
An atomic commit protocol for gigabit-networked distributed
25
An atomic commit protocol for gigabit-networked distributed database systems Yousef J. Al-Houmaily a , Panos K. Chrysanthis b,1 * a Department of Computer Programs, Institute of Public Administration, Riyadh 11141, Saudi Arabia b Department of Computer Science, University of Pittsburgh, 220 Alumni Hall, Pittsburgh, PA 15260, USA Received 10 September 1998; received in revised form 19 March 1999; accepted 10 September 1999 Abstract In the near future, dierent database sites will be interconnected via gigabit networks, forming a very powerful distributed database system. In such an environment, the propagation latency will be the dominant component of the overall communication cost while the migration of large amounts of data will not pose a problem. Furthermore, computer systems are expected to become even more reliable than todayÕs systems with long mean time between failures and short mean time to repair. In this paper, we present implicit yes-vote (IYV), a one-phase atomic commit protocol, that exploits these new domain characteristics to minimize the cost of distributed transaction commitment. IYV eliminates the explicit voting phase of the two-phase commit protocol, hence reducing the number of sequential phases of message passing during normal processing. In the case of a participantÕs site failure, IYV supports the option of forward recovery by enabling partially executed transactions that are still active in the system to resume their execution when the failed participant is recovered. Ó 2000 Elsevier Science B.V. All rights reserved. Keywords: Atomic commit protocols; One-phase commit protocol; Distributed transaction processing; High speed networks; Distributed systems 1. Introduction and motivation Transactions in a distributed database system (DDBS) access data located at dierent sites. Part of the correctness of a distributed transaction is to ensure its atomicity which requires that all the transactionÕs eects either persist at all the sites the transaction has visited or are obliterated from them as if the transaction has never existed. This is achieved by employing an atomic commit protocol (ACP) that executes a commit or an abort opera- tion across multiple sites as a single logical oper- ation. The simplest and most studied ACP is the two-phase commit protocol (2PC) [17,22]. Commit processing consumes a substantial amount of a transactionÕs execution time [30] and any delay in making and propagating the final decision reduces the level of concurrency and ad- versely aects the performance of a DDBS. The system performance is also degraded by having to abort partially executed transactions due to com- munication and site failures, in particular just be- fore a commit decision is made. In other words, an www.elsevier.com/locate/sysarc Journal of Systems Architecture 46 (2000) 809–833 * Corresponding author. Tel.: 41-412-6248924; fax: 41-412- 6248854. E-mail address: [email protected] (P.K. Chrysanthis). 1 Supported in part by National Science Foundation under grant IRI-9210588 and IRI-9502091. 1383-7621/00/$ - see front matter Ó 2000 Elsevier Science B.V. All rights reserved. PII: S 1 3 8 3 - 7 6 2 1 ( 9 9 ) 0 0 0 4 0 - 5
Transcript of An atomic commit protocol for gigabit-networked distributed

An atomic commit protocol for gigabit-networked distributeddatabase systems
Yousef J. Al-Houmaily a, Panos K. Chrysanthis b,1 *
a Department of Computer Programs, Institute of Public Administration, Riyadh 11141, Saudi Arabiab Department of Computer Science, University of Pittsburgh, 220 Alumni Hall, Pittsburgh, PA 15260, USA
Received 10 September 1998; received in revised form 19 March 1999; accepted 10 September 1999
Abstract
In the near future, di�erent database sites will be interconnected via gigabit networks, forming a very powerful
distributed database system. In such an environment, the propagation latency will be the dominant component of the
overall communication cost while the migration of large amounts of data will not pose a problem. Furthermore,
computer systems are expected to become even more reliable than todayÕs systems with long mean time between failures
and short mean time to repair. In this paper, we present implicit yes-vote (IYV), a one-phase atomic commit protocol,
that exploits these new domain characteristics to minimize the cost of distributed transaction commitment. IYV
eliminates the explicit voting phase of the two-phase commit protocol, hence reducing the number of sequential phases of
message passing during normal processing. In the case of a participantÕs site failure, IYV supports the option of forward
recovery by enabling partially executed transactions that are still active in the system to resume their execution when the
failed participant is recovered. Ó 2000 Elsevier Science B.V. All rights reserved.
Keywords: Atomic commit protocols; One-phase commit protocol; Distributed transaction processing; High speed networks;
Distributed systems
1. Introduction and motivation
Transactions in a distributed database system(DDBS) access data located at di�erent sites. Partof the correctness of a distributed transaction is toensure its atomicity which requires that all thetransactionÕs e�ects either persist at all the sites thetransaction has visited or are obliterated from
them as if the transaction has never existed. This isachieved by employing an atomic commit protocol(ACP) that executes a commit or an abort opera-tion across multiple sites as a single logical oper-ation. The simplest and most studied ACP is thetwo-phase commit protocol (2PC) [17,22].
Commit processing consumes a substantialamount of a transactionÕs execution time [30] andany delay in making and propagating the ®naldecision reduces the level of concurrency and ad-versely a�ects the performance of a DDBS. Thesystem performance is also degraded by having toabort partially executed transactions due to com-munication and site failures, in particular just be-fore a commit decision is made. In other words, an
www.elsevier.com/locate/sysarc
Journal of Systems Architecture 46 (2000) 809±833
* Corresponding author. Tel.: 41-412-6248924; fax: 41-412-
6248854.
E-mail address: [email protected] (P.K. Chrysanthis).1 Supported in part by National Science Foundation under
grant IRI-9210588 and IRI-9502091.
1383-7621/00/$ - see front matter Ó 2000 Elsevier Science B.V. All rights reserved.
PII: S 1 3 8 3 - 7 6 2 1 ( 9 9 ) 0 0 0 4 0 - 5

e�cient ACP should reach a ®nal decision withminimum communication delay and should allowpartially executed transactions to resume theirexecution on a failed participant when the partic-ipant recovers. Owing to the relatively low datatransfer rates of traditional networks, currentACPs have been designed with the focus on min-imizing the amount of data to be transferred andthe number of messages to be exchanged whilecurrent database management systems do notsupport forward recovery of atomic transactions.
However, future DDBSs are expected to be-come even more reliable than todayÕs systems ex-ecuting on computers with relatively long meantime between failures and short mean time to repairinterconnected via high speed networks. Thesenetworks will support data transfer rates in theorder of gigabits per second. In such gigabit-net-worked DDBSs, the propagation latency will bethe dominant component of the overall commu-nication cost while the migration of large amountsof data will not pose a problem [7,8,21]. That is,the size of messages in a database protocol will beless of a concern than the required number ofrounds or sequential phases of message passing.Given this observation, we are prompted to askthe following two questions:1. Is it possible to improve the performance of the
2PC by permitting large messages; that is, canwe reduce the number or rounds of messagesin the 2PC?
2. Is it possible to support forward recovery, i.e.,recover partially executed transactions after afailure by not placing any limitations on the sizeof a message?In this paper, we present implicit yes-vote (IYV),
a one-phase ACP, that combines the propertiesimplied in both of the above two questions. IYV istargeted for environments with ®xed number ofhigh performance coordinators or applicationservers. IYV improves on the current ACPs byexploiting the performance and reliability proper-ties of future gigabit-networked DDBSs. Speci®-cally, IYV eliminates the explicit voting phase ofthe 2PC by overlapping the participantsÕ voteswith the execution of transactionsÕ operations,hence reducing the number of sequential co-ordi-nation messages during normal commit process-
ing. The underlying system assumption in IYV isthat all sites employ strict two-phase locking pro-tocol (S-2PL) for concurrency control [16,10],which is the most commonly used protocol.
In the case of a participant failure, IYV sup-ports the option of forward recovery by enablingpartially executed transactions to resume theirexecution on a failed participant when the par-ticipant recovers. By assuming context freetransactions at the participants, 2 forward recov-ery is achieved through a low-cost replication ofthe redo log records that are generated during theexecution of a transactionÕs operations at both thetransactionÕs coordinator and the participants,and by propagating the read locks that are held bythe transaction at a participant to the transac-tionÕs coordinator. Thus, forward recovery in IYVcan be thought of as an instance of forward re-covery proposed for distributed computations,e.g., [15]. As opposed to forward recovery indistributed processes, participants in IYV do notasynchronously checkpoint their local states andafter a participant failure, non-failed participantsdo not have to partially rollback for the entiredistributed transaction to reach a consistent statefrom which the transaction can resume its execu-tion. Here, a transactionÕs view of the databasestate at a failed participant is reconstructed, if thelocal execution state of the transaction residing atits coordinator site is una�ected. In this respect,forward recovery in IYV is not the same as thenotion of partial recovery in extended transac-tions, such as in nested transactions where a failedsubtransaction may be rolled back and re-exe-cuted by design [27]. In IYV, distributed trans-actions are traditional, unstructured transactionswhich are executed in a distributed manner by thedatabase system.
The rest of the paper is structured as follows. InSection 2, we overview the 2PC and its two com-mon variants as well as previously proposed one-
2 A transaction is said to be context free at a participant if
each operation execution at the participant is not a function of
the previously executed operations invoked by the same
transaction [19]. For example, read operations using a common
cursor are not independent where the cursor is part of the
context of the invoking transaction.
810 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

