
Approximate Scalable Bounded Space Sketch for Large Data NLP
30
Approximate Scalable Bounded Space Sketch for Large Data NLP Amit Goyal and Hal Daume III (EMNLP2011) 紹介者 : 松田 2011/10/13 1
-
Upload
koji-matsuda -
Category
Documents
-
view
2.008 -
download
0
Transcript of Approximate Scalable Bounded Space Sketch for Large Data NLP

Approximate Scalable Bounded Space Sketch for Large Data NLP
Amit Goyal and Hal Daume III (EMNLP2011)紹介者 : 松田2011/10/13
1

Abstract
• Count-Min sketch(以下CM)という sketch-based アルゴリズムを単語ペアの計数に用いる
• CMを用いることで、単語ペアそれ自体を保持することなく、共起頻度の近似値を(空間,時間ともに)効率よく保持することができる
• 共起頻度の近似値を以下の三つにタスクに適用し、state-of-the-artな手法、及びExact Countと性能を比較– 単語の感情極性判別– 分布アプローチに基づく単語の類似性判別– 教師なし係り受け解析
• 49GBのテキストからの共起情報を8GBほどのメモリで扱うことができる事を示す
2

Introduction
• NLPで利用可能なデータはテラバイト級に達しつつある
• 大規模なクラスターを用いた計算が主流– Brants et al. (2007) : 1500台で 1.8TB– Aggire et al. (2009) : 2000コアで 1.6 Terawords
• しかしながら、多くの研究者は大規模な計算資源を持っていない– 何らかの「妥協」をしながら大規模なデータを扱う研究も盛んになってきている
– Streaming, Randomized, Approximate…
• しかし、それらは汎用性に欠けるものであることが多い
3

Introduction
• 本論文では、 Count-Min sketch(Cormode and Muthukrishnan 2004)というデータ構造を用いる
• 「一つの」モデルで以下のような複数のタスクで効果があることを示す
– Semantic Orientation of the word
– Distributional Similarity
– Unsupervised Dependency Parsing
• 多くのNLPタスクで重要な、PMI, LLRのよう
な、関連性尺度を効率的に計算できることを示す
4

ストリーム計数界隈の最近の動向
• Nグラム(あるいは共起)情報をワンパス、コンパクト、高速に格納する研究が盛んに行われている
• Counter-based Algorithm
– 高頻度の要素に絞って、多少の誤差を許してカウント
– 高頻度の要素であればあるほど、より正確な値が得られる
• Sketch-based Algorithm– 要素自体は陽に保存せず、複数のhash関数の値を用いてカウントを格納(問い合わせにもhash関数を用いる)
– Count-Min sketchなど今日扱うのはこちら
5

Counter-based Algorithm
• 高頻度のデータをストリームから抽出する手法として開発– Frequent(2002), Lossy Counting(2002) etc…
• N個のデータ中で Nε (0 < ε < 1) 回以上出現するアイテムの近似頻度を効率よく保持するアルゴリズム
• Pros.– 高頻度のものについてはデータを陽に保存する
• Cons.– 低頻度のデータについては保存されない– (私があまり勉強してないので説明できない)
6

Sketch-based Algorithm
• 複数のハッシュ関数の値を用いて、データを陽に保存せず、ハッシュの値とカウントを関連づける
– CountSketch (2002), Count-Min sketch(2004), Multistage Filter(2002) etc.
– ルーツはBloom filter(1970)にさかのぼる
• Pros.
– Update, Query, 共に定数時間(ハッシュ関数の個数に比例)
– 低頻度のitemについても(正確性はともかく)何らかの値を保持できる
• Cons.
– 確率 δ で overestimate する• ハッシュの衝突に起因するFalse Positiveが起こる
– データを陽に保存しない• つまり、sketch中に何が保存されているかは問い合せてみないと分からない
7

Bloom Filter Algorithm
• Bloom(1970)– itemがデータベースに「存在するか否か」を効率よく保持する
アルゴリズム– mビットのビット配列, k個の(pairwise independentな)ハッシュ関
数– 確率 δ で False Positive(実際は存在しないのに真を返す)
• データベース/辞書に問い合わせる「前段階」でクエリをフィルタリングする用途に用いられることが多い– Google日本語入力 (Mozc)– 分散KVS (Cassandra, HBase等)– Google Code searchで検索するとワサワサ出てきます
• 最近(実用レベルで)よく見かけるようになってきたデータ構造なので、興味があれば調べてみてください– Wikipediaに理論的なところも含めて解説があります
8

