
Anything Data: Big, Streaming, NoSQL, Cloud, Science ... A Sloppy Travel Guide
33
Anything data Big, Streaming, NoSQL, Cloud, Science … a sloppy travel guide
-
Upload
comodo -
Category
Data & Analytics
-
view
119 -
download
0
Transcript of Anything Data: Big, Streaming, NoSQL, Cloud, Science ... A Sloppy Travel Guide

Anything dataBig, Streaming, NoSQL, Cloud, Science… a sloppy travel guide

whoami ( linkedin. com/in/ahmetakyol )

whoami - Dilbert already did it

Agenda
● Why a (sloppy) travel guide?
● Chasing Cool Technologies (Big Data Envy)○ Architectural complexity
○ Operational complexity
● The cliff of confusion & The Unknown Unknowns
● Guidelines○ Making simple but not simpler
○ Right task right tool right usage
○ Don’t let API fool you
○ loading data, layouts and file formats
○ learning from costs

Why a travel guide ?
“... Martin is an excellent map reader even in the most
hectic Italian traffic … And after Martin and Cindy
left us, we did better because we had learned from what
they had showed us … When there’s no guide available, it
helps to have someone who understands how to read the
maps, tracks, signs, and indications. When we’re on our
own, it helps to learn how to do those things ourselves“
“Software projects are always traveling in
areas they don’t know “ Ron Jeffries (from his foreword for PoAPA book)

Why a ‘sloppy’ travel guide - (Big Data Landscape 2012 )

Why a ‘sloppy’ travel guide - (Big Data Landscape 2016 )

Why a ‘sloppy’ travel guide - ( the ‘n’ V’s of Big Data )

Chasing Cool Technologies - Big Data Envy “We continue to see organizations chasing ‘cool’ technologies,
taking on unnecessary complexity and risk when a simpler choice
would be better.”
“ While we've long understood the value of Big Data to better
understand how people interact with us, we've noticed an alarming
trend of Big Data envy: organizations using complex tools to handle
‘not-really-that-big’ Data.”
“ The Apache Cassandra database promises massive scalability on commodity
hardware, but we have seen teams overwhelmed by its architectural and
operational complexity. Unless you have data volumes that require a 100+
node cluster, we recommend against using Cassandra. ”
https://www.thoughtworks.com/radar/techniques/big-data-envy
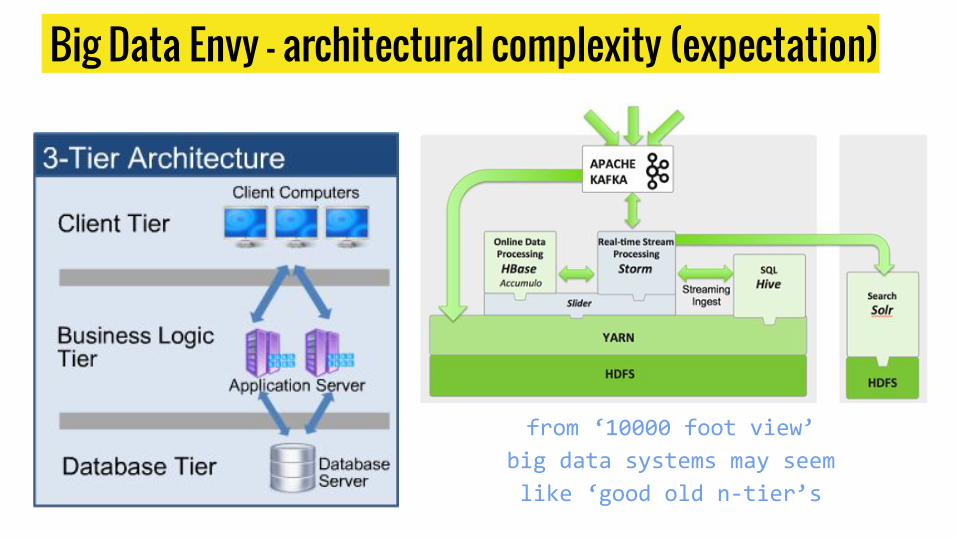
Big Data Envy - architectural complexity (expectation)
from ‘10000 foot view’
big data systems may seem
like ‘good old n-tier’s

Big Data Envy - architectural complexity (example) A dataflow diagram
from a good (but still a)
reference application.
Real life examples are
usually more complex !

