
Applied Soft Computing - University of Malaya · PDF fileApplied Soft Computing 53 (2017)...
11
Applied Soft Computing 53 (2017) 34–44 Contents lists available at ScienceDirect Applied Soft Computing journal homepage: www.elsevier.com/locate/asoc A robust incremental clustering-based facial feature tracking Md. Nazrul Islam a , Manjeevan Seera b,∗ , Chu Kiong Loo c a Department of Computer Science & Engineering, Dhaka University of Engineering & Technology, Gazipur, Bangladesh b Faculty of Engineering, Computing and Science, Swinburne University of Technology (Sarawak Campus), Malaysia c Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia a r t i c l e i n f o Article history: Received 4 January 2015 Received in revised form 2 December 2016 Accepted 19 December 2016 Available online 24 December 2016 Keywords: Facial feature tracking Incremental clustering Feature tracking framework Facial feature model Constrained local model a b s t r a c t Emerging significance of person-independent, emotion specific facial feature tracking has been actively tracked in the machine vision society for decades. Among distinct methods, the Constrained Local Model (CLM) has shown significant results in person-independent feature tracking. In this paper, we propose an automatic, efficient, and robust method for emotion specific facial feature detection and tracking from image sequences. A novel tracking system along with 17-point feature model on the frontal face region has also been proposed to facilitate the tracking of human basic facial expressions. The proposed feature tracking system keeps patch images and face shapes till certain number of key frames incorporating CLM-based tracker. After that, incremental patch and shape clustering algorithms is applied to build appearance model and structure model of similar patches and similar shapes respectively. The clusters in each model are built and updated incrementally and online, controlled by amount of facial muscle movement. The overall performance of the proposed Robust Incremental Clustering-based Facial Feature Tracking (RICFFT) is evaluated on the FGnet database and the Extended Cohn-Kanade (CK+) database. RICFFT demonstrates mean tracking accuracy of 97.45% and 96.64% for FGnet and CK+ database respec- tively. Also, RICFFT is more robust by minimizing average shape distortion error of 0.20% and 1.86% for FGnet and CK+ (apex frame) database, as compared with classic method CLM. © 2016 Elsevier B.V. All rights reserved. 1. Introduction State-of-the-art computing systems are anticipated to estab- lish interactions with humans in a harmonious and natural way that emulates face-to-face encounters. With relevant communica- tion tools and techniques, computing systems are well equipped and smart enough to interact with the users. Not only treated as imitating user’s doings, it also has self-learning capabilities to respond with user’s dynamic behaviour [1]. Computing system has gained popularity [2] in various aspects such as motion tracking [3], telemonitoring of elderly people, video-conferencing with family members, customer satisfaction studies, e-health [4], and in edu- cation and learning [5]. Using visual cues and embedding emotional intelligence in computing system, future generations of human-computer inter- action (HCI) will be more sophisticated and human-like [6]. In a human–human communication (HHC), implicit and non-verbal information such as facial expressions, transmit their emotions to other people in a non-ambiguous way [7]. Several researchers in the field of psychology have reported facial expressions and emotions ∗ Corresponding author. E-mail addresses: [email protected] (Md.N. Islam), [email protected] (M. Seera), [email protected] (C.K. Loo). are closely related to each other, and it can be regarded as one of the most essential methods to represent one’s emotions [8]. It is an important tool for analysing abnormality of neuropsychiatric dis- orders to evaluate their emotional impairment level [2,9]. Utilizing this tool with facial features, several significant researches have been carried out to criminal investigation [10], identify speaker [11], detect fatigue level of driver [12], and warn driver [13] in real time. In this regard, precise localization of facial feature points surrounding facial components such as the mouth, nose, eyes, and eyebrows would greatly benefit to both HCI and HHC. At this point, critical information can be encoded on dynamic changes of facial expressions, expectation about automatic and accurate tracking of the prominent feature points simultaneously. In this paper, a complete emotion-specific facial feature tracking framework [14] is followed with a 17-point feature model to sup- port different facial expressions as well as recognize and classify them [15]. Using the Constrained Local Model (CLM)-based tech- nique [16], previous researches focused on person-independent tracking. In this regard, the proposed model would capture the distinctions such as increase robustness, avoid shape distortion, minimize tracking error, and accurate localization on face image sequence. Specifically, during tracking an appearance model and a shape model is build until certain number of ‘Key Frame’. The appearance model contains a number of local patch images such http://dx.doi.org/10.1016/j.asoc.2016.12.033 1568-4946/© 2016 Elsevier B.V. All rights reserved.
Transcript of Applied Soft Computing - University of Malaya · PDF fileApplied Soft Computing 53 (2017)...

A
Ma
b
c
a
ARRAA
KFIFFC
1
lttaargtmc
caaiofi
(
h1
Applied Soft Computing 53 (2017) 34–44
Contents lists available at ScienceDirect
Applied Soft Computing
journa l homepage: www.e lsev ier .com/ locate /asoc
robust incremental clustering-based facial feature tracking
d. Nazrul Islam a, Manjeevan Seera b,∗, Chu Kiong Loo c
Department of Computer Science & Engineering, Dhaka University of Engineering & Technology, Gazipur, BangladeshFaculty of Engineering, Computing and Science, Swinburne University of Technology (Sarawak Campus), MalaysiaFaculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia
r t i c l e i n f o
rticle history:eceived 4 January 2015eceived in revised form 2 December 2016ccepted 19 December 2016vailable online 24 December 2016
eywords:acial feature trackingncremental clusteringeature tracking frameworkacial feature model
a b s t r a c t
Emerging significance of person-independent, emotion specific facial feature tracking has been activelytracked in the machine vision society for decades. Among distinct methods, the Constrained Local Model(CLM) has shown significant results in person-independent feature tracking. In this paper, we propose anautomatic, efficient, and robust method for emotion specific facial feature detection and tracking fromimage sequences. A novel tracking system along with 17-point feature model on the frontal face regionhas also been proposed to facilitate the tracking of human basic facial expressions. The proposed featuretracking system keeps patch images and face shapes till certain number of key frames incorporatingCLM-based tracker. After that, incremental patch and shape clustering algorithms is applied to buildappearance model and structure model of similar patches and similar shapes respectively. The clustersin each model are built and updated incrementally and online, controlled by amount of facial muscle
onstrained local model movement. The overall performance of the proposed Robust Incremental Clustering-based Facial FeatureTracking (RICFFT) is evaluated on the FGnet database and the Extended Cohn-Kanade (CK+) database.RICFFT demonstrates mean tracking accuracy of 97.45% and 96.64% for FGnet and CK+ database respec-tively. Also, RICFFT is more robust by minimizing average shape distortion error of 0.20% and 1.86% for
e) da
FGnet and CK+ (apex fram. Introduction
State-of-the-art computing systems are anticipated to estab-ish interactions with humans in a harmonious and natural wayhat emulates face-to-face encounters. With relevant communica-ion tools and techniques, computing systems are well equippednd smart enough to interact with the users. Not only treateds imitating user’s doings, it also has self-learning capabilities toespond with user’s dynamic behaviour [1]. Computing system hasained popularity [2] in various aspects such as motion tracking [3],elemonitoring of elderly people, video-conferencing with family
embers, customer satisfaction studies, e-health [4], and in edu-ation and learning [5].
