
AN EFFICIENT PIPELINED COMPLEX MULTIPLIER · PDF fileAN EFFICIENT PIPELINED COMPLEX MULTIPLIER...
5
AN EFFICIENT PIPELINED COMPLEX MULTIPLIER Weidong Li, Shengxian Zhuang, and Lars Wanhammar Department of Electrical Engineering SE-581 83 Linköping, Sweden E-mail: {weidongl, zhuangsx, larsw}@isy.liu.se ABSTRACT In this paper, we propose a pipeline scheme for efficient realization of a complex multiplier using distributed arith- metic. The pipelined multiplier consists of one conven- tional multiplier that is multiplexed and some small additional circuitry on the boundary. The proposed scheme reduces the chip area as well as the interconnec- tions by nearly half compared to a conventional complex multiplier. The pipelined multiplier is efficient in terms of chip area and interconnect, which reduces the power con- sumption. 1. INTRODUCTION Arithmetic operations with complex numbers are required in many DSP algorithms, e.g., in digital filters and FFT. The complex multiplication is often the most expensive arithmetic operation and one of the dominating factors in determining the performance in terms of speed and power consumption. Therefore, the design of an efficient com- plex multiplier is important. Straightforward implementation of complex multipli- cation requires four real multiplications, one addition and one subtraction. However, the number of multiplications can be reduced to three with a transformation that uses extra pre and post additions [1]. A more efficient way to reduce the cost of multiplication is to use distributed arithmetic [2]. Distributed arithmetic is based on addition of precomputed sums of coefficient values. With this algorithm, the complexity of complex multiplication cor- responds to two real multiplications. In this paper, we present an efficient pipelined com- plex multiplier and its implementation. By adding some logical control circuitry on the boundary, the partial prod- uct generator is shared by both the real part and the imag- inary part. This leads to area efficiency and has little interconnect, which tends to reduce the power consump- tion. In the following section, we first review the principles of distributed arithmetic using offset binary coding and show how it can be used to realize a complex multiplier [3]. Then in section 3, we discuss the pipelined complex multiplier. In section 4, the detailed implementation is presented. Finally, conclusions are given in section 5. 2. DISTRIBUTED ARITHMETIC Distributed arithmetic uses precomputed partial sums for an efficient computation of inner products of a constant vector and a variable vector. Let C R + jC I and X R + jX I be two complex numbers of which C R + jC I is the coefficient and X R + jX I is the varia- ble complex number. In the case of a complex multiplica- tion, we have Z R + jZ I = (C R + jC I )(X R + jX I ) = = (C R X R – C I X I ) +j(C R X I + C I X R ) (1) Hence, a complex multiplication can be considered as two inner products of two vectors with two elements. We will realize the real and imaginary parts separately. For the sake of simplicity we will only consider the first inner product equation (1), i.e., the real part. The complex coefficient, C R + jC I , is assumed to be fixed and two’s-complement representation is used for both coeffi- cient and data. The data is scaled so that |Z R + jZ I | < 1. The inner product can be rewritten where x Rk and x Ik are the k:th bits in the real and imagi- nary parts, respectively. By interchanging the order of the two summations we get which can be written (2) where (3) Z R C R x R 0 – x Rk 2 k – k 1 = W d 1 – ∑ + – = C I x I 0 – x Ik 2 k – k 1 = W d 1 – ∑ + – Z R C – R x R 0 C I x I 0 + + = C R x Rk C – I x Ik ( 29 2 k – k 1 = W d 1 – ∑ + Z R F k x R 0 x I 0 , ( 29 – F k x Rk x Ik , ( 29 2 k – k 1 = W d 1 – ∑ + = F k x Rk x Ik , ( 29 C R x Rk C – I x Ik =
Transcript of AN EFFICIENT PIPELINED COMPLEX MULTIPLIER · PDF fileAN EFFICIENT PIPELINED COMPLEX MULTIPLIER...