phase ACPs. In Section 3, the IYV protocol isintroduced and its behavior in the presence offailures is discussed in detail. In Section 4, wediscuss the applicability of IYV and its assump-tions. In Section 5, we apply the presumed abort2PC (PrA) optimization [25,26] to IYV, motivatedby the fact that PrA has been widely implemented[12] and adopted by the ISO OSI-TP [36] and X/Open DTP [11] standards. We also propose a read-only optimization that can be combined with IYVand its PrA optimization to further reduce theircost for read-only transactions and extend IYV tothe multi-level transaction execution model [5,26].In Section 6, we compare IYV with those proto-cols discussed in Section 2. Unlike the traditionalway of evaluating the performance of ACPs whichis based on counting the number of messages andforced log writes, in Section 7, we evaluate thesedi�erent commit protocols in terms of the numberof sequential messages and forced log writes thatare required to reach a decision point and to re-lease all the locks held by transactions as in [33,34].Section 8 concludes this paper.
2. Background and related work
In a distributed database system, data are typ-ically stored in disjoint partitions at di�erent sites.This data distribution is transparent to a distrib-uted transaction that accesses data by submittingdatabase operations to its coordinator which isassumed to be, without loss of generality, thetransaction manager of the site where the trans-action has been initiated. In this paper, we assumethat a transaction is a partial order of read (R) andwrite (W) operations that are con®ned within abegin (B) and a commit (C) or an abort (A)transaction management primitives.
When a coordinator receives an operation on adata item, it sends the operation to the appropriatesite for execution. If the coordinator receives anabort request from the transaction, it sends anabort request to all the participants, i.e., the sitesparticipating in the execution of the transaction.On the other hand, when the coordinator receivesa commit request from the transaction, it initiatesan atomic commit protocol.
As shown in Fig. 1, the basic 2PC [17,22], asthe name implies, consists of two phases, namelya voting phase and a decision phase. During thevoting phase, the coordinator of a distributedtransaction requests all the sites participating inthe transactionÕs execution to prepare to commitwhereas, during the decision phase, the coordi-nator either decides to commit the transaction ifall the participants are prepared to commit (voted``yes''), or to abort if any participant has decidedto abort (voted ``no''). If a participant has voted``yes'', it can neither commit nor abort thetransaction until it receives the ®nal decision fromthe coordinator. When a participant receivesthe ®nal decision, it complies, acknowledges thedecision and releases all the resources held bythe transaction (i.e., releases the locks held by thetransaction, removes the transaction controlblock from its table, etc.). The coordinatorcompletes the protocol when it receives ac-knowledgments from all the participants andforgets about the transaction by removing anyentry associated with the completed transactionfrom its protocol table. The protocol table isstored in main memory and for each transaction,the coordinator records the identities of the sitesthat need to participate in the commitment of thetransaction and the progress of the protocol onceit is initiated.
The resilience of 2PC to system and communi-cation failures is achieved by recording the
Fig. 1. The basic two-phase commit protocol.
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 811

progress of the protocol in the logs of the coor-dinator and the participants (see Fig. 1). The co-ordinator is required to force-write a decisionrecord prior to sending the ®nal decision to theparticipants. Since a force-write ensures that all thelog records are written into a stable storage thatsustains system failures, the ®nal decision is notlost in the case of a coordinator failure. Similarly,each participant force-writes a prepared recordbefore sending its vote and a decision record beforeacting on and acknowledging a ®nal decision.When the coordinator completes the protocol, itwrites an end record without forcing it into stablestorage, indicating that all participants have re-ceived the ®nal decision and the log records per-taining to the transaction can be garbage collectedwhen necessary.
The basic 2PC protocol is also referred to as thepresumed nothing 2PC (PrN) [23] because it treatsall transactions uniformly, whether they are to becommitted or aborted, requiring information to beexplicitly exchanged and logged at all times.However, in case of a coordinatorÕs failure, there isa hidden presumption in PrN by which the coor-dinator considers all active transactions at the timeof the failure as aborted transactions. This pre-sumption allows a coordinator in 2PC not to re-cord the beginning of the protocol in the stable logand hence not to force-write any log records priorto the decision phase. (Note that a force-write in-volves a disk access that suspends the protocoluntil the disk access is completed.) If a participantinquires the coordinator about an active transac-tion after the coordinator has failed and recovered,the coordinator, not remembering the transaction,will direct the participant to abort the transactionby presumption.
The presumed abort PrA is a 2PC variant thatreduces the cost associated with aborted transac-tions by making the abort presumption of PrNexplicit [25,26]. When the coordinator of a trans-action decides to abort the transaction, in PrA, thecoordinator discards all information about thetransaction from its protocol table and submits anabort message to all the participants without log-ging an abort decision, as opposed to PrN. After acoordinator failure, if a participant inquires aboutthe outcome of a transaction, the coordinator, not
®nding any information regarding the transactionwill direct the participant to abort the transactionby presumption. Furthermore, in PrA, the coor-dinator of a transaction does not require abortacknowledgments from the participants because itcan discard all information pertaining to thetransaction from its protocol table without them.Since the participants are not required to ac-knowledge abort decisions, they do not have toforce-write abort log records. Instead, they write(non-forced) abort records in the log bu�er inmain memory. Hence, in the case of abort, PrAsaves a forced log write at the coordinatorÕs siteand a forced log write and an acknowledgmentmessage from each participant. For the commitcase, the cost of PrA remains the same as in thePrN.
Assuming that a transaction is most probablygoing to commit if it has ®nished its execution andissued a commit request, the PrC variant [26] wasdesigned to reduce the cost associated with com-mitting transactions. Instead of interpreting miss-ing information about transactions as abortdecisions which is the case in PrA, in PrC, coor-dinators interpret missing information abouttransactions as commit decisions. However, inPrC, the coordinator of a transaction has to force-write an initiation log record before submitting theprepare to commit message to the participants.The initiation record ensures that missing infor-mation about the transaction will not be wronglymis-interpreted as a commit case after a coordi-natorÕs site failure. Thus, this record is necessaryfor the correctness of this 2PC variant. In addition,the initiation record contains the identities of theparticipants that are needed for recovery. In thecase of PrN and PrA, this information is recordedin the decision log record.
To commit a transaction, the transactionÕs co-ordinator force-writes a commit record to logicallyeliminate the initiation record, then sends out thecommit decision to all the participants and dis-cards any information about the transaction.When a participant receives the commit message, itwrites a non-forced commit record and commitsthe transaction. Since the coordinator can discardall information about a committed transactionwithout the acknowledgments of the participants,
812 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

a participant does not have to acknowledge acommit decision.
To abort a transaction, on the other hand, thetransactionÕs coordinator does not have to force anabort record. Instead, the coordinator submits theabort decision to all the participants and waits fortheir acknowledgments. Once the coordinator re-ceives the acknowledgments, it discards all infor-mation pertaining to the transaction from itsprotocol table and writes a non-forced end record.Each participant, in this case, has to force-write anabort record and then acknowledges the coordi-nator. As far as the total message count and forcedlog writes are concerned, the cost to abort atransaction remains the same as in the PrN 3 whilethe cost to commit a transaction is reduced by aforced log write and an acknowledgment messagefrom each participant on the expense of an extraforced log write at the coordinator (i.e., the initi-ation record).
PrA and PrC are usually coupled with theread-only optimization [25,26,30]. In this optimi-zation, a participant votes read-only if it hasexecuted only read operations. Using this opti-mization, a participant can release all the locksheld by the transaction once it votes. Further-more, a read-only participant does not participatein the second phase of these protocols and henceit does not have to know about the outcome ofthe transaction. Also, a participant does not haveto write any log records regarding a read-onlytransaction. If a transaction is read-only (i.e., allthe operations it has submitted to all the partic-ipants are read operations), the coordinator, inboth PrA and PrC, treats the transaction as anaborted one. This is because it is cheaper to abortthan to commit a read-only transaction withrespect to logging. Recall that a coordinatordoes not write any log records in PrA whereasabort records are written in a non-forced mannerin PrC. (For a new read-only optimization see[4,5].)
Another optimization that eliminates a partici-pant from the voting phase is the unsolicited vote
(UV) optimization [35]. In this optimization, if aparticipant knows when it has executed the lastoperation pertaining to a transaction, it does nothave to wait for a prepare to commit message.Instead, it sends its vote in its own initiative once itrecognizes that the transaction has no more op-erations to process. In the case that all the par-ticipants can send unsolicited votes, thisoptimization completely eliminates the explicitvoting phase of 2PC and becomes a one-phaseACP.
The early prepare protocol (EP) combines theUV with PrC [33,34]. Since PrC requires theidentities of the participants to be explicitly re-corded at the coordinatorÕs log in a forced ini-tiation record, the number of forced initiationrecords pertaining to a transaction is equal tothe number of participants that executed thetransaction in EP. This is because the initiationrecord has to be updated and force-written eachtime a new participant is involved in the execu-tion of the transaction. Furthermore, since EPdoes not make any assumptions about the lastoperation of a transaction submitted to a par-ticipant, the participant has to prepare thetransaction each time it executes an operation forthe transaction and prior to acknowledging theoperation. This means that the number of forcedprepared records pertaining to a transaction at aparticipant is equal to the number of operationssubmitted by the transaction and executed by theparticipant.
Another one-phase atomic commit protocolthat builds on EP is the coordinator log protocol(CL) which assumes that transactions are mostprobably going to commit and are (very) short(i.e., transactions deal with small amount of data)[33,34]. CL eliminates the need for the forcedlogging activities required by EP at the partici-pantsÕ sites by having the coordinators maintainthe logs and using distributed write-ahead logging(DWAL) [13]. That is, the stable log of a partici-pant is distributed (i.e., scattered) across multiple-coordinator sites. The CL protocol also eliminatesthe need for the initiation log records of EP at thecoordinators at the expense of requiring from acoordinator to communicate with all the partici-pants in the system during its recovery after a
3 The forced abort record in PrN is replaced by a forced
initiation record in PrC.
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 813

