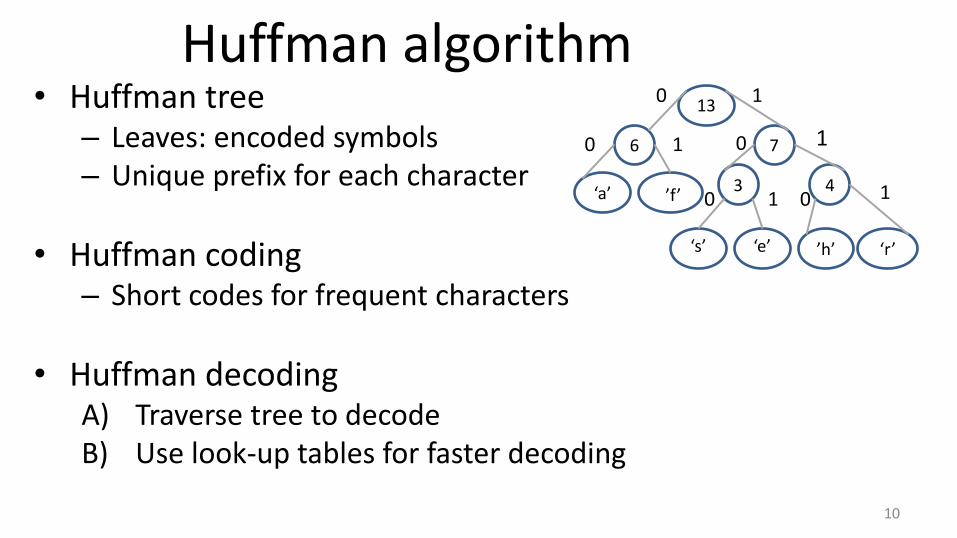
Huffman algorithm • Huffman tree
– Leaves: encoded symbols – Unique prefix for each character
• Huffman coding – Short codes for frequent characters
• Huffman decoding A) Traverse tree to decode B) Use look-up tables for faster decoding
10
13
6 7
‘a’ ‘’f’ 3 4
‘s’
‘e’
’h’ ‘r’
0 1
0 1 1
1 1 0 0
0
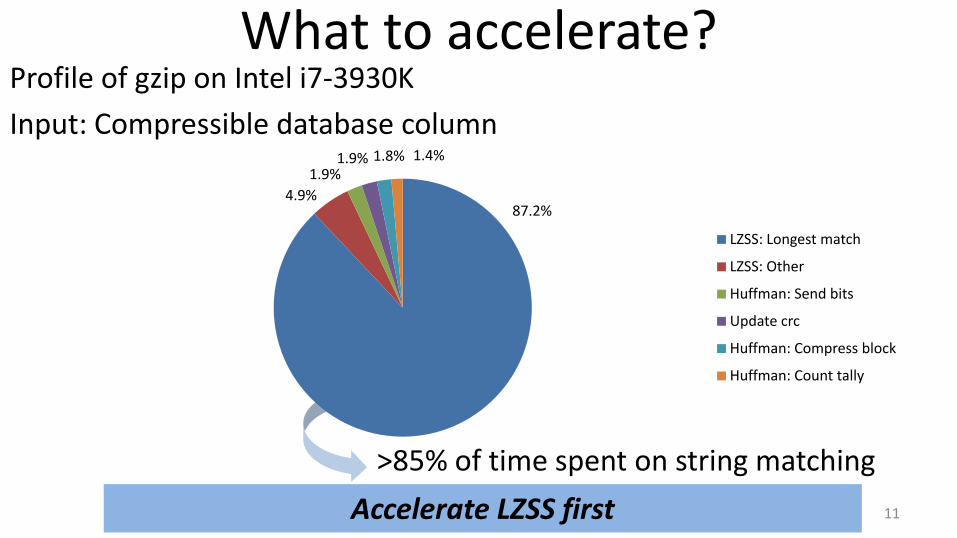
What to accelerate? Profile of gzip on Intel i7-3930K
Input: Compressible database column
11
>85% of time spent on string matching
Accelerate LZSS first
LZSS: Longest match
LZSS: Other
Huffman: Send bits
Update crc
Huffman: Compress block
Huffman: Count tally
87.2% 4.9%
1.9% 1.4% 1.9% 1.8%

Why GPUs?
Intel i7-3930K Tesla K20x
Memory Bandwidth (Spec)
51.2 GB/s 250 GB/s
Memory Bandwidth (Measured)
40.4 GB/s 197GB/s
#Cores 6 2688
12
•LZSS string matching is memory bandwidth intensive - Leverage GPU bandwidth

How to parallelize compression/decompression?
13
Thread 1
Thread 2
Data block 1
Data block 2
…
Naïve approach: Threads process independent data/file blocks Input file
Split input file in independent blocks
>1000 cores available!
