
Andrej Dobnikar - laspp.fri.uni-lj.silaspp.fri.uni-lj.si/css/CSS.pdf · 1.2 Genetski algoritmi GA...
120
CELULARNE STRUKTURE IN SISTEMI Andrej Dobnikar 21. februar 2007
Transcript of Andrej Dobnikar - laspp.fri.uni-lj.silaspp.fri.uni-lj.si/css/CSS.pdf · 1.2 Genetski algoritmi GA...

CELULARNE STRUKTUREIN SISTEMI
Andrej Dobnikar
21. februar 2007

2

Kazalo
1 Celularni avtomat in evolucija 7
1.1 Osnovni pojmi in definicije CA . . . . . . . . . . . . . . . . . . . . . 7
1.2 Genetski algoritmi . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3 Univerzalno racunanje in kvazi-uniformni CA . . . . . . . . . . . . . 9
1.3.1 Univerzalni 2-stanjski, 5-sosednostni ne-uniformni CA 9
1.3.2 Redukcija pravil . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.3.3 Implementacija Univerzalnega Stroja s CA . . . . . . . 14
2 ALIFE s pomocjo splosnega CA modela 17
2.1 ALIFE model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.1.1 Samo-Reprodukcijska zanka . . . . . . . . . . . . . . . . . . . 18
2.1.2 Evolucija v prostoru pravil . . . . . . . . . . . . . . . . . . . . 19
3 Celularno programiranje 23
3.1 ”Gostota”in standardne resitve . . . . . . . . . . . . . . . . . . . . . 23
3.2 “Sinhronizacija”in standardne resitve . . . . . . . . . . . . . . . . . . 24
3.3 Celularni programski algoritem (CPA) . . . . . . . . . . . . . . . . . 25
3.4 Rezultati CPA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.4.1 Gostota . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3

4 KAZALO
3.4.2 Sinhronizacija . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4.3 Skaliranje razvijajocih CA . . . . . . . . . . . . . . . . . . . . 29
3.4.4 Diskusija k poglavju 3 . . . . . . . . . . . . . . . . . . . . . . 29
4 Primeri aplikacij celularnega programiranja 39
5 Programirne logicne naprave 49
5.1 Programirna integrirana vezja . . . . . . . . . . . . . . . . . . . . . . 49
5.1.1 Programirna logicna vezja . . . . . . . . . . . . . . . . . . . . 50
5.1.2 Programirne logicne naprave (PLD) . . . . . . . . . . . . . . . 51
5.1.3 Kompleksna PLD vezja (CPLD) . . . . . . . . . . . . . . . . . 53
5.2 FPGA vezja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.2.1 Programirne tehnologije . . . . . . . . . . . . . . . . . . . . . 56
5.2.2 Proces snovanja . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.3 XILINX vezja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.3.1 Arhitektura blokov . . . . . . . . . . . . . . . . . . . . . . . . 57
5.3.2 Struktura povezav . . . . . . . . . . . . . . . . . . . . . . . . 59
5.3.3 Programiranje . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.4 ACTEL vezja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.4.1 Arhitektura blokov . . . . . . . . . . . . . . . . . . . . . . . . 61
5.4.2 Struktura povezav . . . . . . . . . . . . . . . . . . . . . . . . 62
5.4.3 Programiranje . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
6 Porazdeljeno (paralelno) procesiranje 65
6.1 Klasifikacija racunalniskih arhitektur . . . . . . . . . . . . . . . . . . 65
6.2 Paralelne arhitekture . . . . . . . . . . . . . . . . . . . . . . . . . . . 67

KAZALO 5
6.2.1 SIMD arhitekture . . . . . . . . . . . . . . . . . . . . . . . . . 68
6.2.2 MIMD arhitekture . . . . . . . . . . . . . . . . . . . . . . . . 71
6.3 Data flow arhitekture . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
6.4 Principi snovanja paralelnih algoritmov . . . . . . . . . . . . . . . . . 75
6.5 Performancne mere in analiza . . . . . . . . . . . . . . . . . . . . . . 78
7 Asinhronsko paralelno programiranje 81
7.1 OCCAM kot jezik transputerjev . . . . . . . . . . . . . . . . . . . . . 81
7.2 Osnove OCCAM jezika . . . . . . . . . . . . . . . . . . . . . . . . . . 84
7.3 Sintaksa OCCAM jezika . . . . . . . . . . . . . . . . . . . . . . . . . 85
7.3.1 Osnove OCCAM jezika . . . . . . . . . . . . . . . . . . . . . . 86
7.3.2 Tipi in specifikacije . . . . . . . . . . . . . . . . . . . . . . . . 88
7.3.3 Programiranje v realnem casu . . . . . . . . . . . . . . . . . . 103
8 Paralelno programiranje z MPI 109
8.1 Uvod . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
8.2 Osnove MPI (Message Passing Interface) . . . . . . . . . . . . . . . . 111
8.2.1 Splosni MPI programi . . . . . . . . . . . . . . . . . . . . . . 112
8.2.2 Ostale osnovne MPI funkcije . . . . . . . . . . . . . . . . . . . 114
8.2.3 Sporocilo: podatki + ovojnica . . . . . . . . . . . . . . . . . . 115
8.3 Kolektivno komuniciranje . . . . . . . . . . . . . . . . . . . . . . . . 116
8.3.1 Oddaja (’Broadcast’) . . . . . . . . . . . . . . . . . . . . . . . 117
8.3.2 Redukcija (’Reduce’) . . . . . . . . . . . . . . . . . . . . . . . 118
8.3.3 Zbiranje (’Gather’) in Raztros (’Scatter’) . . . . . . . . . . . . 118
8.3.4 Zdruzevanje (’Allgather’) . . . . . . . . . . . . . . . . . . . . . 120

6 KAZALO

Poglavje 1
Celularni avtomat in evolucija
1.1 Osnovni pojmi in definicije CA
• CA je vpeljal 1940 Von Neuman kot orodje za raziskovanje obnasanja komple-ksnih sistemov
• CA je dinamicni sistem, diskreten v casu in prostoru
• CA je D-dimenzionalna mreza, z D=1,2,3 v praksi
• celica CA je koncni avtomat (KA) s svojo tabelo prehajanja stanj
• sosednost doloca celice v okolici, ki vplivajo na prehajanje stanj opazovanecelice (r - doloca stevilo sosednih celic)
• Definicije za D=2 (Codd, 1968)
- I × I doloca prostor CA, I ⊂ N- sosednost doloca funkcija g:
g(α) = {α + δ1, α + δ2, ..., α + δn}α ∈ I × I, δi ∈ I × I (1.1)
opazovana celica je ena iz sosednosti; obicajno ima δ1 = (0, 0)
- celica CA je koncni avtomat (KA), podan z (V, v0, f)V - mnozica stanjv0 - zacetno stanjef - tabela prehajanja stanj (operator prehajanja stanj)
7

8 POGLAVJE 1. CELULARNI AVTOMAT IN EVOLUCIJA
- stanja celic v sosednosti (skupaj s stanjem opazovane celice α) dolocajo so-sednostno stanje (v casu t):
ht(α) = (vt(α), vt(α + δ2), ..., vt(α + δn)) (1.2)
- stanje celice α v casu t + 1:
f(ht(α)) = vt+1(α) (1.3)
- funkcija prehajanja stanj f , ki jo imenujemo tudi CA-pravilo, je podana stabelo vseh moznih parov oblike
(ht(α), vt+1(α)) (1.4)
- konfiguracija je dovoljena kombinacija vseh stanj celic v CA
- globalna prenosna funkcija F :
F (c)(α) = f(h(α)), za vse α ∈ I × I , (1.5)
c ∈ C pa je mnozica vseh konfiguracij.F doloca sekvenco konfiguracij c0, c1, ..., ct, ...,oz. ct+1 = F (ct)
• CA je UNIFORMEN, ce so vse f(α), α ∈ I×I, enake. Sicer je NE-UNIFORMEN(tudi ne-homogen)
• WOLFRAM je na osnovi sistematicne studije CA definiral, glede na njihovomozno dinamiko, 4 kvalitativne razrede:
I: relaksirajo v homogeno stanje (limitno tocko)
II: konvergirajo v preproste periodicne strukture (limitni cikli)
III: izkazujejo kaoticne aperiodicne vzorce
IV: izkazujejo kompleksne vzorce lokalnih struktur z dolgimi prehodnimi po-javi - ni primerne analogije pri zveznih dinamicnih sistemih
1.2 Genetski algoritmi
GA je iterativna iskalna procedura, ki po zgledu iz narave na osnovi razvoja popu-lacije genomov (moznih resitev) isce resitev v problemski domeni.
Standardni GA deluje takole:

1.3. UNIVERZALNO RACUNANJE IN KVAZI-UNIFORMNI CA 9
BEGIN GA
g := 0 { stevec generacij }
Inicializiraj populacijo P(g)
Evaluiraj populacijo P(g) { fitness function }
WHILE ni konca DO
g := g+1
Izberi P(g) iz P(g-1)
Krizanje P(g)
Mutacije P(g)
Evaluacije P(g)
END WHILE
END GA
S pomocjo variante GA (CPA) bomo v nadaljevanju iskali F za CA tako, da bopreslikava c0 → ck cim bolj uspesna. (c0 - zacetna konfiguracija, ck - koncna konfi-guracija)
1.3 Univerzalno racunanje in kvazi-uniformni CA
• Zanima nas univerzalna moc racunanja CA (D=2) glede na UTS (UniverzalniTuringov stroj)
• Obstaja dokaz (Codd, 1968), da ne eksistira univerzalno uniformno ce-lularno polje (CA) z 2-stanjskimi celicami in 5 sosedi ter koncno zacetnokonfiguracijo.
• Iskanje univerzalnosti CA je mozno v dveh smereh:
- v povecevanju sosednosti/stanj
- v neuniformnih CA
1.3.1 Univerzalni 2-stanjski, 5-sosednostni ne-uniformni CA
Za dokaz o racunski univerzalnosti bomo uporabili:
A - signale in signalne poti
B - funkcijsko polni sistem operatorjev (|)C - ura, ki generira verigo sinhronih impulzov
D - pomnilnik

10 POGLAVJE 1. CELULARNI AVTOMAT IN EVOLUCIJA
• Implementacija A, B, C, D s CA:
A Pravila za razsirjanje signala
Pravilo kaze prehod sredinske celice (opazovane) v novo stanje
PRIMER: programiranje ozicenja v CA:
a.)• • • • • • • ↑ → → → → → •• • • • • • • ← ↑ • • • ↓ •• • • → → → → → → • • • ↓ •• • • • • • • • • • • • ↓ •
b.) Signal 101 v t = 0 na zacetku poti:

1.3. UNIVERZALNO RACUNANJE IN KVAZI-UNIFORMNI CA 11
• • • • • • • ↑ → → → → → •• • • • • • • ← ↑ • • • ↓ •1 0 1 → → → → → → • • • ↓ •• • • • • • • • • • • • ↓ •
in signal 101 v casu t = 9:• • • • • • • 1 → → → → → •• • • • • • • 0 1 • • • ↓ •→ → → → → → → → → • • • ↓ •• • • • • • • • • • • • ↓ •
c.) Razcep:• • • • • • • • • • •• • • • • ↑ → → → → →• → → → → → • • • • •• • • • • ↓ → → → → →
d.) 4 tipi preckanja:
Za preckanje rabimo najmanj 3 vrata (celice):
• • Y • •• • ↓ • •X → ? → →• • ↓ • •• • ↓ • •
Ena celica je premalo, saj moramo prenesti 2 bita (X in Y) na dve smeri.
Resitev:

12 POGLAVJE 1. CELULARNI AVTOMAT IN EVOLUCIJA
• • Y • •• • ↓ → •X → ⊕ ⊕ → X• ↓ ⊕ • •• • ↓ • •
Y
≡
X=(X⊕
Y)⊕
YY=(X
⊕Y)
⊕X
Uporabljena sta XOR tipa a
POZOR: Pri uniformnih CA je implementacija ozicenja zelo komplici-rana in prakticno predstavlja neresljiv problem (von Neuman, 1966;Codd, 1968; Banks 1970).
B Implementacija funkcijsko polnega sistema s CA:
NAND(|) je funkcijsko poln sistem, kar dokazemo s prehodom na (−,∨
,&).
• • • • •X → → • •• ↓ | • •• • ↓ • •• • ↓ • •
X
• Y • • •X | → • •• ↓ | • •• • ↓ • •• • ↓ • •
XY
X → • • Y →↓ | • • ↓ |• ↓ • ← ← ↓• ↓ → | • •• • • ↓ • •
X∨
Y
C Uro implementiramo z zanko razsirjevalnih celic. S spreminjanjem (veli-kost, vsebina) zanke je mogoce izdelati poljubno obliko ure
D Pomnilnik sicer lahko sestavimo iz dveh NAND celic, vendar je bolj zani-

1.3. UNIVERZALNO RACUNANJE IN KVAZI-UNIFORMNI CA 13
miva naslednja implementacija 1-bitne pomnilne celice:
1.3.2 Redukcija pravil
Zgornjih 10 pravil (→, ←, ↑ , ↓, |, ⊕(4x), •) je mogoce skrciti na 6 z uporabo
kompleksnejsega ozicenja. 6 pravil je:⊕
(4x), |, •
• Ozicenje (razsirjanje, cepitev, preckanje) resimo z⊕
(tip a, b, c, d):
PRIMER:
a.) Razsirjanje:
ali0 d . c 0 0 a . b 0
0 0 0 0 0 0 0 0 0 0 0 d . c 0 0 a . b 0a a a a a b b b b b 0 d . c 0 0 a . b 0
ali . . . . . . . . . . . 0 d . c 0 0 a . b 0d d d d d c c c c c 0 d . c 0 0 a . b 00 0 0 0 0 0 0 0 0 0 0 d . c 0 0 a . b 0
→ ← ↑ ↓b.) Razcep:

14 POGLAVJE 1. CELULARNI AVTOMAT IN EVOLUCIJA
• • • 0 0 0• 0 d a a a → X0 0 d 0 • •
X → a a d a 0 0• 0 0 a a a → X• • • • • •
c.) Preckanje:
Y↓
• • 0 a • •• • 0 a 0 •0 0 0 a a 0
X → a a a a a a → X• 0 a a • •• • 0 a • •
↓Y
d.) Ura:
• • 0 0 0 • • •0 d a a a • • •0 d • • b 0 • •0 d • • b 0 • •• c c c b 0 0 0• 0 0 0 a a a a
1.3.3 Implementacija Univerzalnega Stroja s CA
• Za dokaz univerzalnosti uporabimo 2-registrski univerzalni stroj (MINSKY),ki sestoji iz:
1. Programske enote (KA)
2. 2 registrov (potencialno neskoncne dolzine)
3. niza instrukcij:
- povecaj vsebino registra za 1
- zmanjsaj vsebino registra za 1
- testiraj, ali je vsebina registra 0

1.3. UNIVERZALNO RACUNANJE IN KVAZI-UNIFORMNI CA 15
• Mozna je implementacija 2-registrskega US s CA in uporabo le dveh pravil (”backgro-und”pravilo in ”Banks-ovo pravilo) za ceno kompleksnejsega ozicenja (Banks,1970)
• CA implementacija US:
”background”:
Ostale kombinacije ohranjajo stanje opazovane celice
”Banks”:(odskrtne robove, zapolni luknje)
Za prvi dve pravili veljajo se 3 podobna, ki jih dobimo z rotacijo
Ostale kombinacije ohranjajo stanje centralne celice
PRIMER:

16 POGLAVJE 1. CELULARNI AVTOMAT IN EVOLUCIJA
a.) Increment: (+1)
b.) Decrement: (-1)
c.) Test: KA opazuje spodnjo celico registra: ce je 1, je vrednost 0, sicer pani.
d.) Reset:
• US je mogoce implementirati s CA, ki uporablja le 2 pravili. Vecina celic upo-rablja ”Background”pravilo, majhen del pa ”Banks-ovo pravilo. CA je kvazi-uniformen.