failure. This is in order to determine the set ofactive transactions prior to the coordinatorÕs fail-ure and to abort them instead of wrongly assum-ing their commitment.
As it will become apparent in the rest of thepaper, the IYV protocol combines the advantagesof UV, EP and CL while alleviating most of theirdisadvantages.
3. The implicit yes-vote protocol
In this section, we present the details of ourprotocol and discuss what kind of information isneeded to be logged and where (see Fig. 2). Then,in Section 3.2, we discuss the recovery aspects ofIYV.
3.1. Description of IYV
As in the case of all the other protocols, a co-ordinator records information pertaining to theexecution of a transaction in its protocol table inmain memory. Speci®cally, a coordinator keepsfor each transaction the identities of the partici-pants and any pending request at a participant.
Each participant maintains a recovery-coordi-nators' list (RCL) that contains the identities of thecoordinators that have active transactions at itssite and must be contacted during the recovery ofthe participant after a failure. In order to survivefailures, an RCL is kept in the stable log. Thus,when a participant receives the ®rst operation of atransaction, if the identity of the coordinator ofthe transaction is not already in its RCL, theparticipant adds it to its RCL, force-writes theRCL in its log and then executes the operation. Inorder to avoid searching the entire RCL in the casethat all the coordinators in the system are active ata participant, an all-active ¯ag (AAF) is used. Aparticipant sets AAF once it force-writes an RCLcontaining the identities of all the coordinatorsand does not consider the RCL as long as the AAFis set.
An operation submitted by a transaction can beeither an update or a read operation. Following theS-2PL, before the execution of an operation, aparticipant places a write lock on each data item
that is to be updated and a read lock on each dataitem that is to be read by the operation. The locksare kept in a lock table in main memory and areheld until the commit time of the transaction.
Once an operation is executed successfully, theparticipant acknowledges (ACK) the coordinatorwith a message that contains the results of theoperation. In IYV, in order to provide for theoption of forward recovery, the participant alsoincludes all the read locks that have been acquiredduring the execution of the operation. For an
Fig. 2. The IYV coordination messages and log writes.
814 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

update operation, a participant also includes in theacknowledgment message all the redo log recordsthat have been generated during the execution ofthe operation with their corresponding local logsequence numbers (LSNs). 4 As shown in Fig. 2, aparticipant does not force its log into stable stor-age prior to acknowledging an operation. Once aparticipant acknowledges an operation, it implic-itly enters a prepared to commit state with respectto the invoking transaction. While in this state, theparticipant cannot unilaterally commit or abortthe transaction until it receives a ®nal decision. Onthe other hand, a participant returns to an activestate with respect to the transaction when it re-ceives a new operation. If a participant fails toprocess an operation, it aborts the transaction andsends a negative acknowledgment (NACK) to thetransactionÕs coordinator.
When a coordinator receives an ACK for awrite operation from a participant, it writes a non-forced log record containing the received redorecords along with the participantÕs identity.Hence, the coordinatorÕs log contains a partialimage of the redo part of each participantÕs logwhich can be used to reconstruct the redo part of aparticipantÕs log in case it is corrupted due to asystem failure. The coordinator also records anyread locks included in an ACK message alongwith the identity of the participant in a partici-pants' lock table (PLT) which is part of its pro-tocol table. As a result, the coordinatorÕs PLTcontains a partial image of the lock table of eachparticipant. The PLT is used in the case of aparticipant failure in order to enable the partici-pant to recover its state exactly as it was prior tothe failure requiring both read and write locks,thereby allowing partially executed transactionsthat are still active in the system to forwardrecover and resume their execution after the par-ticipant has recovered without violating serializ-ability (see Section 4).
If the coordinator receives either an abort re-quest from a transaction or a negative acknowl-edgment regarding the transaction from a
participant, the coordinator decides to abort thetransaction. Once the coordinator decides to abortthe transaction, it force-writes an abort log recordand then, sends an abort message to all the par-ticipants. On the other hand, when the coordinatorof a transaction receives a commit primitive fromthe transaction, it waits for the acknowledgmentsof the transactionÕs pending operations and thencommits the transaction. On a commit decision,the coordinator force-writes a commit log recordprior to sending commit messages to the partici-pants. In either case, the decision log record in-cludes the identities of all the participants.
When a participant receives a commit (abort)message regarding a transaction, it writes a non-forced commit (abort) log record and commits(aborts) the transaction, releasing all the transac-tionÕs resources. A participant acknowledges adecision message only after the corresponding de-cision log record is placed into stable storage as aresult of a subsequent force-write or ¯ush of thelog onto stable storage. If the transaction was thelast active transaction submitted by its coordina-tor, the participant resets its AAF if it is set, de-letes the transactionÕs coordinator from the RCL,force-writes the updated list in its log and thenacknowledges the message.
Finally, when the coordinator receives the ac-knowledgment of the decision message from all theparticipants, it writes a non-forced end log recordand discards all information pertaining to thetransaction from its protocol table including thelocks in PLT, knowing that no participant willinquire about the transactionÕs status in the future.We summarize the IYV protocol in Fig. 3.
3.2. Recovery in IYV protocol
As shown in Fig. 4, IYV is resilient to bothcommunication and site failures. As is the case inthe basic 2PC and all its variants, site and com-munication failures are detected by timeouts. Inthe following two subsections, we discuss the cor-rectness of IYV in the presence of failures. Ourdiscussion also serves as an informal prove ofcorrectness which is similar to the prove of cor-rectness of the basic 2PC [10].
4 The LSNs can be uniquely identi®ed using increasing
integers that are preceded by (logical) site numbers.
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 815

3.2.1. Communication failuresAlthough communication failures are assumed
to be rare in high speed networks, there are threepoints during the execution of IYV where a com-munication failure might occur while a site iswaiting for a message. The ®rst point is when aparticipant has no pending acknowledgments andis waiting for a new operation or a ®nal decision.
This is shown as the ®rst case of the communica-tion failure in the participant algorithm in Fig. 4.In this case, the participant is blocked until thecommunication with the coordinator is re-estab-lished. Then, the participant inquires the coordi-nator about the transactionÕs status. Thecoordinator replies with either a ®nal decision ora still active message. In the former case, the
Fig. 3. The IYV protocol.
816 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

participant enforces the ®nal decision and thenacknowledges it, while in the latter case, the par-ticipant waits for further operations.
The second point is when the coordinator of atransaction is waiting for an operation acknowl-edgment from a participant. This is shown as the®rst case of communication failures in the algo-rithm of the coordinator in Fig. 4. In this case, thecoordinator may abort the transaction and submita ®nal abort decision to the rest of the participants.Similarly, the participant may abort the transac-tion if the communication failure has occurredwhile the participant has a pending acknowledg-ment. This is shown as the second case of com-munication failures in the participant algorithm in
Fig. 4. Notice that the coordinator of a transactionmay commit the transaction despite communica-tion failures with some participants as long asthese participants have no pending acknowledg-ments.
The third point is when the coordinator of atransaction is waiting for the acknowledgments ofa commit decision. Since the coordinator needs theacknowledgments in order to discard the infor-mation pertaining to the transaction from itsprotocol table and its log, it re-submits the deci-sion once these communication failures are ®xed(the second case of communication failures in thecoordinatorÕs algorithm). When a participant re-ceives the commit decision after a failure, it either
Fig. 4. Recovery in IYV protocol.
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 817

just acknowledges the decision if it has alreadyreceived and enforced the decision prior to thefailure, 5 or enforces the decision and then sendsback an acknowledgment.
3.2.2. Site failuresAs mentioned above, we are assuming that each
site employs physical logging and uses an Undo/Redo crash recovery protocol in which the undophase precedes the redo phase. It should bepointed out that IYV can also be combined withlogical or physiological write-ahead loggingschemes [19,24]. However, for ease of presentation,we only discuss IYV when physical write-aheadlogging (WAL) is used [19,20].
3.2.2.1. Coordinator failure. Upon a coordinatorrestart, after a failure, the coordinator re-builds itsprotocol table by scanning its stable log. The co-ordinator needs to consider only those transac-tions that have commit decision records without acorresponding end records. As shown in the co-ordinator recovery algorithm (the ®rst step after asite failure in Fig. 4), for each of these transac-tions, the coordinator), creates an entry in itsprotocol table that includes the identities of theparticipants as recorded in the transactionÕs deci-sion record. Then, it restarts the decision phase foreach of these transactions by re-submitting itsdecision to all the participants and resumes normaloperation.
As in the case of a communication failure, if aparticipant has already received and enforced a®nal decision prior to the failure, the participantsimply responds with an acknowledgment. If theparticipant has not received the decision, it musthave been waiting for the decision and once it re-ceives the decision, it writes a non-forced decisionrecord and then sends an ACK message when thedecision record is in the stable log.
For those transactions without ®nal decisionrecords (i.e., those transactions that were activeprior to the failure or their non-forced abort re-
cords did not make it to the stable log before thefailure), the coordinator can safely forget themand consider them as aborted transactions (thesecond case of the coordinator recovery algo-rithm). If a participant in the execution of one ofthese transactions has a pending acknowledgment,when it times out due to the coordinator sitefailure, it will abort the transaction, as in the caseof a communication failure that we discussedabove. On the other hand, if the participant is leftblocked (i.e., the participant has acknowledged allof a transactionÕs operations and is in the implicitprepared to commit state), when the coordinatorrecovers, the participant will inquire about thestatus of the transaction. The coordinator, notremembering the transaction after its recovery,will respond with an abort message by using animplicit presumption as in PrN. For those trans-actions that are associated with decision recordsas well as end records (the third case in the co-ordinator recovery algorithm), the coordinatorcan safely discard all information about thesetransactions, knowing that all participants areinformed of its decisions and no participantwill inquire about these transactions' outcome inthe future.
3.2.2.2. Participant failure. Also shown in Fig. 4are the steps of the participant recovery after a sitefailure. Since the entire log might not be writteninto a stable storage until after the log bu�erover¯ows, the log may not contain all the redorecords of the transactions committed by theirperspective coordinators after a failure of a par-ticipant. Thus, at the beginning of the analysisphase of the restart procedure, the participant de-termines the largest LSN which is associated withthe last record written in its log that survived thefailure (the ®rst step in the participant recoveryalgorithm) and sends a recovering message thatcontains the largest LSN to all coordinators in itsRCL (the second step in the recovery algorithm).This LSN is used by the coordinators to determinemissing redo log records at the participant whichare replicated in their logs and are needed by theparticipant to fully recover.
While waiting for the reply messages to arrivefrom the coordinators, the undo phase can be
5 A Participant without any memory regarding the transac-
tion is assumed to have already enforced the decision and
discarded all information pertaining to the transaction.
818 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