Big Data Envy - architectural complexity (blueprints)

Big Data Envy - operational complexity (devops)

Big Data Envy - operational complexity (devops)
http://www.slideshare.net/jcmia1/apache-spark-20-tuning-guide
● Tuning JVM, OS and
each (big) data
system
● Choosing right
hardware for each
‘right solution’
● Orchestrating /
monitoring /
debugging many
small applications
running on and/or
interacting with such
distributed systems
OOM Troubleshooting example for Apache Spark

Know thyself - reaching the cliff of confusion
https://www.vikingcodeschool.com/posts/why-learning-to-code-is-so-damn-hard

The Unknown Unknowns - the iceberg of ignorance In his acclaimed study “The Iceberg of Ignorance”, consultant Sidney Yoshida concluded: “Only 4% of an organization’s front line problems are known by top management, 9% are known by middle management, 74% by supervisors and 100% by employees…”

Guidelines - the first principle
“DDD isn’t first and foremost about technology.
In its most central principles, DDD is about
discussion, listening, understanding, discovery,
and business value, all in an effort to
centralize knowledge. If you are capable of
understanding the business in which your company
works, you can at a minimum participate in the
software model discovery process to produce a
Ubiquitous Language.”
Our highest priority is to satisfy
the customerthrough early and continuous
delivery of
valuable softwarethe very first principle of the agile manifesto

Guidelines - science before technology

Guidelines - making simple but not simpler● “ Make things as simple as possible,
but not simpler.” (Albert Einstein)
● Simple as simple: no over-engineering. search for most simplest feasible solution possible
○ feasible ‘ready’ solution○ fully managed solutions ○ manageable packed solutions with support○ solutions known for stability, manageability
● Not simpler: no under-engineering
○ right task, right tool○ right usage: design patterns, best practices

Guidelines - right task right tool isn’t enough

Guidelines - right task right tool right usage
DynamoDB Design Patterns and Best Practices : https://www.youtube.com/watch?v=PDQ3jbDyTQ4

Guidelines - don’t let API fool you (cassandra)
CQL Under The Hood : https://www.youtube.com/watch?v=CY5-bWpqAVA

Guidelines - don’t let API fool you (cassandra)
CQL Under The Hood : https://www.youtube.com/watch?v=CY5-bWpqAVA

Guidelines - learn data paths and structures ( C* )learning “write path”, “read path” and main
internal data structures gives critical hints
about “do’s and don’ts”; especially anti-patterns:
● Queue-like designs● Intensive updates● Deletes
http://www.slideshare.net/doanduyhai/cassandra-nice-use-cases-and-worst-anti-patterns

Guidelines - loading data, layouts and file formats (hdfs)
● Data distribution , small files problem
● Row v.s. columnar formats● I/O advantage, read only what you
need:○ Vertical: projection○ Horizontal: predicate pushdown

Guidelines - learning from costs (google)

Guidelines - learning from costs (bigquery)

Guidelines - learning from costs (kinesis)“ Pricing is based on volume of data ingested into Amazon Kinesis Firehose, which is calculated as the number of data records you send to the service, times the size of each record rounded up to the nearest 5KB. For example, if your data records are 42KB each, Amazon Kinesis Firehose will count each record as 45 KB of data ingested. ”
“ A record is the data that your data producer adds to your Amazon Kinesis Stream. A PUT Payload Unit is counted in 25KB payload “chunks” that comprise a record. For example, a 5KB record contains one PUT Payload Unit, a 45KB record contains two PUT Payload Units, and a 1MB record contains 40 PUT Payload Units. PUT Payload Unit is charged with a per million PUT Payload Units rate. ”

Guidelines - learn windows of opportunity (streaming)
SELECT sensorid, Count(*) AS count FROM sensorreadings TIMESTAMP by time GROUP BY sensorid, tumblingwindow(second, 10)

Guidelines - learn windows of opportunity (streaming)
SELECT sensorid, Count(*) AS count FROM sensorreadings TIMESTAMP by time GROUP BY sensorid, hoppingwindow(second, 10, 5)

Guidelines (bonus) - know thy theorem ( CAP )

Guidelines (bonus) - know thy theorem ( PACELC )



