Poglavje 2
ALIFE s pomocjo splosnega CAmodela
Originalni CA model bomo modificirali tako, da bomo lahko povecali kompleksnostracunanja (tocneje: kapaciteto za kompleksno racunanje) in da bomo lahko modeli-rali ARTIFICIAL LIFE. Ohranili bomo osnovne znacilnosti CA, tj.masivni para-lelizem, lokalno interakcijo celic in enostavnost celic.
• Znacilnost ALIFE modela je kompleksno obnasanje na osnovi interakcije pre-prostih elementov. Slednje je posledica evolucije.
• Studirali bomo evolucijo, adaptacijo in celularnost s pomocjo preprostega, asplosnega modela
• ALIFE model se razlikuje od CA po:
1. celice so ne-uniformne
2. pravila so lahko bolj kompleksna
3. evolucija se izvaja v prostoru stanj in prostoru pravil (s casom se ne menjajole stanja, ampak tudi pravila)
2.1 ALIFE model
ALIFE model bo sestavljala mnozica celic, ki bodo ali prazne (brez pravila zaprehajanje stanj) ali pa delujoce (”operational”) z vgrajenim pravilom ((FS)-FiniteState Rule), ki lahko v enem koraku naredi sledece:
17

18 POGLAVJE 2. ALIFE S POMOCJO SPLOSNEGA CA MODELA
1.) izvede dostop (”access”) do lastnega stanja in stanja sosednih celic
2.) spremeni lastno stanje in stanja sosednih celic. Pri tem lahko nastopi ko-lizija, ko hoce vec celic spremeniti isto celico. Taksne situacije se resujejonakljucno.
3.) Kopira lastno pravilo v sosednjo prazno celico. Tudi tukaj se kolizija, ce na-stopi, resuje nakljucno.
• Pri CA modelu lahko vsaka celica na osnovi lastnega stanja in stanja celic izsosescine spremeni le lastno stanje. ALIFE pa dovoljuje spreminjanjestanj tudi sosednjim celicam, poleg tega pa se kopiranje pravil vprazne celice v sosescini. Ima tudi ne-uniformno strukturo in pra-vila celic se s casom lahko spreminjajo (evolucija).
• ALIFE model je nedeterministicen, ker se kolizije resujejo nakljucno. To paje bistvena znacilnost zivih organizmov.
2.1.1 Samo-Reprodukcijska zanka
V tem poglavju bomo v ALIFE modelu predpostavljali 3-stanjske celice (0, 1, b ≡blank) in 9 sosedov.
• SR-zanko je definiral Langton 1986. Osnovna zanka ima na zacetku le 5 celic v
stanju 1 (1 11 1
-zanka + 1-roka) ostale celice pa so prazne (brez pravila). V
6 korakih se na osnovi zancnih pravil zanka reproducira:
11
1110
t=1
11
11100
t=2
11
11101
1
t=3
11
111
t=0
11
11101
11
t=4
11
11011
11
1
t=5
1
11
11 11
11
1
0
1 2 3 4
t=6

2.1. ALIFE MODEL 19
Zancna pravila:
(pojavijo se se v ostalih 3 orientacijah, zato jih je skupaj 40. Ostale kombinacije nespreminjajo stanja)
S spremembo stanja celice b → 0/1 se kopira tudi pravilo v to celico. Pri 0/1 → bse pravilo unici (b ≡ ’blank’).
2.1.2 Evolucija v prostoru pravil
V tem poglavju se bomo omejili na celularni prostor z 2-stanjskimi in 5-sosednostnimicelicami.
• Vsaki celici celularnega modela ALIFE priredimo genotip ali genom, ki spe-cificira tabelo pravil, kar pomeni, da za vsako od 25 = 32 sosednostnihkombinacij podaja 10 bitov (gen), ki opisujejo spremembe stanj sosednjihcelic (biti SC , SN , SE, SS, SW ) in kopiranje pravila sosednjim celicam (bitiCC , CN , CE, CS, CW ).

20 POGLAVJE 2. ALIFE S POMOCJO SPLOSNEGA CA MODELA
Genotip ali genom (tudi kromosom)
Genotip celice sestavlja torej 32 genov.
Indeksi v genu pomenijo
• C - Center
• N - North
• E - East
• S - South
• W - West
Pomen bitov, n.pr. SE in CW :
SE =
{0 : spremeni stanje v E celici na 01 : spremeni stanje v E celici na 1
CW =
{0 : pravilo se ne kopira v W celico1 : pravilo se kopira v W celico
• Celularna struktura deluje tako, da vsaka celica glede na sosednostno kombinacijo(ki doloca njen gen) izvede pravila (spremembe stanj, kopiranje pravila). Za-tem se izvedejo se genetski operatorji (mutacija, krizanje), kot bo razlozeno

2.1. ALIFE MODEL 21
v nadaljevanju.
• Genetski operatorji se izvedejo na naslednji nacin:
Krizanje:V vsakem casovnem koraku vsaka celica v 2D strukturi, n. pr. (i, j) nakljucnoizbere celico v sosescini, n. pr. (in, jn). Krizanje se izvede med genotipiobeh celic z verjetnostjo Pcross, ki doloci na osnovi enakomerne porazdelitvenad geni, mesto (tocko) krizanja (gen). Novi genotip z zamenjanim genom(ali geni, ce jih Pcross doloci vec) nadomesti stari genotip v celici (i, j). Ve-lja asimetrija, kar pomeni, da celica (in, jn) lahko izbere celico (i’, j’) 6= (i,j). To zmanjsuje povezovanje med celicami, kar povecuje lokalnost in splosnost.
Mutacija:Sledi krizanju. Za celico (i, j) oz. njen genotip z verjetnostjo Pmut izbere bit(bite) in ga (jih) invertira. Pri tem so vsi biti vseh genov v genotipu string, kise mutira.
• Pri obravnavi posameznih genov se uporabljajo oznake:
C N E S W → ZC ZN ZE ZS ZW ,
kjer je C N E S W oznaka za konfiguracijo sosedov, Zx pa je dolocen iz tabele:
Cx = 0 Cx = 1Sx=0 Zx=0 Zx= -Sx=1 Zx=1 Zx= +
Primer:
Zapis: 00101 → 01++− pomeni, da sosednostna konfiguracija 00101 speci-ficira
SC = 0, CC = 0; SN = 1, CN = 0; SE = 1, CE = 1; SS = 1, CS = 1 inSW = 0, CW = 1.
• Obstaja pomembna razlika med evolucijo pravil (EP) in GA: pri EP ni me-hanizma selekcije na globalni ravni z uporabo funkcije prileganja. Prileganjeje odvisno od interakcije z okoljem spremenljivega organizma (namestomnozice oz. populacije subjektov).
• ALIFE model oz. njegove zahteve po hardware-skih resursih le v manjsi meripresegajo zahteve glede na CA model.

22 POGLAVJE 2. ALIFE S POMOCJO SPLOSNEGA CA MODELA
ALIFE CAVelikost genoma 320 bitov 32 bitov ∗
Kopiranje pravil DA, zahteva ”memory transfer” NE∗ podatki za simulacijo
• Tipicne vrednosti parametrov pri simulaciji modela ALIFE:
Splosni parametri casovni koraki 3000-30000Velikost mreze 40 x 50
Pcross 0.9Pmut 0.001
Inicializacijski parametri Poperational 0.5p(SX=1) 0.5p(CX=1) 0.5

Poglavje 3
Celularno programiranje
• Ogledali si bomo celularno programiranje na bazi lokalnih genetskih ope-ratorjev, ki omogocajo evolucijo celularnih strojev.
• Celularno programiranje lahko implementiramo v okviru simulacije ali pa st.im. razvijajocim se hardware-om (EVOLWARE = EVOLving hardWARE)
• Celularna struktura bo izvajala racunanje tako, da bo vhod dolocal zacetnokonfiguracijo, izhod racunanja pa bo enak konfiguraciji po dolocenemstevilu korakov. Vmesne konfiguracije so koraki racunanja. Taksna rabaCA je drugacna od tiste, s katero smo implementirali US (univerzalni stroj -MINSKY-jev model).
• Obravnavali bomo 2 globalna in netrivialna problema, “gostoto”in “sinhroni-zacijo”.
• Primerjali bomo standardni GA pristop za razvoj uniformnega CA in lokalniCPA (Cellular programming algorithm) pristop za razvoj ne-uniformnega CA.
3.1 ”Gostota”in standardne resitve
• 1D problem: v 1D CA z 2r+1 sosedi na celico (r ≡ radij) je ρ(0) zacetnagostota enic, ρ(t) gostota enic v casu t in ρc prag gostote.
Ce ρ(0) > ρc, potem se mora CA preslikati v vzorec samih enic, ce pa jeρ(0) < ρc, pa v vzorec samih 0.
Ce je ρ(0) = ρc, je obnasanje nedefinirano, cemur se izognemo z lihim stevilomcelic v CA in z ρc = 0.5
• Ce je r << N (stevilo celic v CA), je problem netrivialen.
23

24 POGLAVJE 3. CELULARNO PROGRAMIRANJE
• Obstaja dokaz ( Land, Belew, 1995) da problem gostote z uniformnim 2-stanjskim CA ni popolnoma resljiv (izhod je 1 sama kombinacija samih 1ali 0)
• Analiticno resitev podaja pravilo GKL (Gacs-Kurdyumov-Levin) s K=2 (st.stanj/celico) in r=3:
Si(t + 1) =
{Majority [Si(t), Si−1(t), Si−3(t)], ce Si(t)=0Majority [Si(t), Si+1(t), Si+3(t)], ce Si(t)=1
Ocenjevalna (”fitness”) funkcija je dolocena kot povprecje stevila pravilnihizhodnih celic preko 100-300 zacetnih konfiguracij, po M korakih (M je dolocens Poisson-ovo distribucijo z µ = 320). GKL daje rezultat ≈ 0,98 (N=149).
• Standardni GA s k=2, r=3, N=149 ima 27=128 dolgo pravilnostno tabelooz. 2128 moznih pravil. GA isce najboljse pravilo, ki glasi na vsako celico(uniformni CA). Rezultati glede na ocenjevalno funkcijo kot v primeru GKLso med 0,93 in 0,95.
Vsako pravilo je bilo uporabljeno M-krat oz. M casovnih korakov (M za vsakopravilo iz Poisson-ove distribucije z µ=320). Ocena vsakega pravila se dolocis povprecenjem deleza pravilnih celic po M korakih, preko 100-300 zacetnihkonfiguracij (nakljucno generiranih z enako verjetnostjo 0 in 1). Pri vsakigeneraciji je generiran nov niz zacetnih konfiguracij in vsa pravila so testiranana njem.
Novo generacijo dobimo tako, da se zgornja polovica kopira, drugo polovicopa dobimo z uporabo krizanja in mutacije nad izbranimi pravili iz trenutnepopulacije.
3.2 “Sinhronizacija”in standardne resitve
Pri poljubni zacetni konfiguraciji mora CA doseci koncno konfiguracijo po M korakih,ki pomeni oscilacijo med samimi 0 in samimi 1. Problem je ne-trivialen, ker jesinhrona oscilacija globalna lastnost.
• Das je leta 1995 objavil resitev s standardnim GA, ki v 20% primerov odkrijeuspesni CA z maksimalnim prileganjem (1).

3.3. CELULARNI PROGRAMSKI ALGORITEM (CPA) 25
3.3 Celularni programski algoritem (CPA)
• Obravnavali bomo 2-stanjski, ne-uniformni CA. Celicna pravila dolocajo ge-notipi.
• Namesto populacije CA, ki se razvijajo skladno s standardnim GA, bo CPA iz-vajal evolucijo nad enim CA, ne-uniformnim, z nakljucnim zacetnimi celicnimipravili.
• Evolucija poteka tako, da se za razlicne, nakljucne zacetne konfiguracije poM korakih doloci prileganje vsake celice posebej na kumulativen nacin. Povsakem teku je ”fitness”funkcija celice 1, ce se stanje celice prilega rezultatuin 0 sicer.
Po C=300 zacetnih nakljucnih konfiguracijah sledi evolucija pravil z uporabokrizanja (lokalno krizanje) in mutacije.
Obicajno je M ≈ N, kjer je N stevilo celic v CA.
CPA:
FOR vsako celico i v CA DO IN PARALLEL
Inicializiraj tabelo pravil (genom) celice i
f_i = 0 {prilagoditev (fitness) i-te celice}
END PARALLEL FOR
c=0 {stevec zacetnih konfiguracij}
WHILE ni konca DO
generiraj nakljucno zacetno konfiguracijo
pozeni CA za M korakov
FOR vsako celico i DO IN PARALLEL
IF celica i je v pravem koncnem stanju THEN
f_i = f_i + 1
END IF
END PARALLEL FOR
c = c + 1
IF c mod C = 0 THEN
FOR vsako celico i DO IN PARALLEL
izracunaj nfi(c) = {stevilo boljsih sosedov}
IF nf_i(c) = 0 THEN pravilo i nespremenjeno
ELSE IF nf_i(c) = 1 THEN zamenjava, mutacija
ELSE IF nf_i(c) = 2 THEN zamenjava s krizancem
boljsih in mutacija
ELSE IF nf_i(c) > 2 THEN zamenjava z krizancem 2
nakljucnih boljsih in mutacija
END IF

26 POGLAVJE 3. CELULARNO PROGRAMIRANJE
f_i = 0
END PARALLEL FOR
END IF
END WHILE
• Krizanje je 1-tockovno (tocka krizanja je nakljucna pri uniformni porazdelitvi),verjetnost krizanja pa doloca Pcross. Mutacija invertira s Pmut izbrane bite vgenotipu.
• Razlika med standardnim GA in CPA:
- GA uporablja evolucijo nad populacijo neodvisnih CA, CPA pa nad 1CAizvaja evolucijo
- GA deluje globalno, CPA pa lokalno, tako kot CA tudi procesira
3.4 Rezultati CPA
• Iskalni prostor pravil v primeru neuniformnih CA je ogromen in bistveno vecjikot pri uniformnih CA:
- uniformni CA: (1D; r=1 → 2r+1=3 )23 = 8 → 28 = 256 razlicnih moznih pravil
- ne-uniformni CA: (1D; r=1; N=149)(28)149 = 21192 ≈ 10400
• WOLFRAMOVA notacija za oznako pravil: (Desetiski ekvivalent binarnegazapisa)PRIMER:
7 6 5 4 3 2 1 0sosednostni biti 111 110 101 100 011 010 001 000
1 1 1 0 0 0 0 0↑ ↑
MSB LSB
(11100000)2 = 22410
PRIMER: pravilo 232:
111 110 101 100 011 010 001 0001 1 1 0 1 0 0 0

3.4. REZULTATI CPA 27
3.4.1 Gostota
• Razvoj pravil pri neuniformnih CA (s pomocjo CPA) kaze, da so pravilaomejena na λ ≈ 0.5 (λ je delez enic v tabeli)
• Pri uniformnih CA dolocimo (r=1) najboljse prileganje (0.83) s pravilom232, ki izvaja majoritetno funkcijo (povprecje preko 1000 nakljucnih zacetnihkonfiguracij)
• S CPA lahko preidemo do rezultata, kjer je dosezeno najvisje prileganje 0,93.(Vecina celic ima pravilo 226, ostale pa drugacna) - evolucija s CPA vodi kkvazi-uniformnim CA. Pravilo 232 dominira tam, kjer je vec 0, 226 pa tam,kjer je vec enic. Pri globalnem prenosu je 226 boljse od 232, zato je 226dominantno pravilo.
• Tipicen CA kot rezultat CPA (r=1) za slucaj gostote daje 3 razlicna pravila(N=149):
vecinsko (146 celic) pravilo je 226
manjsinsko (2 celice) pravilo je 224
manjsinsko (1 celica) pravilo je 234
Vsem 3 pravilom je skupno, da imajo enake vrednosti pri sosednosti 2 in 5:010 → 0, 101 → 1, kar pomeni spremembo centralne celice glede na sosede. Tadva gena pomenita prenos informacije, ki narasca z evolucijo (tako kot stevilouporabljenih genov 2 in 5 v ”genescape”diagramu).
Po genih 1 in 3 se 226 razlikuje od 224 in 234 - ta dva gena sta redko upora-bljena, sta pa bistvena za uspeh CA, saj spreminjata vecinsko cifro v sosedno-stni konfiguraciji in s tem prekinjata doloceno dinamiko (slabo). Gena 0 in 7pa v vseh pravilih ohranjata lokalno stanje.

28 POGLAVJE 3. CELULARNO PROGRAMIRANJE
3.4.2 Sinhronizacija
• Fitness funkcija je naslednja. Ce je gostota enic po M korakih vecja od 0.5,mora slediti sekvenca 0 → 1 → 0 → 1 oz. ce je manjsa od 0.5, mora slediti1 → 0 → 1 → 0...
• Pri uniformnem CA (stand. GA), r=1, je najvecje prileganje 0.84, kar selahko doseze z vec pravili. Za ta (uspesna) pravila je znacilno:111 → 0 in 000 → 1 in 110 → 0 in/ali 001 → 1
• V vecini poizkusov s CPA dobimo prileganje 1. Stevilo pravil varira med 3-9,z 2-3 dominantnimi pravili (r=1).
UGOTOVITEV:
Ne-uniformnost reducira zahteve po povezavah, kar omogoca uporabo manjsegaradija sosednosti.
• Ilustracija problema GOSTOTA (1D):
SLIKA 1 (4.5): Prileganje vseh moznih pravil (r = 1 → 23 = 8 → 28 = 256)za slucaj uniformnega CA
SLIKA 2 (4.8): Primer procesiranja uniformnega CA s pravili 232 (majori-tetno) in 226 (globalni transfer)
SLIKA 3 (4.7): Prikaz tipicnega teka evolucije ne-uniformnega CA (prilega-nje kot funkcija casa oz. konfiguracij)
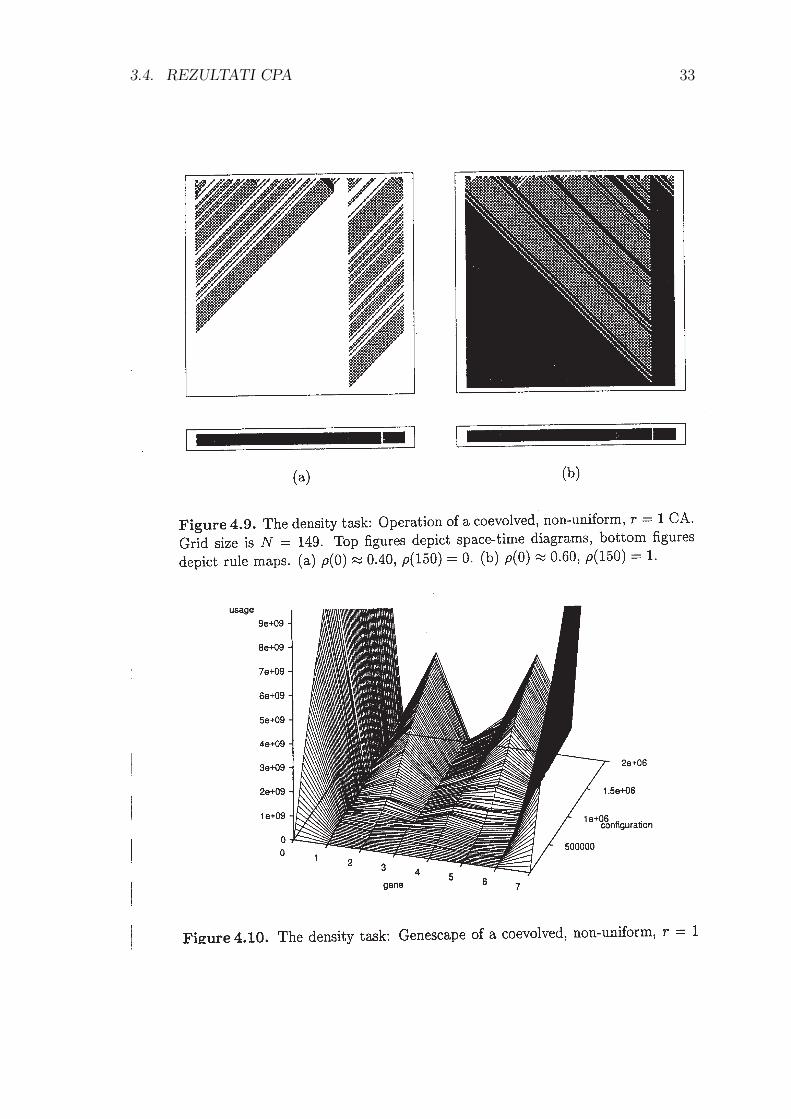
SLIKA 4 (4.9, 4.10): Prikaz evolucije dveh zacetnih konfiguracij z ne-uniformnimCA.
• Ilustracija problema SINHRONIZACIJA (1D):
SLIKA 1 (4.11): Prileganje pravil za slucaj uniformnega CA
SLIKA 2 (4.12): Primer procesiranja uniformnega CA s pravili 21 in 31
SLIKA 3 (4.13): Prikaz evolucije ne-uniformnega CA na dveh nakljucnihzacetnih konfiguracijah
• Ilustracija problema GOSTOTA (2D):Znacilnost 2D: boljse prileganje in krajsi cas procesiranja (manj korakov)
SLIKA 1 (4.14): 2D procesiranje gostote, N = 15 × 15;
a.) ρ(0) = 0.49 → ρ(M) = 0