…
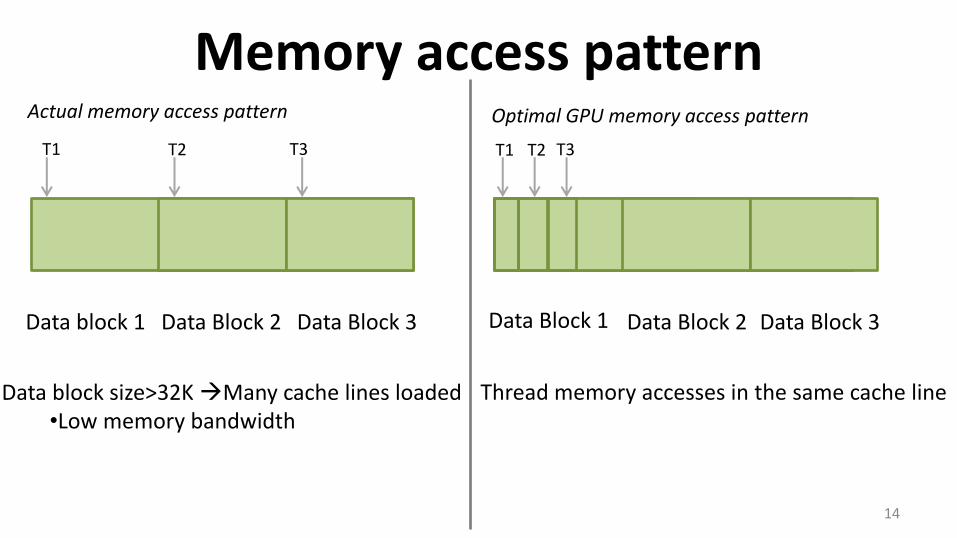
Memory access pattern
14
Data Block 1 Data Block 2 Data Block 3
T1 T2 T3
Thread memory accesses in the same cache line
Optimal GPU memory access pattern
Data block 1 Data Block 2 Data Block 3
T1 T2 T3
Data block size>32K Many cache lines loaded •Low memory bandwidth
Actual memory access pattern
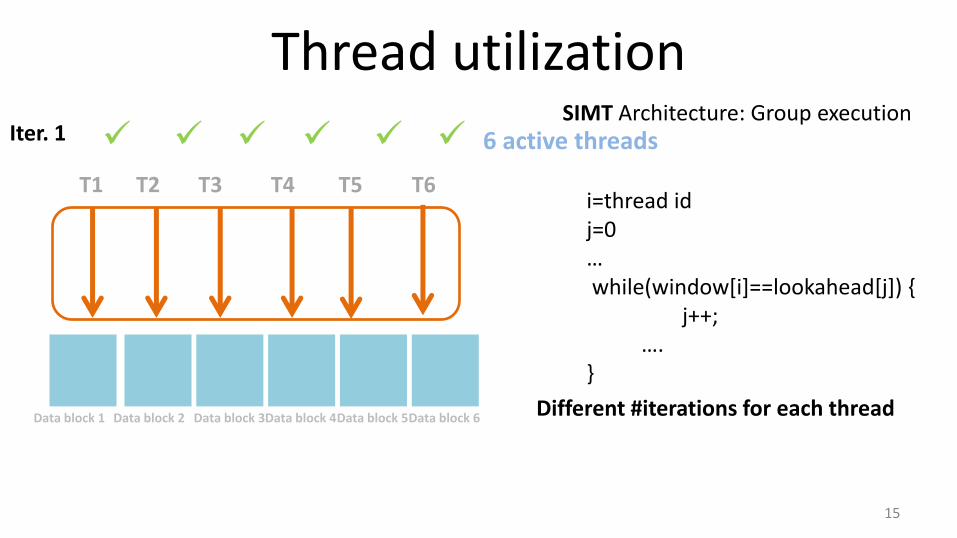
Thread utilization
15
T1 T2 T3 T4 T5 T6
SIMT Architecture: Group execution
Data block 1
6 active threads Iter. 1
i=thread id j=0 … while(window[i]==lookahead[j]) { j++; …. }
Data block 2 Data block 3 Data block 4 Data block 5 Data block 6 Different #iterations for each thread
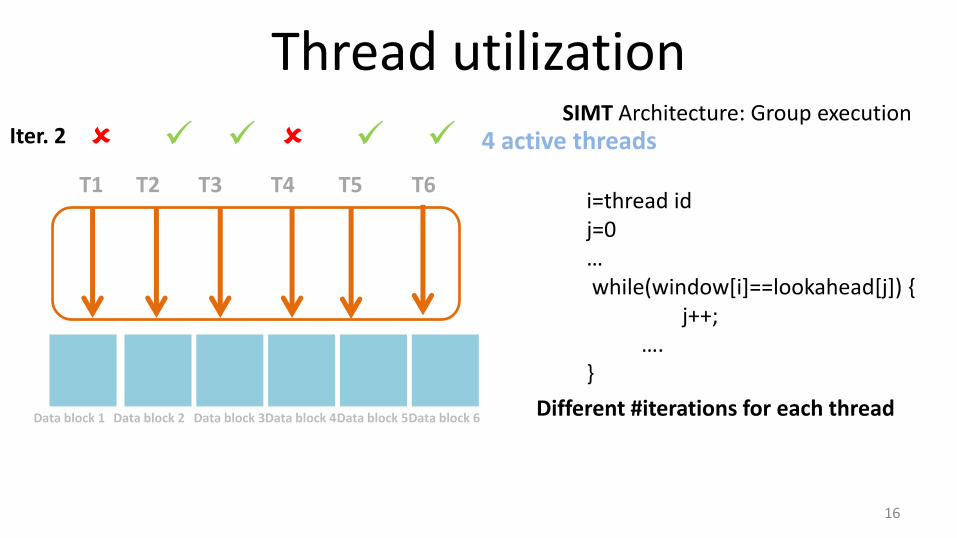
Thread utilization
16
T1 T2 T3 T4 T5 T6
SIMT Architecture: Group execution
Data block 1
i=thread id j=0 … while(window[i]==lookahead[j]) { j++; …. }
Data block 2 Data block 3 Data block 4 Data block 5 Data block 6
4 active threads Iter. 2
Different #iterations for each thread
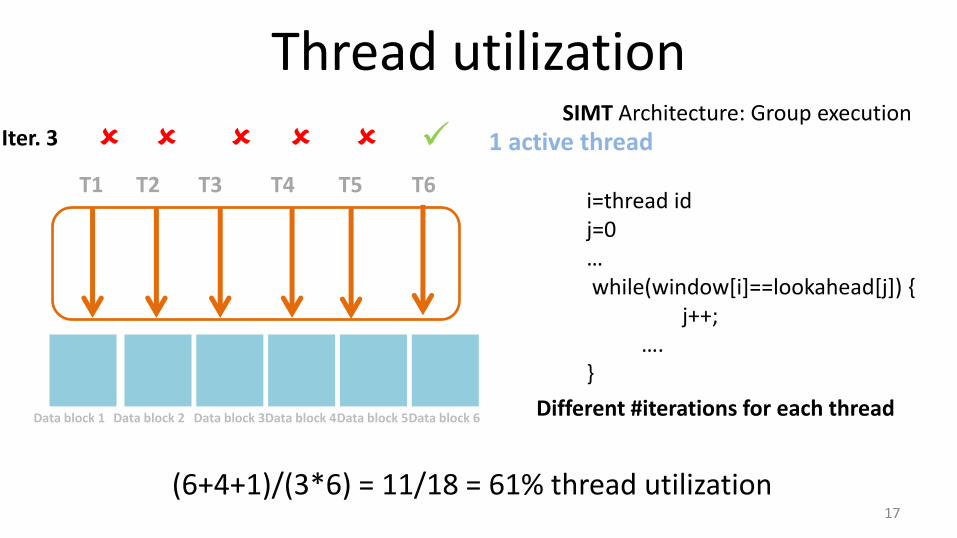
Thread utilization
17
T1 T2 T3 T4 T5 T6
