
Announcements Final exam: Friday Dec 19, 8am-11am, 1 Pimentel Closed-book, closed-notes except 1...
28
Announcements Final exam: Friday Dec 19, 8am-11am, 1 Pimentel Closed-book, closed-notes except 1 page of notes Grading Your midterm score is replaced by final exam score if the final score is higher Review sessions here TuTh 12.30-2; practice final posted soon HKN Survey 1.30pm today Lecture on “Consciousness” by Christof Koch today 4pm 125 Li Ka Shing Suggested reading: Tononi, G., & Koch, C. (2014). Consciousness: Here, There but Not Everywhere. 1
-
Upload
basil-newton -
Category
Documents
-
view
235 -
download
2
Transcript of Announcements Final exam: Friday Dec 19, 8am-11am, 1 Pimentel Closed-book, closed-notes except 1...

Announcements
Final exam: Friday Dec 19, 8am-11am, 1 Pimentel Closed-book, closed-notes except 1 page of notes
Grading Your midterm score is replaced by final exam score if the final score is higher
Review sessions here TuTh 12.30-2; practice final posted soon HKN Survey 1.30pm today Lecture on “Consciousness” by Christof Koch today 4pm 125 Li Ka Shing
Suggested reading: Tononi, G., & Koch, C. (2014). Consciousness: Here, There but Not Everywhere. arXiv:1405.7089.
Office hours today just 3.30-4pm1

CS 188: Artificial IntelligenceComputer Vision (all too briefly)*
Instructor: Stuart Russell --- University of California, Berkeley

Outline
Perception generally Approaches to vision Edge detection Image classification by object category
3

Perception generally Stimulus (percept) S, world W
For some function g, S = g(W) (e.g., W=scene, g=rendering, S=image) Can we do perception by inverting g?
W = g-1(S) (e.g., vision = inverse graphics) No! Percepts are usually massively ambiguous…

Percepts are evidence…
Can we just apply Bayes’ rule? P(W|S) = P(S|W) P(W) P(W) is higher for students with heads attached P(S|W) is just graphics, i.e., 1 when S=g(W), 0 otherwise
The problem is computation: Sampling from P(W) until we find a world that agrees with S is hopeless! Vision researchers have identified all sorts of cues in the image that
suggest hypotheses about (parts of) the world Need a combination of bottom-up and top-down reasoning
5

Top-down example: blind spot fill-in
http://www.colorcube.com/illusions/blndspot.htm
6
Actual image Perceived image

More examples
7http://www.skidmore.edu/~hfoley/Perc4.htm

Lightness constancy: Which has lighter pixels, A or B?
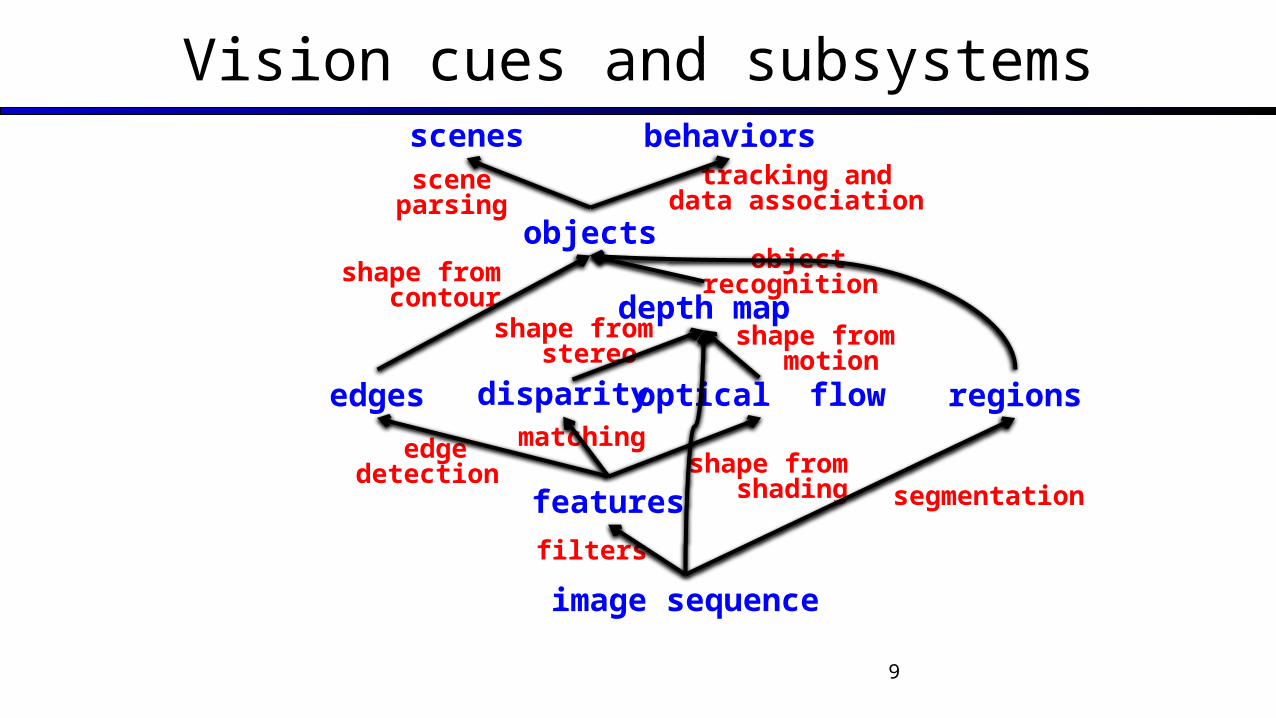
Vision cues and subsystems
9
scenes behaviors
optical flow
depth map
edges
objects
disparity
features
regions
image sequence
tracking anddata association
objectrecognition
segmentation
filters
edgedetection
matching
shape from contour
shape from stereo
shape from motion
shape from shading
scene parsing

ImagesAn image I(x,y)(t) is an array of integers [0..255] (or triples for RGB)
10
Cameras ~ 1Mpixel, human eyes ~240Mpixel x 25 fps

Edge detection
Edges in image discontinuities in scene: ⇐1) depth 2) surface orientation3) reflectance (surface markings) 4) illumination (shadows, etc.)