Using visual cues and embedding emotional intelligence inomputing system, future generations of human-computer inter-ction (HCI) will be more sophisticated and human-like [6]. In
human–human communication (HHC), implicit and non-verbal
nformation such as facial expressions, transmit their emotions tother people in a non-ambiguous way [7]. Several researchers in theeld of psychology have reported facial expressions and emotions∗ Corresponding author.E-mail addresses: [email protected] (Md.N. Islam), [email protected]
M. Seera), [email protected] (C.K. Loo).
ttp://dx.doi.org/10.1016/j.asoc.2016.12.033568-4946/© 2016 Elsevier B.V. All rights reserved.
tabase, as compared with classic method CLM.© 2016 Elsevier B.V. All rights reserved.
are closely related to each other, and it can be regarded as one ofthe most essential methods to represent one’s emotions [8]. It is animportant tool for analysing abnormality of neuropsychiatric dis-orders to evaluate their emotional impairment level [2,9]. Utilizingthis tool with facial features, several significant researches havebeen carried out to criminal investigation [10], identify speaker[11], detect fatigue level of driver [12], and warn driver [13] inreal time. In this regard, precise localization of facial feature pointssurrounding facial components such as the mouth, nose, eyes, andeyebrows would greatly benefit to both HCI and HHC. At this point,critical information can be encoded on dynamic changes of facialexpressions, expectation about automatic and accurate tracking ofthe prominent feature points simultaneously.
In this paper, a complete emotion-specific facial feature trackingframework [14] is followed with a 17-point feature model to sup-port different facial expressions as well as recognize and classifythem [15]. Using the Constrained Local Model (CLM)-based tech-nique [16], previous researches focused on person-independenttracking. In this regard, the proposed model would capture thedistinctions such as increase robustness, avoid shape distortion,minimize tracking error, and accurate localization on face image
sequence. Specifically, during tracking an appearance model anda shape model is build until certain number of ‘Key Frame’. Theappearance model contains a number of local patch images such
Md.N. Islam et al. / Applied Soft Computing 53 (2017) 34–44 35
fic 17-
afoTftdcamic
fiptItstfdtepltttipp
roo
Fig. 1. Facial emotion speci
s eyebrow corner, nose bottom, lip corner, representing object ineature space. Similarly, the structure model contains a numberf shape variations of each face shape in point distribution space.he term ‘Key Frame’ is defined as a definite number of initial facerames to build an appearance model and a structure model. Then,wo incremental clustering algorithms are incorporated with tra-itional CLM to build clusters of prior models in online. The firstlustering algorithm, ‘Patch Clustering’, inspired by LeaderP [17]lgorithm is used to build clusters of facial local appearances incre-entally. The second clustering algorithm, ‘Shape Clustering’, is
nspired by Incremental Learning [18] algorithm and is used to buildlusters of different face shapes incrementally.
The contribution of the proposed techniques is two-fold. Therst contribution includes the development of an automatic,erson-independent emotion-specific facial feature tracking sys-em to adapt with facial dynamic feature through online learning.n this regard, two incremental clustering algorithms are presentedo build and update clusters of similar patch images and similar facehapes. In addition, a 17-point feature model is also proposed forhe analytic representation of face toward capturing of differentacial expressions with comparative less tendency of being shapeistortion during tracking. Fig. 1 and represents the aforemen-ioned statements. Fig. 6 has shown a sample of dynamic featurextraction accuracy for frame #540 with higher error (7.1%) rateredicted for the baseline CLM-based tracking, as compared with
ower error (2.1%) rate predicted for the proposed RICFFT-basedracking. The second contribution is the implementation of RICFFTo increase tracking accuracy as well as robustness during facial fea-ure tracking. The significance of the proposed technique is shownn Fig. 8, and Table 1. The cumulative error distribution of theoint-to-point measure (me17) has shown the significance of theroposed RICFFT in comparison with the baseline tracker CLM.
The rest of the paper is organized as follows. The literatureeview is first presented in Section 2. Section 3 provides a briefverview of the proposed RICFFT system along with necessary the-retical discussions, and details of 17-point feature model. Two
point facial feature model.
incremental clustering algorithms along with the necessary math-ematical model are also elaborated. In Section 4, performanceevaluation of the proposed RICFFT over two publicly availabledatabases on the task of facial feature tracking accuracy is done.Concluding remarks and suggestions for future work is presentedin Section 5.
2. Literature review
Affective computing has been gaining popularity in the arenaof Human Computer Interfaces (HCI) which empowers computersto detect, realize and synthesize emotions, and to behave vividly.Apart from HCI, emotion recognition using machine vision hasmany interesting and real-life applications such as virtual reality,video-conferencing, lie detection, and anti-social intentions. Inregards to these applications areas, facial emotion recognitionthrough machine vision has been gaining much attention lately[19].
In general, two major parts are distinguished for facial emotionrecognition, i.e., facial feature extraction and emotion classification.The first step of facial feature extraction is facial feature tracking,which refers to localizing certain landmarks of interest from a faceimage, such as eyebrows corners, nose top, eye corners, and outlineof the lips. Existing approaches are capable of initializing the featurepoints, exploring the tracking, and extracting the feature pointsfrom image sequences [20].
Two different research trends have been considered in previ-ously for facial feature extraction, which are appearance-based andmodel-based. Appearance-based models are linear-nonlinear andfully person dependent whereas model-based provides 2D and 3Dperson-independent face fitting model. Some of the well-knownfeatures such as optical flow [21], Local Binary Patterns (LBP)
features [22], Binary Particle Swarm Optimization (BPSO) [23], andGabor wavelets [24] are extracted to represent the facial gesturesor facial movements. The common limitation of these approachesis analysis of image data only, ignoring the semantic and dynamic
36 Md.N. Islam et al. / Applied Soft Computing 53 (2017) 34–44
Table 1Shape Distortion for RICFFT and CLM-based tracking and types of emotion sequences for middle (onset) and last (apex) frame on distinct databases.
Method Sequences Middle (Onset) Frame Last (Apex) Frame
Mean (%) Max (%) Min (%) Mean (%) Max (%) Min (%)
RICFFT FGnet – 0.20 11.77 0CK+ Surprise 0.59 5.88 0 6.47 35.29 0CK+ Sadness 0 0 0 0 0 0CK+ Fear 0 0 0 0.59 5.88 0CK+ Angry 0 0 0 0 0 0CK+ Disgust 0 0 0 0.29 5.88 0CK+ Happiness 0.29 5.88 0 3.82 5.88 0
CLM FGnet – 9.60 47.06 0CK+ Surprise 9.71 35.29 0 28.24 88.24 0CK+ Sadness 0 0 0 3.24 47.06 0CK+ Fear 2.06 17.65 0 13.24 41.18 0
rlfp
lmapaabfanr[tibaAortemw
bM(c[etsiimemtsdomm
CK+ Angry 0 0
CK+ Disgust 0.88 11.76
CK+ Happiness 7.65 35.29
elationships among facial muscle movements. Integrating grey-evel information with Gabor wavelets, a hybrid representation ofeature points is proposed in [25] for efficient tracking of featureoints.
Model-based methods however overcome the above mentionedimitation by incorporating relationships among facial muscle
ovements. Active Shape Models (ASM) [26,27] are similar to thective contours (snakes), utilize a statistical shape model [28] toredict feature points around face regions. To locate feature pointsccurately and best fit shape model, an iterative search strategy ispplied. The proper initialization of ASM is ensured by three pertur-ations such as translation, rotation, and scaling of the detected facerame [29]. As ASM does not utilize all available grey informationcross the object and texture only in the area of the landmarks, erro-eous feature detection may be experienced during tracking. Lately,esearchers have focussed on Active Appearance Models (AAMs)30], an extension of ASM by modelling of texture information ofhe whole face. The texture and shape information are combinedn one PCA space to the AAM for model matching. A regression-ased approach, Kernel Ridge Regression (KRR) [31] is proposed forutomatic initialization to handle missing frames during tracking.lthough AAM provides a more robust model compared with theriginal ASM, the problem with both the strategies is that an accu-ate initialization to best fit the model, else the methods are proneo local minima. In [32], a non-linear optimization of the param-ters of shape model is proposed to mitigate the problem of localinima. At the same time, combining detection of facial featuresith shape modelling was another direction to address that issue.