Count-Min sketch (1/3)
• d × w の二次元テーブル、d個のハッシュ関数で表されるデータ構造– d : ハッシュ関数の個数
• 大きくすると、ハッシュの衝突に対してロバストになる
– w : ハッシュ関数の値域• 大きくすると、ハッシュの衝突が起こりにくくなる
ハッシュ関数の個数
ハッシュ関数の値域
各セル(カウンタ)はゼロで初期化(4Byteのintで実験を行っている)
9

Count-Min sketch (2/3)
• Update Procedure– xがc個観測された場合、xに対して、それぞれの行に対応するハッシュを求めて、該当するセルに+ c する
• Query Procedure– 対応するハッシュを求めて、セルの最小値をとる
– なぜ最小値?• ハッシュの衝突が発生した場合 の値は実際の頻度値よりも大きくなるため
• dを大きくするとハッシュの衝突に対して頑健になる
10

Count-Min sketch (3/3)
• 基本的性質– Update, Query共に定数時間(ハッシュをd個計算するだけ)
– メモリ使用量は w × d
– 確率δで誤差がεNを超える(が、必ずoverestimate)
• その他の性質– 線形性 : sketches s1, s2 をそれぞれ別々のデータから計算した場合も、単純に足すだけで合計頻度を求めることができる
– そのため、分散計算にも向いている
11