AN EFFICIENT PIPELINED COMPLEX MULTIPLIERWeidong Li, Shengxian Zhuang, and Lars Wanhammar
Department of Electrical EngineeringSE-581 83 Linköping, SwedenE-mail: {weidongl, zhuangsx, larsw}@isy.liu.se
ornt
-
ase
e
fi-
e
ABSTRACTIn this paper, we propose a pipeline scheme for efficientrealization of a complex multiplier using distributed arith-metic. The pipelined multiplier consists of one conven-tional multiplier that is multiplexed and some smalladditional circuitry on the boundary. The proposedscheme reduces the chip area as well as the interconnec-tions by nearly half compared to a conventional complexmultiplier. The pipelined multiplier is efficient in terms ofchip area and interconnect, which reduces the power con-sumption.
1. INTRODUCTIONArithmetic operations with complex numbers are requiredin many DSP algorithms, e.g., in digital filters and FFT.The complex multiplication is often the most expensivearithmetic operation and one of the dominating factors indetermining the performance in terms of speed and powerconsumption. Therefore, the design of an efficient com-plex multiplier is important.
Straightforward implementation of complex multipli-cation requires four real multiplications, one addition andone subtraction. However, the number of multiplicationscan be reduced to three with a transformation that usesextra pre and post additions [1]. A more efficient way toreduce the cost of multiplication is to use distributedarithmetic [2]. Distributed arithmetic is based on additionof precomputed sums of coefficient values. With thisalgorithm, the complexity of complex multiplication cor-responds to two real multiplications.
In this paper, we present an efficient pipelined com-plex multiplier and its implementation. By adding somelogical control circuitry on the boundary, the partial prod-uct generator is shared by both the real part and the imag-inary part. This leads to area efficiency and has littleinterconnect, which tends to reduce the power consump-tion.
In the following section, we first review the principlesof distributed arithmetic using offset binary coding andshow how it can be used to realize a complex multiplier[3]. Then in section 3, we discuss the pipelined complexmultiplier. In section 4, the detailed implementation ispresented. Finally, conclusions are given in section 5.
2. DISTRIBUTED ARITHMETICDistributed arithmetic uses precomputed partial sums fan efficient computation of inner products of a constavector and a variable vector.
Let CR + jCI andXR + jXI be two complex numbers ofwhichCR + jCI is the coefficient andXR + jXI is the varia-ble complex number. In the case of a complex multiplication, we have
ZR + jZI = (CR + jCI)(XR + jXI) =
= (CR XR– CIXI) +j(CRXI + CIXR) (1)
Hence, a complex multiplication can be consideredtwo inner products of two vectors with two elements. Wwill realize the real and imaginary parts separately.
For the sake of simplicity we will only consider thefirst inner product equation (1), i.e., the real part. Thcomplex coefficient,CR + jCI, is assumed to be fixed andtwo’s-complement representation is used for both coefcient and data. The data is scaled so that |ZR + jZI | < 1.The inner product can be rewritten
wherexRk andxIk are thek:th bits in the real and imagi-nary parts, respectively. By interchanging the order of thtwo summations we get
which can be written
(2)
where
(3)
ZR CR xR0– xRk2k–
k 1=
Wd 1–
∑+ –=
CI xI 0– xIk2 k–
k 1=
Wd 1–
∑+–
ZR C– RxR0 CI xI 0+ +=
CRxRk C– I xIk( )2 k–
k 1=
Wd 1–
∑+
ZR Fk xR0 xI 0,( )– Fk xRk xIk,( )2 k–
k 1=
Wd 1–
∑+=
Fk xRk xIk,( ) CRxRk C– I xIk=

i-t
1
e
Fk is a function of two binary variables, i.e., thek:thbits inXR andXI. SinceFk can take on only four values, itcan be computed and stored in a look-up table.
In the same way we get the corresponding binaryfunction for the imaginary part as
Equation (2) can be illustrated as shown below.Notethe similarity between equation (2) and the correspondingexpression for a conventional real multiplier in which thefunctionsFk (Gk) are bit-products between the coefficientbits and thek:th data bit. The bit-products can be stored ina look-up table with only four words as illustrated inFigure 2. Hence, equation (2) and its imaginary counter-part can be realized with any real multiplication algorithmwhere the bit-products are replaced with the correspond-ing bits from the functionsFk andGk. For example, bit-parallel array or tree multiplier structures [1], or bit-serialmultipliers [3 - 4] can be used. Each inner product can beimplemented directly with an addition tree and precom-puted partial products.