In recent research, a number of facial feature extractors haveeen proposed for face alignment, such as Supervised Descentethod (SDM) [33], Spatio-Temporal Cascade Shape Regression
STCSR) [34], multi-view, multi-scale and multi-component cas-ade shape regression (M3CSR) [35], Explicit Shape Regression36], and Dual Sparse Constrained Cascade Regression [37]. How-ver, CLM [38] has shown significant use [39] in face fitting modelhrough an iterative template generation and shape constrainedearching to calculate the best match for facial features of an incom-ng face. It has several advantages, i.e. handling larger mismatchesn initial registration and parallel computational architecture that
akes CLM an accurate feature fitting model [40,41]. The RICFFTmploys CLM for its person-independent, automatic, and accurateodel fitting followed by three consecutive steps; CLM initializa-
ion, model fitting, and optimization. Firstly, a local and exhaustiveearch of each landmark is performed using dedicated landmark
etectors and secondly, parameters of a PDM are jointly optimizedver all the detector responses. The local support of the appearanceodel, combined with global shape constrained regularizationakes CLM very robust to identity, illumination, and occlusion.0 3.82 41.18 00 4.12 23.53 00 36.47 47.06 0
Considering these features, CLM is chosen as a baseline method andintegrated with Incremental Clustering algorithm to track frontaland near frontal facial movements based on online learning. In [42],KDE yielded the best performance among existing optimizer andhad shown a lower root-mean-squared (RMS) error than others forfitting CLM. It is shown that better performance of feature pointinitialization and tracking can be achieved through applying opti-mization strategies, but robustness is needed to minimize trackingerror and avoiding shape distortion in the image sequence.
Current research trends focuses on classic approaches whereextracted local patches from the first frame will be used to searchthe similar patches on the following image frames. Lukas andKanade [43] extracted a template at the start frame of the sequence,employ it for tracking, and will fail if the appearance of the patchchanges significantly. A strategic update of the template is pro-posed in [44], where each patch images from the first frame is keptto correct the localization error. Robust SMAT (RSMAT) [17], theextension of SMAT [45], has proposed some modifications to obtaina more robust model and better tracking. However, RSMAT has lim-itations of feature point initialization as well cluster weight updateequations. In this paper, the Patch Clustering algorithm inspired byLeaderP algorithm of RSMAT is proposed to learn, build and updateclusters of all upcoming patches through online learning duringtracking.
3. Robust incremental clustering-based facial featuretracking
In this section, the proposed Robust Incremental Clustering-Based Facial Feature Tracking (RICFFT) system, which is acombination of three models: CLM, Appearance Model, and Struc-ture Model are introduced. The vision system employed a featuremodel to define prominent facial feature points in the frontal faceregions. A novel feature tracking framework is also incorporated toensure robustness during tracking.
3.1. 17-Point facial feature model
In automatic facial emotion recognition, the most crucial stepis to track the prominent facial features surrounding different faceregions such as mouth, eyes, and eyebrows. The original PDM [42]was created using facial muscle movement video sequences of theMulti-PIE [46] dataset comprising of 66 feature points. However,the RICFFT is proposed with a 17-point feature model for the ana-
lytic representation of face to boost up tracking process in 3 ways.First, with carefully selected frontal 17 feature points, the RICFFTis considered to have less tendency of having shape distortion dur-ing tracking. Next, considering the issue of computational time,
Soft Computing 53 (2017) 34–44 37
Rpemma
3
dafeai
ftna(panfk
siarctm
3
ibtprod
x
w
pif
uac
p
w
tl
C
wherei is the index of patch class and˛1 ∈ [0, 1] is defined as the
Md.N. Islam et al. / Applied
ICFFT is also intended to minimize the number of feature trackingoints. Finally, the selected points can address distinct facial macro-xpressions on the frontal face regions. Then, the feature points areapped (red dots) as: 4 on eyebrows, 4 on eyes, 3 on nose, and 6 onouth regions with their significance to address specific emotion
s shown in Fig. 1.
.2. RICFFT framework
The RICFFT framework [14] is divided into two major sequencesepending on the number of key frames. The key frames are defineds the number of initial frames to keep patch images and shapesor initializing appearance model and structure model [47]. CLM ismployed as a baseline method for our proposed RICFFT due to itsccurate and automatic initialization of facial feature points. Afternitialization, both models will be updated through online learning.
During tracking, static or dynamic faces are captured to detectace once at the first frame using a face detector [48]. Using CLM,he face shape is initialized as in Eq. (1). For face model fitting, weeed to recall previously calculated reference shape, mean shape,nd eigenvectors from training faces. Then, the local parametersvariations of each basis face shapes) and global parameters (scale,itch, yaw, roll, x-shift, y-shift) are calculated for fitting face modelccurately on face and optimization purpose as in Eqs. (2)–(5). Theeutral face shape is stored to recognize facial emotion. Till key
rames, the local components (patch images) and face shapes areept in order to build appearance model and structure model.
In the second sequence, at the key frame, appearance model andtructure model will organize previously stored patches and shapesnto clusters according to the Patch Clustering and Shape Clusteringlgorithms. After that, clusters will grow incrementally incorpo-ating incoming patches and shapes as long as the tracking taskontinues. Correct positions of patch images will update the struc-ure model as well as the appearance model. In this way appearance
odel and structure model updates through online learning.
.2.1. CLM building approachThe vision-based system employed CLM for person-
ndependent, automatic, and accurate model fitting followedy three consecutive steps; CLM initialization, model fit-ing, and optimization [42]. CLM can first be described byarametersp =
{s, R, t, q
}wheres is the global scale factor, R is the
otation of face, t is the 2D translation (tx, ty), and q is the variationf the face shape. With this parameter the PDM of CLM can beescribed as [49],
i = s.R(xi + ˚iq
)+ t (1)
here xi = (x, y) indicates the 2D position of the PDM’s ith feature
oint on face region, xi = (X, Y, Z) is the mean of the ithfeature pointn 3D reference frame, and finally ˚i is the itheigenvector obtainedrom training set of facial images.
Secondly, the response map is generated for each feature pointsing linear logistic regressor [50] for facial model fitting. Thepproximate probabilistic response map for ith feature point is cal-ulated as follows,
(li|I, xi
)= 1
1 + exp{˛Ci
(I, xi
)+ ˇ
} (2)
here li ∈{notaligned (−1) , aligned (+1)
}, I is the face image, xi is
raining sample of ith patch, ̨ is the regression coefficient, ̌ is the
ogistic regressor intercept, and Ci is a linear classifier as in Eq. (3),i
(I, xi
)= wT.xi + � (3)
Fig. 2. Cluster Representation of Appearance Model where Cluster 1 contains eyecorner patches, Cluster 2 contains leap corner patches, and Cluster 3 contains outereyebrow patches.
where wT = [w1w2. . .. . .wn] represent the weight for each element
of training data, xi =[xi1, xi2, . . .. . ., xin
]Tis a column vector of n
dimensions, and � is a constant, acting as a bias.Finally, ASM is used as an optimization approach for CLM fitting.