3.4. REZULTATI CPA 29
b.) ρ(0) = 0.51 → ρ(M) = 1 (M=34)
• Ilustracija problema SINHRONIZACIJA (2D):
SLIKA 1 (4.15): 2D procesiranje sinhronizacije, N = 15 × 15, M=35
3.4.3 Skaliranje razvijajocih CA
Gre za vprasanje, kako lahko rezultat razvite ne-uniformne strukture CA velikostiN uporabimo pri strukturi velikosti N’ (N’ > N ali N’ < N) tako, da bodo ohranjeneoriginalne performanse.
Iscemo postopek (algoritem), ki bo dolocil, katero pravilo uporabimo v vsaki celiciN’ tako, da bo globalno obnasanje N’ enako N.
• Obstajata 2 osnovni strukturi pravil v originalni CA mrezi dimenzije N (pri-kazani v nadaljevanju za r=1 slucaj):
→ Lokalna struktura glede na celico i, i ∈ {0, ..., N − 1} je niz treh pravilv celicah i-1, i in i+1 (predpostavka, da je mreza celularna)
→ Globalna struktura pomeni bloke z identicnimi pravili. Podana je z ni-zom, ki pove za vsak blok pravilo.N. pr.: N=15, 1D, 6 blokov in 5 pravil
R1R1R1R1 R2R2 R3 R4R4R4R4 R1 R5R5R5
Za to mrezo je globalna struktura enaka : R1, R2, R3, R4, R1, R5
• Ce se lokalna in globalna struktura ohranita v mrezi z N’ celicami, potem seohranijo tudi performanse (Sipper, 96). To zahteva ohranitev blokov z 1, 2, 3celicami, ostali bloki pa se lahko spremenijo. N. pr. za zgornjo mrezo z N=15celicami bi dobili na osnovi tega pravila mrezo z N’=25 celicami takole:
4 → 8 4 → 10R1R1R1R1R1R1R1R1 R2R2 R3 R4R4R4R4R4R4R4R4R4R4 R1 R5R5R5
Dokaz: Sinhronizacija N = 149 → N’ = 350 (Sipper, str. 98)
3.4.4 Diskusija k poglavju 3
1. Ne-uniformni CA lahko dosezejo visoke performanse racunanja na ne-trivialnihproblemih

30 POGLAVJE 3. CELULARNO PROGRAMIRANJE
2. Ne-uniformne CA lahko dolocimo z razvojem in ne s snovanjem, saj je stevilokombinacij za to preveliko.
3. Eksperimenti kazejo, da pri r=1 z ne-uniformnimi CA dobimo boljse rezultatekot pri uniformnem CA (priblizno taksne, kot pri uniformnem CA z r=3) →ne-uniformnost reducira zahteve po povezavah, oz. omogoca uporabo CA zmanjsim r.
4. Rezultati evolucije so ”kvazi-uniformne”mreze, kjer nedominantna pravila delu-jejo kot ”bufferji”(za lokalne korekcije)
5. Povprecna Hammingova razdalja nad pravili upada s povecano uspesnostjo pro-cesiranja.

3.4. REZULTATI CPA 31

32 POGLAVJE 3. CELULARNO PROGRAMIRANJE
3.4. REZULTATI CPA 33

34 POGLAVJE 3. CELULARNO PROGRAMIRANJE

3.4. REZULTATI CPA 35

36 POGLAVJE 3. CELULARNO PROGRAMIRANJE

3.4. REZULTATI CPA 37

38 POGLAVJE 3. CELULARNO PROGRAMIRANJE

Poglavje 4
Primeri aplikacij celularnegaprogramiranja
1. KONSTRUIRANJE STEVCEV NA OSNOVI SINHRONIZACIJE
• Namesto ponavljanja samih 0 in 1 (modul 2) lahko iscemo module 4, 8,...
• 2-bitni stevec ima modul m=4. Dobimo ga s pomocjo dveh prepletajocihse CA struktur z r=1:
• 3 bitni stevec dobimo s tremi prepletajocimi CA
39

40POGLAVJE 4. PRIMERI APLIKACIJ CELULARNEGA PROGRAMIRANJA
2. UREJANJEPoljubno vhodno kombinacijo uredimo po M korakih tako, da so vse 0 levopozicionirane, vse 1 pa desno.
• Uniformni CA daje najboljse rezultate (prileganje 0.71) s pravilom 232(majoritetno), pravilo 184 pa deluje 100% ob fiksnih robnih pogojih (0na levi, 1 na desni).
• S CPA pridemo do ne-uniformnega CA s prileganjem 0.93.
3. POLNJENJE PRAVOKOTNIKATo je 2D problem. Na podrocju s povecanim delezem 1 zelimo podrocje za-polniti s samimi 1. Zacetna konfiguracija sestoji iz nakljucno velikih pravoko-tnikov, na poljubnem mestu 2D polja, znotraj katerih je p(1)=0.3, zunaj pap(1)=0. Tudi robne celice imajo p(1)=0.
• S CPA dosezemo povprecno prileganje 0.99.
• 1D verzija problema je zapolnitev linije.
4. TANJSANJE LINIJTo je eden od tipicnih korakov predprocesiranja pri procesiranju (analizi) slik.Problem je, ce je sosednost majhna.
• S CPA lahko pridemo do uspesne strukture CA.
5. NAKLJUCNI GENERATORDober nakljucni generator je problem. V praksi imamo psevdo-nakljucne ge-neratorje:
• Wolfram je studiral realizacijo nakljucnega generatorja z 1D-CA, z 2 sta-nji in r=1 (pravilo 30)
- uniformna izvedba. Zacetna konfiguracija je imela le 1 enico - to jejedro nakljucne casovne sekvence.
- neuniformna izvedba CA nakljucnega generatorja vsebuje 2 pravili (90in 150). Enako dobro deluje, realizacija pa je cenejsa.
• Sipper in Tomassini sta predstavila razvojno verzijo CA, z uporabo CPA
Prilagoditev celice (”fitness”) tukaj je definirano kot entropija H casovne se-kvence po M korakih. V CPA algoritmu je:
fi = fi + Hhi
(entropija casovne sekvence dolzine h=4 celice i). Vsaka celica v 1D CA pred-stavlja 1 nakljucni generator.
Zacetna konfiguracija je dolocena z 48-bitnim linearnim kongruencnim algo-ritmom, CA je pognan za M=4096 korakov. Entropija se racuna s pomocjoverjetnosti pojava kombinacij v drsecem oknu dolzine h=4 (16 kombinacij).

41
Rezultat z ne-uniformnim CA s pomocjo CPA: f = 3, 997, kar je zelo blizumax. entropiji za h=4 (Hmax = log216 = 4).
• Ilustracije skaliranja in aplikacij
Slika 1 (4.16): skaliranje N=149 → N’=350 za problem Sinhronizacije
Slika 2 (5.3): Uniformni CA in urejenost (r=1)
Slika 3 (5.4): S CPA razviti CA (urejenost)
Slika 4 (5.5): “Genescape“ za slucaj urejanja
Slika 5 (5.6): Polnenje pravokotnika s CPA
Slika 6 (5.7): Razporeditev pravil pri CPA
Slika 7 (5.10): Tanjsanje linij s CPA
Slika 8 (5.11): Evolucija nakljucnega generatorja s CPA
Slika 9 (5.12): Nakljucni generator: uniformni, ne-uniformni CA z 2praviloma in s 3 pravili

42POGLAVJE 4. PRIMERI APLIKACIJ CELULARNEGA PROGRAMIRANJA

43

44POGLAVJE 4. PRIMERI APLIKACIJ CELULARNEGA PROGRAMIRANJA

45

46POGLAVJE 4. PRIMERI APLIKACIJ CELULARNEGA PROGRAMIRANJA

47
6. AVTONOMNI ”ON-LINE EVOLWARE”V temu poglavju zelimo pokazati nekatere detajle, vezane na implementacijoCPA algoritma z FPGA komponentami.
• Z danasnjo stopnjo tehnologije (FPGA) je mogoce realizirati ”on line”evolucijo,ki deluje avtonomno, brez vsakega vplivanja od zunaj (zunanjega racunalnika)
• EVOLWARE je rezultat umetne evolucije, pri kateri je glavni cilj sintezaelektronskega vezja.
• Dve karakteristiki klasificirata razvijajoce aparaturne sisteme:
→ prva razlikuje med off-line genetskimi operacijami in on-line postopkievolucije
→ druga pa locuje med nadzirano in nenadzirano evolucijo (z evaluacij-sko funkcijo oz. brez nje - ”open-ended”evolucija)
Glede na ti dve karakteristiki locimo 4 kategorije razvijajoce aparaturneopreme:
A. Software-ska izvedba evolucije na osnovi genetskih operatorjev (OFF-LINE, NADZIRANA). Rezultat se prenese (”download”) v hardware.
B. Evolucija se izvaja software-sko, nadzor pa hardware-sko (OFF/ON-LINE, NADZIRANA).
C. Vsi genetski operatorji se izvajajo on-line aparaturno, evolucija pa jenadzorovana (ON-LINE, NADZIRANA) - sem sodi ”FIRE-FLY”.
D. Evolucija poteka aparaturno v ”open-ended”okolju (ON-LINE, OPEN-ENDED ali NENADZIRANA) Sem sodijo zivi organizmi.
• Implementacija CPA z FPGAKrizanje in mutacijo bomo zamenjali z enim operatorjem - uniformnimkrizanjem. Nov genotip bo nastal iz dveh genotipov (starsev) tako, dabo vsak bit potomca dolocen s 50% verjetnostjo vsakega prednika.CPA se zato spremeni v enem detajlu
ELSE IF nf_i(c) = 1 THENzamenjaj pravilo i s prileganim sosedovim pravilom (brez mutacije)
ELSE IF nf_i(c) = 2 THENzamenjaj pravilo i z uniformnim krizanjem dveh prileganih sosedovoz. njunih genotipov (brez mutacije)
Slika podaja arhitekturo ene celice:

48POGLAVJE 4. PRIMERI APLIKACIJ CELULARNEGA PROGRAMIRANJA
Locimo naslednje faze:
→ Inicializacija: pravilo se zapise z nakljucnimi vrednostmi (enkrat zavsak evolucijski tek)
→ Eksekucija: pravila se ne spreminjajo za cas C × M korakov (C jestevilo konfiguracij, vsaka se izvaja M korakov). Konfiguracija sezapise z nakljucnimi vrednostmi.
→ Evolucija: glede na nfi(c) se pravilo ali ohranja (nfi(c)=0), zamenjaza levega ali desnega (nfi(c)=1), ali zamenja za krizanega (nfi(c)=2).

Poglavje 5
Programirne logicne naprave
5.1 Programirna integrirana vezja
(”Programmable Integrated Circuits”, PIC)
• Integrirana vezja imenujemo programirna, kadar lahko uporabnik konfigu-rira njihove funkcije s programiranjem. Proizvajalec dostavlja vezje v t.im.genericnem stanju, uporabnik pa ga lahko s programiranjem adaptira nadoloceno funkcijo.
• Obstaja vec metod programiranja z varovalkami, pomnilnimi celicami itd),vendar v nobenem primeru ne potrebujemo proizvajalca. To predstavlja pred-nost pred vezji GA (”gate array”), SC (“standard cell”) ali ASIC predvsem vhitrem snovanju prototipov in seveda v nizji ceni snovanja in procesira-nja.
• Obstajajo 3 tipi PIC vezij:
→ POMNILNIKI: njihova funkcija je shranjevanje informacij na permanenten(’non-volatile’) (ROM) ali spremenljiv (’volatile’) (RAM) nacin.
→ MIKROPROCESORJI: omogocajo programiranje z uporabo danega nizainstrukcij.
→ LOGICNA VEZJA: programirna funkcija je logicna funkcija od decisijskihdo sekvencnih. V nadaljevanju bomo obravnavali samo ta vezja.
49

50 POGLAVJE 5. PROGRAMIRNE LOGICNE NAPRAVE
5.1.1 Programirna logicna vezja
• Znano je, da je mogoce realizirati vsako decizijsko (Boolovo) funkcijo z elemen-tarnim sistemom operatorjev (AND, OR, NOT), ki je tudi funkcijsko polnsistem. Tudi (NAND) in (NOR) sta funkcijsko polna sistema.
• Univerzalna funkcija n spremenljivk je naprava, ki je sposobna realiziratisama poljubno funkcijo n spremenljivk. Sem sodijo multipleksor, demultiple-ksor in pomnilnik.
• Programabilno logicno vezje je v splosnem polje funkcijsko polnih napravali univerzalnih funkcij. V prvem primeru so povezave med napravamiprogramirane, zato da lahko implementiramo doloceno funkcijo; v drugem pri-meru so programirane tako univerzalne funkcije kot povezave med njimi.
Zato je mogoce klasificirati programabilna logicna vezja glede na interno or-ganizacijo in glede na tip programiranja.
• Locimo 3 tipe notranje organizacije:
→ PLD (Programmable Logic Device)
→ CPLD (Complex PLD)
→ FPGA (Field Programmable Gate Array)
in 2 tipa programiranja
→ Neponovljivo (”irreversible”): varovalke se prizgejo (poti nazaj ni)
→ Reprogramabilno: pomnilne celice kontrolirajo programirne povezave innotranje funkcije. Program je mogoce zbrisati z UV svetlobo (EPROMtehnologija) ali elektricno (EEPROM tehnologija). Slednja varianta jecenejsa in bolj fleksibilna (brez okenca, moznost reprogramiranja po de-lih)
• Kratka zgodovina programirnih logicnih vezij:
→ Prvo PLV je bilo izdelano v 60 letih (Harris), kot polje diod, programiranoz varovalkami.
→ Prvi komercialni uspeh sega v leto 1978 z vezjem PAL16L8 firme MonolithicMemories (MMI). Uspeh je bil posledica spremljajocega softwarea, ki jeomogocal generiranje programske datoteke iz enacb. Uporabljen je bilFORTRAN.

5.1. PROGRAMIRNA INTEGRIRANA VEZJA 51
5.1.2 Programirne logicne naprave (PLD)
• Vsako kombinacijsko logicno funkcijo je mogoce izraziti z vsoto produktov (vlogicnem smislu): PDNO → DNO → MDNO.
• Osnovna arhitektura PLD sledi zgornjemu dejstvu. Sestavlja jo polje ANDvrat in polje OR vrat:
Taksno arhitekturo pisemo tudi v obliki:
X YAND OR
• Parametri kompleksnosti PLD so: stevilo vhodov, stevilo produktov (AND)in stevilo izhodov (OR).
• Glede na mesto programiranja v PLD locujemo:
→ PROM: programira se samo OR polje
X YX
→ PAL: (Programmable Array Logic): programira se samo AND polje
X YX
→ PLA: (Programmable Logic Array): programirata se AND in OR polje
X YX X
Primeri vezij:

52 POGLAVJE 5. PROGRAMIRNE LOGICNE NAPRAVE
• Pri uporabi varovalk na mestih X so na zacetku varovalke sklenjene, s progra-miranjem pa jih razklenemo. (Pri ”anti-fuse”varovalkah pa je ravno obratno).
Elemente EPLD (Erasable PLD) je mogoce programirati z EPROM ali EE-PROM celicami.
• Ceprav so PLA vezja najbolj fleksibilna, pa se manj uporabljajo kot PAL.Vecje stevilo varovalk pomeni vecje tezave pri programiranju in pocasnejsedelovanje vezja.
• Za realizacijo sekvencnih vezij je bil k PAL vezju dodan FF. Taksna vezjaimenujemo sekvencna PAL vezja.
• S casom so bile k PAL vezjem dodane opcije za: programiranje polariteteizhodov, uporaba XOR vrat.