2.1 Complex Multiplier with Offset BinaryCoding
The offset binary coding can be applied to complex multplication. Without any loss of generality, we assume thathe magnitudes ofCR, CI, XR, andXI all are less than 1.The word length ofXR, andXI is Wd. Then, the complexmultiplication can be written
ZR + jZI = (CR XR– CIXI) + j(CRXI + CIXR)
(4)
The functionsF andG can be expressed as follows.
(5)
(6)
In equation (6), is either 1 or –1. Hencethe partial product, i.e., functionFk (Gk), for each bit is ofthe formCR ± CI. All possible partial products are tabu-lated in Table 1. Obviously, only two coefficients, i.e.,–(CR – CI) and –(CR + CI), are sufficient to store since(CR – CI) and (CR + CI) can easily be generated from thetwo former coefficients by inverting all bits and addingin the least-significant position.
The complex multiplier with distributed arithmetic isillustrated in Figure 3. The accumulators, which adds th
Gk xRk xIk,( ) CRxIk C+IxRk=
–F0
FWd-1FWd-2
F1
Figure 1. Bit-products in Eq. (2) to be added.
Look-upTable forCR
Dec
oder
XRLook-up
Table forCI
Decoder
XI
Accumulator ZR
Look-upTable forCI
Dec
oder
XRLook-up
Table forCR
Decoder
XI
Accumulator ZI
Figure 2. Complex multiplier using distributedarithmetic.
xRi xIi F(xRi,xIi) G(xRi,xIi)
0 0 –(CR–CI) –(CR+CI)
0 1 –(CR+CI) (CR–CI)
1 0 (CR+CI) –(CR–CI)
1 1 (CR–CI) (CR+CI)
Table 1: Partial Products.
CR xR0 xR0–( )2 1–– CR xRi xRi–( )2 i– 1–
i 1=
Wd 1–
∑ CR2Wd–
–+
=
CI xI 0 xI 0–( )2 1–– CI xIi xIi–( )2 i– 1–
i 1=
Wd 1–
∑ CI 2Wd–
–+
–
+ j CR xI 0 xI 0–( )2 1–– CR xIi xIi–( )2 i– 1–
i 1=
Wd 1–
∑ CR2Wd–
–+
+ j CI xR0 xR0–( )2 1–– CI xRi xRi–( )2 i– 1–
i 1=
Wd 1–
∑ CI 2Wd–
–+
F– xR0 xI 0,( ) F xRi xIi,( )2 i– 1–
i 1=
Wd 1–
∑ F 0 0,( )2Wd–
+ +
=
+ j G– xR0 xI 0,( ) G xRi xIi,( )2 i– 1–
i 1=
Wd 1–
∑ G 0 0,( )2Wd–
+ +
F xRi xRi,( ) CR xRi xRi–( ) CI xIi xIi–( )–=
G xRi xRi,( ) CI xRi xRi–( ) CR xIi xIi–( )+=
xi xi–( ) 2⁄

-
td-
resdx-eth
partial products, are the same as in a real multiplication.The partial product generation is only slightly more com-plicated than for a real multiplier. Hence, the complexityof the complex multiplier in term of chip area corre-sponds to approximately two real multipliers.
The complex multiplier requires that the coefficients,–(CR– CI) and –(CR+ CI), are precomputed. However, formany applications, like the FFT, the coefficients areknown in advance and can be stored in ROM, which sim-ply changes the content of the coefficient ROM from stor-ing CR andCI to storing –(CR– CI) and –(CR+ CI).
3. PIPELINED COMPLEXMULTIPLIER
As discussed in section 2, a complex multiplier with dis-tributed arithmetic has approximately the same area com-plexity as two real multipliers. However, theimplementation of the complex multiplier (accumulator)is still a difficult task due to the complex routing.
In order to reduce the complexity of the wire routing,we propose the use of a pipelined multiplier. The pipe-lined multiplier is based on the fact that the real part andimaginary part are identical in circuit realization exceptthe partial product generation.
3.1 Pipelining of the MultiplierTo obtain a pipelining scheme for the complex multiplier,the partial product generation for the real and imaginaryparts has to be merged. For the sake of simplicity, wedefineS= –(CR – CI) andT = –(CR + CI) and for thej:thbit, Sj = –(CRj – CIj) andTj = –(CRj + CIj).
Consider now the bit partial product forxRi, xIi , sj,and tj. Let be the real partial product and bethe imaginary partial product. The partial products can beobtained from the following equations.