The approach first finds the locations corresponding to the maxi-mum response within ith response map. Then, the weighted leastsquare difference between feature point locationxi and maximumresponse location (�i) is calculated as in Eq. (4),
Q (p) =∑n
i=1wi‖xi − �i‖2 (4)
A first-order Taylor expansion of feature point’s location is cal-culated to minimize the Eq. (4) as follows,
xi ≈ xci + Ji�p (5)
where �p is the parameter update used to calculate the parame-ter, p ←− p + �p,Ji is the PDM’s Jacobian, and xc
iis the estimated
current feature point.
3.2.2. Appearance model building and updatingAppearance model is a group of clusters of similar local com-
ponents or image patches (e.g., eye corner, mouth-corner, outereyebrow) in feature space as shown in Fig. 2.
Clusters in appearance model are defined by their median andvariance. The median in image space is free from blurring, keeporiginal patch information, and robust to outliers. Utilizing thisadvantage, the median is selected as a representative of each clus-ter. To calculate the median of a patch cluster (PCij) of a patchclass (Patchi), we follow the standard way [42] to build a matrixof distances between each pair of local components (LCijk) as in Eq.(6),
PCij =
⎛⎝ d
(LCij1, LCij1
)d(LCij1, LCij2
). . .. . . d
(LCij1, LCijM
): : :
d(LCijM, LCij1
)d(LCijM, LCij2
). . .. . . d
(LCijM, LCijM
)⎞⎠ (6)
For median computation, the column wise sum of each distanceis first calculated. Then, the local component related to the col-umn with the lowest sum is selected as the median (Repij) of thepatch cluster (PCij). To measure the distance between two localcomponents, the Zero-mean Normalized Cross-Correlation (ZNCC)[51] method is chosen for its reliability and faster computation. Tolimit computation time as well as memory space, we restrict thenumber of local components per cluster is up toLCompMAX and thenumber of clusters per patch class are up toPCMAX . After that, clusteris allowed to update their weights only as follows,⎧⎪⎨⎪⎩
(w(t)ik
+ ˛1
)1
1 + ˛1ifk = indexofupdatedCluster
w(t)ik
11 + ˛1
Otherwise
(7)
learning rate. When numbers of clusters of a patch class reachesto,PCMAX the cluster corresponding to the lowest weight will bereplaced by newly added cluster.

38 Md.N. Islam et al. / Applied Soft C
Fff
smf
m
wva
T
w
ocmp
3
op
tsavd
p
wvt
K
i
e
lwaofi
ig. 3. Cluster Representation of Structure Model where Cluster 1 contains happyace shapes, Cluster 2 contains angry face shapes, and Cluster 3 contains surpriseace shapes.
During tracking, clusters will update incrementally, wheneverystem experience a new local component (image patch). Theembership of a test patch (TestPi) to a cluster PCij is defined as
ollows,
PCij (TestPi) ={
1 ifd(Repsij, TestPi
)< Tij
0 Otherwise(8)
hereTij , represents membership threshold is calculated by theariance of the previously encountered distances of the cluster PCijs follows,
ij =∑LCompMAX
k=1
(Xk − X̄
)2
LCompMAX(9)
here Xk = d(Repsij, LCijk
), k = 1, 2, . . .. . ., LCompMAX andX =∑LCompMAX
k=1Xk
LCompMAXThe appearance model discards patches that are detected as
uter to the system. The tracking system will be restarted wheneverertain amount patches detects as outliers. In this way, appearanceodel will continue to grow incrementally by incorporating new
atches and update existing clusters through online learning.
.2.3. Structure model building and updatingThe structure model is a group of clusters of similar shapes [52]
f different facial expressions (e.g., happy, angry, and surprise) inoint distribution space as shown in Fig. 3.
Clusters in structure model is defined by Gaussian distribu-ion [16], with mean (�i) and covariance (
∑i). When the tracking
ystem is experienced with any new frame after key frames, weddress the shape of that frame as an observation shapeOs. The acti-ation value for each cluster (SCi) is calculated by the conditionalensity ofOs as follows,
(Os|i) = 1
(2�)M/2|∑
i|1/2
exp
[− 1
2(Os − �i)
T∑ −1
i(Os − �i)
](10)
here M is the dimensionality of the shape vectors. Among the pre-iously calculated activation value, the shape cluster correspondingo the highest probability will be selected as a winner as follows,
= argmaxip (Os|i) (11)
However, the winner shape cluster is allowed to update only ift passes the vigilance criterion as follows,
xp
[− 1
2(Os − �K )T
∑ −1
K(Os − �K )
]≥ � (12)
If the current winner shape cluster is failed to satisfy the vigi-ance criterion, the activation value will be reset and current winner
ill be disqualified for the updates. If no such shape cluster is found,
new shape cluster will be created with only one element i.e.,bservation shapeOs However, if the winner shape cluster success-ully passed the vigilance condition, the cluster is selected to updatets mean (�K ), covariance (∑K ), number of component (CompKj),
omputing 53 (2017) 34–44
and weight (wK ) as in Eqs. (13)–(15) and Eq. (7). Other clusters areprohibited to update and lose their weights as in Eq. (7). To limitcomputation time as well as memory space, we restrict the numberof component per shape cluster is up toCompMAX . After that, clusteris allowed to update its weight only as in Eq. (7). Also, when num-ber of shape cluster is reach toSCMAX , the cluster corresponding tothe lowest weight will be replaced by newly added cluster.
�K =(
1 − 1CompKj
)�K +
(1
CompKj
)Os (13)
∑K
=(
1 − 1CompKj
)∑K
+(
1CompKj
)(Os − �K ) (Os − �K )T (14)
CompKj = CompKj + 1 (15)
However, if the current winner shape cluster fails to satisfy thevigilance criterion, the activation value will be reset and currentwinner will be disqualified for the updates. Another way, if theobservation shape (Os) is not similar with any of the existing shapeclusters (SCi), a new cluster will be created with Os,as its only mem-ber. The mean shape of the newly created cluster is alsoOs. Theweight assigned to this cluster is zero and the number of compo-nents is initialized with 1. In this way, structure model will continueto grow incrementally by incorporating new shapes and updateexisting clusters through online learning. Correct positions of patchimages will update the structure model and the appearance model.
3.3. RICFFT algorithms
Facial feature tracking based on incremental clustering has per-formed a better accuracy in recent advancements. Due to clusteringof similar features and update them through online learning, thetracking system is more stable against some of the previouslymentioned factors such as shape distortion, and tracking error.The RICFFT proposes two incremental clustering algorithms forachieving best tracking. The Patch Clustering and Shape Clusteringare designed to build and update appearance model and struc-ture model, respectively. To measure individual performance ofeach ICA, we split the tracking task into two categories; PatchClustering-based tracking only (ICFFT) and Combined Patch andShape Clustering-based tracking (RICFFT).