Conservative Update
• Update時にQueryを挟むことによって、誤差を小さくできることが経験的に知られている– ただし、更新はちょっと遅くなる
• ARE (後述) で 1.5 倍程度の精度向上
• 以後の表記– Count-Min sketch : CM
– Count-Min sketch with Conservative Update : CU
12
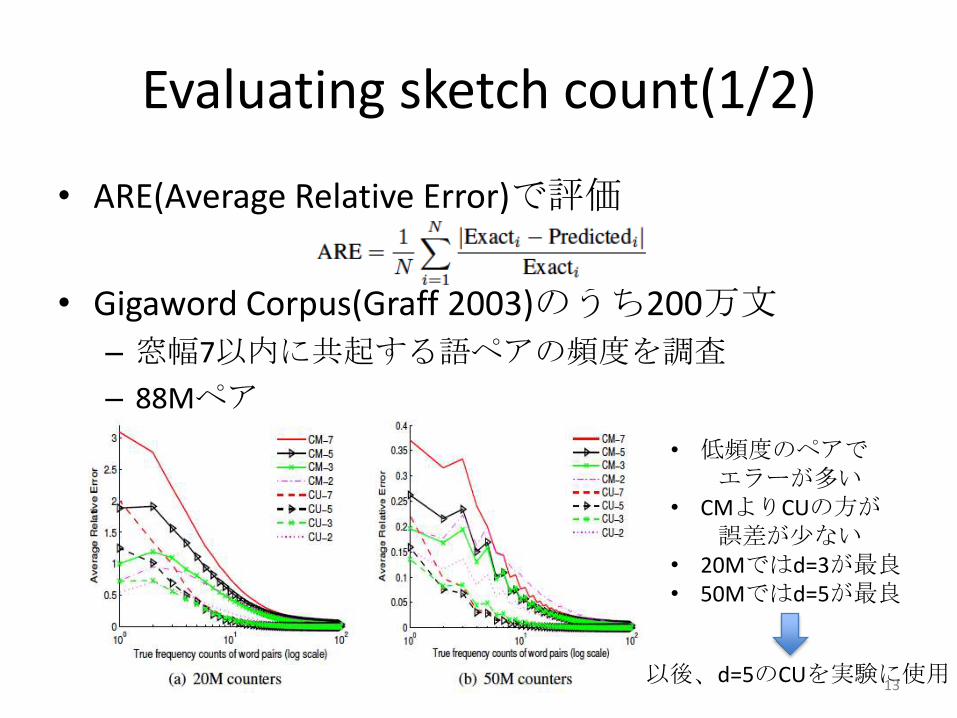
Evaluating sketch count(1/2)
• ARE(Average Relative Error)で評価
• Gigaword Corpus(Graff 2003)のうち200万文
– 窓幅7以内に共起する語ペアの頻度を調査
– 88Mペア
• 低頻度のペアでエラーが多い
• CMよりCUの方が誤差が少ない
• 20Mではd=3が最良• 50Mではd=5が最良
以後、d=5のCUを実験に使用13
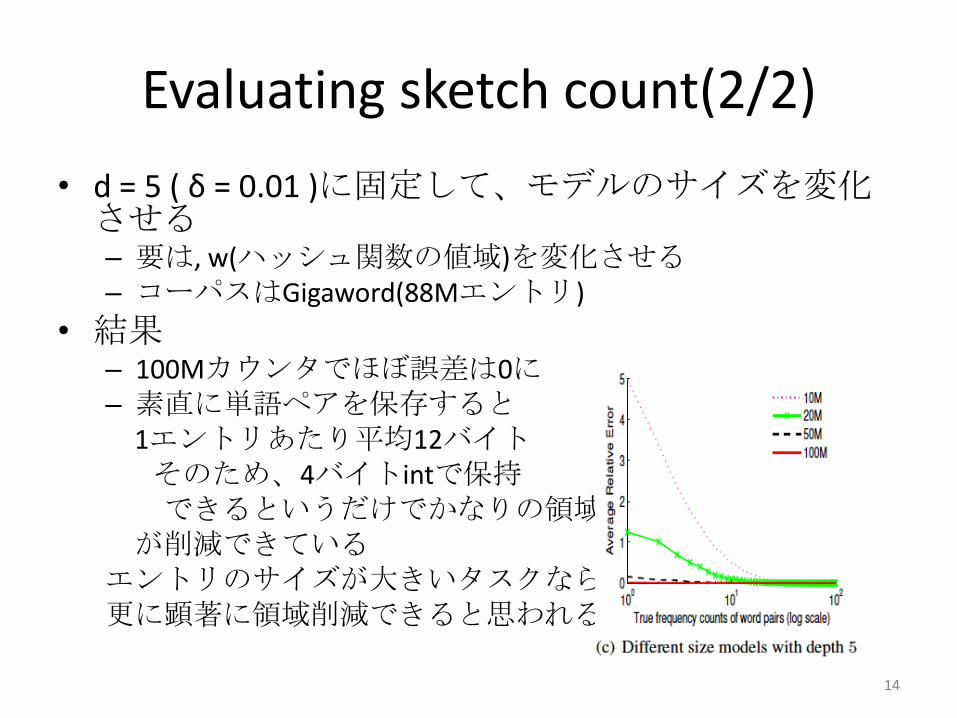
Evaluating sketch count(2/2)
• d = 5 ( δ = 0.01 )に固定して、モデルのサイズを変化させる– 要は, w(ハッシュ関数の値域)を変化させる– コーパスはGigaword(88Mエントリ)
• 結果– 100Mカウンタでほぼ誤差は0に– 素直に単語ペアを保存すると
1エントリあたり平均12バイトそのため、4バイトintで保持できるというだけでかなりの領域
が削減できているエントリのサイズが大きいタスクなら更に顕著に領域削減できると思われる
14
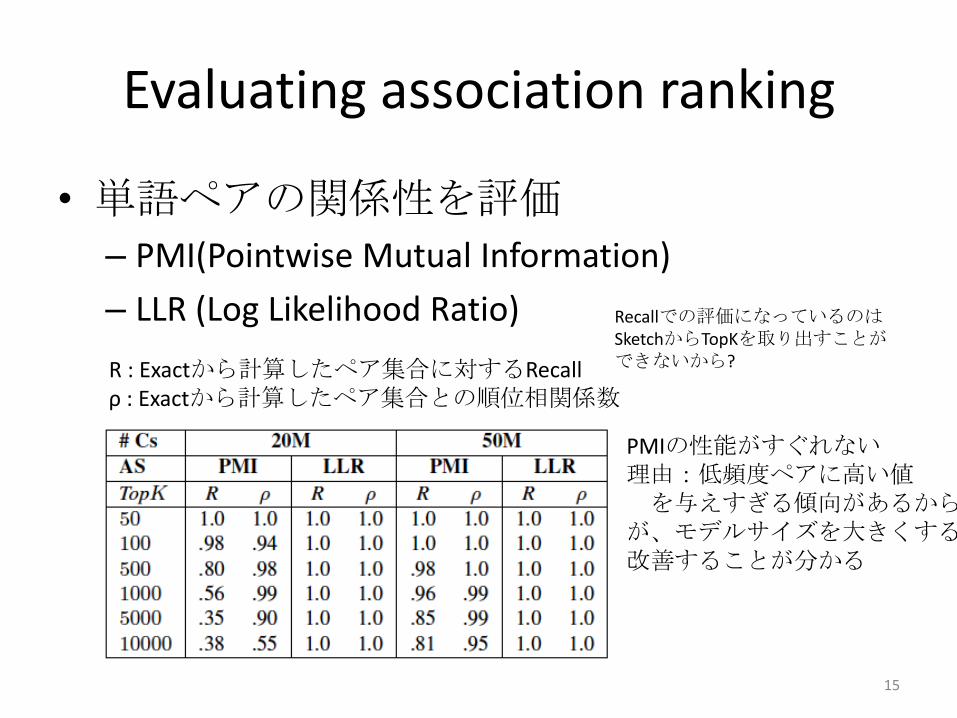
Evaluating association ranking
• 単語ペアの関係性を評価
– PMI(Pointwise Mutual Information)
– LLR (Log Likelihood Ratio)
R : Exactから計算したペア集合に対するRecallρ : Exactから計算したペア集合との順位相関係数
Recallでの評価になっているのはSketchからTopKを取り出すことができないから?
15
PMIの性能がすぐれない理由:低頻度ペアに高い値を与えすぎる傾向があるから
が、モデルサイズを大きくすると改善することが分かる