5.1. PROGRAMIRNA INTEGRIRANA VEZJA 53
• V splosnem velja, da je s PLD vezjem mogoce nadomestiti 5 do 15 standardnihTTL vezij.
5.1.3 Kompleksna PLD vezja (CPLD)
• PLD vezja imajo dve omejitvi:
→ ni mogoce realizirati vecnivojskih funkcij
→ ni mogoce deliti skupnih produktov pri razlicnih funkcijah
Vzrok je v tem, da ni mogoce povezovati funkcij med seboj. CPLD je bil razvitz namenom, da odpravi te pomanjkljivosti.
• CPLD vezja sestavljata 2 elementa:
→ programabilna celica, ki realizira univerzalno funkcijo n-spremenljivk. Pritem je moznih vec implementacij MX, pomnilnik, AND-OR polje, itd.
→ povezovalna mreza (”interconnection network”), ki izbira vhode v progra-mabilne celice izmed zunanjih vhodov in izhodov celic.
• Tipicen predstavnik CPLD arhitekture je vezje MAX firme ALTERA:

54 POGLAVJE 5. PROGRAMIRNE LOGICNE NAPRAVE
Lastnosti:
→ Logicne funkcije v LAB (Logic Array Block) so programabilne (16 celic, 32AND vrat)
→ Celice so preproste: FF + vsota 3 produktov
→ Dodatna AND vrata si lahko delijo vse celice znotraj LAB
→ Izhod iz celice gre lahko na izhodni pin ali preko PIA na drugo celico
• Obstaja pomembna razlika med CPLD in FPGA: pri CPLD je programabilnostpovezav omejena s tem, da obstaja samo ena mozna povezava med dvematockama. To pa vnasa prednost: casovne zakasnitve so vnaprej napovedljive,kar ni slucaj pri FPGA vezjih.
5.2 FPGA vezja
• FPGA vezje je polje logicnih celic znotraj povezovalne infrastrukture

5.2. FPGA VEZJA 55
• Vsaka LC je univerzalna funkcija ali funkcijsko polna logicna naprava, kiomogoca s programiranjem realizacijo zelene funkcije.
• Povezave med celicami so programabilne in razlicnih tipov (za razliko odCPLD). Obstaja tudi vec poti med dvema tockama, zato napovedovanje casovnihzakasnitev na poti med 2 tockama ni mozno vnaprej (pred koncnim “routing“-om).
• I/O celice so programabilne, vendar z manj moznostimi kot LC. (Izbiramolahko smer informacije, pomnilni element, elektricni nivo).
• Bistvena prednost FPGA pred GA (Gate Array) je v hitrosti snovanja in ceni.Logicne kompleksnosti pa so primerljive. Pri kolicini nad 10.000 je cena GAugodnejsa. Zato so ta vezja namenjena izdelovanju prototipov v seriji do nekajtisoc kosov.
• FPGA vezja delimo v 2 veliki druzini, glede na nivo kompleksnosti logicnihcelic:
→ ”fine-grained”vezja - vsaka celica vsebuje nekaj funkcijsko polnih naprav(n. pr. NAND, NOR) ali nekaj univerzalnih funkcij z nizko kompleksno-stjo (n. pr. MX 2/1, 4/1).
Ta vezja imajo zelo razvejane povezave, kar otezkoca ”routing”. Slednjekompenzira optimalna celicna izkoriscenost.
Primeri: CROSSPOINT (par tranzistorjev), ALGOTRONIX (MX 2/1),CONCURRENT LOGIC (nekaj vrat razlicnih tipov), ACTEL (MX 4/1),QUICKLOGIC (MX 4/1)
→ ”coarse-grained”vezja - LC je univerzalna funkcija z vec vhodi (obicajno”look-up”tabela oz. RAM)
Primeri: XILINX (9 spremenljivk)
• Za dano funkcijo zahteva “coarse-grained“ FPGA manj celic in manj povezavkot “fine-grained“ FPGA, vendar je izkoriscenost prostora integrirane kompo-nente slabsa.

56 POGLAVJE 5. PROGRAMIRNE LOGICNE NAPRAVE
• Pri racunanju kompleksnosti FPGA pride pogosto do napak, ker se ne uposteva% uporabljenih celic: proizvajalec doloca kompleksnost s produktom stevilacelic in stevila vrat na celico. To pa je tezko doseci, zlasti pri “coarse-grained“FPGA.
5.2.1 Programirne tehnologije
• Po nacinu programiranja delimo FPGA vezja v 2 skupini:
→ Staticna RAM tehnologija: vsaka programirna tocka je kontrolirana z1 bitom staticnega RAM-a.Prednost: je v moznosti reprogramiranjaSlabost: 1 staticni RAM bit zahteva najmanj 5 tranzistorjev, kar pomeniveliko porabo silicija.
→ ANTI-FUSE tehnologija: vsaka programirna tocka je kontrolirana zantivarovalko, kot pri PLD.Normalno stanje (ODPRT - visoka impedanca). Z visoko napetostjo gaspremenimo v programirano stanje (SKLENJEN - nizka impedanca)Slabost: ni mogoce reprogramiranjePrednost: majhne zakasnitve
5.2.2 Proces snovanja
• Zaradi visoke stopnje fleksibilnosti obstaja tudi pri snovanju visoka stopnjasvobodnih odlocitev. Omejitev predstavlja prakticno le hitrost prenosa signa-lov od vhoda na izhod. (Proizvajalec podaja frekvenco glede na 1 sam blok)
1 → Prvi korak pri snovanju je specifikacija, podana ali v naravnem jezikuali v formalnih specifikacijah (logicni diagram, booleanove enacbe, opisnijezik (HDL) ali mesano). Koncni rezultat mora biti logicni diagram.Komponente za realizacijo logicnega diagrama dobimo iz knjizice proi-zvajalca.
2 → Sledi delitev in pozicioniranje, ki vsako komponento logicnega dia-grama preslika v doloceno stevilo logicnih blokov FPGA vezja ter dolocipozicijo teh blokov. Ce stevilo blokov ni zadostno, vzamemo vecji FPGAali pa problem razbijemo na vec manjsih.
3 → Sledi faza povezovanja (”routing”), ki realizira povezovanje logicnihblokov. Obicajno je 75% koriscenost blokov meja za uspesno povezovanje.
4 → Na vrsti je casovna simulacija, saj je sele po fazi povezovanja moznaanaliza casovnih zakasnitev. Obicajno je to zelo zahtevna in dolgotrajnafaza. Ob uspesnem koncu je FPGA pripravljen za programiranje.

5.3. XILINX VEZJA 57
5 → Faza programiranja vpise vse kontrolne bite v FPGA vezje.
Za vse faze obstajajo programi, vendar se obicajno sodeluje “rocno“ v fazah 2in 3.
5.3 XILINX vezja
• XILINX je prvi proizvajalec FPGA (od 1984), ki se imenujejo LCA (Logic CellArray).
• Obstaja druzina LCA vezij (serije 2000, 3000, 4000, 5200, Spartan, Virtex).Vse sodijo v “coarse grained“ FPGA vezja, s staticnim RAM-om kot progra-mabilno tehnologijo.
5.3.1 Arhitektura blokov
• Kompleksnost funkcijskega bloka (CLB - Configurable Logic Block) zavisi oddruzine, vendar je v vseh primerih osrednji del RAM oz. LUT (Look-Up Table)v katerega se programira pravilnostna tabela logicne funkcije.
• CLB druzine 4000:

58 POGLAVJE 5. PROGRAMIRNE LOGICNE NAPRAVE
Ima naslednje karakteristike:
→ ima do 2 izhoda, ali kombinacijska (X,Y), ali sekvencna (Q1, Q2)
→ mozno je generirati poljubni dve kombinacijski 4-vhodni funkciji, poljubno5-vhodno kombinacijsko funkcijo ali nekaj kombinacijskih 9-vhodnih funk-cij
→ kombinacijske funkcije se generirajo z 2 LUT, ki se lahko uporabljata tudikot RAM. V slednjem primeru lahko dobimo naslednje konfiguracije:16 X 2 RAM, 32 X 1 RAM, dva 16 X 1 RAM ali 16 X 1 RAM in kombi-nacijsko funkcijo s 4 spremenljivkami.
→ Oba FF imata globalni SET/RESET signal in individualne programirnesignale. Polariteto ure je mogoce programirati. FF lahko uporabljamoneodvisno od logicnih funkcij bloka.
• Vsak vhodno/izhodni blok (IOB) kontrolira vec lastnosti pina v vezje: smer,nivo napetosti, hitrost, pomnilnik itd. IOB druzine 4000:

5.3. XILINX VEZJA 59
• Osnovne znacilnosti nekaterih druzin:
2000 3000 4000Max st. CLB 100 320 900Max st. FF 174 928 2280Max st. IOB 74 144 240
st funkcij/CLB 2 2 3st vhodov/CLB 4 5 9
Max st. RAM bitov 0 0 28800st. izhodov/CLB 2 2 4
5.3.2 Struktura povezav
• Obstajajo 3 tipi povezav:
→ DIREKTNE: izhod X vsakega bloka je povezan direktno z bloki, ki so hori-zontalno sosednji in izhod Y je povezan direktno z bloki, ki so vertikalnososednji
→ SPLOSNO NAMENSKE (”general purpose”): to so kratke linije med CLB,horizontalne in vertikalne. Na sticiscu je Preklopna matrika (“Switchingmatrix“), ki omogoca nekaj povezav med linijami:

60 POGLAVJE 5. PROGRAMIRNE LOGICNE NAPRAVE
→ DOLGE LINIJE: gredo po horizontali in vertikali preko celotnega vezjabrez uporabe Preklopne matrike. Njihovo stevilo je manjse od splosnonamenskih linij - rezervirane so za casovno kriticne signale.
5.3.3 Programiranje
• Konfiguracijo XILINX vezij se doloci s programiranjem LUT za vsak logicniblok in bitov (RAM) za kontroliranje povezav. Druzina 4000 ima 350 bitovza konfiguriranje CLB in ustreznih povezav. Te programirne bite generirasoftware “placement & routing“ in sicer v formatu, ki omogoca programiranjepomnilnika (PROM).
• Nalaganje bitov konfiguracije je mogoce v sestih razlicnih nacinih, ki se izberejoob “start-up“ vezja.
→ 3 nacini so tipa MASTER - konfiguracija je v tem primeru zapisana vPROM vezju, povezanem z XILINX vezjem. FPGA kontrolira dostopdo PROM, generiranih adres in casovnih signalov. PROM se lahko citaparalelno (8 bitov) ali serijsko (1bit). V prvem primeru se adresa lahkogenerira v narascajocem ali v padajocem vrstnem redu. Vendar je v vsehslucajih informacija zapisana v FPGA serijsko.
→ 2 nacina sta PERIFERNA, kar pomeni, da nalaganje kontrolira zunanjanaprava (v splosnem ”host processor”), povezava z FPGA z 8-bitnimvodilom. Urin signal za serijski sprejem je lahko interni ali eksterni.
→ 1 serijski SLAVE nacin je podoben perifernemu, le da je realiziran serijsko.
• Nalaganje konfiguracije XILINX vezja zahteva vec milisekund, v tem casu jevezje neuporabno. Tudi ni mogoce konfigurirati le dela vezja. Novejse druzinepa omogocajo tudi to (VIRTEX).

5.4. ACTEL VEZJA 61
5.4 ACTEL vezja
• FPGA vezja firme ACTEL predstavljajo “fine grained“ logicne bloke, katerihprogramiranje bazira na “anti-fuse“ elementih in so zato nereprogramabilna
• Antivarovalke se imenujejo PLICE (Programmable Low Impedance CircuitElement)
• Obstajajo 3 druzine: ACT1, ACT2, ACT3
5.4.1 Arhitektura blokov
• ACT1 vsebuje samo kombinacijske bloke, ki bazirajo na univerzalnosti MX.Vsak blok ima 8 vhodov in 1 izhod, vsi so dostopni na povezovalnih linijah:
• Pri ACT2 je k nekaterim blokom dodan D-FF in tudi kombinacijski del jespremenjen:

62 POGLAVJE 5. PROGRAMIRNE LOGICNE NAPRAVE
• Razlika med ACT2 in ACT3 je le v hitrosti (ACT3 je hitrejsi).
• Tudi I/O bloki pri ACT1 in ACT2 so enostavnejsi kot pri XILINX. Vsak pinvezja je lahko konfiguriran kot vhod ali izhod, ni pa pomnilnih elementov vI/O blokih.ACT3 ima vecje I/O bloke z D FF za shranjevanje signalov.
• Edina “tri-state“ vrata, dostopna v vezjih ACTEL, so v I/O blokih. Izhodnisignali so lahko “tri-state“, interni pa ne.
• Osnovne znacilnosti ACTEL vezij:
ACT1 (1010) ACT2 (1225) ACT2 (1240) ACT2 (1280) ACT3 (1460)st. logicnih blokov 295 451 684 1232 768
st. vrat 1200 2500 4000 8000 6000max st. I/O blokov 57 82 104 140 168
max st. FF-ov 147 341 565 998 768
5.4.2 Struktura povezav
• Obstaja dva tipa povezovalnih linij: horizontalne in vertikalne linije. 8vhodnih signalov vsakega logicnega bloka je povezanih na horizontalne linije(4 na vsaki strani), izhodni signal pa je povezan na vertikalno linijo. Na vsakempreseciscu dveh linij razlicnih tipov se nahaja anti-varovalka.
• Stevilo linij zavisi od druzine: 22 horizontalnih linij med dvema vrsticamalogicnih blokov pri ACT1 in 36 pri ACT2. ACT1 ima 13 vertikalnih linij nastolpec logicnih blokov.
• ACTEL zagotavlja, da so na katerikoli povezavi med dvema poljubnima tockamanajvec 4 anti-varovalke.

5.4. ACTEL VEZJA 63
5.4.3 Programiranje
• ACTEL-ov software za “placement“ in “routing“ generira datoteko s konfigu-racijskim stanjem vsake anti-varovalke (“fusemap“). Ta informacija se moraprenesti v programirano napravo (ACTIVATOR), ki generira potrebno nape-tost za zazig antivarovalk v dani konfiguraciji. Celoten programirni procestraja vec minut.
Nalaganje datoteke v ACTIVATOR uporablja serijska vrata “host“ racunalnika,kjer je datoteka zgrajena.
• Rekonfiguracija ni mogoca.

64 POGLAVJE 5. PROGRAMIRNE LOGICNE NAPRAVE

Poglavje 6
Porazdeljeno (paralelno)procesiranje
6.1 Klasifikacija racunalniskih arhitektur
MICHAEL FLYNN (1966) je postavil znamenito klasifikacijo racunalniskih arhitek-tur:
→ SISD (Single Instruction stream, Single Data stream)Model SISD arhitekture:
Ima 1 CPU, ki izvaja 1 instrukcijo naenkrat in dostavlja ali shranjuje 1 podateknaenkrat. SISD racunalniki uporabljajo 1 register (PC-programski stevec), kiomogoca serijsko izvajanje instrukcij.
→ SIMD (Single Instruction stream, Multiple Data stream)Model SIMD arhitekture:
65

66 POGLAVJE 6. PORAZDELJENO (PARALELNO) PROCESIRANJE
Ima 1 CPU, ki izvaja 1 instrukcijski niz (“stream“), vendar ima vec PE. CPUgenerira krmilne signale za vse PE, ki izvajajo isto operacijo nad razlicnimipodatki (”multiple data stream”). Vsak PE ima svoj podatkovni niz.
Obicajno se uporablja pri problemih z visoko stopnjo majhno-zrnatega para-lelizma.
Primeri: ILLIAC IV, DAP, CM-2 (Connection Machine).Lahko podpirajo vektorsko procesiranje.
→ MISD (Multiple Instruction stream, Single Data stream)MISD racunalniki lahko izvajajo vec razlicnih programov nad enim samim po-datkovnim nizom:
Sem sodijo tudi “cevovodne“ (“pipelined“) arhitekture, npr. sistolicna polja.
→ MIMD (Multiple Instruction stream, Multiple Data stream)Imenujemo jih tudi multiprocesorji. Vsak od procesorjev lahko izvaja razlicen