3.3.1. Patch clusteringClustering a set of similar patches from facial appearance, we
propose a Patch Clustering algorithm inspired by LeaderP algo-rithm. Combining all the patch clusters, an appearance model isbuilt to track similar patches from image sequences. To do this,we firstly classify all the patches on different facial regions inton fixed classes. Each patch class (Patchi) individually consists of aset of clusters (PCij) of similar local components (LCijk). Each patchcluster is defined by a representatives (Repsij), a weight (wij) anda membership threshold (Tij). At beginning of the tracking (afterkey frames), the similarity between the incoming patch (TestPi)and existing cluster representatives will be calculated using thedistance measure method. The minimum distance is checked withan outlier sensitive parameter, ˇ1 ∈ [0, 1]to confirm whether theincoming patch is outlier or not. If the incoming patch is an outlier,the patch will be ignored; otherwise it will be checked for member-ship condition of the cluster corresponding minimum distance. Thecluster will be updated if the minimum distance is below the mem-bership threshold, otherwise a new cluster will be created withonly local component asTestPi. To limit memory requirements, the
number of local components and the number of patch clusters arelimited toLCompMAXandPCMAX , respectively. During tracking, if halfof the incoming patches are detected as outlier, the tracking methodwill be restarted as the shape is already distorted. In this way,
Soft Co
Pt
3
t(dsiaspavpctubmt
Md.N. Islam et al. / Applied
atch Clustering creates and updates patch clusters incrementallyhrough online learning.
.3.2. Shape clusteringClustering a set similar shape from facial structure, a Shape Clus-
ering algorithm inspired by Gaussian Adaptive Resonance TheoryGART) [18] is proposed. During tracking, the current face shape isenoted by a set of facial feature points. In the PDM, similar facehapes will be placed together, away from other shapes represent-ng different facial expression. Combining all the shape clusters,
structure model is built to track similar shapes from imageequences. Each shape cluster, SCi,can be defined by a group of com-onents (individual shape) Compij, mean shape�j , covariance
∑i,
nd a weightwj . At beginning of tracking after key frames, the acti-ation value for each shape cluster is calculated on the conditionalrobability of an incoming shape or observation shape (Os). Theluster with highest activation value will be selected as winner. Ifhe winner cluster satisfies the vigilance criteria, the cluster will be
pdated. When no such existing cluster is found, a new cluster wille created with only component asOs. To limit memory require-ents, the number of components and shape clusters are limitedoCompMAXandSCMAX , respectively. The tracking system is initial-
mputing 53 (2017) 34–44 39
ized with two parameters: baseline vigilance parameter, � ∈ [0, 1]and initial covariance matrix,
∑0,with appropriate values. The
performance of the tracking system depends on these parameters.In this way, Shape Clustering creates and updates shape clustersincrementally through online learning.
The computational complexity of Patch Clustering and ShapeClustering algorithms are O(kn) and O(km) respectively with lowmemory requirements O(k), where k is the number of clusters, n isthe dimension of the patch images, and m is the dimension of faceshapes) [53].
4. Experimental results
In this section, effectiveness of RICFFT on different imagesequences is demonstrated. RICFFT utilized CLM for its accurateand automatic feature point initialization. Till the key frames, thetracking task is continued by baseline method CLM. The trackingperformance of RICFFT and ICFFT will be considered as same asCLM at this stage. Then, a combination of RICFFT, ICFFT, and CLMmethods will be carried out for the tracking process. A comparisonof the tracking performance of our proposed method with basicCLM is presented.
4.1. Dataset description
The RICFFT is evaluated on two publicly available databases, i.e.,the FGnet talking face database [54] and the extended Cohn-Kanade(CK+) database [55]. The FGnet talking face database contains5000 image sequence of basic facial expressions of a single sub-ject throughout the oral conversation. We manually labelled eachframe per ten consecutive image sequence as ground truth. The
CK+ database contains different facial expression videos of 123subjects corresponding to the 7 basic facial emotions, includingsurprise, sadness, fear angry, disgust, happiness, and contempt.We utilize our 17-point feature model to track the facial mus-
40 Md.N. Islam et al. / Applied Soft Computing 53 (2017) 34–44
ampl
cos3ow(Fp
4
tpa
m
d
wEpap
4
ea
4
fte#adRfn
Fig. 4. Error Plots for CLM, ICFFT, and RICFFT in a S
le movement for 6 basic facial emotions. Due to a few numberf contempt expression presents in the database, we exclude theequences of contempt facial expression.The CK+ database contains05 sequences in total. Each sequence contains a set face imagef a single facial expression, begins with a neutral face and endsith a specific facial expression. We manually label the middle
onset) and last (apex) frames for each sequence as ground truth.inally, we compare theground truth with our predicted featureoint positions of individual methods.
.2. Tracking accuracy analysis
The criteria for calculating the tracking accuracy is to computehe distance of the predicted coordinate using feature tracker com-ared with the manually labelled ground truth coordinate [16]. Theverage error is given as:
e = 1nS
∑i=n
i=1di (15)
i =√
(x2 − x1)2 + (y2 − y1)2 (16)
here n denotes the number of feature points, S is stand for theuclidean distance between pair of reference points (e.g., two pupilosition in our case), and diis the Euclidean distance between actualnd predicted locations of each feature point. As we used 17 featureoints, we labelled the distance metric asme17 [17].
.3. Results discussion
In this section, effectiveness of the proposed RICFFT on differ-nt image sequences is demonstrated. RICFFT utilized CLM for itsccurate and automatic feature point initialization.
.3.1. Tracking sequence analysisFig. 4 shows the tracking performances of individual tracker
or an image sequence in FGnet talking face database. As shown,he proposed method (ICFFT and RICFFT) shows lower trackingrror than the baseline method (CLM). Frame #420 and frame850 shows theme17of RICFFT are 0.9% and 0.1%, respectively duepproximately neutral and frontal face image. Due to the eyelids
rooped in frame #260,a tracking error4.6% was calculated for bothICFFT and ICFFT, while 5.4% was noticed for CLM. During happyacial expression in frame #480, the me17 for all the methods wereear about 4.5% due to mouth corner tracking error. Frame #540
e Image Sequence of FGnet Talking Face Database.
has shown the significance of RICFFT over CLM when head turns alittle bit right. The feature points (#4, #10, and #11) has marked alarge displacement for CLM-based tracker, resulted a tracking error7.1%. On the other hand, 2.6% and 2.1% tracking error was countedfor ICFFT and RICFFT method-based tracking respectively due to thedisplacement of those feature points was customary.
Fig. 5 shows some representative cases where RICFFT-basedtracking accuracy is superior to both ICFFT and CLM. The first rowindicates the frame numbers of the FGnet database and the first col-umn indicates individual tracker names. The tracking error level ofme17 is mentioned below each frame.
The tracking performance [56] of individual tracker for a sur-prise image sequence in CK+ database is shown in Fig. 6. It is clearlyvisible that both RICFFT and ICFFT outperform the baseline methodCLM. Until frame #8, the face was approximately neutral and theentire tracker has same error level. At frame #9, the person is tryingto show a big surprise following the Action Units (#1, #2, #26, and#27). At that time, using CLM-based tracking a large displacement(distance between predicted and ground truth) was noticed for thefeature point #17, while the displacement was regular for bothICFFT and RICFFT. In this regard, the proposed incremental clus-tering (Patch Clustering and Shape Clustering) algorithms exhibitbetter accuracy for feature point tracking with minimizing track-ing error. Frame #15 indicates, the consistency of avoiding shapedistortion for ICFFT and RICFFT based feature point tracking.
Fig. 7 illustrates some representative cases where RICFFT-basedtracking accuracy is superior to both ICFFT and CLM. The first rowindicates the sequence number/level number/frame number of CK+database and first column indicates the individual tracker name.The tracking error level of me17 is mentioned below each frame.
The average tracking error [57] for individual tracker in differ-ent image sequences of facial databases is shown in Fig. 8. Due to asingle person-based facial feature tracking, the calculated track-ing error in FGnet database is lower than each sequence in theCK+ database as shown in the figure. As it can be seen that bothRICFFT and ICFFT minimizes tracking error than baseline trackerCLM. Among three trackers, RICFFT has shown better accuracy dur-ing feature point tracking.