復習 : PMI と LLR
• どちらもアイテムの共起性、独立性を示す指標• PMI ( Pointwise Mutual Information)
– x,yの出現確率の独立性を直接に用いている。頻度自体は考慮しないので、低頻度のアイテムに不当に高い値がつくことがある
• LLR ( Log-Likelihood Ratio)– 数式は省略。分割表に基づいて L(データ|従属)と L(データ|
独立) の比を求めることによって、共起性をはかる– “尤度比検定”に用いられる
• 分割表の各セルの値がそれなりに大きい値を持つことを期待• 低頻度のペアに対しては概して小さい値が得られる
PMI(x, y) = logp(x.y)
p(x)p(y)
16
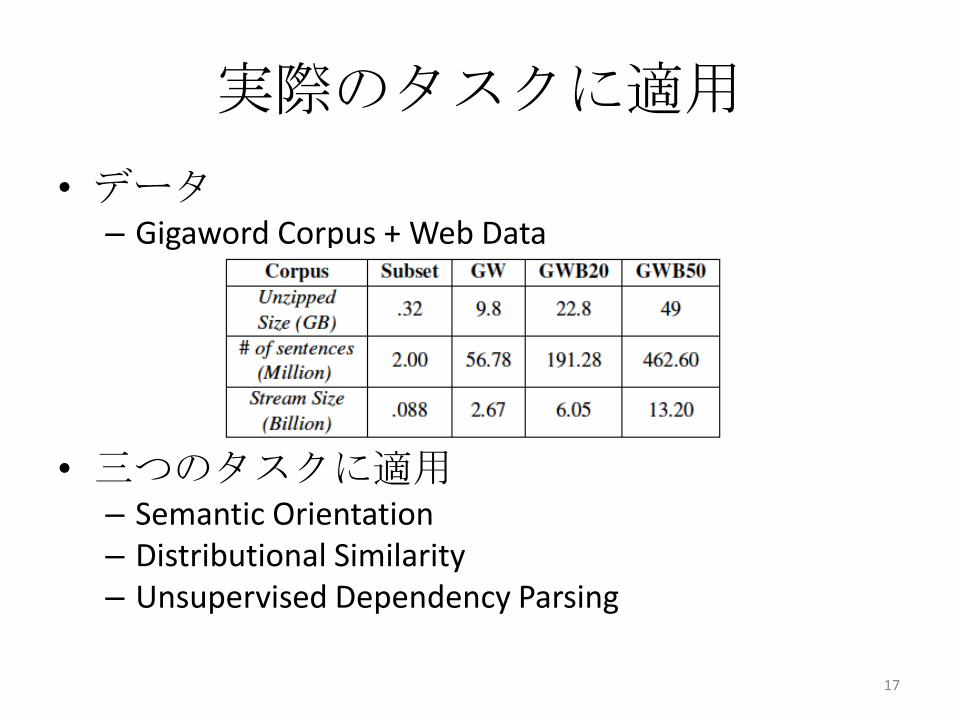
実際のタスクに適用
• データ– Gigaword Corpus + Web Data
• 三つのタスクに適用– Semantic Orientation– Distributional Similarity– Unsupervised Dependency Parsing
17

Semantic Orientation (1/2)
• 単語のPositive / Negative を判定するタスク– 種語との関連性に基づく単純なモデル(Turney and Littman, 2003)
– 正解データ: General Inquirer lexicon (Stone et al., 1966)
精度のモデルサイズに対する変化
モデルサイズを増やすことで性能向上がみられる
PMIを用いたほうが精度が良く、20億カウンタ(8GB)でExactと差が見られなくなる
18