Edge detection contd.
1) Convolve image with spatially oriented filters (possibly multi-scale)E(x,y) = f(u,v) I(x+u,y+v) du dv
2) Label above-threshold pixels with edge orientation3) Find line segments by combining edge pixels with same orientation
12

Good, bad, and ugly
13

Illusory edges
14

Object Detection

Method 1: Deformable part-based models

Deformable part-based models
HOG features (Histogram of Oriented Gradients)
Whole-object + part-based Model of
P(part-pose | whole-pose) Efficient dynamic programming
algorithm for optimal matching Automatically learns where the
parts appear and what they look like
17

State-of-the-art results (2010)
[Girschik, Felzenszwalb, McAllester]
sofa
bottle
cat

State-of-the-art results (2010)
[Girschik, Felzenszwalb, McAllester]
person
car
horse

Method 2: Deep Learning

How Many Computers to Identify a Cat?
[Le, Ng, Dean, et al, 2012]
“Google Brain”

A typical deep learning architecture

Deep learning: Convolution network structure
Nodes in layer n take input from small patch in layer n-1
Weights are copied across all nodes in a given layer translational invariance fewer parameters =>
faster learning
23

Deep learning: Auto-encoding Stacked auto-encoder for “unsupervised” training of hidden layers from huge
collections of unlabeled images Layer 0 = input image Layer 1 = “compressed” version of Layer 0, trained with Layer 0 as output layer 2 = “compressed” version of Layer 1, trained with Layer 1 as output etc.
Then add a final layer for supervised training on categories
>0?
>0?
>0?
>0?
>0? f1
f2
f3
f1
f2
f3

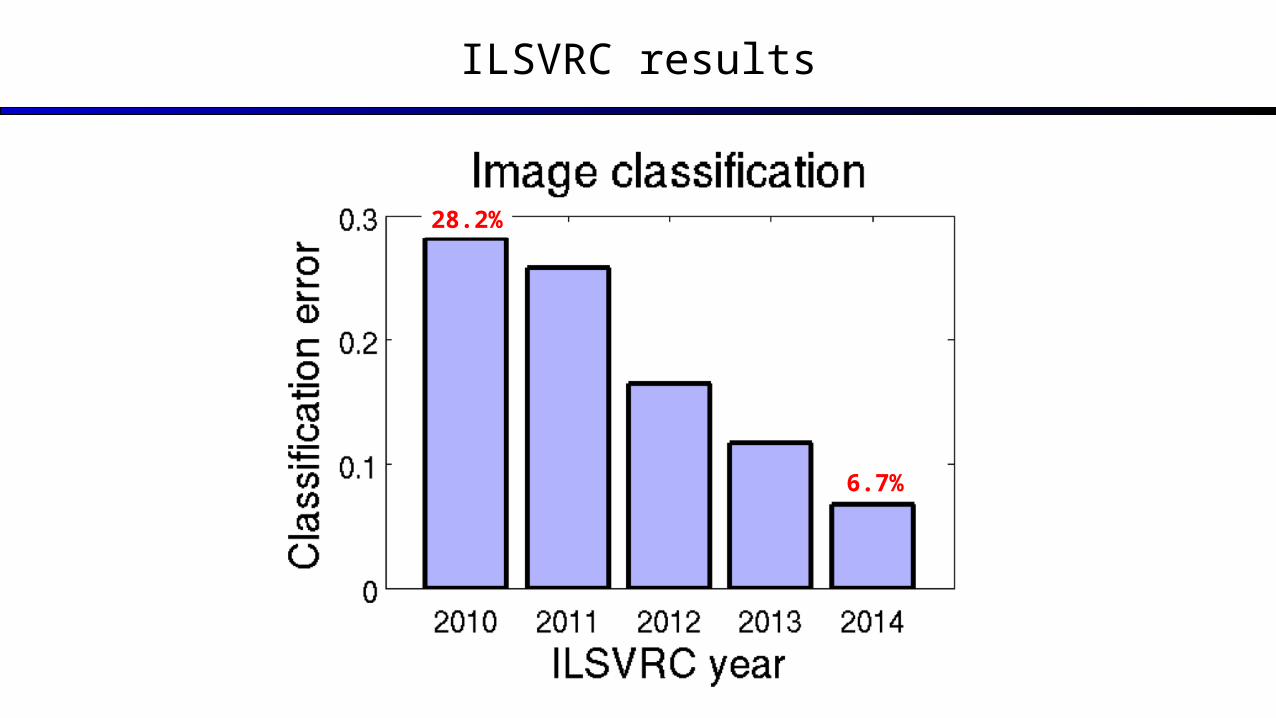
ImageNet Large-Scale Visual Recognition Challenge
25
1.2 million training images in 1000 categories chosen from 14 million
images in 21,841 categories 100,000 test images “Correct” if true class is in
top-5 prediction list
ILSVRC results
26
28.2%
6.7%
Results contd.
27

Next Time
Robotics Interim results from EC3 contest Where to go next to learn more Final thoughts on the future of AI


