The significance of the proposed RICFFT includes tracking ofdynamic facial features through online learning. A complete and
automated system toward robust tracking is also presented with17-point feature model. Based on FACS standards, muscle move-ment (Action Units) are calculated to build and update clusters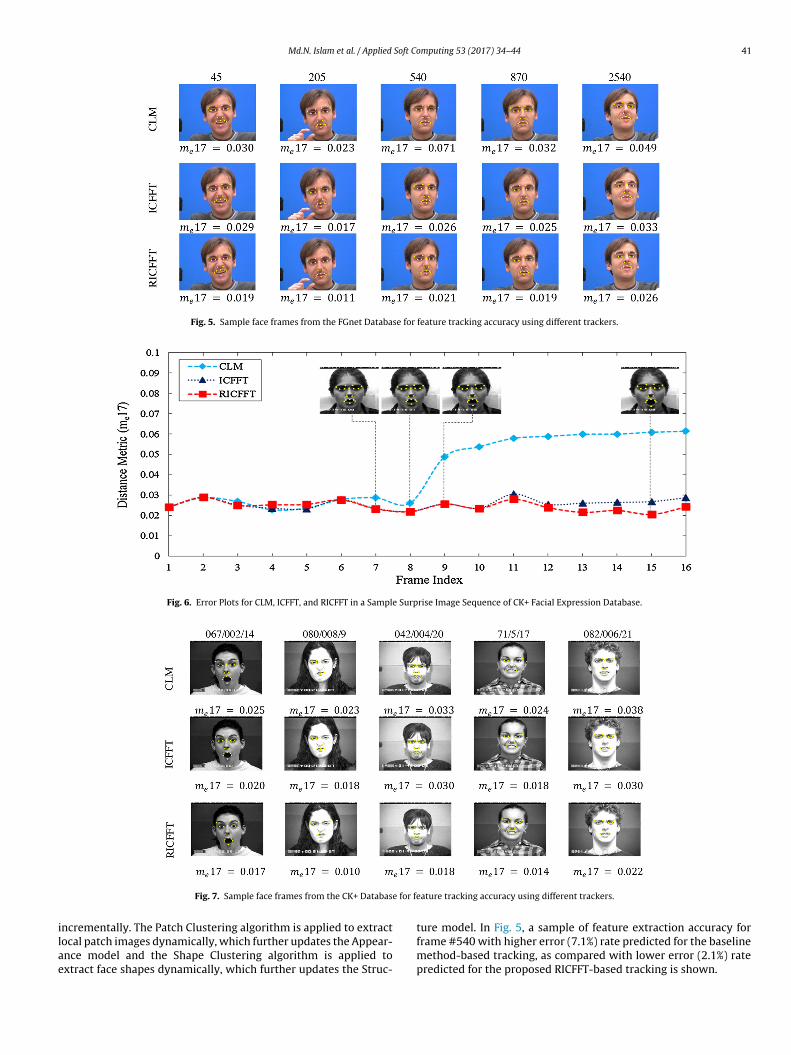
Md.N. Islam et al. / Applied Soft Computing 53 (2017) 34–44 41
Fig. 5. Sample face frames from the FGnet Database for feature tracking accuracy using different trackers.
Fig. 6. Error Plots for CLM, ICFFT, and RICFFT in a Sample Surprise Image Sequence of CK+ Facial Expression Database.
e for fe
ilae
Fig. 7. Sample face frames from the CK+ Databas
ncrementally. The Patch Clustering algorithm is applied to extract
ocal patch images dynamically, which further updates the Appear-nce model and the Shape Clustering algorithm is applied toxtract face shapes dynamically, which further updates the Struc-ature tracking accuracy using different trackers.
ture model. In Fig. 5, a sample of feature extraction accuracy for
frame #540 with higher error (7.1%) rate predicted for the baselinemethod-based tracking, as compared with lower error (2.1%) ratepredicted for the proposed RICFFT-based tracking is shown.
42 Md.N. Islam et al. / Applied Soft Computing 53 (2017) 34–44
Fig. 8. Observation of Average Tracking Error usin
4
pdoc#
s#utfo
4
piecmrtit
ospfw
Based on a literature search that we conducted, it resulted in
Fig. 9. The Performance of Different Tracker on FGnet Talking Face Database.
.3.2. Shape distortion analysisTable 1 shows the shape distortion as a percentage of the outlier
resents in image sequence of FGnet talking face database and CK+atabase respectively. For FGnet database, the highest percentagef the shape distortion for CLM-based tracker is marked due to inac-urate face fitting during face turned at frame (#540, #1130, and4050) and stopped down at frame #4000.
On the other hand, a remarkable shape distortion observed inurprise and happiness image sequences due to feature points (#12,16, and #17) are marked as an outlier for most of the sequencesing CLM-based tracking. As shown, the amount of shape distor-ion is significant for last (apex) frame rather than middle (onset)rame. However, RICFFT shows less shape distortion as the numberf outlier is decreased during tracking.
.3.3. Performance analysisThe cumulative distribution of the mean error over all feature
oints in the image sequence of FGnet talking database is shownn Fig. 9. It can be seen that the RICFFT has predictions with lowerrror: 40% of the images have an average error ofme17 < 0.02, asompared to the 20% of the images for the CLM. The RICFFT is alsoore accurate than CLM finding facial feature points with an accu-
acy ofme17 < 0.04 in 80% of the cases compared to 50% of cases forhe CLM. From Fig. 10, it is noted that RICFFT and ICFFT achieve sim-lar performance and about 99% of the images are with an averageracking error ofme17 < 0.05. Both are superior to the CLM.
The cumulative distribution of the feature point search accuracyn middle (onset) and last (apex) image of each emotion specificequence of CK+ database is shown in Fig. 10. It is noted that the
redicted tracking accuracy for onset frames is higher than apexrames of each sequence. In both cases, ICFFT performed similarith RICFFT and both trackers is superior to CLM.
g Different Trackers on Different Databases.
During tracking surprise sequences in Fig. 10(a), it can be seenthat RICFFT has predictions with lower error: 20% of the imageshave an average error ofme17 < 0.02 and 95% of the images havean average error ofme17 < 0.04, as compared with CLM there isno image below the error ofme17 < 0.02 and only 50% images arebelow the error ofme17 < 0.04. In Fig. 10(b), using RICFFT, 95% ofthe images have an average error ofme17 < 0.06, as compared withCLM the same percentage of images have an error level of me17 =0.08.
In the case of sadness sequences as in Fig. 10(c), it can be seenthat the RICFFT has predictions with lower error: 85% of the imageshave an average error ofme17 < 0.04, as compared with CLM thesame error level is observed in 63% of images. However, duringtracking features on apex frame as shown in Fig. 10(d), 85% of theimages have an increased error level of me17 = 0.05 for RICFFT, ascompared with CLM the same error level is observed in 65% of theimages.
Considering fear sequences as in Fig. 10(e), it can be seen that91% of the images have an average error ofme17 < 0.04, as com-pared with CLM the same error level is observed in71% of imagesduring onset frame tracking. In the case of tracking with apex frame,as shown in Fig. 10(f), 91% of the images have an increased errorlevel of me17 > 0.04 for RICFFT, as compared with CLM the sameerror level is observed in55% of the images. From the sharp risingCLM curve, it is predicted that some of the images have higher errorlevel in between me17 > 0.05 andme17 < 0.08, where no imageshave that error levels for RICFFT.