Semantic Orientation (2/2)
• コーパスサイズを変化させて精度を確認
– モデルサイズは 2Billion (8GB) に固定
• Webデータを加えることで精度の向上が見られる• どのコーパスサイズでもExactと同等の精度を達成• 2B個のカウンタで GWB20 (6.05B), GWB50 (13.2B) の情報を保持できた• このタスクのstate-of-the-art (82.84%) に近い結果をより小さなコーパスで得られた
• (Turney and Littman, 2003)の結果. 1000億語使っているらしい・・・ 19

Distributional Similarity (1/4)
• 「(意味的に)似た単語は、似たコンテキストに出現する」という仮説に基づく語の類似性判定
• 提案されている効率的な計算方法1. 単語それ自体に対してはExactカウント, 単語ペ
アに対してはCU-sketchを用いて近似値を計数
2. ある対象語 “x” に対してすべての語との共起尺度(PMI, LLR)をsketchを用いて計算
3. Top K( K= 1000 ) だけを保持して、 K個のベクトルとのcosine尺度を計算
4. cosine尺度が高いほど “x” との類似性が高い
20

Distributional Similarity (2/4)
• 用いた Gold-standard データセット– どちらも (Aggire et al. 2009)で用いられているもの
– WS-353 ( Finkelstein et al. 2002)• 353ペアに対して 0(無関係) 〜 10(同じ意味)のアノテート (13〜16人による平均)
– RG-65 (Rubenstein and Goodenough 1965)• 65ペアに対して51人に同様の調査を行った古典的データ
• それぞれに対して、スピアマンの順位相関係数で評価を行った
21
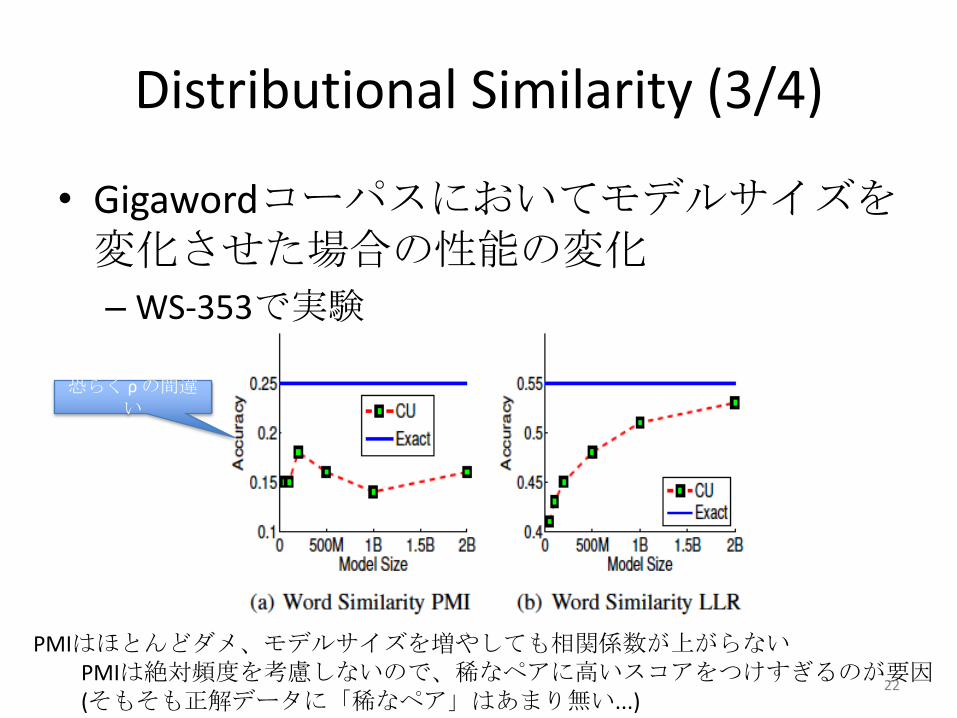
Distributional Similarity (3/4)
• Gigawordコーパスにおいてモデルサイズを変化させた場合の性能の変化
– WS-353で実験
恐らく ρ の間違い
PMIはほとんどダメ、モデルサイズを増やしても相関係数が上がらないPMIは絶対頻度を考慮しないので、稀なペアに高いスコアをつけすぎるのが要因(そもそも正解データに「稀なペア」はあまり無い...)
22
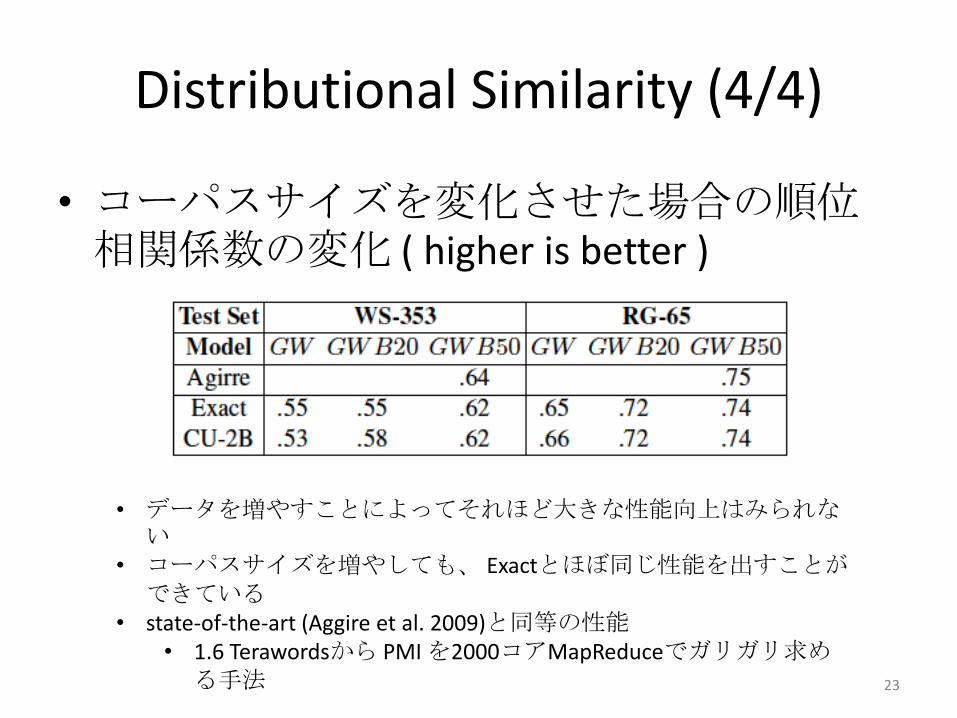
Distributional Similarity (4/4)
• コーパスサイズを変化させた場合の順位相関係数の変化 ( higher is better )
• データを増やすことによってそれほど大きな性能向上はみられない
• コーパスサイズを増やしても、 Exactとほぼ同じ性能を出すことができている
• state-of-the-art (Aggire et al. 2009)と同等の性能• 1.6 Terawordsから PMI を2000コアMapReduceでガリガリ求め
る手法 23