SIMT Architecture: Group execution
Data block 1
i=thread id j=0 … while(window[i]==lookahead[j]) { j++; …. }
Data block 2 Data block 3 Data block 4 Data block 5 Data block 6
1 active thread Iter. 3
Different #iterations for each thread
(6+4+1)/(3*6) = 11/18 = 61% thread utilization
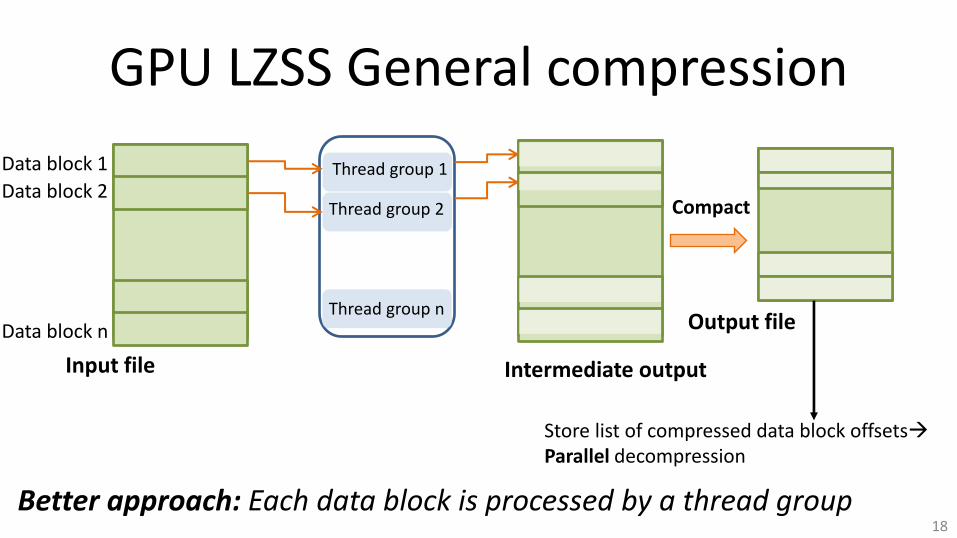
GPU LZSS General compression
Thread group 1
Thread group 2
Input file
Data block 1
Data block 2
Store list of compressed data block offsets Parallel decompression
Compact
Output file
Intermediate output
Thread group n
Data block n
18
Better approach: Each data block is processed by a thread group
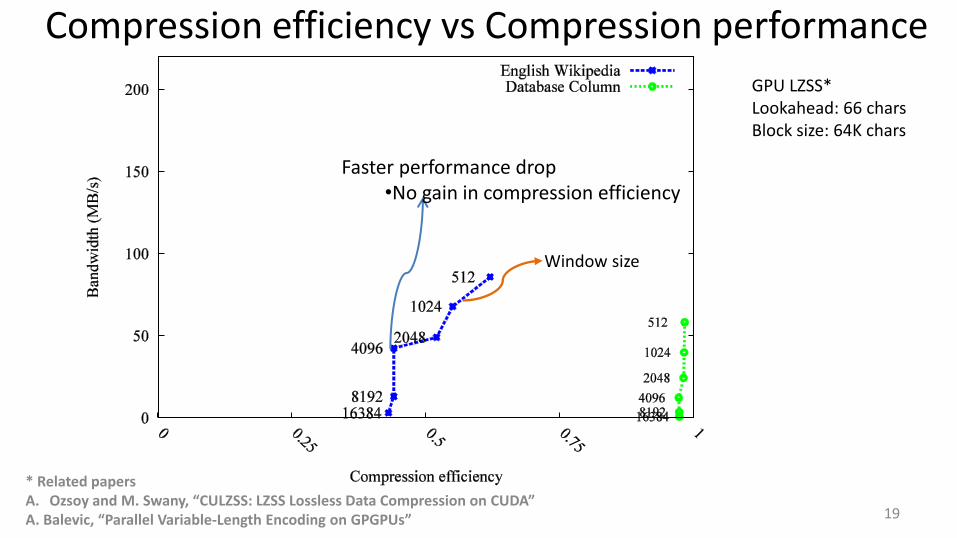
Compression efficiency vs Compression performance
19
Faster performance drop •No gain in compression efficiency
Window size
GPU LZSS* Lookahead: 66 chars Block size: 64K chars
* Related papers A. Ozsoy and M. Swany, “CULZSS: LZSS Lossless Data Compression on CUDA” A. Balevic, “Parallel Variable-Length Encoding on GPGPUs”
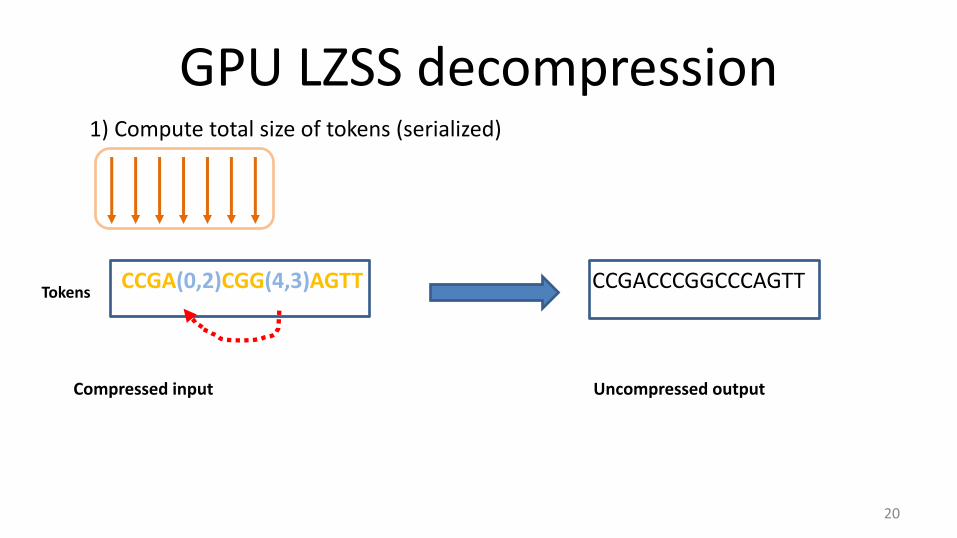
GPU LZSS decompression