performed, even potentially completed, and theredo phase can be initiated. That is, the partici-pant recovers those aborted and committedtransactions that have decision records pertainingto them already stored in its stable log (the thirdstep in the algorithm) while waiting for the replymessages to arrive from the coordinators. Thisability of overlapping the undo phase with theresolution of the status of active transactions andthe repairing of the redo part of the log, partiallymasks the e�ects of dual logging and communi-cation delays. Note that because of the use ofWAL, all the required undo log records that areneeded to eliminate the e�ects of any transactionon the database are always available in the par-ticipantÕs stable log and never replicated at thecoordinatorsÕ sites.
When a coordinator receives a recoveringmessage from a participant, it will know that theparticipant has failed and is recovering from thefailure. Based on this knowledge, the coordinatorchecks its protocol table to determine eachtransaction that the participant has executed someof its operations and the transaction is either stillactive in the system (i.e., still executing at othersites and no decision has been made about its ®nalstatus, yet) or has committed but did not ®nishthe protocol (i.e., a ®nal decision has been madebut the participant has not acknowledged thedecision prior to its failure). For each transactionthat is ®nally committed, the coordinator re-sponds with a commit status along with a list ofall the transactionÕs redo records that are stored inits log and have LSNs greater than the one thatwas included in the recovering message of theparticipant.
For each active transaction that is still in pro-gress in other sites, the coordinator has the optionto either abort or forward recover the transaction.If the coordinator decides to abort the transaction,it sends abort messages to all participants to roll-back the transaction. If the coordinator decides toforward recover the transaction, it responds with astill-active status containing, as in the case of acommitted transaction, a list of the redo recordsassociated with LSNs greater than the one in-cluded in the recovering message of the partici-pant. The message also contains all the read locks
that were held by the transaction at the partici-pantÕs site prior to its failure.
All these responses and redo log records arepackaged with the read locks acquired by activetransactions in a single repair message and sentback to the participant. If a coordinator has noactive transactions and all committed transactionshave been acknowledged as far as the failed par-ticipant is concerned, the coordinator sends anACK repair message, indicating to the participantthat there are no transactions to be recovered asfar as this coordinator is concerned.
Once the participant has received reply mes-sages from all the coordinators (the fourth step inthe participant recovery algorithm in Fig. 4), theparticipant repairs its log and completes the redophase. The participant also re-builds its lock tableby re-acquiring the update locks during the redophase in conjunction with the read locks receivedfrom the coordinators. Once the redo phase iscompleted (the ®fth step in the participant recov-ery algorithm), the participant acknowledges allcommit decision responses once these commit de-cisions are in its stable log, as in the case of normalprocessing. Then the participant resumes its nor-mal processing (the last step in the participant re-covery algorithm). Thus, in IYVÕs recoveryalgorithm, a long-executing transaction is notnecessarily aborted as a result of a participantfailure as would be the case in all other ACPs.That is, since a participant can rebuild its locktable after a failure and redo the e�ects of partiallyexecuted transactions, the coordinator of a trans-action has the option to forward recover thetransaction if it is still active in the system after thefailed participant is recovered.
3.2.2.3. Simultaneous coordinator and participantfailures. The case of an overlapped coordinatorand participant failure is handled using the sameprocedure as we discussed above. That is, a failedcoordinator recovers the transactions initiated atits site as we discussed above. Similarly, a failedparticipant recovers as we discussed above. How-ever, it should be noticed that if one of the coor-dinators in the RCL of a recovering participant isdown, the participant is left blocked and cannotrecover until the failed coordinator has recovered
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 819

and sent to the participant the pending repairmessage. Although this situation might seem to bedrastic, it is expected to be very rare in the contextof future database systems given the reliabilitycharacteristics of modern computing systems.Hence, this represents a reasonable trade-o� be-tween fast commit processing during the normal(i.e., non-failure) case at the expense of slowerrecovery in the rare failure case.
4. Assumptions, correctness and applicability
4.1. Basic system assumptions
The essence of 2PC that ensures the atomicityof a distributed transaction is that it prevents atransaction from unilaterally committing oraborting at a site while it is in the prepared tocommit state. A participant may be required toabort a transaction either for correctness reasons,such as ensuring serializability, or for performancereasons, such as minimizing transaction blocking.Regarding the latter, given that transactions are®nite, we assume that a participant does not aborta transaction because it has not received an oper-ation from the transaction for some time. It is theresponsibility of the coordinator to decide whetheror not it is necessary to abort a long-executingtransaction.
As we mentioned earlier, most commercialdatabase management systems use S-2PL forconcurrency control and physical WAL for re-covery. Now, consider a distributed system inwhich all the sites employ S-2PL. In such a distrib-uted system, participants never abort transactionsto ensure atomicity, i.e., there are no cascadingaborts, and only abort transactions in active states(i.e., transactions having outstanding operationsÕacknowledgments) to resolve deadlocks.
Theorem 1. If each participant employs S-2PL forconcurrency control, it is not possible for a trans-action to be involved in a non-serializable execution,a local deadlock at a participant, or a global dead-lock when all the operations that were submitted bythe transaction to the participants have been exe-cuted and acknowledged.
Proof. The proof proceeds by contradiction. As-sume that all the operations submitted by atransaction have been executed and acknowledgedand the transaction is involved in (1) a non-seri-alizable execution or (2) a deadlock.
According to the S-2PL rules, an operationsubmitted by a transaction is executed only afterthe locks required for the execution of the opera-tion on the data items are acquired. This rule im-plies that an operation is not acknowledged untilafter the required locks for the execution of theoperation are acquired.
The ®rst part (1) contradicts the fact that S-2PLschedulers produce serializable histories [10]. If thetransaction is involved in a non-serializable exe-cution, at least one of its operations would havebeen blocked rather being acknowledged whichcontradicts the assumption that all the transac-tionÕs operations have been executed andacknowledged.
The second part (2) contradicts the fact that if atransaction is involved in a deadlock, at least oneof its operations is blocked awaiting to hold somelocks on some data items which again contradictsthe assumption that all the operations pertainingto the transaction have been acknowledged. �
Corollary 1. A local deadlock at a participant sitethat employs S-2PL involves only active transac-tions (i.e., transactions with pending operations).
Proof. As above, the proof proceeds by contradic-tion. For a deadlock to occur, the hold-and-waitcondition must exist. If we assume that a transac-tion is involved in a local deadlock at a participantsite after all the operations submitted to the par-ticipant have been executed and acknowledged, itmeans that the transaction is holding locks on somedata items and is waiting to hold locks on otherdata items. However, since all the operations of thetransaction have been executed and acknowledgedby the participant, all the locks required for theexecution of the operations submitted to the par-ticipant have been acquired. Hence, the hold-and-wait condition cannot exist after all the operationssubmitted by a transaction to a participant havebeen acknowledged and a local deadlock can onlyinvolve active transactions. �
820 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

Note that participants using an optimistic con-currency control protocol [10] do not exhibit theabove property. That is, they might abort atransaction even though the transaction is not inan active state in order to ensure serializability[10]. Hence, IYV is not applicable in this case. Onthe other hand, it can be shown, as in Theorem 1,that participants using a pessimistic concurrencycontrol protocol (other than S-2PL) that avoidscascading aborts never abort transactions to en-sure atomicity and only abort transactions in ac-tive state to ensure serializability.
It should be pointed out that IYV is designedfor client±server architecture in which interactionsbetween sites are structured along the lines of re-mote procedure calls in a synchronous or asyn-chronous manner. IYV is not suitable forenvironments where requests are not always ac-knowledged as in peer-to-peer environments usingconversations. Also, as any other one-phase ACP,IYV is not applicable in systems where a votingphase is required to perform some form of vali-dation at commit time. Such systems include thosethat process transactions associated with di�eredconsistency constraints which are validated atcommit time.
4.2. Assumptions on transaction properties
Many applications trade-o� increased concur-rency for consistency. For this reason, ANSI SQLde®nes four isolation levels [6]: (1) read uncom-mitted, (2) read committed, (3) repeatable read and(4) serializable. The main underlying assumptionof IYV is that each site employs a scheduler thatproduces rigorous histories such as S-2PL whichcorresponds to isolation level 3. Note that, in thispaper, we follow the de®nitions of the isolationlevels for locking-based systems that are presentedin [9].
IYV, as any other ACP, is not necessary in thecase of isolation level 0 because there is no notionof transaction at this level. A transaction runningin this level can read any data item without re-questing a lock and writes data items with short-term locks which are held only for the duration ofthe operation (non-two-phase writes).
In isolation level 1, a transaction is allowed toread uncommitted data. If isolation level 1 atom-icity is de®ned such that a transaction is aborted ifit has read data written by an aborted transaction(traditional notion of atomicity), then IYV is notapplicable. This is because a participant in IYVcannot abort a transaction due to cascading abortsat the commit time of the transaction. On the otherhand, if isolation level 1 atomicity is only withrespect to the write operations, then IYV can beused to ensure that either all the writes are com-mitted at all participants or none at all.
IYV is applicable in isolation level 2 (whichincludes the cursor stability and repeatable readre®nements). In this level, transactions read onlycommitted data while write locks are of longduration (i.e., writes locks are held until a trans-action is either committed or aborted). Thus, thereis no possibility of cascading aborts and there is aneed to synchronize the writes. But, it should benoted here that the forward recovery option is notapplicable except in the case of repeatable readssince read locks are of short term and reads cannotbe repeated.
4.3. Assumptions on recovery
As discussed above, recovery in IYV is based onthe traditional Undo/Redo schemes in which theundo phase precedes the redo phase. This allowsthe analysis phase at a participant that involvescommunication with the coordinators to proceedconcurrently with the undo phase and potentiallypart of the redo phase. This is not possible in thecase of recovery schemes such as ARIES [24], inwhich the redo phase precedes the undo phase. Inthe case of a recovery scheme where the redo phaseprecedes the undo phase, a participant is blockedand cannot initiate recovery until it receives re-sponses from the required coordinators (i.e., allcoordinators in the RCL of the participant). Thatis, IYV can incorporate other recovery schemessuch as ARIES, which is a physiological recoveryscheme, but it will not o�er the same e�ciencyduring recovery in this case.
Now, let us also make the need for replicatingthe read locks that are held by the transactions atthe coordinatorsÕ sites clear, a need which allows
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 821