Dependency Parsing (1/5)
• MST Parser (McDonald et al. 2005)のフレームワークのもとで実験– すべての語のペアに重みつきのエッジがあり、その合計の重みを最大化する全域木を求める問題
– エッジの重みは MIRA 等で学習するのが普通
• 要は、 unsupervisedに最適な重み w(wi,wj) を求めることが出来るかどうかという問題– 結論:「明らかに無理」
• PMIは稀なペアに高いスコアを付け過ぎる傾向– 主に内容語同士
• LLRは頻出するペアに高いスコアを付け過ぎる傾向
• 言語学に基づくヒューリスティックスを入れてみよう
24

Dependency Parsing (2/5)
• ヒューリスティックス入りの重み
関連度に基づく重み(PMI, LLR)
係り受けの距離に基づく重み
文法ヒューリスティックスに基づく重み
• 係り受け距離に基づく重み•
• 右向きの短いエッジに大きな値がつくように設計• 文法的なヒューリスティックスに基づく重み
• (Naseem et al. 2010)で提案されているもの(p258 下段)• いずれかのルールにマッチしたら1, そうでなければ0
• データとしては Pen Treebank の Section23を使用• 評価指標は directed , unlabeled dependency accuracy.
25
αをどのように求めるか?
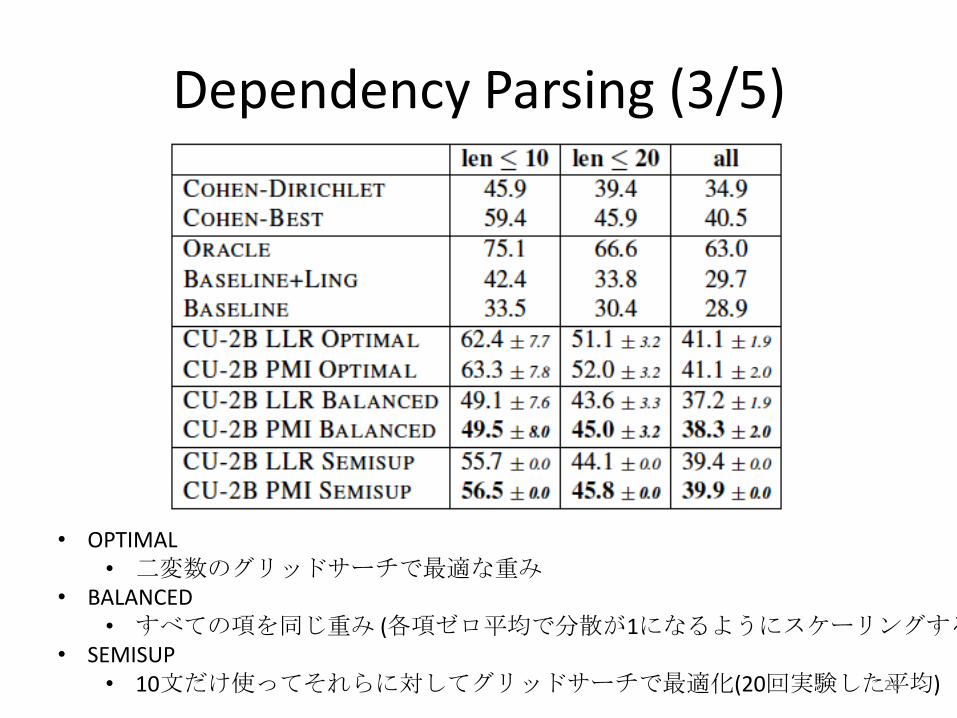