6.2. PARALELNE ARHITEKTURE 67
program nad razlicnim nizom podatkov.
Pri vecini MIMD racunalnikov ima vsak procesor dostop do globalnega pomnil-nika, poleg tega pa ima se privatni pomnilnik. Uporabljajo se pri srednjemali veliko-zrnatem paralelizmu. Stevilo procesorjev je manjse kot pri SIMD.So najbolj kompleksni, v bodocnosti se pricakuje kompletna povezljivost medprocesorji. Primer: Intel iPSC, BBN Buterfly, Alliant FX.
6.2 Paralelne arhitekture
• Relacija med paralelnimi arhitekturami in klasifikacija Flynn-e:
V nadaljevanju se bomo omejili na dve najbolj zanimivi arhitekturi, na SIMDin MIMD.
68 POGLAVJE 6. PORAZDELJENO (PARALELNO) PROCESIRANJE
6.2.1 SIMD arhitekture
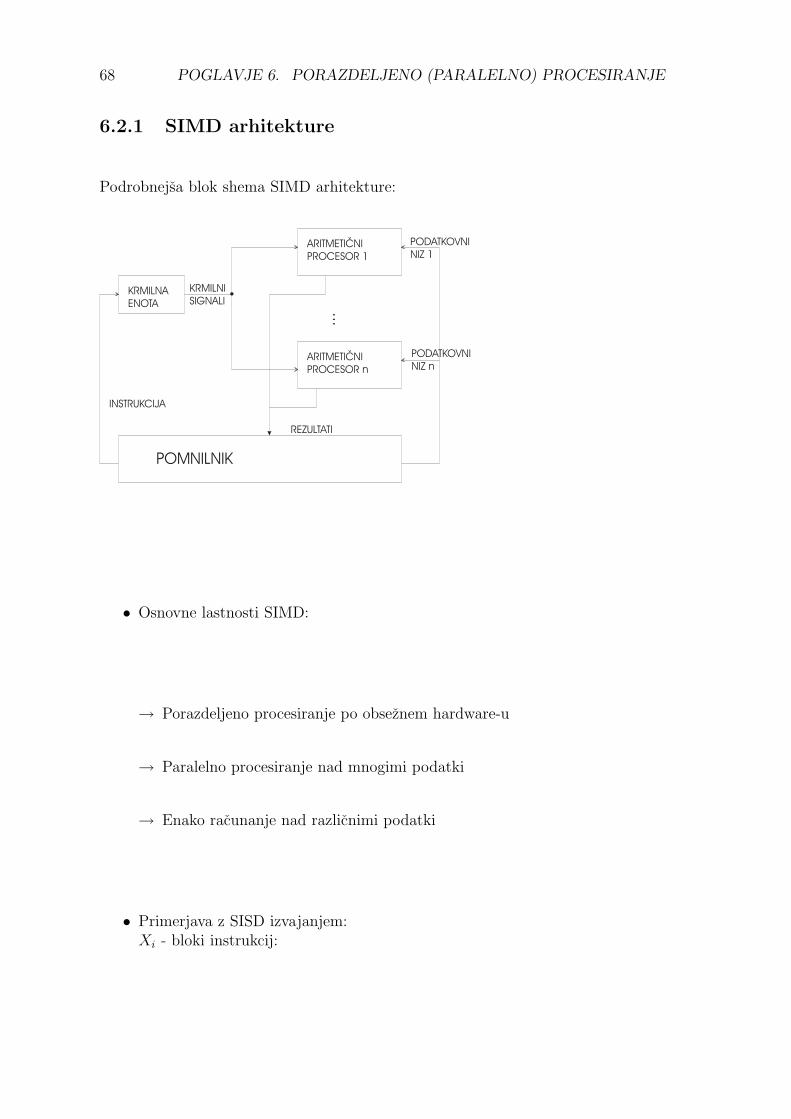
Podrobnejsa blok shema SIMD arhitekture:
• Osnovne lastnosti SIMD:
→ Porazdeljeno procesiranje po obseznem hardware-u
→ Paralelno procesiranje nad mnogimi podatki
→ Enako racunanje nad razlicnimi podatki
• Primerjava z SISD izvajanjem:Xi - bloki instrukcij:

6.2. PARALELNE ARHITEKTURE 69
• Splosna struktura SIMD s poljem 16 PE in eno krmilno enoto je podana nasliki:
Za procesno polje veljajo naslednje prostostne stopnje:

70 POGLAVJE 6. PORAZDELJENO (PARALELNO) PROCESIRANJE
– struktura PE
– struktura krmilne enote
– pomnilne strukture
– povezovalna topologija
– vhodne/izhodne strukture
Glede na procesiranje v polju PE locimo 2 tipa SIMD strojev:
– izvajajo bitne operacije (MPP, CM-1,2)
– izvajajo besedne operacije (ILLIAC IV)
• Eden najatraktivnejsih predstavnikov SIMD racunalnikov je CONNECTIONMACHINE (proizvajalec ”Thinking Machine Corporation”)
→ Osnovna ideja CM je, da se podatki razprsijo po omrezju in da se s temreducira breme posameznega pomnilnika
→ CM-1: izvaja 1 niz instrukcij na osnovi 1 krmilne enote, ki poganja vsePE. Baziral je na semanticnem omrezju, tj. podatkovni strukturi, kise je uporabljala v UI (umetni intelegenci) za modeliranje mozganskihsposobnosti z manipuliranjem nestrukturiranih podatkov.
→ CM-2: je fino-zrnat SIMD z mnozico od 4096 do 65536 procesorjev. Vsakprocesor je sirine 1 bita in ima od 65.536 do 262.144 bitov lokalnega po-mnilnika. CM-2 sestoji iz enega do stirih FE (front-end) racunalnikov,PPU (Paralelne procesne enote) in I/O sistema, ki podpira masovni po-mnilnik in graficne naprave.
FE racunalnik krmili procesorje. Po distribuciji podatkov se instrukcija posljeod FE k vsem procesorjem. Sledi njena eksekucija nad podatki vsakega pro-cesorja. Slika:

6.2. PARALELNE ARHITEKTURE 71
CM-2 predstavlja premik od simbolicnega k numericnemu procesiranju. CMparalelni instrukcijski niz (PARIS - PARallel Instruction Set) vsebuje bogatniz paralelnih primitivov od preprostih aritmeticnih in logicnih operacij dosortiranja in komunikacijskih operacij.
6.2.2 MIMD arhitekture
• To so multiprocesorski oz. multiracunalniski sistemi, kjer ima vsak procesorlastno krmilno enoto in izvaja lasten program.
Osnovne znacilnosti MIMD sistemov:
→ Procesiranje se distribuira preko stevilnih neodvisnih procesorjev
→ Resursi se delijo med procesorje, vstevsi glavni pomnilnik
→ Vsak procesor deluje neodvisno in sproti (paralelno, “concurrently“)
→ Vsak procesor izvaja lasten program
• MIMD arhitekture se razlikujejo po povezovalnem omrezju, procesorjih, nacinihadresiranja, sinhronizaciji in po krmilnih strukturah.
Primeri MIMD: Cosmic Cube, iPSC, Symetry, FX-8, FX-2800, TC-2000, CM-5, KSR-1, Paragon XP/s.
• Med MIMD sistemi locujemo: tesno sklopljene in sibko sklopljene sisteme(”tightly coupled”, ”loosely coupled”), glede na to, kako procesorji dosegajo

72 POGLAVJE 6. PORAZDELJENO (PARALELNO) PROCESIRANJE
pomnilnike ostalih procesorjev.
Tesno sklopljene imenujemo tudi “Shared Memory“ sistemi, ker si delijoen globalni pomnilnik. Sibko sklopljeni si tudi lahko delijo pomnilnik, vendarimajo se lokalne pomnilnike. Imenujejo se tudi “Message-Passing“ sistemi.
Tesno sklopljen MIMD sistem: (GM-MIMD) global memory
Sibko sklopljen MIMD sistem: (LM-MIMD) local memory
• Primerjava SIMD in MIMD:
SIMD:
→ Manj hardwarea (kot MIMD) zaradi 1 krmilne enote
→ Manj pomnilnika, samo 1 kopija instrukcije v pomnilniku
→ Krajsi cas (“start up“) za komuniciranje s sosednjimi procesorji
→ Enostavnejse programiranje in testiranje (“debugging“)

6.3. DATA FLOW ARHITEKTURE 73
→ Instrukcije za kontrolo programskega toka se izvajajo v krmilni enoti, ostalev procesorjih
→ Potrebuje se sinhronizacija med procesorji po vsaki instrukciji, pri MIMDsinhronizacija primitivov ni nujna
MIMD:
→ Vsak procesor ima shranjen program in OS
→ Omogoca funkcijski in podatkovni paralelizem (razlicni programi nad razlicnimipodatki)
→ Vec hardware-a zaradi vec krmilnih enot
→ Ni potrebno prenasati instrukcij
→ Mogoca je uporabiti splosen mikroprocesor na mestu procesne enote
→ Vsak procesor lahko sledi katerikoli poti pri eksekuciji pogojnega stavka.Pri SIMD vsi procesorji najprej sledijo eni poti (”then”), potem pa drugi(”else”), pri cemer se v obeh primerih nekateri procesorji maskirajo (gledena podatke).
→ Procesorji so lahko cenejsi in bolj zmogljivi kot pri SIMD
→ Zaradi neodvisnega procesiranja je:
TMIMD = MaxPE ∗∑instr.(instr.time) (Max-of-Sums)
TSIMD =∑
instr. MaxPE(instr.time) (Sums-of-Max)
→ MIMD sistemi lahko delujejo v SIMD nacinu
6.3 Data flow arhitekture
• Tukaj vrstni red izvajanja ne doloca krmilna enota, temvec dostopnost podat-kov. Ce so podatki za vec instrukcij dostopni v istem casu, potem se ustrezneinstrukcije lahko izvedejo paralelno
• Osnova za arhitekturo sestoji iz t.im. data flow modela racunanja
• Programer opisuje racunanje z data flow grafom, kjer vozlisca ustrezajooperacijam povezave pa dolocajo, kam se prenasajo rezultati. Vsak proces invsaka povezava se oznacita z imeni, ki se uporabijo v t.im. data graf jeziku
• Primer:Izraz: X = (A + B) * (C - D)Izvedba s konvencionalno arhitekturo:
Add A, BStore T1

74 POGLAVJE 6. PORAZDELJENO (PARALELNO) PROCESIRANJE
Sub C ,DStore T2
Mult T1, T2
Store X
Potrebujemo 6 operacij. A, B, C, D, X, T1, T2 pa so simbolicna imena zapomnilne lokacije. Z data flow arhitekturo lahko izkoristimo naravno paralel-nost na osnovi grafa:
Pravokotniki ustrezajo vozliscem, povezave pa dolocajo pot rezultatom.
• Lastnosti data flow arhitektur:
→ Arhitektura se mora rekonfigurirati med izvajanjem racunanja
→ Vozlisca morajo izvajati razlicne pomozne funkcije n.pr. uvrscanje podat-kov (“queueing“). Ce en operand obstaja na vhodu procesne enote, drugipa se ne, je potrebno obstojeci operand shraniti v vrsto, ter pocakati nadrugega.
→ Ne pripadata niti SIMD niti MIMD sistemom
• Data flow arhitekture dosegajo visoko prepustnost, ker je algoritem racunanjaprikazan na najbolj fini stopnji granulacije paralelizma (”finest grain paralle-lism”) in zato dopusca maksimalno stopnjo socasnosti procesiranja.
• Obstajajo 3 kategorije data flow arhitektur:
→ Staticna arhitektura:lahko izvede samo en programski graf. Ce naj bo program poljuben, topomeni, da smo tezo problema prenesli na fazo kompilacije. Ne podpiraklicev procedur, rekurzij in polj.
→ Rekonfigurabilna staticna arhitektura:sestoji iz stevilnih procesorjev, za katere se medsebojne logicne povezavevzpostavijo ob nalozitvi programa za eksekucijo. To pomeni, da odlocitve

6.4. PRINCIPI SNOVANJA PARALELNIH ALGORITMOV 75
o povezavah sprejme prevajalnik in da program ostaja fiksen med ekse-kucijo.
Ta arhitektura zahteva: obstoj fizicnih povezav in vecje stevilo dosegljivihprocesorjev, kot je zahtevano minimalno stevilo. Primer: MIT DF, LAV,DDP (Texas Instruments)
→ Dinamicna arhitektura:dopusca evaluacijo programov dinamicno. Logicne povezave med pro-cesorji se lahko spremenijo med izvajanjem programa. Primer: MDM,Sigma-1, LDF100
6.4 Principi snovanja paralelnih algoritmov
• Paralelni algoritem je definiran kot niz procesov ali opravil, ki se lahko izvajajohkrati in lahko komunicirajo med seboj s ciljem, da resijo dolocen problem.
• Pri paralelnih arhitekturah obstajajo pojmi/izrazi, ki jih pri sekvencnih nenajdemo n. pr.: stevilo procesorjev, lokalna/globalna pomnilna organizacija,sinhronsko/asinhronsko izvajanje, povezovalne topologije.
• Pri paralelnih algoritmih najdemo pojme/izraze, ki jih pri sekvencnih algorit-mih ni: potrebno stevilo procesov, alokacija podatkov v pomnilniku, interpro-cesne komunikacijske zahteve itd.
• Za uspesno uporabo paralelnih sistemov je potrebno dobro prileganje algori-temskih zahtev in arhitekturnih moznosti.
Paralelnost zavisi od:
→ kako so dosegljivi podatki
→ kako lahko podatke delimo po opravilih
→ kako alociramo opravila po procesih
→ kako so procesi sinhronizirani
• Pri snovanju paralelnih algoritmov obstaja vec principov:
→ ”The Brent Scheduling Principle”:omogoca reducirati stevilo procesorjev v obstojecem paralelnem algo-ritmu, brez povecanja skupnega casa eksekucije. Ce ima algoritem ekse-kucijski cas O(ln n), se celotni cas eksekucije lahko poveca za konstantnifaktor.
→ ”The Pipeline Principle”:se lahko uporabi tam, kjer hocemo izvajati operacije v sekvenci {P1, ..., Pn},kjer imajo te operacije lastnost, da se Pi+1 lahko izvede, preden je Pi

76 POGLAVJE 6. PORAZDELJENO (PARALELNO) PROCESIRANJE
koncana. Pri paralelnih algoritmih je mogoce tako prekrivati dolocenekorake in s tem pohitriti eksekucijo.
→ ”The Divide and Conquer Principle”:pomeni razdeliti problem na manjse in jih resevati paralelno. Primer: is-kanje najkrajse poti, matricno mnozenje. To je bistven korak pri snovanjuMIMD algoritmov.
→ ”The Dependency Graph Principle”:kreiramo usmerjen graf, kjer vozlisca predstavljajo bloke neodvisnih ope-racij in povezave odvisnosti med bloki.
→ ”The Race Condition Principle:”ce dva procesa poskusata doseci isti podatek (“shared“) se morata ”vmesavati”(”interfere”)drug v drugega. Za pravilen rezultat je pomemben vrstni red dostopa.
• Algoritme je mogoce transformirati iz sekvencne oblike v paralelno ali pa izene paralelne oblike v drugo paralelno obliko. Pri tem je seveda pomembno,da se ohranja ekvivalenca.
• Nekatere oblike paralelnih algoritmov se bolje prilegajo doloceni strukturi (ar-hitekturi) racunalnika kot druge. N. pr. SIMD racunalniki niso primerni zaizvajanje asinhronih algoritmov, MIMD racunalniki pa ne za sinhronske algo-ritme.
• Relacije med paralelnimi algoritmi in paralelnimi arhitekturami:
Paralelni Algoritem Paralelna ArhitekturaZrnatost KompleksnostSocasnost Nacin delovanja
Podatkovna struktura Pomnilna strukturaKomunikacijsko okolje Povezovalno omrezje
Velikost algoritma Stevilo procesnih elementovProgramski pristop Tip arhitekture
• Faze snovanja paralelnega algoritma je mogoce deliti na 4 dele:

6.4. PRINCIPI SNOVANJA PARALELNIH ALGORITMOV 77
V 3. fazi pregledamo prvi dve s ciljem, da odgovorimo na vprasanja (kaksnoobnasanje, stroski?)
– zdruzevati ali razdruzevati (kopirati, aglomerirati) definirana opravila?
– replicirati podatke in racunanje?
– ohraniti fleksibilnost glede na skalabilnost?
– reducirati ceno software-skega inzeniringa?
– definirati preslikavo na procesorje?
• Z zgornjim snovanjem zelimo doseci naslednje lastnosti ciljnega algoritma:
→ Podatkovni paralelizem:pomeni delitev podatkov med procesorje z njihovo dekompozicijo v opra-vila (”tasks”), ki jih lahko pripisemo razlicnim procesorjem. Pogosto vodik SIMD implementaciji.
→ Funkcijski paralelizem:pomeni delitev algoritma na segmente, ki jih lahko dodelimo razlicnimprocesorjem. Vedno vodi k MIMD eksekuciji.

78 POGLAVJE 6. PORAZDELJENO (PARALELNO) PROCESIRANJE
→ Modulska zrnatost:glasi na obseg neodvisnega procesiranja. Vpliva na izbiro med SIMD inMIMD arhitekturama. Fina zrnatost zahteva pogosto sinhronizacijo invodi k SIMD eksekuciji. Groba zrnatost zahteva manj komunikacij invodi k MIMD operacijam.
→ Podatkovna zrnatost:kvantificira obseg podatkov za procesiranje. Vpliva na lokacijo podatkov,komunikacijske zahteve, procesorsko sposobnost in pomnilne zahteve.
→ Stopnja paralelnosti:je odvisna od podatkovne zrnatosti in modulske zrnatosti. Vpliva naizbor velikosti stroja in njegove maksimalne pohitritve.
→ Sinhronizacija:vpliva na povezovanje procesov s procesorji in na delitev razlicnih kom-ponent algoritma.
→ Podatkovna odvisnost:specificira vzorec alociranja podatkov, komunikacijske karakteristike inpomnilno organizacijo (lokalni proti globalni).
→ Generiranje in zakljucevanje procesov:vpliva na rabo procesorja, razvrscanje subprocesov, na nacin procesiranja,pomnilno organizacijo in komunikacijske zahteve.
6.5 Performancne mere in analiza
• Ocenjevanje performans bazira na stopnji paralelnosti, oz. maksimalnemustevilu neodvisnih operacij, ki se lahko izvajajo naenkrat.
• Naslednje karakteristike vplivajo na performance paralelnega sistema:
- hitrost ure
- velikost in stevilo registrov
- stevilo socasnih poti do pomnilnika
- hitrost izvajanja instrukcij
- velikost pomnilnika
- sposobnost efektivnega dostavljanja / shranjevanja vektorjev
- stevilo dupliciranih aritmeticnih funkcijskih enot
- ali je mogoce povezovati funkcijske klice skupaj
- sposobnost indirektnega adresiranja
- obvladovanje pogojnih blokov