20
CCGA(0,2)CGG(4,3)AGTT
1) Compute total size of tokens (serialized)
CCGACCCGGCCCAGTT
Compressed input Uncompressed output
Tokens
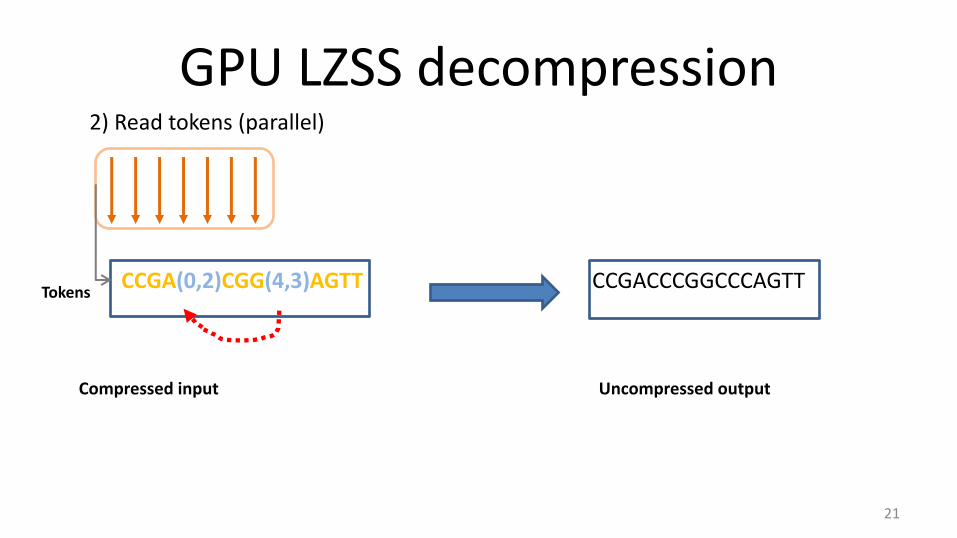
GPU LZSS decompression
21
CCGA(0,2)CGG(4,3)AGTT
Compressed input Uncompressed output
2) Read tokens (parallel)
Tokens CCGACCCGGCCCAGTT
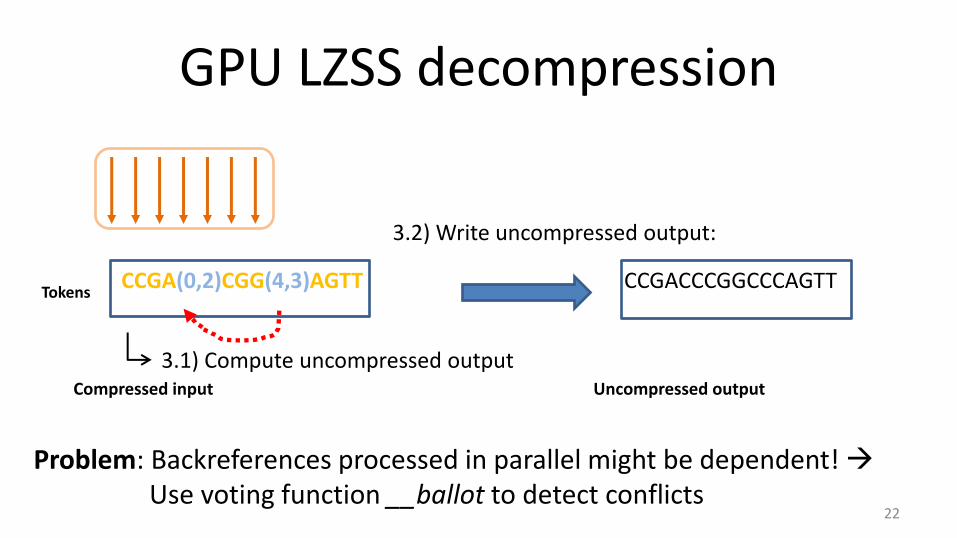
GPU LZSS decompression
22
CCGA(0,2)CGG(4,3)AGTT
3.2) Write uncompressed output:
CCGACCCGGCCCAGTT
Compressed input Uncompressed output
Problem: Backreferences processed in parallel might be dependent! Use voting function __ballot to detect conflicts
3.1) Compute uncompressed output
Tokens

Writing LZSS tokens to output Case A: All literals
Case B: Literals & non-conflicting backreferences
Case C: Literals & conflicting backreferences
23
CCGAGATTGAGTT Tokens
1) Write literals (parallel)
CCGA(0,2)CGG(0,3)AGTT Tokens 1) Write literals (parallel) 2) Write backreferences (parallel)
CCGA(0,2)CGG(4,3)AGTT Tokens 1) Write literals (parallel) 2) Write non-conflicting backreferences (parallel) 3) Write remaining backreferences (serial)