the option of forward recovery without violatingconsistency. Assume that we have two transactionsT1 and T2, submitted at two di�erent coordinators.T1 reads data item x, writes data item y and thencommits, whereas T2 writes both data items x andy, and then commits. Here, ri [x] (wi [x]) denotes aread (write) operation performed by transaction Ti
T1 : r1�x�w1�y�c1;
T2 : w2�x�w2�y�c2:
Furthermore, assume that the ®rst operation ofT1, r1 [x], has been executed successfully and ac-knowledged. After that, the participant where thedata items are stored fails. The resulting history ofexecution is as follows:
H1 : r1�x�Crash:
At this point, assume that the participant hasreceived acknowledgment messages in response toits recovering messages from all coordinators in-cluding the coordinator of T1 which has indicatedthat T1 is still active in its acknowledgment mes-sage. Based on these replies, the participant ®n-ishes its recovery procedure using its own log andknowing that T1 is still in progress but there is noredo actions that are needed to be used with thistransaction since the transaction has performedonly a read operation. Now, if we allow T1 toforward recover after the participant has recoveredwithout being able to reconstruct the exact locktable of the participant as it was before the failure,we might end up with the following non-serializ-able history
H2 : r1�x�w2�x�w2�y�c2 w1�y�c1:
H2 is not serializable because it is cyclic (i.e.,T1 ! T2 ! T1). H2 is possible because the partici-pant after losing its lock table, could not re-ac-quire the read lock on x on behave of T1 as it wasthe case prior to the failure, allowing T2 to acquirea write lock and change x after the participant hasrecovered. Once T2 has committed, the participantreceives a new operation pertaining to T1 that alsomodi®es the value of x. Since T2 has alreadycommitted and all its locks have been released, T1
can acquire a write lock on x and modi®es it, re-sulting in a non-serializable execution. However,
duplicating the read locks at the coordinators inIYV allows a participant to re-build its lock tableafter a failure and to prevent execution historiessimilar to the one described above from occurring.
Here, it should be pointed out again that for-ward recovery is an option in IYV which is cur-rently applicable only for context-free transactionswith respect to participants. A transaction pro-gram always executes at the site of its coordinatorand cannot be forward recovered in the case of thecoordinatorÕs site failure without the help ofcheckpoints which save the transaction programÕslocal state [15]. In IYV, by assuming context-freetransactions at the participants, the read locks andwrite log records are su�cient to reconstruct thecontext of transactions and forward recover themon a failed participant. For more complicated typeof contexts, a coordinator needs to store a highlevel description of a transactionÕs context to en-able the transaction to forward recover at a par-ticipant site. Finally, because forward recovery isan option in IYV, IYV can be used to committransactions with complex context without thisoption.
5. IYV optimizations and extensions
5.1. IYV presumed abort (IYV-PRA) optimization
Since the decision phase of IYV is exactly thesame as in the PrN, we augmented IYV with thePrA optimization which makes the abort pre-sumption more explicit than IYV. In IYV-PrA (seeFig. 5), the coordinator of a transaction needs onlyto force-write a commit log record and any missinginformation about a transaction is presumed tomean that the transaction has been aborted. Theabort presumption is made explicit by not writingan abort log record at all and by discarding all theinformation about an aborted transaction fromthe protocol table.
IYV-PrA also reduces the number of coordi-nation messages for aborted transactions. Theparticipants do not have to acknowledge abortmessages as they do not have to force-write abortdecisions. If a participant fails before an abortdecision is in stable storage, upon its recovery, it
822 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

will undo the e�ects of such an (active) transactionand inquire the transactionÕs coordinator with arecovering message. Since the transaction has beenaborted, its coordinator would not have any in-formation pertaining to the transaction in itsprotocol table and therefore, it either replies with arepair message that does not contain any infor-mation about the transaction or an inactive mes-sage. An inactive message is sent as opposed to arepair message if the coordinator does not ®nd anytransaction in its protocol table that needs to berecovered at the participant. In IYV-PrA, this ispossible since the coordinator may discard theinformation in its protocol regarding an abortedtransaction which happens to be the last transac-tion executing at the participant before the par-ticipant has the chance to update its RCL. Ineither case, when the participant receives the replymessage, it does not have to take any further ac-tions since it has already obliterated the e�ects ofthe aborted transaction during the undo phase.The cost of a commit decision, however, remainsthe same as in the (basic) IYV.
5.2. IYV read-only optimization
The read-only optimization (see Section 2) canalso be coupled with IYV in order to release locksat the participants earlier and to eliminate some
forced log writes. A participant is termed as read-only if it has executed only read operations onbehalf of a transaction. Otherwise, it is termed asan update participant. Since read operations donot a�ect the state of the database, a read-onlyparticipant does not have to be concerned withfailures but only to ensure the serializability of thetransaction. That is, as opposed to an updateparticipant, when a read-only participant receivesa commit or an abort decision, it does not have toperform any logging activities before releasing thetransaction locks. In the absence of loggingactivities, read-only participants do not have toacknowledge that the decision has been forced.
In IYV read-only optimization (IYV-RO),when a commit primitive is received from atransaction, the coordinator determines whichparticipants are read-only based on the acknowl-edgments it has received during the execution ofthe transaction. Speci®cally, once the last opera-tion submitted to a participant is acknowledgedand the participant did not send a redo record aspart of any of its acknowledgment messages, thecoordinator knows that the participant is read-only. If a participant is read-only, the coordinatorimmediately sends a read-only message to theparticipant without having to wait until a ®naldecision is reached and is in the stable log. Once aparticipant receives a read-only message regardinga transaction, the participant releases the locksassociated with the transaction and updates itsRCL if necessary.
Since read-only participants in a transactionexecution do not have to wait for a ®nal decisionto be reached and forced written into the stable logof the transactionÕs coordinator, read-only partic-ipants release the locks held by the transactionearlier than their update counterparts. Further-more, as mentioned above, regardless of the ®naloutcome of a transaction, a read-only participantdoes not have to acknowledge a read-only mes-sage. In the case that all the participants in theexecution of a transaction are read-only and thecoordinator has sent them read-only messages, thecoordinator does not have to write decision andend log records. IYV's read-only optimization canbe generalized and made applicable to the two-phase commit protocols [1,4,5].
Fig. 5. The IYV-PrA protocol.
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 823

5.3. IYV in multi-level transactions
The multi-level transaction execution (MLTE)model, the one speci®ed by the standards andadopted by commercial database systems, is simi-lar to the tree of processes model [5,26]. In thismodel, a participant is a process that is able todecompose a subtransaction further. Thus, a par-ticipant can initiate other participant processes atits site or di�erent sites. Hence, the processespertaining to a transaction can be represented by amulti-level execution tree where the coordinatorprocess resides at the root of the tree. In thismodel, the interactions between the coordinator ofthe transaction and any process have to gothrough all the intermediate processes that havecaused the creation of a process.
In the MLTE model, the behavior of the rootcoordinator and each leaf participant in thetransaction execution tree, in both IYV and IYV-PrA, remains the same as in two-level transactions.The only di�erence is the behavior of cascadedcoordinators (i.e., non-root and non-leaf partici-pants) since an acknowledgment message of anoperation represents the successful execution ofthe operation at the cascaded coordinator as wellas all the descendants of the cascaded coordinator.
As in the case of the (two-level) IYV, in multi-level IYV, the root coordinators are responsiblefor maintaining the replicated redo logs. In multi-level IYV, all the redo log records that are gener-ated during the execution of an operation arepropagated to the root coordinator. Thus, when acascaded coordinator receives acknowledgmentmessages from all its descendants that participatedin the execution of an operation, it sends an ac-knowledgment to its direct ancestor in the trans-action tree containing the redo log recordsgenerated across all participating sites as well asthe read locks held at them during the execution ofthe operation. That is, an acknowledgment mes-sage from a cascaded coordinator represents theimplicit vote of its subtree. When the root coor-dinator receives an acknowledgment message, itwrites any redo records contained in the messagein its log and any read locks in its PLT as it is thecase of IYV in the two-level transaction executionmodel.
With respect to RCL, a cascaded coordinatorupdates its RCL to include the identity of the rootcoordinator only if it participates in the executionof the operation. If a cascaded coordinator doesnot participate in the execution of an operation, itsimply sends the operation to the appropriateparticipant(s) without including the identity of theroot in its RCL. Thus, when a transaction ®nishesits execution, all the replicated redo records andread locks are replicated at the root coordinatorand, therefore, the coordinator knows all theparticipants (i.e., both leaf and cascaded coordi-nators). Similarly, each participant knows theidentity of the root coordinator which is re¯ectedin its RCL.
While the execution phase of a transaction ismulti-level, the decision phase is not because theroot coordinator of the transaction knows all theparticipants at the time the transaction ®nishes itsexecution. Therefore, the coordinator sends itsdecision directly to each participant without goingthrough cascaded coordinators as in the two-levelIYV. Similarly, each participant sends its ac-knowledgment of the decision directly to the rootcoordinator without going through the cascadedcoordinators. 6
In summary, in multi-level IYV, the behavior ofthe root coordinators remains the same as in IYV,cascaded coordinator is responsible about the co-ordination of acknowledgment messages of indi-vidual operations, while the behavior ofparticipants remains the same as in the basic IYV.After a failure, the recovery of the participants(both cascaded coordinators and leaf participants)is as in IYV discussed in Section 3.2. A recoveringparticipant waits for the responses of the coordi-nators included in its RCL, performs the undo andredo phases, and then resumes normal processing.Similarly, a recovering root coordinator gathersthe acknowledgments of all participants in a
6 This is similar to the ¯attening of the commit tree optimi-
zation [31]. Notice that the execution phase cannot be ¯attened
as the decision phase because the acknowledgment message
re¯ects the execution of a complete operation that is executed at
several participants and the collective implicit vote.
824 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