From Table 1, we see that all of possible partial products can be expressed with
Defining , the above equa-tions can be rewritten as
By introducing an extra control signalm, the partialproduct generation can be expressed by
where whenm = 1, andwhenm = 0. Hence the computation of the real produccan be changed to the computation of the imaginary prouct by a simple multiplexing scheme.
3.2 Multiplexed AccumulatorThe realization of the pipelined complex multiplier isillustrated in Figure 4. The pipelined complex multiplieuses a multiplexed pipelined accumulator and requironly multiplexers and demultiplexers at the inputs anoutputs. The cost in terms of chip area for this complemultiplier is therefore about half of a direct implementation with distributed arithmetic. We can simply use thclock as control signal and add pipeline stages wi
XR XI –(CR+CI) –(CR–CI)
Partial productgenerator
F G
Accumulator Accumulator
ZR ZI
Figure 3. Complex multiplier using DA.
Partial productgenerator
pri j, pii j,
pri j, CRj xRi xRi–( ) CIj xIi xIi–( )–=
pii j, CIj xRi xRi–( ) CRj xIi xIi–( )+=
pri j, xRi xIi sj t j, , ,( ) xRi xRi xIi⊕( )t j xRi xIi⊕( )sj+( )⊕=
pii j, xRi xIi sj t j, , ,( ) xIi xRi xIi⊕( )sj xRi xIi⊕( )t j+( )⊕=
mux a b m, ,( ) ma mb+=
pri j, XRi XIi sj t j, , ,( ) XRi mux tj sj XRi XIi⊕, ,( )⊕=
pii j, XRi XIi sj t j, , ,( ) XIi mux sj t j XRi, XIi⊕,( )⊕=
ppi j, mux xRi XIi m, ,( ) mux mux tj sj m, ,( )mux sj t j m, ,( ) xRi, xIi⊕
,()
⊕=
pri j, ppi j,= pii j, ppi j,=
XR
XI
–(CR–CI)
–(CR+CI)Partial productgenerator
Pipelined
ZR ZI
control
Figure 4. Pipelined complex multiplier.
Accumulator
s
hesneg-de
-g-sts,ithg-
iscan
s-ti-ee-trs
ial
latches.The routing is also simplified since there is only one
of two parts to be implemented. The disadvantage of thepipelined multiplier is the computation time which istwice as long as the non-pipelined one.
4. IMPLEMENTATIONIn this section, we discuss the parallel implementation forthe complex multipliers. There are two main blocks forthe complex multiplier: the partial product generationblock, and the accumulation block. These two blocks willbe studied in more detail.
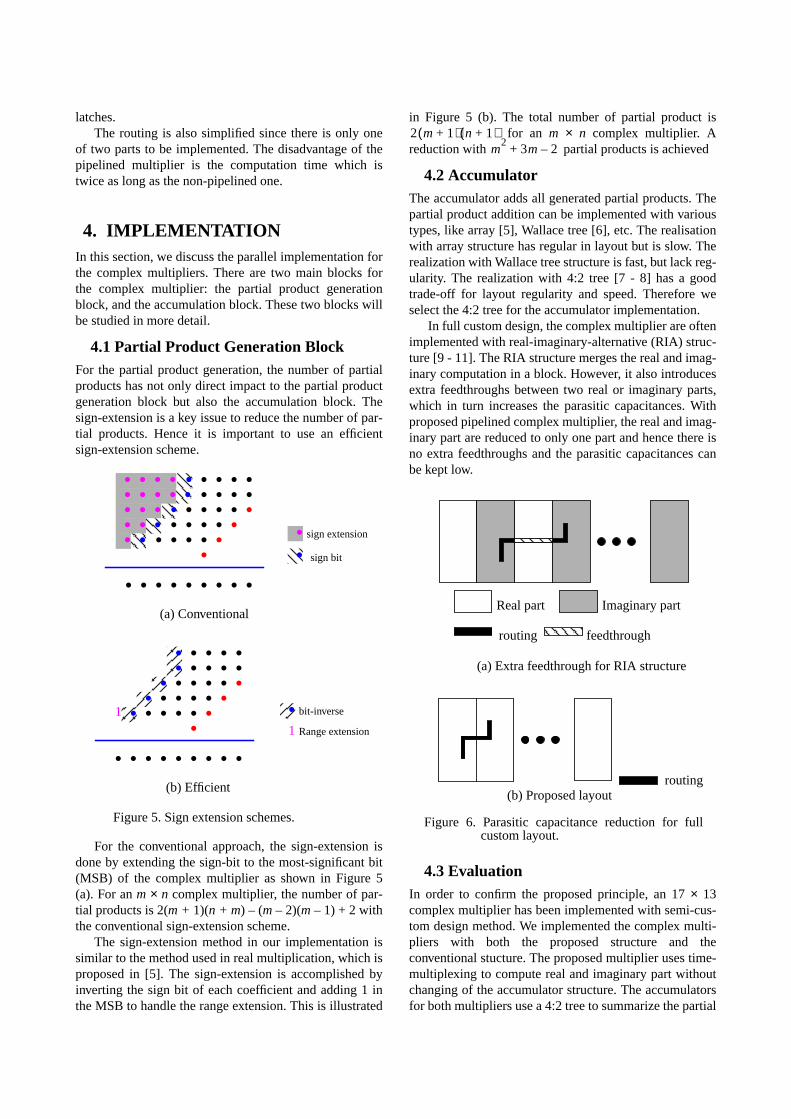
4.1 Partial Product Generation BlockFor the partial product generation, the number of partialproducts has not only direct impact to the partial productgeneration block but also the accumulation block. Thesign-extension is a key issue to reduce the number of par-tial products. Hence it is important to use an efficientsign-extension scheme.