Huffman entropy coding • Inherently sequential
• Coding challenge
– Compute destination of encoded data
• Decoding challenge
– Determine codeword boundaries
24
Focus on decoding for end-to-end decompression

Parallel Huffman decoding
25
01100110 10111001 11010110 11100001 10111011 01110001 00000010 00001110
File block

Parallel Huffman decoding
26
01100110 10111001 11010110 11100001 10111011 01110001 00000010 00001110
•During coding •Split data blocks in sub-blocks •Store sub-block offsets Parallel sub-block decoding
File block
Offset 1
Offset 2
Offset 3
Offset 4

Parallel Huffman decoding
27
01100110 10111001 11010110 11100001 10111011 01110001 00000010 00001110
•During coding •Split data blocks in sub-blocks •Store sub-block offsets Parallel sub-block decoding
File block
Offset 1
Offset 2
Offset 3
Offset 4
•During decoding •Use look-up tables for decoding rather than Huffman trees •Fit look-up table in shared memory
•Reduce number of codes for length and distance

Parallel Huffman decoding
28
01100110 10111001 11010110 11100001 10111011 01110001 00000010 00001110
•During coding •Split data blocks in sub-blocks •Store sub-block offsets Parallel sub-block decoding
File block
Trade compression efficiency for decompression speed
Offset 1
Offset 2
Offset 3
Offset 4
•During decoding •Use look-up tables for decoding rather than Huffman trees •Fit look-up table in shared memory
•Reduce number of codes for length and distance
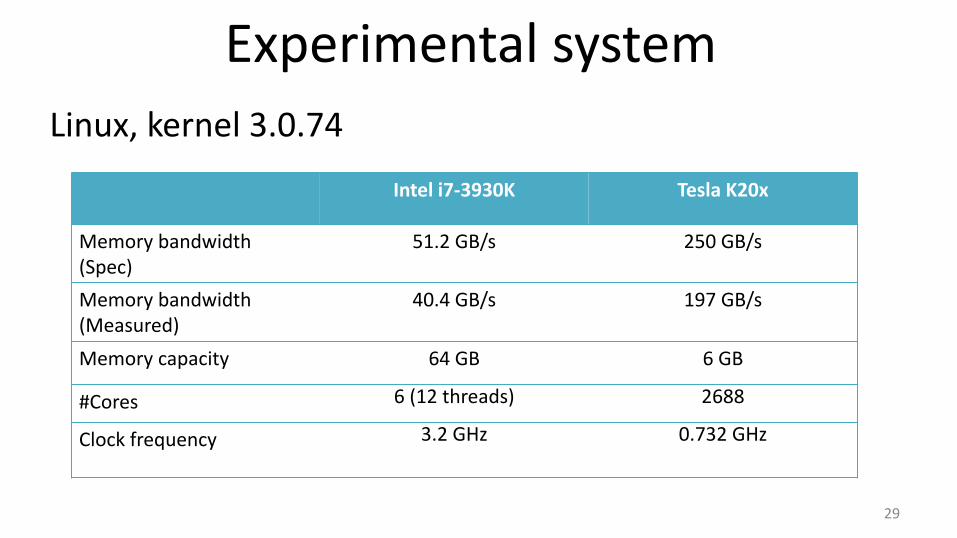
Experimental system
29
Intel i7-3930K Tesla K20x
Memory bandwidth (Spec)
51.2 GB/s 250 GB/s
Memory bandwidth (Measured)
40.4 GB/s 197 GB/s
Memory capacity 64 GB 6 GB
#Cores 6 (12 threads) 2688
Clock frequency 3.2 GHz 0.732 GHz
Linux, kernel 3.0.74
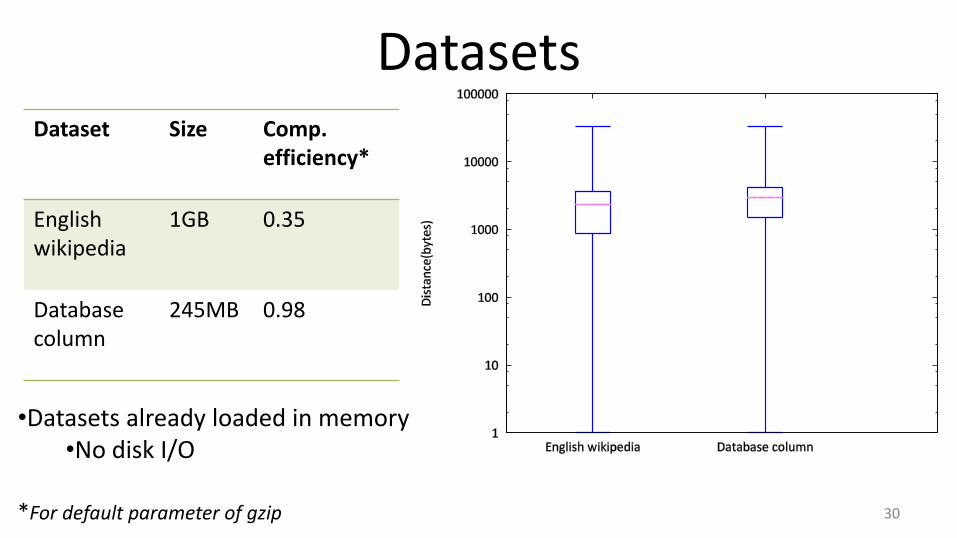
Datasets
30
Dataset Size Comp. efficiency*
English wikipedia
1GB 0.35
Database column
245MB 0.98
*For default parameter of gzip
•Datasets already loaded in memory •No disk I/O
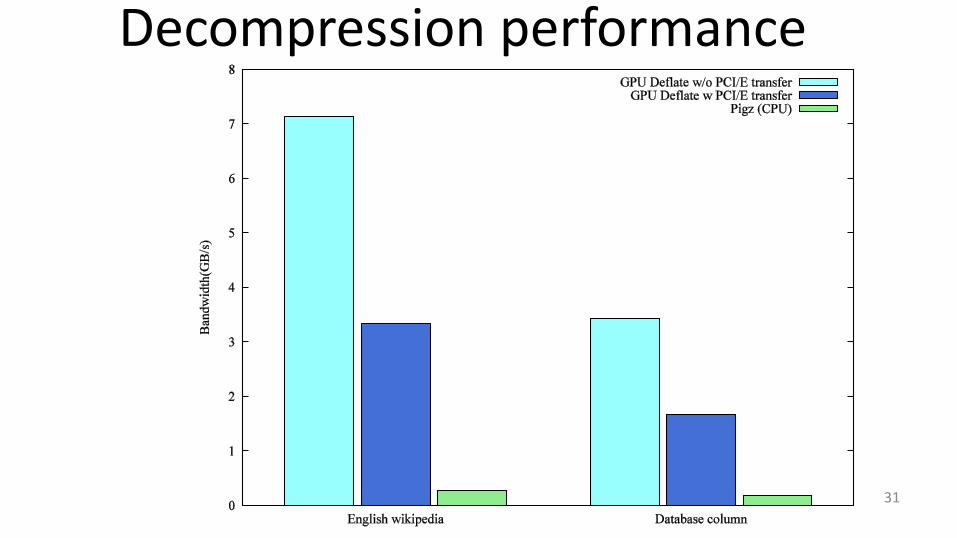
Decompression performance
31
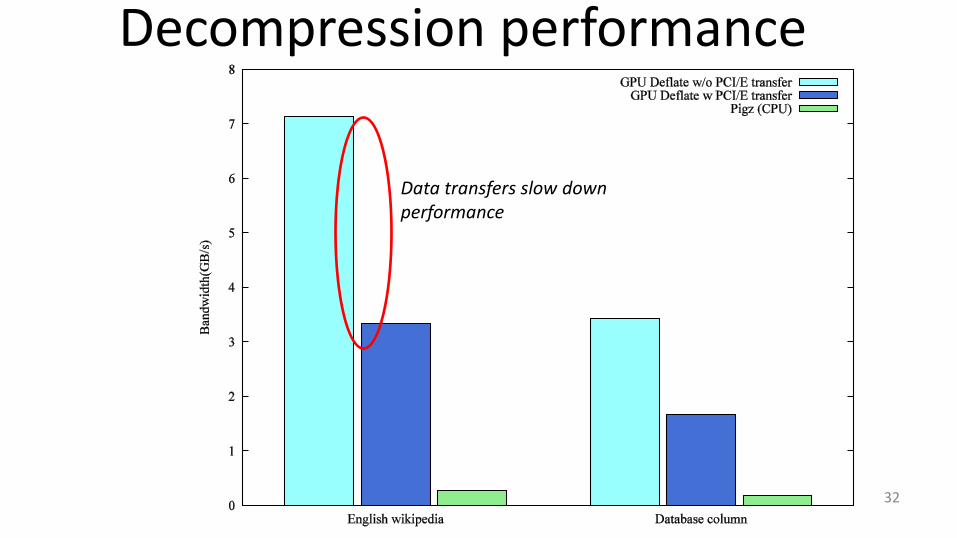