6.5. PERFORMANCNE MERE IN ANALIZA 79
• Amdahl-ov zakon:doloca meje paralelnega racunanja. Ce RH pomeni visoko hitrost eksekucije,RL nizko hitrost eksekucije, f delez rezultatov pri sekvencni (nizki) hitrosti in(1-f) delez generiranih rezultatov pri RH , potem velja:
R(f) =1
fRL
+ (1−f)RH
(6.1)
Ce je f = 0 → R(f) = RH , kar pomeni, da je znatno pohitritev mogoce dobitile z visokim delezem visoke hitrosti, oz. f ≈ 0, kar pomeni visoko stopnjo para-lelnosti. V nasprotnem primeru dominira pocasnejsi skalarni nacin izvajanja.
Ta zakon omogoca analizo performans serijske in paralelne eksekucije (en delprograma se izvaja serijsko, drug pa paralelno) v primeru deljenega pomnil-nika. Zakon pravi, da je hitrost omejena s konstanto, ki je neodvisna odstevila procesorjev in arhitekture. Paralelnost omogoca le omejeno izboljsanjeperformans, zato je omejitev procesorjev smiselna.
• Gustafson-ov zakon:se nanasa na arhitekture z distribuiranim pomnilnikom. Bazira na pred-postavkah:
– eksekucijski cas paralelnega algoritma za p procesorjev je S + P
– eksekucijski cas sekvencnega algoritma za p procesorjev je S + p*P,
kjer je S sekvencni del, P paralelni eksekucijski del in velja S + P = 1. Njegovzakon ima obliko:
Gp =S + p ∗ P
S + P= S + p ∗ P ≤ p ∗ P (6.2)
in pove, da pohitritev narasca linearno s p, s stevilom dostopnih procesorjev.(Navezuje se na probleme, kjer eksekucijski cas narasca z velikostjo problema).
• Faktor pohitritve paralelnega racunanja z p procesorji doloca razmerje:
Sp =Ts
Tp
, (6.3)
kjer je Ts eksekucijski cas z 1 procesorjem in Tp s p procesorji. Obicajno velja:1 ≤ Sp ≤ p
• Efektnost paralelnega racunanja je definirana z:
Ep =Sp
p=
Ts
p ∗ Tp
(6.4)

80 POGLAVJE 6. PORAZDELJENO (PARALELNO) PROCESIRANJE
p ≡ stevilo procesnih elementov. V idealnih razmerah je Sp = p in Ep = 1
Primer:Sestevanje n stevil s p-procesorskim sistemom.
Tp =n
p− 1+ 2 ln p ≈ n
p+ 2 ln p (6.5)
n/(p− 1) ... sestevanje n/p stevil2 ln p ... parcialno sestevanje + komunikacija≈ ... za velike n, p
Sp =Ts
Tp
=n
np
+ 2 ln p=
np
n + 2p ln p(6.6)
Ep =Sp
p=
np
n + 2p ln p(6.7)

Poglavje 7
Asinhronsko paralelnoprogramiranje
• Asinhronski paralelizem je najsplosnejsa oblika paralelizma, saj procesorji de-lujejo vsak nad svojim opravilom in globalna sinhronizacija ni potrebna.
• Pri enoprocesorskih sistemih, ki realizirajo vecprocesni program, govorimoo kvazi-paralelnem procesiranju (”interleaved concurrency”), ki je posledicadodeljevanja procesorskega casa procesom (time sharing) s strani OS. Privecprocesorskih sistemih pa govorimo o dejanskem paralelnem procesiranju(”overlapped concurrency”).
• Procesi, ki se izvajajo neodvisno, so sinhronski. Tisti pa, ki zaradi koopera-tivnosti komunicirajo, so asinhronski.
• Situacije, ki zahtevajo interakcijo med procesi, delimo v 2 kategoriji:
→ ko procesi zelijo azurirati deljeno spremenljivko ali resurs v istem casu -temu pravimo “mutual exclusion“ (medsebojna izkljucitev)
→ ko se zahteva pravilna vkljucitev procesov pri resevanju skupnega problema- tedaj govorimo o “message-passing“ mehanizmu (izmenjava sporocil).
• V rubriko asinhronega paralelnega programiranja sodijo jeziki ADA, OCCAM.Ker sta si zelo podobna, bomo osvetlili le OCCAM.
7.1 OCCAM kot jezik transputerjev
(firma INMOS)
81

82 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
• OCCAM bazira na Hoare-ovi definiciji (CSP - Communicating Sequential Pro-cess) komunikacije in socasnosti. Je “naravni“ jezik Transputerja.
• Transputer je von Neumanov sistem v enem cipu in omogoca konstrukcijofleksibilnega multiracunalniskega sistema.
• Tipi transputerjev:
LASTNOSTI MODEL T212 MODEL T414 MODEL T800Vodilo 16-bit 32-bit 32-bit
on chip RAM 2K byte 2K byte 4K byteRAM - add. space 64K byte 4G byte 4G byte
Hitrost 10 MIPS 10 MIPS 10 MIPS
• Mozne povezave multi-transputerskih sistemov:

7.1. OCCAM KOT JEZIK TRANSPUTERJEV 83
• Transputerji omogocajo kvazi in dejansko paralelnost procesiranja.
• OCAMM programi omogocajo razvoj na enem Transputerju in izvedbo namulti-transputerskem sistemu poljubne topologije.
• Delitev programskih jezikov za paralelno procesiranje
→ jeziki, ki bazirajo na deljenih spremenljivkah, sestojijo iz aktivnih objek-tov (procesov) in pasivnih objektov (moduli in monitorji). Sem sodijo:Concurrent Pascal, Pascal Plus, Modula-2, Edison
→ jeziki, ki bazirajo na sporocilih: (sinhronski in asinhronski tipi). Semsodijo: CSP, Gypsy, PLITS, OCCAM
• OCCAM-2 bazira na paralelnih procesih, ki izmenjujejo sporocila po enosmer-nih kanalih
• Pripada asinhronskim paralelnim jezikom, ceprav je komunikacija medprocesi sinhronizirana na nivoju komunikacije med procesorji.

84 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
7.2 Osnove OCCAM jezika
• Osnovna enota OCCAM jezika je proces.
• Obstajajo 3 primitivni procesi: oznacitev, vhod, izhod. Z njimi formiramostrukturirane procese, ki imajo sekvencne, paralelne in alternation eksekutivnelastnosti.
• Po mnenju INMOS-a je OCCAM strojni jezik, ki zagotavlja uspesnost in za-nesljivost visokih jezikov.
• Osnovni princip OCCAM jezika je v izogibanju nepotrebnih duplikacij meha-nizmov jezika. Zato je OCCAM glede na stevilo kljucnih besed in simbolov“majhen“ jezik. Vendar je vseeno primerljiv z jeziki, kot so C ali Fortran.
• OCCAM ima dodatne mehanizme glede na aspekte sodobne racunalniske ar-hitekture. Socasnost (“concurrency“), zamenljivost (”alteration”), komunika-cije, casovniki (”timers”) so integralni deli OCCAM-a.
Aplikacija je zbirka procesov, ki delujejo socasno in komunicirajo preko kana-lov.
• Jezik C je bil razvit z namenom, da odgovori na sposobnosti sodobnih racunalnikov,OCCAM pa je bil razvit skupaj z arhitekturo INMOS-ovega Transputerja, kimu pravijo tudi OCCAM-ov stroj.
• OCCAM je vec kot programski jezik. Je razvojni formalizem (”design for-malism”), program ali predikatni zapis, ki dopusca logicne dedukcije.
• Slabost von Neumanove arhitekture je ”ozko grlo“ med pomnilnikom in pro-cesorjem. Cilj OCCAM-a je razbiti velik sistem na manjse, ki procesirajolokalno (celularno) in med seboj lokalno tudi komunicirajo.
Transputer podpira taksno usmeritev. Proces je misljen kot crna skatla zvhodi in izhodi in komunicira s sosednjimi procesi preko kanalov. Vsak kanalomogoca enosmerno komunikacijo med dvema socasnima procesoma. Komuni-kacija je sinhronizirana na nacin, da se izvaja le, ce sta oba, izvorni in ponorniproces, pripravljena. Tudi zbirka procesov je proces, tako da imajo tudi procesisvojo notranjo socasnost.

7.3. SINTAKSA OCCAM JEZIKA 85
• OCCAM omogoca opis sistema z zbirko socasnih procesov, ki komunicirajopreko kanalov
• OCCAM program lahko izvedemo s poljem transputerjev ali pa skoraj nespre-menjenega na enem samem transputerju.
7.3 Sintaksa OCCAM jezika
• OCCAM 2 vsebuje lastnosti, ki olajsajo razvoj zanesljivih in efektnih socasnihprogramov na kateremkoli ciljnem transputerskem sistemu.
• Socasno programiranje je modelirano na paralelnih procesih, ki posiljajo sporocilapo eksplicitno definiranih enosmernih kanalih.
• Vsa komunikacija je sinhronizirana, tako da tudi asinhroni procesi sodelujejov urejenem smislu. Obstajajo posebni konstrukti za delo v realnem casu.
• Osnovna enota jezika je proces. Obstajajo trije primitivni procesi:
prireditev (”assignment”),
vhod (”input”), in
izhod (”output”).
• S kombiniranjem primitivnih procesov formiramo strukturirane procese, kiimajo sekvencne, paralelne in alternativne izvrsilne lastnosti.

86 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
7.3.1 Osnove OCCAM jezika
• Primitivni procesi:
1. Prireditev:X := 7X := 7 + YSimbol za prireditev je ’:=’ . Znak ’=’ je test za enakost.
2. Vhod:Vhodni proces prebere vrednost iz kanala v spremenljivko. Simbol za toje ’?’:
chan1 ? X,
proces sprejme iz kanala ’chan1’ vrednost in jo shrani v spremenljivko X.
Branje je mozno samo v spremenljivko in ne v konstanto ali izraz. Vhodniproces se ne izvede, dokler izhodni proces na istem kanalu ni pripravljen.
3. Izhod:Izhodni proces daje vrednost na kanal iz definirane spremenljivke. Sim-bol za to je ’ !’:
chan2 ! Y
vrednost spremenljivke Y se prenese na kanal z imenom chan2.
Na izhodni kanal lahko prenesemo vse, kar lahko priredimo spremenljivki.Tudi ta proces se ne more izvesti, ce ustrezni vhodni proces ni pripravljen.
Do tedaj mora cakati, kar imenujemo sinhronizacijo vhodnega in izho-dnega procesa. Ko sta oba pripravljena nad istim kanalom, se izhodnavrednost izhodne spremenljivke kopira iz izhodnega procesa v vhodnospremenljivko vhodnega procesa.
• Vsak primitivni proces mora zasedati loceno vrstico v OCCAM programu.
• 2 specialna procesa sta SKIP in STOP.SKIP je proces, ki starta, ne naredi nic in se konca. Uporabno tam, kjersintaksa zahteva prisotnost procesa (ali ko procesa se nismo napisali).STOP je proces, ki se zacne, pa se nikoli ne konca. Uporablja se za detekcijonapak.
• Konstruktorji:se uporabljajo za zdruzevanje procesov v vecje procese.

7.3. SINTAKSA OCCAM JEZIKA 87
SEQ povezuje procese po vrsti, enega za drugim. Konca se ob zadnjem pro-cesu.PAR povzroci socasno izvedbo procesov, ki jih povezuje. Konca se, ko sokoncani vsi procesi.ALT izbere en proces za izvajanje in se konca ob zakljucku le-tega.IF, WHILE konstruktorja imata podoben pomen kot pri ostalih programskihjezikih.
PRIMER: SEQ konstruktor:
SEQ
chan1 ? X - input to X
Y := X + 1 - assign X+1 to Y
chan2 ! Y - output Y to chan2
(zamik seq. procesov za 2 znaka glede na konstruktor SEQ)
PRIMER: Replikacija SEQ:
INT var1
SEQ index = 0 FOR 6
channel.out ! var1 + index
Rezultirajoca koda je:
INT var1
SEQ
channel.out ! var1
channel.out ! var1 + 1
channel.out ! var1 + 2
channel.out ! var1 + 3
channel.out ! var1 + 4
channel.out ! var1 + 5
(6 vrstic)
Splosna oblika za replikacijo SEQ:
SEQ index = base FOR countprocess
PRIMER: PAR konstrukt:

88 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
PAR
SEQ
chan1 ? X
X := X + 1
SEQ
chan2 ? Y
Y := Y + 1
Vrstni red ni pomemben. Oba prenosa se zacneta hkrati. PAR se konca, kose konca zadnji paralelni proces.
PRIMER: Replicirani PAR konstrukt:
Splosno:
PAR index = base FOR countprocess
Primer: ”PIPELINE”:
[10] CHAN link - deklaracija kanalskega vektorja
PAR process = 0 FOR 9
WHILE TRUE
INT data:
SEQ
link [process] ? data
link [process+1] ! data
7.3.2 Tipi in specifikacije
• OCCAM locuje med velikimi in malimi crkami. Konstruktorji in posebnebesede so pisane z velikimi crkami. (n.pr. SEQ, CHAN, PROC) - to so rezer-virane besede.
• Podatkovni tipi
INT - integer

7.3. SINTAKSA OCCAM JEZIKA 89
BYTE - int 0 - 255
BOOL - TRUE ali FALSE
INT16 - 16 bitni integer
INT32 - 32 bitni integer
INT64 - 64 bitni integer
REAL32
REAL64
• Pri kanalih moramo specificirati podatkovni tip in strukturo, ki se prenasa pokanalu. Temu pravimo “channel protocol“.N.pr. :
CHAN OF INT chan1:(kanal z imenom chan1 bo prenasal integer tipe)
• Kanalu damo lahko tudi ime s pomocjo definicijskega protokola (poimenova-nje):
PROTOCOL CHAR IS BYTE:(CHAR je ime tipa)
Sedaj lahko ime tipa uporabimo pri kanalski deklaraciji:
CHAN OF CHAR screen:(screen je kanal za prenos bytov)
• S protokolom lahko specificiramo tudi sekvenco, n.pr.:
PROTOCOL COORDS︸ ︷︷ ︸koordinate (ime)
IS INT; INT:
(kanal, deklariran s COORDS lahko posilja par integer podatkov)
CHAN OF COORDS mousemouse ? X; Y(v X, Y se vpisejo koordinate miske)
• “Counted array“ protokol omogoca komunikacijo polj vrednosti, pri cemerstevilo komponent polja ni znano do samega prenosa.
CHAN OF INT︸ ︷︷ ︸st komponent
:: [ ] BY TE︸ ︷︷ ︸polje
string (ime kanala za prenos polj):
Tej deklaraciji lahko sledi:

90 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
string ! 15 :: ”
15︷ ︸︸ ︷Variable length ”
in
string ? len︸︷︷︸dolzina
:: buffer
(velikost bufferja mora biti najmanj len)
PRIMER: Protokol, ki podpira komunikacijo podatkov razlicnih for-matov:
PROTOCOL ANALYSIS - ime protokola
CASE
word; INT
fourchars; [4] BYTE
error; INT16::[]BYTE
halt
:
Ime formata (”tag”) mora biti poslano pred podatki, n.pr. :
chan1 ! fourchar; “SIZE“
ali pa:
chan1 ! halt
Tukaj gre samo za prenos informacije brez podatkov.
fourchar in halt ... “tag“
PRIMER: Branje kanala s CASE stavkom in protokolom ANALYSIS zgo-raj:
chan1 ? CASE
word; X
... proces, povezan na ta vhod
fourchars; array
... podobno
error; len :: message
... proces, vezan na napako
halt

7.3. SINTAKSA OCCAM JEZIKA 91
Ce se ime formata ne ujema s tistimi znotraj CASE stavka, sledi STOP.
• OCCAM predstavlja znake v strukturi tipa BYTE, stringe pa v polju BYTE-ov. Ne pozna tipov CHAR oz. STRING, lahko pa jih tako poimenujemo.
• BOOLOVI operatorji:
= enak
<> razlicen
>
<
>=
<=
Boolove konstante so TRUE in FALSE, standardni operatorji pa AND, OR,NOT
• BITNI operatorji:
/\ AND
\/ OR
>< EX-OR
∼ NOT
<< SHIFT LEFT
>> SHIFT RIGHT
• Konstante se poimenujejo s specifikacijo:
VAL type name IS value
N.pr.:
VAL INT hours IS 24,minutes IS 60:
Z eksplicitno specifikacijo se izognemo dvomu:
VAL empty IS 0 (BYTE)
To je enako kot: VAL BYTE empty IS 0
Ali:
VAL pi IS 3.14159 (REAL32)

92 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
Dvopicje povezuje specifikacijo s procesom, ki ji sledi.
• DOMET:Spremenljivke, kanali in drugi objekti so lokalni glede na proces, ki sledi nji-hovi specifikaciji. To pomeni, da ne eksistirajo izven tega procesa.
N. pr. :
PAR
INT X :
SEQ
chan1 ? X
INT Y :
SEQ
chan2 ? X ---> NAPAKA (X ni specificiran)
... nadaljni procesi
Pravilno:
CHAN OF IN T chan1, chan2:
PAR
INT X :
SEQ
chan1 ? X
X := X + 1
INT Y:
SEQ
chan2 ? Y
Y : = Y + 1
V primeru, da zelimo spremenljivko aktivno pri vecih procesih, jo moramospecificirati pred ”kompleksnim procesom”.
• OPERATORJI:Osnovni aritmeticni operatorji so:
a + b
a - b
a * b
a / b deli a z b

7.3. SINTAKSA OCCAM JEZIKA 93
a REM b ostanek (Remainder) pri deljenju a z b
a \ b celi rezultat deljenja
POZOR: vsi operatorji imajo enako tezo in asociativnost, kar pomeni, da sopotrebni oklepaji za zeleni vrstni red racunanja:
N. pr. :
(2 + 1) * (3 + 4) rezultat je 21
3 + (3 * (2 + 6) rezultat je 27
4 + 6 * 8 + 3 nepravilno
(1 + (2 * 3)) + 6 rezultat je 13
(1 + (2 * 3) + 6) nepravilno
Moduli operatorji pri celih stevilih so:PLUS, MINUS, TIMES, vsi mod 2n − 1, kjer je n stevilo bitov v INT.
• Komunikacijski procesi:Komunikacija med paralelnimi procesi je bistvo OCCAM programiranja. Zah-teva najmanj 2 procesa, ki se izvajata paralelno, in kanal, ki ju povezuje.
PRIMER:
INT a :
CHAN OF INT chan1 :
PAR
chan1 ! 7 ( En proces daje 7 v kanal,
chan1 ? a drugi pa vpise 7 v spremenljivko a)
Komunikacija med procesi v PAR konstruktu poteka izkljucno preko kanala.Uporaba deljene (“shared“) spremenljivke tukaj ni dovoljena!
POZOR:Ce ena komponenta PAR konstrukta vsebuje prireditev ali branje neke spre-menljivke, potem ta spremenljivka ne sme biti uporabljena v nobeni drugikomponenti.
N. pr. :
INT a, b :
PAR
SEQ
a := 7