For the conventional approach, the sign-extension isdone by extending the sign-bit to the most-significant bit(MSB) of the complex multiplier as shown in Figure 5(a). For anm × n complex multiplier, the number of par-tial products is 2(m + 1)(n + m) – (m– 2)(m– 1) + 2 withthe conventional sign-extension scheme.
The sign-extension method in our implementation issimilar to the method used in real multiplication, which isproposed in [5]. The sign-extension is accomplished byinverting the sign bit of each coefficient and adding 1 inthe MSB to handle the range extension. This is illustrated
in Figure 5 (b). The total number of partial product ifor an m × n complex multiplier. A
reduction with partial products is achieved
4.2 AccumulatorThe accumulator adds all generated partial products. Tpartial product addition can be implemented with varioutypes, like array [5], Wallace tree [6], etc. The realisatiowith array structure has regular in layout but is slow. Threalization with Wallace tree structure is fast, but lack reularity. The realization with 4:2 tree [7 - 8] has a gootrade-off for layout regularity and speed. Therefore wselect the 4:2 tree for the accumulator implementation.
In full custom design, the complex multiplier are oftenimplemented with real-imaginary-alternative (RIA) structure [9 - 11]. The RIA structure merges the real and imainary computation in a block. However, it also introduceextra feedthroughs between two real or imaginary parwhich in turn increases the parasitic capacitances. Wproposed pipelined complex multiplier, the real and imainary part are reduced to only one part and hence thereno extra feedthroughs and the parasitic capacitancesbe kept low.
4.3 EvaluationIn order to confirm the proposed principle, an 17× 13complex multiplier has been implemented with semi-cutom design method. We implemented the complex mulpliers with both the proposed structure and thconventional stucture. The proposed multiplier uses timmultiplexing to compute real and imaginary part withouchanging of the accumulator structure. The accumulatofor both multipliers use a 4:2 tree to summarize the part
•
• • • • •• • • •
• • • • • •• • • • •
1 • • • • ••
• • • • • • • • •
• bit-inverse
1 Range extension
• • • • •• • • •
• • • • • •• • • • •
• • • • ••
• • • • • • • • •
• sign extension
• • • •• • • •• ••• • •
••
•• sign bit
Figure 5. Sign extension schemes.
(a) Conventional
(b) Efficient
••
2 m 1+( ) n 1+( )m
23m 2–+
Real part Imaginary part
feedthrough
(a) Extra feedthrough for RIA structure
(b) Proposed layoutrouting
routing
Figure 6. Parasitic capacitance reduction for fullcustom layout.