Dependency Parsing (3/5)
• OPTIMAL• 二変数のグリッドサーチで最適な重み
• BALANCED• すべての項を同じ重み (各項ゼロ平均で分散が1になるようにスケーリングする
• SEMISUP• 10文だけ使ってそれらに対してグリッドサーチで最適化(20回実験した平均)26
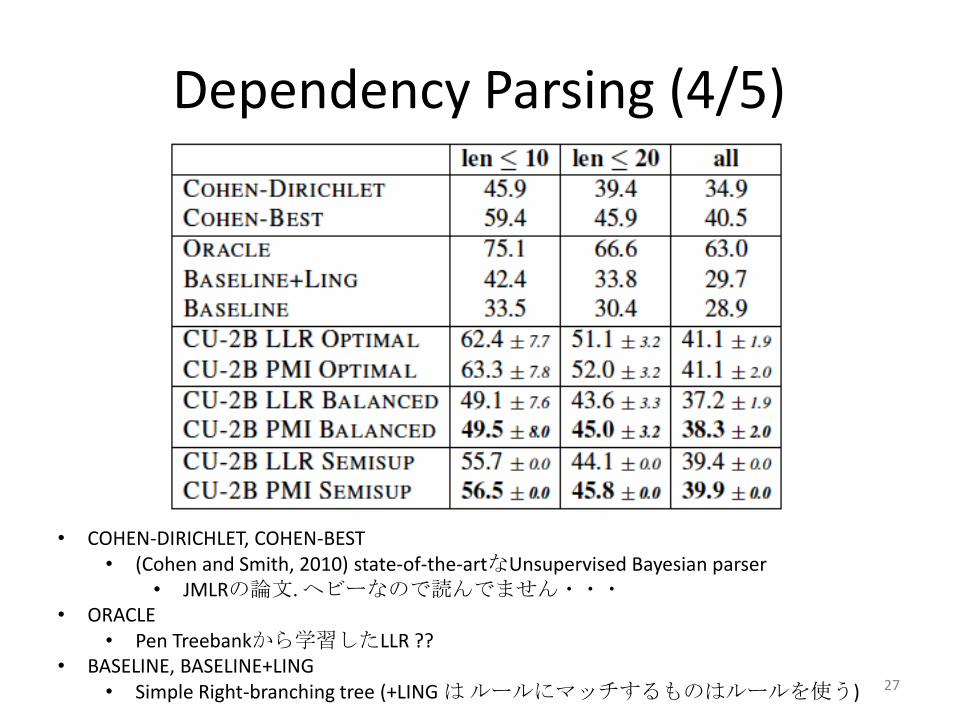
Dependency Parsing (4/5)
• COHEN-DIRICHLET, COHEN-BEST• (Cohen and Smith, 2010) state-of-the-artなUnsupervised Bayesian parser
• JMLRの論文. ヘビーなので読んでません・・・• ORACLE
• Pen Treebankから学習したLLR ??• BASELINE, BASELINE+LING
• Simple Right-branching tree (+LING はルールにマッチするものはルールを使う) 27
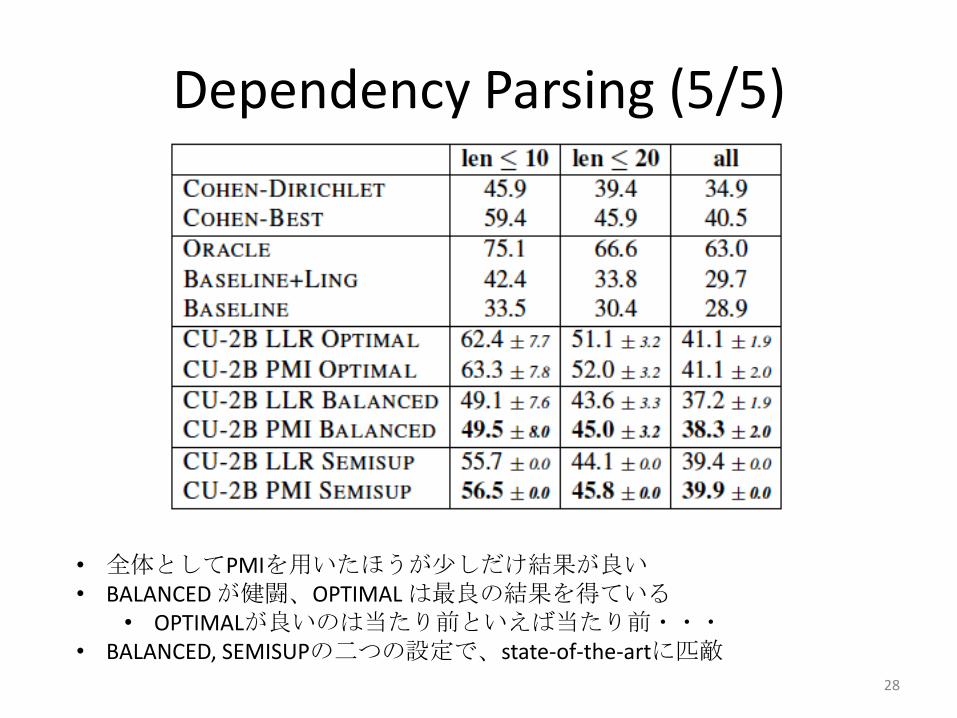
Dependency Parsing (5/5)
• 全体としてPMIを用いたほうが少しだけ結果が良い• BALANCED が健闘、OPTIMAL は最良の結果を得ている
• OPTIMALが良いのは当たり前といえば当たり前・・・• BALANCED, SEMISUPの二つの設定で、state-of-the-artに匹敵
28