94 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
...
SEQ
b := a ---> NAROBE
...
PRAVILNO: uporaba lokalnih spremenljivk in komuniciranje preko kanala.
• Kanal predstavlja enosmerno povezavo med dvema procesoma, tako da:
1. je en proces oddajni, drug pa sprejemni
2. oddajni samo oddaja v kanal, sprejemni pa samo sprejema iz kanala
Pri dvosmerni povezani med dvema procesoma potrebujemo 2 kanala.
PRIMER:
CHAN OF INT chan1, chan2:
PAR
INT a:
SEQ
chan1 ! 7
chan2 ? a
INT b :
SEQ
chan1 ? b
chan2 ! 40
Tukaj je vrstni red znotraj SEQ bistven, kaj lahko pride do mrtve zanke(“deadlock“), n.pr. ce v prvem SEQ predpisemo:
chan2 ? a
chan1 ! 7,
tedaj oba SEQ procesa cakata na vhod.
• Pogojni procesi
IF
temp = 1
chan1 ! a
temp = 2
chan2 ! a
TRUE ---> namesto tega lahko uporabimo tudi SKIP
chan3 ! a

7.3. SINTAKSA OCCAM JEZIKA 95
Pogoji so lahko vgnezdeni, kar omogoca kompleksne kretnice:
IF
temp = 1
chan1 ! a
temp = 2
IF
a = 7
chan2 ! a
TRUE
chan3 ! a
TRUE
SKIP
• Alternativni procesi
ALT konstrukti omogocajo izbiro procesov glede na stanje kanalov in neglede na vrednosti spremenljivk, kot pri pogojnih procesih.Komponente ALT konstruktov so alternative. Vsaka ima t.im. cuvaja (”gu-ard”), ki pa predstavlja vhod s poljubnim pogojem. Izbere se prvi proces,ki je pripravljen za eksekucijo. Ce je vec procesov pripravljenih, se izbere po-ljuben med njimi.
PRIMER:
WHILE going
ALT
buffer.in ? ch
buffer.out ! ch Tukaj je citaj enostavno
stop ? ANY prisotnost vhoda na kanalu.
going: = FALSE (availability of an input
on the channel)

96 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
Pri ALT komponentah s pogoji in vhodi je izbran proces, katerega vhod jeprvi pripravljen in katerega pogoj je TRUE.
PRIMER:
CHAN OF INT chan1, chan2, chan3:
INT a
ALT
(temp < 0) & chan1 ? a
... proces1
(temp = 0) & chan2 ? a
... proces2
(temp > 0) & chan3 ? a
... proces3
Ce nobena alternativa ni izpolnjena, se ALT obnasa kot STOP. Tudi ALTkonstrukt so lahko vgnezdeni (kot IF).
ALT je izjemno mocan konstruktor - omogoca zdruzevanje komple-ksnih omrezij in njihovo preklapljanje oz. aktiviranje ustreznih procesov.
• Ponovljivi procesi:
Vcasih zelimo ponavljanje procesa, dokler ni izpolnjen dolocen pogoj. Pri temlahko uporabimo konstrukt WHILE:
N. pr. :
INT a :
SEQ
a: = 0
WHILE a >= 0
SEQ
buffer.in ? a
buffer.out ! a
PRIMER:Program za kontrolo ogrevanja: 2 dig. kontroli + 1 za izklop + 1 za prenos

7.3. SINTAKSA OCCAM JEZIKA 97
4 kanali:- hot: poveca ogr. za 1 enoto- cold: zmanjsa ogr. za 1 enoto- off: izklop regulatorja- regulator: prenasa vrednost reg. mehanizma na izvor gretja
VAL min.temp IS 0, max.temp IS 85:
BOOL operational:
INT temp, any:
SEQ
operational := TRUE
temp := min.temp
regulator ! temp
WHILE operational
ALT
(temp < max.temp) & hot ? any
SEQ
temp := temp + 1
regulator ! temp
(temp > max.temp) & cold ? any
SEQ
temp := temp - 1
regulator ! temp
off ? any
operational := FALSE
• Okrajsave:
S tem dajemo dolgim izrazom imena. Splosna oblika je:
VAL INT name IS expression
N. pr. :VAL seconds IS 60 * ((60 * hours) + min)tip je izpuscen
• Procedure:
Procedura je proces z imenom. Beseda PROC in ime sta pred procesom, kiga imenujemo tudi telo procedure.
Telo procedure se izvede vsakic, ko se v programu pojavi ime procedure (”in-stance”). Procedura je razpoznana le v procesu, ki sledi definiciji:

98 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
PRIMER:
PROC delay () - glava
definicija
{V AL interval IS 100 :INT n :
teloprocedure
SEQn := intervalWHILE n > 0
n := n− 1
: - link med definicijo in procesom
proces
INT Y :SEQ
input1 ? Ydelay() − instance (klic)
• Parametri procedure:
Parameter v definiciji je formalni parameter, ki je lahko poljubnega tipa, tudiCHAN. V zgornjem primeru parameter ni bil potreben, ker je bila zakasnitevfiksna. Stevilo formalnih parametrov je poljubno, loceni so z vejico.
Dejanski parametri v imenu znotraj procesa morajo po stevilu, poziciji intipu ustrezati formalnim.
OCCAM uporablja t.im. VAR parametre (klicanje po referenci - kot pri Pa-scalu), kar pomeni, da jih procedura spreminja (vrednosti spremenljivke) tudiizven procedure. Ce zelimo spreminjati samo znotraj procedure, moramo pri-rediti vrednost parametra lokalni spremenljivki znotraj PROC.
PRIMER:
VAL more IS 1, less IS -1 :
BOOL operational:
INT temp, any:
PROC change.temp (VAL INT step) ---> INT .. konst, kar pomeni, da se
SEQ spr. v proceduri ne spreminja
temp := temp + step
regulator ! temp

7.3. SINTAKSA OCCAM JEZIKA 99
:
SEQ
temp := 0
regulator ! temp
operational := TRUE
WHILE operational
ALT
hot ? any
change.temp (more)
cold ? any
change.temp (less)
off ? any
operational := FALSE
• Funkcije:
Ne vplivajo na druge dele programa. Definicija funkcije ima splosno obliko:
type FUNCTION name ({, formal parameters })specification:VALOF
processRESULT expression
Pravila za konstruiranje funkcij:
- formalni parametri so lahko samo VAL
- PAR in ALT konstrukta se ne smeta uporabljati
- vhodi (?) in izhodi (!) se ne smejo uporabljati
- prireditve so dovoljene samo pri spremenljivkah, deklariranih znotraj funk-cije.
• Polja:
OCCAM 2 podpira vecdimenzionalna polja. Polje je niz elementov istega tipa.Specificirano je, ce damo vrednost vsaki njegovi komponenti.
Definicija polj - primeri:
[7] INT Ken: - 1D polje 7 INT spr. z imenom Ken
[40][40] BYTE twod: - 2D polje byte-ov
[10][10][10] INT thread: - 3D integer polje

100 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
[1000] REAL32 results: - vektor 1000 realnih stevil
[7] CHAN switch: - vektor 7 kanalov
Velikost polja mora biti fiksna ob casu kompilacije in se ne more spreminjatimed eksekucijo. Pri referiranju polja sledi za imenom specifikacije dimen-zije.
PRIMER:
Izhod polja v kanal:
CHAN output:
[40] INT data:
SEQ
element := 0
WHILE element < 40
SEQ
output ! data[element]
element := element + 1
• Isto lahko dosezemo tudi z uporabo replikatorja FOR:
CHAN output:
[40] INT data:
SEQ element = 0 FOR 40
output ! data[element]
• Ce je polje parameter v PROC, potem njegove velikosti ni potrebno dekla-rirati ob specifikaciji (definiciji) PROC. To pomeni, da je dejanski parameterlahko poljubne velikosti, le tip mora biti pravi.
Ce procedura rabi velikost polja, je potrebno uporabiti operator SIZE, ki vrnevelikost polja kot INT vrednost.
PRIMER:Deklaracija procedure s poljem kot formalnim parametrom:
PROC input (CHAN in, [] INT store) - definicija
INT element: - definicija
SEQ - telo
element := 0 .
WHILE element < (SIZE store) .
SEQ .

7.3. SINTAKSA OCCAM JEZIKA 101
in ? store [element] .
element := element + 1 - telo
: - link med deklaracijo in procesom, ki klice proceduro
• Segmenti polja: so zaporedja komponent polja. Doloceni so z:
[array FROM subscript FOR count]
Segment se lahko obravnava kot polje.
N.pr. :
[40] INT data
.
.
.
[data FROM 7 FOR 10]
To je polje 10 komponent, ki se zacne z data[7] in konca z data[16].
• Okrajsave polj: olajsajo vpisovanje segmentov polj, n. pr. :
dat IS [data FROM 7 FOR 10]:
Sedaj dat[2] pomeni isto kot data[9], ker tecejo oznake od 0 do 9.
N.pr. :
VAL months IS [1, 2, 3, ..., 11, 12] :
Sedaj je months[2] = 3, ker indeks polja tece od 0 dalje.
• Replikatorji IF, ALT:Replicirani IF:splosna oblika:
IF index = base FOR countchoice
“choice“ je pogoj, ki mu sledi proces
PRIMER:

102 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
IF element = 0 FOR 10
data[element] = 1 - pogoj
data[element] := 0 - proces
S tem testiramo prvih 10 elementov polja data in prvega, ki je 1, zamenjamoz 0. Ce ne najdemo 1, se proces ustavi. Tukaj ne moremo uporabiti TRUESKIP, da preprecimo ustavitev procesa, lahko pa uporabimo vgnezdene IFstavke:
IF
IF element = 0 FOR 10
data[element] = 1
data[element] := 0
TRUE
SKIP
PRIMER: Iskanje znaka v stringu:
INT FUNCTION getchar (VAL BYTE char, VAL [] BYTE string)
VAL INT nomatch IS -1 :
INT result1 :
VALOF
IF
IF position = 0 FOR SIZE string
string[position] = char
result1 := position
TRUE
result1 := nomatch
RESULT result1
- Replicirani ALT:
– Sestoji iz stevilnih identicno strukturiranih elementov. Splosna oblikaje:
ALT index = base FOR countalternative
kjer je “alternative“ cuvaj, ki mu sledi proces (cuvaj je vhod z pogo-jem).
– Sluzi za nadzor polja kanalov. Z njim lahko konstruiramo n.pr. MX,splosno pa je uporaben pri gradnji in kontroli Preklopnih omrezij(“switching networks“) vseh moznih oblik in velikosti.

7.3. SINTAKSA OCCAM JEZIKA 103
PRIMER: Multipleksor(MX):
PROC multiplexor ([]CHAN in, CHAN out, disable)
INT any, data:
BOOL operational:
SEQ
operational := TRUE
WHILE operational
ALT
ALT X = 0 FOR (SIZE in) - alternative
in [X ? data]
output ! data
disable ? any - alternative
operational := FALSE
:
7.3.3 Programiranje v realnem casu
• OCCAM pozna objekt TIMER, ki se obnasa kot kanal, ki daje procesu trenu-tni cas, kot vrednost tipa INT.
N. pr. :
TIMER clock:
INT time:
clock ? time
• Takt specificira verzija Transputerja, obicajno je to 64 µs. Ce v taktu povecujemo16 bitni INT, potem le-ta postane po maksimumu negativen in zacne steti nav-zdol do 0 (v 2’kompl). Pri 64 µs taktu in INT16 je perioda 4.2 sekunde (4.2/ 64µ ≈ 16k).Pri racunanju cas. diferenc se uporablja modulska aritmetika.
• Operator AFTER, ki mu sledi izraz, ki predstavlja cas, sluzi za izvedbo zaka-snitve (DELAY):
PROC delay (VAL INT period)
TIMER clock:
INT present.time:
SEQ
clock ? present.time

104 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
clock ? AFTER present.time PLUS perioda
:
(PLUS ... operator modulske aritmetike)
PRIMER: uporaba procedure “delay“ v ALT konstruktu za implementacijo“real-time wait“:
TIMER clock:
VAL time.limit IS 700:
INT present.time:
SEQ
clock ? present.time
INT Z :
ALT
input ? Z
... further
... process
clock ? AFTER present.time PLUS time.limit
warning ! (17 :: "Time out on input!")
Ce ne bo vhoda znotraj 700 taktov, bomo dobili opozorilo.
• Prioriteta:
Vcasih, posebno pa pri programiranju v realnem casu, zelimo dolociti prioritetoprocesom. Videli smo, da je pri ALT konstruktih v primeru vec procesov, kizadovoljujejo pogoje, izbira nakljucna. OCCAM omogoca v taksnem primerudolocitev prioritete z vrstnim redom, kar napravimo s PRI ALT konstruktom.
PRIMER:
WHILE operational
INT any:
PRI ALT
reset ? any
operational := FALSE
TRUE & SKIP
... main body

7.3. SINTAKSA OCCAM JEZIKA 105
• Konfiguracija:
I/O se izvaja preko kanalov, zato je potrebno vedeti le, kako povezati OCCAMkanale z I/O napravami, ki jih lahko obravnavamo kot OCCAM procese.
• I/O kanali lahko vodijo direktno k ”hardwareu”, ali pa preko ”driver”programov,ki jih OCCAM prevajalnik poveze k programu.
Lahko pa vodijo I/O kanali k operacijskemu sistemu ”host”racunalnika, ki po-tem izvede I/O ”v imenu”OCCAM-a.
Kanali k zaslonu, tastaturi in datotecnemu sistemu so standardni in imajosvoje stevilke, kot:
1 ”Output to screen”
2 ”Input from keyboard”
Te stevilke lahko povezujemo s kanalskimi imeni v programu, n.pr.:
PLACE screen AT 1 :
PLACE keyboard AT 2 :
Znotraj programa te kanale uporabljamo na standardni nacin kot vse ostalekanale.
• Nekatere I/O naprave zahtevajo specificne protokole in znotraj njih specificnekomande in znake:
PRIMER: Bufferiran zaslonski kanal.Znaki so prikazani samo, ko je buffer izpraznjen (po izpisu ali na zahtevo -endrecord)
VAL endrecord IS -2 :
...
SEQ
VAL string IS "Good Morning" :
SEQ i = 0 FOR SIZE string
screen ! INT string [i]
screen ! endrecord
• OCCAM lahko adresira tudi I/O vrata. Deklaracijo vrat ima podatkovni tip,n.pr.:

106 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE
PORT OF BYTE serialcom1 :
Dovoljeni procesi so samo input, output,n.pr. :
serialcom1 ! ′k′
serialcom2 ? Z
}s tem lahko vrata uporabljamokot kanale namesto kot spremenljivke
• Alokacija:
OCAMM programi so lahko razviti, napisani, stestirani na enoprocesorskemsistemu in sele nato preneseni na mrezo paralelnih racunalnikov.
Koncna faza pri tem je alokacija paralelnih procesov v programu na razlicneprocesorje. Taksna alokacija se izvede z zamenjavo PAR konstruktov s PLA-CED PAR, cemur sledi specifikacija procesorja in procesa:
PLACED PAR
PROCESSOR i
SEQ
... process
PRIMER:Cevovodni sortirni program je mogoce prevesti na polje transputerjev, kotsledi:
PLACED PAR
PLACED PAR i = 0 FOR tosort
PROCESSOR i
in IS pipe[i]:
out IS pipe[i+1]:
INT largest:
SEQ
in ? largest
SEQ j = 0 FOR tosort - 1
INT nextnumber:
SEQ
in ? nextnumber
IF
nextnumber <= largest
out ! nextnumber
nextnumber > largest
SEQ

7.3. SINTAKSA OCCAM JEZIKA 107
out ! largest
largest := nextnumber
out ! largest
... rest of routine
...
...

108 POGLAVJE 7. ASINHRONSKO PARALELNO PROGRAMIRANJE

Poglavje 8
Paralelno programiranje z MPI
8.1 Uvod
• Proces je osnovni blok pri paralelnem racunanju. To je del programa, ki se izvajaavtonomno na fizicnem procesorju.
• Program je paralelen, ce se v casu njegove eksekucije lahko razdeli na vec kot enproces.
• Pri programiranju s skupnim pomnilnikom (’shared memory’ - tesno-sklopljenMIMD sistem) uporabljamo pri deljenih spremenljivkah t.im. binarne semaforje,ozr. spremenljivke, n.pr. s, katere vrednost pove, ali je skupna spremenljivka (alikriticna sekcija v programu) prosta, ali ne.
• PRIMER: Vsota dveh lokalnih spremenljivk na skupni spremenljivki sum:
shared int s = 1;
while (!s) ; // wait until s=1
s = 0; // close down access
sum = sum + private_x;
s = 1; // re-open access
• Zgornji semafor se ne resi problema, saj lahko en proces dostavlja s=1 v register za
109

110 POGLAVJE 8. PARALELNO PROGRAMIRANJE Z MPI
testiranje, drug proces pa hkrati shranjuje s=0. Potrebujemo mehanizem, ki potem,ko ima en proces dostop do semaforja (s), drugim prepreci dostop do njega.
• Binarni semafor se zato sestoji iz dveh specialnih funkcij:
void P( int* s); // in/out
void V( int* s); // out
Funkcija P zapre, V pa odpre semafor, vendar pa P prepreci dostop ostalim procesomdo s, ko en proces pride do semaforja. Podobno V postavi s na 1. Taksni funkcijizahtevata dodatne strojne instrukcije. Samo proces, ki zaklene spremenljivko, lahkovpisuje vanjo.
• Potrebujemo se nacin, ki zagotavlja, da je rezultat res vsota vseh lokalnih spre-menljivk. To omogoca funkcija barrier. Ko proces klice to funkcijo, se le-ta ne konca,dokler je ne klice vsak od preostalih procesov.
• PRIMER:
.
.
.
int private_x;
shared int sum = 0;
shared int s = 1; // semafor spr. sum
// compute private_x
.
.
.
P(&s); // zapre sum, &s - naslov spr.s
sum = sum + private_x;
V(&s); // odpre sum
Barrier();
if (I’m process 0)
printf("sum=%d\n", sum);
• Razlicni monitorji predstavljajo alternative semaforjem na visjih nivojih. Deljenepodatkovne strukture so definirane v monitorju in kriticne sekcije so funkcije mo-nitorja. Ko proces klice monitorsko funkcijo, so ostali procesi blokirani (ne morejoklicati monitorskih funkcij).