The remarkable tracking accuracy is observed for RICFFT-basedtracking with angry sequences. During tracking with onset frames,92% of the images have and average error ofme17 < 0.036, as com-pared with 41% of the images have same error level for CLM-basedtracking as shown in Fig. 10(g). For apex frame tracking for thesame sequence with RICFFT, 92% of the images have an averageerror level ofme17 ≈ 0.04, as compared with 35% of the images havesame error level as shown in Fig. 10(h).
During tracking with disgust sequences, most of the apex framesare with error levels of betweenme17 > 0.03 and me17 < 0.05 forRICFFT-based tracking, as compared higher error level for CLM asshown in Fig. 10(i). Due to feature points (#13, #15) acted as anoutlier for most of the cases, higher error level were predicted.However, for the case of onset frames, tracking the error level wascustomary as shown in Fig. 10(j).Finally, tracking with happinesssequences on onset frames the tracking error was regular as shownin Fig. 10(k). However, tracking on apex frames using RICFFT, alower error level was predicted; 98% of the images have an averageerror ofme17 < 0.05, as compared with CLM the same error levelis observed for 72% of the images as shown in Fig. 10(l).
no similar research for a fair comparison. It is worth mentioningthat the performances of existing methods for facial feature track-

Md.N. Islam et al. / Applied Soft Computing 53 (2017) 34–44 43
d apex
iia[cvlM6(Cr6
ititotHpo
5
tpmtts
Fig. 10. The Performance of Different Tracker on onset an
ng are not exactly comparable. This is due to each method reportsts accuracy for feature tracking with a specific tracker such asppearance-based: DE-MC [6], AAM with KRR [31], DBN with RBM57] and model-based: ASM [27], SDM [33], STCSR [34], Hierarchi-al Clustering [47], CLM [49]). In addition, the tracking accuracyaries for individual factor such as: extracted features (Gabor [6],ocal patches [14], distance displacement [27], SIFT features [33],
ulti-level [57]), number of landmarks (17 [17], 26 [6], 66 [33,39],8 [49],82 [27]), and finally, databases to evaluate distinct trackerBIOID [6,58], CK+ [55,57], FGnet [54], Multi-PIE [59,39], and so on).onsidering aforementioned factors, the state-of-the-art methodseported their tracking error as: 9.14% [6], 5.03% [33], 4.68% [34],.77% [57], and 7.56% [39].
In this manuscript, the tracking error of the proposed RICFFTs reported as 2.55% for FGnet and 3.36% for CK+ database whileracking task is based on Incremental Clustering with local patchmages and face shapes are as extracted features considering 17 fea-ure points only. Adopting two Incremental Clustering algorithmsn the task of facial feature tracking, we evaluate and comparehe performance of the proposed RICFFT with classic method CLM.owever, this is not limited to the mentioned trackers. The pro-osed RICFFT can also accept changes in the current tracker withther sophisticated methods.
. Conclusions
In this paper, RICFFT, an automatic and accurate facial featureracking system based on incremental clustering algorithms is pro-osed. The improvements for tracking facial feature points come
ainly from combining Patch Clustering and Shape Clustering withhe baseline method, CLM. Specifically, the erroneous facial fea-ure tracking can be compensated by modelling appearances andhapes online during tracking. The performance of the RICFFT and
frames of different emotion sequences of CK+ Database.
the baseline method CLM have been evaluated and compared tothe sequences of two publicly available databases. Experimentalresults demonstrate that RICFFT significantly improves the meantracking accuracy of 97.45% and 96.64% for FGnet and CK+ database,as compared with the classic method CLM. Also, RICFFT is morerobust by minimizing average shape distortion error of 0.20% and1.86% for FGnet and CK+ (apex frame) database. For future work, wewill explore ways to recognize and classify facial emotions, utiliz-ing the facial features generated from RICFFT. Our future work willalso investigate SDM and cascade regression methods to comparethe performance of our proposed method. In addition, introduc-ing multi-scale and multi-view face fitting approach, which isimportant for understanding the spontaneous expression, will beexplored.
Acknowledgement
This research is supported by The Sumitomo Foundation:FY2015, Reg. no. 158401.
References
[1] M. Pantic, L.J. Rothkrantz, Toward an affect-sensitive multimodalhuman-computer interaction, Proc. IEEE 91 (9) (2003) 1370–1390.
[2] C.A. Frantzidis, et al., Toward emotion aware computing: an integratedapproach using multichannel neurophysiological recordings and affectivevisual stimuli, IEEE Trans. Inf. Technol. Biomed. 14 (3) (2010) 589–597.
[3] J. Moreno-Garcia, et al., Video sequence motion tracking by fuzzificationtechniques, Appl. Soft Comput. 10 (1) (2010) 318–331.
[4] C. Lisetti, et al., Developing multimodal intelligent affective interfaces for
tele-home health care, Int. J. Hum. Comput. Stud. 59 (1) (2003) 245–255.[5] A. Luneski, et al., Affective computer-aided learning for autistic children,WOCCI (2008).
[6] Y. Tie, L. Guan, Automatic landmark point detection and tracking for humanfacial expressions, EURASIP J. Image Video Process. 2013 (1) (2013) 1–15.

4 Soft C
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[[
[
[
[
[
[
[
[
[
[
[
[58] O. Jesorsky, K.J. Kirchberg, R.W. Frischholz, Robust face detection using thehausdorff distance, in: Audio-and Video-based Biometric Person
4 Md.N. Islam et al. / Applied
[7] H.S. Friedman, Nonverbal communication between patients and medicalpractitioners, J. Soc. Issues 35 (1) (1979) 82–99.
[8] P. Ekman, W.V. Friesen, A Technique for the Measurement of FacialMovement. Palo Alto, Consulting Psychologists Press, CA, 1978.
[9] J. Hamm, et al., Automated facial action coding system for dynamic analysis offacial expressions in neuropsychiatric disorders, J. Neurosci. Methods 200 (2)(2011) 237–256.
10] C.J. Solomon, S.J. Gibson, J.J. Mist, Interactive evolutionary generation of facialcomposites for locating suspects in criminal investigations, Appl. SoftComput. 13 (7) (2013) 3298–3306.
11] V. Asadpour, M.M.F. Homayounpour Towhidkhah, Audio-visual speakeridentification using dynamic facial movements and utterance phoneticcontent, Appl. Soft Comput. 11 (2) (2011) 2083–2093.
12] T. Azim, M.A. Jaffar, A.M. Mirza, Fully automated real time fatigue detection ofdrivers through Fuzzy Expert Systems, Appl. Soft Comput. 18 (2014) 25–38.
13] J.-C. Chien, et al., An integrated driver warning system for driver andpedestrian safety, Appl. Soft Comput. 13 (11) (2013) 4413–4427.
14] N. Masuyama, M.N. Islam, M. Seera, C.K. Loo, Application of emotion affectedassociative memory based on mood congruency effects for a humanoid,Neural Comput. Appl. (2015) 1–16.
15] M.N. Islam, C.K. Loo, Geometric feature-based facial emotion recognitionusing two-Stage fuzzy reasoning model, in: Neural Information Processing,Springer, 2014.
16] D. Cristinacce, T. Cootes, Automatic feature localisation with constrained localmodels, Pattern Recogn. 41 (10) (2008) 3054–3067.
17] J. Nuevo, L.M. Bergasa, P. Jiménez, RSMAT: Robust simultaneous modeling andtracking, Pattern Recognit. Lett. 31 (16) (2010) 2455–2463.
18] F. Dawood, C.K.W.H. Loo Chin, Incremental on-line learning of human motionusing Gaussian adaptive resonance hidden Markov model, Neural Networks(IJCNN), The 2013 International Joint Conference on IEEE (2013).