Discussion and Conclusion
• コーパス中のすべての語に対してPMI, LLRといった関連性指標を効率よく計算するために、 sketch技法が有効であることを示した
• 三つのタスクで実験を行い、 Exactカウント、state-of-the-artのいずれとも同等の性能を得ることができた– 49GBのコーパスから得た共起情報(13.2Bエントリ)を
2B個のカウンタ(8GBのメモリ)で扱うことができることを示した
• sketchは線形性があるので、分散環境でも有効に用いることができる
• sketchから得られる関連性指標は他のタスクにも用いることができる– randomized LM, WSD, スペル訂正, 関連学習, 換言, MT等
29

Web上で参考になる資料等
• Sketching data structures — next big thing syndrome – http://lkozma.net/blog/sketching-data-structures/– 英語による簡単なBloom Filter, CM-sketchの解説記事
• Everything counts - ny23の日記– http://d.hatena.ne.jp/ny23/20101108– さまざまな近似カウンティングの手法がまとめられている(実装もある)
• ブルームフィルタ - Wikipedia – http://ja.wikipedia.org/wiki/ブルームフィルタ– Wikipediaの日本語ページにしては充実している
• Count-Min Sketch– https://sites.google.com/site/countminsketch/– 公式?サイト. 実装も配っている
• Amit Goyal– http://www.umiacs.umd.edu/~amit/– 第一著者のサイト (NAACL-HLT 2010の論文が直接のprior work, 扱ってい
るデータ、タスクが違うが論旨はほぼ同じ)
30


