Decompression performance
32
Data transfers slow down performance

Hide GPU to CPU transfer I/O using CUDA Streams
Stre
am
Batch processing
… Read B1 Decompress B1 Write B1 Read B2 Decode B1
Time
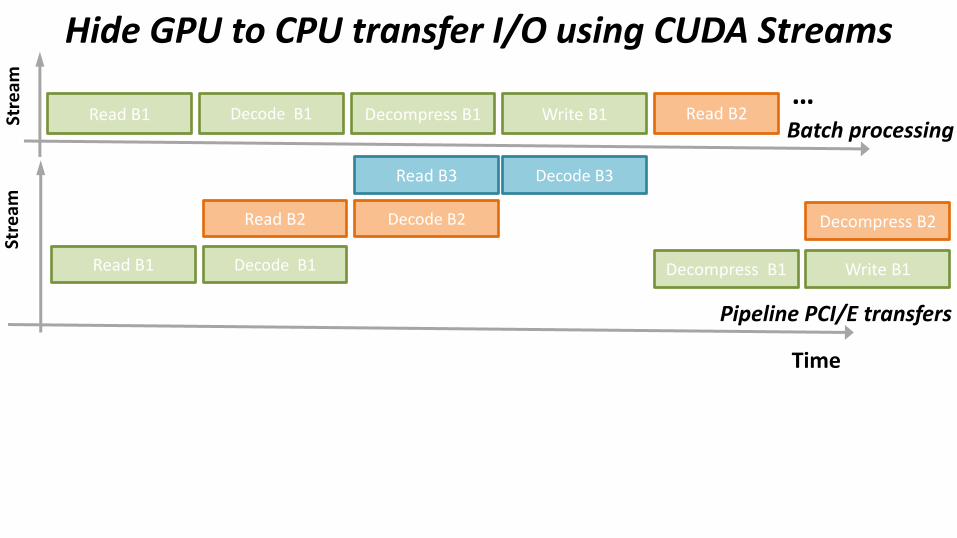
Hide GPU to CPU transfer I/O using CUDA Streams
Read B1 Decode B1
Decode B2 Read B2
Read B3 Decode B3
Stre
am
Stre
am
Batch processing
…
Decompress B1 Write B1
Decompress B2
Pipeline PCI/E transfers
Read B1 Decompress B1 Write B1 Read B2 Decode B1
Time
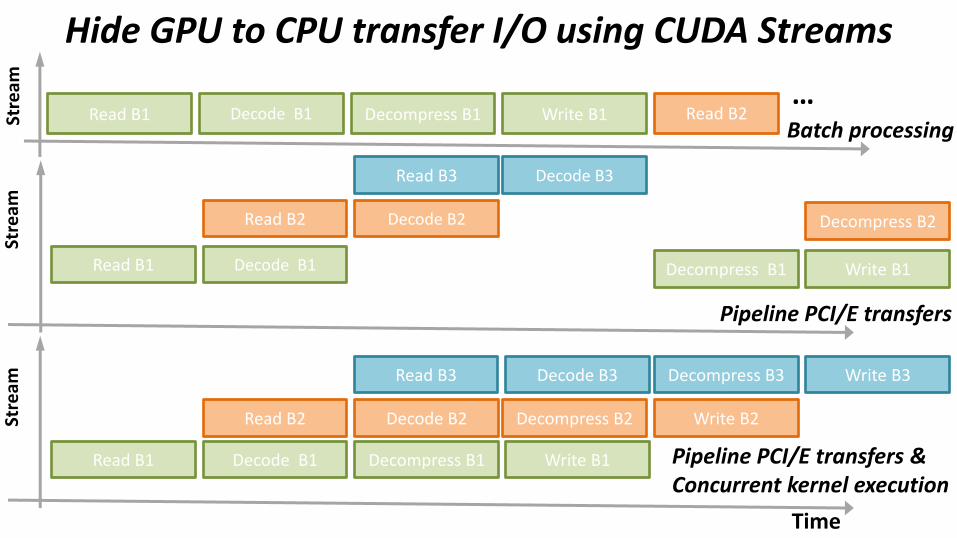
Hide GPU to CPU transfer I/O using CUDA Streams
Read B1 Decode B1
Decode B2 Read B2
Read B3 Decode B3
Stre
am
Stre
am
Batch processing
…
Time
Read B1 Decode B1
Decode B2
Decompress B1
Read B2
Read B3 Decode B3
Write B2
Decompress B3
Stre
am
Write B1
Write B3
Decompress B2
Decompress B1 Write B1
Decompress B2
Pipeline PCI/E transfers & Concurrent kernel execution
Pipeline PCI/E transfers
Read B1 Decompress B1 Write B1 Read B2 Decode B1
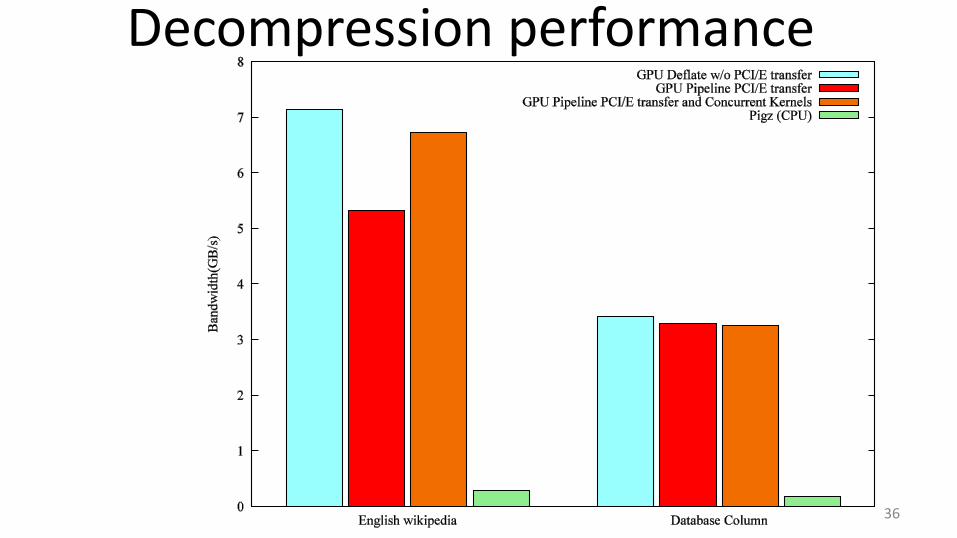
Decompression performance