19] R.W. Picard, Affective computing: challenges, Int. J. Hum. Comput. Stud. 59 (1)(2003) 55–64.
20] E. Vezzetti, F. Marcolin, 3D human face description: landmarks measures andgeometrical features, Image Vision Comput. 30 (10) (2012) 698–712.
21] J.J.-J. Lien, et al., Detection: tracking, and classification of action units in facialexpression, Rob. Auton. Syst. 31 (3) (2000) 131–146.
22] C. Shan, S. Gong, P.W. McOwan, Facial expression recognition based on localbinary patterns: a comprehensive study, Image Vision Comput. 27 (6) (2009)803–816.
23] N. Ajit Krisshna, et al., Face recognition using transform domain featureextraction and PSO-based feature selection, Appl. Soft Comput. (2014).
24] M.S. Bartlett, et al., Recognizing facial expression: machine learning andapplication to spontaneous behavior, Computer Vision and PatternRecognition, 2005. CVPR 2005. IEEE Computer Society Conference on IEEE(2005).
25] Y. Tong, et al., Robust facial feature tracking under varying face pose and facialexpression, Pattern Recogn. 40 (11) (2007) 3195–3208.
26] T.F. Cootes, et al., Active shape models-their training and application, Comput.Vision Image Understanding 61 (1) (1995) 38–59.
27] F. Tsalakanidou, S. Malassiotis, Real-time 2D+ 3D facial action and expressionrecognition, Pattern Recogn. 43 (5) (2010) 1763–1775.
28] I.L. Dryden, K.V. Mardia, Statistical Shape Analysis, vol. 4, John Wiley & Sons,New York, 1998.
29] K. Seshadri, M. Savvides, An analysis of the sensitivity of active shape modelsto initialization when applied to automatic facial landmarking, IEEE Trans. Inf.Forensics Secur. 7 (4) (2012) 1255–1269.
30] T.F. Cootes, G.J. Edwards, C.J. Taylor, Active appearance models, IEEE Trans.Pattern Anal. Mach. Intell. 23 (6) (2001) 681–685.
31] Y. Chen, C. Hua, R. Bai, Regression-based Active Appearance Modelinitialization for facial feature tracking with missing frames, Pattern Recognit.Lett. 38 (2014) 113–119.
32] J. Haslam, C.J. Taylor, T. Cootes, A Probabilistic Fitness Measure for DeformableTemplate Models, in BMVC, 1994, Citeseer.
33] X. Xiong, F. Torre, Supervised descent method and its applications to facealignment. in computer vision and pattern recognition, Proceedings of theIEEE Conference on 2013, IEEE (2013).
[
omputing 53 (2017) 34–44
34] J. Yang, J. Deng, K. Zhang, Q. Liu, Facial shape tracking via spatio-temporalcascade shape regression. in Computer Vision Workshops, Proceedings of theIEEE International Conference On. 2015. IEEE (2015).
35] J. Deng, Q. Liu, J. Yang, D. Tao, M 3 CSR: multi-view, multi-scale andmulti-component cascade shape regression, Image Vision Comput. 47 (2015)19–26.
36] X. Cao, Y. Wei, F. Wen, J. Sun, Face alignment by explicit shape regression, Int.J. Comput. Vision 107 (2) (2014) 177–190.
37] Q. Liu, J. Deng, D. Tao, Dual sparse constrained cascade regression for robustface alignment, IEEE Trans. Image Process. 25 (2) (2015) 700–712.
38] S. Lucey, et al., Non-rigid face tracking with enforced convexity and localappearance consistency constraint, Image Vision Comput. 28 (5) (2010)781–789.
39] N. Wang, X. Gao, D. Tao, X. Li, Facial feature point detection: A comprehensivesurvey. arXiv preprint arXiv:1410.1037.
40] G. Rajamanoharan, T. Cootes, Multi-view constrained local models for largehead angle face tracking, ICCV-W, First Facial Landmark Tracking In-the-WildChallenge and Workshop (2015).
41] L. Zamuner, K. Bailly, E. Bigorgne, 2014 August. A Pose-Adaptive ConstrainedLocal Model for Accurate Head Pose Tracking, in: ICPR, pp. 2525–2530.
42] J.M. Saragih, S.J.F. Lucey Cohn, Face alignment through subspace constrainedmean-shifts. in Computer Vision, IEEE 12th International Conference On.2009. IEEE (2009).
43] B.D. Lucas, T. Kanade, An iterative image registration technique with anapplication to stereo vision, Ijcai (1981).
44] I. Matthews, T. Ishikawa, S. Baker, The template update problem, IEEE Trans.Pattern Anal. Mach. Intell. 26 (6) (2004) 810–815.
45] N.D. Dowson, R. Bowden, Simultaneous modeling and tracking (smat) offeature sets. in Computer Vision and Pattern Recognition, CVPR 2005. IEEEComputer Society Conference On. 2005. IEEE (2005).
46] R. Gross, et al., Multi-pie, Image Vision Comput. 28 (5) (2010) 807–813.47] J. Nuevo, et al., Face tracking with automatic model construction, Image
Vision Comput. 29 (4) (2011) 209–218.48] P. Viola, M. Jones, Rapid object detection using a boosted cascade of simple
features, Computer Vision and Pattern Recognition. CVPR 2001. Proceedingsof the 2001 IEEE Computer Society Conference On. 2001. IEEE (2001).
49] J.M. Saragih, S. Lucey, J.F. Cohn, Deformable model fitting by regularizedlandmark mean-shift, Int. J. Comput. Vision 91 (2) (2011) 200–215.
50] Y. Wang, S. Lucey, J.F. Cohn, Enforcing convexity for improved alignment withconstrained local models. in Computer Vision and Pattern Recognition, 2008.CVPR 2008. IEEE Conference on. 2008. IEEE.
51] L. Di Stefano, S. Mattoccia, F. Tombari, ZNCC-based template matching usingbounded partial correlation, Pattern Recognit. Lett. 26 (14) (2005) 2129–2134.
52] A. Kanaujia, Y. Huang, D. Metaxas, Tracking facial features using mixture ofpoint distribution models, in: Computer Vision, Graphics and ImageProcessing, Springer, 2006, pp. 492–503.
53] A.K. Jain, M.N. Murty, P.J. Flynn, Data Clustering: A review, vol. 31, 3,ACMcomputing surveys (CSUR), 1999, pp. 264–323.
54] FGNet, Fgnet Talking Face Video, 2004 (Available from:) http://www-prima.inrialpes.fr/FGnet/data/01-TalkingFace/talking face.html.
55] P. Lucey, et al., The extended cohn-kanade dataset (CK+): A complete datasetfor action unit and emotion-specified expression, Computer Vision andPattern Recognition Workshops (CVPRW), 2010 IEEE Computer SocietyConference On. 2010. IEEE (2010).
56] Y. Li, et al., Simultaneous facial feature tracking and facial expressionrecognition, IEEE Trans. Image Process. 22 (7) (2013) 2559–2573.
57] Y. Wu, Q. Ji Z. Wang, Facial feature tracking under varying facial expressionsand face poses based on restricted boltzmann machines, Computer Vision andPattern Recognition (CVPR), 2013 IEEE Conference On. 2013. IEEE (2013).
Authentication, Springer, Berlin, Heidelberg, 2001.59] R. Gross, I. Matthews, J. Cohn, T. Kanade, S. Baker, Multi-pie, Image Vision
Comput. 28 (5) (2010) 807–813.


