transaction execution before forgetting the trans-action.
IYV-PrA can be extended in a similar manneras IYV. The only di�erence is that a coordinatordoes not wait for the acknowledgment of anyparticipant for the abort case.
6. Comparison with other atomic commit protocols
IYV combines the advantages of UV, EP andCL protocols, as we mentioned earlier. Here, wecompare IYV with these protocols and in partic-ular with CL which shares the same basic idea withIYV in order to reduce the number of log force-writes while eliminating the explicit voting phaseof 2PC.
To avoid force writing the log records that aregenerated during the execution of each and everyoperation prior to acknowledging them, UV as-sumes that each site knows when it has executedthe last operation on behalf of a transaction [35].This means that the coordinator either submits toa site all the operations at the same time (which isa form of predeclaration) or indicates to the par-ticipant the last operation at the time that theoperation is submitted. The former is possible invery special cases. The latter is only possible ifeach transaction has knowledge of the data dis-tribution in the system and indicates to the coor-dinator the last operation to be executed at aparticipant.
In contrast to UV, IYV does not make anyassumption about the structure of transactionsand does not assume any knowledge of the datadistribution by the transactions. Thus, IYV ismore general compared to UV. In the specialcases in which UV is applicable, IYV and UVwould exhibit similar behavior during normalprocessing.
In EP, which is derived from PrC, the numberof forced log writes pertaining to a transaction atits coordinator is equal to the number of partici-pants that executed the transaction since EP re-quires the identities of the participants to beexplicitly recorded at the coordinatorÕs log in aforced initiation log record. This is because aninitiation log record has to be force-written each
time a new participant is about to execute an op-eration of the transaction. Furthermore, a partic-ipant force-writes a prepared log record beforeacknowledging a transactionÕs operation. In con-trast, in IYV, a coordinator does not force-writeany initiation record and a participant does notforce-write any prepared log records.
To alleviate the drawback of the initiation re-cords as well as the prepared log records of EP,CL uses distributed write-ahead logging DWAL.Using DWAL, only the coordinators maintainstable logs. In the case of CL, since a participantmight inquire a coordinator about the latestforced log write (i.e., to ensure the DWAL), CLmight become very costly and less e�cient whencompared with any of the 2PC variants. Considerthe case when a number of long-living transac-tions execute at a participant without excessivemain memory. In this case, the participant mightrequest a transactionÕs coordinator (explicitly) toforce-write its log more than once resulting in agreat number of sequential messages. Also, roll-ing back aborted transactions has to be per-formed completely over the network. This meansthat when a participant aborts a transaction, itcannot release the resources held by the transac-tion until it communicates with the transactionÕscoordinator and receives the undo log recordspertaining to the transaction, which is a signi®-cant overhead.
Another signi®cant di�erence between IYV andCL is the case of a coordinatorÕs recovery after afailure. A coordinator in IYV can recover inde-pendently without communicating with any par-ticipant. In contrast, a recovering coordinator, inCL, has to communicate with all possible partici-pants in the system in order to determine the set of``unknown transactions'' so that it can abort theminstead of presuming their commitment since CL isa descendant from PrC protocol [33,34]. An un-known transaction is a transaction that is execut-ing at a participant but the coordinator has norecollection about the transaction since it does not®nd any log records pertaining to the transactionin its log during its recovery. Furthermore, a re-covering participant in CL has to wait until it re-ceives all the log records from the coordinatorsand until all active transactions have been decided
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 825

upon. In IYV, however, using the ``still active''message, a participant can recover its state up tothe point prior to its failure and resume its normalprocessing without having to wait until all activetransactions have been decided upon, allowinglong-living transactions to forward recover andresume their execution. Aborted transactions inIYV are handled locally by a participant withoutany communication with the coordinators (i.e., theundo log records do not have to be requested fromthe coordinators).
Even though IYV requires that the redo logrecords generated during the execution of atransactionÕs operation be logged at both its co-ordinator as well as at the participant that exe-cuted the operation, such a duplicate loggingshould incur negligible overhead because the logrecords are written in a non-forced manner andwithout involving any extra coordination messag-es. The only overhead is that IYV requires morebu�er space for the log of the coordinator so thatlogging does not cause frequent ¯ushing to the logbu�er. As mentioned earlier, we believe that, ingeneral, the overhead associated with the dupli-cation of logs and the extra information containedin the commit and still-active messages is wello�set by the reduction in the number of sequentialcoordination messages and the gain of being ableto support forward recovery of interrupted, pos-sibly long-lived, transactions due to participantand communication failures.
It should be pointed out that not forcingcommit records at the participants in IYV di�ersfrom the group commit optimization [14,18] in twoways, although both trade-o� performance duringnormal processing for reduced independent re-covery for participants. First, in IYV, there is nonotion of a group or a timer that determines whena force should take place. Second, by not forcingindividual commit records, group commit in-creases blocking after a participant failurewhereas in IYV the blocking of a participant isthe same irrespective of whether commit recordsare forced or not. This is because, in IYV, aparticipant cannot determine all transactions thatwere active at its site prior to a failure or their®nal status without contacting all coordinators inits RCL.
7. Analytical evaluation
In this section, we evaluate the performance ofIYV and compare its performance with the per-formance of 2PC, PrA, PrC, EP and CL. Theevaluation is based on the log, message and timecomplexities. In our evaluation, we use best (ideal)and worst case scenarios, as in [33,34], to highlightthe performance di�erences among the variousACPs. Also, we consider the number of coordi-nation messages and forced log writes that are dueto the protocols only (e.g., we do not consider thenumber of messages that are due to the operationsand their acknowledgments). The cost of the pro-tocols in both scenarios are evaluated duringnormal processing and in absence of failures.
Fig. 6 graphically illustrates the sequence ofcoordination messages and forced log writes in-volved in 2PC and IYV to reach a decision pointand to release the resources held at the participantsfor the commit as well as the abort case. The ®gureshows how we will evaluate the performance of theACPs that we listed above, considering the se-quential e�ects of coordination messages andforced log writes. In our evaluation, we will as-sume that AAF is always set by the participantsites since we do not evaluate the cost of recoveryafter a site failure.
Tables 1 and 2 compare the di�erent protocolsunder the worst case scenario. It should be pointedout that this ``worst'' case scenario is very close tothe expected average behavior of transactions andthe distributed environment. This is because theassumptions that we make in this case are morerealistic than the assumptions that we make in thebest case scenario. We denote by n the number ofparticipants that executed a transaction and by dthe number of data items that have been accessedby the transaction. In this scenario, we assume thefollowing:· A transaction has more than one write opera-
tion at each participant it accesses (i.e., d > n).· Transactions execute sequentially (e.g., an oper-
ation is submitted by a transaction only whenthe previous operation has been executed andacknowledged).
· The participants are not known at the beginningof transactions.
826 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

Fig
.6
.T
he
seq
uen
ceo
fco
ord
inati
on
mes
sages
an
dfo
rced
log
wri
tes
req
uir
edd
uri
ng
no
rmal
pro
cess
ing.
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 827
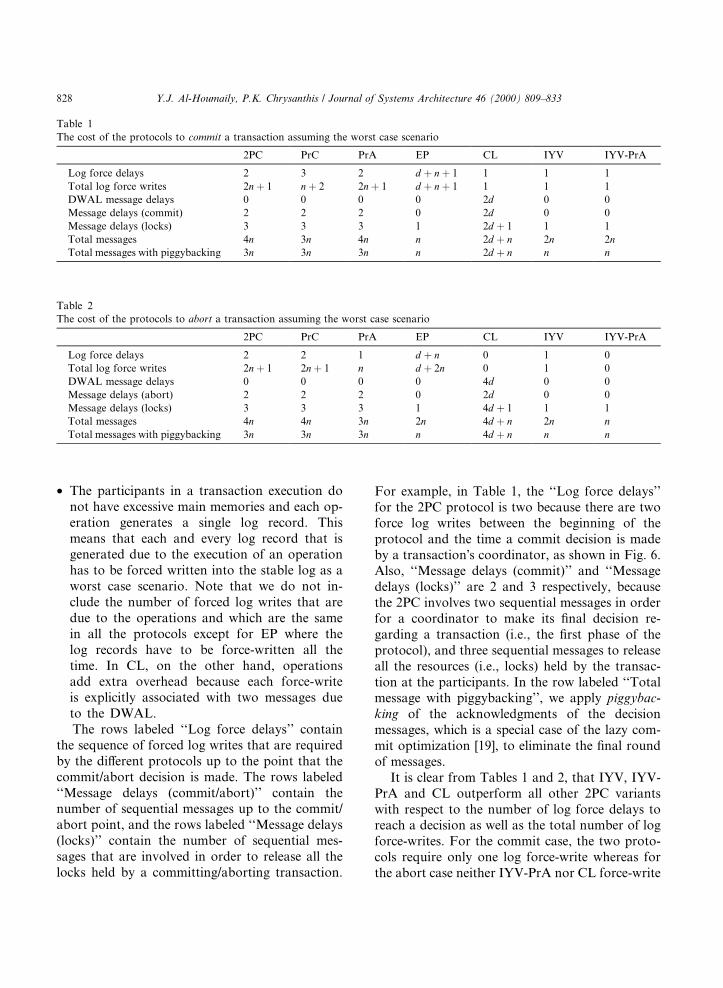
· The participants in a transaction execution donot have excessive main memories and each op-eration generates a single log record. Thismeans that each and every log record that isgenerated due to the execution of an operationhas to be forced written into the stable log as aworst case scenario. Note that we do not in-clude the number of forced log writes that aredue to the operations and which are the samein all the protocols except for EP where thelog records have to be force-written all thetime. In CL, on the other hand, operationsadd extra overhead because each force-writeis explicitly associated with two messages dueto the DWAL.The rows labeled ``Log force delays'' contain
the sequence of forced log writes that are requiredby the di�erent protocols up to the point that thecommit/abort decision is made. The rows labeled``Message delays (commit/abort)'' contain thenumber of sequential messages up to the commit/abort point, and the rows labeled ``Message delays(locks)'' contain the number of sequential mes-sages that are involved in order to release all thelocks held by a committing/aborting transaction.
For example, in Table 1, the ``Log force delays''for the 2PC protocol is two because there are twoforce log writes between the beginning of theprotocol and the time a commit decision is madeby a transactionÕs coordinator, as shown in Fig. 6.Also, ``Message delays (commit)'' and ``Messagedelays (locks)'' are 2 and 3 respectively, becausethe 2PC involves two sequential messages in orderfor a coordinator to make its ®nal decision re-garding a transaction (i.e., the ®rst phase of theprotocol), and three sequential messages to releaseall the resources (i.e., locks) held by the transac-tion at the participants. In the row labeled ``Totalmessage with piggybacking'', we apply piggybac-king of the acknowledgments of the decisionmessages, which is a special case of the lazy com-mit optimization [19], to eliminate the ®nal roundof messages.
It is clear from Tables 1 and 2, that IYV, IYV-PrA and CL outperform all other 2PC variantswith respect to the number of log force delays toreach a decision as well as the total number of logforce-writes. For the commit case, the two proto-cols require only one log force-write whereas forthe abort case neither IYV-PrA nor CL force-write
Table 1
The cost of the protocols to commit a transaction assuming the worst case scenario
2PC PrC PrA EP CL IYV IYV-PrA
Log force delays 2 3 2 d � n� 1 1 1 1
Total log force writes 2n� 1 n� 2 2n� 1 d � n� 1 1 1 1
DWAL message delays 0 0 0 0 2d 0 0
Message delays (commit) 2 2 2 0 2d 0 0
Message delays (locks) 3 3 3 1 2d � 1 1 1
Total messages 4n 3n 4n n 2d � n 2n 2nTotal messages with piggybacking 3n 3n 3n n 2d � n n n
Table 2
The cost of the protocols to abort a transaction assuming the worst case scenario
2PC PrC PrA EP CL IYV IYV-PrA
Log force delays 2 2 1 d � n 0 1 0
Total log force writes 2n� 1 2n� 1 n d � 2n 0 1 0
DWAL message delays 0 0 0 0 4d 0 0
Message delays (abort) 2 2 2 0 2d 0 0
Message delays (locks) 3 3 3 1 4d � 1 1 1
Total messages 4n 4n 3n 2n 4d � n 2n n
Total messages with piggybacking 3n 3n 3n n 4d � n n n
828 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