36
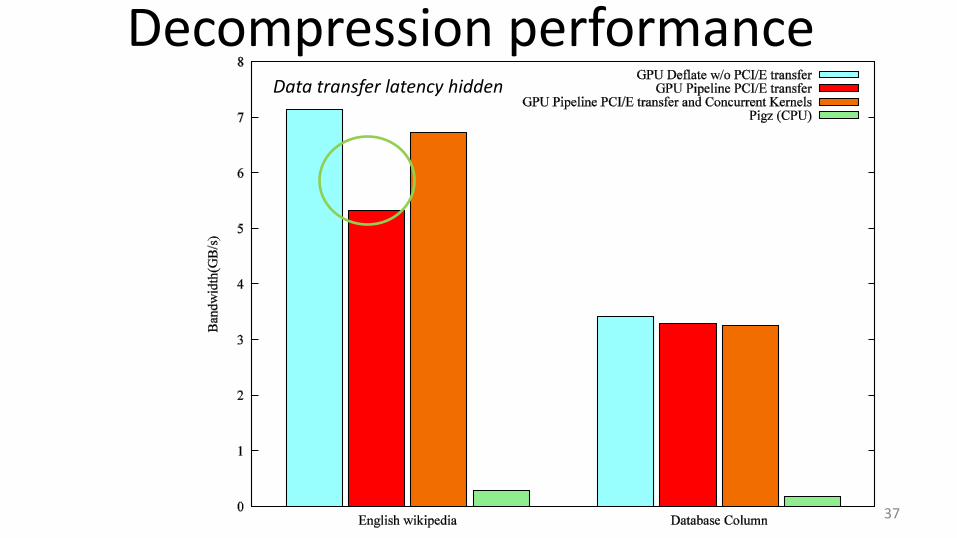
Data transfer latency hidden
Decompression performance
37
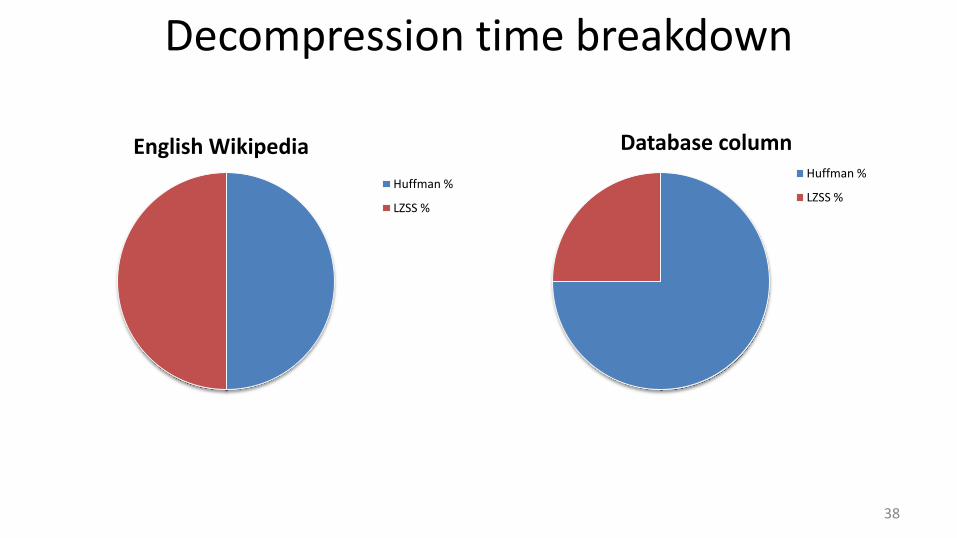
Database column Huffman %
LZSS %
Decompression time breakdown
38
English Wikipedia
Huffman %
LZSS %
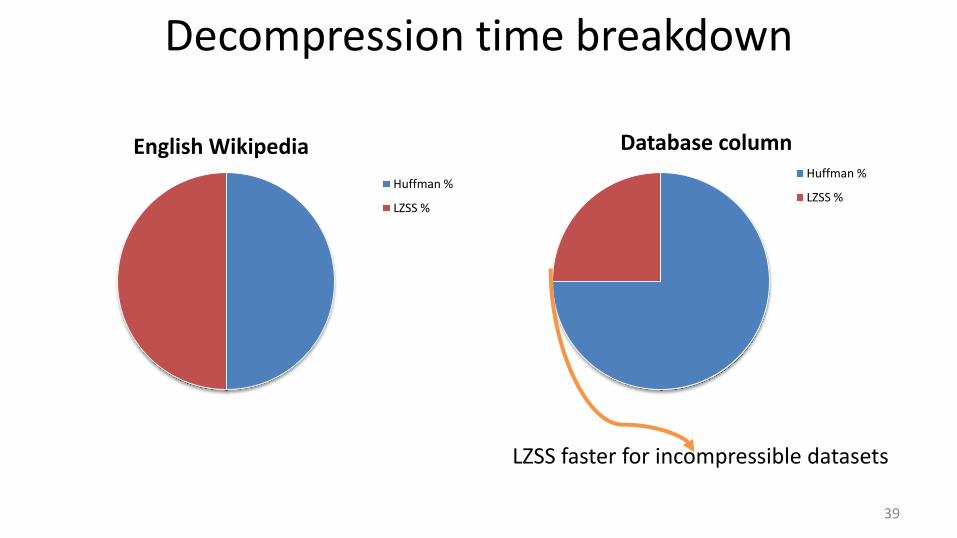
Database column Huffman %
LZSS %
Decompression time breakdown
39
LZSS faster for incompressible datasets
English Wikipedia
Huffman %
LZSS %
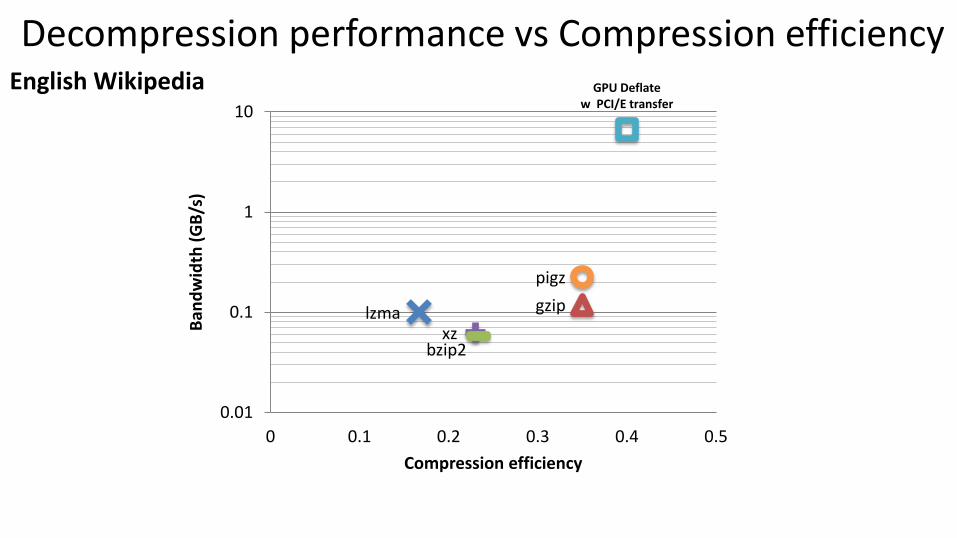
Decompression performance vs Compression efficiency English Wikipedia
gzip
pigz
xz
GPU Deflate w PCI/E transfer
bzip2
lzma
0.01
0.1
1
10
0 0.1 0.2 0.3 0.4 0.5
Ban
dw
idth
(G
B/s
)
Compression efficiency

Conclusions • Decompression
– Hide GPU-CPU latency using 4-stage pipelining
– LZSS faster for incompressible files
• Compression
– Reduce search time (using hash tables ?)
41

Conclusions • Decompression
– Hide GPU-CPU latency using 4-stage pipelining
– LZSS faster for incompressible files
• Compression
– Reduce search time (using hash tables ?)
42
Questions?


