8.2. OSNOVE MPI (MESSAGE PASSING INTERFACE) 111
8.2 Osnove MPI (Message Passing Interface)
• Najpogostejsa sodobna metoda programiranja MIMD sistemov s porazdeljenimipomnilniki je metoda prenasanja sporocil (’message passing’). Procesi pri tem ko-ordinirajo aktivnosti s posiljanjem in sprejemanjem sporocil.
• MPI knjiznica vsebuje med drugim najosnovnejsi funkciji za posiljanje in spreje-manje sporocil:
int MPI_Send( void* buffer, // in
int count, // in
MPI_Datatype datatype, // in
int destination, // in
int tag, // in
MPI_Comm communicator) // in
int MPI_Recv( void* buffer, // out
int count, // in
MPI_Datatype datatype, // in
int source, // in
int tag, // in
MPI_Comm communicator, // in
MPI_Status status) // out
• Enostavnejsa verzija MPI predpostavlja staticno alokacijo procesov, kar po-meni, da je stevilo procesov doloceno ob zacetku izvajanja in se med izvajanjem nekreira nobenih dodatnih procesov. Vsakemu procesu je oznacen edinstven celostevilcni(int) rang (’rank’) v obmocju 0,1,...,p-1, kjer je p stevilo procesov.
• PRIMER: Proces 0 zeli poslati float x k procesu 1. Poklice MPI Send takole:
MPI_Send( &x, 1, MPI_Float, 1, 0, MPI_COMM_WORLD);
Proces 1 mora klicati MPI Recv, pri cemer se morata ujemati tag in komunikatorargumenta ter pomnilni parametri buffer, count in datatype, ki morajo biti vsajtako veliki kot poslani. Status parameter vrne informacijo o velikosti sprejetegasporocila. Proces 1 klice torej:
MPI_Recv( &x, 1, MPI_Float, 0, 0, MPI_COMM_WORLD, &status);
• Taksen pristop k programiranju MIMD se imenuje SPMD (’Single-Program, Multiple-Data’). Gre za eno kodo, vsak procesor pa glede na kretnice (identiteta procesorja)izvaja svojo pot v programu.

112 POGLAVJE 8. PARALELNO PROGRAMIRANJE Z MPI
• Pri prenasanju sporocil igra pomembno vlogo ’bufferiranje’. N.pr. proces 0 posljeprocesu 1 sporocilo in ce je ta zaseden, se sporocilo bufferira. Ko je proces 1 prost,vzame sporocilo iz bufferja. Taksna komunikacija je bufferirana, brez bufferjev paje sinhronska (tedaj proces 0 caka na prost proces 1). Na sprejemni strani obstajatudi funkcija MPI Irecv, ki ima en parameter vec kot MPI Recv. Namesto cakanjana sprejem sporocila se inicializira argument zahteve, nakar lahko proces 1 izvajadruga dela, kasneje pa preveri, ce je sporocilo ze prislo.
8.2.1 Splosni MPI programi
• Vsak MPI program mora na zacetku vsebovati direktivo:
#include "mpi.h"
Datoteka mpi.h vsebuje definicije in deklaracije, potrebne za prevajanje.
• Vsi MPI identifikatorji vsebujejo na zacetku niz MPI , n.pr. MPI Char (prvi znak,ki sledi, je velika crka).
• Pred klicem MPI funkcij mora biti v programu funkcija MPI Init, katere parametriso kazalci na parametre funkcije main, t.j. na argc in argv. To omogoca poljubenzacetek (‘setup’) ob uporabi MPI knjiznice.
• Na koncu mora biti funkcija MPI Finalize, ki pocisti vse nedokoncane posle sstrani MPI.
PRIMER:
.
#include "mpi.h"
.
.
main (int argc, char *argv[])
{
.
.
// No MPI functions till here
MPI_Init(&argc, &argv);
.
MPI_Finalize();
// No MPI functions called after this
.
} // main

8.2. OSNOVE MPI (MESSAGE PASSING INTERFACE) 113
argc je stevilo parametrov ukazne vrstice, argv[] pa so kazalci na imena parametrov(nizi)
• Vzemimo nov primer, ko imamo p procesov, vsi z ID razlicnim od 0, in da tiposljejo pozdrave procesu 0.
PRIMER:
#include <stdio.h>
#include <string.h>
#include "mpi.h"
main(init argc, char* argv[])
{
int my_rank; // rank of processor
int p; // number of processes
int source; // rank of sender
int dest; // rank of receiver
int tag=0; // tag for messages
char message[100]}; // place for message
MPI_Status status; // return status for receive
// Start up MPI
MPI_Init( &argc, &argv);
// Find out proces rank
MPI_Comm_rank( MPI_COMM_WORLD, &my_rank);
// Find out number of processes
MPI_Comm_size( MPI_COMM_WORLD, &p);
if (my_rank !=0)
{
// Create message
sprintf( message, "Greetings from process %d!", my_rank);
dest=0;
// Use strlen+1 so that ’\0’ gets transmitted
MPI_Send( message, strlen(message)+1, MPI_CHAR, dest, tag,
MPI_COMM_WORLD);
}
else // my_rank==0
{
for (source=1; source<p; source++)
{

114 POGLAVJE 8. PARALELNO PROGRAMIRANJE Z MPI
MPI_Recv( message, 100, MPI_CHAR, source, tag,
MPI_COMM_WORLD, &status);
printf("%s\n", message);
}
}
// Shut down MPI
MPI_Finalize();
}
’\0’ ... znak za konec niza v ANSI C
• Prevajanje sprozimo z:
cc -o greetings greetings.c -lmpi
Rezultat dobimo v obliki:
Greetings from process 1!
.
Greetings from process p!
8.2.2 Ostale osnovne MPI funkcije
int MPI_Init( int argc, // in/out
char *argv[]) // in/out
int MPI_Finalize(void)
int MPI_Comm_Size ( MPI_Comm comm, // in
int* number_of_processes) // out
int MPI_Comm_rank( MPI_Comm comm, // in
int* my_rank) // out
• int MPI Send, int MPI Recv, glej zgoraj.
• Spremenljivki dest in source sta ranga ponora in izvora.

8.2. OSNOVE MPI (MESSAGE PASSING INTERFACE) 115
MPI dovoljuje, da je izvor ’wild card’ (MPI ANY SOURCE), ponor pa to ne sme biti.Tudi tag je lahko ’wild card’ (MPI ANY TAG), communicator (zbirka procesov, kilahko posiljajo sporocila drug drugemu) pa ne. N.pr. MPI COMM WORLD sestoji izvseh procesov, ki se odvijajo ob izvajanju programa.
8.2.3 Sporocilo: podatki + ovojnica
• Sporocilo sestavljajo podatki in ovojnica. Ovojnica vsebuje naslov (’rank’) ciljain oznako izvora, velikost sporocila, tip (’tag’) sporocila ter komunikator (’commu-nicator’), ki pove, kateri procesi so v ’igri’. Najmanj, kar mora vsebovati ovojnica,je:
1. Rang sprejemnika
2. Rang posiljatelja
3. Tip sporocila
4. Komunikator
• Parameter status v funkciji MPI Recv vrne informacijo o podatkih, ki so bilisprejeti. To je struktura z najmanj 3 clani (source, tag, error code):
status -> MPI_SOURCE
status -> MPI_TAG
status -> MPI_ERROR
• Statusni parameter vrne tudi informacijo o velikosti sporocila, vendar ta ni di-rektno dosegljiva uporabniku v obliki clana strukture. Ustrezne podatke dobimo sklicem naslednjih funkcij:
int MPI_Get_count(
MPI_Status* status, // in
MPI_Datatype datatype, // in
int* count_ptr) // out
• Obe osnovni funkciji, MPI Send in MPI Recv, dajeta kot odgovor ’int’ vrednosti, kipomenijo kode napak. Obicajno napaka MPI funkcije prekine izvrsevanje programa.
PRIMER: Paralelizacija integracije trapeznega pravila
Pri tem vsak proces potrebuje:
1. p, stevilo procesov (racunalnikov)

116 POGLAVJE 8. PARALELNO PROGRAMIRANJE Z MPI
2. svoj rang
3. celotno delovno podrocje (integracije)
4. stevilo podintervalov integracije
Te podatke se poda ali z argumenti v programu, ali pa s pomocjo posebnega pro-grama ob instalaciji MPI (’MPI-run’).
8.3 Kolektivno komuniciranje
• V primeru, ko en procesor (n.pr. proces 0) dodeljuje podatke ostalim, pride doprecejsnje neaktivnosti (primer racunanja ploscine s trapeznim pravilom). Izboljsavodosezemo n.pr. z drevesno komunikacijo, ki jo prikazuje slika:
V prvem koraku poslje proces 0 podatke procesu 1. V naslednji fazi poslje proces 0podatke procesu 2, proces 1 pa procesu 3, itd. Pri p procesih v splosnem porazdelimopodatke v log2(p) korakih, zaokrozeno navzgor, namesto v p − 1 korakih. Ce jep = 1024, je log21024=10, p− 1 pa je 1023, ozr. prenos smo skrajsali za faktor 100.
• Zgornjo drevesno porazdelitev realiziramo s programsko zanko:
for ( stage=first; stage<=last; stage++)
if( I_receive( stage, my_rank, &source) )
Receive( data, source);
else if( I_send( stage, my_rank, p, &dest) )
Send( data, dest);

8.3. KOLEKTIVNO KOMUNICIRANJE 117
• Funkcija I receive vrne 1, ce je med trenutnim korakom (’stage’) klicani processprejemal podatke, sicer vrne 0. V primeru 1 se parameter source uporabi privracanju ranga posiljatelja.
• Funkcija I send izvaja podobno funkcijo in testira, ali proces posilja v trenutnemkoraku, in ce posilja, se uporabi dest pri sprejemanju povratne informacije (status).
• Za zgornje drevo to lahko pomeni (mozne so tudi druge oznake):
0. korak: 0 → 1
1. korak: 0 → 2, 1 → 3
2. korak: 0 → 4, 1 → 5, 2 → 6, 3 → 7,
itd.
Slednje pomeni:
if 2stage <= my rank < 2stage+1(stage od 0 naprej)
then I receive from: (my rank - 2stage )
if my rank < 2stage
then I send to: (my rank + 2stage)
8.3.1 Oddaja (’Broadcast’)
• V primeru, ko komunikacijski vzorec zajema vse procese v komunikatorju, takvzorec imenujemo kolektivna komunikacija (’collective communication’).
• BROADCAST je taksna kolektivna komunikacija, v kateri posamezni proces posiljaiste podatke vsakemu procesu v komunikatorju. Videli smo ze, da je drevesno od-dajanje podatkov bolj efektno kot oddajanje iz enega mesta, vendar je programskoprecej bolj zahtevno. Velja, da brez poznavanja topologije sistema ne moremo vedeti,ali je doloceno oddajanje najbolj uspesno.
• Vsak sistem s knjiznico MPI ima tudi funkcijo oddajanja MPI Bcast. Pri temje specificirana le sintaksa funkcije in rezultat, zato je mogoce implementirati opti-malno funkcijo. Sintaksa MPI Bcast je naslednja:
int MPI_Bcast(
void* message, // in/out

118 POGLAVJE 8. PARALELNO PROGRAMIRANJE Z MPI
int count, // in
MPI_Datatype datatype, // in
int root, // in
MPI_Comm comm) // in
Ta funkcija posilja kopijo sporocila od procesa z rangom ’root’ do vseh procesov vkomunikatorju ’comm’. Pri tem se za sprejem ne uporablja MPI Recv. Namesto tegase klice MPI Bcast z vseh procesov v komunikatorju z enakimi argumenti za ’root’ in’comm’. Argumenta ’count’ in ’datatype’ imata enak pomen kot pri MPI Send ozr.MPI Recv. Ker ni prisoten ’tag’ argument, je za prenose od vseh procesov upora-bljen isti par ’count’ in ’datatype’, kar je vzrok, da statusni parameter ni potreben.’Message’ je specificiran kot ’in/out’ parameter (kar pri serijskih programih pomeni’used’ in ’modified’), kar pa pri paralelnih programih pomeni za nekatere procese’in’, za druge pa ’out’. Pri MPI Bcast je za ’root’ proces ’message’ tipa ’out’, zaostale pa ’in’.
8.3.2 Redukcija (’Reduce’)
• To je kolektivna komunikacija, kjer vsi procesi v komunikatorju prispevajo po-datke, ki se zdruzujejo z binarno operacijo (n.pr. sestevanje, max, min, logicni in,...). Namesto, da en proces n.pr. sesteva delne rezultate (n.pr. integracija trapezov),lahko uporabimo drevo, kot pri posiljanju podatkov, samo v obratnem redu, torejod listov proti korenu. Sintaksa reduciranja je naslednja:
int MPI_Reduce(
void* operand, // in
void* result, // out
int count, // in
MPI_Datatype datatype, // in
MPI_Op operator, // in
int root, // in
MPI_Comm comm) // in
Ta funkcija zdruzuje operande (shranjene v pomnilniku, na katerega kaze operand),z operacijo, ki jo doloca operator in shrani rezultat v lokacijo, na katero kazekazalec result na procesorju root. Pri tem vsak proces klice MPI Reduce z istimiargumenti.
8.3.3 Zbiranje (’Gather’) in Raztros (’Scatter’)
• Pri strukturnih operacijah je potrebno zaradi paralelnosti uporabiti ali eno alidrugo od omenjenih operacij. Vzemimo, da zelimo paralelizirati mnozenje matrike

8.3. KOLEKTIVNO KOMUNICIRANJE 119
z vektorjem, n.pr.: Amxn ·Xn. Rezultat je vektor Ym, katerega komponente dobimos skalarnim produktom vrstic matrike A z vektorjem X. Z operacijo MPI Gather
moramo vektor X zbrati na vseh procesih, ki bodo izvajali skalarne produkte, alipa z MPI Scatter raztresti vrstice matrike A procesom, ki imajo vsi X in bodo tudiizvajali skalarne produkte.
int MPI_Gather(
void* send_data, // in
int send_count, // in
MPI_Datatype send_type, // in
void* recv_data, // out
int recv_count, // in
MPI_Datatype recv_type, // in
int root, // in
MPI_Comm comm) // in
MPI Gather zbira podatke, ki jih referencira send data iz vsakega procesa v ko-munikatorju comm in shrani podatke v urejenem redu (’rank order’) na procesu zrangom root v pomnilniku, na katerega kaze recv data. Ostali parametri imajoobicajen pomen.
int MPI_Scatter(
void* send_data, // in
int send_count, // in
MPI_Datatype send_type, // in
void* recv_data, // out
int recv_count, // in
MPI_datatype recv_type, // in
int root, // in
MPI_Comm comm) // in
MPI Scatter razdeli podatke opisane z send data na procesu z rangom root v psegmentov, od katerih vsak vsebuje send count elementov tipa send type. Prvisegment je poslan procesu 0, drugi procesu 1, itd. Parametra root in comm moratabiti enaka na vseh procesih.

120 POGLAVJE 8. PARALELNO PROGRAMIRANJE Z MPI
8.3.4 Zdruzevanje (’Allgather’)
• Pri strukturnem mnozenju se vedno rabimo sestevanje delnih produktov. Prizdruzevanju vektorja X na mesta vrstic matrike A dobimo ze komponento vektorjaY na ustreznem procesu. Pri razdruzitvi vrstice A po procesih pa dobimo le delneprodukte, ki jih je potrebno se sesteti. Tedaj bi potrebovali se MPI Reduce, zadokoncanje skalarnega produkta.
• Vendar pa obstaja boljsa resitev, MPI Allgather, ki zbere vsebine vsakega procesa(send data) v recv data vsakega procesa. Simultano torej zbere vse komponenteX na vsakem procesu.
int MPI_Allgather(
void* send_data, // in
int send_count, // in
MPI_Datatype send_type, // in
void* recv_data, // out
int recv_count, // in
MPI_Datatype recv_type, // in
MPI_Comm comm) // in
Program mnozenja (matrika m x n):
(local m = m/p; local n = n/p; )
.
. podatki
.
MPI_Allgather( local_x, local_n, MPI_FLOAT, global_x, global_n,
MPI_FLOAT, MPI_COMM_WORLD);
for ( i=0; i<local_m; i++)
{
local_y[i] = 0.0;
for ( j=0; j<n; j++)
local_y[i] = local_y[i] + local_A[i][j]*global_x[j];
}






![Developing Windows 8 Apps with HTML, CSS & JavaScript ...download.microsoft.com/.../480.2.CSS.pdf · Selectors type selectors.class selectors #id selectors [attribute] selectors:pseudo-class](https://static.fdocuments.in/doc/165x107/5ed5cf5ed48e3c5e0c2a9cd5/developing-windows-8-apps-with-html-css-javascript-selectors-type-selectorsclass.jpg)