any log records. In this respect, EP is the mostexpensive of all protocols.
CL becomes more expensive than IYV whenmessage delays and total number of messages areconsidered. Due to DWAL, CL requires two ex-plicit sequential messages to be exchanged betweena participant and the coordinator of a transactionfor each operation executed by the participant forthe commit case (thus, the 2d in ``DWAL Messagedelays''). For the abort case, four messages areneeded to be exchanged between the participantand the coordinator of an aborted transaction.This is because undoing an operation using therecovery scheme of CL, ARIES, is another oper-ation that has to be executed and logged. Since CLuses DWAL, undoing an operation requires twomore explicit messages to be exchanged betweenthe coordinator and the participant in the worstcase scenario. Note that because of its dependencyon the number of data operations, CL can po-tentially involve more messages to commit orabort a transaction than any of the 2PC variants inthe case of long transactions. On the other hand,with respect to messages, IYV and EP performbetter than the other protocols. For the commitcase, EP incurs the least number of total messages.This situation changes when piggybacking is con-
sidered where both EP and IYV incurs the samemessage complexities.
Piggybacking the acknowledgments of the de-cision messages can only be used to eliminate the®nal round of messages for the commit case in2PC, PrA, IYV, and IYV-PrA, but not in the caseof PrC, EP and CL because a commit ®nal deci-sion is never acknowledged in these protocols.Similarly, this optimization can be used in theabort case with the 2PC, PrC, EP, and IYV butnot with PrA, CL and IYV-PrA. In PrA and IYV-PrA, an abort decision is never acknowledgedwhile in CL, the acknowledgment is sent immedi-ately because it contains the undo log records ofthe aborted transaction.
Tables 3 and 4 compare the number of messagesand forced log writes that are needed for the com-mit and abort cases, respectively, for the di�erentprotocols based on the ideal case scenario. In thisideal scenario, we make the following assumptions:· A transaction performs at most one write oper-
ation per each site it accesses (i.e., n � d).· The operations of a transaction execute in paral-
lel.· The participants are known at the beginning of
transactions.· The participants have excessive main memory.
Table 3
The cost of the protocols to commit a transaction assuming the ideal case scenario
2PC PrC PrA EP CL IYV IYV-PrA
Log force delays 2 3 2 3 1 1 1
Total log force writes 2n� 1 n� 2 2n� 1 n� 2 1 1 1
Message delays (commit) 2 2 2 0 0 0 0
Message delays (locks) 3 3 3 1 1 1 1
Total messages 4n 3n 4n n n 2n 2nTotal messages with piggybacking 3n 3n 3n n n n n
Table 4
The cost of the protocols to abort a transaction assuming the ideal case scenario
2PC PrC PrA EP CL IYV IYV-PrA
Log force delays 2 2 1 2 0 1 0
Total log force writes 2n� 1 2n� 1 n 2n� 1 0 1 0
Message delays (abort) 2 2 2 0 0 0 0
Message delays (locks) 3 3 3 1 1 1 1
Total messages 4n 4n 3n 2n 2n 2n nTotal messages with piggybacking 3n 3n 3n n 2n n n
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 829

In the ideal case, CL and IYV have the samecost as far as the number of sequential force logwrites and messages are concerned for the commitcase, dominating the other ACPs with CL domi-nating IYV and IYV-PrA with respect to the totalnumber of messages. When piggybacking is con-sidered, CL, IYV and IYV-PrA have exactly thesame cost. For the abort case, CL dominates IYVwith respect to the number of sequential force-writes and the total number of forced log writeswhile they have the same cost considering thenumber of sequential and total number of mes-sages. On the other hand, IYV-PrA is better thanCL by n in the total message count.
Comparing the two scenarios, we note that thecost associated with EP is highly dependent on thenumber of operations submitted by the transac-tions while CL is also dependent on the behaviorof the system (e.g., the propagation latency of thecommunication network, the log bu�er size, andthe main memory size of the participants, etc.).This makes EP and CL completely ine�cient indistributed database systems with long-livingtransactions where a transaction typically executesa large number of operations at a small number ofsites (i.e., d � n), a situation common in advanceddistributed database applications. Ruling out EPand CL, it is clear from our comparisonÕs tables
that IYV and its PrA optimization promise theminimum cost among the other ACPs.
Tables 5 and 6 show the cost of the di�erentACPs for read-only transactions assuming acommit ®nal outcome. Table 5 considers the bestcase scenario while Table 6 considers the worstcase scenario. The standard read-only optimiza-tion is used with PrC and PrA while the IYV-ROoptimization is used with IYV and IYV-PrA. Allthe protocols in the two tables have the same costas far as the number of sequential messages torelease all the locks held by read-only transactionsis concerned (i.e., only a single message). However,IYV and IYV-PrA dominate CL, EP and PrCas far as the number of sequential forced log delaysto reach the commit point as well as the totalnumber of forced log writes in both scenarios. Asfar as the total number of messages and messagedelays to reach a commit decision is concerned,EP, CL, IYV, and IYV-PrA have the same costwhich dominates the cost associated with PrC andPrA.
8. Conclusions
In this paper, we presented IYV, a new one-phase atomic commit protocol for future gigabit-
Table 5
The cost of the di�erent protocols for read-only transactions assuming ideal case scenario
PrC PrA EP CL IYV IYV-PrA
Log force delays 1 0 1 1 0 0
Total log force writes 1 0 1 1 0 0
Message delays (decision) 2 2 0 0 0 0
Message delays (locks) 1 1 1 1 1 1
Total messages 2n 2n n n n n
Table 6
The cost of the di�erent protocols for read-only transactions assuming worst case scenario
PrC PrA EP CL IYV IYV-PrA
Log force delays 1 0 n 1 0 0
Total log force writes 1 0 n 1 0 0
Message delays (decision) 2 2 0 0 0 0
Message delays (locks) 1 1 1 1 1 1
Total messages 2n 2n n n n n
830 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