xit-
tye.-
e
-ygic
.nl
”
ll
x
products. Both multipliers are written with structuralVHDL and synthesized using standard triple metal 0.35µm CMOS technology. The place and route is performedwith Silicon Ensemblefrom Cadence. We consider onlythe interconnections within the multiplier cores andexclude the I/O interconnections. The result is shown inthe Table 2. Even though the automatic place and routetool cannot retain the structure, we still find that the aver-age parasitic capacitance is reduced with the proposedstructure.
We cannot simulate the power consumption due to thelack of backannotation. However, there are two factorswhich contribute to the reduction of power cunsumptionin the proposed complex multiplier. One is the reductionon parasitic capacitances as shown in Table 2. The otheris the reduction of glitches due to the proposed schemeapplies more pipelining to the complex multiplier.
5. CONCLUSIONSIn this paper we present an efficient pipelined complemultiplier based on distributed arithmetic and comparewith conventional complex multiplier. The proposed pipelined complex multiplier has less area, routing complexiand power consumption than that of the conventional on
Full custom implementation and evaluation of the proposed pipelined complex multiplier would be the futurworks.
ACCKNOWLEDGEMENTThe authors would like to thank Henrik Ohlsson for supports with the logic synthesis. The project is financiallsupported by SSF, the Swedish Foundation for StrateResearch.
REFERENCES[1] I. Koren, Computer Arithmetic Algorithms, Prentice
Hall, 1993.[2] A. Croisier, D. J. Esteban, M. E. Levilion, and V.
Rizo, Digital Filter for PCM Encoded Signals, U. S.Patent 3777130, Dec., 1973.
[3] L. Wanhammar,DSP Integrated Circuits, AcademicPress, 1999.
[4] J. Melander, T. Widhe, P. Sandberg, K. Palmkvist, MVesterbacka, and L. Wanhammar, “Implementatioof a Bit-Serial FFT Processor with a HierachicaControl Structure,”Proceedings of European Conf.on Circuit Theory and Design(ECCTD), Vol. 1, pp.423-426, Turkey, Aug. 1995.
[5] C. R. Baugh and B. A. Wooley, “A two’s complementparallel array multiplication algorithm,”IEEE Trans.on Computers, C-22, pp. 1045-1047, Dec., 1973.
[6] C. S. Wallace, “A suggestion for a fast multiplier,”IEEE trans. on Electronic Computers, EC-13, pp. 14-17, Feb., 1964.
[7] W. Li, J. B. Burr, A. Peterson, “A fully parallel VLSIimplementation of distributed arithmetic,”Proceed-ings of IEEE Int. Conf. on Circuits and Systems, pp.1511-1515, Finland, 1988.
[8] M. Santoro and M. Horowitz, “SPIM: Apipelined64x64-bit iterative multiplier,”IEEE J. Solid-StateCircuits, pp. 487-493, April, 1989.
[9] Y. Chang and K. K. Parhi, “High-performance digit-serial complex-number multiplier-accumulator,Proc. of Int. Conf. on Computer Design(ICCD), pp.211-213, USA, Oct., 1998.
[10] T. Aoki, Y. Ohi, and T. Higuchi, “Redundant com-plex number arithmetic for high-speed signaprocessing,”Proc. of IEEE Workshop on VLSI SignaProcessing, pp. 523-531, Japan, Oct., 1995.
[11] T. Aoki, H. Amada, and T. Higuchi, “Real/complexreconfigurable arithmetic using redundant complenumber systems,”Proc. of IEEE Symp. on ComputerArithmetic, pp. 200-207, USA, Jul., 1997.
ConventionalReal Multiplier
PipelinedComplex Mul-
tiplier
Area 0.56 mm2 0.28 mm2
Average intercon-nection parasitic
capacitance
5.80 fF 5.61 fF
Table 2: Comparison of conventional complex multiplierand pipelined complex multiplier.
540µm
540
µm
Figure 7. Layout of the pipelined complex multiplier.
Figure 8. Layout of the conventional multiplier.
750µm
750
µm













![SPIM: A Pipelined 64 X 64 bit Iterative Multiplier · It has a core size of 3.8 X 6.5mm and contains 41 ... A Pipelined 64 X 64 bit Iterative Multiplier ... Dadda [4], and most other](https://static.fdocuments.in/doc/165x107/5afdb58a7f8b9a864d8deb59/spim-a-pipelined-64-x-64-bit-iterative-has-a-core-size-of-38-x-65mm-and-contains.jpg)