networked distributed databases. IYV is targetedfor environments with ®xed number of high per-formance coordinators or application servers.IYV exploits the semantics of (1) database man-agement mechanisms and (2) gigabit-networks toenhance performance over the other well-knownatomic commit protocols [1,2]. Speci®cally, itexploits the S-2PL and the huge capacity of thenetwork. IYV reduces the cost of commit pro-cessing at the cost of independent recovery.However, IYV compensates for the lack of in-dependent recovery by providing the option offorward recovery where partially executed trans-actions at a failed participant that are still activein the system can resume their execution after theparticipant has recovered.
To highlight the performance enhancement ofour commit protocol, we compared its perfor-mance to the performance of other known proto-cols based on the traditional analytical method.This method is based on evaluating the perfor-mance of the di�erent protocols under worst andideal case scenarios. Our evaluation reveals thatthe performance of our proposed protocol is verypromising, a fact that has also been shown by ourinitial simulation results [1].
Even though IYV seems to be a very promisingprotocol with respect to performance, it is notapplicable in resource-constrained systems (e.g.,low bandwidth networks, small main memory orhigh cost disk access systems) or in client±serversystems where the interactions between sites arenot structured along the lines of remote proce-dure calls. Also, as any other one-phase protocol,IYV is not applicable in systems that requireatomic commit protocols with explicit votingphase to perform some form of validation atcommit time. This includes systems that useoptimistic concurrency control protocols andsystems that support validation of deferred con-sistency constraints.
Finally, IYV was designed for relatively reliablesystems in mind. However, in the case of less re-liable sites, unlike in [32], its blocking aspects canbe reduced by combining IYV with the delegationof commitment technique, found in open commitprotocols [28,29], and a novel timestamp synchro-nization mechanism while retaining its perfor-
mance advantages over the other atomic commitprotocols [3].
A clear conclusion of our analysis is that thereis no single atomic commit protocol that is best forany system and for all transaction types. Fur-thermore, this points to the direction of integratedatomic commit protocols where for example IYVcan be integrated with presumed abort protocol.This in fact constitutes the line of our currentinvestigation along with the performance evalua-tion of the di�erent atomic commit protocols usingsimulation.
References
[1] Y.J. Al-Houmaily, Commit processing in distributed dat-
abase systems and in heterogeneous multidatabase systems,
Ph.D. thesis, Department of Electrical Engineering, Uni-
versity of Pittsburgh, Pittsburgh, Pennsylvania, April 1997.
[2] Y.J. Al-Houmaily, P.K. Chrysanthis, Two-phase commit
in gigabit-networked distributed databases, in: Proceedings
of the Eighth ISCA International Conference on Parallel
and Distributed Computing Systems, 1995, pp. 554±560.
[3] Y.J. Al-Houmaily, P.K. Chrysanthis, The implicit yes-vote
commit protocol with delegation of commitment, in:
Proceedings of the Ninth International Conference on
Parallel and Distributed Computing Systems, 1996,
pp. 804±810.
[4] Y.J. Al-Houmaily, P.K. Chrysanthis, S.P. Levitan, En-
hancing the performance of presumed commit protocol, in:
Proceedings of the 12th ACM Annual Symposium on
Applied Computing, 1997, pp. 131±133.
[5] Y.J. Al-Houmaily, P.K. Chrysanthis, S.P. Levitan, An
argument in favor of the presumed commit protocol, in:
Proceedings of the 13th International Conference on Data
Engineering, 1997, pp. 255±265.
[6] ANSI X3.135-1992, American National Standard for
Information Systems ± Database Language ± SQL,
November 1992.
[7] S. Banerjee, P.K. Chrysanthis, Data sharing and recovery
in gigabit-networked databases, in: Proceedings of the
Fourth International Conference on Computer Communi-
cations and Networks, 1995.
[8] S. Banerjee, V. Li, C. Wang, Distributed database systems
in high-speed wide-area networks, IEEE Journal on
Selected Areas in Communications 11 (4) (1993) 617±630.
[9] H. Berenson, P. Bernstein, J. Gray, J. Melton, E. OÕNeil, P.
OÕNeil, A critique of ANSI SQL isolation levels, in:
Proceedings of ACM SIGMOD International Conference
on Management of Data, 1995, pp. 1±10.
[10] P.A. Bernstein, V. Hadzilacos, N. Goodman, Concurrency
Control and Recovery in Database Systems, Adison-
Wesley, Reading, MA, 1987.
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 831

[11] E. Braginski, The X/Open DTP e�ort, in: Proceedings of
the Fourth International Workshop on High Performance
Transaction Systems, CA, 1991.
[12] A. Citron, LU 6.2 Directions, in: Proceedings of the
Fourth International Workshop on High Performance
Transaction Systems, CA, 1991.
[13] D. DeWitt et al., The gamma database machine project,
IEEE Transactions on Knowledge and Data Engineering 2
(1) (1990) 44±69.
[14] D. DeWitt, R. Katz, F. Olken, L. Shapiro, M. Stonebrak-
er, D. Wood, Implementation techniques for main memory
database systems, in: Proceedings of ACM SIGMOD
International Conference on Management of Data, 1984,
pp. 1±8.
[15] E.N. Elnozahy, W. Zwaenepoel, Manetho: Transparent
rollback-recovery with low overhead, limited rollback and
fast output commit, IEEE Transactions on Computers,
Special Issue on Fault-Tolerant Computing 41 (5) (1992)
526±531.
[16] K.P. Eswaran, J.N. Gray, R.A. Lorie, I.L. Traiger, The
notion of consistency and predicate locks in a database
system, Communications of the ACM 19 (11) (1976)
624±633.
[17] J. Gray, Notes on data base operating systems, in: R.
Bayer, R.M. Graham, G. Seegmuller (Eds.), Operating
Systems: An Advanced Course, Lecture Notes in Comput-
er Science, vol. 60, Springer, Berlin, 1978, pp. 393±481.
[18] D. Gawlick, D. Kinkade, Varieties of concurrency control
in IMS/VS fast path, IEEE Database Engineering 8 (2)
(1985).
[19] J.N. Gray, A. Reuter, Transaction Processing: Con-
cepts and Techniques, Morgan Kaufmann, Los Altos,
CA, 1993.
[20] T. Haerder, A. Reuter, Principles of transaction-oriented
database recovery, ACM Computing Surveys 15 (4) (1983)
287±317.
[21] L. Kleinrock, The latency/bandwidth tradeo� in gigabit
networks, IEEE Communications Magazine 30 (4) (1992)
36±40.
[22] B.W. Lampson, Atomic transactions, in: B.W. Lampson
(Ed.), Distributed Systems: Architecture and Implementa-
tion ± An Advanced Course, Lecture Notes in Computer
Science, vol. 105, Springer, 1981, pp. 246±265.
[23] B. Lampson, D. Lomet, A new presumed commit optimi-
zation for two phase commit, in: Proceedings of the 19th
VLDB Conference, 1993, pp. 630±640.
[24] C. Mohan, D. Haderle, B. Lindsay, H. Pirahesh, P.
Schwarz, ARIES: A transaction recovery method support-
ing ®ne-granularity locking and partial rollbacks using
write-ahead logging, ACM Transactions on Database
Systems 17 (1) (1992) 94±162.
[25] C. Mohan, B. Lindsay, E�cient commit protocols for the
tree of processes model of distributed transactions, in:
Proceedings of the Second ACM SIGACT/SIGOPS Sym-
posium on Principles of Distributed Computing, 1983.
[26] C. Mohan, B. Lindsay, R. Obermarck, Transaction man-
agement in the R� distributed data base management
system, ACM Transactions on Database Systems 11 (4)
(1986).
[27] J.E.B Moss, Nested Transactions: An Approach to Reli-
able Computing, MIT Press, Boston, 1985.
[28] K. Rothermel, S. Pappe, Open commit protocols for the
tree of processes model, in: Proceedings of the 10th
International Conference on Distributed Computing Sys-
tems, 1990, pp. 236±244.
[29] K. Rothermel, S. Pappe, Open commit protocols tolerating
commission failures, ACM Transactions on Database
Systems 18 (2) (1993) 289±332.
[30] G. Samaras, K. Britton, A. Citron, C. Mohan, Two-phase
commit optimizations and tradeo�s in the commercial
environment, in: Proceedings of the Ninth International
Conference on Data Engineering, 1993, pp. 520±529.
[31] G. Samaras, K. Britton, A. Citron, C. Mohan, Two-phase
commit optimizations in a commercial distributed envi-
ronment, Distributed and Parallel Databases 3 (4) (1995)
325±360.
[32] D. Skeen, Non-blocking commit protocols, in: Proceedings
of ACM SIGMOD International Conference on Manage-
ment of Data, 1982, pp. 133±147.
[33] J. Stamos, F. Cristian, A low-cost atomic commit protocol,
in: Proceedings of the Ninth Symposium on Reliable
Distributed Systems, 1990, pp. 66±75.
[34] J. Stamos, F. Cristian, Coordinator log transaction execu-
tion protocol, Distributed and Parallel Databases 1 (1993)
383±408.
[35] M. Stonebraker, Concurrency control and consistency of
multiple copies of data in distributed INGRES, IEEE
Transactions on Software Engineering 5 (3) (1979)
188±194.
[36] F. Upton IV, OSI distributed transaction processing, an
overview, in: Proceedings of the Fourth International
Workshop on High Performance Transaction Systems,
CA, 1991.
Yousef J. Al-Houmaily received a B.S.in computer engineering from KingSaud University, Riyadh, Saudi Ara-bia in 1986, a M.S. in computer sciencefrom George Washington University,Washington, D.C. in 1990, and aPh.D. in computer engineering fromthe University of Pittsburgh, Pennsyl-vania in 1997. Currently, Dr. Al-Houmaily is an Assistant Professorand the director of Computer Pro-grams Department at the Institute ofPublic Administration, Riyadh, Saudi
Arabia. He served on a number of program committees in-cluding MobiDEÕ99 and IRIÕ99. His current research interestsare in the areas of transaction processing and management indistributed and mobile database environments. Dr. Al-Hou-maily is a member of ACM, ISCA and the Saudi ComputerSociety (SCS).
832 Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833

Panos K. Chrysanthis is currently atenured Associate Professor of Com-puter Science at the University ofPittsburgh. He received the B.S. degreein Physics with concentration inComputer Science from the Universityof Athens, Greece, in 1982. He earnedthe M.S. and Ph.D. degrees in Com-puter and Information Sciences fromthe University of Massachusetts atAmherst, in 1986 and 1991 respec-tively, and joined the University ofPittsburgh in 1991 as an Assistant
Professor. His research interests lie within the areas of databasesystems, distributed and mobile computing, operating system
and real-time systems. In 1995, he was a recipient of theNational Science Foundation CAREER Award for his inves-tigation on the management of data for mobile and wirelesscomputing. Dr. Chrysanthis has chaired and served on ProgramCommittees of several Database and Distributed ComputingConferences. He also served as guest editor and reviewer forseveral journals. He is a member of the ACM (Sigmod, Sigops),the IEEE Computer Society, Sigma Xi the Scienti®c ResearchSociety, and the USENIX Association.
Y.J. Al-Houmaily, P.K. Chrysanthis / Journal of Systems Architecture 46 (2000) 809±833 833


















